3. genome annotation: gene prediction. gene: a sequence of nucleotides coding for protein gene...
TRANSCRIPT

3. Genome Annotation:Gene Prediction

• Gene: A sequence of nucleotides coding for protein
• Gene Prediction Problem: Determine the beginning and end positions of genes in a genome
Gene Prediction: Computational Challenge

Gene Prediction: Computational Challenge
aatgcatgcggctatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatcctgcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcatgcgg

Gene Prediction: Computational Challenge
aatgcatgcggctatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatcctgcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcatgcgg

Gene Prediction: Computational Challenge
aatgcatgcggctatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatcctgcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcggctatgctaatgaatggtcttgggatttaccttggaatgctaagctgggatccgatgacaatgcatgcggctatgctaatgaatggtcttgggatttaccttggaatatgctaatgcatgcggctatgctaagctgggaatgcatgcggctatgctaagctgggatccgatgacaatgcatgcggctatgctaatgcatgcggctatgcaagctgggatccgatgactatgctaagctgcggctatgctaatgcatgcggctatgctaagctcatgcgg
Gene!
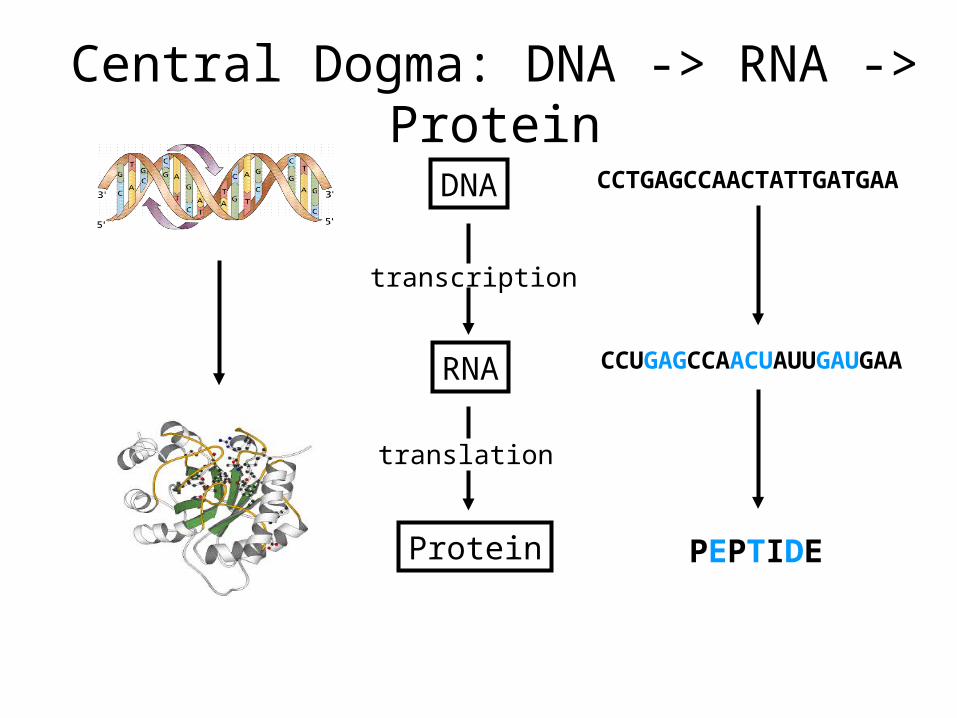
Protein
RNA
DNA
transcription
translation
CCTGAGCCAACTATTGATGAA
PEPTIDE
CCUGAGCCAACUAUUGAUGAA
Central Dogma: DNA -> RNA -> Protein
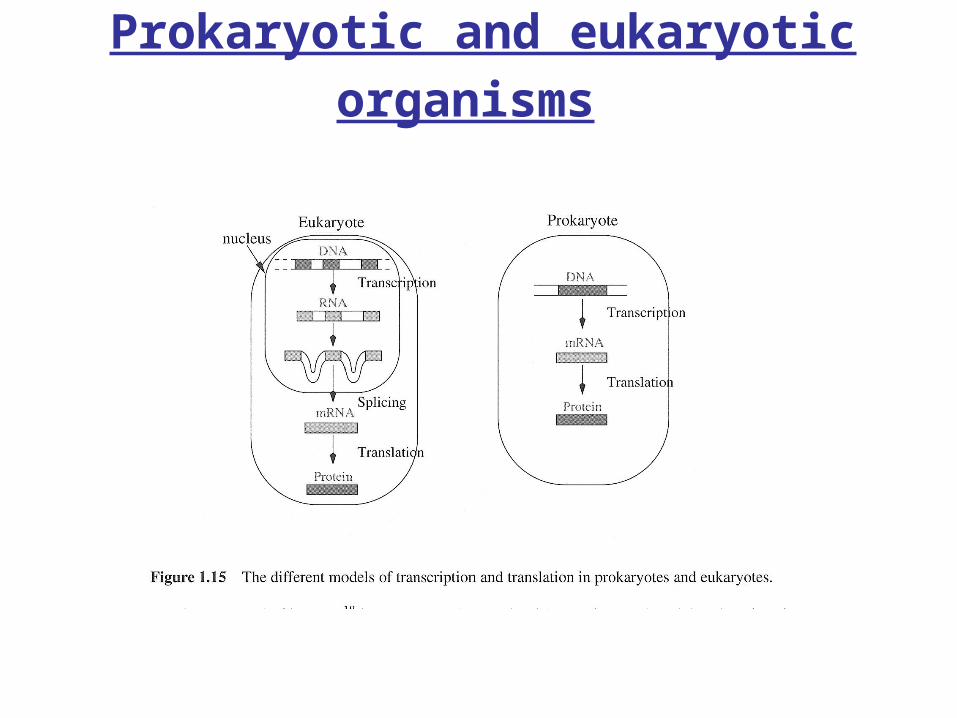
Prokaryotic and eukaryotic
organisms

• Codon: 3 consecutive nucleotides
• 4 3 = 64 possible codons
• Genetic code is degenerative and redundant
– Includes start and stop codons
– An amino acid may be coded by more than one codon
Translating Nucleotides into Amino Acids

• In 1961 Sydney Brenner and Francis Crick discovered frameshift mutations
• Systematically deleted nucleotides from DNA– Single and double deletions dramatically
altered protein product– Effects of triple deletions were minor– Conclusion: every triplet of nucleotides, each codon, codes for exactly one amino acid in a protein
Codons
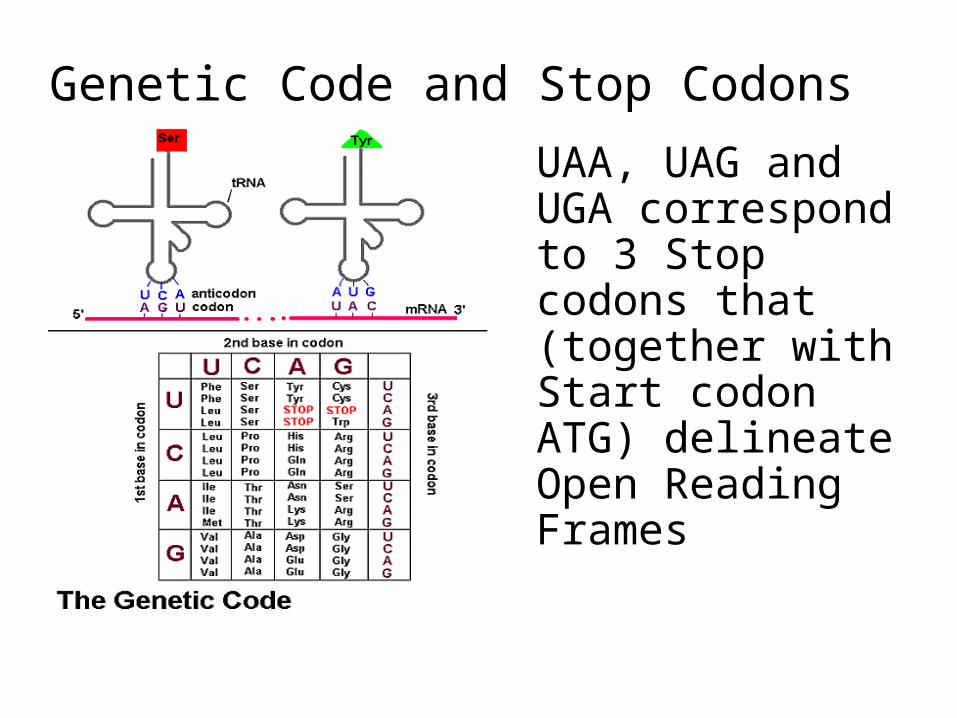
UAA, UAG and UGA correspond to 3 Stop codons that (together with Start codon ATG) delineate Open Reading Frames
Genetic Code and Stop Codons

Six Frames in a DNA Sequence
• stop codons – TAA, TAG, TGA
• start codons - ATG
GACGTCTGCTTTGGAGAACTACATCAACCGGACTGTGGCTGTTATTACTTCTGATGGCAGAATGATTGTG
CTGCAGACGAAACCTCTTGATGTAGTTGGCCTGACACCGACAATAATGAAGACTACCGTCTTACTAACAC
GACGTCTGCTTTGGAGAACTACATCAACCGGACTGTGGCTGTTATTACTTCTGATGGCAGAATGATTGTGGACGTCTGCTTTGGAGAACTACATCAACCGGACTGTGGCTGTTATTACTTCTGATGGCAGAATGATTGTGGACGTCTGCTTTGGAGAACTACATCAACCGGACTGTGGCTGTTATTACTTCTGATGGCAGAATGATTGTG
CTGCAGACGAAACCTCTTGATGTAGTTGGCCTGACACCGACAATAATGAAGACTACCGTCTTACTAACACCTGCAGACGAAACCTCTTGATGTAGTTGGCCTGACACCGACAATAATGAAGACTACCGTCTTACTAACACCTGCAGACGAAACCTCTTGATGTAGTTGGCCTGACACCGACAATAATGAAGACTACCGTCTTACTAACAC

• Detect potential coding regions by looking at ORFs– A genome of length n is comprised of (n/3) codons– Stop codons break genome into segments between
consecutive Stop codons– The subsegments of these that start from the Start codon
(ATG) are ORFs• ORFs in different frames may overlap
3
n
3
n
3
n
Genomic Sequence
Open reading frame
ATG TGA
Open Reading Frames (ORFs)

• Long open reading frames may be a gene– At random, we should expect one stop codon
every (64/3) ~= 21 codons– However, genes are usually much longer
than this• A basic approach is to scan for ORFs whose
length exceeds certain threshold– This is naïve because some genes (e.g. some
neural and immune system genes) are relatively short
Long vs.Short ORFs

Testing ORFs: Codon Usage
• Create a 64-element hash table and count the frequencies of codons in an ORF
• Amino acids typically have more than one codon, but in nature certain codons are more in use
• Uneven use of the codons may characterize a real gene
• This compensate for pitfalls of the ORF length test
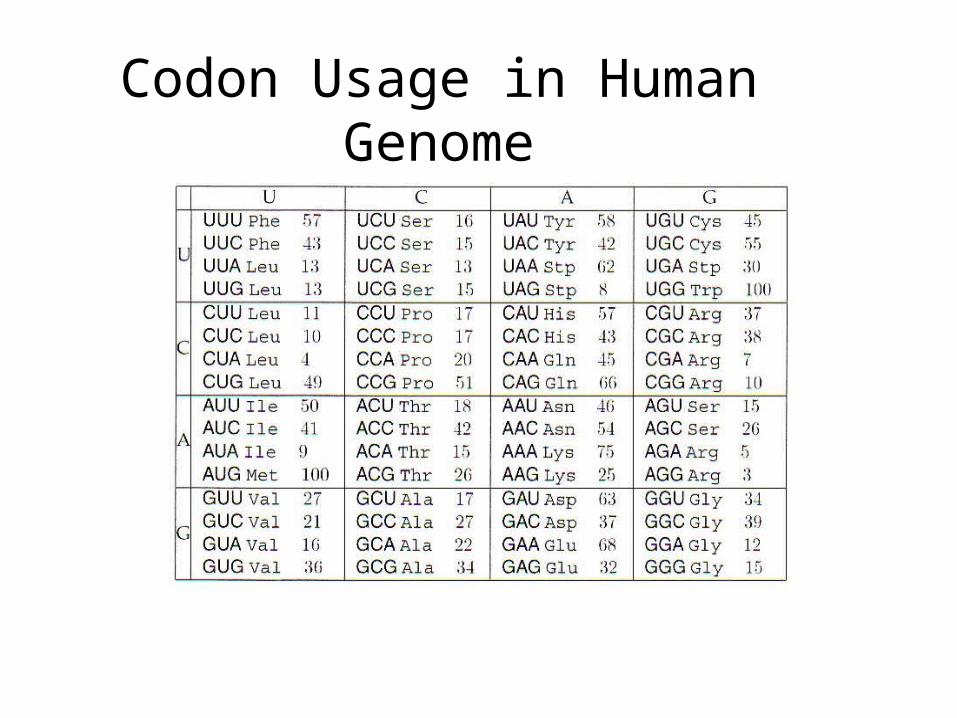
Codon Usage in Human Genome

AA codon /1000 frac Ser TCG 4.31 0.05Ser TCA 11.44 0.14Ser TCT 15.70 0.19Ser TCC 17.92 0.22Ser AGT 12.25 0.15Ser AGC 19.54 0.24
Pro CCG 6.33 0.11Pro CCA 17.10 0.28Pro CCT 18.31 0.30Pro CCC 18.42 0.31
AA codon /1000 frac Leu CTG 39.95 0.40Leu CTA 7.89 0.08Leu CTT 12.97 0.13Leu CTC 20.04 0.20
Ala GCG 6.72 0.10Ala GCA 15.80 0.23Ala GCT 20.12 0.29Ala GCC 26.51 0.38
Gln CAG 34.18 0.75Gln CAA 11.51 0.25
Codon Usage in Mouse Genome
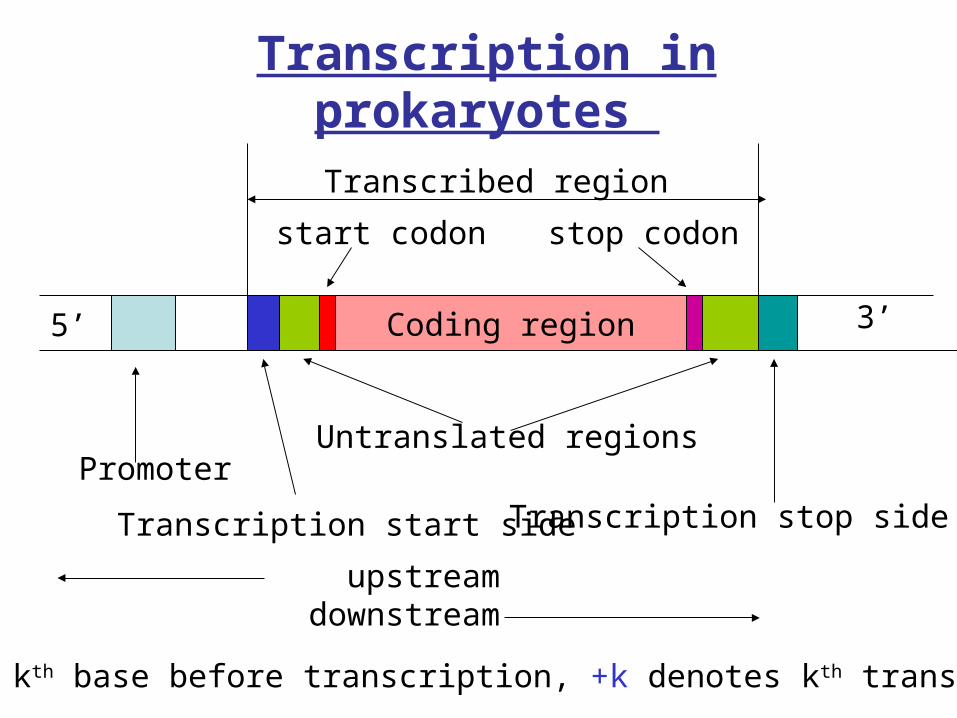
Transcription in prokaryotes
Coding region
Promoter
Transcription start side
Untranslated regions
Transcribed region
start codon stop codon
5’ 3’
upstream downstream
Transcription stop side
-k denotes kth base before transcription, +k denotes kth transcribed base

Microbial gene finding
• Microbial genome tends to be gene rich (80%-90% of the sequence is coding)
• The most reliable method – homology searches (e.g. using BLAST and/or FASTA)
• Major problem – finding genes without known homologue.

Open Reading Frame
Open Reading Frame (ORF) is a sequence of codons which starts with start codon, ends with an end codon and has no end codons in-between.
Searching for ORFs – consider all 6 possible reading frames: 3 forward and 3 reverse
Is the ORF a coding sequence?1. Must be long enough (roughly 300 bp or more)2. Should have average amino-acid composition specific for a give
organism.3. Should have codon use specific for the given organism.
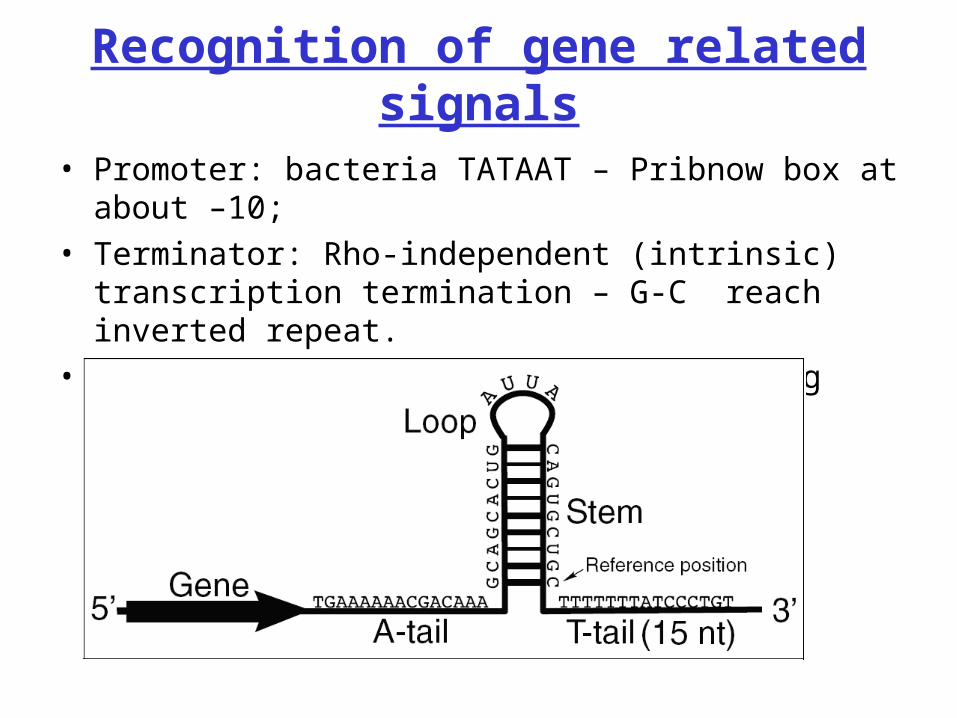
Recognition of gene related signals
• Promoter: bacteria TATAAT – Pribnow box at about –10; • Terminator: Rho-independent (intrinsic) transcription
termination – G-C reach inverted repeat. • Other signal recognition –e.g binding motifs

Codon frequency
frequency in coding region frequency in non-coding region
Input sequence
Compare
Coding region or non-coding region

Example codon position
A C T G
1 28% 33% 18% 21%
2 32% 16% 21% 32%
3 33% 15% 14% 38%
freqency in
genome
31% 18% 19% 31%
Assume: bases making codon are independent
P(x|in coding)P(x|random)
=
P(Ai at ith position)P(Ai in the sequence)i
Score of AAAGAT:
.28*.32*.33*.21*.26*.14
.31*.31*.31*.31*.31*.19

Using codon frequency to find correct reading frame
Consider sequence x1 x2 x3 x4 x5 x6 x7 x8 x9….
where xi is a nucleotide
let p1 = p x1 x2 x3 p x3 x4 x5…. p2 = p x2 x3 x4 p x5 x6 x7….
p3 = p x3 x4 x5 p x6 x7 x8….
then probability that ith reading frame is the coding frame is:
pi
p1 + p2 + p3
Algorithm:• slide a window along the sequence and compute Pi
•Plot the results
Pi =

First order Markov chain: formal def.
M = (Q, , P)
Q – finite set of states, say |Q|= n
a – n x n transition probability matrix
a(i,j)= P[q t+1=j|g t=i]
– n-vector, starting probability vector (i) = Pr[q 0=i]
For any row of a the sum of entries = 1
(i) = 1
Comment: Frequently extra start and end states are added and vector is not needed.

Hidden Markov Model
Hidden Markov Model is a Markov model in which one does not observe a sequence of states but results of a function prescribed on states – in our case this is emission of a symbol (amino acid or a nucleotide).
States are hidden to the observers.

Introducing emission probabilities
• Assume that at each state a Markov process emits (with some distribution) a symbol from alphabet .
• Rather than observing a sequence of states we observe a sequence of emitted symbols.
Example: ={A,C,T,G}. Generate a sequence where A,C,T,G have frequency p(A) =.33, p(G)=.2, p(C)=.2, p(T) = .27 respectively
A .33T .27C .2G .2
1.0
one stateemission probabilities

HMM – formal definitionHMM is a Markov process that at each time step generates a
symbol from some alphabet, , according to emission probability that depends on state.
M = (Q, , , a,e)Q – finite set of states, say n states ={q0,q1,…}
a – n x n transition probability matrix: a(i,j) = Pr[q t+1=j|g t=i] – n-vector, start probability vector: (i) = Pr[q 0=i]
= {1, …,k}-alphabet
e(i,j) = P[ot=j|qt = i]; ot –tth element of generated sequences
= probability of generating j in state qi (S=o0,…oT the output sequence)

Algorithmic problems related to HMM
• Given HMM M and a sequence S compute Pr(S|M) – probability of generating S by M.
• Given HMM M and a sequence S compute most likely sequence of states generating S.
• What is the most likely state at position i.
• Given a representative sample (training set) of a sequence property construct HMM that best models this property.

Probability of generating a sequence S by HMM
Recall: probability of a sequence of states S=q0,…,qn in Markov chain :
P(S|M) =a(q0,q1) a(q1 , q2) a(q2 , q3) … a(qn-1 , qn)
Now: Our sequence S = 0,…,T is a word over and there can be many paths leading to the generation of this sequence. Need to find all these paths and sum the probabilities.

Formal definition of P(S|M)
M = (Q, , a,e) ; ( is dropped: q0 is the starting state)
S = 0…n
P[S|M] = pQn+1P[p|M]P[S|p,M] (sum over all possible paths p=q0,…qn of product: probability of the path
times the probability of generating given sequence assuming given path.)
P[p|M] =a(q0,q1) a(q1 , q2) a(q2 , q3) … a(qn-1 , qn)
P[S|p,M] = e(q0,1) e(q1,2) e(q2 , 3) … e(qn , n)
Computing LS(M) from the definition (enumerating all sequences p) would take exponential time!

Example
A .5T .25C .25
A .25T .25C .25G .25
A .3T .3C .3G .1
A .3T .3C .1G .3
A .5T .5
Sample sequence:S=ATCACATAssume: 0 start state4 – end state
1.0
.5
.5
.4
.4
.6
.6
Two possible paths: p1=0,1,3,3,3,3,4 and p2=0,1,2,2,2,4 P(p1|M) = 1*.5*.4*.4*.4*.6=.0192; P(S|p1) = .5*.25*.3*.3*.3*.3*.5 =.00050625; P(p1|M) * P(S|p1) = .00000972P(p2|M) =.0192; P(S|p2) =1*.5*.25*.1*.3*.1*.3*.5 =.00005625; P(p2|M) * P(S|p2) = .000000198
P(S|M) = .00000972 + 000000198 = 0.000009828Observe how small are the numbers – we need to switch from probabilities to log.
0 1 2
3
4

Most likely path
• Most likely path for sequence S is a path p in M that maximizes P(S|p).
• Why it may be interesting to know most likely path:– Frequently HMM are designed in such a
way that one can assign biological relevance to a state: e.g. position in protein sequence, beginning of coding region, beginning/end of an intron.
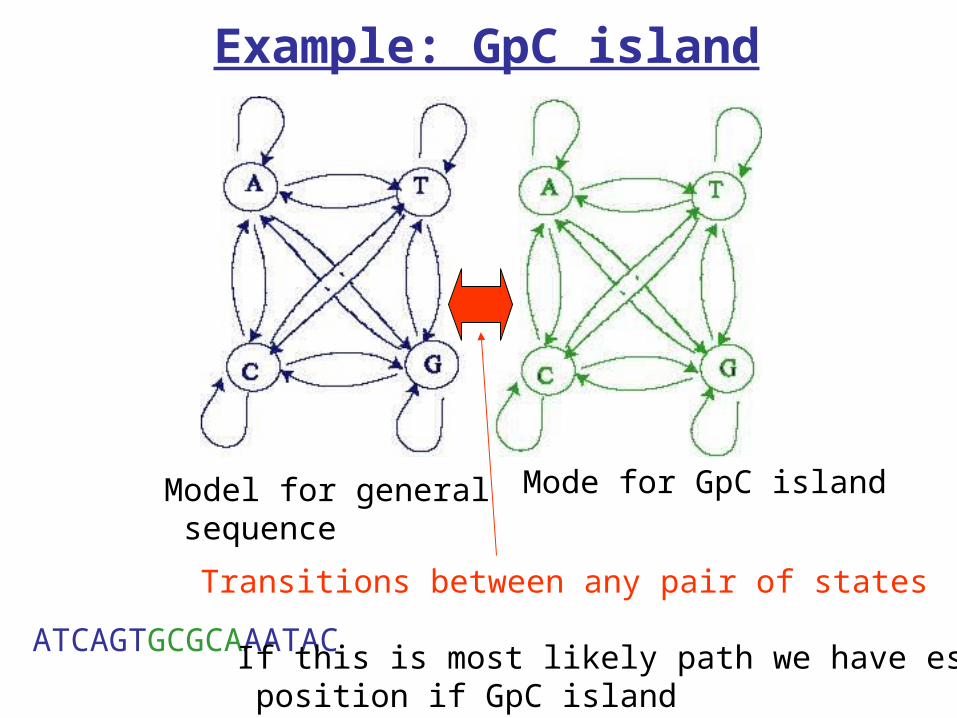
Example: GpC island
Model for general sequence
Mode for GpC island
Transitions between any pair of states
ATCAGTGCGCAAATAC If this is most likely path we have estimated position if GpC island
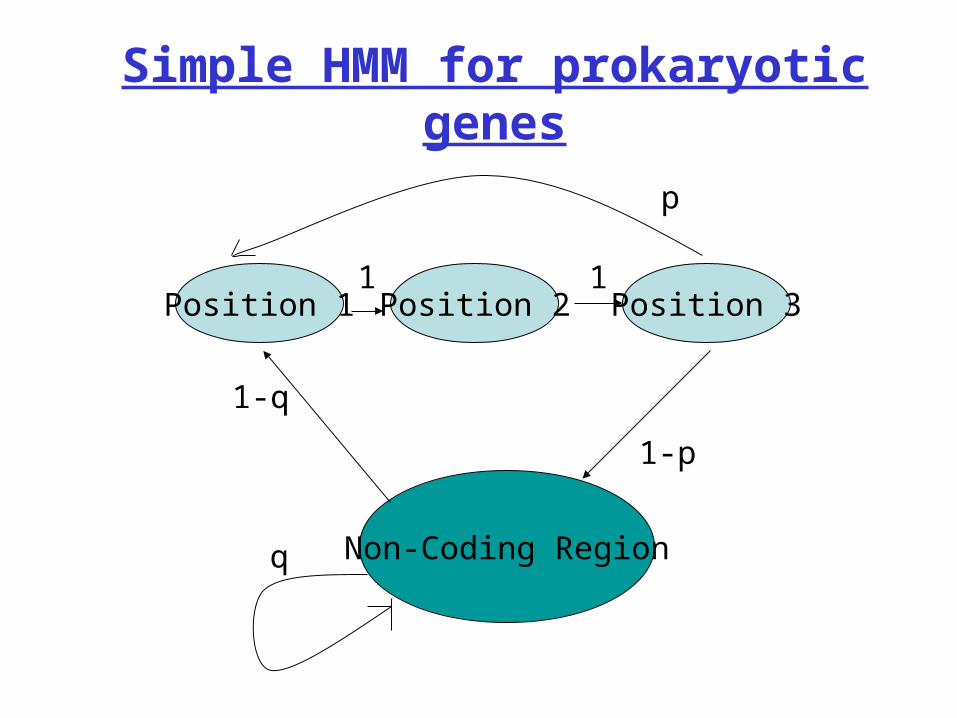
Simple HMM for prokaryotic genes
Position 1 Position 3Position 2
Non-Coding Region
1 1
p
1-p
q
1-q

HMM-based Gene finding programs for microbial genes
• GenMark- [Borodovsky, McInnich – 1993, Comp. Chem., 17, 123-133] 5th order HMM
• GLIMMER[Salzberg, Delcher, Kasif,White 1998, Nucleic Acids Research, Vol 26, 2 55408] – Interpolated Markov Model (IMM)

Eukaryotic gene finding
• On average, vertebrate gene is about 30KB long
• Coding region takes about 1KB• Exon sizes vary from double digit numbers to
kilobases• An average 5’ UTR is about 750 bp• An average 3’UTR is about 450 bp but both
can be much longer.

Exons and Introns
• In eukaryotes, the gene is a combination of coding segments (exons) that are interrupted by non-coding segments (introns)
• This makes computational gene prediction in eukaryotes even more difficult
• Prokaryotes don’t have introns - Genes in prokaryotes are continuous
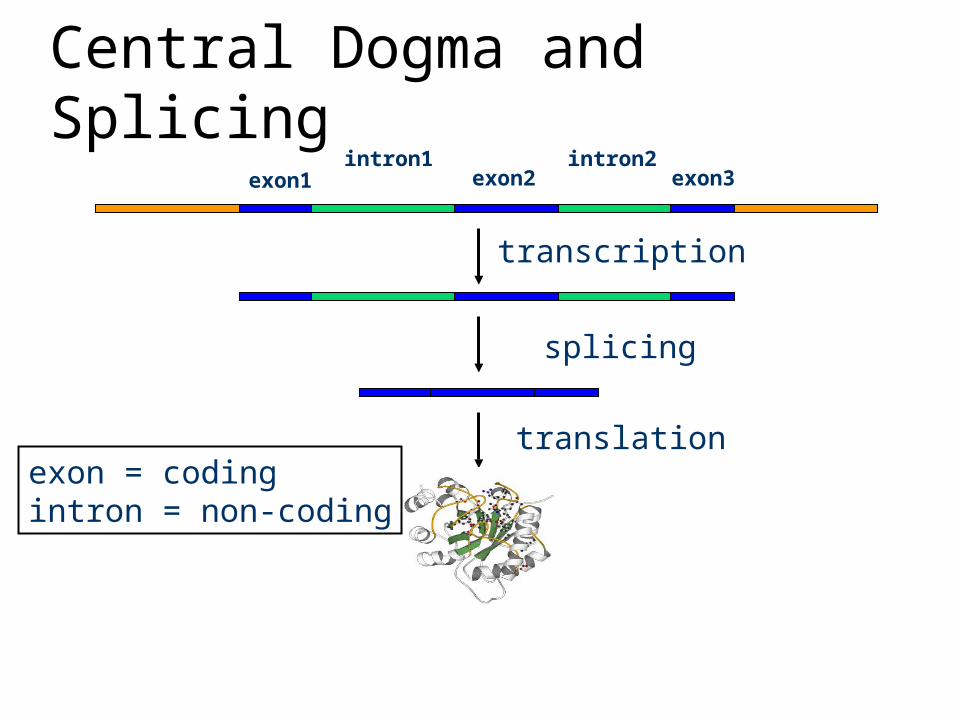
Central Dogma and Splicingexon1 exon2 exon3
intron1 intron2
transcription
translation
splicing
exon = codingintron = non-coding

Gene Structure

Splicing Signals
Exons are interspersed with introns and typically flanked by GT and AG

Splice site detection
5’ 3’Donor site
Position
% -8 … -2 -1 0 1 2 … 17
A 26 … 60 9 0 1 54 … 21C 26 … 15 5 0 1 2 … 27G 25 … 12 78 99 0 41 … 27T 23 … 13 8 1 98 3 … 25

Consensus splice sites
Donor: 7.9 bitsAcceptor: 9.4 bits

Promoters• Promoters are DNA segments upstream
of transcripts that initiate transcription
• Promoter attracts RNA Polymerase to the transcription start site
5’Promoter 3’

Splicing mechanism
(http://genes.mit.edu/chris/)

Splicing mechanism
• Adenine recognition site marks intron
• snRNPs bind around adenine recognition site
• The spliceosome thus forms
• Spliceosome excises introns in the mRNA