a measurement-based model for estimation of resource exhaustion in operational software systems
TRANSCRIPT

“A Measurement-Based Model for Estimation of
Resource Exhaustion in Operational Software Systems”
Vaidyanathan, K., Trivedi, K.S. [1999]
Apresentador: Carlos Eduardo Dantas
1

ROTEIRO
• Introdução.
• Trabalhos relacionados.
• Modelos de Recompensa Semi-Markov.
• Ajustes experimentais e coleta de dados.
• Caracterização e modelagem da carga de trabalho.
• Uso dos Recursos de Modelagem.
• Resultados.
• Conclusão.
• Análise Crítica.
• Referências.
2

INTRODUÇÃO
• Recentemente tem sido reportado o fenômeno do “Envelhecimento de Software”, aquele onde o estado do sistema do Software se degrada com o tempo;
• Trabalhos anteriores nesta área para detectar envelhecimento e estimar seus efeitos não levaram em conta a carga de trabalho do sistema.
• Cargas de trabalho são geradas para monitorar os efeitos de envelhecimento, pois ativam Faltas relacionadas ao envelhecimento (AR Faults).
3

INTRODUÇÃO
• Proposta de estimar as tendências de exaustão de recursos do Sistema Operacional, em função do tempo e o estado da carga de trabalho do sistema;
• Identificar diferentes estados de carga de trabalho por meio de análise de cluster, para depois construir um modelo de estados no espaço;
• Uma função de recompensa é definida para o modelo, com base na taxa de exaustão de recursos em diferentes estados;
• O modelo é resolvido para obter tendências e taxas de estimativas, e tempos de exaustão para recursos;
• Os resultados serão comparados com os resultados obtidos usando a abordagem puramente baseada em tempo.
4

INTRODUÇÃO
• Contribuições• O modelo de medição baseado em tempo para capturar o efeito da carga de
trabalho do sistema em recursos do sistema operacional;
• Investigar o efeito da carga de trabalho nos recursos do sistema, particularmente em relação à exaustão.
5

TRABALHOS RELACIONADOS
• Garg et. al. [2] apresentou uma metodologia geral para detectar e estimar as tendências e tempos para exaustão dos recursos do Sistema Operacional devido ao envelhecimento de Software;
• Outros trabalhos anteriores trabalharam em medições tanto em momentos de falha quanto em momentos de erro;
• Métodos de cluster tem sido utilizados em estudos sobre cargas de trabalho e uso de recursos [3,4];
• Modelos de recompensa de Markov e semi-Markov tem sido utilizados largamente para análises de “Reliability” em sistemas de computadores.
6

Modelos de Recompensa Semi-Markov
• SMPs Independentes – Definida uma matriz P e um vetor H(t),
método de dois estágios, transições em duas fases;
• No primeiro estágio, a cadeia permanece no estado i por uma
quantidade de tempo descrita pela distribuição de permanência
Hi(t);
• No segundo estágio, a cadeia move para o estado j,
determinado pela probabilidade Pij.
7

Modelos de Recompensa Semi-Markov
• Neste trabalho, a estrutura do estado do processo captura a
dinâmica de carga de trabalho do sistema e a estrutura de
recompensa caracteriza a taxa de consumo dos recursos para
cada estado.
8

Ajustes experimentais e Coleta de Dados
• Ferramenta de Monitoramento de recursos baseada em SNMP
• Ferramenta utilizada para coleta de dados;
• SNMP é um protocolo para gerenciamento de dispositivos em redes IP.
• Coleta de dados
• A ferramenta foi utilizada para coletar o uso de recursos do Sistema
Operacional e os dados de atividades do sistema de 9 estações UNIX,
conectadas em LAN.
• Envia requisições get periodicamente, obtendo dados de programascomo pstat,iostat e vmstat
9
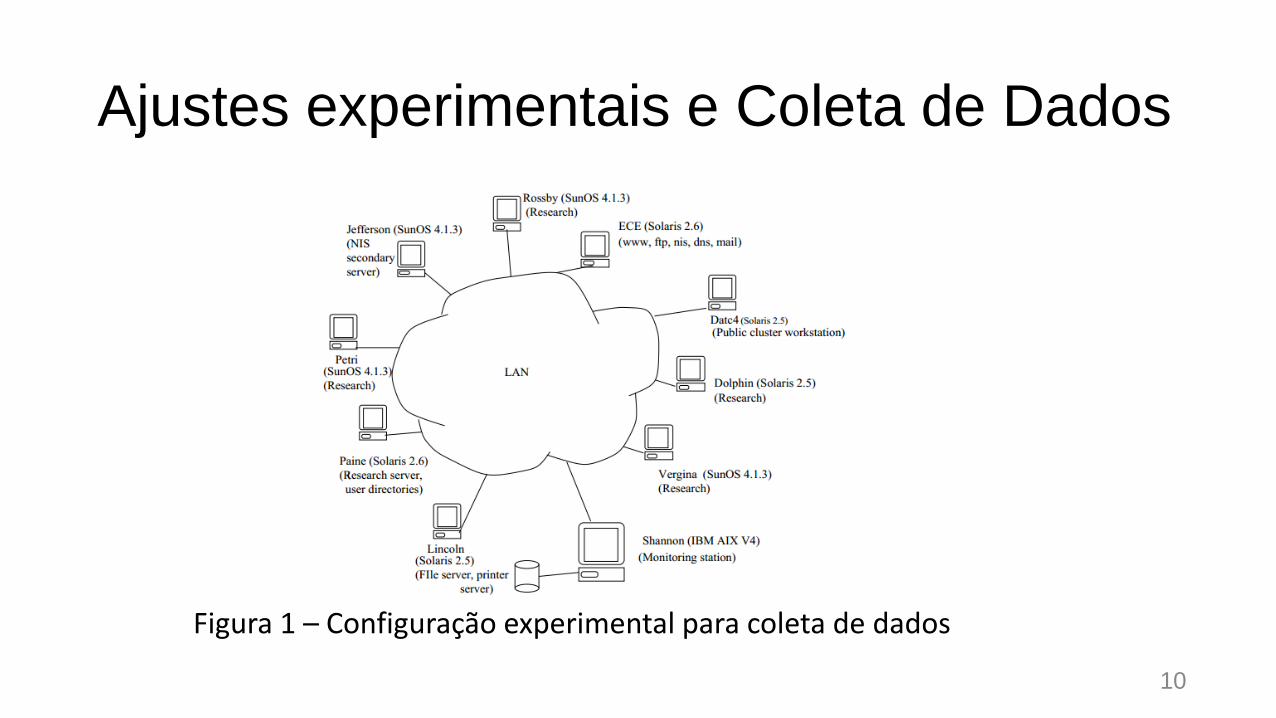
Ajustes experimentais e Coleta de Dados
Figura 1 – Configuração experimental para coleta de dados
10

Ajustes experimentais e Coleta de Dados
• Coleta de Dados
• Mais de 100 parâmetros monitorados em intervalos regulares de 10 minutos, por mais de 3 meses;
• Serão discutidos apenas os resultados dos dados coletados pela máquina ROSSBY;
• Os dois recursos selecionados para estudo são usedSwapSpace e realMemoryFree.
11

Caracterização e modelagem da carga de trabalho
• A carga de trabalho é caracterizada obtendo o número de variáveis pertencente a uma atividade de CPU e sistema de arquivos I/O;
• Variáveis que caracterizam a carga de trabalho: cpuContextSwitch, sysCall, pageIn e pageOut;
• Em qualquer intervalo, um ponto em um espaço de 4 dimensões representa a medida da carga de trabalho;
• Os pontos serão particionados em clusters, identificando pontos similares;
• Estados representativos das cargas de trabalho serão identificados.
12

Caracterização e modelagem da carga de trabalho
• Análise do Cluster• Determina uma partição de um conjunto de pontos em grupos, onde os pontos dentro
destes grupos são similares, de acordo com um certo critério;
• O algoritmo utilizado foi Hartigan´s K-means clustering;
• O objetivo do algoritmo é dividir um conjunto de pontos em k clusters não vazios, até que a soma dos quadrados até sua centroide correspondente seja minimizada.
• Se as variáveis do cluster não estão expressadas em unidades homogêneas, uma normalização precisa ser feita, restringindo os valores para o intervalo [0,1];
13
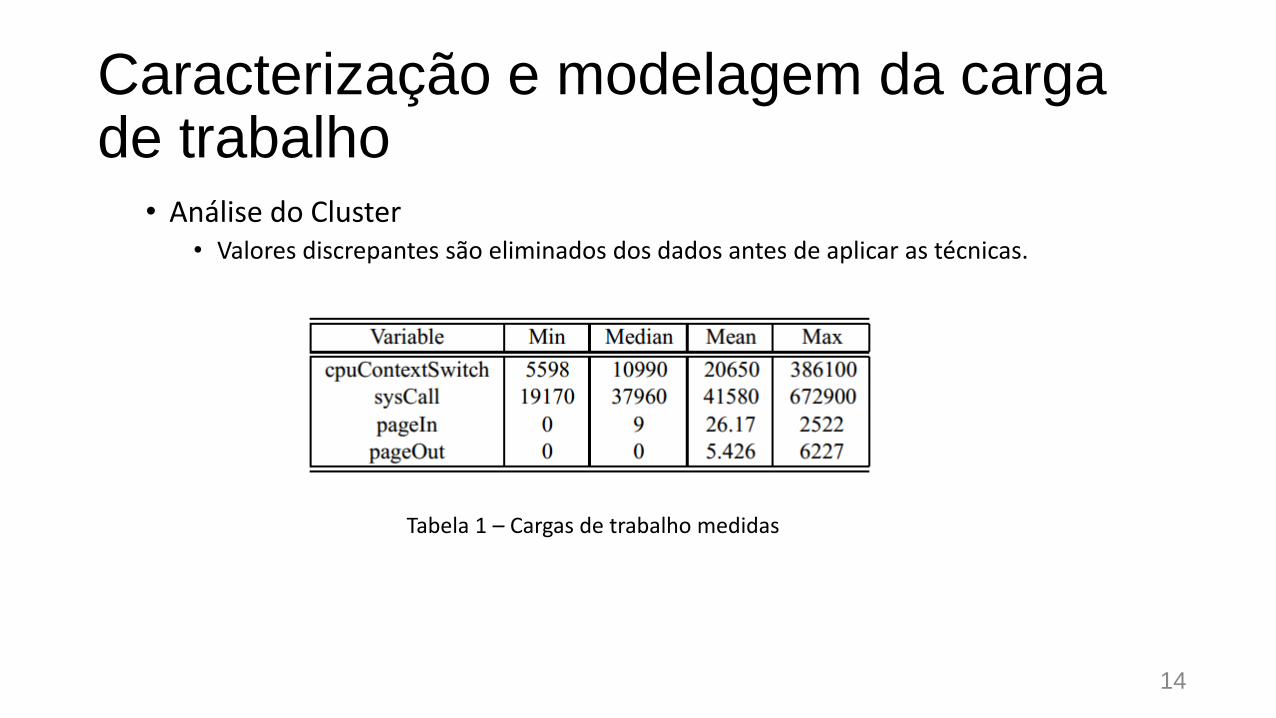
Caracterização e modelagem da carga de trabalho
• Análise do Cluster• Valores discrepantes são eliminados dos dados antes de aplicar as técnicas.
Tabela 1 – Cargas de trabalho medidas
14

Caracterização e modelagem da carga de trabalho
• Análise do Cluster• A aplicação do algoritmo k-means na carga de trabalho resultou em 11 clusters
Tabela 2 – Clusters da carga de trabalho
15

Caracterização e modelagem da carga de trabalho
• Modelo de transição do estado• Determinar as probabilidades de transição de um estado para outro;
• Realização de um merge entre os clusters W1 = {1,2,3} e W2 = {4,5};
• Aplicação da matriz de probabilidades de transição P, na cadeia de Markov
16
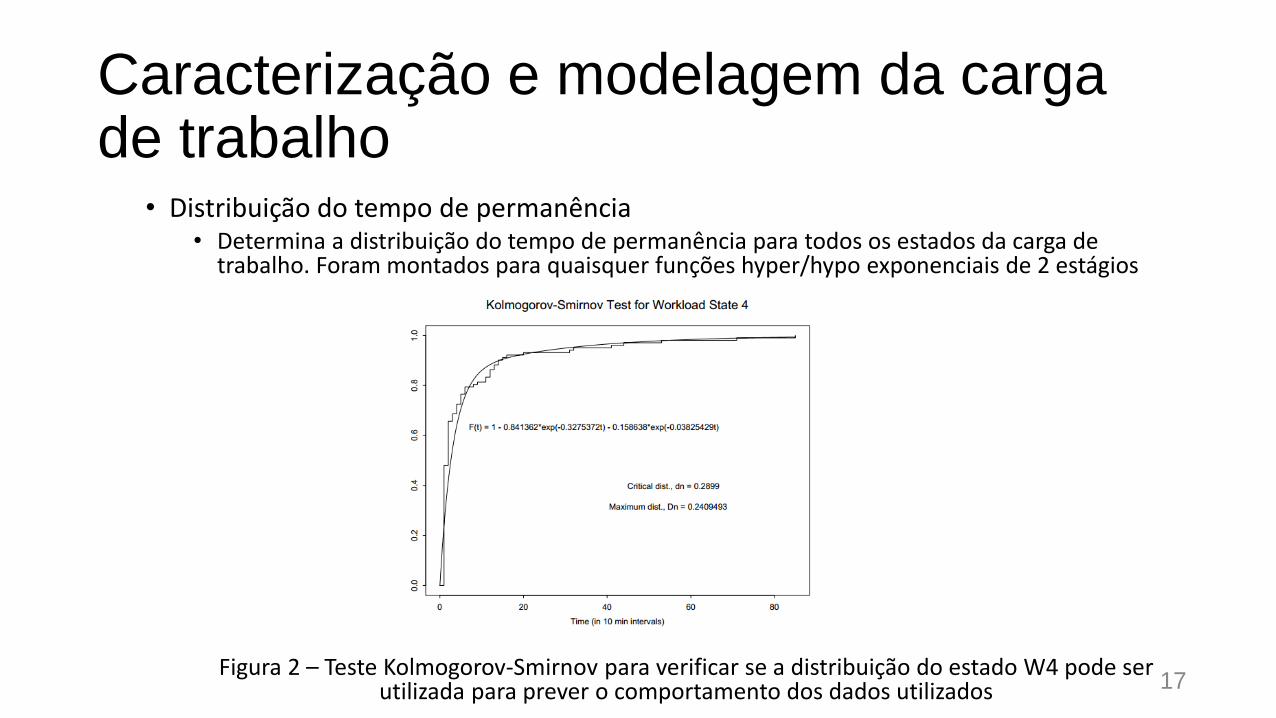
Caracterização e modelagem da carga de trabalho
• Distribuição do tempo de permanência• Determina a distribuição do tempo de permanência para todos os estados da carga de
trabalho. Foram montados para quaisquer funções hyper/hypo exponenciais de 2 estágios
Figura 2 – Teste Kolmogorov-Smirnov para verificar se a distribuição do estado W4 pode ser utilizada para prever o comportamento dos dados utilizados 17

Caracterização e modelagem da carga de trabalho
• Distribuição do tempo de permanência
• Tabela 3 – Distribuição do tempo de permanência nos oito estados da carga de trabalho.
18

Caracterização e modelagem da carga de trabalho
• Validação do Modelo• A probabilidade de um estado estacionário ocupar um estado de uma carga de trabalho
calculada pelo modelo foi comparada com a probabilidade real a partir dos dados;• Os resultados abaixo comprovam que o processo de semi-Markov obtido pode ser usado para
descrever a carga de trabalho do sistema.
Tabela 4 – Comparação da probabilidade de ocupação de um estado.19
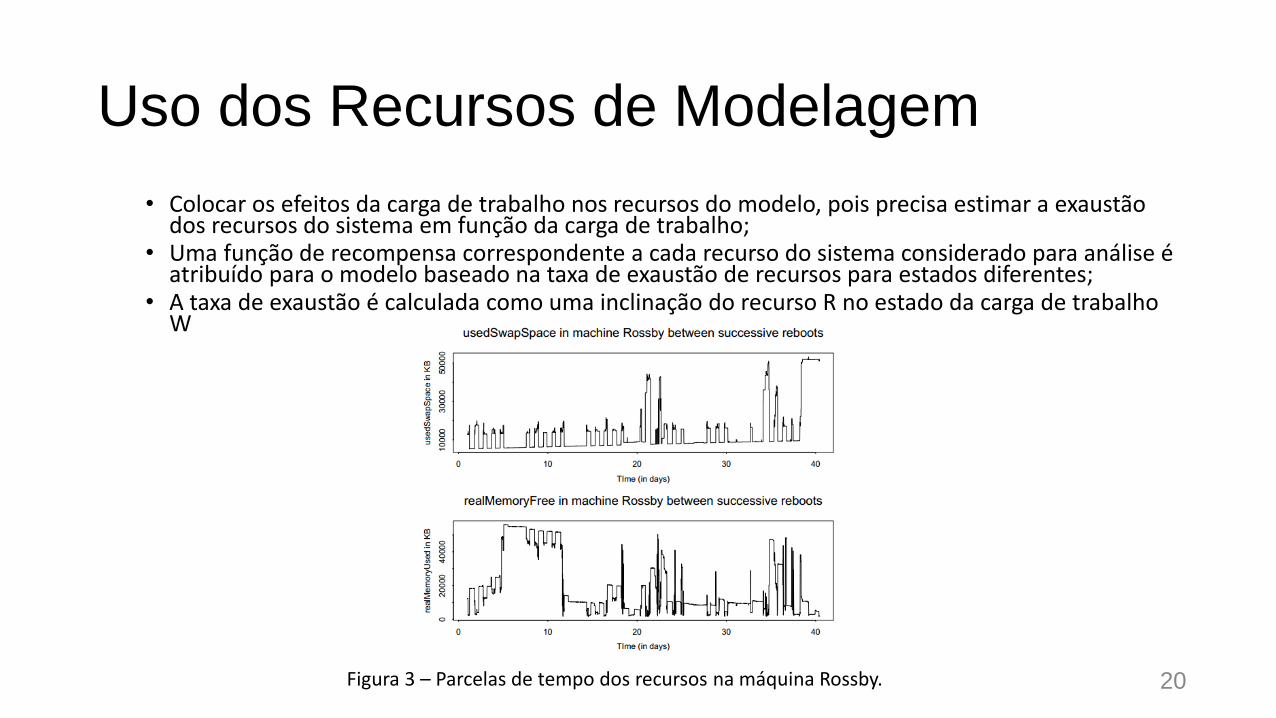
Uso dos Recursos de Modelagem
• Colocar os efeitos da carga de trabalho nos recursos do modelo, pois precisa estimar a exaustão dos recursos do sistema em função da carga de trabalho;
• Uma função de recompensa correspondente a cada recurso do sistema considerado para análise é atribuído para o modelo baseado na taxa de exaustão de recursos para estados diferentes;
• A taxa de exaustão é calculada como uma inclinação do recurso R no estado da carga de trabalho W
Figura 3 – Parcelas de tempo dos recursos na máquina Rossby. 20

Uso dos Recursos de Modelagem
• Calculando a inclinação• Calcula-se por um processo não paramétrico desenvolvido por Sen[7], pois não é afetado por
valores atípicos.
• Figura 4 – Inclinação em (KB/10 min) em W4, em duas visitas diferentes.
21
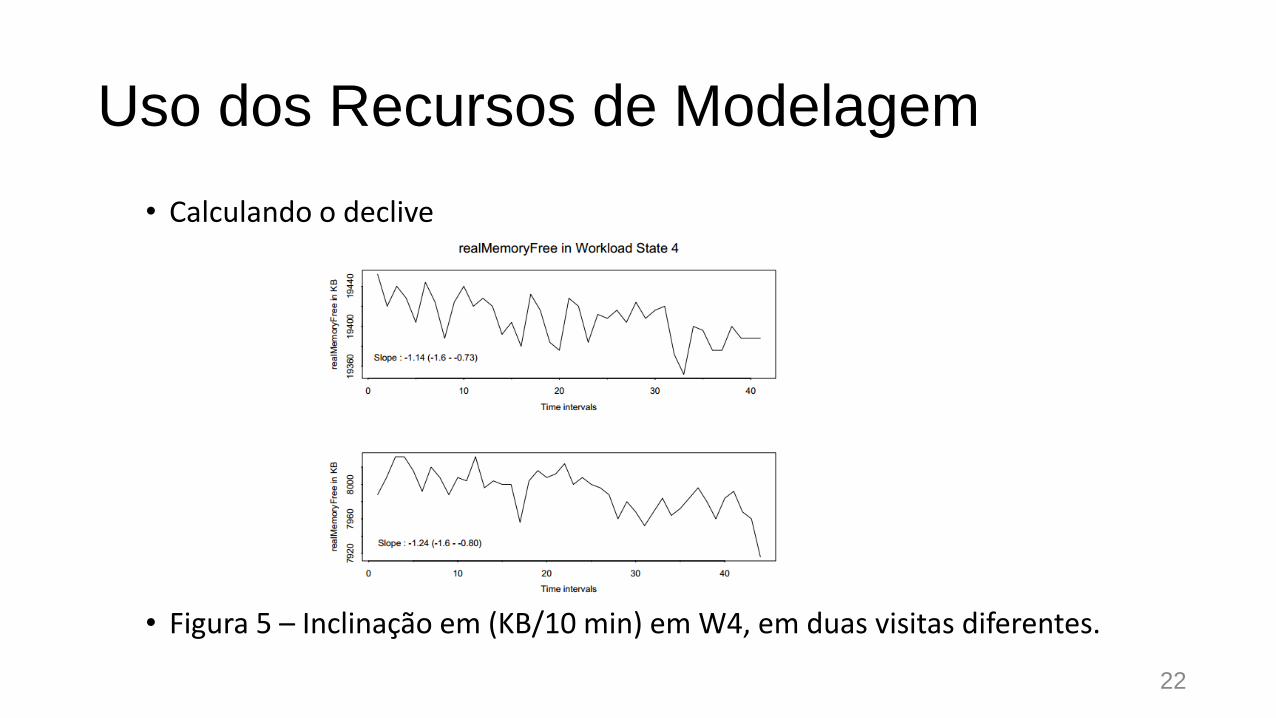
Uso dos Recursos de Modelagem
• Calculando o declive
• Figura 5 – Inclinação em (KB/10 min) em W4, em duas visitas diferentes.
22

Uso dos Recursos de Modelagem
• Calculando o declive• O uso dos recursos independe da carga de trabalho do sistema e as taxas de exaustão variam com
as mudanças nas cargas de trabalho;• usedSwapSpace incrementa e realMemoryFree decrementa no decorrer do tempo.
Tabela 5 – Estimativa de declive (KB/10 min) em diferentes estados para cargas de trabalho 23

Resultados
• Estimar tendências e taxas de exaustão• A estimativa baseada em tempo é calculada usando a inclinação de Sen[7] estimada para
dados com estações, como proposto em [2].
Figura 6 – Estimativa de tendência x tempo na máquina Rossby24
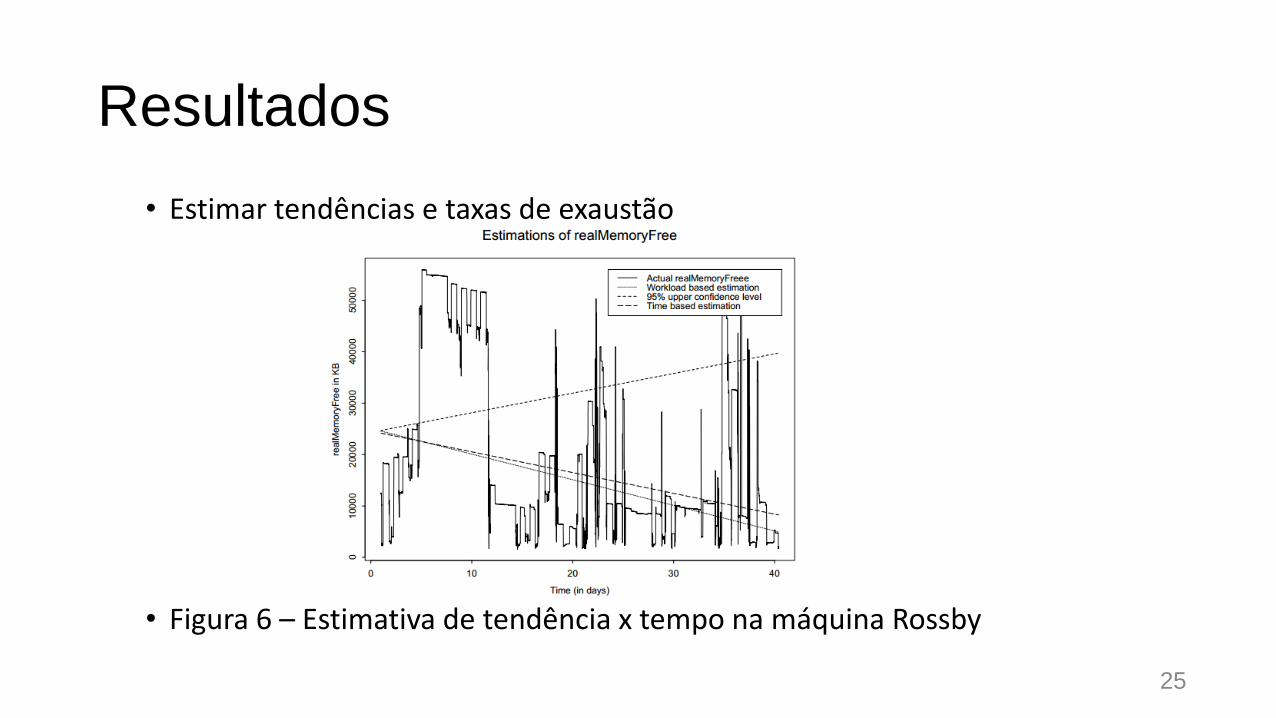
Resultados
• Estimar tendências e taxas de exaustão
• Figura 6 – Estimativa de tendência x tempo na máquina Rossby
25

Resultados
• Estimar tendências e taxas de exaustão• Estimativas baseadas em tempo podem dar uma previsão de quais são os recursos mais
importantes para se verificar, porém não quando estes vão falhar.
• Tabela 7 - Estimativa de tendência (em kb/10 min) e o tempo para exaustão em dias.
26

Conclusões
• Contribuição com a criação do modelo baseado em medição, que incorpora o efeito da carga de trabalho do sistema sobre os recursos do Sistema Operacional, para investigar os efeitos sobre o esgotamento de recursos;
• Melhoria em relação aos modelos que são puramente baseados em tempo;
• Validação do fenômeno “Envelhecimento de Software” em relação ao esgotamento de recursos;
• As estimativas obtidas dessas metodologias não podem ser consideradas como estimativas de tempos de falha de máquinas reais, pois podem depender de vários outros fatores.
27

Análise Crítica
• Embora as centroides estivessem relativamente próximas, o merge entre os clusters {1,2,3} e {4,5} podem ter gerado impacto nos resultados obtidos, pois foram reduzidos de 11 para 8 estados, para simplificar a computação.
28

REFERÊNCIA
• [1] Vaidyanathan, K. Trivedi, K.S. A Measurement-Based Model for Estimation of Resource Exhaustion in Operational Software Systems, 1999;
• [2] S. Garg, A. van Moorsel, K. Vaidyanathan, K. Trivedi. A Methodology for Detection and Estimation ofSoftware Aging. In Proc. of 9th Intnl. Symposium on Software Reliability Engineering, pages 282-292, Paderborn, Germany, November ,1998.[3] M. V. Devarakonda, and R. K. Iyer. Predictability of Process Resource Usage: A Measurement-Based Study on UNIX. IEEE Transactions on Computers, 15(12):1579-1586, December 1989.
• [4] M. C. Hsueh, R. K. Iyer, and K. S. Trivedi. Performability. Modeling Based on Real Data: A Case Study.IEEE Transactions on Computers, 37(4):478-484, April 1988.
• [5] Link http://www.seer.ufrgs.br/rita/article/viewFile/rita_v14_n2_p133-179/3544 acessado em19/04/2015.
• [6] Link https://sites.google.com/site/dataclusteringalgorithms/k-means-clustering-algorithm acessadoem 19/04/2015.
• [7] P. K. Sen. Estimates of the Regression Coefficient Based on Kendall’s Tau.Journal of the American Statistical Association, 63:1379–1389, 1968.
29