a virtual observatory for pulsar astronomy
TRANSCRIPT

Master Project Initial Report 2008-09
A Virtual Observatory for Pulsar Astronomy
Supervisor: Dr. John Brooke
MASTERS PROJECT INITIAL REPORT 2008-2009
Akshay M. SangodkarID: 7348050
Akshay Sangodkar ID: 7348050 1

Master Project Initial Report 2008-09
Table of ContentsAbstract.................................................................................................................................................3Introduction..........................................................................................................................................3Background...........................................................................................................................................4
Pulsars..............................................................................................................................................4Workflow for processing pulsar radio signals.................................................................................5
Architecture..........................................................................................................................................6Model for work distribution.............................................................................................................6High-level architectural view...........................................................................................................7Workflows........................................................................................................................................8Risk analysis..................................................................................................................................10
Tools...................................................................................................................................................11g-Eclipse........................................................................................................................................11
Authentication and authorisation .............................................................................................11Grid project...............................................................................................................................13Job submission and monitoring.................................................................................................14Workflow builder......................................................................................................................16Grid application deployment.....................................................................................................17
SIGPROC.......................................................................................................................................17Project Plan.........................................................................................................................................18Conclusion..........................................................................................................................................20References..........................................................................................................................................21Appendix I..........................................................................................................................................22
Akshay Sangodkar ID: 7348050 2

Master Project Initial Report 2008-09
AbstractElectromagnetic signals received by a radio telescope need to be processed in order to detect existence of pulsars. The processing is highly resource intensive. This report discusses the feasibility of running parallel workflows on the Grid. It describes an architecture which can invoke workflows that are resource-aware and can efficiently utilise the power of the Grid resources. Workflow models are compared and evaluated. In a diverse distributed Grid environment, a software application should be robust and fault-tolerant. Therefore, the risk factors have been examined. g-Eclipse [1] is described in detail because it is an integrated Grid environment which will be used to develop and manage workflows.
IntroductionRadio telescopes observing or searching for pulsars receive electromagnetic signals. These signals are weak and spread across a wide frequency spectrum. In order to detect a pulsar, these signals need to be combined in different frequency bands. Complex algorithms need to be applied to observe pulsar signal characteristics. These algorithms are computationally expensive. Earlier, algorithms were applied on a set of distributed supercomputers using Internet-aware Message Passing Interface (MPI) [2]. Workflows were implemented using real-time parallelism on dedicated clusters. These were developed using PACX-MPI [3] as an unconventional workflow language. Parallelism is necessary because the exploration of new pulsars is in a large parameter space spanning multiple frequency bands. Computational efficiency can be achieved if the parameter space is divided and processed in parallel.
The current work on Service Oriented Architecture (SOA) based Grid middlewares has leveraged the possibility of creating workflows based on services. Parallelism in a workflow can be achieved by instantiating multiple independent worker services. These services can specify resource requirements such as a dedicated number of processors, software requirements, environment variables, estimated time for execution etc. Hence, a workflow processing radio signals on a Grid to detect pulsars, characterises a virtual observatory.
The report describes the architecture and tools to be used to invoke workflows in a Grid. It also describes and evaluates workflow approaches which can efficiently utilise the Grid resources. The tools include g-Eclipse which is an integrated Grid environment. It provides a user-friendly interface and tools, to connect and manage jobs submitted to the Grid. It has a collection of editors and wizards which facilitate development of Grid applications and workflows. The architecture uses g-Eclipse to connect to gLite [4] middleware to submit workflows for pulsar processing.
Akshay Sangodkar ID: 7348050 3

Master Project Initial Report 2008-09
Background
Pulsars
Pulsars are neutron stars emitting concentrated beams of electromagnetic radiation from its radio-emitting region. As shown in the Figure 1, the centre of the neutron star has a powerful magnetic field, O(1012)Gauss. These rotate rapidly and if the direction of the radiation beam is not aligned with the rotational axis then it characterises the working of a lighthouse. This radiation beam is picked up as a radio signal by a telescope on the earth, if it coincides periodically with the line of sight between the earth and the pulsar. These periodic signals can act as highly accurate clocks because of the frictionless rotation of massive and condensed star mass. Pulsar astronomy is described comprehensively in [5].
Figure 1: Illustration of a pulsar.
When a pulsar radio signal is received at a radio telescope, a periodic increase in the broadband radio noise is observed. The radio signal travels through charged interstellar medium which has a frequency-dependent refractive index. This means that the higher frequency radio waves travel faster through the medium than those at a lower frequency. As a result, in the frequency spectrum that the radio telescope is tuned into, it receives the radio signal earlier in the higher frequency than the lower frequency. This is called dispersion. In order to observe the “pulse profile” (periodic detection of radio waves), the dispersion from the received signal needs to be cleaned. Several dispersion measures (DMs) are applied to the received signal depending on the distance between the earth and the pulsar, and the charge density of the interstellar medium along the path of the signal. Terrestrial noise is also a part of the received signal, but it is not affected by the interstellar dispersion and hence can be removed.
Applying multiple DM to a received radio signal, real-time computing, storing and re-analysing requires high computing power and storage space. This problem is important in both astronomical as well computational science perspective. In [6], the aspects of pulsar observation are described in detail.
Akshay Sangodkar ID: 7348050 4

Master Project Initial Report 2008-09
Workflow for processing pulsar radio signals
The chapter, Workflows in Pulsar Astronomy by Brooke et al. in the book [7], describes a workflow to analyse stored radio telescope signals received from pulsars and how parallelism can be introduced during the de-dispersion stage of the workflow.
Figure 2: Workflow to analyse stored radio telescope signals from pulsars. [Taken from the chapter, Workflows in Pulsar Astronomy by Brooke et al. in the book [7]]
The antenna of a radio telescope gathers electromagnetic radiation by focussing at a particular region in the sky. This is called a pointing. It receives a signal in a range of frequencies from the pointing which is then stored as one or more beams. Each beam has a range of frequencies with an upper limit, depending on the smoothness of the received signal. If the received signal surface is rough with respect to the wavelength, then it will be scattered across multiple beams.
The received radio signal contains interference due to terrestrial noise and the noise generated from the antenna. Such interferences are not affected by interstellar dispersion and are cleaned. Digital sampling is applied to the analog signal and stored. As shown in Figure 2, beams are read from the repository and passed over to the de-dispersion stage of the workflow. The radio signal contains dispersion which is caused due to the charged interstellar medium along its path towards the earth. The radio waves at a higher frequency travel faster and reach the earth earlier than those at a lower frequency. DMs are applied to each beam. If unknown pulsars are being searched then a specific DM is not known before hand, hence a range of DMs are applied on an trial and error basis. Fourier transforms are applied to each de-dispersed beam in the next stage. Fourier transforms correct Doppler shifting of frequency due to orbital acceleration. For example, some exotic pulsars belong to a binary star system, such as a pulsar and a normal star, a pulsar and a white dwarf etc., which rotate along an orbit. There may be different types of orbits depending on the pulsar period and the orbit period. Fourier transforms need to be applied to correct the radio signals received from such binary star systems in order to observe the “pulse profile”. Again, for unknown pulsars, a range of fast Fourier transforms (FFTs) need to be applied.
We observe that there is ample opportunity to introduce parallelism during the de-dispersion stage of the workflow which involves application of multiple independent DMs and FFTs. After FFTs are applied to the beam, raw files are generated for each trial DM which are then passed to the post-analysis and visualization stage to determine the presence of periodic signals. These raw files may
Akshay Sangodkar ID: 7348050 5
Master Project Initial Report 2008-09
represent pulsars, terrestrial interference or the noise due to the antenna and other equipment. Further observations determine whether they are confirmed or rejected.
Architecture
Model for work distribution
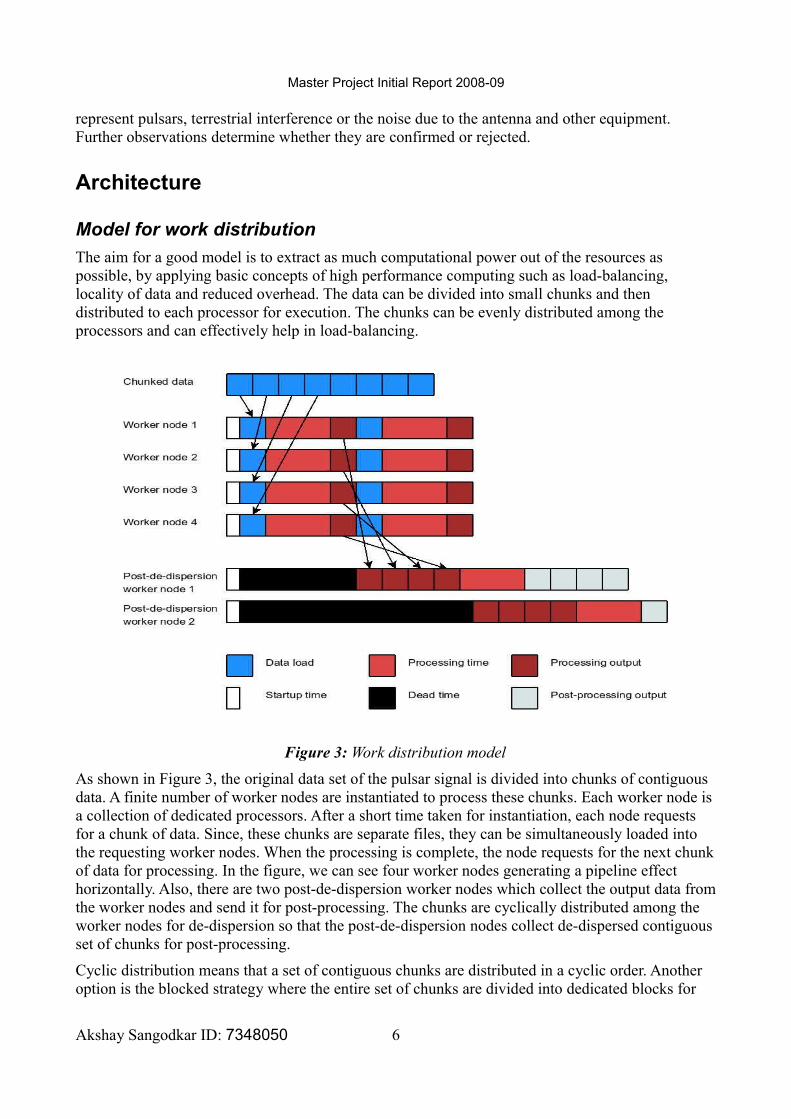
The aim for a good model is to extract as much computational power out of the resources as possible, by applying basic concepts of high performance computing such as load-balancing, locality of data and reduced overhead. The data can be divided into small chunks and then distributed to each processor for execution. The chunks can be evenly distributed among the processors and can effectively help in load-balancing.
Figure 3: Work distribution model
As shown in Figure 3, the original data set of the pulsar signal is divided into chunks of contiguous data. A finite number of worker nodes are instantiated to process these chunks. Each worker node is a collection of dedicated processors. After a short time taken for instantiation, each node requests for a chunk of data. Since, these chunks are separate files, they can be simultaneously loaded into the requesting worker nodes. When the processing is complete, the node requests for the next chunk of data for processing. In the figure, we can see four worker nodes generating a pipeline effect horizontally. Also, there are two post-de-dispersion worker nodes which collect the output data from the worker nodes and send it for post-processing. The chunks are cyclically distributed among the worker nodes for de-dispersion so that the post-de-dispersion nodes collect de-dispersed contiguous set of chunks for post-processing.
Cyclic distribution means that a set of contiguous chunks are distributed in a cyclic order. Another option is the blocked strategy where the entire set of chunks are divided into dedicated blocks for
Akshay Sangodkar ID: 7348050 6
Master Project Initial Report 2008-09
each worker node. A worker node gets a chunk of data from its own dedicated block. This strategy is not advantageous because then, the post-de-dispersion nodes cannot collect a contiguous set of chunks for post-processing. If we just post-process one output chunk of a block at a time then we will not use the full processing power of the post-de-dispersion node in a processing cycle.
Post-processing requires lesser processing power therefore we instantiate fewer post-de-dispersion nodes and process more chunks at a time. This is a work distribution model which is similar to the client-server model in [7] but, it eliminates the dead time observed due to sequential loading of data into the clients via the servers. This model can be extended to support varying number of worker nodes, processors, memory etc.
High-level architectural view
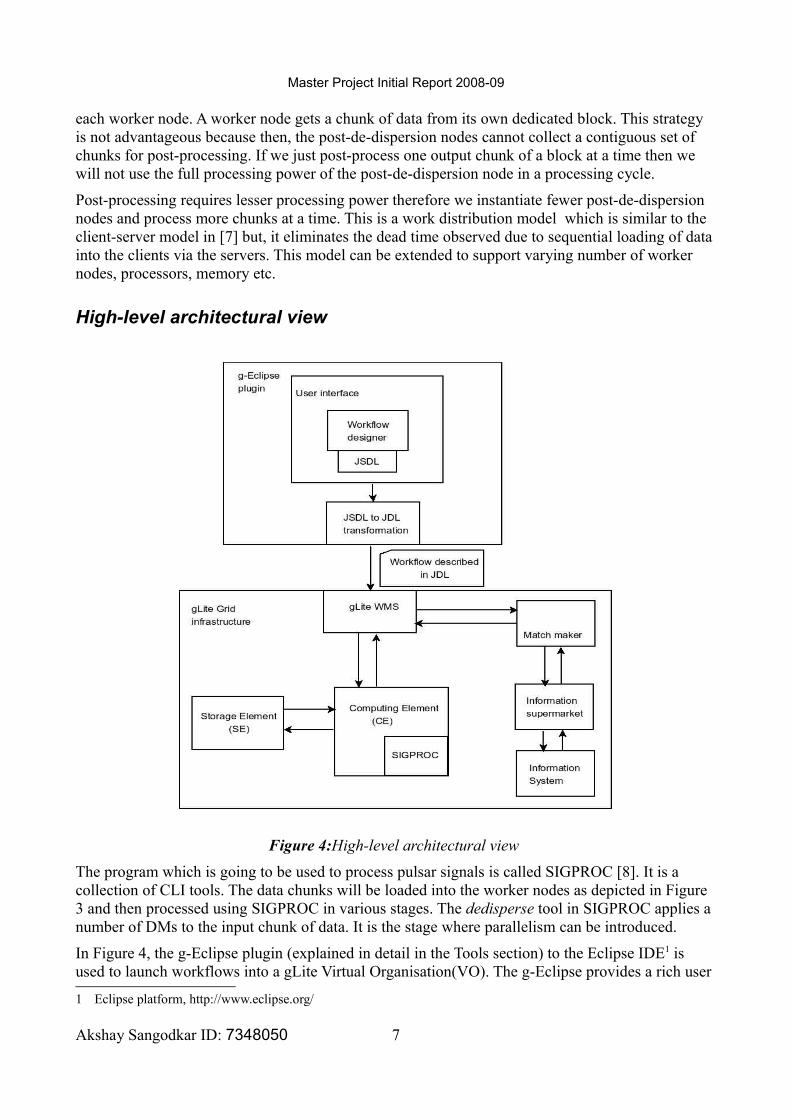
Figure 4:High-level architectural view
The program which is going to be used to process pulsar signals is called SIGPROC [8]. It is a collection of CLI tools. The data chunks will be loaded into the worker nodes as depicted in Figure 3 and then processed using SIGPROC in various stages. The dedisperse tool in SIGPROC applies a number of DMs to the input chunk of data. It is the stage where parallelism can be introduced.
In Figure 4, the g-Eclipse plugin (explained in detail in the Tools section) to the Eclipse IDE1 is used to launch workflows into a gLite Virtual Organisation(VO). The g-Eclipse provides a rich user
1 Eclipse platform, http://www.eclipse.org/
Akshay Sangodkar ID: 7348050 7

Master Project Initial Report 2008-09
interface and a Grid middleware independent framework to connect to various existing Grid infrastructures. Jobs are described in the form of Job Service Description Language (JSDL) [9] which is Grid middleware independent and defined by the OGF2. Its user interface supports creation of workflows as a diagrammatic representation, direct acyclic graph (DAG), consisting of jobs and directed connectives. Dependency between a job pair is described using a directed connective.
gLite is a Grid middleware which provides SOA-based Grid services. Researchers can access the vast geographically distributed computing and storage resources using these services. Jobs can be submitted using the Job Description Language (JDL) [10] to the gLite infrastructure through a gLite Workload Management System (WMS). Since gLite does not accept jobs described in JSDL, g-Eclipse automatically transforms it to JDL before submitting. The g-Eclipse framework can be extended to transform jobs described in JSDL in the UI to any existing Grid middleware dependent language. This ability makes g-Eclipse an integrated Grid environment for connecting to Grid resources and developing applications.
When a job is submitted to the gLite WMS, it will try to choose the best suiting Computing Element (CE) which matches the resource requirements in the job description. A CE is a collection of computing resources such as a cluster, which is local to a site. Matching is done using the cached information at the Information Supermarket. Information Supermarket contains the information about the current status of the computing and storage resources. The WMS then prepares the job for submission to the matched CE. The CE then receives the job, gathers all the required files, sets up the environment and then submits the job for execution. More detailed information on the working of gLite can be found in [11].
Workflows
In Figure 3, we saw how the chunks of pulsar signal data set can be distributed among worker nodes. We will now discuss and evaluate some possible model of workflows to execute the jobs.
Figure 5: Workflow using data collector mechanism
2 Open Grid Forum, http://www.ogf.org/
Akshay Sangodkar ID: 7348050 8

Master Project Initial Report 2008-09
Figure 5 shows that, the entire work of de-dispersion of the pulsar signal data set, can be sub-divided into a collection of worker nodes. Each worker node can specify the resource requirements such as the processor count, the operating system, the main memory size, the execution time required etc. Each worker node instantiated will be independent of other worker nodes. A data collector node will be instantiated, in order to manage the chunks of data being sent to the worker nodes. When a worker node is instantiated, it will request the data collector node for a chunk of data. The data collector will then lookup for the next chunk to be processed and respond to the worker node with a specific URI for the chunk. The worker node then will download the chunk and process it. Some post-de-dispersion worker nodes will also be instantiated to collect the output data from the worker nodes and start post-processing. The post-de-dispersion worker nodes request the data collector for a set of de-dispersed chunks generated by the worker nodes after a processing cycle.
Figure 6: Workflow which assigns jobs to worker nodes prior to submission
In the workflow shown in Figure 6, the collector mechanism is not needed. The pulsar signal data set can be divided into multiple files (chunks) of a desired size (size determined by the duration of the pulsar signal in seconds) using the filterbank tool in SIGPROC. Each file will have a specific URI known prior to job submission. Hence, a workflow can be generated using g-Eclipse. For example, lets say the data set is divided into nine chunks named as File 1 to File 9 as shown in the above figure. Then we can generate a workflow which instantiates three worker nodes. Each worker node will have three jobs to be instantiated in sequence. Each job will process (apply DM) to a unique file (chunk) and generate output. The number of worker nodes can be decided depending on the number of processors reserved at the CE to run the entire workflow. The number of jobs in each node can be decided depending upon the number of processors dedicated to a worker node.
In g-Eclipse, a workflow can describe a dependency between a pair of jobs. A dependent job will start only after its parent job has completed execution. Hence, we can generate a pipeline of jobs
Akshay Sangodkar ID: 7348050 9

Master Project Initial Report 2008-09
within a worker node. Also, dependency can be asserted on the post-de-dispersion nodes to start execution only after the relevant de-dispersion jobs have completed execution.
This workflow model is advantageous than the workflow in Figure 5 because we do not need additional collector mechanism to manage the sending of chunks to each worker node and to send the output data for post-processing. Hence, it will be used during the development phase.
Risk analysis
The Grid infrastructure can be unreliable, especially due to the vast geographically distributed computing resources, storage resources, instrumentation and connectivity. A running application may experience problems due to factors such as unreliable communication bandwidth, crashing of requisite software, changes made by administrator, processor malfunctioning etc. In Figure 6, a failure of a worker node may leave it in an inconsistent state. In such a case, the workflow should be able to re-instantiate the worker node and continue processing. A mechanism is needed which can make the system robust and fault-tolerant.
Figure 7: Queuing structure
A queuing structure is used in AQuA[12], which is an object-based storage device, to control and maintain consistent data-transfer rates to clients. A similar queuing structure can be used for fault-tolerance in a workflow as shown in Figure 7.
A queue hierarchy is maintained having a root queue and a set of second level queues. The root queue will represent the entire workflow and the second level queues will represent the individual worker nodes. In Figure 6, each worker node has a set of jobs which process a unique file. Correspondingly, the worker node queue will have entries of the files to be processed. When a worker node completes a job, it will remove the corresponding entry in its dedicated queue. All post-processing worker nodes will share one post-processing worker node queue. Each entry in the queue will be a set of files that will be processed by a post-processing worker node at a time. When a post-processing worker node has completed its work, it will remove the corresponding entry in the queue. The root queue will have entries of all the files and the set of files (for post-processing). Whenever any entry is removed from the second level queues, the corresponding entry will also be removed from the root queue.
Akshay Sangodkar ID: 7348050 10

Master Project Initial Report 2008-09
If a job in a worker node fails, then the corresponding entry in the second level queue and the root queue will not be removed. A mechanism at the root queue can detect that a job has failed and other dependent jobs have starved. This way we can detect a worker node malfunction and re-instantiate it.
Tools
g-Eclipse
The need for computational power and storage requirements have increased tremendously which has given way to the development of Grid infrastructure. In order to coordinate and manage such large distributed resources, several Grid middlewares have been developed. Earlier, the primary focus was to develop the core services required to work with the underlying Grid infrastructure. Basically, they were command-line interfaces which were used mostly by the people who developed them. GUIs have been developed to connect to these CLIs, but mostly they are middleware dependent.
The popularity and usefulness of the Grid has rapidly increased the number of potential users. A user-friendly interface is needed for the inexperienced users to connect to the Grid. The g-Eclipse is a user-friendly integrated Grid environment which has a Grid middleware independent framework. It can be used to develop Grid applications and connect to Grid resources. It has been built as a plugin to the Eclipse platform, which is an IDE for software development. Currently, it provides connectives to middlewares such as gLite, Globus[14], GRIA[15] and AWS[16] [13]. The framework provided by g-Eclipse can be extended, to incorporate the functionality to connect to new middlewares.
The g-Eclipse plugin was used to submit jobs and workflows using the tutorials provided by the g-Eclipse team[17, 18, 19]. The following describes the important features of g-Eclipse and the experiences while working with it.
Authentication and authorisation
In order to connect to a gLite infrastructure, the g-Eclipse needs to be configured using a Certification Authority (CA) certificate, the VO settings and a signed personal certificate. The CA certificate is mostly available at the CA website. This certificate is imported into the internet browser and the g-Eclipse. A personal certificate is generated using the same browser. This new personal certificate is sent to the CA for signing. The CA then signs the certificate using its private key, hence anybody who has the CA's public key can authenticate the signed certificate. A personal certificate signed by a CA is required for authentication at the gLite WMS.
Akshay Sangodkar ID: 7348050 11

Master Project Initial Report 2008-09
Figure 8: VOMS VO connection settings
Connection settings can be taken from a VO manager or can be imported from the VOMS (Virtual Organisation Membership Service) [11] repository. A VOMS repository maintains the information of roles and privileges of users, of VOMS-aware VOs. Figure 8 shows the settings to connect to the geclipsetutor VO.
Also, the user needs to register at the VO by sending the public key to the VO manager. The manager then assigns the privileges to the user to use the VO.
Figure 9: Proxy certificates
When a job is submitted to the gLite VO, the user needs to prove his identity by using the signed personal certificate and also a VOMS proxy certificate. This is because a remote service may need to communicate with another service on the user's behalf. A proxy certificate will enable the remote service to prove its entitlement to work on the user's behalf. First a public/private key pair is generated locally and then a new proxy certificate is built having the public key and a Subject Name (SN) having the user's information. When the proxy certificate is activated, the one of the VOMS servers is contacted to get an Attribute Certificate (AC) containing the information about the user's role and privileges at the gLite VO. The AC is then embedded into the proxy certificate. It is then signed by the user's personal private key. When a job needs to be submitted from gEclipse to the gLite VO then, the proxy certificate, the private key for the proxy certificate and the user's personal certificate are sent along with it. The user's private key is never shared. Figure 9 shows two proxy certificates generated in the Authentication Tokens tab. It is a security risk to send the private key with the proxy certificate, but these are time limited. Therefore, long term harm can be avoided.
Akshay Sangodkar ID: 7348050 12

Master Project Initial Report 2008-09
Grid project
A g-Eclipse Grid project is an entity which has a structure suited to manage jobs, workflows, files, resources etc. A project is created for a single VO. In Figure 10, the project is created for the geclipsetutor VO. A virtual folder representing the VO is created in the project structure having the name of the VO. This folder is a virtual representation of the VO infrastructure and gives detailed information about Computing Elements (CE), Storage Elements (SE), installed applications and other services. A CE is a collection of computing resources such as a cluster, which is local to a site. A SE provides virtual links to the storage resources available at the VO. Researchers require certain applications to be deployed at every CE in a VO, so that experiments can be run using all the computational power. These applications are listed in the Applications folder. Other services include information services, job services etc. Information services provide access to information servers, which in turn provide detailed information about the VO. Job services are the available gLite WMS to which a job can be submitted for execution.
A user can create a connection to any SEs available to allocate and access a personal user space. When an attempt was made to create a personal folder at an SE, only “iwrse.fzk.de” allowed access. All other SEs rejected the request. When a user is granted access to a VO, the access should be consistent with all the resources the VO is collaborating with.
When a connection is established at an SE, it appears in the Connections folder in the Grid project. This connection is like an ordinary folder on the local system. Files can be created, edited, moved in , moved out and deleted. Job Descriptions folder contains a list of jobs created in JSDL/JDL in the local workspace. When these jobs are submitted to the gLite, a new entry is created in the Jobs folder. This entry contains the submitted JSDL/JDL jobs, the files staged-in and the files staged out. Workflows folder contains a list of workflow jobs in the local workspace. When a workflow is submitted, a new entry is created in the jobs folder.
Figure 10: Grid project
Akshay Sangodkar ID: 7348050 13

Master Project Initial Report 2008-09
Job submission and monitoring
When a new job is created, an entry is created in the Job Descriptions folder in the Grid project. The job is described in JSDL by default. As shown in the Figure 11, the job EnvJob1.jsdl is opened in a multi-page JSDL editor. Each page is a collection of settings which can be specified in the job. The editor is very user-friendly and provides an easier way to create and describe a job. The tabs to each page can be found in the bottom-left corner. The Overview page gives a brief introduction of the other pages in the editor.
The job can be transformed from the JSDL format to the JDL format as shown in Figure 12. This job runs the command /usr/bin/env at the CE and returns the output to a file wf_env_out in the user space at the SE. The staging-in and staging-out of files is described in the InputSandbox and OutputSandbox constructs respectively in JDL. Multiple CEs may be defined under a single VO. The JDL file in Figure 12 specifies that the job requirement is that it should be submitted to the CE having the name iwrce.fzk.de.
When this job was submitted without the requirement of a specific CE, it was by default redirected to a CE having the name gilda-01.pd.infn.it. The job would fail consistently due to some authorisation issues. When a specific CE requirement was asserted in the job, it would then get submitted to that CE. It was observed that although all the CEs belong to the geclipsetutor VO, each CE has a dedicated administrator. Hence, a user's roles and permissions may not be applied to all the resources. Moreover, each CE has its own dedicated support team. Each team had to be approached separately; inter-team (inter-CE) support was lacking. It was noted that a single manager for the geclipsetutor VO was a necessity.
Figure 11: Multi-page JSDL editor
Akshay Sangodkar ID: 7348050 14

Master Project Initial Report 2008-09
Figure 12: Job described in JDL
When a job is submitted to gLite, the JSDL job gets automatically transformed into JDL, which gLite understands. An entry is created in the Jobs folder in the Grid project. Also, the status of the submitted jobs can be viewed in the Jobs tab shown in Figure 13.
Figure 13: Jobs tab showing submitted job information
The statuses of submitted jobs are mentioned in detail in the Table 1 [11]. If a submitted job fails then it is resubmitted automatically until allowed resubmission limit has reached. The resubmission count can also be mentioned in the job description.
Job submission status Description
SUBMITTED A job is submitted to the gLite WMS and the files mentioned in the InputSandbox are copied initially to WMS.
WAITING The WMS queries the Information Services to find a CE which matches the job requirements.
READY The WMS readies the job by creating a job-wrapper with required instructions and sending it to the selected CE.
SCHEDULED The CE submits the job to a local Worker Node after receiving the instructions from the WMS.
RUNNING The files mentioned in the InputSandbox are copied from the WMS to the Worker node and execution starts.
DONE Indicates that the job has executed successfully. The files mentioned in the OutputSandbox are copied back to the gLite WMS.
CLEARED The output can now be retrieved.
ABORTED Some error has occurred and the job has failed.Table 1: Submitted job statuses
Akshay Sangodkar ID: 7348050 15

Master Project Initial Report 2008-09
The Logging and Bookkeeping service in gLite is always active in the background. It keeps track of the events and logs the status of the submitted job. The logs maintained by the service can be retrieved during job execution using g-Eclipse UI. Appendix I is a log for the job EnvJob1.jsdl after its successful completion.
Workflow builder
The workflow builder UI in g-Eclipse provides an easy way to create workflows. In Figure 14, a simple workflow is shown where two JSDL jobs interact with each other. The EnvJob1 job runs the command /usr/bin/env at the submitted CE and retrieves all the environment variables at the CE in the output file. The GrepJob1 job runs the command /bin/grep with an argument “HOME” on the output file generated by EnvJob1 job and generates the output. The workflow palette on the right is used to generate workflows. A job can be added in the workflow using the Workflow Job icon. Input Port and Output Port icons describe the staging-in and staging-out of files in a workflow job respectively. The Link icon is used to connect an output port of a workflow job to an input port of another workflow job. This introduces dependency between the linked jobs. Once the output port generates a file, the dependent job can then retrieve the file at the input port and start running.
When a workflow is submitted to gLite, an entry is created at the Jobs folder and the Jobs tab. The entry contains the workflow file and the workflow jobs as shown in Figure 14.
The JDL version of the workflow is shown in Figure 15. It describes both the workflow jobs which is similar to that of a standalone job description. It also has a Dependencies construct which specifies the dependencies among the included workflow jobs. In JDL, a workflow is represented as a direct acyclic graphs (DAG). Hence, the type of the workflow is defined as Type=”dag”.
Figure 14: Workflow builder
Akshay Sangodkar ID: 7348050 16

Master Project Initial Report 2008-09
Figure 15: Workflow job in JDL
Grid application deployment
Sometimes, Grid users have to install a software at a specific CE before they can run a job. In gLite, deployment of requisite software on a specific CE is done using job submission. The g-Eclipse provides deployment wizards to assist users in the deployment process. In gLite, the users have to write a script which describes how to install/uninstall a software on a specific CE. The deployment wizard accepts this script and proceeds for deployment. This may be an option to deploy SIGPROC at a CE before submitting a job.
SIGPROC
SIGPROC is a set of tools designed to process electromagnetic signals received from a radio telescope and facilitate the search for “pulsar profiles”. The tool used for chunking of the raw pulsar signal dataset is called the filterbank program. The pulsar signal received by the radio telescope for a particular duration is stored as a raw dataset. This dataset can be divided into smaller chunks using filterbank by specifying the chunk size (duration in seconds). For example, the following command takes the rawdata as the input. The filterbank program then skips 10 seconds of data and then reads for the next 20 seconds indicated by -s and -r options respectively. The resultant dataset is stored in chunk1.
% filterbank rawdata -s 10.0 -r 20.0 > chunk1
Multiple chunks of the raw dataset can be generated and then assigned to individual jobs for processing as shown in Figure 6. Each processing job will use tools such as dedisperse to apply a specific DM and FFTs, to generate a de-dispersed output dataset. The other post-processing tools in SIGPROC can be applied to the output dataset in the post-de-dispersion worker nodes. The post-processing output can then be used for off-line analyses to detect and visualize pulsars.
Akshay Sangodkar ID: 7348050 17

Master Project Initial Report 2008-09
Project PlanThe project is based on a software development life cycle model which is derived from the waterfall model and the incremental model. As shown in Figure 16, the requirement gathering, design, development, integration, testing and acceptance phases belong primarily to the waterfall model. But the development, testing and integration phases are performed incrementally. At the time of writing this report the requirement gathering and the design phases have been completed. One component of the workflow at a time will be developed, tested and integrated, before the next component is developed. This incremental approach will help in achieving the milestones more effectively. Any shortfall in meeting a milestone can be detected early and addressed appropriately.
Figure 16: SDLC for the project
The Gantt chart describing the project plan is shown in Figure 17.
Figure 17: Gantt chart describing the project plan
Akshay Sangodkar ID: 7348050 18

Master Project Initial Report 2008-09
Requirement gathering and design phases have been completed. This includes the background study, learning g-Eclipse and gLite, developing a suitable architecture and workflow models to process pulsar signals et al. Milestones are indicated as diamonds in the chart. Development and testing phase will take around two months to complete. Setting up of an account in a Grid such as the National Grid Service (NGS)3 may take some days due to creation and signing of certificates and becoming a member of a VO. Therefore, 11 days have been marked for setting up of account and obtaining the required permissions. A break of 12 days from 11th May 2009 to 23rd May 2009 is considered because of the second semester examinations. There are two major milestones during this phase. First, the implementation of the workflow model in Figure 6 must be ready and tested by 29th June 2009. This will mark the end of one iteration of the development and testing cycle. In the second iteration, the queuing structure as shown in Figure 7 will enter development phase. The second milestone on 20th July 2009 is achieved when the queuing structure is implemented and tested successfully. This will mark the end of the second iteration of the development and testing cycle.
The entire workflow implementation will then have to be approved through acceptance testing. The buffer time contains a few days meant for catching up if the project is lagging behind. Around one month is allocated to write up the dissertation before the submission deadline on 7th September 2009.
3 National Grid Service (NGS), http://www.grid-support.ac.uk/
Akshay Sangodkar ID: 7348050 19

Master Project Initial Report 2008-09
ConclusionThe dataset extracted from the output of the pulsar signal received from a radio telescope, contains a weak “pulse profile” signal embedded within the noise. Intensive computing is required to search for a new pulsar from such a dataset. The described architecture includes g-Eclipse, SIGPROC and gLite middleware and it is feasible. It will be used to instantiate workflows for processing the pulsar data. Parallelism will be achieved using the workflow models described. Each workflow will be resource-aware such that, the Grid resources which it uses, satisfy the job's requirements. An application running on a diverse distributed Grid infrastructure should be robust and fault-tolerant. The queuing structure will be used so that a failed node is re-instantiated and pending work is completed. The g-Eclipse is an integrated Grid environment and will be used to submit jobs to gLite and manage them. Tools and wizards in the g-Eclipse to create and deploy Grid applications, will be used. The workflow builder in the g-Eclipse is a user-friendly tool and will be used to quickly generate workflows.
Akshay Sangodkar ID: 7348050 20

Master Project Initial Report 2008-09
References[1] Wolniewicz, P., Meyer, N., Stroiński, M., Stümpert, M., Kornmayer, H., Polak, M., et al. (2007). Accessing Grid computing resources with g-Eclipse platform. Computational Methods in Science and Technologies , 13 (2), 131-141.
[2] Pickles, S. M., Brooke, J. M., Costen, F. M., Gabriel, E., Müller, M., Resch, M., et al. (2001). Metacomputing across intercontinental networks. Future Generation Computer Systems , 17, 911–918.
[3] Brune, M. A., Fagg, E. G., & Resch, M. M. (1999). Message-passing environments for metacomputing. Future Generation Computer Systems , 15, 699–712.
[4] (n.d.). Retrieved April 25, 2009, from gLite: http://glite.web.cern.ch/glite/
[5] Lyne, A. G., & Smith, G. (2005). Pulsar Astronomy (3rd edition ed.). Cambridge: Cambridge University Press.
[6] Lorimer, D., & Kramer, M. (2005). A Handbook of Pulsar Astronomy. Cambridge: Cambridge University Press.
[7] Taylor, I. J., Deelman, E., Gannon, D. B., & Shields, M. (2007). Workflows for e-Science: Scientific Workflows for Grids. London: Springer-Verlag London Limited.
[8] Lorimer, D. (2006, March 25). SIGPROC v3.7: (Pulsar) Signal Processing Programs. Retrieved April 25, 2009, from http://sigproc.sourceforge.net/sigproc.pdf
[9] Job Submission Description Language (JSDL) Specification, Version 1.0. (n.d.). Retrieved April 25, 2009, from http://www.gridforum.org/documents/GFD.56.pdf
[10] Job Description Language Attributes Specification. (n.d.). Retrieved April 25, 2009, from https://edms.cern.ch/file/590869/1/EGEE-JRA1-TEC-590869-JDL-Attributes-v0-9.pdf
[11] gLite 3.1 User Guide. (n.d.). Retrieved April 25, 2009, from https://edms.cern.ch/file/722398//gLite-3-UserGuide.pdf
[12] Wu, J. C., & Brandt, S. A. (2006). The design and implementation of AQuA: an adaptive quality of service aware object-based storage device. In Proceedings of the 23rd IEEE / 14th NASA Goddard Conference on Mass Storage Systems and Technologies , 209—218.
[13] g-Eclipse User Guide. (n.d.). Retrieved April 25, 2009, from http://www.g-eclipse.eu/documentation/index.jsp?nav=/1
[14] Globus. (n.d.). Retrieved April 25, 2009, from http://www.globus.org/
[15] GRIA. (n.d.). Retrieved April 25, 2009, from http://www.gria.org/
[16] Amazon web services. (n.d.). Retrieved April 25, 2009, from http://aws.amazon.com/
[17] g-Eclipse Tutorial @ GridKA School 2008 Handout. (n.d.). Retrieved April 25, 2009, from http://www.geclipse.org/fileadmin/Documents/Documentation/gks08-handout.pdf
[18] Köckerbauer, T. (n.d.). Access the power of the Grid: Tutorial - Dornbirn. Retrieved April 25, 2009, from http://www2.staff.fh-vorarlberg.ac.at/~tf/grid/Notes/Grid_gEclipse.pdf
[19] Kornmayer, H. (n.d.). g-Eclipse Hands On. Retrieved from http://www.it.irf.tu-dortmund.de/IT/CoreGRID/talks/Kornmayer2.pdf
Akshay Sangodkar ID: 7348050 21

Master Project Initial Report 2008-09
Appendix ILogging and Bookkeeping service report for EnvJob1.jsdl**********************************************************************LOGGING INFORMATION:
Printing info for the Job : https://dgrid-rb.fzk.de:9000/urBZhZqrNSm2K1PEXO7sDw
---Event: RegJob- arrived = 25-Apr-2009 16:05:37- host = dgrid-rb.fzk.de- ns = https://141.52.170.92:7443/glite_wms_wmproxy_server- nsubjobs = 0- seed = - source = NetworkServer- src_instance = https://141.52.170.92:7443/glite_wms_wmproxy_server- timestamp = 25-Apr-2009 16:05:37- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar
---Event: RegJob- arrived = 25-Apr-2009 16:05:38- host = dgrid-rb.fzk.de- ns = https://141.52.170.92:7443/glite_wms_wmproxy_server- nsubjobs = 0- seed = - source = NetworkServer- src_instance = https://141.52.170.92:7443/glite_wms_wmproxy_server- timestamp = 25-Apr-2009 16:05:37- user = /C=DE/O=GermanGrid/OU=FZK/CN=host/dgrid-rb.fzk.de
---Event: Accepted- arrived = 25-Apr-2009 16:05:39- from = NetworkServer- from_host = host86-165-116-48.range86-165.btcentralplus.com- host = dgrid-rb.fzk.de- source = NetworkServer- src_instance = https://141.52.170.92:7443/glite_wms_wmproxy_server- timestamp = 25-Apr-2009 16:05:39- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar
---Event: EnQueued- arrived = 25-Apr-2009 16:05:39- host = dgrid-rb.fzk.de- queue = /var/glite/workload_manager/input.fl- result = START- source = NetworkServer- src_instance = https://141.52.170.92:7443/glite_wms_wmproxy_server- timestamp = 25-Apr-2009 16:05:39- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar
---Event: EnQueued- arrived = 25-Apr-2009 16:05:39- host = dgrid-rb.fzk.de- queue = /var/glite/workload_manager/input.fl- result = OK- source = NetworkServer- src_instance = https://141.52.170.92:7443/glite_wms_wmproxy_server- timestamp = 25-Apr-2009 16:05:39- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar
---Event: DeQueued- arrived = 25-Apr-2009 16:05:40- host = dgrid-rb.fzk.de- local_jobid = - queue = /var/glite/workload_manager/input.fl- source = WorkloadManager- src_instance = 27124- timestamp = 25-Apr-2009 16:05:39- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: Match- arrived = 25-Apr-2009 16:05:40- dest_id = iwrce.fzk.de:2119/jobmanager-lcgpbs-dgiseq- host = dgrid-rb.fzk.de- source = WorkloadManager- src_instance = 27124- timestamp = 25-Apr-2009 16:05:40- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: EnQueued- arrived = 25-Apr-2009 16:05:40- host = dgrid-rb.fzk.de- queue = /var/glite/jobcontrol/queue.fl- result = START- source = WorkloadManager- src_instance = 27124- timestamp = 25-Apr-2009 16:05:40- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: EnQueued- arrived = 25-Apr-2009 16:05:40- host = dgrid-rb.fzk.de
Akshay Sangodkar ID: 7348050 22

Master Project Initial Report 2008-09
- queue = /var/glite/jobcontrol/queue.fl- result = OK- source = WorkloadManager- src_instance = 27124- timestamp = 25-Apr-2009 16:05:40- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: DeQueued- arrived = 25-Apr-2009 16:05:41- host = dgrid-rb.fzk.de- local_jobid = unavailable- queue = /var/glite/jobcontrol/queue.fl- source = JobSubmission- src_instance = unique- timestamp = 25-Apr-2009 16:05:41- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: Transfer- arrived = 25-Apr-2009 16:05:41- dest_host = localhost- dest_instance = /var/glite/logmonitor/CondorG.log/CondorG.1240390839.log- dest_jobid = unavailable- destination = LogMonitor- host = dgrid-rb.fzk.de- reason = unavailable- result = START- source = JobSubmission- src_instance = unique- timestamp = 25-Apr-2009 16:05:41- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: Transfer- arrived = 25-Apr-2009 16:05:42- dest_host = localhost- dest_instance = /var/glite/logmonitor/CondorG.log/CondorG.1240390839.log- dest_jobid = 18952- destination = LogMonitor- host = dgrid-rb.fzk.de- reason = unavailable- result = OK- source = JobSubmission- src_instance = unique- timestamp = 25-Apr-2009 16:05:42- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: Running- arrived = 25-Apr-2009 16:09:05- host = iwrwn02.fzk.de- node = iwrwn02.fzk.de- source = LRMS- timestamp = 25-Apr-2009 16:07:22- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar
---Event: Done- arrived = 25-Apr-2009 16:09:05- exit_code = 0- host = iwrwn02.fzk.de- reason = (nil)- source = LRMS- src_instance = - status_code = OK- timestamp = 25-Apr-2009 16:07:32- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar
---Event: Accepted- arrived = 25-Apr-2009 16:05:45- from = JobSubmission- from_host = localhost- host = dgrid-rb.fzk.de- source = LogMonitor- src_instance = unique- timestamp = 25-Apr-2009 16:05:45- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: Transfer- arrived = 25-Apr-2009 16:06:03- dest_host = iwrce.fzk.de:2119/jobmanager-lcgpbs- dest_instance = /var/glite/logmonitor/CondorG.log/CondorG.1240390839.log- dest_jobid = unavailable- destination = LRMS- host = dgrid-rb.fzk.de- reason = Job successfully submitted to Globus- result = OK- source = LogMonitor- src_instance = unique- timestamp = 25-Apr-2009 16:06:03- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: Running- arrived = 25-Apr-2009 16:09:32- host = dgrid-rb.fzk.de- node = gt2 iwrce.fzk.de:2119/jobmanager-lcgpbs- source = LogMonitor
Akshay Sangodkar ID: 7348050 23

Master Project Initial Report 2008-09
- timestamp = 25-Apr-2009 16:09:28- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: ReallyRunning- arrived = 25-Apr-2009 16:11:39- host = dgrid-rb.fzk.de- source = LogMonitor- src_instance = unique- timestamp = 25-Apr-2009 16:11:39- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
---Event: Done- arrived = 25-Apr-2009 16:11:39- exit_code = 0- host = dgrid-rb.fzk.de- reason = Job terminated successfully- source = LogMonitor- src_instance = unique- status_code = OK- timestamp = 25-Apr-2009 16:11:39- user = /C=IT/O=GILDA/OU=Personal Certificate/L=The University of Manchester/CN=Akshay Sangodkar/CN=proxy/CN=proxy
Akshay Sangodkar ID: 7348050 24