abstracts - university of michiganncellis/nickellis/publications_files... · as german (wimmer...
TRANSCRIPT

Reading Research QuarterlyVol 39 No 4
OctoberNovemberDecember 2004copy 2004 International Reading Association
(pp 438ndash468)doi101598RRQ3945
The effects of orthographicdepth on learning to readalphabetic syllabic andlogographic scriptsNICK C ELLIS MIWA NATSUME KATERINA STAVROPOULOU LORENCHOXHALLARI VICTOR HP VAN DAAL NICOLETTA POLYZOE MARIA-LOUISA TSIPAMICHALIS PETALASUniversity of Wales Bangor United Kingdom
he problem of how to represent spoken language in writing has historically beensolved in different ways (Daniels amp Bright 1996 Gaur 1992) One distinction iswhether to ldquowrite what you meanrdquo or ldquowrite what you sayrdquo Logographic systemssuch as Chinese and Japanese kanji use symbols to represent meaning directly andhave no or comparatively few cues to pronunciation Other writing systems repre-sent speech sounds The characters of syllabic systems such as the Japanese kanacorrespond with spoken syllables whereas those of alphabetic systems correspondwith separate phonemes However alphabetic orthographies vary in the degree towhich they are regular in their representation of sound The writing systems ofSerbo-Croatian Finnish Welsh Spanish Dutch Turkish and German are on thewhole much more regular in symbolndashsound correspondences than those of Englishand French The former are referred to as transparent or shallow orthographies inwhich soundndashsymbol correspondences are highly consistent while the latter are re-ferred to as opaque or deep orthographies that are less consistent because each let-ter or group of letters may represent different sounds in different words
Do these different writing systems affect the ways in which children learn toread What if any are the effects of a written languagersquos writing system on rate ofliteracy acquisition The orthographic depth hypothesis (Katz amp Frost 1992)speaks to these questions because it postulates that shallow orthographies should beeasier to read using word-recognition processes that involve the languagersquos phonology
T
438
RRQ4-04 Ellis 92204 1151 AM Page 438
439
THIS STUDY investigated the effects of orthographic depth on reading acquisition in alphabetic syllabic and lo-gographic scripts Children between 6 and 15 years old read aloud in transparent syllabic Japanese hiragana al-phabets of increasing orthographic depth (Albanian Greek English) and orthographically opaque Japanese kanjiideograms with items being matched cross-linguistically for word frequency This study analyzed response accura-cy latency and error types Accuracy correlated with depth Hiragana was read more accurately than in turnAlbanian Greek English and kanji The deeper the orthography the less latency was a function of word length thegreater the proportion of errors that were no-responses and the more the substantive errors tended to be whole-wordsubstitutions rather than nonword mispronunciations Orthographic depth thus affected both rate and strategy ofreading
The effects oforthographic depthon learning to readalphabetic syllabicand logographicscripts
ESTE ESTUDIO investigoacute los efectos de la profundidad ortograacutefica en la adquisicioacuten de la lectura en sistemas deescritura alfabeacutetico silaacutebico y logograacutefico Nintildeos entre 6 y 15 antildeos leyeron en voz alta en el sistema transparentesilaacutebico japoneacutes hiragana en sistemas alfabeacuteticos de opacidad creciente (albaneacutes griego ingleacutes) y en el sistema or-tograacuteficamente opaco de los ideogramas japoneses kanji Los iacutetem fueron apareados seguacuten la frecuencia de las pa-labras en las lenguas estudiadas El estudio analizoacute precisioacuten latencia y tipos de error de las respuestas La precisioacutencorrelacionoacute con la profundidad ortograacutefica el hiragana se leyoacute maacutes correctamente que en orden decreciente elalbaneacutes griego ingleacutes y kanji A ortografiacutea maacutes profunda correspondieron menor efecto del largo de las palabrassobre la latencia de las respuestas y mayor la cantidad de errores tendientes a ser sustituciones de palabras comple-tas en lugar de no-palabras En siacutentesis la profundidad ortograacutefica afectoacute tanto la velocidad como la estrategia delectura
Los efectos de laprofundidad ortograacuteficaen el aprendizaje de lalectura en sistemas deescritura alfabeacuteticosilaacutebico y logograacutefico
DIESE STUDIE untersuchte die Effekte der orthographischen Vertiefung beim Erlernen des Lesens innerhalb al-phabetischer syllabischer und logographischer Schriften Kinder zwischen 6 und 15 Jahren lesen laut vor imtransparenten syllabischen japanischen Hiragana in Alphabeten mit steigender orthographischer Tiefe (albanischgriechisch englisch) und orthographisch unscharfen japanischen Kanji-Ideogrammen mit Einzelheiten kreuzweise-liguistisch verglichen auf Worthaumlufigkeit Diese Studie analysierte die Genauigkeit der Antwort Latenz und derFehlerarten Genauigkeit verlief korrelativ mit der Vertiefung Hiragana wurde sorgfaumlltiger gelesen als umgekehrtalbanisch griechisch englisch und Kanji Je tiefer die Orthographie je geringer war die Latenz als eine Funktion derWortlaumlnge desto groumlszliger war das Verhaumlltnis an Fehlern aufgrund von Nichtbeantwortungen und um so mehrneigten die wesentlichen Fehler Ganzwortsubstitutionen zu sein anstatt Nichtwort-FalschaussprachenOrthographische Vertiefung beeinflusste daher beides Grad und Strategie des Lesens
Die EffekteorthographischerVertiefung beimErlernen des Lesensvon alphabetischensyllabischen undlogographischenSchriften
ABSTRACTS
RRQ4-04 Ellis 92204 1151 AM Page 439
440
CETTE EacuteTUDE srsquoest inteacuteresseacutee aux effets de la profondeur orthographique sur lrsquoapprentissage de la lecture avec deseacutecritures alphabeacutetique syllabique et logographique Des enfants de 6 agrave 15 ans ont lu agrave haute voix avec le syl-labique japonais transparent qursquoest lrsquohiragana avec des alphabets de plus grande profondeur orthographique (al-banais grec anglais) et avec les ideacuteogrammes orthographiquement opaques que sont les kanji japonais les itemsayant eacuteteacute apparieacutes drsquoune langue agrave lrsquoautre quant agrave la freacutequence des mots Lrsquoexactitude des reacuteponses leur latence etles types drsquoerreurs ont eacuteteacute analyseacutes Lrsquoexactitude est correacuteleacutee agrave la profondeur lrsquohiragana est lu avec moins drsquoerreursque dans lrsquoordre lrsquoalbanais le grec lrsquoanglais et le kanji Plus lrsquoorthographe est profonde moins la latence deacutependde la longueur du mot plus grande est la proportion drsquoerreurs qui sont des non-reacuteponses et plus les erreurs sub-stantielles tendent agrave ecirctre des substitutions de mots entiers plutocirct que de mauvaises prononciations de non-motsLa profondeur orthographique affecte donc aussi bien la vitesse que la faccedilon de lire
Les effets de laprofondeur
orthographiquesur lrsquoapprentissage
de la lecturedrsquoeacutecritures
alphabeacutetiquesyllabique et
logographique
ABSTRACTS
RRQ4-04 Ellis 92204 1151 AM Page 440
It further predicts the consequence that childrenlearning to read a transparent orthography wheresoundndashsymbol mappings are regular and consistentshould learn to read aloud and to spell faster thanthose learning an opaque orthography where thecues to pronunciation are more ambiguous
There have been some recent demonstrationsthat as predicted by the orthographic depth hypoth-esis learning to read a transparent orthography suchas German (Wimmer amp Hummer 1990) Greek(Goswami Porpodas amp Wheelwright 1997) Italian(Thorstad 1991) Spanish (Goswami Gombert ampDe Barrera 1998) Turkish (Oumlney amp Durgunoglu1997) or Welsh (Ellis amp Hooper 2001) is easierthan learning to read an orthographically opaque lan-guage such as French or English (Goswami et al1998 Landerl Wimmer amp Frith 1997) SeymourAro and Erskine (2003) compared the abilities offirst-grade children to read familiar words and simplenonwords in English and 12 other European orthog-raphies The results showed that children from mostEuropean countries were accurate and fluent in read-ing before the end of the first school year with wordreading accuracies exceeding 90 in all except themore opaque orthographies of Portuguese FrenchDanish and particularly English Seymour Aroand Erskine attributed these findings to orthographicdepth which affected both word and nonword read-ing and to syllabic complexity which affected non-word decoding These findings suggested that therate of learning to read in English was more thantwice as slow as in the other orthographies
The orthographic depthhypothesis and strategy ofreading different scripts
The orthographic depth hypothesis postulatesthat there are different routes to fluent reading thatare dependent on the nature of a particular orthogra-phy Fluent English readersrsquo ability to read nonwordslike nabe or sloppendash demonstrates the availabilityof a route to reading using decoding where pronun-ciation is assembled from known symbolndashsound as-sociations Their ability to pronounce irregular orinconsistent words such as island or Wednesday im-plicates the availability of another reading route onewhere the word cannot be decoded entirely bymatching symbols and sounds Learners of Englishuse different strategies of reading at different stagesof development they move from recognizing whole
words (logographic reading) through a stage wherethey begin to apply soundndashsymbol correspondences(alphabetic reading) to skilled reading that predomi-nantly involves direct lexical access by way of theorthography at least for high-frequency words (or-thographic reading) (Ehri 1999 Frith 1985 MarshFriedman Welch amp Desberg 1981) Readers oftransparent orthographies are more likely to succeedin reading by means of alphabetic reading strategiesthan readers of opaque orthographies and their dif-ferential histories of success or failure may determinetheir respective strategies with readers of transparentscripts being more likely to rely on alphabetic read-ing strategies Thus there are two sides to the ortho-graphic depth hypothesis (a) Transparentorthographies support word recognition involvingphonology and (b) opaque orthographies encouragea reader to process words by accessing the lexiconand meaning via the wordrsquos visual orthographicstructure (Katz amp Frost 1992)
Support for this hypothesis comes from threetypes of evidence First learners of transparentorthographies are better able to read nonwordsLearners of German (Wimmer amp Goswami 1994)and Spanish (Lopez amp Gonzalez 1999) are more ableto read nonwords than are learners of English (RackSnowling amp Olson 1992) Second learners of trans-parent and opaque orthographies produce differentpatterns of reading errors Adherence to an alphabeticdecoding strategy produces errors that are mispro-nunciations whereas orthographic reading strategiesgenerate visually similar real-word substitution er-rors The majority of the reading errors of German(Wimmer amp Hummer 1990) and Welsh (Ellis ampHooper 2001) children are nonwords whereasyoung English-speaking children make frequent read-ing errors that are actual words (Seymour amp Elder1986 Stuart amp Coltheart 1988) Finally there is astronger relationship between word length and read-ing latency in transparent orthographies Ellis andHooper showed that word length determined 70 ofthe difference in times to read words in Welsh butonly 22 in English suggesting that Welsh pronun-ciations were assembled by means of a left-to-rightparse of the written string with longer words conse-quently requiring more time to recognize
Such findings support the hypothesis thattransparent orthographies promote faster rates ofreading acquisition and encourage an alphabeticreading strategy The current study aimed to extendthe comparison of effects of orthography on readingacquisition Previous research assessed the effects oforthographic depth within alphabetic languages Thegoal of the present study was to make further com-
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 441
RRQ4-04 Ellis 92204 1151 AM Page 441
parisons among alphabetic writing systems and tocompare these with other types of script positionedmore extremely on the dimension of orthographicdepth a highly transparent syllabic script and adeeply opaque logographic one
Methods of cross-linguisticreading comparison
It is difficult to compare literacy developmentacross different orthographies because the stimulimust necessarily be different So how can assessmentmaterials across languages be matched Traditionallythere have been three main approaches First readersof different languages can be compared for their abil-ity to read nonwords For example Wimmer andGoswami (1994) showed that children learning toread German were better able to read nonsensewords derived from number words such as vechs andzieben from sechs and sieben than were children learn-ing to read English able to read items such as tix andfeven from six and seven This method has since beenwidely adopted because it provides an index of chil-drenrsquos decoding abilities for novel material Secondcross-linguistic translation equivalents can be com-pared for readability Landerl et al (1997) showedthat German children were better able to read theirtransparent orthography instantiation of pairs oftranslation equivalents (eg Pflug-plough) than werematched learners of English Thorstad (1991) trans-lated a difficult passage of 56 words taken from anItalian journal for adults into English to be used as areading and spelling test Spencer and Hanley(2003) showed that Welsh children were better ablethan their English peers to read both nonwords andtranslation-equivalent words A third approach hasbeen to sample high-frequency words from childrenrsquosschool reading schemes Thus Goswami et al(1998) showed that Spanish children were able toread more of a sample of eight monosyllabic andeight disyllabic words in their language than werematched French or English children Seymour et al(2003) had children read 18 familiar high-frequencycontent words and 18 function words The wordswere sampled from the reading material used in theearly stage of primary schooling in each language
But each of these methods has its limitations asa comparative measure of reading acquisition in dif-ferent languages Nonword reading ability indexeschildrenrsquos decoding skill but nonwords may not begood indicators of skill at reading real wordsTranslations are rarely equivalent either in the rela-
tive frequencies of words or symbols or in their rangeof usage in the respective languages Although thesampling of test items from typical school textbooksis a reasonable start at controlling exposure factorstextbook writers tune their books to their audienceand to the difficulty of the task with which theirreaders are faced so there is no guarantee that a read-ing text in one language is equivalent for comparablechildren in another language
The current study therefore took an alterna-tive approach to the issue of whether it is easier tolearn to read in one language than anotherSpecifically we developed parallel reading tests forwhich the items in the two languages were matchedfor word frequency A longstanding method of as-sessing an individualrsquos ability to read aloud has beento see how many items he or she can read from astandardized list of approximately 100 words ofincreasing difficulty Illustrative examples are theSchonell Graded Word Reading Test and the WideRange Achievement Tests We extended this idea toconstruct parallel cross-linguistic tests where foreach language the items are randomly selected from100 frequency bands representing the most frequentto the least frequent words of the language Thuseach test is a stratified random sample of the wordsof the language with pairs of test items in the twolanguages being matched for frequency of writtenoccurrence The matching process should not controlany other factors such as word length imageabilityutility morphological complexity syntactic rolesemantic richness orthographic complexitysoundndashsymbol consistency or any other intrinsic as-pects of the languages under study that might affecthow easy or difficult it is to learn the words Ideallyeverything to do with learning opportunity shouldbe matched everything to do with language shouldbe free to vary The rationale is based on input-dri-ven perspectives of language acquisition The learn-ability of an item is largely dependent upon theamount of experience a learner has with it and withsimilar items Thus if children of two languages startlearning to read at the same time and they haveroughly equivalent time on task then if the two or-thographies are equally difficult to acquire learnersof similar experience should be able to read words atroughly the same frequency level
Ellis and Hooper (2001) used this method intheir comparisons of Welsh and English The wordtypes that composed a representative million writtenwords of English (Baayen Piepenbrock amp Van Rijn1995) and Welsh (Ellis OrsquoDochartaigh HicksMorgan amp Laporte 2001) were sorted in decreasingfrequency of occurrence and sampled so that a test
442 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 442
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 443
word was selected at every decreasing step of 10000word tokens or its nearest approximation The twolists of 100 words were then used as frequency-matched samples of written English and Welsh Thismethod is promising in assessing the acquisition ofliteracy in children learning to read in different lan-guages and in the multiple languages of multiliterateindividuals for several reasons First it produces teststhat are matched in a principled fashion for inputfrequency Second it generates a broad range of fre-quencies of items from approximately 60000 wordsper million to just 1 per million and so it is appro-priately discriminating for learners at different stagesof proficiency Third it is psychophysically scaledPsycholinguistic experimentation shows that there ismore of a linear relationship between proficiencyand log exposure than between proficiency and ex-posure The method of sampling used by Ellis andHooper effectively provided items representing log-frequency strata
Extending the range ofcomparison beyond alphabeticorthographies
In the present study we therefore used thesemethods to develop tests matched cross-linguisticallyfor frequency of written exposure in order to com-pare the rate of acquisition of reading in 6- to 15-year-old children reading a range of different nativeorthographies the orthographically transparent syl-labic Japanese hiragana system alphabets of decreas-ing orthographic transparency (Albanian Greek andEnglish) and the orthographically opaque ideo-graphic Japanese kanji system We also investigatedwhether these different types of orthography affectthe strategies of lexical access adopted by learners asis predicted by the orthographic depth hypothesis
The orthographies investigated in this study Hiragana
Japanese orthography comprises four types ofscript hiragana and katakana (the kana) kanji andromaji (Kess amp Miyamoto 1999) Hiragana andkatakana are syllabic scripts Most Japanese syllableshave the canonical shape of a consonantndashvowel (CV)combination and can be represented by single kana
symbols There is one-to-one correspondence be-tween hiragana and katakana symbols with both sys-tems containing 46 basic symbols (called seion) 40unvoiced CV combinations five vowels and onenasal coda In addition to these there are other char-acters including 25 symbols that are the voicedequivalents of the basic seion formed by adding a spe-cial mark for voicing or semivoicing making a totalof 71 symbols in all Most kana symbols have a sin-gle unique pronunciation although combinations ofsymbols and their use in certain word classes canmodify the pronunciation slightly (Akita amp Hatano1999) Hiragana is mainly used for function wordsmorphological endings and the rest of the grammati-cal scaffolding of Japanese sentences AlthoughJapanese content words are usually written in kanji itis possible to write all native Japanese words in hira-gana Katakana is mainly used for foreign loan wordsand Japanese interjections Nomura (1980) estimatedthat journals published in Japan contain 50 hira-gana 30 kanji and 10 katakana
The regularity of the symbolndashsound mappingsmakes hiragana an exceptionally transparent orthog-raphy Furthermore because children are better ableto break up speech and identify its syllable parts thanthey are to segment it into phonemes (AlegriaPignot amp Morais 1982 Liberman ShankweilerFischer amp Carter 1974 Rozin amp Gleitman 1977)the canonical CV syllable shape of spoken Japaneseallows for easy phonological segmentation Thesetwo factors should thus combine to promote fast ac-quisition The spoken language is easily segmentedinto its syllable parts and each of these individualphonological units has its unique written symbol
Learning to read and write in Japanese official-ly begins at the age of 6 in the first grade of elemen-tary school The seion symbols are first introducedfollowed by the rest of hiragana Katakana is intro-duced in the latter half of the first grade and iscompleted by the end of the second grade Childrenalso start learning some easier kanji in the firstgrade Notwithstanding the official syllabus mostpreschoolers are able to read at least the 46 basichiragana by the time they start the first gradeShimamura and Mikami (1994) reported that 16of 3-year-olds 59 of 4-year-olds and 89 of 5-year-olds could read 60 or more of the 71 hiragana symbols
AlbanianAlbanian forms a single branch of the Indo-
European family that is spoken by over three millionpeople in Albania and in parts of the former republic
RRQ4-04 Ellis 92204 1151 AM Page 443
of Yugoslavia Greece and Italy The writing systemwas not introduced until 1909 hence few languagesare more orthographically transparent than AlbanianIt uses Roman characters and has 36 letters 29 con-sonants and 7 vowels Nine of the consonants arepresented as bigraphs (dh gj ll nj rr sh th xh zh)These bigraphs are explicitly taught to the children asseparate ldquolettersrdquo of the alphabet and if they appeartogether are never considered as separate graphemes(this rule does not apply to compound words whichoccur rather infrequently) The bidirectionalgraphemendashphoneme and phonemendashgrapheme map-ping is consistent for both consonants and vowelsThese symbols do not change their sound accordingto their position in the word
In Albania there are very few nursery schoolsand only a minority of preschoolers go to kinder-garten The consequence is that most first graders inAlbania enter school without letter or written wordawareness The teaching of reading in Albanian pri-mary schools is introduced in year 1 The officialteaching method is a whole-word method called theGlobal Method However many teachers who havebeen using phonics approaches for many years preferto use mixed methods including both whole-wordand phonics approaches (Hoxhallari 2000)
GreekGreek is highly regular in its symbol-to-sound
mappings for reading though less so in its soundndashsymbol mappings for spelling In spoken Greek thereare only five vowels that sound the same whetherstressed or unstressed (Harris amp Giannouli 1999)While the majority of Greek words are polysyllabicthere are fewer than half the syllable types of Englishwith the majority of them being open syllables of theconsonantndashvowel type (V CV VC CCV CCCV)(Magoulas 1979) As with Japanese these syllablecharacteristics presumably allow children an easiertask of phonological segmentation of their spokenlanguage In the written language each letterrsquos singlesound remains relatively constant in different con-texts (Chitiri amp Willows 1994)
Nevertheless written Greek is not entirelytransparent Whereas the written form has remainedessentially intact since its development as an alpha-betic script the spoken language has undergone ma-jor developmental changes in its evolution towardmodern Greek (Babiniotis 1980 Tombaidis 1987Triantaphyllidis 1913) As a result modern spellingis not entirely phonetic but has a morphophonemicnature that reflects the etymology of words(Porpodas 1991 1999) Spoken Greek is composed
of 32 phonemes that are represented by the 24Greek letters (Bakamidis amp Carayannis 1987Triantaphyllidis 1980) Several phonemendashgraphemeinconsistencies occur including homophone vowelsand vowel and consonant clusters (diphthongs anddipsipha) The pronunciation of dipsipha varies ac-cording to their position in the word and the contextin which they occur In exceptional cases some let-ters are almost voiceless (Porpodas 1991 Tombaidis1987 Triantaphyllidis 1913) Greek has the addedfeature whereby the position of prosodic stress ismarked for each written word Stress which canoccur on any of the final three syllables of a worddepending on a variety of morphological phonologi-cal and lexical factors must be properly interpretedfor successful reading because there are many wordsthat are differentiated only by stress (Tombaidis1986)
Reading instruction is standardized in GreeceIt usually starts at 55 to 6 years old beginning withletterndashsound correspondences Thereafter a syntheticphonics method is used to encourage phonologicalrecoding of simple CV syllables that form simplewords and there is an emphasis on rhyming wordsOnce children have established good letterndashsoundknowledge and have built an initial sight vocabularyletter names are taught and a phonics method is usedto teach graphemendashphoneme correspondences thatinclude more complex syllables like CCV The stressmark is also introduced The basic reading process istypically well established by the end of the first grade(Harris amp Giannouli 1999 Porpodas 1991)
EnglishThe English alphabet consists of 26 letters (5
vowels and 21 consonants) that represent over 40phonemes Letters or letter combinations are oftenambiguous in terms of the sounds they represent AsVenezky (1970) concluded from his analysis of thestructure of English orthography ldquoa person who at-tempts to scan left to right letter by letter pronounc-ing as he goes could not correctly read most Englishwordsrdquo (p 127) The 5 written vowels are particularlyvaried in their mappings to speech and there are 12vowel digraphs 6 of which have alternate pronuncia-tions according to their position Consonants aremore consistent in their graphemendashphoneme corre-spondences with the exceptions of c and g which areread differently according to the vowels that followNevertheless only three consonants (n r and v) haveonly one sound that cannot be produced by othercombinations and are never silent (Venezky) SpokenEnglish also has a complex syllable structure with
444 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 444
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 445
many different types of syllables most of them closed(eg CVC CVCC CCVC) These characteristicspose difficulty for children learning to phonologicallysegment their spoken language
Although English is varied in its graphemendashphoneme correspondences it has a higher degree ofspellingndashsound consistency at the level of the rimeTreiman Mullennix Bijeljac-Babic and Richmond-Welty (1995) estimated that the pronunciation ofmodern English written vowels is only 51 consis-tent over different words whereas initial and finalconsonants are much more consistent (96 and91 respectively) as are rime units (77) For ex-ample a is pronounced differently in cat call carcake and care but it is pronounced the same in therimes cat hat and mat Phonological segmentationinto onset-rime units and the use of orthographicrime analogies have been shown to be importantprocesses in learning to read and spell English(Goswami 1999 2000 Goswami et al 1998Treiman et al 1995)
The majority of English children begin preread-ing exposure quite early at 3 or 4 years old InNursery children are taught the shapes of most lettersof the alphabet and introduced to book use They areread to on a daily basis and there is emphasis on rep-etition and rhyming In Reception there is at least 30minutes per day dedicated solely to reading There ismuch use of word-building pattern recognition andodd-one-out games In year 1 the recognition of thewords as a whole is supported with the use of look-and-say and odd-one-out games Flash cards are usedto introduce individual words to build a startingsight vocabulary and to form simple sentencesChildren are taught families of word patterns thatshare orthographic and phonological resemblance atonset or rime Phonics is typically introduced at theend of year 1 and children are encouraged to practicesounding out and blending phonemes Literacy re-mains a significant part of the national curriculumright through Upper Key Stage 2 that is 9 to 11 yearsold In sum much time and effort is put into teach-ing children to learn to read in English
Kanji The kanji writing system originated in the log-
ographs of Chinese orthography Content words inJapanese are usually written in kanji because doingso resolves the ambiguity of the many homophonesof spoken Japanese The higher homophony rate inJapanese than in other languages is due to its simpleCV spoken syllable structure which restricts thenumber of possible spoken syllables that can be used
individually and in combination to form a spokenword (Akita amp Hatano 1999) In general there aretwo ways to read a given kanji referred to as kunyo-mi or onyomi Kunyomi is the Japanese word corre-sponding to the logogram onyomi is a pronunciationthat is similar to the original Chinese Thus the kanji
(tree) has the kunyomi ldquokirdquo and the onyomildquomokurdquo the kanji (forest) is pronounced respec-tively ldquohayashirdquo and ldquorinrdquo According to Kess andMiyamoto (1999) between 12000 and 50000 en-tries are included in comprehensive kanji dictionar-ies The Japanese educational system explicitlyteaches a set of 1945 Joyo Kanji (kanji for dailyuse) However Kess and Miyamoto argued that mostJapanese know many more than these and that 3000or more kanji are required to read a daily newspaper
Children start learning 80 of the easier JoyoKanji toward the end of the first grade The sequenceof introduction of kanji in the curriculum is standard-ized and by the end of elementary school children areexpected to have mastered 1006 characters (NationalLanguage Research Institute 1988) They are expect-ed to master the complete set of Joyo Kanji by the endof the third year of junior high school
Research questionsThis study was designed to compare the rate of
reading acquisition in 6- to 15-year-old childrenlearning to read in a transparent orthographic system(the syllabic Japanese hiragana) in alphabets ofdecreasing orthographic transparency (AlbanianGreek and English) and in the ideographic Japanesekanji system
The orthographic depth hypothesis predictsthat the more transparent the orthography the fasterchildren will learn to read aloud The almost perfectsymbolndashsound correspondence of hiragana its repre-sentation of psycholinguistically accessible syllablesrather than phonemes and the simple syllable struc-ture of Japanese each contributed to the expectationthat learning to read aloud will be easiest in hira-gana All of the alphabetic scripts provide cues topronunciation but some of the systems are moreregular and consistent than others Thus we expect-ed the alphabetic systems to be the next most easy toacquire but that the ease with which reading is ac-quired would vary within alphabetic systems withthe more transparent languages (Albanian andGreek) being easier to learn than the more opaquelanguage (English) Finally we believed that theideographic kanji system which contains few or nocues to assembled pronunciation would be the mostdifficult to acquire
RRQ4-04 Ellis 92204 1151 AM Page 445
The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

439
THIS STUDY investigated the effects of orthographic depth on reading acquisition in alphabetic syllabic and lo-gographic scripts Children between 6 and 15 years old read aloud in transparent syllabic Japanese hiragana al-phabets of increasing orthographic depth (Albanian Greek English) and orthographically opaque Japanese kanjiideograms with items being matched cross-linguistically for word frequency This study analyzed response accura-cy latency and error types Accuracy correlated with depth Hiragana was read more accurately than in turnAlbanian Greek English and kanji The deeper the orthography the less latency was a function of word length thegreater the proportion of errors that were no-responses and the more the substantive errors tended to be whole-wordsubstitutions rather than nonword mispronunciations Orthographic depth thus affected both rate and strategy ofreading
The effects oforthographic depthon learning to readalphabetic syllabicand logographicscripts
ESTE ESTUDIO investigoacute los efectos de la profundidad ortograacutefica en la adquisicioacuten de la lectura en sistemas deescritura alfabeacutetico silaacutebico y logograacutefico Nintildeos entre 6 y 15 antildeos leyeron en voz alta en el sistema transparentesilaacutebico japoneacutes hiragana en sistemas alfabeacuteticos de opacidad creciente (albaneacutes griego ingleacutes) y en el sistema or-tograacuteficamente opaco de los ideogramas japoneses kanji Los iacutetem fueron apareados seguacuten la frecuencia de las pa-labras en las lenguas estudiadas El estudio analizoacute precisioacuten latencia y tipos de error de las respuestas La precisioacutencorrelacionoacute con la profundidad ortograacutefica el hiragana se leyoacute maacutes correctamente que en orden decreciente elalbaneacutes griego ingleacutes y kanji A ortografiacutea maacutes profunda correspondieron menor efecto del largo de las palabrassobre la latencia de las respuestas y mayor la cantidad de errores tendientes a ser sustituciones de palabras comple-tas en lugar de no-palabras En siacutentesis la profundidad ortograacutefica afectoacute tanto la velocidad como la estrategia delectura
Los efectos de laprofundidad ortograacuteficaen el aprendizaje de lalectura en sistemas deescritura alfabeacuteticosilaacutebico y logograacutefico
DIESE STUDIE untersuchte die Effekte der orthographischen Vertiefung beim Erlernen des Lesens innerhalb al-phabetischer syllabischer und logographischer Schriften Kinder zwischen 6 und 15 Jahren lesen laut vor imtransparenten syllabischen japanischen Hiragana in Alphabeten mit steigender orthographischer Tiefe (albanischgriechisch englisch) und orthographisch unscharfen japanischen Kanji-Ideogrammen mit Einzelheiten kreuzweise-liguistisch verglichen auf Worthaumlufigkeit Diese Studie analysierte die Genauigkeit der Antwort Latenz und derFehlerarten Genauigkeit verlief korrelativ mit der Vertiefung Hiragana wurde sorgfaumlltiger gelesen als umgekehrtalbanisch griechisch englisch und Kanji Je tiefer die Orthographie je geringer war die Latenz als eine Funktion derWortlaumlnge desto groumlszliger war das Verhaumlltnis an Fehlern aufgrund von Nichtbeantwortungen und um so mehrneigten die wesentlichen Fehler Ganzwortsubstitutionen zu sein anstatt Nichtwort-FalschaussprachenOrthographische Vertiefung beeinflusste daher beides Grad und Strategie des Lesens
Die EffekteorthographischerVertiefung beimErlernen des Lesensvon alphabetischensyllabischen undlogographischenSchriften
ABSTRACTS
RRQ4-04 Ellis 92204 1151 AM Page 439
440
CETTE EacuteTUDE srsquoest inteacuteresseacutee aux effets de la profondeur orthographique sur lrsquoapprentissage de la lecture avec deseacutecritures alphabeacutetique syllabique et logographique Des enfants de 6 agrave 15 ans ont lu agrave haute voix avec le syl-labique japonais transparent qursquoest lrsquohiragana avec des alphabets de plus grande profondeur orthographique (al-banais grec anglais) et avec les ideacuteogrammes orthographiquement opaques que sont les kanji japonais les itemsayant eacuteteacute apparieacutes drsquoune langue agrave lrsquoautre quant agrave la freacutequence des mots Lrsquoexactitude des reacuteponses leur latence etles types drsquoerreurs ont eacuteteacute analyseacutes Lrsquoexactitude est correacuteleacutee agrave la profondeur lrsquohiragana est lu avec moins drsquoerreursque dans lrsquoordre lrsquoalbanais le grec lrsquoanglais et le kanji Plus lrsquoorthographe est profonde moins la latence deacutependde la longueur du mot plus grande est la proportion drsquoerreurs qui sont des non-reacuteponses et plus les erreurs sub-stantielles tendent agrave ecirctre des substitutions de mots entiers plutocirct que de mauvaises prononciations de non-motsLa profondeur orthographique affecte donc aussi bien la vitesse que la faccedilon de lire
Les effets de laprofondeur
orthographiquesur lrsquoapprentissage
de la lecturedrsquoeacutecritures
alphabeacutetiquesyllabique et
logographique
ABSTRACTS
RRQ4-04 Ellis 92204 1151 AM Page 440
It further predicts the consequence that childrenlearning to read a transparent orthography wheresoundndashsymbol mappings are regular and consistentshould learn to read aloud and to spell faster thanthose learning an opaque orthography where thecues to pronunciation are more ambiguous
There have been some recent demonstrationsthat as predicted by the orthographic depth hypoth-esis learning to read a transparent orthography suchas German (Wimmer amp Hummer 1990) Greek(Goswami Porpodas amp Wheelwright 1997) Italian(Thorstad 1991) Spanish (Goswami Gombert ampDe Barrera 1998) Turkish (Oumlney amp Durgunoglu1997) or Welsh (Ellis amp Hooper 2001) is easierthan learning to read an orthographically opaque lan-guage such as French or English (Goswami et al1998 Landerl Wimmer amp Frith 1997) SeymourAro and Erskine (2003) compared the abilities offirst-grade children to read familiar words and simplenonwords in English and 12 other European orthog-raphies The results showed that children from mostEuropean countries were accurate and fluent in read-ing before the end of the first school year with wordreading accuracies exceeding 90 in all except themore opaque orthographies of Portuguese FrenchDanish and particularly English Seymour Aroand Erskine attributed these findings to orthographicdepth which affected both word and nonword read-ing and to syllabic complexity which affected non-word decoding These findings suggested that therate of learning to read in English was more thantwice as slow as in the other orthographies
The orthographic depthhypothesis and strategy ofreading different scripts
The orthographic depth hypothesis postulatesthat there are different routes to fluent reading thatare dependent on the nature of a particular orthogra-phy Fluent English readersrsquo ability to read nonwordslike nabe or sloppendash demonstrates the availabilityof a route to reading using decoding where pronun-ciation is assembled from known symbolndashsound as-sociations Their ability to pronounce irregular orinconsistent words such as island or Wednesday im-plicates the availability of another reading route onewhere the word cannot be decoded entirely bymatching symbols and sounds Learners of Englishuse different strategies of reading at different stagesof development they move from recognizing whole
words (logographic reading) through a stage wherethey begin to apply soundndashsymbol correspondences(alphabetic reading) to skilled reading that predomi-nantly involves direct lexical access by way of theorthography at least for high-frequency words (or-thographic reading) (Ehri 1999 Frith 1985 MarshFriedman Welch amp Desberg 1981) Readers oftransparent orthographies are more likely to succeedin reading by means of alphabetic reading strategiesthan readers of opaque orthographies and their dif-ferential histories of success or failure may determinetheir respective strategies with readers of transparentscripts being more likely to rely on alphabetic read-ing strategies Thus there are two sides to the ortho-graphic depth hypothesis (a) Transparentorthographies support word recognition involvingphonology and (b) opaque orthographies encouragea reader to process words by accessing the lexiconand meaning via the wordrsquos visual orthographicstructure (Katz amp Frost 1992)
Support for this hypothesis comes from threetypes of evidence First learners of transparentorthographies are better able to read nonwordsLearners of German (Wimmer amp Goswami 1994)and Spanish (Lopez amp Gonzalez 1999) are more ableto read nonwords than are learners of English (RackSnowling amp Olson 1992) Second learners of trans-parent and opaque orthographies produce differentpatterns of reading errors Adherence to an alphabeticdecoding strategy produces errors that are mispro-nunciations whereas orthographic reading strategiesgenerate visually similar real-word substitution er-rors The majority of the reading errors of German(Wimmer amp Hummer 1990) and Welsh (Ellis ampHooper 2001) children are nonwords whereasyoung English-speaking children make frequent read-ing errors that are actual words (Seymour amp Elder1986 Stuart amp Coltheart 1988) Finally there is astronger relationship between word length and read-ing latency in transparent orthographies Ellis andHooper showed that word length determined 70 ofthe difference in times to read words in Welsh butonly 22 in English suggesting that Welsh pronun-ciations were assembled by means of a left-to-rightparse of the written string with longer words conse-quently requiring more time to recognize
Such findings support the hypothesis thattransparent orthographies promote faster rates ofreading acquisition and encourage an alphabeticreading strategy The current study aimed to extendthe comparison of effects of orthography on readingacquisition Previous research assessed the effects oforthographic depth within alphabetic languages Thegoal of the present study was to make further com-
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 441
RRQ4-04 Ellis 92204 1151 AM Page 441
parisons among alphabetic writing systems and tocompare these with other types of script positionedmore extremely on the dimension of orthographicdepth a highly transparent syllabic script and adeeply opaque logographic one
Methods of cross-linguisticreading comparison
It is difficult to compare literacy developmentacross different orthographies because the stimulimust necessarily be different So how can assessmentmaterials across languages be matched Traditionallythere have been three main approaches First readersof different languages can be compared for their abil-ity to read nonwords For example Wimmer andGoswami (1994) showed that children learning toread German were better able to read nonsensewords derived from number words such as vechs andzieben from sechs and sieben than were children learn-ing to read English able to read items such as tix andfeven from six and seven This method has since beenwidely adopted because it provides an index of chil-drenrsquos decoding abilities for novel material Secondcross-linguistic translation equivalents can be com-pared for readability Landerl et al (1997) showedthat German children were better able to read theirtransparent orthography instantiation of pairs oftranslation equivalents (eg Pflug-plough) than werematched learners of English Thorstad (1991) trans-lated a difficult passage of 56 words taken from anItalian journal for adults into English to be used as areading and spelling test Spencer and Hanley(2003) showed that Welsh children were better ablethan their English peers to read both nonwords andtranslation-equivalent words A third approach hasbeen to sample high-frequency words from childrenrsquosschool reading schemes Thus Goswami et al(1998) showed that Spanish children were able toread more of a sample of eight monosyllabic andeight disyllabic words in their language than werematched French or English children Seymour et al(2003) had children read 18 familiar high-frequencycontent words and 18 function words The wordswere sampled from the reading material used in theearly stage of primary schooling in each language
But each of these methods has its limitations asa comparative measure of reading acquisition in dif-ferent languages Nonword reading ability indexeschildrenrsquos decoding skill but nonwords may not begood indicators of skill at reading real wordsTranslations are rarely equivalent either in the rela-
tive frequencies of words or symbols or in their rangeof usage in the respective languages Although thesampling of test items from typical school textbooksis a reasonable start at controlling exposure factorstextbook writers tune their books to their audienceand to the difficulty of the task with which theirreaders are faced so there is no guarantee that a read-ing text in one language is equivalent for comparablechildren in another language
The current study therefore took an alterna-tive approach to the issue of whether it is easier tolearn to read in one language than anotherSpecifically we developed parallel reading tests forwhich the items in the two languages were matchedfor word frequency A longstanding method of as-sessing an individualrsquos ability to read aloud has beento see how many items he or she can read from astandardized list of approximately 100 words ofincreasing difficulty Illustrative examples are theSchonell Graded Word Reading Test and the WideRange Achievement Tests We extended this idea toconstruct parallel cross-linguistic tests where foreach language the items are randomly selected from100 frequency bands representing the most frequentto the least frequent words of the language Thuseach test is a stratified random sample of the wordsof the language with pairs of test items in the twolanguages being matched for frequency of writtenoccurrence The matching process should not controlany other factors such as word length imageabilityutility morphological complexity syntactic rolesemantic richness orthographic complexitysoundndashsymbol consistency or any other intrinsic as-pects of the languages under study that might affecthow easy or difficult it is to learn the words Ideallyeverything to do with learning opportunity shouldbe matched everything to do with language shouldbe free to vary The rationale is based on input-dri-ven perspectives of language acquisition The learn-ability of an item is largely dependent upon theamount of experience a learner has with it and withsimilar items Thus if children of two languages startlearning to read at the same time and they haveroughly equivalent time on task then if the two or-thographies are equally difficult to acquire learnersof similar experience should be able to read words atroughly the same frequency level
Ellis and Hooper (2001) used this method intheir comparisons of Welsh and English The wordtypes that composed a representative million writtenwords of English (Baayen Piepenbrock amp Van Rijn1995) and Welsh (Ellis OrsquoDochartaigh HicksMorgan amp Laporte 2001) were sorted in decreasingfrequency of occurrence and sampled so that a test
442 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 442
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 443
word was selected at every decreasing step of 10000word tokens or its nearest approximation The twolists of 100 words were then used as frequency-matched samples of written English and Welsh Thismethod is promising in assessing the acquisition ofliteracy in children learning to read in different lan-guages and in the multiple languages of multiliterateindividuals for several reasons First it produces teststhat are matched in a principled fashion for inputfrequency Second it generates a broad range of fre-quencies of items from approximately 60000 wordsper million to just 1 per million and so it is appro-priately discriminating for learners at different stagesof proficiency Third it is psychophysically scaledPsycholinguistic experimentation shows that there ismore of a linear relationship between proficiencyand log exposure than between proficiency and ex-posure The method of sampling used by Ellis andHooper effectively provided items representing log-frequency strata
Extending the range ofcomparison beyond alphabeticorthographies
In the present study we therefore used thesemethods to develop tests matched cross-linguisticallyfor frequency of written exposure in order to com-pare the rate of acquisition of reading in 6- to 15-year-old children reading a range of different nativeorthographies the orthographically transparent syl-labic Japanese hiragana system alphabets of decreas-ing orthographic transparency (Albanian Greek andEnglish) and the orthographically opaque ideo-graphic Japanese kanji system We also investigatedwhether these different types of orthography affectthe strategies of lexical access adopted by learners asis predicted by the orthographic depth hypothesis
The orthographies investigated in this study Hiragana
Japanese orthography comprises four types ofscript hiragana and katakana (the kana) kanji andromaji (Kess amp Miyamoto 1999) Hiragana andkatakana are syllabic scripts Most Japanese syllableshave the canonical shape of a consonantndashvowel (CV)combination and can be represented by single kana
symbols There is one-to-one correspondence be-tween hiragana and katakana symbols with both sys-tems containing 46 basic symbols (called seion) 40unvoiced CV combinations five vowels and onenasal coda In addition to these there are other char-acters including 25 symbols that are the voicedequivalents of the basic seion formed by adding a spe-cial mark for voicing or semivoicing making a totalof 71 symbols in all Most kana symbols have a sin-gle unique pronunciation although combinations ofsymbols and their use in certain word classes canmodify the pronunciation slightly (Akita amp Hatano1999) Hiragana is mainly used for function wordsmorphological endings and the rest of the grammati-cal scaffolding of Japanese sentences AlthoughJapanese content words are usually written in kanji itis possible to write all native Japanese words in hira-gana Katakana is mainly used for foreign loan wordsand Japanese interjections Nomura (1980) estimatedthat journals published in Japan contain 50 hira-gana 30 kanji and 10 katakana
The regularity of the symbolndashsound mappingsmakes hiragana an exceptionally transparent orthog-raphy Furthermore because children are better ableto break up speech and identify its syllable parts thanthey are to segment it into phonemes (AlegriaPignot amp Morais 1982 Liberman ShankweilerFischer amp Carter 1974 Rozin amp Gleitman 1977)the canonical CV syllable shape of spoken Japaneseallows for easy phonological segmentation Thesetwo factors should thus combine to promote fast ac-quisition The spoken language is easily segmentedinto its syllable parts and each of these individualphonological units has its unique written symbol
Learning to read and write in Japanese official-ly begins at the age of 6 in the first grade of elemen-tary school The seion symbols are first introducedfollowed by the rest of hiragana Katakana is intro-duced in the latter half of the first grade and iscompleted by the end of the second grade Childrenalso start learning some easier kanji in the firstgrade Notwithstanding the official syllabus mostpreschoolers are able to read at least the 46 basichiragana by the time they start the first gradeShimamura and Mikami (1994) reported that 16of 3-year-olds 59 of 4-year-olds and 89 of 5-year-olds could read 60 or more of the 71 hiragana symbols
AlbanianAlbanian forms a single branch of the Indo-
European family that is spoken by over three millionpeople in Albania and in parts of the former republic
RRQ4-04 Ellis 92204 1151 AM Page 443
of Yugoslavia Greece and Italy The writing systemwas not introduced until 1909 hence few languagesare more orthographically transparent than AlbanianIt uses Roman characters and has 36 letters 29 con-sonants and 7 vowels Nine of the consonants arepresented as bigraphs (dh gj ll nj rr sh th xh zh)These bigraphs are explicitly taught to the children asseparate ldquolettersrdquo of the alphabet and if they appeartogether are never considered as separate graphemes(this rule does not apply to compound words whichoccur rather infrequently) The bidirectionalgraphemendashphoneme and phonemendashgrapheme map-ping is consistent for both consonants and vowelsThese symbols do not change their sound accordingto their position in the word
In Albania there are very few nursery schoolsand only a minority of preschoolers go to kinder-garten The consequence is that most first graders inAlbania enter school without letter or written wordawareness The teaching of reading in Albanian pri-mary schools is introduced in year 1 The officialteaching method is a whole-word method called theGlobal Method However many teachers who havebeen using phonics approaches for many years preferto use mixed methods including both whole-wordand phonics approaches (Hoxhallari 2000)
GreekGreek is highly regular in its symbol-to-sound
mappings for reading though less so in its soundndashsymbol mappings for spelling In spoken Greek thereare only five vowels that sound the same whetherstressed or unstressed (Harris amp Giannouli 1999)While the majority of Greek words are polysyllabicthere are fewer than half the syllable types of Englishwith the majority of them being open syllables of theconsonantndashvowel type (V CV VC CCV CCCV)(Magoulas 1979) As with Japanese these syllablecharacteristics presumably allow children an easiertask of phonological segmentation of their spokenlanguage In the written language each letterrsquos singlesound remains relatively constant in different con-texts (Chitiri amp Willows 1994)
Nevertheless written Greek is not entirelytransparent Whereas the written form has remainedessentially intact since its development as an alpha-betic script the spoken language has undergone ma-jor developmental changes in its evolution towardmodern Greek (Babiniotis 1980 Tombaidis 1987Triantaphyllidis 1913) As a result modern spellingis not entirely phonetic but has a morphophonemicnature that reflects the etymology of words(Porpodas 1991 1999) Spoken Greek is composed
of 32 phonemes that are represented by the 24Greek letters (Bakamidis amp Carayannis 1987Triantaphyllidis 1980) Several phonemendashgraphemeinconsistencies occur including homophone vowelsand vowel and consonant clusters (diphthongs anddipsipha) The pronunciation of dipsipha varies ac-cording to their position in the word and the contextin which they occur In exceptional cases some let-ters are almost voiceless (Porpodas 1991 Tombaidis1987 Triantaphyllidis 1913) Greek has the addedfeature whereby the position of prosodic stress ismarked for each written word Stress which canoccur on any of the final three syllables of a worddepending on a variety of morphological phonologi-cal and lexical factors must be properly interpretedfor successful reading because there are many wordsthat are differentiated only by stress (Tombaidis1986)
Reading instruction is standardized in GreeceIt usually starts at 55 to 6 years old beginning withletterndashsound correspondences Thereafter a syntheticphonics method is used to encourage phonologicalrecoding of simple CV syllables that form simplewords and there is an emphasis on rhyming wordsOnce children have established good letterndashsoundknowledge and have built an initial sight vocabularyletter names are taught and a phonics method is usedto teach graphemendashphoneme correspondences thatinclude more complex syllables like CCV The stressmark is also introduced The basic reading process istypically well established by the end of the first grade(Harris amp Giannouli 1999 Porpodas 1991)
EnglishThe English alphabet consists of 26 letters (5
vowels and 21 consonants) that represent over 40phonemes Letters or letter combinations are oftenambiguous in terms of the sounds they represent AsVenezky (1970) concluded from his analysis of thestructure of English orthography ldquoa person who at-tempts to scan left to right letter by letter pronounc-ing as he goes could not correctly read most Englishwordsrdquo (p 127) The 5 written vowels are particularlyvaried in their mappings to speech and there are 12vowel digraphs 6 of which have alternate pronuncia-tions according to their position Consonants aremore consistent in their graphemendashphoneme corre-spondences with the exceptions of c and g which areread differently according to the vowels that followNevertheless only three consonants (n r and v) haveonly one sound that cannot be produced by othercombinations and are never silent (Venezky) SpokenEnglish also has a complex syllable structure with
444 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 444
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 445
many different types of syllables most of them closed(eg CVC CVCC CCVC) These characteristicspose difficulty for children learning to phonologicallysegment their spoken language
Although English is varied in its graphemendashphoneme correspondences it has a higher degree ofspellingndashsound consistency at the level of the rimeTreiman Mullennix Bijeljac-Babic and Richmond-Welty (1995) estimated that the pronunciation ofmodern English written vowels is only 51 consis-tent over different words whereas initial and finalconsonants are much more consistent (96 and91 respectively) as are rime units (77) For ex-ample a is pronounced differently in cat call carcake and care but it is pronounced the same in therimes cat hat and mat Phonological segmentationinto onset-rime units and the use of orthographicrime analogies have been shown to be importantprocesses in learning to read and spell English(Goswami 1999 2000 Goswami et al 1998Treiman et al 1995)
The majority of English children begin preread-ing exposure quite early at 3 or 4 years old InNursery children are taught the shapes of most lettersof the alphabet and introduced to book use They areread to on a daily basis and there is emphasis on rep-etition and rhyming In Reception there is at least 30minutes per day dedicated solely to reading There ismuch use of word-building pattern recognition andodd-one-out games In year 1 the recognition of thewords as a whole is supported with the use of look-and-say and odd-one-out games Flash cards are usedto introduce individual words to build a startingsight vocabulary and to form simple sentencesChildren are taught families of word patterns thatshare orthographic and phonological resemblance atonset or rime Phonics is typically introduced at theend of year 1 and children are encouraged to practicesounding out and blending phonemes Literacy re-mains a significant part of the national curriculumright through Upper Key Stage 2 that is 9 to 11 yearsold In sum much time and effort is put into teach-ing children to learn to read in English
Kanji The kanji writing system originated in the log-
ographs of Chinese orthography Content words inJapanese are usually written in kanji because doingso resolves the ambiguity of the many homophonesof spoken Japanese The higher homophony rate inJapanese than in other languages is due to its simpleCV spoken syllable structure which restricts thenumber of possible spoken syllables that can be used
individually and in combination to form a spokenword (Akita amp Hatano 1999) In general there aretwo ways to read a given kanji referred to as kunyo-mi or onyomi Kunyomi is the Japanese word corre-sponding to the logogram onyomi is a pronunciationthat is similar to the original Chinese Thus the kanji
(tree) has the kunyomi ldquokirdquo and the onyomildquomokurdquo the kanji (forest) is pronounced respec-tively ldquohayashirdquo and ldquorinrdquo According to Kess andMiyamoto (1999) between 12000 and 50000 en-tries are included in comprehensive kanji dictionar-ies The Japanese educational system explicitlyteaches a set of 1945 Joyo Kanji (kanji for dailyuse) However Kess and Miyamoto argued that mostJapanese know many more than these and that 3000or more kanji are required to read a daily newspaper
Children start learning 80 of the easier JoyoKanji toward the end of the first grade The sequenceof introduction of kanji in the curriculum is standard-ized and by the end of elementary school children areexpected to have mastered 1006 characters (NationalLanguage Research Institute 1988) They are expect-ed to master the complete set of Joyo Kanji by the endof the third year of junior high school
Research questionsThis study was designed to compare the rate of
reading acquisition in 6- to 15-year-old childrenlearning to read in a transparent orthographic system(the syllabic Japanese hiragana) in alphabets ofdecreasing orthographic transparency (AlbanianGreek and English) and in the ideographic Japanesekanji system
The orthographic depth hypothesis predictsthat the more transparent the orthography the fasterchildren will learn to read aloud The almost perfectsymbolndashsound correspondence of hiragana its repre-sentation of psycholinguistically accessible syllablesrather than phonemes and the simple syllable struc-ture of Japanese each contributed to the expectationthat learning to read aloud will be easiest in hira-gana All of the alphabetic scripts provide cues topronunciation but some of the systems are moreregular and consistent than others Thus we expect-ed the alphabetic systems to be the next most easy toacquire but that the ease with which reading is ac-quired would vary within alphabetic systems withthe more transparent languages (Albanian andGreek) being easier to learn than the more opaquelanguage (English) Finally we believed that theideographic kanji system which contains few or nocues to assembled pronunciation would be the mostdifficult to acquire
RRQ4-04 Ellis 92204 1151 AM Page 445
The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

440
CETTE EacuteTUDE srsquoest inteacuteresseacutee aux effets de la profondeur orthographique sur lrsquoapprentissage de la lecture avec deseacutecritures alphabeacutetique syllabique et logographique Des enfants de 6 agrave 15 ans ont lu agrave haute voix avec le syl-labique japonais transparent qursquoest lrsquohiragana avec des alphabets de plus grande profondeur orthographique (al-banais grec anglais) et avec les ideacuteogrammes orthographiquement opaques que sont les kanji japonais les itemsayant eacuteteacute apparieacutes drsquoune langue agrave lrsquoautre quant agrave la freacutequence des mots Lrsquoexactitude des reacuteponses leur latence etles types drsquoerreurs ont eacuteteacute analyseacutes Lrsquoexactitude est correacuteleacutee agrave la profondeur lrsquohiragana est lu avec moins drsquoerreursque dans lrsquoordre lrsquoalbanais le grec lrsquoanglais et le kanji Plus lrsquoorthographe est profonde moins la latence deacutependde la longueur du mot plus grande est la proportion drsquoerreurs qui sont des non-reacuteponses et plus les erreurs sub-stantielles tendent agrave ecirctre des substitutions de mots entiers plutocirct que de mauvaises prononciations de non-motsLa profondeur orthographique affecte donc aussi bien la vitesse que la faccedilon de lire
Les effets de laprofondeur
orthographiquesur lrsquoapprentissage
de la lecturedrsquoeacutecritures
alphabeacutetiquesyllabique et
logographique
ABSTRACTS
RRQ4-04 Ellis 92204 1151 AM Page 440
It further predicts the consequence that childrenlearning to read a transparent orthography wheresoundndashsymbol mappings are regular and consistentshould learn to read aloud and to spell faster thanthose learning an opaque orthography where thecues to pronunciation are more ambiguous
There have been some recent demonstrationsthat as predicted by the orthographic depth hypoth-esis learning to read a transparent orthography suchas German (Wimmer amp Hummer 1990) Greek(Goswami Porpodas amp Wheelwright 1997) Italian(Thorstad 1991) Spanish (Goswami Gombert ampDe Barrera 1998) Turkish (Oumlney amp Durgunoglu1997) or Welsh (Ellis amp Hooper 2001) is easierthan learning to read an orthographically opaque lan-guage such as French or English (Goswami et al1998 Landerl Wimmer amp Frith 1997) SeymourAro and Erskine (2003) compared the abilities offirst-grade children to read familiar words and simplenonwords in English and 12 other European orthog-raphies The results showed that children from mostEuropean countries were accurate and fluent in read-ing before the end of the first school year with wordreading accuracies exceeding 90 in all except themore opaque orthographies of Portuguese FrenchDanish and particularly English Seymour Aroand Erskine attributed these findings to orthographicdepth which affected both word and nonword read-ing and to syllabic complexity which affected non-word decoding These findings suggested that therate of learning to read in English was more thantwice as slow as in the other orthographies
The orthographic depthhypothesis and strategy ofreading different scripts
The orthographic depth hypothesis postulatesthat there are different routes to fluent reading thatare dependent on the nature of a particular orthogra-phy Fluent English readersrsquo ability to read nonwordslike nabe or sloppendash demonstrates the availabilityof a route to reading using decoding where pronun-ciation is assembled from known symbolndashsound as-sociations Their ability to pronounce irregular orinconsistent words such as island or Wednesday im-plicates the availability of another reading route onewhere the word cannot be decoded entirely bymatching symbols and sounds Learners of Englishuse different strategies of reading at different stagesof development they move from recognizing whole
words (logographic reading) through a stage wherethey begin to apply soundndashsymbol correspondences(alphabetic reading) to skilled reading that predomi-nantly involves direct lexical access by way of theorthography at least for high-frequency words (or-thographic reading) (Ehri 1999 Frith 1985 MarshFriedman Welch amp Desberg 1981) Readers oftransparent orthographies are more likely to succeedin reading by means of alphabetic reading strategiesthan readers of opaque orthographies and their dif-ferential histories of success or failure may determinetheir respective strategies with readers of transparentscripts being more likely to rely on alphabetic read-ing strategies Thus there are two sides to the ortho-graphic depth hypothesis (a) Transparentorthographies support word recognition involvingphonology and (b) opaque orthographies encouragea reader to process words by accessing the lexiconand meaning via the wordrsquos visual orthographicstructure (Katz amp Frost 1992)
Support for this hypothesis comes from threetypes of evidence First learners of transparentorthographies are better able to read nonwordsLearners of German (Wimmer amp Goswami 1994)and Spanish (Lopez amp Gonzalez 1999) are more ableto read nonwords than are learners of English (RackSnowling amp Olson 1992) Second learners of trans-parent and opaque orthographies produce differentpatterns of reading errors Adherence to an alphabeticdecoding strategy produces errors that are mispro-nunciations whereas orthographic reading strategiesgenerate visually similar real-word substitution er-rors The majority of the reading errors of German(Wimmer amp Hummer 1990) and Welsh (Ellis ampHooper 2001) children are nonwords whereasyoung English-speaking children make frequent read-ing errors that are actual words (Seymour amp Elder1986 Stuart amp Coltheart 1988) Finally there is astronger relationship between word length and read-ing latency in transparent orthographies Ellis andHooper showed that word length determined 70 ofthe difference in times to read words in Welsh butonly 22 in English suggesting that Welsh pronun-ciations were assembled by means of a left-to-rightparse of the written string with longer words conse-quently requiring more time to recognize
Such findings support the hypothesis thattransparent orthographies promote faster rates ofreading acquisition and encourage an alphabeticreading strategy The current study aimed to extendthe comparison of effects of orthography on readingacquisition Previous research assessed the effects oforthographic depth within alphabetic languages Thegoal of the present study was to make further com-
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 441
RRQ4-04 Ellis 92204 1151 AM Page 441
parisons among alphabetic writing systems and tocompare these with other types of script positionedmore extremely on the dimension of orthographicdepth a highly transparent syllabic script and adeeply opaque logographic one
Methods of cross-linguisticreading comparison
It is difficult to compare literacy developmentacross different orthographies because the stimulimust necessarily be different So how can assessmentmaterials across languages be matched Traditionallythere have been three main approaches First readersof different languages can be compared for their abil-ity to read nonwords For example Wimmer andGoswami (1994) showed that children learning toread German were better able to read nonsensewords derived from number words such as vechs andzieben from sechs and sieben than were children learn-ing to read English able to read items such as tix andfeven from six and seven This method has since beenwidely adopted because it provides an index of chil-drenrsquos decoding abilities for novel material Secondcross-linguistic translation equivalents can be com-pared for readability Landerl et al (1997) showedthat German children were better able to read theirtransparent orthography instantiation of pairs oftranslation equivalents (eg Pflug-plough) than werematched learners of English Thorstad (1991) trans-lated a difficult passage of 56 words taken from anItalian journal for adults into English to be used as areading and spelling test Spencer and Hanley(2003) showed that Welsh children were better ablethan their English peers to read both nonwords andtranslation-equivalent words A third approach hasbeen to sample high-frequency words from childrenrsquosschool reading schemes Thus Goswami et al(1998) showed that Spanish children were able toread more of a sample of eight monosyllabic andeight disyllabic words in their language than werematched French or English children Seymour et al(2003) had children read 18 familiar high-frequencycontent words and 18 function words The wordswere sampled from the reading material used in theearly stage of primary schooling in each language
But each of these methods has its limitations asa comparative measure of reading acquisition in dif-ferent languages Nonword reading ability indexeschildrenrsquos decoding skill but nonwords may not begood indicators of skill at reading real wordsTranslations are rarely equivalent either in the rela-
tive frequencies of words or symbols or in their rangeof usage in the respective languages Although thesampling of test items from typical school textbooksis a reasonable start at controlling exposure factorstextbook writers tune their books to their audienceand to the difficulty of the task with which theirreaders are faced so there is no guarantee that a read-ing text in one language is equivalent for comparablechildren in another language
The current study therefore took an alterna-tive approach to the issue of whether it is easier tolearn to read in one language than anotherSpecifically we developed parallel reading tests forwhich the items in the two languages were matchedfor word frequency A longstanding method of as-sessing an individualrsquos ability to read aloud has beento see how many items he or she can read from astandardized list of approximately 100 words ofincreasing difficulty Illustrative examples are theSchonell Graded Word Reading Test and the WideRange Achievement Tests We extended this idea toconstruct parallel cross-linguistic tests where foreach language the items are randomly selected from100 frequency bands representing the most frequentto the least frequent words of the language Thuseach test is a stratified random sample of the wordsof the language with pairs of test items in the twolanguages being matched for frequency of writtenoccurrence The matching process should not controlany other factors such as word length imageabilityutility morphological complexity syntactic rolesemantic richness orthographic complexitysoundndashsymbol consistency or any other intrinsic as-pects of the languages under study that might affecthow easy or difficult it is to learn the words Ideallyeverything to do with learning opportunity shouldbe matched everything to do with language shouldbe free to vary The rationale is based on input-dri-ven perspectives of language acquisition The learn-ability of an item is largely dependent upon theamount of experience a learner has with it and withsimilar items Thus if children of two languages startlearning to read at the same time and they haveroughly equivalent time on task then if the two or-thographies are equally difficult to acquire learnersof similar experience should be able to read words atroughly the same frequency level
Ellis and Hooper (2001) used this method intheir comparisons of Welsh and English The wordtypes that composed a representative million writtenwords of English (Baayen Piepenbrock amp Van Rijn1995) and Welsh (Ellis OrsquoDochartaigh HicksMorgan amp Laporte 2001) were sorted in decreasingfrequency of occurrence and sampled so that a test
442 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 442
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 443
word was selected at every decreasing step of 10000word tokens or its nearest approximation The twolists of 100 words were then used as frequency-matched samples of written English and Welsh Thismethod is promising in assessing the acquisition ofliteracy in children learning to read in different lan-guages and in the multiple languages of multiliterateindividuals for several reasons First it produces teststhat are matched in a principled fashion for inputfrequency Second it generates a broad range of fre-quencies of items from approximately 60000 wordsper million to just 1 per million and so it is appro-priately discriminating for learners at different stagesof proficiency Third it is psychophysically scaledPsycholinguistic experimentation shows that there ismore of a linear relationship between proficiencyand log exposure than between proficiency and ex-posure The method of sampling used by Ellis andHooper effectively provided items representing log-frequency strata
Extending the range ofcomparison beyond alphabeticorthographies
In the present study we therefore used thesemethods to develop tests matched cross-linguisticallyfor frequency of written exposure in order to com-pare the rate of acquisition of reading in 6- to 15-year-old children reading a range of different nativeorthographies the orthographically transparent syl-labic Japanese hiragana system alphabets of decreas-ing orthographic transparency (Albanian Greek andEnglish) and the orthographically opaque ideo-graphic Japanese kanji system We also investigatedwhether these different types of orthography affectthe strategies of lexical access adopted by learners asis predicted by the orthographic depth hypothesis
The orthographies investigated in this study Hiragana
Japanese orthography comprises four types ofscript hiragana and katakana (the kana) kanji andromaji (Kess amp Miyamoto 1999) Hiragana andkatakana are syllabic scripts Most Japanese syllableshave the canonical shape of a consonantndashvowel (CV)combination and can be represented by single kana
symbols There is one-to-one correspondence be-tween hiragana and katakana symbols with both sys-tems containing 46 basic symbols (called seion) 40unvoiced CV combinations five vowels and onenasal coda In addition to these there are other char-acters including 25 symbols that are the voicedequivalents of the basic seion formed by adding a spe-cial mark for voicing or semivoicing making a totalof 71 symbols in all Most kana symbols have a sin-gle unique pronunciation although combinations ofsymbols and their use in certain word classes canmodify the pronunciation slightly (Akita amp Hatano1999) Hiragana is mainly used for function wordsmorphological endings and the rest of the grammati-cal scaffolding of Japanese sentences AlthoughJapanese content words are usually written in kanji itis possible to write all native Japanese words in hira-gana Katakana is mainly used for foreign loan wordsand Japanese interjections Nomura (1980) estimatedthat journals published in Japan contain 50 hira-gana 30 kanji and 10 katakana
The regularity of the symbolndashsound mappingsmakes hiragana an exceptionally transparent orthog-raphy Furthermore because children are better ableto break up speech and identify its syllable parts thanthey are to segment it into phonemes (AlegriaPignot amp Morais 1982 Liberman ShankweilerFischer amp Carter 1974 Rozin amp Gleitman 1977)the canonical CV syllable shape of spoken Japaneseallows for easy phonological segmentation Thesetwo factors should thus combine to promote fast ac-quisition The spoken language is easily segmentedinto its syllable parts and each of these individualphonological units has its unique written symbol
Learning to read and write in Japanese official-ly begins at the age of 6 in the first grade of elemen-tary school The seion symbols are first introducedfollowed by the rest of hiragana Katakana is intro-duced in the latter half of the first grade and iscompleted by the end of the second grade Childrenalso start learning some easier kanji in the firstgrade Notwithstanding the official syllabus mostpreschoolers are able to read at least the 46 basichiragana by the time they start the first gradeShimamura and Mikami (1994) reported that 16of 3-year-olds 59 of 4-year-olds and 89 of 5-year-olds could read 60 or more of the 71 hiragana symbols
AlbanianAlbanian forms a single branch of the Indo-
European family that is spoken by over three millionpeople in Albania and in parts of the former republic
RRQ4-04 Ellis 92204 1151 AM Page 443
of Yugoslavia Greece and Italy The writing systemwas not introduced until 1909 hence few languagesare more orthographically transparent than AlbanianIt uses Roman characters and has 36 letters 29 con-sonants and 7 vowels Nine of the consonants arepresented as bigraphs (dh gj ll nj rr sh th xh zh)These bigraphs are explicitly taught to the children asseparate ldquolettersrdquo of the alphabet and if they appeartogether are never considered as separate graphemes(this rule does not apply to compound words whichoccur rather infrequently) The bidirectionalgraphemendashphoneme and phonemendashgrapheme map-ping is consistent for both consonants and vowelsThese symbols do not change their sound accordingto their position in the word
In Albania there are very few nursery schoolsand only a minority of preschoolers go to kinder-garten The consequence is that most first graders inAlbania enter school without letter or written wordawareness The teaching of reading in Albanian pri-mary schools is introduced in year 1 The officialteaching method is a whole-word method called theGlobal Method However many teachers who havebeen using phonics approaches for many years preferto use mixed methods including both whole-wordand phonics approaches (Hoxhallari 2000)
GreekGreek is highly regular in its symbol-to-sound
mappings for reading though less so in its soundndashsymbol mappings for spelling In spoken Greek thereare only five vowels that sound the same whetherstressed or unstressed (Harris amp Giannouli 1999)While the majority of Greek words are polysyllabicthere are fewer than half the syllable types of Englishwith the majority of them being open syllables of theconsonantndashvowel type (V CV VC CCV CCCV)(Magoulas 1979) As with Japanese these syllablecharacteristics presumably allow children an easiertask of phonological segmentation of their spokenlanguage In the written language each letterrsquos singlesound remains relatively constant in different con-texts (Chitiri amp Willows 1994)
Nevertheless written Greek is not entirelytransparent Whereas the written form has remainedessentially intact since its development as an alpha-betic script the spoken language has undergone ma-jor developmental changes in its evolution towardmodern Greek (Babiniotis 1980 Tombaidis 1987Triantaphyllidis 1913) As a result modern spellingis not entirely phonetic but has a morphophonemicnature that reflects the etymology of words(Porpodas 1991 1999) Spoken Greek is composed
of 32 phonemes that are represented by the 24Greek letters (Bakamidis amp Carayannis 1987Triantaphyllidis 1980) Several phonemendashgraphemeinconsistencies occur including homophone vowelsand vowel and consonant clusters (diphthongs anddipsipha) The pronunciation of dipsipha varies ac-cording to their position in the word and the contextin which they occur In exceptional cases some let-ters are almost voiceless (Porpodas 1991 Tombaidis1987 Triantaphyllidis 1913) Greek has the addedfeature whereby the position of prosodic stress ismarked for each written word Stress which canoccur on any of the final three syllables of a worddepending on a variety of morphological phonologi-cal and lexical factors must be properly interpretedfor successful reading because there are many wordsthat are differentiated only by stress (Tombaidis1986)
Reading instruction is standardized in GreeceIt usually starts at 55 to 6 years old beginning withletterndashsound correspondences Thereafter a syntheticphonics method is used to encourage phonologicalrecoding of simple CV syllables that form simplewords and there is an emphasis on rhyming wordsOnce children have established good letterndashsoundknowledge and have built an initial sight vocabularyletter names are taught and a phonics method is usedto teach graphemendashphoneme correspondences thatinclude more complex syllables like CCV The stressmark is also introduced The basic reading process istypically well established by the end of the first grade(Harris amp Giannouli 1999 Porpodas 1991)
EnglishThe English alphabet consists of 26 letters (5
vowels and 21 consonants) that represent over 40phonemes Letters or letter combinations are oftenambiguous in terms of the sounds they represent AsVenezky (1970) concluded from his analysis of thestructure of English orthography ldquoa person who at-tempts to scan left to right letter by letter pronounc-ing as he goes could not correctly read most Englishwordsrdquo (p 127) The 5 written vowels are particularlyvaried in their mappings to speech and there are 12vowel digraphs 6 of which have alternate pronuncia-tions according to their position Consonants aremore consistent in their graphemendashphoneme corre-spondences with the exceptions of c and g which areread differently according to the vowels that followNevertheless only three consonants (n r and v) haveonly one sound that cannot be produced by othercombinations and are never silent (Venezky) SpokenEnglish also has a complex syllable structure with
444 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 444
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 445
many different types of syllables most of them closed(eg CVC CVCC CCVC) These characteristicspose difficulty for children learning to phonologicallysegment their spoken language
Although English is varied in its graphemendashphoneme correspondences it has a higher degree ofspellingndashsound consistency at the level of the rimeTreiman Mullennix Bijeljac-Babic and Richmond-Welty (1995) estimated that the pronunciation ofmodern English written vowels is only 51 consis-tent over different words whereas initial and finalconsonants are much more consistent (96 and91 respectively) as are rime units (77) For ex-ample a is pronounced differently in cat call carcake and care but it is pronounced the same in therimes cat hat and mat Phonological segmentationinto onset-rime units and the use of orthographicrime analogies have been shown to be importantprocesses in learning to read and spell English(Goswami 1999 2000 Goswami et al 1998Treiman et al 1995)
The majority of English children begin preread-ing exposure quite early at 3 or 4 years old InNursery children are taught the shapes of most lettersof the alphabet and introduced to book use They areread to on a daily basis and there is emphasis on rep-etition and rhyming In Reception there is at least 30minutes per day dedicated solely to reading There ismuch use of word-building pattern recognition andodd-one-out games In year 1 the recognition of thewords as a whole is supported with the use of look-and-say and odd-one-out games Flash cards are usedto introduce individual words to build a startingsight vocabulary and to form simple sentencesChildren are taught families of word patterns thatshare orthographic and phonological resemblance atonset or rime Phonics is typically introduced at theend of year 1 and children are encouraged to practicesounding out and blending phonemes Literacy re-mains a significant part of the national curriculumright through Upper Key Stage 2 that is 9 to 11 yearsold In sum much time and effort is put into teach-ing children to learn to read in English
Kanji The kanji writing system originated in the log-
ographs of Chinese orthography Content words inJapanese are usually written in kanji because doingso resolves the ambiguity of the many homophonesof spoken Japanese The higher homophony rate inJapanese than in other languages is due to its simpleCV spoken syllable structure which restricts thenumber of possible spoken syllables that can be used
individually and in combination to form a spokenword (Akita amp Hatano 1999) In general there aretwo ways to read a given kanji referred to as kunyo-mi or onyomi Kunyomi is the Japanese word corre-sponding to the logogram onyomi is a pronunciationthat is similar to the original Chinese Thus the kanji
(tree) has the kunyomi ldquokirdquo and the onyomildquomokurdquo the kanji (forest) is pronounced respec-tively ldquohayashirdquo and ldquorinrdquo According to Kess andMiyamoto (1999) between 12000 and 50000 en-tries are included in comprehensive kanji dictionar-ies The Japanese educational system explicitlyteaches a set of 1945 Joyo Kanji (kanji for dailyuse) However Kess and Miyamoto argued that mostJapanese know many more than these and that 3000or more kanji are required to read a daily newspaper
Children start learning 80 of the easier JoyoKanji toward the end of the first grade The sequenceof introduction of kanji in the curriculum is standard-ized and by the end of elementary school children areexpected to have mastered 1006 characters (NationalLanguage Research Institute 1988) They are expect-ed to master the complete set of Joyo Kanji by the endof the third year of junior high school
Research questionsThis study was designed to compare the rate of
reading acquisition in 6- to 15-year-old childrenlearning to read in a transparent orthographic system(the syllabic Japanese hiragana) in alphabets ofdecreasing orthographic transparency (AlbanianGreek and English) and in the ideographic Japanesekanji system
The orthographic depth hypothesis predictsthat the more transparent the orthography the fasterchildren will learn to read aloud The almost perfectsymbolndashsound correspondence of hiragana its repre-sentation of psycholinguistically accessible syllablesrather than phonemes and the simple syllable struc-ture of Japanese each contributed to the expectationthat learning to read aloud will be easiest in hira-gana All of the alphabetic scripts provide cues topronunciation but some of the systems are moreregular and consistent than others Thus we expect-ed the alphabetic systems to be the next most easy toacquire but that the ease with which reading is ac-quired would vary within alphabetic systems withthe more transparent languages (Albanian andGreek) being easier to learn than the more opaquelanguage (English) Finally we believed that theideographic kanji system which contains few or nocues to assembled pronunciation would be the mostdifficult to acquire
RRQ4-04 Ellis 92204 1151 AM Page 445
The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

It further predicts the consequence that childrenlearning to read a transparent orthography wheresoundndashsymbol mappings are regular and consistentshould learn to read aloud and to spell faster thanthose learning an opaque orthography where thecues to pronunciation are more ambiguous
There have been some recent demonstrationsthat as predicted by the orthographic depth hypoth-esis learning to read a transparent orthography suchas German (Wimmer amp Hummer 1990) Greek(Goswami Porpodas amp Wheelwright 1997) Italian(Thorstad 1991) Spanish (Goswami Gombert ampDe Barrera 1998) Turkish (Oumlney amp Durgunoglu1997) or Welsh (Ellis amp Hooper 2001) is easierthan learning to read an orthographically opaque lan-guage such as French or English (Goswami et al1998 Landerl Wimmer amp Frith 1997) SeymourAro and Erskine (2003) compared the abilities offirst-grade children to read familiar words and simplenonwords in English and 12 other European orthog-raphies The results showed that children from mostEuropean countries were accurate and fluent in read-ing before the end of the first school year with wordreading accuracies exceeding 90 in all except themore opaque orthographies of Portuguese FrenchDanish and particularly English Seymour Aroand Erskine attributed these findings to orthographicdepth which affected both word and nonword read-ing and to syllabic complexity which affected non-word decoding These findings suggested that therate of learning to read in English was more thantwice as slow as in the other orthographies
The orthographic depthhypothesis and strategy ofreading different scripts
The orthographic depth hypothesis postulatesthat there are different routes to fluent reading thatare dependent on the nature of a particular orthogra-phy Fluent English readersrsquo ability to read nonwordslike nabe or sloppendash demonstrates the availabilityof a route to reading using decoding where pronun-ciation is assembled from known symbolndashsound as-sociations Their ability to pronounce irregular orinconsistent words such as island or Wednesday im-plicates the availability of another reading route onewhere the word cannot be decoded entirely bymatching symbols and sounds Learners of Englishuse different strategies of reading at different stagesof development they move from recognizing whole
words (logographic reading) through a stage wherethey begin to apply soundndashsymbol correspondences(alphabetic reading) to skilled reading that predomi-nantly involves direct lexical access by way of theorthography at least for high-frequency words (or-thographic reading) (Ehri 1999 Frith 1985 MarshFriedman Welch amp Desberg 1981) Readers oftransparent orthographies are more likely to succeedin reading by means of alphabetic reading strategiesthan readers of opaque orthographies and their dif-ferential histories of success or failure may determinetheir respective strategies with readers of transparentscripts being more likely to rely on alphabetic read-ing strategies Thus there are two sides to the ortho-graphic depth hypothesis (a) Transparentorthographies support word recognition involvingphonology and (b) opaque orthographies encouragea reader to process words by accessing the lexiconand meaning via the wordrsquos visual orthographicstructure (Katz amp Frost 1992)
Support for this hypothesis comes from threetypes of evidence First learners of transparentorthographies are better able to read nonwordsLearners of German (Wimmer amp Goswami 1994)and Spanish (Lopez amp Gonzalez 1999) are more ableto read nonwords than are learners of English (RackSnowling amp Olson 1992) Second learners of trans-parent and opaque orthographies produce differentpatterns of reading errors Adherence to an alphabeticdecoding strategy produces errors that are mispro-nunciations whereas orthographic reading strategiesgenerate visually similar real-word substitution er-rors The majority of the reading errors of German(Wimmer amp Hummer 1990) and Welsh (Ellis ampHooper 2001) children are nonwords whereasyoung English-speaking children make frequent read-ing errors that are actual words (Seymour amp Elder1986 Stuart amp Coltheart 1988) Finally there is astronger relationship between word length and read-ing latency in transparent orthographies Ellis andHooper showed that word length determined 70 ofthe difference in times to read words in Welsh butonly 22 in English suggesting that Welsh pronun-ciations were assembled by means of a left-to-rightparse of the written string with longer words conse-quently requiring more time to recognize
Such findings support the hypothesis thattransparent orthographies promote faster rates ofreading acquisition and encourage an alphabeticreading strategy The current study aimed to extendthe comparison of effects of orthography on readingacquisition Previous research assessed the effects oforthographic depth within alphabetic languages Thegoal of the present study was to make further com-
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 441
RRQ4-04 Ellis 92204 1151 AM Page 441
parisons among alphabetic writing systems and tocompare these with other types of script positionedmore extremely on the dimension of orthographicdepth a highly transparent syllabic script and adeeply opaque logographic one
Methods of cross-linguisticreading comparison
It is difficult to compare literacy developmentacross different orthographies because the stimulimust necessarily be different So how can assessmentmaterials across languages be matched Traditionallythere have been three main approaches First readersof different languages can be compared for their abil-ity to read nonwords For example Wimmer andGoswami (1994) showed that children learning toread German were better able to read nonsensewords derived from number words such as vechs andzieben from sechs and sieben than were children learn-ing to read English able to read items such as tix andfeven from six and seven This method has since beenwidely adopted because it provides an index of chil-drenrsquos decoding abilities for novel material Secondcross-linguistic translation equivalents can be com-pared for readability Landerl et al (1997) showedthat German children were better able to read theirtransparent orthography instantiation of pairs oftranslation equivalents (eg Pflug-plough) than werematched learners of English Thorstad (1991) trans-lated a difficult passage of 56 words taken from anItalian journal for adults into English to be used as areading and spelling test Spencer and Hanley(2003) showed that Welsh children were better ablethan their English peers to read both nonwords andtranslation-equivalent words A third approach hasbeen to sample high-frequency words from childrenrsquosschool reading schemes Thus Goswami et al(1998) showed that Spanish children were able toread more of a sample of eight monosyllabic andeight disyllabic words in their language than werematched French or English children Seymour et al(2003) had children read 18 familiar high-frequencycontent words and 18 function words The wordswere sampled from the reading material used in theearly stage of primary schooling in each language
But each of these methods has its limitations asa comparative measure of reading acquisition in dif-ferent languages Nonword reading ability indexeschildrenrsquos decoding skill but nonwords may not begood indicators of skill at reading real wordsTranslations are rarely equivalent either in the rela-
tive frequencies of words or symbols or in their rangeof usage in the respective languages Although thesampling of test items from typical school textbooksis a reasonable start at controlling exposure factorstextbook writers tune their books to their audienceand to the difficulty of the task with which theirreaders are faced so there is no guarantee that a read-ing text in one language is equivalent for comparablechildren in another language
The current study therefore took an alterna-tive approach to the issue of whether it is easier tolearn to read in one language than anotherSpecifically we developed parallel reading tests forwhich the items in the two languages were matchedfor word frequency A longstanding method of as-sessing an individualrsquos ability to read aloud has beento see how many items he or she can read from astandardized list of approximately 100 words ofincreasing difficulty Illustrative examples are theSchonell Graded Word Reading Test and the WideRange Achievement Tests We extended this idea toconstruct parallel cross-linguistic tests where foreach language the items are randomly selected from100 frequency bands representing the most frequentto the least frequent words of the language Thuseach test is a stratified random sample of the wordsof the language with pairs of test items in the twolanguages being matched for frequency of writtenoccurrence The matching process should not controlany other factors such as word length imageabilityutility morphological complexity syntactic rolesemantic richness orthographic complexitysoundndashsymbol consistency or any other intrinsic as-pects of the languages under study that might affecthow easy or difficult it is to learn the words Ideallyeverything to do with learning opportunity shouldbe matched everything to do with language shouldbe free to vary The rationale is based on input-dri-ven perspectives of language acquisition The learn-ability of an item is largely dependent upon theamount of experience a learner has with it and withsimilar items Thus if children of two languages startlearning to read at the same time and they haveroughly equivalent time on task then if the two or-thographies are equally difficult to acquire learnersof similar experience should be able to read words atroughly the same frequency level
Ellis and Hooper (2001) used this method intheir comparisons of Welsh and English The wordtypes that composed a representative million writtenwords of English (Baayen Piepenbrock amp Van Rijn1995) and Welsh (Ellis OrsquoDochartaigh HicksMorgan amp Laporte 2001) were sorted in decreasingfrequency of occurrence and sampled so that a test
442 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 442
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 443
word was selected at every decreasing step of 10000word tokens or its nearest approximation The twolists of 100 words were then used as frequency-matched samples of written English and Welsh Thismethod is promising in assessing the acquisition ofliteracy in children learning to read in different lan-guages and in the multiple languages of multiliterateindividuals for several reasons First it produces teststhat are matched in a principled fashion for inputfrequency Second it generates a broad range of fre-quencies of items from approximately 60000 wordsper million to just 1 per million and so it is appro-priately discriminating for learners at different stagesof proficiency Third it is psychophysically scaledPsycholinguistic experimentation shows that there ismore of a linear relationship between proficiencyand log exposure than between proficiency and ex-posure The method of sampling used by Ellis andHooper effectively provided items representing log-frequency strata
Extending the range ofcomparison beyond alphabeticorthographies
In the present study we therefore used thesemethods to develop tests matched cross-linguisticallyfor frequency of written exposure in order to com-pare the rate of acquisition of reading in 6- to 15-year-old children reading a range of different nativeorthographies the orthographically transparent syl-labic Japanese hiragana system alphabets of decreas-ing orthographic transparency (Albanian Greek andEnglish) and the orthographically opaque ideo-graphic Japanese kanji system We also investigatedwhether these different types of orthography affectthe strategies of lexical access adopted by learners asis predicted by the orthographic depth hypothesis
The orthographies investigated in this study Hiragana
Japanese orthography comprises four types ofscript hiragana and katakana (the kana) kanji andromaji (Kess amp Miyamoto 1999) Hiragana andkatakana are syllabic scripts Most Japanese syllableshave the canonical shape of a consonantndashvowel (CV)combination and can be represented by single kana
symbols There is one-to-one correspondence be-tween hiragana and katakana symbols with both sys-tems containing 46 basic symbols (called seion) 40unvoiced CV combinations five vowels and onenasal coda In addition to these there are other char-acters including 25 symbols that are the voicedequivalents of the basic seion formed by adding a spe-cial mark for voicing or semivoicing making a totalof 71 symbols in all Most kana symbols have a sin-gle unique pronunciation although combinations ofsymbols and their use in certain word classes canmodify the pronunciation slightly (Akita amp Hatano1999) Hiragana is mainly used for function wordsmorphological endings and the rest of the grammati-cal scaffolding of Japanese sentences AlthoughJapanese content words are usually written in kanji itis possible to write all native Japanese words in hira-gana Katakana is mainly used for foreign loan wordsand Japanese interjections Nomura (1980) estimatedthat journals published in Japan contain 50 hira-gana 30 kanji and 10 katakana
The regularity of the symbolndashsound mappingsmakes hiragana an exceptionally transparent orthog-raphy Furthermore because children are better ableto break up speech and identify its syllable parts thanthey are to segment it into phonemes (AlegriaPignot amp Morais 1982 Liberman ShankweilerFischer amp Carter 1974 Rozin amp Gleitman 1977)the canonical CV syllable shape of spoken Japaneseallows for easy phonological segmentation Thesetwo factors should thus combine to promote fast ac-quisition The spoken language is easily segmentedinto its syllable parts and each of these individualphonological units has its unique written symbol
Learning to read and write in Japanese official-ly begins at the age of 6 in the first grade of elemen-tary school The seion symbols are first introducedfollowed by the rest of hiragana Katakana is intro-duced in the latter half of the first grade and iscompleted by the end of the second grade Childrenalso start learning some easier kanji in the firstgrade Notwithstanding the official syllabus mostpreschoolers are able to read at least the 46 basichiragana by the time they start the first gradeShimamura and Mikami (1994) reported that 16of 3-year-olds 59 of 4-year-olds and 89 of 5-year-olds could read 60 or more of the 71 hiragana symbols
AlbanianAlbanian forms a single branch of the Indo-
European family that is spoken by over three millionpeople in Albania and in parts of the former republic
RRQ4-04 Ellis 92204 1151 AM Page 443
of Yugoslavia Greece and Italy The writing systemwas not introduced until 1909 hence few languagesare more orthographically transparent than AlbanianIt uses Roman characters and has 36 letters 29 con-sonants and 7 vowels Nine of the consonants arepresented as bigraphs (dh gj ll nj rr sh th xh zh)These bigraphs are explicitly taught to the children asseparate ldquolettersrdquo of the alphabet and if they appeartogether are never considered as separate graphemes(this rule does not apply to compound words whichoccur rather infrequently) The bidirectionalgraphemendashphoneme and phonemendashgrapheme map-ping is consistent for both consonants and vowelsThese symbols do not change their sound accordingto their position in the word
In Albania there are very few nursery schoolsand only a minority of preschoolers go to kinder-garten The consequence is that most first graders inAlbania enter school without letter or written wordawareness The teaching of reading in Albanian pri-mary schools is introduced in year 1 The officialteaching method is a whole-word method called theGlobal Method However many teachers who havebeen using phonics approaches for many years preferto use mixed methods including both whole-wordand phonics approaches (Hoxhallari 2000)
GreekGreek is highly regular in its symbol-to-sound
mappings for reading though less so in its soundndashsymbol mappings for spelling In spoken Greek thereare only five vowels that sound the same whetherstressed or unstressed (Harris amp Giannouli 1999)While the majority of Greek words are polysyllabicthere are fewer than half the syllable types of Englishwith the majority of them being open syllables of theconsonantndashvowel type (V CV VC CCV CCCV)(Magoulas 1979) As with Japanese these syllablecharacteristics presumably allow children an easiertask of phonological segmentation of their spokenlanguage In the written language each letterrsquos singlesound remains relatively constant in different con-texts (Chitiri amp Willows 1994)
Nevertheless written Greek is not entirelytransparent Whereas the written form has remainedessentially intact since its development as an alpha-betic script the spoken language has undergone ma-jor developmental changes in its evolution towardmodern Greek (Babiniotis 1980 Tombaidis 1987Triantaphyllidis 1913) As a result modern spellingis not entirely phonetic but has a morphophonemicnature that reflects the etymology of words(Porpodas 1991 1999) Spoken Greek is composed
of 32 phonemes that are represented by the 24Greek letters (Bakamidis amp Carayannis 1987Triantaphyllidis 1980) Several phonemendashgraphemeinconsistencies occur including homophone vowelsand vowel and consonant clusters (diphthongs anddipsipha) The pronunciation of dipsipha varies ac-cording to their position in the word and the contextin which they occur In exceptional cases some let-ters are almost voiceless (Porpodas 1991 Tombaidis1987 Triantaphyllidis 1913) Greek has the addedfeature whereby the position of prosodic stress ismarked for each written word Stress which canoccur on any of the final three syllables of a worddepending on a variety of morphological phonologi-cal and lexical factors must be properly interpretedfor successful reading because there are many wordsthat are differentiated only by stress (Tombaidis1986)
Reading instruction is standardized in GreeceIt usually starts at 55 to 6 years old beginning withletterndashsound correspondences Thereafter a syntheticphonics method is used to encourage phonologicalrecoding of simple CV syllables that form simplewords and there is an emphasis on rhyming wordsOnce children have established good letterndashsoundknowledge and have built an initial sight vocabularyletter names are taught and a phonics method is usedto teach graphemendashphoneme correspondences thatinclude more complex syllables like CCV The stressmark is also introduced The basic reading process istypically well established by the end of the first grade(Harris amp Giannouli 1999 Porpodas 1991)
EnglishThe English alphabet consists of 26 letters (5
vowels and 21 consonants) that represent over 40phonemes Letters or letter combinations are oftenambiguous in terms of the sounds they represent AsVenezky (1970) concluded from his analysis of thestructure of English orthography ldquoa person who at-tempts to scan left to right letter by letter pronounc-ing as he goes could not correctly read most Englishwordsrdquo (p 127) The 5 written vowels are particularlyvaried in their mappings to speech and there are 12vowel digraphs 6 of which have alternate pronuncia-tions according to their position Consonants aremore consistent in their graphemendashphoneme corre-spondences with the exceptions of c and g which areread differently according to the vowels that followNevertheless only three consonants (n r and v) haveonly one sound that cannot be produced by othercombinations and are never silent (Venezky) SpokenEnglish also has a complex syllable structure with
444 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 444
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 445
many different types of syllables most of them closed(eg CVC CVCC CCVC) These characteristicspose difficulty for children learning to phonologicallysegment their spoken language
Although English is varied in its graphemendashphoneme correspondences it has a higher degree ofspellingndashsound consistency at the level of the rimeTreiman Mullennix Bijeljac-Babic and Richmond-Welty (1995) estimated that the pronunciation ofmodern English written vowels is only 51 consis-tent over different words whereas initial and finalconsonants are much more consistent (96 and91 respectively) as are rime units (77) For ex-ample a is pronounced differently in cat call carcake and care but it is pronounced the same in therimes cat hat and mat Phonological segmentationinto onset-rime units and the use of orthographicrime analogies have been shown to be importantprocesses in learning to read and spell English(Goswami 1999 2000 Goswami et al 1998Treiman et al 1995)
The majority of English children begin preread-ing exposure quite early at 3 or 4 years old InNursery children are taught the shapes of most lettersof the alphabet and introduced to book use They areread to on a daily basis and there is emphasis on rep-etition and rhyming In Reception there is at least 30minutes per day dedicated solely to reading There ismuch use of word-building pattern recognition andodd-one-out games In year 1 the recognition of thewords as a whole is supported with the use of look-and-say and odd-one-out games Flash cards are usedto introduce individual words to build a startingsight vocabulary and to form simple sentencesChildren are taught families of word patterns thatshare orthographic and phonological resemblance atonset or rime Phonics is typically introduced at theend of year 1 and children are encouraged to practicesounding out and blending phonemes Literacy re-mains a significant part of the national curriculumright through Upper Key Stage 2 that is 9 to 11 yearsold In sum much time and effort is put into teach-ing children to learn to read in English
Kanji The kanji writing system originated in the log-
ographs of Chinese orthography Content words inJapanese are usually written in kanji because doingso resolves the ambiguity of the many homophonesof spoken Japanese The higher homophony rate inJapanese than in other languages is due to its simpleCV spoken syllable structure which restricts thenumber of possible spoken syllables that can be used
individually and in combination to form a spokenword (Akita amp Hatano 1999) In general there aretwo ways to read a given kanji referred to as kunyo-mi or onyomi Kunyomi is the Japanese word corre-sponding to the logogram onyomi is a pronunciationthat is similar to the original Chinese Thus the kanji
(tree) has the kunyomi ldquokirdquo and the onyomildquomokurdquo the kanji (forest) is pronounced respec-tively ldquohayashirdquo and ldquorinrdquo According to Kess andMiyamoto (1999) between 12000 and 50000 en-tries are included in comprehensive kanji dictionar-ies The Japanese educational system explicitlyteaches a set of 1945 Joyo Kanji (kanji for dailyuse) However Kess and Miyamoto argued that mostJapanese know many more than these and that 3000or more kanji are required to read a daily newspaper
Children start learning 80 of the easier JoyoKanji toward the end of the first grade The sequenceof introduction of kanji in the curriculum is standard-ized and by the end of elementary school children areexpected to have mastered 1006 characters (NationalLanguage Research Institute 1988) They are expect-ed to master the complete set of Joyo Kanji by the endof the third year of junior high school
Research questionsThis study was designed to compare the rate of
reading acquisition in 6- to 15-year-old childrenlearning to read in a transparent orthographic system(the syllabic Japanese hiragana) in alphabets ofdecreasing orthographic transparency (AlbanianGreek and English) and in the ideographic Japanesekanji system
The orthographic depth hypothesis predictsthat the more transparent the orthography the fasterchildren will learn to read aloud The almost perfectsymbolndashsound correspondence of hiragana its repre-sentation of psycholinguistically accessible syllablesrather than phonemes and the simple syllable struc-ture of Japanese each contributed to the expectationthat learning to read aloud will be easiest in hira-gana All of the alphabetic scripts provide cues topronunciation but some of the systems are moreregular and consistent than others Thus we expect-ed the alphabetic systems to be the next most easy toacquire but that the ease with which reading is ac-quired would vary within alphabetic systems withthe more transparent languages (Albanian andGreek) being easier to learn than the more opaquelanguage (English) Finally we believed that theideographic kanji system which contains few or nocues to assembled pronunciation would be the mostdifficult to acquire
RRQ4-04 Ellis 92204 1151 AM Page 445
The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

parisons among alphabetic writing systems and tocompare these with other types of script positionedmore extremely on the dimension of orthographicdepth a highly transparent syllabic script and adeeply opaque logographic one
Methods of cross-linguisticreading comparison
It is difficult to compare literacy developmentacross different orthographies because the stimulimust necessarily be different So how can assessmentmaterials across languages be matched Traditionallythere have been three main approaches First readersof different languages can be compared for their abil-ity to read nonwords For example Wimmer andGoswami (1994) showed that children learning toread German were better able to read nonsensewords derived from number words such as vechs andzieben from sechs and sieben than were children learn-ing to read English able to read items such as tix andfeven from six and seven This method has since beenwidely adopted because it provides an index of chil-drenrsquos decoding abilities for novel material Secondcross-linguistic translation equivalents can be com-pared for readability Landerl et al (1997) showedthat German children were better able to read theirtransparent orthography instantiation of pairs oftranslation equivalents (eg Pflug-plough) than werematched learners of English Thorstad (1991) trans-lated a difficult passage of 56 words taken from anItalian journal for adults into English to be used as areading and spelling test Spencer and Hanley(2003) showed that Welsh children were better ablethan their English peers to read both nonwords andtranslation-equivalent words A third approach hasbeen to sample high-frequency words from childrenrsquosschool reading schemes Thus Goswami et al(1998) showed that Spanish children were able toread more of a sample of eight monosyllabic andeight disyllabic words in their language than werematched French or English children Seymour et al(2003) had children read 18 familiar high-frequencycontent words and 18 function words The wordswere sampled from the reading material used in theearly stage of primary schooling in each language
But each of these methods has its limitations asa comparative measure of reading acquisition in dif-ferent languages Nonword reading ability indexeschildrenrsquos decoding skill but nonwords may not begood indicators of skill at reading real wordsTranslations are rarely equivalent either in the rela-
tive frequencies of words or symbols or in their rangeof usage in the respective languages Although thesampling of test items from typical school textbooksis a reasonable start at controlling exposure factorstextbook writers tune their books to their audienceand to the difficulty of the task with which theirreaders are faced so there is no guarantee that a read-ing text in one language is equivalent for comparablechildren in another language
The current study therefore took an alterna-tive approach to the issue of whether it is easier tolearn to read in one language than anotherSpecifically we developed parallel reading tests forwhich the items in the two languages were matchedfor word frequency A longstanding method of as-sessing an individualrsquos ability to read aloud has beento see how many items he or she can read from astandardized list of approximately 100 words ofincreasing difficulty Illustrative examples are theSchonell Graded Word Reading Test and the WideRange Achievement Tests We extended this idea toconstruct parallel cross-linguistic tests where foreach language the items are randomly selected from100 frequency bands representing the most frequentto the least frequent words of the language Thuseach test is a stratified random sample of the wordsof the language with pairs of test items in the twolanguages being matched for frequency of writtenoccurrence The matching process should not controlany other factors such as word length imageabilityutility morphological complexity syntactic rolesemantic richness orthographic complexitysoundndashsymbol consistency or any other intrinsic as-pects of the languages under study that might affecthow easy or difficult it is to learn the words Ideallyeverything to do with learning opportunity shouldbe matched everything to do with language shouldbe free to vary The rationale is based on input-dri-ven perspectives of language acquisition The learn-ability of an item is largely dependent upon theamount of experience a learner has with it and withsimilar items Thus if children of two languages startlearning to read at the same time and they haveroughly equivalent time on task then if the two or-thographies are equally difficult to acquire learnersof similar experience should be able to read words atroughly the same frequency level
Ellis and Hooper (2001) used this method intheir comparisons of Welsh and English The wordtypes that composed a representative million writtenwords of English (Baayen Piepenbrock amp Van Rijn1995) and Welsh (Ellis OrsquoDochartaigh HicksMorgan amp Laporte 2001) were sorted in decreasingfrequency of occurrence and sampled so that a test
442 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 442
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 443
word was selected at every decreasing step of 10000word tokens or its nearest approximation The twolists of 100 words were then used as frequency-matched samples of written English and Welsh Thismethod is promising in assessing the acquisition ofliteracy in children learning to read in different lan-guages and in the multiple languages of multiliterateindividuals for several reasons First it produces teststhat are matched in a principled fashion for inputfrequency Second it generates a broad range of fre-quencies of items from approximately 60000 wordsper million to just 1 per million and so it is appro-priately discriminating for learners at different stagesof proficiency Third it is psychophysically scaledPsycholinguistic experimentation shows that there ismore of a linear relationship between proficiencyand log exposure than between proficiency and ex-posure The method of sampling used by Ellis andHooper effectively provided items representing log-frequency strata
Extending the range ofcomparison beyond alphabeticorthographies
In the present study we therefore used thesemethods to develop tests matched cross-linguisticallyfor frequency of written exposure in order to com-pare the rate of acquisition of reading in 6- to 15-year-old children reading a range of different nativeorthographies the orthographically transparent syl-labic Japanese hiragana system alphabets of decreas-ing orthographic transparency (Albanian Greek andEnglish) and the orthographically opaque ideo-graphic Japanese kanji system We also investigatedwhether these different types of orthography affectthe strategies of lexical access adopted by learners asis predicted by the orthographic depth hypothesis
The orthographies investigated in this study Hiragana
Japanese orthography comprises four types ofscript hiragana and katakana (the kana) kanji andromaji (Kess amp Miyamoto 1999) Hiragana andkatakana are syllabic scripts Most Japanese syllableshave the canonical shape of a consonantndashvowel (CV)combination and can be represented by single kana
symbols There is one-to-one correspondence be-tween hiragana and katakana symbols with both sys-tems containing 46 basic symbols (called seion) 40unvoiced CV combinations five vowels and onenasal coda In addition to these there are other char-acters including 25 symbols that are the voicedequivalents of the basic seion formed by adding a spe-cial mark for voicing or semivoicing making a totalof 71 symbols in all Most kana symbols have a sin-gle unique pronunciation although combinations ofsymbols and their use in certain word classes canmodify the pronunciation slightly (Akita amp Hatano1999) Hiragana is mainly used for function wordsmorphological endings and the rest of the grammati-cal scaffolding of Japanese sentences AlthoughJapanese content words are usually written in kanji itis possible to write all native Japanese words in hira-gana Katakana is mainly used for foreign loan wordsand Japanese interjections Nomura (1980) estimatedthat journals published in Japan contain 50 hira-gana 30 kanji and 10 katakana
The regularity of the symbolndashsound mappingsmakes hiragana an exceptionally transparent orthog-raphy Furthermore because children are better ableto break up speech and identify its syllable parts thanthey are to segment it into phonemes (AlegriaPignot amp Morais 1982 Liberman ShankweilerFischer amp Carter 1974 Rozin amp Gleitman 1977)the canonical CV syllable shape of spoken Japaneseallows for easy phonological segmentation Thesetwo factors should thus combine to promote fast ac-quisition The spoken language is easily segmentedinto its syllable parts and each of these individualphonological units has its unique written symbol
Learning to read and write in Japanese official-ly begins at the age of 6 in the first grade of elemen-tary school The seion symbols are first introducedfollowed by the rest of hiragana Katakana is intro-duced in the latter half of the first grade and iscompleted by the end of the second grade Childrenalso start learning some easier kanji in the firstgrade Notwithstanding the official syllabus mostpreschoolers are able to read at least the 46 basichiragana by the time they start the first gradeShimamura and Mikami (1994) reported that 16of 3-year-olds 59 of 4-year-olds and 89 of 5-year-olds could read 60 or more of the 71 hiragana symbols
AlbanianAlbanian forms a single branch of the Indo-
European family that is spoken by over three millionpeople in Albania and in parts of the former republic
RRQ4-04 Ellis 92204 1151 AM Page 443
of Yugoslavia Greece and Italy The writing systemwas not introduced until 1909 hence few languagesare more orthographically transparent than AlbanianIt uses Roman characters and has 36 letters 29 con-sonants and 7 vowels Nine of the consonants arepresented as bigraphs (dh gj ll nj rr sh th xh zh)These bigraphs are explicitly taught to the children asseparate ldquolettersrdquo of the alphabet and if they appeartogether are never considered as separate graphemes(this rule does not apply to compound words whichoccur rather infrequently) The bidirectionalgraphemendashphoneme and phonemendashgrapheme map-ping is consistent for both consonants and vowelsThese symbols do not change their sound accordingto their position in the word
In Albania there are very few nursery schoolsand only a minority of preschoolers go to kinder-garten The consequence is that most first graders inAlbania enter school without letter or written wordawareness The teaching of reading in Albanian pri-mary schools is introduced in year 1 The officialteaching method is a whole-word method called theGlobal Method However many teachers who havebeen using phonics approaches for many years preferto use mixed methods including both whole-wordand phonics approaches (Hoxhallari 2000)
GreekGreek is highly regular in its symbol-to-sound
mappings for reading though less so in its soundndashsymbol mappings for spelling In spoken Greek thereare only five vowels that sound the same whetherstressed or unstressed (Harris amp Giannouli 1999)While the majority of Greek words are polysyllabicthere are fewer than half the syllable types of Englishwith the majority of them being open syllables of theconsonantndashvowel type (V CV VC CCV CCCV)(Magoulas 1979) As with Japanese these syllablecharacteristics presumably allow children an easiertask of phonological segmentation of their spokenlanguage In the written language each letterrsquos singlesound remains relatively constant in different con-texts (Chitiri amp Willows 1994)
Nevertheless written Greek is not entirelytransparent Whereas the written form has remainedessentially intact since its development as an alpha-betic script the spoken language has undergone ma-jor developmental changes in its evolution towardmodern Greek (Babiniotis 1980 Tombaidis 1987Triantaphyllidis 1913) As a result modern spellingis not entirely phonetic but has a morphophonemicnature that reflects the etymology of words(Porpodas 1991 1999) Spoken Greek is composed
of 32 phonemes that are represented by the 24Greek letters (Bakamidis amp Carayannis 1987Triantaphyllidis 1980) Several phonemendashgraphemeinconsistencies occur including homophone vowelsand vowel and consonant clusters (diphthongs anddipsipha) The pronunciation of dipsipha varies ac-cording to their position in the word and the contextin which they occur In exceptional cases some let-ters are almost voiceless (Porpodas 1991 Tombaidis1987 Triantaphyllidis 1913) Greek has the addedfeature whereby the position of prosodic stress ismarked for each written word Stress which canoccur on any of the final three syllables of a worddepending on a variety of morphological phonologi-cal and lexical factors must be properly interpretedfor successful reading because there are many wordsthat are differentiated only by stress (Tombaidis1986)
Reading instruction is standardized in GreeceIt usually starts at 55 to 6 years old beginning withletterndashsound correspondences Thereafter a syntheticphonics method is used to encourage phonologicalrecoding of simple CV syllables that form simplewords and there is an emphasis on rhyming wordsOnce children have established good letterndashsoundknowledge and have built an initial sight vocabularyletter names are taught and a phonics method is usedto teach graphemendashphoneme correspondences thatinclude more complex syllables like CCV The stressmark is also introduced The basic reading process istypically well established by the end of the first grade(Harris amp Giannouli 1999 Porpodas 1991)
EnglishThe English alphabet consists of 26 letters (5
vowels and 21 consonants) that represent over 40phonemes Letters or letter combinations are oftenambiguous in terms of the sounds they represent AsVenezky (1970) concluded from his analysis of thestructure of English orthography ldquoa person who at-tempts to scan left to right letter by letter pronounc-ing as he goes could not correctly read most Englishwordsrdquo (p 127) The 5 written vowels are particularlyvaried in their mappings to speech and there are 12vowel digraphs 6 of which have alternate pronuncia-tions according to their position Consonants aremore consistent in their graphemendashphoneme corre-spondences with the exceptions of c and g which areread differently according to the vowels that followNevertheless only three consonants (n r and v) haveonly one sound that cannot be produced by othercombinations and are never silent (Venezky) SpokenEnglish also has a complex syllable structure with
444 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 444
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 445
many different types of syllables most of them closed(eg CVC CVCC CCVC) These characteristicspose difficulty for children learning to phonologicallysegment their spoken language
Although English is varied in its graphemendashphoneme correspondences it has a higher degree ofspellingndashsound consistency at the level of the rimeTreiman Mullennix Bijeljac-Babic and Richmond-Welty (1995) estimated that the pronunciation ofmodern English written vowels is only 51 consis-tent over different words whereas initial and finalconsonants are much more consistent (96 and91 respectively) as are rime units (77) For ex-ample a is pronounced differently in cat call carcake and care but it is pronounced the same in therimes cat hat and mat Phonological segmentationinto onset-rime units and the use of orthographicrime analogies have been shown to be importantprocesses in learning to read and spell English(Goswami 1999 2000 Goswami et al 1998Treiman et al 1995)
The majority of English children begin preread-ing exposure quite early at 3 or 4 years old InNursery children are taught the shapes of most lettersof the alphabet and introduced to book use They areread to on a daily basis and there is emphasis on rep-etition and rhyming In Reception there is at least 30minutes per day dedicated solely to reading There ismuch use of word-building pattern recognition andodd-one-out games In year 1 the recognition of thewords as a whole is supported with the use of look-and-say and odd-one-out games Flash cards are usedto introduce individual words to build a startingsight vocabulary and to form simple sentencesChildren are taught families of word patterns thatshare orthographic and phonological resemblance atonset or rime Phonics is typically introduced at theend of year 1 and children are encouraged to practicesounding out and blending phonemes Literacy re-mains a significant part of the national curriculumright through Upper Key Stage 2 that is 9 to 11 yearsold In sum much time and effort is put into teach-ing children to learn to read in English
Kanji The kanji writing system originated in the log-
ographs of Chinese orthography Content words inJapanese are usually written in kanji because doingso resolves the ambiguity of the many homophonesof spoken Japanese The higher homophony rate inJapanese than in other languages is due to its simpleCV spoken syllable structure which restricts thenumber of possible spoken syllables that can be used
individually and in combination to form a spokenword (Akita amp Hatano 1999) In general there aretwo ways to read a given kanji referred to as kunyo-mi or onyomi Kunyomi is the Japanese word corre-sponding to the logogram onyomi is a pronunciationthat is similar to the original Chinese Thus the kanji
(tree) has the kunyomi ldquokirdquo and the onyomildquomokurdquo the kanji (forest) is pronounced respec-tively ldquohayashirdquo and ldquorinrdquo According to Kess andMiyamoto (1999) between 12000 and 50000 en-tries are included in comprehensive kanji dictionar-ies The Japanese educational system explicitlyteaches a set of 1945 Joyo Kanji (kanji for dailyuse) However Kess and Miyamoto argued that mostJapanese know many more than these and that 3000or more kanji are required to read a daily newspaper
Children start learning 80 of the easier JoyoKanji toward the end of the first grade The sequenceof introduction of kanji in the curriculum is standard-ized and by the end of elementary school children areexpected to have mastered 1006 characters (NationalLanguage Research Institute 1988) They are expect-ed to master the complete set of Joyo Kanji by the endof the third year of junior high school
Research questionsThis study was designed to compare the rate of
reading acquisition in 6- to 15-year-old childrenlearning to read in a transparent orthographic system(the syllabic Japanese hiragana) in alphabets ofdecreasing orthographic transparency (AlbanianGreek and English) and in the ideographic Japanesekanji system
The orthographic depth hypothesis predictsthat the more transparent the orthography the fasterchildren will learn to read aloud The almost perfectsymbolndashsound correspondence of hiragana its repre-sentation of psycholinguistically accessible syllablesrather than phonemes and the simple syllable struc-ture of Japanese each contributed to the expectationthat learning to read aloud will be easiest in hira-gana All of the alphabetic scripts provide cues topronunciation but some of the systems are moreregular and consistent than others Thus we expect-ed the alphabetic systems to be the next most easy toacquire but that the ease with which reading is ac-quired would vary within alphabetic systems withthe more transparent languages (Albanian andGreek) being easier to learn than the more opaquelanguage (English) Finally we believed that theideographic kanji system which contains few or nocues to assembled pronunciation would be the mostdifficult to acquire
RRQ4-04 Ellis 92204 1151 AM Page 445
The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 443
word was selected at every decreasing step of 10000word tokens or its nearest approximation The twolists of 100 words were then used as frequency-matched samples of written English and Welsh Thismethod is promising in assessing the acquisition ofliteracy in children learning to read in different lan-guages and in the multiple languages of multiliterateindividuals for several reasons First it produces teststhat are matched in a principled fashion for inputfrequency Second it generates a broad range of fre-quencies of items from approximately 60000 wordsper million to just 1 per million and so it is appro-priately discriminating for learners at different stagesof proficiency Third it is psychophysically scaledPsycholinguistic experimentation shows that there ismore of a linear relationship between proficiencyand log exposure than between proficiency and ex-posure The method of sampling used by Ellis andHooper effectively provided items representing log-frequency strata
Extending the range ofcomparison beyond alphabeticorthographies
In the present study we therefore used thesemethods to develop tests matched cross-linguisticallyfor frequency of written exposure in order to com-pare the rate of acquisition of reading in 6- to 15-year-old children reading a range of different nativeorthographies the orthographically transparent syl-labic Japanese hiragana system alphabets of decreas-ing orthographic transparency (Albanian Greek andEnglish) and the orthographically opaque ideo-graphic Japanese kanji system We also investigatedwhether these different types of orthography affectthe strategies of lexical access adopted by learners asis predicted by the orthographic depth hypothesis
The orthographies investigated in this study Hiragana
Japanese orthography comprises four types ofscript hiragana and katakana (the kana) kanji andromaji (Kess amp Miyamoto 1999) Hiragana andkatakana are syllabic scripts Most Japanese syllableshave the canonical shape of a consonantndashvowel (CV)combination and can be represented by single kana
symbols There is one-to-one correspondence be-tween hiragana and katakana symbols with both sys-tems containing 46 basic symbols (called seion) 40unvoiced CV combinations five vowels and onenasal coda In addition to these there are other char-acters including 25 symbols that are the voicedequivalents of the basic seion formed by adding a spe-cial mark for voicing or semivoicing making a totalof 71 symbols in all Most kana symbols have a sin-gle unique pronunciation although combinations ofsymbols and their use in certain word classes canmodify the pronunciation slightly (Akita amp Hatano1999) Hiragana is mainly used for function wordsmorphological endings and the rest of the grammati-cal scaffolding of Japanese sentences AlthoughJapanese content words are usually written in kanji itis possible to write all native Japanese words in hira-gana Katakana is mainly used for foreign loan wordsand Japanese interjections Nomura (1980) estimatedthat journals published in Japan contain 50 hira-gana 30 kanji and 10 katakana
The regularity of the symbolndashsound mappingsmakes hiragana an exceptionally transparent orthog-raphy Furthermore because children are better ableto break up speech and identify its syllable parts thanthey are to segment it into phonemes (AlegriaPignot amp Morais 1982 Liberman ShankweilerFischer amp Carter 1974 Rozin amp Gleitman 1977)the canonical CV syllable shape of spoken Japaneseallows for easy phonological segmentation Thesetwo factors should thus combine to promote fast ac-quisition The spoken language is easily segmentedinto its syllable parts and each of these individualphonological units has its unique written symbol
Learning to read and write in Japanese official-ly begins at the age of 6 in the first grade of elemen-tary school The seion symbols are first introducedfollowed by the rest of hiragana Katakana is intro-duced in the latter half of the first grade and iscompleted by the end of the second grade Childrenalso start learning some easier kanji in the firstgrade Notwithstanding the official syllabus mostpreschoolers are able to read at least the 46 basichiragana by the time they start the first gradeShimamura and Mikami (1994) reported that 16of 3-year-olds 59 of 4-year-olds and 89 of 5-year-olds could read 60 or more of the 71 hiragana symbols
AlbanianAlbanian forms a single branch of the Indo-
European family that is spoken by over three millionpeople in Albania and in parts of the former republic
RRQ4-04 Ellis 92204 1151 AM Page 443
of Yugoslavia Greece and Italy The writing systemwas not introduced until 1909 hence few languagesare more orthographically transparent than AlbanianIt uses Roman characters and has 36 letters 29 con-sonants and 7 vowels Nine of the consonants arepresented as bigraphs (dh gj ll nj rr sh th xh zh)These bigraphs are explicitly taught to the children asseparate ldquolettersrdquo of the alphabet and if they appeartogether are never considered as separate graphemes(this rule does not apply to compound words whichoccur rather infrequently) The bidirectionalgraphemendashphoneme and phonemendashgrapheme map-ping is consistent for both consonants and vowelsThese symbols do not change their sound accordingto their position in the word
In Albania there are very few nursery schoolsand only a minority of preschoolers go to kinder-garten The consequence is that most first graders inAlbania enter school without letter or written wordawareness The teaching of reading in Albanian pri-mary schools is introduced in year 1 The officialteaching method is a whole-word method called theGlobal Method However many teachers who havebeen using phonics approaches for many years preferto use mixed methods including both whole-wordand phonics approaches (Hoxhallari 2000)
GreekGreek is highly regular in its symbol-to-sound
mappings for reading though less so in its soundndashsymbol mappings for spelling In spoken Greek thereare only five vowels that sound the same whetherstressed or unstressed (Harris amp Giannouli 1999)While the majority of Greek words are polysyllabicthere are fewer than half the syllable types of Englishwith the majority of them being open syllables of theconsonantndashvowel type (V CV VC CCV CCCV)(Magoulas 1979) As with Japanese these syllablecharacteristics presumably allow children an easiertask of phonological segmentation of their spokenlanguage In the written language each letterrsquos singlesound remains relatively constant in different con-texts (Chitiri amp Willows 1994)
Nevertheless written Greek is not entirelytransparent Whereas the written form has remainedessentially intact since its development as an alpha-betic script the spoken language has undergone ma-jor developmental changes in its evolution towardmodern Greek (Babiniotis 1980 Tombaidis 1987Triantaphyllidis 1913) As a result modern spellingis not entirely phonetic but has a morphophonemicnature that reflects the etymology of words(Porpodas 1991 1999) Spoken Greek is composed
of 32 phonemes that are represented by the 24Greek letters (Bakamidis amp Carayannis 1987Triantaphyllidis 1980) Several phonemendashgraphemeinconsistencies occur including homophone vowelsand vowel and consonant clusters (diphthongs anddipsipha) The pronunciation of dipsipha varies ac-cording to their position in the word and the contextin which they occur In exceptional cases some let-ters are almost voiceless (Porpodas 1991 Tombaidis1987 Triantaphyllidis 1913) Greek has the addedfeature whereby the position of prosodic stress ismarked for each written word Stress which canoccur on any of the final three syllables of a worddepending on a variety of morphological phonologi-cal and lexical factors must be properly interpretedfor successful reading because there are many wordsthat are differentiated only by stress (Tombaidis1986)
Reading instruction is standardized in GreeceIt usually starts at 55 to 6 years old beginning withletterndashsound correspondences Thereafter a syntheticphonics method is used to encourage phonologicalrecoding of simple CV syllables that form simplewords and there is an emphasis on rhyming wordsOnce children have established good letterndashsoundknowledge and have built an initial sight vocabularyletter names are taught and a phonics method is usedto teach graphemendashphoneme correspondences thatinclude more complex syllables like CCV The stressmark is also introduced The basic reading process istypically well established by the end of the first grade(Harris amp Giannouli 1999 Porpodas 1991)
EnglishThe English alphabet consists of 26 letters (5
vowels and 21 consonants) that represent over 40phonemes Letters or letter combinations are oftenambiguous in terms of the sounds they represent AsVenezky (1970) concluded from his analysis of thestructure of English orthography ldquoa person who at-tempts to scan left to right letter by letter pronounc-ing as he goes could not correctly read most Englishwordsrdquo (p 127) The 5 written vowels are particularlyvaried in their mappings to speech and there are 12vowel digraphs 6 of which have alternate pronuncia-tions according to their position Consonants aremore consistent in their graphemendashphoneme corre-spondences with the exceptions of c and g which areread differently according to the vowels that followNevertheless only three consonants (n r and v) haveonly one sound that cannot be produced by othercombinations and are never silent (Venezky) SpokenEnglish also has a complex syllable structure with
444 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 444
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 445
many different types of syllables most of them closed(eg CVC CVCC CCVC) These characteristicspose difficulty for children learning to phonologicallysegment their spoken language
Although English is varied in its graphemendashphoneme correspondences it has a higher degree ofspellingndashsound consistency at the level of the rimeTreiman Mullennix Bijeljac-Babic and Richmond-Welty (1995) estimated that the pronunciation ofmodern English written vowels is only 51 consis-tent over different words whereas initial and finalconsonants are much more consistent (96 and91 respectively) as are rime units (77) For ex-ample a is pronounced differently in cat call carcake and care but it is pronounced the same in therimes cat hat and mat Phonological segmentationinto onset-rime units and the use of orthographicrime analogies have been shown to be importantprocesses in learning to read and spell English(Goswami 1999 2000 Goswami et al 1998Treiman et al 1995)
The majority of English children begin preread-ing exposure quite early at 3 or 4 years old InNursery children are taught the shapes of most lettersof the alphabet and introduced to book use They areread to on a daily basis and there is emphasis on rep-etition and rhyming In Reception there is at least 30minutes per day dedicated solely to reading There ismuch use of word-building pattern recognition andodd-one-out games In year 1 the recognition of thewords as a whole is supported with the use of look-and-say and odd-one-out games Flash cards are usedto introduce individual words to build a startingsight vocabulary and to form simple sentencesChildren are taught families of word patterns thatshare orthographic and phonological resemblance atonset or rime Phonics is typically introduced at theend of year 1 and children are encouraged to practicesounding out and blending phonemes Literacy re-mains a significant part of the national curriculumright through Upper Key Stage 2 that is 9 to 11 yearsold In sum much time and effort is put into teach-ing children to learn to read in English
Kanji The kanji writing system originated in the log-
ographs of Chinese orthography Content words inJapanese are usually written in kanji because doingso resolves the ambiguity of the many homophonesof spoken Japanese The higher homophony rate inJapanese than in other languages is due to its simpleCV spoken syllable structure which restricts thenumber of possible spoken syllables that can be used
individually and in combination to form a spokenword (Akita amp Hatano 1999) In general there aretwo ways to read a given kanji referred to as kunyo-mi or onyomi Kunyomi is the Japanese word corre-sponding to the logogram onyomi is a pronunciationthat is similar to the original Chinese Thus the kanji
(tree) has the kunyomi ldquokirdquo and the onyomildquomokurdquo the kanji (forest) is pronounced respec-tively ldquohayashirdquo and ldquorinrdquo According to Kess andMiyamoto (1999) between 12000 and 50000 en-tries are included in comprehensive kanji dictionar-ies The Japanese educational system explicitlyteaches a set of 1945 Joyo Kanji (kanji for dailyuse) However Kess and Miyamoto argued that mostJapanese know many more than these and that 3000or more kanji are required to read a daily newspaper
Children start learning 80 of the easier JoyoKanji toward the end of the first grade The sequenceof introduction of kanji in the curriculum is standard-ized and by the end of elementary school children areexpected to have mastered 1006 characters (NationalLanguage Research Institute 1988) They are expect-ed to master the complete set of Joyo Kanji by the endof the third year of junior high school
Research questionsThis study was designed to compare the rate of
reading acquisition in 6- to 15-year-old childrenlearning to read in a transparent orthographic system(the syllabic Japanese hiragana) in alphabets ofdecreasing orthographic transparency (AlbanianGreek and English) and in the ideographic Japanesekanji system
The orthographic depth hypothesis predictsthat the more transparent the orthography the fasterchildren will learn to read aloud The almost perfectsymbolndashsound correspondence of hiragana its repre-sentation of psycholinguistically accessible syllablesrather than phonemes and the simple syllable struc-ture of Japanese each contributed to the expectationthat learning to read aloud will be easiest in hira-gana All of the alphabetic scripts provide cues topronunciation but some of the systems are moreregular and consistent than others Thus we expect-ed the alphabetic systems to be the next most easy toacquire but that the ease with which reading is ac-quired would vary within alphabetic systems withthe more transparent languages (Albanian andGreek) being easier to learn than the more opaquelanguage (English) Finally we believed that theideographic kanji system which contains few or nocues to assembled pronunciation would be the mostdifficult to acquire
RRQ4-04 Ellis 92204 1151 AM Page 445
The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

of Yugoslavia Greece and Italy The writing systemwas not introduced until 1909 hence few languagesare more orthographically transparent than AlbanianIt uses Roman characters and has 36 letters 29 con-sonants and 7 vowels Nine of the consonants arepresented as bigraphs (dh gj ll nj rr sh th xh zh)These bigraphs are explicitly taught to the children asseparate ldquolettersrdquo of the alphabet and if they appeartogether are never considered as separate graphemes(this rule does not apply to compound words whichoccur rather infrequently) The bidirectionalgraphemendashphoneme and phonemendashgrapheme map-ping is consistent for both consonants and vowelsThese symbols do not change their sound accordingto their position in the word
In Albania there are very few nursery schoolsand only a minority of preschoolers go to kinder-garten The consequence is that most first graders inAlbania enter school without letter or written wordawareness The teaching of reading in Albanian pri-mary schools is introduced in year 1 The officialteaching method is a whole-word method called theGlobal Method However many teachers who havebeen using phonics approaches for many years preferto use mixed methods including both whole-wordand phonics approaches (Hoxhallari 2000)
GreekGreek is highly regular in its symbol-to-sound
mappings for reading though less so in its soundndashsymbol mappings for spelling In spoken Greek thereare only five vowels that sound the same whetherstressed or unstressed (Harris amp Giannouli 1999)While the majority of Greek words are polysyllabicthere are fewer than half the syllable types of Englishwith the majority of them being open syllables of theconsonantndashvowel type (V CV VC CCV CCCV)(Magoulas 1979) As with Japanese these syllablecharacteristics presumably allow children an easiertask of phonological segmentation of their spokenlanguage In the written language each letterrsquos singlesound remains relatively constant in different con-texts (Chitiri amp Willows 1994)
Nevertheless written Greek is not entirelytransparent Whereas the written form has remainedessentially intact since its development as an alpha-betic script the spoken language has undergone ma-jor developmental changes in its evolution towardmodern Greek (Babiniotis 1980 Tombaidis 1987Triantaphyllidis 1913) As a result modern spellingis not entirely phonetic but has a morphophonemicnature that reflects the etymology of words(Porpodas 1991 1999) Spoken Greek is composed
of 32 phonemes that are represented by the 24Greek letters (Bakamidis amp Carayannis 1987Triantaphyllidis 1980) Several phonemendashgraphemeinconsistencies occur including homophone vowelsand vowel and consonant clusters (diphthongs anddipsipha) The pronunciation of dipsipha varies ac-cording to their position in the word and the contextin which they occur In exceptional cases some let-ters are almost voiceless (Porpodas 1991 Tombaidis1987 Triantaphyllidis 1913) Greek has the addedfeature whereby the position of prosodic stress ismarked for each written word Stress which canoccur on any of the final three syllables of a worddepending on a variety of morphological phonologi-cal and lexical factors must be properly interpretedfor successful reading because there are many wordsthat are differentiated only by stress (Tombaidis1986)
Reading instruction is standardized in GreeceIt usually starts at 55 to 6 years old beginning withletterndashsound correspondences Thereafter a syntheticphonics method is used to encourage phonologicalrecoding of simple CV syllables that form simplewords and there is an emphasis on rhyming wordsOnce children have established good letterndashsoundknowledge and have built an initial sight vocabularyletter names are taught and a phonics method is usedto teach graphemendashphoneme correspondences thatinclude more complex syllables like CCV The stressmark is also introduced The basic reading process istypically well established by the end of the first grade(Harris amp Giannouli 1999 Porpodas 1991)
EnglishThe English alphabet consists of 26 letters (5
vowels and 21 consonants) that represent over 40phonemes Letters or letter combinations are oftenambiguous in terms of the sounds they represent AsVenezky (1970) concluded from his analysis of thestructure of English orthography ldquoa person who at-tempts to scan left to right letter by letter pronounc-ing as he goes could not correctly read most Englishwordsrdquo (p 127) The 5 written vowels are particularlyvaried in their mappings to speech and there are 12vowel digraphs 6 of which have alternate pronuncia-tions according to their position Consonants aremore consistent in their graphemendashphoneme corre-spondences with the exceptions of c and g which areread differently according to the vowels that followNevertheless only three consonants (n r and v) haveonly one sound that cannot be produced by othercombinations and are never silent (Venezky) SpokenEnglish also has a complex syllable structure with
444 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 444
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 445
many different types of syllables most of them closed(eg CVC CVCC CCVC) These characteristicspose difficulty for children learning to phonologicallysegment their spoken language
Although English is varied in its graphemendashphoneme correspondences it has a higher degree ofspellingndashsound consistency at the level of the rimeTreiman Mullennix Bijeljac-Babic and Richmond-Welty (1995) estimated that the pronunciation ofmodern English written vowels is only 51 consis-tent over different words whereas initial and finalconsonants are much more consistent (96 and91 respectively) as are rime units (77) For ex-ample a is pronounced differently in cat call carcake and care but it is pronounced the same in therimes cat hat and mat Phonological segmentationinto onset-rime units and the use of orthographicrime analogies have been shown to be importantprocesses in learning to read and spell English(Goswami 1999 2000 Goswami et al 1998Treiman et al 1995)
The majority of English children begin preread-ing exposure quite early at 3 or 4 years old InNursery children are taught the shapes of most lettersof the alphabet and introduced to book use They areread to on a daily basis and there is emphasis on rep-etition and rhyming In Reception there is at least 30minutes per day dedicated solely to reading There ismuch use of word-building pattern recognition andodd-one-out games In year 1 the recognition of thewords as a whole is supported with the use of look-and-say and odd-one-out games Flash cards are usedto introduce individual words to build a startingsight vocabulary and to form simple sentencesChildren are taught families of word patterns thatshare orthographic and phonological resemblance atonset or rime Phonics is typically introduced at theend of year 1 and children are encouraged to practicesounding out and blending phonemes Literacy re-mains a significant part of the national curriculumright through Upper Key Stage 2 that is 9 to 11 yearsold In sum much time and effort is put into teach-ing children to learn to read in English
Kanji The kanji writing system originated in the log-
ographs of Chinese orthography Content words inJapanese are usually written in kanji because doingso resolves the ambiguity of the many homophonesof spoken Japanese The higher homophony rate inJapanese than in other languages is due to its simpleCV spoken syllable structure which restricts thenumber of possible spoken syllables that can be used
individually and in combination to form a spokenword (Akita amp Hatano 1999) In general there aretwo ways to read a given kanji referred to as kunyo-mi or onyomi Kunyomi is the Japanese word corre-sponding to the logogram onyomi is a pronunciationthat is similar to the original Chinese Thus the kanji
(tree) has the kunyomi ldquokirdquo and the onyomildquomokurdquo the kanji (forest) is pronounced respec-tively ldquohayashirdquo and ldquorinrdquo According to Kess andMiyamoto (1999) between 12000 and 50000 en-tries are included in comprehensive kanji dictionar-ies The Japanese educational system explicitlyteaches a set of 1945 Joyo Kanji (kanji for dailyuse) However Kess and Miyamoto argued that mostJapanese know many more than these and that 3000or more kanji are required to read a daily newspaper
Children start learning 80 of the easier JoyoKanji toward the end of the first grade The sequenceof introduction of kanji in the curriculum is standard-ized and by the end of elementary school children areexpected to have mastered 1006 characters (NationalLanguage Research Institute 1988) They are expect-ed to master the complete set of Joyo Kanji by the endof the third year of junior high school
Research questionsThis study was designed to compare the rate of
reading acquisition in 6- to 15-year-old childrenlearning to read in a transparent orthographic system(the syllabic Japanese hiragana) in alphabets ofdecreasing orthographic transparency (AlbanianGreek and English) and in the ideographic Japanesekanji system
The orthographic depth hypothesis predictsthat the more transparent the orthography the fasterchildren will learn to read aloud The almost perfectsymbolndashsound correspondence of hiragana its repre-sentation of psycholinguistically accessible syllablesrather than phonemes and the simple syllable struc-ture of Japanese each contributed to the expectationthat learning to read aloud will be easiest in hira-gana All of the alphabetic scripts provide cues topronunciation but some of the systems are moreregular and consistent than others Thus we expect-ed the alphabetic systems to be the next most easy toacquire but that the ease with which reading is ac-quired would vary within alphabetic systems withthe more transparent languages (Albanian andGreek) being easier to learn than the more opaquelanguage (English) Finally we believed that theideographic kanji system which contains few or nocues to assembled pronunciation would be the mostdifficult to acquire
RRQ4-04 Ellis 92204 1151 AM Page 445
The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 445
many different types of syllables most of them closed(eg CVC CVCC CCVC) These characteristicspose difficulty for children learning to phonologicallysegment their spoken language
Although English is varied in its graphemendashphoneme correspondences it has a higher degree ofspellingndashsound consistency at the level of the rimeTreiman Mullennix Bijeljac-Babic and Richmond-Welty (1995) estimated that the pronunciation ofmodern English written vowels is only 51 consis-tent over different words whereas initial and finalconsonants are much more consistent (96 and91 respectively) as are rime units (77) For ex-ample a is pronounced differently in cat call carcake and care but it is pronounced the same in therimes cat hat and mat Phonological segmentationinto onset-rime units and the use of orthographicrime analogies have been shown to be importantprocesses in learning to read and spell English(Goswami 1999 2000 Goswami et al 1998Treiman et al 1995)
The majority of English children begin preread-ing exposure quite early at 3 or 4 years old InNursery children are taught the shapes of most lettersof the alphabet and introduced to book use They areread to on a daily basis and there is emphasis on rep-etition and rhyming In Reception there is at least 30minutes per day dedicated solely to reading There ismuch use of word-building pattern recognition andodd-one-out games In year 1 the recognition of thewords as a whole is supported with the use of look-and-say and odd-one-out games Flash cards are usedto introduce individual words to build a startingsight vocabulary and to form simple sentencesChildren are taught families of word patterns thatshare orthographic and phonological resemblance atonset or rime Phonics is typically introduced at theend of year 1 and children are encouraged to practicesounding out and blending phonemes Literacy re-mains a significant part of the national curriculumright through Upper Key Stage 2 that is 9 to 11 yearsold In sum much time and effort is put into teach-ing children to learn to read in English
Kanji The kanji writing system originated in the log-
ographs of Chinese orthography Content words inJapanese are usually written in kanji because doingso resolves the ambiguity of the many homophonesof spoken Japanese The higher homophony rate inJapanese than in other languages is due to its simpleCV spoken syllable structure which restricts thenumber of possible spoken syllables that can be used
individually and in combination to form a spokenword (Akita amp Hatano 1999) In general there aretwo ways to read a given kanji referred to as kunyo-mi or onyomi Kunyomi is the Japanese word corre-sponding to the logogram onyomi is a pronunciationthat is similar to the original Chinese Thus the kanji
(tree) has the kunyomi ldquokirdquo and the onyomildquomokurdquo the kanji (forest) is pronounced respec-tively ldquohayashirdquo and ldquorinrdquo According to Kess andMiyamoto (1999) between 12000 and 50000 en-tries are included in comprehensive kanji dictionar-ies The Japanese educational system explicitlyteaches a set of 1945 Joyo Kanji (kanji for dailyuse) However Kess and Miyamoto argued that mostJapanese know many more than these and that 3000or more kanji are required to read a daily newspaper
Children start learning 80 of the easier JoyoKanji toward the end of the first grade The sequenceof introduction of kanji in the curriculum is standard-ized and by the end of elementary school children areexpected to have mastered 1006 characters (NationalLanguage Research Institute 1988) They are expect-ed to master the complete set of Joyo Kanji by the endof the third year of junior high school
Research questionsThis study was designed to compare the rate of
reading acquisition in 6- to 15-year-old childrenlearning to read in a transparent orthographic system(the syllabic Japanese hiragana) in alphabets ofdecreasing orthographic transparency (AlbanianGreek and English) and in the ideographic Japanesekanji system
The orthographic depth hypothesis predictsthat the more transparent the orthography the fasterchildren will learn to read aloud The almost perfectsymbolndashsound correspondence of hiragana its repre-sentation of psycholinguistically accessible syllablesrather than phonemes and the simple syllable struc-ture of Japanese each contributed to the expectationthat learning to read aloud will be easiest in hira-gana All of the alphabetic scripts provide cues topronunciation but some of the systems are moreregular and consistent than others Thus we expect-ed the alphabetic systems to be the next most easy toacquire but that the ease with which reading is ac-quired would vary within alphabetic systems withthe more transparent languages (Albanian andGreek) being easier to learn than the more opaquelanguage (English) Finally we believed that theideographic kanji system which contains few or nocues to assembled pronunciation would be the mostdifficult to acquire
RRQ4-04 Ellis 92204 1151 AM Page 445
The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The orthographic depth hypothesis also led usto predict that these different scripts would affect thestrategies of lexical access that were adopted by learn-ers with transparent orthographies supporting wordrecognition involving phonology and opaque or-thographies encouraging readers to process words byaccessing the lexicon and meaning via the wordrsquosvisual appearance As in Ellis and Hooper (2001)reading strategy was assessed by examining the rela-tion between word length and response latency ineach script and by analyzing and categorizing thetypes of errors that children made while reading Itwas predicted that opaque scripts would promote sit-uations where a child is unable to make any responseat all (nonresponses) along with mistakes where thechild says a wrong word that is visually similar to thetarget (whole-word substitutions such as computerfor complete and near for never) Transparent scriptsin contrast were expected to be associated with rela-tively few nonresponses or whole-word substitutionsbut with mistakes that result in mispronunciationsthat are nonwords (nonword errors such as polical orpoltac for political)
MethodSummary of design
This study designed to assess the effects of writ-ing system upon reading acquisition among 6- to 15-year-old children involved the comparison of op-portunity samples of participants learning to read infive different native scripts in four countries Thesechildren had been taught by different teachers in dif-ferent classrooms and schools using potentially differ-ent methods of instruction in different cultures It isimpossible to control all of these potential confoundsHowever we tried to ensure that our participants werematched on verbal and nonverbal abilities and whencomparison cell levels were not exactly equated onthese measures after selection we statistically con-trolled them Following Paulesu et al (2000) we as-sessed childrenrsquos verbal ability using a picture-namingtask measuring accuracy and latency Nonverbal rea-soning ability was estimated with use of items fromthe Standard Progressive Matrices Subsequent comparisons across language groups could thus bestatistically controlled for any differences in thesebackground abilities with use of analysis of covarianceThe first wave of testing involved English Greek andJapanese scripts The Albanian data were collected oneyear later in order to triangulate the Greek findingsagainst another orthographically transparent script
Limited resources meant that we were only able to testAlbanian children 7 to 9 years old and that we wereunable to assess their ability on control measures relat-ing to verbal and nonverbal abilities This abbreviatedtesting means that the Albanian accuracy data must beviewed only as supplemental findings to add perspec-tive on the more rigorous and extensive results fromthe other language groups Within each languagegroup we assessed the relation between word lengthand latency and performed qualitative analyses of thechildrenrsquos reading errors as evidence of their strategiesof lexical access
Participants Children were recruited by opportunity sam-
pling from areas close to the homes of the research-ers The parents guardians or teachers of each childreceived a brief description of the nature and thegoals of the research and were asked to sign a con-sent form authorizing participation if the childrenthemselves also agreed to take part Our goal was torecruit roughly 15 students of each language at thefollowing ages 6 to 7 years 8 to 9 years 10 to 11years 12 to 13 years and 14 to 15 years The agecharacteristics of all language groups are shown inTable 1
Greek children were recruited from among theinvestigatorsrsquo friends and family in Volo AthensPireaus Evia Rodos and Korinthos Japanese chil-dren were recruited from municipal primary and ju-nior high schools in the Gifu prefecture of JapanEnglish children were recruited from four monolin-gual (English) private primary and secondary schoolssituated in North Wales (Colwyn Bay Bangor andMenai Bridge) The large majority came from mono-lingual English-speaking families although a fewwere able to speak some Welsh
The Albanian sample came from a primaryschool located in Korccedileuml in southeast Albania Theywere average-achieving pupils on the most recentmath test administered by the classroom teacher
MaterialsReading
The reading tests for each language were con-structed with an adaptation of the method used byEllis and Hooper (2001) sampling every decreasing10000 word token step from a frequency-sorted 1-million-word language corpus This original
446 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 446
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 447
method although broadly satisfactory in producingequal strata in terms of log frequency did causesome deviation from linearity at lower frequencies(see Figure 1) To correct for this lack of linearity wecompiled 100-word reading tests for the differentlanguages by selecting randomly from the 100 de-creasing log10-frequency strata bounded by the mostand least frequent words in 1-million-word countsThis helped to ensure that the reading tests werematched across the various languages in terms ofword frequency Word form lists were used with in-flected forms (eg walked walks walking) beingenumerated separately rather than gathered underthe root (walk) The resultant items for each lan-guage are shown in Appendix A
The English test was formed by taking theword types that comprised 1 million token word fre-quency profiles for English in the CELEX LexicalDatabase (Baayen Piepenbrock amp van Rijn 1995)which estimated these written word frequencies fromanalysis of the 166 million token Cobuild corpus ofsamples of written English from hundreds of differ-ent sources including newspapers magazines fictionand nonfiction books brochures leaflets reportsletters and so on with the majority of texts originat-ing after 1990 This 1 million token list was madeup of word types ranging in frequencies from 59739(the) down to 1 (surveyed) The list was then splitinto 100 log-frequency strata with a word being ran-domly selected from each of these
The Greek test was formed by taking the wordtypes that composed approximately 15 million tokenword frequency profiles for Greek taken from theweekly newspaper TO BHMA by Stathis Stamatatos(personal communication 2000) of University ofPatras A 1 million token subset was then counted toproduce a word type list ranging in frequencies permillion from 52887 to 1
The list was then split into 100 log-frequency stratawith a word being randomly selected from each
The Japanese tests were based on the frequencylists from Nihongo-no Goitokusei (Lexical propertiesof Japanese) (Amano amp Kondo 2000) This databaseis the largest electronically provided frequency countdatabase for Japanese words and characters in kanji hi-ragana and katakana and is taken from a corpus of theAsahi newspapers published over 14 years from 1986to 1998 A 1-million token subset was then counted toproduce a word type list ranging in frequencies from71546 ( in both lists) to 1 ( in kana in kanji) The list was then split into 100 log-frequencystrata with a word being randomly selected from eachWhere possible each of these words was then present-ed in its hiragana form for the kana test and its kanjiform for the kanji test This was not possible for thefirst 30 or so most frequent words of the languagewhich are all usually only written as hiragana
The Albanian reading test was designed byrandomly sampling one word from each of 100successive strata of decreasing log10 written word fre-quency from an Albanian text corpus created by thefourth author comprising just over 1 million wordsfrom a novel the New Testament from the ChristianBible one childrenrsquos book one online Albanian news-paper (dates ranging from early January to lateFebruary 2001) and two short passages from booksadvertised on the Internet The most frequent wordof the list was teuml (you) with frequency 67713 in amillion and one of the last words was leumlvdoni(praise) which occurred only once
The resultant frequencies of test items for eachof these reading tests are plotted in Figure 1 along-side those from the original Ellis and Hooper (2001)English and Welsh tests This figure shows the im-proved linearity of log word frequency sampling thatresulted from the changed sampling procedure Italso illustrates the tight frequency-matching of the
Age bands (months)
Language 73ndash102 103ndash120 121ndash150 151ndash183 Total Girls Boys
English 15 14 11 27 67 37 30
Greek 18 26 5 30 79 33 46
Japanese 30 11 30 71 30 41
Albanian 34 26 60 29 31
Total 97 66 27 87 277 129 148
TABLE 1NUMBER OF CHILDREN IN EACH AGE BAND FOR EACH LANGUAGE GROUP
RRQ4-04 Ellis 92204 1151 AM Page 447
items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

items in the current English Greek Japanese andAlbanian tests That this design produces tests of ad-equate internal consistency is indicated by the highreliability of the reading accuracy scores over theseitems for the English kanji Greek and hiraganachildren Cronbachrsquos alpha = 0976
These scripts did differ in terms of the lengthin characters of the words sampled with alphabeticscripts having most characters per word (English M= 525 SD = 265 Greek M = 628 SD = 325Albanian M = 536 SD = 294) syllabic hiraganafewer (M = 313 SD = 164) and logographic kanjifewest of all (M = 204 SD = 084)
Picture namingA picture-naming task was used to assess
general verbal ability in the Greek Japanese andEnglish children The stimuli were 20 pictures devel-oped by Snodgrass and Vanderwart (1980) that werestandardized for such variables as familiarity andvisual complexity The particular items (objects and
animals) chosen because of their high name agree-ment and name frequency were the followinghouse hand saw car eye book key watch dogtelephone television hat piano pencil guitar lionumbrella elephant helicopter and butterfly
Nonverbal reasoningItems from the Standard Progressive Matrices
were used to assess nonverbal reasoning ability in theEnglish Greek and Japanese samples Three practiceitems were followed by a selection of 15 items in in-creasing difficulty The items were presented one at atime at the top of a page of paper and followed bysix alternative answers
Procedure Children were tested individually by a native
speaker of their respective languages either in a quietfamiliar room within the school (for the EnglishJapanese and Albanian children) or in the childrsquos or
448 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 1THE MATCHED WRITTEN FREQUENCY PROFILES OF THE HIRAGANA GREEK ALBANIANENGLISH AND KANJI READING TESTS ALONG WITH THOSE OF ELLIS AND HOOPER (2001)FOR ENGLISH AND WELSH
Reading test word number
log 1
0w
ord
freq
uenc
y pe
r m
illio
n
5
4
3
2
1
0
English (Ellis and Hooper)Welsh (Ellis and Hooper)GreekEnglishJapanseseAlbanian
0 10 20 30 40 50 60 70 80 90 100
RRQ4-04 Ellis 92204 1151 AM Page 448
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 449
experimenterrsquos home (for the Greek-speaking chil-dren) The picture-naming task was presented firstbecause of its ease and simplicity followed by thereading test and then the nonverbal reasoning test
ReadingAn Apple Macintosh laptop programmed in
SuperLab (Abboud amp Sugar 1997) presented thereading items Accuracy latency and reading timewere measured for each word A microphone wasused to detect the onset of the childrsquos pronunciationof a spoken word with voice onset time being meas-ured in milliseconds from the visual presentation ofthe word midscreen The experimenter pressed a keywhen the child had finished saying each word thusallowing a measure of reading time for each wordThe experimenter also keyed in whether each re-sponse was correct or not Childrenrsquos responses weretape recorded to allow subsequent analysis of errors
The reading test items were presented in orderof decreasing frequency after three high-frequencyanimal names had served as practice items in orderto familiarize children with the procedure Childrenwere instructed to try to read aloud each word asquickly as possible after its appearance on screenThey were encouraged to ldquohave a gordquo at each oneeven if they did not know it at first sight Testingstopped after the child had made five consecutive re-sponses that were not correct Each Japanese childdid both the hiragana and then after a short breakthe kanji versions of the reading test
The Albanian children were not tested by com-puter Instead the procedure of Ellis and Hooper(2001) was followed The word list was printed with17 words per A4-sized page double-spaced centeredon the line and set in bold lowercase 20-pointTimes font Accuracy and reading latency for correctanswers were measured A piece of plain card wasused to cover the list and the child was asked tomove the card down when the first experimenter saidldquonextrdquo and to read the following word immediatelyA stopwatch was used to record latencies from theonset of word presentation to the response onsetand responses were also tape recorded for furtheranalysis Use of a stopwatch in this way provided suf-ficient reliability of measurement The interobservercorrelation between the latencies measured by twoseparate observers measuring the word readings ofthe same child was r = 093 p lt 01 Neverthelessbecause latency was measured by stopwatch ratherthan by computer for the Albanian children we donot analyze their latencies here
Picture naming The picture stimuli were presented in a similar
fashion to that in the reading test with a micro-phone being used to measure voice onset time andthe experimenter determining whether each verbalresponse was appropriate as a name for that picturein their language The pictures were presented in afixed order as described in the Materials section ofthis article after three additional pictures had servedas practice items Children were instructed to nameeach picture as quickly as possible after its appear-ance on screen For each child we computed thetotal number of pictures correctly named and theaverage latency for these correctly named items
Nonverbal reasoningThe experimenter showed the Standards
Progressive Matrices items one at a time and a childwas asked to solve each puzzle by pointing out thepicture alternative that would properly fill in themissing part of the top diagram The test ended afterfive successive errors The nonverbal score for eachchild was simply the total number correct
Group matchingWe attempted to match the three main lan-
guage groups for age picture-naming ability andnonverbal reasoning Limited resources meant thatwe were only able to recruit 7- to 9-year-old Albanianchildren and that we were unable to assess their abili-ty on control measures relating to verbal and nonver-bal abilities The main language groups were fairlywell matched for age in months English (M = 1330SD = 346) Greek (M = 1251 SD = 321) Japanese(M = 1273 SD = 428) F(2 214) p lt 1 nsNevertheless with such a large age spread it is appro-priate that subsequent analyses of language differ-ences either include age as an explicit factor or elsecontrol for age with use of ANCOVA On picture-naming accuracy the English Greek and Japanesegroups were equally able English (M = 958 SD =125) Greek (M = 930 SD = 100) and Japanese(M = 957 SD = 48) F(2 212) = 205 ns agecorrected F(2 211) = 180 ns However it appearedthat the Greek children were somewhat slower intheir picture-naming RTs (msec) English (M =8691 SD = 2396) Greek (M = 10798 SD =3641) and Japanese (M = 8984 SD = 2533) F(2212) = 1115 p lt 001 age corrected F(2 211) =1069 p lt 001 The English Greek and Japanese
RRQ4-04 Ellis 92204 1151 AM Page 449
groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

groups differed significantly in their nonverbal rea-soning with the advantage going to the Greek stu-dents The number of Ravens problems solvedcorrectly by each group were English (M = 530 SD= 247) Greek (M = 682 SD = 336) and Japanese(M = 514 SD = 276) F(2 213) = 760 p lt 001age corrected F(2 212) = 1129 p lt 001
Thus the English and Japanese groups werebroadly equivalent in their verbal abilities and non-verbal reasoning but for whatever reasons theGreek students showed some advantage in nonverbalreasoning but a relative slowness in verbal access forpicture naming For these reasons we used picturenaming and nonverbal reasoning as covariates insubsequent analyses
ResultsResults focus on the comparison of English
Greek and Japanese orthographies Because only ayounger sample of Albanian children were assessedand then with only a subset of the measures theseare only described with regard to their reading accu-racy and the nature of their errors
Reading accuracyThere were statistically significant differences
in reading accuracy as a function of orthography inboth a by-word ANOVA using test words 1ndash100 asrepeated measures across orthography F(3 97) =7220 p lt 001 macr2 = 0420 and in a by-subjectsANOVA using children within orthography group asthe error term F(3 283) = 2101 p lt 001 macr2 =0182 Japanese children could read on average 914(SD = 128) words in their hiragana reading testNext came the Greek children who could read 868(SD = 149) words The English children could readon average 820 (SD = 188) words Finally came theJapanese children reading in kanji who managed just661 (SD = 304) words
The effect of age was statistically significantF(1 282) = 24588 p lt 001 macr2 = 0466 With agecorrection the effect of script increased F(3 282) =4047 p lt 001 macr2 = 0301 with means correctedfor an age of 128 months being Japanese hiragana(M = 916 SE = 18) Greek (M = 879 SE = 18)English (M = 802 SE = 18) and Japanese kanji (M= 664 SE = 18) The effect of orthography also re-mained significant when controlling statistically forage picture-naming accuracy picture-naming timeand nonverbal intelligence F(3 275) = 3776 p lt
001 macr2 = 0292 with all pairwise comparisons be-ing statistically significant at p lt 05
These differences are presented in Figure 2which plots the proportion of children in each or-thography group who were able to read each testword correctly As log word frequency decreasedfrom test word 1 to test word 100 so performancedeclined for all orthographies But there were clearseparations between them particularly on the lowerfrequency items 70ndash100 where the vast majority ofhiragana words were read by more than 80 of thechildren next came the Greek items typically readby 60ndash70 of the children then the English andkanji items which overlapped at these lowest fre-quencies but separated in the mid-frequencies 40ndash70where the advantage is clearly to the English items
Table 2 shows the reading accuracy levels as afunction of orthography and age When these effectswere assessed in a two-factor ANOVA (four scripts four age bands as described in Table 1) theorthography-by-age interaction was statistically sig-nificant F(7 273) = 3363 p lt 001 macr2 = 0463thus qualifying the main effects of orthography F(3273) = 3393 p lt 001 macr2 = 0272 and age bandF(3 273) = 14724 p lt 001 macr2 = 0618 These ef-fects remained statistically significant when control-ling for both verbal fluency (picture-naming time)and nonverbal reasoning ability orthography by ageinteraction F(7 266) = 3335 p lt 001 macr2 = 0467script F(3 266) = 3165 p lt 001 macr2 = 0263 andage band F(3 266) = 13254 p lt 001 macr2 = 0599Bonferroni testing showed that the four orthographygroups were significantly different from one anotherin terms of accuracy in the youngest 73ndash102-monthage band at p lt 001 they did not differ significantlyfrom one another at the two higher age bands span-ning 121ndash150 and 151ndash183 months Figure 3 illus-trates this interaction of orthography and age onreading accuracy using more fine-grained age incre-ments and including the supplemental accuracy datafor the Albanian children The Albanian year 1 chil-dren were able to read 795 of their words (SD =164) the year 2 children 862 (SD = 1081) andthe year 3 children 947 (SD = 473)mdasha significantage effect F(2 59) = 735 p lt 01 These levels areclose although numerically slightly superior tothose of the readers of Greek which similarly is anorthographically transparent alphabet
Reading onset latencyAnalysis of the effect of orthography on latency
using the orthography group mean latency on eachof the test words 1ndash100 as repeated measures showed
450 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1151 AM Page 450
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468
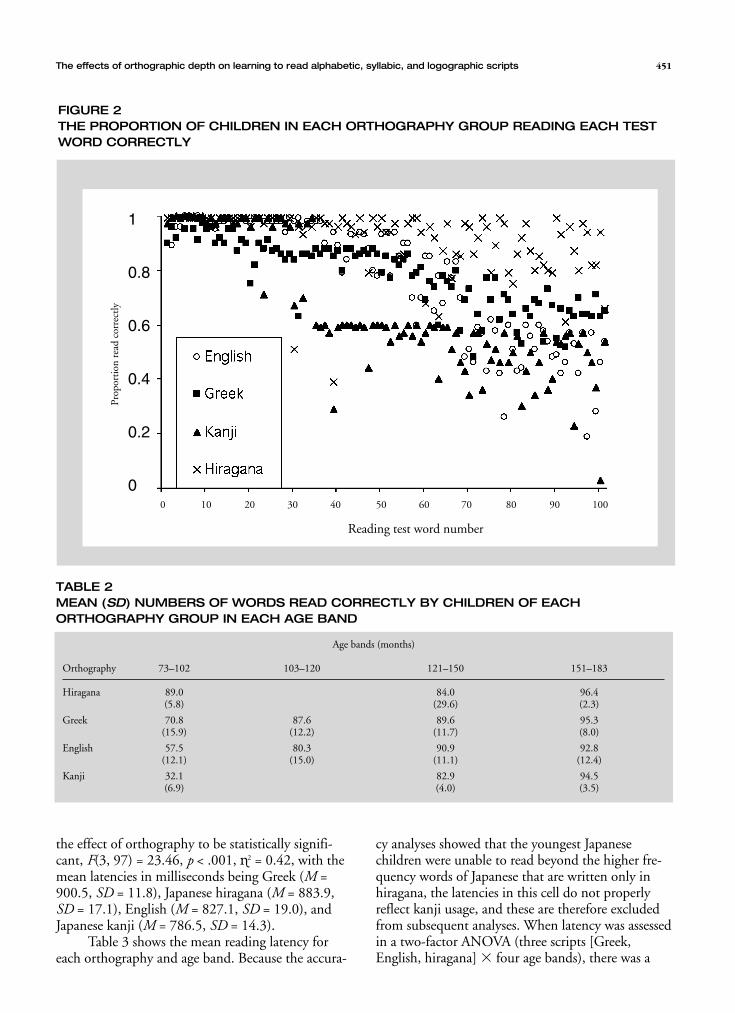
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 451
the effect of orthography to be statistically signifi-cant F(3 97) = 2346 p lt 001 macr2 = 042 with themean latencies in milliseconds being Greek (M =9005 SD = 118) Japanese hiragana (M = 8839SD = 171) English (M = 8271 SD = 190) andJapanese kanji (M = 7865 SD = 143)
Table 3 shows the mean reading latency foreach orthography and age band Because the accura-
cy analyses showed that the youngest Japanesechildren were unable to read beyond the higher fre-quency words of Japanese that are written only inhiragana the latencies in this cell do not properlyreflect kanji usage and these are therefore excludedfrom subsequent analyses When latency was assessedin a two-factor ANOVA (three scripts [GreekEnglish hiragana] four age bands) there was a
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 890 840 964(58) (296) (23)
Greek 708 876 896 953(159) (122) (117) (80)
English 575 803 909 928(121) (150) (111) (124)
Kanji 321 829 945(69) (40) (35)
TABLE 2MEAN (SD) NUMBERS OF WORDS READ CORRECTLY BY CHILDREN OF EACHORTHOGRAPHY GROUP IN EACH AGE BAND
FIGURE 2THE PROPORTION OF CHILDREN IN EACH ORTHOGRAPHY GROUP READING EACH TESTWORD CORRECTLY
Prop
ortio
n re
ad c
orre
ctly
1
08
06
04
02
00 10 20 30 40 50 60 70 80 90 100
Reading test word number
RRQ4-04 Ellis 92204 1151 AM Page 451
significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

significant orthography by age interaction F(5 187)= 433 p lt 001 which qualified the main effects ofage band F(3 187) = 2817 p lt 001 and orthogra-phy F(2 187) = 271 p = 07 These statistically sig-nificant effects remained when controlling for verbalfluency (picture-naming time) and nonverbal reason-ing ability orthography by age interaction F(5 182)= 354 p lt 005 and age band F(3 182) = 157 p lt001 When we focused on latencies of the correctresponses in the younger children in the 73ndash102-month age band Bonferroni testing showed a statis-tically significant contrast between the Greek andEnglish latencies (p lt 001) and between the twomore transparent orthographies Greek and hiraganacombined against the more opaque English (p lt001) The four group latency averages did not differsignificantly from each other at the two higher agebands spanning 121ndash150 and 151ndash183 monthsFigure 4 illustrates the interaction of orthographyand age on reading latency using more fine-grainedage increments
Latency as a function of word lengthAs already reported there were differences in
the average length of the reading test items acrosslanguages with alphabetic orthographies havingmost characters per word (English M = 525 GreekM = 628 Albanian M = 536) syllabic hiraganafewer (M = 313) and logographic kanji fewest of all(M = 204)
We analyzed reading onset time for correctitems as a function of word length within each or-thography Regression analyses demonstrated that la-tency of correct responses is more a function of wordlength in hiragana (B = 8129 SE B = 663 int =078 F[1 98] = 15039 p lt 0001) than it is inGreek (B = 2252 SE B = 287 int = 062 F[1 98] =6147 p lt 0001) English (B = 4302 SE B = 577int = 060 F[1 98] = 5554 p lt 0001) or kanji (B =4436 SE B = 1655 int = 026 F[1 98] = 719 p lt01] The mean response times averaged for eachlength are shown in Figure 5 where the relationshipbetween length and latency is more linear and asshown by the tighter standard errors more pre-dictable as one moves from ideographic kanjithrough orthographically opaque English and ortho-graphically transparent Greek alphabets to syllabic
452 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 3THE PROPORTION OF WORDS CORRECTLYREAD ALOUD IN HIRAGANA ALBANIANGREEK ENGLISH AND KANJI BYCHILDREN OF EACH AGE
Prop
ortio
n of
wor
ds c
orre
ctly
rea
d al
oud
Age (months)
FIGURE 4READING ONSET LATENCY FOR THE TESTITEMS CORRECTLY READ ALOUD INHIRAGANA GREEK ENGLISH AND KANJIAT EACH AGE
Rea
ding
ons
et la
tenc
y (m
s)
Age (months)
RRQ4-04 Ellis 92204 1151 AM Page 452
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 453
hiragana It is clear that reading latency is moreclearly a function of word length in hiragana (R2 =060) than in Greek (R2 = 038) English (R2 =036) or kanji (R2 = 006)
Reading errors The reading test was discontinued after a child
made five consecutive errors a procedure that result-ed in a variable number of total errors per child Weanalyzed the tape recorded errors of 72 English chil-dren (M = 805 errors) 69 Japanese readers of hira-gana (M = 703 errors) 72 Japanese readers of kanji(M = 820 errors) and 65 Greek children (M = 889errors) Each error was classified into one of threecategories no response within 15 seconds whole-word substitutions and responses of nonwords Weused these categories because they are simple andclearly distinguishable The number of items in eachcell can be seen in Table 4 where the scripts are or-dered in terms of decreasing orthographic trans-parency There is a statistically significant associationbetween orthography and error type χ2 (8 N =2887) = 11273 p lt 00001
The midsection of Table 4 shows these data asthe percentage of the errors made on each orthogra-phy of these three different types It also highlightsthe cells with the largest residuals these being theones that contributed most to the overall associationbetween orthography and error type The no-response data followed a linear relationship with or-thographic transparency with the percentage oferrors of this type increasing from 1 for syllabic
hiragana through 2 14 and 22 respectivelyfor orthographically transparent Albanian and Greekand orthographically opaque English alphabets to66 for the kanji ideographs
These large differences in the rate of no-response errors necessitated a separate analysis in or-der to determine the relative likelihood of the othererror types The bottom section of Table 4 shows thepercentage of substantive errors that were whole-word substitutions or nonwords There was a statisti-cally significant association between orthographyand these types of error χ2 (4 N = 2273) = 1443 plt 001 Whole-word substitutions constituted thelarge majority of substantive kanji errors at 69(138 word substitutions 63 nonword responses) Incontrast whole-word substitutions only constituted31 of the substantive errors in Albanian (205 wordsubstitutions 457 nonword responses) with non-word errors predominating in Albanian We had pre-dicted that orthographically opaque scripts wouldtend to generate more whole-word substitution er-rors and more transparent scripts would generatemore nonword errors The whole-word substitutionrates of Albanian (31) English (50) and Kanji(69) were in accord with this prediction Howeverthe proportions of this error type in Greek (53)and hiragana (60) were higher than were expectedAppendix B lists 30 error responses that are represen-tative of those made within each orthography In thediscussion these errors informed our considerationof the aspects of the Greek spelling system and of theJapanese language that helped explain these two un-expectedly high rates of word-substitution error
Age bands (months)
Orthography 73ndash102 103ndash120 121ndash150 151ndash183
Hiragana 12009 8011 6079(3274) (1225) (967)
Greek 15310 8528 8005 7141(10024) (2459) (1030) (1693)
English 9413 8254 7325 7832(1626) (1555) (1742) (2126)
Kanji 10323a 8771 6627(2713) (1310) (1167)
aBecause the youngest Japanese children were unable to read beyond the higher frequency words of Japanese that are written only in hiragana theselatencies do not properly reflect kanji usage
TABLE 3MEAN (SD) LATENCY (MILLISECONDS) OF WORDS READ CORRECTLY BY CHILDREN OF EACH ORTHOGRAPHY GROUP IN EACH AGE BAND
RRQ4-04 Ellis 92204 1151 AM Page 453
DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

DiscussionThe orthographic depth hypothesis and rate of reading acquisition
Our first question concerned whether greaterorthographic transparency led children to read aloudmore quickly The data clearly demonstrated such an
association All contrasts between the levels of read-ing accuracy in hiragana Greek English and kanjiby children in the youngest 73ndash102-month age bandwere statistically significant with hiragana the mosttransparent orthography being the most successfullyread followed in order of decreasing orthographictransparency by Greek then English and then kan-ji Consideration of the children ages 75 years old(90 months) allowed us to broaden the contrast set
454 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
FIGURE 5READING ONSET LATENCY FOR CORRECT ITEMS AS A FUNCTION OF WORD LENGTH INHIRAGANA GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 454
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 455
with the addition of Albanian the most transparentalphabetic orthography tested here Japanese chil-dren were successful on 88 of their hiragana testitems Albanian children on 80 of theirs Greek chil-dren on 78 and English children on 60 Japanesechildren managed just 31 of their kanji items butbecause the most frequent Japanese words are writ-ten only in hiragana 31 of the items of this test wereactually in hiragana in other words Japanese chil-dren at this age are hardly able to read kanji at all
Zipf rsquos law (Zipf 1935) describes how for anylanguage when the number of occurrences of wordsis plotted as the function of their rank frequency(eg 1st 2nd 3rd) the functional form has an ex-ponential distribution with the higher frequencyword types of a language accounting for a very largeproportion of word tokens Thus for example whilethere are more than 114000 word families inWebsterrsquos Third New International Dictionary(Merriam-Webster 1961) just the thousand mostfrequent words of English suffice to account for
about 80 of the total language we experience on adaily basis One consequence of this law as wasdemonstrated when we used our sampling proce-dures to work backwards from samples to corpora isthat on average 75-year-old Japanese childrencould successfully read 998 of the word tokensthey might meet in hiragana Albanian children877 of word tokens that might typically occur intheir written language Greek children 85 andEnglish children just 697 Thus it is much harderto learn to read aloud in orthographically opaquescripts Children schooled in these writing systemshave greater difficulty and take longer in achievingthis goal
Does this ability to read aloud constrain chil-drenrsquos comprehension of written words and their lit-eracy development as a whole We believe theliterature says it does First even learners of ortho-graphically opaque scripts like English pass throughan alphabetic stage of reading with phonologypaving the development of the lexical reading path-
Error type
No Whole-wordOrthography response substitution Nonword Total
Raw count dataHiragana 7 286 189 482Albanian 13 205 457 675Greek 78 247 219 544English 130 235 234 599Kanji 386 138 63 587Total 614 1111 1162 2887
Row percentages for all errors analysisa
Hiragana 1 dArrdArr 59 uArruArr 39Albanian 2 dArrdArr 30 dArr 68 uArruArrGreek 14 dArr 45 uArr 40English 22 39 39Kanji 66 uArruArr 24 dArr 11 dArrdArrMean 21 38 40
Row percentages for analysis of substantive errors onlyb
Hiragana 60 uArr 40Albanian 31 dArr 69 Greek 53 47English 50 50Kanji 69 uArr 31Mean 49 51
aAll errors analysis χ2 (8 N = 2887) = 11273 p lt 00001 bSubstantive errors analysis χ2 (4 N = 2273) = 1443 p lt 001dArrdArr Haberman standardized residuals lt ndash100dArr Haberman standardized residuals lt ndash20uArr Haberman standardized residuals gt 20uArruArr Haberman standardized residuals gt 100
TABLE 4CLASSIFICATION OF THE READING ERRORS MADE BY CHILDREN READING HIRAGANAALBANIAN GREEK ENGLISH AND KANJI
RRQ4-04 Ellis 92204 1152 AM Page 455
way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

way (Ehri 1999 Frith 1985 Marsh et al 1981)Share (1995) dubbed phonological recoding the sinequa non of reading since it is by ldquoself-teachingrdquo thatchildren eventually achieve direct access to meaningShare holds that a childrsquos alphabetic reading(graphemendashphoneme decoding blending and as-sembled pronunciation) if successful results in ap-propriate whole-word pronunciations while thecorresponding orthographic patterns are still avail-able for scrutiny In this way larger chunks of or-thography can become associated with larger chunksof pronunciation orthographic rimes with rhymeslarger spelling patterns with more reliable pronuncia-tions and eventually lexical orthographic specifica-tions with whole-word pronunciations This processcan succeed only with consistent patterns where analphabetic reading strategy generates a ldquobarking atprintrdquo that is approximate enough to allow recogni-tion of the appropriate word which implies that self-teaching might be more difficult in orthographicallyopaque scripts than in transparent ones Secondphonological impairments in dyslexic (Frith 1981Snowling 1998) and deaf (Perfetti amp Sandak 2000)individuals profoundly restrict their acquisition ofliteracy Finally phonological processing is a neces-sary component even in Chinese character identifica-tion (eg Perfetti amp Tan 1999 Spinks Liu Perfettiamp Tan 2000) an observation that promptedDeFrancis (1989) to observe a ldquodiverse onenessrdquowhereby all writing systems are in essence ldquovisiblespeechrdquo sharing a common goal of representingphonetic utterances with written symbols
Notwithstanding these arguments relating or-thographic depth and reading comprehension theeffect of orthographic transparency on rate of acqui-sition of reading comprehension is an empirical is-sue and the rankings of learnability of scripts maylook different if investigation focuses on readingcomprehension rather than reading aloudSymbolndashsound consistency covaries withsymbolndashmeaning consistency In transparent or-thographies there are many homographs where thesame written word is associated with a number ofdifferent senses Evolutionary changes in languagecreate irregularities in symbolndashsound correspon-dences when a wordrsquos spelling becomes influenced byits morphemic structure (eg healhealthsignaturesign and the spelling of the plural mor-pheme -s despite its varying sound as in ropes robesroses) (Chomsky amp Halle 1968 Ellis 1993 NunesBryant amp Bindman 1997 Rayner amp Pollatsek1989 Venezky 1970) Meaning is similarly spelledout for us in the disambiguation of homophones(eg bebee tootwo witchwhich) The clearer
marking of morphology in logographic scripts maytherefore provide their readers with a less ambiguousroute to semantic access and thus it may affordsome consequent advantages for reading comprehen-sion Further research is needed therefore to extendthe current comparisons by applying the frequency-sampling cross-linguistic assessment method tomeasure comprehension alongside naming
The orthographic depth hypothesis and strategy of reading
Another focus of our study concerned thestrategy implications of the orthographic depth hy-pothesis Do differences in orthographic transparen-cy result in different reading strategies We lookedfor evidence from reaction times and from error pat-terns There were various confirmations First wordlength determined 60 of the variance of reading la-tency in hiragana 38 in Greek 36 in Englishand 6 in kanji Second readers of transparent or-thographies had longer reading latencies Third therate of no-response errors increased from 1 for hi-ragana through 2 14 and 22 respectivelyfor Albanian Greek and English alphabets to 66for kanji Finally readers of opaque orthographiestended to make whole-word substitution errorswhile those of transparent orthographies tendedmore to make nonword mispronunciations We con-sidered each finding in turn
The data demonstrated that the more transpar-ent the orthography the much more linear the rela-tion between successful word-naming time and wordlength This is the pattern that would result if pro-nunciation were assembled by means of a left-to-right parsing of the graphemes that constitute eachword with concomitant decoding of the correspond-ing phonemes the more graphemes to process thelonger is the assembly time That readers of Englishwere not so affected by word length suggested thatthey are less likely to attempt to construct pronunci-ations in this way and instead they use partial cueswith words being discriminated by reference to asubset of their component letters particularly thoseat the beginnings and ends of words (Ehri 1997Stuart amp Coltheart 1988) The fact that readers ofkanji were little affected by word length representedthe extreme of this process Kanji provides compara-tively few cues for pronunciation (Perfetti amp Tan1999) and what little association there is betweenword length and naming latency for kanji probablyreflects the processes of blending kanji symbols and
456 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 456
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 457
hiragana inflections in some of the grammaticallymarked words
The younger children reading the two moretransparent orthographies Greek and hiragana evi-denced significantly longer correct reading onset la-tencies than did readers of orthographically opaqueEnglish Ellis and Hooper (2001) reported similarlythat the latencies of children reading orthograph-ically transparent Welsh were longer than those ofmatched English readers This overall pattern sug-gests that longer latencies are a natural consequenceof using a phonological route to lexical access be-cause decoding takes time the longer the words thelonger the time
The different nature of the reading errors inthe five orthographies generally supported the strate-gy implications of the orthographic depth hypothesisand the ways these were evidenced in Ellis andHooper (2001) First the greater the proportion ofno-response errors for more opaque orthographiesindicates that children reading these scripts are un-able to successfully synthesize pronunciations bymeans of decoding Readers of opaque orthographiesalso tended to make whole-word substitution errorswith 69 of substantive kanji errors being of thistype compared with only 31 for transparentAlbanian Inspection of the real-word errors inAppendix B shows that these substitutions are on thewhole visually similar to the targets a finding thatsupports the idea that readers of opaque orthogra-phies tend to recognize written words on the basis ofpartial visual analysis of the reading stimuli In con-trast the 68 nonword mispronunciation error ratein Albanian confirms the suggestion that childrenlearning to read transparent orthographies attackeach new word by means of a left-to-right parse ofthe graphemes decoding of the correspondingphonemes and subsequent pronunciation assembledfrom a blending of these parts The Albanian non-word errors in Appendix B tend to be mistakeswhereby correct segments are interspersed with sub-stitutions gaps or misorderingsmdashall processes thatresult in nonwords
However this pattern whereby transparent or-thographies promoted more nonwords and opaqueorthographies more real-word substitution errors wasnot absolute over all five orthographies in our sam-ple Although transparent Albanian produced fewreal-word substitutions the proportions of this errortype in hiragana and Greek were higher than wereexpected from previous findings with transparent or-thographies What factors might have led to thisInspection of the reading errors in Appendix B givessome pointers The hiragana errors tended to be very
close to the targets differing usually in only onecharacter which is often visually similar to the origi-nal (eg ) or where there is asingle character addition or omission One factor indetermining the likelihood of real-word reading-er-ror substitutions is the lexical density of an ortho-graphic neighborhood The orthographicneighborhood of a word is the range of strings thatcan be made by changing one letter or character at atime Imagine all possible single-letter substitutionsfrom the word pig aig big zig pag pbg pzgpia pib piz Relatively few of these are actualwords (eg big dig pit) 21 of them to be precise Alexically dense neighborhood is one where manywords are created a sparse neighborhood is onewhere few are generated scratch has but 4 neighborsThe simpler syllable structure of Japanese constrainsthe possible combinations of spoken sound se-quences and this results both in there being relative-ly high rates of homophony in spoken Japanese andin the orthographic neighborhoods of written kanabeing relatively more lexically dense Thus a singlestroke or character substitution is more likely to gen-erate another real word in hiragana than it is in analphabetic orthography representing a syllabicallycomplex language like English In order to test thissupposition informally a computer program waswritten to generate random letter strings by choosingcharacters from the English alphabet or hiraganacharacter set at random and then stringing them to-gether into character sequences We generated 100two-letter strings and three-letter strings each forEnglish and hiragana and then had a native speakercheck how many of these were words In the 200random strings for each language there were 21Japanese words but only 6 English words Thus theJapanese lexicon does seem to make more use of thepossible permutations of written hiragana charactersequences than does English and this greater lexicaldensity makes the misreading of a hiragana charactermore likely to generate a real-word substitution errorin Japanese
What of Greek As described previously thereare many homonyms that share the same phonemesequence but are differentiated by a change inacoustic stress that causes a shift in meaning andusually a change in spelling For example word 73rsquo (keacuteria) meaning ldquovitalrdquo becomes onchange of stress the word rsquo (kerjaacute) which iscorrectly spelled rsquo and means ldquocandlesrdquo Errorsinvolving changes in the positioning of stress areshown for Greek in Appendix B For the corpusstress errors resulted in 486 of the real-word sub-stitution errors and 416 of the nonword errors
RRQ4-04 Ellis 92204 1152 AM Page 457
and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

and were thus responsible for at least some of thehigher-than-expected incidence of real-word errorsin Greek
Finally what about the substantive kanji er-rors Given the opacity of kanji how might childrenmake any substantive errors at allmdashdonrsquot they eitherknow it or not Clues are to be found in the factsthat the majority of words written in kanji comprisemore than one character that children are likely tohave previously encountered these characters ontheir own or in combination with other charactersand that there is a high degree of homography Thusfor example the pronunciation of the 54th testword is ldquomikatardquo Some children read this asldquokenpourdquoan incorrect but logical pronunciation forthat word Kanji have different pronunciationsWhen the word is separated can be read asldquomirdquo or ldquokenrdquo and can be read as ldquokatardquo ldquogatardquoldquohourdquo or ldquopourdquo Kanji are first learned singly andonly later as combinations with other kanji Thuswhen confronted with combinations that they havenot yet seen before children very sensibly try to syn-thesize a correct pronunciation from knowledge ofthe parts Ninety-seven of the 201 substantive kanjierrors were of this type (50 of 138 being 36 of thereal-word substitutions and 47 of 63 being 75 ofthe nonword errors)
LimitationsThere are many factors other than orthograph-
ic depth affecting literacy with national economicand social development outstripping orthographictransparency in determining reading attainment(Lundberg 2002 Stevenson 1984 StevensonStigler Lucker Lee Hsu amp Kitamura 1982) Incountries with strong economies and high levels ofhealth and adult literacy most students becomecompetent readers (Elley 1994) Lack of access towritten materials lack of parental involvement inpromoting literacy and lack of educational opportu-nity can prohibit literacy development before anymodulating effects of orthographic transparency cantake hold Such international differences in wealthhealth education expectation and educational prac-tices as they affect childrenrsquos literacy attainmentspoint to limitations of this research that must beborne in mind in its interpretation The study man-aged only a relatively small and nonrandom oppor-tunity sample of participants These children weretaught by different teachers in different classroomsand schools using different methods of instruction indifferent cultures We simply could not control these
potential confounds Further research with largersamples and better control is clearly warranted
Other limitations concern the adequacy of lan-guage corpora as indexes of learnersrsquo language expo-sure The method of language sampling has the sameprincipled advantages as does the survey method inthe description of people and populations (Kidder ampJudd 1986) hence the continued interest in corpuslinguistics over the last 20 years (McEnery ampWilson 1996) Nevertheless as pollsters and politi-cians know there is always scope for sampling errorThe corpora we used were largely drawn from adultwritten language rather than from child inputAlthough the particularities of a corpus probablyhave little effect upon the higher frequency words ofa language they can have marked influence uponfrequency estimates of less common items and solack of adequate representation necessarily results inmeasurement error It would be better to sample thelanguage from literature for children It would alsobe preferable to have individual random samplingfor every test with computerized sampling of log fre-quency using psychophysical methods of thresholddetection rather than just one sample frozen andduplicated for all children
In light of these limitations further research isrequired to fully describe and compare the rates andprocesses of learning to read in different orthogra-phies Then when different patterns of learnabilityand strategy have been firmly identified there will besubsequent need for guided experimentation into thecognitive factors that might underpin these differ-ences These experiments would control other factorswhile targeting particular facets of the language ororthography such as the lexical range of the lan-guage alphabet size letter sequence complexityphonological structure phonotactic complexitymorphological complexity word length word fre-quencies typendashtoken ratios accenting and so forth
Meanwhile the pattern of differences in read-ing acquisition identified in the present study sug-gests that it does matter whether an orthographywrites what is meant or writes what is saidOrthographies that represent pronunciation encour-age faster learning for reading aloud and the moretransparently they do this the faster the learning rateand the more they encourage lexical access viaphonology Such results illustrate a more generalprinciple that in solving a particular problem learn-ers find and exploit the regularities that help them toachieve their task and as they practice so their rep-resentations and strategies become tuned to that par-ticular problem space
458 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 458
The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

The effects of orthographic depth on learning to read alphabetic syllabic and logographic scripts 459
NICK C ELLIS is professor of psychology at University of WalesBangor His research concerns applied psycholinguistics first- andsecond-language acquisition reading and spelling and bilingualismand cognition He can be contacted at School of Psychology Universityof Wales Bangor LL57 2AS UK or by e-mail at nellisbangoracuk
VICTOR HP VAN DAAL is Senior Research Fellow in the School ofPsychology at University of Wales Bangor (UWB) and Director of theUWB Dyslexia Unit His research concerns the nature and treatment ofchildren with developmental dyslexia in different languages He can becontacted at School of Psychology University of Wales Bangor LL572AS UK or by e-mail at vhpvandaalbangoracuk
LORENC HOXHALLARI is a final-year PhD student at the Universityof Wales Bangor UK His research examines the effect oforthographic depth on reading and spelling acquisition in AlbanianEnglish and Welsh He can be contacted at School of PsychologyUniversity of Wales Bangor LL57 2AS UK or by e-mail atpss81ebangoracuk
MIWA NATSUME KATERINA STAVROPOULOU NICOLETTAPOLYZOE MARIA-LOUISA TSIPA and MICHALIS PETALAS wereadvanced undergraduate students at University of Wales Bangor atthe time of the study reported here Miwa Natsume went on topostgraduate study in child development Katerina Stavropoulou inautism Nicoletta Polyzoe in consumer psychology Maria-Louisa Tsipain social intervention and health and Michalis Petalas in cognitivebehavioral therapy They may be contacted co Dr Nick C Ellis at theSchool of Psychology University of Wales Bangor LL57 2AS UK
R E F E R E N C E SABBOUD A amp SUGAR D (1997) SuperLab (Version 103)
[Computer software] Phoenix AZ CedrusAKITA K amp HATANO G (1999) Learning to read and write in
Japanese In M Harris amp G Hatano (Eds) Learning to read and writeA cross-linguistic perspective (pp 214ndash234) Cambridge UK CambridgeUniversity Press
ALEGRIA L PIGNOT E amp MORAIS J (1982) Phonetic analy-sis of speech and memory codes in beginning readers Memory ampCognition 10 451ndash456
AMANO N amp KONDO K (2000) NTT database seriesmdashNihongono goitokusei dai 7 kan Hindo [Lexical properties of Japanese Vol7 Frequency Database 1] Tokyo NTT Communication ScienceLaboratories Producer 1
BAAYEN RH PIEPENBROCK R amp VAN RIJN H (1995)The Celex Lexical Database (Release 2) [CD-ROM] PhiladelphiaLinguistic Data Consortium University of Pennsylvania [Distributor]
BABINIOTIS G (1980) Theoritiki glossologia [Linguistics in theo-ry] Athens Greece University of Athens Press
BAKAMIDIS S amp CARAYANNIS G (1987) ldquoPhonemiardquo Aphoneme transcription system for speech synthesis in modern GreekSpeech Communication 6 159ndash169
CHITIRI HF amp WILLOWS DM (1994) Word recognition intwo languages and orthographies English and Greek Memory ampCognition 22 313ndash325
CHOMSKY N amp HALLE M (1968) The sound pattern of EnglishNew York Harper amp Row
DANIELS PT amp BRIGHT W (Eds) (1996) The worldrsquos writ-ing systems New York Oxford University Press
DEFRANCIS J (1989) Visible speech The diverse oneness of writingsystems Honolulu University of Hawaii Press
EHRI LC (1997) Learning to read and learning to spell are one andthe same almost In CA Perfetti L Rieben amp M Fayol (Eds) Learningto spell Research theory and practice across languages (pp 237ndash269)Hillsdale NJ Erlbaum
EHRI LC (1999) Phases of development in learning to read wordsIn J Oakhill amp R Beard (Eds) Reading development and the teaching ofreading (pp 79ndash108) Oxford UK Blackwell
ELLEY WB (Ed) (1994) The IEA study of reading literacyAchievement and instruction in thirty-two school systems Oxford UKElsevier Science
ELLIS AW (1993) Reading writing and dyslexia A cognitive analy-sis Hillsdale NJ Erlbaum
ELLIS NC amp HOOPER AM (2001) It is easier to learn to readin Welsh than in English Effects of orthographic transparency demon-strated using frequency-matched cross-linguistic reading tests AppliedPsycholinguistics 22 571ndash599
ELLIS NC OrsquoDOCHARTAIGH C HICKS W MORGANM amp LAPORTE N (2001) Cronfa Electroneg o GymraegA 1 millionword lexical database and frequency count for Welsh Retrieved August2001 from University of Wales Bangor website httpwwwbangoracukarcbcegceg_enghtml
FRITH U (1981) Experimental approaches to developmentaldyslexia An introduction Psychological Research 43 97ndash109
FRITH U (1985) Beneath the surface of developmental dyslexiaIn K Patterson M Coltheart amp J Marshall (Eds) Surface dyslexiaNeuropsychological and cognitive studies of phonological reading (pp301ndash330) London Erlbaum
GAUR A (1992) A history of writing London The British LibraryGOSWAMI U (1999) Causal connections in beginning reading
The importance of rhyme Journal of Research in Reading 22 217ndash240GOSWAMI U (2000) Phonological representations reading de-
velopment and dyslexia Towards a cross-linguistic theoretical frameworkDyslexia 6 133ndash151
GOSWAMI U GOMBERT JE amp DE BARRERA LF (1998)Childrenrsquos orthographic representations and linguistic transparencyNonsense word reading in English French and Spanish AppliedPsycholinguistics 19 19ndash52
GOSWAMI U PORPODAS C amp WHEELWRIGHT S(1997) Childrenrsquos orthographic representations in English and GreekEuropean Journal of Psychology of Education 12 273ndash292
HARRIS M amp GIANNOULI V (1999) Learning to read andspell in Greek In M Harris amp G Hatano (Eds) Learning to read andwrite A cross-linguistic perspective (pp 51ndash70) Cambridge UKCambridge University Press
HOXHALLARI L (2000) Teacherrsquos beliefs about learning to readAlbanian English and Welsh The effect of a regular orthographyUnpublished manuscript University of Wales Bangor UK
KATZ L amp FROST R (1992) Reading in different orthographiesThe orthographic depth hypothesis In R Frost amp L Katz (Eds)Orthography phonology morphology and meaning (pp 67ndash84)Amsterdam New Holland
KESS JF amp MIYAMOTO T (1999) The Japanese mental lexiconPsycholinguistic studies of kana and kanji processing Philadelphia JohnBenjamins
KIDDER LH amp JUDD CM (1986) Research methods in social re-lations (5th ed) New York Holt Rinehart and Winston
LANDERL K WIMMER H amp FRITH U (1997) The impactof orthographic consistency on dyslexia A German-English comparisonCognition 63 315ndash334
LIBERMAN I SHANKWEILER D FISCHER FW ampCARTER B (1974) Explicit syllable and phoneme segmentation in theyoung child Journal of Experimental Child Psychology 18 201ndash212
LOPEZ MR amp GONZALEZ JEJ (1999) An analysis of theword naming errors of normal readers and reading disabled children inSpanish Journal of Research in Reading 22 180ndash197
LUNDBERG I (2002 June) Reading in a second language with theextra load of dyslexia Keynote presentation at the International Conferenceon Multilingual and Cross-Cultural Perspectives on DyslexiaWashington DC
MAGOULAS G (1979) Eisagogi sti neoelliniki phonologia[Introduction to modern Greek phonology] Athens Greece Universityof Athens Press
MARSH G FRIEDMAN MP WELCH V amp DESBERG P(1981) A cognitive-developmental theory of reading acquisition In TGWaller amp GE MacKinnon (Eds) Reading research Advances in theoryand practice (Vol 3 pp 201ndash215) New York Academic Press
MCENERY T amp WILSON A (1996) Corpus linguisticsEdinburgh UK Edinburgh University Press
MERRIAM-WEBSTER A (Ed) (1961) Websterrsquos third new inter-national dictionary of the English language Springfield MA G amp CMerriam
NATIONAL LANGUAGE RESEARCH INSTITUTE (1988) Theacquisition of common kanji by elementary and secondary school children
RRQ4-04 Ellis 92204 1152 AM Page 459
Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

Tokyo Tokyo ShosekiNOMURA M (1980) Chinese characters content of weeklyrsquos writ-
ing Mathematical Linguistics 12 215ndash222NUNES T BRYANT P amp BINDMAN M (1997)
Morphological spelling strategies Developmental stages and processesDevelopmental Psychology 33 637ndash649
OumlNEY B amp DURGUNOGLU AY (1997) Beginning to read inTurkish A phonologically transparent orthography AppliedPsycholinguistics 18 1ndash15
PAULESU E MCCRORY E FAZIO F MENONCELLO LBRUNSWICK N CAPPA SF ET AL (2000) A cultural effect onbrain function Nature Neuroscience 3 91ndash96
PERFETTI CA amp SANDAK R (2000) Reading optimally buildson spoken language Implications for deaf readers Journal of Deaf Studiesamp Deaf Education 5 32ndash50
PERFETTI CA amp TAN LH (1999) The constituency model ofChinese word identification In J Wang AW Inhoff amp H-C Chen(Eds) Reading Chinese script A cognitive analysis (pp 115ndash134) MahwahNJ Erlbaum
PORPODAS CD (1991) The relation between phonemic aware-ness and reading and spelling of Greek words in the first school years InM Carretero amp ML Pope (Eds) Learning and instruction European re-search in an international context (Vol 3 pp 203ndash217) Oxford UKPergamon Press
PORPODAS CD (1999) Patterns of phonological and memoryprocessing in beginning readers and spellers of Greek Journal of LearningDisabilities 32 406ndash416
RACK JP SNOWLING MJ amp OLSON RK (1992) The non-word reading deficit in developmental dyslexia A review Reading ResearchQuarterly 27 28ndash53
RAYNER K amp POLLATSEK A (1989) Psychology of readingEnglewood Cliffs NJ Prentice-Hall
ROZIN P amp GLEITMAN LR (1977) The structure and acqui-sition of reading II The reading process and the acquisition of the alpha-betic principle In AS Reber amp DL Scarborough (Eds) Toward a psy-chology of reading (pp 55ndash141) New York Erlbaum
SEYMOUR PHK ARO M amp ERSKINE JM (2003)Foundation literacy acquisition in European orthographies British Journalof Psychology 94 143ndash174
SEYMOUR PHK amp ELDER E (1986) Beginning reading with-out phonology Cognitive Neuropsychology 3 1ndash36
SHARE DL (1995) Phonological recoding and self-teaching Sinequa non of reading acquisition Cognition 55 151ndash218
SHIMAMURA N amp MIKAMI H (1994) Acquisition of hiraganaletters by preschool children In comparison with the investigation by theNational Language Research Institute [In Japanese with English summa-ry] Japanese Journal of Educational Psychology 42 70ndash76
SNODGRASS JG amp VANDERWART M (1980) A standard-ized set of 260 pictures Norms for name agreement image agreement fa-miliarity and visual complexity Journal of Experimental PsychologyHuman Learning and Memory 6 174ndash215
SNOWLING M (1998) Dyslexia as a phonological deficitEvidence and implications Child Psychology amp Psychiatry Review 3 4ndash11
SPENCER LH amp HANLEY JR (2003) Effects of orthographictransparency on reading and phoneme awareness in children learning toread in Wales British Journal of Psychology 94 1ndash28
SPINKS JA LIU Y PERFETTI CA amp TAN LH (2000)Reading Chinese characters for meaning The role of phonological infor-mation Cognition 76 B1ndashB11
STEVENSON HW (1984) Orthography and reading disabilitiesJournal of Reading Disabilities 17 296ndash301
STEVENSON HW STIGLER JW LUCKER GW LEE S-Y HSU C-C amp KITAMURA S (1982) Reading disabilities The caseof Chinese Japanese and English Child Development 53 1164ndash1181
STUART M amp COLTHEART MC (1988) Does reading de-velop in a sequence of stages Cognition 30 139ndash181
THORSTAD G (1991) The effect of orthography on the acquisi-tion of literacy skills British Journal of Psychology 82 527ndash537
TOMBAIDIS DE (1986) Epitomi tis historias tis Ellinikis glossas[Compendium of the history of the Greek language] Athens GreeceOEDB (Organization of Textbooks Publishing)
TOMBAIDIS DE (1987) Synoptiki historia tis Ellinikis glossas[Concise history of the Greek language] Athens Greece OEDB
TREIMAN R MULLENNIX J BIJELJAC-BABIC R amp RICHMOND-WELTY ED (1995) The special role of rimes in the de-scription use and acquisition of English orthography Journal ofExperimental Psychology General 124 107ndash136
TRIANTAPHYLLIDIS M (1913) Horthographia mas [Our orthog-raphy] Athens Greece Estia
TRIANTAPHYLLIDIS M (1980) Neoelliniki grammatiki [ModernGreek grammar] Athens Greece Estia
VENEZKY R (1970) The structure of English orthography TheHague the Netherlands Mouton
WIMMER H amp GOSWAMI U (1994) The influence of ortho-graphic consistency on reading development Word recognition in Englishand German children Cognition 51 91ndash103
WIMMER H amp HUMMER P (1990) How German speakingfirst graders read and spell Doubts on the importance of the logographicstage Applied Psycholinguistics 11 349ndash368
ZIPF GK (1935) The psycho-biology of language An introduction todynamic philology Cambridge MA MIT Press
Received July 10 2003Final revision received March 8 2004
Accepted March 17 2004
A U T H O R S rsquo N O T E SWe thank the children and their parents and the head teachers teach-
ers and schools that took part in this study Thanks to Elaine Miles andSatsuki Nakai for constructive comments on an earlier draft
This work was supported by the Economic and Social ResearchCouncil (ESRC award H474 25 4101) and by a grant from the DaiwaAnglo-Japanese Foundation
460 Reading Research Quarterly OCTOBERNOVEMBERDECEMBER 2004 394
RRQ4-04 Ellis 92204 1152 AM Page 460
461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

461
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 461
462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

462
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTS FOR THE FIVE SCRIPTS (continued)
APPENDIX A
(continued)
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1152 AM Page 462
463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

463
APPENDIX
THE ITEMS OF THE SINGLE WORD READING TESTSFOR THE FIVE SCRIPTS (continued)
APPENDIX A
Wordnumber English Greek Hiragana Kanji Albanian
RRQ4-04 Ellis 92204 1153 AM Page 463
464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

464
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS
APPENDIX B
(continued)
Hiragana reading errorsReal-word Nonword
Correct word Error response substitution error
RRQ4-04 Ellis 92204 1153 AM Page 464
465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

465
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
(continued)
Kanji reading errorsKanji
Real-word Nonword StructuralCorrect word Error response substitution error error
RRQ4-04 Ellis 92204 1154 AM Page 465
466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468

466
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Greek reading errorsGreek
Real-word Nonword StressCorrect word Error response substitution error error
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 466
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468
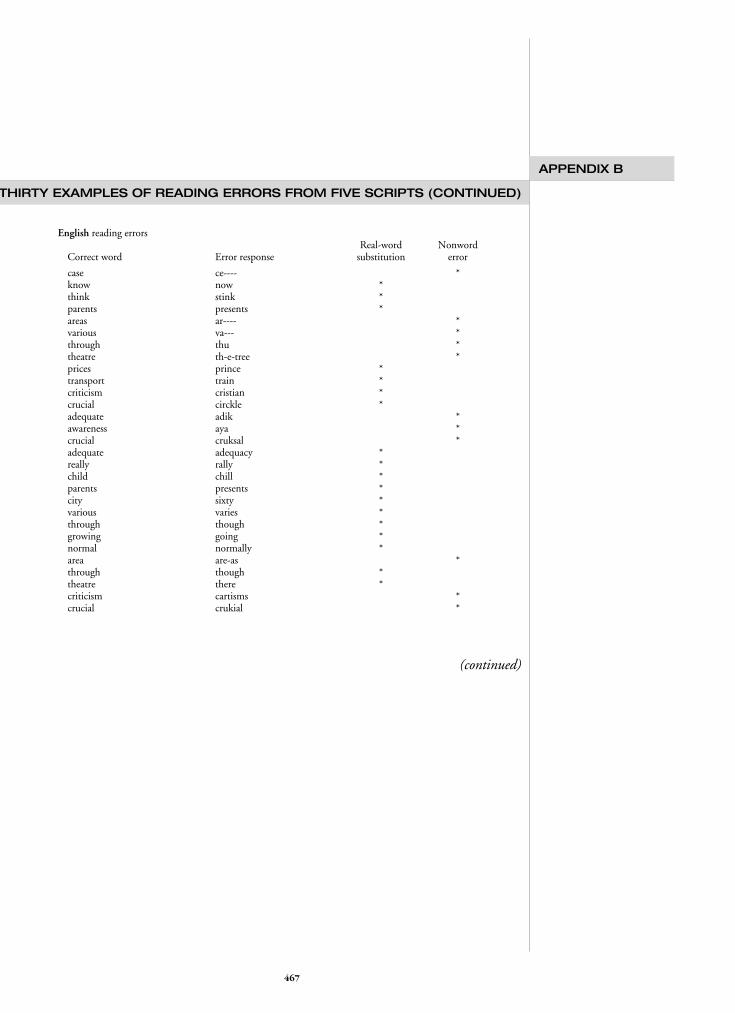
467
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (CONTINUED)
APPENDIX B
English reading errorsReal-word Nonword
Correct word Error response substitution error
case ce---- know now think stink parents presents areas ar---- various va--- through thu theatre th-e-tree prices prince transport train criticism cristian crucial circkle adequate adik awareness aya crucial cruksal adequate adequacy really rally child chill parents presents city sixty various varies through though growing going normal normally area are-as through though theatre there criticism cartisms crucial crukial
(continued)
RRQ4-04 Ellis 92204 1154 AM Page 467
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468
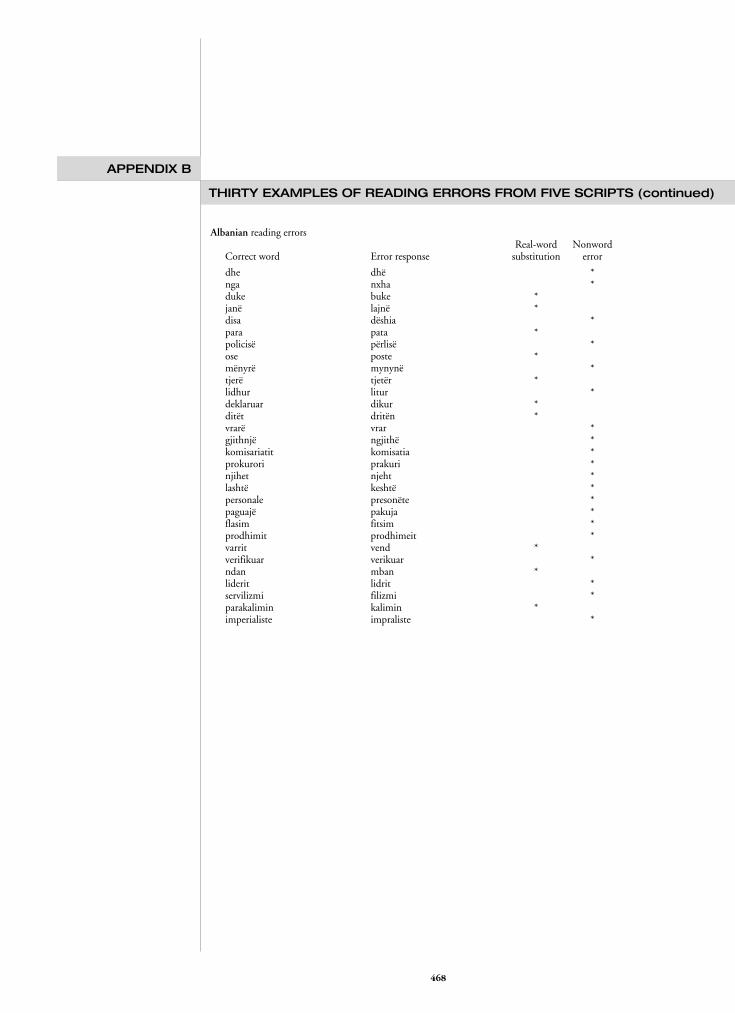
468
APPENDIX
THIRTY EXAMPLES OF READING ERRORS FROM FIVE SCRIPTS (continued)
APPENDIX B
Albanian reading errorsReal-word Nonword
Correct word Error response substitution error
dhe dheuml nga nxha duke buke janeuml lajneuml disa deumlshia para pata policiseuml peumlrliseuml ose poste meumlnyreuml mynyneuml tjereuml tjeteumlr lidhur litur deklaruar dikur diteumlt driteumln vrareuml vrar gjithnjeuml ngjitheuml komisariatit komisatia prokurori prakuri njihet njeht lashteuml keshteuml personale presoneumlte paguajeuml pakuja flasim fitsim prodhimit prodhimeit varrit vend verifikuar verikuar ndan mban liderit lidrit servilizmi filizmi parakalimin kalimin imperialiste impraliste
RRQ4-04 Ellis 92204 1154 AM Page 468