accelerating machine learning applications on graphics processors narayanan sundaram and bryan...
Post on 22-Dec-2015
223 views
TRANSCRIPT

Accelerating Machine Learning Applications on Graphics Processors
Narayanan Sundaram and Bryan CatanzaroPresented by
Narayanan Sundaram

Big Picture
FrameworksCBIR ApplicationFramework
Patterns
Application Framework Developer Map Reduce
ProgrammingFramework
Map Reduce ProgrammingPattern Map Reduce
ProgrammingFramework Developer
CUDAComputation &
CommunicationFramework
Barrier/Reduction Computation &CommunicationPatterns
CUDAFramework Developer
Face SearchDeveloper
Consumer Search
Searcher
Feature Extraction& Classifier ApplicationPatterns
Nvidia G80
Hardware Architect
Patt
ern
Lan
guage
SW
In
frast
ruct
ure
Platform
Application

GPUs as proxy for manycore
• GPUs are interesting architectures to program • Transitioning from highly specialized pipelines
to general purpose• The only way to get performance from GPUs is
through parallelism (No caching, branch prediction, prefetching etc.)
• Can launch millions of threads in one call
35/14/08 CS258 Parallel Computer Architecture

GPUs are not for everyone• Memory coalescing is really important• Irregular memory accesses to even local stores is
discouraged - up to 30% performance hit on some apps for local memory bank conflicts
• Cannot forget that it is a SIMD machine• Memory consistency is non-existent & inter-SM
synchronization is absent• Hardware scheduled threads• 20 us overhead for kernel call (20,000
instructions @ 1GHz)
45/14/08 CS258 Parallel Computer Architecture

NVIDIA G80 Architecture
5/14/08 CS258 Parallel Computer Architecture 5

NVIDIA GeForce 8800 GTX Specifications
Number of Streaming Multiprocessors 16
Multiprocessor Width 8
Local Store Size 16 KB
Total number of Stream Processors 128
Peak SP Floating Point Rate 346 Gflops
Clock 1.35 GHz
Device Memory 768 MB
Peak Memory Bandwidth 86.4 GB/s
Connection to Host CPU PCI Express
CPU -> GPU bandwidth 2.2 GB/s*
GPU -> CPU bandwidth 1.7 GB/s*
5/14/08 CS258 Parallel Computer Architecture 6* measured values

GPU programming - CUDA
• Each block can have upto 512 threads that synchronize
• Millions of blocks can be issued
• No synchronization between blocks
• No control over scheduling
5/14/08 CS258 Parallel Computer Architecture 7

Support Vector Machines
• A hugely popular machine learning technique for classification
• Tries to find a hyperplane separating the different classes with “maximum margin”
• Non-linear surfaces can be generated through non-linear kernel functions
• Uses Quadratic Programming for training (specific set of constraints imply a wide variety of techniques for solving it)
85/14/08 CS258 Parallel Computer Architecture

SVM Training• Quadratic Program
• Some kernel functions:
Variables:α: Weight for each training point (determines classifier)
Data:l: number of training pointsC: trades off error on training set for generalization performancey: Label (+/- 1) for each training pointx: training points

Choice of parallel algorithm(among chunking algorithms)
5/14/08 CS258 Parallel Computer Architecture 10
SequentialMinimal Optimization(SMO)

Fitting SMO on a GPU
• Shared memory constraints on the GPU fits the algorithm as only two vectors need to be shared among all the threads
• Performance strongly dependent on the choice of the working set
• Several heuristics proposed – two are popular (1st and 2nd order)
• 2nd order heuristic is almost twice as costly, but saves on the number of iterations
115/14/08 CS258 Parallel Computer Architecture

Adaptive heuristic• Both heuristics can be expressed as a series of
“Map Reduce” stages• A Map Reduce code generator was used to
generate the code• Sample periodically and adapt depending on the
most converging heuristic at any given time • Tightly coupled map-reduces are essential for
machine learning algorithms• Cannot afford the overhead of general library call
when called millions of times
125/14/08 CS258 Parallel Computer Architecture
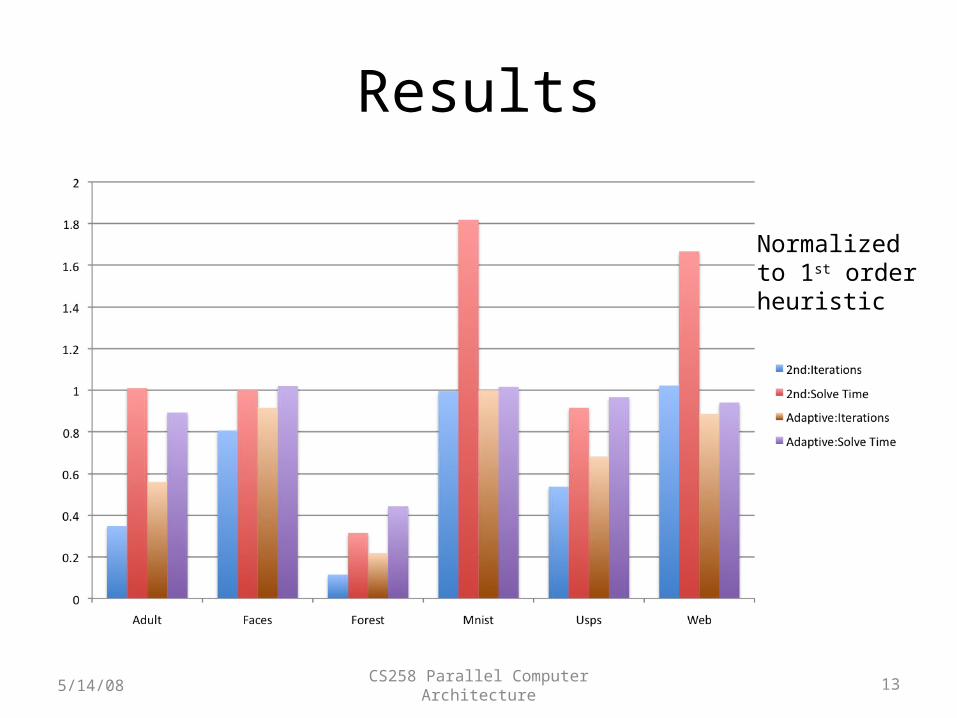
Results
135/14/08 CS258 Parallel Computer Architecture
Normalizedto 1st orderheuristic

Overall speedup compared to LIBSVM

SVM Classification
• SVM classification task involves finding which side of the hyperplane a point lies on
• Specifically,
where
• Insight : Instead of doing this serially for all points, note that

Restructuring the Classification problemSV Test Data
Output
Vs
Output
Test Data
SV

Results
5/14/08 CS258 Parallel Computer Architecture 17
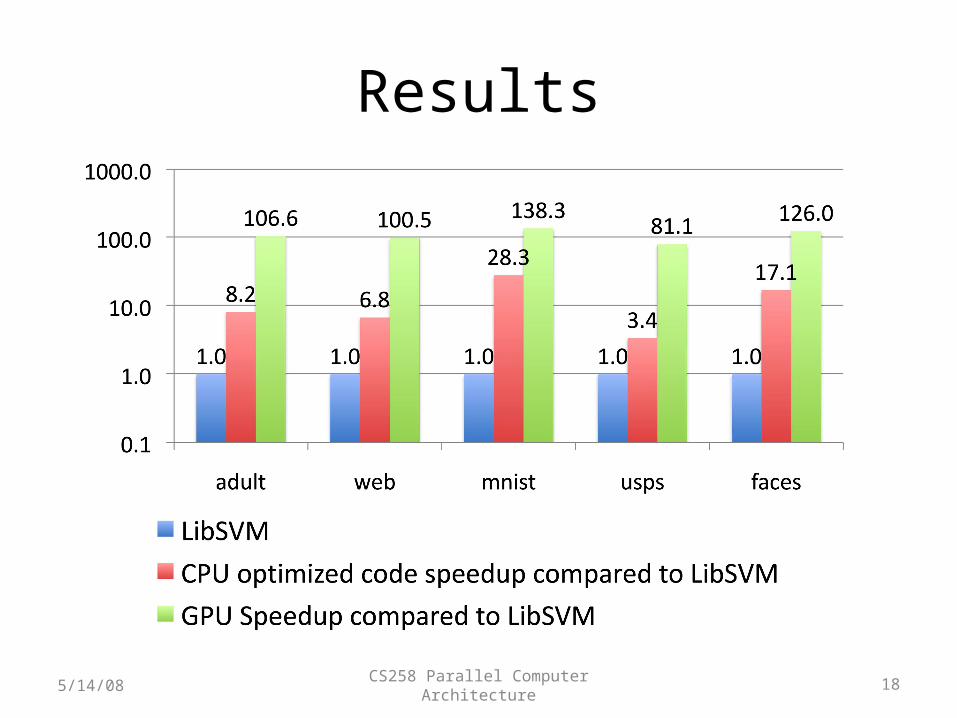
Results
5/14/08 CS258 Parallel Computer Architecture 18

Is this compute or memory bound?
• GPUs are better for memory bound jobs (Observed 7 GB/s vs 1 GB/s for other streaming-like apps)
5/14/08 CS258 Parallel Computer Architecture 19

Importance of memory coalescing
• In order to avoid non-coalesced memory accesses, carried both Data and DataT into GPU memory
• Letting 0.05% of memory accesses to be non-coalesced led to a 21% drop in performance for one case
• Well written code should scale with GPU size (parallelism should be limited by problem size, not machine size)
5/14/08 CS258 Parallel Computer Architecture 20

Is SIMD becoming ubiquitous?
• SIMD already important for performance on uniprocessor systems
• Task Vs Data parallelism• Intel’s new GPU has wide SIMD• CUDA lesson - Runtime SIMD binding easier
for programmers• Non-SIMD leads to performance penalty, not
incorrect programs – prevents premature optimizations and keep code flexible
5/14/08 CS258 Parallel Computer Architecture 21

Conclusion
• GPUs and Manycore CPUs are on a collision course
• Data parallelism on GPUs or Task parallelism on CPUs
• Rethink serial control and data structures• Sequential optimizations may harm
parallelism• Machine learning can use a lot of parallel
hardware if software engineered properly
5/14/08 CS258 Parallel Computer Architecture 22