adopte une bdd
TRANSCRIPT

BIEN CHOISIR SA PARTENAIRE API HOUR #22
*

INTRODUCTION
Applications manipulent des données (I/O)
Données vivantes destinées à être trouvées
Stockage intelligent via SGBD
Données multiformes
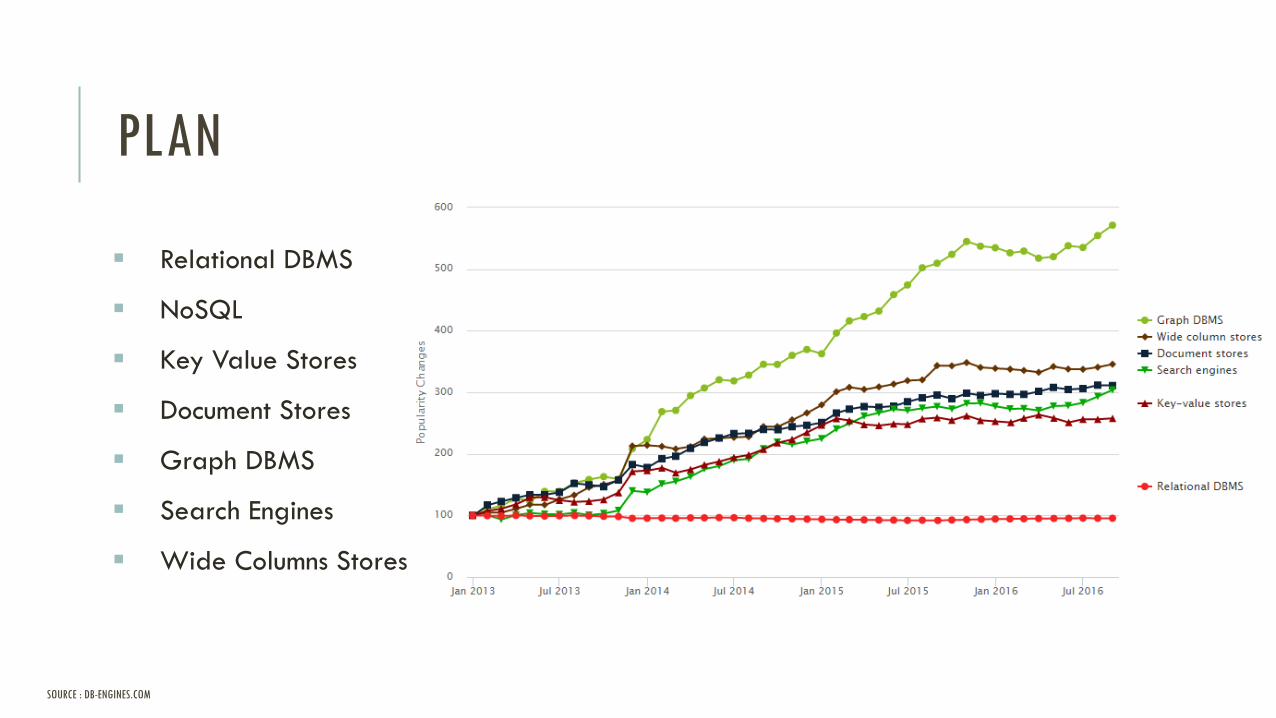
Choisir le bon outil
Nombre croissant de solutions (> 300)
SOURCE : DB-ENGINES.COM
PLAN
Relational DBMS
NoSQL
Key Value Stores
Document Stores
Graph DBMS
Search Engines
Wide Columns Stores
SOURCE : DB-ENGINES.COM

#1 - RELATIONAL DBMS Love Compatibility : 81.4%
ORGANISATION
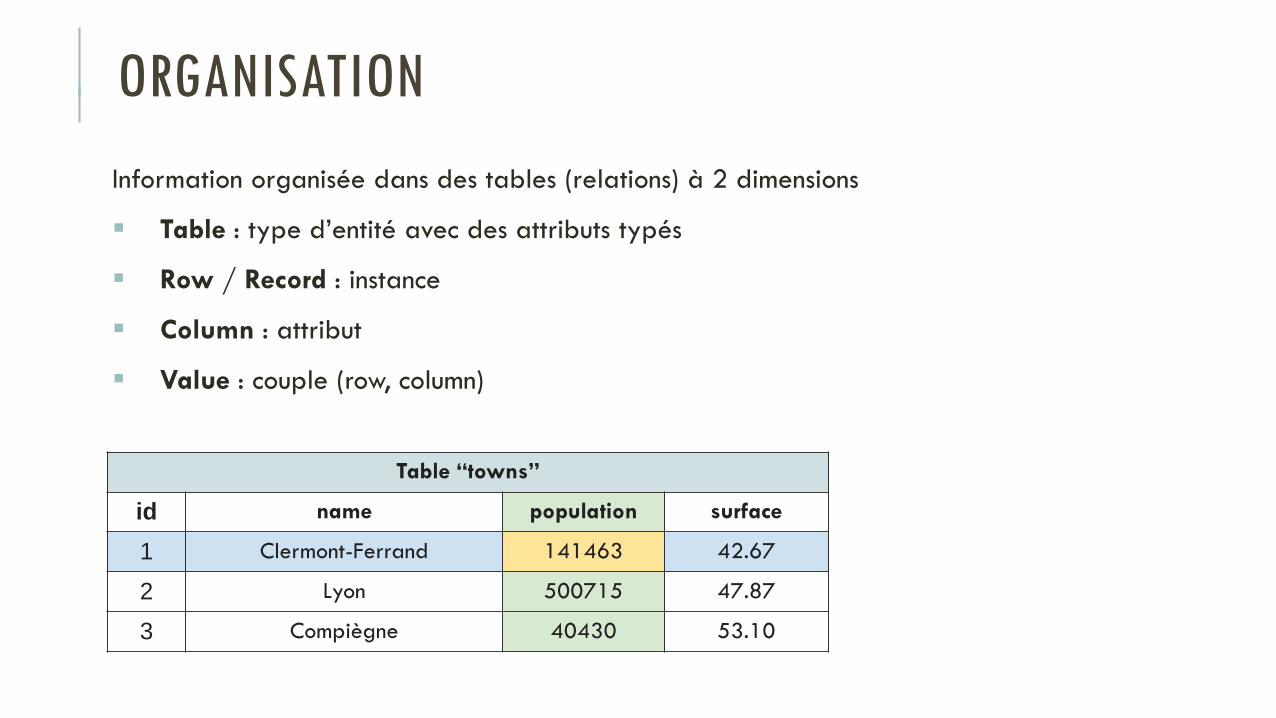
Information organisée dans des tables (relations) à 2 dimensions
Table : type d’entité avec des attributs typés
Row / Record : instance
Column : attribut
Value : couple (row, column)
Table “towns”
id name population surface
1 Clermont-Ferrand 141463 42.67
2 Lyon 500715 47.87
3 Compiègne 40430 53.10
NORMALISATIONS & JOINTURES
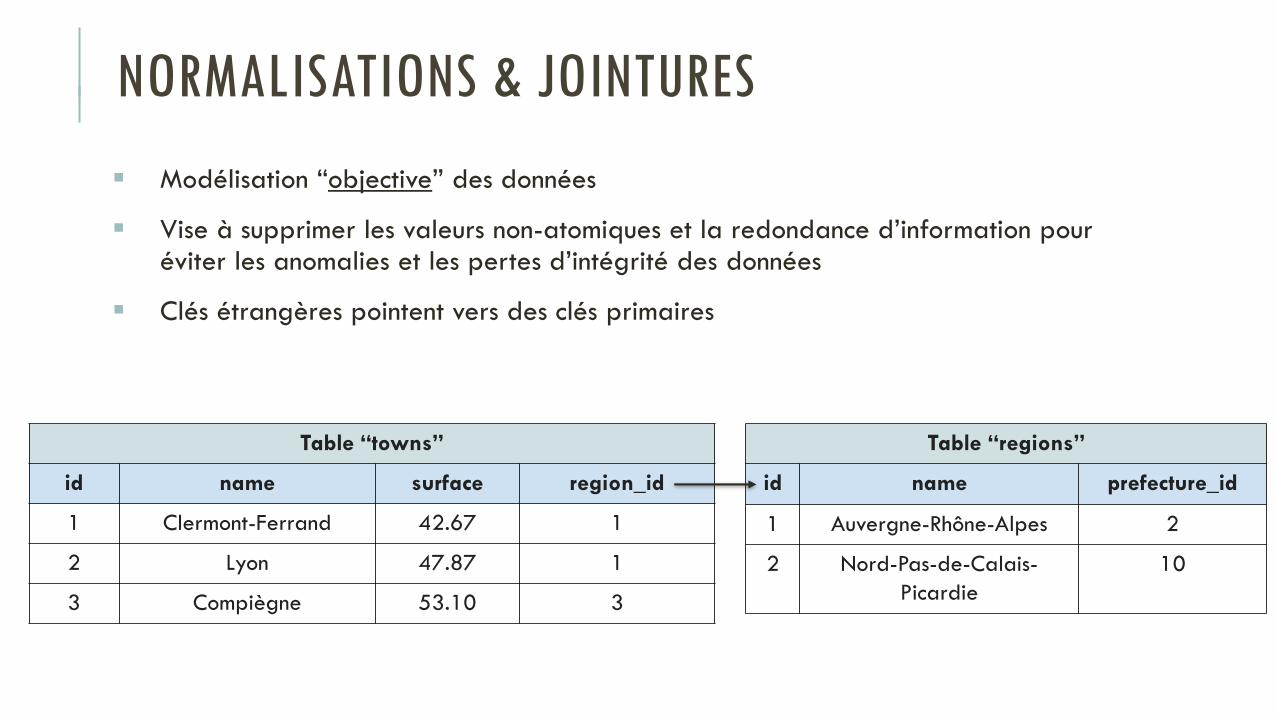
Modélisation “objective” des données
Vise à supprimer les valeurs non-atomiques et la redondance d’information pour éviter les anomalies et les pertes d’intégrité des données
Clés étrangères pointent vers des clés primaires
Table “towns”
id name surface region_id
1 Clermont-Ferrand 42.67 1
2 Lyon 47.87 1
3 Compiègne 53.10 3
Table “regions”
id name prefecture_id
1 Auvergne-Rhône-Alpes 2
2 Nord-Pas-de-Calais-
Picardie
10

INDEXES
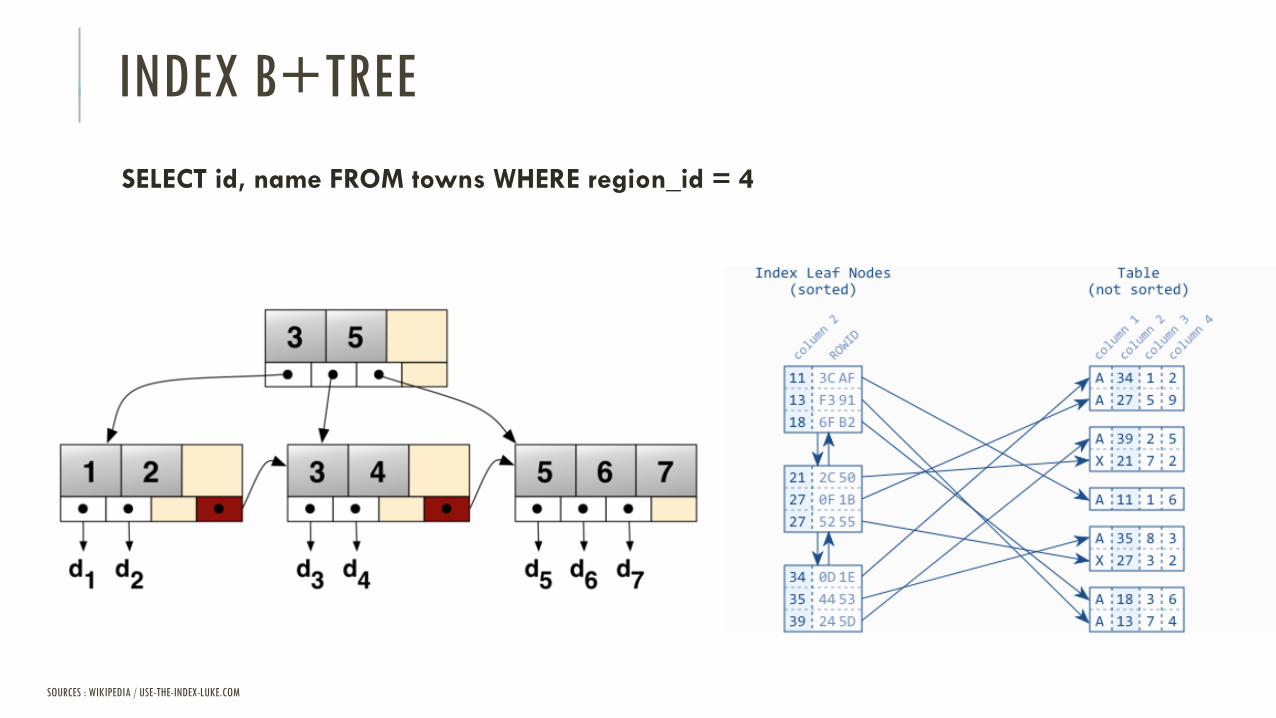
Index terminologique (Livre)
Réduit la complexité de recherche O(n) => O(log(n))Exemple : log²(1000000) ~ 20
Appliqués aux clés primaires, clés étrangères, critères de tri, filtres
Implémentations : B+tree, bitmaps, R-tree
SOURCES : WIKIPEDIA / USE-THE-INDEX-LUKE.COM
INDEX B+TREE
SELECT id, name FROM towns WHERE region_id = 4

TRANSACTIONS ACID
Atomicité (tout ou rien)
Cohérence (passage d’un état à un autre)
Isolation (indépendance)
Durabilité (résistance au crashes / erreurs)

SELECT id, nameFROM townsWHERE population > 100000ORDER BY population DESCLIMIT 10
LANGAGE STANDARD : SQL
Langage riche (LDD/LMD/LCD)
Jointures, agrégations, etc.
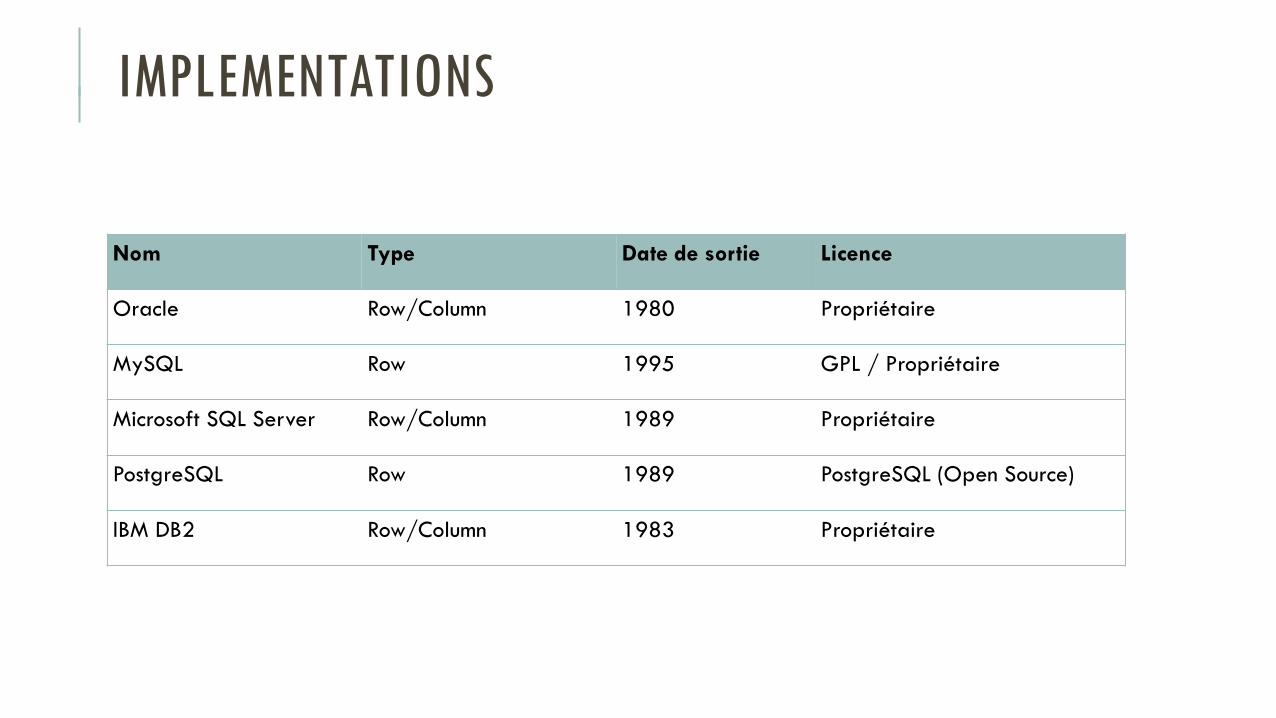
IMPLEMENTATIONS
Nom Type Date de sortie Licence
Oracle Row/Column 1980 Propriétaire
MySQL Row 1995 GPL / Propriétaire
Microsoft SQL Server Row/Column 1989 Propriétaire
PostgreSQL Row 1989 PostgreSQL (Open Source)
IBM DB2 Row/Column 1983 Propriétaire

NOSQL Notions

HISTORIQUE
Géants du Web (Google, Amazon, LinkedIn, Facebook) confrontés aux limitations intrinsèques des RDBMS (ACID)
Problèmes de scalabilité (verticale seulement avec 1 master)
Conception de nouvelles base de données pour architectures matérielles distribuées pour traiter des volumes importants
SOURCE : WIKIPEDIA
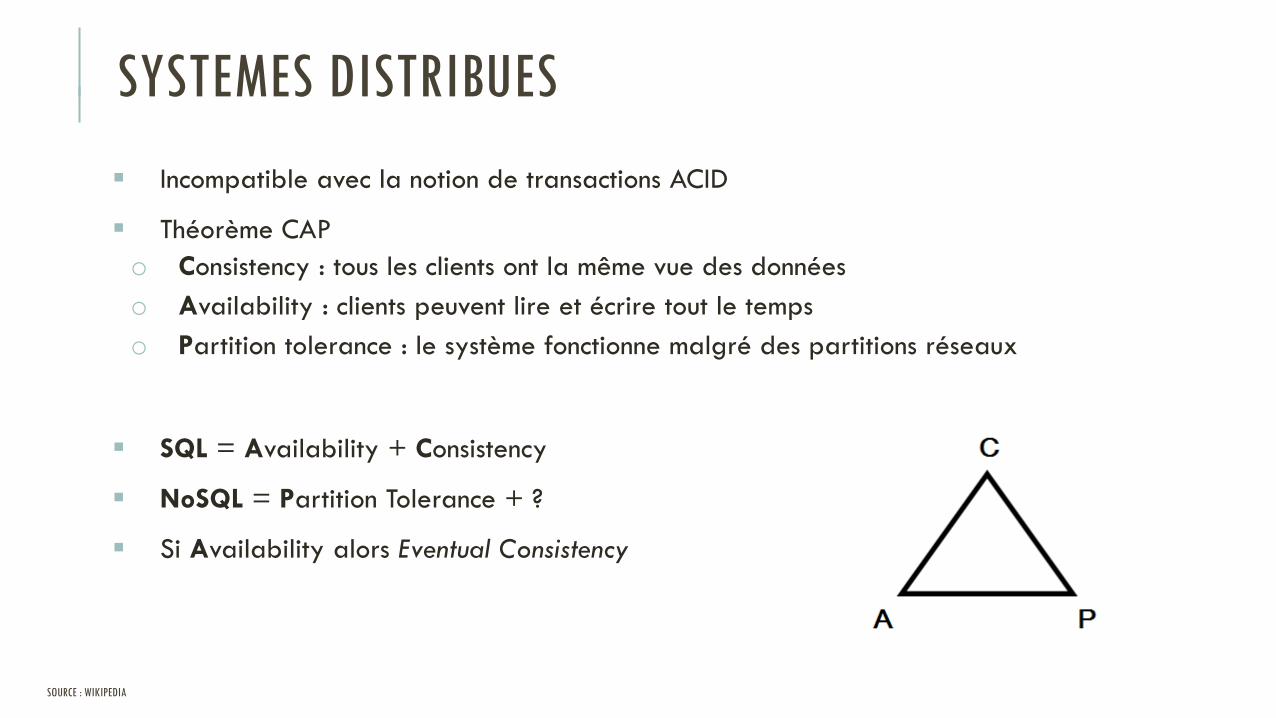
SYSTEMES DISTRIBUES
Incompatible avec la notion de transactions ACID
Théorème CAP
o Consistency : tous les clients ont la même vue des données
o Availability : clients peuvent lire et écrire tout le temps
o Partition tolerance : le système fonctionne malgré des partitions réseaux
SQL = Availability + Consistency
NoSQL = Partition Tolerance + ?
Si Availability alors Eventual Consistency

#2 - KEY VALUE STORES Love Compatibility : 3.1%

ORGANISATION
Information organisée sous forme de tableau associatif (Hash)
Key : identifiant unique
Value : donnée plus ou moins opaque pour le système
key value
city:1 Clermont-Ferrand|141463|42.67
city:2 { "name":"Lyon", "population":500715, "surface":47.87 }
city:3:population 40430

SOURCE : WIKIPEDIA
FONCTIONNALITES
Très rapide : complexité en temps d’un Hash table O(1)
Tient en RAM
Valeurs potentiellement typées (String, Lists, Sets, Sorted set, Hashes, Bitmaps, etc.)

LANGAGE
API ou Protocole diffère pour chaque implémentation
redis> GET “city:3:population”
(nil)
redis> SET “city:3:population” 40430
OK
redis> GET “city:3:population”
40430

USE CASES
Cache de données (TTL, LRU)
Transient Cache (session, panier, etc.)
Compteurs, classements
Queues
Servir de base à l’implémentation d’autres DBMS NoSQL.
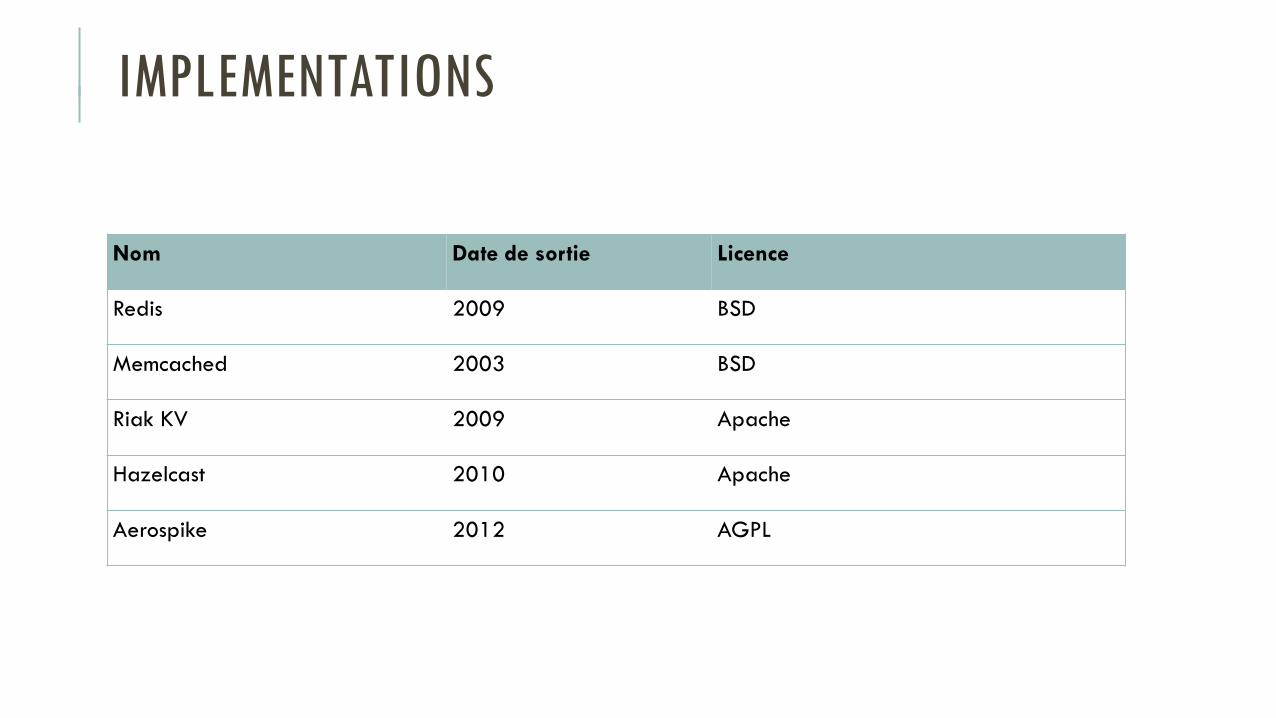
IMPLEMENTATIONS
Nom Date de sortie Licence
Redis 2009 BSD
Memcached 2003 BSD
Riak KV 2009 Apache
Hazelcast 2010 Apache
Aerospike 2012 AGPL

#3 - DOCUMENT STORES Love Compatibility : 6.8%

ORGANISATION
Information organisée dans des collections
Collection : ensemble de documents
Document : objet contenant un ensemble d’attributs et de valeurs
Field / Key : attribut
Value : valeur d’un field
Le Document encapsule et encode ses attributs dans un standard (JSON, XML, etc.)
{
"id": "110e8400-e29b-11d4-a716-446655440000",
"name": "Clermont-Ferrand",
"population": 141463,
"surface" : 42.67
}

DÉNORMALISATION & NESTED DOCUMENTS
Modélisation “subjective” des données en fonction de la manière dont on va les consulter (query).
Vise à supprimer les jointures.
{
"id": "110e8400-e29b-11d4-a716-446655440000",
"name": "Clermont-Ferrand",
"population": 141463,
"surface" : 42.67,
"region" : {
"id": "c65642b5-c46e-46ea-abd7-d27862498f7f",
"name": "Auvergne-Rhône-Alpes"
}
}

INDEXES
Appliqués aux clés primaires, critères de tri, filtres

LANGAGE
API ou Protocole diffère pour chaque implémentation
db.towns.find({ population: { $gt: 100000 } }).sort({ population: -1 }).limit(10)

USE CASES
Gestion de documents complexes (embedded documents)
Applications utilisant du JSON
Beaucoup d’écritures concurrentes
Intégrité et cohérence non cruciales
Requêtes statiques
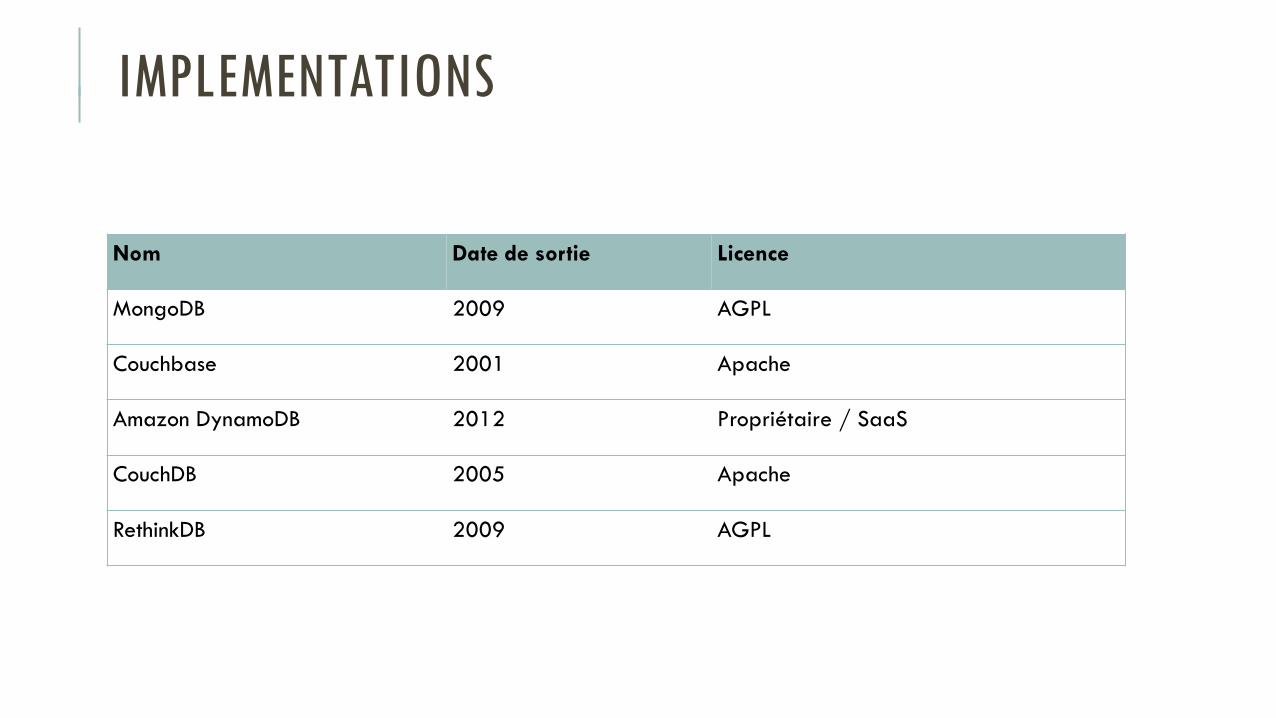
IMPLEMENTATIONS
Nom Date de sortie Licence
MongoDB 2009 AGPL
Couchbase 2001 Apache
Amazon DynamoDB 2012 Propriétaire / SaaS
CouchDB 2005 Apache
RethinkDB 2009 AGPL

#4 - SEARCH ENGINES Love Compatibility : 3.7%

ORGANISATION
SearchEngine = DBMS + outils dédiés à la fouille de texte
2 étapes clés :
Indexation
Recherche
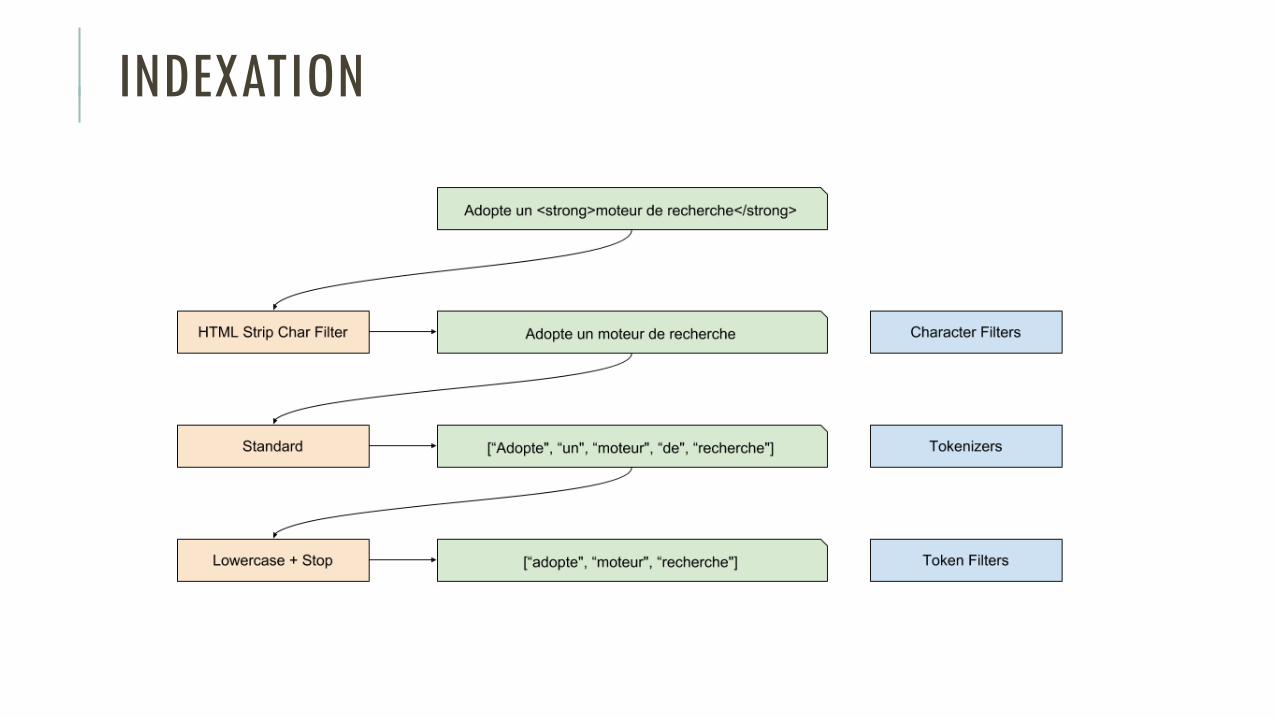
INDEXATION

INDEXES
Doc 1 : { “title“ : “Adopte un moteur de recherche“ }
Doc 2 : { “title“ : “Adopte le language ruby“ }
Index inversé “title”
ID Item Document
1 adopte Doc 1, Doc 2
2 language Doc 2
3 moteur Doc 1
4 recherche Doc 1
5 ruby Doc 2

RECHERCHE - REQUÊTEPOST /index/document/_search{"query": {
"filtered": {"query": {
"query_string": {"fields": [
"title^5","description^2","content"
],"query": "moteur de recheche en ruby","fuzzy_prefix_length": 2,"fuzziness": 1
}},"filter": {
"bool": {"must": [
{"match": {
"rights": "public"},"should": {
"types": "article"}
}]
}}
}}
}

RECHERCHE – RÉSULTAT AVEC SCORING{"hits": {"total": 2,"max_score": 0.11843335,"hits": [{"_index": “index","_type": “document","_id": "1","_score": 0.30052114,"_source": {“title": "adopte un moteur de recherche"
}},{"_index": " index ","_type": " document ","_id": "2","_score": 0.038161416,"_source": {“title": "adopte le language ruby"
}}
]}
}

FONCTIONNALITES
Full Text Search
Racinisation / Lemmatisation
Mots vides
Synonymes
Recherche par phrase
Recherche de proximité
Recherche approximative (distance de Levenshtein)
Auto complétion
Suggestion
Classement (td-idf, Okapi BM25, etc.)
Facettes
Recherche géospatiale

IMPLEMENTATIONS
Nom Date de sortie Licence
Elasticsearch (Lucene) 2010 Apache
Solr (Lucene) 2004 Apache
Splunk 1998 Propriétaire
Sphinx 2001 GPL + Propriétaire
Amazon CloudSearch 2012 Propriétaire / SaaS

#5 - GRAPH DBMS Love Compatibility : 0.9%

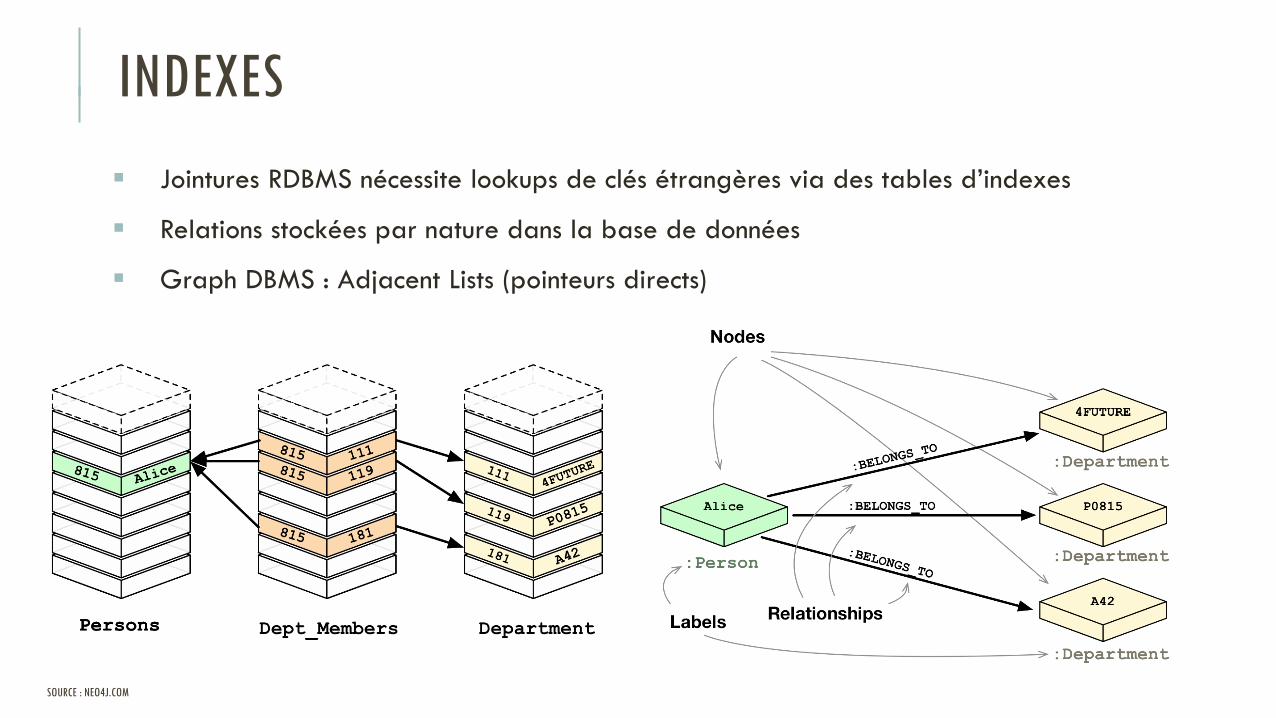
ORGANISATION
Information organisée par des relations orientées
Node: noeud
Edge : relation
Property : propriété sur un noeudou sur une relation
SOURCE : NEO4J.COM
INDEXES
Jointures RDBMS nécessite lookups de clés étrangères via des tables d’indexes
Relations stockées par nature dans la base de données
Graph DBMS : Adjacent Lists (pointeurs directs)

LANGUAGES
Pas de norme type SQL pour le Query Language. Des efforts de standardisations.
Gremlin (Graph stores)
SPARQL (RDF stores)
g.V.has(‘id’, ‘Node_1’).out(‘regions’).out(‘prefecture’).values(‘id’,‘name’)
SELECT ?town ?nameWHERE {:Node_1 ns:region/ns:prefecture ?town .?region ns:name ?name
}

USE CASES
Modélisation orientée relations
Réseaux sociaux
Recommandation
Réseau/ IT management
Algorithmes liés à la théorie des graphes type plus court chemin

IMPLEMENTATIONS
Nom Date de sortie Licence
Neo4j 2007 GPL + Propriétaire
Titan 2012 Apache
Virtuoso 1998 GPL + Propriétaire
Apache Giraph 2013 Apache
Stardog 2010 Propriétaire

#6 - WIDE COLUMNS STORES Love Compatibility : 3.0%
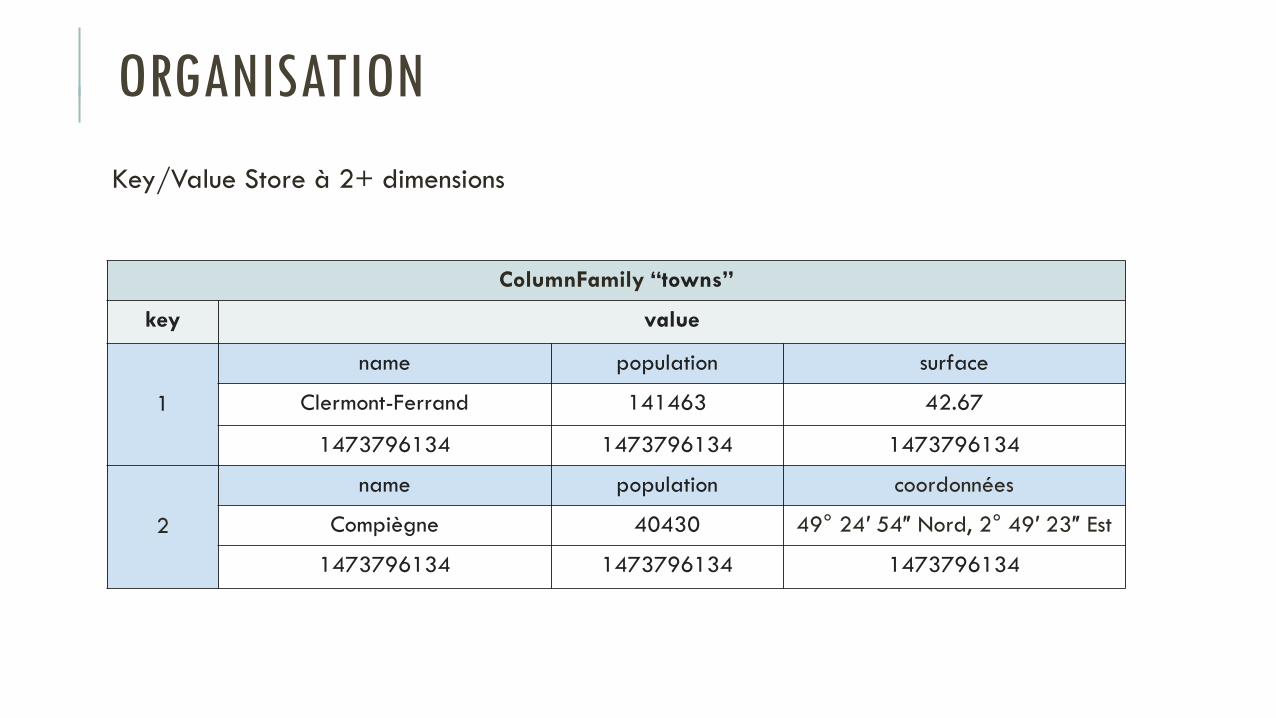
ORGANISATION
Key/Value Store à 2+ dimensions
ColumnFamily “towns”
key value
1
name population surface
Clermont-Ferrand 141463 42.67
1473796134 1473796134 1473796134
2
name population coordonnées
Compiègne 40430 49° 24′ 54″ Nord, 2° 49′ 23″ Est
1473796134 1473796134 1473796134

LANGAGE
Langage diffère pour chaque implémentation
Exemple : Cassandra CQL = Query Language (SQL like)
RowKey: 1=> (name=, value=, timestamp=1473796134)=> (name=name, value=Clermont-Ferrand, timestamp=1473796134)=> (name=population, value=141463, timestamp=42.67)=> (name=surface, value=42.67, timestamp=1473796134)
SELECT *FROM townsWHERE id = 1

INDEXES
Indexes secondaires déconseillés (maintenance complexe)
Systèmes répartis, partitionnement par clé primaire (répartition sur les nodes)
Filtres : clé primaire composites
Ordre : unique défini lors de la création de la ColumnFamily
Dénormalisation extrême = 1 ColumnFamily par query

USE CASES
Volumétrie importante (milliards d’enregistrements)
Performances
Distribution géographique avec plusieurs data centers
Données déstructurées / flexibles
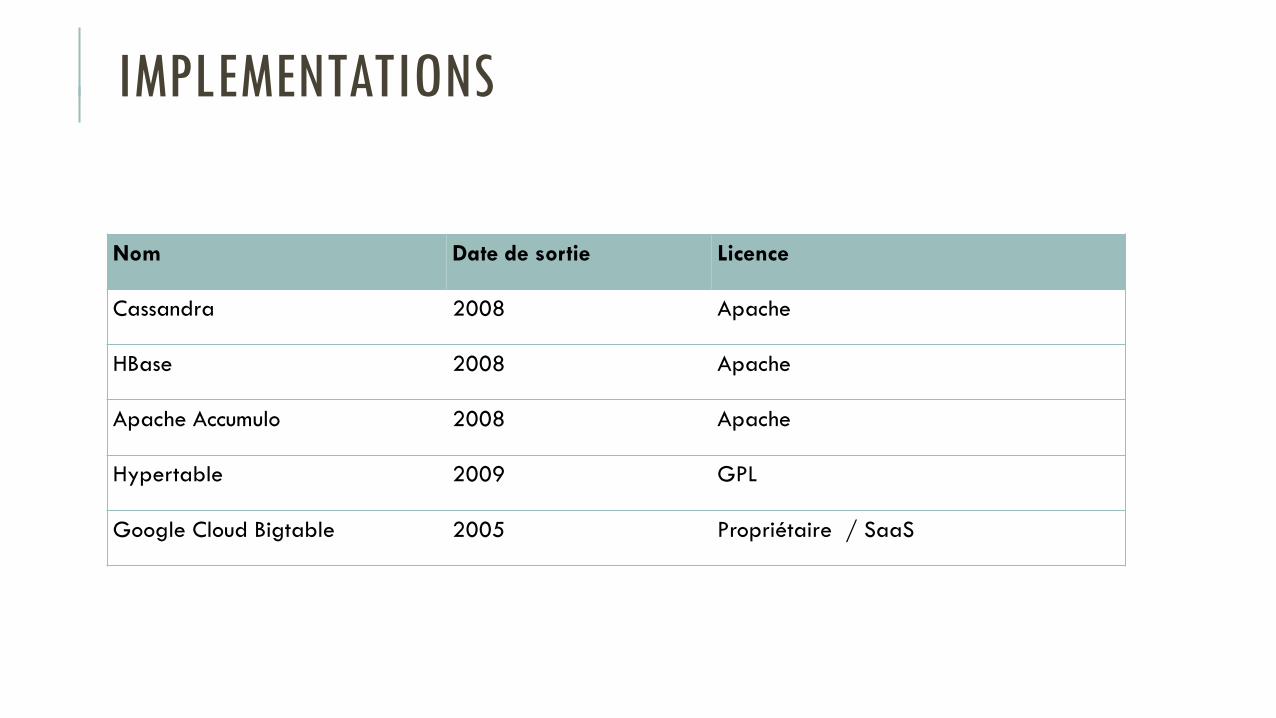
IMPLEMENTATIONS
Nom Date de sortie Licence
Cassandra 2008 Apache
HBase 2008 Apache
Apache Accumulo 2008 Apache
Hypertable 2009 GPL
Google Cloud Bigtable 2005 Propriétaire / SaaS

CONCLUSION So what ?

QUESTIONS
Flexibilité du modèle de données
Nature des relations entre les entités
Contraintes transactionnelles et d’intégrité des données
Disponibilité & Cohérence des réplicas
Volumétrie lecture / écriture
Performances / SLA
OS / Ecosystème / Licence

FUTUR ?
Variété de bases NoSQL pérennisée par le nombre croissant d’applications avec des contraintes variées et exigeantes en termes de performance & volumétrie
Multi-model databases (OrientDB, ArangoDB, etc.)
Evolution constante du NoSQL : NotOnlySQL (ex : jointures)
NewSQL : performance du NoSQL avec du SQL (VoltDB)

QUESTIONS ? @aymericbrisse
SOURCE : GEEK-AND-POKE.COM

BONUS

ALTERNATIVE : COLUMN-ORIENTED DBMS
Table “town”
id 1 2 3
name Clermont-Ferrand Lyon Compiègne
population 141463 500715 40430
surface 42.67 47.87 53.10
Table “town”
name Compiègne : 3 Clermont-Ferrand : 1 Lyon : 2 Paris : 4,16,18
population 40430 : 3 141463 : 1 500715 : 2
surface 42.67 : 1 47.87 : 2 53.10 : 3

ALTERNATIVE : COLUMN-ORIENTED DBMS
Avantages :
“Toutes les villes dont le nom est Paris" (22) : 1 seule opération
Stocker l’information sous forme d’indexes
Colonnes optionnelles (compression)
Opérations Filtres, Aggrégation, compteurs, etc
Orientation OLAP
Désavantages :
Récupérer toutes informations sur une entité est plus lent
Ecritures