強化学習の汎用化ai
TRANSCRIPT

Science And Technology
特徴量関数近似による
強化学習の汎用化
2016/09/08mabonki0725

Science And Technology
自己紹介
データ分析と統計モデル構築15年
学習データ以外のデータでも予測が当たることに驚く
統計数理研究所の機械学習ゼミに6年間通学
殆どの統計モデルを開発
(判別木 SVM DeepLearning ベイジアンネット 等)
ロボット技術習得のため産業技術大学院に入学
米国の機械学習の莫大な論文量に呆然としている
日米のAI関係の投資額は1000倍差がある
(2015年 米国5.7兆円 日本政府投資額64億円)

Science And Technology
機械学習の進展
2000年頃までは古典的な頻度統計があったデータが貴重で計算機のパワーも小さい
2000年以降ベイズ統計が発展する豊富なデータと計算機パワーで隠れ変数を暴く
DeepLearningの特徴量抽出能力が認識されるHintonの教師なしDeepLearningが再認識させる
強化学習+DeepLearningのAlpha碁が出現DeepMind社が状況認識と最適行動を合体する(DQNモデル)
粒子フィルター+強化学習による自動運転が実現Thurnの確率ロボテックス技術
Freeの機械学習ソフトによって他分野の参入が容易Pythonは全ての言語の長所を取り込む

Science And Technology
趣旨Alpha碁はDQN(DeepQlearningNet)を採用している
DQNは画像から特徴量を抽出して、特徴量で強化学習する
DeepLearningで特徴量抽出 Qlearningで強化学習
sarsa(λ)モデルは特徴量による強化学習(DQNの後半)
(例)特徴量:重回帰では変数のこと 学習:重みの最適化
特徴量による強化学習モデルの汎用性を示す問題に関わらずゴールと特徴量と行動の定義だけで、最適な行動を学習させることができる
Science And Technology
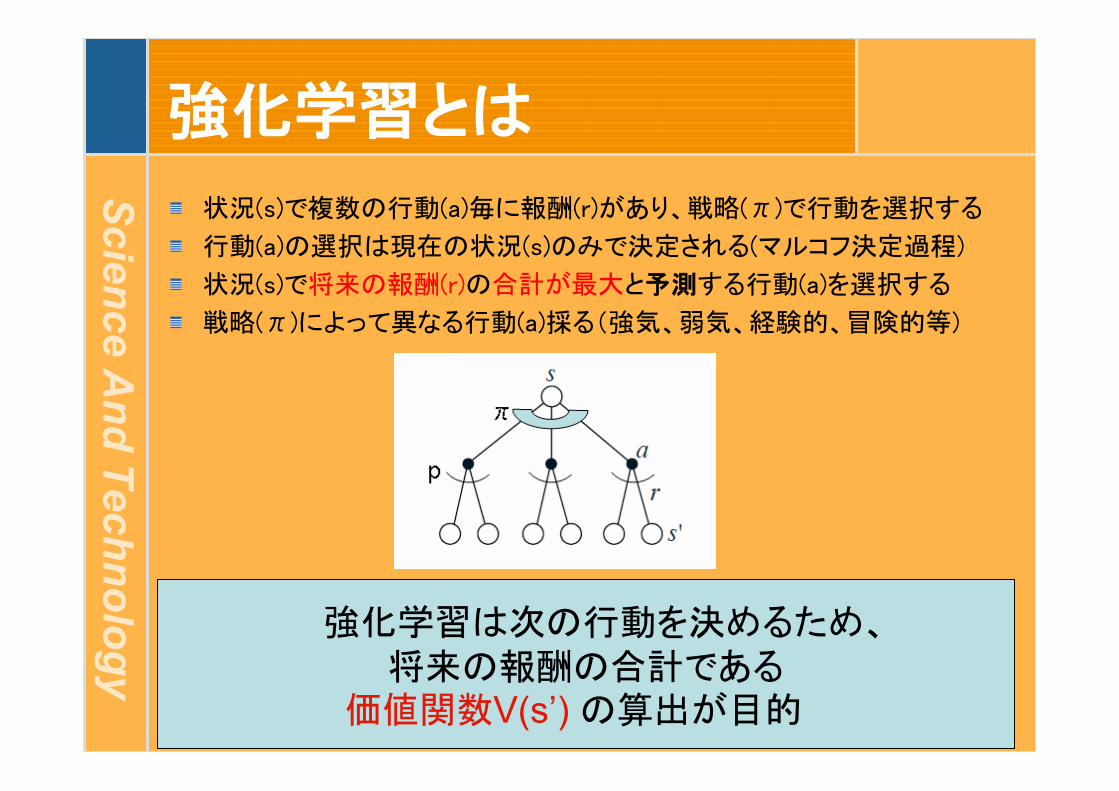
強化学習とは
状況(s)で複数の行動(a)毎に報酬(r)があり、戦略(π)で行動を選択する
行動(a)の選択は現在の状況(s)のみで決定される(マルコフ決定過程)
状況(s)で将来の報酬(r)の合計が最大と予測する行動(a)を選択する
戦略(π)によって異なる行動(a)採る(強気、弱気、経験的、冒険的等)
強化学習は次の行動を決めるため、将来の報酬の合計である
価値関数V(s’) の算出が目的

Science And Technology
脳と強化学習の類似
大脳パターン認識
画像
小脳行動伝達
大脳基底核強化学習
報酬:ドーパミン
目
大脳基底核の脳波と強化学習の価値関数のプロット図が同形を示す
銅谷賢治

Science And Technology
価値関数V の算出方法
将来の状況と行動の分岐を繰返し展開して末端からBackUpして関数を算出する(rollout)
将来価値にγ:減少率があるので無限に展開しなくて良い(n期先まで展開)。
動的計画法 (遷移を定常になるまで繰返し)
モンテカルロ法 (ランダムに経路を辿り出現確率で計算)
TD(λ)法 (V関数の重みをTD誤差で計算)
Sarsa(λ)法 (V関数の重みをSDGで計算)
ニューロ法 (V関数をニューロで汎用化)
DQN (DeepLearningで特徴量を抽出して計算)

Science And Technology
特徴量で価値関数を近似
価値関数Vを線形関数で近似 (Sarsaλ法)
Vθ(S)=θ1*特徴量1(S)+・・+θn*特徴量n(S)
特徴量1(S)~特徴量n(S)は状況Sを表現する
例)碁:盤の局面 特徴量は石の配置
行動の選択子がa1~amで、その結果の状態S1
~Sm の時、Vθ(S1)~Vθ(Sm)の最大となる行動を選択する。(戦略πによっては常に採らない)
重みΘは行動を多数回繰返す度、その結果より更新され改善される。
実現報酬Zと近似Vθとの差で更新

Science And Technology
特徴量による価値関数近似sarsa(λ) プログラム
C言語で90行で実現
方策πで行動選択
状況を更新
重みを更新
実際の報酬との差
重み改善幅

Science And Technology
強化学習の汎用化
問題毎に特徴量のみ設定する局面毎に報酬を設定しなくてよい目標や障害との位置によって適切な報酬を決めるのは困難
下記のみ設定すれば汎用的に解ける①行動の設定②特徴量の設定③行動後の特徴量の変化④初期条件⑤終了条件

Science And Technology
(例1)馬力不足の車の登り学習
馬力不足の車があり坂を登れない。後退、前進を繰返して下降時の加速度を利用して坂登りを学習します
汎用プラットホームに設定する値
① 行動 前進 後進 自由降下
③ 行動後の特徴量 前進:P=P+V 後進:P=P-V V=C1-sin(P*C2)
④ 初期条件 出発点
② 特徴量 位置P 速度V
⑤ 終了条件 終点に達する

Science And Technology
(例1)馬力不足の車の登り学習
最初は4000回で達するが最後は3回の操作で登る
Science And Technology
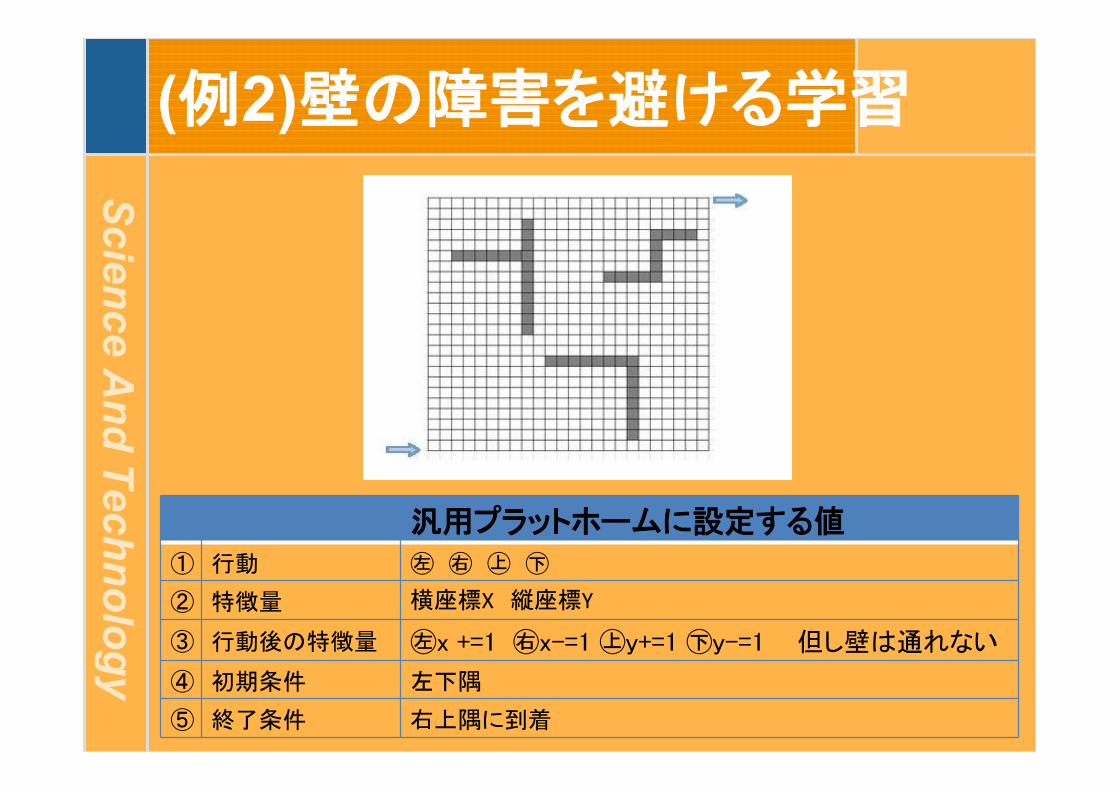
(例2)壁の障害を避ける学習
汎用プラットホームに設定する値
① 行動 ㊧ ㊨ ㊤ ㊦
③ 行動後の特徴量 ㊧x +=1 ㊨x-=1 ㊤y+=1 ㊦y-=1 但し壁は通れない
④ 初期条件 左下隅
② 特徴量 横座標X 縦座標Y
⑤ 終了条件 右上隅に到着

Science And Technology
(例2)壁の障害を避ける学習
最初は7000回かかるが最後は60回で出口に達する

Science And Technology
まとめ
強化学習sarsa(λ)の特徴量近似モデルは全く別の問題を特徴量の指定のみによって汎用的に解けることを示した逆に適切な特徴量の指定が大事
DQN=DeepLearning(特徴量抽出)+強化学習
ゲーム作成ソフトUnityとDQNで強いキャラクターを作る試みがあるDeepLearningや強化学習ツールは簡単に手に入る今や理論の問題では無く、どの分野に応用すると面白いかのデザイナー志向の時代逆にデザイナーの要求を応えるため理論が進展すると考えるべき皆で面白いモデルを試作し合って1000倍投資額が違う米国を見返そう

Science And Technology
参考文献
Mastering the Game of Go with Deep Neural Network and Tree Seach DeepMind
Playing Atari with Deep Reinforcement Learning DeepMind
Reinforcement Learning Sutton
心の分子機構への計算理論的アプローチ 銅谷 賢治
Probablistic Robtics Thurn
Maximum Entropy Deep Inverse Reinforcement Learning ICPR2014
Inverse Reinforcement Learning with Locally Consistent Reward Functions NIPS2015