alignment to a database - biostatistics - departments - … · · 2017-10-281990 basic local...
TRANSCRIPT
Alignment to a database
November 3, 2016

How do you create a database?
1982 GenBank (at LANL, 2000 sequences)1988 A way to search GenBank (FASTA)
Genome Project
1982 GenBank (at LANL, 2000 sequences)1988 A way to search GenBank (FASTA)
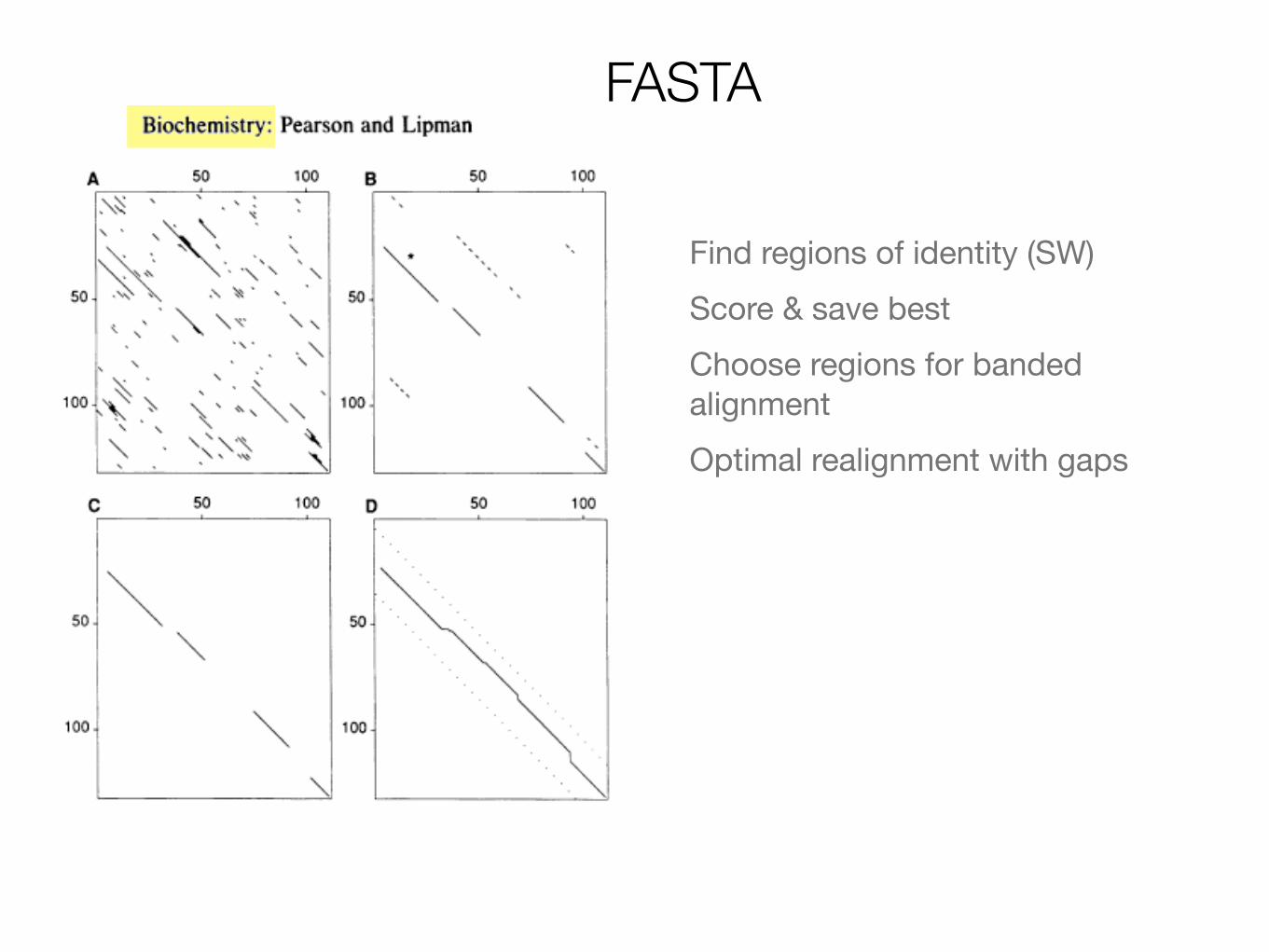
FASTA
Find regions of identity (SW)Score & save bestChoose regions for banded alignmentOptimal realignment with gaps
FASTA
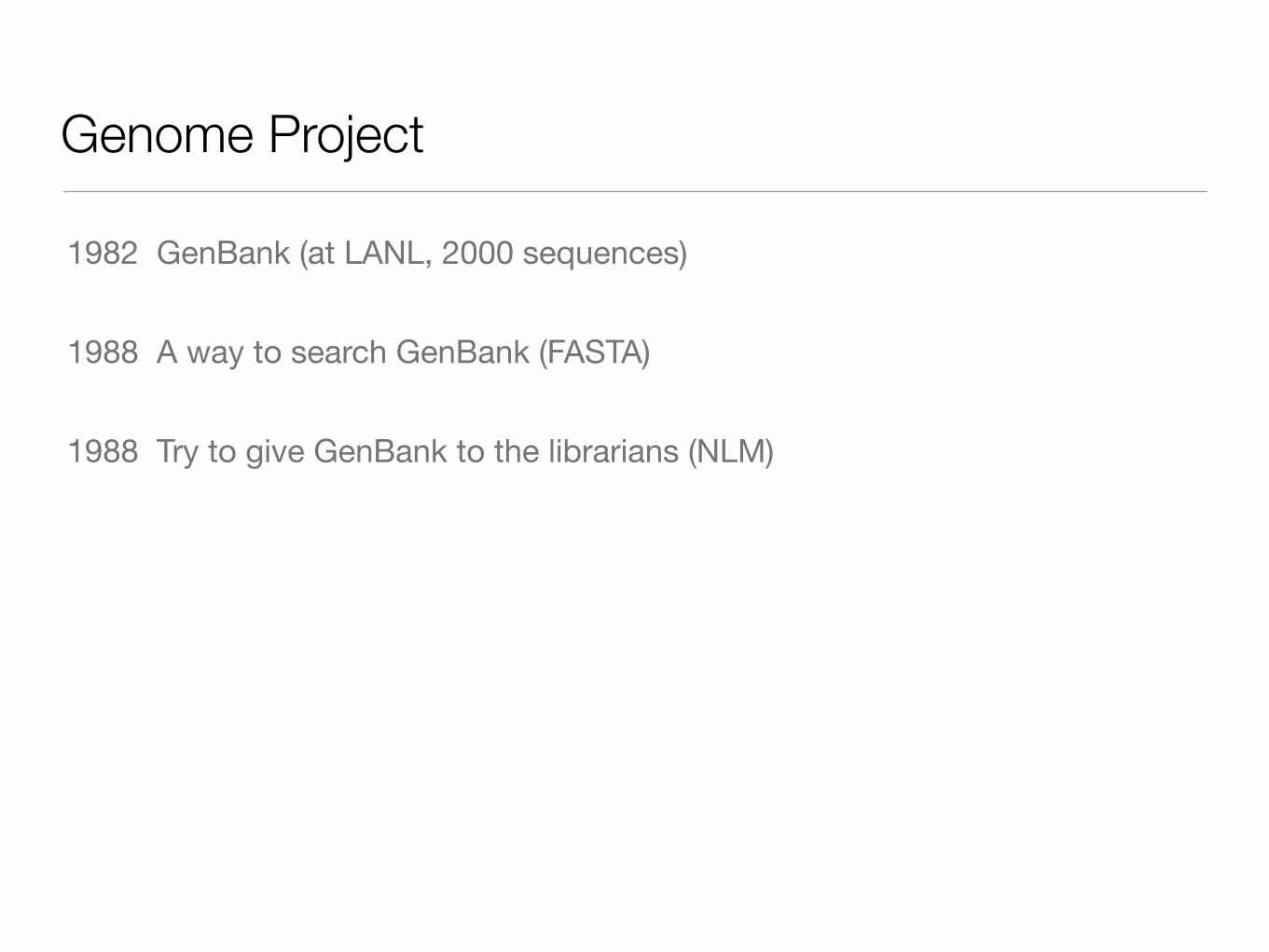
Genome Project
1982 GenBank (at LANL, 2000 sequences)
1988 A way to search GenBank (FASTA)
1988 Try to give GenBank to the librarians (NLM)

Genome Project
1982 GenBank (at LANL, 2000 sequences)
1988 A way to search GenBank (FASTA)
1988 Try to give GenBank to the librarians (NLM)
1990 NCBI established
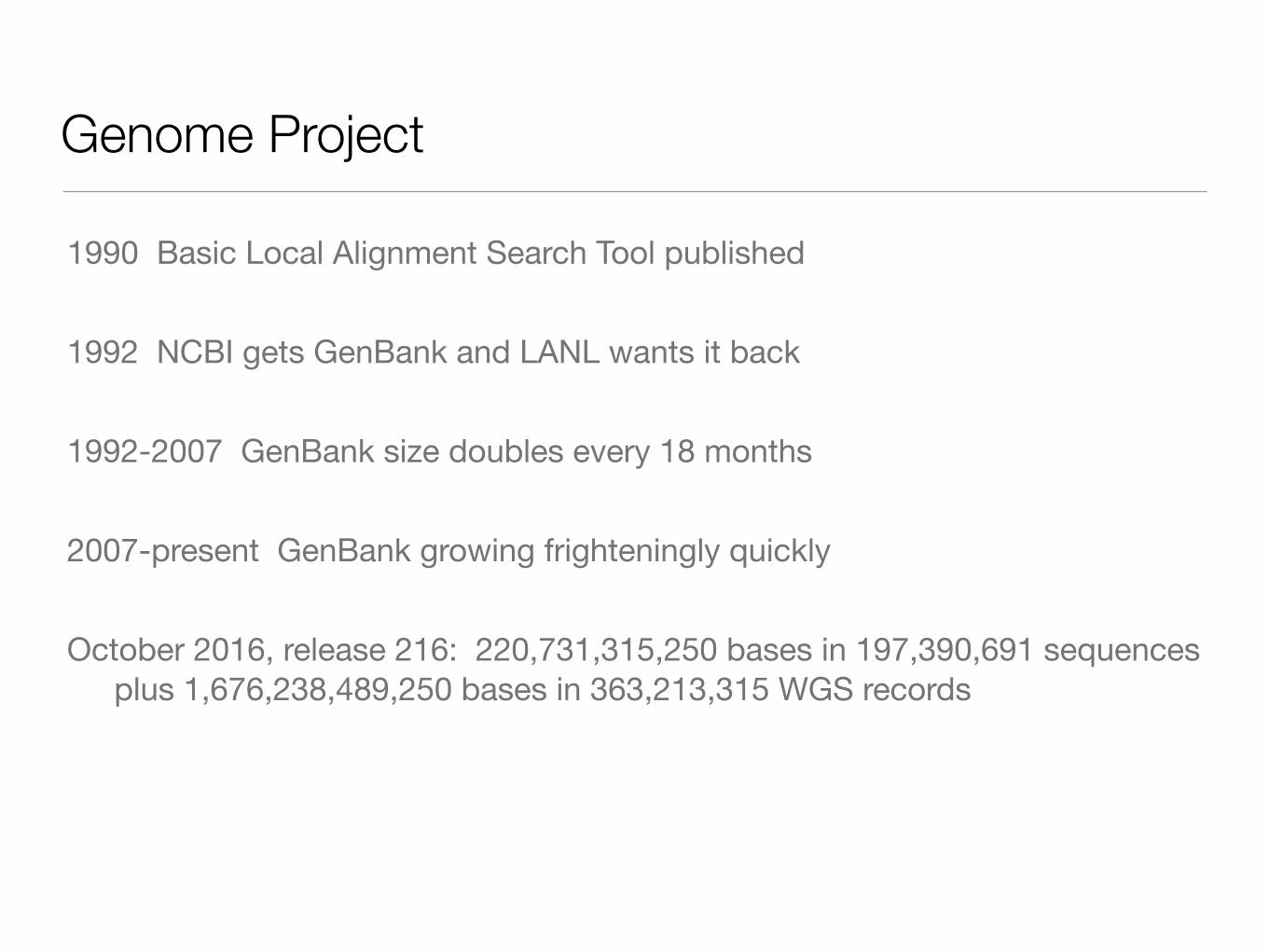
Genome Project
1990 Basic Local Alignment Search Tool published
1992 NCBI gets GenBank and LANL wants it back
1992-2007 GenBank size doubles every 18 months
2007-present GenBank growing frighteningly quickly
October 2016, release 216: 220,731,315,250 bases in 197,390,691 sequences plus 1,676,238,489,250 bases in 363,213,315 WGS records

Why align to a database?
• Align unknown sequence to annotated genome to discover function
• Search RNA and EST databases to see if sequence is expressed
• mRNA-to-genomic alignment for gene and isoform structure
• Search for unexpected conservation between sequences

BLAST — Basic Local Alignment and Search Tool
• Rapid comparison of a query sequence against a database of nucleotide or protein sequences
• Why not use dynamic programming? it’s guaranteed to find the optimal answer!
• Takes waaaaaay too long and requires too much memory on even a moderately-sized database
• BLAST is an efficient and effective alternative to dynamic programming.

BLAST
How does it work?
looks for small, high-scoring sequence matches to an indexed database
extends the matches when it finds them, to create longer high-scoring matches
alignment scores based on PAM/BLOSUM or gap/match/mismatch

BLAST — how does it really work?
Begin with a matrix of similarity scores for all possible residues, compile list of high-scoring words in the queryScan the indexed database for exact word hits (word length is a parameter)
ACTTGTGAACAT
TGTGAAC|||||||
TAGGCTTGTGAACAGT
query
CTTGTGA
wordsACTTGTG
TTGTGAA
TGTGAAC
TGAACAT
GTGAACA
database match

extend the match to create a maximal scoring pair (MSP)stop extending when the score drops below a threshold; trim backward to get maximal score
BLAST — how does it really work?
TAGGCTTGTGAACAGTTAGGCTTGTGAACAGT
ACTTGTGAACAT |||||||
ACTTGTGAACAT ||||||||
TAGGCTTGTGAACAGT
ACTTGTGAACAT ||||||||||
scoring: match +1, mismatch -1
7
TAGGCTTGTGAACAGT
ACTTGTGAACAT ||||||||||
10
8
9

BLAST — how does it really work?
BLAST avoids low-complexity regions tabulates all k-tuples in the database DNA (k is usually around 8) and filters those that occur more frequently than some parameter
BLAST has a “mask at hash” option that allows you to extend through the filtered regionsLater versions of BLAST require two neighboring word hits to extend -> reduces # extensions sevenfold
CAGCCTCTTACCAGCTTAGCTACAGTTGATTTCTCGGTCAGGCTCTTACCAGCTCAGGCTATTATTAGCTTAGCTACAGTAGATTTCTCGGTCAGGCTGGTACCATCT

Choice of parameters
Time required = time to compile list of words + time to scan database + time to extend all hitsYou can modify both the wordsize and the thresholdIncreased wordsize = fewer hits, but greater number of wordsInitial word score threshold T will pare down the number of hits to be extended

BLAST — statistics
Karlin-Altschul statistics
We don’t know what the a priori score distribution looks like.
In fact, we’re looking for the maximum of a bunch of independently and identically distributed variables, which is more like an extreme value distribution.

BLAST — statistics
Karlin-Altschul statistics The expected number of HSPs with score at least S is:
This is the E-value for the score S. K and λ are the Karlin-Altschul parameters.
m and n are the lengths of the sequences

BLAST — statistics
x
prob
abili
ty
extreme value
distribution
normal distribution
0 1 2 3 4 5-1-2-3-4-5
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0

Gapped BLAST
We have talked about ungapped BLAST so far. The statistics for gapped BLAST are trickier and they are not mathematically complete.affine gapped BLAST score = #matches*match score + #mismatches*mismatch penalty + #gaps*gap opening penalty + total gap length*extension penalty
Things to consider when choosing a gap penalty:• Both the opening (g) and extension (r) penalties should be nonzero• g + r should be greater than the max score for a match if you want gaps to
be rarer than substitutions
ACTTGTGCATT || | || || ACAT-TG--TT

PSI-BLAST: Position-specific iterated BLAST
Database search with queryLook to see if newest hits are significantly related to query
If yes, repeat #1 and 2If no, finish
Creates a PSSM (position-specific scoring matrix)

PSI-BLAST and PSSMs
PSSMGapless alignment matrixAdd pseudocounts to avoid “tuning” to most closely related sequencesAlign to database with very high gap penaltiesGenerally use dynamic programming to align

PSI-BLAST and PSSMs
PSI-BLAST performs well compared to other motif-finding programsMore sensitive to weak but biologically relevant similaritiesCan use resulting PSSMs to score other alignments or in PHI-BLAST, rpsBLAST (finding conserved domains) etc.
PSI-BLAST
PSI-BLAST
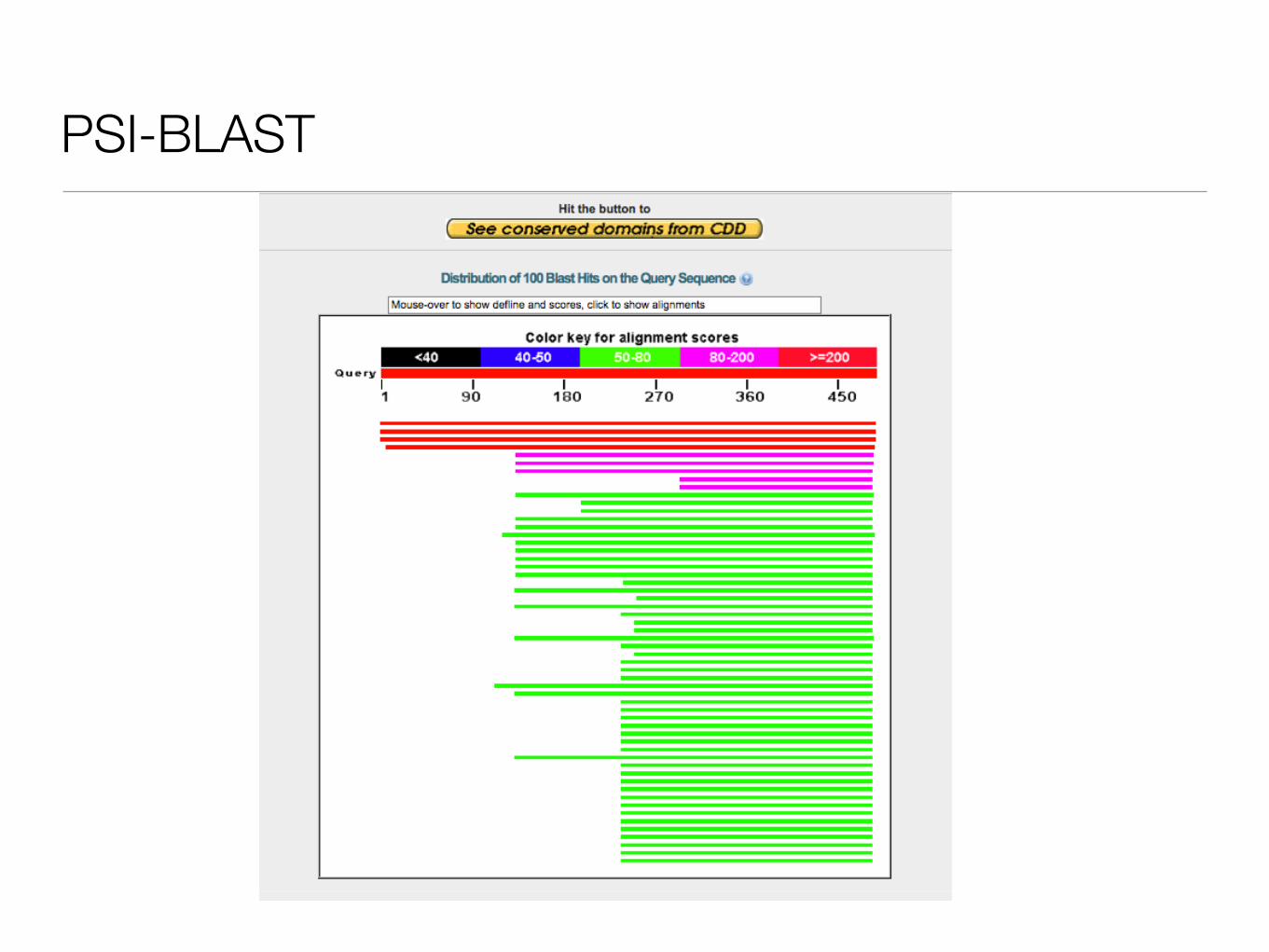
PSI-BLAST

PSI-BLAST
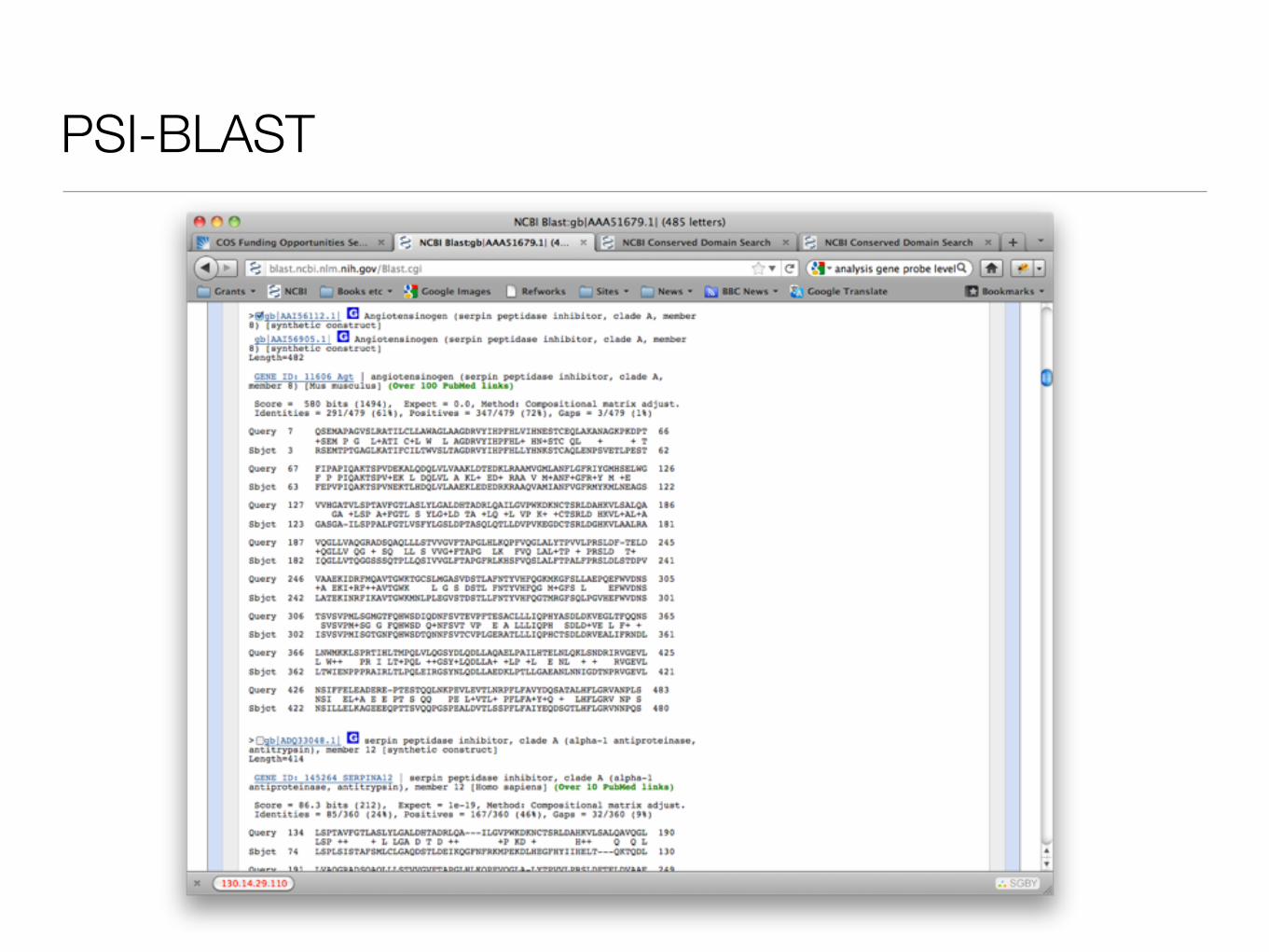
PSI-BLAST
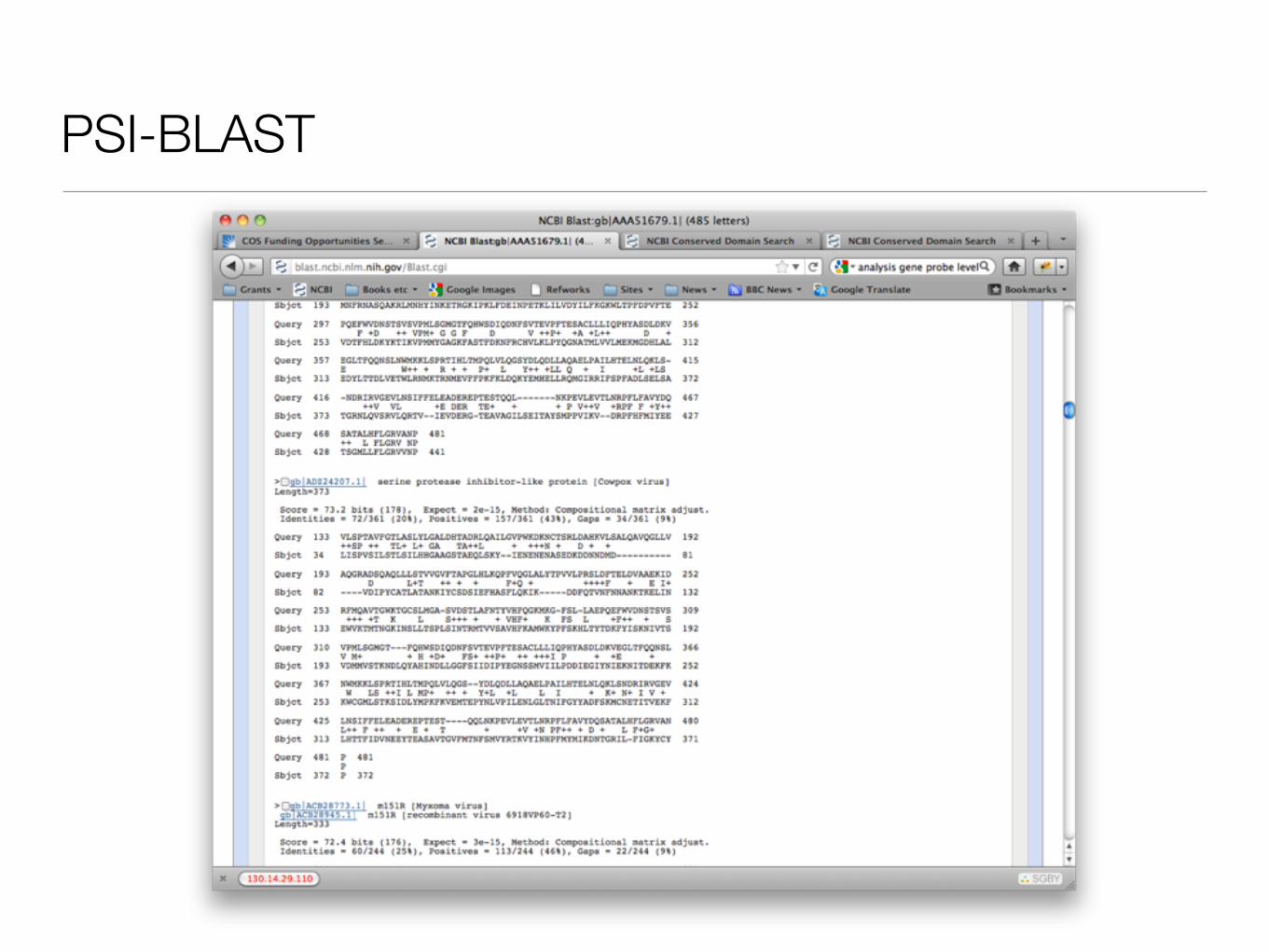
PSI-BLAST
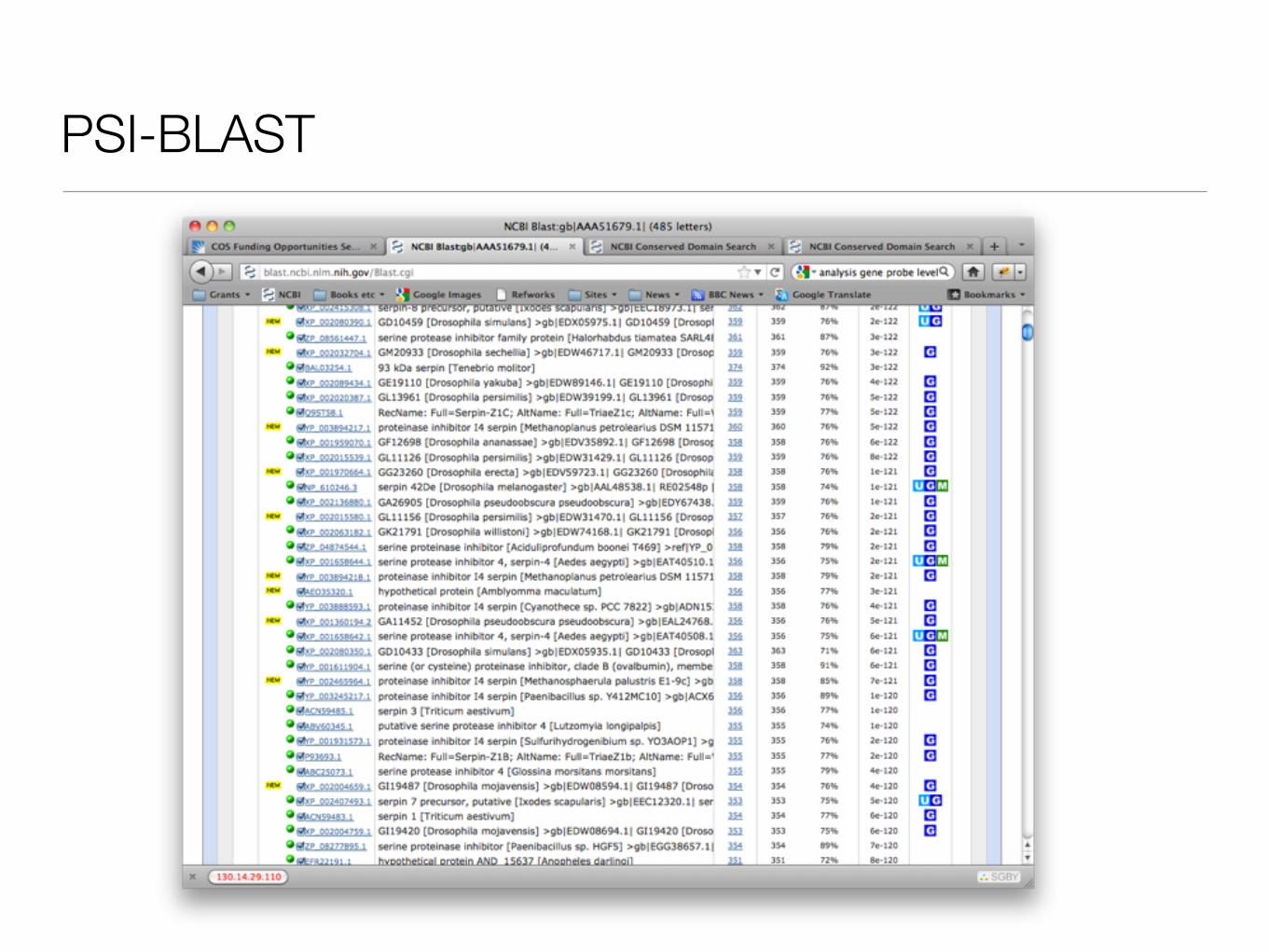
PSI-BLAST
PSI-BLAST
PSI-BLAST
PSI-BLAST

PHI-BLAST: Pattern hit initiated BLAST
Investigator supplies a complex pattern to be searched against the database of interestCan use PSSMs created by PSI-BLASTVery sensitiveVery fast

BLAT
Designed to find DNA sequences 30+ bp long and > 95% identity, or protein sequences greater than 80% similarity over 20 amino acids or more
DNA searches best between primates, protein among land vertebratesKeeps index of all non-overlapping 11mers of entire genome in memory (not repeats though)
Takes up < 1GB RAMDNA wordsize 11, protein 4Written by Jim Kent, free.
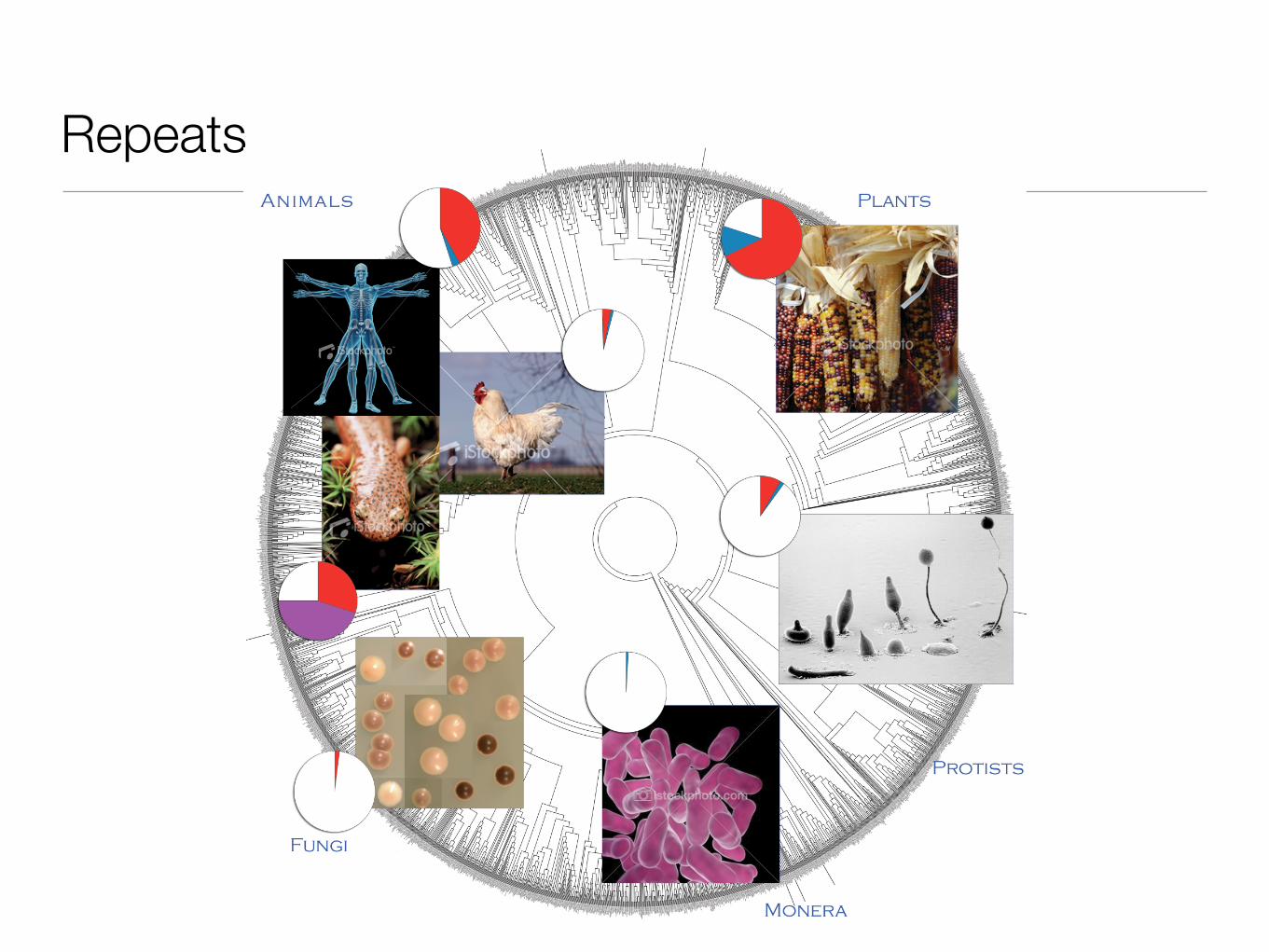
Repeats

The repeat problem
Genomes, especially those of vertebrates (not pufferfish though) and plants, are highly repetitive
• Transposons (DNA and retrotransposons)• Simple sequence, centromeres, telomeres• Other semicomplex repeats of uncertain purpose
If a large sequence is searched against a repeat-laden database, you’ll just get the repeatsSolution: pre-mask known repeats -- is this a good idea?

>sequence1gcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgc ggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcg tgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggc tgctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtg ccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaa agtaggacaggtgccggcagcgctctgggtcattttcggcgaggaccgctttcgctggag atcggcctgtcgcttgcggtattcggaatcttgcacgccctcgctcaagccttcgtcact ccaaacgtttcggcgagaagcaggccattatcgccggcatggcggccgacgcgctgggct ggcgttcgcgacgcgaggctggatggccttccccattatgattcttctcgcttccggcgg cccgcgttgcaggccatgctgtccaggcaggtagatgacgaccatcagggacagcttcaa cggctcttaccagcctaacttcgatcactggaccgctgatcgtcacggcgatttatgccg caagtcagaggtggcgaaacccgacaaggactataaagataccaggcgtttcccctggaa gcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcggg ctttctcattgctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctg acgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtcca acacgacttaacgggttggcatggattgtaggcgccgccctataccttgtctgcctcccc gcggtgcatggagccgggccacctcgacctgaatggaagccggcggcacctcgctaacgg ccaagaattggagccaatcaattcttgcggagaactgtgaatgcgcaaaccaacccttgg ccatcgcgtccgccatctccagcagccgcacgcggcgcatctcgggcagcgttgggtcct gcgcatgatcgtgctagcctgtcgttgaggacccggctaggctggcggggttgccttact atgaatcaccgatacgcgagcgaacgtgaagcgactgctgctgcaaaacgtctgcgacct atgaatggtcttcggtttccgtgtttcgtaaagtctggaaacgcggaagtcagcgccctg


>sequence2gaattccggaagcgagcaagagataagtcctggcatcagatacagttggagataaggacg gacgtgtggcagctcccgcagaggattcactggaagtgcattacctatcccatgggagcc atggagttcgtggcgctgggggggccggatgcgggctcccccactccgttccctgatgaa gccggagccttcctggggctgggggggggcgagaggacggaggcgggggggctgctggcc tcctaccccccctcaggccgcgtgtccctggtgccgtgggcagacacgggtactttgggg accccccagtgggtgccgcccgccacccaaatggagcccccccactacctggagctgctg caacccccccggggcagccccccccatccctcctccgggcccctactgccactcagcagc gggcccccaccctgcgaggcccgtgagtgcgtcatggccaggaagaactgcggagcgacg gcaacgccgctgtggcgccgggacggcaccgggcattacctgtgcaactgggcctcagcc tgcgggctctaccaccgcctcaacggccagaaccgcccgctcatccgccccaaaaagcgc ctgcgggtgagtaagcgcgcaggcacagtgtgcagccacgagcgtgaaaactgccagaca tccaccaccactctgtggcgtcgcagccccatgggggaccccgtctgcaacaacattcac gcctgcggcctctactacaaactgcaccaagtgaaccgccccctcacgatgcgcaaagac ggaatccaaacccgaaaccgcaaagtttcctccaagggtaaaaagcggcgccccccgggg gggggaaacccctccgccaccgcgggagggggcgctcctatggggggagggggggacccc tctatgccccccccgccgccccccccggccgccgccccccctcaaagcgacgctctgtac gctctcggccccgtggtcctttcgggccattttctgccctttggaaactccggagggttt tttggggggggggcggggggttacacggcccccccggggctgagcccgcagatttaaata ataactctgacgtgggcaagtgggccttgctgagaagacagtgtaacataataatttgca cctcggcaattgcagagggtcgatctccactttggacacaacagggctactcggtaggac cagataagcactttgctccctggactgaaaaagaaaggatttatctgtttgcttcttgct gacaaatccctgtgaaaggtaaaagtcggacacagcaatcgattatttctcgcctgtgtg aaattactgtgaatattgtaaatatatatatatatatatatatatctgtatagaacagcc tcggaggcggcatggacccagcgtagatcatgctggatttgtactgccggaattc