announcements project proposal is due on 03/11 three seminars this friday (eb 3105) dealing with...
Post on 20-Dec-2015
214 views
TRANSCRIPT

Announcements Project proposal is due on 03/11 Three seminars this Friday (EB 3105)
Dealing with Indefinite Representations in Pattern Recognition (10:00 am - 11:00 am)
Computational Analysis of Drosophila Gene Expression Pattern Image (11:00 am - 12:00 pm)
3D General Lesion Segmentation in CT (3:00 pm - 4:00 pm)

Hierarchical Mixture Expert Model
Rong Jin

Good Things about Decision Trees Decision trees introduce nonlinearity through the tree
structure Viewing A^B^C as A*B*C Compared to kernel methods
Less adhoc Easy understanding

Example
Kernel method
x=0
x=0
x=0
Generalized Tree
+ +
In general, mixture model is powerful in fitting complex decision boundary, for instance, stacking, boosting, bagging

Generalize Decision Trees
From slides of Andrew Moore
Each node of decision tree only depends on a single feature.
Is this the best idea?

Partition Datasets The goal of each node is to partition the data set into disjoint
subsets such that each subset is easier to classify.
OriginalDataset
Partition by a single attribute
cylinders = 4
cylinders = 5
cylinders = 6
cylinders = 8

Partition Datasets (cont’d) More complicated partitions
OriginalDataset
Partition by multiple attributes Other cases
Cylinders< 6 and Weight > 4
ton
Cylinders 6 and Weight < 3
ton
How to accomplish such a complicated partition?
Each partition a class Partition a dataset into disjoint subsets Classify a
dataset into multiple classes
Using a classification model for each node

A More General Decision Tree
+ +
a decision tree with simple data partition
+
a decision tree using classifiers for data partition
+
Each node is a linear classifier
Attribute 1
Attribute 2
classifier

General Schemes for Decision Trees Each node within the tree is a linear classifier Pro:
Usually result in shallow trees Introducing nonlinearity into linear classifiers (e.g. logistic
regression) Overcoming overfitting issues through the regularization mechanism
within the classifier. Partition datasets with soft memberships A better way to deal with real-value attributes
Example: Neural network Hierarchical Mixture Expert Model
+

Hierarchical Mixture Expert Model (HME)
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
Classifier
Determines the class for input x
, ( ) : 1, 1di jm x
Router
Decides which classifier should x be route to
( ) : 1, 1
( ) : 1, 1
d
di
r x
g x
x
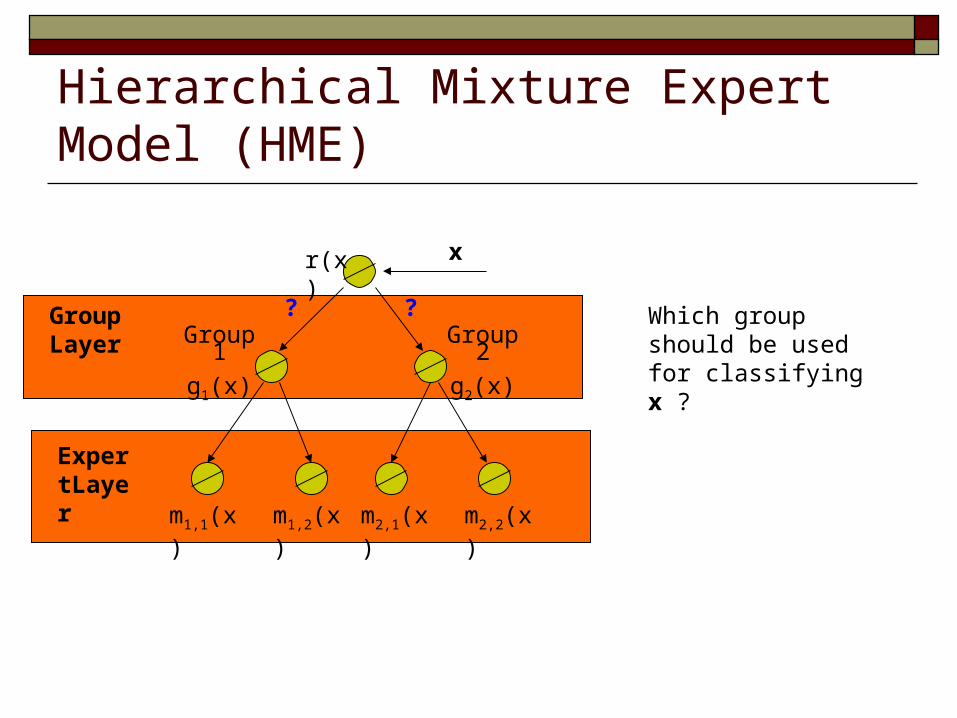
Hierarchical Mixture Expert Model (HME)
x
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
Which group should be used for classifying x ?
? ?

Hierarchical Mixture Expert Model (HME)
x
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
r(x) = +1
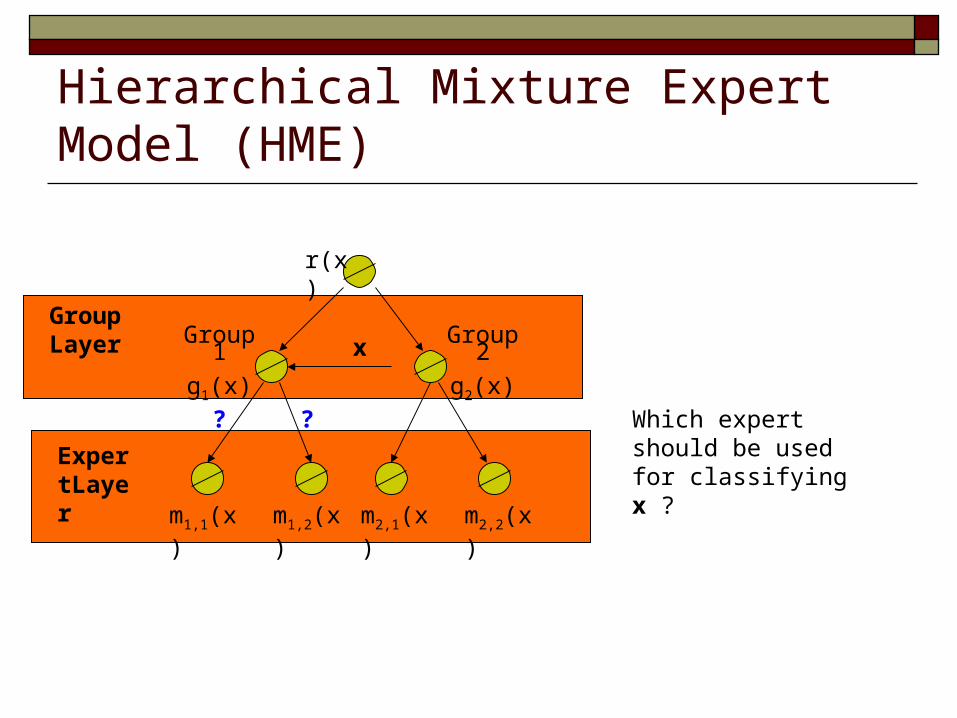
Hierarchical Mixture Expert Model (HME)
xGroup 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
Which expert should be used for classifying x ?
? ?

Hierarchical Mixture Expert Model (HME)
xGroup 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
g1(x) = -1

Hierarchical Mixture Expert Model (HME)
x
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x) m1,2(x) =+1
The class label for +1

Hierarchical Mixture Expert Model (HME)
x
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
Which group should be used for classifying x ?
? ?
More Complicated Case

Hierarchical Mixture Expert Model (HME)
x
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
r(+1|x) = ¾, r(-1|x) = ¼
More Complicated Case

Hierarchical Mixture Expert Model (HME)
x
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
x
Which expert should be used for classifying x ?
? ? ? ?
r(+1|x) = ¾, r(-1|x) = ¼
More Complicated Case

Hierarchical Mixture Expert Model (HME)
xGroup 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
g1(+1|x) = ¼, g1(-1|x) = ¾
g2(+1|x) = ½ , g2(-1|x) = ½
r(+1|x) = ¾, r(-1|x) = ¼
+1 -1
m1,1(x) ¼ ¾
m1,2(x) ¾ ¼
m2,1(x) ¼ ¾
m2,2(x) ¾ ¼
More Complicated Case
x
How to compute the probability p(+1|x) and p(-1|x)?

HME: Probabilistic Description
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
Random variable g = {1, 2}
r(+1|x)=p(g = 1|x), r(-1|x)=p(g = 2|x)
Random variable m = {11, 12, 21, 22}g1(+1|x) = p(m=11|x, g=1), g1(-1|x) = p(m=12|x, g=1)g2(+1|x) =p(m=21|x, g=2)g2(-1|x) =p(m=22|x, g=2)
( 1 | ) ( , , 1 | )g m
p x p g m x

HME: Probabilistic Description
g1(+1|x) = ¼, g1(-1|x) = ¾
g2(+1|x) = ½ , g2(-1|x) = ½
r(+1|x) = ¾, r(-1|x) = ¼
+1 -1
m1,1(x) ¼ ¾
m1,2(x) ¾ ¼
m2,1(x) ¼ ¾
m2,2(x) ¾ ¼
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
Compute P(+1|x) and P(-1|x)

HME: Probabilistic Description
g1(+1|x) = ¼, g1(-1|x) = ¾
g2(+1|x) = ½ , g2(-1|x) = ½
r(+1|x) = ¾, r(-1|x) = ¼
+1 -1
m1,1(x) ¼ ¾
m1,2(x) ¾ ¼
m2,1(x) ¼ ¾
m2,2(x) ¾ ¼
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
{1,2} {11,12,21,22} {1,2} {11,12,21,22}
1 11 2 21
1 12 2 22
( | ) ( , , | ) ( | ) ( | , ) ( | , )
( 1 | ) ( | ) ( 1 | ) ( | )( 1 | ) ( 1 | )
( 1 | ) ( | ) ( 1 | ) ( | )
g m g m
p y x p y g m x p g x p m g x p y m x
g x m y x g x m y xr x r x
g x m y x g x m y x

HME: Probabilistic Description
g1(+1|x) = ¼, g1(-1|x) = ¾
g2(+1|x) = ½ , g2(-1|x) = ½
r(+1|x) = ¾, r(-1|x) = ¼
+1 -1
m1,1(x) ¼ ¾
m1,2(x) ¾ ¼
m2,1(x) ¼ ¾
m2,2(x) ¾ ¼
( 1, 11, 1 | )
( 1 | ) ( 11 | 1, ) ( 1 | , 11)
3/ 4*1/ 4*1/ 4 3/ 64
( 1, 12, 1 | )
( 1 | ) ( 12 | 1, ) ( 1 | , 12)
3/ 4*3/ 4*3/ 4 27 / 64
( 2, 21, 1 | )
( 2 | ) ( 21| 1, ) ( 1 | , 21)
1/ 4*1/ 2*1/ 4 2 /
p g m x
p g x p m g x p x m
p g m x
p g x p m g x p x m
p g m x
p g x p m g x p x m
64
( 2, 22, 1 | )
( 2 | ) ( 22 | 1, ) ( 1 | , 22)
1/ 4*1/ 2*3/ 4 6 / 64
( 1| ) 3 / 64 27 / 64 2 / 64 6 / 64 19 / 32
( 1| ) 13/ 32
p g m x
p g x p m g x p x m
p x
p x

Hierarchical Mixture Expert Model (HME)
r(x)
x
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
1 11 2 21
1 12 2 22
( 1| ) ( | ) ( 1| ) ( | )( | ) ( 1| ) ( 1| )
( 1| ) ( | ) ( 1| ) ( | )
g x m y x g x m y xp y x r x r x
g x m y x g x m y x
y
Is HME more powerful than a simple majority vote approach?

Problem with Training HME Using logistic regression to model r(x), g(x), and m(x) No training examples r(x), g(x)
For each training example (x, y), we don’t know its group ID or expert ID.
can’t apply training procedure of logistic regression model to train r(x) and g(x) directly.
Random variables g, m are called hidden variables since they are not exposed in the training data.
How to train a model with incomplete data?

Start with Random Guess …
xg1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
g2(x)
m1,2(x) m2,1(x) m2,2(x)
+: {1, 2, 3, 4, 5}
: {6, 7, 8, 9}
Iteration 1: random guess:
• Randomly assign points to groups and experts

Start with Random Guess …
xg1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
g2(x)
m1,2(x) m2,1(x) m2,2(x)
+: {1, 2, 3, 4, 5}
: {6, 7, 8, 9}
Iteration 1: random guess:
• Randomly assign points to groups and experts
{1,2,} {6,7} {3,4,5} {8,9}
{1}{6} {2}{7} {3}{9} {5,4}{8}

Start with Random Guess …
xg1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
g2(x)
m1,2(x) m2,1(x) m2,2(x)
+: {1, 2, 3, 4, 5}
: {6, 7, 8, 9}
Iteration 1: random guess:
• Randomly assign points to groups and experts
• Learn r(x), g1(x), g2(x), m11(x), m12(x), m21(x), m22(x)
{1,2,} {6,7} {3,4,5} {8,9}
{1}{6} {2}{7} {3}{9} {5,4}{8}
Now, what should we do?

Refine HME Model
xg1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
g2(x)
m1,2(x) m2,1(x) m2,2(x)
+: {1, 2, 3, 4, 5}
: {6, 7, 8, 9}
Iteration 2: regroup data points
• Reassign the group membership to each data point
• Reassign the expert membership to each expert
{1,5} {6,7} {2,3,4} {8,9}
But, how?

Determine Group Memberships
g1(+1|x) = ¼, g1(-1|x) = ¾
g2(+1|x) = ½ , g2(-1|x) = ½
r(+1|x) = ¾, r(-1|x) = ¼
+1 -1
m1,1(x) ¼ ¾
m1,2(x) ¾ ¼
m2,1(x) ¼ ¾
m2,2(x) ¾ ¼
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
x
Consider an example (x, +1)
( 1 | , 1)p g x y
Compute the posterior on your own sheet !

Determine Group Memberships
g1(+1|x) = ¼, g1(-1|x) = ¾
g2(+1|x) = ½ , g2(-1|x) = ½
r(+1|x) = ¾, r(-1|x) = ¼
+1 -1
m1,1(x) ¼ ¾
m1,2(x) ¾ ¼
m2,1(x) ¼ ¾
m2,2(x) ¾ ¼
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
x
Consider an example (x, +1)
( 1, 1 | )( 1 | , 1)
( 1 | )
( 1, 1 | )
( 1, 1 | ) ( 2, 1 | )
3 / 4 1/ 4*1/ 4 3/ 4*3/ 4
3/ 4 1/ 4*1/ 4 3/ 4*3/ 4 1/ 4 1/ 2*1/ 4 1/ 2*3/ 4
15 /19
p g y xp g x y
p y x
p g y x
p g y x p g y x

Determine Expert Memberships
g1(+1|x) = ¼, g1(-1|x) = ¾
g2(+1|x) = ½ , g2(-1|x) = ½
r(+1|x) = ¾, r(-1|x) = ¼
+1 -1
m1,1(x) ¼ ¾
m1,2(x) ¾ ¼
m2,1(x) ¼ ¾
m2,2(x) ¾ ¼
Group 1
g1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
Group 2
g2(x)
m1,2(x) m2,1(x) m2,2(x)
x
Consider an example (x, +1)
( 11, 1, 1 | )( 11 | , 1, 1)
( 1, 1 | )
( 11, 1, 1 | )
( 11, 1, 1 | ) ( 12, 1, 1 | )
3 / 4*1/ 4*1/ 4
3/ 4 1/ 4*1/ 4 3/ 4*3/ 4
1/10
p m g y xp m x y g
p g y x
p m g y x
p m g y x p m g y x
( 11 | , 1) ( 11 | , 1, 1) ( 1 | , 1)p m x y p m x y g p g x y

Refine HME Model
xg1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
g2(x)
m1,2(x) m2,1(x) m2,2(x)
+: {1, 2, 3, 4, 5}
: {6, 7, 8, 9}
Iteration 2: regroup data points
• Reassign the group membership to each data point
• Reassign the expert membership to each expert
• Compute the posteriors p(g|x,y) and p(m|x,y,g) for each training example (x,y)
• Retrain r(x), g1(x), g2(x), m11(x), m12(x), m21(x), m22(x) using estimated posteriors
{1,5} {6,7} {2,3,4} {8,9}
But, how ?

Logistic Regression: Soft Memberships
Example: train r(x)
2
1 1
1( ) log
1 exp ( )N m
reg train ii ii i
l D s wy c x w
2
1 1
1 1ˆ ˆ( ) ( ) log ( ) log
1 exp ( ) 1 expN m
reg train i i ii ii i
l D p p s wc x w c x w
Soft memberships
21 1
1( 1| , ) log
1 exp ( )( )
1( 2 | , ) log
1 exp
i iiN m
reg train ii i
i ii
p g x yc x w
l D s w
p g x yc x w

Logistic Regression: Soft Memberships
Example: train m11(x)
2
1 1
1( ) log
1 exp ( )N m
reg train ii ii i
l D s wy c x w
2
1 1
1 1ˆ ˆ( ) ( ) log ( ) log
1 exp ( ) 1 expN m
reg train i i ii ii i
l D p p s wc x w c x w
Soft memberships
2
1 1
1( ) ( 11| , ) log
1 exp ( )
N mreg train i i ii i
i i
l D p m x y s wy c x w

Start with Random Guess …
xg1(x)
m1,1(x)
Group Layer
ExpertLayer
r(x)
g2(x)
m1,2(x) m2,1(x) m2,2(x)
+: {1, 2, 3, 4, 5}
: {6, 7, 8, 9}
Repeat the above procedure until it converges (it guarantees to converge a local minimum)
{1,5} {6,7} {2,3,4} {8,9}
{1}{6} {5}{7} {2,3}{9} {4}{8}
This is famous Expectation-Maximization Algorithm (EM) !
Iteration 2: regroup data points
• Reassign the group membership to each data point
• Reassign the expert membership to each expert
• Compute the posteriors p(g|x,y) and p(m|x,y,g) for each training example (x,y)
• Retrain r(x), g1(x), g2(x), m11(x), m12(x), m21(x), m22(x)

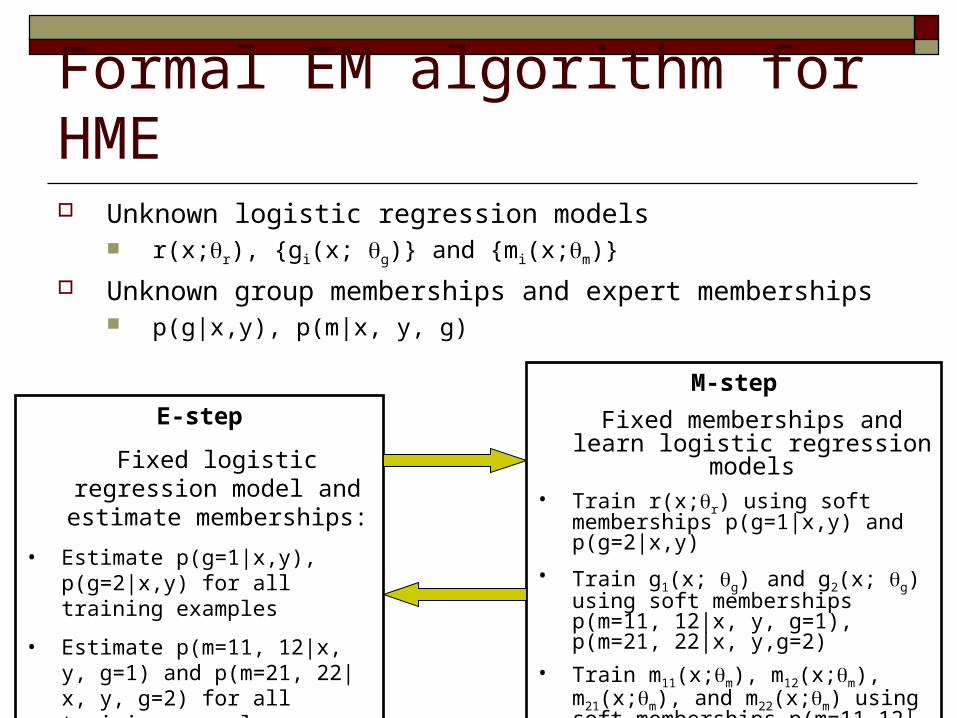
Formal EM algorithm for HME Unknown logistic regression models
r(x;r), {gi(x; g)} and {mi(x;m)}
Unknown group memberships and expert memberships p(g|x,y), p(m|x, y, g)
E-step
Fixed logistic regression model and estimate memberships:
• Estimate p(g=1|x,y), p(g=2|x,y) for all training examples
• Estimate p(m=11, 12|x, y, g=1) and p(m=21, 22|x, y, g=2) for all training examples
M-step
Fixed memberships and learn logistic regression models
• Train r(x;r) using soft memberships p(g=1|x,y) and p(g=2|x,y)
• Train g1(x; g) and g2(x; g) using soft memberships p(m=11, 12|x, y, g=1), p(m=21, 22|x, y,g=2)
• Train m11(x;m), m12(x;m), m21(x;m), and m22(x;m) using soft memberships p(m=11,12|x,y,g=1), p(m=21,22|x,y,g=2)
Formal EM algorithm for HME Unknown logistic regression models
r(x;r), {gi(x; g)} and {mi(x;m)}
Unknown group memberships and expert memberships p(g|x,y), p(m|x, y, g)
E-step
Fixed logistic regression model and estimate memberships:
• Estimate p(g=1|x,y), p(g=2|x,y) for all training examples
• Estimate p(m=11, 12|x, y, g=1) and p(m=21, 22|x, y, g=2) for all training examples
M-step
Fixed memberships and learn logistic regression models
• Train r(x;r) using soft memberships p(g=1|x,y) and p(g=2|x,y)
• Train g1(x; g) and g2(x; g) using soft memberships p(m=11, 12|x, y, g=1), p(m=21, 22|x, y,g=2)
• Train m11(x;m), m12(x;m), m21(x;m), and m22(x;m) using soft memberships p(m=11,12|x,y,g=1), p(m=21,22|x,y,g=2)

What are We Doing? What is the objective of doing Expectation-Maximization? It is still a simple maximum likelihood!
( | ) ( , , | ) ( | ) ( | , ) ( | , )g m g m
p y x p y g m x p g x p m x g p y x m
log ( | ) log ( | ) ( | , ) ( | , )i i i i i ii i g m
l p y x p g x p m x g p y x m
Expectation-Maximization algorithm actually tries to maximize the log-likelihood function Most time, it converges to local maximum, not a global one Improved version: annealing EM

Annealing EM
21 1
1( 1| , ) log
1 exp ( )( )
1( 2 | , ) log
1 exp ( )
i iiN m
reg train ii i
i ii
p g x yc x w
l D s w
p g x yc x w
( 1 | , )( 1 | , ) ( 1 | , )
( 1 | , ) ( 2 | , )
( 2 | , )( 2 | , ) ( 2 | , )
( 1 | , ) ( 2 | , )
bi i
i i i i b bi i i i
bi i
i i i i b bi i i i
p g x yp g x y p g x y
p g x y p g x y
p g x yp g x y p g x y
p g x y p g x y
21 1
1( 1| , ) log
1 exp ( )( )
1( 2 | , ) log
1 exp ( )
i iiN m
reg train ii i
i ii
p g x yc x w
l D s w
p g x yc x w

Improve HME It is sensitive to initial assignments
How can we reduce the risk of initial assignments? Binary tree K-way trees
Logistic regression conditional exponential model Tree structure
Can we determine the optimal tree structure for a given dataset?

Comparison of Classification Models The goal of classifier
Predicting class label y for an input x Estimate p(y|x)
Gaussian generative model p(y|x) ~ p(x|y) p(y): posterior = likelihood prior Difficulty in estimating p(x|y) if x comprises of multiple elements Naïve Bayes: p(x|y) ~ p(x1|y) p(x2|y)… p(xd|y)
Linear discriminative model Estimate p(y|x) Focusing on finding the decision boundary

Comparison of Classification Models Logistic regression model
A linear decision boundary: wx+b
A probabilistic model p(y|x)
Maximum likelihood approach for estimating weights w and threshold b
0 positive
0 negative
w x b
w x b
1( 1| )
1 exp( ( ))p y x
y w x b
( ) ( )
1 1
( ) ( )
1 1 2
( ) log ( | ) log ( | )
1 1log log
1 exp 1 exp
N Ntrain i ii i
N N
i ii i
l D p x p x
w x b w x b

Comparison of Classification Models Logistic regression model
Overfitting issue In text classification problem, words that only appears in only one
document will be assigned with infinite large weight Solution: regularization
Conditional exponential model Maximum entropy model
A dual problem of conditional exponential model
( ) ( )
21 1
( ) ( ) 21 1 1
( ) log ( | ) log ( | )
1 1log log
1 exp 1 exp
N Ntrain i ii i
N N mji i j
i i
l D p x p x s w
s ww x b w x b

Comparison of Classification Models
Support vector machine Classification margin Maximum margin principle:
two objective Minimize the classification
error over training data Maximize classification
margin Support vector
Only support vectors have impact on the location of decision boundary
denotes +1
denotes -1
1w x b
1w x b
w
Support Vectors

Comparison of Classification Models Separable case
Noisy case
* * 21
,
1 1
2 2
{ , }= argmin
subject to
1
1
....
1
mii
w b
N N
w b w
y w x b
y w x b
y w x b
* * 21 1
,
1 1 1 1
2 2 2 2
{ , }= argmin
subject to
1 , 0
1 , 0
....
1 , 0
m Ni ji j
w b
N N N N
w b w c
y w x b
y w x b
y w x b
Quadratic programming!

Comparison of Classification Models Similarity between logistic regression model
and support vector machine2
1 1,
1{ , }* arg max log
1 exp ( )
N mji j
w b i
w b s wy w x b
* * 21 1
,
1 1 1 1
2 2 2 2
{ , }= argmin
subject to
1 , 0
1 , 0
....
1 , 0
N mi ji j
w b
N N N N
w b c w
y w x b
y w x b
y w x b
Log-likelihood can be viewed as a measurement
of accuracy
Identical terms
Logistic regression model is almost identical to support vector machine except for different expression for classification errors

0.5 1 1.5 2 2.5 3 3.5 4 4.50
10
20
30
40
50
60
X
Cou
nt
fitting curve for positive datafitting curve for negative datahistogram for negative datahistogram for positive data
Comparison of Classification Models
• Generative models have trouble at the decision boundary
• Classification boundary that achieves the least training error
• Classification boundary that achieves large margin