apostila_2012_1_semestre_2
TRANSCRIPT

ESTATÍSTICA E
PROBABILIDADE
VOLUME 1
Prof. Dr. JOÃO MÁRIO ANDRADE PINTO
Prof. PEDRO ARTHUR VICTER
Edição: 2012, 2º.Semestre

SUMÁRIO
ALFABETO GREGO.................................................................................................3
1INTRODUÇÃO........................................................................................................5
1.1.1GRANDEZA......................................................................................................6
1.1.2GRAFIA DOS NÚMEROS................................................................................6
1.1.3ALGARISMOS SIGNIFICATIVOS....................................................................6
1.1.4ARREDONDAMENTO......................................................................................6
1.1.5OPERAÇÕES COM ALGARISMOS SIGNIFICATIVOS..................................7
2TÉCNICAS DE AMOSTRAGEM............................................................................9
1.1.1POPULAÇÕES E QUESTÕES........................................................................9
1.1.2AMOSTRAGEM..............................................................................................10
1.1.3A URNA IDEAL...............................................................................................10
1.1.4TABELA DE NÚMEROS ALEATÓRIOS........................................................11
1.1.5AMOSTRAGEM ALEATÓRIA SIMPLES.......................................................11
1.1.6AMOSTRAGEM ESTRATIFICADA................................................................15
1.1.7AMOSTRAGEM POR CONGLOMERADO....................................................18
1.1.8AMOSTRAGEM SISTEMÁTICA....................................................................18
3RESUMO E APRESENTAÇÃO DE DADOS........................................................26

1.1.1ORDENAÇÃO E ESTATÍSTICAS DE ORDEM..............................................26
1.1.2MEDIDAS DE POSIÇÃO OU DE TENDÊNCIA CENTRAL...........................27
3.1.2.1Média Aritmética...........................................................................................................................27
3.1.2.2Média Ponderada...........................................................................................................................27
3.1.2.3Média Geométrica.........................................................................................................................28
3.1.2.4Média Harmônica..........................................................................................................................28
3.1.2.5Mediana.........................................................................................................................................29
3.1.2.6Comparação entre a Média Aritmética e a Mediana.....................................................................29
3.1.2.7Moda.............................................................................................................................................30
3.1.2.8Ponto Médio..................................................................................................................................30
3.1.2.9Percentil........................................................................................................................................30
3.1.2.10Conclusão....................................................................................................................................32
1.1.3MEDIDAS DE DISPERSÃO OU DE VARIABILIDADE..................................32
3.1.3.1Amplitude......................................................................................................................................32
3.1.3.2Variância e Desvio Padrão............................................................................................................32
3.1.3.3Coeficiente de Variação.................................................................................................................33
1.1.4APRESENTAÇÃO DE DADOS POR MEIO DE GRÁFICOS.........................33
3.1.4.1Diagrama de pontos......................................................................................................................33
3.1.4.2Diagrama de ramo e folhas...........................................................................................................34
1.1.5ORGANIZAÇÃO E APRESENTAÇÃO DOS DADOS...................................36
3.1.5.1Distribuição de frequência............................................................................................................36
3.1.5.2Histograma....................................................................................................................................39
3.1.5.3Polígono de frequência..................................................................................................................39
3.1.5.4Ogiva.............................................................................................................................................39
1.1.6MEDIDAS DE TENDÊNCIA CENTRAL PARA DADOS GRUPADOS EM
CLASSES...............................................................................................................39
3.1.6.1Média............................................................................................................................................39
3.1.6.2Percentil........................................................................................................................................40
3.1.6.3Moda.............................................................................................................................................41
3.1.6.4Relação entre as três medidas de posição (média, mediana e moda) – moda de Pearson............42
1.1.7MEDIDAS DE DISPERSÃO OU DE VARIABILIDADE PARA DADOS
GRUPADOS EM CLASSES...................................................................................42

3.1.7.1Variância........................................................................................................................................42
4PROBABILIDADE................................................................................................54
1.1.1EXPERIMENTOS ALEATÓRIOS...................................................................54
1.1.2ESPAÇO AMOSTRAL....................................................................................54
1.1.3EVENTO..........................................................................................................55
1.1.4COMPOSIÇÃO DE EVENTOS.......................................................................56
1.1.5AXIOMAS........................................................................................................57
1.1.6TEOREMAS....................................................................................................57
1.1.7ESPAÇO AMOSTRAL FINITO.......................................................................58
1.1.8RESULTADOS IGUALMENTE PROVÁVEIS.................................................58
1.1.9PROBABILIDADE CONDICIONADA.............................................................59
1.1.10INDEPENDÊNCIA ESTATÍSTICA................................................................60
5 DISTRIBUIÇÃO DE VARIÁVEL ALEATÓRIA DISCRETA.................................73
1.1.1FUNÇÃO.........................................................................................................73
1.1.2VARIÁVEL ALEATÓRIA.................................................................................75
1.1.3VARIÁVEIS ALEATÓRIAS DISCRETAS E CONTÍNUAS.............................75
1.1.4DISTRIBUIÇÃO DE PROBABILIDADES DE UMA VARIÁVEL ALEATÓRIA
DISCRETA..............................................................................................................76

1.1.5ESPECIFICAÇÃO DE UMA DISTRIBUIÇÃO DE VARIÁVEL ALEATÓRIA
DISCRETA..............................................................................................................77
1.1.6ESPECIFICAÇÃO DA DISTRIBUIÇÃO.........................................................78
1.1.7EMPREGO DA DISTRIBUIÇÃO HIPERGEOMÉTRICA................................78
1.1.8ESPECIFICAÇÃO DA DISTRIBUIÇÃO.........................................................79
1.1.9EMPREGO DA DISTRIBUIÇÃO BINOMIAL..................................................79
1.1.10USO DA BINOMIAL COMO APROXIMAÇÃO DA HIPERGEOMÉTRICA..79
1.1.11EMPREGO DA DISTRIBUIÇÃO..................................................................79
1.1.12ESPECIFICAÇÃO DA DISTRIBUIÇÃO.......................................................80
1.1.13POISSON COMO DISTRIBUIÇÃO LIMITE DA BINOMIAL........................80
1.1.14PROPRIEDADE ADITIVA DA DISTRIBUIÇÃO DE POISSON....................80
APÊNDICE B: DEMONSTRAÇÃO DO LIMITE DA DISTRIBUIÇÃO BINOMIAL90

ALFABETO GREGO
Alfa Α α
Beta Β β
Gama Γ γ
Delta ∆ δ
Epsílon Ε ε
Dzeta Ζ ζ
Eta Η ε
Teta Θ θ
Iota Ι ι
capa Κ κ
Lambda Λ λ
Mi Μ µ
Ni Ν ν
Csi Ξ ξ
Ômicron Ο ο
Pi Π π
Rô Ρ ρ
Sigma Σ σ
Tau Τ τ
Ípsilon Υ υ
Fi Φ φ
Qui Χ χ
Psi Ψ ψ
Ômega Ω ω

“Viva um dia de cada vez. Assim, viverá todos os dias de sua vida.
Não desista quando ainda é capaz de um esforço a mais.”
(Autor desconhecido).

1 INTRODUÇÃO
Natureza da Estatística
Muitas pessoas estão familiarizadas com o termo estatística, quando
usado para registrar e apresentar dados e gráficos, como por exemplo:
•os registros de medidas de resistência à compressão
de corpos-de-prova de concreto;
•os registros das medidas das características de uma
peça;
•a evolução do número de carros vendidos no país de
um ano para o outro;
•os dados numéricos apresentados num relatório anual
de uma companhia específica;
•a evolução do peso de bois de uma determinada raça
no tempo;
•a taxa de mortalidade infantil em uma determinada
região;
•a taxa de desemprego;
•a evolução do preço das ações de uma companhia.
Assim, um número é denominado uma estatística (singular). Por
exemplo: a taxa de desemprego alcança, hoje, 6% na Região Metropolitana de
Belo Horizonte; a receita bruta de uma empresa de pequeno porte no mês de
outubro do ano passado foi de R$ 55.000,00. Já um conjunto de números ou fatos
é denominado de estatísticas (plural). Por exemplo, o faturamento, em milhões
reais, de uma determinada empresa totalizou: 3,1 em janeiro, 3,7 em fevereiro,
4,1 em março e 4,5 em abril.

Entretanto, este uso do termo não é o foco central da questão, pois o
termo estatística tem um sentido muito mais amplo do que apenas números ou
coleção de números. Estatística lida, principalmente, com situações em que a
ocorrência de algum evento não pode ser predita com certeza. Nossas
conclusões são frequentemente incertas porque a característica básica de nosso
mundo é a variabilidade, pelo menos do pouco que se conhece dele, além de nos
basearmos em dados incompletos. É o que acontece quando avaliamos a taxa de
desemprego em um estado, com base em uma pesquisa de uns poucos milhares
de pessoas. Incertezas também surgem em observações repetidas de um
experimento. Apesar de tentativas serem feitas para controlar os fatores que
influem no experimento os resultados são diferentes. Por exemplo, pés de milho
maduro não são todos de mesmo tamanho, nem as espigas de milho estão todas
a iguais distâncias do solo, mesmo se os pés de milho forem plantados com
sementes de um mesmo lote e em condições aproximadamente idênticas de solo
e de tempo. O peso de frangos com idade de seis semanas de uma determinada
granja, o período de alívio dos sintomas de uma determinada doença após ter
tomado um determinado remédio são outros exemplos de situações em que
ocorre a variabilidade em observações repetidas.
A ciência estatística surge em estudo de fenômenos onde incertezas e
variações ocorrem. Assim, estatística pode ser definida como:
A ciência de coletar, organizar, resumir, apresentar, analisar e
interpretar dados relativos a um fenômeno objeto de estudo com vistas a tirar
conclusões ou tomar decisões em situações em que incertezas e variações
estão presentes.
A origem da palavra estatística está associada à palavra latina status
(Estado), de onde surgiu a palavra alemã Statistik, designando a análise de dados
sobre o Estado. Esta palavra foi proposta pela primeira vez no século XVII por
Schmeitzel. Na Enciclopédia Britânica aparece como verbete em 1797. Estatística
só adquiriu um significado de coleta, classificação e análise de dados, no início do
século XIX.
A consideração de que a etimologia do verbete estatística é a locução
latina status é reforçado quando se procuram os primeiros exemplos escritos de

aplicação da Estatística. Existem evidências de que 3000 anos A.C. já se faziam
censos na Babilônia, China e Egito com objetivo de coletar dados sobre colheitas,
composição da população humana ou de animais, impostos, etc.. O 4º livro do
Antigo Testamento, denominado livro dos Números, cita a seguinte instrução dada
a Moisés por Deus, no deserto de Sinai, em torno de 1250 A.C.: “Fazei o
recenseamento de toda a congregação dos filhos de Israel pelas suas famílias e
casas, e nomes de cada um dos varões, dos vinte anos para cima, e de todos os
homens fortes de Israel; e contá-lo-eis pelas suas turmas, tu e Aarão”. O objetivo
desse censo era conhecer o número dos homens fortes de Israel que podiam ir à
guerra. O total, segundo o livro dos Números, foi de 603.550 homens. Um outro
registro bíblico que faz referência a recenseamento é o Evangelho de São Lucas
(2, 1-3). Cita a determinação do Imperador César Augusto para que se fizesse o
recenseamento de todo o império romano, ocasião do nascimento de Jesus. A
palavra censo, cujo sinônimo é recenseamento, é derivada da palavra census,
que em latim significa, segundo o dicionário do Houaiss: levantamento e registro
(a princípio quadrienal, posteriormente quinquenal) feitos pelo censor dos
cidadãos romanos e de suas propriedades; rol, lista; posses, bens reais de um
cidadão. As informações obtidas eram utilizadas para a taxação de impostos ou
para o alistamento militar, ou seja, voltadas para os interesses do estado.
A Estatística teve a sua grande arrancada como ciência no século XVII,
ainda tendo como objetivo a descrição dos bens do Estado. Hoje em dia, os
relatórios governamentais que contém maciça documentação numérica com
títulos, tais como “Estatística de Produção Agrícola”, “Estatística de Produção
Industrial” e “Estatística de Desemprego”, são reminiscências da origem da
palavra estatística.
Assim, por motivos históricos, um grande segmento do público, em
geral, ainda tem a conceituação errada, de que estatística é exclusivamente
associada com arranjos traumáticos de números e, algumas vezes, séries
intrincadas de gráficos. Entretanto, é essencial lembrar que a teoria e a
metodologia estatística moderna têm feito enormes progressos, além da mera
compilação de tabelas e gráficos numéricos. Como uma ciência, estatística
contém conceitos e métodos, de grande importância em todas as investigações

que envolvem a coleta de dados, por um processo de experimentação ou
observação e envolvem as inferências ou a tomada de decisões pela análise de
tais dados.
Desde então o campo de aplicação da estatística tem-se ampliado
consideravelmente, por causa, principalmente, da necessidade de se tomarem
decisões rápidas com risco controlado. Atualmente, além de ser um instrumento
indispensável aos pesquisadores, a estatística é essencial para uma
compreensão e uma comunicação clara e efetiva, sendo, portanto, fundamental
para todo profissional que precisa conhecer e compreender fatos de várias
naturezas. O pensamento estatístico baseia-se em fatos, em dados e, não, em
opiniões ou “achismos”.
Os avanços tecnológicos, principalmente na informática, também têm
contribuído muito para a expansão e desenvolvimento do pensamento estatístico,
pois, os computadores, com alguns softwares, liberaram o ser humano para as
atividades de análise e interpretação dos dados.
A reputação de dificuldade da Estatística provém, em parte, da época
anterior às calculadoras eletrônicas e aos computadores, quando os profissionais
que utilizam dos métodos estatísticos eram forçados a efetuar manualmente
laboriosos cálculos. Hoje uma calculadora ou um computador faz esta parte
maçante do trabalho, deixando esses profissionais muito mais livres para estudar
e entender o significado do que se passa. Neste texto será usado o Excel para
fazer os cálculos. Assim após cada capítulo será apresentado, de maneira
detalhada, um exemplo com uso do Excel e sua análise e interpretação.
Estatística e a Vida Diária
Conhecimentos adquiridos por meio da coleta e interpretação de dados
não é prerrogativa só de pesquisadores. Ela permeia a vida quotidiana de todas
as pessoas que se esforçam, consciente ou inconscientemente, para entender
assuntos de interesse da sociedade, das condições de vida, do meio ambiente, e
do mundo em geral. Assim, para aprender sobre o desemprego, a poluição de
rejeitos industriais, o desempenho de times de futebol, a eficiência de analgésicos
e outros interesses da vida contemporânea, é preciso coletar dados numéricos

que serão interpretados por nós ou por terceiros. Mesmo que a interpretação
desses dados numéricos seja realizada por terceiros é necessário ter
minimamente um conhecimento de estatística para que se possam entender os
resultados apresentados.
Fontes de informação factual abrangem desde experiência individual a
registros da mídia, registros governamentais, registros de uma empresa, e artigos
profissionais. Previsão do tempo, relatórios de venda, índices do custo de vida e
resultados de opinião pública a respeito de candidatos ao governo são alguns
exemplos. Essas informações precisam ser preparadas e dispostas de modo a
propiciar ao leitor condição de interpretá-las. Para se atingir esse objetivo é
empregado extensivamente os denominados métodos estatísticos. Métodos
estatísticos têm um importante papel num moderno estado democrático. Por
exemplo, se o governo puder determinar os desejos e necessidades de seu
eleitorado por meio de métodos de amostragem confiáveis e rápidos, as políticas
públicas formuladas com base nessas informações podem ser mais receptivas
aos anseios do povo.
Relatórios, baseados em dados estatísticos, contendo interpretações e
conclusões, são muito úteis. No entanto, frequentemente, o emprego incorreto de
estatística, de modo deliberado ou inadvertido, leva a conclusão errada e,
portanto, a distorção da verdade. Para o público em geral, que são os
consumidores desses relatórios, raciocínio estatístico é essencial para poder
interpretar adequadamente os dados e avaliar as conclusões que são tiradas.
Raciocínio estatístico fornece critérios para discernir as conclusões que são, de
fato, suportadas por dados daquelas que não o são. Em todos os campos do
estudo, em que inferências são obtidas a partir das análises dos dados, a
credibilidade das conclusões também depende fortemente do método estatístico
usado no estágio da coleta de dados.
O novelista, historiador e sociólogo inglês, H. G. Wells (1866 - 1946)
fez a seguinte previsão: “o pensamento estatístico será um dia tão necessário
para o cidadão eficiente quanto à habilidade de ler e escrever”. Talvez, não
chegamos nesse dia ainda, mas estamos vendo, cada dia mais, o uso do
pensamento estatístico crescer cada vez mais entre nós.

Particularmente, nas ciências sociais, biológicas, físicas e na
engenharia, o uso dos métodos estatísticos aumentou consideravelmente nas
últimas décadas, confirmando a previsão de Wells. Devido a esse interesse
variado e amplo, tais métodos desenvolveram-se consideravelmente e cresceram
em diversidade e complexidade. Contudo, muitas das técnicas mais importantes
são as mesmas para os vários ramos de aplicação. Esses métodos “universais” é
que serão estudados neste curso.
De tudo que vimos, um estudante poderia ainda fazer as seguintes
perguntas:
• Por que estudar estatística?
• Quem necessita estudar estatística?
• Como pode um conjunto de números fornecer qualquer
informação útil?
As respostas a estas questões seriam: Estudamos dados numéricos
para ganhar conhecimento sobre vários fenômenos que existem no nosso meio e
que são de nosso interesse. Qualquer pessoa que depende de medidas
numéricas para tomar decisão necessita de estatística. É possível tomar decisão
sem estatística, mas a qualidade da decisão será provavelmente melhor utilizando
estatística. Estatística oferece técnicas para introduzir evidência numérica em
nosso processo de tomar decisão. Isto é, métodos estatísticos para preparar,
apresentar, e interpretar evidências numéricas são úteis para tomar decisão, seja
como um meio para que a pessoa que vai tomar decisão possa tirar proveito de
todos os fatos pertinentes, seja como um meio pela qual a decisão possa ser
“justificada” para os outros.
Para ser específico em nossa discussão, necessitamos alguns
conceitos básicos. Em particular, necessitamos identificar os seguintes itens:
1. Conjunto de questões para as quais se desejam
respostas. (As decisões a serem tomadas).
2. A variável a ser medida e/ou estudada para obter
dados.
3. As fontes das observações numéricas (medidas).
4. Método ou técnica para coletar os dados.

5. Os usos a serem feitos dos dados.
Nas próximas seções esses conceitos, definições específicas e
terminologias estatísticas serão apresentadas para que se possa obter
familiaridade com a linguagem estatística.
O maior impacto na estatística foi o surgimento dos computadores e o
efeito dramático que tiveram na sua prática diária. Hoje temos diversos pacotes
estatísticos tais como Minitab®, SAS®, SPSS®, etc. O estudante que realmente
planeja se concentrar em estatística precisará certamente de um desses
softwares estatístico mais sofisticado. No entanto, para a maior parte das
aplicações no dia a dia da estatística, uma planilha eletrônica resolve, com as
seguintes vantagens:
1. os programas de planilhas, por serem de ampla utilização, são
mais baratos que os programas estatísticos que têm um
mercado bem restrito.
2. Os profissionais que necessitam manipular e analisar dados
numéricos, tais como engenheiros, administradores, contadores
e gerentes utilizam frequentemente planilhas. Já o uso de
pacotes estatísticos é de uso esporádico tornando difícil o seu
uso, pois a cada aplicação é necessário um reaprendizado.
Por que o uso do Microsoft Excel? Este pacote tornou-se a planilha
eletrônica mais conhecida e usada nos computadores pessoais.
Neste texto, após cada capítulo, com exceção do Cap. 3 -
Probabilidade, serão introduzidas aplicações usando o Excel. Instruções passo a
passo são fornecidas cada vez que um novo tópico é apresentado. De modo que
mesmo os menos ‘fluentes’ em Excel não devem ter maiores dificuldades na sua
aplicação.

Algarismos Significativos
1.1.1 Grandeza
Grandeza é uma entidade suscetível de medida. São exemplos de
grandezas: comprimento, tempo, peso, temperatura, área, volume, velocidade,
etc.
Medir uma grandeza é compará-la com outra fixa, de mesma espécie e
considerada como padrão. Após ser feita a comparação, obtemos o que
chamamos de medida. Logo:
• Medição ⇒ ato de medir
• Medida ⇒ resultado de uma medição.Uma medida é composta de: Medida = (Número)(unidade)Ex: 0,01mm, 2m, 10g
1.1.2 Grafia dos números
Segundo a Resolução nº 12, de 12 de outubro de 1988 do Conselho
Nacional de Metrologia, Normalização e Qualidade Industrial – CONMETRO, a
grafia das grandezas obedece ao seguinte:
“Para separar a parte inteira da parte decimal de um
número, é empregada sempre uma vírgula; quando o valor
absoluto do número é menor que 1, coloca-se 0 à esquerda da
vírgula”.
1.1.3 Algarismos significativos
Seja a medição de um comprimento de um objeto utilizando uma régua
milimetrada como na Fig 1.
Figura 1: Realização de uma medida
Qual o valor da leitura? Se o valor da medida for expresso por 2,6234cm, essa
medida tem sentido? Tem significado? É claro que não, pois o terceiro algarismo é

duvidoso e por tanto com muito mais força de razão os outros dois seguintes o
são e, portanto deverão ser desprezados. No valor que expressa a magnitude de
uma grandeza por meio de uma unidade de medida, os algarismos conhecidos
com certeza mais o algarismo duvidoso são denominados de algarismos
significativos. Assim, algarismos significativos são os algarismos de um
número que são necessários para expressar a precisão da medida.
Se à esquerda de um número só houver zeros, estes zeros não são
algarismos significativos.
Nos números que não têm vírgula decimal, os zeros podem ser ou não
significativos. Para eliminar possíveis confusões, vamos adotar a convenção de
incluir uma vírgula decimal se os zeros forem significativos. Assim, o número
(100,) tem três algarismos significativos, enquanto (100) só tem um. Ou então,
escreve-se em notação científica 1,00 × 102 (com três algarismos significativos) ou
1 × 102 (com um algarismo significativo).
No exemplo da figura 1 pode-se expressar o resultado da medida por: 3,62cm,
3,63cm. Das duas leituras os algarismos 3 e 6 não são duvidosos, porém o
terceiro algarismo é.
Exemplos:
a) 0,01521m – tem 4 algarismos significativos, sendo 1 o duvidoso.
b) 248.350m = 248,350km – tem 6 algarismos significativos, sendo 0 o
duvidoso.
c) 13,2s – tem 3 algarismos significativos, sendo 2 o duvidoso.
d) 13,20s – tem 4 algarismos significativos, sendo 0 o duvidoso.
e) 13,200s – tem 5 algarismos significativos, sendo 0 o duvidoso.
Observe que 13,2s, 13,20s e 13,200s não têm o mesmo significado, pois cada
uma dessas medidas informa precisão diferente.

1.1.4 Arredondamento
Em alguns casos pode ser necessário fazer arredondamentos,
eliminando AS. Para fazer arredondamentos usamos a regra :
1) O último algarismo significativo conservado não se altera se o
algarismo eliminado é menor do que 5.
Ex:• 2,422 reduzido a 2 algarismos significativos fica 2,4
• 25.323 reduzido a 3 algarismos significativos fica 253.102
• 25.323 reduzido a 2 algarismos significativos fica 25.103
2) O último algarismo significativo conservado é acrescido de uma
unidade se o algarismo eliminado for maior ou igual a 5.
Ex:• 43,768 reduzido a 4 algarismos significativos fica 43,77
• 45.768 reduzido a 2 algarismos significativos fica 46.103
• 0,0379 reduzido a 2 algarismos significativos fica 0,038
1.1.5 Operações com algarismos significativos
Adição e subtração:
O resultado de uma soma ou de uma subtração deve ser relatado com
o mesmo número de casas decimais que o termo com o menor número de casas
decimais. Por exemplo, os resultados das seguintes soma e subtração:
1) 6,3 + 8,44 = 14,37 = 14,4
2) 90 – 2,28 = 87,72 = 87
3) 2,432 x 106 + 6,512 x 104 - 1,227 x 105 = 2,432 x 106 + 0,06512 x
106 +0,1227 x 106 = 2,374 x 106
Multiplicação e divisão:
O resultado de uma multiplicação ou de uma divisão deve ser
arredondado para o mesmo número de algarismos significativos que o do termo
com o menor número de algarismos significativos.
6,3 2,14 = 13,482 = 13
6,3 2,14 = 2,9439252 = 2,9

Quando um cálculo envolver mais de uma operação, após a realização
de cada operação, pose-se ou não efetuar o arredondamento para o devido
número de algarismos significativos. Por exemplo:
13,428 × (6,2 90,14356) = 13,428 × 0,069 = 0,93
13,428 × (6,2 90,14356) = 0,923566... = 0,92
Note que no segundo caso o arredondamento só foi feito após a
realização de todas as operações, mostrando que o resultado final depende de
como a operação foi feita e da realização ao não de arredondamentos(s) a cada
etapa do cálculo. Assim, para fins de padronização e considerando o uso de
calculadores eletrônicas, nos cálculos ao longo do curso os arredondamentos
deverão ser feitos somente no resultado final.

APÊNDICE: USANDO O EXCEL
A1. Nomes das partes da interface
Os nomes das várias partes da interface do programa são mostrados
na figura a seguir.
Barra de título
Caixa de nome
Barra de ferramen-tas
formatação
Barra de fórmulasCaixa de nome
Barra de ferramen-tas
padrãoBarra de menus
Ferramentas de desenho
Célula ativa

Após cada capítulo será apresentado um exercício de aplicação
usando o Excel.
A2. Para Inserir a Macro "FERRAMENTAS DE ANÁLISE"
Selecione, com o mouse, o menu FERRAMENTAS e escolha então a
opção SUPLEMENTOS, como apresentado na figura a seguir.
Guia das planilhas
Barras de rolagem
Barra de status
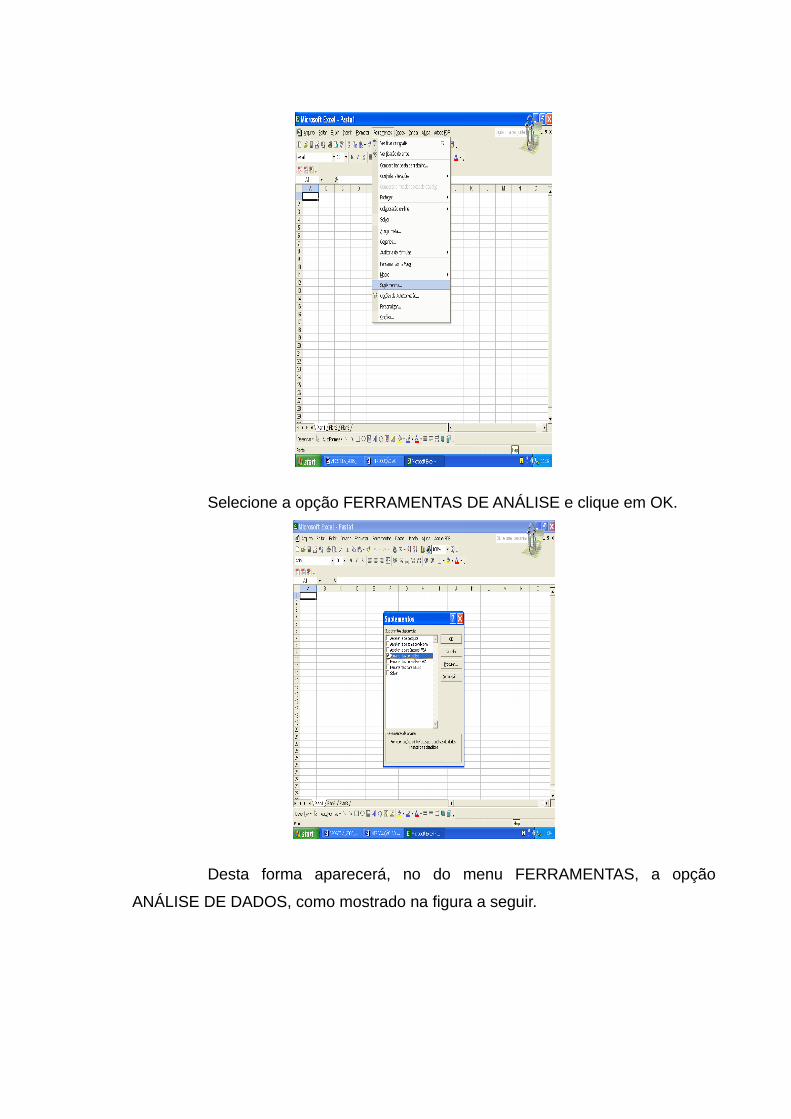
Selecione a opção FERRAMENTAS DE ANÁLISE e clique em OK.
Desta forma aparecerá, no do menu FERRAMENTAS, a opção
ANÁLISE DE DADOS, como mostrado na figura a seguir.
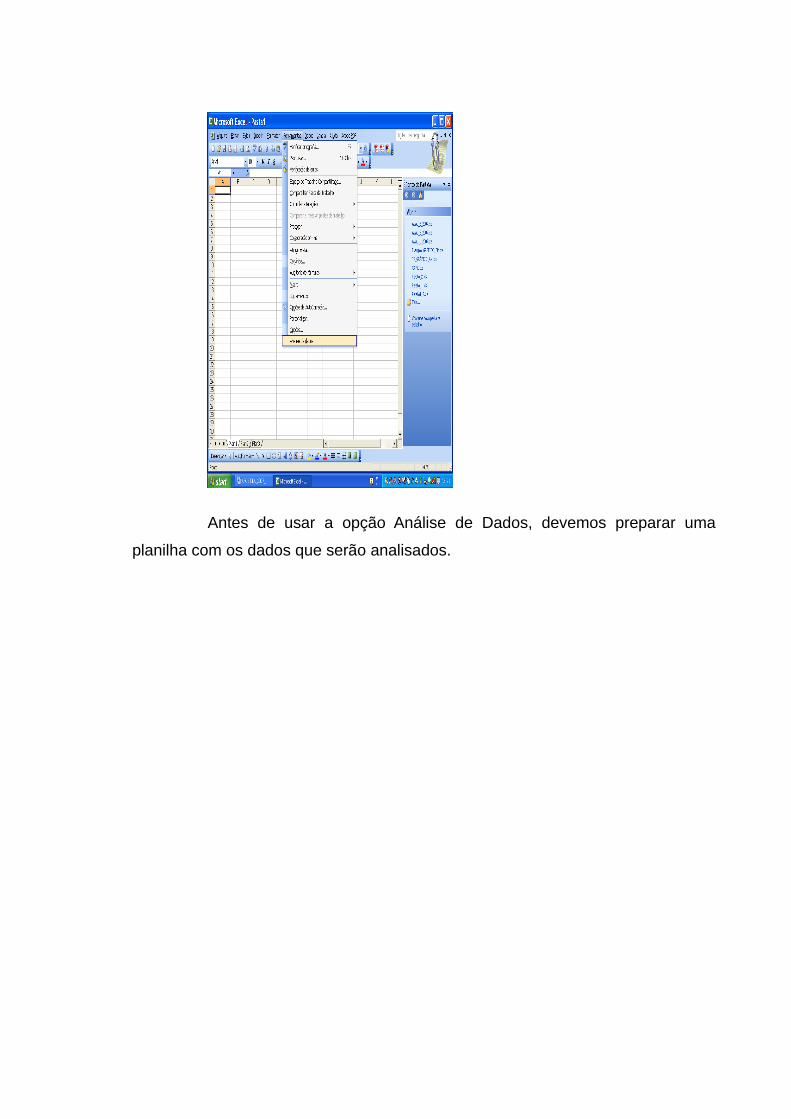
Antes de usar a opção Análise de Dados, devemos preparar uma
planilha com os dados que serão analisados.

2 TÉCNICAS DE AMOSTRAGEM
Introdução
Pesquisa experimental é um processo de aprendizado iterativo.
Questões relativas ao entendimento de algum fenômeno social, físico, químico ou
biológico são formuladas e testadas por meio de um conjunto de dados. Por sua
vez, uma análise dos dados obtidos experimentalmente ou por observação
geralmente propicia um entendimento modificado do fenômeno. Por meio deste
processo de aprendizado iterativo, variáveis podem ser eliminadas ou adicionadas
ao estudo. Assim, pesquisa experimental compreende uma sequência, que
corresponde às seguintes etapas:
1. formulação de questões que surgem do estudo de algum fenômeno;
2. identificação de variáveis mensuráveis que contém informação sobre
aquelas questões;
3. condução de experimento para acumular dados daquelas variáveis;
4. análise dos dados;
5. conclusão.
Para ilustrar, consideremos o seguinte exemplo simples: estudo da
obesidade entre os alunos de uma faculdade (adultos).
1. Questões de interesse:
• qual a percentagem de alunos de peso abaixo do normal?
• qual a percentagem de alunos de peso normal?
• qual a percentagem de alunos obesos?
2. Variável medida: índice de massa corporal (IMC)
( )( )[ ] 2maltura
kgfpeso
.
Categoria:
• IMC 20 kgf/m 2 indivíduos abaixo do peso
normal;
• 20 < IMC 25 indivíduos com peso normal;

• 25 < IMC 30 indivíduos acima do peso normal;
• 30 < IMC 35 indivíduos com obesidade grau I;
• 35 < IMC 40 indivíduos com obesidade grau II
(obesidade mórbida);
• MC > 40 indivíduos com obesidade grau III.
3. Experimento:
i. escolha dos alunos que irão representar os alunos da faculdade;
ii. medições de peso e altura dos alunos selecionados.
4. Análise dos dados: enquadrar o IMC nas categorias.
5. Tirar conclusões.
A partir desse exemplo simples vê-se que, para se conduzir o
experimento, é necessário escolher os representantes dos alunos que serão
objeto do estudo e as conclusões obtidas valerão para todos os alunos da
faculdade.
Percebe-se, desse modo, que o processo da escolha dos
representantes do todo é fundamental para a qualidade da análise.
Neste Capítulo estudaremos os métodos para a composição do
conjunto que representará o todo.
Conceitos Fundamentais
1.1.1 Populações e Questões
Em estatística, o termo fenômeno, referido anteriormente, é
denominado população. Assim, a investigação, a pesquisa, é feita em relação a
uma população e portanto é necessário defini-lo com precisão.
População é o conjunto de indivíduos ou objetos ou entes materiais
portadores de pelo menos uma característica comum e cujo comportamento
pretende-se estudar. Exemplos de população:
1. Todos os estudantes desta Faculdade que estão matriculados em
Estatística e Probabilidade.

1. Todos os pães tipo francês assados nas padarias de uma
determinada localidade em 25 de janeiro desse ano.
2. Todos os lotes usados por uma estação experimental de
agricultura para plantação de milho.
3. Todas as lâmpadas de 100 watts fabricadas por uma determinada
companhia durante o mês de setembro.
4. Todas as latas de ervilha produzidas por uma determinada
companhia no dia 7 de março.
5. Todo o concreto transportado por um determinado caminhão
betoneira em uma determinada viagem.
Uma vez que, inequivocamente, definimos as populações, o próximo
passo é identificar as questões que gostaríamos de investigar e eventualmente
responder. Por exemplo, para cada uma das populações definidas acima,
poderíamos ter as seguintes questões:
1. Qual foi o desempenho dos estudantes de Estatística e
Probabilidade desta Faculdade?
1. Qual o peso médio dos pães tipo francês?
2. De todas as variedades de milho plantadas, quais as que têm o
melhor rendimento?
3. Qual a vida média das lâmpadas de 100 watts? Qual a
porcentagem de lâmpadas defeituosas?
4. Qual a porcentagem das latas de ervilha está com os rótulos
adequadamente colados? Qual o peso médio das latas de
ervilha?
5. Qual a resistência média do concreto? Ele atende às
especificações?
Estas são somente umas poucas questões que podemos formular
sobre as populações anteriormente definidas. O leitor poderá tentar listar pelo
menos mais uma questão para cada uma das populações.

Exercício no 1: Aplicação do conceito de população.
a) Identificar três populações de sua área principal de interesse que
tem propriedades que poderiam ser estudadas pelo uso de
medidas numéricas.
b) Para cada uma das populações em (a), formular uma ou mais
questões que você gostaria de responder.
Exercício no 2: Estatística explorada na experiência do dia a dia.
1) Identificar o uso de estatística em jornais, revistas, notícias,
reportagens e comerciais de televisão.
2) Formular questões sobre o que você observou, tais como:
a) Quem coletou os números?
b) Como os números foram obtidos?
c) Os números representam o(s) grupo(s) do(s) qual(is) eles
foram extraídos?
1.1.2 Amostragem
Após definir uma população a ser estudada e listar o conjunto de
questões concernentes àquela população, o próximo passo é especificar os
métodos ou as técnicas que serão utilizadas para coletar dados numéricos que
fornecerão informações úteis para responder as questões levantadas. Uma das
primeiras questões que a pessoa que vai coletar os dados tem de responder é se
os dados serão coletados por meio de um levantamento efetuado sobre toda a
população e, neste caso, é denominado levantamento censitário (ou
simplesmente censo ou recenseamento) ou de somente parte da população.
Fazer levantamentos, estudos, pesquisas, sobre toda uma população
(censo) pode ser desaconselhável, seja devido ao tempo, ou ao custo, ou então,
porque o ensaio feito para se obter o valor da variável destrói o item. Assim, o
método estatístico possibilita chegar a conclusões sobre o todo (população),
analisando partes deste todo (amostra). Uma amostra é, portanto, um
subconjunto finito de uma população.

A amostragem consiste, essencialmente, em selecionar itens de uma
população, denominados unidades amostrais, com vistas a investigar alguma
característica dessa população. As unidades amostrais selecionadas compõem o
que se denomina amostra (uma parte ou uma parcela da população escolhida de
maneira conveniente) e a quantidade dessas unidades amostrais é denominado
tamanho da amostra. As conclusões obtidas a partir do estudo da amostra é
extrapolada para toda a população, ou seja, a partir das propriedades da amostra
inferem-se (isto é, concluem-se) as da população. É um instrumento valioso para
se obter dados ou informações de forma rápida, econômica e precisa.
Utilizar amostras para se ter conhecimento sobre populações é
realizado intensamente na Agricultura, Política, Negócios, Marketing, Governo,
Engenharia, Medicina, Psicologia, Biologia, etc., como se pode ver pelos
seguintes exemplos:
Antes da eleição diversos órgãos de pesquisa e imprensa ouvem um
conjunto selecionado de eleitores para ter uma idéia do desempenho dos
candidatos.
Biólogos marcam pássaros, peixes, etc. para estudar seus hábitos.
O IBGE faz levantamentos periódicos sobre desemprego, inflação,
correntes migratórias, escolaridade, etc.
Uma empresa metal-mecânica toma uma amostra do produto fabricado
em intervalos de tempo especificados para verificar se o processo está sob
controle estatístico e, com isso prevenir a ocorrência de itens defeituosos.
Redes de rádio e tv utilizam-se constantemente dos índices de
audiência dos programas para fixar valores da propaganda ou então modificar ou
eliminar programas com nível de desempenho baixo.
Antes de comercializar um medicamento é necessário demonstrar a
sua eficácia e identificar seus efeitos coletarais.
Seria desejável que uma amostra fosse uma réplica fiel da população,
ou seja, a população em escala reduzida. No entanto, a variabilidade novamente

se faz presente de modo que é quase impossível extrair uma amostra que seja
uma réplica perfeita da população. Assim, procura-se extrair uma amostra que
tenha o maior grau de representatividade possível da população. O grau de
representatividade da população por meio da amostra é função tanto do tamanho
da amostra como da técnica a ser utilizada para sua extração. O
dimensionamento da amostra será abordado no capítulo 7.
Devido à presença da variabilidade o processo de decisão ou de
conclusão baseado em amostra envolve riscos. A teoria da probabilidade será
utilizada para fornecer o risco envolvido, ou seja, do erro que se comete ao utilizar
uma amostra ao invés de toda a população. Para se poder utilizar o modelo
probabilístico é necessário que a amostra seja selecionada por meio de critérios
específicos, como serão vistos a seguir.
O critério de seleção dos itens da população que irão constituir a
amostra caracteriza a modalidade de amostragem, que poderá ser determinística
ou aleatória. Uma amostra é determinística quando os itens são escolhidos por
meio de alguma preferência. Uma amostra é aleatória quando, durante a escolha
dos itens que irão compor a amostra, não se registra qualquer preferência,
consciente ou inconsciente, por qualquer dos itens da população. Estudaremos
apenas a amostragem aleatória, pois só este critério de seleção é que permitirá
controlar o risco envolvido no processo de tomar decisão ou tirar conclusão sobre
a população com base nas observações amostrais.
Sorteio Aleatório
1.1.3 A Urna Ideal
Para o atendimento da condição de aleatoriedade na escolha dos itens
que irão compor a amostra deveremos poder identificá-los, e, para isso, associar
um número de ordem a cada um deles; a operação inicial consiste, pois, na
enumeração dos itens da população.
Deve-se em seguida, imaginar uma urna ideal que contenha tantas
bolas iguais quantos forem os itens da população. As bolas serão numeradas, de
modo a associarem-se cada uma a um dos itens e reciprocamente. A extração da

amostra, isto é, a seleção dos itens que irão compô-la ou seja das unidades
amostrais, faz-se por sorteio. Agita-se a urna e extrai-se uma bola, observando-se
o seu número, retirando da população a unidade amostral que corresponde ao
número sorteado, e assim sucessivamente.
As extrações, por sorteio, podem ser feitas de duas maneiras:
• s em reposição da bola extraída, antes de se fazer nova extração;
• com reposição dessa bola.
No primeiro caso, cada unidade amostral da população somente
poderá figurar uma vez na amostra, pois uma vez sorteada a bola com o número
correspondente, ela não voltará à urna. Portanto, o processo de extração sem
reposição é tal que a composição da urna se modifica após cada extração.
No segundo caso, a reposição da bola extraída torna estável a
composição da urna e, assim, cada item poderá figurar uma ou mais vezes na
amostra.
A escolha de uma ou outra maneira de extrair a amostra dependerá do
problema em estudo. Por exemplo, se usarmos os ensaios destrutivos para
determinar as propriedades da amostra, a amostragem sem reposição será
obrigatória.
1.1.4 Tabela de Números Aleatórios
Para a extração de amostras aleatórias, a utilização de urna com bolas
numeradas não é indispensável. Existem outros dispositivos que reproduzem
perfeitamente as condições da urna ideal. Um desses dispositivos mais usados é
a chamada Tabela de Números Aleatórios (TNA), apresentada na apostila
‘Tábuas Estatísticas’.
O procedimento para utilização da TNA é:
1. atribui-se a cada item da população (de tamanho N) um número de ordem
com tantos algarismos quantos forem os algarismos do número N;
2. seleciona-se, arbitrariamente, uma página da TNA e, nessa página, um
ponto de partida (interseção de linha e coluna) e, a partir deste ponto,

adotam-se tantas colunas quantos forem os algarismos do número relativo
ao tamanho da população;
3. faz-se a leitura dos números sorteados, percorrendo a TNA segundo as
colunas; todo número maior que N será desprezado; todo número menor
ou igual a N será registrado, para inclusão na amostra, do item a ele
correspondente;
4. registram-se as repetições se a amostra for com reposição; se for sem
reposição, as repetições não serão registradas.
No exemplo 2.1, a seguir, será mostrado a aplicação do uso da TNA.
Exemplo 2.1:
Seja extrair uma amostra de tamanho n = 12 de uma população de N =
120 itens. O primeiro passo é enumerar os itens da população, atribuindo a cada
elemento um número de ordem. Assim, os números de ordem dos itens da
população serão: 001, 002, ..., 119, 120.
A segunda etapa se refere à obtenção dos números de ordem dos itens
que irão compor a amostra. Para isso, é importante lembrar que a população é
constituída de N=120 peças, o que determina a leitura de três colunas na TNA.
Será importante também, neste estágio, fixar se a amostragem se fará com
reposição dos itens, ou sem reposição. Será adotada a primeira modalidade,
assim as leituras deverão considerar aquelas eventualmente repetidas.
Como observação adicional, deve-se informar que, na TNA, cada
algarismo será considerado como uma coluna. É apenas uma convenção a ser
usada. Desse modo, será possível reconstituir as leituras que deram origem à
amostra de interesse, desde que se tenha a tabela usada e o início das leituras
adotado, o qual, por sua vez, deve ser também inteiramente livre, para que seja
cada vez menor, ou mesmo inexistente, qualquer influência na obtenção dos itens
que irão compor a amostra.
Considere-se o início de leitura na TNA na 21ª. linha e 12ª. coluna, cuja
interseção é o algarismo 4. Como o tamanho da população é composto por três

algarismos, adotam-se três colunas a partir do início de leitura (12ª, 13ª e 14ª),
correspondendo ao número 455, que como é maior que 120 será descartado.
Percorrem-se as três colunas de cima para baixo, escolhendo os números
menores ou iguais a 120, até a última linha. Se até esse ponto não tiverem sido
selecionadas todas as doze leituras, volta-se à primeira linha, nas três colunas
subsequentes (15ª, 16ª e 17ª) e retoma-se o procedimento de leitura. Esse
procedimento será mantido, até que sejam conseguidas todas as leituras.
Seguindo este método, foram encontrados:. 053, 114, 106, 007, 017, 038, 104,
009, 106, 027, 044, 115. Se a amostragem for realizada sem reposição, o número
106, que saiu pela segunda vez, deverá ser descartado e, portanto, dever-se-á
sortear mais um número, que no caso será o 089. Esses números indicam quais
os elementos da população devem ser extraídos para compor a amostra.
Tipos de Amostragem
Existem diversos tipos de amostragem aleatória. Estudaremos, apenas,
alguns deles: amostragem aleatória simples, amostragem estratificada,
amostragem por conglomerado e amostragem sistemática.
1.1.5 Amostragem Aleatória Simples
A Amostragem Aleatória Simples é o tipo de amostragem mais usado.
Nesse processo, todos os elementos da população têm igual chance de vir a ser
escolhido para compor a amostra. É usada quando a população se apresenta
distribuída homogeneamente, que é o caso do exemplo 2.2, ou o pouco
conhecimento que se tem dela nos leva a admitir esta condição.
Exemplo 2.2:
Extrair uma amostra aleatória de tamanho n=12 itens, de um estoque
de peças de tamanho N=120, para estimar o peso médio das peças do estoque.
Para fins didáticos serão apresentados os pesos (em daN) das peças na tabela
2.1.
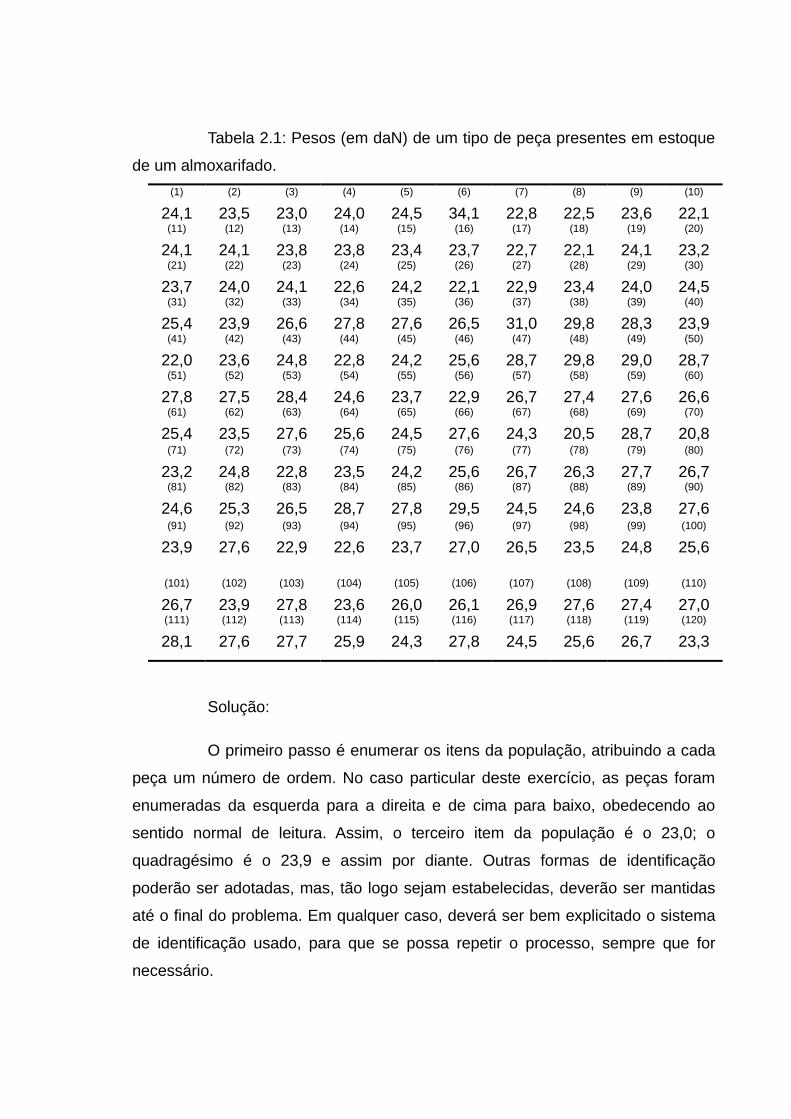
Tabela 2.1: Pesos (em daN) de um tipo de peça presentes em estoque
de um almoxarifado.
(1)
24,1
(2)
23,5
(3)
23,0
(4)
24,0
(5)
24,5
(6)
34,1
(7)
22,8
(8)
22,5
(9)
23,6
(10)
22,1(11)
24,1
(12)
24,1
(13)
23,8
(14)
23,8
(15)
23,4
(16)
23,7
(17)
22,7
(18)
22,1
(19)
24,1
(20)
23,2(21)
23,7
(22)
24,0
(23)
24,1
(24)
22,6
(25)
24,2
(26)
22,1
(27)
22,9
(28)
23,4
(29)
24,0
(30)
24,5(31)
25,4
(32)
23,9
(33)
26,6
(34)
27,8
(35)
27,6
(36)
26,5
(37)
31,0
(38)
29,8
(39)
28,3
(40)
23,9(41)
22,0
(42)
23,6
(43)
24,8
(44)
22,8
(45)
24,2
(46)
25,6
(47)
28,7
(48)
29,8
(49)
29,0
(50)
28,7(51)
27,8
(52)
27,5
(53)
28,4
(54)
24,6
(55)
23,7
(56)
22,9
(57)
26,7
(58)
27,4
(59)
27,6
(60)
26,6(61)
25,4
(62)
23,5
(63)
27,6
(64)
25,6
(65)
24,5
(66)
27,6
(67)
24,3
(68)
20,5
(69)
28,7
(70)
20,8(71)
23,2
(72)
24,8
(73)
22,8
(74)
23,5
(75)
24,2
(76)
25,6
(77)
26,7
(78)
26,3
(79)
27,7
(80)
26,7(81)
24,6
(82)
25,3
(83)
26,5
(84)
28,7
(85)
27,8
(86)
29,5
(87)
24,5
(88)
24,6
(89)
23,8
(90)
27,6(91)
23,9
(92)
27,6
(93)
22,9
(94)
22,6
(95)
23,7
(96)
27,0
(97)
26,5
(98)
23,5
(99)
24,8
(100)
25,6
(101)
26,7
(102)
23,9
(103)
27,8
(104)
23,6
(105)
26,0
(106)
26,1
(107)
26,9
(108)
27,6
(109)
27,4
(110)
27,0(111)
28,1
(112)
27,6
(113)
27,7
(114)
25,9
(115)
24,3
(116)
27,8
(117)
24,5
(118)
25,6
(119)
26,7
(120)
23,3
Solução:
O primeiro passo é enumerar os itens da população, atribuindo a cada
peça um número de ordem. No caso particular deste exercício, as peças foram
enumeradas da esquerda para a direita e de cima para baixo, obedecendo ao
sentido normal de leitura. Assim, o terceiro item da população é o 23,0; o
quadragésimo é o 23,9 e assim por diante. Outras formas de identificação
poderão ser adotadas, mas, tão logo sejam estabelecidas, deverão ser mantidas
até o final do problema. Em qualquer caso, deverá ser bem explicitado o sistema
de identificação usado, para que se possa repetir o processo, sempre que for
necessário.

O procedimento restante para a escolha do número de ordem
correspondente a cada peça é análogo ao do exemplo 2.1. Na interseção da 23ª.
linha com a 15ª. coluna (cada algarismo pertence uma coluna) encontra-se o
algarismo 6, que corresponde ao início de leitura na TNA. Uma vez que o
tamanho da população (N =120) é composto por três algarismos, as leituras na
TNA deverão ser feitas adotando-se três colunas a partir do início de leitura (15ª,
16ª e 17ª colunas). O primeiro número de ordem é então 680, que deve ser
desprezado porquanto não há correspondência com um número de ordem da
população. A seguir se encontra o 595 que também deve ser abandonado, por
não ter correspondência na população. Em seguida, são extraídos os números:
042, 066, 093, 013, 014, 040, 079, 009, 014, 118, 007, 086. Neste momento, é
necessário definir-se se a amostragem é com reposição ou sem reposição. Se a
opção é pela amostragem com reposição, os números sorteados são os
apresentados anteriormente, caso contrário, se a opção é pela amostragem sem
reposição é necessário descartar os números repetidos e os números sorteados
serão: 042, 066, 093, 013, 014, 040, 079, 009, 118, 007, 086, 111.
Se a amostragem for com reposição o resultado final é o apresentado
na tabela 2.2.

Tabela 2.2: Amostra aleatória simples com reposição
ITEM TNAAMOSTRA
(daN)
1 042 23,6
2 066 27,6
3 093 22,9
4 013 23,8
5 014 23,8
6 040 23,9
7 079 27,7
8 009 23,6
9 014 23,8
10 118 25,6
11 007 22,8
12 086 29,5
TOTAL 298,6
MÉDIA 24,9
Se a amostragem for sem reposição o resultado final é o apresentado
na tabela 2.3. Perceba que a amostragem sem reposição se refere a
impossibilidade de repetição dos números de ordem sorteados e não a repetição
dos resultados, como por exemplo as peças de número de ordem 042 e 009 que
são peças diferentes mas têm o mesmo peso de 23,6 daN.

Tabela 2.3: Amostra aleatória simples sem reposição
ITEM TNAAMOSTRA
(daN)
1 042 23,6
2 066 27,6
3 093 22,9
4 013 23,8
5 014 23,8
6 040 23,9
7 079 27,7
8 009 23,6
9 118 25,6
10 007 22,8
11 086 29,5
12 111 28,1
TOTAL 302,9
MÉDIA 25,2
A seguir será apresentado outro exemplo de aplicação da técnica de
amostragem aleatória simples.
Exemplo 2.3:
Uma população de peças de tamanho N = 30 deverá ser transportada
de uma cidade para outra. Externamente, essas peças são iguais e o problema
consiste em estimar o valor total do transporte, cobrado a “R” reais por
decanewton transportado. Suponha que dificuldades de ordem prática (quanto ao
manuseio ou mesmo quanto à exiguidade do tempo) impeçam o levantamento
censitário da população. Diante destas considerações, extrair uma amostra de
tamanho n = 6 peças para obter a estimativa desejada. Para fins didáticos é
apresentado na tabela 2.4 os pesos dessas peças da população e seus números
de ordem.

Tabela 2.4: População de peças e seus pesos em daN
N da
PeçaPeso
N da
PeçaPeso
N da
PeçaPeso
1 41 11 66 21 422 64 12 37 22 363 37 13 95 23 384 62 14 39 24 695 93 15 67 25 1016 97 16 40 26 397 68 17 39 27 408 38 18 64 28 689 38 19 103 29 4110 42 20 71 30 70
Em vista de que a população se apresenta distribuída de forma
homogênea, utilizaremos a técnica de amostragem aleatória simples para extrair
a amostra solicitada. Para tanto, utilizamos a TNA, com início na 17ª linha e 19ª
coluna, selecionando os 6 primeiros números (sem reposição), encontrados entre
os números 01 e 30. A amostra encontrada é apresentada na tabela 2.5.
Tabela 2.5: Amostra aleatória simples
N da peça Peso (daN)22 3614 3918 6428 6816 4007 68Total
Média
315
53
1.1.6 Amostragem Estratificada1
Às vezes a população que está sendo estudada se encontra dividida
em subgrupos homogêneos, chamados estratos. Neste caso, somente umas
poucas observações de cada subgrupo são necessárias. A idéia importante é que
todos os subgrupos estejam representados na amostra.
1 Estratificação: divisão ou separação em subgrupos homogêneos com relação a algum fator de
estratificação.

O princípio básico em amostragem estratificada é que elementos
dentro de um subgrupo tendem a variar menos que elementos de subgrupos
diferentes. É esta homogeneidade dentro e heterogeneidade entre os subgrupos
que determinam uma amostra composta de poucos elementos de cada um dos
subgrupos.
Pesquisas eleitorais nacionais são usualmente baseadas em tais
amostras estratificadas, porque opiniões em muitos tópicos tendem a variar mais
de uma localidade para outra localidade do que dentro das localidades.
Existem dois tipos de amostragem estratificada:
De igual tamanho;
Proporcional ao tamanho do estrato.
No primeiro tipo sorteia-se igual número de elementos em cada estrato.
A média e a variância são calculadas
No outro caso, utiliza-se a amostragem estratificada proporcional, cujo
processo é:
Exemplo 2.4:
Utilizando o exemplo 2.3, mas supondo agora que as peças estejam
separadas em três classes (A, B e C), em função do material utilizado para sua
confecção, conforme apresentado na tabela 2.6, extrair uma amostra de tamanho
n = 6.

Tabela 2.6: População de peças e seus pesos em daN distribuídas em
classes.

Classe A Classe B Classe CN da
Peça
Peso
(daN)
N da
Peça
Peso
(daN)
N da
Peça
Peso
(daN)1 93 6 64 16 412 97 7 62 17 373 95 8 68 18 384 103 9 66 19 385 101 10 67 20 42.. .. 11 64 21 37.. .. 12 71 22 39.. .. 13 69 23 40.. .. 14 68 24 39.. .. 15 70 25 42.. .. .. .. 26 36.. .. .. .. 27 38.. .. .. .. 28 39.. .. .. .. 29 40.. .. .. .. 30 41
Nota: Sinal convencional utilizado:
.. Não se aplica dado numérico.
Examinaremos dois critérios para extração da amostra: proporcional ao
tamanho do estrato e igual tamanho.
Proporcional ao Tamanho do Estrato
Se uma população de tamanho N está dividida em k estratos de
tamanhos N1, N2, ..., Nk, e deseja-se extrair uma amostra de tamanho n, o número
de representantes que se devemos extrair de cada estrato, n1, n2, ..., nk, é
proporcional ao tamanho de cada estrato, assim
k
k
N
n
N
n
N
n
N
n ==== 2
2
1
1
.
Retomando o exemplo 2.4, para extrair, da população de tamanho
N=30 dividida em três estratos, uma amostra de tamanho n = 6, utilizando a
técnica de amostragem aleatória estratificada proporcional ao tamanho do estrato,
selecionaremos uma das 5 peças da classe A, 2 das 10 da classe B e 3 das 15 da
classe C, (isto é, n/N = 1/5 das peças de cada estrato). Para isto, iniciando a
leitura na TNA no mesmo ponto que no exemplo 2.3, procuraremos o primeiro
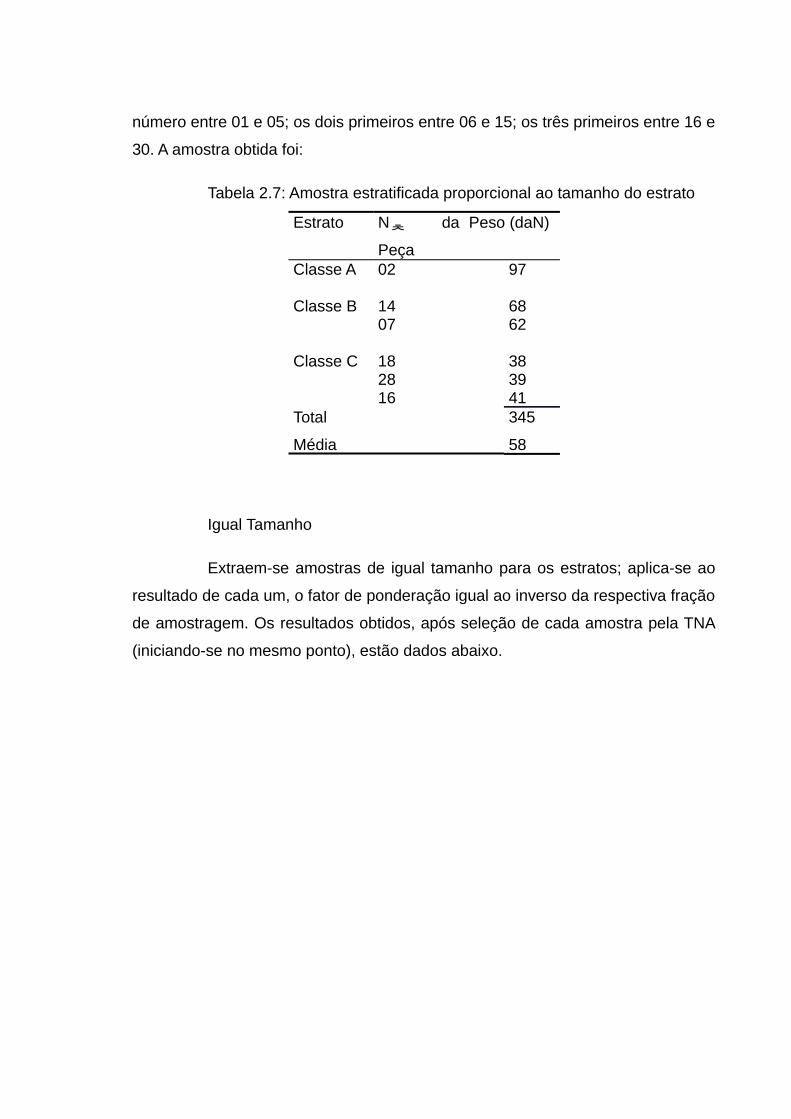
número entre 01 e 05; os dois primeiros entre 06 e 15; os três primeiros entre 16 e
30. A amostra obtida foi:
Tabela 2.7: Amostra estratificada proporcional ao tamanho do estrato
Estrato N da
Peça
Peso (daN)
Classe A 02 97
Classe B 14 6807 62
Classe C 18 3828 3916 41
Total
Média
345
58
Igual Tamanho
Extraem-se amostras de igual tamanho para os estratos; aplica-se ao
resultado de cada um, o fator de ponderação igual ao inverso da respectiva fração
de amostragem. Os resultados obtidos, após seleção de cada amostra pela TNA
(iniciando-se no mesmo ponto), estão dados abaixo.

Tabela 2.8: Amostra estratificada de igual tamanhoi
Estrato N da
Peça
Peso
(daN)
Fator de ponderação Totais
A02 9705 101
Total de A
Média A
198
99 5 495
B14 6807 62
Total de B
Média B
130
65 10 650
C18 3828 39
Total de C
Média C
77
38,5 15 577,5Total geral
Média ponderada (total geral 30)
1722,5
57
1.1.7 Amostragem por Conglomerado
A idéia de amostragem por conglomerado é quase oposta a da
amostragem estratificada. Nesse caso, supõe-se que a população seja composta
de subgrupos heterogêneos, chamados conglomerados. De fato, cada
conglomerado é uma “miniatura” da população. Portanto, podemos ver a
população melhor e mais economicamente pela observação de todos os
elementos de uns poucos conglomerados (possivelmente apenas um
conglomerado) que pela observação de uma parte de muitos conglomerados.
Exemplos de populações para os quais amostragem por conglomerado são
aplicáveis são os seguintes:
Um estudo de hospitais (100 - 200 leitos) está sendo conduzido para
determinar o nível de treinamento de seus funcionários. Pode-se admitir que o
corpo de funcionários de um hospital do tamanho indicado é aproximadamente
uma miniatura de todos os dos outros hospitais. Então, resultados obtidos pelo
estudo dos funcionários de uns poucos hospitais podem ser uma boa
representação de toda a população.

Um biólogo está interessado em determinar a composição da idade de
uma população de cachorros-do-mato que reside dentro dos limites de um
determinado parque nacional. Se admitirmos que cada colônia de cachorros-do-
mato é uma pequena réplica da população completa, necessitamos estudar
somente umas poucas (talvez somente uma) colônias para obter a informação,
aproximada, da composição da idade desejada.
Formiga saúva, abelha, etc. são exemplos de populações para os quais
amostragem por conglomerado é aplicável.
Em amostragem por conglomerado, os conglomerados que comporão
a amostra são selecionados de modo aleatório. Para aquelas populações, que
têm conglomerados de tamanho tão grande que se torna impraticável obter dados
de todos os seus elementos, é comum selecionar os elementos aleatoriamente do
conglomerado para compor a amostra. A última técnica é chamada de
amostragem por conglomerado em dois estágios. No primeiro estágio um
conjunto de conglomerados é aleatoriamente selecionado. Então, o segundo
estágio envolve a seleção aleatória de elementos a partir dos conglomerados
selecionados.
1.1.8 Amostragem Sistemática
Outra técnica de amostragem usada frequentemente é a chamada
amostragem sistemática. Nesse caso, a regra de amostragem envolve uma
seleção aleatória inicial seguida de uma sistemática. É usada quando a população
está naturalmente ordenada, como fichas em um fichário, listas telefônicas, etc.
Exemplos comuns são:
Para obter uma amostra de estudantes de uma universidade um nome,
dentre os primeiros cem nomes da lista de estudantes regularmente matriculados,
é selecionado aleatoriamente, digamos que foi o de número 61. Após a seleção
inicial é adicionado 100 ao sorteado e assim sucessivamente, por exemplo os de
número 161, 261, 361, ..., até obtermos a amostra. Desse modo, a amostra
resultante incluirá 1% do corpo de estudantes.

Sortear um número aleatório entre 1 e 100, digamos 39. Então
selecionar os nomes da lista de telefone local que corresponde aos números 39,
139, 239, ... para compor a amostra.
Selecionar aleatoriamente o primeiro cliente para entrevistá-lo quando
estiver deixando o supermercado. Então entrevistar cada quinquagésimo cliente
que deixar o supermercado após a entrevista inicial.
O procedimento para extrair a amostra é:
1. calcula-se o intervalo de amostragem N/n;
2. adota-se o maior número inteiro, r, menor ou igual a N/n;
3. sorteia-se pela tabela de números aleatórios um número b, entre 01 e r,
esse corresponderá ao primeiro item da população que irá compor a
amostra;
4. os demais itens da população a serem escolhidos serão obtidos somando-
se, sistematicamente, ao primeiro, parcelas iguais a r;
5. a amostra de n unidades amostrais será, pois, formada pelos itens da
população de número de ordem: b, b + r, b + 2r, ..., b + (n-1)r, de acordo
com uma progressão aritmética de razão r.
Algumas precauções devem ser tomadas na utilização da amostragem
sistemática:
• a escolha do item da população de número de ordem 1 deve ser evitada,
sobretudo se a ordenação corresponder a alguma forma de hierarquia, pois
nesse caso ele constitui um exemplar especial. Por exemplo, no fichário de
pessoas lotadas em um departamento, o número 1 será o chefe do
departamento, ou talvez o empregado mais antigo;
• quando a população já estiver organizada por estratos, uma amostra
sistemática será também estratificada. É o caso do fichário de pessoal de
fábrica, arrumado por departamento; uma amostra sistemática, de certo
modo, reproduzirá a estrutura administrativa da fábrica. Muito embora,
usualmente, a amostra sistemática forneça estimativas muito precisas, não
é possível obter uma medida dessa precisão;
• a amostragem sistemática pode ser tendenciosa quando coincidir o
intervalo de amostragem com um intervalo de variação periódica dos itens

da população. Apesar da comodidade de extração de amostra a intervalos
de tempo periódicos (nas fábricas, nas instalações químicas, etc.), é
necessário eliminar essa coincidência. Por exemplo, é possível ocorrerem
variações periódicas nas características químicas e bacteriológicas do
esgoto de uma cidade ou de um parque industrial; ou na composição do
concreto em uma central; ou no número de veículos que passam por uma
rua, etc.
Exemplo 2.5
Considerando a população ordenada apresentada na Tabela 2.9,
extrair uma amostra de tamanho n=6, iniciando na TNA na 15 linha e 19
coluna.
Tabela 2.9: População ordenada
(1)
34
(2)
34
(3)
35
(4)
36
(5)
36
(6)
37
(7)
38
(8)
40
(9)
40
(10)
41(11)
41
(12)
42
(13)
43
(14)
45
(15)
47
(16)
48
(17)
48
(18)
49
(19)
50
(20)
51(21)
51
(22)
55
(23)
55
(24)
55
(25)
57
(26)
58
(27)
58
(28)
59
(29)
59
(30)
60(31)
61
(32)
61
(33)
62
(34)
63
(35)
64
(36)
65
(37)
65
(38)
66
(39)
67
(40)
70(41)
70
(42)
70
(43)
72
(44)
73
(45)
73
(46)
75
Solução:
1. Calcula-se o intervalo de amostragem N/n = 46/6 = 7,7;
2. adota-se r = 7;
3. o número entre 01 e 07, dado pela TNA, foi 06;
4. a amostra será:

Tabela 2.10: Amostra extraída usando a técnica de
amostragemsistemática
I TNA Número Amostra1 06 06 372 .. 13 433 .. 20 514 .. 27 585 .. 34 636 .. 41 70
Total
Média
322
54
Nota: Sinal convencional utilizado:
.. Não se aplica dado numérico.
Exercícios Propostos
1) Uma empresa tem 3414 empregados repartidos nos seguintes
departamentos:
Administração 914
Transporte 348
Produção 1401
Outros 751
Deseja-se extrair uma amostra entre os empregados para verificar o
grau de satisfação em relação à qualidade da comida servida no refeitório. Diga
como a amostragem seria realizada considerando uma amostra de 20 % da
população.
2) Dada a população a seguir:
1 1 1 1 1 1 1 1 1 1

58 68 65 89 48 87 69 87 48 49
1
98
1
57
1
34
1
62
1
67
1
58
1
95
1
32
1
67
1
49
1
98
1
89
1
51
1
35
1
48
1
68
1
24
1
17
1
18
1
28
1
65
1
97
1
58
1
49
1
28
1
18
1
52
1
51
1
58
1
68
1
58
1
56
1
28
1
84
1
49
1
58
1
65
1
51
1
95
1
84
1
59
1
58
1
96
1
85
1
96
1
52
1
77
1
65
1
64
1
26
1
65
1
69
1
12
1
11
1
22
1
28
a) Extrair uma amostra aleatória, com reposição, de tamanho 15. Iniciar a leitura na TNA na 15º linha e 12º coluna.
b) Justificar o emprego da técnica de amostragem utilizada.
c) Determinar: a média, a mediana, o ponto médio, a moda, a amplitude, a variância, o desvio-padrão e o coeficiente de variação.
3) Dada a população a seguir:
Classe A: 165 197 158 149 128 118 152 151 158 168
159 158 196 185 196 152 177 165 164 126
196 185 196 152
Classe B: 358 368 365 389 348 387 369 387 348 349
398 357 334 362 367 358 395 332
Classe C: 767 749 798 789 751 735 748 768 724 717
718 728
Classe D: 98 89 51 35 48 68 24 17 18 28
65 97 58 49 28 18 52 51 58 68
58 56 28 84 49 58 65 51 95 84

a) Extrair uma amostra aleatória, sem reposição, de tamanho 14. Iniciar a leitura na TNA na 7º linha e 20º coluna.
b) Justificar o emprego da técnica de amostragem utilizada.
c) Determinar: média, mediana, ponto médio, moda, amplitude, variância, desvio-padrão, coeficiente de variação.
4) Dada a população ordenada a seguir:
123 123 123 125 125 126 127 129 130 130
131 131 131 133 133 134 135 135 135 136
137 138 139 140 142 143 145 145 145 146
150 151 154 155 158 160 160 165 166 167
170 171 171 175 176 177 178 180 182 183
185 188 190 190 191 191 194 195 195 196
200 200 201 201 205 205 206 207 208 210
a) Extrair uma amostra aleatória de tamanho 9. Iniciar a leitura na TNA na 15º linha e 14º coluna.
b) Justificar o emprego da técnica de amostragem utilizada.
c) Determinar: média, mediana, ponto médio, moda, amplitude, variância, desvio-padrão, coeficiente de variação.
5) Observe a população abaixo, de N = 50 pessoas que, se
responderem a uma pesquisa de opinião sobre determinado assunto irão
responder S (sim), N (não) ou NS (não sabem ou não querem responder):
a) determine os percentuais de pessoas que responderam S, N e NS
na população;
b) enumere os itens da população da esquerda para a direita e de cima
para baixo e extraia uma amostra aleatória simples de n = 8 pessoas
da população, sem reposição. Da amostra extraída calcule os
percentuais de respostas S, N e NS nas amostras, para início das
leituras em:
I. TNA (8ª L; 17ª C);
II. TNA (3ª L; 3ª C);
III. TNA (25ª L; 2ª C);
IV. TNA (7ª L; 11ª C);

V. TNA (4ª L; 8ª C).
População:
NS N NS S S N S N S SN NS S S S S S N N SS N S S N N N S S NSNS NS N N S S N S NS NSNS S S NS S N S N S S
c) Comente os resultados amostrais em relação
aos da população.
6) Em um almoxarifado existem 25 peças fabricadas por duas
máquinas A e B. Suponha conhecidos os seus comprimento, assim como se
relacionam a seguir:
75 58 57 72 7379 78 86 60 7876 61 64 58 8285 57 55 57 7980 76 60 74 76
a) Enumere os itens da população da esquerda
para a direita e de cima para baixo. Fixando o início das leituras
na TNA (7ª L; 25ª C), extraia uma amostra aleatória simples de n
= 5 itens, sem reposição. Da amostra extraída calcule:
I. média;
II. ponto médio;
III. moda;
IV. mediana;
V. variância;
VI. amplitude;
VII. desvio padrão;
VIII. coeficiente de variação.
b) Admita conhecida a informação de que as peças
de A são, em geral, menores. Como deve ser extraída uma nova
amostra de n = 5? Reorganize e renumere os itens da população
como na alínea a e extraia essa nova amostra sem reposição,
para o início das leituras na TNA (10ª L; 7ª C). Para n = 6 e o
início na TNA (27ª L; 16ª C), quais itens comporão a amostra?

7) Extrair uma amostra de n = 5 itens da população de N = 32 estaturas
ordenada em um rol crescente e calcular: a média, a mediana, o ponto médio, a
moda, a amplitude, a variância, o desvio padrão e o coeficiente de variação.
Justificar a técnica de amostragem utilizada. Início de leitura na TNA (22ª L; 25ª
C).
1,64 1,65 1,65 1,68 1,681,69 1,69 1,71 1,72 1,721,74 1,76 1,76 1,77 1,771,77 1,78 1,78 1,79 1,791,79 1,80 1,80 1,81 1,811,82 1,82 1,83 1,84 1,851,85 1,87

APÊNDICE A: SOMATÓRIO
O somatório facilita bastante a indicação e a formulação de medidas,
bem como algumas operações algébricas desenvolvidas pela Estatística.
Notação: (sigma maiúsculo)
xxxx n
n
ii
+++=∑=
...21
1
Que se lê somatório de xi, para i variando de 1 a n.
Propriedades:
Considerando a e b constantes:
a)∑
=
=++++=n
i
naaaaaa1
...
b)∑∑
==
=n
i
i
n
i
i xaax11
c)
( ) ∑∑∑===
+=+n
i
i
n
i
i
n
i
ii ybxabyax111

APÊNDICE B: USANDO O EXCEL
B1. Amostragem
Exemplo
No exemplo N=18 e n=6.
Abre-se o menu FERRAMENTAS e escolhe-se a opção ANALISE DE
DADOS.
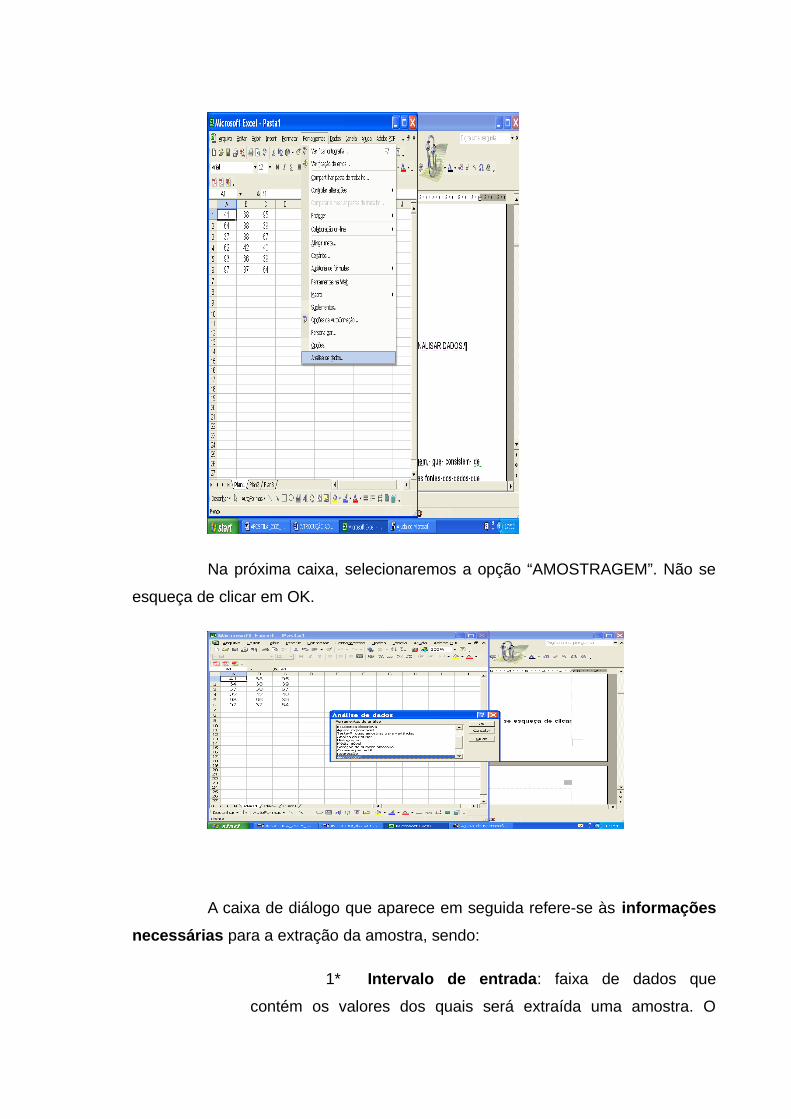
Na próxima caixa, selecionaremos a opção “AMOSTRAGEM”. Não se
esqueça de clicar em OK.
A caixa de diálogo que aparece em seguida refere-se às informações
necessárias para a extração da amostra, sendo:
1* Intervalo de entrada: faixa de dados que
contém os valores dos quais será extraída uma amostra. O

Microsoft Excel extrai as amostras da primeira coluna, depois da
segunda coluna, e assim por diante.
2* Rótulos: Selecione esta opção se a primeira
linha ou coluna do intervalo de entrada contiver rótulos.
Desmarque esta opção se o intervalo de entrada não contiver
rótulos; o Excel gera os rótulos de dados adequados para a
tabela de saída.
3* Método de amostragem: Clique em Periódico ou
Aleatório para indicar a técnica de amostragem a ser utilizada.
Periódico: corresponde a amostragem sistemática; e Aleatório:
a amostragem aleatória simples.
4* Período: corresponde ao intervalo de
amostragem.
5* Número de amostras: corresponde ao tamanho
da amostra.
6* Intervalo de saída: Insira a referência para a
célula superior esquerda da tabela de saída. Os dados são
escritos em uma única coluna abaixo da célula. Se selecionar
Periódico, o número de valores na tabela de saída será igual ao
número de valores no intervalo de entrada (tamanho da
população), dividido pelo intervalo de amostragem. Se você
selecionar Aleatório, o número de valores na tabela de saída
será igual ao tamanho da amostra.
7* Nova planilha: Clique nesta opção para inserir
uma nova planilha na pasta de trabalho atual e colar os
resultados começando pela célula A1 da nova planilha. Para
nomear a nova planilha, digite um nome na caixa.
8* Nova pasta de trabalho: Clique nesta opção
para criar uma nova pasta de trabalho e colar os resultados em
uma nova planilha na nova pasta de trabalho.

Finalmente, pressionando o botão OK, obteremos a amostra desejada.
B2. Geração de números aleatórios
Abre-se o menu FERRAMENTAS e escolhe-se a opção ANALISE DE
DADOS.
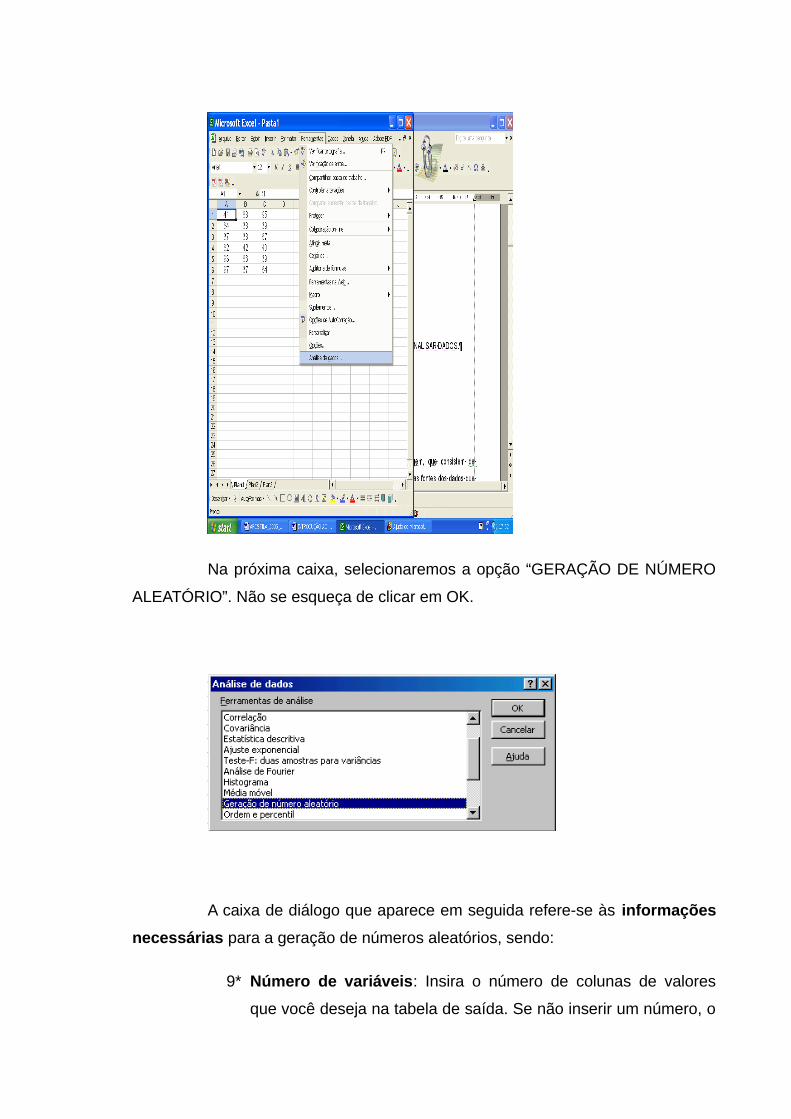
Na próxima caixa, selecionaremos a opção “GERAÇÃO DE NÚMERO
ALEATÓRIO”. Não se esqueça de clicar em OK.
A caixa de diálogo que aparece em seguida refere-se às informações
necessárias para a geração de números aleatórios, sendo:
9* Número de variáveis: Insira o número de colunas de valores
que você deseja na tabela de saída. Se não inserir um número, o

Microsoft Excel preencherá as colunas da tabela de saída
especificada.
10* Número de números aleatórios: Insira a quantidade de
números aleatórios que se deseja. Cada número aleatório
aparece em uma linha da tabela de saída. Se você não inserir um
número, o Microsoft Excel preencherá todas as linhas da tabela
de saída especificada.
11* Distribuição: Selecione o modelo de distribuição que se
deseja usar para criar valores aleatórios (uniforme, normal,
Bernoulli, binomial, Poisson, padronizada, discreta). Para sorteio
de itens de uma população para compor uma amostra usa-se a
distribuição uniforme.
12* Parâmetros: Insira um valor ou valores para caracterizar a
distribuição selecionada.
13* Semente aleatória: Insira um valor opcional a partir do qual
números aleatórios possam ser gerados. Pode-se voltar a usar
este valor para produzir os mesmos números aleatórios
posteriormente.
14* Intervalo de saída: Insira a referência para a célula superior
esquerda da tabela de saída.
15* Nova planilha: Clique nesta opção para inserir uma nova
planilha na pasta de trabalho atual e colar os resultados
começando pela célula A1 da nova planilha. Para nomear a nova
planilha, digite um nome na caixa.
16* Nova pasta de trabalho: Clique nesta opção para criar uma
nova pasta de trabalho e colar os resultados em uma nova
planilha na nova pasta de trabalho.
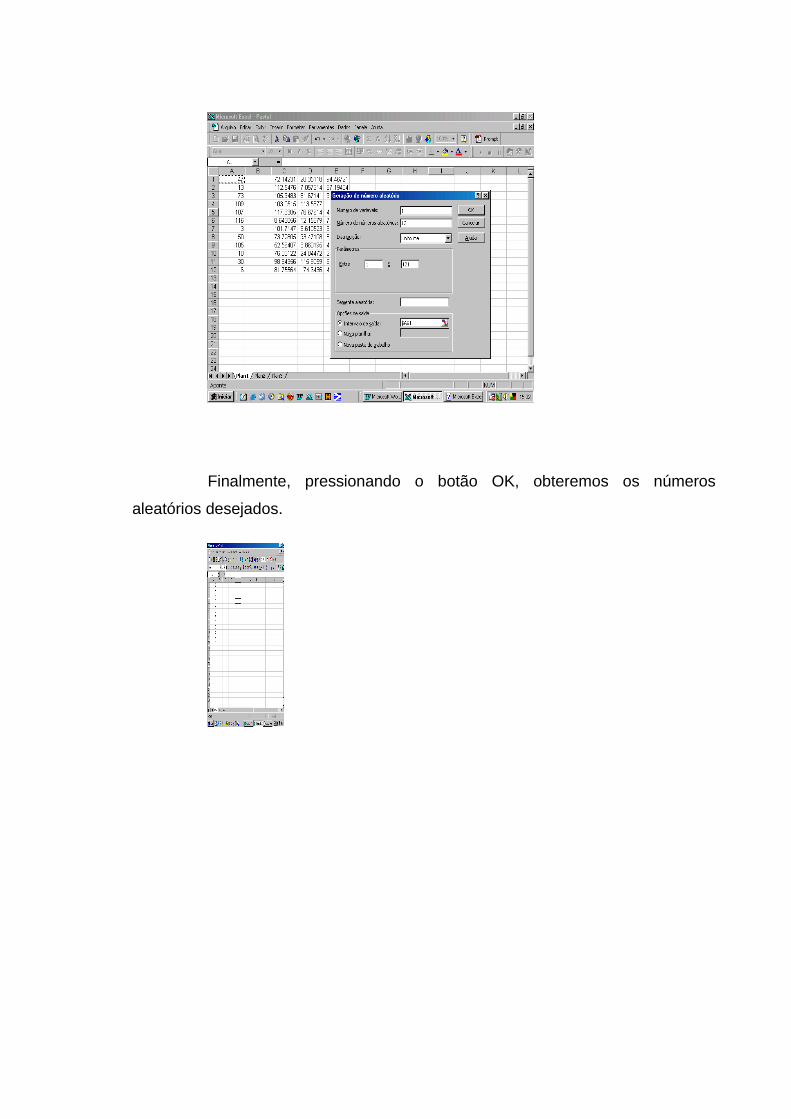
Finalmente, pressionando o botão OK, obteremos os números
aleatórios desejados.

3 RESUMO E APRESENTAÇÃO DE DADOS
Introdução
No capítulo anterior foram vistas as técnicas de amostragem, que
consistem de procedimentos para coletar amostras de uma população, que são
as fontes dos dados que serão usados para responder as questões levantadas
sobre a população. Portanto, o próximo passo é começar o desenvolvimento de
métodos para resumo, organização e apresentação de dados para permitir a sua
analise.
O objetivo deste capítulo, portanto, é apresentar técnicas que tem por
finalidade resumir, organizar e apresentar conjuntos de dados numéricos, de
modo a facilitar a análise desses dados.
Para facilitar este estudo os conjuntos de dados serão classificados
como pequenos e grandes. Assim, se um conjunto de dados tiver 30 ou menos
valores a análise será feita sem o agrupamento em classe. Caso o conjunto de
dados tenha mais do que 30 valores então primeiramente será feito o
agrupamento em classe de acordo com o tipo de variável considerada. O valor 30
é apenas um ponto de referência escolhido arbitrariamente e dependendo da
situação pode-se considerar o agrupamento com mais ou menos valores
envolvidos.
Os dados observados podem ser classificados em dois tipos:
categorizados e numéricos. Dados categorizados referem-se a observações
que são classificadas em categorias de modo que o conjunto de dados consiste
de frequência de contagens das ocorrências das categorias. Tais dados ocorrem
em grande quantidade em quase todos os campos do conhecimento que
necessitam realizar estudos quantitativos, particularmente nas ciências sociais.
Em um estudo de afiliações religiosas, as pessoas podem ser classificadas nas
seguintes categorias: católicas, protestantes, judeus, espíritas, ou outras. Diante
da pergunta: Você possui automóvel? A resposta é categorizada, podendo ser
“sim” ou “não”. Dados numéricos podem ser classificados como contínuos e
discretos. Um dado numérico é contínuo se é proveniente de uma mensuração,

por exemplo: resistência a compressão de corpos-de-prova de concreto, altura e
peso de pessoas. Um dado numérico é discreto se é proveniente de contagem
por exemplo produção de carros FIAT no mês de janeiro deste ano, quantidade de
alunos de Probabilidade e Estatística de uma determinada turma da Universidade
que responderão presença hoje.
Resumo, organização e apresentação de pequenos conjuntos de dados numéricos.
1.1.1 Ordenação e estatísticas de ordem
Um método conveniente para organizar dados, quando n, o tamanho
da amostra, não for tão grande, é por meio de um arranjo ordenado. A
ordenação pode ser ou do maior para o menor (ordenação decrescente) ou do
menor para o maior (ordenação crescente). Quando os dados (x1, x2, x3, ..., xn)
são ordenados para dar x(1) ≤ x(2) ≤ x(3) ≤ ... x(n), os valores x(1), x(2), x(3), ... x(n) são
chamados de estatísticas de ordem dos dados. Em particular,
x(1) = min (x1, x2, x3, ..., xn) = a menor observação
x(n) = max (x1, x2, x3, ..., xn) = a maior observação,
são estatísticas de ordem especiais que serão usadas mais tarde.

Exemplo 3.1
i xi x(i)
1 29 18
2 18 20
3 26 22
4 22 24
5 24 26
6 20 29
A coluna xi corresponde às observações amostrais registradas na
ordem de extração da amostra e a coluna x(i) as observações amostrais são as
estatísticas de ordem.
Assim, neste exemplo,
18)1( =x
e
29)6( =x
que são o menor e o maior valor, respectivamente, dos dados.
1.1.2 Medidas de Posição ou de Tendência Central
As medidas de posição têm por objetivo representar, de forma sintética,
um conjunto de dados observados. Dizendo de outra forma, essas medidas são
usadas para sintetizar em um único número o conjunto de dados observados. Tais
medidas orientam-nos quanto à posição da distribuição no eixo X (o eixo dos
números reais), possibilitando que duas séries de dados possam ser comparadas
entre si realizando o confronto desses números. São também chamadas de
medidas de tendência central, pois, representam as características pelos seus
valores “centrais”, em torno das quais tendem a se concentrar os dados.

3.1.2.1 Média Aritmética
A medida de posição mais comum é a média aritmética, ou
simplesmente média. Sendo as n observações indicadas por x1, x2, x3, ..., xn, a
média aritmética x é:
x =
ixn
n
i∑
=1
1
3.1
Exemplo 3.2
Determinar a média aritmética dos valores: 3, 7, 10, 8, 11.
x = (3 + 7 + 10 + 8 + 11)/5 = 8
3.1.2.2 Média Ponderada
Usada quando se torna necessário valorizar diferentemente, ou seja,
dar pesos diferentes para os dados que entrarão no cálculo da média.
∑
∑
=
==++++++
=n
i
i
n
i
ii
n
nnp
w
xw
www
xwxwxwx
1
1
21
2211
3.2
Na expressão 3.2, ∑
=
⋅n
i
ii xw
é a soma dos produtos de cada xi pelo
seu respectivo peso wi, e ∑
=
n
i
iw1 é a soma dos pesos. Observe que quando os
pesos são todos iguais, a expressão 3.2 se reduz à 3.1, que é média aritmética.
Exemplo 3.3

Um grupo de 64 pessoas, que trabalha em uma empresa, tem a
seguinte distribuição salarial, em quantidade de salários-mínimos:
Quantidade de
trabalhadores
Salário (em
salários-mínimos)20 2,515 412 810 167 30
Para calcular a média salarial (por dia) de todo o grupo devemos usar a
média aritmética ponderada:
964
576
710121520
7301016128154205,2 ==++++
×+×+×+×+×px
O salário médio dos empregados dessa empresa em termos de
salários-mínimos é então igual a 9.
3.1.2.3 Média Geométrica
Consideremos uma coleção formada por n números racionais não
negativos: x1, x2, x3, ..., xn. A média geométrica entre esses n números é a raiz n-
ésima do produto entre esses números, isto é:
nng xxxxx ⋅⋅⋅⋅= 321 3.3
É aplicada quando se está diante de casos de qualidades
multiplicativas.
Exemplo 3.4
Nos dois últimos anos o faturamento de uma empresa cresceu 22,5%
no primeiro e 60% no segundo ano. Em média, quanto cresceu por ano? Ao
responder essa questão, muitos pensam na média aritmética: (22,5% + 60%)/2 =
41,25%

Será que se o crescimento tivesse sido de 41,25% a cada ano, teria
produzido o mesmo efeito? Pois é esta a questão que se coloca quando se pede
uma média: deve ser o número que, colocado em lugar de cada número dado,
produz o mesmo efeito que aqueles produziriam acumulativamente.
Partindo de um faturamento de R$ 100, um aumento de 22,5% o eleva
para R$ 122,50 e, sobre este último, um aumento de 60% o eleva para R$ 196.
Repetindo o raciocínio com a média aritmética, os R$ 100 aumentados de 41,25%
viram R$ 141,25, que aumentados novamente de 41,25% viram R$ 199,52
-portanto não chegando aos mesmos R$ 196.
E como resolver a questão? Que média devemos calcular?
Veja: partindo de 100 multiplicamos por 1,225 (que é 1 + 22,5%) e
depois por 1,60 (que é 1 + 60%) para chegar aos 196.
O que precisamos descobrir é uma taxa t (taxa média) de modo que
partindo de 100 e multiplicando por (1 + t), depois novamente por (1 + t),
cheguemos aos mesmos 196. Daí, o que queremos é descobrir t na equação (1 +
t) (1 + t) = 1,225 x 1,60, ou seja, (1 + t) é a média geométrica de 1,225 e 1,60.
Extraindo a raiz quadrada em ambos os membros da equação obtemos
1 + t = 1,40, logo a taxa média é 40%. Confira: partindo de R$ 100, um aumento
de 40% eleva para R$ 140 e com outro aumento de 40% chegamos aos R$ 196.
Exemplo 3.5
A média geométrica entre os números 12, 64, 126 e 345, é dada por:
7634512664124 =×××=gx
Aplicação prática: Dentre todos os retângulos com a área igual a 64
cm², qual é o retângulo cujo perímetro é o menor possível, isto é, o mais
econômico? A resposta a este tipo de questão é dada pela média geométrica
entre as medidas do comprimento a e da largura b, uma vez que a.b=64.
A média geométrica G entre a e b fornece a medida desejada.

864 ==×= baxg
Resposta: É o retângulo cujo comprimento mede 8 cm e é lógico que a
altura também mede 8 cm, logo só pode ser um quadrado! O perímetro neste
caso é p=32 cm. Em qualquer outra situação em que as medidas dos
comprimentos forem diferentes das alturas, teremos perímetros maiores do que
32 cm.
Interpretação gráfica: A média geométrica entre dois segmentos de reta
pode ser obtida geometricamente de uma forma bastante simples.
Sejam AB e BC segmentos de reta. Trace um segmento de reta que
contenha a junção dos segmentos AB e BC, de forma que eles formem
segmentos consecutivos sobre a mesma reta.
Dessa junção aparecerá um novo segmento AC. Obtenha o ponto
médio O deste segmento e com um compasso centrado em O e raio OA, trace
uma semi-circunferencia começando em A e terminando em C. O segmento
vertical traçado para cima a partir de B encontrará o ponto D na semi-
circunferência. A medida do segmento BD corresponde à média geométrica das
medidas dos segmentos AB e BC.
De acordo com o teorema: “a medida do ângulo inscrito é igual a
metade do arco subtendido”, então o ângulo ADC é reto e, portanto, pelo teorema
de Pitágoras:
( )222BCABDCAD +=+ 3.4
Como os triângulos ABD e BDC são triângulos retângulos, por
construção, pelo mesmo teorema de Pitágoras obtém-se:

222BDABAD += 3.5
e
222BDBCDC += 3.6
Substituindo as expressões 3.5 e 3.6 na expressão 3.4, obtém-se
BCABBCABBDBCBDAB ×++=+++ 2222222
3.7
Simplificando a expressão 3.7, obtém-se
BCABBD ×= 3.8
3.1.2.4 Média Harmônica
Seja uma coleção formada por n números reais positivos: x1, x2, x3, ...,
xn. A média harmônica H entre esses n números é a divisão de n pela soma dos
inversos desses n números, ou seja é o inverso da média aritmética dos inversos
dos n números reais positivos dados, isto é:
∑=
=n
i i
h
x
nx
1
1
3.9
ou
∑=
=n
i ih xx
n
1
1
3.10
Assim, estamos realizando o somatório sobre todos os inversos dos n
números reais positivos dados.
Utilizamos a Média Harmônica quando estamos tratando de
observações de grandezas inversamente proporcionais como, por exemplo,

velocidade e tempo. A média harmônica é particularmente recomendada para
uma série de valores que são inversamente proporcional, como para o cálculo da
velocidade média, custo médio de bens comprados com uma quantia fixa.
Em uma certa situação, a média harmônica provê a correta noção de
média. Por exemplo, se metade da distância de uma viagem é feita a 40 km por
hora e a outra metade da distância a 60 km por hora, então a velocidade média
para a viagem é dada pela média harmônica, que é 48; isso é, o total de tempo
para a viagem seria o mesma se se viajasse a viagem inteira a 48 quilômetros por
hora. (Note, entretanto que se se tivesse viajado por metade do tempo em uma
velocidade e a outra metade na outra velocidade, a média aritmética, nesse caso
50 km por hora, proveria a correta noção de média).
Da mesma forma, se um circuito elétrico contém duas resistências
conectadas em paralelo, uma com uma resistência de 40 ohm e outra com 60
ohm, então a média das resistências das duas resistências é 48 ohm; isso é, a
resistência do circuito é a mesma que a de duas resistências de 48 ohm
conectadas em paralelo. Isso não é pra ser confundido com sua resistência
equivalente, 24Ω, que é a resistência necessária para substituir as duas
resistências em paralelo. Note que a resistência equivalente é igual a metade do
valor da média harmônica de duas resistências em paralelo.
Em finanças, a média harmônica é usada para calcular o custo médio
de ações compradas durante um período. Por exemplo, um investidor compra
$1000 em ações todo mês durante três meses. Se os preços na hora de compra
forem de $8, $9 e $10, então o preço médio que o investidor pagou por ação é de
$8,926. Entretanto, se um investidor comprasse 1000 ações por mês, a média
aritmética seria usada.
Exemplo 3.6: Velocidade média
Um carro se desloca de Belo Horizonte até a cidade de Ubá (distância
de 296 Km), mantendo na ida uma velocidade média de 60 Km/h e na volta a Belo
Horizonte mantendo a velocidade média de 100 Km/h. Qual é a velocidade média
durante todo o trajeto?

Utilizando a expressão 3.9 obtém-se:
hkmxh /75
100
1
60
12 =+
=
Este problema é uma aplicação imediata da média harmônica e a
resposta acima deve dar um susto em muita gente descuidada, pois a maioria das
pessoas "gostaria" que fosse 80 km/h!
O tempo total do percurso BH-Ubá-BH é
h893,7100
296
60
296 =+
Se usarmos o valor médio de 80 km/h, o tempo total do percurso é:
h4,780
2962 =×
,
cujo resultado é diferente do anterior.
Usando o valor da média harmônica para determinar o tempo total do
percurso, obtém-se
h893,775
2962 =×
cujo resultado é o mesmo que o obtido calculando-se o tempo de ida
quando se mantém a velocidade de 60km/h e o de volta com a velocidade de
100km/h. Portanto, deve-se utilizar a média harmônica para calcular a velocidade
média do percurso total.
3.1.2.5 Mediana
A segunda medida de posição mais largamente usada é a mediana.
Em palavras, a mediana de um conjunto de dados é o valor central dos dados
ordenados. Assim, se as estatísticas de ordem dos dados são x (1), x(2), x(3), ..., x(n) ,
a mediana, denotada por ~x , é definida por

+
=
+
+
par. for n quando ,xx2
1
impar, for n quando , x
2
n
2
n
2
1n
1
~x
3.11
Exemplo 3.7
Encontrar a mediana para os dados 3,5; 2,7; 0,9; 3,1; 4,3.
Solução: os dados ordenados são: 0,9; 2,7; 3,1; 3,5; 4,3. Como n = 5,
(n + 1)/2 = 3. Isto é, a mediana é o terceiro termo dos dados ordenados. Portanto
~x = 3,1.
Exemplo 3.8
Encontrar a mediana para os dados: 15, 8, 10, 7, 14, 5.
Solução : os dados ordenados são: 5, 7, 8, 10, 14, 15. Como n = 6
~x = (x(6/2) + x(6/2 + 1))/2 = (x(3) + x(4))/2 = (8 + 10)/2 = 9
3.1.2.6 Comparação entre a Média Aritmética e a Mediana
A média aritmética é o “centro de gravidade” do conjunto de dados. Isto
é, é o ponto de equilíbrio das observações. A Fig. 3.1 ilustra essa propriedade
para os seguintes dados observados: 3, 1, 4, 7, 6.
= 4,21 2 3 4 5 6 7
Figura 3.1: ilustração da propriedade da média.

Um outro modo de demonstrar essa propriedade é observar que a
soma dos desvios entre as observações e x é zero. Isto é,
( )x xii
n
− ==∑
1
0
A mediana ~x divide os dados ordenados ao meio, isto é, 50% dos
dados são menores que ~x e 50% são maiores que ~x .
Uma consequência dessas propriedades é que x é mais sensível aos
valores extremos que ~x . Por exemplo, suponha que consideramos os quatro
números (1, 2, 4, 7), a média é x = 14/4 = 3,5 e a mediana é ~x = 3. Agora, se
adicionarmos o número 31 a esse conjunto de dados obtemos (1, 2, 4, 7, 31), e os
novos valores da média e da mediana são x = 45/5 = 9 e ~x = 4. Observamos que
a x está longe de ser um valor central para o conjunto de dados onde quatro dos
cinco dados são menores que x e somente um é maior que x . Ao contrário, o
efeito de “31” sobre ~x é simplesmente adicionar um valor a mais ao conjunto de
dados. A falta de sensibilidade a grandes valores extremos por parte da mediana
torna-a um valor central “melhor” que x para a distribuição de dados que é
fortemente assimétrica.
Uma outra comparação de x e ~x é fornecida pelas seguintes
propriedades. Primeiro, o valor de c (uma constante) que minimiza ( ) 2∑ −
Ax
cxε é c =
x . Segundo, o valor de k (uma constante) que minimiza ∑ −
Ax
kxε é k = ~x .
Portanto, se quisermos obter a menor soma dos desvios ao quadrado para um
conjunto de dados, adotaremos desvios em torno de x , mas se a menor soma de
desvios absolutos é desejada os desvios terão de ser obtidos em torno de ~x .
Uma outra propriedade digna de nota é que para qualquer distribuição
simétrica x = ~x .

A despeito da média e mediana serem as medidas de posição mais
usadas, existem outras medidas que são mais apropriadas em função de certas
particularidades dos dados observados, conforme veremos a seguir.
3.1.2.7 Moda
Define-se a moda como o valor observado de maior frequência.
Exemplo 3.9
Sejam os seguintes dados numéricos:
10, 15, 14, 11, 16, 14.
Determinar a moda.
Como o valor numérico de maior frequência é o 14 a moda é
Mo = 14
3.1.2.8 Ponto Médio
O ponto médio é a semi-soma dos valores extremos de uma
distribuição, ou seja:
PM = (x(1) +x(n))/2 3.12
Exemplo 3.10
Com os dados do exemplo 3.9, calcular o ponto médio.
Usando a expressão 3.12, obtém-se
132
1610 =+=PM
Uma desvantagem do ponto médio é que ele é fortemente dependente
dos valores extremos de uma distribuição e, portanto, poderá ocorrer uma grande
flutuação de uma amostra para outra amostra. Sua vantagem é a facilidade para a
sua determinação.

3.1.2.9 Percentil
O percentil 100p, que é também denominado de separatriz de ordem p,
divide o conjunto ordenado de dados em dois subconjuntos de tamanhos na
elementos, à esquerda, e nb elementos, à direita, tais que:
ba
a
nn
np
+=
3.13
Então, o percentil 10 é o valor da distribuição do conjunto de dados que
deixa a sua esquerda 10% do total dos elementos.
Há alguns percentis de interesse, que decorrem de valores particulares
de p. São eles:
Mediana – divide o conjunto ordenado de dados em 2 partes, portanto,
p = 0,50.
Quartil – divide o conjunto de dados ordenados em 4 partes. Assim, um
conjunto de dados tem 3 quartis, a saber:
O primeiro quartil, Q1, para p = 0,25;
O segundo quartil, Q2, para p = 0,50, portanto é igual a mediana;
O terceiro quartil, Q3, para p = 0,75;
Decil – divide o conjunto de dados ordenados em 10 partes. Assim, o
conjunto de dados tem 9 decis:
O primeiro decil, D1, para p = 0,10;
O segundo decil, D2, para p = 0,20; etc
O nono decil, D9, para p = 0,90.
Centil – divide o conjunto de dados ordenados em 100 partes. Assim, o
conjunto de dados tem 99 centis:
O primeiro centil, C1, para p = 0,01;

O segundo centil, C2, para p = 0,02; etc;
O 99-ésimo centil, C99, para p = 0,99.
Para calcular o percentil 100p%, primeiro é necessário colocar as
observações amostrais em ordem crescente. O percentil 100p% é a observação
de ordem p(n + 1), onde n é o tamanho da amostra. Se o número de ordem,
assim calculado, não for um número inteiro é necessário fazer interpolação linear.
Exemplo 3.11
Considere as observações da tabela 3.1 sobre a resistência a tração
(em MPa) de uma determinada liga metálica. Calcular:
O terceiro quartil;
O terceiro decil; e
O quadragésimo terceiro centil.
Tabela 3.1: Resistência a tração de 28 corpos de prova de uma
determinada liga metálica.
105 97 163 134
131 180 178 157
174 99 107 101
167 171 121 165
154 135 149 151
153 183 169 142
115 175 160 172
Solução:
O primeiro passo é ordenar os dados observados em ordem crescente,
conforme apresentado na tabela 3.2.
Tabela 3.2: Resistência a tração de 28 corpos de prova de uma
determinada liga metálica apresentada em ordem crescente.

(1)
97
(2)
99
(3)
101
(4)
105(5)
107
(6)
115
(7)
121
(8)
131(9)
134
(10)
135
(11)
142
(12)
149(13)
151
(14)
153
(15)
154
(16)
157(17)
160
(18)
163
(19)
165
(20)
167(21)
169
(22)
171
(23)
172
(24)
174(25)
175
(26)
178
(27)
180
(28)
183
A ordem do terceiro quartil é
0,75(28+1) = 21,75.
Então Q3 está entre a vigésima primeira,x(21), e a vigésima segunda,
x(22), observação. Fazendo-se a interpolação, ou seja, a seguinte regra de três:
Q3 – x(21) 0,75
x(22) – x(21) 1
Q3 = x(21) + 0,75(x(22) - x(21)),
ou seja
Q3 = 169 + 0,75(171 - 169), portanto
Q3 = 171.
A ordem do terceiro decil é
0,30(28+1) = 8,7.
Então D3 está entre a oitava,x(8), e a nona, x(9), observação. Fazendo-
se a interpolação
D3 = x(8) + 0,70(x(9) - x(8)),
ou seja

D3 = 131 + 0,70(134 - 131), portanto
D3 = 133.
A ordem do quadragésimo terceiro centil é
0,43(28+1) = 12,47.
Então C43 está entre a décima segunda,x(12), e a décima terceira, x(13),
observação. Fazendo-se a interpolação
C43 = x(12) + 0,47(x(13) - x(12)),
ou seja
C43 = 149 + 0,47(151 - 149), portanto
C43 = 150.
3.1.2.10 Conclusão
Oito estatísticas diferentes foram apresentadas como medida de
posição para conjuntos de dados observados. Nenhuma delas é apropriada para
todos os tipos de dados, embora as medidas mais frequentemente usadas sejam
a média aritmética e a mediana.
Neste ponto, é bom revermos o objetivo desse capítulo. Um conjunto
de estatísticas é desejado para que possamos representar, sintetizar, resumir ou
descrever um conjunto de dados. A primeira estatística incluída no conjunto de
estatísticas descritivas é uma medida de posição. Nossa filosofia é que podemos
sintetizar ou resumir nossos dados por uma estatística chave. Portanto, temos de
reduzir nossos dados a um número que representa o tamanho médio da variável.
A representação de uma distribuição ou conjunto de dados por uma
medida de posição pode distinguir distribuições somente com relação à posição.
No entanto, há muitas distribuições que mesmo tendo o mesmo valor da média
aritmética, por exemplo, são distribuições muito diferentes. A Fig. 3.2 ilustra seis
diferentes distribuições que têm a mesma média aritmética 4.
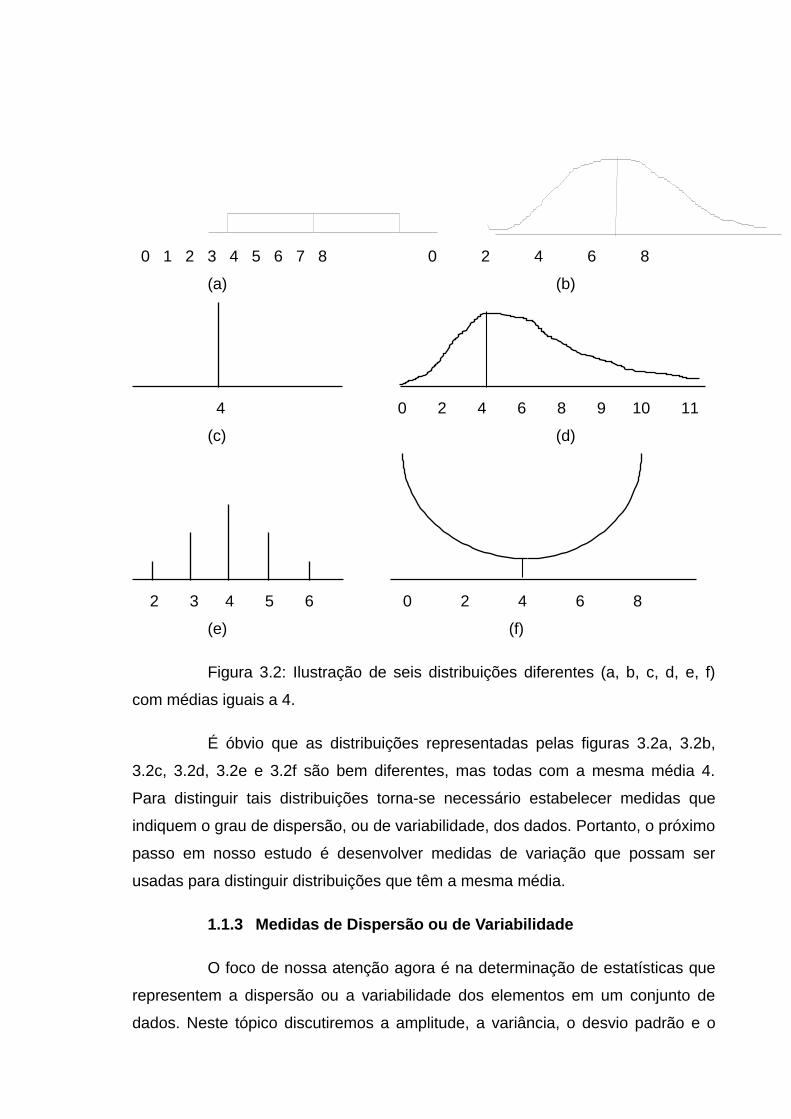
0 1 2 3 4 5 6 7 8 0 2 4 6 8
(a) (b)
4 0 2 4 6 8 9 10 11
(c) (d)
2 3 4 5 6 0 2 4 6 8
(e) (f)
Figura 3.2: Ilustração de seis distribuições diferentes (a, b, c, d, e, f)
com médias iguais a 4.
É óbvio que as distribuições representadas pelas figuras 3.2a, 3.2b,
3.2c, 3.2d, 3.2e e 3.2f são bem diferentes, mas todas com a mesma média 4.
Para distinguir tais distribuições torna-se necessário estabelecer medidas que
indiquem o grau de dispersão, ou de variabilidade, dos dados. Portanto, o próximo
passo em nosso estudo é desenvolver medidas de variação que possam ser
usadas para distinguir distribuições que têm a mesma média.
1.1.3 Medidas de Dispersão ou de Variabilidade
O foco de nossa atenção agora é na determinação de estatísticas que
representem a dispersão ou a variabilidade dos elementos em um conjunto de
dados. Neste tópico discutiremos a amplitude, a variância, o desvio padrão e o

coeficiente de variação. Há outras medidas, certamente, mas essas são as mais
usadas.
3.1.3.1 Amplitude
A amplitude de um conjunto de dados é definida como a diferença entre
o maior e o menor valor do conjunto. Em termos de estatística de ordem
R = x(n) - x(1) 3.14
Exemplo 3.12
Determinar a amplitude do seguinte conjunto de observações: 54, 64,
51, 58, 50.
Utilizando a expressão 3.14, a amplitude é:
R = 64 - 50 = 14.
3.1.3.2 Variância e Desvio Padrão
Como temos as medidas de posição para qualquer conjunto de dados
que desejamos descrever, é razoável discutir a dispersão dos dados relativos à
medida de posição. A medida mais comum de dispersão é chamada de variância.
A variância para dados não agrupados é definida como: Se x1, x2, ..., xn representa
um conjunto de n observações da variável X, a variância de x, denotada por s2, é
definida por
( )sn
x xii
n2 2
1
1
1=
−−
=∑
3.15
Se as observações xi e x forem inteiros, o uso da equação 3.15 é mais
conveniente para o cálculo da variância. Mas, quando frações e decimais são
envolvidas, a seguinte fórmula equivalente é mais útil:
sn
xn
xi ii
n
i
n2 2
1
2
1
1
1
1=
−−
==
∑∑3.16

A expressão 3.16 é obtida por meio do desenvolvimento da expressão
3.15. Esta demonstração fica a cargo do aluno.
A variância é uma estatística descritiva que fornece uma medida de
como os elementos de um conjunto de dados estão dispersos ao redor de sua
média. Assim, deve-se observar que os valores pequenos de s2 estão associados
a valores observados concentrados em torno da média, enquanto valores
elevados de s2 correspondem a valores observados bastante dispersos.
Um problema da variância é que é uma quantidade quadrática. Isto é,
se X é medida em kg, a variância é expressa em kg2, que é uma unidade de
medida não familiar. Então, é útil obter uma estatística descritiva que seja
expressa na mesma unidade da variável cuja dispersão está sendo descrita. A
estatística mais comum para esse propósito é o desvio padrão, que é definido
como a raiz quadrada positiva da variância e é representado por s. Ou seja,
s s= 23.17
Para sintetizar dados, é comum usar duas estatísticas descritivas.
Essas estatísticas são usualmente a média aritmética e o desvio padrão (ou a
variância). Para a maior parte dos conjuntos de dados, a média aritmética, como
uma medida de posição, e o desvio padrão, como uma medida de dispersão,
resume em dois números muitas das informações sobre a variável que está sendo
estudada.
Nesta disciplina, apesar de algumas regras existentes e não bem
definidas, utilizaremos a tendência geral de indicar o desvio padrão com 2
algarismos significativos, além dos zeros à esquerda.
Exemplo 3.13
Usando os dados do exemplo 3.12, calcular a variância e o desvio
padrão.
i ix 2ix ( ) 2xxi −
1 54 2916 1,96

2 64 4096 73,96
3 51 2601 19,36
4 58 3364 6,76
5 50 2500 29,16
Total 277 15477 131,20
1. Cálculo da média
Usando a expressão 3.1, obtém-se
4,555
277 ==x
2. Cálculo da variância
Usando a expressão 3.15, obtém-se
8,3220,13115
12 =×−
=s
Usando a expressão 3.16, obtém-se
8,322775
115477
15
1 22 =
×−
−=s
3. Cálculo do desvio-padrão
Usando a expressão 3.17, obtém-se
7,58,32 ==s
3.1.3.3 Coeficiente de Variação
Os pesos de pulgas são mais variáveis que os pesos de elefantes?
Observamos que pulgas não podem variar de peso em uma grande quantidade;
isto é, a amplitude de possíveis pesos (em daN) para pulgas é muito estreita. Por

outro lado, a amplitude de pesos possíveis (em daN) de elefantes adultos é
bastante grande. Assim, espera-se que a variância para uma amostra de pesos
de pulgas é bem menor que a variância para uma amostra de pesos de elefantes.
Para responder questões desse tipo, desejamos um medida de variabilidade
relativa ao tamanho das observações. A medida deve ser um número puro de tal
modo que os resultados não dependam de qualquer unidade particular de
medida. O coeficiente de variação é essa medida e é definida como: Se x e s
são a média e desvio padrão, respectivamente, para um conjunto de observações
positivas, o coeficiente de variação é denotado por Cv e definido por:
%100×=x
sCv
3.18
Exemplo 3.14
Usando os dados do exemplo 3.13, calcular o coeficiente de variação.
Pela fórmula 3.18, obtém-se
%34,10%1004,55
73,5=×=Cv
1.1.4 Apresentação de dados por meio de gráficos
3.1.4.1 Diagrama de pontos
O diagrama de pontos é uma apresentação útil de dados para o caso
de amostras de pequeno tamanho. É construído traçando uma linha com uma
escala que cubra toda a faixa de valores dos dados e marcando os dados
individuais nesta linha.
Exemplo 3.15
Representar os dados abaixo em um diagrama de pontos.

98 105 108 107 95 104 109 102 119 117 99
110 107 98 114 103 112 101 107 108 106 100
113 112 104 101 92 93 94 115 118.
Estes dados estão compreendidos entre 95 e 120. Traçando um
segmento de linha com uma escala entre 90 e 120, representa-se os dados no
diagrama de pontos da Fig. 3.3.
90100110120
Figura 3.3: Diagrama de pontos do exemplo 3.15.
3.1.4.2 Diagrama de ramo e folhas
O diagrama de ramo e folhas é uma técnica utilizada para apresentar
dados permitindo uma boa visualização global desses dados. Para construir o
diagrama de ramo e folhas dividimos cada número em duas partes: um ramo,
consistindo pelos primeiros algarismos e uma folha, consistindo pelo último
algarismo. Em geral devem-se escolher poucos ramos em comparação ao
número de observações. A sugestão é utilizar entre 5 e 20 ramos. Uma vez que
os ramos foram definidos, eles são listados na margem esquerda do diagrama. Ao
lado de cada ramo são listadas as folhas correspondentes aos valores
observados na ordem em que os dados foram listados.
Exemplo 3.16
Utilizando os dados do exemplo 3.15, construir um diagrama de ramo e
folhas.

As tabelas 3.3, 3.4 e 3.5 ilustram a construção do diagrama de ramo e
folhas para os 31 dados relativos ao exemplo 3.15. Na tabela 3.3 foi usado 9, 10 e
11 como os ramos. Como foram utilizados poucos ramos na construção do
diagrama de ramo e folhas este ficou muito resumido não fornecendo, portanto,
muitas informações. Na tabela 3.4, cada ramo foi dividido em dois, um acrescido,
na sua representação, da letra I, e o outro ramo acrescido da letra S. Os ramos
com a letra I têm as folhas 0, 1, 2, 3, 4 e os ramos com a letra S têm as folhas 5,
6, 7, 8, 9. Percebe-se, neste caso, uma representação mais adequada dos dados.
Na tabela 3.5, cada um foi dividido em cinco ramos, um acrescido, na sua
representação, da letra a, que têm as folhas 0 e 1, outro acrescido da letra b, que
têm as folhas 2 e 3, e assim sucessivamente até o que foi acrescido da letra e,
que têm as folhas 8 e 9. Para este caso foi adotado um número excessivo de
ramos perdendo-se a informação a respeito da forma que os dados estão
distribuídos.
Tabela 3.3: Diagrama de ramo e folhas para o exemplo 3.15 usando 3
ramos.
R
amo
Folha F
requência
9 8 5 9 8 2 3 4 7
10 5 8 7 4 9 2 7 3 1 7 8 6 0 4 1 15
11 9 7 0 4 2 3 2 5 8 9

Tabela 3.4: Diagrama de ramo e folhas para o exemplo 3.15 usando 6
ramos.
R
amo
Folha F
requência
9I 2 3 4 3
9S 8 5 9 8 4
10I 4 2 3 1 0 4 1 7
10S 5 8 7 9 7 7 8 6 8
11I 0 4 2 3 2 5
11S 9 7 5 8 4

Tabela 3.5: Diagrama de ramo e folhas para o exemplo 3.15 usando 15
ramos.
Ramo Folha Frequência
9a 0
9b 2 3 2
9c 4 5 2
9d 0
9e 8 9 8 3
10a 1 0 1 3
10b 2 3 2
10c 4 4 5 3
10d 7 7 7 6 4
10e 8 9 8 3
11a 0 1
11b 2 3 2 3
11c 4 5 2
11d 7 1
11e 9 8 2
Para nos ajudar a encontrar os percentis os algarismos que
representam as folhas do diagrama de ramo e folhas da tabela 3.4 são dispostos
em ordem crescente resultando em um diagrama de ramo e folhas ordenado
conforme a tabela 3.6. Para ilustração, desde que n = 31, o primeiro quartil é a
observação que tem número de ordem
0,25(31+1) = 8.
Então Q1 é a oitava observação. Logo:
Q1 = 100.

Tabela 3.6: Diagrama ordenado de ramo e folhas para o exemplo 3.15
usando 6 ramos.
Ramo Folha Frequência
9I 2 3 4 3
9S 5 8 8 9 4
10I 0 1 1 2 3 4 4 7
10S 5 6 7 7 7 8 8 9 8
11I 0 2 2 3 4 5
11S 5 7 8 9 4
Organização, apresentação e resumo de grandes conjuntos de dados numéricos.
É praticamente inviável tirar conclusões diretamente baseadas em um
grande número de dados. Assim, se o tamanho do conjunto de dados for muito
grande, superior a 30, é de toda conveniência que estes dados sejam
organizados e/ou condensados previamente. O propósito desta seção é
desenvolver métodos para resumir, organizar e apresentar grandes conjuntos de
dados, de modo a facilitar sua interpretação.
1.1.5 Organização e apresentação dos dados
3.1.5.1 Distribuição de frequência
A introdução deste assunto será feita por meio de um exemplo por
considerar didaticamente melhor.
Exemplo 3.17
Considerem-se os resultados dos ensaios de tração em corpos-de-
prova de aço CA-50 apresentados na Tabela 3.7.

Tabela 3.7: Resultados, em MPa, dos limites de resistência em 95
corpos-de-prova de aço CA-50
490 461 569 657 353 647 628 598 647 549
569 775 510 579 559 382 637 618 559 598
539 667 637 441 667 657 579 579 735 471
598 588 500 637 549 775 598 579 686 500
500 500 637 539 618 637 804 441 598 569
500 677 510 657 755 588 745 539 569 559
510 647 667 579 373 422 628 588 706 294
883 569 598 579 431 637 588 667 628 667
510 735 579 471 588 657 490 569 471 569
569 598 588 628 598
Os dados da Tabela 3.7 estão registrados na ordem em que os ensaios
foram realizados. Nessa apresentação, os números não indicam qualquer coisa
de maior interesse. Naturalmente, a melhor maneira de dispor os dados depende
da pergunta que se deseja responder. No estudo da resistência a tração, muitas
perguntas podem surgir. Por exemplo: Qual a resistência média para os corpos-
de-prova ensaiados? Qual a porcentagem de ensaios com resistência mínima de
700 MPa? Qual o valor da resistência acima do qual encontramos 95% dos
resultados dos ensaios? Qual a faixa de variabilidade de todos os resultados?
Que intervalo, em torno da média, abrange 50% dos dados, com metade dessa
porcentagem à esquerda da média? O exame dos dados revela que a resistência
a tração dessas barras de aço varia desde o menor valor 294 MPa até o maior
valor 883 MPa; mas as demais perguntas não poderão ser respondidas
diretamente com os dados dessa tabela.
O primeiro passo para analisar dados numerosos é realizar seu
grupamento em classes. Para isso, devemos selecionar as classes, dentro dos
quais os dados são agrupados. Após o agrupamento dos dados em classe,

procedemos como se os dados dentro de cada classe fossem todos iguais ao
ponto médio da classe.
Para a seleção das classes, é conveniente atender aos seguintes
critérios:
1. as classes têm de ser selecionadas de maneira tal que elas sejam
mutuamente exclusivas e exaustivas para o conjunto de dados. Em
outras palavras, cada dado numérico tem de pertencer a uma e
somente uma classe;
2. o número de classes não pode ser nem muito grande nem muito
pequeno. O número é uma função crescente do tamanho da
amostra e é usualmente escolhido entre quatro e quinze;
3. classes que têm pontos médios inteiros são mais convenientes que
aquelas que têm pontos médios fracionários;
4. é mais conveniente que as classes tenham a mesma amplitude;
5. classes de limites abertos, tais como “maior que 40” e “menor que
60”, devem ser evitadas.
De toda essa discussão, a idéia importante é que um número razoável
de intervalos mutuamente exclusivos e exaustivos deve ser escolhido para
fornecer uma imagem realista da distribuição dos dados.
Uma sugestão útil, que pode auxiliar na escolha do número de classes,
é dada pela regra de Sturges. Esta regra estabelece que para agrupar n
observações, o número de classes necessário é aproximadamente:
( )( ) 12log
log += nk
3.19
onde log(n) é o logaritmo decimal de n. Por exemplo, usar 5 ou 6
classes para 25 observações, usar 7 ou 8 classes para 100 observações, e usar
10 ou 11 classes para 1000 observações. Deve ficar claro que o valor de k
fornecido por essa equação é apenas uma sugestão.
Uma outra sugestão é a fornecida por Ishikawa (ISHIKAWA, 1982):

Tabela 3.8: Sugestão de Ishikawa para o número de classes
n k
< 50 5 – 7
50 – 100 6 – 10
100 – 250 7 – 12
> 250 10 – 20
Para obter o intervalo aproximado de uma classe, deve-se proceder
como segue:
1) determinar a amplitude dos dados, R;
2) o intervalo de classe será no mínimo h = R/k, onde k é o número de
classes.
Em nosso exemplo, adotando como sugestão a regra de Sturges,
( )( ) 6,712log
95log =+=k
adotaremos k = 7.
Como
R = 883 - 294 = 589,
calcularemos
h = 589/7 = 84,1,
fazendo com que adotemos para h o valor 90, para que o ponto médio
tenha o mesmo número de algarismos significativos que os dos dados originais.
Dessa forma os limites da primeira classe são
294 384,
fechado à esquerda (para incluir o 294 no intervalo de classe) e aberto
à direita (para excluir o 384).

No entanto, como o valor de h escolhido é aproximado, devemos
calcular a amplitude de cálculo para distribuirmos o excesso por todas as classes,
não deixando que esse excesso fique apenas na última classe. Assim,
Rc = 7 x 90 = 630
como o excesso, Rc - R, é igual a 41, poderemos adotar como limite
inferior da primeira classe o valor 274. Assim, os limites da primeira classe serão:
274 364.
Os limites assim definidos são denominados limites aparentes da
primeira classe, por que eles não levam em conta a precisão dos resultados, nem
a regra normal de arredondamento que é:
manter o algarismo da casa de interesse, se o da casa seguinte (da
direita) for 0, 1, 2, 3, 4;
acrescentar uma unidade ao algarismo da casa de interesse, se o da
casa seguinte for 5, 6, 7, 8, 9.
Por exemplo, um número real, digamos, 17,53 é o ponto médio de um
intervalo, fechado a esquerda e aberto a direita, que pela regra de
arredondamento, tem como limites: 17,525 e 17,535. Ou seja,
17,52517,53517,53
Assim, qualquer número que cair dentro deste intervalo será
arredondado para 17,53.
Limites reais de uma determinada classe são aqueles que levam em
conta a precisão das medidas. Assim, os limites reais da primeira classe são:
273,5 363,5.

Fixados os limites reais da primeira classe, será fácil determinar os
limites reais das demais classes; bastará somar aos primeiros o intervalo de
classe h, constante; no caso presente h = 90. Os limites reais inferiores serão,
pois, 273,5 + 90 = 363,5; 363,5 + 90 = 453,5 ... ; analogamente, os limites reais
superiores serão 363,5 + 90 = 453,5; 453,5 + 90 = 543,5; ...
O ponto médio xi , da classe i, será a média aritmética dos limites reais
da classe i, assim, para a primeira classe o ponto médio é
x1 = (273,5 + 363,5)/2 = 318,5.
Achado o ponto médio da primeira classe os demais se obtêm pela
soma, sucessiva, do intervalo de classe h.
Como dito anteriormente, a significação do ponto médio é a seguinte:
em cada classe, supõe-se que todos os itens nela incluídos tenham valor igual ao
respectivo ponto médio da classe; o grupamento de dados em classes consiste,
portanto, em substituir os diversos valores diferentes, incluídos numa classe, por
igual número de itens todos iguais ao ponto médio da classe.
A seguir são distribuídos os dados pelas classes, determinando a
quantidade de dados em cada classe, que se denomina de frequência absoluta
simples ni.
Tabela 3.9: Distribuição de frequência para os dados da Tabela 3.7
i Limites reais Pt.médio xi Contagem ni fi (%) Ni Fi(%)1 273,5
363,5318,5
2 2,11 2 2,112 363,5
453,5408,5
6 6,32 8 8,423 453,5
543,5498,5
18 18,95 26 27,374 543,5
633,5588,5
40 42,11 66 69,47
5 633,5 723,5
678,5
21 22,11 87 91,586 723,5
813,5768,5
7 7,37 94 98,95

7 813,5 903,5
858,5 1 1,05 95 100,0
O quociente da frequência ni pelo total de itens de todas as classes, n,
é denominado frequência relativa simples (ou, por abreviação, “frequência”) da
i-ésima classe; representada por fi.
( ) %100% ×=n
nf ii
3.20
Com relação à j-ésima classe, pode-se calcular a frequência absoluta
acumulada, somando-se as frequências absolutas das classes precedentes.
∑=
=i
jji nN
1 3.21
Esta fórmula se desdobra em:
323213
21212
11
nNnnnN
nNnnN
nN
+=++=+=+=
=
3.22
Procedimento análogo nos conduz à frequência relativa acumulada
ou simplesmente frequência acumulada, calculada por:
%100%100(%)1
×=×= ∑= n
NfF j
i
jji
3.23
Fi dá a proporção dos itens que, na distribuição dada, apresentam
valores menores do que o limite real superior da i-ésima classe.
3.1.5.2 Histograma
Os dados grupados em classes podem ser representados graficamente
em um histograma. Um histograma é um gráfico de barras, construído tal que as
áreas dos retângulos são iguais às frequências relativas das classes. Desse

modo, marcam-se os limites reais das classes nas abscissas e as frequências
relativas divididas pelo intervalo de classe nas ordenadas. Ou seja a
classedeIntervalo
classeumaderelativaFreqüênciaretânguloumdeAltura =
O histograma construído a partir dos dados da Tabela 3.9 é mostrado
na Fig. 3.4.
3.1.5.3 Polígono de frequência
Para a confecção do polígono de frequência, marcam-se nas abscissas
os pontos médios de cada classe e nas ordenadas as frequências relativas
divididas pelo intervalo de classe nas ordenadas. O polígono de frequência
construído a partir dos dados da Tabela 3.9 é mostrada na Fig. 3.4.
Polígono de FrequênciaHistograma

Figura 3.4: Histograma e polígono de frequência dos dados da Tabela
3.9
3.1.5.4 Ogiva
A representação gráfica da distribuição de frequência acumulada é
denominada ogiva. Para a confecção da ogiva, marcam-se nas abscissas, os
limites reais das classes; nas ordenadas, as frequências acumuladas. A ogiva
construída a partir dos dados da Tabela 3.9 é mostrada na Fig. 3.5.
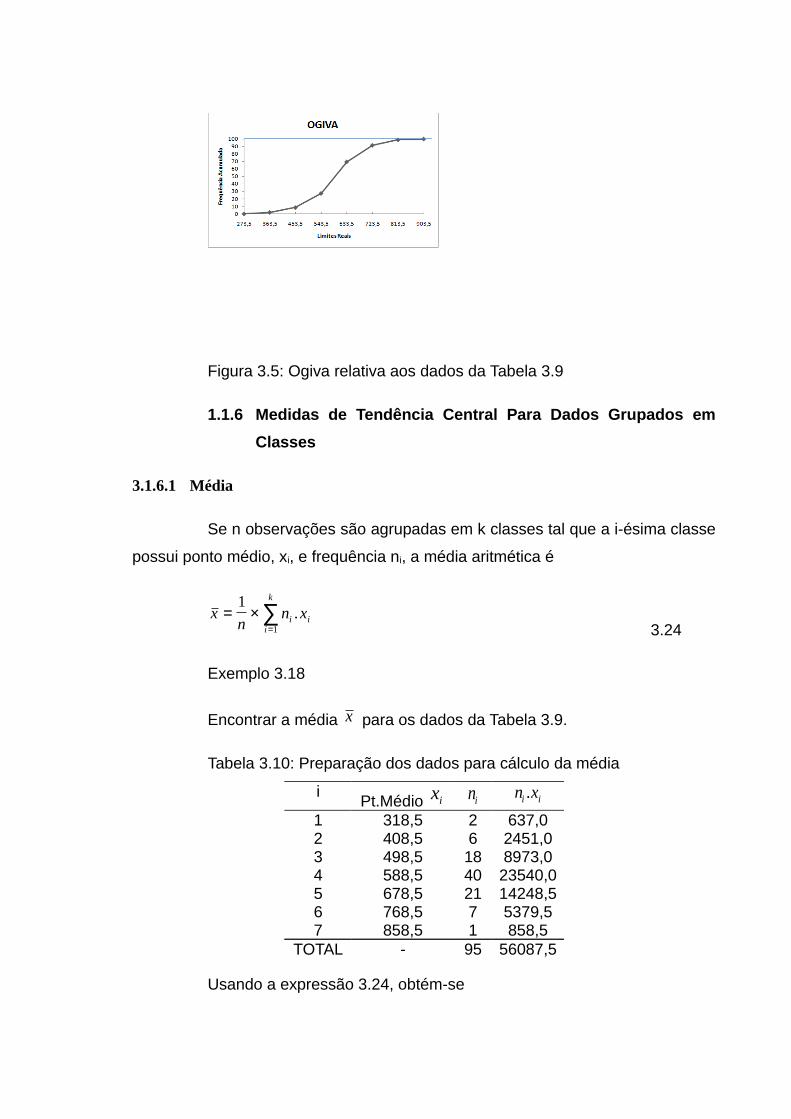
Figura 3.5: Ogiva relativa aos dados da Tabela 3.9
1.1.6 Medidas de Tendência Central Para Dados Grupados em
Classes
3.1.6.1 Média
Se n observações são agrupadas em k classes tal que a i-ésima classe
possui ponto médio, xi, e frequência ni, a média aritmética é
xn
n xi ii
k
= ×=∑1
1
.3.24
Exemplo 3.18
Encontrar a média x para os dados da Tabela 3.9.
Tabela 3.10: Preparação dos dados para cálculo da média
iPt.Médio xi ni n xi i.
1 318,5 2 637,02 408,5 6 2451,03 498,5 18 8973,04 588,5 40 23540,05 678,5 21 14248,56 768,5 7 5379,57 858,5 1 858,5
TOTAL - 95 56087,5
Usando a expressão 3.24, obtém-se

4,59095
5,56087 ==x
3.1.6.2 Percentil
Separatriz de ordem p, designada por Sp, que é também denominada
de percentil de ordem p, divide o conjunto ordenado em dois subconjuntos de
tamanhos na elementos, à esquerda, e nb elementos, à direita, tais que:
ba
a
nn
np
+=
Então, a separatriz de ordem p = 0,10 é o valor da distribuição que
deixa a sua esquerda 10% do total dos elementos.
Há algumas separatrizes de interesse, que decorrem de valores
particulares de p. São elas:
mediana – é a separatriz de ordem p = 0,50.
1o quartil, 2o quartil, 3o quartil – são as separatrizes cujos valores de p
são, respectivamente, 0,25, 0,50 e 0,75, também denominados Q1, Q2 e Q3.
1o decil, 2o decil, ...,9o decil – são as separatrizes cujos valores de p
são, respectivamente, 0,10, 0,20, ..., 0,90, também denominados D1, D2, ..., D9.
1o centil, 2o centil, ..., 99o centil – são as separatrizes cujos valores de p
são, respectivamente, 0,01, 0,02, ..., 0,99, também denominados C1, C2, ..., C9.
Para se determinar o valor de uma separatriz de uma amostra é
necessário que os valores amostrais sejam organizados em um rol crescente ou
decrescente. Em seguida, faz-se a contagem dos itens que ficarão à esquerda da
ordenada Sp. Se o número total de itens for tal que a separatriz não coincida com
um dos valores da amostra, adota-se para Sp a média aritmética dos dois valores
adjacentes.
Exemplo 3.19
Sejam os seguintes valores do peso de 12 pessoas, em daN:

51 72 68 83 59 63 92 85 57 77 79 65
Determinar os valores de S0,25 e S0,50. Ordenando os valores em ordem
crescentes, tem-se:
51 57 59 63 65 68 72 77 79 83 85 92
e, em seguida:
2
6359125,0
+== QS
kgQS 61125,0 ==
2
7268~50,0
+== xS
kgxS 70~50,0 ==
Se os dados estiverem grupados, o cálculo do valor da separatriz leva
em conta que a distribuição das frequências se faz linearmente ao longo de cada
classe. Assim, para se determinar o valor de uma separatriz basta verificar qual a
classe que a contém e fazer uma interpolação linear entre os seus limites reais.
Exemplo 3.20
Para os dados da Tabela 3.9, encontrar:
a mediana
Solução: Abaixo do limite real superior da terceira classe (543,5)
existem 27,37% dos dados e abaixo de 633,5 69,47% dos dados. Portanto, a
mediana está na quarta classe, conforme representado na figura a seguir.
543,5 Obj197 633,5
27,37% 50% 69,47%

Interpolando,
633,5 – 543,5 69,47% - 27,37%
~x - 543,5 50% - 27,37%
~x = 591,9
o primeiro quartil
Solução: Abaixo do limite real superior da segunda classe (453,5)
existem 8,42% dos dados e abaixo de 543,5 27,37% dos dados. Portanto, a
mediana está na quarta classe, conforme representado na figura a seguir.
453,5 Q1 543,5
8,42% 25% 27,37%
Interpolando,
543,5 – 453,5 27,37% - 8,42%
~x - 453,5 25% - 8,42%
Q 1 = 532,2
3.1.6.3 Moda
Se os dados estiverem agrupados em classe, o ponto médio da classe
de maior frequência é denominado moda bruta. No exemplo da Tabela 3.9, a
moda bruta é 588,5.
Com objetivo de se obter um resultado mais preciso da moda algumas
fórmulas foram propostas, das quais serão citadas as de King e de Kzuber, por
serem as mais usadas. Estas fórmulas foram desenvolvidas relacionando a moda

com a possível forma da distribuição, sugerida pelas frequências das classes
adjacentes àquela da moda bruta.
+
+=+−
+
11
1
mm
mmo nn
nhLIm
, denominada de moda de King.
3.25
( )
+−
−+=
+−
−
11
1
2 mmm
mmmo nnn
nnhLIm
, denominada de moda de
Kzuber. 3.26
Onde:
LIm – limite inferior da classe modal, isto é, a classe de maior
frequência;
h – amplitude de classe
nm – frequência absoluta simples da classe modal;
nm-1 – frequência absoluta simples da classe anterior à classe modal;
nm+1 – frequência absoluta simples da classe superior à classe modal.
A moda é uma medida de posição mais adequada no caso de dados
agrupados. No caso de dados não agrupados, a moda nem sempre tem utilidade
como elemento representativo ou sintetizador do conjunto de dados.
Exemplo 3.21
Usando os dados da Tabela 3.9 determinar a moda de King e a de
Kzuber.
Da Tabela 3.9 obtém-se:
LIm = 543,5
h = 90

nm = 40
nm-1 = 18
nm+1 = 21
Moda de King
Substituindo estes valores na expressão 3.25, obtém-se
0,5922118
21905,543 =
++=om
Moda de Kzuber
Substituindo estes valores na expressão 3.26, obtém-se
( ) 8,5912118402
1840905,543 =
+−×
−+=om
3.1.6.4 Relação entre as três medidas de posição (média, mediana e moda) – moda de
Pearson
Karl Pearson estabeleceu a seguinte relação aproximada entre as três
medidas de posição: média, mediana e moda:
( )xxmx o~3 −×=−
3.27
Ou seja, em uma distribuição de frequências à diferença entre a média
e a moda é 3 vezes maior do que a diferença entre a média e a mediana.
Exemplo 3.22
Usando os dados da Tabela 3.9 determinar a moda de Pearson.
~x = 591,9
4,590=x

Explicitando mo na expressão 3.27, obtém-se
( )9,5914,59034,590 −×−=om
9,594=om
1.1.7 Medidas de Dispersão ou de Variabilidade Para Dados
Grupados em Classes
3.1.7.1 Variância
Se as n observações estão agrupadas em k classes, tal que a i-ésima
classe tem ponto médio xi e frequência ni, a variância do conjunto de dados é
sn
n xn
n xi i i ii
k
i
k2 2
1
2
1
1
1
1=
−−
==
∑∑3.28
Exemplo 3.23
Utilizando os dados da Tabela 3.9, calcular a média e a variância.
Tabela 3.11: Preparação dos dados para cálculo da média e da
variância
iPt.Médio xi ni n xi i. n xi i. 2
1 318,5 2 637,0 202884,52 408,5 6 2451,0 1001233,53 498,5 18 8973,0 4473040,54 588,5 40 23540,0 13853290,05 678,5 21 14248,5 9667607,36 768,5 7 5379,5 4134145,87 858,5 1 858,5 737022,3
TOTAL - 95 56087,5 34069223,8
Utilizando as expressões 3.24 e 3.28 para calcular a média e a
variância dos dados grupados obtém-se:
4,59095
1 =×= 56087,5x

( ) 5,101645,5608795
1
94
1 22 =
−= 34069223,8s

Exercícios Propostos
1. A Tabela abaixo se refere à distribuição de tempo de vida de
lâmpadas, expresso em horas, testadas em uma fábrica.
i Limites reais Ni
1 949,5 4
2 13
3 28
4 46
5 71
6 1549,5
100
Com relação a esta Tabela, calcular:
a) o tempo de vida médio;
b) o tempo de vida mediana;
c) o tempo de vida modal;
d) a variância do tempo de vida;
e) a porcentagem de lâmpadas com tempo de vida superior a 1300
horas.
f) o valor do tempo de vida de lâmpadas abaixo do qual se encontram
90% dos tempos de vida.
2. A Tabela abaixo se refere à distribuição dos diâmetros (em mm) de
uma partida de 80 eixos produzidos em determinada indústria.

i Limites reais ni
1 5,5 3
2 10
3 15
4 20,5
5 16
6 12
7 6
a) Calcular a média dos diâmetros dessa partida.
b) Calcular o coeficiente de variação dessa partida.
c) Achar o diâmetro, abaixo do qual se encontra 30% dos eixos dessa
partida.
d) Calcular a porcentagem dos eixos com diâmetro superior a 22 mm.
e) Encontrar o intervalo, em torno da média, que contenha 50% dos
eixos.
f) Calcular as seguintes modas:
i) de King;
ii) de Kzuber;
iii) de Person.
g) Construir o histograma.
h) Construir a ogiva.

3. O quadro abaixo nos dá o tempo em horas na execução de
determinada tarefa e o número de operários que a executaram.
i Limites reais ni
1 40,5 45,5
3
2 8
3 15
4 24
5 51
6 48
7 20
8 18
9 9
10 4
a) Calcular o tempo mediano.
b) Calcular o coeficiente de variação.
c) Calcular as seguintes modas: de King, de Kzuber e de Pearson.
d) Construir o histograma.
e) Construir a ogiva.
f) Determinar, utilizando a ogiva, a mediana.

4. A Tabela abaixo se refere à distribuição das espessuras, em mm, de
40 chapas produzidas.
i Limites reais ni
1 10,5 4
2 8
3 25,5
4 12
5 2
a) Calcular a espessura mediana da distribuição.
b) Calcular a porcentagem de chapas com espessura inferior a 28 mm
c) Calcular a espessura média da distribuição.
d) Calcular as seguintes modas: de King, de Kzuber e de Pearson.
e) Calcular a variância das espessuras.
f) Determinar a espessura que deixa acima dela 5 chapas da distribuição.
5. A Tabela abaixo é referente a uma distribuição de frequência do
número de passageiros por ônibus, na hora do “rush”:
i No de Passageiros No de Ônibus
1 20 7
2 13
3 17
4 21
5 12
6 80 5

Determinar:
a) a média e a variância;
b) as seguintes modas: de King, de Kzuber e de Pearson;
c) a porcentagem de ônibus que transportam mais de 60 passageiros
(incluindo 60).
6. Se 3,020 - 3,070 - 3,120 - 3,170 - 3,220 são pontos médios de um
distribuição de frequência de medidas da seção reta de fios de cobre utilizados
em certa obra, com aproximação de centésimos de milímetros, determinar:
a) o intervalo de classe;
b) os limites de classe.
7. Os dados relativos ao problema anterior são:
3,05 3,20 3,09 3,13 3,12 3,05 3,17 3,11 3,21 3,12
3,10 3,01 3,13 3,14 3,17 3,12 3,10 3,08 3,15 3,16
3,19 3,11 3,22 3,07 3,10 3,03 3,13 3,07 3,15 3,14
3,12 3,07 3,17 3,11 3,16 3,22 3,19 3,13 3,15 3,06
a) Construir o histograma e a ogiva.
b) Calcular a média e o desvio padrão.
c) Calcular as seguintes modas: de King, de Kzuber e de Pearson.
d) Determinar a porcentagem cuja secão reta é superior a 3,22.
e) Determinar o valor acima do qual estão 80% das medidas.

8. Dada a distribuição de 50 dados observados, onde x i é o ponto
médio e n a frequência absoluta de cada classe:
i Limites reais de classe
xi ni
1 2
2 14,0
3 13
4 20,0 18
5 6
6 4
a) Calcular a média e a variância.
b) Calcular as seguintes modas: de King, de Kzuber e de Pearson.
c) Qual a porcentagem dos dados que se encontra acima de 23,0?
9. Em uma plantação experimental, o pesquisador colheu os seguintes
dados relativos ao crescimento de pés de milho até a época da colheita:
2,20 2,00 2,20 2,28 2,30 2,12 2,12
1,95 2,42 2,20 2,00 2,01 2,28 2,25
2,18 2,15 1,92 2,15 2,12 2,15 2,16
2,50 2,25 2,27 1,90 2,35 1,84 2,08
I. Representar esses dados por meio de:
a) diagrama de pontos;
b) diagrama de ramo e folhas.
II. Calcular:
a) a mediana;

b) a média;
c) o desvio padrão.
10. Seja o seguinte conjunto de números: 7, 9, 1, 5, 6, 8, 5, 4.
Calcular:
a) a média;
b) a variância;
c) a moda;
d) o ponto médio;
e) a mediana;
f) a amplitude.
11. Considere os resultados abaixo, em um total de 80 valores,
relativos a ensaios de compressão de corpos-de-prova de concreto, testados aos
7 dias, em MPa, registrados na ordem em que os ensaios foram realizados.
27,0 26,8 26,8 26,2 26,7 26,7 26,5 26,5 27,0 27,0
26,8 26,2 26,8 26,6 26,6 26,5 26,8 26,6 26,6 26,3
26,6 26,6 26,5 25,9 27,0 26,6 26,4 26,3 27,0 26,7
26,4 26,3 26,6 26,4 26,3 26,0 27,0 26,9 26,7 26,5
26,7 26,5 26,4 26,4 26,6 26,5 26,2 26,0 26,7 26,6
26,5 26,0 26,8 26,7 26,6 26,4 26,8 26,8 26,7 26,4
27,2 26,8 26,6 26,6 27,2 26,8 26,6 25,7 26,9 26,6
26,5 26,4 27,2 26,8 26,8 26,6 27,1 26,6 26,5 26,2
Usando o Excel:

a) Agrupar os dados em uma distribuição de frequência e construir o
histograma.
b) Calcular a média e o desvio padrão.
c) Determinar a moda e a mediana.
d) Construir a ogiva e determinar a mediana, comparando com o
resultado anterior.
e) Extrair uma amostra aleatória simples de tamanho 8 e calcular, com
relação a esta amostra, a média e o desvio padrão. Comparar esses valores
encontrados com o valor da média e desvio padrão de todos os resultados.
12. A Tabela abaixo se refere à distribuição porcentual dos salários
recebidos pelos funcionários de uma empresa, em número de salários mínimos.
i Limites de classe fi (%)
1 1 35
2 19
3 14
4 12
5 10
6 7
7 57 3
a) Calcular o salário mediano e o salário médio, em unidades de salário
mínimo. Em sua opinião, qual dos dois representa “melhor” o valor médio? Por
que?
b) Supondo que determinado imposto incida sobre o salário dos
funcionários a uma taxa constante de 2%, determinar o montante do imposto para
um total de 3000 funcionários, em unidades de salário mínimo.

13. Uma firma abre concorrência para aquisição de 300 peças e impõe,
como especificação para a dimensão principal, 3,50 mm no mínimo. Propõe
pagar:
a) R$1,20 por peça dentro da especificação e R$0,50 para as fora de
especificação;
b) um prêmio de R$100,00 para cada peça que tiver sua dimensão
principal dentro do seguinte intervalo 3,49 x 3,51 mm.
Calcular o valor que o fornecedor irá receber no caso de suas peças
apresentarem a distribuição da Tabela abaixo:
i Limites reais xi ni
1 3,445 12
2 3,465 33
3 3,485 66
4 3,505 77
5 3,525 68
6 3,545 34
7 3,565 10
APÊNDICE A: USANDO O EXCEL
A1. Resumo estatístico
O Excel retorna os valores para cada uma das seguintes estatísticas:
Média, Erro padrão (da média), Mediana, Moda, Desvio padrão, Variância,
Curtose, Distorção, Amplitude, Mínimo, Máximo, Soma e Contagem.
Abre-se o menu FERRAMENTAS e escolhe-se a opção ANALISE DE
DADOS.
Na próxima caixa, selecionaremos a opção ESTATÍSTICA
DESCRITIVA. Não se esqueça de clicar em OK.

Siga o exemplo apresentado a seguir:
O resultado é:

A2. Grupamentos dos dados em classe
Para agrupar os dados em classes é necessário definir o número de
classes. Usando a regra de Sturges:
k = 3,3 (log n) + 1
Para encontrar o número de elementos (n) devemos seguir os
seguintes passos:
17* Coloque o cursor em uma célula vazia;
18* No menu INSERIR escolha a opção FUNÇÃO.
Na categoria da função escolha a opção ESTATÍSTICA e em nome
da função escolha a opção CONT. NÚM. A seguir, clique em OK.

Com o cursor posicionado em valor 1, marque o bloco onde estão os
dados que serão contados. No nosso exemplo (Figura 1) corresponde às células
A2:J11. A seguir clique em OK.
Após sabermos o número de dados (n) que compõem a tabela (Figura
1), podemos calcular o número de classes.
Devemos posicionar o cursor em uma célula vazia e escolher a opção
FUNÇÃO do menu INSERIR.
Em categoria da função devemos escolher MATEMÁTICA E
TRIGONOMÉTRICA e em nome da função escolheremos LOG10, que retorna o
logaritmo na base 10 de um número.

Após clicarmos em OK, teremos na célula escolhida o resultado do
logaritmo. Na Barra de Fórmulas multiplicar o logaritmo por 3,3 e somar 1,
teremos, assim, o resultado da aplicação da regra de Sturges e,
consequentemente, o número de classes.
Agora devemos calcular o intervalo de classes, ou seja, o quanto a
classe vai variar (tamanho da classe). Ela será obtida com o conhecimento do
número de classes e dos valores mínimo e máximo da série de dados do nosso

exemplo. Para encontrarmos os valores mínimo e máximo devemos prosseguir da
seguinte maneira, sempre com o cursor em uma célula vazia:
No menu INSERIR escolha a opção FUNÇÃO. Em categoria da
função escolha a opção ESTATÍSTICA. Para o valor mínimo devemos escolher a
opção MÍNIMO. Feito isso, clique em OK.
Veremos então a caixa de diálogo abaixo. Com o cursor em núm 1,
devemos marcar o bloco onde estão os dados (A1:J10). Clique em OK.
Para obter o valor máximo repita a operação, apenas mudando a
opção em nome da função para MÁXIMO.
Após termos seguido todos as etapas anteriores, deveremos ter obtido
os seguintes resultados:
Número de classes = 7,5 Valor mínimo = 294

Valor máximo = 883
Podemos agora calcular o intervalo das classes (h) utilizando a
seguinte fórmula bem simples:
h = Valor máximo - Valor mínimo / Número de classes
h = (883 - 294) / 7 = 84,1
Como visto na seção anterior, adotaremos para h o valor 90.
Teremos então:
A partir desses resultados poderemos construir a tabela de classes
abaixo:
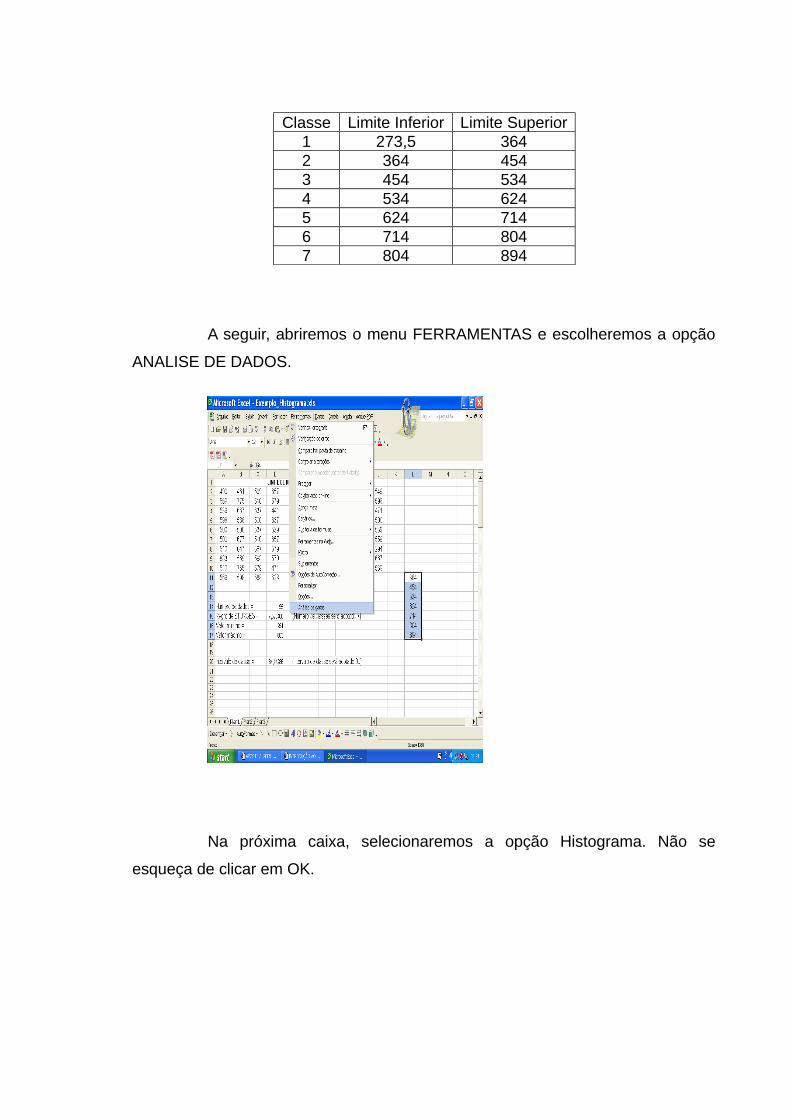
Classe Limite Inferior Limite Superior1 273,5 3642 364 4543 454 5344 534 6245 624 7146 714 8047 804 894
A seguir, abriremos o menu FERRAMENTAS e escolheremos a opção
ANALISE DE DADOS.
Na próxima caixa, selecionaremos a opção Histograma. Não se
esqueça de clicar em OK.
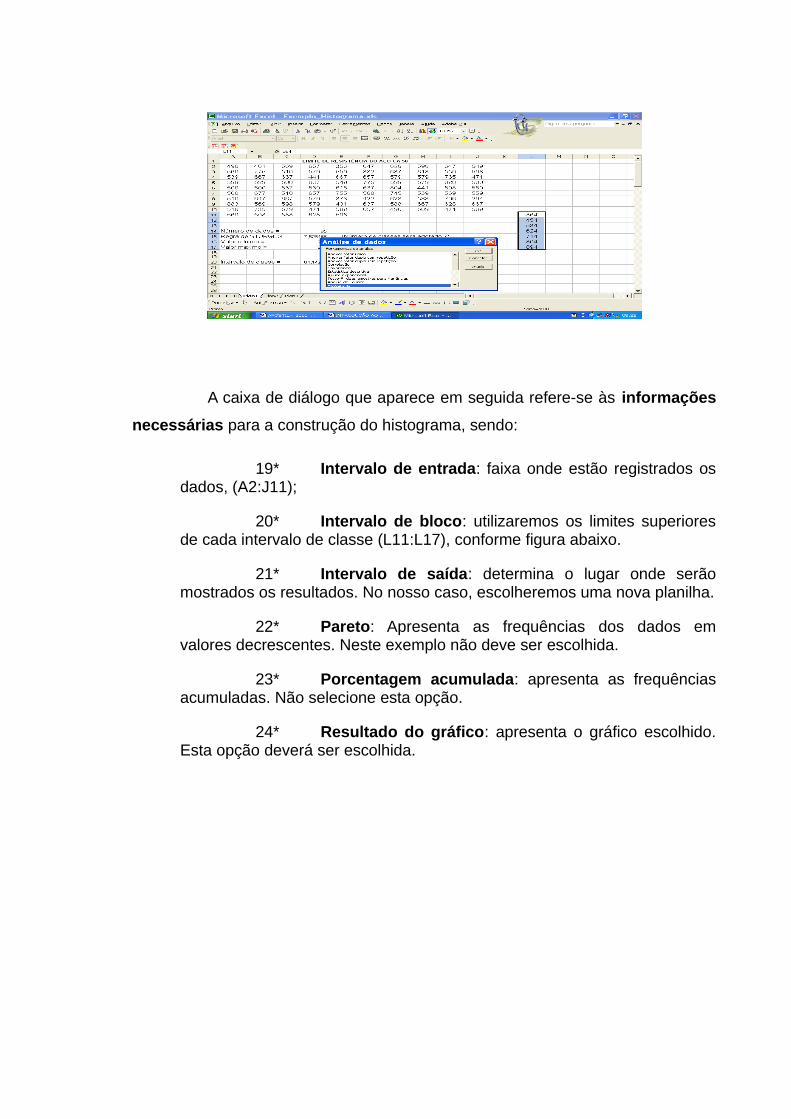
A caixa de diálogo que aparece em seguida refere-se às informações
necessárias para a construção do histograma, sendo:
19* Intervalo de entrada: faixa onde estão registrados os dados, (A2:J11);
20* Intervalo de bloco: utilizaremos os limites superiores de cada intervalo de classe (L11:L17), conforme figura abaixo.
21* Intervalo de saída: determina o lugar onde serão mostrados os resultados. No nosso caso, escolheremos uma nova planilha.
22* Pareto: Apresenta as frequências dos dados em valores decrescentes. Neste exemplo não deve ser escolhida.
23* Porcentagem acumulada: apresenta as frequências acumuladas. Não selecione esta opção.
24* Resultado do gráfico: apresenta o gráfico escolhido. Esta opção deverá ser escolhida.
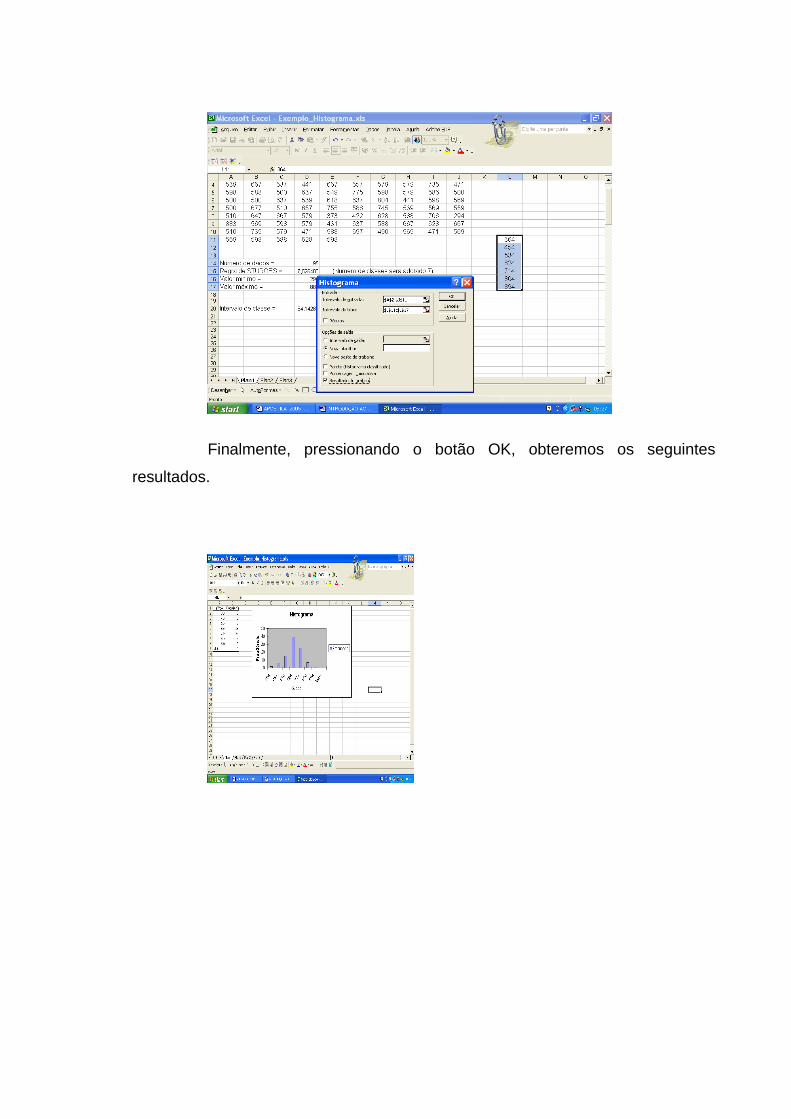
Finalmente, pressionando o botão OK, obteremos os seguintes
resultados.

APÊNDICE B: PROCESSO ABREVIADO PARA O
CÁLCULO DA MÉDIA E DA VARIÂNCIA DE DADOS
AGRUPADOS
B1. Dados Codificados por Transformação Linear
Algumas vezes é desejável transformar os dados de modo que os
cálculos envolvidos na estatística descritiva possam ser realizados com números
menores, facilitando, assim, a sua determinação. A codificação utilizada é uma
transformação linear do tipo
yi = A + Bxi
onde A e B são constantes escolhidas pela conveniência dos cálculos.
Se usarmos y e sy2 para denotar a média e a variância de y, e x e sx
2
para denotar a média e a variância de x, respectivamente, então
xy A
B=
−
ss
Bs
s
Bx
y
x
y2
2
2= ⇒ =
B2. Processo Abreviado para o Cálculo da Média e da Variância
de Dados Agrupados
O cálculo da média e da variância pelas expressões anteriormente
vista, denominado “processo direto”, é muito trabalhoso, muito embora possa ser
facilitado pelo emprego de uma máquina de calcular ou um computador.
Com uma simples mudança de variável, o cálculo pode ser feito mais
rapidamente e com menos riscos de errar. Esse processo é denominado
“processo abreviado”. A nova variável é
ux x
hii=
− 0

onde xi é o ponto médio da i-ésima classe, x0 é um dos pontos médios
que se deve escolher de acordo com a conveniência dos cálculos (normalmente é
o ponto médio que corresponde à classe de maior frequência) e h é o intervalo de
classe.
Introduzindo essa expressão de ui nas expressões do processo direto
obtém-se
x xh
nn ui i
i
k
= +=∑0
1
.
sh
nn u
nn ui i i i
i
k
i
k2
22
1
2
11
1=
−−
==
∑∑ . .
Exemplo
Utilizando os dados da Tabela 3.2, calcular a média e a variância pelos
processos direto e abreviado.
iPt.Médio xi ni ui n ui i. n ui i. 2
1 319 2 -3 -6 182 409 6 -2 -12 243 499 18 -1 -18 184 589 40 0 0 05 679 21 1 21 216 769 7 2 14 287 859 1 3 3 9
TOTAL - 95 - 2 118
9,59095
290589 =×+=x
( ) 46,10164295
1118
94
90 22
2 =
−=s

4 PROBABILIDADE
Introdução
O Capítulo 3 lidou com os aspectos da estatística relacionados à
manipulação de dados. Uma grande quantidade de dados foi acumulada e tinham
de ser organizados e resumidos para que possam ser analisados. Neste capítulo
serão abordados os conceitos de probabilidade e suas aplicações e nos capítulos
5 e 6 os modelos probabilísticos necessários para fundamentar os aspectos da
estatística que lidam com tomadas de decisão em face de incertezas.
Probabilidade pertence ao campo da Matemática. A necessidade de
estudar esse assunto em Estatística, que é o objetivo essencial deste curso, é
pelo fato que os fenômenos estudados pela Estatística Inferencial ou Indutiva
são de natureza aleatória ou não determinística.
Define-se por modelo científico a representação simplificada de
algum fenômeno do mundo real com o propósito de analisar, descrever, explicar,
simular (em geral), explorar, controlar e predizer esses fenômenos. Assim, a
utilização de modelos, como representação de determinada realidade, facilita a
compreensão de relações complexas. Por exemplo, para estudar as relações
químicas entre os elementos é necessário conhecer o átomo. No entanto, pelas
dimensões do átomo é necessário estabelecer um modelo que possa explicar
essas relações. Note que um modelo deve ser aperfeiçoado continuamente na
medida em que ele não consegue explicar certas ocorrências. Assim, o modelo do
átomo evoluiu a partir do modelo de Dalton (esfera indivisível), de Thomson
(pudim de ameixa), de Rutherford (bombardeamento de lâmina de ouro com
partículas alfa – núcleo atômico), de Chadwick (descoberta dos nêutrons), de
Bohr (níveis quantizados de energia – órbitas circulares), de Sommerfeld (órbitas
elípticas para explicar que um elétron numa mesma camada apresentava
energias diferentes). O modelo atômico atual é um modelo matemático-
probabilístico que se baseia em dois princípios:
• Princípio da Incerteza de Heizenberg: é impossível determinar
com precisão a posição e a velocidade de um elétron num mesmo instante.

• Princípio da Dualidade da matéria de Louis de Broglie: o
elétron apresenta característica DUAL, ou seja, comporta-se como matéria e
energia sendo uma partícula-onda.
Erwin Schröndinger baseado nesses dois princípios criou o conceito de
ORBITAL, que é a região onde é mais provável encontrar um elétron. Dirac
calculou estas regiões de probabilidade e determinou os quatro números
quânticos, principal (localiza o elétron em seu nível de energia), secundário
(localiza o elétron no seu subnível de energia e dá o formato do orbital),
magnético (localiza o elétron no orbital e dá a orientação espacial dos orbitais) e
spin (relacionado com o movimento de rotação do elétron em um orbital). Depois
vem o Princípio de Exclusão de Wolfgang Pauli (em um mesmo átomo, não
existem dois elétrons com quatro números quânticos iguais), a Regra de Hund
(preenchimento dos subníveis) e a equação de Schröndinger (os números
quânticos são uma aproximação para a equação de Schröndinger).
Um modelo científico pode ser determinístico ou probabilístico. Modelo
determinístico é um modelo matemático que determina, exatamente ou com um
erro que pode ser considerado desprezível, os resultados a partir das condições
iniciais. Por exemplo, o fluxo de corrente elétrica em um circuito simples ligado a
uma bateria é determinado com exatidão pela lei de Ohm I=V/R ao fornecer os
valores de V (diferença de potencial) e R (resistência).
Modelo probabilístico, ou distribuição de probabilidade, é um modelo
matemático que descreve o comportamento de uma variável definida em
experimentos estatísticos. Esse tipo de experimento baseia-se em amostra na
qual se apóia para tomar decisões ou tirar conclusões sobre o fenômeno
(população) objeto de estudo. Um experimento especifica exatamente que teste
ou ensaio deve ser realizado e qual a característica que deve ser observada.
Esses testes, que lidam com resultados ou observações, geralmente são
repetidos várias vezes sob condições controladas. No entanto, mesmo tomando
grande cuidado para manter as condições do experimento tão uniforme quanto
possível, as observações individuais apresentam uma variabilidade intrínseca que
não se consegue eliminar, pois os fenômenos estudados pela Estatística são
fenômenos cujos resultados, mesmo em condições controladas de

experimentação, variam de uma observação para outra, sendo, portanto, difícil
para tirar conclusões ou tomar decisões. Esta variabilidade inerente é
frequentemente referida como erro experimental, que corresponde ao resultado
da influência de um grande conjunto de fatores que fogem ao controle. Assim, em
todos os tipos de experimentos repetidos realizados sob condições “controladas”,
os resultados das repetições variam.
Ao invés de ignorar esta variabilidade, ou tratá-la qualitativamente, ela
pode ser incorporada em um modelo matemático para representar o fenômeno
objeto de estudo, fenômeno esse que, em estatística, é denominado de
população. Assim, tal modelo é uma descrição matemática da população e é
geralmente de natureza simplificada. Essa formulação pode então ser usada para
caracterizar o fenômeno e ser usada para análise posterior.
Os modelos matemáticos das populações são criados empregando a
teoria da probabilidade, onde especificamos a estrutura de um problema,
construímos um modelo matemático a ele correspondente, especificamos os
valores dos parâmetros (que são as constantes numéricas que aparecem
explicitamente no modelo), e depois deduzimos o comportamento da população,
por exemplo, a distribuição do número relativo de vezes que ocorrerá cada
resultado possível.
A probabilidade, portanto, constitui um fundamento importante para a
estatística, e vamos examiná-la com o aprofundamento necessário e suficiente ao
nosso curso.
Nas exemplificações dos conceitos de probabilidade, frequentemente,
recorre-se a dados, cartas, moedas, urnas, bolas, etc. Isto é devido não só a
simplicidade de tais objetos como o fato de que eles reproduzem de modo quase
perfeito, as condições abstratas dos modelos matemáticos de probabilidade.
Assim, se esses exemplos simples forem bem compreendidos não haverá
maiores dificuldades em resolver problemas mais complexos e de maior interesse
no nosso campo de atuação.

Conceitos
1.1.1 Experimentos Aleatórios
Como visto geralmente os resultados de um determinado experimento
não pode ser predito exatamente, devido à variabilidade inerente associada ao
experimento. Entretanto, é possível identificar todos os resultados possíveis
desse experimento.
Seja um experimento simples como o lançamento de uma moeda. É
fácil enumerar os resultados possíveis, pois são apenas dois: cara e coroa. No
entanto, não se pode antecipar, com certeza, qual desses dois resultados irá
ocorrer em uma jogada. Desse modo, podemos conceituar um experimento
aleatório, representado por ε , como um experimento cujo resultado não se pode
antecipar, com absoluta certeza, apesar de se poderem prever todos os
resultados possíveis.
A consequência de uma única execução do experimento é chamada
resultado.
São exemplos de experimentos aleatórios:
• lançamento de dados;
• lançamento de uma moeda;
• extração de três cartas de um baralho adequadamente
embaralhado;
• número de partículas que atinge um contador colocado a uma
distância conhecida de uma fonte radioativa durante um intervalo
de 10 segundos;
• seleção aleatória de 10 peças de um lote com 100 unidades;
• medição da dureza Rockwell em cinco regiões de uma chapa de
aço;
• medição do tempo de vida de 5 lâmpadas elétricas escolhidas ao
acaso de um lote dessas lâmpadas;

• escolha aleatória de 20 pessoas de um grupo e a determinação
de suas pressões sanguíneas ou suas opiniões sobre
determinado produto;
• medição da resistência à compressão de cinco corpos-de-prova
confeccionados com concreto extraído de um caminhão
betoneira cheio de concreto; etc.
1.1.2 Espaço Amostral
O conjunto de todos os possíveis resultados de um experimento ε é
chamado espaço amostral do experimento e é representado por E. Cada
resultado é chamado um elemento de E e é representado por e. Um espaço
amostral, E, é dito finito ou infinito conforme consista em um número finito ou
infinito de elementos, respectivamente.
Exemplo 4.1
Quando lançamos um dado uma vez, ele pode apresentar uma das
seis faces, voltada para cima, numeradas 1, 2, 3, 4, 5 e 6, e o espaço amostral
consiste destes 6 elementos. Em notação de conjunto este espaço amostral pode
ser escrito como
E = 1, 2, 3, 4, 5, 6.
Se dois dados são lançados, em cada dado pode ocorrer qualquer
número de 1 a 6 inclusive. Representando o valor da face voltada para cima do
primeiro dado por x1 e o valor da face voltada para cima do segundo dado por x2,
o espaço amostral consiste de todos os pontos e = (x1, x2) tal que x1 e x2 são
inteiros e contidos no intervalo de 1 a 6 inclusive os extremos. Se um único dado
for lançado duas vezes, o espaço amostral é o mesmo que o representado acima
onde x1 agora denota o valor da face voltada para cima do primeiro lançamento e
x2 denota o valor da face voltada para cima do segundo lançamento. Se o mesmo
dado for lançado n vezes, o espaço amostral E consiste de todos os pontos
e = (x1, x2, . . . xn) tal que xi, o valor da face voltada para cima do i-ésimo
lançamento, está entre 1 e 6 inclusive.

Exemplo 4.2
Seja o número de partículas que atinge um contador colocado a
uma distância conhecida da fonte radioativa durante um intervalo de 15 segundos.
O número dessas partículas é um número inteiro positivo. Então, o espaço
amostral pode ser representado como
E = 0, 1, 2, ....2
Exemplo 4.3
Este exemplo ilustra o fato de que um espaço amostral não consiste,
necessariamente, de um conjunto de números. Na produção industrial, pode-se
retirar uma peça para verificar se ela é defeituosa ou não. Então, E consiste nos
dois elementos: defeituosa e perfeita. Se extrair duas peças, a primeira pode ser
perfeita ou defeituosa e de modo semelhante a segunda peça. Se x1 denota o
resultado da primeira peça e x2 o resultado da segunda, o espaço amostral E
consiste de todos os pontos e = (x1, x2) tal que x1 representa uma peça defeituosa
ou uma peça perfeita e x2 representa uma peça defeituosa ou uma peça perfeita.
Uma enumeração dos quatro pontos de E é dado por e = (x1, x2) = (D, D); (D, D );
(D ; D); e (D , D ), onde D representa peça defeituosa e D peça perfeita.
Portanto, e = (D , D ) significa que o resultado da primeira peça é perfeita e o
resultado da segunda peça também é perfeita. Este exemplo é um caso particular
de um experimento mais geral em que o resultado pode ser caracterizado por um
de dois valores, ou seja, pode ser classificado por uma dicotomia. Ao invés de
extrair uma peça para verificar se é perfeita ou defeituosa, o experimento pode
consistir em identificar o sexo de uma criança recém-nascida. O espaço amostral
consiste de dois pontos, macho e fêmea. Outro tipo de experimento pode consistir
no lançamento de uma moeda. O espaço amostral consiste dos dois elementos,
cara e coroa.
Exemplo 4.4
2 Embora os resultados possíveis do experimento são representados como sendo
ilimitado, isto é claramente uma aproximação matemática, em vista de que o número de partículas
de certa quantidade de um determinado radioisótopo é limitado.

Seja a determinação da resistência à compressão de corpos de prova
de concreto com sete dias de cura. O espaço amostral do experimento é infinito,
porque o resultado pode ser qualquer número positivo situado entre 0 (zero) e o
limite superior da escala de medição LS. Isto pode ser escrito em notação de
conjunto como
LSeeE ≤≤= 0| 3
Se dois corpos de prova são ensaiados, cada corpo de prova pode ter
a resistência à compressão entre 0 e LS. Chamando a resistência à compressão
do primeiro corpo de prova de x1 e do segundo corpo de prova de x2, o conjunto E
consiste de todos os pontos e = (x1, x2), tal que
LSx ≤≤ 10 e LSx ≤≤ 20
O espaço amostral pode ser escrito, novamente, em notação de
conjunto como
( ) LSxxxxeE ≤≤== 2121 ,0|, .
Se uma amostra de n corpos de prova são ensaiados e xi representa a
resistência à compressão após sete dias de cura do i-ésimo corpo de prova, o
conjunto de todos os resultados possíveis do experimento E consiste de todos os
pontos e = (x1, x2, ...,xn) tal que
LSx ≤≤ 10 , LSx ≤≤ 20 , ..., LSxn ≤≤0 .
Exemplo 4.5
De um grupo de relés, produzidos sob condições similares, uma única
unidade é escolhida, colocada em uma bancada de teste, em um ambiente similar
às condições de projeto, e então testada até a sua falha. Em vista de que a vida
do componente pode ser qualquer número não negativo, o espaço amostral E
consiste de todos os pontos e que se encontra dentro do intervalo 0 (zero) e
(infinito), isto é,
3 Esta notação é lida como “E é o conjunto de todos e, onde e é um número real
entre 0 e LS inclusive os extremos.”

∞≤≤= eeE 0| 4
Se ao invés de testar um relé, o experimento consistir em escolher dois
relés, colocá-los em uma bancada de teste, e submetê-los a teste até ocorrer a
falha, o espaço amostral E é dado por
( ) ∞≤≤== 2121 ,0|, xxxxeE ,
onde x1 representa o tempo até a falha do componente definido como
número 1 e x2 o tempo até a falha do componente definido como número 2. De
modo semelhante, se uma amostra de n relés são colocados em uma bancada de
teste e testados até a falha, o espaço amostral E é dado por
( ) ∞≤≤== nn xxxxxxeE ,,,0|,,, 2121 ,
onde xi denota o tempo até a falha do componente designado como
número i.
Os experimentos acima são muito mais complexos do que foi descrito.
Por exemplo, o valor da resistência à compressão dos corpos de prova de
concreto com cura de sete dias depende de uma série de outras variáveis,
atuando simultaneamente, ou não, sobre o processo. Entre essas variáveis
podem ser citadas, desde a confecção do corpo de prova (entre as quais: as
dimensões do molde, a pessoa que confeccionou o corpo de prova, paralelismo
das faces, etc.) , até o operador que faz o teste, incluindo ainda outras, tais como
a hora em que foi realizado o ensaio, o equipamento de teste empregado, os
constituintes do concreto (tanto em quantidade quanto em qualidade), as
condições ambientais com que foi realizado o ensaio, etc. Assim, há muitas
variáveis, cujos resultados poderiam ser incluídos no conjunto de todos os
possíveis resultados do experimento, mas que é sem importância do ponto de
vista de tomar decisão baseada no resultado do experimento.
4 Do ponto de vista prático é preciso reconhecer que a vida de qualquer componente
eletrônico não pode ser infinita nem os instrumentos de medida são capazes de registrar valores
contínuos. Entretanto, o modelo matemático é somente uma aproximação do fenômeno físico que
está sendo estudado. Nos exemplos, estas aproximações geralmente não distorcem os
resultados.

Consequentemente, estes fatores irrelevantes serão excluídos da representação
formal do espaço amostral, e E será o conjunto de todos os possíveis resultados
dos fatores relevantes do experimento.
1.1.3 Evento
Um evento A (relativo a um espaço amostral E particular, associado a
um experimento ε ) é simplesmente um conjunto de resultados possíveis. Na
terminologia dos conjuntos, um evento é um subconjunto de um espaço amostral
E. Em particular, E e (conjunto vazio) são eventos; E é dito o evento certo e
o evento impossível. Qualquer resultado individual pode também ser definido
como um evento.
Exemplo 4.6:
Se retirarmos duas peças de um conjunto de cinco (numeradas de 1 a
5) o espaço amostral consiste nos seguintes 10 resultados possíveis:
1,2 1,3 1,4 1,5 2,3 2,4 2,5 3,4 3,5 4,5.
No entanto, podemos estar interessados no número de peças
defeituosas, que obtemos nas retiradas e, então, distinguimos entre os três
eventos possíveis:
A: nenhuma peça defeituosa, B: uma peça defeituosa e C: duas peças
defeituosas.
Supondo que três peças, digamos 1, 2 e 3, sejam defeituosas, vemos
que:
A ocorre, se retiramos 4 e 5.
B ocorre, se retiramos 1 e 4; 1 e 5; 2 e 4; 2 e 5; 3 e 4 ou 3 e 5.
C ocorre, se retiramos 1 e 2; 1 e 3 ou 2 e 3.
Um espaço amostral E e os eventos de um experimento podem ser
representados graficamente por um diagrama denominado Diagrama de Venn ,
como se segue. Suponhamos que o conjunto de pontos no interior do retângulo

da Fig. 4.1 represente E. Então, o interior de uma curva fechada dentro do
retângulo representa um evento que podemos representar por A. O conjunto de
todos os elementos (resultados) que não se situam em A é chamado o evento
contrário a A e é representado por A .
Fig.4.1 Diagrama de Venn representando um espaço amostral E e os
eventos A e A .
Por exemplo, quando jogamos um dado uma vez, o evento contrário do
evento:
A: o dado apresenta na face superior um número par,
é o evento:
A : O dado apresenta na face superior um número impar.
Desse modo, ao se definir um evento em um espaço amostral E, fica
automaticamente definido o seu evento contrário.
1.1.4 Composição de Eventos
Usando as operações com conjuntos, poderemos formar novos
eventos. Assim, sendo A e B dois eventos diferentes do espaço amostral E:
Evento união (A B) é o evento que ocorre se A ocorrer ou B
ocorrer
Ā
A

Evento interseção (A B ou AB) é o evento que ocorre se A e B
ocorrerem
Evento diferença (A B) é o evento que ocorre se A ocorrer,
menos os casos que B também ocorrer.
Exemplo 4.7:
Sejam: E 1, 2, 3, 4, 5, 6, A = 1, 2, B = 2, 4, 6, C 2, 5, 6 e D = 1,
5.
Então: = 2, B C = 2, 6, AB = 1, 2, 4, 6, (AB) C = 2,
(AB) C = 1, 2, 4, 5, 6, BD = .
Os eventos B e D acima são denominados mutuamente exclusivos ou
incompatíveis, eles não podem ocorrer simultaneamente, em vista de que sua
interseção é um conjunto vazio (a ocorrência de um impede a ocorrência do
outro).
Interpretação Frequencial da Probabilidade
Consideremos as seguintes questões:
1. Qual é a probabilidade de chover o correspondente a 10mm nas
próximas 24 horas em Belo Horizonte?
2. Qual é a probabilidade de que o cavalo no 2 vença o primeiro
páreo no hipódromo da Gávea em um determinado dia?
3. Qual é a probabilidade de existir vida em Marte?
4. Qual é a probabilidade de ocorrer cara no lançamento de uma
moeda?
5. Qual é a probabilidade de ocorrer 4 ases, para uma pessoa, após
a distribuição de cartas de um baralho bem embaralhado,
durante um jogo de pôquer?
6. Qual é a probabilidade de ocorrer a face 1 num lançamento de
um dado?

As três primeiras questões referem-se à probabilidade do tipo subjetivo.
Essas questões referem-se a situações para as quais o resultado é incerto. Ou
seja, não podemos estudar os resultados por meio de experimentos reprodutíveis.
Nesse texto será abordado o cálculo das probabilidades de resultados
oriundos de experimentos aleatórios, ou seja são experimentos reprodutíveis e,
portanto, que podem responder as questões do tipo 4, 5 e 6 acima.
A frequência relativa de um evento é definida como sendo a relação
entre o número de vezes em que o evento ocorreu numa determinada série de
repetições de um experimento aleatório e o número total de realizações desse
experimento. Ou seja:
Frequênciarelativa=númerodeocorrênciasdo evento
número total derealizações doexperimento
O teorema de Bernoulli5, também conhecido como a Lei dos Grandes
Números, estabelece que, à medida que se aumenta o número de realizações do
experimento a frequência relativa se aproxima cada vez mais de sua
probabilidade.
Como exemplo, seja o seguinte experimento aleatório: lançamento de
moeda e registrar a ocorrência da face cara. Se essa moeda for “honesta” essa
probabilidade é 0,50. No entanto, na prática essa probabilidade é apenas
aproximada. Essa aproximação é tanto mais exata quanto maior for o número
realizações do experimento, chegando a 0,50 se esse número tender para o
infinito. Para simular esse experimento e verificar a aplicação da Lei dos Grandes
Números, foi solicitado a 20 estudantes de uma turma da disciplina Estatística e
Probabilidade que lance uma moeda 10 vezes e registre o número de caras
ocorridas. Os resultados obtidos constam na Tabela 4.1.
Tabela 4.1: Resultado de 10 lançamentos de uma moeda por cada
estudante.
5 Jacob Bernoulli (1654 – 1705) descreveu a Lei dos Grandes Números em 1692. Em
1713, depois de sua morte, foi publicada a demonstração rigorosa dessa Lei no artigo intitulado
Ars Conjectanti (A arte da conjetura).

Estudante 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20No de caras 7 6 6 7 6 7 8 4 5 4 3 4 5 3 4 6 3 5 4 4
Note que cada estudante registrou um resultado para o experimento de
lançamento de uma moeda 10 vezes. Deste resultado, a frequência relativa de
caras por estudante pode ser obtida por
( )f Cn
i
ci=10
onde:
f Ci ( ) – é a frequência relativa correspondente ao experimento do i-
ésimo estudante.
nci – é o número de ocorrências de faces cara no lançamento de uma
moeda pelo i-ésimo estudante.
Consideramos cada conjunto de 10 tentativas como uma amostra de
tamanho 10 (isto é, n = 10). O resultado para cada estudante ou para o conjunto
de todos os estudantes conduz a um resultado (experimental) empírico para
responder a questão da probabilidade de ocorrência da face cara no lançamento
de uma moeda. O resultado que obtivemos é o valor da probabilidade desejada?
Os resultados obtidos são somente parciais porque ( )f C mudará seja pela
mudança de estudante seja pela mudança do tamanho da amostra n. Desse
modo, o modelo probabilístico que representa todos os resultados empíricos é:
( )P Cn
nn
c=→∞
lim
Onde:
P(C) – denota a probabilidade de ocorrências de face cara no
lançamento de uma moeda;
nc – é o número de ocorrências da face cara.
n – é o total de lançamentos da moeda.

Para se ter uma idéia de como a razão
n
nc
flutua à medida que n
cresce, trataremos os dados dos 20 estudantes da tabela 4.1 como uma
sequência de lançamentos de uma moeda para n = 10, 20, ..., 200. Um gráfico
dos resultados é dado na Figura 4.2.
Figura 4.2: Gráfico da razão
n
nc
versus n mostrando a convergência
para o valor da probabilidade a medida que n cresce.
Observando as mudanças que ocorreram em f(C) a medida que n
cresce de 10 até 200, parece razoável adotar P(C) = 0,5. Portanto, do ponto de
vista da frequência relativa, P(C) = 0,5 é representativo de todos os dados
observados pela repetição do lançamento de uma moeda 10 vezes. Note que
probabilidades baseadas em frequências relativas de diferentes resultados para
um experimento são resultados limites que são obtidos para grandes valores de n.
Uma das vantagens da interpretação frequencial da probabilidade é
que permite entender, com simplicidade, o conceito de probabilidade. Assim,
pode-se perceber que probabilidade não dá força ao acontecimento, mas mede o
grau com que um evento pode vir a ocorrer com base na experiência passada.
Segundo Cordeiro (1992), a probabilidade expressa a crença que temos num
resultado do experimento aleatório que não sabemos qual é. Outra vantagem é
que permite que se estabeleçam algumas condições a serem satisfeitas para que
um determinado número possa ser considerado probabilidade, por exemplo, para
que um número possa ser considerado probabilidade ele não pode ser negativo e
nem maior que um. A desvantagem da interpretação frequencial da probabilidade
é que é necessário realizar experimentação para determinar o valor da
probabilidade de ocorrência de um determinado evento. Isto pode se tornar muito
difícil, ou às vezes impossível. É o caso, por exemplo, de ensaios destrutivos,
restrições quanto ao tempo ou custo para a realização do experimento.

Axiomas e Teoremas da Probabilidade
1.1.5 Axiomas
Dado um espaço amostral E, a probabilidade de ocorrer um evento A,
denotada por P(A), é uma função definida em E que associa cada evento a um
número real, satisfazendo os seguintes axiomas:
i. P(A) ≥ 0;
ii. P(E) = 1;
iii. Se A1, A2, ..., An forem, dois a dois, eventos
mutuamente exclusivos, ou seja Ai A j = , i j, i e j = 1, 2, ...,
n, então,
P(A1 A2 ... An) = P(A1) + P(A2) + ... +P(An).
1.1.6 Teoremas
A partir destes axiomas, podemos demonstrar os seguintes teoremas:
Teorema 1. Se é o conjunto vazio, então P( ) = 0.
Demonstração:
Tomemos um evento qualquer A. A e são mutuamente exclusivos,
pois A = . Assim, pelo axioma 3:
P(A ) = P(A) + P( ).
Mas, a união dos eventos A e é
A = A.
Logo,
P(A) = P(A) + P( )
Portanto,
P( ) = 0.
Teorema 2. Se A é o evento contrário de A, então P( A ) = 1 - P(A)

Demonstração:
A Ā = E
Pelo Axioma 2:
P(A Ā) = P(E) = 1
Mas,
A Ā = .
Então, pelo Axioma 3, tem-se
P(A Ā) = P(A) + P(Ā).
Logo,
1)()()( ==+ EPAPAP .
Portanto,
)(1)( APAP −= .
Teorema 3. Se A é o evento contrário de A, então:
( ) ( ) ( )ABPBPBAP −=
Demonstração:
B = AB ĀB
e
AB ĀB =
Então, pelo axioma 3:
( ) ( ) ( )BAPABPBP +=
Finalmente,

( ) ( ) ( )ABPBPBAP −= .
Teorema 4. Se A e B são dois eventos quaisquer, então:
P(A B) = P(A) + P(B) - P(AB)
Demonstração:
(A B) = A ĀB
Os eventos A e AB são mutuamente exclusivos, logo, pelo axioma 3:
P(A B) = P(A) + P(ĀB)
Pelo teorema 3, tem-se que
P AB P B P AB( ) ( ) ( )= −
Então:
P(A B) = P(A) + P(B) - P(AB)
Exercício: Provar o teorema união de três eventos:
P(A B C) = P(A) + P(B) + P(C) – PAB) – PAC) – P(BC) + P(ABC)
Sugestão: faça A B C = (A B) C e aplique o teorema acima.
Cálculo das Probabilidades
1.1.7 Espaço Amostral Finito
Sejam experimentos para os quais o espaço amostral E seja formado
de um número finito de elementos, isto é, admitiremos que E possa ser expresso
sob a forma E = e1, e2, ..., ek. Consideremos o evento formado por um resultado
simples, algumas vezes denominado evento simples ou elementar, e i.
A cada evento simples ei associaremos um número pi, denominado
probabilidade de ei, que satisfaça às seguintes condições:
pi 0, i = 1, 2, ..., k,

p1 + p2 + ...+ pk =1.
Em seguida, suponha-se que um evento A seja constituído por r
resultados, 1 r k. Consequentemente, conclui-se, do axioma 3, que:
P(A) = p1 + p2 + ...+pr.
Exemplo 4.8:
Suponha que somente três resultados sejam possíveis em um
experimento, a saber, e1, e2 e e3. Além disso, suponha que e1 seja duas vezes
mais provável de ocorrer que e2, o qual por sua vez é duas vezes mais provável
de ocorrer que e3. Qual a probabilidade de ocorrer o elemento e1? E o elemento
e2? E o elemento e3?
Como p1 = 2p2 e p2 = 2p3, dados pelo problema, e que p1 + p2 + p3 = 1,
pelo axioma 2, teremos 4p3 + 2p3 + p3 = 1, o que finalmente dá
p3 = 1/7, p2 = 2/7 e p1 = 4/7.
1.1.8 Resultados Igualmente Prováveis
Quando associamos cada elemento do espaço amostral a uma mesma
probabilidade, o espaço amostral chama-se equiprovável. Em particular, se E
contém k elementos, então, a probabilidade de cada elemento será 1/k, pois
p1 + p2 + ...+ pk = 1
e como
p1 = p2 = ...= pk = p,
então
kpkp
11 =⇒=
Por outro lado, se um evento A contém r elementos, 1 r k, então:

( ) .1
k
r
krAP =
=
Este método de avaliar P(A) é frequentemente enunciado da seguinte
maneira:
( )ocorreEamostralespaçooqueemvezesdenúmero
ocorrerpodeAeventooqueemvezesdenúmeroAP =
ou
( ) ( ) ( )( ) ( )possíveiscasosdenúmeroEn
AeventoaofavoráveiscasosdenúmeroAnAP
.
.=
É muito importante compreender que a expressão de P(A) acima é
apenas uma consequência da suposição de que todos os resultados sejam
igualmente prováveis, e ela é aplicável somente quando essa suposição for
atendida. Ela certamente não serve como uma definição geral de probabilidade.
No entanto, como em estatística a extração da amostra se dá de modo aleatório,
ou seja os itens da população têm a mesma chance de ser escolhido para
participar da amostra, o modelo probabilístico que fundamenta a teoria da
estatística pressupõe que os experimentos são equiprováveis.
Exemplo 4.9:
Escolha aleatoriamente (a expressão aleatória nos indicará que o
espaço é equiprovável) uma carta de um baralho com 52 cartas.
Seja:
A = a carta é de ouros
B = a carta é uma figura
Calcular P(A) e P(B).
( )( ) 4
1
52
13)( ===
En
AnAP

( )( ) 13
3
52
12)( ===
En
BnBP
Exemplo 4.10:
Num lote de 12 peças, 4 são defeituosas; duas peças são retiradas
aleatoriamente. Calcule:
a) a probabilidade de ambas serem defeituosas;
b) a probabilidade de ambas não serem defeituosas;
c) a probabilidade de ao menos uma ser defeituosa.
Solução:
a)
A = ambas defeituosas
A pode ocorrer C42 6= vezes
E pode ocorrer C122 66= vezes
( ) ( )( ) 11
1
66
6 ===En
AnAP
b)
B = ambas não defeituosas
B pode ocorrer C82 28=
E pode ocorrer C122 66= vezes
( )( ) 33
14
66
28)( ===
En
BnBP
c)
C = ao menos uma é defeituosa

C é o complemento de B, então C = B
P C P B( ) ( )= − = − =1 114
33
19
33
1.1.9 Probabilidade Condicionada
Seja ε o seguinte experimento: lançar um dado honesto. E o seguinte
evento A = sair o no 4. Então
P A( ) =1
6
tendo em vista o espaço amostral equiprovável E = 1, 2, 3, 4, 5, 6.
Consideremos agora o evento B = sair um no par = 2, 4, 6. Calcular a
probabilidade de ocorrer o evento A condicionada à ocorrência do evento B. Em
símbolo denotamos P(A|B); lê-se: “probabilidade de ocorrer o evento A
condicionada à ocorrência de B”, ou “probabilidade de ocorrer o evento A
sabendo-se que ocorreu o evento B”, ou, ainda, “probabilidade de ocorrer o
evento A dado B”. Assim,
3
1)|( =BAP
isto porque, sabendo-se que ocorreu o evento B, os resultados
possíveis passam a ser E* = 2, 4, 6, ou seja, houve uma redução do espaço
amostral. Desse modo o referencial deixa de ser o espaço amostral E e passa a
ser o evento B.
Desse modo, a definição da probabilidade condicionada é:
)(
)()|(
BP
BAPBAP
=
e
)(
)()|(
AP
BAPABP
=.

A mais importante consequência da definição acima de probabilidade
condicionada é obtida ao se escrever:
P(A∩B) = P(A) x P(B|A)
ou, de modo equivalente:
P(A∩B) = P(B) x P(A|B)
Exemplo 4.11:
Suponha que um escritório possua 100 máquinas. Algumas dessas
máquinas são elétricas (E), enquanto outras são manuais (M); e algumas são
novas (N), enquanto outras são muito usadas (U). A tabela abaixo dá o número de
máquinas de cada categoria. Uma pessoa entra no escritório, pega uma máquina
ao acaso, e descobre que é nova. Qual será a probabilidade de que seja elétrica?
Tabela 4.2: Representação do espaço amostral por meio de uma tabela
de dupla entrada.
E M TOTALN 40 30 70U 20 10 30
TOTAL 60 40 100
Considerando somente o espaço amostral reduzido N (isto é, as 70
máquinas novas), temos:
7
4
70
40)|( ==NEP
Empregando a definição de probabilidade condicionada, temos:
( ).
7
4
10070
10040
)()|( ===
NP
NEPNEP
Exemplo 4.12:

Seja um lote de peças contendo 20 peças defeituosas e 80 perfeitas.
Se escolhermos ao acaso duas peças, sem reposição, qual será a probabilidade
de que ambas as peças sejam defeituosas?
Sejam os eventos: A = a primeira peça é defeituosa; B = a segunda
peça é defeituosa
P(AB) = P(A).P(B|A) =
20
100
19
99
19
495× =
1.1.10 Independência Estatística
Um evento A é considerado independente de outro evento B se a
probabilidade de ocorrer A é igual à probabilidade de ocorrer A dado B, isto é, se
P(A) = P(A|B)
É claro que se o evento A é independente do evento B, o evento B é
independente do evento A, assim:
P(B) = P(B|A)
Então:
P(AB) = P(A) . P(B)
Exemplo 4.13:
Em uma caixa temos 10 peças, das quais 4 são defeituosas. São
retiradas, aleatoriamente, duas peças, uma após a outra, com reposição. Calcular
a probabilidade de ambas serem defeituosas.
Sejam: A = a primeira peça é defeituosa; B = a segunda peça é
defeituosa
Como os eventos A e B são independentes, pois P(B) = P(B|A), então:
P(AB) = P(A) . P(B) =
4
10
4
10
4
25× =

Exemplo 4.14:
Sendo E = 1, 2, 3, 4 um espaço amostral equiprovável e A = 1, 2; B
= 1, 3; C = 1, 4 três eventos de E, verificar se os eventos A, B e C são
independentes.
Para A e B P(A) = 21
; P(B) = 21
; P(AB) = 41
; logo: P(AB) = P(A) =
P(B) = 1/4.
Para A e C P(A) = 2
1
; P( C) = 2
1
; P(AC) = 4
1
; logo: P(AC) = P(A) .
P(C) = 4
1
.
Para B e C P(B) = 2
1
; P( C) = 2
1
; P(BC) = 4
1
; logo: P(BC) = P(B) .
P(C) = 4
1
Para A, B e C P(A) = 2
1
; P(B) = 2
1
; P(C) = 2
1
; P(ABC) = 4
1
; logo:
P(ABC) P(A) . P(B) . P( C).
Conclusão, os eventos A, B e C não são independentes.
Regra de Bayes
Sejam A1, A2, A3, ..., An, n eventos mutuamente exclusivos tais que
A A A A En1 2 3 ... = , onde E é o espaço de resultados. Sejam P(A i) as
probabilidades conhecidas dos vários eventos A i e B, condicionado a Ai, um
evento qualquer de E tal que conhecemos todas as probabilidades condicionadas
P(B/Ai). A figura a seguir representa estas condições.
B

An
A3
A1
A2
.............E
Assim,
B = A1B A 2B ... A nB
Como:
(AiB) ∩ (AjB) = i j,
tem-se:
( ) ( ) ( ) ( )BAPBAPBAPBP n+++= 21 ,
ou seja:
( ) ( )∑=
=n
i
iBAPBP1
Então:
( ) ( ) ( )[ ]∑=
=n
iii ABPAPBP
1
|
A Regra de Bayes se presta a responder a seguinte questão: sabendo-
se que o evento B ocorreu, qual é a probabilidade de ocorrer algum dos eventos
Ai?
Denominando esse evento de Ar, obtém-se:

( ) ( ) ( ) ( ) ( )BAPBPABPAPBAP rrrr || ×=×=
Explicitando ( )BAP r | , obtém-se:
( ) ( ) ( )( )BP
ABPAPBAP rr
r
|| =
.
Finalmente, a expressão da Regra de Bayes é:
( ) ( ) ( )
( ) ( )[ ]∑=
=n
i
ii
rrr
ABPAP
ABPAPBAP
1
|
||
.
Esta regra é bastante importante, pois, relaciona probabilidades “a
priori” P(Ai) com probabilidades “a posteriori” P(A i|B), ou seja, probabilidades de A i
depois que ocorrer B.
Exemplo 4.15:
Um determinado tipo de peça é fabricado por três máquinas, digamos
M1, M2 e M3. Sabe-se que a máquina M1 produz o dobro de peças que a máquina
M2, e que M2 e M3 produzem o mesmo número de peças, durante um determinado
período de produção. Sabe-se também que 2% das peças produzidas por M1 e
por M2 são defeituosas, enquanto que 4% daquelas produzidas por M3 são
defeituosas. Todas as peças produzidas são colocadas em um depósito, e depois
uma peça é extraída ao acaso verificando-se que é defeituosa. Qual é a
probabilidade de que tenha sido produzida pela máquina M1? E pela máquina M2?
E pela M3?
Sejam os seguintes eventos:
D: a peça é defeituosa
M1: a peça foi fabricada pela máquina 1
M2: a peça foi fabricada pela máquina 2
M3: a peça foi fabricada pela máquina 3

( ) ( ) 02,0|| 21 == MDPMDP
( ) 04,0| 3 =MDP
Cálculo de P(M1), P(M2) e P(M3):
P(M1) + P(M2) + P(M3) = 1
P(M1) = 2P(M2)
P(M2) = P(M3)
2P(M2) + P(M2) + P(M2) = 1
P(M3) = P(M2) = 0,25
P(M1) = 0,50
40,025,004,025,002,050,002,0
50,002,0)/( 1 =
×+×+××=DMP
20,025,004,025,002,050,002,0
25,002,0)/( 2 =
×+×+××=DMP
40,025,004,025,002,050,002,0
25,004,0)/( 3 =
×+×+××=DMP

Tabela 4.3: Resultados das probabilidades
MÁQUINASPROBABILIDADES
“a priori” “a posteriori”
M1 0,50 0,40
M2 0,25 0,20
M3 0,25 0,40
TOTAL 1,00 1,00
Exercícios Propostos
1. Certo tipo de motor elétrico falha se ocorrer uma das
seguintes situações: emperramento dos mancais, queima dos enrolamentos,
desgaste das escovas. Suponha que o emperramento seja duas vezes mais
provável do que a queima; esta sendo quatro vezes mais provável do que o
desgaste das escovas. Qual será a probabilidade de que a falha seja devida a
cada uma dessas circunstâncias?
Resp.: 8/13, 4/13, 1/13.
2. Suponha que A e B sejam eventos tais que P(A) = x, P(B) = y,
e P(A B) = z. Exprima cada uma das seguintes probabilidades em termos de
x, y e z.
a) AP( )B
b) AP( )B
c) AP( )B
d) AP( )B

3. Uma caixa contém 25 bolas numeradas de 1 a 25. Extraindo-
se uma bola ao acaso, qual a probabilidade de que seu número seja:
a) par;
b) ímpar;
c) par e maior que 10;
d) primo e maior que 3;
e) múltiplo de 3 e 5.
Resp.: a) 12/25; b) 13/25; c) 7/25; d) 7/25; e) 1/25.
4. O seguinte grupo de pessoas está numa sala: 5 homens maiores de 21
anos de idade; 4 homens com menos de 21 anos de idade; 6 mulheres
maiores de 21 anos de idade e 3 mulheres menores de 21 anos de idade.
Uma pessoa é escolhida ao acaso. Definem-se os seguintes eventos: A =
a pessoa é maior de 21 anos; B = a pessoa é menor de 21 anos; C = a
pessoa é homem; D = a pessoa é mulher. Calcule:
a) P(B D);
b) AP( C )
Resp.: a) 13/18; b) 1/6
5. Em uma sala, 10 pessoas estão usando emblemas numerados de 1 a 10.
Três pessoas são escolhidas ao acaso e convidadas a saírem da sala
simultaneamente. O número de seus emblemas é anotado.
a) Qual é a probabilidade de que o menor número de emblema seja 5 ?
b) Qual é a probabilidade de que o maior número de emblema seja 5 ?
Resp.: a) 1/6 b) 1/12.

6. Dez fichas numeradas de 1 até 10 são misturadas em uma urna. Duas
fichas, numeradas (X, Y), são extraídas da urna, sucessivamente e sem
reposição. Qual é a probabilidade de que seja X + Y = 10 ?
Resp.: 4/45
7. Um lote é formado de 10 artigos bons, 4 com defeitos menores e 2 com
defeitos graves. Um artigo é escolhido ao acaso. Ache a probabilidade de
que:
a) Ele não tenha defeitos.
b) Ele não tenha defeitos graves.
c) Ele, ou seja, perfeito ou tenha defeitos graves.
Resp.: a) 5/8 b) 7/8 c) 3/4.
8. Se do lote de artigos descrito no Probl. 7, dois artigos forem escolhidos
(sem reposição), ache a probabilidade de que:
a) Ambos sejam perfeitos;
b) Ambos tenham defeitos graves;
c) Ao menos um seja perfeito.
d) No máximo um seja perfeito
e) Exatamente um seja perfeito.
f) Nenhum deles tenha defeitos graves.
g) Nenhum deles seja perfeito.
Resp.: a) 3/8; b) 1/120; c) 7/8; d) 5/8; e) 1/2; f) 91/120; g) 1/8.
9. Um produto é montado em três estágios. No primeiro estágio, existem 5
linhas de montagem, no segundo estágio, existem 4 linhas de montagem e

no terceiro estágio, existem 6 linhas de montagem. De quantas maneiras
diferentes poderá o produto se deslocar durante o processo de montagem?
Resp.: 120
10.Um inspetor visita 6 máquinas diferentes durante um dia. A fim de evitar
que os operários saibam quando ele os irá inspecionar, o inspetor varia a
ordenação de suas visitas. De quantas maneiras isto poderá ser feito ?
Resp.: 720
11.Existem 12 tipos de defeitos menores de uma peça manufaturada, e 10
tipos de defeitos graves. De quantas maneiras poderão ocorrer 1 defeito
menor e 1 grave? E 2 defeitos menores e 2 graves?
Resp.: 120; 2970.
12.Um mecanismo pode ser posto em uma dentre quatro posições: a, b, c e d.
Existem 8 desses mecanismos incluídos em um sistema.
a) De quantas maneiras esse sistema pode ser disposto?
b) Admita que esses mecanismos sejam instalados em determinada
ordem (linear) preestabelecida. De quantas maneiras o sistema poderá ser
disposto, se dois mecanismos adjacentes não estiverem em igual posição?
c) Quantas maneiras de dispor serão possíveis, se somente as
posições a e b forem usadas, e o forem com igual frequência?
d) Quantas maneiras serão possíveis, se somente duas posições forem
usadas, e dessas posições uma ocorrer três vezes mais frequentemente que a
outra?
Resp.: a) 48; b) 4.37; c) 70; d) 336.
13.Com as seis letras a, b, c, d, e, f quantas palavras-código de 4 letras
poderão ser formadas se:
a) Nenhuma letra puder ser repetida?

b) Qualquer letra puder ser repetida qualquer número de vezes?
Resp.: a) 360; b) 1296
14.Determinado composto químico é obtido pela mistura de 5 líquidos
diferentes. Propõe-se despejar um líquido em um tanque e, em seguida,
juntar os outros líquidos sucessivamente. Todas as sequências possíveis
devem ser ensaiadas, para verificar-se qual delas dará o melhor resultado.
Quantos ensaios deverão ser efetuados?
Resp.: 120
15.Uma caixa contém 3 bolas brancas e 2 bolas pretas. Extraindo-se duas
bolas simultaneamente, calcule a probabilidade de serem:
a) uma de cada cor;
b) ambas da mesma cor;
Resp.: a) 3/5; b) 2/5.
16.Resolva o problema 15, admitindo-se que as duas bolas são extraídas uma
a uma , com reposição.
Resp.: a) 12/25; b) 13/25.
17.Se as cinco bolas da caixa citada no problema 15 forem extraídas uma a
uma sem reposição, calcule a probabilidade de que:
a) as três brancas saiam sucessivamente;
b) as duas pretas saiam sucessivamente;
c) ao menos um dos eventos mencionados em a) e b) ocorra.
Resp.: a) 0,3; b) 0,4; c) 0,5.
18.Um dado honesto é lançado duas vezes. Seja a o número de pontos obtido
no primeiro lançamento e b os obtidos no segundo lançamento. Determinar
a probabilidade da equação ax – b = 0 ter raiz inteira.

19.Uma companhia de seguros extraiu uma amostra aleatória estratificada, de
tamanho 500, da população de seus segurados, com a seguinte
composição: metade mulheres e metade homens. Nessa amostra foi
encontrado que dos 65 segurados que usaram hospital 40 eram mulheres.
Com base nesses dados responda:
1. Qual a probabilidade de um segurado usar o hospital?
2. Qual a probabilidade de um segurado ser do sexo
masculino?
3. Qual a probabilidade de um segurado ser do sexo
feminino e não usar hospital?
4. Qual a probabilidade de um segurado ser do sexo
masculino e usar hospital?
5. Se um segurado é do sexo masculino, qual a
probabilidade de não usar o hospital?
6. Se um segurado usou hospital, qual a probabilidade de
ser do sexo feminino?
7. Pode-se afirmar que o sexo do segurado e se ele usou
ou não hospital são eventos independentes?
20.Uma determinada empresa decide aceitar um lote de matéria prima se, de
uma amostra de 20 unidades, nenhuma for defeituosas.
1. Qual a probabilidade de um lote ser aceito quando
nenhuma unidade for defeituosa?
2. Qual a probabilidade de um lote ser aceito quando 15%
das unidades forem defeituosas?
3. Qual a probabilidade de um lote ser aceito quando 25%
das unidades forem defeituosas?

21.Em uma pesquisa de associação entre a venda de sabão em pó e
amaciante foi entrevistado 20.000 pessoas. Observou-se que 16.000
pessoas compraram sabão em pó, 12.000 compraram amaciante e 2.500
não compraram nem sabão em pó nem amaciante.
1. Pode-se afirmar que comprar sabão em pó e comprar
amaciante são independentes?
2. Qual a probabilidade de uma pessoa selecionada ao
acaso ter comprado sabão em pó?
3. Qual a probabilidade de uma pessoa selecionada
aleatoriamente não ter comprado amaciante?
4. Qual a probabilidade de uma pessoa selecionada
aleatoriamente não ter comprado sabão em pó e ter comprado
amaciante?
5. Qual a probabilidade de uma pessoa selecionada
aleatoriamente não ter comprado sabão em pó ou ter comprado
amaciante?
6. Sabendo que uma pessoa não comprou sabão em pó,
qual a probabilidade dela ter comprado amaciante?
22.Dentre 7 pessoas, será escolhida por sorteio uma comissão de 3 membros.
Qual a probabilidade de que uma determinada pessoa venha a figurar na
comissão?
Resp.: 3/7
23.A probabilidade de que um aluno A resolva um problema é de 2/3 e de um
aluno B é de 3/4. Se ambos tentarem independentemente, qual a
probabilidade de o problema ser resolvido?
24.Em que condição:
1. P (A )=P(A∪B)

2. P (B )=2× P(A∩B)
3. P (A∪B )=3×P ( A∩B )
4. P (A∪B )=P(A∩B)
25.Um sistema automático de alarme contra incêndio utiliza três células
sensíveis ao calor, que agem independentemente uma da outra. Cada
célula entra em funcionamento com probabilidade 0,8 quando a
temperatura atingir a 600 C. Se pelo menos uma das células entrar em
funcionamento, o alarme soa. Calcular a probabilidade de que o alarme
seja acionado, quando a temperatura atingir a 600 C.
Resp.: 0,992
26.Sejam A e B dois eventos tais que P(A) = 0,4 e P(A B) = 0,7. Seja P(B) =
p.
a) Para que valor de p, A e B serão mutuamente exclusivos?
b) Para que valor de p, A e B serão independentes?
Resp.: a) 0,3; b) 0,5.
27.Considere os algarismos de 0 a 9. Sorteados dois destes algarismos, sem
repetição, calcule a probabilidade de que:
a) sua soma seja menor que 4;
b) seu produto seja menor que 4.
Resp.: a) 4/45; b) 11/45
28.No circuito elétrico dado abaixo, em que existe tensão entre os pontos A e
B, determine a probabilidade de passar corrente entre A e B, sabendo-se
que a probabilidade de cada chave estar fechada é 0,5 e que cada chave
está aberta ou fechada independentemente de qualquer outra.

•B A•
Resp: 0,5312
29.Uma caixa A contém nove fichas numeradas de 1 a 9 e uma caixa B
contém cinco fichas numeradas de 1 a 5, para efeito de inspeção de
pessoal. Uma caixa é escolhida aleatoriamente e uma ficha é retirada. Qual
é a probabilidade de a ficha ser par? E de ser ímpar?
Resp: 19/45 e 26/45.
30.Joga-se um dado. Calcule a probabilidade de obter-se o resultado:
a) 1 ou 2;
b) 2 ou 5 ou 6;
c) um número ímpar;
d) qualquer número exceto 5.
Resp: 1/3, 1/2, 1/2, 5/6.
31.Lançam-se dois dados. Seja X a face superior do primeiro dado e Y a face
superior do segundo dado. Assim, o par de números (X, Y) representa um
resultado simples do experimento. Realizando o experimento, marque no
espaço amostral os seguintes eventos:
a) A = X = Y;
b) B = a face do segundo vale duas vezes a face do primeiro;
c) C = a média dos resultados dos dados é maior ou igual a três.
32.Com relação ao espaço amostral associado ao experimento aleatório
acima, exemplifique:

a) evento união;
b) evento interseção;
c) evento diferença;
d) eventos incompatíveis.
33.Joga-se um dado não tendencioso. Se o resultado não foi a face “quatro”,
qual é a probabilidade de que tenha sido a face “um”?
34.Num lançamento de 2 dados, seja X a soma dos números das faces
voltadas para cima. Determinar o valor de X que tem maior probabilidade
de ocorrer.
Resp: 7
35.Uma urna contém 7 bolas vermelhas e 3 brancas. Três bolas são retiradas
da urna, uma após a outra sem reposição. Calcular a probabilidade de que
as duas primeiras sejam vermelhas e a terceira branca.
Resp: 7/40
36.Certo computador torna-se inoperante se ambos componentes A e B
falharem. A probabilidade que A falhe é 0,01 e a probabilidade que B falhe
é 0,005. Entretanto, a probabilidade que B falhe aumenta por um fator de 3
se A tiver falhado.
a) Calcular a probabilidade de o computador tornar-se inoperante.
b) Encontrar a probabilidade de A falhar se B falhou.
37.Certo sistema binário PCM transmite os dois estados binários X = +1 e X =
-1 com igual probabilidade. Entretanto, devido a ruído de canal, o receptor
acusa erros de reconhecimento. Também, como resultado de distorção do
meio de comunicação, o receptor pode perder a intensidade necessária do
sinal para tomar qualquer decisão. Portanto, há três estados de recepção
possíveis: Y = +1, Y = 0 e Y = -1, onde Y = 0 corresponde a “perda de

sinal”. Admita que P(Y = -1|X = +1) = 0,1, P(Y = +1|X = -1) = 0,2 e P(Y = 0|
X = +1) = P(Y = 0|X = -1) = 0,05.
a) Encontrar as probabilidades P(Y = +1), P(Y = -1) e P(Y = 0).
b) Encontrar a probabilidades P(X = +1|Y = +1) e P(X = -1|Y = -1).
Resp.
P(Y = +1) = 0,525, P(Y = -1) = 0,425 e P(Y = 0) = 0,05.
P(X = +1|Y = +1) = 0,81 e P(X = -1|Y = -1) = 0,88.
38.Em um sistema binário de comunicação (representado na figura a seguir),
um 0 ou 1 é transmitido. Devido ao ruído de canal, um 0 pode ser recebido
como um 1 e vice-versa. Sejam to e t1 os eventos que correspondem a
transmissão de 0 e de 1, respectivamente. Sejam ro e r1 os eventos que
correspondem ao recebimento de 0 e de 1, respectivamente. Sejam P(to) =
0,5, P(r1|to) = 0,1, e P(ro|t1) = 0,2.
P(r1|to)
t1
P(t1)
to
P(to)
ro
r1
P(ro|to)
P(r1|t1)
P(ro|t1)
a) Encontrar P(ro) e P(r1).
b) Se um 0 foi recebido, qual é a probabilidade que um 0 foi enviado?

c) Se um 1 foi recebido, qual é a probabilidade que um 1 foi enviado?
d) Calcule a probabilidade que o sinal transmitido é corretamente lido
pelo recebedor.
e) Calcule a probabilidade do erro Pe.
Resp.:
a) P(ro) = 0,55 e P(r1) = 0,45.
b) P(to|ro) = 0,818.
c) P(t1|r1) = 0,889.
d) Pc = 0,85.
e) Pe = 0,15.
39.Considere um sistema binário de comunicação, representado pela figura do
problema 31, com P(ro|to) = 0,9, P(r1|t1) = 0,6. Para decidir qual das
mensagens foi enviada para uma resposta observada ro ou r1, utilizamos o
seguinte critério:
Se ro é recebido:
Decide por to se P(to|ro) > P(t1|ro)
Decido por t1 se P(t1|ro) > P(to|ro)
Se r1 é recebido:
Decide por to se P(to|r1) > P(t1|r1)
Decido por t1 se P(t1|r1) > P(to|r1)
a) Encontrar a faixa do valor de P(to) para o qual a critério de decisão
acima especificado prescreva que decidiremos por to se ro é recebido.
b) Encontrar a faixa do valor de P(to) para o qual a critério de decisão
acima especificado prescreva que decidiremos por t1 se r1 é recebido.

c) Encontrar a faixa do valor de P(to) para o qual a critério de decisão
acima especificado prescreva que decidiremos por to não importando o que foi
recebido.
d) Encontrar a faixa do valor de P(to) para o qual a critério de decisão
acima especificado prescreva que decidiremos por t1 não importando o que foi
recebido.
Resp.:
a) 0,31 < P(to) 1
b) 0 P(to) < 0,86
c) 0,86 < P(to) 1
d) 0 P(t o) < 0,31
40.Considere um experimento que consiste da observação de seis posições
de pulso sucessivas em um link de comunicação. Suponha que para cada
uma das seis posições de pulso possíveis possa haver um pulso positivo,
um pulso negativo, ou nenhum pulso. Suponha também que os
experimentos individuais que determina o tipo de pulso para cada posição
possível sejam independentes. Denominemos o evento que o i-ésimo pulso
seja positivo por xi = +1 , se for negativo por xi = -1, e se for zero por
xi = 0. Admita que
P(xi = +1) = 0,4 P(xi = -1) = 0,3 para i = 1, 2, , 6
a) Encontrar a probabilidade que todos os pulsos sejam positivos.
b) Encontrar a probabilidade que os primeiros três pulsos sejam
positivos, o próximo seja zero, e o último negativo.
Resp.:
a) 0,0041
b) 0,0017

41.Uma urna contém duas bolas brancas e duas pretas. Outra contém duas
bolas brancas e quatro pretas.
a) Tira-se uma bola de cada urna. Calcular a probabilidade de serem
ambas da mesma cor.
b) Escolhe-se uma das urnas ao acaso e dela tira-se uma bola.
Calcular a probabilidade de ela ser branca.
c) Escolhe-se uma das urnas ao acaso e tiram-se duas bolas. Qual a
probabilidade de serem da mesma cor?
42.Três eventos A, B e C mutuamente exclusivos têm, respectivamente, as
probabilidades P(A) = 1/3; P(B) = 1/6 e P(C) = 1/2. Quais as probabilidades
de se obter:
a) A ou B ?
b) A ou C ?
c) B ou C ?
d) A ou B ou C ?
43.Dois times A e B jogaram 15 partidas de futebol das quais 7 foram vencidas
por A, 5 por B e 3 terminaram empatadas. Eles combinaram a disputa de
um torneio constante de 3 partidas. Determinar a probabilidade de que:
a) A vença as três partidas;
b) B vença as três partidas;
c) duas partidas terminem empatadas;
d) B vença pelo menos uma partida;
e) A vença duas e empate uma.
44.Uma caixa A contém 6 máquinas elétricas e 2 manuais enquanto que uma
caixa B contém 3 máquinas elétricas e 4 manuais. Escolhe-se uma destas

duas caixas, ao acaso, e dela tira-se uma máquina. Qual é a probabilidade
de que ela seja elétrica?
A probabilidade de um time Y ganhar um jogo é constante e igual a
0,60.
a) Em 10 jogos, qual é a probabilidade de Y ganhar 5 jogos ?
b) Qual a probabilidade de Y ter que jogar 3 vezes, para que ganhe 2
jogos?
c) Qual a probabilidade de Y ter que jogar mais de 5 vezes, para que
vença 2 vezes?
d) Qual a probabilidade de que Y perca ou empate 4 jogos se fizer 7
jogos?
45.Um homem de 40 anos investe numa anuidade que começará a receber 20
anos mais tarde. Sua esposa tem 38 anos. De todos os homens de 40
anos, 4/5 ainda sobrevivem depois de 20 anos e de todas as mulheres de
38 anos, 9/10 ainda sobrevivem depois de 20 anos. Qual a probabilidade
de que pelo menos um dos dois esteja vivo quando a anuidade começar a
ser paga?
46.A probabilidade de que um elo de uma corrente se rompa sob a ação de
uma determinada força F é igual a 1/3. Considere uma corrente formada
por três desses elos e calcule a probabilidade de que ela venha a se
romper sob a ação dessa mesma força F.
47.Verifica-se que a resistência à inoculação de determinado vírus em ratos é
igual a 90% e em coelhos é igual a 70%. Tomou-se um grupo de 20 ratos e
outro de 30 coelhos para teste, aos quais foi inoculado o vírus. Calcular a
probabilidade de que:
a) em três ratos observados, todos resistirem;
b) em três coelhos observados, apenas um não resistir;

c) em três animais observados, apenas um ser rato e não resistir;
d) um animal inoculado não resistiu. Calcular a probabilidade de ser
coelho.
48.Uma água é contaminada se forem encontrados bacilos tipo A ou bacilos
tipos B e C, simultaneamente. As probabilidades de se encontrarem bacilos
tipos A, B e C são respectivamente, 30%, 20% e 80%. Existindo bacilos
tipos B, a probabilidade de existirem bacilos tipo C é reduzida à metade.
Considere, ainda, que é nula a probabilidade de existirem os três bacilos
na água simultaneamente e que os bacilos A e B ocorrem de modo
independente um do outro.
a) Qual a probabilidade de aparecerem bacilos B ou C?
b) Qual a probabilidade da água estar contaminada?
c) Se a água estiver contaminada, qual a probabilidade de aparecerem
bacilos tipo B?
Resp.: a) 0,92; b) 0,38; c) 0,3684
49.Três departamentos A, B e C de uma escola tem, respectivamente, a
seguinte composição: 2 doutores, 3 mestres e 4 instrutores; 3 doutores, 2
mestres e 2 instrutores; 4 doutores, 1 mestre e 1 instrutor. Escolhe-se um
departamento ao acaso e sorteiam-se dois professores. Se os professores
forem um instrutor e um doutor, qual a probabilidade de que tenham vindo
do departamento A? e do departamento B? e do departamento C?
Resp.: 14/43; 15/43; 14/43.
50.Um carro pode parar por defeito elétrico ou mecânico. Se houver defeito
elétrico, o carro para na proporção de 1 para 5 e, se mecânico, ele para na
proporção de 1 para 20. Em 10% das viagens, há defeito elétrico e, em
20%, mecânico, não ocorrendo mais de um defeito na mesma viagem,
igual ou de tipo diferente. Se o carro para, qual é a probabilidade de ser por
defeito elétrico?

Resp.: 2/3
51.Um método A de diagnóstico de certa enfermidade dá resultados positivos
para 80% dos portadores da enfermidade e para 10% dos sãos. Um
método B de diagnóstico da mesma enfermidade dá positivo para 70% dos
portadores e 50% para os sãos. Se 15% da população forem portadores
dessa enfermidade, calcular a probabilidade de que:
a) para uma pessoa, os resultados sejam positivos pelos dois métodos;
b) entre duas pessoas enfermas, pelo menos para uma o resultado
seja positivo por qualquer dos dois métodos.
Resp.: a) 0,08825; b) 0,9964
52.Em um colégio, 30% dos alunos e 15% das alunas estão estudando Inglês.
Os alunos constituem 60% do corpo de estudantes. Um estudante é
selecionado aleatoriamente.
a) Determine a probabilidade de ele estar estudando Inglês.
b) Se o estudante escolhido estiver estudando Inglês, qual é a
probabilidade de que ele seja do sexo feminino?
53.As urnas 1, 2 e 3 contêm bolas coloridas nas seguintes composições:
Urna 1: 1 branca, 2 pretas e 3 vermelhas;
Urna 2: 2 brancas, 1 preta e 1 vermelha;
Urna 3: 4 brancas, 5 pretas e 3 vermelhas.
Escolhe-se uma urna ao acaso e dela extraem-se duas bolas. Verifica-
se que uma é branca e a outra é vermelha. Qual é a probabilidade de que
provenham da urna 2 ou 3?
54.A urna 1 contém duas bolas brancas e uma preta; a urna 2, uma bola
branca e 5 pretas. Passa-se uma bola da urna 1 para a 2, sem lhe ver a
cor; em seguida, extrai-se uma bola da urna 2, que se verifica ser branca.

Que probabilidade existe de que a bola transferida da urna 1 para a 2
tenha sido preta?
Resp.: 1/5
55.Uma companhia de seguros classifica os motoristas em classe A (risco
bom), classe B (risco médio) e classe C (risco ruim). Ela acredita que a
classe A compreenda 30% dos motoristas que fazem o seguro; a classe B,
50% e a classe C, 20%. A probabilidade de que um motorista classe A
tenha um ou mais acidentes, em qualquer período de 12 meses, é de 0,01;
para a classe B, essa probabilidade é de 0,03; para a classe C, 0,10. A
companhia vende ao Sr. José uma apólice de seguros e dentro de 12
meses ele sofre um acidente. Qual a probabilidade de que ele pertença à
classe A ? E à classe B ?
56.Três máquinas A, B e C produzem, respectivamente, 60%, 30% e 10% do
total das peças de uma fábrica. As percentagens de peças defeituosas na
produção dessas máquinas são, respectivamente, 2%, 1% e 4%. Uma
peça é selecionada aleatoriamente e é defeituosa. Encontre a
probabilidade de que a peça tenha sido produzida pela máquina C.
57.Uma peça é feita por três fábricas A, B e C. Sabe-se que a fábrica A produz
o triplo de peças da fábrica B. A fábrica B produz o dobro de peças da
fábrica C. Sabe-se também que 1%, 3% e 5% das peças produzidas,
respectivamente, por A, B e C são defeituosas. Todas as peças produzidas
são colocadas em um depósito, de onde uma delas é retirada ao acaso.
Denominando D o evento peça defeituosa na extração, calcular:
a) P(A D);
b) P(A D);
c) P(A/D).
58.Há três moedas em uma sacola. Apenas uma delas é uma moeda normal,
com “cara” em uma face e “coroa” na outra. As demais são moedas
defeituosas. Uma delas tem “cara” em ambas as faces. A outra tem “coroa”

em ambas as faces. Uma moeda é retirada da sacola, ao acaso, e é
colocada sobre a mesa sem que se veja qual a face que ficou voltada para
baixo. Vê-se que a face voltada para cima é “cara”. Considerando todas
estas informações, qual a probabilidade de que a face voltada para baixo
seja “coroa”? Resp.: 1/3
59.Em uma empresa de pesquisa determinou-se que a probabilidade de haver
crise energética é de 40% e que a probabilidade de haver aumento do
desemprego é de 35%. Sabendo-se que a probabilidade de aumento no
desemprego dado que houve crise energética é de 70%, responda:
a) Qual a probabilidade de não haver crise energética e haver aumento no
desemprego?
b) Qual a probabilidade de haver aumento no desemprego dado que não
houve crise energética?
c) Qual a probabilidade de não haver aumento no desemprego e nem crise
energética?
d) Pode-se afirmar que os eventos haver crise energética e aumento no
desemprego são independentes?
Resp.: a) 0,07, b) 0,1167

APÊNDICE: MÉTODOS DE ENUMERAÇÃO
A1. FATORIAL
Fatorial de um número natural n, é o produto dos n primeiros números
naturais.
Notação:
n! = 1.2.3. ... .(n-2).(n-1).n, n 2
Por definição:
1! = 1
0! = 1
Consequência: n! = n.(n-1)!
Exemplo 4.16:
a) 5! = 1.2.3.4.5 = 120
b) 4! = 1.2.3.4 = 24
c) 10! = 10.9!
A2. MÉTODOS DE ENUMERAÇÃO
Considere o seguinte problema: “Uma partida de 100 peças é
composta de 20 peças defeituosas e 80 peças perfeitas. Dez dessas peças são
escolhidas ao acaso, sem reposição de qualquer peça escolhida antes que a
seguinte seja escolhida. Qual é a probabilidade de que exatamente metade das
peças escolhidas seja defeituosa?”
Para analisarmos este problema, consideremos o seguinte espaço
amostral E. Cada elemento de E é constituído de dez possíveis peças da partida.

Quantos resultados desses existem? E dentre esses resultados, quantos têm a
característica de que exatamente a metade das peças seja defeituosa? Nós,
evidentemente, precisamos ter condições de responder a tais questões a fim de
resolvermos o problema em estudo. Muitos problemas semelhantes dão origem a
questões análogas. A seguir serão apresentadas algumas técnicas de
enumeração.
A3. REGRA DE MULTIPLICAÇÃO
Suponha-se que um procedimento designado por 1 possa ser
executado de n1 maneiras. Admita-se que um segundo procedimento, designado
por 2, possa ser executado de n2 maneiras. Suponha-se, também, que cada
maneira de executar 1 possa ser seguida por qualquer daquelas para executar 2.
Então, o procedimento 1 seguido pelo 2 poderá ser executado de (n1 n 2)
maneiras. Para indicar a validade deste princípio, é mais fácil considerar o
seguinte tratamento: considere um ponto P e duas retas paralelas L1 e L2. Admita
que o procedimento 1 consista em ir de P até L1, enquanto o procedimento 2
consista em ir de L1 até L2, além disso, vamos considerar, como exemplo, que
n1=4 e n2=3 A Fig. 4.3 indica como o resultado final é obtido. Assim, o
procedimento 1 seguido pelo 2 poderá ser executado de 3x4=12 maneiras, como
pode ser visualizado pela Fig. 4.3.

P
1 2 3 1 2 3 1 2 3 1 2 3 L1
L2
Figura 3.3: Visualização da Regra da Multiplicação.
Exemplo 4.17:
Durante a fabricação uma peça deve passar por três estações de
controle. Em cada estação, a peça é inspecionada quanto a uma determinada
característica e marcada adequadamente. Na primeira estação, três
classificações são possíveis, enquanto nas duas últimas, quatro classificações
são possíveis. Consequentemente, existem 3 x 4 x 4 =48 maneiras pelas quais
uma peça pode ser marcada.
A4. PERMUTAÇÃO
Permutações de m elementos são os diversos grupos formados de
todos modos possíveis com estes elementos, colocando-os em linha, ao lado uns
dos outros, de modo que cada grupo contenha os m elementos e difira dos outros
somente pela ordem dos elementos.
Exemplo 4.18:

Com as três letras a, b e c, podem-se formar as seguintes
permutações:
abc, acb, bac, bca, cab, cba.
A fórmula para o cálculo do número de permutações simples é:
Pm = m! = 1 x 2 x 3 ... x m
Exemplo 4.19:
a) De quantas maneiras podemos extrair todas as 5 bolas de urna?
P5 = 5! = 120
b) Determinar o número de grupos de 5 elementos que começam
por um elemento escolhido.
P4 = 4! = 24
c) Em cada carteira de uma fila de 5 carteiras duplas, estão
sentados um rapaz e uma moça. De quantos modos podemos
dispor estes 10 alunos, de modo que não fiquem rapazes ou
moças juntos?
2(P5)2 = 28.800
A fórmula para o cálculo do número de permutações com elementos
repetidos é
( )Pm
a b kma b k, ,..., !
! !... !=
,
onde:
m = a + b + ...+ k
Exemplo 4.20:
Quantos anagramas podem ser formados com a palavra
ESTATÍSTICA?

( )P111 2 3 2 2 1 11
1 2 3 2 2 1831600, , , , , !
! ! ! ! ! != =
A5. ARRANJO
Arranjos de m elementos tomados p a p são os diversos grupos que
se podem formar com os m elementos, colocando-os ao lado uns dos outros, de
modo que cada grupo contenha somente p elementos e difira dos outros pela
natureza ou pela ordem dos elementos.
Exemplo 421:
Com as três letras a, b, c, tomadas duas a duas, podem-se formar os
arranjos seguintes:
ab, ba, ac, ca, bc, cb.
A fórmula para o cálculo do número de arranjos simples é:
( )Am
m pmp =
−!
!
Exemplo 4.22:
Quantos números de 4 algarismos podem ser formados, sem o
algarismo zero e sem incluir os de algarismos repetidos?
( )A94 9
9 49 8 7 6 3024=
−= × × × =
!
!
Estabelecer um código de almoxarifado utilizando 15 dígitos (6 letras:
A, B, C, D, E, F; 9 algarismos: 1, 2, 3, 4, 5, 6, 7, 8, 9) de modo a identificar cada
tipo de peça por um grupo de 5 dígitos, sem repetição. Quantos tipos de peça
poderão ser assim codificados?
360.360)!515(
!15515 =
−=A

Quando for permitido repetições na formação dos grupos a
denominação é arranjos com repetição. Sua fórmula é:
( )AR mmp p=
Exemplo 4.23:
Quantos carros podem ser emplacados usando a codificação atual
para as placas (os três primeiros dígitos são letras e os quatro dígitos restantes
números)?
( ) ( )AR AR103
264 3 410 26 456 976 000× = × = . .
A7.COMBINAÇÃO
Combinações de m elementos tomados p a p são os diversos grupos
que se podem formar com os m elementos, colocando-os em linha, de modo que
cada grupo contenha somente p elementos e difira dos outros pela natureza de
seus elementos.
Exemplo 4.24:
Com as três letras a, b, c, tomadas duas a duas, podem-se formar as
seguintes combinações:
ab, ac, bc.
A fórmula para o cálculo do número de combinações simples é:
( )!!
!
pmp
mp
mC p
m −=
=
Exemplo 4.25:
Dentre oito pessoas, quantas comissões de três membros podem ser
escolhidas? Desde que duas comissões sejam a mesma comissão se forem
constituídas pelas mesmas pessoas (não se levando em conta a ordem em que
sejam escolhidas), teremos

( )C83 8!
3 8 3
8 7 6
656=
−=
× ×=
! !
Quando for permitido repetições na formação dos grupos a
denominação é combinações com repetição. Sua fórmula é:
( ) ( )( )CR C
m p
p mmp
m pp= =
+ −−+ −1
1
1
!
! !
Exemplo 4.26:
Quantas e quais são as maneiras de distribuir dois objetos por três
pessoas?
( )CR C32
42 6= =
1a pessoa: 2 0 0 1 1 0
2a pessoa: 0 2 0 1 0 1
3a pessoa: 0 0 2 0 1 1

5 DISTRIBUIÇÃO DE VARIÁVEL ALEATÓRIA
DISCRETA
Conceitos
1.1.1 Função
Função f de A em B é uma correspondência que associa a cada
elemento x pertencente a A um e somente um elemento y pertencente a B. A é
denominado domínio e B de contradomínio. Assim, função é uma relação (regra)
que associa a cada elemento do domínio um e somente um elemento do
contradomínio.
Injetora
Sobrejetora
Bijetora
y1
y2
y3
y4
y1
y2
y3
x1
x2
x3
x4
y1
y2
y3
y4
y5
x1
x2
x3
x4
x1
x2
x3
x4

A
B
A
B
A

B
Função Constante Não É Função
x1
x2
x3
x4
y1
y2
y3
y4y5
A
B
y1
y2
y3
y4
x1
x2
x3
x4
A
B
f:Domínio = AContradomínio = B
Domínio de f(x) = x A
Contradomínio de f(x) = y B
Imagem de f(x) = ( ) xfyBy =∈
1.1.2 Variável Aleatória
Experimentos são realizados com a finalidade de obter informações por
meio das quais são tomadas decisões ou tiradas conclusões. No entanto, como
visto no capítulo anterior, ao estudarmos probabilidade, aprendemos o conceito
de experimento aleatório, no qual não se pode determinar de antemão o seu
resultado, posto que um experimento aleatório depende de muitas causas

fortuitas que não são passíveis de serem levadas em consideração. Desse modo
as conclusões ou decisões são tomadas em um ambiente de incerteza a qual
deve ser medida e os riscos associados, devem ser especificados e controlados.
Para se atingir este objetivo é que se necessita do conceito de variável aleatória.
Por exemplo, suponha que um determinado tipo de relé deverá ser
usado em centrais de comutação telefônica. Esta central deverá funcionar durante
cinco anos. Os componentes críticos desta instalação são os relés. Ao longo
deste tempo estima-se que, em média, alguns deles, os mais solicitados, realizam
2x105 operações. O contratante estabeleceu junto ao fornecedor destes relés que
iria testar uma única unidade. Se a vida útil deste relé ultrapassar 4x105
operações o lote inteiro seria adquirido. Neste exemplo, o contratante dividiu o
espaço amostral em dois eventos disjuntos A e B, onde A é o evento que
representa que o número de operações excederá a 4x105 e B é o evento que
representa que o número de operações será menor ou igual a 4x105. Se o
resultado do experimento encontrar-se em A, os relés serão comprados. Se o
resultado do experimento encontrar-se em B, os relés não serão comprados.
Por outro lado, é concebível que o contratante não queira tomar
decisão com base na ocorrência ou não ocorrência de um único evento no espaço
amostral. Por exemplo, suponha que o contratante combinou com o fabricante
testar dois relés. Suponha, além disso, que tenham acordado que se a média dos
números de operações exceder a 4x105 o contratante comprará o lote de relés.
Caso contrário ele não aceitará os relés. O conjunto que representa o número
médio de operações dos dois relés que excede 4x105 não é um evento do espaço
amostral (nem é o número médio de operações um ponto e do espaço amostral)
de forma que o contratante não pode basear sua decisão em observação direta
do resultado do experimento. Pelo contrário, ele toma decisão usando a regra que
associa a cada ponto e do espaço amostral um valor numérico obtido pelo cálculo
da média dos números de ocorrência dos dois relés, x1 e x2, respectivamente,
associado a cada ponto e, isto é, para cada ( )21 , xxe = em E, ( ) ( ) 2/21 xxeX += é
calculado. Este conjunto de valores é então dividido em dois grupos: aqueles
cujos valores médios são maiores que 4x105 operações e aqueles cujo valor
médio seja menor ou igual a 4x105 operações. Se o valor médio obtido de um

experimento particular encontrar-se no grupo que tem valores maiores que 4x10 5
operações, o lote de relés será adquirido. Caso contrário, os relés não serão
aceitos. De maneira equivalente, se o resultado do experimento e foi tal que o
número médio das operações dos relés conduzirem a um valor que exceda a
4x105, o lote será comprado.
A regra que, no exemplo, associa a cada elemento do espaço amostral
um e somente um valor numérico (obtido pela média dos números de operações
dos dois relés) é dado o nome de variável aleatória.
Seja E o espaço amostral de um experimento aleatório . Uma
variável aleatória X é uma função de valor numérico (ou uma regra) que associa
a cada elemento e do espaço amostral E um e somente um número real X(e) = x.
Portanto, o conjunto E é o domínio da variável aleatória X e o conjunto de
números reais x é o contradomínio.
Ao longo do texto, as variáveis aleatórias são representadas por letras
maiúsculas e seus possíveis valores por letras minúsculas. No exemplo particular
de testar dois relés até a falha, a variável aleatória, o tempo até a falha, foi
escolhido para fins de tomada de decisão, isto é, a função que associa cada
ponto e=(x1, x2) em E a um valor X =(x1+x2)/26.
Representa-se por Χ o conjunto de valores possíveis de uma variável
aleatória, ou seja Χ é o conjunto imagem da função variável aleatória X. Então,
ao especificar um modelo para dados empíricos, primeiro defini-se uma variável
aleatória X e seu respectivo conjunto imagem Χ . Segundo, probabilidades são
associadas aos valores de Χ de modo tal que modelam (representam) as
frequências relativas dos respectivos resultados experimentais sob tentativas
repetidas.
Exemplo 5.1
6 Note que é uma função e portanto, sua notação, que realmente representa uma função, deveria
ser onde é usado para indicar que a função é definida em relação a algum domínio. Quando o
ponto for substituído por algum elemento desse domínio a função assume um valor particular. No
entanto, devido à tradição e comodidade esta função é representada por .

O número de crianças, que sobrevivem após 1 ano entre 100 recém-
nascidos, é uma variável aleatória que tem os seguintes resultados possíveis: 0,
1, 2, ..., 100. Portanto,
Χ = 0, 1, 2, ..., 100
Exemplo 5.2
A distância que percorre um projétil, ao ser disparado por um canhão, é
uma variável aleatória. Com efeito, a distância depende não somente da mira,
mas também de muitas outras causas (força e direção do vento, temperatura,
etc.), que não podem ser inteiramente consideradas. Os valores possíveis desta
variável correspondem a certo intervalo, Χ=(a,b).
As variáveis aleatórias serão designadas pelas letras maiúsculas X, Y,
Z, e seus valores possíveis, respectivamente, por suas letras minúsculas x, y, z.
Por exemplo, se a variável aleatória X tem três valores possíveis, estes valores
serão designados por: x1, x2, x3, ou seja,
Χ = x1, x2, x3
Um teorema básico sobre variáveis aleatórias (que não
demonstraremos) afirma que se X for variável aleatória e construirmos uma
função (unívoca) de X, g(X = x), então a variável Y = g(X = x) será também
aleatória. Assim, o valor da função de uma variável aleatória é também uma
variável aleatória. Exemplificando, se X for uma variável aleatória, A e B
constantes, então Y = A + BX é uma variável aleatória.
1.1.3 Variáveis Aleatórias Discretas e Contínuas
Voltemos aos exemplos da seção anterior. No primeiro deles, a variável
aleatória X poderia admitir um dos seguintes valores possíveis: 0, 1, 2, ..., 100.
Estes valores estão separados entre si por intervalos, nos quais não há valores
possíveis de X. Em consequência, neste exemplo, a variável aleatória assume
valores possíveis individuais isolados.

No exemplo 5.2, a variável aleatória poderia admitir qualquer dos
valores do intervalo (a, b). Neste caso, não se pode separar um valor possível de
outro por um intervalo que não contenha valores possíveis da variável aleatória.
Do exposto se deduz a conveniência de distinguir as variáveis
aleatórias que assumem somente valores individuais, isolados, em determinado
intervalo da reta real, daquelas variáveis aleatórias, cujos valores possíveis
variam continuamente dentro de certo intervalo.
Denomina-se variável aleatória discreta (descontínua) a variável
aleatória cujo contradomínio é constituído somente por valores isolados de um
intervalo (valores inteiros é um caso particular) com probabilidades determinadas.
O número de valores possíveis de uma variável aleatória discreta pode ser
limitado ou ilimitado. Uma maneira prática para identificar uma variável discreta é
quando, para encontrar o seu valor, for necessário realizar contagem.
Denomina-se variável aleatória contínua a variável aleatória que
assume qualquer valor em um intervalo, finito ou infinito, da reta real, portanto é
aquela cujo contradomínio é constituído por todos os valores de um intervalo, ou
seja, seus valores variam continuamente. Evidentemente, o número de valores
possíveis de uma variável aleatória contínua é infinito, independente se o intervalo
é limitado ou ilimitado. Assim sendo, pode-se dizer que a variável aleatória
contínua resulta, normalmente, de mensuração, e a escala numérica de seus
possíveis valores corresponde ao conjunto R dos números reais.
1.1.4 Distribuição de Probabilidades de uma Variável Aleatória
Discreta
À primeira vista pode parecer que para expressar uma variável
aleatória discreta é suficiente enumerar todos seus valores possíveis. Na
realidade, isto não é bem assim: as variáveis aleatórias podem ter os mesmos
valores possíveis, e suas probabilidades serem distintas. Por isso, para expressar
uma variável aleatória discreta não é suficiente enumerar todos seus valores
possíveis, mas é necessário indicar também suas probabilidades.

Denomina-se distribuição de variável aleatória discreta ao conjunto
de todos os valores possíveis xi da variável aleatória discreta X e suas respectivas
probabilidades pi. A função f(x) que estabelece a correspondência de cada x i e
sua respectiva pi denomina-se função de probabilidade. Uma função de
probabilidade pode ser expressa por meio de uma tabela, de uma expressão
analítica ou de um gráfico.
Uma função f(x) é uma função de probabilidade se ela satisfizer as
seguintes condições:
( )( )
( ) ( )ii
xi
xXPxXf
xf
xf
i
===
=≥
∑Χ∈
;1
;0
5.1
Estas condições são as únicas condições que uma função f tem de
satisfazer para ser um modelo potencial de um conjunto de dados experimentais
discretos. Isto é, qualquer função que satisfaça estas condições é um modelo
válido no sentido matemático. Para que uma função seja útil é necessário, além
do sentido matemático, que obrigatoriamente tem de satisfazer, levar em
consideração se efetivamente representa as observações do mundo
experimental.
Parâmetros são as constantes, particulares para cada problema, que
aparecem de forma explícita na expressão analítica da função de probabilidade
(ou função de distribuição). Assim, para se individualizar uma distribuição é
necessário o conhecimento numérico dos parâmetros.
Levando em consideração que uma variável aleatória discreta assume
um e somente um valor possível, e ela está associada a um elemento de um
espaço amostral, deduzimos que os resultados X = x1, X = x2, ..., X = xn formam
um grupo completo, ou seja, são os resultados possíveis do experimento
aleatório. Desse modo, a soma das probabilidades correspondentes aos
resultados da variável aleatória é igual a unidade:
p1 + p2 + ... + pn = 1.

Exemplo 5.3
Em uma loteria foram emitidos 100 bilhetes. Sorteiam-se um prêmio de
R$ 500,00 e dez prêmios de R$ 50,00 a cada mês. Descrever a distribuição da
variável aleatória X, isto é, o valor do prêmio possível para o possuidor de um
bilhete de loteria.
Solução. Escrevemos os valores possíveis de X:
x1 = 500, x2 = 50, x3 = 0.
As probabilidades destes valores possíveis são:
p1 = 0,01, p2 = 0,1, p3 = 1 - (p1 + p2) = 0,89.
Descreva a distribuição pedida:
X p500,00 0,0150,00 0,10,00 0,89
Verificação: 0,01 + 0,1 + 0,89 = 1.
Exemplo 5.4
Colocar três moedas em um copo e após agitar o copo várias vezes
lançar as moedas sobre uma mesa ou outra superfície dura e plana qualquer.
Seja X a variável que denota o número de “caras” após cada lançamento.
Registre o valor de X para 16 realizações independentes do experimento e
apresente os resultados em forma de distribuição. (O espaço amostral para X é 0,
1, 2 e 3).
A Tabela 5.1 apresenta cinco amostras independentes que foram
observadas utilizando-se o experimento anterior.

Tabela 5.1: Distribuições empíricas para o número de “caras”, X,
observadas em 16 lançamentos independentes de três moedas.
x Amostra 1 Amostra 2 Amostra 3 Amostra 4 Amostra 50 2 3 1 4 11 7 5 6 7 82 6 6 7 4 73 1 2 2 1 0Total 16 16 16 16 16
A Tabela 5.2 apresenta 4 diferentes distribuições de probabilidade que
poderia servir para modelar o experimento de 16 lançamentos independentes de
três moedas.
Tabela 5.2: Quatro distribuições de probabilidade.
(a) (b) (c) (d)w f(w) x f(x) y f(y) z f(z)0 0,25 0 0,125 0 0,3 0 0,11 0,25 1 0,375 1 0,2 1 0,42 0,25 2 0,375 2 0,2 2 0,43 0,25 3 0,125 3 0,3 3 0,1
Total 1,00 Total 1,000 Total 1,0 Total 1,0
Todas as quatro distribuições da Tabela 5.2 associam probabilidades
ao conjunto de pontos (0, 1, 2, 3), que é o espaço amostral, E, para a variável X,
que representa o número de “caras” observadas no lançamento de três moedas.
Estas distribuições de probabilidade ilustram quatro das infinitas possibilidades de
como associar probabilidades aos possíveis resultados de modo a satisfazer as
condições que devem atender uma função de probabilidade, no sentido
matemático. Se as três moedas forem honestas verifica-se que a distribuição que
melhor se ajusta aos dados experimentais é a que corresponde a letra (b),
conforme mostraremos nas seções posteriores.
A função de probabilidades pode ser acumulada, considerando-se a
soma de probabilidades de todos os valores de X menores ou iguais a um
determinado valor xr:
F(xr) = )()(
1r
r
ii xXPxf ≤=∑
= 5.2
F(x) denomina-se função de distribuição. Se escolhermos um valor
para X, por exemplo, xr, a f(X = xr) dá a probabilidade de que X assuma o valor xr,

ou seja, f(x = xr) = P(x = xr); enquanto F(x) dará a probabilidade de que X assuma
um valor no máximo igual a xr, ou seja F(X = xr) = P(X x r).
1.1.5 Especificação de uma Distribuição de Variável Aleatória
Discreta
Para se especificar uma distribuição de variável aleatória discreta é
necessário conhecer, com relação a sua função de probabilidade:
• o seu domínio;
• a sua forma;
• os seus parâmetros.
Esperança Matemática e Suas Propriedades
Desde que há muitos modelos (distribuições de probabilidade) é
importante que tenhamos um método pelo qual possamos comparar essas
distribuições. Como visto no Capítulo 2, o uso de estatísticas descritivas como
uma maneira para comparar distribuições empíricas, sugere que utilizemos
medidas de localização e de dispersão para comparar distribuições de
probabilidade.
A medida usual de localização é a média da distribuição ou valor
esperado enquanto a variância da distribuição é uma medida comum de
dispersão.
O valor esperado (ou média) de uma variável aleatória discreta X é
denotado por E(X) ou e definido por
( ) ( )∑Χ∈
==ix
ii xfxXEµ
. 5.3
A variância de uma variável aleatória X é denotada por 2 ou V(X) e
definida por
( ) ( ) ( )∑Χ∈
−=−==ix
ii xfxXEXVar 222)( µµσ
. 5.4

Desenvolvendo a expressão 5.4, obtém-se:
( )
∑∑
∑
Χ∈
Χ∈
Χ∈
−=
=+−=
=+−
i
i
i
x
ii
x
ii
i
x
ii
xfx
xfx
xfxx
22
222
22
)(
2)(
)(2
µ
µµ
µµ
5.5
ou seja,
( ) 222)( µσ −== XEXVar
Exemplo 5.5
Encontrar a média e a variância para (c) e (d) da Tabela 5.2.
Solução:
Distribuição (c): = 0(0,3) + 1(0,2) + 2(0,2) + 3(0,3) = 1,5.
2 = (0 – 1,5)2(0,3) + (1 – 1,5)2(0,2) + (2 – 1,5)2(0,2) + (3 – 1,5)2(0,3)
= 2,25(0,3) +0,25(0,2) + 0,25(0,2) + 2,25(0,3) = 1,45
Distribuição (d) : = 0(0,1) + 1(0,4) + 2(0,4) + 3(0,1) = 1,5.
2 = (0 – 1,5)2(0,1) + (1 – 1,5)2(0,4) + (2 – 1,5)2(0,4) + (3 – 1,5)2(0,1)
= 2,25(0,1) +0,25(0,4) + 0,25(0,4) + 2,25(0,1) = 0,65
Observação: Note que e 2 ajudam a distinguir as distribuições (c) e
(d). Primeiro, ambas as distribuições são localizadas em = 1,5. Segundo, a
distribuição (d) é mais concentrada em torno de 1,5 que (c), como indicado pelo
menor valor da variância.
Como a definição da esperança de variáveis discretas é uma operação
de soma, podem-se estabelecer regras para manipulação de esperanças. Tais
regras são as seguintes:

Regra 1: Para qualquer constante a,
E(a) = a.
Regra 2: Para qualquer constante a e qualquer variável X,
E(aX) = a E(X).
O resultado de maior utilidade é a combinação das Regras 1 e 2. Isto é,
se a e b são constantes, então
E(aX + b) = a E(X) + b. 5.6
A utilidade da expressão 5.6 pode ser resumida como a seguir: seja X
uma variável aleatória com média e variância 2. Sejam a e b constantes e a
variável aleatória Y = aX + b. Então
y = E(Y) = a + b,
222 σσ ay =, ·5.7
y = |a| .
A demonstração de 5.7 fica a cargo do aluno.
Distribuição Hipergeométrica
1.1.6 Especificação da Distribuição
Suponha que extraímos, sem reposição, uma amostra de tamanho n de
uma população dicotômica de N elementos. Adotando os nomes defeituoso e
não-defeituoso, para tecnicamente descrever as duas categorias, denotamos o
número de defeituosos na população por D. Portanto o número de não
defeituosos é N - D. Seja X o número de defeituosos presentes na amostra.
Assim, a especificação da distribuição é:
I. Domínio da função de probabilidade
0 X n, se n D;

0 X D, se D < n.
II. Função de probabilidade
( ) ( )( )( )Nn
DNxn
DxxXf
−−==
5.9
III.Parâmetros: N, D e n
E(X) = np
V(X) =
N n
Nnp p
−−
−1
1( )
onde p = D/N é a fração de peças defeituosas da população.
1.1.7 Emprego da Distribuição Hipergeométrica
Emprega-se a distribuição hipergeométrica quando:
• a variável for discreta;
• a extração for sem reposição;
• os N itens da população puderem ser classificados por uma
dicotomia, ou seja, há apenas duas possibilidades incompatíveis em
cada realização do experimento.
Uma população dicotômica é aquela que pode ser dividida em dois
grupos distintos: aquele cujos elementos possuem uma característica específica e
aquele cujos elementos não possuem essa característica. Poderiam ser macho e
fêmea, empregado e não empregado, defeituoso e não defeituoso, etc.
Exemplo 5.6
Uma caixa contém 10 peças, das quais 4 são defeituosas. Extrai-se,
dessa caixa, sem reposição, uma amostra aleatória de tamanho n = 3 peças.
Calcular a probabilidade de ocorrer 1 peça defeituosa na amostra.

Considerando a variável aleatória X como sendo o número de peças
defeituosas na amostra e utilizando a expressão 5.8, obtém-se:
( ) ( )( )P X( ) ,= = =
×=1
4 15
1200 5
14
26
310
Distribuição de Bernoulli
Quando é executado um experimento do tipo Bernoulli, associado a
esse experimento, tem-se uma variável aleatória com o seguinte comportamento:
• Na realização de um experimento o resultado pode ser
classificado por uma dicotomia.
• Seja p a probabilidade de sucesso (se acontecer o evento de
interesse) e q a probabilidade de fracasso (o evento de interesse
não se realiza).
• A variável aleatória X é o nº de sucessos em uma única tentativa
do experimento.
• X assume os seguintes valores possíveis:
X=0, fracasso1, sucesso
com P(X = 0) = q e P(X = 1) = p.
Nessas condições a v.a. X tem distribuição de Bernoulli, e sua função
de probabilidade é dada por
P (X=x )=px . q1−x
Parâmetro: p
Esperança e Variância
O calculo da esperança e variância da distribuição de Bernoulli pode
ser feito por:
X P(X) X.P(X) X2 .P(X )

0 q 0 0
1 p p p
Soma 1 p p
Logo: E(X) = p e V (X )=p−p2=p (1−p )=pq
Exemplo 5.7
Uma urna tem 30 bolas brancas e 20 verdes. Retira-se uma bola dessa
urna. Seja X: nº de bolas verdes. Calcular E(X), Var(X) e determinar P(X). →
X=0→3050
=35
1→2050
=25
Distribuição Binomial
1.1.8 Especificação da distribuição
Suponha que extraímos, com reposição, uma amostra de tamanho n de
uma população dicotômica de N elementos com fração de peças defeituosas p.
Seja X o número de defeituosos presentes na amostra. Assim, a especificação da
distribuição é:
I. Domínio da função de probabilidade
0 X n.
II. Função de probabilidade
( ) ( ) xnxnx ppxXf −−== 1)( 5.10
III.Parâmetros: p e n
E(X) = np
V(X) = np(1 – p).

OBS.: O nome binomial vem do fato que seus termos correspondem
aos do desenvolvimento do binômio de Newton
(p + q)n
Exemplo 5.7
Uma moeda não viciada é lançada 8 vezes. Encontre a probabilidade
de:
1. dar 5 caras;
2. pelo menos 3 caras;
3. no máximo 3 caras.
Utilizando-se a expressão 5.9:
1. P(X = 5) ( ) ( ) 58585 5,015,0 −− = 0,2188
2. P(X 3) = 1 - P(X < 3) = 1 - P(X 2) =1 – [P(X = 0) + P(X = 1) +
P(X = 2)] = 0,8555
3. P(X 3) = P(X = 0) + P(X = 1) + P(X = 2) + P(X = 3) = 0,3633
1.1.9 Emprego da distribuição binomial
Emprega-se a distribuição binomial quando:
• a variável for discreta;
• a extração for com reposição;
• os N itens da população puderem ser classificados por uma
dicotomia.
1.1.10 Uso da binomial como aproximação da hipergeométrica
A média desta distribuição tem expressão igual a da distribuição
hipergeométrica. Entretanto a variância da hipergeométrica é igual a variância da
binominal multiplicada pelo fator 1−−
N
nN
, que é denominado fator de correção para
populações finitas. Quando a fração de amostragem, Nn
, é pequena, este fator é
próximo de 1, portanto a hipergeométrica se aproxima da binomial. O uso da

binomial como aproximação da hipergeométrica é conveniente porquanto a
binomial tem a fração N
Dp =
como um parâmetro, enquanto o modelo
hipergeométrico requer o conhecimento de D e de N individualmente. Portanto o
modelo binomial é mais simples que o modelo hipergeométrico. Alguns textos
sugerem utilizar a distribuição binomial como aproximação da hipergeométrica
para a fração de amostragem 10,0<
N
n
.
Distribuição de Poisson
1.1.11 Emprego da Distribuição
A distribuição de Poisson é empregada em situações em que a variável
aleatória X assume valores ao longo de um espaço (comprimento, área, volume,
tempo), sem periodicidade, de modo independente.
Exemplos:
• número de chamadas recebidas por uma central telefônica;
• falhas no recobrimento de fios elétricos utilizado em bobinas;
• número de defeitos em chapas de aço;
• número de bactérias em um litro de água não purificada;
• número de defeitos em um determinado tipo de equipamento;
• número de veículos que passam num determinado ponto de uma
estrada e num determinado período de tempo;
• número de partículas alfa emitidas por uma fonte de cobalto-60 em
20 minutos.
Observação: A aplicação da distribuição de Poisson ao decaimento
radioativo não é geral. Uma condicionante é que a meia-vida seja muito superior
ao tempo de observação. No caso mais geral, é a binomial que se aplica!
1.1.12 Especificação da Distribuição
A especificação da distribuição de Poisson é:

I. Domínio da função de probabilidade
0 X <
II. Função de probabilidade
f X xe x
x
( ). !
= =µµ
5.11
III.Parâmetro:
E(X) = V(X) =
1.1.13 Poisson como Distribuição Limite da Binomial
Em uma distribuição binomial com tamanho da amostra n muito
grande, a fração p muito pequena, e np = de valor moderado, a função de
probabilidade da binomial ( ) ( ) xnxnx pp −−1 é aproximadamente igual à de Poisson !.xe
x
µµ
. A natureza da aproximação é ilustrada na tabela a seguir, onde np = = 5 é
fixado.
Probabilidade binomialn p X=0 X=4 X=7
10 0,50 0,0010 0,2051 0,117220 0,25 0,0032 0,1897 0,112450 0,10 0,0052 0,1809 0,1076100 0,05 0,0059 0,1781 0,1060200 0,03 0,0063 0,1768 0,1052Probabilidade
Poisson0,0067 0,1755 0,1044
Em termos práticos, a distribuição de Poisson pode ser usada como
distribuição limite da binomial, quando o número n de repetições do experimento
for maior que 10 e a probabilidade p de ocorrência do evento for menor que 0,10,
com 0< np 10. Nesse caso a média da Poisson é = np.
Sob as mesmas condições, a Poisson pode também ser usada como
limite da distribuição hipergeométrica, após a sua convergência para a binomial.

1.1.14 Propriedade Aditiva da Distribuição de Poisson
Se X1 e X2 forem duas variáveis independentes com distribuição de
Poisson, com médias 1 e 2, respectivamente, a variável
X = X1 + X2
seguirá a distribuição de Poisson, com média
= 1 + 2.
Dessa propriedade resulta que, se forem feitas k observações x i de
uma distribuição de Poisson de parâmetro , x i se distribuirá segundo a
mesma lei, com média k . Exemplificando: se na produção de determinada
máquina o número de defeitos por unidade tiver distribuição de Poisson com
média = 2, a distribuição do número de defeitos por 5 unidades terá a mesma
distribuição, com média = 10.
Exemplo 5.8
Em média há 2,5 chamadas por hora num certo telefone. Calcular a
probabilidade de recebermos:
a) uma chamada em 1 hora;
b) nenhuma chamada em 2 horas
c) no máximo 3 chamadas em 2 horas.
Solução. A solução será obtida utilizando-se a expressão 5.10.
a) P(X = 1| = 2,5) = !1.
5,25,2
1
e = 0,2052
b) se a média é 2,5 por hora, então em 2 h a média será 5. Assim:
P(X = 0| = 5) = !0.
55
0
e = 0,0067
c) P(X 3| = 5) = P(X = 0) + P(X = 1) + P(X = 2) + P(X = 3)= !0.
55
0
e +
!1.
55
1
e + !2.
55
2
e = 0,2650


,Exercícios Propostos1)Analisar criticamente os seguintes cálculos de probabilidade:
a) O Engº Fernando, Chefe de uma grande obra de construção civil,
determinou, com base em experiência passada, as probabilidades
da variável, X, que representa o número de acidentes com
afastamento que ocorrerá na obra no próximo ano: P(X = 0) = 0,80;
P(X = 1) = 0,05; P(X 2) = 0,05.
b) O Sr. Carlos, professor de estatística de uma determinada
universidade, determinou as seguintes probabilidades para a
variável G, que representa o grau recebido por um aluno: P(G = A) =
0,25; P(G = B) = 0,30; P(G = C) = 0,40; P(G = D) = 0,05.
c) Uma grande rede de lojas, que vende uma determinada marca de
computador, determinou a seguinte distribuição de probabilidade
para X, número de defeitos durante os primeiros dois anos de
serviço: P(X = 0) = 0,50; P(X = 1) = 0,25; P(X = 2) = 0,20; P(X = 3) =
0,10.
2)Calcular a média e a variância das distribuições (a) e (b) da Tabela
5.2.
3)Em um lote de N peças D são defeituosas. Extraem-se, sem
reposição, uma amostra de n peças deste lote. Calcular as seguintes
probabilidades:
a) De ocorrer 2 peças defeituosas na amostra, para N=50, D=15 e
n=10.
Resp.: 0,2406
b) De ocorrer pelo menos 3 peças defeituosas na amostra, para
N=500, D=25 e n=10.
Resp.: 0,0148.
4)Num determinado processo de fabricação 10% das peças são
consideradas defeituosas. As peças são condicionadas em caixas
com 5 unidades cada uma.

a) Qual a probabilidade de haver exatamente 3 peças defeituosas
numa caixa?
b) Qual a probabilidade de haver 2 ou mais peças defeituosas numa
caixa?
c) Se a empresa pagar uma multa de R$ 10,00 por caixa em que
houver alguma peça defeituosa, qual o valor esperado da multa num
total de 1000 caixas?
5)Um processo industrial produz 10% de itens defeituosos quando o
processo está ajustado corretamente. O procedimento do controle da
qualidade consiste em:
i. selecionar, aleatoriamente, uma amostra de tamanho dez;
ii. determinar o número de itens defeituosos na amostra;
iii. ajustar o processo se houver mais que três itens defeituoso na
amostra.
Pergunta-se:
a) Qual é a probabilidade que o processo seja ajustado
quando estiver operando com uma taxa de 10% de defeituosos?
b) Qual é a probabilidade que o processo não seja
ajustado quando estiver operando com uma taxa de 20% de
defeituosos?
6)Qual é a principal diferença entre o modelo binomial e o modelo
hipergeométrico?
7)Um comitê de três pessoas é formado pela seleção aleatória dos
membros de um clube. Os membros do clube são compostos de 140
homens e 60 mulheres. A questão de interesse é a probabilidade de
uma mulher ser sorteada para fazer parte do comitê.
a) Qual é o modelo de probabilidade, teoricamente correto,
aplicado a situação?
b) Qual é a probabilidade, usando o modelo de a), de uma mulher
vir a fazer parte do comitê?
c) Que modelo e probabilidade aproximado pode ser usado?

d) Qual é a probabilidade aproximada, usando o modelo de c), de
uma mulher vir a fazer parte do comitê?
8)Na fabricação de certo tipo de chapa de aço, defeitos ocorrem à
razão média de 0,5 por chapa. Calcular:
a) a probabilidade de uma chapa ter no máximo dois defeitos;
b) em um grupo de seis chapas, a probabilidade de que o número
total de defeitos seja igual três;
c) em um grupo de dez chapas, a probabilidade de que quatro
delas suam defeituosas.
9)Em testes da qualidade, ao longo de terreno acidentado,
10) As faces de um dado são formadas com chapas de plástico de 10
X 10 cm2. Em média aparecem 50 defeitos cada metro quadrado de
plástico.
a) Qual a probabilidade de uma determinada face apresentar
exatamente dois defeitos?
b) Qual a probabilidade de o dado apresentar no mínimo dois defeitos?
c) Qual a probabilidade de, pelo menos, 5 faces serem perfeitas?
d) Lançado o dado, qual a probabilidade de que a soma dos pontos
com o número de defeitos da face obtida seja menor do que 3?
11) Se 5% das reses de uma fazenda são doentes; achar a
probabilidade de que, numa amostra de 6 reses escolhidas ao acaso,
tenhamos:
a) nenhuma doente;
b) uma doente;
c) mais do que uma doente.
12) Numa estrada de pouco movimento passam, em média, 2 carros
por minuto. Supondo a média estável, calcular a probabilidade de que
em 2 minutos passem:
a) mais de 4 carros;
b) exatamente 4 carros.

13) Os defeitos em certos tipos de chapas de vidro aparecem à razão
média de 5 para cada 10 m2 de chapa. Essas chapas serão usadas
na construção de janelas para uma instalação industrial. Sabendo
que essas janelas medem 150 X 80 cm2, calcular:
a) a probabilidade de que uma janela tenha 2 ou mais defeitos;
b) em um grupo de 10 janelas, a probabilidade de que o número total
de defeitos seja inferior a 5;
c) em um grupo de 5 janelas, a probabilidade de que ao menos 4 delas
não tenham defeitos.
14) Em um grupo de 15 jovens, 10 são contra o divórcio. Em uma
comissão de 5 desses jovens, calcular a probabilidade de que:
a) 2 serem contra;
b) a maioria seja a favor.
15) Se no problema anterior o grupo fosse constituído de 500 jovens,
sendo 5% contra o divórcio, em uma comissão de 20, calcular a
probabilidade de que:
a) todos serem a favor;
b) mais de 15 serem a favor.
16) Sendo X o número de peças defeituosas em embalagens de n
peças, conhecendo-se porcentagem de defeituosas da fabricação,
calcular as probabilidade de que:
a) P(X = 3/n= 15; p = 0,30);
b) P(X 5/n = 10; p = 0,60);
c) PX < 4/n = 60; p = 0,05);
d) P[(X = 2) (X 5)/n = 10; p = 0,30]
e) P(X > 8/n = 20; p = 0,70).
17) Sabe-se que uma população é composta de peças A, B e C, sendo
20% de A e 70% de B. Calcule a probabilidade de que, em uma
amostra de tamanho n, extraída com reposição, tenhamos:

a) o número de itens de A entre 2 e 7, para n = 20 (incluindo os
extremos);
b) o número de itens de B entre 2 e 7, inclusive os extremos, para n =
10;
c) o número de itens de A ou B maior que 27, para n = 30.
18) As variáveis independentes X e Y tem distribuição de Poisson com
x =1,5 e y = 3,0. Calcule:
a) P(X 2);
b) P(Y < 4);
c) P[(X < 2) (Y > 5)];
d) P[(X + Y) < 2].
19) Uma partida de 500 peças, das quais 50 são defeituosas, é
apresentada para inspeção. Testa-se uma amostra de n peças,
extraídas com reposição, aceitando-se a partida se ocorrerem, na
amostra, no máximo x0 peças defeituosas. Qual a probabilidade da:
a) aceitação da partida, para n = 20 e x0 = 2?
b) aceitação da partida, para n = 100 e x0 = 12.
20) O número de navios que chegam em um porto por dia é uma
variável aleatória X com média igual a 4. Calcular:
a) P(X > 7);
b) P(2 < X 5);
c) x0 tal que P(X > x0) = 0,7619;
d) a capacidade de atracamento do porto, dada em número de navios
por dia, a fim de que só haja congestionamento em 10%, ou menos,
dos dias.
21) Em certo processo de fabricação de baterias, a probabilidade de
fabricar-se uma bateria defeituosa é 2%. Em um dia de trabalho, são
produzidas 300 baterias. Qual é a probabilidade, na produção diária
de:

a) saírem 5 baterias defeituosas?
b) saírem no máximo 10 baterias defeituosas?
c) saírem pelo menos 2 defeituosas?
d) todas as baterias serem perfeitas?
22) As variáveis X e Y têm distribuição binomial com px = 0,20 e py =
0,70, respectivamente. Calcule:
a) P(X = 4), para nx = 3;
b) P(1< X < 6), para nx = 4;
c) P[(Y > 2) (X < 1)], para nx = ny = 4;
d) P(Y > 4), para ny = 10;
e) P(X < ¨), para nx = 5.
23) Uma fonte binária gera dígitos 1 e 0 aleatoriamente com
probabilidades 0,6 e 0,4, respectivamente.
a) Qual é a probabilidade de ocorrerem dois 1s e três 0s em uma
sequência de cinco dígitos?
b) Qual é a probabilidade de ocorrerem pelo menos três 1s em uma
sequência de cinco dígitos?
Resp.:
a) 0,2304
b) 0,6826
24) Um canal de transmissão com ruído tem uma probabilidade de erro
por dígito pe = 0,01.
a) Calcule a probabilidade de ocorrer mais que um erro em 10 dígitos
recebidos.
b) Repetir a), usando a aproximação Poisson.
a) 0,0042
b) 0,0047.

25) Suponha que 10000 dígitos são transmitidos sobre um canal de
ruído que tem probabilidade p = 5x10-5 de erro por dígito. Encontrar a
probabilidade de que não haverá mais que dois dígitos errados.
Resp.: 0,9856.
26) As variáveis X e Y tem distribuição de Poisson, com médias iguais
a 2,5 e 1,0, respectivamente. Calcule:
a) P(X = 4);
b) P(1 < X < 5);
c) P(Y 2);
d) P(3 < Y 7).
27) Em 5000 peças há 30% de peças da marca X e 70% da marca Y.
Em uma amostra de tamanho n = 10, determinar a probabilidade de
que ocorram:
a) duas ou mais peças de X;
b) exatamente 4 peças de Y.
28) Uma máquina produz peças com proporção de 0,05 de
defeituosas.
a) Qual a probabilidade de, em 10 itens examinados, no máximo 2
serem defeituosas?
b) Qual a probabilidade de em 3 peças examinadas, 2 serem perfeitas,
ou 3 serem defeituosas?
c) Qual o número médio de defeituosas em lotes de 100 dessas peças.
Qual é a variância?
29) Os erros de impressão de um determinado jornal de uma cidade A
podem ser considerados aleatórios com média igual a 4, para cada
folha. Calcular:
a) a probabilidade de que um leitor encontre menos de 5 erros em uma
folha desse jornal;
b) a probabilidade de que um leitor encontre menos de 7 erros em 2
folhas desse jornal.

30) Uma banca vende em média 3 centenas do jornal A, diariamente.
Sabendo-se que o estoque desse jornal é renovado todas as
manhãs, qual deve ser o estoque mínimo de modo que não seja
necessário que o dono desta banca tenha que recorrer a outra banca,
durante o dia de trabalho, mais do que uma vez em cada 15 dias?
31) Em um almoxarifado foram colocadas 50 peças, das quais 10 são
defeituosas. Tomando-se 2 peças ao acaso, com reposição, qual a
probabilidade
a) de que ambas sejam defeituosas?
b) de que uma seja defeituosa?
32) Na realização de um experimento sabe-se que determinado
resultado tem a probabilidade p = 0,20 de ocorrer em uma prova.
Realizando-se 15 provas repetidas, qual a probabilidade de que o
evento ocorra:
a) 6 vezes;
b) no máximo 5 vezes;
c) no mínimo 6 vezes.
33) Uma firma construtora deseja adquirir uma partida de 1500
esquadrias metálicas. Sabe-se que observações anteriores indicaram
p = 0,20 da produção como defeituosas. Para testar a qualidade da
partida, um engenheiro examina n = 10 esquadrias. Sendo X o
número de esquadrias defeituosas na amostra, calcular:
a) P(X < 4);
b) P(1< X < 6).
34) Se 10% dos tubos de imagem de televisão a cores se queimam
antes de sua garantia expirar,
a) qual a probabilidade de que um comerciante que vendeu 100
cinescópios seja forçado a substituir pelo menos 20 deles?

b) qual a probabilidade de que substitua pelo menos 5 e não mais de
15 tubos?
35) Um fabricante de certa peça de automóvel garante que uma caixa
de peças conterá, no máximo, 2 itens defeituosos. Se a caixa contiver
20 peças e a experiência tiver demonstrado que esse processo de
fabricação produz 2% de itens defeituosos, qual a probabilidade de
que uma caixa de suas peças vá satisfazer a garantia?
36) Os inspetores de uma fábrica devem inspecionar partidas de 2000
peças que são entregues semanalmente. O fabricante informa que a
fração defeituosa é p = 0,10. Para testar a informação do fabricante, o
Chefe dos inspetores resolve examinar uma amostra de n = 10 peças
e aceitar que p = 10% se nessa amostra o número X de defeituosos
for no máximo igual a 2. Qual é a probabilidade de aceitação
correspondente?
37) Considere a variável X com distribuição de Poisson e média .
Calcular a probabilidade de ocorrência de:
a) X maior ou igual a 5, para = 7;
b) 3 menor que X e menor que 8, para = 10;
c) X menor que 4, para = 8;
d) 3 menor ou igual a X menor que 9, para = 12.
38) Entre as 14 e 16 horas, o número médio de chamadas telefônicas
por minuto, atendidos pela mesa de ligações de uma companhia é
2,50. Determinar a probabilidade de que em determinado minuto
ocorram:
a) 1 chamada;
b) 4 ou menos chamadas;
c) mais de 6 chamadas.
39) Se a probabilidade de um indivíduo sofrer uma reação nociva,
resultante da exposição prolongam a tintas à base de água é 0,001,

determinar a probabilidade de que entre 2000 pintores, venham a
sofrer a reação nociva:
a) exatamente 3 pintores;
b) mais do que dois pintores.
40) Seja uma caixa de N = 10 peças, das quais D = 4 são defeituosas.
Calcular a probabilidade de ocorrência de peças defeituosas em
amostras de n = 3, extraídas sem reposição.
41) Em uma caixa, onde há 60 lâmpadas da marca I, foram colocadas
mais 20 lâmpadas de outra marca. Qual a probabilidade de:
a) retirar, sem reposição, um grupo de 10 lâmpadas, todas da marca I?
b) sair no mínimo uma lâmpada de outra marca entre as 10 extraídas
sem reposição?
42) Em uma urna há 10 fichas brancas e 5 vermelhas. Retiram-se 4
fichas simultaneamente (ou uma a uma, sem reposição). Sendo X o
número de vermelhas na amostra, construir uma tábua com os
valores f(X = x) e calcular a média e variância da distribuição.

APÊNDICE A: USANDO O EXCEL
A1. Distribuição Hipergeométrica
Consideremos o seguinte problema.
Em um lote de 100 peças, 20 são defeituosas. Calcular a probabilidade
de ocorrência de peças defeituosas em amostras de n=10, extraídas sem
reposição.
O domínio da variável aleatória X, número de peças defeituosas na
amostra, é 0 x 10.
Prepare uma planilha como mostrado na figura a seguir.
Para encontrar as probabilidades simples de ocorrência de peças
defeituosas em amostras de tamanho 10, devemos seguir os seguintes passos:
25* Coloque o cursor na célula E2;
26* No menu INSERIR escolha a opção FUNÇÃO.
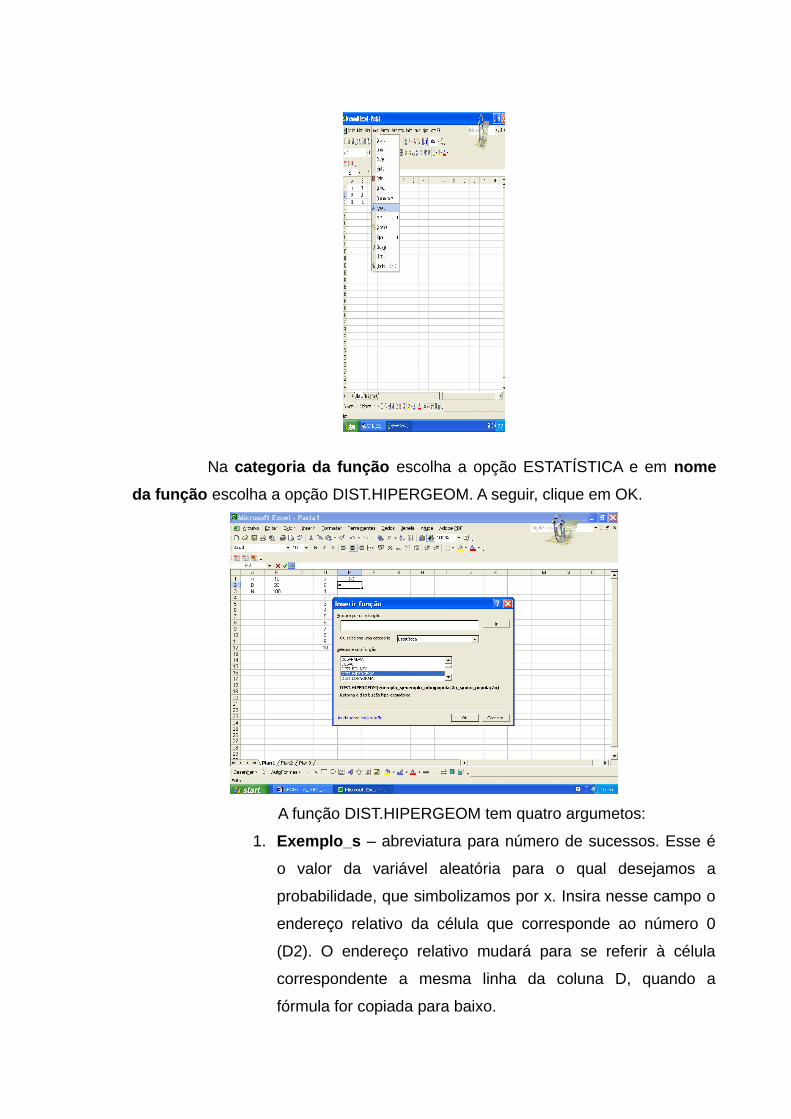
Na categoria da função escolha a opção ESTATÍSTICA e em nome
da função escolha a opção DIST.HIPERGEOM. A seguir, clique em OK.
A função DIST.HIPERGEOM tem quatro argumetos:
1. Exemplo_s – abreviatura para número de sucessos. Esse é
o valor da variável aleatória para o qual desejamos a
probabilidade, que simbolizamos por x. Insira nesse campo o
endereço relativo da célula que corresponde ao número 0
(D2). O endereço relativo mudará para se referir à célula
correspondente a mesma linha da coluna D, quando a
fórmula for copiada para baixo.

2. Exemplo_núm – esse argumento é o tamanho da amostra,
n, (ou número de tentativas ou provas). Esse argumento é um
dos parâmetros que distinguem uma distribuição
hipergeométrica de outra. Em vez de inserir diretamente o
número correspondente ao tamanho da amostra coloque o
endereço absoluto B1 (para tornar o endereço de um célula
um endereço absoluto pressione a tecla de função F4). Isso
nos permitirá observar outros valores de n simplesmente
trocando o conteúdo de B1. Além disso, quando a fórmula for
copiada para baixo, a referência à célula B1 permanecerá.
3. População_s – abreviatura usada para “número de peças
defeituosas na população”, aqui denominado D. Esse é outro
parâmetro da distribuição hipergeométrica. Aqui também ao
em vez de inserir diretamente o número correspondente ao
“número de peças defeituosas na população” coloque o
endereço absoluto B2.
4. Num_população – abreviatura usada para tamanho da
população, aqui denominado N. Esse é outro parâmetro da
distribuição hipergeométrica. Aqui também ao em vez de
inserir diretamente o número correspondente ao tamanho da
população coloque o endereço absoluto B3.

Após preenchido os campos dos argumentos da função
DIST.HIPERGEOM clicar em OK, obtendo-se, assim, o valor 0,0951 que
corresponde a probabilidade de ocorrer 0 peças defeituosas na amostra.
Em seguida, a fórmula da célula E2 deve ser copiada para baixo,
obtendo-se, assim, as probabilidades de ocorrência de peças defeituosas em
amostras de n=10, extraídas sem reposição.
O cálculo das probabilidades acumuladas deve ser feito acumulando as
probabilidades simples.
A2 Distribuição Binomial
Consideremos o seguinte problema.

Em um lote de peças, 20% são defeituosas. Calcular a probabilidade
de ocorrência de peças defeituosas em amostras de n=10, extraídas com
reposição.
O domínio da variável aleatória X, número de peças defeituosas na
amostra, é 0 x 10.
Prepare uma planilha como mostrado na figura a seguir.
Para encontrar as probabilidades simples e acumuladas de ocorrência
de peças defeituosas em amostras de tamanho 10, devemos seguir os seguintes
passos:
27* Coloque o cursor na célula E2;
28* No menu INSERIR escolha a opção FUNÇÃO.
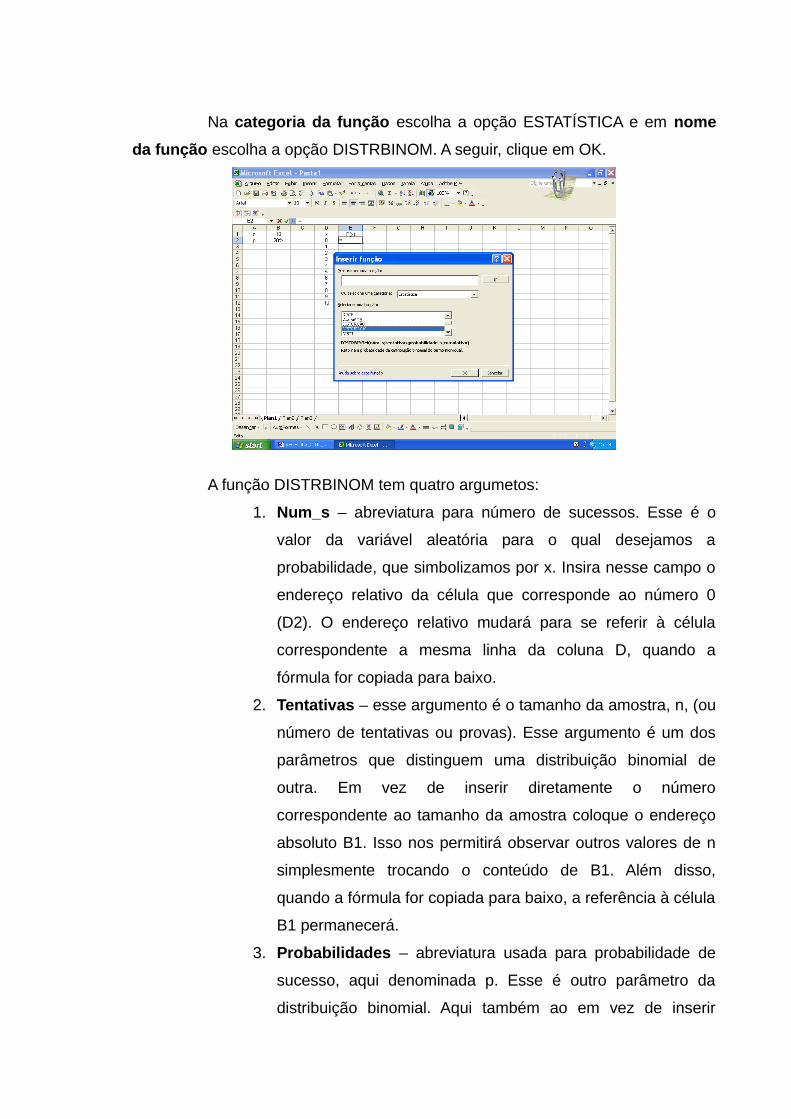
Na categoria da função escolha a opção ESTATÍSTICA e em nome
da função escolha a opção DISTRBINOM. A seguir, clique em OK.
A função DISTRBINOM tem quatro argumetos:
1. Num_s – abreviatura para número de sucessos. Esse é o
valor da variável aleatória para o qual desejamos a
probabilidade, que simbolizamos por x. Insira nesse campo o
endereço relativo da célula que corresponde ao número 0
(D2). O endereço relativo mudará para se referir à célula
correspondente a mesma linha da coluna D, quando a
fórmula for copiada para baixo.
2. Tentativas – esse argumento é o tamanho da amostra, n, (ou
número de tentativas ou provas). Esse argumento é um dos
parâmetros que distinguem uma distribuição binomial de
outra. Em vez de inserir diretamente o número
correspondente ao tamanho da amostra coloque o endereço
absoluto B1. Isso nos permitirá observar outros valores de n
simplesmente trocando o conteúdo de B1. Além disso,
quando a fórmula for copiada para baixo, a referência à célula
B1 permanecerá.
3. Probabilidades – abreviatura usada para probabilidade de
sucesso, aqui denominada p. Esse é outro parâmetro da
distribuição binomial. Aqui também ao em vez de inserir

diretamente o número correspondente a probabilidade de
sucesso coloque o endereço absoluto B2.
4. Cumulativo – esse argumento vai determinar se o Excel
fornece a probabilidade de que a variável aleatória seja igual
a x (probabilidade simples) ou a probabilidade de que a
variável aleatória seja menor ou igual a x (probabilidade
acumulada). Para determinar a probabilidade simples
inserimos a palavra FALSO ou o número 0 no campo do
argumento. Para determinar a probabilidade acumulada,
então colocamos VERDADEIRO ou o número 1.
Após preenchido os campos dos argumentos da função DISTRBINOM
clicar em OK, obtendo-se, assim, o valor 0,1074 que corresponde a probabilidade
de ocorrer 0 peças defeituosas na amostra.
Em seguida, a fórmula da célula E2 deve ser copiada para baixo,
obtendo-se, assim, as probabilidades de ocorrência de peças defeituosas em
amostras de n=10, extraídas com reposição.
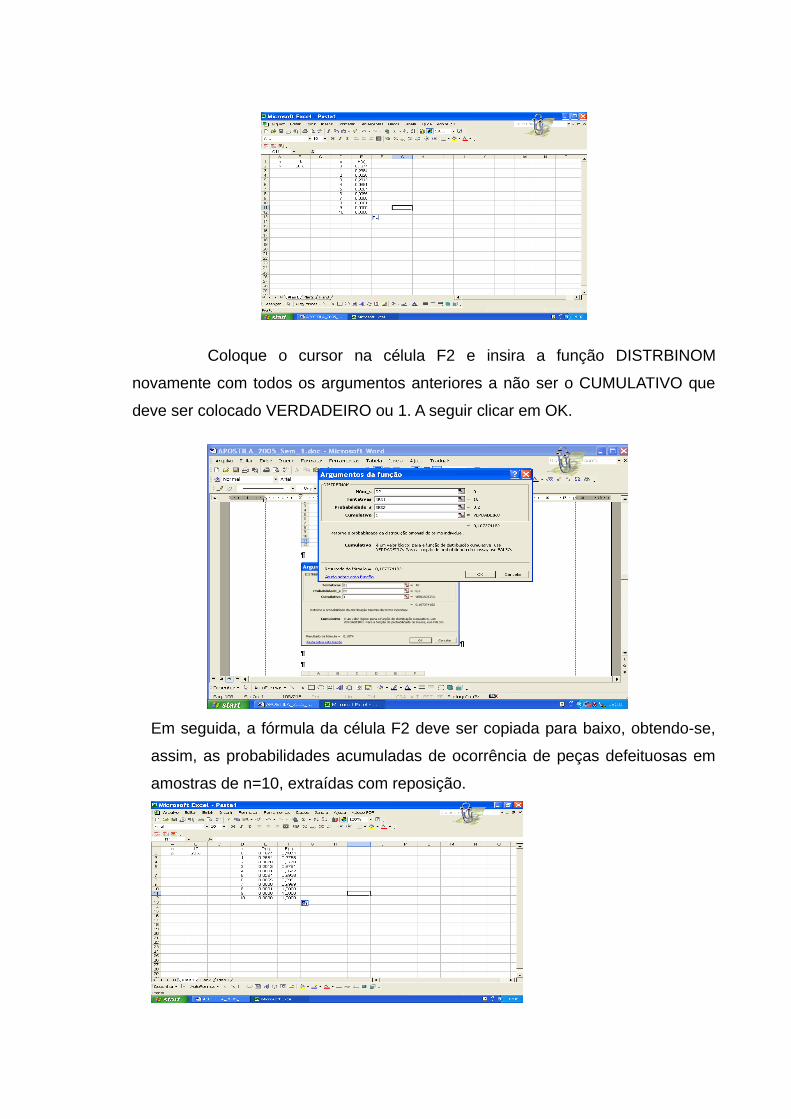
Coloque o cursor na célula F2 e insira a função DISTRBINOM
novamente com todos os argumentos anteriores a não ser o CUMULATIVO que
deve ser colocado VERDADEIRO ou 1. A seguir clicar em OK.
Em seguida, a fórmula da célula F2 deve ser copiada para baixo, obtendo-se,
assim, as probabilidades acumuladas de ocorrência de peças defeituosas em
amostras de n=10, extraídas com reposição.

A3 Distribuição de Poisson
Consideremos o seguinte problema.
Entre as 14 e 18 horas, o número médio de chamadas telefônicas por minuto
atendidas pela mesa de ligações de uma empresa é 5,5. Calcular a probabilidade
de ocorrência de chamadas telefônicas em um determinado minuto.
O domínio da variável aleatória X, número de chamadas telefônicas em um
determinado minuto, é 0 x ∞.
Prepare uma planilha como mostrado na figura a seguir.
Para encontrar as probabilidades simples e acumuladas de ocorrência
de chamadas telefônicas em um determinado minuto, devemos seguir os
seguintes passos:
29* Coloque o cursor na célula E2;
30* No menu INSERIR escolha a opção FUNÇÃO.

Na categoria da função escolha a opção ESTATÍSTICA e em nome
da função escolha a opção POISSON. A seguir, clique em OK.
A função POISSON tem três argumetos:
1. x – abreviatura para número de ocorrências. Esse é o valor
da variável aleatória para o qual desejamos a probabilidade,
que simbolizamos por x. Insira nesse campo o endereço
relativo da célula que corresponde ao número 0 (D2). O
endereço relativo mudará para se referir à célula

correspondente a mesma linha da coluna D, quando a
fórmula for copiada para baixo.
2. Média – é a média μ. Esse argumento é o parâmetro que
distingue uma distribuição de Poisson de outra. Em vez de
inserir diretamente o número correspondente à média
coloque o endereço absoluto B1. Isso nos permitirá observar
outros valores para a média simplesmente trocando o
conteúdo de B1. Além disso, quando a fórmula for copiada
para baixo, a referência à célula B1 permanecerá.
3. Cumulativo – esse argumento vai determinar se o Excel
fornece a probabilidade de que a variável aleatória seja igual
a x (probabilidade simples) ou a probabilidade de que a
variável aleatória seja menor ou igual a x (probabilidade
acumulada). Para determinar a probabilidade simples
inserimos a palavra FALSO ou o número 0 no campo do
argumento. Para determinar a probabilidade acumulada,
então colocamos VERDADEIRO ou o número 1
Após preenchido os campos dos argumentos da função POISSON clicar em
OK, obtendo-se, assim, o valor 0,0041 que corresponde a probabilidade de
ocorrer 0 chamadas telefônicas em um determinado minuto.
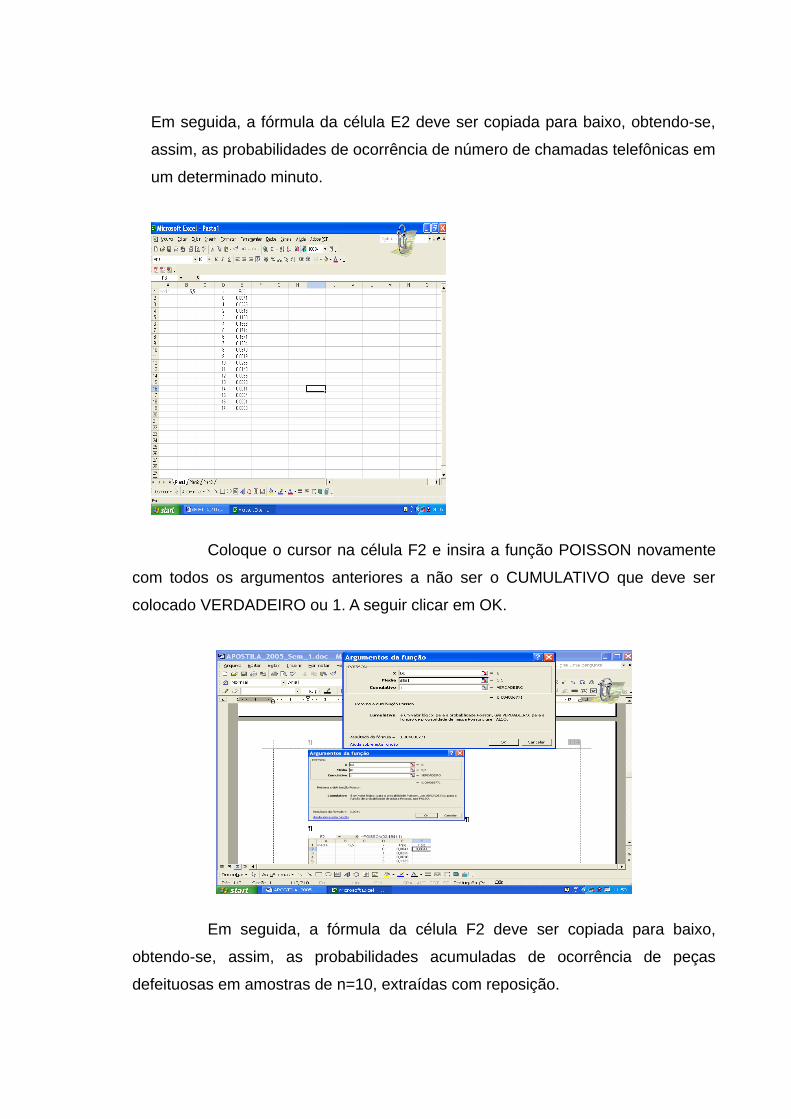
Em seguida, a fórmula da célula E2 deve ser copiada para baixo, obtendo-se,
assim, as probabilidades de ocorrência de número de chamadas telefônicas em
um determinado minuto.
Coloque o cursor na célula F2 e insira a função POISSON novamente
com todos os argumentos anteriores a não ser o CUMULATIVO que deve ser
colocado VERDADEIRO ou 1. A seguir clicar em OK.
Em seguida, a fórmula da célula F2 deve ser copiada para baixo,
obtendo-se, assim, as probabilidades acumuladas de ocorrência de peças
defeituosas em amostras de n=10, extraídas com reposição.


APÊNDICE B: Demonstração do limite da distribuição
binomial
( ) ( )xn
pn
xnx pppm
>>→
∞→
−−0
1lim
nenn nn π2! −≅ (fórmula de Stirling)
( ) ( ) ( ) ( )x
xn
n
xnxn
nn
nn
n
xnexn
nen
xn
n =≅−−
≅− −−−−
−
ππ2
2
!
!
( ) ( ) ( ) npxnp
xnxn ee
xn
xnpp −−−
−− ≅=
−−−+=− 11
para n>>x.
( ) ( ) ( )
xnpn
xexe
npep
x
nppp
mx
np
xnpx
xxnx
>>→
∞→
===− −−
0
!!!1lim µ
µ
∞→
+
x
x
x
21lim
yxyx
212 =⇒=
∞→
=
+
y
ey
y
2
21
1lim