aws re:invent 2016: disrupting big data with cost-effective compute (cmp302)
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
November 30, 2016
Disrupting Big Data with
Cost-effective ComputeCharles Allen, Metamarkets
Durga Nemani, Gaurav Agrawal, AOL
Anu Sharma, Amazon EC2
CMP302

Amazon EC2 Spot instances
• Regular EC2 instances opened to the Spot market when
spare
• Prices on average 70-80% lower than On-Demand
• Best suited for workloads that can scale with compute
• Accelerate jobs 5-10 times e.g. run faster CI/CD pipelines
(case study: Yelp)
• Reduce costs by 5-10 times, scale stateless web applications
(case study: Mapbox, Ad-tech)
• Generate better business insights from your event stream

In this session
• Use Case: context and history
• AOL: Separation of Compute and Storage using Amazon EMR and
EC2 Spot instances
• Architecture
• Cost Optimization
• Orchestration
• Monitoring
• Best Practices
• Metamarkets: Spark and Druid on EC2 Spot instances
• Architecture Overview: Real-time, Batch Jobs, Lambda
• Spark on Spot instances
• Druid on Spot instances
• Monitoring

Business Intelligence Data Set
• Event Data • Timestamp
• Dimensions/Attributes
• Measures
• Total data set is huge, billions of events per day

Relational Databases
Traditional Data Warehouse Star
Schema
• FACT table contains primary information
and measures to aggregate
• DIM tables contain additional attributes
about entities
• Queries involve joins between central
FACT and DIM tables
Performance degrades as data scales.
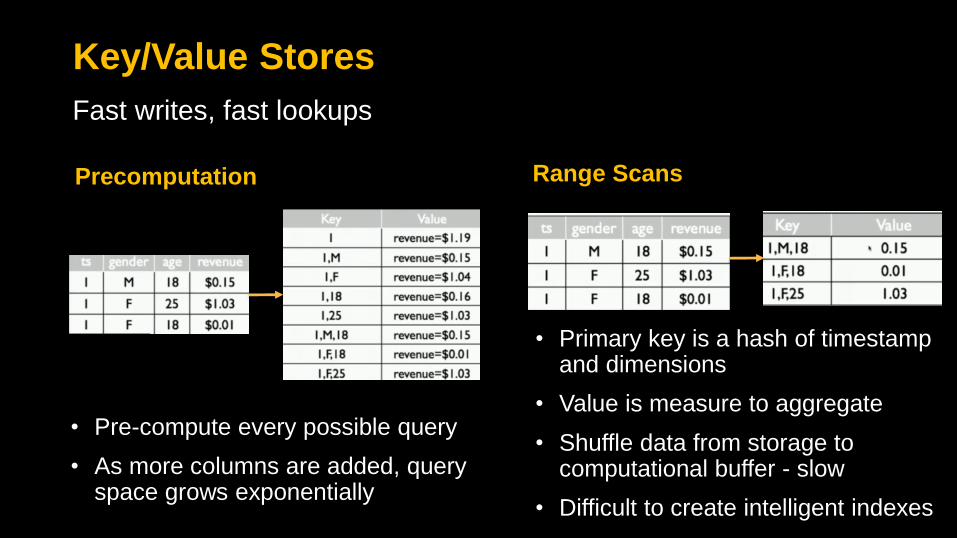
Key/Value Stores
Fast writes, fast lookups
• Pre-compute every possible query
• As more columns are added, query space grows exponentially
• Primary key is a hash of timestamp and dimensions
• Value is measure to aggregate
• Shuffle data from storage to computational buffer - slow
• Difficult to create intelligent indexes
Precomputation Range Scans

General Compute Engines
SQL on Hadoop
• Scale with compute power
• Generate up to 5-10x faster
business insights with cheaper
compute
• Or just reduce costs by 80-90%

Pioneers to Settlers
Algorithmic Efficiency to Mundane Efficiency

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Separation of Compute and Storage
Durga Nemani, System Architect, AOL
Gaurav Agrawal, Software Engineer, AOL
Big Data Processing with Amazon EMR and EC2 Spot instances

Architecture
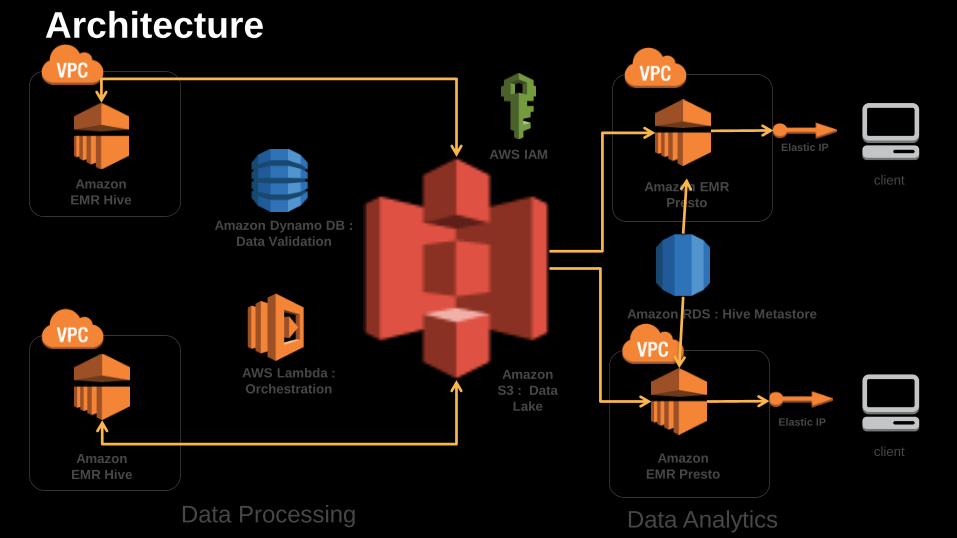
Architecture
AWS Lambda :
Orchestration
Elastic IP
Amazon
EMR Hive
AWS IAM
Amazon
S3 : Data
Lake
Amazon Dynamo DB :
Data Validation
Amazon
EMR Hive
client
Amazon RDS : Hive Metastore
Data Processing Data Analytics
Amazon EMR
Presto
Elastic IP
Amazon
EMR Presto
client

Key features and advantages• Separation of compute and storage
• Scale compute and storage independently
• Separate data processing and analytics
• Hive for processing, Presto for analytics
• No data migration
• S3 Data lake
• Single source of truth
• Columnar format for performance and compression
• VPC design
• Identified by Name Tags
• AOL CIDR, VPN
• Few lines of code change vs big data migration efforts

Cost Optimization

Amazon EC2 Spot Instances
• Keep in mind
• Availability
• Spot pricing vary for
• Instance Types
• Availability Zone
• Different provisioning time
• AOL Requirement
• Major restatement - 15-20K EC2 Instances
• Data for 15+ countries
• Frequency : HLY, DLY, WLY, MTD, MLY, 28 Days

EMR Deployment Setup
• Set up VPC in all regions
• Ensure Spot Limits
• Setup Hard EC2 limit per AZ
• Multiple instance types
• Define Instance Type-Core Mapping
• Data Volume
• Code Complexity
• Pay actual price not bid price!

Deployment Logic Diagram
Data Volume
+
Code
Complexity
Pick
Instance
Type
Sorted Spot
Price AZ
List
Number of
Cores = A
Next AZ
in List?
Open/Active
Instances =
B
A + B <
AZ Limit
Kick off
EMR
Yes
Yes
No
No

Average Cost Saving Graphs
**m3.xlarge Sept’2016 Cost
On Demand
Static AZ
~80%
Savings

Average Cost Saving Graphs
Static AZ
Cheap AZ
10-15%
Savings
**m3.xlarge Sept’2016 Cost

Size ( GB
)Cores Hours
Local AZ
Cost
Cheaper
AZ Cost
Transfer
Cost
Total
Cost
Cost
Savings
50 100 2 3,431 2,847 365 3,212 6%
100 300 3 20,586 17,082 730 17,812 13%
200 500 5 51,465 42,705 1,460 44,165 14%
300 700 7 109,792 91,104 2,190 93,294 15%
Why cheaper AZ matters?
• Data transfer cost
• Worst Case scenario – Cheaper AZ not in local region
• More Data => More Nodes + More Hours
Size ( GB
)Cores Hours
Local AZ
Cost
Cheaper
AZ Cost
Transfer
Cost
Total
Cost
Cost
Savings
10 25 1 429 356 73 429 0%
**m3.xlarge Sept’2016 Cost

EMR Region Distribution
us-east-120%
ap-northeast-11%
sa-east-19%
ap-southeast-13%
ap-southeast-29%
us-west-226%
us-west-14%
eu-west-128%
AOL DW Sept-Oct 2016
80% times
Cheaper AZ is
not in local
region
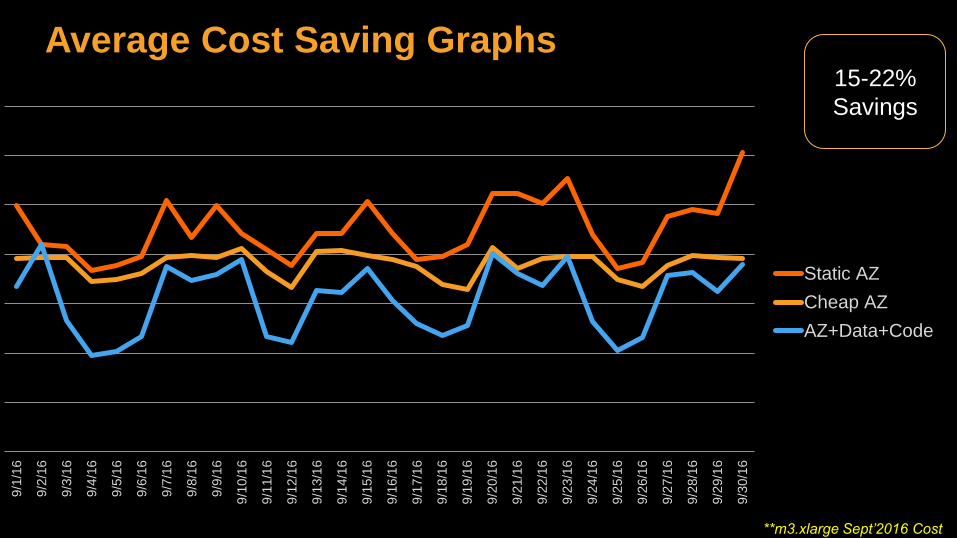
Average Cost Saving Graphs9/1
/16
9/2
/16
9/3
/16
9/4
/16
9/5
/16
9/6
/16
9/7
/16
9/8
/16
9/9
/16
9/1
0/1
6
9/1
1/1
6
9/1
2/1
6
9/1
3/1
6
9/1
4/1
6
9/1
5/1
6
9/1
6/1
6
9/1
7/1
6
9/1
8/1
6
9/1
9/1
6
9/2
0/1
6
9/2
1/1
6
9/2
2/1
6
9/2
3/1
6
9/2
4/1
6
9/2
5/1
6
9/2
6/1
6
9/2
7/1
6
9/2
8/1
6
9/2
9/1
6
9/3
0/1
6
Static AZ
Cheap AZ
AZ+Data+Code
15-22%
Savings
**m3.xlarge Sept’2016 Cost

Orchestration: AWS Lambda

Process Pipeline Overview
• Multiple Stages b/w Raw Data & Final Summary
• Ensure dependencies
• Integration with Data services
• Extensible, Scalable & Reliable
• Recovery Options
• Notifications
• Directed Acyclic Graph
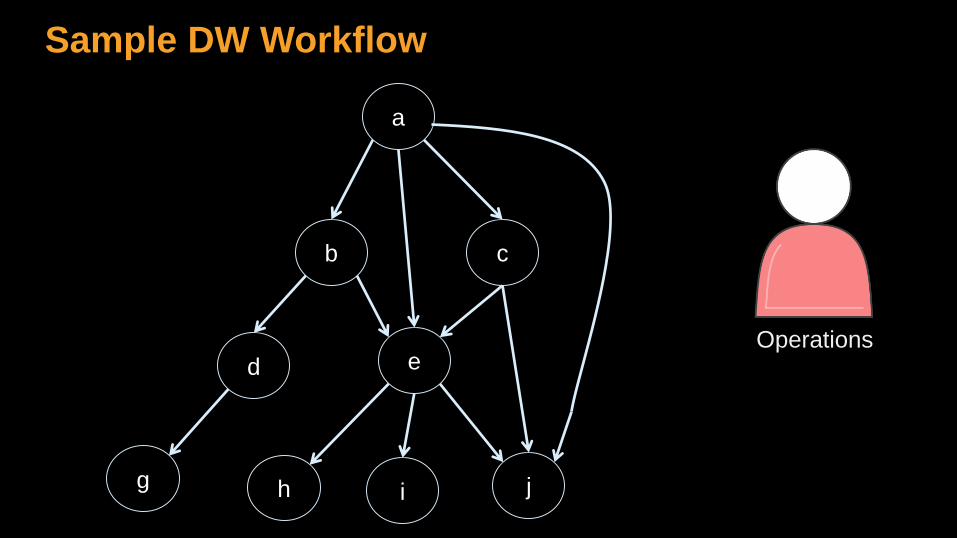
Sample DW Workflow
a
b c
e
jg h i
dOperations

AOL DW Process Pipeline
Amazon S3
Amazon S3
Amazon EMR
Amazon EMR
AWS Lambda
Python Boto
AWS Lambda
Python Boto

Benefits & Suggestions
• Improved SLA due to Event based model
• Serverless – Zero Administration
• Millisecond response time
• Pricing – 1 million requests/month Free
• Generic utilities for Extensibility
• Built in Auto Scaling
• CloudWatch Logging
• Replaced ~2000 Autosys jobs

EMR Monitoring

EMR Monitoring - Prunella
• Tons of clusters/day
• EMR Failure causes
• Network Connectivity
• Bootstrap Actions
• Zero OPS Hours
• SLA improvement
• No datacenter dependency
• Notifications – Email/Slack


Good to have
• S3 Lifecycle based on Tags
• Terminate Long STARTING EMR Cluster
• Python 3 Lambda Support
• Lambda Code Test/Deployment
• Kappa
• Global EMR Dashboard
• Redshift External Tables

Recap
• Transient Spot Architecture
• S3 as Data Lake
• Cost Optimization
• Dynamic choice of Spot AZ and Number of Cores
• Server less Process Pipeline
• AWS Lambda for event driven design
• Automated EMR Monitoring
• Reduce Manual intervention for 1000s of clusters

Photo Credits
• Gabor Kiss - http://bit.ly/2epkQJY
• AustinPixels- http://bit.ly/2eAenqr
• Mike - http://bit.ly/2eqGx82

Related Sessions
• AWS re:Invent 2015 | (BDT208) A Technical Introduction
to Amazon Elastic MapReduce
• https://www.youtube.com/watch?v=WnFYoiRqEHw
• AWS re:Invent 2015 | (BDT210) Building Scalable Big
Data Solutions: Intel & AOL
• https://www.youtube.com/watch?v=2yZginBYcEo

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Spark and Druid on EC2 Spot Instances
Charles Allen, Metamarkets


Programmatic data is 100x larger than Wall
Street

Metamarkets
+ Industry leader in interactive analytics for
programmatic marketing
+ > 100B events / day
+ Typical peak approx 2,000,000 events / sec
+ Massaged, joined, HA replicated → 3M/s
Move fast. Think big. Be open. Have fun.

Metamarkets
+ Event ingestion lag down to few ms
+ Dynamic queries
+ Query latency less than 1 second
+ Specially tailored for real-time bidding

Current Spot Usage

Current Spot Usage
+ Spark
+ Druid
+ Jenkins

Brief Architecture Overview - Real-time
Kafk
a Druid Real-
time
Indexing
Kafka / Samza
Very Fast
● Pretty accurate
● On-time data

Brief Architecture Overview - BatchK
afk
a
Druid
HistoricalS3 Spark
A Few Hours Later
● Highly accurate
● Deduplicated
● Late data
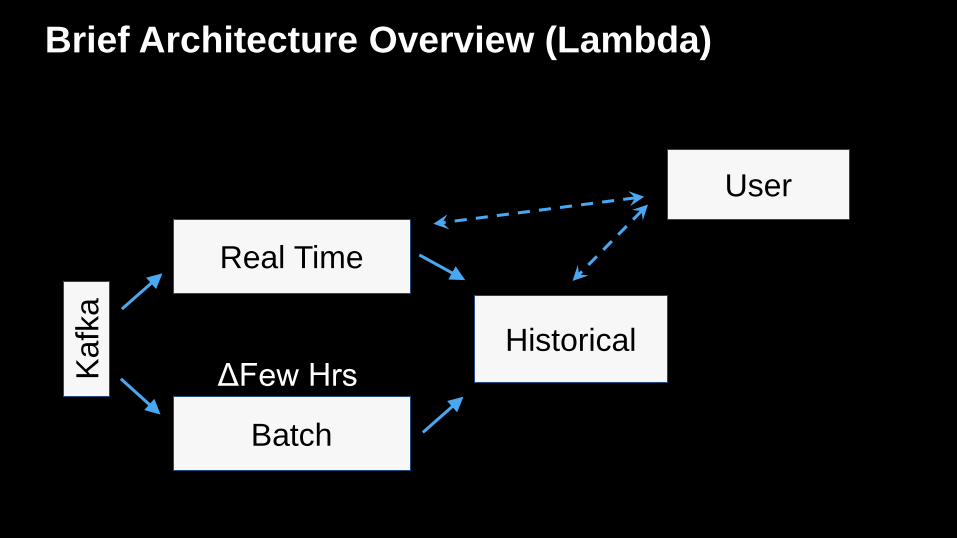
Brief Architecture Overview (Lambda)
Real Time
Batch
Kafk
a
ΔFew HrsHistorical
User

Key Technologies Used
+ Kafka
+ Samza
+ Spark
+ Druid

Spark on Spot

Why Spark?
The Good:
+ No HDFS
+ Good enough partial failure recovery
+ Native Mesos, Yarn, and Stand-alone
The Bad:
+ Rough to configure multi-tenant

Spark
+ Between 1 and 4 PiB / day
(mem bytes spilled)
+ Between 200B and 1T events / day
+ Peak days can be up to 5x baseline
Think Big.

Cost Savings
SPARK
Savings vs. on-demand
Approx equal to 3-year term
>60%

Tradeoff
+ More complex job failure handling
+ “Did my job die because of Me, Spark, the
Data, or the Market?”
+ More random delays
+ More man-hours to manage, or
automation to build

Druid on Spot

Druid on Spot
Some of our Historical nodes run on Spot
185 TB (compressed)
state on EBS on Spot
⅕ of a petabyte can vanish… and come back in
15 minutes

Druid Historical Data
1 hr < EVENT_TIME < X Months
X Months < EVENT_TIME < Y Months
HOT
Y Months < EVENT_TIME < Z Years
COLD
ICY

Historical Tier QPS (Logscale)

Historical Tier QPS (Logscale)
Spot can
go here

Using EBS With Druid on Spot
+ Define a “pool” tag or EBS volumes
+ If EBS “pool” is “empty” (no unmounted volumes)
Create a new volume (with proper tags) and mount it
+ Otherwise, claim drive from pool
+ Sanity check on volume, discard if unrecoverable

Using EBS With Druid on Spot
+ Monitor spot notifications[1] to stop gracefully
+ If stop is detected, prepare to die gracefully
+ Stop applications (hook)
+ Unmount volume cleanly
+ Do not actually terminate instance; wait for death
[1] https://aws.amazon.com/blogs/aws/new-ec2-spot-instance-termination-notices/

Terrifying to Boring
(Originally ran without EBS reattachment)
[ops] Search Alert: More than 0 results found
for "DRUID - Spot Market Fluctuations"
Now mundane.

Druid Tips
+ Coordinator (thing that moves state around) does
better with NO tier than with a half-tier
+ Flapping nodes can cause backpressure, better to
kill entire tier than repeatedly flap up and down.
+ Nodes usually have a burn-in time before they reach
steady-state fast queries (few minutes)

Druid + Spot + EBS
Accomplished by EBS re-attachment
Metamarkets is proud to Open Source this tool
Be Open.

Monitoring

Spot Price on the AWS Management Console
If only there was some tool that allowed
powerful, drill-down analytics on real-time
markets…


x1.32xl price stability across zones

Final Thoughts

Spot Caveats
+ Switching from Spot to On-Demand does NOT
always work
+ Pricing strategy tuned to value of lost work
+ Scaling in a Spot market must be done SLOWLY
(tens of nodes at a time)
+ us-east-1 is crowded

Lessons Learned… “If I could do it all over
again”
+ Multi-homed (at least by AZ) from the very start
+ us-west
+ More ZK quorums
+ Build on cluster resource framework

We Are Hiring!
Have Fun!

Metamarkets and Spot
+ Metamarkets has great internal tooling for Spot
market insight
+ Druid uses EBS reattachment
+ Spark works well with proper configuration

Thank you!

Remember to complete
your evaluations!

Related Sessions
• AWS re:Invent 2015 | (BDT208) A Technical Introduction
to Amazon Elastic MapReduce
• https://www.youtube.com/watch?v=WnFYoiRqEHw
AWS re:Invent 2015 | (BDT210) Building Scalable Big Data
Solutions: Intel & AOL
• https://www.youtube.com/watch?v=2yZginBYcEo