bart oldeman, mcgill hpc [email protected] … · 1 intel xeon phi workshop bart oldeman,...
TRANSCRIPT


2
Online Slides
● http://tinyurl.com/xeon-phi-handout-may2015– OR
● http://www.hpc.mcgill.ca/downloads/xeon_phi_workshop_may2015/handout.pdf

3
Outline
● Login and Setup● Overview of Xeon Phi● Interacting with Xeon Phi
– Linux shell
– Ways to program the Xeon Phi
● Native Programming● Offload Programming● Choosing how to run your code

4
Exercise 0: Login and Setup
● Please use class accounts to access reserved resources
● $ ssh class##@guillimin.hpc.mcgill.ca
– enter password● [class##@lg1r17n01]$ module add ifort_icc/15.0
● ifort_icc module: In Intel's documentation you will see instructions to run 'source compilervars.sh'– On guillimin, this script is replaced by this module

5
Exercise 0: Workshop Files
● Please copy the workshop files to your home directory– $ cp R /software/workshop/phi/* ~/.
● Contains:– Code for the exercises
– An example submission script
– Solutions to the exercises

6
Exercise 1: Interactive Session
● For the workshop, we want interactive access to the phis
● [class01@lg1r17n01]$ qsub I l nodes=1:ppn=16:mics=2 l walltime=8:00:00
● [class01@aw4r13n01]$ module add ifort_icc/15.0

7
Exercise 2: OpenMP on CPU
● Compile the OpenMP program axpy_omp.c– $ icc openmp o axpy axpy_omp.c
● Run this program on the aw node– $ ./axpy
● This program ran on the host● Use OMP_NUM_THREADS environment variable
to control the number of parallel threads

8
What is a Xeon Phi?

9
What is a Xeon Phi?
● A device for handling computationally expensive hot spots in your code ('co-processor' or 'accelerator')
● Large number of low-powered, but low cost (computational overhead, power, size, monetary cost) processors (modified Pentium cores)
● “Supercomputer on a chip”: Teraflops through massive parallelism (dozens or 100s of parallel threads)
● Heterogeneous computing: Host and Phi can work together on the problem

10
What was the ASCI Red?
● 1997, first teraflop supercomputer, same compute power as single Xeon Phi● 4,510 nodes (9298 processors), total 1,212 GB of RAM,12.5 TB of disk storage● 850 kW vs. 225 W for Xeon Phi

11
Performance vs. parallelism
(c) 2013 Jim Jeffers and James Reinders, used with permission.
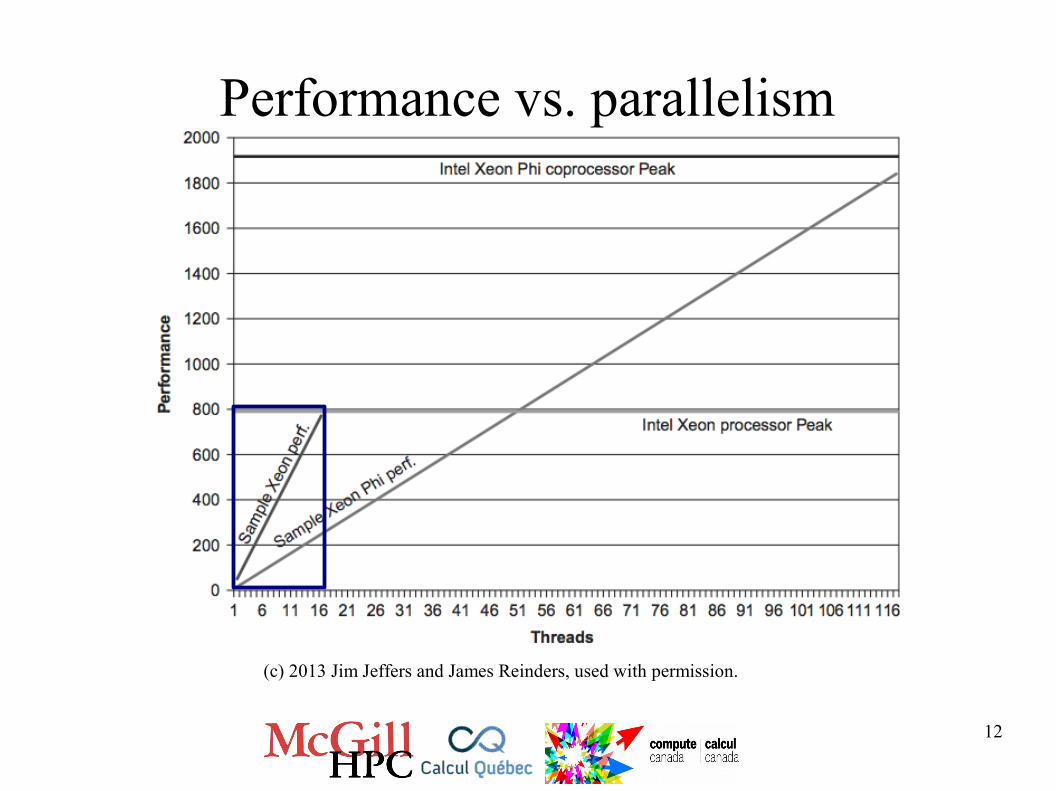
12
Performance vs. parallelism
(c) 2013 Jim Jeffers and James Reinders, used with permission.

13
Performance vs. parallelism
(c) 2013 Jim Jeffers and James Reinders, used with permission.
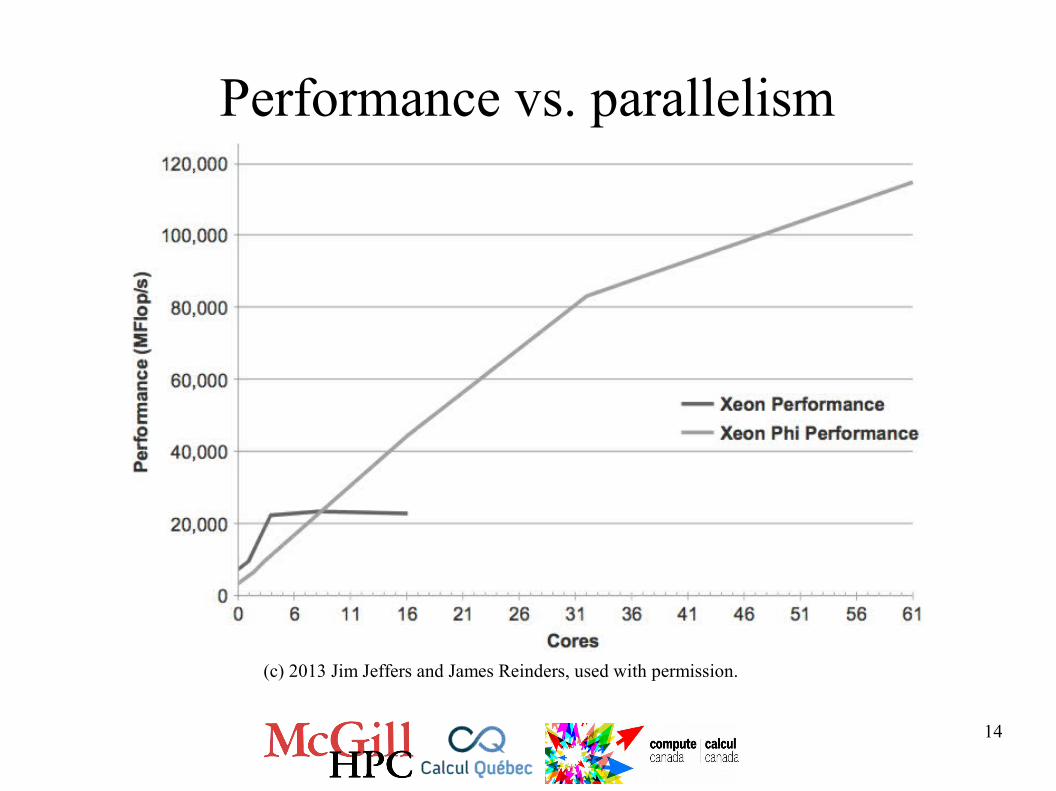
14
Performance vs. parallelism
(c) 2013 Jim Jeffers and James Reinders, used with permission.

15
Terminology
● MIC = Many Integrated Cores (Intel developed architecture)● GPU = Graphics Processing Unit (Xeon Phi is not a GPU,
but we will refer to GPUs)● Possibly confusing terminology:
– Architecture: Many Integrated Cores (MIC)
– Product name (uses MIC architecture): Intel Xeon Phi
– Development Codename: Knight's corner
– “The device” (in contrast to “the host”)
– “The target” of an offload statement

16
MIC architecture under the hood

17
MIC architecture under the hood
(c) 2013 Jim Jeffers and James Reinders, used with permission.

18
Xeon Phis on Guillimin
● Nodes– 50 Xeon Phi nodes, 2 devices per node = 100 Xeon Phis
– 2 x Intel Sandy Bridge EP E5-2670 (8-core, 2.6 GHz, 20MB Cache, 115W)
– 64 GB RAM
● Cards– 2 x Intel Xeon Phi 5110P
– 60 cores, 1.053 GHz, 30 MB cache, 8 GB memory (GDDR5), Peak SP FP: 2.0 TFlops, Peak DP FP: 1.0 Tflops (=1.053GHz*60 cores*8 vector lanes*2 flops/FMA)

19
Comparisons
Notes:• Chart denotes theoretical maximum values. Actual performance is application
dependent• The K20 GPU has 13 streaming multiprocessors (SMXs) with 2496 CUDA cores, not
directly comparable to x86 cores• The K20 GPU and Xeon Phi have GDDR5 memory, the Sandy Bridge has DDR3
memory• Accelerator workloads can be shared with the host CPUs

20
Benchmark Tests
Matrix multiplication resultsSE10P is a Xeon Phi Coprocessor with slightly higher specifications than the 5110PSource: Saule et. al, 2013 - http://arxiv.org/abs/1302.1078

21
Benchmark Tests
Embarrassingly parallel financial Monte-Carlo
Iterative financial Monte-Carlo with regression across all paths
Source: xcelerit blog, Sept. 4, 2013 (http://blog.xcelerit.com/intel-xeon-phi-vs-nvidia-tesla-gpu/)
“Tesla GPU” is a K20X, which has slightly higher specifications than the K20
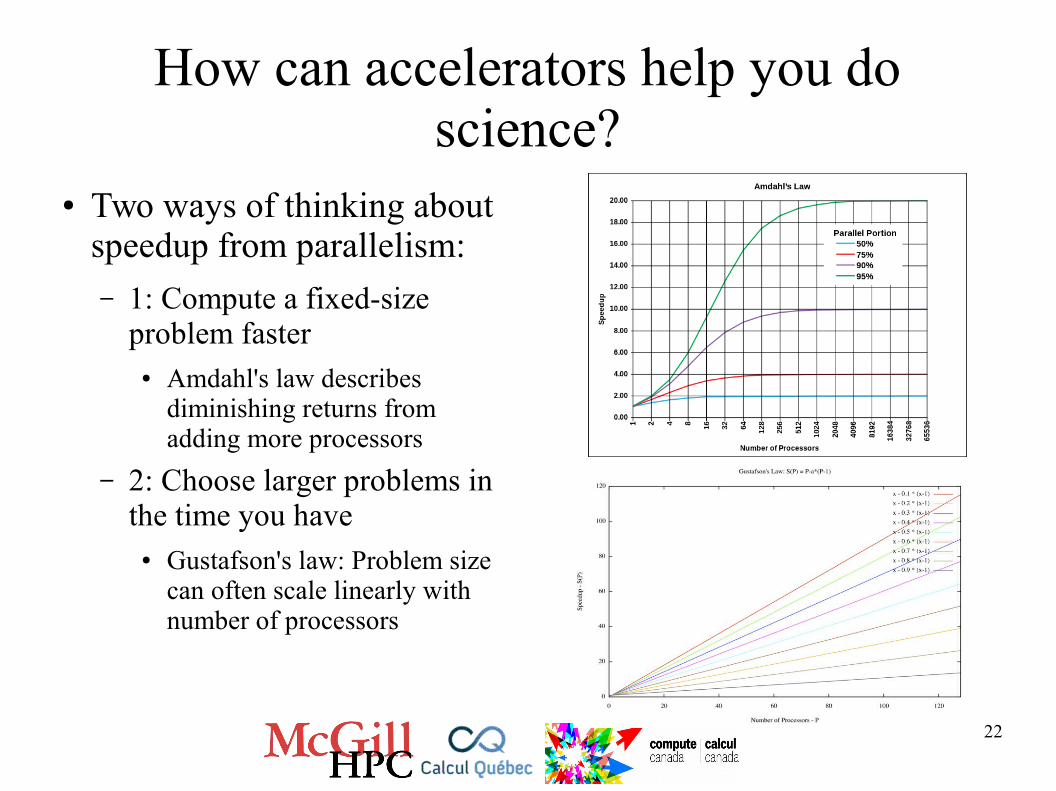
22
How can accelerators help you do science?
● Two ways of thinking about speedup from parallelism:– 1: Compute a fixed-size
problem faster● Amdahl's law describes
diminishing returns from adding more processors
– 2: Choose larger problems in the time you have
● Gustafson's law: Problem size can often scale linearly with number of processors

23
Ways to use accelerators
● Accelerated application ● Libraries ● Directives and Pragmas
(OpenMP)● Explicit parallel programming
(OpenMP, MPI, OpenCL, TBB, etc.)
Increasing effort

24
MIC Software Stack

25
MIC Linux Libraries
Library Purpose
glibc GNU C standard library
libc The C standard library
libm The math library
libdl Dynamic linking
librt POSIX real-time library (shared memory, time, etc.)
libcrypt Passwords, encryption
libutil Utility functions
libstdc++ GNU C++ standard library
libgcc_s Low-level functions for gcc
libz Lossless compression
libcurses Displaying characters in terminal
libpam Authentication
The following Linux Standard Base (LSB) libraries are available on the Xeon Phi

26
Focus For Today
● Some - Accelerated Applications and Libraries– Incredibly useful for research, relatively easy to use
– Will not teach you much about how Xeon Phis work
● Some - Explicit Programming– Device supports your favourite parallel programming models
– We will keep the programming simple for the workshop
● Yes - Directives/Pragmas and compilation– Will teach you about Xeon Phis
– We will focus mainly on OpenMP and MPI as parallel programming models

27
Scheduling Xeon Phi Jobs
● Workshop jobs run on a single node + one or two Xeon Phi devices– $ qsub l nodes=1:ppn=16:mics=2
● $ qsub ./subJob.sh
● Example: subMiccheck.sh

28
Exercise 3: Interacting with Phi
● Use your interactive session on the phi nodes● Log in to phi cards
– $ ssh mic0
● Try some of your favourite Linux commands– $ cat /proc/cpuinfo | less
– $ cat /proc/meminfo | less
– $ cat /etc/issue
– $ uname a
– $ env
● How many cores are available? How much memory is available? What operating system is running? What special environment variables are set?

29
Filesystem on Phi
● The guillimin GPFS filesystem is mounted on the Xeon Phis using NFS
● You can access your home directory, project space(s), scratch, and the /software directory
● In general, reading and writing to the file system from the phi is very slow
● Performance tip: minimize data transfers (and therefore file system use) from the Phi and use /tmp for temporary files (file system in 8 GB memory)

30
Native mode and Offload mode
● There are two main ways to use the phi– Compile a program to run directly on the device (native
mode)
– Compile a program to run on the CPU, but offload hotspots to the device (offload mode, heterogeneous computing)
– Offload is more versatile● Uses resources of both node and device

31
Automatic Offload mode
● Offloading linear algebra to the Phi using MKL– Only need to set MKL_MIC_ENABLE=1
– Can be used by Python, R, Octave, Matlab, etc.
– Or from Intel C/C++/Fortran using -mkl switch
– Only effective for large matrices, at least 512x512 to 9216x9216, depending on function
– Uses both node and device
– Example: module python/2.7.3-MKL

32
Exercise 4: Automatic offload
● See the script matmul.py, multiplying two random 8192x8192 matrices● Run on host only
– $module add python/2.7.3MKL
– $python matmul.py
– 8192, 4.160015, 264.2886
● Use automatic offload– $export MKL_MIC_ENABLE=1
– $export OFFLOAD_REPORT=1
– $python matmul.py
– 8192, 2.237704, 491.3271
● Now experiment with smaller and larger values of M, N, and K.

33
Exercise 5: Native Compilation
● axpy_omp.c is a regular OpenMP vector a*x+y program – Only phi-specific code is within a #ifdef OFFLOAD pre-compiler
conditional
● Use the compiler option -mmic to compile for native mic execution– $icc o axpy_omp.MIC mmic openmp axpy_omp.c
● Attempt to run this program on the CPU. – The Linux kernel automatically runs it on the Phi as “micrun
./axpy_omp.MIC”, where /usr/bin/micrun is a shell script.
● Attempt to run this program via ssh. – $ ssh mic0 ./axpy_omp.MIC
– It fails. Why?

34
Exercise 5: Native Compilation
● Using plain ssh the library paths are not set up properly! Alternatively, use micnativeloadex to copy libraries from the host and execute the program on the mic.– $ micnativeloadex ./axpy_omp.MIC
● Environment variables can be changed via the MIC_ prefix:– MIC_OMP_NUM_THREADS=60 ./axpy_omp.MIC
● Device number selected with the OFFLOAD_DEVICES variable (e.g. 1)– $ OFFLOAD_DEVICES=1 ./axpy_omp.MIC

35
ResultsHost: $ icc openmp o axpy axpy_omp.c; ./axpy
OpenMP threads: 16
GFLOPS = 134.218, SECS = 11.103, GFLOPS per sec = 12.088
Offload: $ icc DOFFLOAD openmp o axpy_offload axpy_omp.c; OMP_PLACES=threads ./axpy_offload
OpenMP threads: 16
OpenMP 4 Offload
GFLOPS = 134.218, SECS = 5.959, GFLOPS per sec = 22.523
Native: $ icc openmp o axpy.MIC mmic axpy_omp.c; MIC_OMP_PLACES=threads ./axpy.MIC
OpenMP threads: 240
GFLOPS = 134.218, SECS = 5.317, GFLOPS per sec = 25.241
Host (16 Sandybridge cores) Offload to Xeon Phi
Native on Xeon Phi
1.9x
2.1x

36
Offload Mode
● Offload computational hotspots to a Xeon Phi device● Requires instructions in the code
– Intel's offload pragmas● Older, more documentation available● Vendor lock-in (Code depends on hardware and compilers from single supplier)● Used in previous workshops, see intel_offload folder for examples
– OpenMP 4.0● Open standard● More high-level than Intel's pragmas (compiler knows more)● Device agnostic (use with hosts, GPUs, or Phis)● Currently, only newest compilers support it (ifort_icc/14.0.4 and ifort_icc/15.0)● Used in this workshop
– OpenCL (module add intel_opencl)● Lower level● Open standard, device agnostic
– Other standards will likely emerge● e.g. CAPS compiler by French company CAPS entreprise supports OpenACC for Xeon Phi. Also future GCC 5.0.

37
Offload Mode (OpenMP4 - C/C++)
● Program runs on the CPU● Programmer specified hotspots are 'offloaded' to the device
– #pragma omp target device(1)
● Variables and functions can be declared on the device– #pragma omp declare target
– static int *data;
– #pragma omp end declare target
● Data is usually copied to and from the device (data can be an array section)– map(tofrom:data[5:3])
● Data can also be allocated on the device without copying– map(alloc:data[:20])

38
Offload Mode (OpenMP4 - Fortran)
● Program runs on the CPU● Programmer specified hotspots are 'offloaded' to the device
– !$omp target device(0)
– parallelloop, parallelsection
– !$omp end target
● Variables, subroutines, functions can be declared on the device– !$omp declare target (data)
● Data is usually copied to and from the device– map(tofrom:data)

39
Offload Mode (Intel - C/C++)
● Program runs on the CPU● Programmer specified hotspots are 'offloaded' to the device
– #pragma offload target(mic:0)
● Variables can be declared on the device– #pragma offload_attribute(push, target(mic))
– static int *data;
– #pragma offload_attribute(pop)
● Data is usually copied to and from the device– in(varname : length(arraylength))
– out(varname : length(arraylength))
– inout(varname : length(arraylength))

40
Offload Mode (Intel - Fortran)
● Program runs on the CPU● Programmer specified hotspots are 'offloaded' to the device
– !DIR$ OFFLOAD BEGIN target(mic:0)
– ...
– !DIR$ END OFFLOAD
● Variables can be declared on the device– !DIR$ OPTIONS /offload_attribute_target=mic
– integer, dimension(:) :: data
– !DIR$ END OPTIONS
● Data is usually copied to and from the device– in(varname : length(arraylength))
– out(varname : length(arraylength))
– inout(varname : length(arraylength))

41
What is the output?
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5; #pragma omp target map(tofrom:tofrom:data) { data += 2; }
printf("data: %d\n", data);
return 0;}
Please see memory.c

42
What is the output?
● A) data: 5● B) data: 7● C) data: 2● D) Error or
segmentation fault● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5; #pragma target map(tofrom:tofrom:data) { data += 2; }
printf("data: %d\n", data); return 0;}

43
What is the output?
#include <stdio.h>
int main(int argc, char* argv[]){
int data = 5;
#pragma omp target map(tofrom:tofrom:data) { data += 2; }
printf("data: %d\n", data); return 0;}
● A) data: 5● B) data: 7● C) data: 2● D) Error or
segmentation fault● E) None of the above
Explanation: default for map(data) ismap(tofrom:data)

44
What is the output?
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5;
#pragma omp target map(totofrom:data) { data += 2; }
printf("data: %d\n", data); return 0;}
● A) data: 5● B) data: 7● C) data: 2● D) Error or
segmentation fault● E) None of the above

45
What is the output?
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5; #pragma omp target map(totofrom:data) { data += 2; }
printf("data: %d\n", data); return 0;}
Explanation: data points to uninitialized memory on the device when 2 is added..
● A) data: 5● B) data: 7● C) data: 2● D) Error or
segmentation fault● E) None of the above

46
What is the output?
● A) data: 5● B) data: 7● C) data: 2● D) Error or
segmentation fault● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){
int data = 5;
#pragma omp target map(tofromfrom:data) { data += 2; }
printf("data: %d\n", data); return 0;}

47
What is the output?
● A) data: 5● B) data: 7● C) data: 2● D) Error or
segmentation fault● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){
int data = 5; #pragma omp target map(tofromfrom:data) { data += 2; }
printf("data: %d\n", data);
return 0;}
Explanation: data is changed to 7 on the device, but the modified data is never copied back to the host.

48
What is the output?
● A) data: 5● B) data: 7● C) data: 2● D) Error or
segmentation fault● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5;
#pragma omp target map(tofrom:data)map(tofrom:data) { data += 2; }
printf("data: %d\n", data); return 0;}

49
What is the output?
● A) data: 5● B) data: 7● C) data: 2● D) Error or
segmentation fault● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5;
#pragma omp target map(tofrom:data)map(tofrom:data) { data += 2; }
printf("data: %d\n", data); return 0;}
Explanation: A variable referenced in a target construct that is not declared in the construct is implicitly treated as if it had appeared in a mapclause with a map-type of tofrom.

50
Important Points about Memory
● Device memory is different than host memory– Device memory not accessible to host code
– Host memory not accessible to device code
● Data is copied to and from the device using pragmas (offload mode) or scp (native mode)
● Some programming models may use a virtual shared memory

51
Exercise 6: Offload Programming
● The file offload.c is an OpenMP CPU program● Compile and run:
– $ icc o offload openmp O0 offload.c
● Modify this program to use the phi card– Use #pragma omp declare target so some_work()is compiled for
execution on the Phi
– Write an appropriate pragma to offload the some_work() call in main() to the Phi device, using the correct map clauses for transferring in_array and out_array.
● Compile and run the program● Try: export OFFLOAD_REPORT=3
– run your program again (no need to re-compile)

52
Exercise 7: Environment Variables in Offload Programming
● Compile and run hello_offload.c, and hello.c
– $ icc openmp o hello_offload hello_offload.c; ./hello_offload
– $ icc openmp o hello hello.c; ./hello
● How many OpenMP threads are used by each (default)?● Change OMP_NUM_THREADS
– $ export OMP_NUM_THREADS=4
● Now how many OpenMP threads are used by each?● Set a different value for OMP_NUM_THREADS for offload execution:
– $ export MIC_ENV_PREFIX=MIC
– $ export MIC_OMP_NUM_THREADS=5
● Now how many OpenMP threads are used by each?● Note: Offload execution copies your environment variables unless you have one or more environment
variables beginning with $MIC_ENV_PREFIX_
– Otherwise, only copies MIC environment variables
● Note: Set variables for a specific coprocessor: $ export MIC_1_OMP_NUM_THREADS=5

53
How should we compile/run this for offload execution?
● A) icc -mmic -openmp code.c; ./a.out
● B) icc -openmp code.c; ./a.out
● C) icc -mmic -openmp code.c; micnativeloadex a.out
● D) icc -openmp code.c; micnativeloadex a.out
● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5;
#pragma omp target { data += 2; }
printf("data: %d\n", data); return 0;}

54
How should we compile/run this for offload execution?
● A) icc -mmic -openmp code.c; ./a.out
● B) icc -openmp code.c; ./a.out
● C) icc -mmic -openmp code.c; micnativeloadex a.out
● D) icc -openmp code.c; micnativeloadex a.out
● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5;
#pragma omp target { data += 2; }
printf("data: %d\n", data); return 0;}

55
How should we compile/run this for native execution?
● A) icc -mmic -openmp code.c; ./a.out
● B) icc -openmp code.c; ./a.out
● C) icc -mmic -openmp code.c; micnativeloadex a.out
● D) icc -openmp code.c; micnativeloadex a.out
● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5;
#pragma omp target { data += 2; }
printf("data: %d\n", data);
return 0;}

56
How should we compile/run this for native execution?
● A) icc -mmic -openmp code.c; ./a.out
● B) icc -openmp code.c; ./a.out
● C) icc -mmic -openmp code.c; micnativeloadex a.out
● D) icc -openmp code.c; micnativeloadex a.out
● E) None of the above
#include <stdio.h>
int main(int argc, char* argv[]){ int data = 5;
#pragma#pragma omp targetomp target { data += 2; }
printf("data: %d\n", data); return 0;}
For target pragmas the compiler gives a warning but they are ignored for native-execution programs.

57
How should we set OMP_NUM_THREADS for native
execution?● A)
– $ export OMP_NUM_THREADS=240
● B)– $ export MIC_ENV_PREFIX=MIC
– $ export MIC_OMP_NUM_THREADS=240
– ./a.out
● C) – $ micnativeloadex ./a.out e “OMP_NUM_THREADS=240”

58
How should we set OMP_NUM_THREADS for native
execution?● A)
– $ export OMP_NUM_THREADS=240
● B)– $ export MIC_ENV_PREFIX=MIC
– $ export MIC_OMP_NUM_THREADS=240
– ./a.out
● C) – $ micnativeloadex ./a.out e “OMP_NUM_THREADS=240”

59
Memory Persistence
● Data transfers to/from the device are expensive and should be minimized
● By default variables are allocated at beginning of offload segment, and free'd at the end
● Data can persist on the device between offload segments
● Must have a way to prevent freeing and re-allocation of memory if we wish to reuse it

60
Memory Persistence//Allocate the arrays only once on target#pragma omp target data map(to:in_data[:SIZE]) \ map(from:out_data[:SIZE]){ for(i=0;i<N;i++){ //Do not copy data inside of loop #pragma omp target { ...offload code... } // Copy out_data from target to host #pragma omp target update from(out_data[:SIZE]) // do something with out_data }}

61
Memory Persistence!Allocate the arrays only once on target!$OMP target data map(to:in_data(:SIZE)) map(from:out_data(:SIZE))
DO i=1,N !Do not allocate or free on target inside of loop !$OMP target ...offload code... !$OMP end target
!Copy out_data from target to host !$OMP target update from(out_data(:SIZE)) !do something with out_dataEND DO
!$OMP end target data

62
Exercise 8: Memory Persistence
● Modify your solution to exercise 5 (offload.c) or copy the solution offload_soln.c from the solutions directory
● We would like to transfer, allocate, and free memory for in_array and out_array only once, instead of once per iteration

63
Vectorization
● Two main requirements to achieve good performance– Multithreading
– Vectorization
● Vectorization - Compiler interprets a sequence of steps (e.g. a loop) as a single vector operation
● Xeon Phi has 512 bit-wide (16 floats) SIMD registers for vectorized operations
for (i=0; i<4; i++) c[i] = a[i] + b[i];

64
Vectorization
(c) 2013 Jim Jeffers and James Reinders, used with permission.

65
Vectorization
● Use qoptreport[=n] qoptreportphase=vec (replaces vecreport[=n]) compiler option to get a vectorization report
● If your code doesn't automatically vectorize, you must communicate to the compiler how to vectorize– Use array notation (e.g. Intel Cilk Plus)
– Use #pragma omp simd (carefully)
● Avoid– Data dependencies
– Strided (non-sequential) memory access

66
Intel Cilk Plus
● C/C++ language extensions for multithreaded programming● Available in Intel compilers (>= composer XE 2010) and gcc (>= 4.9)● Keywords
– cilk_for - Parallel for loop
– cilk_spawn - Execute function asynchronously
– cilk_sync - Synchronize cilk_spawn'd tasks
● Array notation– array-expression[lower-bound : length : stride]
– C[0:5:2][:] = A[:];
● #pragma simd– Simplest way to manually vectorize a code segment
● More information: – https://www.cilkplus.org/

67
Exercise 9: Vectorization
● Compile offload_novec.c with vectorization reporting
– $ icc openmp o offload_novec qoptreport=3 qoptreportphase=vec offload_novec.c sini.c
● Note that the loop around the call to sini() does not vectorize. Why?● We know that this algorithm should vectorize (try compiling offload_soln.c with qoptreport=3 qoptreportphase=vec)
● Put a simd clause behind for in the omp parallel for pragma before the loop and recompile. Alternative: use the ipo switch.

68
MPI on Xeon Phi
● Message Passing Interface (MPI) is a popular parallel programing standard– especially useful for parallel programs using multiple nodes
● There are three main ways to use MPI with Xeon– Native mode - directly on the device
– Symmetric mode - MPI processes run on both the CPU and the Xeon Phi
– Offload mode - MPI used for inter-node communication, code portions offloaded to Xeon Phi (e.g. with OpenMP)

69
Exercise 10: Native MPI on Xeon Phi
● Setup your environment for Intel MPI on Xeon Phi– $ module add intel_mpi
– $ export I_MPI_MIC=enable
● Compile hello.c for native execution
– $ mpiicc mmic o hello.MIC hello_mpi.c
● Run with mpirun (executed on host)– $ I_MPI_FABRICS=shm mpirun n 60 host mic0 ./hello.MIC
– Normally use fewer MPI processes per node without explicit shm setting

70
Exercise 11: Symmetric MPI on Xeon Phi
● Use the same environment described in exercise 9● Compile binaries for MIC and CPU
– $ mpiicc mmic o hello.MIC hello_mpi.c
– $ mpiicc o hello hello_mpi.c
● Intel MPI must know the difference between MIC and CPU binaries– $ export I_MPI_MIC_POSTFIX=.MIC
● Run with mpirun– $ mpirun perhost 1 n 2 host localhost,mic0 ./hello
– Or without I_MPI_MIC_POSTFIX=.MIC
– $ mpirun host localhost n 3 ./hello : host mic0 n 10 ./hello.MIC
– Use export I_MPI_FABRICS=shm:tcp in case of issues.

71
Symmetric mode load-balancing
● Phi tasks will run slower than host tasks● Programmer's responsibility to balance workloads
between fast and slow processors

72
Optimizing for Xeon Phi
● General tips– Optimize for the host node Xeon processors first
– Expose lots of parallelism● SIMD● Vectorization
– Minimize data transfers
– Try different numbers of threads from 60 to 240– Try different thread affinities
● e.g. OpenMP: –$ export MIC_ENV_PREFIX=MIC–$ MIC_OMP_PLACES=threads/cores

73
KMP_AFFINITY/OMP_PLACESOMP_PLACES=threadsorKMP_AFFINITY=compact:
KMP_AFFINITY=scatter(default):
KMP_AFFINITY=balanced
Likely to leavecores unused
Neighbouring threadson the same core - more efficient cacheutilization
Neighbouring threadson different cores - do not share cache

74
Identifying Accelerator Algorithms
● SIMD Parallelizability– Number of concurrent threads (need dozens)
– Minimize conditionals and divergences
● Operations performed per datum transferred to device (FLOPs/GB)– Data transfer is overhead
– Keep data on device and reuse it

75
Identifying Accelerator Algorithms
● SIMD Parallelizability– Number of concurrent threads (need dozens)
– Minimize conditionals and divergences
● Operations performed per datum transferred to device (FLOPs/GB)– Data transfer is overhead
– Keep data on device and reuse it

76
Which algorithm gives the most Phi performance boost?
Put the following in order from least work per datum to most:
● i) matrix-vector multiplication
● ii) matrix-matrix multiplication
● iii) matrix trace (sum of diagonal elements)
● A) i, ii, iii● B) iii, i, ii● C) iii, ii, i● D) i, iii, ii● E) They are all about
the same

77
Which algorithm gives the most Phi performance boost?
Put the following in order from least work per datum to most:
● i) matrix-vector multiplication
● ii) matrix-matrix multiplication
● iii) matrix trace (sum of diagonal elements)
● A) i, ii, iii● B) iii, i, ii● C) iii, ii, i● D) i, iii, ii● E) They are all about
the same

78
Which algorithm gives the most Phi performance boost?
● Matrix trace– assume you naively transfer the entire matrix to the
device
– Work Data
● Matrix vector multiplication– Work Data
● Matrix-matrix multiplication– Work Data

79
Choosing a mode
Study optimized CPU run time
Study native modescaling (30, 60,
120, 240 threads)
Is native mode
(at any scaling)faster than the
CPU?
Consider nativemode
Arethere functions which execute
faster onphi?
Consider offloadingthose functions
Consider runningon CPU only
Work per datum
benefit > cost?
Collect CPU and native mode
profiling data
Yes
No
Yes
Yes
No
No

80
Review
● We learned how to:– Gain access to the Xeon Phis through Guillimin's scheduler
– Log in and explore the Xeon Phis operating system
– Compile and run parallel software for native execution on the Xeon Phis
– Compile and run parallel software for offload execution on the Xeon Phis
● Offload pragmas (target, map)● Data persistence (target data)
– Ensure your code vectorizes for maximum performance
– Choose when to use the Xeon Phi and which mode to use

81
Keep Learning...
● Xeon Phi documentation, training materials, example codes:– http://software.intel.com/en-us/mic-developer
– https://software.intel.com/en-us/articles/intel-xeon-phi-coprocessor-applications-and-solutions-catalog
● General parallel programming:– http://openmp.org/wp/
– http://www.mpi-forum.org/
– http://cilkplus.org
– http://www.hpc.mcgill.ca/index.php/training
● Xeon Phi Tutorials:– http://software.intel.com/en-us/articles/intelr-xeon-phitm-advanced-workshop-labs
– http://www.drdobbs.com/parallel/programming-intels-xeon-phi-a-jumpstart/240144160?pgno=1
– https://www.cac.cornell.edu/vw/mic/
● Questions:– http://software.intel.com/en-us/forums/intel-many-integrated-core
– http://stackoverflow.com


83
Bonus Topics (Time permitting)

84
More Xeon Phi practice
● Intel Math Kernel Library (MKL) examples– $ cp $MKLROOT/examples/* .
– $ tar xvf examples_mic.tgz
● Compile and run Hybrid MPI+OpenMP for native and offload execution– misc/hybrid_mpi_omp_mv4.c
● Compile and run OpenCL code for offload execution– misc/vecadd_opencl.c