basic quantitative methods in the social sciences (aka intro stats)
DESCRIPTION
Basic Quantitative Methods in the Social Sciences (AKA Intro Stats). 02-250-01 Lecture 10. Quantitative vs. Frequency Data. Recall from our first lecture, that data could take the form of: Quantitative data (AKA measurement data) whereby each observation represents a score on a continuum - PowerPoint PPT PresentationTRANSCRIPT

Basic Quantitative Basic Quantitative Methods in the Social Methods in the Social
SciencesSciences
(AKA Intro Stats)(AKA Intro Stats)02-250-0102-250-01
Lecture 10Lecture 10

Quantitative vs. Frequency DataQuantitative vs. Frequency Data• Recall from our first lecture, that data could Recall from our first lecture, that data could
take the form of:take the form of: Quantitative data (AKA measurement data) Quantitative data (AKA measurement data)
whereby each observation represents a score on whereby each observation represents a score on a continuuma continuum• Most common statistics: mean and SDMost common statistics: mean and SD• Examples: height, weight, IQ, rating of Chretien on Examples: height, weight, IQ, rating of Chretien on
a scale of 1-10.a scale of 1-10. Categorical data (AKA frequency data) whereby Categorical data (AKA frequency data) whereby
frequencies of observations fall into one of two frequencies of observations fall into one of two or more categories.or more categories.• Examples: female vs. male, brown eyes vs. blue Examples: female vs. male, brown eyes vs. blue
eyes, opposed to Chretien vs. support Chretieneyes, opposed to Chretien vs. support Chretien• This type of data is not a measurement of This type of data is not a measurement of
anything per se, it is simply frequencies of anything per se, it is simply frequencies of occurrence in the nominal classes (e.g., # of occurrence in the nominal classes (e.g., # of males vs. females, etc.)males vs. females, etc.)

What if we want to know whether What if we want to know whether the observed frequencies were the observed frequencies were
what we had expected?what we had expected?
• When it comes to frequency data, once we When it comes to frequency data, once we have counted our observations, we have…have counted our observations, we have… Observed FrequenciesObserved Frequencies – frequencies that have – frequencies that have
actually occurredactually occurred
Expected FrequenciesExpected Frequencies – frequencies that we – frequencies that we expected to occur if some assumption is trueexpected to occur if some assumption is true
• The Null Hypothesis (HThe Null Hypothesis (H00) is that the observed ) is that the observed frequencies do not differ from what we had frequencies do not differ from what we had expected (the “expected frequencies”)expected (the “expected frequencies”)

Chi - SquareChi - SquareChi - SquareChi - Square• Examines the difference between the Examines the difference between the
Observed and the Expected frequencies Observed and the Expected frequencies among groups among groups
• Both variables are Nominal (therefore all Both variables are Nominal (therefore all we can measure is observed we can measure is observed frequencies)frequencies) E.g., we know how many males are in this E.g., we know how many males are in this
class (the observed frequency), and how class (the observed frequency), and how many we would expect to be in this classmany we would expect to be in this class

Non-parametric testsNon-parametric tests• The Chi-Square test is a The Chi-Square test is a non-parametricnon-parametric test. test.
• With non-parametric tests, we do not need With non-parametric tests, we do not need to assume that the population data are to assume that the population data are normally distributed.normally distributed.
• Non parametric tests allow for nominal and Non parametric tests allow for nominal and ordinal scales of measurement.ordinal scales of measurement.
• Although non-parametric tests are still Although non-parametric tests are still inferential, they are less “powerful” than are inferential, they are less “powerful” than are parametric tests (e.g., t-tests, correlations). parametric tests (e.g., t-tests, correlations). This means that parametric tests are not as This means that parametric tests are not as likely to find significant results when the likely to find significant results when the effect size is small.effect size is small.

• Cindy was hired at a fitness club in town. She Cindy was hired at a fitness club in town. She was told by the boss that 68% of people who was told by the boss that 68% of people who come in and inquire about becoming a come in and inquire about becoming a member end up joining after they are shown member end up joining after they are shown around the club.around the club.
• Three months later, Cindy is fired because the Three months later, Cindy is fired because the boss feels that she is not good at “selling” the boss feels that she is not good at “selling” the club to people inquiring about memberships. club to people inquiring about memberships. Over the three months, Cindy gave tours to 75 Over the three months, Cindy gave tours to 75 people. 44 of them ended up joining.people. 44 of them ended up joining.
• Cindy thinks that the boss just doesn’t like Cindy thinks that the boss just doesn’t like her.her.

Is the Boss’ Accusation True?Is the Boss’ Accusation True?
• The boss The boss originally said originally said that 68% of that 68% of people typically people typically join. Therefore, join. Therefore, of the 75 people of the 75 people Cindy gave tours Cindy gave tours to, 51 of them to, 51 of them should have should have joined if Cindy is joined if Cindy is on par with the on par with the other other employees.employees.
JoinJoin Don’t JoinDon’t Join
Observed Observed
4444 3131
ExpectedExpected
5151 2424

The Chi-Square Goodness-of-Fit TestThe Chi-Square Goodness-of-Fit Test
• The Chi-Square Goodness-of-Fit Test is used when The Chi-Square Goodness-of-Fit Test is used when you have you have oneone classification variable (but it has 2 or classification variable (but it has 2 or more categories).more categories).
• HH00: The assumption that Cindy is on par with the : The assumption that Cindy is on par with the other employees is true.other employees is true.
• HHaa: The assumption that Cindy is on par with the : The assumption that Cindy is on par with the other employees is not true.other employees is not true.
• The Chi-Square test allows a decision about The Chi-Square test allows a decision about whether observed and expected frequencies differ whether observed and expected frequencies differ significantly.significantly.
• Rejection of HRejection of H00 suggests that our assumption that suggests that our assumption that led to the expected frequencies is wrong (or in this led to the expected frequencies is wrong (or in this example, Cindy is not on par with the other club example, Cindy is not on par with the other club employees).employees).

= Greek letter Chi, O = observed = Greek letter Chi, O = observed frequencies, E = expected frequencies, E = expected
frequenciesfrequencies
= Greek letter Chi, O = observed = Greek letter Chi, O = observed frequencies, E = expected frequencies, E = expected
frequenciesfrequencies
( fo - fe ) 2
fe
2 = =
HH00: O-E = 0 (no difference between observed : O-E = 0 (no difference between observed and expected frequencies), therefore, and expected frequencies), therefore, 2 = 0.

Calculating Chi SquareCalculating Chi Square• Create a table with columns for each Create a table with columns for each
category (so here, “join” and “not join”)category (so here, “join” and “not join”)
• Create a row for each of the following:Create a row for each of the following: Observed frequencies (O)Observed frequencies (O) Expected frequencies (E)Expected frequencies (E) O – EO – E (O – E)(O – E)22
(O – E)(O – E)22 / E / E
• The Chi Square statistic is then the sum of The Chi Square statistic is then the sum of this final row of (O – E)this final row of (O – E)22 / E / E

Chi Square Goodness of Chi Square Goodness of Fit TableFit Table
JoinJoin Not JoinNot Join
OO nn join join nn not not joinjoin
EE
O – EO – E
(O – E)(O – E)22
(O – E)(O – E)22/E/E
Sum Sum (O – E)(O – E)22/E/E
Chi Square Statistic Chi Square Statistic ValueValue
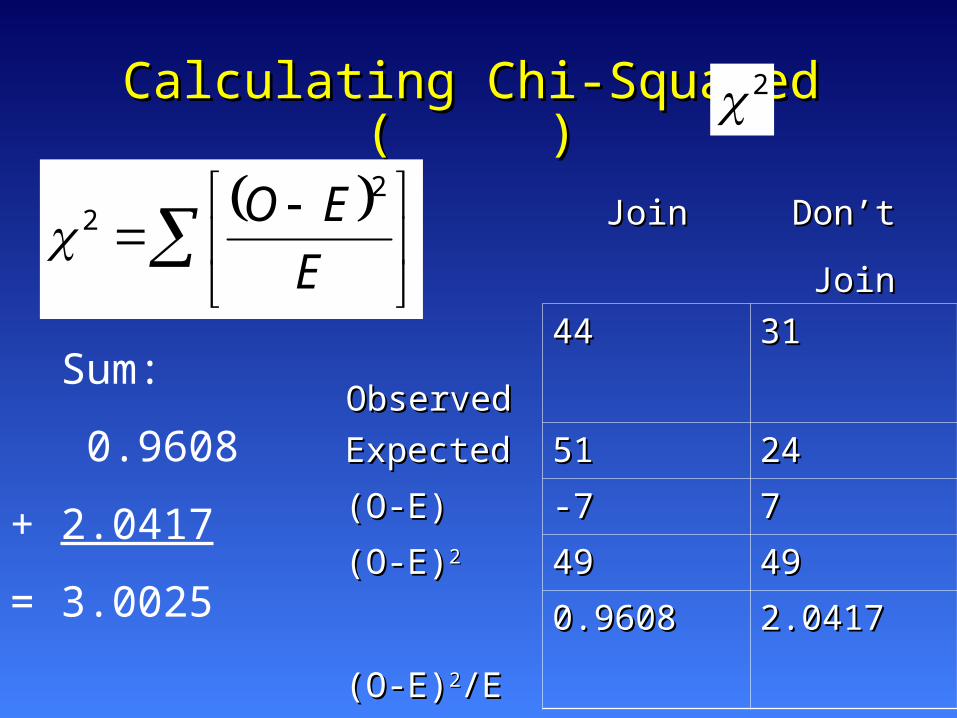
Calculating Chi-Squared ( )Calculating Chi-Squared ( )
JoinJoin Don’t Don’t
JoinJoin
Observed Observed
4444 3131
ExpectedExpected 5151 2424
(O-E)(O-E) -7-7 77
(O-E)(O-E)22 4949 4949
(O-E)(O-E)22/E/E
0.96080.9608 2.04172.0417
Sum:
0.9608
+ 2.0417
= 3.0025
2
E
EO 22

Testing the Significance of Testing the Significance of • DF = k-1 where k = the number of DF = k-1 where k = the number of
outcome categories.outcome categories.
• Table E.1 in the text (p. 439) – at Table E.1 in the text (p. 439) – at the .050 level of significance, df = 1the .050 level of significance, df = 1 22
critcrit = 3.84 = 3.84
• Since Since 22obtobt = 3.00, we retain H = 3.00, we retain H0 0 (NOTE: (NOTE:
give obt value to 2 decimal places)give obt value to 2 decimal places)
• Therefore, the result is not significant, Therefore, the result is not significant, Cindy’s recruiting performance at the Cindy’s recruiting performance at the fitness club is not significantly different fitness club is not significantly different than that of the other employees. than that of the other employees.
2

•It is easy to see that in the numerator of the formula, observed frequencies are compared to expected frequencies to assess how well the sample data match the hypothesized data. Why must we divide the numerator by the expected frequency for each category?
•Suppose you were going to throw a party and you expected 1000 people to show up. However, at the party, you counted the number of guests and observed that 1040 actually showed up. Forty more guests than expected are no major problem when all along you were planning for 1000. There will probably still be enough beer and chips for everyone.
E
EO 22

•On the other hand, suppose you had a party and you expected 10 people to attend but instead 50 actually showed up. Forty more guests in this case spell big trouble. How “significant” the discrepancy is depends in part on what you were originally expecting.
•With very large expected frequencies, allowances are made for more errors between observed and expected frequencies. This is accomplished in the chi-square formula by dividing the squared discrepancy for each category by its expected frequency.

What About When There are What About When There are More Than Two Categories?More Than Two Categories?
• In the preceding example, observed In the preceding example, observed frequencies fell into one of two frequencies fell into one of two categories: joined or did not join.categories: joined or did not join.
• What if there are more than two What if there are more than two categories?categories?

ExampleExample• Suppose a study showed that of 90 people in Suppose a study showed that of 90 people in
trauma-induced comas who were treated with trauma-induced comas who were treated with traditional medicine, 30 died, 30 woke up and traditional medicine, 30 died, 30 woke up and fully recovered, and 30 remained comatose fully recovered, and 30 remained comatose indefinitely. (Note: These data were made up).indefinitely. (Note: These data were made up).
• Dr. X, a naturopathic doctor who works with Dr. X, a naturopathic doctor who works with patients with trauma-induced comas, claims that patients with trauma-induced comas, claims that alternative approaches result in superior recovery alternative approaches result in superior recovery rates. To test his claim, 90 comatose people were rates. To test his claim, 90 comatose people were treated with his alternative approach and were treated with his alternative approach and were then observed. 40 of them woke up and were fully then observed. 40 of them woke up and were fully recovered, 30 died, and 20 remained comatose recovered, 30 died, and 20 remained comatose indefinitely. indefinitely.

Chi- SquareChi- SquareChi- SquareChi- Square
O
E EO30 30
40
E
O 30
30 20Total O = 90
Woke Died
Stayed in
Coma
What’s H0?

Chi- SquareChi- SquareChi- SquareChi- Square
O
E E E
O O30 30 30
40 30 20Total O = 90
n = 30 + 30 + 30 = 90
Woke Died
Stayed in
Coma

Chi- SquareChi- SquareChi- SquareChi- Square
( fo - fe ) 2
fe
2 = =
Figure for Each Cell

Chi- SquareChi- SquareChi- SquareChi- Square
( fo - fe ) 2
fe
( fo - fe ) 2
fe
( fo - fe ) 2
fe
Woke Died
StayedIn
Coma
+ +

Chi- SquareChi- SquareChi- SquareChi- Square
( 40 - 30 ) 2
fe
( 30 - 30 ) 2( 20 - 30 ) 2
fe
Woke Died
StayedIn
Coma
+ +
fe

Chi- SquareChi- SquareChi- SquareChi- Square
( 10 ) 2
fe
( 0 ) 2 ( -10 ) 2
fe
Woke Died
StayedIn
Coma
+ +
fe

Chi- SquareChi- SquareChi- SquareChi- Square
100
fe
0 100
fe
Woke Died
Stayed in
Coma
+ +
fe

Chi- SquareChi- SquareChi- SquareChi- Square
100
30
0 100
30
Woke Died
StayedIn
Coma
+ +
30

Chi- SquareChi- SquareChi- SquareChi- Square
3.3333 0 3.3333
Woke Died
StayedIn
Coma
+ +

Chi- SquareChi- SquareChi- SquareChi- Square
2obt = 6.6666 = 6.67
df = k - 1 = 2
2crit = 5.99
Therefore: We reject H0, Dr. X’s alternative approach does indeedgenerate significantly more recoveries.

Distribution of violent Distribution of violent crimes in the United States, crimes in the United States,
19951995

Sample results for 500 Sample results for 500 randomly selected violent-randomly selected violent-
crime reports from last yearcrime reports from last year

Expected frequencies if last Expected frequencies if last year’s violent-crime year’s violent-crime
distribution is the same as distribution is the same as thethe
1995 distribution1995 distribution

Calculating the goodness of Calculating the goodness of fit fit
(Chi-Square)(Chi-Square)
2obt = 4.219. With df=k-1=3, at .05, 2
crit =7.81 Therefore, we retain H0, last year’s crime distribution is not significantly different from that in 1995.

The Chi-Square Test for The Chi-Square Test for IndependenceIndependence
• The The 22 statistic can also be used to test statistic can also be used to test whether or not there is a relationship whether or not there is a relationship between between twotwo categorical (nominal) categorical (nominal) variables.variables.
• Each individual in the sample is Each individual in the sample is measured or classified on two separate measured or classified on two separate variables.variables.
• Also known as the Contingency Table Also known as the Contingency Table AnalysisAnalysis

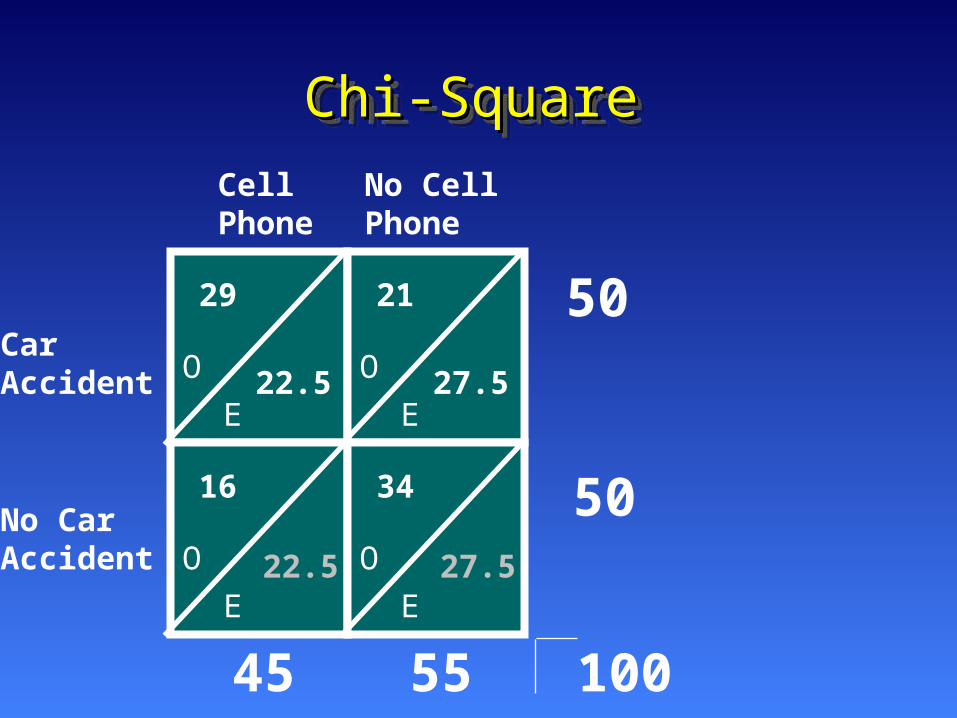
Do people with cell phones have more car Do people with cell phones have more car accidents than people without cell phones?accidents than people without cell phones?
• The Department of Transportation The Department of Transportation wanted to see if cell phone users have wanted to see if cell phone users have more car accidents than non-cell phone more car accidents than non-cell phone users. The following data are a sample users. The following data are a sample of 50 people who have had car of 50 people who have had car accidents over the past month, and 50 accidents over the past month, and 50 randomly sampled drivers who have not randomly sampled drivers who have not had car accidents over the past month:had car accidents over the past month:

Chi-SquareChi-SquareChi-SquareChi-Square
E
O
29
E
O
21
E
O
16
E
O
34
CellPhone
No CellPhone
CarAccident
No CarAccident

So what now?So what now?
• Notice that here, only observed Notice that here, only observed frequencies are given to you. You frequencies are given to you. You have to calculate the expected have to calculate the expected frequencies.frequencies.
• First, total your rows and columns.First, total your rows and columns.

Chi-SquareChi-SquareChi-SquareChi-Square
E
O
29
E
O
21
E
O
16
E
O
34
Cell Phone
No Cell Phone
CarAccident
No CarAccident
50
50
5545 100

Eij = RiCj / N
where:
Eij = the expected frequency at row i, column j.
Ri = Row i’s total
Cj = Column j’s total
N = Grand total (all cells included)

Chi-SquareChi-SquareChi-SquareChi-Square
E
O
29
E
O
21
E
O
16
E
O
34
CellPhone
No CellPhone
CarAccident
No CarAccident
50
50
5545 100
50 X 45 100
22.5 =22.5

Chi-SquareChi-SquareChi-SquareChi-Square
E
O
29
E
O
21
E
O
16
E
O
34
CellPhone
No CellPhone
CarAccident
No CarAccident
50
50
5545 100
50 X 55 100
27.5 =22.5 27.5
Chi-SquareChi-SquareChi-SquareChi-Square
E
O
29
E
O
21
E
O
16
E
O
34
CellPhone
No CellPhone
CarAccident
No CarAccident
50
50
5545 100
22.5 27.5
22.5 27.5

And then….And then….You now have four cells with expected and observed frequencies. Now use the Chi Square formula!
[(29-22.5)2/22.5] = 1.8778+
[(21-27.5)2/27.5] = 1.5364+
[(16-22.5)2/22.5] = 1.8778+
[(34-27.5)2/27.5] = 1.5364 2
obt = 6.8284
= 6.83
E
EO 22

To test this statistic:To test this statistic:• Let’s use the .05 level of significance.Let’s use the .05 level of significance.
• Variable 1: Cell phone? Variable 1: Cell phone?
• Variable 2: Car accident?Variable 2: Car accident?
• Because we are dealing with frequency data of Because we are dealing with frequency data of two categorical variables, we will perform a chi-two categorical variables, we will perform a chi-square test of independence.square test of independence.
• Because it is a chi-square, it is a two-tailed test.Because it is a chi-square, it is a two-tailed test.
• HH00: Cell phones and car accidents are : Cell phones and car accidents are independent independent
• HHaa: Cell phones and car accidents are not : Cell phones and car accidents are not independent independent

Chi-SquareChi-SquareChi-SquareChi-Square
• DF (for test of independence):DF (for test of independence): df df = (R-1) (C-1)= (R-1) (C-1) Where R = number of rowsWhere R = number of rows
Where C = number of columnsWhere C = number of columns
df = (2-1)(2-1)=1, df = (2-1)(2-1)=1, 22critcrit = 3.84 (from table = 3.84 (from table
E.1, page. 439)E.1, page. 439)
22obtobt = 6.83, so reject the H = 6.83, so reject the H00..

SO….SO….
• Results are significant. The frequency of Results are significant. The frequency of being in a car accident depends on being in a car accident depends on whether or not one uses a cell phone.whether or not one uses a cell phone.

Note:Note:• When the expected frequencies are too When the expected frequencies are too
small, chi-square may not be a valid test, small, chi-square may not be a valid test, therefore all expected frequencies should therefore all expected frequencies should be at least 5 (dependent on sample size).be at least 5 (dependent on sample size).
• The chi-square test is also only valid The chi-square test is also only valid when the observations are independent when the observations are independent from each other, therefore N should be from each other, therefore N should be equal to the number of subjects (every equal to the number of subjects (every subject should only be measured once).subject should only be measured once).

What about when you What about when you have more than two have more than two
categories? categories? • A fast-food marketing consultant A fast-food marketing consultant
wanted to know whether men and wanted to know whether men and women had different preferences for women had different preferences for fast-food restaurants. She randomly fast-food restaurants. She randomly sampled 150 men and 100 women and sampled 150 men and 100 women and asked each to declare his or her asked each to declare his or her preference for four fast foods preference for four fast foods restaurants. Here are her data:restaurants. Here are her data:

E
O
35
E
O
25
E
O
20
E
O
30
Subway Harvey’s
Women
E
O
15
E
O
25
E
O
70
E
O
30
McDonaldsBurgerKing
Men
Total
100
150
-----
250Total: 55 55 85 55

Now remember….Now remember….• To calculate expected frequencies for To calculate expected frequencies for
each cell, each cell, Eij = RiCj / N
• So: (Row sum) (Column sum) / N
• Do this for each cell to get expected frequencies.

E
O
35
E
O
25
E
O
20
E
O
30
Subway Harvey’s
E
O
15
E
O
25
E
O
70
E
O
30
McDonaldsBurgerKing
Men
Total:
Total
100
150
-----
250
Women
55 55 85 55
22
33
22
33
34
51
22
33

You now have what you need You now have what you need to calculate to calculate 22
[(35-22)2/22] = 7.6818
[(25-22)2/22] = 0.4091
[(15-34)2/34] = 10.6176
[(25-22)2/22] = 0.4091
[(20-33)2/33] = 5.1212
[(30-33)2/33] = 0.2727
[(70-51)2/51] = 7.0784
[(30-33)2/33] = 0.2727
Add these up!
2obt = 31.8626
= 31.86df= (R-1)(C-1) = (2-1)(4-1) = 3
2crit = 7.82 (at .05)
E
EO 22

So….So….
• HH00: Gender and fast food preference are : Gender and fast food preference are independent.independent.
• HHaa: Gender and fast food preference are : Gender and fast food preference are dependent. dependent.
• We reject the null hypothesis. We reject the null hypothesis.
• SO: Gender and preference for fast food SO: Gender and preference for fast food are dependent.are dependent.
• Stated differently, men and women do Stated differently, men and women do not prefer the same fast food joints.not prefer the same fast food joints.

Time for Some ReviewTime for Some Review

Final Exam InfoFinal Exam Info
Wednesday, June 25 from 7:00 pm to 10:00 pmWednesday, June 25 from 7:00 pm to 10:00 pm
REMINDERS: Bring pencils, calculator, TEXTBOOK, REMINDERS: Bring pencils, calculator, TEXTBOOK, student IDstudent ID