big data analytics 2: leveraging customer behavior to enhance relevancy in personalization
TRANSCRIPT

Leveraging Customer Data to Enhance Relevancy in Personalization
“Using Apache Data Processing Projects on top of MongoDB”
Marc Schwering
Sr. Solution Architect – EMEA
@m4rcsch

2
Big Data Analytics Track
1. Driving Personalized Experiences Using Customer Profiles
2. Leveraging Data to Enhance Relevancy in Personalization
3. Machine Learning to Engage the Customer, with Apache Spark, IBM Watson, and MongoDB

3
Agenda For This Session
• Personalization Process Review• The Life of an Application• Separation of Concerns / Real World Architecture• Apache Spark and Flink Data Processing Projects• Clustering with Apache Flink• Next Steps

4
High Level Personalization Process
1. Profile created
2. Enrich with public data
3. Capture activity
4. Clustering analysis
5. Define Personas
6. Tag with personas
7. Personalize interactions
Batch analytics
Public dataCommon technologies• R• Hadoop• Spark• Python• Java• Many other
options Personas changed much less often than tagging

5
Evolution of a Profile (1)
{"_id" : ObjectId("553ea57b588ac9ef066428e1"),"ipAddress" : "216.58.219.238","referrer" : ”kay.com","firstName" : "John","lastName" : "Doe","email" : "[email protected]"
}

6
Evolution of a Profile (n+1){
"_id" : ObjectId("553e7dca588ac9ef066428e0"),"firstName" : "John","lastName" : "Doe","address" : "229 W. 43rd St.","city" : "New York","state" : "NY","zipCode" : "10036","age" : 30,"email" : "[email protected]","twitterHandle" : "johndoe","gender" : "male","interests" : [
"electronics","basketball","weightlifting","ultimate frisbee","traveling","technology"
],"visitedCounts" : {
"watches" : 3,"shirts" : 1,"sunglasses" : 1,"bags" : 2
},"purchases" : [
{"id" : 1,"desc" : "Power Oxford Dress
Shoe","category" : "Mens shoes"
},{
"id" : 2,"desc" : "Striped Sportshirt","category" : "Mens shirts"
}],"persona" : "shoe-fanatic”
}

7
One size/document fits all?
• Profile Data– Preferences– Personal information
• Contact information• DOB, gender, ZIP...
• Customer Data– Purchase History– Marketing History
• „Session Data“– View History– Shopping Cart Data– Information Broker Data
• Personalisation Data– Persona Vectors– Product and Category recommendations
Application
Batch analytics

8
Separation of Concerns
• Profile Data– Preferences– Personal information
• Contact information• DOB, gender, ZIP...
• Customer Data– Purchase History– Marketing History
• „Session Data“– View History– Shopping Cart Data– Information Broker Data
• Personalisation Data– Persona Vectors– Product and Category recommendations
Batch analytics Layer
Frontend - System
Profile ServiceCustomer Service
Session Service Persona Service

9
Benefits
• Code does less, Document and Code stays focused• Split ability
– Different Teams– New Languages– Defined Dependencies

10
Result
• Code does less, Document and Code stays focused• Split ability
– Different Teams– New Languages– Defined Dependencies
KISS => Keep it simple and save!
=> Clean Code <=
• Robert C. Marten: https://cleancoders.com/• M. Fowler / B. Meyer. et. al.: Command Query Separation

Analytics and Personalization
From Query to Clustering

12
Separation of Concerns
• Profile Data– Preferences– Personal information
• Contact information• DOB, gender, ZIP...
• Customer Data– Purchase History– Marketing History
• „Session Data“– View History– Shopping Cart Data– Information Broker Data
• Personalisation Data– Persona Vectors– Product and Category recommendations
Batch analytics Layer
Frontend – System
Profile ServiceCustomer Service
Session Service Persona Service
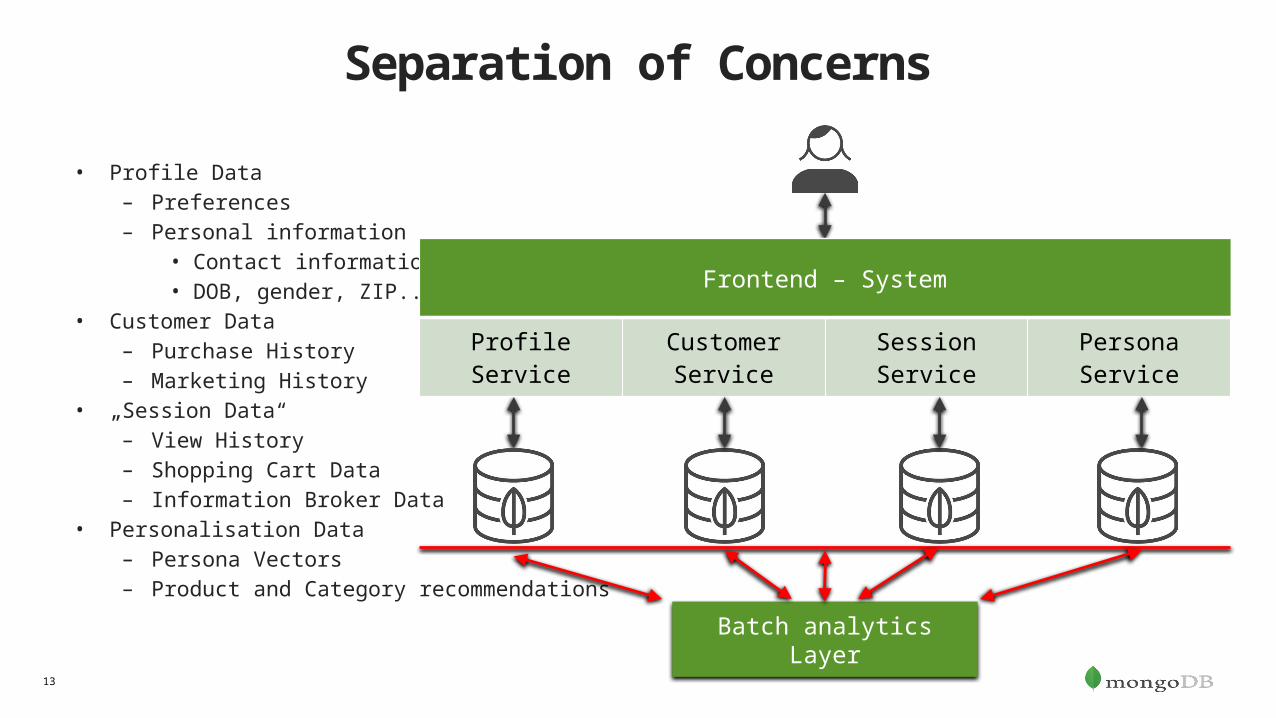
13
Separation of Concerns
• Profile Data– Preferences– Personal information
• Contact information• DOB, gender, ZIP...
• Customer Data– Purchase History– Marketing History
• „Session Data“– View History– Shopping Cart Data– Information Broker Data
• Personalisation Data– Persona Vectors– Product and Category recommendations
Batch analytics Layer
Frontend – System
Profile ServiceCustomer Service
Session Service Persona Service

14
Architecture revised
Profile ServiceCustomer Service
Session Service Persona Service
Frontend – System Backend– Systems
Data Processing

15
Advice for Developers
• OWN YOUR DATA! (but only relevant Data)• Say no! (to direct Data ie. DB Access)

Data Processing

17
Hadoop in a Nutshell
• An open source distributed storage and
distributed batch oriented processing framework
• Hadoop Distributed File System (HDFS) to store data on
commodity hardware• Yarn as resource management platform• MapReduce as programming model working on top of HDFS

18
Spark in a Nutshell
• Spark is a top-level Apache project
• Can be run on top of YARN and can read any
Hadoop API data, including HDFS or MongoDB
• Fast and general engine for large-scale data processing and
analytics• Advanced DAG execution engine with support for data locality
and in-memory computing

19
Flink in a Nutshell
• Flink is a top-level Apache project
• Can be run on top of YARN and can read any
Hadoop API data, including HDFS or MongoDB
• A distributed streaming dataflow engine• Streaming and batch• Iterative in memory execution and handling• Cost based optimizer

20
Latency of query operations
Query Aggregation MapReduce Cluster Algorithms
MongoDBHadoopSpark/Flink
tim
e

Iterative Algorithms / Clustering


23
K-Means as a Process

24
Iterations in Hadoop and Spark

25
Iterations in Flink
• Dedicated iteration operators• Tasks keep running for the iterations, not redeployed for each step• Caching and optimizations done automatically

Demo
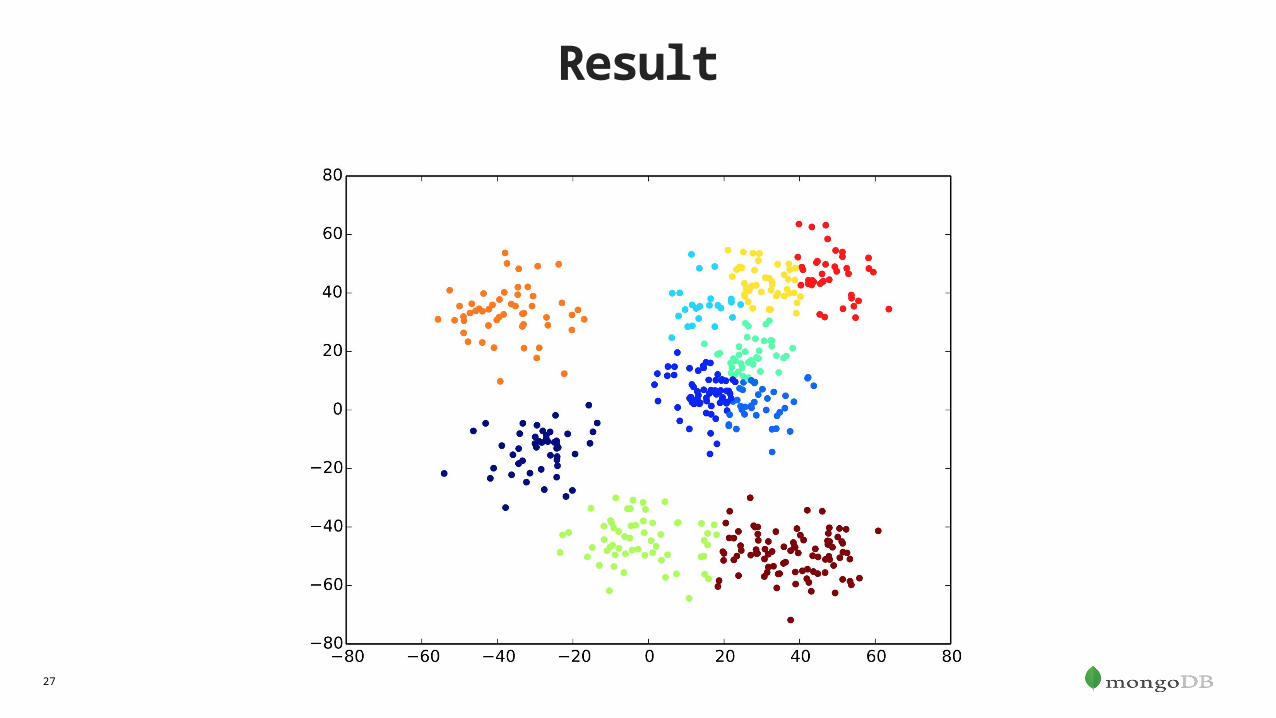
27
Result

28
More…?

29
Takeaways
• Stay focussed => Start and stay small– Evaluate with BigDocuments but do a PoC focussed on the
topic• Extending functionality is easy
– Aggregation, MapReduce– Hadoop Connector opens a new variety of Use Cases
• Extending functionality could be challenging– Evolution is outpacing help channels– A lot of options (Spark, Flink, Storm, Hadoop….)– More than just a binary

30
Next Steps
• Next Session => Hands on Spark and Whatson Content!– „Machine Learning to Engage the Customer, with Apache Spark, IBM
Watson, and MongoDB“– RDD Examples
• Try out Spark and Flink– http://bit.ly/MongoDB_Hadoop_Spark_Webinar– http://flink.apache.org/– https://github.com/mongodb/mongo-hadoop– https://github.com/m4rcsch/flink-mongodb-example
• Participate and ask Questions!– @m4rcsch– [email protected]

Thank you!
Marc Schwering
Sr. Solutions Architect – EMEA
@m4rcsch