building mt for a severely under-resourced language and ... · building mt for a severely...
TRANSCRIPT

BUILDING MT FOR A SEVERELY UNDER-RESOURCED
LANGUAGE AND CRISIS MT
Shideh Almasian Supervisor : Prof.Alexis Palmer

OVERVIEW AND CONTENT
➤ Importance of MT for SURLs
➤ Haiti Crisis
•What Made Haiti Different?
• Problems with Haiti
➤ The MT Crisis Cookbook
•Data
•Infrastructure
➤ building MT for the severely under-resourced languages
•White Hmong and community
•Data and Training Pipeline
•The Effects of the Hmong Translator
➤ Conclusion

IMPORTANCE OF MT FOR SURLS
➤ Crisis MT
➤ people use their communication technologies/languages – to report their situations, request help.
➤ MT can increase the speed by which relief can be provided
➤ contribute to aid efforts when the scale of information is big
➤ translation into a high resource language aids discovering information.
➤ make a language spoken by a local population accessible to aid agencies.
we will consider 2 examples :
➤ White Hmong project
➤ building MT for the severely under-resourced languages
➤ Through MT, a community->gains accessibility to content that might have otherwise been unavailable
➤ viable method to preserve the language.

EXAMPLE OF CRISIS
most of the aid that was provided by groups that did not communicate in Kreyo`l.
people texting, calling, use social media ->in Haitian Kreyo`l
January 12, 2010 earthquake in Haiti
Multiple groups set to work to make MT available as soon as possible

FRIST STEPS : MISSION 4636
➤ crowdsourced translation-> enabled communications between Haitian and English-speaking emergency responders.
➤ international aid workers -> phone-number,‘4636’ for free text
➤ The translations were made by about 2000 Kreyo`l and French speaking volunteers ->translate, categorize, identify missing people and geolocate information on a map

➤ messages, about 80,000->translated in real-time
➤ member of Mission 4636 built a high-precision, low- coverage dictionary-based system
➤ Days later->world’s first publically accessible Stastical Machine Translation (SMT) engine for Kreyo`l by Microsoft Research and Google Research Engine

OTHER EXAMPLES AND FURTHER STEPS
Standby Task Force was established in late 2010
• crowdsourced and machine translation have been combined for aid efforts
vote monitoring for the referendem in Southern Sudan
(Arabic)
a earthquake simulation in
Colombia (Spanish)
crisis mapping following the
tsunami in Japan (Japanese)
• task of manually correcting any mistranslations can be performed in parallel
volume of digital information > volume of information that aid-workers collect
cloud-based and automated solutions to language processing

SURPRISE LANGUAGES: WHAT MADE HAITI DIFFERENT?
➤ At first->no publicly available MT engine existed for Kreyo`l.
➤ there was a surprising amount of data for Kreyo`l
➤ the language is reduced morphologically-> easier for SMT
growth of the Web work that was done in the DIPLOMAT and NESPOLE! projects at CMU
Morphological richness -> data sparsity problem, reducing the quality of the result

PROBLEMS WITH KREYO`L
➤ “young” as a written language -> inconsistencies in the orthography -> increases data sparseness and noise.
➤ multiple registers in its written form
➤ the first person pronoun->mwen(high register) -> m’(low register) . Can be written attached or with space.
➤ the first person possessive is also mwen -> written following the word that is possessed .can be written as ’m, and can be attached to the word or delimited by a space.
➤ Both m’ and ’m appear in some texts as just m.
“high” register that uses full forms for pronouns and a set of function
words
low” register that corresponds more closely to its spoken form

➤ writers of Kreyo`l use a large number of abbreviated forms -> a kind of shorthand
➤ ave`n can be used to represent ave`k nou, mandem can be used for mande mwen
➤ number of alternations and multiway ambiguities-> increases the level of noise and data sparsity

RESEARCH AREAS TO COUNTER DATA SPARSITY
➤ Crowdsourcing Repairing and evaluation
Active Crowd Translation
Translating content, generating new data
➤ Tapping non-traditional sources Translating content, generating new data
Monolingual sources of data
Field data from linguists
Dictionary bootstraps and backoffs
Mining comparable sources of data
➤ Novel ways of countering data sparsity Systematizing data cleaning heuristics
make source look more like the target (or vice versa)

➤ Strategies to systematically deal with complex morphology discriminative lexicons
sub-word alignment strategies
learning the morphological variants in a language
using off-the-shelf morphological tools, e.g., Morfessor
➤ Use syntax or linguistic knowledge in the translation task

THE MT CRISIS COOKBOOK
➤ vocabulary and data should be centred on relief work ,medical interactions, and communicating with the affected populations
➤ no data be thrown out
➤
➤ Outline of the Book 1. content that would be most useful in crisis situations.
2. infrastructure to support relief workers, aid agencies, and the affected population
relief-centric vocabulary, phrases, sentences
in some common “source” language,
in Haiti, an SMS messaging infrastructure integrated into a crowd-sourced translation infrastructure

COOKBOOK DATA
➤ Where There is No Doctor
➤ CMU Medical Domain Phrases, Sentences, and Glossary – Collected under the jointly NSF/EU funded NESPOLE! and DIPLOMAT projects
➤ Anonymized Crisis-related SMS Messages – Relief-related SMS messages
➤ Red Cross Emergency Multilingual Phrasebook
➤ Emergency and Crisis Communication Vocabulary
➤ High Frequency Wikipedia Disaster Content

COOKBOOK INFRASTRUCTURE
➤ A crowd sourced microtasking infrastructure to translate and route messages from the field
➤ Integration of the APIs for the publicly available MT services, ->Microsoft Translator and Google Translate, into the microtasking and messaging infrastructure
➤ A smart phone app that acts as a crisis Translation Memory, populated with Cookbook content as it becomes available

A MODEL FOR BUILDING MT FOR THE SEVERELY UNDER-RESOURCED LANGUAGES
➤ The Hmong Languages : from Southern China into Southeast Asia, with scattered populations in Vietnam and Laos.
➤ The Vietnam War->Spread the population (300,000 in the United States, and lesser numbers elsewhere)
➤ Hmong dialects spoken in the United States
White Hmong (in native orthography, Hmoob Daw)
Green Hmong (Moob Njua, sometimes Blue Hmong)

➤ fairly reduced morphology can help counter data sparsity for MT
➤ very rich classifier system, which increases sparsity:Hmong has approximately 70 nominal classes.
➤ Each noun in Hmong has a classifier->generally used in discourse with the nouns they attach to
➤ to learn the correct word alignments->learn that each noun (mostly) co-occurs with a specific classifier, thus aligning a or the with that classifier.
WHITE HMONG

➤ aligner must also recognise the contexts where the classifiers are used in Hmong but the equivalent determiners are not used in English (e.g., with quantifiers)
➤ represent semantic classes->not necessarily 1:1 correspondences between each noun and each classifier; a different classifier can be used if the context requires it (e.g., the meaning of mov can alternate between ‘meal’ and ‘rice’ depending on the classifier used with it)

THE HUNT FOR DATA
➤ exceptionally difficult to find data in Hmong
➤ not the official language of any government or country
➤ there are also no readily available corpora in the language, neither bilingual nor mono- lingual
➤ resources gathered through engagement with the community, and off the Web
➤ first Bible
➤ Hmong dictionary at HmongDictionary.com (6000 words)
➤ set of parallel sentences used in classroom instruction (3200 sentences)
➤ set of phrases used on a mobile phone app for Hmong (300 phrases)
still <5000 bilingual sentences/translation units

➤ common source of data for MT is the Web
➤ BUT :no search engine indexes the language, making it difficult to query to find pages in the language
Notable efforts by Scannell and colleagues ->collect monolingual content for many SURLs (to date Scannell has collected corpora for over 1,000 languages)
To locate data ->finding a few high quality Hmong pages on the Web, ->via existing search engines using very simple and unique Hmong strings, namely, xov xwm hmoob, which means ‘Hmong
news’, and dab neeg hmoob, which means ’Stories of the Hmong people’.
identified additional common n-gram sequences (1-4 grams) -> used to do large-scale queries against the Bing index
approximately 16K pages that likely contained Hmong data

➤ small number of college students
➤ Review the pages and verify that they were in fact in Hmong-> monolingual data in Hmong that could be useful for English>Hmong system
➤ Identify additional pages on the relevant sites that might be source English pages ->parallel training sentences crucial for developing MT
➤ Identifying parallel pages ->simple STRAND-like pattern matching,
➤Result:16K pages into -> 2,700 Hmong pages and documents, of which 1,000 were parallel with pages and documents in English. core training set of over 30,000 sentences/600,000 words.
➤To facilitate the engagement with the Hmong Community -> newly developed Microsoft Translator Hub infrastructure.

DESCRIPTION OF THE DATA AND TRAINING PIPELINE
1. Extract Data from native file formats (TET tool -> for Pdf and custom tools -> for html) -> all converted to Unicode.
2. Extracting sentences :saved in files, one sentence per line
3. Sentence alignment :derivative of the Moore aligner
4. Data cleaning :to remove noise, badly encoded characters, HTML tags, any alignments that showed a highly skewed ratio between source and ,overly long sentences
5. Dev/Test/Train :1500 sentences extracted from the training data for dev and test, with 1000 for dev, and 500 for test.
6. Training models :custom-built phrasal and tree-to-string (T2S) systemsEnglish-Hmong -> source-side parser and T2S (4-gram LM over all monolingual data, including the
target side of the parallel data )
Hmong-English->a phrasal system (trained a 4-gram LM .also trained a second 5-gram English language model trained over a much larger corpus of English)

T2S

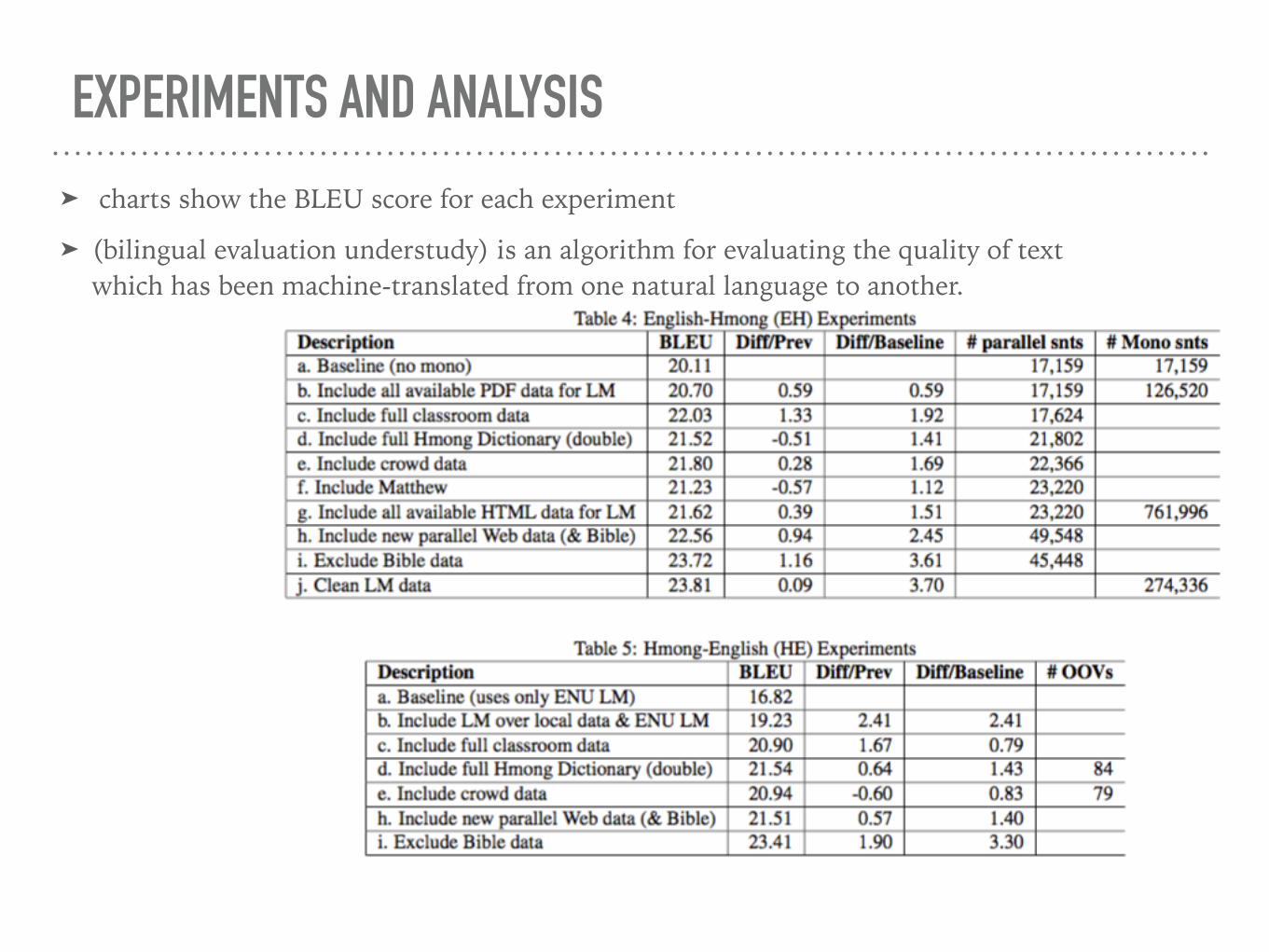
EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

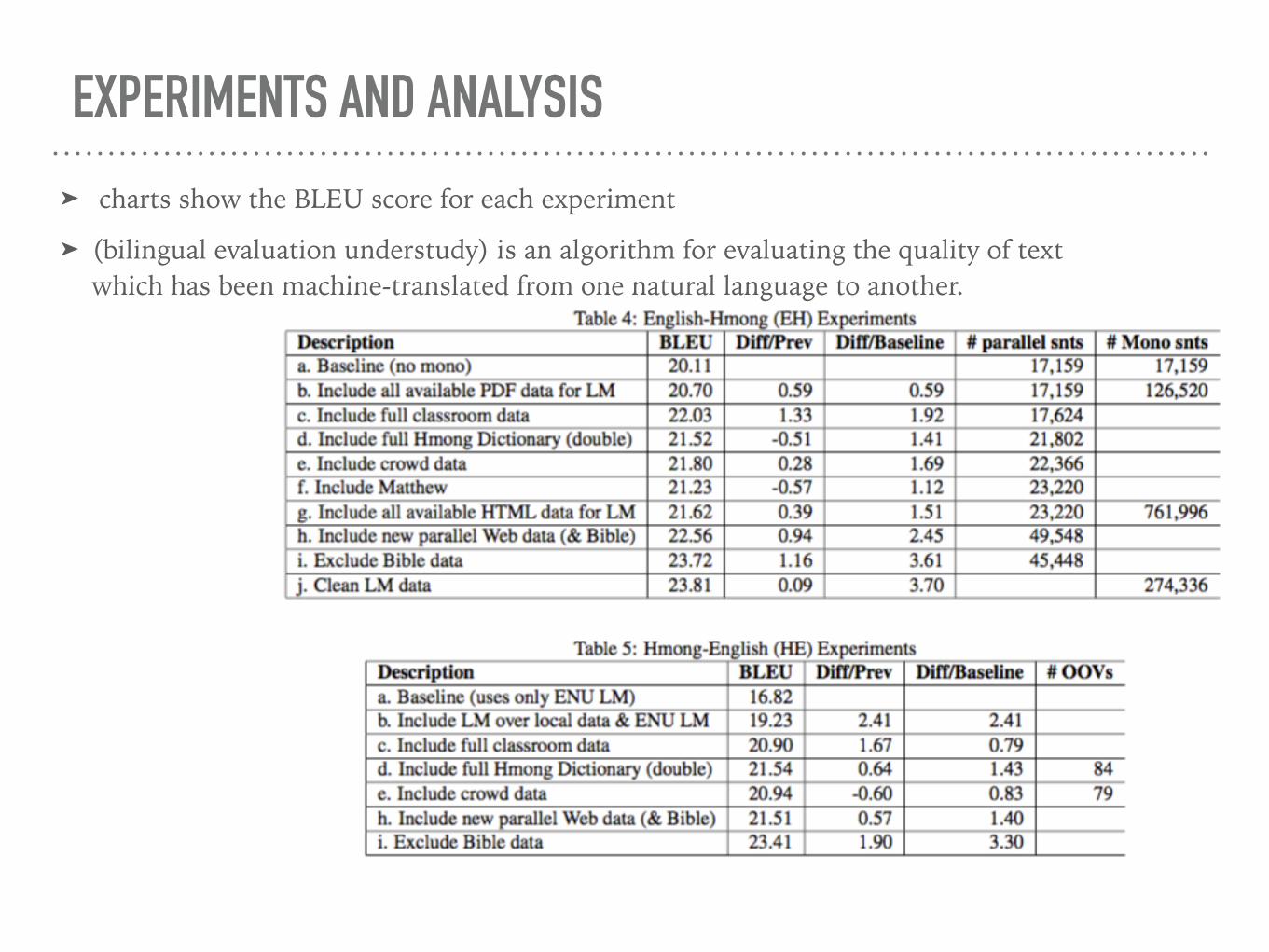
EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(a)the set of data first provided by the Hmong community.small subset of parallel data from the Web. For English-Hmong (EH), no monolingual data . For Hmong-English (HE), the baseline used only our default English LM

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(b) For EH, we added all monolingual Hmong PDF data that we had crawled. For HE, built a second LM over the English side of the parallel data

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(c)The classroom data of approximately 3,000 sen- tences was added.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(d)The entirety of the Hmong dictionary was added ->EH dropped by about 1/2 point,and HE increased by 0.64.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(e)first pass of crowd collected data was added, consisting of 500+ sentences.
EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(f)(EH only) We included the Matthew chapter of the Bible as a test of the Bible data.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(g)all monolingual Hmong data that had been collected.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(h)All parallel Web data was included, as was the Bible data

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
(i)After some analysis as to the quality of the aligned text from the Bible, it was decided to exclude the data from training.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

EXPERIMENTS AND ANALYSIS ➤ charts show the BLEU score for each experiment
➤ (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.

THE HMONG COMMUNITY ENGAGEMENT
➤ community provides a means to access data by reviewing it, and means for generating it
➤ crucial for the eventual uptake of the results of project
➤ involves two critical groups In
community of native speakers who are willing to spend time
on the project
community leader(s) who can engage with and motivate the
community
In Hmoung through leaders:
• college students
• school teachers
• school administrators,
• business people
• elders
• high school students
COMMUNITY AND CROWD ENGAGEMENT AFTER RELEASE
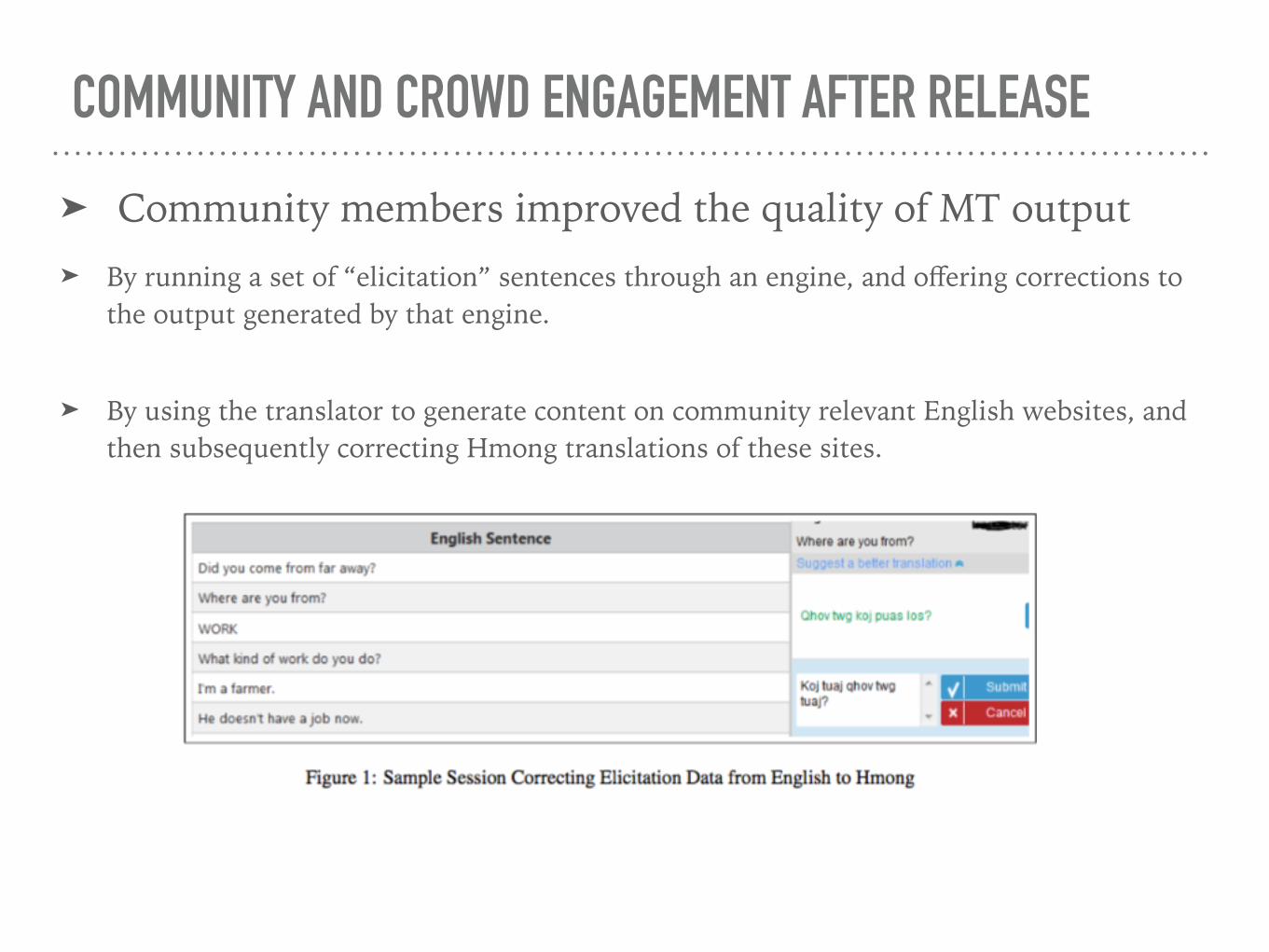
➤ Community members improved the quality of MT output
➤ By running a set of “elicitation” sentences through an engine, and offering corrections to the output generated by that engine.
➤ By using the translator to generate content on community relevant English websites, and then subsequently correcting Hmong translations of these sites.

THE EFFECTS OF THE HMONG TRANSLATOR WITHIN THE COMMUNITY
➤ Hmong translator has been widely publicised throughout the community
➤ Community members continue to add Hmong translations to English only sites and engage with other community members to repair these translations.
➤ The Fresno Unified and Lake Washington School Districts have adopted the translator on some or all of their sites
➤ California State University Fresno is planning on using the translator to localise content for their Web sites
➤ All the data has been or will be added into train- ing data to improve the Hmong translators

CONCLUSION
➤ MT is an important technology in crisis events
➤ provide first pass translations into a majority language and routing them to appropriate aid agencies.
➤ Increase the speed of help
➤ To ensure that MT is a standard tool ->Crisis Cookbook, the contents could be translated immediately after a crisis event takes place.
➤ to build a statistical machine translation system for a severely under- resourced language-> close collaboration with the native speaking language community, and active participation is needed
➤ classifier- noun data sparsity problem in Hmong still needs improvements .

Questions ?