cern it department ch-1211 genève 23 switzerland t tape-dev update castor f2f meeting, 14/10/09...
TRANSCRIPT

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Tape-dev update
Castor F2F meeting, 14/10/09
Nicola Bessone, German Cancio, Steven Murray, Giulia Taurelli

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Slide 2
DriveScheduler
TapeServer
DiskServerDisk
ServerDiskServer
1 2
1. Stager requests a drive2. Drive is allocated3. Data is transferred to/from disk/tape based on file list given by stager
3
3
Legend
Data
Control messages
Host
StagerStager
Stager
Current Architecture
1 data file=
1 tape file
Reminder – last F2F

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
StagerStager
New Architecture
Slide 3
DriveScheduler
Tape Server
DiskServerDisk
ServerDiskServer
Stager
Legend
Data to be stored
Control messages
Host
Server process(es)
Tape Gateway
Tape Aggregator
n data files=
1 tape file
The tape gateway will replace RTCPClientD
The tape gateway will be stateless
The tape aggregator will wrap RTCPD
Reminder – last F2F

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
New software Goals: code refresh (unmaintained/unknown), component
reuse (Castor C++ / DB framework), improved (DB) consistency, enhanced stability -> performance, ground work for future new tape format (block-based metadata)
2 new daemons developed:
tapegatewayd (on the stager) -> replaces rtcpclientd / recaller / migrator.
aggregatord (on the tape server) -> acts as a proxy or bridge between rtcpd and tapegatewayd. (No new tape format yet)
Rewritten migHunter
Transactional handling (at stager DB level) of new migration candidates
[email protected] Slide 4

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Status software has been installed on CERN’s stress test instance (ITDC)
~4w ago, started end-to-end tests and stress tests (~20 tape servers, ~25 disk servers)
So far, significant improvements in terms of stability (no software-related tape unmounts during migrations and recalls)
However: testing not completed yet, many issues found on the way unveiled by the new software
See next slides
New migHunter to be released ASAP (2.1.9-2 if tests with rtcpclientd ok)
Tape gateway + aggregator to be released in 2.1.9-x as optional component - not part of the default deployment, and there are no dependencies on it from the rest of the CASTOR software.
[email protected] Slide 5

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Test findings (1) Performance degradations during migrations
Already observed in production, but difficult to trace down as long-lived migration streams rarely occur (cf savannah)
Found to be a misconfiguration in the rtcpd / syslog config, causing log messages to be generated growing @ O(n*n) ,, n=migrated files
Another problem to be understood is stager DB time for disk server/ fs selection, which tends to grow during migration lifetime. Currently not limited by this but could become a bottleneck
Slide 6

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
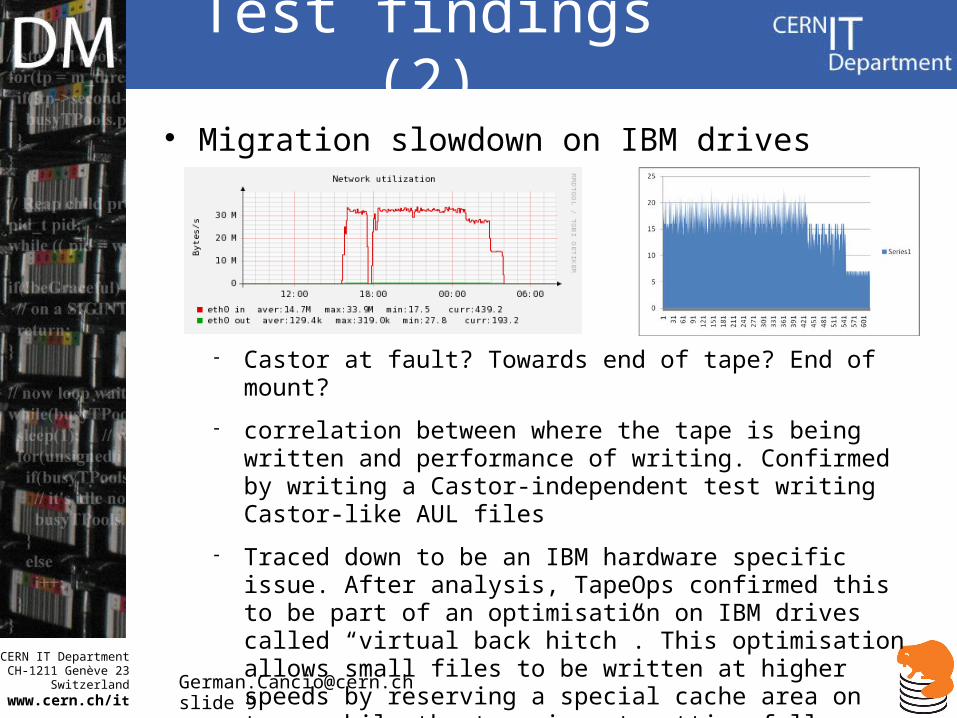
Test findings (2) Migration slowdown on IBM drives
Castor at fault? Towards end of tape? End of mount?
[email protected] Slide 7

Tpsrv150, 23/9/09
Tpsrv151, 23/9/09
Tpsrv001, 23/9/09
Tpsrv235, 23/9/09
Tpsrv204, 23/9/09
Tpsrv203, 24/9/09
Tpsrv204, 24/9/09
CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Test findings (2) Migration slowdown on IBM drives
Castor at fault? Towards end of tape? End of mount?
correlation between where the tape is being written and performance of writing. Confirmed by writing a Castor-independent test writing Castor-like AUL files
Traced down to be an IBM hardware specific issue. After analysis, TapeOps confirmed this to be part of an optimisation on IBM drives called “virtual back hitch”. This optimisation allows small files to be written at higher speeds by reserving a special cache area on tape, while the tape is not getting full.
NVC can be switched off, but performance drops to ~15MB/[email protected] slide 9

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Test findings (3) Under (yet) unknown circumstances, IBM tapes hit end-of-
tape at 10-30% less than their nominal capacity. Read performance on these tapes is also suboptimal
Seems to be related to a suboptimal working of NVC / virtual back hitch
Does not occur when NVC is switched off
To be reported to IBM
[email protected] Slide 10
reading tape with urandom-generated 100MB files to /dev/null using dd (X: seconds, Y: MB/s throughput). The tape contains 8222 AUL files of 100M each

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Test findings (4) Suboptimal file placement strategy on recalls?
which apparently causes interference
Recall using default Castor file placement
Same recall using 2 dedicated disk servers per tape server
[email protected] Slide 11
3 tape servers recalling on 7 disk servers (all files distributed over all disk servers/file systems
3 tape and 6 disk servers (all filesystems), same as above yields ~310-320 MB/s

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Test findings (5) Recall performance limited by central element
(gateway/stager/..?)
a central limitation which prevents performance to go higher than a threshold, even if distinct pools are being used
[email protected] Slide 12
c2itdc total throughput
c2itdc/ pool 1
c2itdc / pool 2
shortly after 21:30, the tape recall on pool 1finished. recall performance of the second pool goes up from then on, and that the total recall performance (both disk pools) stays at ~255MB/s. No DB / network contention.

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
Test findings (7) Performance degradation on recalls on new tape server HW
observed that new-generation tape servers (Dell 4core) are capable to read out data from tape at a higher than rtcpd is capable to process it. This eventually causes the attached drives to stall. It happens equally if an IBM or an STK drive is attached. The stalling problem does not happen on all other older servers (elonex 2core, clustervision) as there, the drives read out at lower speeds.
Traced down (yesterday..) to a too verbose logging of the tape positioning executable (posovl) when using the new syslog-based DLF.
[email protected] Slide 13
,

CERN IT DepartmentCH-1211 Genève 23
Switzerlandwww.cern.ch/it
“tape” bug fixes in 2.1.9
“tape” = repack, VDQM, VMGR, rcpclientd, rtcpd, taped, and the new components
2.1.9-0
https://twiki.cern.ch/twiki/bin/view/DataManagement/CastorReleasePlan21900
2.1.9-2 (planned)
https://twiki.cern.ch/twiki/bin/view/DataManagement/CastorReleasePlan21902
2.1.9-X
https://twiki.cern.ch/twiki/bin/view/DataManagement/CastorTapeReleasePlan219X
[email protected] Slide 14