compresión de la información de vídeo 3. compresión ... -...
TRANSCRIPT

Compresión de la información de vídeo
1
3. Compresión de la información de vídeo
3.1. IntroducciónLa necesidad de la compresión en vídeo digital aparece en el momento que se tratan las
secuencias de imágenes como señales digitales. El problema principal que tiene el manejo delvídeo digital es la cantidad de bits que aparecen al realizar la codificación. En la siguiente tabla,se muestran varios ejemplos. En ella, se considera la digitalización de una señal de televisión de625 líneas a una velocidad de 25 imágenes por segundo.
EstándarFrecuencia
muestreo (Y)(MHz)
Frecuenciamuestreo
(CR,CB) (MHz)
Datos 1 seg.almacenados(Mb/s) (*)
Datos 1 seg.parte activa(Mb/s) (**)
Capacidad dedisco 10 GB
(mm:ss)
4:4:44:2:24:1:1
13.513.513.5
13.56.75
3.375
324216162
248.8165.9124.4
5m 22s8m 02s10m 43s
(*).- Cantidad de datos que se necesitan para almacenar 1 segundo de señal de televisión digitalizada a la frecuenciade muestreo real.(**).- Cantidad de datos que se necesitan para almacenar 1 segundo de señal de televisión, eliminando todo aquelloque no es directamente imagen (intervalos de sincronismo...).
Si nos centramos en el estándar 4:2:2 definido por la recomendación ITU-R BT.601,puede observarse que, sin aplicar compresión, en un disco duro con una capacidad de 10GigaBytes podemos almacenar algo más de ocho minutos de imágenes. Y esto considerandoexclusivamente la información de la imagen, y eliminando las partes de la señal dedicadas a lossincronismos.
Si ahora aplicamos sobre esta información distintos factores de compresión, veremos quela eficiencia de almacenamiento aumenta considerablemente. Así para el estándar 4:2:2 condiferentes factores de compresión se obtendrían los resultados de esta tabla:
Compresión Tamaño parte activa (Mb/s) Capacidad en disco 10GB
1:12:1
3.3:15:1
10:150:1
165.983.050.333.216.63.3
8m 02s16m 04s26m 30s40m 10s
1h 20m 20s6h 41m 40s
En el caso de la transmisión o distribución de señales por cualquier medio físico(radioenlaces, redes de banda ancha, satélite, cable...) Si consideramos que una transmisióndigital de un canal telefónico de voz ocupa 64 kb/s, en el ancho de banda espectral en el que se

Vídeo Digital
2
enviaría un canal de televisión en formato 4:2:2 sin comprimir se podrían enviar del orden de2590 canales telefónicos.
Puesto que, tanto el espacio en disco por minuto como el ancho de banda radioeléctricoson recursos limitados, se hace conveniente aplicar factores de compresión para la transmisión,para el almacenamiento, e incluso para la producción de programas. Una vez comprimida lainformación será más sencillo almacenarla o transmitirla.
Así pues, la compresión, por un lado, es un factor económico ya que reduce el costo dela transmisión, o distribución de señales. Dado un medio de transmisión concreto con undeterminado coste de amortización, cuanto menor sea el ancho de banda de los canales atransmitir, más canales estarán disponibles, y más económico resultará cada canal.
Además, en determinadas aplicaciones, el factor de compresión va a venir impuesto porla velocidad binaria del canal de transmisión disponible. Este es el caso, por ejemplo, de lavideoconferencia. En la videoconferencia, la información de vídeo digital se manda a través deun canal telefónico disponiendose de una velocidad binaria de 64kb/s. En este caso, el factor decompresión hemos de ajustarlo a esta restricción, aún a costa, como veremos, de la calidad, yaque lo esencial es la disponibilidad del servicio.
Todo proceso de compresión, para ser útil, debe llevar asociado un proceso dedescompresión posterior, por el cual se recupera el tren de datos original a partir de los datoscomprimidos. Para ello se seguirá el orden inverso al de la compresión.
3.2. La compresión de la señal de videoEn el ámbito digital, para almacenar o transmitir información se utiliza un tren de datos.
Para que sea posible la compresión de este tren de datos, es necesario que en él exista, ademásde información real, información redundante. Esta información redundante podremos eliminarladurante el proceso de compresión, y posteriormente reconstruirla en el proceso de descompresióna partir de la información real. La información real en cambio, será imprescindible para recuperarlos datos originales de forma correcta, de modo que no es posible obviarla.
La misión de un sistema de compresión consiste en detectar y eliminar la informaciónredundante, codificando solamente la información útil. Por lo tanto, podemos considerar lacompresión digital como un procedimiento, matemático en general, que rebaja el flujo binariode un tren de datos, en base a la eliminación de información redundante y a una codificacióninteligente de la información real.
La compresión, a partir de ciertos valores influye negativamente en la calidad del vídeo.Por eso, debe utilizarse un algoritmo y un factor de compresión que minimicen dichadegradación. Según estas consideraciones, podemos clasificar la compresión en tres tiposdiferentes: compresión sin pérdidas, compresión subjetivamente sin pérdidas y compresiónsubjetivamente con pérdidas. Éstas, las vamos a tratar en los próximos párrafos.

Compresión de la información de vídeo
3
En la compresión sin pérdidas, la información original se recupera en su integridaddespués del proceso de compresión-descompresión. Este tipo es muy utilizado para la compresiónde datos informáticos. Dependiendo del tipo de archivo, este modo tiene niveles de compresiónvariables. Con algunos archivos puede llegar a compresiones de 70:1, pero en otros casos, no esposible comprimir ya que el archivo comprimido podría ser incluso de mayor tamaño que eloriginal.
Por otra parte, con la compresión subjetivamente sin pérdidas, en el proceso decompresión-descompresión, no se recupera absolutamente toda la información original, pero elsistema receptor, como por ejemplo el sistema visual humano, no detecta las diferencias. En elámbito de la compresión digital de sonido e imagen, existe una norma general y es que “lo queel ojo no ve, o lo que el oído no oye, no se codifica”. Este tipo de compresión, es el que se utilizaen vídeo digital, y es el que más nos interesa por su mantenimiento de la calidad, consiguiendofactores de compresión interesantes.
Finalmente, en la compresión subjetivamente con pérdidas, durante el proceso decompresión-descompresión se degrada significativamente la calidad de la información, pero elusuario lo tolera en beneficio del servicio recibido. Este tipo de compresión, lleva asociadosgrandes factores de compresión y se utiliza generalmente en multimedia; en los sistemas devideoconferencia como se dijo anteriormente; en sistemas de vigilancia y seguridad; en consultasde video y en edición fuera de línea; es decir, procesos todos ellos en los que la calidad no es unfactor importante, sino el mantenimiento del servicio con un coste razonable.
Dentro de todas estas categorías existen gran cantidad de técnicas de compresióndependiendo de la aplicación para la que se utilizan. En el caso del vídeo, el número de métodosse dispara; y actualmente, es uno de los campos de mayor investigación dentro del mundo deltratamiento digital de las imágenes.
Algunas técnicas de compresión se han conseguido, simplemente atendiendo a lasdiferentes sensibilidades que tiene el ojo humano frente al brillo y a los colores. Esta posibilidadde compresión, viene expresada en la recomendación ITU-R BT.601 cuando habla de las distintasfamilias que se desarrollan bajo esta norma (4:4:4, 4:2:2, 4:1:1, 4:2:0, ...), cada una de ellas, condiferentes flujos binarios.
El conocido formato de video 4:4:4 utiliza la misma frecuencia de muestreo para lasseñales de color que para la de luminancia. En el formato 4:2:2, en cambio, la frecuencia demuestreo de las señales de color pasa a ser la mitad. Sin embargo, esta forma de compresión nodegrada subjetivamente la calidad, sino que este formato se ajusta más a las distintassensibilidades del ojo.
El sistema 4:4:4 se utiliza, no porque ofrezca una mayor calidad subjetiva, sino porquelas operaciones de tratamiento digital de imágenes, u otras operaciones como el croma-key (llavede color), en el que se conmuta de imagen a partir de la información del color de los píxeles, serealiza con mucha más precisión.

Vídeo Digital
4
El paso del formato 4:2:2 al 4:1:1 o al 4:2:0 sí supone eliminar información sensible alojo. Esta información que se elimina, no es en este caso redundante, y no puede recuperarse enun hipotético proceso de descompresión. Por ello esta compresión se denomina con pérdidas, odegradante.
Otros métodos de compresión que se han establecido como estándar por sus prestacionesy su amplia aplicación son los métodos denominados MPEG. Las siglas MPEG vienen de(Motion Pictures Expert Group) nombre de un grupo de expertos común entre la ISO(International Standards Organization) y la IEC (International Electrotechnical committe). Elfundamento básico de la compresión MPEG es el siguiente:
a)- Se busca una representación válida de la imagen que concentre la información en unapequeña parte de la descripción.
b)- Se cuantifican los elementos de dicha representación de modo que se discretizan susposibles valores.
c)- A cada nivel de cuantificación se le asigna un código de bits.
Concretamente el método MPEG-2 se utiliza en todos los ámbitos de la televisión digital.Este método, que será el que estudiemos más profundamente en este tema, tiene doscaracterísticas muy importantes para su aplicación en video digital. La primera es que permiteutilizar múltiples factores de compresión en función de las necesidades de la aplicación. Lasegunda es que las pérdidas de calidad al comprimir son relativamente bajas. Incluso se hademostrado que la compresión MPEG-2 con factor 1:3,3 puede considerarse comosubjetivamente sin pérdidas. Esto la hace apropiada para aplicaciones en las que se quieramantener la posibilidad de multigeneración, es decir, efectuar sucesivamente procesos decompresión y descompresión sin la aparición de defectos de imagen, o artefactos.
A continuación pueden verse algunos ejemplos de utilización de la compresión, referidosa las velocidades binarias utilizadas en algunos modos de transmisión:
- Para comunicaciones dentro de un estudio se utilizan enlaces a 50Mb/s. En este punto debemosobservar que el flujo binario resultante de la parte activa del formato 4:2:2 es de 165,9Mb/s.; y si se aplica el factor 1:3,3 a este flujo obtenemos 50,3 Mb/s, con lo que lastransmisiones a 50 Mb/s podemos considerarlas sin pérdidas.
- También se utilizan 50Mb/s para comunicaciones mediante fibra óptica.
- Para comunicaciones vía satélite es común utilizar enlaces a 34 Mb/s, aunque a veces tambiénse utilizan 50Mb/s.

Compresión de la información de vídeo
5
- En los casos de distribución de la señal vía radio, se aplican factores de compresión másgrandes según el canal disponible. Por ejemplo, en los satélites de distribución lo normales utilizar un factor de compresión que permite enviar de 4 a 7 canales digitales en elmismo ancho de banda que ocuparía uno analógico.
- En la difusión de televisión digital, el flujo binario es diferente, según la calidad requerida. Enla siguiente tabla se muestran los distintos niveles de calidad y sus flujos binariosrecomendados:
Calidad - Definición Flujo binario
HDTV (alta definición)EDTV (Calidad de estudio ITU-R BT.601)
SDTV (Calidad estándar -PAL / SECAM / NTSC)LDTV (Calidad VHS)
15-30 Mb/s6-12 Mb/s3-6 Mb/s
1.5-3 Mb/s
3.3. La redundancia en la información de videoLos algoritmos de compresión en vídeo digital se basan, como hemos visto en los
apartados anteriores, en la existencia de información redundante a lo largo de cualquiersecuencia. Dentro de la corriente de datos que supone una comunicación de vídeo digitalpodemos detectar una parte de los datos que corresponden a información real, que será necesariapara reproducir dicha secuencia; e información redundante, que no proporcionará informaciónal decodificador y que por tanto podemos eliminar.
En términos de compresión, sería muy beneficioso minimizar al máximo la informaciónredundante de forma que reduzcamos el flujo binario sin perder la información necesaria pararecuperar una secuencia. Sin embargo, en términos de seguridad en la transmisión, hemos dedecir que la redundancia es positiva, ya que proporciona cierta protección ante cortes de lainformación que se está transmitiendo.
La información redundante que aparece en una secuencia de vídeo digital podemosconsiderarla de tres tipos: redundancia espacial, redundancia temporal y redundancia estadística.A cada una de ellas se les asocian diferentes procedimientos mediante los cuales se minimizadicha redundancia aumentando la compresión.

Vídeo Digital
6
Figura 1. Redundancia espacial. Zonasamplias de píxeles iguales.
Figura 2. Redundancia temporal: cambiomínimo de fotograma en fotograma.
3.3.1. Redundancia espacial.La redundancia espacial tiene lugar dentro
de cada fotograma. Ésta, viene asociada al hechode que la naturaleza está llena de objetos sólidoscon superficies y texturas uniformes; losdecorados, los paisajes, e incluso los rostros novarían significativamente la información de pixela pixel, sino que encontraremos generalmentegrandes superficies sin variación.
El hecho de que varios píxeles adyacentessean prácticamente iguales nos va a permitir, envez de transmitirlos todos o almacenarlos todos, transmitir un píxel representativo del conjunto,y las diferencias de cada uno respecto a éste. Dichas diferencias, por ser generalmente pequeñas,pueden codificarse con menos bits.
Uno de los ejemplos de compresión aprovechando la redundancia espacial son lacodificación de cadenas largas de datos iguales (RLC - Run Lenght Code, codificación delongitudes de recorrido). En el caso de que se detecte en el tren binario una cadena larga dedígitos que se repiten, en lugar de codificar cada dígito, parece una buena técnica codificar cuáles el dígito de que se trata, y cuantas veces se repite. Un ejemplo de dispositivo que utiliza estatécnica es el fax. Esta técnica se utiliza habitualmente en lo que llamaremos codificación“intracuadro”, es decir dentro de cada fotograma.
3.3.2. Redundancia temporal.La redundancia temporal viene dada por
la relación entre los píxeles homólogos deimágenes sucesivas. Esta redundancia apareceporque la vida no cambia significativamente defotograma a fotograma. Evidentemente, en 40ms.suponiendo una frecuencia de cuadro de 25 f/s.no ocurren grandes cosas desde el punto de vistadel espectador. Lo que el espectador espera alcontemplar una secuencia de vídeo, es unacontinuidad en la acción, y no un cambiocontinuo en los planos.
Así, en la mayoría de los casos podemosafirmar que un fotograma va a ser similar alsiguiente o al anterior. Si comparamos los
Compresión de la información de vídeo
7
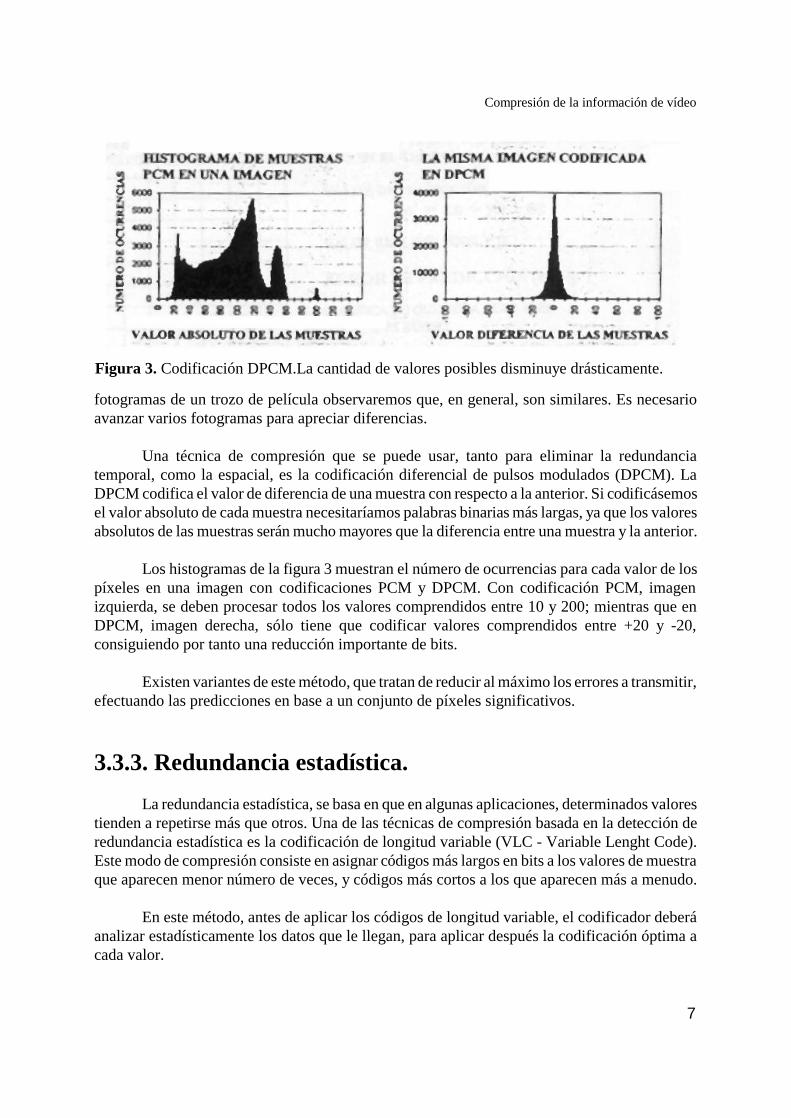
Figura 3. Codificación DPCM.La cantidad de valores posibles disminuye drásticamente.
fotogramas de un trozo de película observaremos que, en general, son similares. Es necesarioavanzar varios fotogramas para apreciar diferencias.
Una técnica de compresión que se puede usar, tanto para eliminar la redundanciatemporal, como la espacial, es la codificación diferencial de pulsos modulados (DPCM). LaDPCM codifica el valor de diferencia de una muestra con respecto a la anterior. Si codificásemosel valor absoluto de cada muestra necesitaríamos palabras binarias más largas, ya que los valoresabsolutos de las muestras serán mucho mayores que la diferencia entre una muestra y la anterior.
Los histogramas de la figura 3 muestran el número de ocurrencias para cada valor de lospíxeles en una imagen con codificaciones PCM y DPCM. Con codificación PCM, imagenizquierda, se deben procesar todos los valores comprendidos entre 10 y 200; mientras que enDPCM, imagen derecha, sólo tiene que codificar valores comprendidos entre +20 y -20,consiguiendo por tanto una reducción importante de bits.
Existen variantes de este método, que tratan de reducir al máximo los errores a transmitir,efectuando las predicciones en base a un conjunto de píxeles significativos.
3.3.3. Redundancia estadística.La redundancia estadística, se basa en que en algunas aplicaciones, determinados valores
tienden a repetirse más que otros. Una de las técnicas de compresión basada en la detección deredundancia estadística es la codificación de longitud variable (VLC - Variable Lenght Code).Este modo de compresión consiste en asignar códigos más largos en bits a los valores de muestraque aparecen menor número de veces, y códigos más cortos a los que aparecen más a menudo.
En este método, antes de aplicar los códigos de longitud variable, el codificador deberáanalizar estadísticamente los datos que le llegan, para aplicar después la codificación óptima acada valor.

Vídeo Digital
8
El ejemplo de compresión VLC más utilizado es quizá el código Huffman. Su ejecuciónes un poco compleja, pero la idea es la misma: asignar cadenas de bits más cortas a los códigosmás frecuentes y más largas a los menos frecuentes.
El método de ejecución es el siguiente:
a)- Se estudia el número de apariciones de cada símbolo, o su probabilidad de aparición y seconfecciona una tabla con todos ellos.
b)- Se escogen los dos códigos (o grupos) que tengan menor número de apariciones, y se lesasigna a cada uno de ellos el bit 0 o 1, y se asocian como si fueran las ramas de un árbol.
c)- Se quitan los dos códigos (o grupos) anteriores y se abre un nuevo grupo cuyo valor deapariciones sea la suma de estos.
d)- Se repiten los pasos b, c, y d hasta que sólo quede un grupo.
f)- Para asignar a cada símbolo un código, se recorre el árbol desde el tronco principal hasta lasramas en las que está cada símbolo, obteniendo su código Huffman para la aplicaciónconcreta que se ha estudiado.
Es obvio que los mismos símbolos pueden tener distintos códigos Huffman dependiendode la aplicación que se trate; ya que en distintas aplicaciones, las probabilidades de aparición delos símbolos puede ser diferente.
3.4. Métodos de compresión por transformación: laDCT
Existe una gran variedad de métodos de compresión que se basan en la detección de laredundancia en un dominio transformado. Esto se realiza transformando la señal desde el ámbitotemporal o espacial al ámbito de las frecuencias.
En el dominio espacio-temporal, la probabilidad de aparición de todos los valores de lospíxeles es constante, y por tanto es difícil reducir el número de datos, en base a una redundanciaestadística. En cambio, en el dominio de la frecuencia no se tiene una distribución uniforme delespectro. En general, las altas frecuencias aparecen menos veces, ya que es más habitualencontrar cambios suaves y grandes superficies monocolor que grandes contrastes. Los contrastesgrandes se sitúan en los contornos de los objetos, que en general son menos abundantes. Por esopodemos decir que existe mucho más contenido en las bajas frecuencias que en las altas. Estehecho ya se comprobó en las prácticas 3 y 4 correspondientes al tema 1.
Otro aspecto que hemos de tener en cuenta, es que nuestro ojo atiende más a las grandessuperficies, por tanto a las bajas frecuencias, que a los detalles pequeños que generarán valores

Compresión de la información de vídeo
9
DCT(x[n]) C[u] α(u) ·N1
n0x[n] · cos (2n1) π u
2N
α(u) | u0 1N
α(u) | u0 2N
DCT 1(C[u]) x[n] N1
u0α(u) ·C[u] · cos (2n1) π u
2N
de alta frecuencia. Los métodos de compresión por transformación se aprovechan de estacircunstancia para reducir el número de datos a codificar.
La transformada discreta del coseno es la herramienta de transformación más utilizadapor los métodos de compresión intracuadro. Esta transformada, que aprovecha la existencia deredundancia espacial en las imágenes y la encontraremos en los estándares JPEG, MJPEG y susderivados, y en la familia MPEG.
3.4.1. Cálculo de la DCT unidimensionalLa DCT es una transformación matemática que convierte una secuencia de muestras de
N valores, en otra secuencia del mismo tamaño N cuyos valores, como ahora veremos,representan una distribución de frecuencias La expresión de la transformada discreta del coseno(DCT) unidimensional correspondiente a una secuencia de números x[n] de tamaño N es lasiguiente.
En esta expresión, la variable “u” de salida, que representa el índice del coeficiente quese está calculando, adopta los valores comprendidos entre 0 y N-1, de manera que la DCT resultaser una secuencia también de tamaño N. Asimismo, el valor de “n” representa a los índices decada elemento de la secuencia que se quiere transformar.
El parámetro α(u) tiene dos valores posibles, que son estos:
Existen otras formas de escribir esta expresión con valores derivados de este α(u), perollevan a resultados equivalentes. Los N valores C[u], obtenidos al aplicar esta transformada a lasecuencia de N valores x[n], se denominan “coeficientes” de dicha transformada.
La transformada inversa (IDCT ó DCT-1) permitirá obtener la secuencia x[n] a partir delos coeficientes transformados, y se define así.
El cálculo de la DCT que se desprende directamente de las fórmulas anteriores resultaengorroso, y cuando el número de elementos de la secuencia es alto, se impone la utilización delordenador. No obstante existen métodos de cálculo más sencillos. De todos ellos, aquí se va apresentar el llamado “método de las funciones base” porque nos permite extraer conclusionesimportantes de esta transformación.

Vídeo Digital
10
f[n] | u cos (2n1) π u2N
DCT(x[n]) C[u] α(u) ·N1
n0x[n] · f[n]|u
Figura 4. Funciones base de la DCT unidimensional.
El método de las funciones base tiene su fundamento en el hecho que, de la expresión dela DCT vista anteriormente, una vez definido el tamaño N de la secuencia a transformar, lafunción coseno tiene valores fijos. A dicha función coseno se le denomina “función base”, y paracada valor de “u” se calcula de esta forma
En esta expresión, el valor de N es, en general, conocido para cada aplicación. Porejemplo, para aplicaciones de video, el valor más usual es N=8. A partir de estas funciones base,el valor de cada C[ui] se calcularía según la siguiente expresión
Considerando la secuencia a transformar x[n] y la función base f[n] |u como vectores deN dimensiones, los C[u] resultadode la DCT resultan ser el productoescalar de estos dos vectores,afectado por el factor constanteα(u). Es conocido, que elresultado del producto escalar dedos vectores depende de losmódulos de ambos, y del cosenodel ángulo que forman, que serámáximo en el caso en que ambosvectores tengan la misma direccióny sentido.
S i se represen tangráficamente los valoresresultantes de calcular lasfunciones base para cada valor de“u” con un tamaño de secuencia deN=8, los resultados pueden verseen la figura 4.
A partir de esta figurapodemos observar que paracualquier secuencia x[n] detamaño N=8, los C[u] secalcularán a partir del productoescalar de dicha secuencia concada una de estas funciones basef[n] aquí representadas. En un

Compresión de la información de vídeo
11
C[u,v] α(u) · β(v) · M1
m0N1
n0x[m,n] · cos (2m1) π u
2M· cos (2n1) π v
2N
α(u) | u0 1M
α(u) | u0 2M
producto escalar entre dos vectores, si fijamos uno de ellos, como es el caso de cada función base,el producto escalar con cualquier vector x[n], nos da un resultado proporcional a la componenteque tiene el vector x[n] en la dirección de cada función base f[n]. Así pues, este producto serámayor cuanto más paralelos sean ambos vectores.
Según esto anterior, el coeficiente C[0] dará una referencia del nivel de continua(frecuencia f=0) de x[n]. Asimismo, el producto escalar de dicha secuencia x[n] por la funciónbase f[n]|1 resultará un C[1] mayor, cuanto más se parezcan la secuencia x[n] al vector f[n]|1; esdecir, C[1] será proporcional al contenido de frecuencia f=1/16 de la secuencia. Sucesivamente,C[2] será proporcional al contenido de la secuencia en la frecuencia f=2/16, etc...
Así pues, mediante la DCT se consigue transformar una secuencia x[n] en otra, C[u] queindica su distribución espectral
3.4.2. Generalización de la DCT bidimensionalLa DCT bidimensional es una transformación matemática que convierte una matriz
genérica de M x N valores, que en el caso de las imágenes corresponderían a niveles de brillo ocolor, en otra matriz del mismo tamaño (MxN), cuyos valores representan la distribución de lasfrecuencias. Una vez visto por encima el desarrollo de la DCT unidimensional podemos ver dela misma manera la DCT bidimensional que es la que se aplica a las imágenes, considerando cadamuestra x[m,n] como el valor del nivel de gris de un píxel.
Dada una secuencia bidimensional x[m, n] formada por una matriz de valores en la que“m” adopta los valores del conjunto (0, ... M-1) y n adopta los valores entre 0 y N-1, su DCT sedefine como sigue.
De la misma manera que antes, las variables “u” y “v” de salida adoptan los valorescomprendidos entre 0 y M-1, y entre 0 y N-1 respectivamente; de manera que la DCT resulta sertambién una matriz de tamaño MxN.
Los parámetros α(u) y β(v) tiene dos valores posibles, que son estos:

Vídeo Digital
12
f(m,n) |u,v cos (2m1) π u2M
cos (2n1) π v2N
β(u) | u0 1N
β(u) | u0 2N
x[m,n] M1
m0α(u) ·
N1
n0β(v) · C[u,v] · cos (2m1) π u
2M· cos (2n1) π v
2N
Figura 5. Representación gráfica de las funciones base dela DCT bidimensional.
Los M x N valores C[u, v], obtenidos al aplicar esta transformada a la secuencia de MxNvalores x[m, n], se denominan “coeficientes” de dicha secuencia.
La transformada inversa, IDCT ó DCT-1, permitirá obtener la secuencia x[n, m] a partirde los coeficientes transformados. Esta trasformada inversa se define como sigue:
Para el cálculo de la DCT bidimensional existe también el método basado en lasfunciones base. En este caso, las funciones base estarán compuestas por los dos cosenos que semuestran en la expresión de la DCT, uno en la dirección m y otro en la n.
En las aplicaciones decompresión de imágenesdigitales, los valores de M y Nson siempre 8. A partir de estasfunciones base, el valor de cadaC[u, v] se calcularía como si setratara del producto escalar de dosvectores: mediante la suma de losproductos entre elementoshomólogos de la función base, yde la matriz a transformar,afectado por los factores α(u) yβ(v).
Si se representan conniveles de gris los valoresresultantes de calcular lasfunciones base para cada par devalores (u, v) con un tamaño desecuencia de M=N=8, losresultados pueden verse en lafigura 5. Los cuadros en blanco

Compresión de la información de vídeo
13
corresponden a valores de coeficientes igual a 1, y los cuadros negros corresponden a coeficientesde valor -1.
Atendiendo a la figura, cada coeficiente de la transformada representará la cantidad deinformación que contiene el bloque 8x8 original en su conjunto, entorno a las frecuenciasverticales y horizontales representadas por los valores u y v. Estas componentes frecuencialescomprenden desde la frecuencia cero (DC) cuyo coeficiente vendrá representado en la partesuperior izquierda, hasta la máxima frecuencia espacial horizontal posible, representada en laparte superior derecha, o la máxima frecuencia espacial vertical posible representada en la parteinferior izquierda, pasando por todas las posibles combinaciones de frecuencias espacialeshorizontales y verticales.
Si el bloque 8x8 a transformar corresponde a un trozo de decorado completamenteuniforme, y completamente blanco, todos los coeficientes frecuenciales serían cero excepto elcorrespondiente a la DC (parte superior izquierda).
El valor de los coeficientes más a la derecha aumentará a medida que aparezcan en él máscontenidos de altas frecuencias horizontales (incremento de perfiles verticales abruptos). Ensentido vertical, los coeficientes se comportan de manera similar.
Si el bloque original correspondiese a un área de la imagen que tuviera un dibujo en formade rayas verticales alternativamente blancas y negras y cada raya coincidiese con la anchura deun píxel, el coeficiente frecuencial correspondiente al bloque situado arriba a la derecha tomaríael valor máximo, y el resto serían cero, excepto el correspondiente a la DC que siempre indicaráel valor medio de la DC de todo el bloque.
Si un bloque de la imagen contiene una gradación de brillo en cualquier dirección, suDCT tiene únicamente el coeficiente de frecuencia cero (el primero) y sus tres coeficientesperiféricos distintos de cero. El resto de los 60 coeficientes serán cercanos o iguales a cero.
Es evidente, que estas situaciones extremas no serán habituales, sino que los coeficientesfrecuenciales estarán distribuidos en función del contenido de la imagen, si bien es cierto queestos coeficientes, por la propia naturaleza de las imágenes, tendrán una tendencia muy clara,como vamos a ver.
De forma general, en las imágenes con poco detalle o normales en detalle, casi todos loscoeficientes que son distintos de cero se agruparán en la esquina superior izquierda de la matrizde coeficientes. Esta característica de la DCT la trataremos en las propiedades que se detallan enel siguiente apartado.

Vídeo Digital
14
3.4.3. Propiedades de la DCTLa DCT por sí misma, al pasar de una matriz a otra del mismo tamaño no implica
compresión alguna, pero tiene algunas características importantes que la hacen muy útil paranuestro propósito. Sin llegar a hacer un estudio exhaustivo, nos vamos a centrar en aquellaspropiedades que nos van a ser útiles en los procesos de compresión de imágenes.
a)- Una de las propiedades más importantes y que se puede comprobar directamente de ladefinición es la de “separabilidad”. En este caso. la separabilidad quiere decir que unaDCT bidimensional se puede expresar como un conjunto de varias DCTsunidimensionales.
Si x[m,n] = x1[m] · x2[n], C[u,v] = C1[u] · C2[v].
b)- La DCT presenta también la propiedad de una gran compactación de la información en loscoeficientes de menor orden, de tal manera que los de orden superior tienen un valor nuloo caso nulo, salvo en el caso de imágenes que presenten una anormalmente alta variaciónespacial.
c)- Los coeficientes resultado de la DCT presentan entre sí una muy pequeña correlación. Estapropiedad es especialmente importante en aplicaciones de compresión de imágenes, yaque de esta forma será posible dar a los coeficientes tratamientos totalmente diferentesdependiendo del lugar que ocupen dentro de la matriz de coeficientes.
d)- La transformada de Fourier es una transformada compleja, con parte real y parte imaginaria,lo que complicado el trabajo con ella. Sin embargo la DCT es una transformada real; susresultados son muestras de la función coseno, y esto simplifica mucho su manejo.
e)- Si en la transformada de una imagen se suprimen los coeficientes de mayor orden, al volvera calcular la transformada inversa, se obtiene una muy buena aproximación de la imageninicial.
3.4.4. Utilización de la DCT para compresión de vídeoLa transformada discreta del coseno se considera la base en la mayoría de los algoritmos
de compresión de video, tanto intracuadro (redundancia espacial) como intercuadro (redundanciatemporal). Esta transformada se suele aplicar dividiendo las 720x576 muestras activas de unaimagen en bloques de 8x8 píxeles.

Compresión de la información de vídeo
15
x[m,n]
76 73 67 62 58 67 64 55
65 69 62 38 19 43 59 56
66 69 60 15 16 24 62 55
65 70 57 6 26 22 28 59
61 67 60 24 28 40 60 58
49 63 68 58 51 65 70 53
43 57 64 69 73 67 63 45
41 49 59 60 63 52 50 34
C[u,v]
414 29 62 25 55 20 1 2
6 21 62 8 12 7 6 7
46 8 77 26 30 10 6 5
49 12 34 14 10 6 1 1
11 8 12 2 1 1 5 2
10 1 3 3 0 0 2 0
3 1 1 0 1 4 2 3
1 1 0 3 0 0 1 0
3.4.4.1. Lectura en zig-zag
La DCT por si sola, como se ha visto en el apartado de propiedades, no comprime. Ésta,al transformar la información del dominio espacial al dominio de la frecuencia, recoloca lainformación de tal manera que es más fácil eliminar la parte redundante, consiguiendo reducirel flujo binario. A continuación, se presenta un ejemplo de matriz 8x8 y su correspondiente DCTbidimensional.
Si observamos detenidamente la distribución de los coeficientes frecuenciales en losbloques transformados, podemos ver que los más significativos se encuentran en el cuadrantesuperior izquierdo, que corresponde a las bajas frecuencias. Conforme nos vamos alejando de estecuadrante hacia la derecha y hacia abajo, el valor de los coeficientes disminuye drásticamente.
Este hecho, surge por la propia información contenida en las imágenes, pero existe otrarazón por la que podemos decir que la información de alta frecuencia, que de por sí es poca,puede despreciarse. Esta razón aparece por la forma en que el sistema visual humano atiende alas imágenes. De toda una imagen, el sistema visual presta atención a un objeto o conjunto deobjetos concretos, considerando lo demás como fondo que carece de importancia. Por lo general,

Vídeo Digital
16
Figura 6. Lectura de la matriz de coeficientes enexploración progresiva y entrelazada
los objetos a los que hay que atender se representan en primer plano, con lo que el contenido debajas frecuencias es todavía más importante que el de altas frecuencias. La mayor parte de loscontenidos de alta frecuencia quedan en el fondo, y su eliminación apenas resta información reala la imagen.
Considerando estas características, a la hora de serializar los coeficientes de la DCT paraalmacenarlos o transmitirlos, se hace conveniente una lectura de las matrices de coeficientes demanera que los de menor peso queden agrupados, y así se puedan eliminar o codificar másfácilmente mediante un código de longitud de recorrido (RLC) que signifique “los siguientes ‘n’coeficientes son nulos”.
Según esto, la lectura de los coeficientes se realiza en zig-zag comenzando desde elcoeficiente DC, y terminando en su lado opuesto. Esto permite procesar en primer lugar las bajasfrecuencias espaciales y decidirposteriormente si se procesan o see l i m i n a n l o s c o e f i c i e n t e scorrespondientes a las altasfrecuencias , y decidir conposterioridad si se procesan o see l i m i n a n l o s c o e f i c i e n t e scorrespondientes a las altasfrecuencias.
Realizando la lectura de estamanera, se pueden procesar loscoeficientes de más nivel, y eliminar el resto consiguiendo factores de compresión, aunquemodestos, sin que la calidad subjetiva de la imagen quede afectada. En este caso se tratará de unacompresión subjetivamente sin pérdidas, consiguiendo una compresión 2:1 directamente alaplicar la DCT sin efectuar redondeos.
3.4.4.2. Cuantificación de los coeficientes
Para conseguir una mayor compresión, podemos aplicar otra herramienta al resultado dela DCT. Esta herramienta va a ser una cuantificación ponderada de los coeficientes. Estacuantificación ponderada se basa, como es lógico, en la mayor o menor importancia de cadacoeficiente respecto de la calidad subjetiva final, es decir en el contenido frecuencial de cadacoeficiente.
A cada coeficiente de la DCT se le aplica una cuantificación definida por un determinadotamaño de escalón de cuantificación. En aquellos coeficientes donde su redondeo afecte más ala calidad, el escalón de cuantificación será menor, y aquellos coeficientes menos importantes secuantificarán con escalones más grandes. Esta cuantificación queda definida por una matriz devalores que representarán los tamaños de los escalones, y que se llama matriz de cuantificación.

Compresión de la información de vídeo
17
JPEG
16 11 10 16 24 40 51 61
12 12 14 19 26 58 60 55
14 13 16 24 40 57 69 56
14 17 22 29 51 87 80 62
18 22 37 56 68 109 103 77
24 35 55 64 81 104 113 92
49 64 78 87 103 121 120 101
72 92 95 98 112 100 103 99
round(C[u,v]/JPEG)
26 3 6 2 2 1 0 0
1 2 4 0 0 0 0 0
3 1 5 1 1 0 0 0
4 1 2 0 0 0 0 0
1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
Esta cuantificación va a hacer que algunos coeficientes que antes eran cercanos a cero,al redondear se vayan a cero, y otros que no se vayan a cero, puede hacerse que se codifiquen conmenor número de bits, y así se consigue un mayor nivel de compresión. De esta manera seconsigue un mayor nivel de compresión. Existe toda un colección de matrices de cuantificaciónestablecidas que minimizan la degradación subjetiva de la calidad. La matriz de cuantificaciónpor defecto aplicada a los algoritmos JPEG aparece en la siguiente expresión.
El resultado del redondeo de coeficientes de C[u,v] anterior es:
como se observa gran parte de los coeficientes se van a cero.
En la actualidad se considera que una compresión 3,3:1, que provoca un redondeomoderado de los coeficientes, tampoco provoca prácticamente degradación subjetiva de lacalidad. Esta no degradación subjetiva viene marcada por la posibilidad de multigeneración vistaen apartados anteriores. Todos los factores de compresión mayores que 3,3:1 necesitarán unmayor redondeo de coeficientes, y por lo tanto mayor pérdida de información. Obviamente, estamayor cuantificación sí merma la calidad de la imagen. Estamos entrando entonces en el terrenode la compresión con pérdidas subjetivas, y dependiendo de los valores de la cuantificacióntendremos una pérdida de calidad mayor o menor, y a costa de ello una mayor o menorcompresión.

Vídeo Digital
18
3.4.4.3. Codificaciones VLC y RLC
A partir de la cuantificación anterior, y mediante la lectura en zig-zag presentada sepretende que al final de cada bloque 8x8 se codifique con el menor número de bits posible.. Loscoeficientes que después del redondeo resulten nulos, se codificarán con técnicas de longitud derecorridos (RLC), que agruparán en un sólo código toda una cadena de ceros.
Existirá un número grande también de coeficientes que no llegarán a ser cero, pero cuyacodificación Huffman de longitud variable (VLC), vista en apartados anteriores, permite sucodificación con pocos bits.
3.5. Algunos estándar de compresión
3.5.1. La norma JPEGLa norma JPEG (Joint Photografic Experts Group) nace como consecuencia de la
necesidad de comprimir imágenes fotográficas, y por tanto estáticas. Se puede utilizar compresiónsubjetivamente sin pérdidas, que alcanzaría factores de compresión de hasta el 3,3:1, ycompresión con pérdidas, que puede llegar hasta el factor 100:1 dependiendo del grado depérdidas que estemos dispuestos a permitir. El estándar JPEG opera bien en el rango de flujosbinarios de 3,3 a 80 Mb/s.
La norma JPEG consiste fundamentalmente en aplicar la DCT a los bloques de imagende 64 píxeles (8x8), realizar el proceso de cuantificación eliminando los coeficientes con menorpeso, realizar la lectura en zig-zag, y posteriormente considerar la redundancia estadísticamediante una codificación Huffman junto con la RLC.
Existen dos tipos de estructuración de los datos comprimidos: la estructura secuencial yla estructura progresiva. Mediante la estructuración secuencial, la información se transmite porbloques de 8x8 completos con toda su definición leídos en zig-zag. En la estructura progresiva,se van enviando sucesivamente los diferentes coeficientes frecuenciales de todos los bloques,comenzando con los correspondientes a la DC y también utilizando la lectura en zig-zag. De estamanera se explica la forma de carga de algunas imágenes en internet que van ganando definiciónconforme van llegando los datos
La norma JPEG es una norma bastante abierta, ya que permite un grado de compresiónvariable en función de las necesidades, suprimiendo los coeficientes frecuenciales necesarioshasta conseguir el grado de compresión requerido.

Compresión de la información de vídeo
19
3.5.2. El estándar MJPEGEl estándar MJPEG nace ante la necesidad de comprimir las imágenes en los procesos de
edición no-lineal. En esta tarea, una compresión intercuadro como la que se definirá en elsiguiente apartado de MPEG se hace difícil de manejar, ya que en algunos casos es necesaria lalectura y decodificación de varias imágenes para obtener la información de un cuadro concreto.
Con este panorama, las compañías fabricantes de equipos de edición no-lineal se vieronen la necesidad de sacar al mercado sus equipos sin que los organismos competentes hubierandesarrollado una norma. En realidad la técnica MJPEG, es un sistema de compresión JPEGaplicado sucesivamente a todas las imágenes.
Al no existir un estándar definido, cada fabricante desarrollo el suyo, siendo normalmenteincompatibles entre sí. El formato AVID utiliza un MJPEG con relación de compresión 3:1,mientras que el EVS utiliza compresión 6:1. Hay que señalar, que la compañía SONY hadesarrollado un sistema de compresión intercuadro válido para postproducción, y que constituyeuna de las variantes de la familia MPEG que veremos más adelante.
3.5.2.1. Diagrama de bloques
Según todo lo explicado hasta ahora, el proceso de compresión de las imágenes detelevisión sería el siguiente: A partir de las tres señales primarias R, G y B se obtendrán lasseñales de luminancia (Y) y de diferencia de color (R-Y, B-Y), se digitalizarán según la norma4:2:2. Posteriormente, se realizará la transformada discreta del coseno, y se procede a cuantificarlos coeficientes frecuenciales; se realiza la lectura en zig-zag, y finalmente, se aplican lascodificaciones VLC y RLC para utilizar el menor número de bits posible para la transmisión oalmacenaje. Todo esto se puede ver en la figura 7.
En esta figura aparecen en la esquina superior derecha dos bloques que analizamos acontinuación. En el caso de querer transmitir la información de vídeo por un canal con tasabinaria constante, la compresión definida de esta manera produce diferentes niveles decompresión dependiendo del contenido del bloque 8x8 a procesar. Un bloque de color uniformese codificará únicamente mediante su coeficiente DC y un bloque con distinto contenidonecesitará más coeficientes para representarlo. Esto hace imprevisible la velocidad a la que puedeenviarse la información comprimida.
Para solucionar esto, los sistemas de codificación y transmisión disponen de una cola, oun “buffer”, de salida y un bucle de control de flujo binario que va cambiando la matriz decuantificación, y con ello la compresión conseguida en función de las necesidades de cadamomento. Si la cola de salida está muy llena, el bloque de control de flujo actúa sobre la matrizde cuantificación aumentando los escalones. Este aumento provocará un aumento en lacompresión, y por tanto, una disminución de la entrada de datos a la cola. En el caso en que la

Vídeo Digital
20
Figura 7. Diagrama de bloques de un compresor de vídeo digital para transmisión basado enla DCT.
cola se esté vaciando, el bloque de control de flujo disminuye el tamaño del escalón,disminuyendo temporalmente la compresión.
La variación de la compresión afectará a la calidad instantánea de las imágenes. Noobstante, se debe tener en cuenta que los aumentos de compresión se producirán en los instantesen que la escena tenga mucho detalle, con lo que el ojo probablemente sea menos sensible a estecambio de compresión. En el caso en que las imágenes tengan poco detalle, el ojo será mássensible, pero al disminuir la compresión se conseguirá mantener una calidad subjetiva alta.
3.6. Estándar de compresión MPEG-2Las normas MPEG, han revolucionado la industria de la televisión y las comunicaciones,
al conseguir reducir de manera drástica el flujo binario, sin pérdida subjetiva de calidad en laimagen. Dada la importancia que tiene el estándar de compresión MPEG-2 en la televisión digitalactual, se ha preferido tratarlo en un apartado completo, aunque como se podrá comprobar, utilizala mayoría de las técnicas de compresión vistas hasta ahora.
En el mundo del vídeo digital, la cantidad de aplicaciones se ha disparado en los últimosaños. Cada aplicación además, requiere unos niveles de calidad distintos, así como un factor decompresión diferente. Mientras que en un sistema de difusión de televisión digital la calidad esun requerimiento importante, en el caso de la videoconferencia, que es el polo opuesto, larestricción está en el ancho de banda del canal de que se dispone, y por tanto, la velocidad binariaque se puede utilizar, quedando la calidad de la imagen en un segundo plano.

Compresión de la información de vídeo
21
Los métodos MPEG de compresión pretenden ser lo suficientemente flexibles para podersatisfacer las necesidades de todos esos usuarios potenciales. Para cada uno de ellos, se ha creadoun único método normalizado de compresión que asegura una forma de trabajo única, pero quepermite manejar distintos niveles de calidad y distintos factores de compresión, de manera quese ajuste fácilmente a los requerimientos de utilización de cada servicio (coste, resolución,velocidad binaria, ...).
Lo que cada uno de estos estándar intenta es ofrecer un mismo núcleo básicoparametrizable para cada una de las aplicaciones. El utilizar este mismo núcleo básico supone unabaratamiento en los equipos de compresión y descompresión, debido a su amplia utilización.
El primer estándar que se desarrolló fue el MPEG-1, que apareció hacia 1988. Esteestándar nació con la idea inicial de reducir el flujo binario al nivel utilizado por los soportes deaudio CD, del cual derivó el CD-ROM, para almacenar en este soporte, imágenes en movimientocon un flujo binario de 1,5Mb/s. De hecho, este estándar opera bien en el rango de flujos binariosde 1,5 a 3 Mb/s.
La norma MPEG-1, antes del proceso de compresión, somete a la señal de entrada aprocesos de eliminación de información drásticos. Lo primero es eliminar un campo de la imagenquedándose con una resolución de 360x288 a 25 f/s. A partir de esto, este método aplica lacompresión intracuadro e intercuadro de forma parecida al formato MPEG-2 que se desarrollarámás ampliamente. Únicamente varían parámetros técnicos, de muestreo, cuantificación, etc.siendo más riguroso en MPEG-2 ya que va destinado al entorno profesional de mayor calidad.
El estándar MPEG-2 está orientado al entorno profesional de la televisión digital. Ésteopera bien para flujos binarios de 3,5 a 100 Mb/s, y se aplica desde en los sistemas deproducción, hasta en las transmisiones de la televisión digital terrestre, por cable, y vía satélite.Este estándar es capaz de soportar desde calidad VHS hasta calidad TVAD (en formato 16 / 9).
La codificación MPEG-2 va orientada a la eliminación de la redundancia espacial ytemporal. Esta compresión es adecuada para imágenes de calidad en movimiento (televisión).Para ello, aplica codificación intracuadro e intercuadro, y además aplica una codificación finalde corrección de errores. Con esto se consiguen relaciones de compresión como 270Mb/s a 50Mb/s para comunicaciones dentro del estudio, 8Mb/s para difusión con calidad de estudio, yhasta 3,5Mb/s y 1,5Mb/s para transmisiones de menor calidad. Este estándar MPEG-2 tambiénse utiliza en servidores de video bajo demanda, y en archivos de imágenes. Para la grabaciónmagnética se utiliza solamente en el formato Betacam SX.
Existió un formato MPEG-3 orientado a la televisión de alta definición, pero sus avancesse incorporaron posteriormente al estándar MPEG-2, no teniendo mayor relevancia.
El grupo MPEG-4 fue creado para investigar varios frentes de necesidades en lacodificación. El más importante fue el de adaptar la información de vídeo a las redes telefónicas.Este grupo trabajó sobre tres posibilidades: para flujos inferiores a 64 kb/s, entre 64 kb/s y 384kb/s, y entre 384 kb/s y 4 Mb/s. La compresión MPEG-4 se aplica en videoconferencias. Los

Vídeo Digital
22
defectos temporales y espaciales son abundantes como corresponde a los bajos flujos binarios detransmisión, pero se atenúan controlando el movimiento de los objetos.
La filosofía de MPEG-4 cambia con respecto al resto de los estándares anteriores, ya queintroduce el concepto de codificación de objetos, es decir, las imágenes se segmentan en objetosy es la información de los mismos la que se transmite. El estándar no fija como se deben obtenerlos objetos, estimar su movimiento, etc. Los algoritmos serán elegidos por cada diseñador; lanorma sólo fija cómo guardar la información de dichos objetos.
La compresión MPEG-4 a pesar de sus niveles de calidad ha permitido poner en servicioaplicaciones de comunicación muy interesantes. Otros trabajos que realiza el grupo MPEG-4están relacionados con el interfaz entre el mundo multimedia, el ordenador y la televisión.
El grupo MPEG-7 no está implicado en temas de compresión, sino en los metadatos. Estetrabajo incluye la preparación de normas sobre los contenidos audiovisuales, como por ejemplollegar a la localización de las escenas en que aparecen ciertos personajes. Con ello se conseguiríaun acceso detalladísimo a todo tipo de contenidos del material audiovisual. Su aplicación está enlos archivos, en la edición y montaje, en la redacción periodística, etc.
El grupo MPEG-21 tampoco trabaja en compresión digital. Su objetivo fundamental escrear la codificación oportuna para la gestión y uso del material audiovisual, incluyendo elsoporte de infraestructura necesario para las transacciones comerciales y la gestión de losderechos correspondientes.
3.6.1. La compresión intracuadro de MPEG-1 y 2La codificación intracuadro elimina la redundancia espacial. La compresión intracuadro
de los estándar MPEG-1 y 2 es similar a la vista en JPEG. Esta compresión está basada en elalgoritmo de la DCT.
La lectura de la matriz de coeficientes resultado de la DCT (de tamaño 8x8) se realiza enzig-zag para imágenes no entrelazadas, ya que los elementos significativos que serán distintosde cero, están más a la izquierda y hacia arriba. Con esto, los ceros de la matriz quedan en losúltimos lugares de la secuencia reordenada. Posteriormente se aplican los métodos VLC y RLCde minimización de la redundancia estadística.

Compresión de la información de vídeo
23
3.6.2. La compresión intercuadro: Compensación demovimiento
La compresión intercuadro intenta detectar y eliminar la redundancia temporal entrecuadros sucesivos. Esta compresión se realiza mediante un proceso de codificación diferencial,y otro llamado “compensación de movimiento”. Con estas técnicas se consiguen los niveles máselevados de compresión.
3.6.2.1. Codificación diferencial
La codificación diferencial se establece de forma parecida a la codificación DPCM vistaen uno de los apartados anteriores. La imagen diferencia de un cuadro con respecto al anteriorse puede obtener de manera sencilla. En primer lugar, se hace pasar a la señal por un circuito quetenga un retardo de un fotograma, o se almacena en una memoria de 1 cuadro de capacidad. Estaimagen retardada un cuadro, se suma posteriormente a la imagen actual (sin retardar) perocambiada de signo, el resultado será la imagen diferencia, que en la mayor parte de su contenidoserá cero.
Con esto, las zonas de la imagen que no cambian, no se codifican, limitándose eldecodificador del receptor a repetir los pixeles del fotograma anterior. La técnica de codificaciónde la diferencia es buena cuando las imágenes son estáticas. En el caso de imágenes con muchomovimiento, como acontecimientos deportivos en los que la imagen diferencia puede contenerbastante información, al producirse cambios importantes de un fotograma al siguiente, será másproductivo utilizar también la técnica de compensación de movimiento que se expone acontinuación.
3.6.2.2. Técnica de compensación de movimiento
La técnica de compensación del movimiento trabaja sobre pequeñas áreas de la imagendenominadas macrobloques de 256 píxeles (16x16); estos macrobloques están compuestos porcuatro bloques. En las imágenes en movimiento, es habitual que algunas zonas de la imagen sedesplacen en un fotograma con respecto al anterior. El sistema de compensación del movimiento,trata de buscar el nuevo emplazamiento de los macrobloques, y calcular los vectores dedesplazamiento codificando solamente dichos vectores.
El proceso de predicción comienza por comparar el macrobloque actual con el homólogodel fotograma anterior, si estos no son iguales, buscará un macrobloque idéntico en ladenominada zona de búsqueda, si lo encuentra codificará los vectores de desplazamiento, y si nolo encuentra realizará la comparación con el más parecido, codificando la diferencia entre los dosy los vectores de movimiento. La búsqueda se realiza en dos niveles, primeramente se realiza enuna zona más amplia, y la comparación es gruesa, posteriormente se afina en una zona másreducida.

Vídeo Digital
24
El codificador compara los resultados y toma las decisiones sobre el bloque idéntico obien sobre el más aproximado. Si la diferencia es mayor que la cifra establecida, abandonará labúsqueda presumiendo que el bloque no se encuentra ya en la imagen, y codificará el mismo concodificación espacial.
3.6.3. Imágenes I, P y BLa mayor compresión de los sistemas MPEG-1 y 2 no radica en la DCT y su mayor o
menor cuantificación. La mayor potencia de estos algoritmos MPEG está en tres modos decompresión de las imágenes. Estos modos de compresión dan lugar a lo que llamamos imágenesI, imágenes P e imágenes B.
3.6.3.1. Imágenes “I” (intracuadro)
Las imágenes I son imágenes que utilizan sólo compresión intracuadro. Cada cuadro I escomprimido y procesado de forma independiente de los demás, y contiene por sí solo toda lainformación necesaria para su reconstrucción.
Las imágenes I son las que más información contienen, y por tanto las que menoscompresión aportan. Las imágenes I, siempre inician una secuencia y sirven de referencia a lasimágenes P y B siguientes.
En secuencias largas, es necesario disponer de imágenes I intercaladas, ya que facilitanel acceso aleatorio a un fotograma dentro de la secuencia. Si todas las imágenes dependen de laanterior podemos llegar a la situación en que para recuperar una imagen, hemos de leeranteriormente todas las anteriores desde el principio, y eso, en ocasiones, no es productivo.
La compresión intracuadro de las imágenes I coincide con el método JPEG para imágenesestáticas. Aquí se busca la redundancia de la imagen dentro del cuadro que se está procesando.
3.6.3.2. Imágenes “P” (predicción)
Las imágenes P se generan a partir de la imagen I o P anterior más próxima. Elcodificador compara la imagen actual con la anterior I o P, y codifica únicamente los vectores demovimiento y el error de predicción. Se utiliza en este caso una predicción hacia adelante. Estasaportan un grado importante de compresión.

Compresión de la información de vídeo
25
Figura 8. Fotogramas I, P y B.
3.6.3.3. Imágenes “B” (bidireccionales)
Por último las imágenes B (Bidireccionales) se generan a partir de imágenes previa yfutura de los tipos I o P. Mientras que las imágenes I y P pueden propagar errores, ya que de ellasdependen otras, las imágenes B no lo hacen, ya que no intervienen en otras prediccionesposteriores.
La filosofía de la predicción bidireccional se fundamenta en el hecho en que la cámaraen cualquier momento puede realizar una panorámica, un “traveling”, o que dentro de la escenalos objetos se mueven. Cuando la cámara hace una panorámica, una parte de la imagen se vaescondiendo por un lado mientras que otra parte se va desvelando por el otro. También aunquela cámara esté fija, cuando se producen desplazamientos de objetos en la escena, por una parteirán desvelando partes fijas de la escena (edificios, decorados, etc), y por otra irán ocultando otraspartes. En estos casos, cuando se quiere predecir el contenido de una imagen, puede resultar máseficaz tomar como referencia imágenesanteriores en una parte del fotograma, yposteriores en otra.
En el ejemplo de la figura 8, semuestra, en primer lugar una escena dela que se realizará una panorámica. En laparte inferior aparecen tres fotogramasde esa panorámica nombrados como F1,F2 y F3. En la explicación siguientevamos a suponer que la imagen F1 se codifica como imagen I, el fotograma F2 se codifica comoB, y el fotograma F3 se codifica como P.
Al fotograma primero, por codificarse como I se le aplica una compresión intracuadro apartir de su propio contenido. Para el fotograma F3 se utiliza la técnica de predicción respectodel fotograma F1; con lo que se extraerán los macrobloques de la zona del personaje, de laimagen F1; y la zona donde aparece la cámara se codificará intracuadro, ya que en el fotogramaI no hay información al respecto.
La imagen F2 se codifica como imagen bidireccional entre los fotogramas F1 y F3. Enella, los macrobloques de la zona del bafle pueden recuperarse de la imagen F1; la parte quecorresponde al personaje puede tomarse de cualquiera de las dos imágenes F1 o F3; y finalmente,la parte de la cámara se puede sacar del fotograma F3, con lo que el fotograma bidireccionalpuede codificarse mediante unos cuantos vectores de movimiento y un error de predicción quepuede llegar a ser muy pequeño.
Aunque el procesamiento de los fotogramas B complica los algoritmos de codificación,esta complicación compensa el beneficio de conseguir importantes niveles de compresión enestos cuadros.

Vídeo Digital
26
3.6.3.4. Grupo de fotogramas (GOP)
La sintaxis de MPEG-1 y 2 permite elegir cuántas imágenes I se dan por segundo asícomo el número de imágenes P y B intercaladas para cada aplicación. Al número de cuadros quese tienen entre dos imágenes I consecutivas se le llama grupo de fotogramas (GOP - Group OfPictures).
El tamaño GOP típico en MPEG-2 es de 12 fotogramas. Esto obliga a los decodificadoresa disponer de un buffer con capacidad para almacenar 12 fotogramas. El GOP puede ser menorde 12 fotogramas pero en general nunca será mayor. Sólo en MPEG-1 se pueden encontrar GOPsmás largos, existiendo un mayor número de imágenes con bajos flujos binarios.
Si durante una secuencia de imágenes se produce un cambio de plano, el codificadordetectará que el contenido del primer fotograma del nuevo plano no encuentra coincidencias conel anterior y por lo tanto lo codificará y definirá como una imagen I.
Dentro de un GOP, el flujo natural de las imágenes que se representan suele ser éste.
I B B P B B P B B P B B I ...
Sin embargo, para la transmisión es preciso cambiar el orden de los fotogramas. Esto esporque, en recepción, para decodificar cada imagen B es necesario antes haber decodificado laimagen I o P anterior y la posterior. De esta manera, el orden de transmisión se ve alteradoadelantando las imágenes P posteriores , o lo que es lo mismo retrasando las imágenes B hastaenviar la imagen I o P posterior; quedando el flujo de imágenes de esta forma:
I P B B P B B P B B I B B ...
Posteriormente, será tarea del decodificador el recuperar el orden natural para lapresentación en pantalla.
El sistema Betacam SX, orientado a aplicaciones de postproducción, utiliza unasecuencia de GOP de tamaño 2 (IBIBIB) con objeto de poder realizar ediciones de precisión,aunque esta variante no constituye un estándar como tal.

Compresión de la información de vídeo
27
3.6.4. Esquema del decodificador MPEG-2El esquema del decodificador es mucho más sencillo que el del codificador. Por ello lo
presentamos en primer lugar
En primer lugar, el demultiplexor separa los datos correspondientes al error de prediccióndel fotograma de los vectores de movimiento. Posteriormente se decodifica el error de predicción,y se suma a la imagen obtenida del fotograma anterior y de los vectores de movimiento,obteniéndose la imagen actual. Esta imagen actual se almacena para la decodificación delsiguiente fotograma. Finalmente, se reordenan los fotogramas para obtener el orden natural dela secuencia a partir del orden de transmisión de la misma.
Hay que destacar que el proceso codificación decodificación en MPEG no es simétrico.El codificador es bastante más complicado y por tanto necesita una mayor potencia de cálculo,mientras que el decodificador debe realizar procesos más sencillos. Esta estructura es lógica,teniendo en cuenta que el codificador se encuentra en el equipamiento profesional de produccióny emisión, y el decodificador es un elemento del equipamiento doméstico de los receptores.
Resumiendo, el sistema MPEG-2 divide la imagen en pequeñas áreas de 8x8 píxelesllamadas bloques, y de 16x16 píxeles llamadas macrobloques, realizando diversosprocesamientos diferentes a cada uno de ellos.
Existen dos etapas diferenciadas; la compresión intracuadro que trata de minimizar laredundancia espacial, y la compresión intercuadro que hace lo propio con la redundanciatemporal. La compresión intracuadro consiste fundamentalmente en aplicar la DCT a los bloques8x8, cuantificar los coeficientes, y aplicar una codificación VLC (normalmente Huffman). Lacompresión intercuadro se basa en la aplicación de la compensación de movimiento a losmacrobloques, y la codificación diferencial a la imagen completa. Según la compresiónintercuadro podemos distinguir imágenes I, imágenes P, e imágenes B.
La suma de todos estos procesos lleva a niveles de compresión notables, manteniendo noobstante la calidad subjetiva de la imagen y haciendo posible la reversibilidad del proceso a finde recuperar la imagen original.

Vídeo Digital
28
3.6.5. Esquema del codificador MPEG-2A la vista del codificador MPEG-2 la primera operación a realizar es reordenar las
imágenes de la secuencia al orden de transmisión, ya que para codificar las imágenes B hemosde haber codificado antes las imágenes I y P posteriores. A continuación, y a partir de lasimágenes ya codificadas se calculan los vectores de movimiento.
A partir de los vectores de movimiento y de la predicción de la imagen ofrecida por elcodec JPEG (bloques TDC, Q, Q-1, y TDC-1) se realiza la codificación diferencial.
Con la imagen diferencia se realiza la DCT y posteriormente el cuantificador realiza unacuantificación distinta en los coeficientes dependiendo de la frecuencia a la que representan.También aparecen el cuantificador inverso y una DCT inversa. Su misión es simular aldecodificador en la forma de predecir las imágenes, para después calcular la diferencia entre laimagen real y la predicción que utiliza el decodificador.
El bloque CLV hace referencia a las codificaciones de longitud variable y de longitud derecorrido. La codificación de longitud variable asigna palabras de código más cortas a aquelloscódigos que tienen una mayor frecuencia de aparición, mientras que la codificación de longitudde recorrido codifica, a partir del último coeficiente distinto de cero, que los demás del bloqueson todos cero hasta el final. Estas dos codificaciones aportan un nivel de compresión moderado.
El multiplexor de salida conforma un tren de datos en el que aparece toda la informaciónnecesaria para el decodificador; incluyendo la información de todos los bloques 8x8 y losvectores de movimiento.

Compresión de la información de vídeo
29
Figura 11. División en slices de una imagen.
Finalmente el buffer de salida y el regulador mantienen constante el flujo binario haciael decodificador.
3.6.6. Estructura del tren de datos MPEG-2El tren de datos de MPEG se estructura de mayor a menor en los siguientes elementos:
Secuencias, GOPs, Imágenes, Slices, Macrobloques, y Bloques. Cada uno de estos elementoscontiene una cabecera de datos en la que se especifican los atributos del mismo, de manera quese facilite el trabajo del decodificador.
Los Bloques son cuadrados de 64 píxeles (8x8), y son la unidad de proceso de la DCT.
El Macrobloque es una asociación de cuatro bloques, y consta de 256 píxeles (16x16).Esta es la unidad de comparación para el cálculo de los vectores de movimiento. Además, en elcaso de codificación 4:2:0, que es habitual en MPEG-2, el macrobloque es la unidad deprocesamiento de la DCT para las señales de diferencia de color.
Un slice son un grupo demacrobloques asociados en sentidohorizontal y tomados de izquierda aderecha. Pueden constar desde unmacrobloque hasta toda una línea, peroun mismo slice nunca debe estarcompuesto por macrobloques dediferentes líneas. En la figura serepresenta un conjunto de slices de unaimagen en determinadas posiciones;estas posiciones pueden cambiar de unaimagen a otra.
No es necesario que toda laimagen esté cubierta por slices, puedenquedar macrobloques que nocorrespondan a ninguno de ellos. Esas zonas sin slice definido quedarán sin codificar para esaimagen. La norma MPEG no especifica lo que debe hacer el decodificador en estos casos, aunquelo más intuitivo es mantener esas zonas iguales a la imagen anterior. Obviamente esto sólo esaplicable a imágenes tipo P y B, ya que las imágenes I, por definición, van codificadas porcompleto.
El concepto de imagen en MPEG-2 no es el mismo al que estamos acostumbrados.Dependiendo de los casos, cuando utilizamos exploración entrelazada puede ser ventajosoconsiderar imagen, tanto un campo, como un cuadro. En imágenes sin movimiento, puedeconsiderarse como imagen un campo o un cuadro indistintamente, puesto que el contenido deambos campos sera muy similar. En cambio, si existen movimientos rápidos utilizando

Vídeo Digital
30
exploración entrelazada, las diferencias en cuanto a contenido entre los campos pueden ser muyimportantes, así que será conveniente procesar por separado cada campo.
En el caso que utilicemos el concepto de imagen como un cuadro completo se habla decodificación “Frame DCT”, y si definimos como imagen a un campo hablaremos de codificación“Field DCT”. Independientemente del tipo de codificación descrito, una imagen puede ser I, Po B, dependiendo de la compresión que se realice sobre ella. Esta información se indica en lacabecera de datos.
Los GOP (group of pictures) son grupos de imágenes, acotados por dos imágenes de tipointracuadro. Normalmente constan de 12 fotogramas y constituyen la unidad de compresióntemporal. El GOP es el mínimo elemento capaz de contener por sí solo toda la informaciónnecesaria para su descompresión, ya que como hemos visto algunos tipos de imágenes necesitande otras para su total descompresión.
Una secuencia consta de varios GOPs, indicando los datos de la cabecera, la relación deaspecto, el flujo binario, y otros datos relacionados con el programa al que pertenecen.
3.6.7. Niveles y perfiles en MPEG-2La familia MPEG-2 se ha presentado en apartados anteriores como un método de
compresión flexible en cuanto a las características de la secuencia de vídeo a comprimir, al factorde compresión, a la calidad de la secuencia de vídeo de salida y al coste de los equipos.
La norma MPEG-2 contempla imágenes con exploración entrelazada y progresiva, asícomo los estándares de codificación 4:4:4, 4:2:2, y 4:2:0. También admite distintos valores deresolución de imágenes, que incluyen todas las frecuencias de campo y trama usadas en televisióndesde la más baja resolución hasta la alta definición. Asimismo, esta norma define diferentestipos de codificación que permiten conseguir diferentes niveles de calidad y de precio. Seincluyen sistemas más económicos aunque de menor calidad, y sistemas de mayor calidad aunquepor supuesto más caros.
Esta flexibilidad es posible mediante la definición de diferentes niveles y perfiles que soncapaces de conseguir un modo de compresión adaptado a las necesidades de cada aplicación.
3.6.7.1. Niveles
El nivel define la resolución de las imágenes en base al número de píxeles y líneas acodificar. El número de cuadros por segundo se define siempre por la señal original antes decomprimir. Esta resolución va desde la más baja resolución SIF (2:1:0) correspondiente a MPEG-1, hasta la televisión de alta definición con 1920x1152 píxeles.

Compresión de la información de vídeo
31
Nivel bajo (Low) Resolución SIF utilizada en MPEG-1Nivel principal (Main) Resolución 4:2:0 normal hasta 720x576Nivel alto 1440 (high-1440) Previsto para TVAD hasta 1440x1152Nivel alto (high) Previsto para TVAD hasta 1920x1152.
Sólo se codifican las muestras activas indicadas. Las señales originales tendrán muestrasactivas y no activas. Las no activas no son codificadas por MPEG-2, y serán regeneradas connivel de borrado en el decodificador. Puede que el número de muestras activas no coincida conla resolución de cada nivel. Para que esto sea posible, uno de los datos de sistema que debenconocerse es el tamaño de imagen digital original.
Es evidente que cada nivel usado dará lugar a un régimen binario diferente. De cara a laconstrucción de los codificadores, no es necesario que todos ellos sean capaces de codificar atodos los niveles sino que existirán codificadores específicos para cada nivel. En este sentido, esimportante saber que un codificador MPEG-2 que codifique en un nivel también lo haga enniveles inferiores.
3.6.7.2. Perfiles
Los perfiles, en cambio, definen un valor de compromiso entre compresión y coste deldecodificador, y además hacen posible la escalabilidad de la corriente de datos. El conseguir unamayor compresión sin perder calidad va a implicar una complicación, tanto en el codificador,como en el decodificador, y esta complicación llevará consigo un mayor coste de ambos. EnMPEG-2 se definen los perfiles siguientes.
Perfil simple.- Simplifica el codificador y decodificador. No utiliza imágenes tipo B(bidireccionales), y el tipo de muestreo soportado es 4:2:0. En este caso el factor de compresiónes bajo.
Perfil principal (main).- Mejor compromiso entre factor de compresión y calidad. Utilizaimágenes I, P y B. El decodificador y el decodificador son más complejos que el anterior. Todaslas imágenes se transmiten en formato 4:2:0.
Perfil 4:2:2.- Este perfil es el que habitualmente se utiliza en producción. Puede manejarimágenes tipo I, P y B. El muestreo es 4:2:2 aunque puede reducirse al 4:2:0. Sólo se utiliza conel “nivel principal”, incrementando el número de píxeles y líneas activas respecto de dicho nivela 720 muestras activas y 608 líneas por cuadro para sistemas 625/50 y 512 para sistemas 525/60.Como en producción habitualmente se necesita acceso a fotogramas concretos para edición,utiliza GOPs muy pequeños, de tamaño 2 como IBIBIB o 3 por ejemplo IPBIPBIPB.Evidentemente, se requiere la presencia de muchas imágenes I con el fin de poder referenciarconstantemente cuadros completos. Este perfil opera con flujos entre 20 y 50 Mb/s y admitegeneraciones múltiples de compresión y descompresión

Vídeo Digital
32
Perfil jerárquico (Scalable).- La información que contiene el flujo de datos MPEG-2 seestructura en dos capas: una primera capa con menor definición llamada “capa base”, y unasegunda capa llamada “capa de mejora” o “capa de realce” con la información suplementaria quese necesita para conseguir la mejora de calidad. La “capa base” contiene la informaciónfundamental para decodificar la señal. Esta capa básica se transmite fuertemente protegidasoportando ambientes muy ruidosos, y puede ser decodificada por todo tipo de decodificador. Aesta capa básica se le añaden capas denominadas de realce que aumentan la definición de laimagen, o su formato, y que sólo podrán ser decodificadas por equipos más complejos, instaladosen los receptores más caros. Las capas de realce suelen ir menos protegidas y por tanto son másvulnerables en entornos ruidosos.
Los perfiles escalables permiten transmitir al mismo tiempo diferentes resolucionesespaciales y diferentes grados de definición, por ejemplo puede transmitir el mismo programa enalta definición y en definición estándar, o en formato 4:3 y 16:9. Esto lo hace, por una parte,jugando con la resolución espacial (spatialy scalable profile), y por otra, con la cuantificación(SNR scalable profile).
En el caso de la escalabilidad SNR, la “capa base” contiene la información de vídeo conmenos bits por muestra, y la “capa de mejora” agrega aquella información que se necesita paraconseguir una mayor calidad. En la escalabilidad espacial la “capa base” contiene la informaciónnecesaria para conseguir un determinado nivel de la norma, como puede ser el nivel “bajo”, y la“capa de mejora” aporta el suplemento necesario para llegar a un nivel superior como el“principal” o el “alto”.
Este concepto de escalabilidad tiene su aplicación en la televisión digital terrestre, en laque van a coexistir dos tipos de receptores: receptores portátiles que solamente utilizarán la capabásica, y receptores estacionarios utilizados en las viviendas, y dotados de un decodificador máscomplejo, y con una señal más estable, que además de la capa básica decodificarán también lascapas de realce.
Para la televisión digital europea, existe un gran interés en las aplicaciones de los perfilesjerárquicos. El perfil de escalabilidad espacial que permite dividir los datos de acuerdo con laresolución y también con la relación SNR, se puede crear una señal compuesta por tres elementosque conjuntamente darán lugar a una señal de alta definición. De las tres partes de la señal, lacapa de base utilizaría jerarquía espacial para proporcionar una señal de 625 líneas. El resto dela señal se puede dividir aplicando el criterio de relación SNR, creando así una segunda señal quejunto con la capa base proporcionaría una señal de alta definición con un formato 4/3 y unarelación señal-ruido reducida. El tercer elemento de la señal, conjuntamente con los otros dos,daría una señal con el formato 16/9 de alta definición
Perfil alto (high).- Está previsto para aplicaciones en HDTV. Se utilizan imágenes tipoI, P y B, y el muestreo puede ser 4:2:2 o 4:2:0. La transmisión es escalable tanto en SNR comoespacialmente.

Compresión de la información de vídeo
33
Entre estos perfiles existe compatibilidad ascendente; los decodificadores de perfil másalto son capaces de soportar perfiles más bajos. La combinación de niveles y perfiles produce unaarquitectura que define la capacidad de un codificador para manejar determinado flujo binario.Los niveles y perfiles utilizados en Europa y América a nivel doméstico son el nivel principal yel perfil principal. El flujo binario oscila entre 5 y 9 Mb/s.
En la tabla siguiente se representan las posibles combinaciones entre niveles y perfiles.No todas ellas encuentran aplicación práctica. Las combinaciones que aparecen son lasespecificadas por la UIT. La difusión de la televisión digital se están realizando en el perfilprincipal y nivel principal, tomando el nombre de MPEG-2 MP@ML. Los flujos que aparecenson flujos máximos, no flujos reales de trabajo.
Perfiles
Niveles
SIMPLE
I,P - 4:2:0
PRINCIPAL
I,P,B - 4:2:0
4:2:2Producción
I,P,B
ESCALABLESNR
I,P,B - 4:2:0
ESCALABLEESPACIAL
I,P,B - 4:2:0
ALTO
I,P,B 4:2:0 y 4:2:2
ALTO1920 Píxeles1152 Líneas
80 Mb/s 100 Mb/s
ALTO -14401440 Píxeles1152 Líneas
60 Mb/s 60 Mb/s 80 Mb/s
PRINCIPAL720 Píxeles576 Líneas
15 Mb/s 15 Mb/s50 Mb/s
720x60815 Mb/s 20 Mb/s
BAJO352 Píxeles288 Líneas
4 Mb/s 4 Mb/s
3.6.8. Organización del flujo de transporteLos flujos binarios de vídeo y de audio de cada programa se comprimen
independientemente formando cada uno de ellos una “corriente elemental” (ES - ElementalStream). Cada una de estas corrientes elementales se estructuran en forma de paquetes llamadosPES (Packetized Elementary Stream). Los paquetes PES son de longitud variable dependiendode como el codificador organiza los datos de salida. Por ejemplo, es normal encontrarse con unflujo de salida del codificador de video que abarque una imagen completa. Esta unidad abarcaráentonces un PES. Cada paquete se inicia con una cabecera que incluye datos sobre el tipo de“carga” que lleva (vídeo audio, etc), información de sincronización, etc.
Estos paquetes de video y de audio, así como de otros datos de un mismo programa pasanposteriormente a un multiplexor donde se conforma un solo tren binario. Para esta multiplexiónexisten dos posibilidades: la conformación de una “corriente de programa” (PS - ProgramStream) y la conformación de una “corriente de transporte” (TS - Transport Stream).

Vídeo Digital
34
Figura 12. Diagrama de bloques de conformación de corrientes de programa o detransporte de programa simple..
La corriente de programa es una multiplexión simple intercalando los PES unos con otros. Estaopción se aplica en canales libres de ruido, como por ejemplo la grabación de un DVD, y de otrossoportes multimedia. Como no se espera ruido en el canal, no es necesario usar corrección deerrores. Este sistema conlleva una gran simplicidad. No obstante una corriente de programa puedeacomodar hasta 16 corrientes de vídeo y 32 de audio. Lo que sí es obligatorio en las corrientesde programa es que todas las corriente sean sincrónicas, es decir que tengan una base de tiemposcomún.
La corriente de transporte es apropiada para entornos ruidosos, opción que encaja en lasnecesidades de la difusión de televisión terrestre, por cable y vía satélite. Esta opción exige pasarlos PES a otros paquetes más cortos, de 188 bytes de longitud, y aplicar técnicas de correcciónde errores. Con esto se puede organizar una corriente de transporte de un sólo programa (SPTS -Single Program Transport Stream). Esta longitud de paquetes incluye 4 bytes de cabecera y esapropiada para utilizarse en redes ATM, así como en una amplia variedad de sistemas detransmisión y almacenamiento.
La corriente de transporte puede formarse con varios programas de televisión, cada unode ellos con varias corrientes elementales. Como es lógico las corrientes elementales que formanun mismo programa de televisión deben ser sincrónicas. Sin embargo, los diferentes programaspueden tener cada uno una sincronización independiente. En este caso, se organiza un múltiplexcon todos los programas. El flujo binario de la corriente de transporte completa es constante, auncuando varíen los flujos de cada corriente elemental. Para mantener este flujo total constante, sepueden incluir paquetes nulos.
Entre otras informaciones, la corriente de transporte también lleva información de cifradopara el acceso condicional a determinados programas de pago.

Compresión de la información de vídeo
35
Figura 13. Conformación de la corriente de transporte en el caso de transmisión multiprograma
3.7. Aplicaciones de la compresión de vídeoLa gran cantidad de información resultante de la digitalización de la señal de vídeo hace
que la compresión sea prácticamente una necesidad en casi todos los ámbitos. No obstante, lasdiferentes aplicaciones para las que está destinada la información de video requieren métodos yfactores de compresión diferentes, en base a la calidad que se pretenda conseguir, y al precio quese esté dispuesto a pagar.
De todos los métodos de compresión que existen, el utilizado más ampliamente en elmundo de la televisión digital es el método MPEG-2, que se ha convertido en un estándar dentrode este sector. En este apartado se tratarán todo tipo de aplicaciones; unas utilizan este estándarcomo medio de compresión, y otras no. Trataremos también de acercarnos a las ventajas einconvenientes de estos métodos en cada caso.

Vídeo Digital
36
3.7.1. Producción en estudios de televisiónEn producción existe un gran atractivo por la reducción del coste de almacenaje de vídeo
usando MPEG-2, especialmente para aplicaciones de archivo, producción de noticias y ediciónde estas. Pero las producciones y ediciones de alta calidad tienen claramente vedado el uso decompresiones elevadas debido a la necesidad de alta multigeneración.
Sin embargo, salvo que el proceso se limite al uso de imágenes codificadas sin predicción,las operaciones de inserción y borrado son difícilmente realizables directamente sobre la señalcomprimida, lo que es una limitación crítica en las aplicaciones de vídeo. MPEG-2 con imágenesexclusivamente de tipo I puede tener alguna ventaja sobre JPEG debido a la posibilidad deseleccionar la cuantificación para una misma imagen y la mayor facilidad para transmitirse comotren de datos, ya que el formato JPEG no se refiere en ningún caso a la transmisión.
Debe tenerse cuidado en las operaciones de producción que involucran múltiplesgeneraciones de manipulación de la señal. En formatos sin comprimir no sufren degradación,pero si se maneja material MPEG-2, especialmente cuando se manejan flujos binariosespecialmente dedicados a transmisión (3-9 Mb/s), la aparición de defectos en la señal puede serrápida en unos pocos procesos de compresión y descompresión.
Para solucionar los problemas de alta compresión, MPEG-2 incluye un perfil de estudio,el perfil 4:2:2, que admite regímenes binarios comprimidos de hasta 50 Mb/s. Este perfil estáteniendo gran aceptación, e incluso se empieza a utilizar en los magnetoscopios digitales. Estaposibilidad de basa en reducir el tamaño del GOP a 2 o 3 imágenes (por ejemplo: IBIBIB,IPBIPB, etc.) de manera que se pueda conseguir una acceso aleatorio sencillo, una compresiónmoderada (3,3:1), y una calidad final muy alta.
3.7.2. Periodismo electrónico (ENG - Electronic NewsGathering)
En el periodismo electrónico, la característica quizá más importante, y que se anteponea las demás es su portabilidad, que viene asociada al tamaño de los equipos y a su peso. Demanera indirecta, también es importante minimizar el consumo de los equipos, lo que redundaen un menor tamaño y peso de las baterías para una determinada autonomía de funcionamiento.Asimismo es importante, en cuanto al tamaño, el tipo de cintas necesarias para sufuncionamiento. Por estas razones, en general los equipos de periodismo electrónico utilizanformatos de muestreo menos exigentes que el conocido 4:2:2.
Generalmente, los formatos de muestreo que se utilizan en ENG son el 4:1:1 y el 4:2:0.Estos formatos de muestreo, por ser más sencillos necesitan almacenar bastante menos cantidadde información, consiguiendose un nivel de calidad bastante aceptable. Esta reducción de lacantidad de información a almacenar implicará un menor tamaño de las cintas, y un menor

Compresión de la información de vídeo
37
consumo de baterías. Pero a pesar de conseguirse un nivel de calidad aceptable, la cantidad demultigeneraciones posibles disminuye a valores entre 6 y 10.
Estos valores de multigeneración son adecuados a la aplicación que se está tratando: lacaptación de imágenes en el lugar de la noticia, y su posterior inserción en el instante adecuadode un programa. Esta aplicación no suele requerir múltiples procesos de decodificación ni grandesprocesos de edición. Por ello, a la hora de valorar la compresión de esta información, se permiteun factor de compresión mayor que en el caso de la señal de estudio. Los factores de compresiónque se suelen dar son entre 5/1 y 10/1; lo que resulta flujos binarios de 15 Mb/s a 30 Mb/s. Laaplicación de estos factores de compresión economiza las transmisiones vía satélite, cuando sonnecesarias, debido a la disminución de los requerimientos de flujo binario.
3.7.3. Transmisión y difusión de la señal de videoEn enlaces punto a punto dentro o fuera del estudio, donde se pretenda mantener una alta
multigeneración debemos aplicar las mismas ideas que el en caso de la producción dentro de losestudios. En estos casos se debe comprimir moderadamente para mantener la calidad de la señalen posibles ediciones posteriores.
En cuanto a las grandes aplicaciones de difusión directa, ya sea por vía terrestre, vía cableo fibra de vidrio, y vía satélite, éstas ya están estandarizadas en base al sistema MPEG-2. En elcaso de la difusión, no se necesita una alta multigeneración, ya que estamos al final de la cadenay los únicos procesos necesarios para la representación en pantalla serán la descompresión, y suconversión a analógico. Por ello, en difusión se permiten factores de compresión más altos.
Se estima que para conseguir calidad de estudio, según la recomendación 601, se necesitaun sistema con velocidad binaria de unos 9Mb/s. Para una calidad equivalente al PAL senecesitan unos 5 Mb/s.
En la actualidad, los satélites de radiodifusión directa actúan como plataformas digitalesde canales de televisión temáticos con posibilidad de distribución de múltiples canalesespecializados en documentales, deportivos, cine, etc. que tratan de competir con el mercado dealquiler de vídeos.
3.7.4. Servidores de videoLos servidores de video para “vídeo bajo demanda” deben almacenar grandes cantidades
de vídeo digital, para que pueda haber un acceso rápido y su posterior transmisión. Los ahorrosen coste de almacenamiento usando compresión MPEG-2 son muy altos, aunque el accesoaleatorio es más complicado que en el material sin comprimir, es posible. En este campo existemucha competencia entre diversos métodos de compresión

Vídeo Digital
38
3.7.5. MultimediaLa compresión de imágenes en los ordenadores tiene su justificación por la poca
capacidad de almacenamiento de los ordenadores domésticos. La escasa implantación en elordenador de sistemas hardware de compresión de vídeo hace que se utilicen en generalalgoritmos software que permitan una alta compresión, aunque no en tiempo real. La necesidadde multigeneración es, en general, baja.
Existen diversos algoritmos de compresión diferentes para su uso con ordenadores,muchos de ellos en base a archivos AVI, lo que quizá dificulta su identificación. Incluso seutilizan algoritmos MJPEG. Estos algoritmos proporcionan una menor calidad a mayor régimenbinario que el formato MPEG al trabajar cuadro a cuadro pero son más económicos. También seutiliza en muchos casos el formato MPEG-1 por su afinidad directa con las posibilidades desoporte CD.
La posible mayor calidad visual de MPEG-2 es atractiva pero requiere una mayor potenciade procesamiento y decodificación. A falta de que se abaraten algo más las tarjetas codificadoras,existen codificadores, no en tiempo real, por software. La progresiva introducción de la familiade discos DVD junto con interfaces y buses más rápidos pueden mejorar las aplicacionesmultimedia basadas en ordenador de propósito general y la codificación MPEG-2.
Otro formato muy utilizado en aplicaciones multimedia por su capacidad de compresiónes el formato MPEG-4. Para este formato existen codificadores software, que aunque no trabajenen tiempo real, ofrecen una calidad razonable con compresiones bastante altas.
3.7.6. Sistemas domésticosLa implantación del DVD como soporte digital para películas de consumo supone la
implantación de MPEG-2 como formato de señal digital en este entorno, ya que el DVD grabapelículas en este formato. El secreto de su implantación es que para ver películas grabadas sóloes necesario el decodificador MPEG-2, que es el elemento más barato de la cadena. Es la mismasituación que las aplicaciones de difusión de TV digital. Otra cuestión es si será tan económicoel grabador de DVD, con codificador MPEG-2. Ese es el punto clave para su generalizacióncomo sustituto del magnetoscopio doméstico.
En cuanto a estos magnetoscopios, la compresión puede disminuir el coste de unvideograbador respecto de su versión sin comprimir dado que los regímenes binarios requeridosson más bajos. Sin embargo un magnetoscopio económico para el consumo requiere uncodificador sencillo, y económico. La codificación MPEG-2 a este nivel de precio está todavíalejana. Por tanto otros formatos menos comprimidos empezarán a dominar la grabacióndoméstica, como es el caso del DV.

Compresión de la información de vídeo
39
3.7.7. VideoconferenciaLas videoconferencias o los enlaces en directo, el retardo que sufre la señal que se
codifica cuando se usan imágenes B puede convertir a MPEG-2 en inútil para la comunicaciónen ambos sentidos. MPEG-2 puede ser utilizado, pero sin cuadros tipo B. No obstante lacodificación que más se utiliza en la actualidad para estas aplicaciones, y que además fuediseñada para ello es el formato MPEG-4. Éste permite la comunicación con regímenes binariosmuy bajos y con una calidad aceptable, con la sola condición de que se limite el movimiento delos objetos en la escena a transmitir.
3.8. Compresión y descompresión en cascadaDadas las diferentes aplicaciones de la compresión de vídeo, en un sistema pueden
encontrarse varias etapas o procesos de compresión-descompresión en cascada. Las sucesivascompresiones y descompresiones cuando se utiliza el mismo algoritmo causan un deterioroprogresivo en la calidad de la imagen en función del factor de compresión empleado.
Si se utilizan algoritmos distintos, con distintos criterios aritméticos, supresión de píxeles,etc. pueden llegar a producirse resultados de degradación imprevisibles. Por ello se recomiendautilizar el mismo algoritmo e incluso el mismo factor de compresión en toda la cadena deproducción de vídeo.

Vídeo Digital
40
3.9. BibliografíaBethencourt Machado, T. “Televisión DIgital” Colección Beta. Temas audiovisuales.
(2001)
Gavilán Estelat, E. “MPEG-2 Pieza clave de la televisión digital” Unidad Didáctica 146IORTV.
Martín Marcos, A. “Compresión de imágenes JPEG”. Ciencia 3. 1999.
Martín Marcos, A. “Televisión Digital Norma MPEG-2 (video)”. Ciencia 3. 1998.
Mead, D. C. “Direct Broadcast Satellite Comunications. An MPEG enabled service.Addison-Wesley. 1999
Mitchell, J.L. “MPEG Video Compression Standard” International Thompson Publishing”1996.
Mossi García, J.M. “Sistemas de televisión”. Servicio Publicaciones UPV.
Ortiz Berenguer, L. “TV Digital: MPEG-2 y DVB”. Servicio Publicaciones UPM. 1999.
Riley, M.J. “Digital Video Communications”. Artech House. 1997.
Tejerina, J.L. “Bit-rate reduction of HDTV, based on Discrete Cosine Transform”.Artículo de Telettra, nº45.