computational intelligence methods for information understanding and information management...
Post on 19-Dec-2015
222 views
TRANSCRIPT

Computational intelligence methods for Computational intelligence methods for information understanding information understanding
and information management and information management
Computational intelligence methods for Computational intelligence methods for information understanding information understanding
and information management and information management
Włodzisław DuchWłodzisław Duch
Department of InformaticsDepartment of InformaticsNicolaNicolauus Copernicus Universitys Copernicus University, , Torun, PolandTorun, Poland
&&School of Computer Engineering,School of Computer Engineering,
Nanyang Technological UniversityNanyang Technological University, , SingaporeSingapore
IIMSMS2002005, Kunming, China5, Kunming, China

PlanPlanPlanPlanWhat is this about ?
• How to discover knowledge in data; • how to create comprehensible models of data; • how to evaluate new data;• how to understand what computational intelligence (CI)
methods really do.
1. AI, CI & Data Mining2. Forms of useful knowledge3. Integration of different methods in GhostMiner 4. Exploration & Visualization5. Rule-based data analysis 6. Neurofuzzy models7. Neural models, understanding what they do8. Similarity-based models, prototype rules9. Case studies10. From data to expert system

AI, CI & DMAI, CI & DMAI, CI & DMAI, CI & DM
Artificial Intelligence: symbolic models of knowledge. • Higher-level cognition: reasoning, problem solving,
planning, heuristic search for solutions.• Machine learning, inductive, rule-based methods.• Technology: expert systems.
Computational Intelligence, Soft Computing:
methods inspired by many sources:
• biology – evolutionary, immune, neural computing
• statistics, patter recognition
• probability – Bayesian networks
• logic – fuzzy, rough …
Perception, object recognition.
Data Mining, Knowledge Discovery in Databases.
• discovery of interesting rules, knowledge => info understanding.
• building predictive data models => part of info management.

Forms of useful knowledgeForms of useful knowledgeForms of useful knowledgeForms of useful knowledge
AI/Machine Learning camp:
Neural nets are black boxes.
Unacceptable! Symbolic rules forever.
But ... knowledge accessible to humans is in:
• symbols and rules; • similarity to prototypes, structures, known cases;• images, visual representations.
What type of explanation is satisfactory?Interesting question for cognitive scientists but ...
in different fields answers are different!

Forms of knowledgeForms of knowledgeForms of knowledgeForms of knowledge
3 types of explanation presented here: • logic-based: symbols and rules;• exemplar-based: prototypes and similarity of structures;• visualization-based: maps, diagrams, relations ...
• Humans remember examples of each category and refer to such examples – as similarity-based, case based or nearest-neighbors methods do.
• Humans create prototypes out of many examples – as Gaussian classifiers, RBF networks, or neurofuzzy systems modeling probability densities do.
• Logical rules are the highest form of summarization of simple forms of knowledge;
• Bayesian networks present complex relationships.

GhostMiner PhilosophyGhostMiner PhilosophyGhostMiner PhilosophyGhostMiner Philosophy
• There is no free lunch – provide different type of tools for knowledge discovery. Decision tree, neural, neurofuzzy, similarity-based, SVM, committees.
• Provide tools for visualization of data.
• Support the process of knowledge discovery/model building and evaluating, organizing it into projects.
GhostMiner tools for data mining & knowledge discovery, from our lab + Fujitsu: http://www.fqspl.com.pl/ghostminer/
• Separate the process of model building (hackers) and knowledge
discovery, from model use (lamers) =>
GhostMiner Developer & GhostMiner Analyzer (ver. 3.0 & newer)

Wine data exampleWine data exampleWine data exampleWine data example
• alcohol content • ash content • magnesium content • flavanoids content • proanthocyanins phenols content • OD280/D315 of diluted wines
Chemical analysis of wine from grapes grown in the same region in Italy, but derived from three different cultivars.
Task: recognize the source of wine sample.13 quantities measured, all features are continuous:
• malic acid content • alkalinity of ash • total phenols content • nonanthocyanins phenols
content • color intensity • hue• proline.
Wine sample => 13 numerical quantities => feature space rep. Complex structures: no feature space, only Similarity(A,B) known.
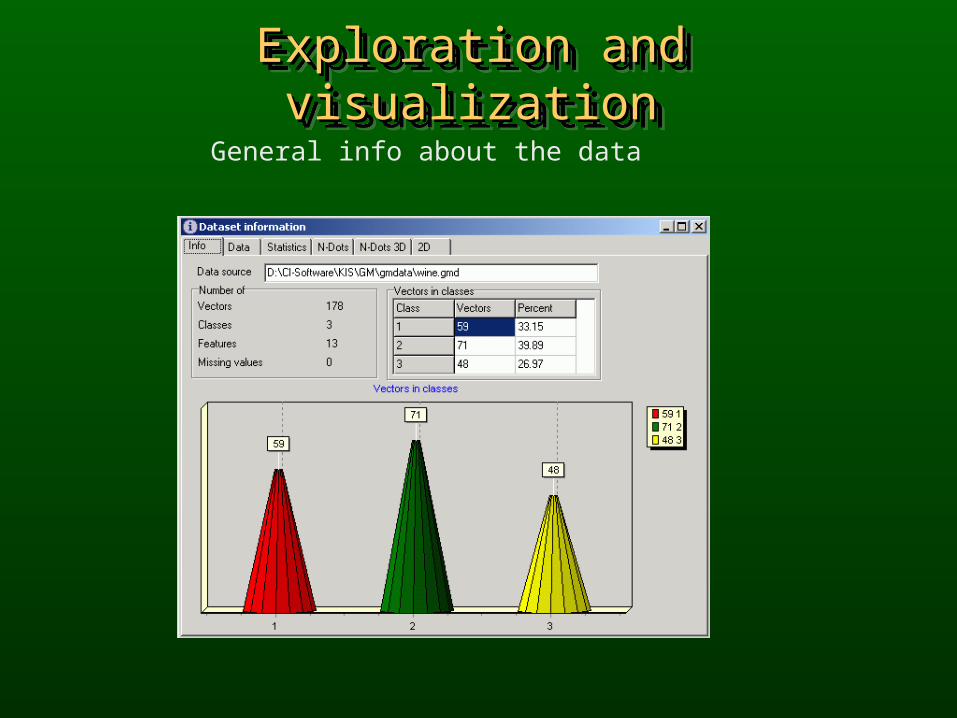
Exploration and visualizationExploration and visualizationExploration and visualizationExploration and visualization
General info about the data
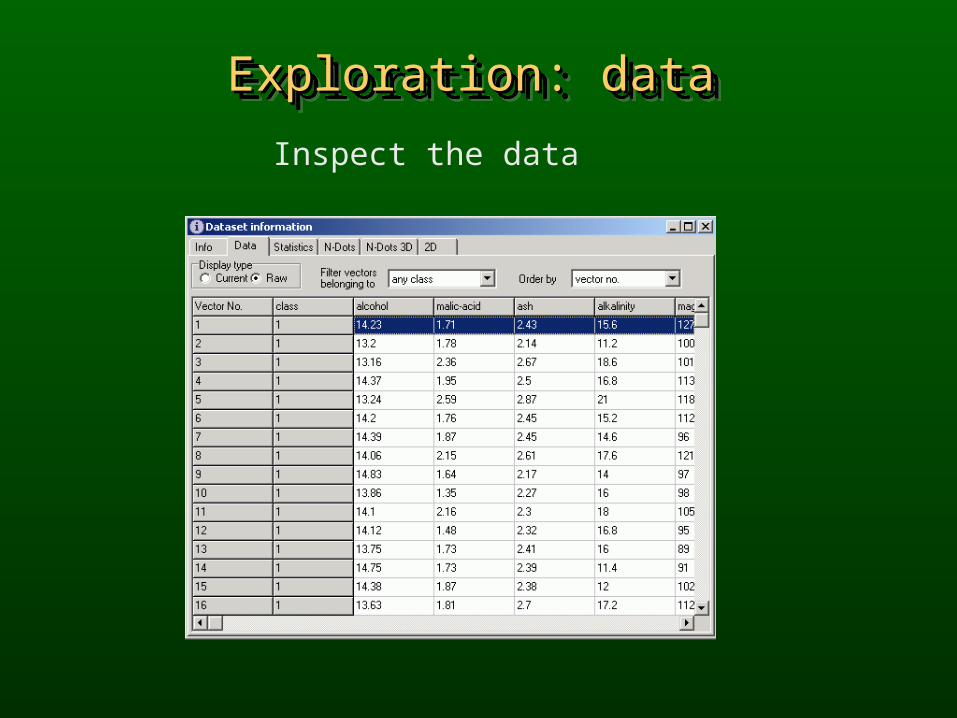
Exploration: dataExploration: dataExploration: dataExploration: data
Inspect the data
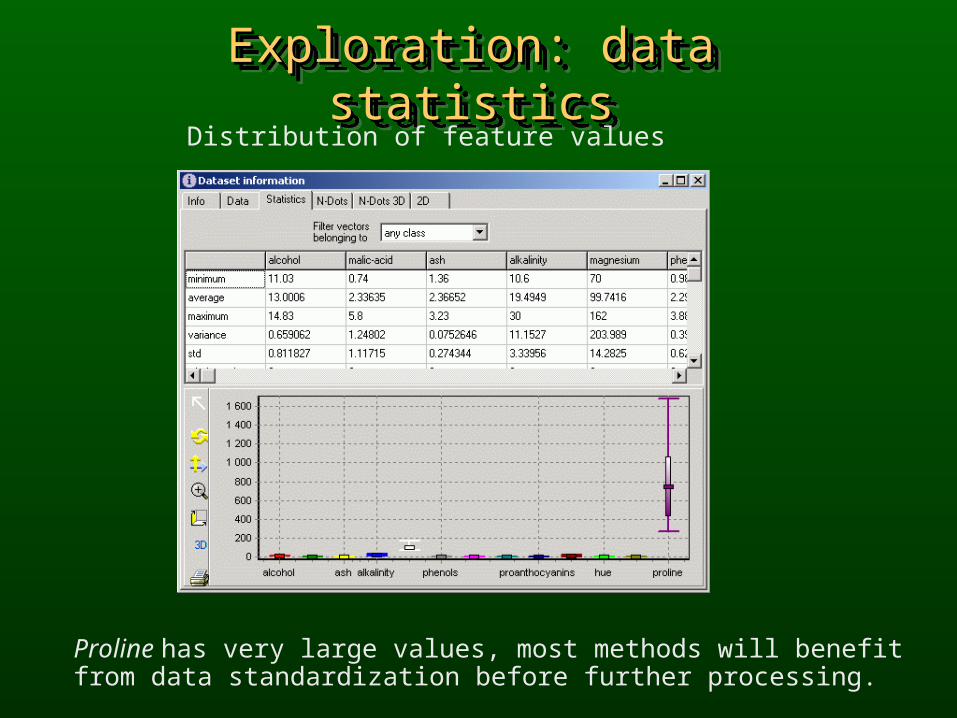
Exploration: data statisticsExploration: data statisticsExploration: data statisticsExploration: data statisticsDistribution of feature values
Proline has very large values, most methods will benefit from data standardization before further processing.
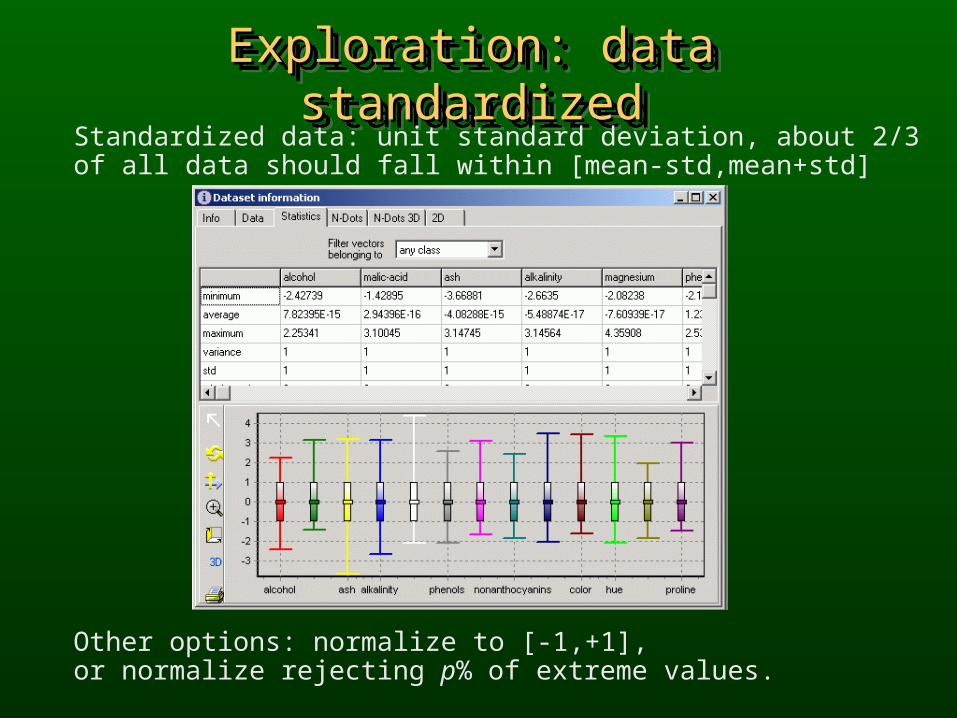
Exploration: data standardizedExploration: data standardizedExploration: data standardizedExploration: data standardizedStandardized data: unit standard deviation, about 2/3 of all data should fall within [mean-std,mean+std]
Other options: normalize to [-1,+1], or normalize rejecting p% of extreme values.

Exploration: 1D histogramsExploration: 1D histogramsExploration: 1D histogramsExploration: 1D histograms
Distribution of feature values in classes
Some features are more useful than the others.
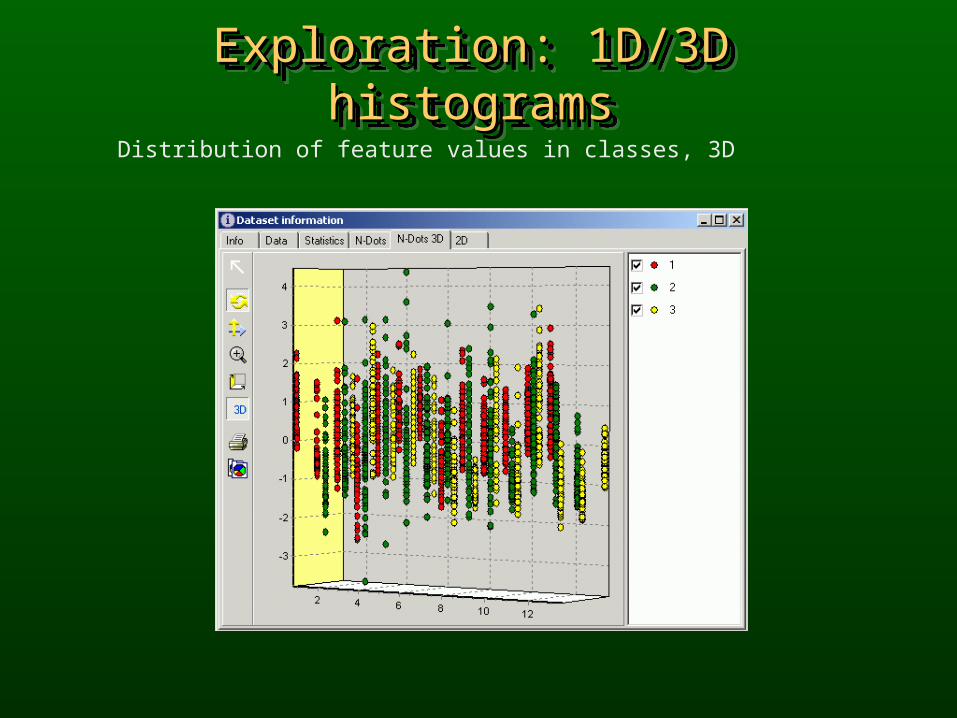
Exploration: 1D/3D histogramsExploration: 1D/3D histogramsExploration: 1D/3D histogramsExploration: 1D/3D histograms
Distribution of feature values in classes, 3D
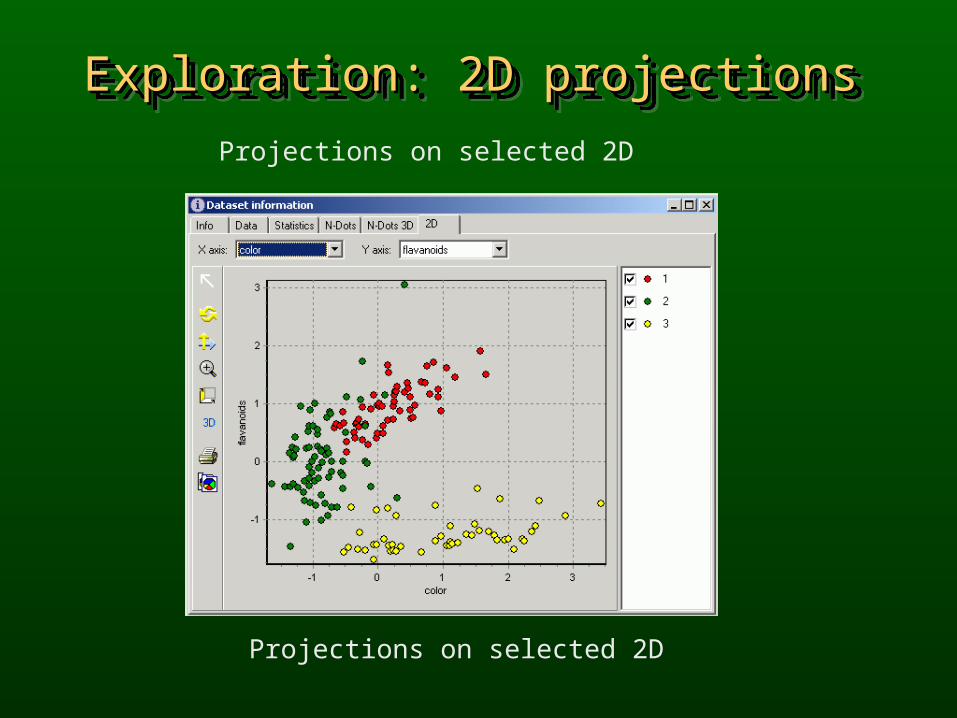
Exploration: 2D projectionsExploration: 2D projectionsExploration: 2D projectionsExploration: 2D projections
Projections on selected 2D
Projections on selected 2D

Visualize data Visualize data Visualize data Visualize data
Hard to imagine relations in more than 3D.
Linear methods: PCA, FDA, PP ... use input combinations.
SOM mappings: popular for visualization, but rather inaccurate, there is no measure of distortions.
Measure of topographical distortions: map all Xi points from Rn to xi points in Rm, m < n, and ask:
how well are Rij = D(Xi, Xj) distances reproduced
by distances rij = d(xi,xj) ?
Use m = 2 for visualization,
use higher m for dimensionality reduction.

Visualize data: MDSVisualize data: MDSVisualize data: MDSVisualize data: MDS
Multidimensional scaling: invented in psychometry by Torgerson (1952), re-invented by Sammon (1969) and myself (1994) …
Minimize measure of topographical distortions moving the x coordinates.
2
1 2
2
2
2
3
1MDS
11Sammon
11 MDS, more local
ij iji jij
i j
ij
i jij iji j
ij iji jij
i j
S R rR
rS
R R
S r RR
x x
xx
x x

Visualize data: WineVisualize data: WineVisualize data: WineVisualize data: Wine
3 clusters are clearly distinguished, 2D is fine.
The green outlier can be identified easily.

Decision treesDecision treesDecision treesDecision treesSimplest things first: use decision tree to find logical rules.
Test single attribute, find good point to split the data, separating vectors from different classes. DT advantages: fast, simple, easy to understand, easy to program, many good algorithms.

Decision bordersDecision bordersDecision bordersDecision bordersUnivariate trees: test the value of a single attribute x < a.
Multivariate trees:test on combinations of attributes.
Result: feature space is divided into large hyperrectangular areas with decision borders perpendicular to axes.

Splitting criteriaSplitting criteriaSplitting criteriaSplitting criteriaMost popular: information gain, used in C4.5 and other trees.
CART trees use Gini index of node purity:
Which attribute is better?
Which should be at the top of the tree?
Look at entropy reduction, or information gain index.2 2( ) lg lgt t f fE S P P P P
( , ) ( ) ( ) ( )S S
G S A E S E S E SS S
2
1
1C
ini ii
G node P

Non-Bayesian selectionNon-Bayesian selectionNon-Bayesian selectionNon-Bayesian selectionBayesian MAP selection: choose max a posteriori P(C|X)
Problem: for binary features non-optimal decisions are taken! But estimation of P(C,A) for non-binary features is not reliable.
A=0 A=1
P(C,A1) 0.0100 0.4900 P(C0)=0.5 0.0900 0.4100 P(C1)=0.5
P(C,A2) 0.0300 0.4700 0.1300 0.3700 P(C|X)=P(C,X)/P(X)
MAP is here equivalent to a majority classifier (MC): given A=x, choose maxC P(C,A=x)
MC(A1)=0.58, S+=0.98, S-=0.18, AUC=0.58, MI= 0.058
MC(A2)=0.60, S+=0.94, S-=0.26, AUC=0.60, MI= 0.057
MC(A1)<MC(A2), AUC(A1)<AUC(A2), but MI(A1)>MI(A2) !

SSV decision treeSSV decision treeSSV decision treeSSV decision treeSeparability Split Value tree: based on the separability criterion.
SSV criterion: separate as many pairs of vectors from different classes as possible; minimize the number of separated from the same class.
( ) 2 , , , ,
min , , , , ,
c cc C
c cc C
SSV s LS s f D D RS s f D D D
LS s f D D RS s f D D
, , : ( , ) T
, , , ,
LS s f D D f s
RS s f D D LS s f D
X X
Define subsets of data D using a binary test f(X,s) to split the data
into left and right subset D = LS RS.

SSV – complex treeSSV – complex treeSSV – complex treeSSV – complex treeTrees may always learn to achieve 100% accuracy.
Very few vectors are left in the leaves – splits are not reliable and will overfit the data!

SSV – simplest treeSSV – simplest treeSSV – simplest treeSSV – simplest treePruning finds the nodes that should be removed to increase generalization – accuracy on unseen data.
Trees with 7 nodes left: 15 errors/178 vectors.

SSV – logical rulesSSV – logical rulesSSV – logical rulesSSV – logical rulesTrees may be converted to logical rules.Simplest tree leads to 4 logical rules:
1. if proline > 719 and flavanoids > 2.3 then class 1
2. if proline < 719 and OD280 > 2.115 then class 2
3. if proline > 719 and flavanoids < 2.3 then class 3
4. if proline < 719 and OD280 < 2.115 then class 3
How accurate are such rules? Not 15/178 errors, or 91.5% accuracy!
Run 10-fold CV and average the results.85±10%? Run 10X and average85±10%±2%? Run again ...
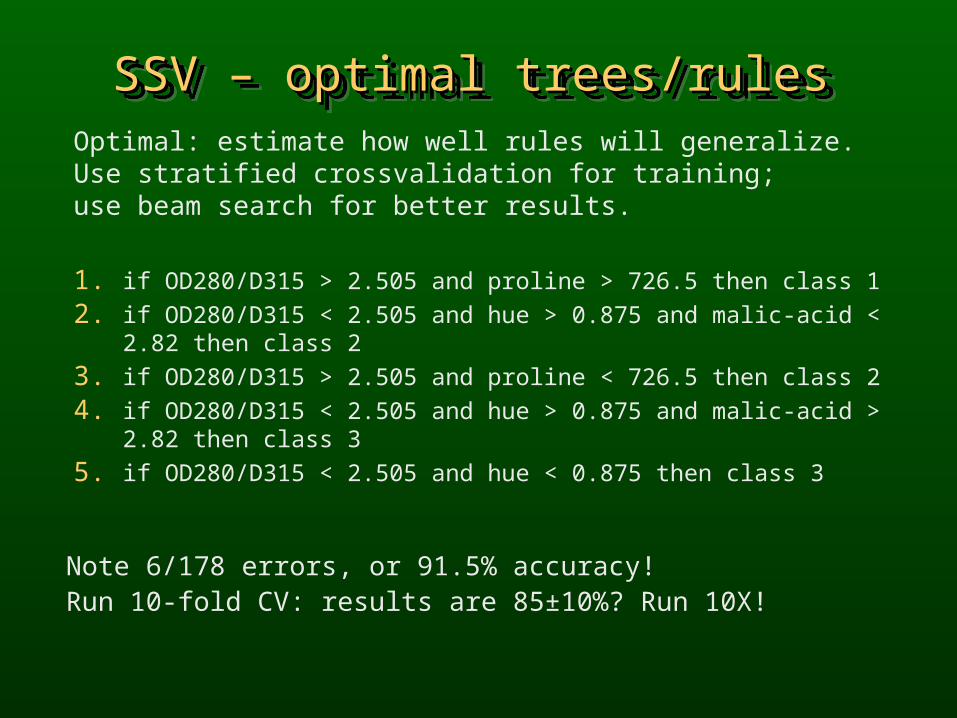
SSV – optimal trees/rulesSSV – optimal trees/rulesSSV – optimal trees/rulesSSV – optimal trees/rulesOptimal: estimate how well rules will generalize.Use stratified crossvalidation for training;use beam search for better results.
1. if OD280/D315 > 2.505 and proline > 726.5 then class 1
2. if OD280/D315 < 2.505 and hue > 0.875 and malic-acid < 2.82 then class 2
3. if OD280/D315 > 2.505 and proline < 726.5 then class 2
4. if OD280/D315 < 2.505 and hue > 0.875 and malic-acid > 2.82 then class 3
5. if OD280/D315 < 2.505 and hue < 0.875 then class 3
Note 6/178 errors, or 91.5% accuracy! Run 10-fold CV: results are 85±10%? Run 10X!

Logical rulesLogical rulesCrisp logic rules: for continuous x use linguistic variables (predicate functions).
sk(x) ş True [XkŁ x ŁX'k], for example: small(x) = True{x|x < 1}medium(x) = True{x|x [1,2]}large(x) = True{x|x > 2}
Linguistic variables are used in crisp (prepositional, Boolean) logic rules:
IF small-height(X) AND has-hat(X) AND has-beard(X) THEN (X is a Brownie) ELSE IF ... ELSE ...

Crisp logic decisionsCrisp logic decisionsCrisp logic decisionsCrisp logic decisions
Crisp logic is based on rectangular membership functions:
True/False values jump from 0 to 1.
Step functions are used for partitioning of the feature space.
Very simple hyper-rectangular decision borders.
Expressive power of crisp logical rules is very limited!
Similarity cannot be captured by rules.

Logical rules - advantagesLogical rules - advantagesLogical rules - advantagesLogical rules - advantagesLogical rules, if simple enough, are preferable.
• Rules may expose limitations of black box solutions.
• Only relevant features are used in rules.
• Rules may sometimes be more accurate than NN and other CI methods.
• Overfitting is easy to control, rules usually have small number of parameters.
• Rules forever !? A logical rule about logical rules is:
IF the number of rules is relatively smallAND the accuracy is sufficiently high. THEN rules may be an optimal choice.

Logical rules - limitationsLogical rules - limitationsLogical rules - limitationsLogical rules - limitationsLogical rules are preferred but ...
• Only one class is predicted p(Ci|X,M) = 0 or 1; such black-and-white picture may be inappropriate in many applications.
• Discontinuous cost function allow only non-gradient optimization methods, more expensive.
• Sets of rules are unstable: small change in the dataset leads to a large change in structure of sets of rules.
• Reliable crisp rules may reject some cases as unclassified.
• Interpretation of crisp rules may be misleading.
• Fuzzy rules remove some limitations, but are not so comprehensible.

Fuzzy inputs vs. fuzzy rulesFuzzy inputs vs. fuzzy rulesFuzzy inputs vs. fuzzy rulesFuzzy inputs vs. fuzzy rules
Crisp rule Ra(x) = (xa) applied to uncertain input with uniform input uncertainty U(x;x)=1 in xx, xx] and zero outside is true to the degree given by a semi-linear function S(x;x):
For example, triangular U(x): leads to sigmoidal S(x) function.For more input conditions rules are true to the degree described by soft trapezoidal functions, difference of two sigmoidal functions.
Input uncertainty and the probability
that Ra(x) rule is true.
For other input uncertainties similar relations hold!
Crisp rules + input uncertainty fuzzy rules for crisp inputs = MLP !

From rules to probabilitiesFrom rules to probabilitiesFrom rules to probabilitiesFrom rules to probabilitiesData has been measured with unknown error. Assume Gaussian distribution:
( ; , )x xx G G y x s
x – fuzzy number with Gaussian membership function.
A set of logical rules R is used for fuzzy input vectors: Monte Carlo simulations for arbitrary system => p(Ci|X)
Analytical evaluation p(C|X) is based on cumulant function:
1; , 1 erf ( )
2 2
a
x
x
a xa x G y x s dy a x
s
2.4 / 2 xs Error function is identical to logistic f. < 0.02

Rules - choicesRules - choicesRules - choicesRules - choicesSimplicity vs. accuracy.
Confidence vs. rejection rate.
true | predicted r
r
p p p pp
p p p p
Accuracy (overall) A(M) = p+ p
Error rate L(M) = p+ p Rejection rate R(M)=p+r+pr= 1L(M)A(M)Sensitivity S+(M)= p+|+ = p++ /p+
Specificity S(M)= p = p /p
p is a hit; p false alarm; p is a miss.

Rules – error functionsRules – error functionsRules – error functionsRules – error functions
The overall accuracy is equal to a combination of sensitivity and selectivity weighted by the a priori probabilities:
A(M) = pS(M)+pS(M)
Optimization of rules for the C+ class;
large means no errors but high rejection rate.
E(M)= L(M)A(M)= (p+p) (p+p)minM E(M;) minM {(1+)L(M)+R(M)}
Optimization with different costs of errors
minM E(M;) = minM {p+ p} = minM {pS(M))pr(M) + [pS(M))pr(M)]}
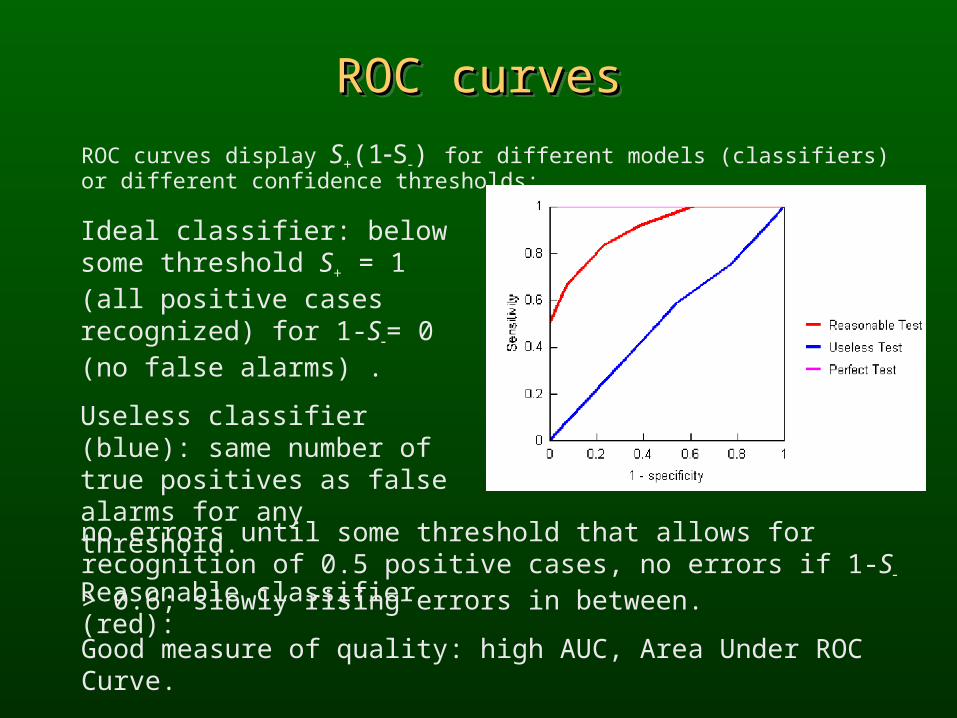
ROC curvesROC curvesROC curvesROC curves
ROC curves display S+(1S) for different models (classifiers) or different confidence thresholds:
Ideal classifier: below some threshold S+ = 1 (all positive cases recognized) for 1-S= 0 (no false alarms) .
Useless classifier (blue): same number of true positives as false alarms for any threshold.
Reasonable classifier (red): no errors until some threshold that allows for recognition of 0.5 positive cases, no errors if 1-S > 0.6; slowly rising errors in between.
Good measure of quality: high AUC, Area Under ROC Curve.
AUC = 0.5 is random guessing, AUC = 1 is perfect prediction.

Gaussian fuzzification of crisp rulesGaussian fuzzification of crisp rulesGaussian fuzzification of crisp rulesGaussian fuzzification of crisp rulesVery important case: Gaussian input uncertainty.
Rule Ra(x) = {xa} is fulfilled by Gx with probability:
( ) T ; , ( )a x x
a
p R G G y x s dy x a
Error function is approximated by logistic function;
assuming error distribution (x)x)), for s2=1.7 approximates Gauss < 3.5%
Rule Rab(x) = {b> x a} is fulfilled by Gx with
probability:
( ) T ; , ( ) ( )b
ab x x
a
p R G G y x s dy x a x b

Soft trapezoids and NNSoft trapezoids and NNSoft trapezoids and NNSoft trapezoids and NNThe difference between two sigmoids makes a soft trapezoidal membership functions.
Conclusion: fuzzy logic with soft trapezoidal membership functions
(x) (x-b) to a crisp logic + Gaussian uncertainty of inputs.

Optimization of rulesOptimization of rulesOptimization of rulesOptimization of rules
Fuzzy: large receptive fields, rough estimations.Gx – uncertainty of inputs, small receptive fields.
Minimization of the number of errors – difficult, non-gradient, but
now Monte Carlo or analytical p(C|X;M).
21{ }; , | ; ( ),
2x i iX i
E X R s p C X M C X C
• Gradient optimization works for large number of parameters.
• Parameters sx are known for some features, use them as
optimization parameters for others! • Probabilities instead of 0/1 rule outcomes.• Vectors that were not classified by crisp rules have now non-zero
probabilities.

MushroomsMushroomsMushroomsMushroomsThe Mushroom Guide: no simple rule for mushrooms; no rule like: ‘leaflets three, let it be’ for Poisonous Oak and Ivy.
8124 cases, 51.8% are edible, the rest non-edible. 22 symbolic attributes, up to 12 values each, equivalent to 118 logical features, or 2118=31035 possible input vectors.
Cap Shape: bell, conical, convex, flat, knobbed, sunkenCap Surface: fibrous, grooves, scaly, smoothCap Color: brown, buff, cinnamon, gray, green, pink, red, white, yellowBruises: bruised, not bruisedOdor: almond, anise, creosote, fishy, foul, musty, none, pungent, spicySpore print color: black, brown, buff, chocolate, green ...yellow.Gill Attachment: attached, descending, free, notchedGill Spacing: close, crowded, distantPopulation: abundant, clustered, numerous, scattered, several, solitaryHabitat: grasses, leaves, meadows, paths, urban, waste, woods ...

Mushrooms dataMushrooms dataMushrooms dataMushrooms data
Mushroom-3 is: edible, bell, smooth, white, bruises, almond, free, close, broad, white, enlarging, club, smooth, smooth, white, white, partial, white, one, pendant, black, scattered, meadows
Mushroom-4 is: poisonous, convex, smooth, white, bruises, pungent, free, close, narrow, white, enlarging, equal, smooth, smooth, white, white, partial, white, one, pendant, black, scattered, urban
Mushroom-5 is: poisonous, convex, smooth, white, bruises, pungent, free, close, narrow, pink, enlarging, equal, smooth, smooth, white, white, partial, white, one, pendant, black, several, urban
Mushroom-8000 is: poisonous, convex, smooth, white, bruises, pungent, free, close, narrow, pink, enlarging, equal, smooth, smooth, white, white, partial, white, one, pendant, brown, scattered, urban.
What knowledge is hidden in this data?

Mushroom ruleMushroom ruleMushroom ruleMushroom rule
Safe rule for edible mushrooms found by the SSV decision tree and MLP2LN network: IF odor is none or almond or anise AND spore_print_color is not green THEN mushroom is edible
This rule makes only 48 errors, is 99.41% correct.
This is why animals have such a good sense of smell ! What does it tell us about odor receptors in animal noses ?
This rule has been quoted by > 50 encyclopedias so far!
To eat or not to eat, this is the question! Well, not any more ...

Mushrooms rulesMushrooms rulesMushrooms rulesMushrooms rulesTo eat or not to eat, this is the question! Well, not any more ...
A mushroom is poisonous if: R1) odor = Ř (almond anise none); 120 errors, 98.52% R2) spore-print-color = green 48 errors, 99.41% R3) odor = none Ů stalk-surface-below-ring = scaly Ů stalk-color-above-ring = Ř brown 8 errors, 99.90% R4) habitat = leaves Ů cap-color = white no errors!
R1 + R2 are quite stable, found even with 10% of data; R3 and R4 may be replaced by other rules, ex:
R'3): gill-size=narrow Ů stalk-surface-above-ring=(silky scaly) R'4): gill-size=narrow Ů population=clustered
Only 5 of 22 attributes used! Simplest possible rules? 100% in CV tests - structure of this data is completely clear.
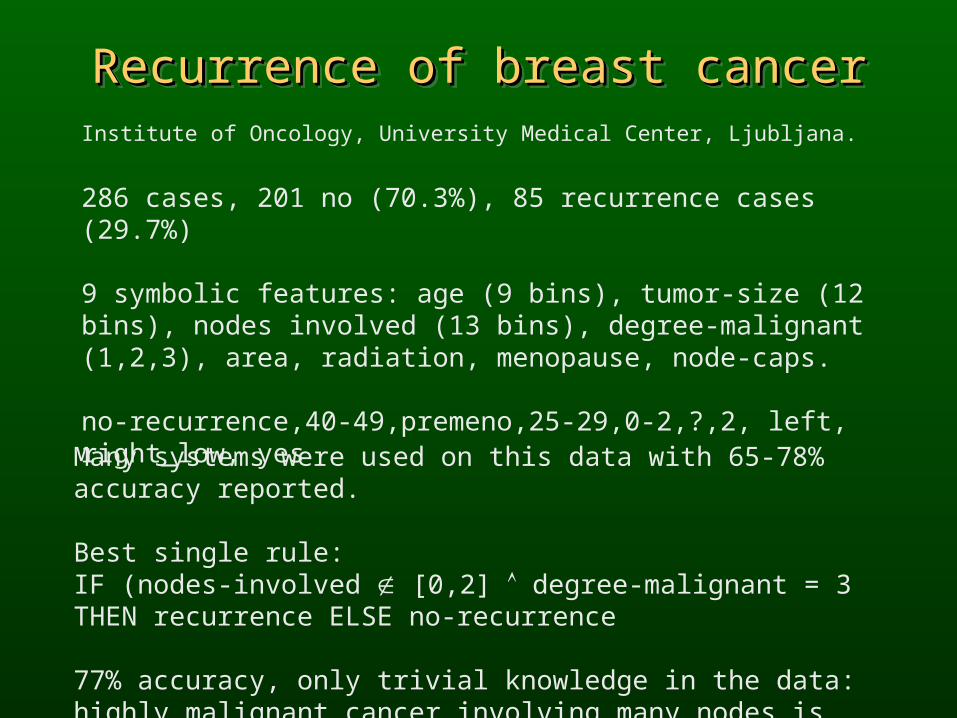
Recurrence of breast cancerRecurrence of breast cancerRecurrence of breast cancerRecurrence of breast cancerInstitute of Oncology, University Medical Center, Ljubljana.
286 cases, 201 no (70.3%), 85 recurrence cases (29.7%)
9 symbolic features: age (9 bins), tumor-size (12 bins), nodes involved (13 bins), degree-malignant (1,2,3), area, radiation, menopause, node-caps. no-recurrence,40-49,premeno,25-29,0-2,?,2, left, right_low, yes
Many systems were used on this data with 65-78% accuracy reported.
Best single rule:IF (nodes-involved [0,2] degree-malignant = 3 THEN recurrence ELSE no-recurrence
77% accuracy, only trivial knowledge in the data: highly malignant cancer involving many nodes is likely to strike back.

Neurofuzzy systemNeurofuzzy systemNeurofuzzy systemNeurofuzzy system
Feature Space Mapping (FSM) neurofuzzy system (1995).Neural adaptation, estimation of probability density distribution (PDF) using single hidden layer network (RBF-like), with nodes realizing separable functions (like in Naive Bayes):
1
; ;i i ii
G X P G X P
Sometimes crisp logical rules may fail.
Fuzzy: x(no/yes) replaced by a degree x. Triangular, trapezoidal, Gaussian or other membership f.
M.f-s in many dimensions:

FSMFSMFSMFSM
Rectangular functions: simple rules are created, many nearly equivalent descriptions of this data exist.
If proline > 929.5 then class 1 (48 cases, 45 correct + 2 recovered by other rules).
If color < 3.79285 then class 2 (63 cases, 60 correct)
Interesting rules, but overall accuracy is only 88±9%
Initialize using clusterization or decision trees.Triangular & Gaussian f. for fuzzy rules.Rectangular functions for crisp rules.
Between 9-14 rules with triangular membership functions are created; accuracy in 10xCV tests about 96±4.5%
Similar results obtained with Gaussian functions.

Prototype-based rulesPrototype-based rulesPrototype-based rulesPrototype-based rules
IF P = arg minR D(X,R) THAN Class(X)=Class(P)
C-rules (Crisp), are a special case of F-rules (fuzzy rules).F-rules (fuzzy rules) are a special case of P-rules (Prototype).P-rules have the form:
D(X,R) is a dissimilarity (distance) function, determining decision borders around prototype P.
P-rules are easy to interpret! F-rules may always be presented as P-rules, so this is an alternative to neurofuzzy systems.
IF X=You are most similar to the P=SupermanTHAN You are in the Super-league.
IF X=You are most similar to the P=Weakling THAN You are in the Failed-league.
“Similar” may involve different features or D(X,P).

P-rulesP-rulesP-rulesP-rulesEuclidean distance leads to a Gaussian fuzzy membership functions + product as T-norm.
Manhattan function => (X;P)=exp{|X-P|}
Various distance functions lead to different MF.Ex. data-dependent distance functions, for symbolic data:
2
2
,,
, ,
,i i
i i ii
i i i i ii i
d X PW X PD
P i i ii i
D d X P W X P
e e e X P
X P
X P
X
, | |
, | |
VDM j i j ii j
PDF i j j ii j
D p C X p C Y
D p X C p C Y
X Y
X Y
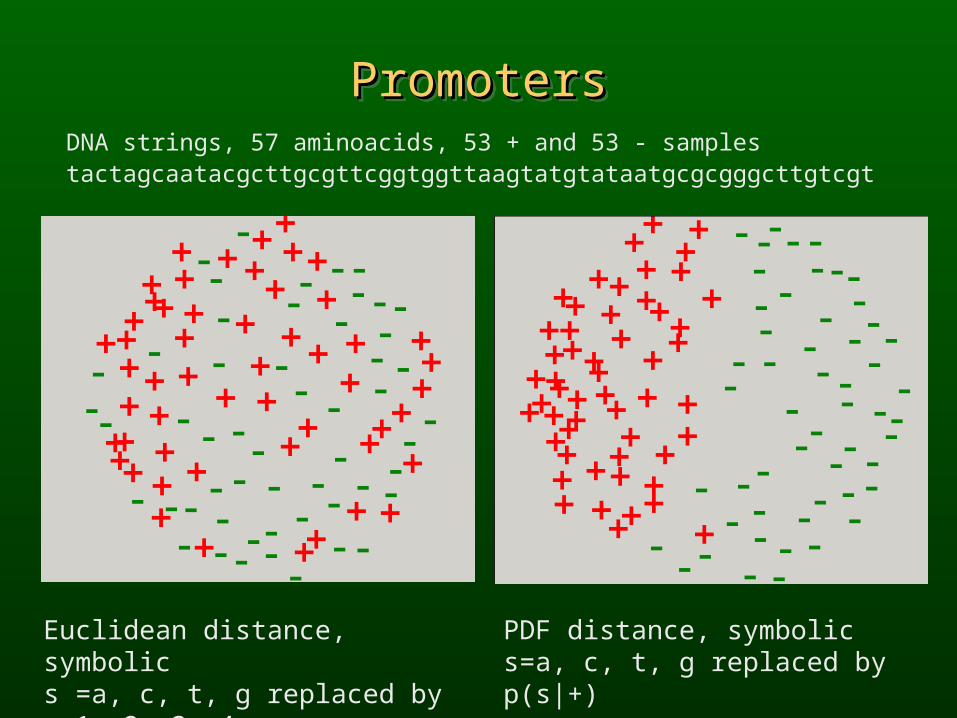
PromotersPromotersPromotersPromotersDNA strings, 57 aminoacids, 53 + and 53 - samples tactagcaatacgcttgcgttcggtggttaagtatgtataatgcgcgggcttgtcgt
Euclidean distance, symbolic s =a, c, t, g replaced by x=1, 2, 3, 4
PDF distance, symbolic s=a, c, t, g replaced by p(s|+)

P-rulesP-rulesP-rulesP-rulesNew distance functions from info theory => interesting MF.
MF => new distance function, with local D(X,R) for each cluster.
Crisp logic rules: use Chebyshev distance (L norm):
DCh(X,P) = ||XP|| = maxi Wi |XiPi|
DCh(X,P) = const => rectangular contours.
Chebyshev distance with thresholds P
IF DCh(X,P) P THEN C(X)=C(P)
is equivalent to a conjunctive crisp rule
IF X1[P1PW1,P1PW1] …XN [PN PWN, PNPWN]THEN C(X)=C(P)
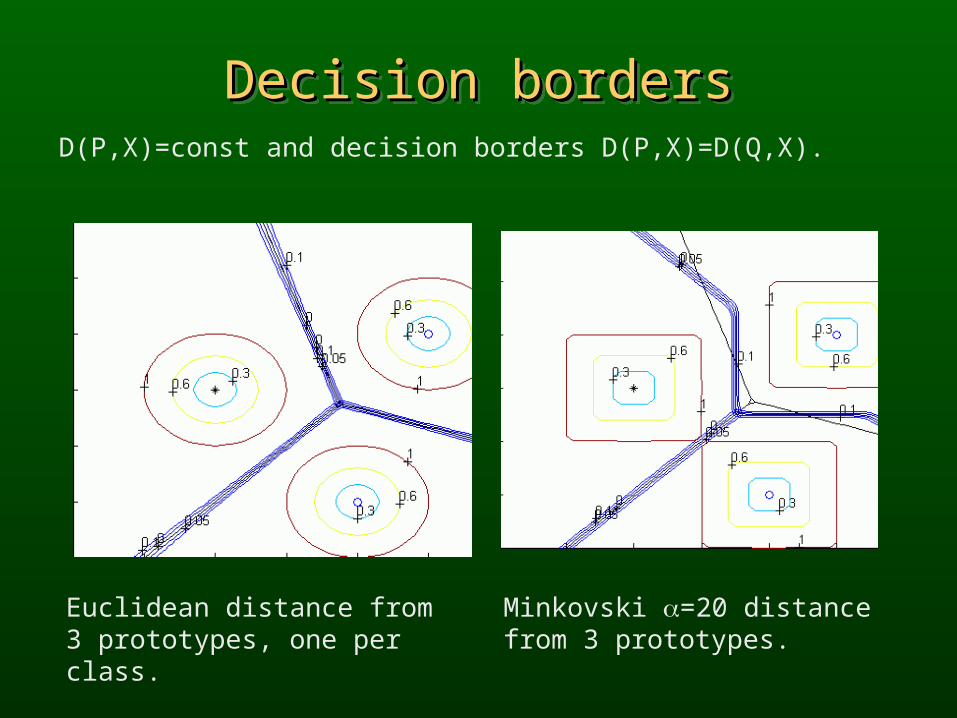
Decision bordersDecision bordersDecision bordersDecision borders
Euclidean distance from 3 prototypes, one per class.
Minkovski =20 distance from 3 prototypes.
D(P,X)=const and decision borders D(P,X)=D(Q,X).

P-rules for WineP-rules for WineP-rules for WineP-rules for WineManhattan distance: 6 prototypes kept, 4 errors, f2 removed
Chebyshev distance:15 prototypes kept, 5 errors, f2, f8, f10 removed
Euclidean distance:11 prototypes kept, 7 errors
Many other solutions.

Scatterograms for Scatterograms for hypothyroidhypothyroidScatterograms for Scatterograms for hypothyroidhypothyroidShows images of training vectors mapped by neural network; for more than 2 classes either linear projections, or several 2D scatterograms, or parallel coordinates.
Good for:
• analysis of the learning process;
• comparison of network solutions;
• stability of the network;
• analysis of the effects of regularization;
• evaluation of confidence by perturbation of the query vector.
...
Details: W. Duch, IJCNN 2003

Neural networksNeural networksNeural networksNeural networks• MLP – Multilayer Perceptrons, most popular NN models.Use soft hyperplanes for discrimination.Results are difficult to interpret, complex decision borders. Prediction, approximation: infinite number of classes.
• RBF – Radial Basis Functions.
RBF with Gaussian functions are equivalent to fuzzy systems with Gaussian membership functions, but …
No feature selection => complex rules.
Other radial functions => not separable!
Use separable functions, not radial => FSM.
• Many methods to convert MLP NN to logical rules.

What NN really do?What NN really do?What NN really do?What NN really do?•Common opinion: NN are black boxes. NN provide complex mappings that may involve various kinks and discontinuities, but NN have the power!
•Solution 1 (common): extract rules approximating NN mapings.
•Solution 2 (new): visualize neural mapping.
RBF network for fuzzy XOR, using 4 Gaussian nodes:
rows for =1/7,1 and 7
left column: scatterogram of the hidden node activity in 4D.
middle columns: parallel coordinate view
right column: output view (2D)
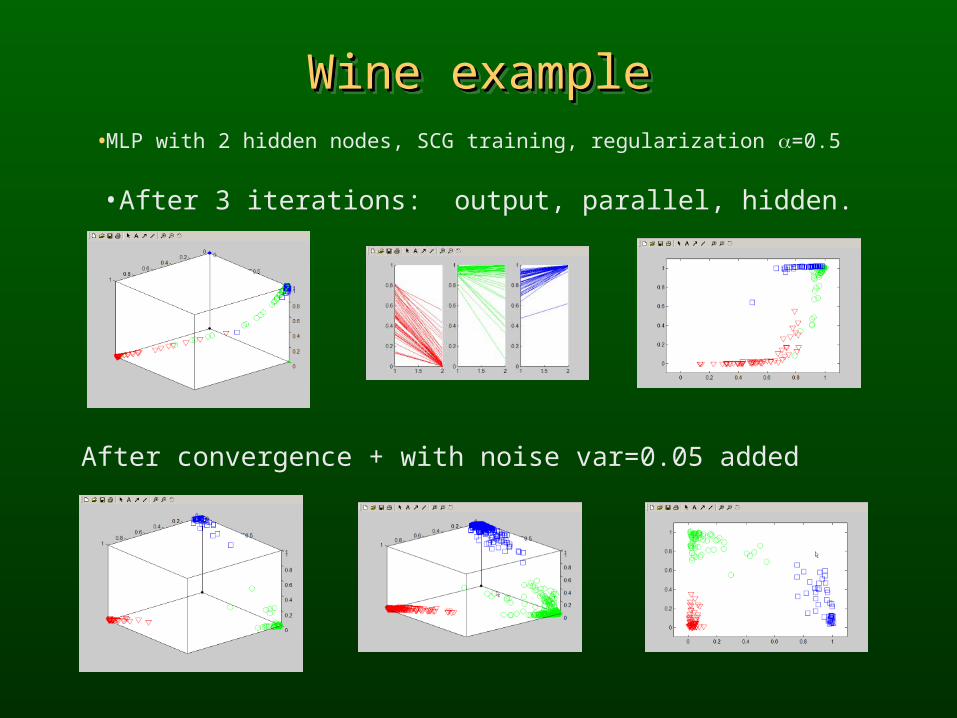
Wine exampleWine exampleWine exampleWine example•MLP with 2 hidden nodes, SCG training, regularization =0.5
•After 3 iterations: output, parallel, hidden.
After convergence + with noise var=0.05 added

Rules from MLPsRules from MLPsRules from MLPsRules from MLPs
Why is it difficult?
Multi-layer perceptron (MLP) networks: stack many perceptron units, performing threshold logic:
M-of-N rule: IF (M conditions of N are true) THEN ...
Problem: for N inputs number of subsets is 2N. Exponentially growing number of possible conjunctive rules.

MLP2LNMLP2LNMLP2LNMLP2LN
Converts MLP neural networks into a network performing logical operations (LN).
Inputlayer
Aggregation: better features
Output: one node per class.
Rule units: threshold logic
Linguistic units: windows, filters

MLP2LN trainingMLP2LN trainingMLP2LN trainingMLP2LN trainingConstructive algorithm: add as many nodes as needed.
Optimize cost function:minimize errors +
enforce zero connections +
leave only +1 and -1 weightsmakes interpretation easy.
2
21
2 2 22
1( ) ( ( ; ) )
2
2
( 1) ( 1)2
p pi i
p i
iji j
ij ij iji j
E F t
W
W W W
W X W

L-unitsL-unitsL-unitsL-unitsCreate linguistic variables.
1 1 2 2( ) 'L X S W x b S W x b
Numerical representation for R-nodes
Vsk=() for sk=low
Vsk=() for sk=normal
L-units: 2 thresholds as adaptive parameters;
logistic (x), or tanh(x)[ Soft trapezoidal functions change into rectangular filters (Parzen windows).
4 types, depending on signs Si.Product of bi-central functions is logical rule, used by IncNet NN.
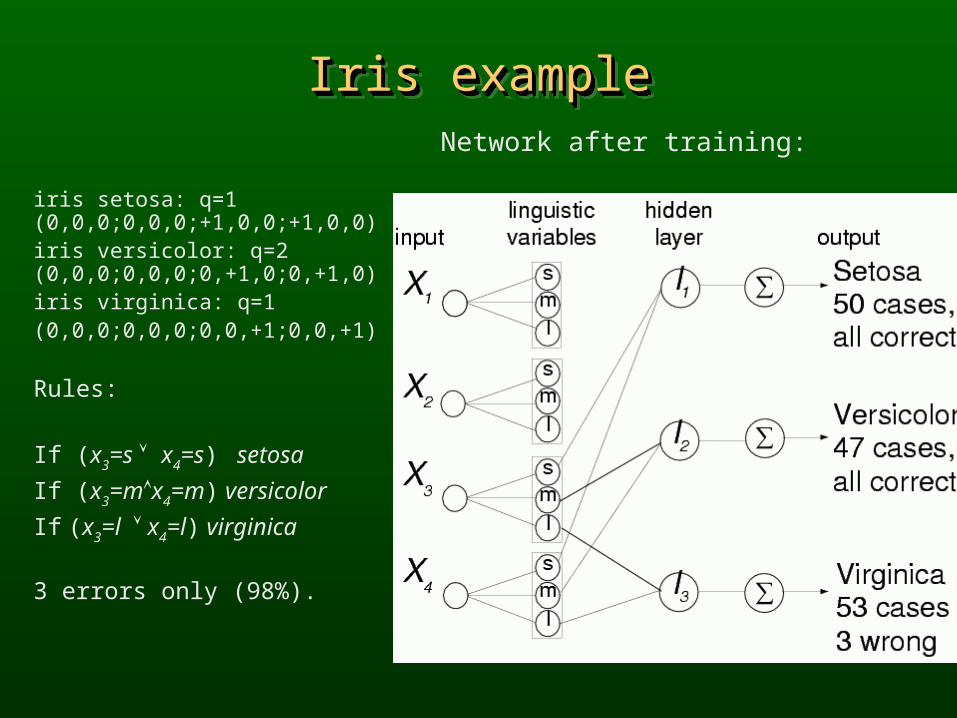
Iris exampleIris exampleIris exampleIris exampleNetwork after training:
iris setosa: q=1 (0,0,0;0,0,0;+1,0,0;+1,0,0) iris versicolor: q=2 (0,0,0;0,0,0;0,+1,0;0,+1,0)iris virginica: q=1(0,0,0;0,0,0;0,0,+1;0,0,+1)
Rules:
If (x3=s x4=s) setosa
If (x3=mx4=m) versicolor
If (x3=l x4=l) virginica
3 errors only (98%).
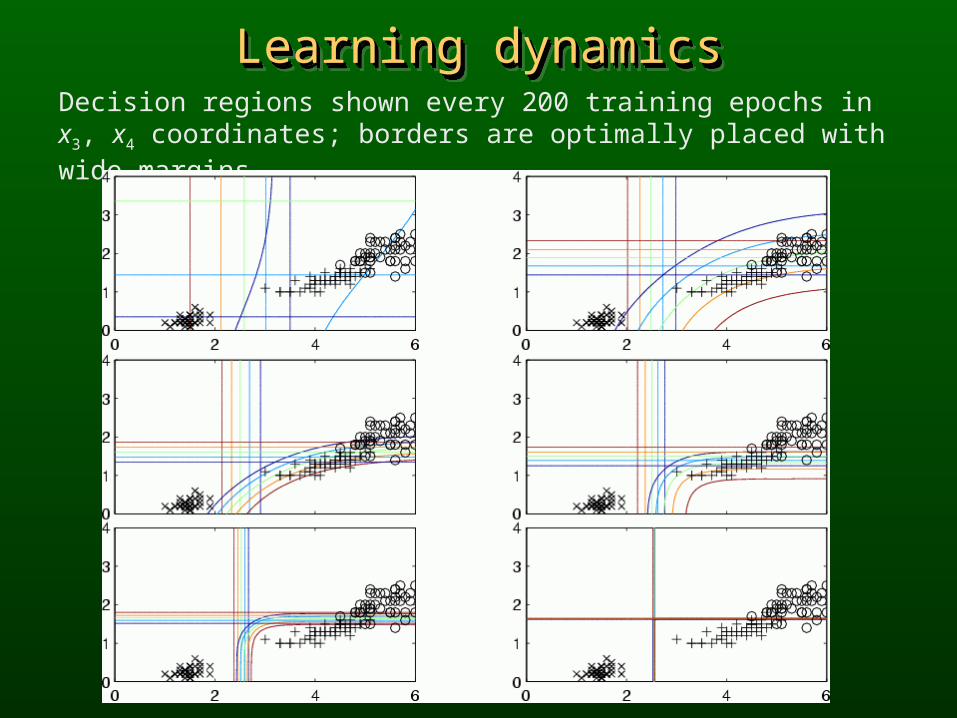
Learning dynamicsLearning dynamicsLearning dynamicsLearning dynamicsDecision regions shown every 200 training epochs in x3, x4 coordinates; borders are optimally placed with wide margins.
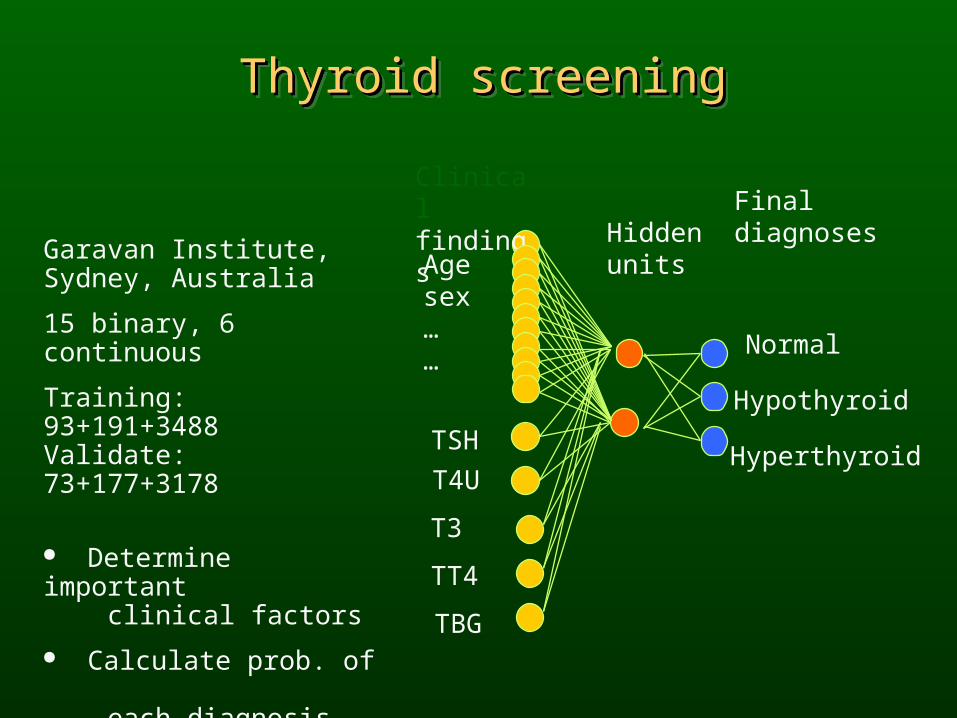
Thyroid screeningThyroid screeningThyroid screeningThyroid screening
Garavan Institute, Sydney, Australia
15 binary, 6 continuous
Training: 93+191+3488 Validate: 73+177+3178
Determine important clinical factors
Calculate prob. of each diagnosis.
Hiddenunits
Finaldiagnoses
TSH
T4U
Clinical findings
Agesex……
T3
TT4
TBG
Normal
Hyperthyroid
Hypothyroid

Thyroid – some results.Thyroid – some results.Thyroid – some results.Thyroid – some results.Accuracy of diagnoses obtained with several systems – rules are accurate.
Method Rules/Features Training % Test %
MLP2LN optimized 4/6 99.9 99.36
CART/SSV Decision Trees 3/5 99.8 99.33
Best Backprop MLP -/21 100 98.5
Naïve Bayes -/- 97.0 96.1
k-nearest neighbors -/- - 93.8

Thyroid – output visualization.Thyroid – output visualization.Thyroid – output visualization.Thyroid – output visualization.2D – plot scatterogram of the vectors transformed by the network.
3D – display it inside the cube, use perspective.
ND – make linear projection of network outputs on the polygon vertices

Feature selectionFeature selectionFeature selectionFeature selectionFeature Extraction, Foundations and Applications. Eds. Guyon, I, Gunn S, Nikravesh M, and Zadeh L, Springer Verlag, Heidelberg, 2005.
NIPS 2003 competition: databases with 10.000-100.000 features, data obtained from text analysis and bioinformatics problems.Without feature selection or extraction analysis is not possible.
Our InfoSel++ library (in C++) implements >20 methods for feature ranking & selection based on: mutual information, information gain, symmetrical uncertainty coefficient, asymmetric dependency coefficients, Mantaras distance using transinformation matrix, distances between probability distributions (Kolmogorov-Smirnov, Kullback-Leibler), Markov blanket, Pearson’s correlations coefficient (CC), Bayesian accuracy, etc.
Such indices depend very strongly on discretization procedures; care has been taken to use unbiased probability and entropy estimators and to find appropriate discretization of continuous feature values.
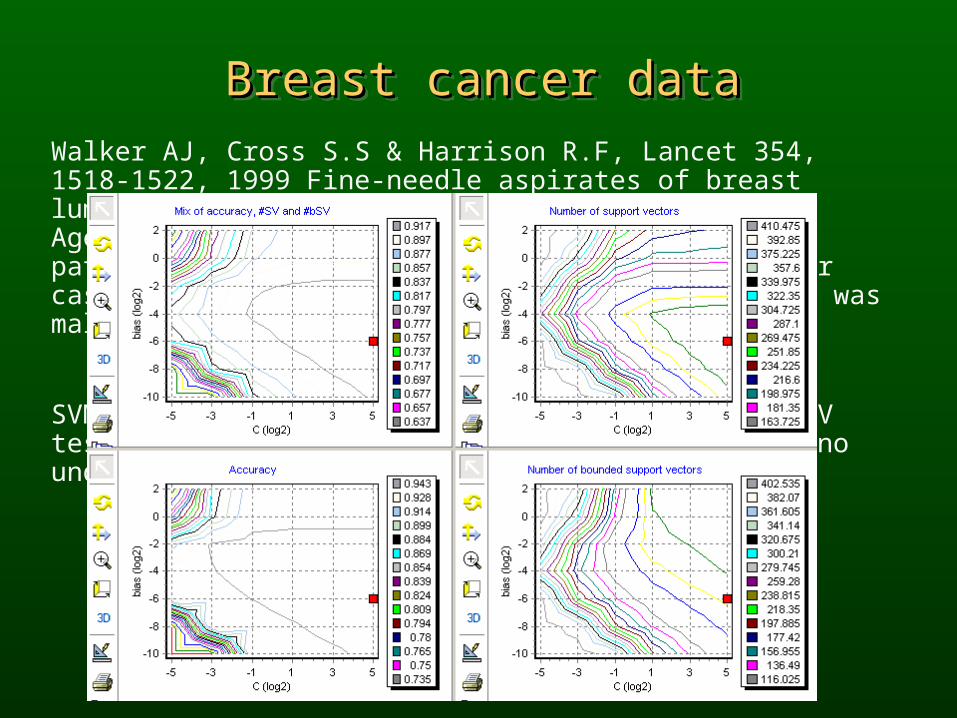
Breast cancer dataBreast cancer dataBreast cancer dataBreast cancer dataWalker AJ, Cross S.S & Harrison R.F, Lancet 354, 1518-1522, 1999 Fine-needle aspirates of breast lumps were performed. Age plus 10 observations made by experienced pathologist were collected for each breast cancer case; the final determination whether the cancer was malignant or benign was confirmed by biopsy.
SVM with optimized Gaussian kernel gives in 10xCV tests very good accuracy 95,49±0,29%, but gives no understanding of the important clinical factors.
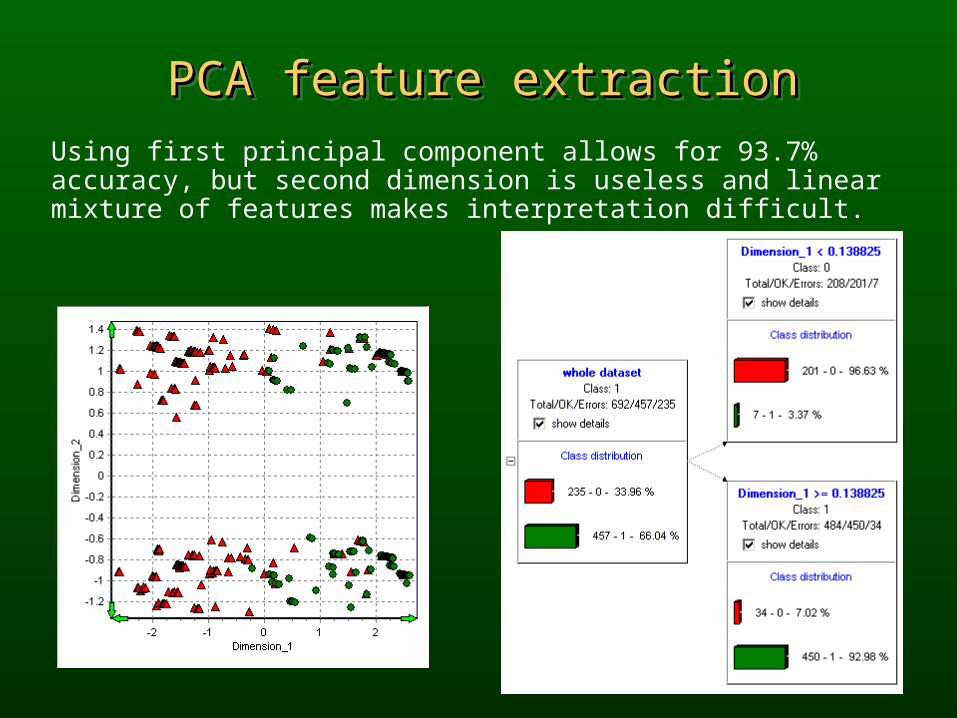
PCA feature extractionPCA feature extractionPCA feature extractionPCA feature extractionUsing first principal component allows for 93.7% accuracy, but second dimension is useless and linear mixture of features makes interpretation difficult.
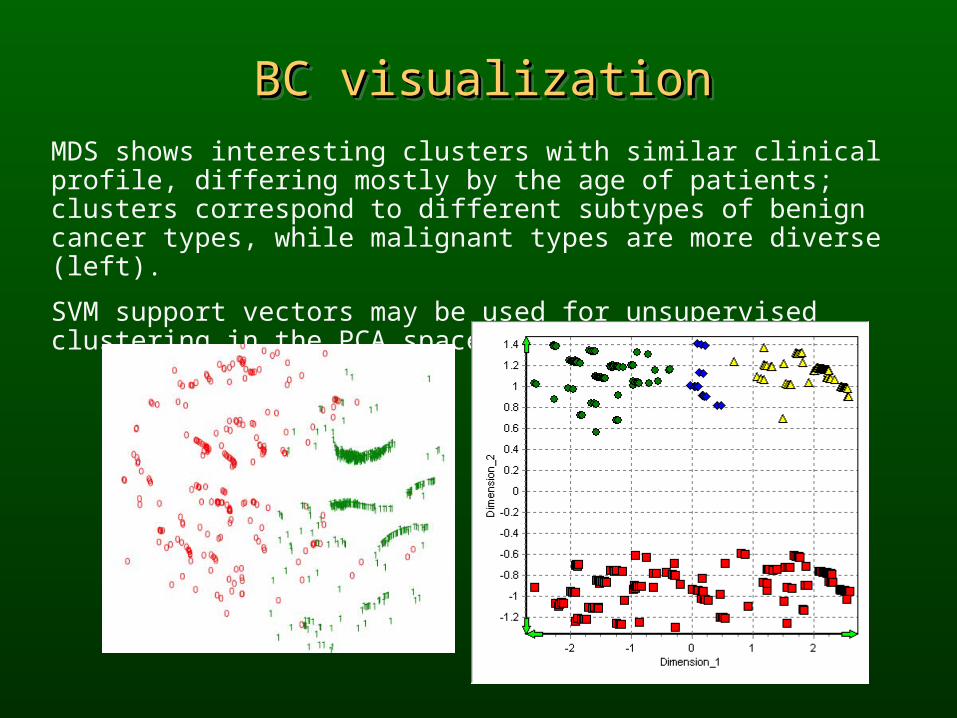
BC visualizationBC visualizationBC visualizationBC visualizationMDS shows interesting clusters with similar clinical profile, differing mostly by the age of patients; clusters correspond to different subtypes of benign cancer types, while malignant types are more diverse (left).
SVM support vectors may be used for unsupervised clustering in the PCA space (right).

BC logical rulesBC logical rulesBC logical rulesBC logical rulesFeature Extraction, Foundations and Applications. Eds. Guyon, I, Gunn S, Nikravesh M, and Zadeh L, Springer Verlag, Heidelberg, 2005.
SSV achieves 95.4,% accuracy, 90% sensitivity, and specificity of 98%. The presence of necrotic epithelial cells is the most important factor. The decision function can be presented in the form of the following logical rules:
1. if F#9 > 0 and F#7 > 0 then class 0
2. if F#9 > 0 and F#7 < 0 and F#1 > 50.5 then class 0
3. if F#9 < 0 and F#1 > 56.5 and F#3 > 0 then class 0
4. else class 1
A forest of trees generated for the breast cancer data reveals another interesting classification rules:
if F#8 > 0 and F#7 > 0 then class 0 else class 1.
Accuracy is lower, 90.6%, but the rule has 100% specificity.
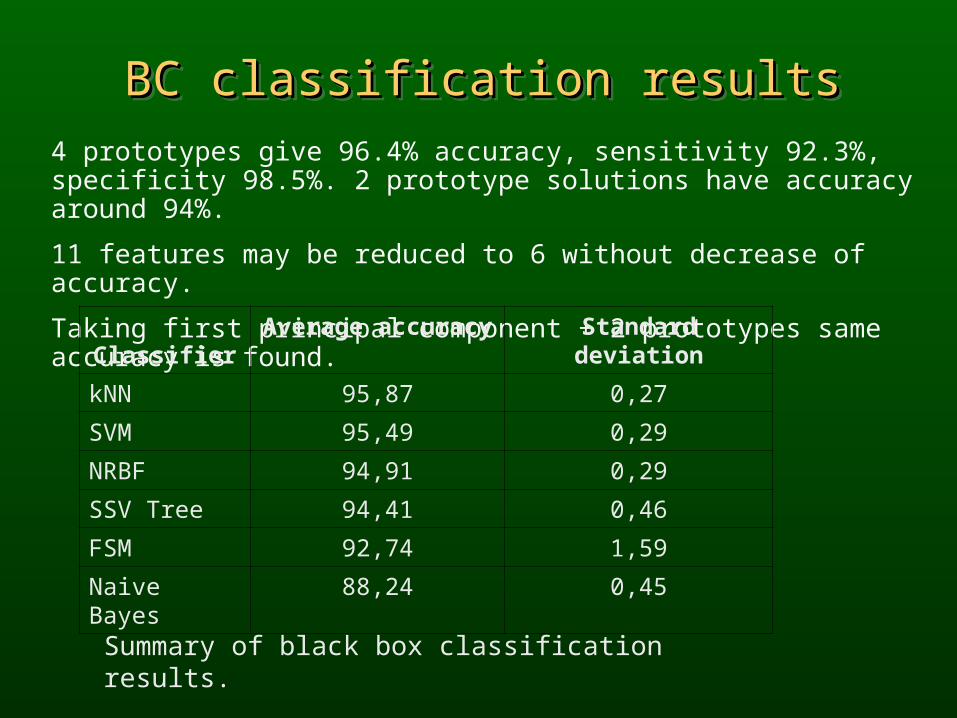
BC classification resultsBC classification resultsBC classification resultsBC classification results4 prototypes give 96.4% accuracy, sensitivity 92.3%, specificity 98.5%. 2 prototype solutions have accuracy around 94%.
11 features may be reduced to 6 without decrease of accuracy.
Taking first principal component + 2 prototypes same accuracy is found.
Summary of black box classification results.
ClassifierAverage accuracy Standard deviation
kNN 95,87 0,27
SVM 95,49 0,29
NRBF 94,91 0,29
SSV Tree 94,41 0,46
FSM 92,74 1,59
Naive Bayes 88,24 0,45
PsychometryPsychometryPsychometryPsychometryUse CI to find knowledge, create Expert System.
MMPI (Minnesota Multiphasic Personality Inventory) psychometric test.
Printed forms are scanned or computerized version of the test is used.
• Raw data: 550 questions, ex:I am getting tired quickly: Yes - Don’t know - No
• Results are combined into 10 clinical scales and 4 validity scales using fixed coefficients.
• Each scale measures tendencies towards hypochondria, schizophrenia, psychopathic deviations, depression, hysteria, paranoia etc.

Psychometry: goalPsychometry: goalPsychometry: goalPsychometry: goal
• There is no simple correlation between single values and final diagnosis.
• Results are displayed in form of a histogram, called ‘a psychogram’. Interpretation depends on the experience and skill of an expert, takes into account correlations between peaks.
Goal: an expert system providing evaluation and interpretation of MMPI tests at an expert level.
Problem: experts agree only about 70% of the time; alternative diagnosis and personality changes over time are important.

Psychometric dataPsychometric dataPsychometric dataPsychometric data
1600 cases for woman, same number for men.
27 classes: norm, psychopathic, schizophrenia, paranoia, neurosis, mania, simulation, alcoholism, drug addiction, criminal tendencies, abnormal behavior due to ...
Extraction of logical rules: 14 scales = features.
Define linguistic variables and use FSM, MLP2LN, SSV - giving about 2-3 rules/class.

Psychometric resultsPsychometric resultsPsychometric resultsPsychometric results
10-CV for FSM is 82-85%, for C4.5 is 79-84%. Input uncertainty ++GGxx around 1.5% (best ROC) improves FSM results to 90-92%.
Method Data N. rules Accuracy +Gx%
C 4.5 ♀ 55 93.0 93.7
♂ 61 92.5 93.1
FSM ♀ 69 95.4 97.6
♂ 98 95.9 96.9

Psychometric ExpertPsychometric ExpertPsychometric ExpertPsychometric Expert
Probabilities for different classes. For greater uncertainties more classes are predicted.
Fitting the rules to the conditions:typically 3-5 conditions per rule, Gaussian distributions around measured values that fall into the rule interval are shown in green.
Verbal interpretation of each case, rule and scale dependent.

VisualizationVisualizationVisualizationVisualizationProbability of classes versus input uncertainty.
Detailed input probabilities around the measured values vs. change in the single scale; changes over time define ‘patients trajectory’.
Interactive multidimensional scaling: zooming on the new case to inspect its similarity to other cases.

SummarySummarySummarySummaryComputational intelligence methods: neural, decision trees, similarity-based & other, help to understand the data.
Understanding data: achieved by rules, prototypes, visualization.
Small is beautiful => simple is the best!
Simplest possible, but not simpler - regularization of models; accurate but not too accurate - handling of uncertainty;
high confidence, but not paranoid - rejecting some cases.
• Challenges:
hierarchical systems – higher-order rules, missing information; discovery of theories rather than data models; reasoning in complex domains/objects; integration with image/signal analysis; applications in data mining, bioinformatics, signal processing, vision ...

The EndThe EndThe EndThe End
Papers describing in details some of the ideas presented here
may be accessed through my home page:
Google: Duch
or
http://www.phys.uni.torun.pl/~duch
We are slowly addressing the challenges. The methods used here (+ many more) are included in the Ghostminer, data mining software developed by my group,
in collaboration with FQS, Fujitsu Kyushu Systems
http://www.fqspl.com.pl/ghostminer/
Completely new version of these tools is being developed.