cs3012: formal languages and compilers -...
TRANSCRIPT

3012Formal Languages&Compilers

CS3012 Formal Languages Course Notes
2

CS3012 Formal Languages Course Notes
UNIVERSITY OF ABERDEENDepartment of Computing Science
CS3012: Formal Languages & CompilersCourse Notes 2006
Frank Guerin1
08/05/2023
About CS3012Formal languages underlie all of Computing Science: if a language is not formally defined it is difficult to use a computer to process it in a consistent manner. This course provides an introduction to how formal languages may be defined and describes how computers may be used to manipulate such languages, with particular reference to compiling programming languages. You will gain practical experience of tools that are widely used in industrial applications to generate parsers and lexical analysers.
AttendanceYou are expected to attend all meetings of CS3012. The course introduces many formal concepts, and builds upon them each week. The only way to do well on this course is to work steadily throughout the term, building up your familiarity with the different formalisms. If you can't do the exercises in the tutorials, you will not be able to understand the lectures. You will not be able to cram in all the information in the weeks before the exam if you have not been working steadily. Attendance will be taken at tutorials. If you are not attending at least 75% of the tutorial classes, you will be reported to the Senate Office as being "at risk".
Motivation for the Course
A compiler takes a program we have written in a particular language, and converts it into another format ready to be executed on a particular computer. In order to write efficient programs, we must understand how a compiler works. The basic ideas of compiling are used in many different areas in computing, including user interfaces, software design, and intelligent agents.
Before we can write a compiler, we must establish the language that we will be compiling. That is, we have to determine what programs are valid. Then, we must be able to recognise valid programs, and process them. We face similar problems understanding natural language. For example, which of the following five examples are proper sentences?
1. large red cars go quickly,2. Large red cars go quickly.3. Colourless green ideas sleep furiously.4. Go cars large red quickly.
5. Coches rojos grandes marchan rapidamente.Even if we can't state clearly which of these are valid sentences, we can still make a good guess at what some of them mean. Unfortunately, we can't get away with hand-waving like this when we are dealing with computer programs – we have to be precise and unambiguous, and the only effective way we have of interpreting programs requires us to be very strict about what is and what is not a valid program. We will then use this strict specification to help us recognise the structure of a program. Once we have recognised the structure, we can start worrying about what it means, and what actions we have to take to execute the program as expected.
To specify the valid programs, we need the concept of a formal language – languages where the programs (or sentences) that are valid are defined solely in terms of the form (or shape, or structure) of the program. The course will begin by looking at some simple ways to define a formal language, and some algorithms for
1 These notes mostly from Ken Brown’s original notes3

CS3012 Formal Languages Course Notes
recognising sentences in those languages. We will see how to define simple examples, and we will investigate how powerful the methods are. We will then look at more powerful methods, which will allow us to specify programming languages, and we will see how to recognise whether or not a program is valid.
Once we have recognised a valid program, we have to start translating it into an executable form. First, we will check that the program is meaningful – i.e. the instructions make sense,
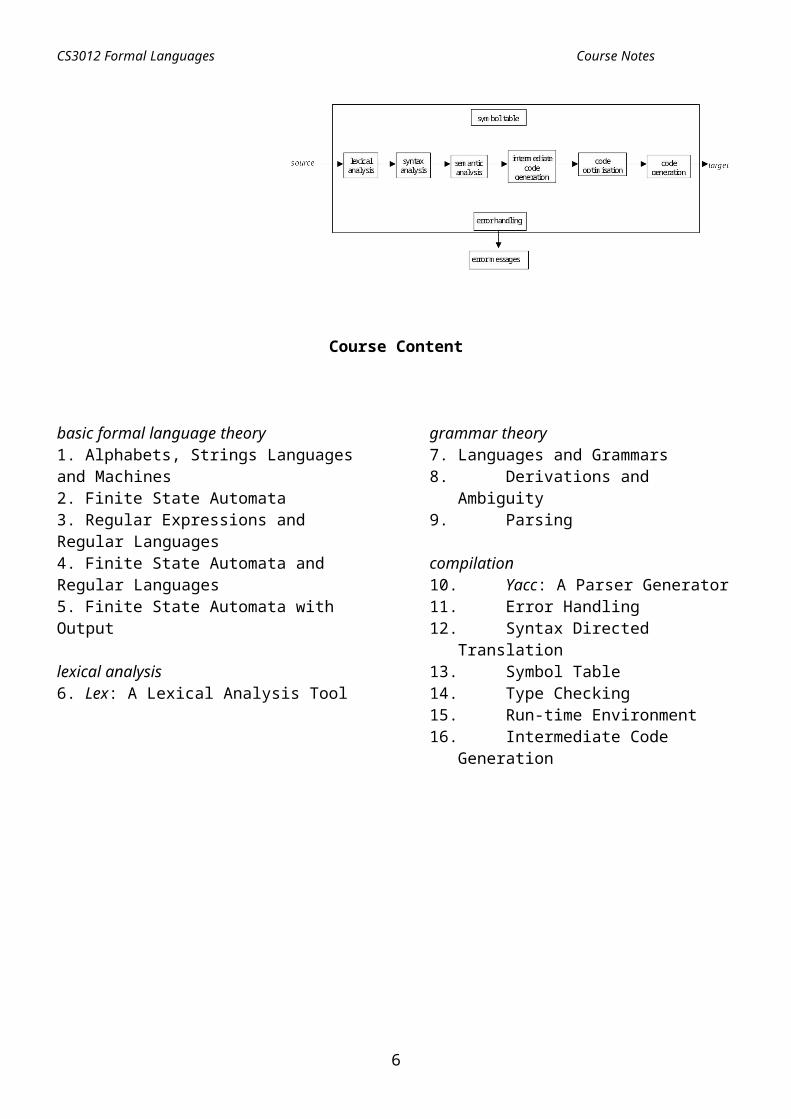
and obey the conventions of the language. We will then start translating the original instructions into a different format, and we will show how to create the necessary structures in memory. We will also look at the runtime environment, showing how diffrent programming language styles manipulate the memory of the computer as programs are executed. We will use the standard UNIX tools of Lex and Yacc to build parts of a working compiler. A schematic model of a compiler is shown below:
Course Content
basic formal language theory1. Alphabets, Strings Languages and Machines 2. Finite State Automata3. Regular Expressions and Regular Languages4. Finite State Automata and Regular Languages5. Finite State Automata with Output
lexical analysis6. Lex: A Lexical Analysis Tool
grammar theory7. Languages and Grammars 8. Derivations and Ambiguity9. Parsing
compilation10. Yacc: A Parser Generator11. Error Handling12. Syntax Directed Translation13. Symbol Table14. Type Checking15. Run-time Environment16. Intermediate Code Generation
4

CS3012 Formal Languages Course Notes
A note on the style of the course
This handout together with the exercise sheets from the problem classes contain all of the required material for the course. However, the handout is concise, may be difficult to read, and will not contain much in the way of discussion, motivation or examples.
The lectures will consist of slides, spoken material, and additional examples given on the blackboard. In order to understand the algorithms and the reasons for studying the material, you will need to attend the lectures and take notes to supplement the handout. This is your responsibility. If there is anything you do not understand during the lectures, then ask, either during or after the lecture. If the lectures are covering the material too quickly, then say so. If there is anything you do not understand in the handout, then ask, either at a lecture or in the problem classes.
The textbooks contain additional material, and may motivate the material in different ways. They are useful background to the course, and may help you understand it.
The exercises in the problem classes are designed to test your understanding of the material and to give you practice applying the definitions and algorithms in solving problems. In order to survive on the course, you are strongly advised to attend the problem classes and attempt the exercises. Much of this material is formal and abstract, and without practice you will quickly fall behind. Make sure you do attempt the exercises for yourself, and don't wait for the solutions - reading solutions is no substitute for trying to solve problems. If there is anything you don't understand in the exercises (or the notes), or you can't see how to generate the solutions for yourself, then ask for help. Do not sit in silence hiding the fact that you are struggling.
There are also continuous assessment exercises. These put into practice the theory you will have learned on the course. They are part of the formal assessment for the course, so it is obviously important that you make serious attempts at solving them. If you do not complete the assessments, you risk failing the course.
5
CS3012 Formal Languages Finite State Automata
1. Alphabets, Strings and Languages
Definitions 1.0: Set and Mathematical Notation
We need to define some mathematical notation before we start, so that we can talk about things concisely, without having to write a paragraph every time.
A B A is a subset of B - every element of A is also in BA B the union of A and B - a set containing every element in either A or BA B the intersection of A and B - a set containing only those elements in both A and B
there exists for all
2P the set of all subsets of P
is an element of is not an element of
A \ B A minus B: all elements of A, except those that are also in B
A B the set of all pairs of elements, where the first is an element of A and the second is an element of B
the empty set - i.e. the set with no members not
{ x | p(x) } means the set of all elements x, such that the sentence p(x) is true for each xExample: {x : x Z, x > 0, x < 10} means the set of all integers between 0 and 10, and is the same set as {1,2,3,4,5,6,7,8,9}
f : X Y :: x y f is a function that maps elements of set X to elements of set Y, and maps a particular element x to a particular element yExample: f: N N :: x x2 is the "square" function for positive integers. It may also be written f(x) = x2. Thus f(2) = 4, f(3) = 9, etc.

CS3012 Formal Languages Finite State Automata
Definitions 1.1
A symbol is a basic unit.An alphabet is a finite set of symbols.A string over an alphabet T is a finite sequence of symbols from T. This may be shortened to T-string, or if the context is clear or unimportant, simply string.
Example 1.2
If T = {a, b, c, d} is an alphabet, then abd, aaaa and abaabc are T-strings.
Definitions 1.3
The empty string is the string with no symbols, denoted .The length of a string w is the number of symbols in the sequence, denoted |w|.Two strings, w and v, are equal if they have exactly the same sequence of symbols, denoted w = v.The concatenation of two strings, w and v, is the string consisting of the sequence of symbols in w followed by the sequence of symbols in v, denoted wv.
Note: concatenation is not commutative - vw and wv need not be equal - but is associative - (uv)w = u(vw).
Example 1.4 If w = abb and v = bab then wv = abbbab and w= abb.
Definitions 1.5
A string u is a substring of w if there exists strings x and y such that (s.t.) w = xuy. If u is a substring of w as above, and x = , then u is a prefix of w. If u w, the u is a proper prefix.If u is a substring of w as above, and y = , then u is a suffix of w. If u w, then u is a proper suffix.
Note that is a substring of every string.
Example 1.6 ba is both a prefix and a suffix of babba.
Definition 1.7 If T is an alphabet, then T* is the set of all strings over T.
Example 1.8 T = {a,b} and T* = {, a, b, aa, ab, ba, bb, aaa, aab, ...}

CS3012 Formal Languages Finite State Automata
Definitions 1.9
T+ is T* without .
If a is a symbol, then (i) an (n ≥ 0) is the string consisting of n a's. Note that anam = an+m.(ii) a* = {, a, aa, aaa, ...}(iii) a+ = {a, aa, aaa, ...}
Definition 1.10 Language over T
A language over an alphabet T is a set of strings over T. This may be abbreviated to T-language, or simply language.
Note that L is a T-language if and only if (iff) L T*.
Example 1.11 If T = (a, b}, then {, ab, babba, bbbbbbb} is a T-language.
Definitions 1.12
Let A and B be languages over an alphabet T.A+B (or A B) denotes the set union of A and B.A B denotes the set intersection of A and B.A' denotes the complement of A - i.e. all the strings in T* but not in AAB denotes the concatenation of A and B - all strings uv s.t. u A and v B. Note that language concatenation is associative, but not commutative.An denotes the concatenation of A with itself n times ( = AA...A). Note: A0 = {}.A* = A0 + A1 + A2 +... i.e. the set of all strings consisting of the concatenation of strings from A. This operation is called the "Kleene closure". Note: A** = A*.A+ = A1 + A2 +...
Definitions 1.13
Let T be an alphabet with an ordering on its symbols. Say T = {t1, t2, t3, ...}. Strings over T can be ordered in two ways:
Dictionary Order All strings beginning t1 are ordered before strings beginning t2, and t2 before t3, etc. Within the group of strings beginning t1, strings are ordered by the second symbol, etc. is always the first string.
Lexical Order Strings are ordered by their length. Within each group of strings of the same length, strings are ordered by dictionary order. Again, is the first string.

CS3012 Formal Languages Finite State Automata
2. Finite State Automata
Definition 2.1 Finite State Automata
A Finite-State Automaton (FSA) is a quintuple (Q,I,F,T,E), whereQ is a finite set (whose elements are called states)I is a subset of Q (whose elements are the initial states)F is a subset of Q (whose elements are the final states)T is an alphabet, andE is a subset of Q (T + ) Q (whose elements are called edges)
Essentially, a FSA is a labelled, directed graph - that is, it is a set of nodes with directed arcs between the nodes, where arcs may have labels from an alphabet.
Notation: We will sketch a FSA as a graph, where the edges of the FSA are the arcs of the graph and the states are the nodes (drawn as circles). The initial states will be drawn with a short incoming arrow, and the final states will be drawn as double circles.
Example 2.2
The FSA A1:Q = {1,2,3,4}, I = {1}F = {4}, T = {a, b}E = {(1,a,2), (1,b,4), (2,b,4), (2,a,3), (3,a,3), (3,b,3), (4,a,2), (4,b,4)}can be sketched as shown:
Example 2.3
The FSA of 2.2 (A1) can be interpreted as follows:
The machine starts in state "1". From there it can move either to state "2", by action labelled "a", or it can move to state "4", by action labelled "b". From state "2" it can move to state "3", by action labelled "a", or it can move to state "4", by action labelled "b". From state "3", it can stay in state "3' by actions labelled "a" or "b". From state "4", it can move to state "2", by action labelled "a", or it can stay in state "4", by action labelled "b". The machine can stop successfully in state "4".
Definitions 2.4
If (x,a,y) is an edge in a FSA, then x is the start state of the edge and y is the end state.A path in a FSA is a sequence of edges, such that the end state of one is the start state of the next.A cycle in a FSA is a path, such that the start state and the end state are the same.
b
1
2
4
a
b
b a
3a,b
a

CS3012 Formal Languages Finite State Automata
A path is successful if its first state is an initial state, and its last state is a final state.The label of a path is the sequence of labels of the edges in the path.A string is accepted by a FSA if it is the label of a successful path. A string is rejected if it is not the label of a successful path.

CS3012 Formal Languages Finite State Automata
Definition 2.5 Language accepted by a FSA
The language accepted by a FSA, A, is the set of strings accepted by A. Denote the language L(A).
Example 2.6
Consider the FSA A1 (example 2.2):
(i) p1 = (2,b,4), (4,a,2), (2,a,3) is a path;(ii) p2 = (2,b,4), (4,b,4), (4,a,2) is a cycle;(iii) p3 = (1,b,4), (4,a,2), (2,b,4), (4,b,4) is a successful path;(iv) The label of p1 = baa;(v) babb is accepted by A1;(vi) baa is rejected by A1;(vii) A1 accepts the language of strings of a's and b's which end in a b, and in which no two a's are adjacent.
Definition 2.7
The transition function of a FSA, A, is the function : (x,t) {y: edge (x, t, y) in A}.
Definition 2.8
If A = (Q,I,F,T,E) is a FSA, then a transition matrix for A is a matrix which has one row for each state in Q and one column for each symbol in T s.t. the entry in row q and column t is (q,t) ( 2Q)
Notation: A transition matrix will be drawn as a table, labelling the rows and columns with states and symbols. Each entry in the table will be the set of states as defined above, or will be left blank in the case of the empty set. Additionally, rows corresponding to initial states will be labelled with an "in" arrow, and final states with an "out" arrow.
Example 2.9
The transition matrix for A1 is:
1 {2} {4} 2 {3} {4} 3 {3} {3} 4 {2} {4}
a bA1

CS3012 Formal Languages Finite State Automata
Definition 2.10
A FSA, A, is non-deterministic if(i) there are edges labelled with , or(ii) there are two edges (x,t,y) and (x,t,z) in A s.t. y z, or(iii) there is more than one initial state.Conversely, if none of (i), (ii) or (iii) hold, then A is a deterministic FSANon-deterministic and deterministic FSA's will be denoted NDFSA and DFSA respectively.
Example 2.11 A1 is a DFSA
Note: For a DFSA, every entry in the transition matrix is either a singleton set or the empty set.
Algorithm 2.12 Recognition Algorithm (DFSA)
Problem: Given a DFSA, A = (Q,I,F,T,E) and a string w, determine whether w L(A).
begin Add symbol # to end of w q := initial state t := first symbol of w# while (t # & q {}) do begin while the current symbol is not the end marker and
we are in a proper stateq := (q, t) get the next state from the transition tablet := next symbol in w# get the next symbol from the input string
end return ((t == #) & (q F)) if the current symbol is the end marker and the
current state is a finish state, return true, else falseend
Theorem 2.13DFSA = NDFSA
Let L be a language. L is accepted by a NDFSA iff L is accepted by a DFSA.
Algorithm 2.14 NDFSA -> DFSA
Problem: Given a NDFSA, A, create a DFSA, A'
begin create unique initial state remove -edges remove edge choicesend

CS3012 Formal Languages Finite State Automata
Algorithm 2.15 create unique initial state
Given a NDFSA, A = (Q,I,F,T,E), create FSA A' with a single initial state s.t. L(A) = L(A')
begin Q := Q {i} (where i Q) /* add a new initial state i */ for each q I do add edge (i,,q) to E I := {i} /* reset the initial set to be just i */ return (Q,I,F,T,E)end
Algorithm 2.16 remove -edges
Given a NDFSA, A = (Q,I,F,T,E), create FSA A' with no -edges
begin remove all edges of form (q,,q) from E while there are cycles of -edges in E do begin select a cycle merge all states in cycle into single state, keeping all edges in/out of cycle end while there are -edges in E do begin select a -edge (p,,q) for each edge (q,t,r) E do add edge (p,t,r) to E if q F then add p to F remove (p,,q) from E end return (Q,I,F,T,E)end

CS3012 Formal Languages Finite State Automata
Algorithm 2.17 remove edge choices (subset construction)
Given a NDFSA, A = (Q,I,F,T,E), create DFSA A' s.t. L(A) = L(A')
begin I' := {I} /* Note: I is a set; I' is a set with one member, I */ F' := {} E' := {} S := {I} Q' := {I} while S is not empty do begin select X S for each t T do begin S' := {q Q : (p,t,q) E, for some p X} if S' {} then begin if S' F {} then F' := F' {S'} E' := E' {(X,t,S')} S := S {S'}\Q' /* if we haven't seen S' before, add to S */ Q' := Q' {S'} /* if S' is already in Q', Q' doesn't change */ end end S := S\{X} end return (Q',I',F',T,E')end
Alternative description of Algorithm 2.17
Make a new initial state, I', representing all the old initial states.Make empty sets F' and E', for the new finish states and new edgesCreate a set S of states we haven't exanded yet, initially containing just I'Create a set Q' of all new states, initially containing just I'.While there are states we haven't expanded yet (i.e. still states left in S)
Pick one of those states, and call it XFor each symbol in the alphabet
Find all the old states that make up XFind all the old states we could have got to from those states by reading in the current alphabet symbolGroup all those old states into a new state, S'If S' is not empty (i.e. there is at least one old state making up S')
If any of the states making up S' were old finish statesMake S' a new finish state (i.e. add to F')
Add a new edge from X to S' for the current symbol (i.e. add to E')If we hadn't seen S' before, add S' to SIf we hadn't seen S' before, add S' to Q'
Take X out of SReturn the new FSA we have just created, where Q' is the set of states, I' is the set of initial states, F' is the set of finish states, T is the alphabet, and E' is the set of edges.

CS3012 Formal Languages Finite State Automata
Example 2.18
A = ({1,2,3},{1},{3},{a,b},{(1,a,1),(1,a,2),(1,b,1),(2,b,3),(3,a,3),(3,b,3)})Convert A into a DFSA.
1 2 3a b
a,b a,b
I' F' E' S Q' X t S'{1} {1} {1} {1} a {1,2}
({1},a,{1,2}) {1,2} {1,2} b {1}({1},b,{1}) {1,2} a {1,2}({1,2},a,{1,2}) b {1,3}
{1,3} ({1,2},b,{1,3}) {1,3} {1,3} {1,3} a {1,2,3}{1,2,3} ({1,3},a,{1,2,3}) {1,2,3} {1,2,3} b {1,3}
({1,3},b,{1,3}) {1,2,3} a {1,2,3}({1,2,3},a,{1,2,3}) b {1,3}({1,2,3},b,{1,3})
a
1 1,2 1,3a b
b b
1,2,3
a
a
b
A' = ({{1},{1,2},{1,3},{1,2,3}}, {{1}}, {{1,3},{1,2,3}}, {a,b), {({1},a,{1,2}),({1},b,{1}),({1,2},a,{1,2}),({1,2},b,{1,3}),
({1,3},a,{1,2,3}), ({1,3),b,{1,3}),({1,2,3},a,{1,2,3})),({1,2,3},b,{1,3})})
Definition 2.19
Let A =(Q,I,F,T,E) be a FSA. For any two strings x, y T*, x and y are distinguishable w.r.t. A if there is a string z T* s.t. exactly one of xz and yz are in L(A). We say z distinguishes x and y w.r.t. A.
Theorem 2.20
L is a language over T. If, for some integer, n, there are n elements of T* s.t. any two are distinguishable w.r.t. A, then any FSA that recognises L must have at least n states.

CS3012 Formal Languages Finite State Automata
Theorem 2.21
For a given language L, there exists a minimal DFSA accepting L, and it is unique.
Algorithm 2.22 DFSA -> minimal DFSA
Given a DFSA A, create a DFSA A' s.t. A' is minimal over all FSAs accepting L(A).
begin R := {} for all edges (p,t,q) E do add (q,t,p) to R remove edge choices from (Q,F,I,T,R) to get (Q',I',F',T,E') Z := equivalent_states(Q, Q') (Q'',I'',F'',T,E'') := merge(Z,Q,I,F,T,E) return (Q'',I'',F'',T,E'')end
Algorithm 2.23 equivalent states
Given two sets of states Q and Q', produce Z, the set of states of Q equivalent in Q'.M is a 2d array, indexed by Q and {} Q
begin set all cells of M to t for all p Q do for all sets S Q' do if p S then for each q Q do begin if q S then M[p][q] := f end else for each q Q do if q S then M[p][q] := f S := {} for each p Q do begin Z := {} if M[p][] = t then for each q Q do if M[p][q] = t then begin add q to Z M[q][] := f end add Z to S end return Send

CS3012 Formal Languages Finite State Automata
Algorithm 2.24 merge
Given a DFSA A and a set of sets of states Z, return a new DFSA A'
begin for all S Z do begin select p S for all q S s.t. q ≠ p do begin delete q from Q for each edge (q,t,w) E do begin delete (q,t,w) from E if (p,t,w) E then add (p,t,w) to E end for each edge (w,t,q) E do begin delete (w,t,q) from E if (w,t,p) E then add (w,t,p) to E end if q I then begin delete q from I if p I then add p to I end if q F then begin delete q from F if p F then add p to F end end end return (Q,I,F,T,E)end
Example 2.25 Minimise the following DFSA:
Reverse:
The set Q' from "remove edge choices" is { {3,4}, {2,3,4}, {2,3,4,5} and {1,2,3,4,5} }
1 2 3 4 5 => 1 2 3 4 5 1 t t t t t t 1 t t f f f f2 t t t t t t 2 t f t f f f3 t t t t t t 3 t f f t t f4 t t t t t t 4 t f f t t f5 t t t t t t 5 t f f f f t
giving merge set Z = { {1}, {2}, {3,4}, {5} }:

CS3012 Formal Languages Regular Expressions and Regular Languages
3. Regular Expressions and Regular Languages
Definition 3.1 Regular Expressions
Let T be an alphabet. A regular expression over T defines a language over T as follows:(i) denotes {}, denotes {}, and t denotes {t} for t T;(ii) if r and s are regular expressions denoting languages R and S, then
(r + s) denoting R + S,(rs) denoting RS, and(r*) denoting R* are regular expressions; and
(iii) nothing else is a regular expression over T.
Note: when writing regular expressions, if we give the operators +, . and * ascending priorities, then we can omit most of the brackets. For example, the regular expression
((a)* + ((b)* + (c))*)((b) + (c))can be written as
(a* + (b* + c)*)(b + c)
Precedence: r + st should be interpreted as r + (st)r + st* should be interpreted as r + (s (t*))
Notation: If T is an alphabet, then T also denotes the regular language of strings over T of length 1.tn denotes ttt...t n times.
Example 3.2
(i)The regular expression (a* + (b* + c)*)(b + c) denotes a set, some of whose members are:aaaab, b, bbbcbbbbcccccc, etc.
(ii) aT* denotes the language consisting of all strings over T starting with a.(iii) T*(a2 + b2)T* denotes the set of all strings over T with a substring of aa or bb.(iv) 0 + 1(0 + 1)* denotes the set of all binary numbers.(v) The set of strings over {0,1} not containing two adjacent 0's is (1 + 01)*( + 0)
Example 3.3
Application of Regular Expressions (I)
Searching for strings of characters in UNIX using ex and other editors, and using grep and egrep.
the ex command /a*[abc]/ means find any line containing a substring starting with any number of a's followed by an a, b, or a c.
Application of Regular Expressions (II)
Lexical analysis, the initial phase of compiling, divides the source code into "tokens". The definition of what constitutes the different tokens is given by regular expressions.
18

CS3012 Formal Languages Regular Expressions and Regular Languages
Definition 3.4
A language L over T is a regular language iff there is a regular expression defining it.
Theorem 3.5 If A and B are regular languages, then so are A+B, AB and A*.
Notation: A' denotes the complement of A: i.e. the set of all strings in T* not in A.
Theorem 3.6 If A and B are regular languages, then so are AB and A'.
Theorem 3.7 Any finite language is regular.
19

CS3012 Formal Languages Finite State Automata and Regular Languages
4. Finite State Automata and Regular Languages
Theorem 4.1 Kleene's Theorem
A language L is accepted by a FSA iff L is regular
Algorithm 4.2Regular Expression -> NDFSA
Given a regular language, L, over T, defined by a regular expression, r, create a NDFSA, A, s.t. L = L(A).
begin if r == , then A := ({q},{q},{q},T,{}) else if r == , then A := ({q},{q},{},T,{}) else if r == t, then A = ({p,q},{p},{q},T,{(p,t,q)}) else if r == r1 + r2 then begin obtain A1 = (Q1,{i1},{f1},T,E1), L1 = L(A1) obtain A2 = (Q2,{i2},{f2},T,E2), L2 = L(A2) A := (Q1Q2{i,f},{i},{f},T,E1E2{(i,,i1),(i,,i2),(f1,,f),(f2,,f)}) end else if r == r1r2 then begin obtain A1 and A2 as above A := (Q1Q2,{i1},{f2},T,E1E2{(f1,,i2)}) end else if r == r1
* then begin obtain A1 as above A := (Q1{i,f},{i},{f},T,E1{(i,,i1),(i,,f),(f1,,f),(f1,,i1)}) end return Aend
Example 4.3 Regular Expression ->NDFSA
Let L = (b+ab)(b+ab)*, T = {a, b}
Find NDFSA's for: (i) a (ii) b (iii) ab (iv) (b+ab) (v) (b+ab)* (vi) (b+ab)(b+ab)*
(i) ({1,2},{1},{2},T,{(1,a,2)})(ii) ({3,4},{3},{4},T,{(3,b,4)})(iii) ({1,2,3,4},{1},{4},T,{(1,a,2),(2,,3),(3,b,4)})(ii)' ({5,6},{5},{6},T,{(5,b,6)})(iv) ({1,2,3,4,5,6,7,8},{7},{8},T,{(7,,1),(7,,5),(1,a,2),(2,,3),(3,b4),(5,b6),(4,,8),(6,,8)})(iv)' ({9,10,11,12,13,14,15,16,{15},{16},T,
{(15, ,9),(15,,13),(9,a,10),(10,,11),(11,b,12),(13,b,14),(12,,16),(14,,16)})(v) ({9,10,11,12,13,14,15,16,17,18},{17},{18},T,{(17,,15),(17,,18),(15,,9),(15,,13),(9,a,10),(10,,11),(11,b,12),
(13,b,14),(12,,16),(14,,16) (16,,18),(16,,15)})(vi) ({1,2,...,18},{7},{18},T,{(7,1),(7,,5),(1,a,2),(2,,3),(3,b,4),(5,b,6),(4,,8),(6,,8),(8,,17),(17,,15),(17,,18),
(15,,9),(15,,13),(9,a,10),(10,,11),(11,b,12), (13,b,14),(12,,16),(14,,16),(16,,18),(16,,15)})
20

CS3012 Formal Languages Finite State Automata and Regular Languages
a b
b
a b
b
7
1 2 3 4
5 6
8 17 15
13 14
9 10 11 12
16 18
Algorithm 4.4FSA -> Regular Expression
Given a FSA, A, create a regular expression defining L(A)
begin create unique initial state create unique final state unique FSA -> regular expressionend
Algorithm 4.5create unique final state
Given a NDFSA, A = (Q,I,F,T,E), create FSA A' with a single final state s.t. L(A) = L(A')
begin Q := Q {f} (where f Q) for each q F do add (q,,f) to E F := {f} return (Q,I,F,T,E)end
Definition 4.6
A regular finite state automaton (RFSA) is a FSA where the edge labels may be regular expressions. An edge labelled with the regular expression r indicates that we can move along that edge on input of any string defined by r.
21

CS3012 Formal Languages Finite State Automata and Regular Languages
Algorithm 4.7unique FSA -> regular expression
Given a FSA, A = (Q,{i},{f},T,E), with unique initial and final states, create a regular expression r defining L(A).
begin convert A to a RFSA %trivial while Q\{i,f} is not empty do begin for each state p Q with more than one edge (p,ri,p) (i ≤ n) do replace all those edges by (p,r1+r2+...+rn,p) for each pair p,q Q with more than one edge (p,ri,q) (i ≤ n) do replace all those edges by (p, r1+r2+...+rn,q) select s Q for each pair p,q Q (p,q s) s.t. there are edges (p,r1,s) and (s,r2,q) do if there is an edge (s,r3,s) then add the edge (p,r1r3
*r2,q) else add the edge (p,r1r2,q) remove all edges to or from s remove all states and edges with no path from i end return r, where E = {(i,r,f)}end
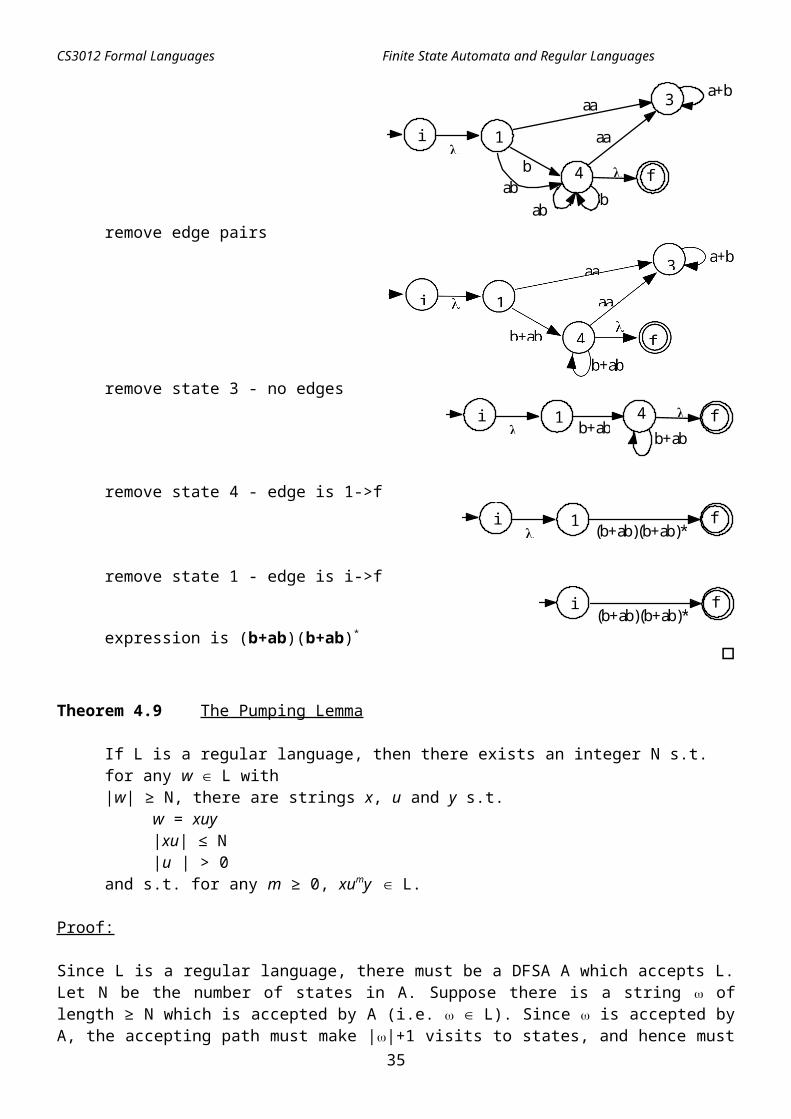
Example 4.8 FSA -> Regular Expression
b
1
a 2 3
b 4
a b
aa+b
create unique initial and final states
b
1
a 2 3
b 4
a b
aa+b
i
f
remove state 2 - edges are 1->3, 1->4, 4->3, 4->4
b
1
3
b 4
aa
aaa+b
i
fab
abremove edge pairs
22

CS3012 Formal Languages Finite State Automata and Regular Languages
remove state 3 - no edges
b+ab1
b+ab4i
f
remove state 4 - edge is 1->f
1(b+ab)(b+ab)*
i
f
remove state 1 - edge is i->f
(b+ab)(b+ab)*i f
expression is (b+ab)(b+ab)*
Theorem 4.9 The Pumping Lemma
If L is a regular language, then there exists an integer N s.t. for any w L with |w| ≥ N, there are strings x, u and y s.t.
w = xuy|xu| ≤ N|u | > 0
and s.t. for any m ≥ 0, xumy L.
Proof:
Since L is a regular language, there must be a DFSA A which accepts L. Let N be the number of states in A. Suppose there is a string of length ≥ N which is accepted by A (i.e. L). Since is accepted by A, the accepting path must make ||+1 visits to states, and hence must make > N visits to states. But A has only N states, and so at least one state must be visited at least twice. Let s be the first state which is visited twice on the accepting path. We can split the path into three sub-paths: from the start to the first visit to s, from the first visit to s to the second visit to s, and from the second visit to s to the end. Let x, u and y be the substrings of corresponding to these three subpaths (so = xuy). The subpath xu does not visit any states more than once except s, and so makes at most N+1 visits, and so must have length ≤ N (so |xu| ≤ N). For the two visits to s to be separate, there must be at least one character accepted in that subpath (so |u| > 0).
Now, if we are in state s, an input of u will take us back to s, and an input of y will take us to the finish state. From the start state, an input of x will take us to state s. Therefore, the input xy will be accepted (x takes us to s, and y takes us to the finish state), and so will xuy, xuuy, xuuuy, etc.. Therefore, for any m ≥ 0, xumy will be accepted by A. But, by definition of A, any string accepted by A is in L. Therefore, for any m ≥ 0, xumy L
23

CS3012 Formal Languages Finite State Automata and Regular Languages
Example 4.10 Using the Pumping Lemma
Show L = {anbn : |n| ≥ 0} is not regular.
Suppose L is regular. Then, by the pumping lemma, there exists some integer N s.t. for any w L with |w| ≥ N, there are strings x, u and y s.t.
w = xuy|xu| ≤ N|u| > 0
and m ≥ 0, xumy LChoose i > N/2. Let w be the string aibi. Then w has length > N. By the pumping lemma, w can be split into substrings xuy, s.t. |xu| ≤ N and |u| > 0.Now u must be of the form an, or anbm, or bm., for some n and m.If u = an, then w = xuy = ajanakbi, where j+n+k = i. So xu2y = ajananakbi, which is not in L, because it has more a's then b's.The same argument works for u = bm.If u = anbm, then w = xuy = ajanbmbk, and xu2y = ajanbmanbmbk, which is obviously not in L, because it has b's before a's.Thus in no case is xu2y in L.But by the Pumping Lemma, xu2y L. Contradiction.Therefore our first assumption must have been wrong, so L is not regular.
24

CS3012 Formal Languages Finite State Automata with Output
5. Finite State Automata with Output
Definition 5.1 Moore Machine
A Moore Machine is a 6-tuple (Q,I,T,E,,O), whereQ, I, T and E are as for DFSA's is an alphabet (called the output alphabet), andO is a subset of Q (called the output function)
Notation: if (q,x) O, then sketch state q by q/x
The output function defines the output of the machine whenever the machine enters a particular state.
Example 5.2
A Moore machine which prints out a "1" every time an aab substring is input:
The input aaababaaab gives the output 11.
Definition 5.3 Mealy Machine
A Mealy Machine is a 6-tuple (Q,I,T,E,,O) whereQ, I, T and E are as for DFSA's is an alphabet (called the output alphabet), andO is a subset of Q T (called the output function).
Notation: if (q,t,x) O, then for any arc (q,t,p) E, label the arc by t/x.
The output function defines the output of the machine whenever the machine leaves a particular state through a particular labelled action.
25

CS3012 Formal Languages Finite State Automata with Output
Example 5.4
A Mealy Machine which takes reversed binary numbers as input, and prints as output the reversed number one larger:
0/10/0, 1/1
0/1
1/01/0
The input 11101 gives the output 00011.
Definitions 5.5
Let M be a Moore machine or a Mealy Machine, with output alphabet . Define Mo(w) to be the output of M on w.
Let M1 = (Q1,I1,T1,E1,1,O1) be a Moore Machine, and M2 = (Q2,I2,T2,E2,2,O2) be a Mealy Machine. Let M1
o() = b.M1 and M2 are equivalent if T1 = T2 and for all strings w T1
*, M1o(w) = bM2
o(w).
Theorem 5.6 Moore-Mealy Equivalence
If M1 is a Moore Machine, then there exists a Mealy Machine M2 equivalent to M1.
If M2 is a Mealy Machine, then there exists a Moore Machine M1 equivalent to M2.
26

CS3012 Formal Languages Languages and Grammars
6. Lex: A Lexical Analysis Tool
Lex is a program generator, accepting a series of regular expression definitions, and producing a program which analyses input to identify lexical tokens defined by those regular expressions.
A Lex script has three sections, separated by a line containing only "%%":
... definitions ...%%... regular expression / action pairs ...%%... user-defined functions ...
Lex Syntax
Let c be a character, x,y regular expressions, s a string, m,n integers, and i an identifier.
regular expressions
c any character except meta characters[...] any of the list of characters enclosed (may be a range of characters)[...] any of the characters not in the list enclosed. any ASCII character except newlinexy the concatenation of x and yx* same as x*
x+ same as x+
x? an optional x (same as x + )x|y x or y{i} the definition of ix/y x, but only if followed by y (and y is not read from the input)x{m,n} m to n occurrences of xx x, but only at the beginning of a linex$ x, but only at the end of a line"s" exactly what is in the quotes (except for "\" and the following character)
Precedence: brackets, then unary operators (+,?,*), then concatenation, then |, then /.
Regular expression are terminated by a space or a tab.
If there is a conflict between different regular expression, then Lex will match against the longest expression, and for the same length expression, will match against the first definition.
meta characters (do not match themselves)
( ) [ ] { } < > + / , ^ * | . \ " $ ? - %
A match with a meta-character can be obtained by preceding with "\"Backslash, tab and newline are represented by \\, \t and \n respectively.Actions
27

CS3012 Formal Languages Languages and Grammars
An action is a C language statement (followed by ";").
For example:
[0-9]+ printf("Integer\n");[a-zA-Z]+ printf("String\n");
will print out "Integer" after receiving a digit string as input, and "String" after receiving a character string.
Thus the input 12+19=sum
will result inInteger+Integer=String
Note that a recognised regular expression is held in the string variable yytext, and its length is held in the integer variable yylen.
Any input not recognised by the regular expression section will simply be echoed to the screen.
Definition Section
If identifier string
appears in the definition section, then string will replace identifier whenever {identifier} appears in the regular expression section.
Thus L [a-zA-Z]%%{L}+
is equivalent to %%[a-zA-Z]+
Anything enclosed between %{ ... %} in this section will be copied into the output program.
include and define statements, all variable declarations, all function definitions and any comments should be so enclosed.
Functions Section
The section should contain the user-defined "main" routine, and any other required functions, written as C code.
A simple "main" routine is found in the lex library, and will be used if no user-defined "main" is supplied.
28

CS3012 Formal Languages Languages and Grammars
Running Lex
The command lex calls the lex program on the specified file (usually with a ".l" suffix). The output, a C file, is called lex.yy.c. This program must then be compiled with the lex library (using the -ll option) with the object file renamed if required. To run the program, simply type the name of the object file.
For example, to compile and run the lex script "example.l", type:
lex example.lcc lex.yy.c -o example.o -llexample.o
Example Lex Program
The following program specifies a simple word recognition lexical analyser
%{/* simple word recognition program */%}L [a-zA-Z]
%%
[ \t]+ ; /* ignore whitespace */is|are printf("verb: %s; ", yytext);a|the printf("determiner: %s; ", yytext);dog |cat |male |female printf("noun: %s; ", yytext);{L}+ printf("unknown: %s; ", yytext);.|\n ECHO;
%%
main(){ yylex();}
Running this program as above would give the following (user input is underlined)
% word.othe dog is a male <cr>determiner: the; noun: dog; verb: is; determiner: a; noun: male;female cat dog is <cr>noun: female; noun: cat; noun: dog; verb: is;catdog is male <cr>unknown: catdog; verb: is; noun: male;
29

CS3012 Formal Languages Languages and Grammars
<ctrl-d>%
30

CS3012 Formal Languages Languages and Grammars
Practical Class: Using Lex
Write a lexical analyser using Lex, for the language C-, defined below.
What is required?
A "y.tab.h" file will be supplied, defining all the different tokens to be used. It is linked from the web page for the practical, and should be copied to your own filespace before beginning the practical. Note that "KEY_REAL_T" is intended for the "real" keyword, and "REAL_T" is intended for real numbers.
You have to write a Lex script, containing a definition section, a regular expression/action pair section, and a function section. The script, when run through Lex, should create a program which takes a file as input, reads the file, and outputs the result of a lexical analysis (either to another file or to the screen).
The output from the analyser should be in the form of <token, attribute> pairs. Every element of an input program should be classified. Thus, on receiving input of z := y*27; the output should be something like:
<ID_T,z><BECOMES_T,:=><ID_T,y><MUL_T,*><INT_T,27><SEMI_T,;>
The input must be described by regular expressions, and you must use Lex. You are advised to use the skeleton file "lexer.l" in the above directory. Note that you are only asked to do word recognition, and not check syntax. The action for each regular expression should be a simple "return" statement.
You have to decide what to do with errors, but do not allow something to pass as a token if it should not pass, do not misclassify tokens, and do not allow valid tokens to pass as errors.
C- language definition
NOTE: A program is a sequence of function declarations and variable declarations.
Each function and each variable must be declared before use. A variable is declared by stating the variable type followed by a non-empty space-separated sequence of identifiers or array specifications, ending with a semi-colon. A function is declared by stating its return type, followed by the function name (an identifier), a (possibly empty) comma-separated list of parameter declarations between "(" and ")", followed by the code block between "{" and "}".
Possible variable and return types are "real" and "int" (and "void" as a special return type).
An identifier is a sequence of letters. An array specification is an identifier followed by an integer between "[" and "]" representing the size
of the array. An array reference is an identifier followed by an integer-valued expression between "[" and "]".
A parameter declaration is a variable type, a space, and an identifier.
Each program must have a "main" function block, which must be the last function to be declared. It has no parameters, and no return type.
The code block is a sequence of statements. Each statement may be a variable declaration, an assignment, a call to a function, a print statement, a code block between "{" and "}", a while statement, an if-then statement, an if-then-else statement, or a return statement. All except the code block and while and if statements must be terminated by a semi-colon.
31

CS3012 Formal Languages Languages and Grammars
An assignment has an array reference or an identifier on the left-hand side, a ":=", and an expression on the right-hand side. Expressions are built from the "+","-", "*" and "/" operators, and the basic factors are reals, integers, identifiers, array references, function calls, or expressions inside "(" and ")".
A call to a function is the function name, and then the argument list between "(" and ")". The argument list is a possibly empty comma-separated sequence of expressions.
A print statement is the keyword "print" followed by an expression between "(" and ")".
A while statement is the keyword "while" followed by a test between "(" and ")" followed by the keyword "do" followed by a statement.
An if-then statement is the keyword "if" followed by a test between "(" and ")" followed by the keyword "then" followed by a statement. An if-then-else statement is an if-then statement followed by the keyword "else" followed by a statement.
A test is two expressions with a relational operator in between. The relational operators are "<", ">", "=<", "=>", "=" and "!=" (standing for "not equals").
A return statement is the keyword "return" followed by an expression.
Integers have an optional sign followed by one or more digits. Reals have an optional sign, one
or more digits, a decimal point, and one or more digits.
Variables or functions which are used before being declared will give an error. Trying to use a return value of a void function gives an error. Using a return statement inside a void function gives an error. Variables are either declared outside a function, and can be accessed by all functions which follow them, or are declared inside a function, and can only be used inside that function. Redeclaring a variable within its scope gives an error. All parameters are passed by value (i.e. the value of a passed parameter does not change once the function has completed).
A small example C- program is given below:
int a b c ;int g[5];
int testFunc(int x) { real y;
y := (x+a)/2; print(y); return a;}
main() {
a := 1; while (a < 3) do { testFunc(a); a := a + 1; }}
32

CS3012 Formal Languages Languages and Grammars
7. Languages and Grammars
Definitions 7.1 Grammar
A grammar is a 4-tuple, G = (N,T,S,P), whereN is a finite alphabet (called the non-terminals);T is a finite alphabet (called the terminals);N T = ;S N is the start symbol; andP is a finite set of productions of the form
->, where (N T)+, has at least one member from N, and (N T)*.
Let G = (N,T,S,P) be a grammar.
If s, t, x, y, u and v are strings s.t. s = xuy, t = xvy, and u -> v P, then s directly derives t, written s => t.
If there is a sequence of strings s0, s1, ..., sn s.t. s0 => s1 => ... => sn-1 => sn, thens0 derives sn, written s0 =>* sn.
A sentential form of G is a string w (N T)* s.t. S =>* w.
A sentence of G is a sentential form w T* - i.e. w has only terminal symbols.
Definition 7.2 Language defined by a grammar
The language defined by G is the set of all sentences of G, denoted L(G).
Example 7.3
Let G = ({S}, {a,b}, S, {S -> , S -> aSb}).
G has one non-terminal: SThe terminals of G are a and b.The start symbol of G is S.G has two productions.
aaaSbbb => aaaaSbbbb.
S =>* aaaabbbb.
aaaSbbb is a sentential form of G
aaaabbbb is a sentence of G.
L(G) = {, ab, aabb, aaabbb, ...}, which is {anbn: n ≥ 0}
33

CS3012 Formal Languages Languages and Grammars
Notation: We will not normally write the grammar as a tuple, but will use the following conventions:
Non-terminals will be uppercaseTerminals will be lowercaseUnless stated otherwise, the start symbol will be S.The set of productions may be numbered.If x => y using production number i, then we write x =>i y.
-> 1 | 2 | ... | n will be shorthand for the n productions
-> i .
Definition 7.4 Context-Free Grammars and Languages
A context-free grammar (denoted CFG) is a grammar in which all productions are of the form -> ,
where N - i.e.the left hand side is a single non-terminal.
A context-free language (denoted CFL) is one defined by a context-free grammar.
Example 7.5 A Grammar of Algebraic Expressions: G 0
G = ({S}, {a, +, *, (, )}, S, {1) S -> S + S2) S -> S * S3) S -> (S)4) S -> a }
Example derivation:
S =>2 S * S =>4 a * S =>3 a * (S) =>1 a * (S + S) =>4 a * (a + S) =>4 a * (a + a).
Note that there are many other ways of deriving the same string.
Definition 7.6 Regular Grammar
A grammar is regular if each production is of the form:
(i) A -> t ,(ii) A -> tB, or(iii) A ->
where A, B N, t T.
34
CS3012 Formal Languages Languages and Grammars
Example 7.7
S -> aA | bBA -> aS | aB -> bS | b
S => aA => aaS => aaaA => aaaaS => aaaabB => aaaabb
The language generated by this grammar is the same as (aa + bb)+.
Theorem 7.8 A language is regular iff it can be defined by a regular grammar.
Techniques for constructing grammars
To create sequences of a symbol (e.g. aaa...a):
A -> aA | or A -> Aa |
Example: A => aA => aaA => ... => aaaaaA => aaaaa
To "bracket" a string (e.g. axxx...xb):
A -> aBb or A -> CbB ->xB | C -> ax | Cx
Example: A => aBb => axBb => axxBb => ... => axxxxxBb => axxxxxb
To create a nested structure (e.g. aaa...<.....>...bbb):
A -> aAb | BB -> xB |
Example A => aAb => aaAbb => ... => aaaaaAbbbbb => aaaaaBbbbbb => aaaaaxBbbbbb => aaaaaxxBbbbbb => aaaaaxxxbbbbb
Example 7.9
Construct a grammar for the language consisting of all strings of the form abccc...cab or abab...abccc...cabab...ab |<-- ntimes -->| |<-- n times -->|
A -> abAab | abBabB -> cB | c
35

CS3012 Formal Languages and Compilers Lex
8. Derivations and Ambiguity
Recognition problem Given a grammar, G, and a string, w, is w L(G)?
Parsing Problem Given a grammar, G, and a string, w L(G), how is w derived in G?
Definition 8.1 Derivation tree
Let (S =) w0 =>i1 w 1 =>i2 w 2 =>i3 ... =>in wn be a derivation. We construct the corresponding derivation tree as follows. It has w0 as its root. Every time a symbol a is replaced by a substring , a branch is added from a to every symbol in , in the same order in which they appear in .
Example 8.2
Let S => S+S => S+(S) => S+(S*S) => S+(S*a) => S+(a*a) => a+(a*a) be a derivation in the gramar G0. Its corresponding derivation tree is
S
S + S
( S )
S * S
a a
a
Definitions 8.3
A derivation in which, at each step, the rightmost non-terminal is replaced is a right-derivation.A CFG is ambiguous if there is at least one string in L(G) having two or more different right derivations.
Note: A string has two different right derivations iff it has two different derivation trees.
36

CS3012 Formal Languages and Compilers Lex
Example 8.4
G0 is ambiguous, since the string a+a*a has two different right derivations:
1. S => S+S => S+S*S => S+S*a => S+a*a => a+a*a2. S => S*S => S*a => S+S*a => S+a*a => a+a*a
with the two derivation trees:
S
S
a
+ S
S * S
a a
1. S
S
a+
S
S
*
S
a a
2.
Example 8.5 An unambiguous grammar of algebraic expressions G
1) S -> S + T2) S -> T3) T -> T * F4) T -> F5) F -> (S)6) F -> a
S => S+T => S+T*F => S+T*a => S+F*a => S+a*a => T+a*a => F+a*a => a+a*a
Definition 8.6
A language for which every defining grammar is ambiguous is inherently ambiguous.
S
S
T
+ T
T * F
F a
a
F
a
37

CS3012 Formal Languages Intermediate Code Generation
9. Parsing
Definition 9.1
Top-down parsing creates a derivation tree for a given string by expanding from the start symbol by applying productions.
Definition 9.2
Recursive-descent parsing is a top-down parsing method that associates a recursive procedure with each non-terminal of the grammar.Predictive parsing is recursive-descent parsing where it is possible to determine which procedure to call at each stage by examining the next symbol of the input.
Example 9.3 Consider the following grammar:
Type ->Simple | array [Simple] of TypeSimple -> int | num .. num
We can write procedures for Type and Simple as follows:
procedure typebegin if token {int, num} then simple else if token = array then begin match(array) match('[') simple match(']') match(of) type end else errorend
procedure simplebegin if token = int then match(int) else if token = num then begin match(num) match(..) match(num) end else errorend
procedure match (t:token)begin if token = t then token := nexttoken else errorend
38

CS3012 Formal Languages Intermediate Code Generation
A parse of "array[3 .. 11] of int" then consists of the following procedure calls:
token: procedure calls: array type
match(array)[ match('[')num simple
match(num ).. match(..)num match(num )] match(']')of match(of )int type
simple match(int )
Definition 9.4
LL(1) parsing means: (i) read the input from the left (to the right)(ii) generate a left derivation(iii) using 1 lookahead symbol.
LL(1) parsing for a given grammar requires a 2D table with a column for each terminal plus a new symbol #, and a row for each non-terminal. Each cell is a single production from the grammar.
Algorithm 9.5 LL(1) Parsing Algorithm
Given a string, a grammar and an LL(1) parse table, parse the string using the table.Variables: z - a string (the parsing stack), w - a string (the input), M - the LL(1) table
begin z := start symbol concatenated with # w := input string concatenated with # while q ≠ # do begin
q represents the first symbol in z %top state in stack t represents the first symbol in w
if q = a and t = a then begin % a is a terminal remove a from front of w % 'match' remove a from front of z end else if q = N and t = a and M[N,a] = p then begin % p = N -> remove N from front of z put onto the front of z end else error %input L(G) end while if q = # and t = # then accept else errorend
Type
array [ Simple ] of Type
Simple
int
numnum ..
39

CS3012 Formal Languages Intermediate Code Generation
Example 9.6
Grammar: 1) S -> ( S ) S 2) S ->
LL(1) table: ( ) # S: 1 2 2
z (parsing stack) w (input stack) action S # ( ) # S -> ( S ) S
( S ) S # ( ) # matchS ) S # ) # S ->
) S # ) # matchS # # S ->
# # accept
Both recursive-descent parsing and LL(1) parsing require first(N) and follow(N) to be known for all non-temrinal symbols N. first(N) is the set of all tokens which could appear as the first symbol in a token substring derived from N, while follow(N) is the set of all tokens which could appear as the next token once N's token substring is finished. Algorithms to compute these sets are known (but are omitted from the course).
Neither recursive-descent nor LL(1) parsing can be used on grammars which are left recursive, or which have two or more productions for the one non-terminal where the right-hand side starts with the same substring.
Definition 9.7
Bottom-up parsing constructs a derivation tree from the input string, applying productions in reverse (called reductions) until the start symbol is reached.
Algorithm 9.8Basic Shift-Reduce Parsing
Given a string and a grammar, construct a derivation of the string.
variables: z - a string (the stack), w - a string (the input), h - a substring (the handle)
begin z := w := input string concatenated with # while z S or w # do begin obtain the handle h (corresponding to production A -> h) if z does not end in h, then move first symbol of w to end of z % shift else begin remove h from z % reduce put A on end of z end endend
Example 9.9 Parse a+a*a in grammar G
40

CS3012 Formal Languages Intermediate Code Generation
Stack Input Actiona+a*a shift
a +a*a reduce (6)F +a*a reduce (4)T +a*a reduce (2)S +a*a shiftS+ a*a shiftS+a *a reduce (6)S+F *a reduce (4)S+T *a shiftS+T* a shiftS+T*a reduce (6)S+T*F reduce (3)S+T reduce (1)S accept
Definition 9.10 LR( k ) Parse Table
An LR(k) parse table is a 2D matrix, with rows indexed by integers and columns indexed by length k strings of grammar symbols plus an endmarker. The entries of the table are of five types:
Rp (reduce by production p)Sn (shift, go to state n)n (go to state n)A (accept) /* there is only one 'A' entry */E (error) /* Notation: appear blank in the table */
"LR(k)" means: (i) read the input from the left (to the right)(ii) generate a right derivation(iii) using k lookahead symbols.
Example 9.11 LR(1) parse table for G
S T F a + * ( ) # 0 1 2 3 S5 S41 S6 A2 R2 S7 R2 R23 R4 R4 R4 R44 8 2 3 S5 S45 R6 R6 R6 R66 9 3 S5 S47 10 S5 S48 S6 S119 R1 S7 R1 R110 R3 R3 R3 R311 R5 R5 R5 R5
41

CS3012 Formal Languages Intermediate Code Generation
Algorithm 9.12 LR(1) Parsing Algorithm
Given a string, a grammar and an LR(1) parse table, parse the string using the table.
begin z := 0 w := input string concatenated with # loop q := last symbol in z %top state in stack t := first symbol in w if M[q, t] = Sn then begin % row q, col t in table remove t from front of w put n on end of z end else if M[q, t] = Rp then begin take the grammar rule numbered with p let the left hand side of it be called B and let the right hand side be called i.e. the grammar rule has the form: p = B -> remove || symbols from end of z q := last symbol in z %top state in stack put M[q,B] on end of z %new state end else if M[q, t] = A then return true %input L(G) else return false %input L(G) endend
Example 9.13 Parse a+a*a using the table of 9.11 and grammar G
1) S -> S + T2) S -> T3) T -> T * F4) T -> F5) F -> (S)6) F -> a
42

CS3012 Formal Languages Intermediate Code Generation
Symbol stack Stack( z ) Input ( w ) q t B Action Grammar Rule 0 a+a*a# 0 a S5
a 05 +a*a# 5 + R6 6) F -> aa 0 +a*a# 0 F R6F 03 +a*a# 3 + R4 4) T -> FF 0 +a*a# 0 T R4T 02 +a*a# 2 + R2 2) S -> TT 0 +a*a# 0 S R2S 01 +a*a# 1 + S6S+ 016 a*a# 6 a S5S+a 0165 *a# 5 * R6 6) F -> aS+a 016 *a# 6 F R6S+F 0163 *a# 3 * R4 4) T -> FS+F 016 *a# 6 T R4S+T 0169 *a# 9 * S7S+T* 01697 a# 7 a S5S+T*a 016975 # 5 # R6 6) F -> aS+T*a 01697 # 7 F R6S+T*F 01697 10 # 10 # R3 3) T -> T * FS+T*F 016 # 6 T R3S+T 0169 # 9 # R1 1) S -> S + TS+T 0 # 0 S R1S 01 # 1 # A
Definitions 9.14
A grammar is LR(k) if we can construct a deterministic LR(k) parse table for it.
A language is LR(k) if it has an LR(k) grammar.
43

CS3012 Formal Languages and Compilers Yacc
10. Yacc: A Parser Generator
Yacc is a parser generator, accepting a context-free grammar, and producing a program which analyses input to check whether it conforms to the syntax of the grammar. Yacc constructs the LR(1) parse table, and implements the LR(1) parsing algorithm (in fact, LALR(1) - a slight restriction of LR(1) - and not LR(1)). The input must first be converted to a stream of integer tokens, using a function yylex(). The function yylex() can be hand-written, or generated by Lex.
A Yacc script has three sections, separated by lines containing only %%:
... definitions ...%%... production rules ...%%... user-defined functions ...
Definitions section
As in Lex, anything in this section enclosed between %{ and %} will be copied into the output program. Any #include or #define statements or variable or function declarations required for the user-defined functions should be enclosed here.
In this section must appear a set of "token" declarations, and there must be a token for each terminal which will appear in the grammar. For example:
%token VERB_T%token NOUN_T
declares two terminals for use in a grammar. A useful convention is to use uppercase ending in "_T" for token names, and to use mixed case, starting with a capital letter, for non-terminals.
Productions section
Instead of writing
A -> a b c | e f g
we now write
A : a b c | e f g ;
and liberal use of white space is encouraged to improve readability, and to make it easier to update scripts. For example, the two productions above would be better written as
A : a b c | e f g;
YACC will take the left-hand symbol of the first rule in this section, and make it the start symbol.Comments can be included in 'C' format. For example:
/* A can be rewritten to abc or to efg */
Functions section
As in Lex, this section should contain the user-defined main() routine, and any other required functions. The usual functions to include here apart from main() are:
lexerr() - defining what to do if the lexical analyser finds an undefined token. This requires that the default case in the lexer has a call to this function as its associated action.
yyerror(char*) - defining what to do if the parser cannot recognise the syntax of part of the input. This function will be called by the parser, which passes a string describing the type of error. Note that when an error occurs, the line number of the input is held in yylineno, and the last token read when the error is reached is held in yytext.
Running Yacc
The command yacc calls the Yacc program on the specified input. Using the "-d" option forces Yacc to create a file y.tab.h, which contains the #define statements for all the tokens declared in the definitions section. If we need to use the integer values of these tokens in the user
44

CS3012 Formal Languages and Compilers Yacc
defined functions, we can then place #include "y.tab.h" between the %{ and %} lines of the definitions section. Using the "-v" option forces Yacc to create a file y.output, which contains information on the parse table useful for debugging. The output of the yacc command is a file y.tab.c, which contains the 'C' source for the parser.
If we have written a Lex script for the lexical analyser, we must also create lex.yy.c as before.
To obtain executable code for the complete parser, we then must link the object files, using both the yacc library, "-ly" and the Lex library, "-ll".
Error Messages
Yacc can only accept grammars of a particular sort. Specifically, it cannot handle ambiguous grammars, nor can it handle grammars requiring two or more symbols of lookahead for parsing. The two messages resulting from ambiguous grammars that you will see most often are:
shift-reduce conflict orreduce-reduce conflict
Example productions giving rise to these messages are:
Expr : TOKEN| Expr + Expr ;
for the first case, where TOKEN+TOKEN+TOKEN could be parsed in two ways, and
Animal: Dog| Cat;
Dog : FRED_T ;
Cat : FRED_T;
for the second, where FRED_T could be parsed two ways.
If these messages appear, then your grammar is not suitable. In most cases, by carefully studying the grammar (using the information in y.output), you can find a different set of productions which Yacc can handle. The two simplest cases are given above. In particular, note that productions of the form E -> E+E are guaranteed to produce conflicts.
Occasionally, it may turn out that the language you are trying to define is inherently ambiguous, in which case Yacc is of no use; however, this is very unlikely. If the language is easy to understand, then, generally, it is easy to write a simple, unambiguous grammar for it. Remember that Yacc can handle even large and relatively complex languages like PASCAL and C - in fact, the Berkeley PASCAL and Sun C compilers are written in Yacc.
If Yacc does output the above messages, do not let your grammar go uncorrected. Although a parser will be generated, it will probably not define the language you intend, and will fail in mysterious ways.
Example 10.1
Write a Yacc script to construct a parser for sentences from the natural language grammar below.
S-> NP VPNP -> Det NP1 | PNNP1 -> Adj NP1 | NDet -> a | thePN -> peter | paul | maryAdj -> large | greyN -> dog | cat | male | femaleVP -> V NPV -> is | likes | hates
First, we will accept files consisting of multiple sentences. Each sentence will be delimited by a ".". Therefore, change the first production to read:
S-> NP VP .
45

CS3012 Formal Languages and Compilers Yacc
and we also add two new productions describing "documents" in terms of sentences:
D -> S D |
Note that we are only trying to parse sentences, and not understand them - therefore, our lexical analysis only needs to be to the level of the parts of speech (i.e. we only need to recognise nouns and verbs, and not individual words).
The lexical analyser is a modification of the example Lex program given on p23. Instead of "print" statements, we will return tokens. Therefore, in the definitions section, we have a line which includes the token list which will be created by Yacc.
%{/* simple part of speech lexer */
#include "y.tab.h"%}
L [a-zA-Z]%%
In the regular expression section, we need expressions for each part of speech, plus special symbols and unknown input.
[ \t\n]+ /* ignore whitespace */;is|likes|hates return VERB_T;a|the return DET_T;dog |cat |male |female return NOUN_T;peter |paul |mary return PROPER_T;large | grey return ADJ_T;\. return PERIOD_T;{L}+ lexerr();. lexerr();%%
We will use the standard yylex() function created by Lex, and so we don't need user-defined functions.
In the definitions section of the Yacc script, we need to declare the variables we will use in the error functions, as well as all the tokens we expect to be passed by the lexer.
%{/* a Yacc script for a simple natural language grammar */
#include <stdio.h>#include "y.tab.h"
extern int yyleng;extern char yytext[];extern int yylineno;extern int yyval;
46

CS3012 Formal Languages and Compilers Yacc
extern int yyparse();%}
%token DET_T%token NOUN_T%token PROPER_T%token VERB_T%token ADJ_T%token PERIOD_T
%%
The grammar rules are straightforward.
/* a document is a sentence and the rest of the document, or is empty */
Doc : Sent Doc| /* empty */;
/* a sentence is a noun phrase, verb phrase, and a period */
Sent : NounPhrase VerbPhrase PERIOD_T ;
/* a noun phrase is a determiner and an undetermined noun phrase, or a proper noun */
NounPhrase : DET_T NounPhraseUn| PROPER_T;
/* an undetermined noun phrase is an adjective and an undetermined noun phrase, or a noun */
NounPhraseUn : ADJ_T NounPhraseUn | NOUN_T;
/* a verb phrase is a verb and a noun phrase */
VerbPhrase : VERB_T NounPhrase ;
%%
In the user-defined functions section, we need to handle errors from the lexical analysis and errors from the syntax analysis, as well as defining the output from successful parsing.
void lexerr(){ printf("Invalid input '%s' at line %i\n",yytext,yylineno);
47

CS3012 Formal Languages and Compilers Yacc
exit(1);}
void yyerror(s)char *s;{ (void)fprintf(stderr, "%s at line %i, last token: %s\n", s, yylineno, yytext);}
void main(){if (yyparse() == 0)
printf("Parse OK\n");else printf("Parse Failed\n");
}
To compile the program, we type:
yacc -d -v parser.ycc -c y.tab.clex parser.lcc -c lex.yy.ccc y.tab.o lex.yy.o -o parser -ly -ll
Suppose we have three different input files, file1, file2 and file 3, as follows:
file1: peter is a large grey cat.the dog is a female.paul is peter.
file2: the cat is mary.a dogcat is a male.
file3: peter is male.mary is a female.
Typing the following commands gives the following results:
% parser < file1Parse OK% parser < file2Invalid input 'dogcat' at line 2% parser < file3syntax error at line 1, last token: male%
The second sentence of file2 contains unknown input - the word "dogcat".The first sentence of file3 has a syntax error - we have defined the word "male" to be a noun, and it must be preceded by a determiner.
48

CS3012 Formal Languages and Compilers Error Handling
11. Error Handling
Error Handling
It is part of the task of a compiler to assist in the identification, location and correction of errors. Errors can occur at any stage in the process, and it is desirable for each component of the compiler to report (and maybe recover from) the errors corresponding to its operation.
Lexical errors
Very few errors can be detected during lexical analysis, because the analyser has a very local view of the code. The main type of error is when the analysis halts because the input cannot be matched to any of the declared regular expressions - i.e. there is an invalid character or sequence of characters in the program.
The easiest way to recover from this type of error (after reporting it) is simply to delete the offending characters from the input, and continue processing. This is not very satisfactory, however, as it is uncontrolled, and may cause confusion during later stages of compilation.
Parsing errors
The error handler in the parser should:
• report errors clearly and accurately
• recover from each error quickly enough to detect subsequent errors
• not significantly slow down the compilation.
The design of parser error handling requires finding a balance between these three objectives.
Error detection
The LR-parsing method has the advantage that it detects the errors at the earliest possible point in the input. The errors are detected by the parser reaching a blank (or "E") entry in the parse table, indicating that this (state,lookahead) pair can never be reached during the parse of a
syntactically correct string. This condition is used to trigger an error recovery procedure which reports the error and then tries to return the parser to a state where it can continue.
Error recovery
Once an error has been detected, the aim is to put the parser in a state such that it can continue processing input with a reasonable hope that subsequent correct input will be parsed, and subsequent errors will be detected.
If the parser is not returned to a good state, there will be an avalanche of spurious errors, which are not actually errors in the source program, but were introduced by the changes made to the state of parser. Even if the rest of the input is accepted, there is no guarantee that it doesn't contain errors
Strategies
panic mode - ignore all input symbols until a designated "synchronising" token is reached - for example, end or ";". Start processing again after this token. This method often skips large parts of code without checking for errors, but it is simple, and it does not enter infinite loops.
phrase level - locally correct the input - that is, replace a prefix of the current input by something that would allow the parser to continue. Commonly, this involves replacing, inserting or deleting delimiters. Care must be taken, however, that the parser does not start to loop - a possibility if it always adds input onto the front rather than replaces input. The method also has a problem if the error actually occurred before the current point on the input stack
error productions - if certain errors are known to happen frequently, it is possible to include in the grammar what are called error productions. The grammar then caters for these errors, includes likely recovery, and allows specific diagnostics to be output.
global correction - ideally, we would want the compiler to carry out the minimum of changes to

CS3012 Formal Languages and Compilers Error Handling
the input in order to jump over an error. Given an incorrect input string x, and a grammar G, it is possible to find a parse tree for a related string y, such that the number of changes made to x to get y is minimised. However, this method is very expensive in time and space, and so, generally, is not used in practice.
Error recovery in LR Parsing
The SLR parser may make a few erroneous reductions before discovering an error, but will never shift an erroneous token from the input onto the stack. We can implement the first two error recovery strategies in the following ways:
panic mode - scan down the stack until we find a state, s, which has a shift command for particular non-terminals (A, say, with shift action Si). We then discard input symbols until
we reach one, a, say, which is in follow(A). Normally, we restrict the possibilities for A to be major program components - e.g. statement - and then a might be a semi-colon or an end. We remove the states above the selected one from the stack, and place i on the stack. Basically, we assume that a string derivable from A contains the error. Part of this string has already been processed (the states above s), and part remains on the input (the symbols to be discarded). The parser tries to skip over the error by assuming that A has been parsed successfully, and jumping to a symbol that should follow it.
phrase level - for this mode, we study each error entry in the table (the blanks or "E"s), and decide on the most likely cause. We then implement recovery procedures which assume that cause and take the appropriate action to modify the input.
Example 11.1 phrase-level error recovery in LR(1) parsing
Consider the LR(1) parse table for the grammar G augmented with error procedures:

CS3012 Formal Languages and Compilers Error Handling
S T F a + * ( ) # 0 1 2 3 S5 e1 e1 S4 e2 e11 e3 S6 e4 e3 e2 A2 e3 R2 S7 e3 R2 R23 e3 R4 R4 e3 R4 R44 8 2 3 S5 e1 e1 S4 e2 e15 e3 R6 R6 e3 R6 R66 9 3 S5 e1 e1 S4 e2 e17 10 S5 e1 e1 S4 e3 e18 e3 S6 e4 e3 S11 e59 e3 R1 S7 e3 R1 R110 e3 R3 R3 e3 R3 R311 e3 R5 R5 e3 R5 R5
e1: /* called from states 0, 4, 6 or 7, that are expecting the beginning of an operand (either an a or a "("), but instead a "+", "*" or "#" is found */ put 5 on top of the stack /* assumes a has been found */ issue message "missing operand"
e2: /* called from states 0, 1, 4, 6 or 7, which find an unexpected ")" */ remove ")" from input /* simply ignore it */ issue message "unmatched right parenthesis"
e3: /* called from states 1 or 8 which expect "+", but find an a or a "(" */ put 6 on to the stack /* assume a "+" has been found */ issue message "missing '+'"
e4: /* called from states 1 or 8 which expect "+" but find "*" */ put 6 on top of stack /* assume a "+" has been found */ remove "*" from input /* assume it was a "+" */ issue message "'*' instead of '+'"
e5: /* called from state 8 which expects a ")" but finds # */ put 11 on stack /* assume ")" is found */ issue message "missing right parenthesis"
Error recovery in Yacc
The easiest way to recover from errors in Yacc is to use error productions. In practice, this corresponds more to the idea of phrase level recovery discussed above. You must decide which non-terminals will have error recovery procedures associated with them, and then add to the grammar productions of the form A -> error where is a string of grammar symbols (possibly empty). When Yacc finds an error, its scans down the stack until it finds a state whose items include a rule of the form A -> something error . The parser then "shifts" a fictitious token, and scans through the input until it finds a substring matching ; once found, it removes everything up to the end of that substring from the input. The parser then reduces to A, and continues. For example, an error production
Statement -> error ;
would say to Yacc to skip beyond the next semi-colon and assume a statement had been parsed. An appropriate error message can be generated at this point.

CS3012 Formal Languages and Compilers Syntax-Directed Translation
12. Syntax-directed Translation
Translation is the process of taking some input and converting it into some other form whose structure and content is dependent on the structure and content of the input. We will do this for programming languages by associating actions with the productions of the grammar defining the programming language.
Example 12.1 translating from infix expressions to postfix expressions
The following actions convert expressions from the grammar G to postfix notation:
number rule action1 S -> S + T print ("+")2 S -> T3 T -> T * F print ("*")4 T -> F5 F -> ( S )6 F -> a print(a)
Parse a + a*a + a
a + a * a + a <=6 F + a * a + a <= T + a * a + a <= S + a * a + a <=6 S + F * a + a <= S + T * a + a <=6 S + T * F + a <=3 S + T + a <=1 S + a <=6 S + F <= S + T <=1 S
Printing output in the order in which the reductions were applied (6, 6, 6, 3, 1, 6, 1) which gives aaa*+a+, which is the corresponding postfix expression.
The Value Stack
A more general scheme is to associate values with each symbol on the parsing stack. On the stack, therefore, we have pairs of <symbol, value>, so we can think of this as two separate stacks, the symbol stack and the value stack. We can then associate with each reduction some action to be carried out on the value stack. The end result of a parse is then a report on whether the input had the correct syntax, and a value derived from the input's structure.
Suppose we are about to apply the reduction A -> x1x2...xn. The parsing stack then has the symbols x1, x2, ... xn on the right. The values corresponding to these symbols we will call $1, $2, ... $n. On performing the reduction, we remove the n symbols from the symbol stack (and eventually replace by A): therefore, we will remove the top n symbols from the value stack,
and replace by some new value defined by the rule augmentation. Call this new value $$. The most general form of this action is then a function, such that $$ = f($1, $2, ..., $n). In practice, this function might be an actual function, or a sequence of lower level actions which take the $i values as parameters. We don't need to use all of the $i.
Putting values on the stack
There are basically two cases: Putting on a non-terminal, and Putting on a terminal.
A non-terminal only goes on during a reduction (or the shift immediately following a reduction). This corresponds to the evaluation of the function defined above. The values of the terminal symbols, on the other hand, generally come from the lexical analysis.
Example 12.2 computing the values of expressions
Assume a lexical analyser returns the value of an integer along with the ID_T token

CS3012 Formal Languages and Compilers Syntax-Directed Translation
1) S -> S + T $$ := $1 + $32) S -> T $$ := $13) T -> T * F $$ := $1 * $34) T -> F $$ := $15) F -> ( S ) $$ := $26) F -> a $$ := $1
Parsing 1 + 2 * 3 is then as follows:
Symbol Values Stack Input Action0 1+2*3# S5
a 1 05 +2*3# R6F 1 03 +2*3# R4T 1 02 +2*3# R2S 1 01 +2*3# S6S+ 1• 016 2*3# S5S+a 1•2 0165 *3# R6S+F 1•2 0163 *3# R4S+T 1•2 0169 *3# S7S+T* 1•2• 01697 3# S5S+T*a 1•2•3 016975 # R6S+T*F 1•2•3 01697 10 # R3S+T 1•6 0169 # R1S 7 01 # A
The Value Stack in Lex and Yacc
Lex
Yacc assumes values are passed to it in the global variable yylval. Lex places the lookahead in yytext; it also must assign values to yylval. There are a number of possibilities:
1. The lookahead is a digit string. The internal value must be computed and placed in yylval.2. The lookahead is a character string. It must be copied from yytext to a safe place, usually either:
(i) a much larger string array, and the value placed in yylval is the position in which it starts in that larger array,
or (ii) a dynamically allocated character
string, and the value placed in yylval is the pointer to that string.
3. The lookahead is a string representing a real number. It should be converted to a floating point, and stored in a real array. Again, its position in the array will be passed to yylval.4. The lookahead is an identifier or a keyword. User-defined identifiers must be stored as for strings (but only one copy should be kept).
Yacc
Yacc allows us to place an action after any production. This action will be performed at the moment the reduction is performed (which is before the values are removed from the stack). The action is a C statement within {...}. Values should be represented by the $i notation described above. When the statement is reached by Yacc, it will translate the $i's into their appropriate values or array positions.

CS3012 Formal Languages and Compilers Syntax-Directed Translation
Example 12.3 using Yacc's value stack
S will be represented by "Expr", T by "Term" and F by "Factor".
%%Finish : Expr { printf("%d", $1); }
;
Expr : Expr PLUS_T Term { $$ = $1 + $3; }| Term;
Term : Term MUL_T Factor { $$ = $1 * $3; }| Factor;
Factor : OB_T Expr CB_T { $$ = $2; }| INT_T;
%%
Definition 12.4 Attribute Grammar
With each symbol in the grammar, we associate a set of attributes. An attribute can represent any form of information we require, including data type, number, pointer or string. The semantic rules we associate with each production determine how the values of the attributes are computed.
In an attribute grammar, each grammar production A -> has associated with it a set of
semantic rules of the form b := f(c1, c2, ..., cn), where f is a function, c1, c2, ..., cn are attributes of any of the grammar symbols in the production.
If b is an attribute of A, and the ci are attributes of symbols in , then b is a synthesised attribute.If b is an attribute of one of the symbols in , then b is an inherited attribute.
Example 12.5 computing the value of expressions
Production Semantic Rules1) S -> E print(E.val)2) E1 -> E2 + T E1.val := E2.val + T.val3) E -> T E.val := T.val4) T1 -> T2 * F T1.val := T2.val * F.val5) T -> F T.val := F.val6) F -> ( E ) F.val := E.val7) F -> digit F.val := digit.lexval
The subscripts on symbols are simply to distinguish which symbol in the semantic rule refers to which symbol in the syntax. The symbol digit is a terminal (or token), and it is assumed to have a single attribute, returned by the lexical analyser. In this case, it will be the value of the particular number token.

CS3012 Formal Languages and Compilers Syntax-Directed Translation
Definition 12.6
A syntax-directed definition which uses only synthesised attributes is called an S-attributed definition.
We can augment parse trees for attribute grammars with the attribute values at each node: for S-attributed definitions, we can evaluate all the attribute values by starting at the leaf nodes and applying the semantic rules from the bottom to the top.
Example 12.7 Annotated parse tree for the expression 6+2*3
S
E
T
F
val = 12
val = 12
E
T
F
digit
val = 6
val = 6
val = 6
lexval = 6
T
Fval = 2
lexval = 2
lexval = 3
val = 2 val = 3
val = 6+
*
digit
digit
An inherited attribute is one whose value is determined by the values of the attributes of its parent or siblings. They are useful for describing the way in which the meaning of a symbol depends upon the context in which it appears. For example, we can use an inherited attribute to keep track of which side of an assignment statement an identifier appears on, so that we know whether to use its address or value during processing.
Example 12.8 using inherited attributes
The following grammar defines a language of integer or real variable declarations. The semantic rules determine how the symbol table is to be updated, by passing the values of the inherited attributes down from the attribute of the T symbol (which is synthesised from rules 2 and 3).
Production Semantic Rules1) D -> T L L.t := T.t2) T -> int T.t := integer3) T -> real T.t := real4) L1 -> L2 , id L2.t := L1.t, addtype(id, L1.t)5) L-> id addtype(id, L.t)

CS3012 Formal Languages and Compilers Syntax-Directed Translation
The augmented parse tree is shown below on the left, and the flow of information between the different attributes is shown on the right:
D
id3Lrealt = real
id1
,
Tt = real
Lt = real
id2Lt = real
,
D
id3Lrealt = real
id1
,
Tt = real
Lt = real
id2Lt = real
,
Dependency graphs
If the value of an attribute b depends on the value of attribute c, then the semantic rule for b must be evaluated after that for c. The interdependencies between the attributes can be drawn as a dependency graph (as above). A topological sort of a graph is an ordering of the attributes of the graph such that all edges in the graph go from the attributes earlier in the ordering to attributes later. A topological sort gives a valid order in which to evaluate the semantic rules.
There are a number of different methods for evaluating semantic rules.
1. Parse-tree based. At compile time, construct a parse tree, then a dependency graph, and then obtain a topological sort. Use the sort to determine the order in which to process the rules. This method works for all dependency graphs with no cycles.2. Rule based. When the compiler is constructed, analyse the rules for dependencies. The order in which rules are to be evaluated is then fixed before compilation starts.3. Oblivious. The compiler simply selects an evaluation order without analysing the
dependencies. This obviously limits the class of attribute grammars that can be implemented.
Methods 2 and 3 are more efficient, in that no compile-time analysis is required.
Abstract Syntax Trees
A useful form of intermediate representation of a program is a syntax tree. Using syntax trees allows the translation process to be separated from the parsing process. This is particularly useful for two reasons:
1. A grammar that is suitable for parsing might not explicitly represent the hierarchical nature of the programs it describes
2. The parsing method constrains the order in which the nodes are considered. This may not be the best order for translation.
A syntax tree is a condensed parse tree, where the operators and keywords do not appear as leaves, but are associated with the interior nodes that would have been their parent node in the parse tree. Also, chains of single productions can be collapsed into a single branch.
Example 12.9 abstract syntax trees

CS3012 Formal Languages and Compilers Syntax-Directed Translation
The derivation step S => if B then S1 else S2 would have the syntax tree:
if then else
B S1 S2
The parse tree below has the syntax tree on the right:
E
T
F
E
T
F
6
T
F
2
3
+
*6
2 3
+
*
Example 12.10 creating abstract syntax trees
We will use the following functions, which return pointers to the newly created nodes:
mknode(op, left, right): creates an internal node for the operator "op", with two fields containing pointers to the left and right operands;
mkleaf_id(id, string): creates a leaf node for the identifier "id", and a field containing a pointer to a string for that identifier;
mkleaf_num(num, val): creates a leaf node, labelled "num", with a field containing the value of the number.
The grammar and semantic rules are given below. Each non-terminal in the grammar has an attribute ptr, which keeps track of the pointers returned by the functions:
Production Semantic Rules1) E1 -> E2 + T E1.ptr := mknode('+', E2.ptr, T.ptr)2) E -> T E.ptr := T.ptr3) T1 -> T2 * F T1.ptr := mknode('*', T2.ptr, F.ptr)4) T -> F T.ptr := F.ptr5) F -> ( E ) F.ptr := E.ptr6) F -> id F.ptr := mkleaf_id(id, id.string)7) F -> num F.ptr := mkleaf_num(num, num.val)
The parse tree for 6+2*x is shown below, with the constructed syntax tree on the right.

CS3012 Formal Languages and Compilers Syntax-Directed Translation
E
T
F
E
T
F
6
T
F
2
x
+
*
+
*num 6
num 2 id
ptr =
ptr =
ptr =
ptr =
ptr =
ptr = ptr =
ptr =
string for x
Example 12.11
The following grammar specifies compound statements:
CStat -> Stat ; CStat | StatStat -> s
The string s ; s ; s ; s has the parse tree below on the left, and one possible syntax tree on the right
CStat
CStatStat
s
;
CStatStat
s
;
CStatStat
s
;
Stat
s
s
;
s
;
s
;
s
The semi-colon serves only to bind the statements into a sequence. A more natural tree is shown below on the left. However, this requires each node to have arbitrarily many children. A better tree is shown on the right, where statements are joined as siblings. This requires only one extra field in our syntax tree nodes.
s
seq
s s s s
seq
s s s
A note on implementing attribute grammars and Yacc and Lex
The value stack in Yacc maintains a single value for each symbol on the symbol stack. In the syntax-directed definitions in these notes,
however, we use multiple attributes of different types for the symbols. We can implement this in Yacc as follows.
Symbol Types

CS3012 Formal Languages and Compilers Syntax-Directed Translation
Internally, Yacc declares each value as a C union. List all types that will be required in a %union declaration in the definitions section of the Yacc script - e.g.
%union{ int intval; char *strptr; struct table *tblptr;}
which declares three symbol types - an integer value, a string pointer, and a pointer to some table structure (which would have to be declared elsewhere).
Each token must be declared to use one of the types from the union, using the %token declaration - e.g.
%token <intval> INT_T%token <tblptr> ID_T
Non-terminals must also be declared, using the %type declaration - e.g.
%type <intval> Expr Term Factor
Referring to a value using the $$, $1,... notation causes Yacc to use the appropriate field of the union.
Multiple Attributes
Multiple attributes can be implemented using the symbol table (see 11) which is defined to have a number of attribute places for each entry. Instead of referring explicitly to values on the value stack, we would then refer to the symbol table entry, and extract the appropriate attribute value as required.
Inherited Attributes
The Yacc value stack is designed for synthesised attributes - that is, when a rule is used as a reduction, the values of all symbols on the right hand side are known. In some cases, however, we would like to use inherited attributes to assign values to symbols on the right hand side. Yacc does allow us to do this, by accessing symbols on the internal stack to the left of the current rule, using the notation $0, $-1, $-2, ... . Thus we might have the rules:
Decl : Type Idlist ;
Type : KEY_REAL_T {$$ = 1;} | KEY_INT_T {$$ = 2;} ;
Idlist : Idlist ID_T {action($0, $2);} | ID_T {action($0, $1);} ;
where action(...) is some function which assigns type information. The symbol Type, which contains that information, always occurs one place to the left of the Idlist non-terminal, and this symbol's value is referred to by the $0 notation. If we wanted to refer to the symbol two places to the left, we would use $-1, etc.. Note that these rules are different from the ones given in lectures (p48) - here the values are not passed in the Decl rules, but in the Idlist rule.
This use of the value stack is not recommended. It is very hard to keep track of positions in more complicated grammars - to use this notation, every time we use Idlist, we must be confident that the symbol one place to the left in the internal stack has the appropriate value.
The preferred method of dealing with inherited values is to create a list of pointers to the attribute places and maintain this list as an attribute of Idlist. The Decl rule would then

CS3012 Formal Languages and Compilers Syntax-Directed Translation
use this list to assign the correct attribute values to the various identifiers.

CS3012 Formal Languages and Compilers Symbol Table
13. Symbol Table
The symbol table stores information about various source language constructs. Information is built up during the analysis stages of compiling, and is used in succeeding stages. Finally, the code generation phase uses the information in the table to generate the target code.
The symbol table is central to the work of the compiler. In practice, efficient methods of manipulating and storing the table must be used. In this course, though, we will not consider efficiency - we will use a linked list and some operations for manipulating the information.
In some compilers, the symbol table is used extensively during lexical analysis and parsing, to represent information and resolve ambiguities. In other cases, lexical analysis and parsing simply construct a complete abstract syntax tree. This tree is then analysed to produce the symbol table.
There are three main functions we need to implement:
• lookup(s): determines whether a particular string has already been stored returns the index of the table entry, or 0 (or -1 in some systems) if it has not been stored
• insert(s,t): inserts a new string (of token t) into the table returns the index of the new entry
• delete(s): deletes an entry from the table (or, typically, hides it)
Example 13.1 A Simple Symbol Table Implementation
An initial node will point to the first and last entries, and store the length of the table. A separate array will store all the string identifiers. Each node will be of the form:
index 7token ID_Tatts •next •strPtr •
. . .
. . .
. . .
The table will be of the form:
1ID_T•••
2ID_T•••
78ID_T•••
.. . . . . . . .
c o u n t # i # . . . n a m e # . . .
Table first length last• 78 •

CS3012 Formal Languages and Compilers Symbol Table
Declarations
There are four basic kinds of declaration that may require entries in the Symbol Table:
Constant: e.g. const int MAX = 10000;
Type: e.g. struct Entry { int index; char *strPtr; };
Variable: e.g. int count, marks[100];
Function: e.g. int gcd(int n, int m) { if (m == 0) return n; else return gcd(m, n % m); }
Constant and variable declarations can be stored in the table in the style shown above. Type declarations may require more work, while function declarations are normally indexed by their name, with the code being treated separately. In some compilers, separate symbols tables are used for each different kind of declaration; in others, each separate region of the program (e.g. functions) may be given a separate table.
The attributes stored with each entry will depend on the kind of declaration: constant declarations will typically have value bindings; type, variable and function declarations will have type signatures. Variables will have pointers to allocated memory for storing values. Functions may have pointers to code representations. All kinds may have scope attributes, defining when memory should be allocated, and when it should be accessible.
Example 13.2 Single scope
In languages with very restricted scoping rules (and in other siutations) it is possible to construct the symbol table during lexical analysis.
Augment the lexical analysis rule for recognising identifiers as follows:
{L}+ {entry = lookup(yytext); if (entry == -1) yylval.entry = insert(yytext, ID_T); }
This will insert an entry the first time an identifier is encountered. Ensuring that, for example, it is properly declared will be a function of the semantic analysis phase.
Scoping Rules
Many languages allow programs to be constructed from blocks. In C, blocks are files, function declarations and compound statements (between "{" and "}"). Also, structures and unions can be considered to be blocks. The use of blocks complicates the symbol table, as the same identifier can refer to different data objects depending on the position it occurs in the code, and the scoping rules. In this situation, it is not sufficient to use lookup during lexical analysis.

CS3012 Formal Languages and Compilers Symbol Table
Example 13.3 Nested scope
int i;
int f1(int k) { int j; ... print i;}
int f2() { int j; ...}
In the above C program fragment, i is a global (integer) variable, normally accessible throughout the code. When f1 is entered, a new (integer) entry is required for k. Immediately, a new (integer) entry for j is also required. Inside the function, i -- in print(i) -- refers to the global variable. Once f1 is exited, the entries for j and k are deleted. Once f2 is entered, a new (integer) entry for j is required - note that this is a different variable from the one inside f1.
To implement nested scopes, the lookup function must find the most recently inserted declaration, the insert function must not overwrite previous declarations of the same name, but should hide them, while the delete function should only delete (or hide) the most recent declaration and uncover the previous one. The symbol table should thus behave as a stack.
Example 13.4 Nesting Level
One possible way of obeying scope rules while constructing the symbol table during the first pass of the compiler is to use explicit nesting level and scope variables. Use an explicit stack where the top entry represents the current nesting level and scoping identifier. We also need last, the index of the last entry in the table. Initially, the top of the stack is set to (0,0), and last is set to 0.
Consider the following grammar fragment for recognising programs similar to 13.3:
Prog -> Dec ProgProg -> MainDec -> VDec ;Dec -> FDecVDec -> int idFDec -> SFDec Par ) { CStat } { decrement(stack); }SFDec -> int id ( { increment(stack); } Par -> Par -> VdecPar -> PList , VdecPList -> VdecPList -> Vdec , PList
The lexical analysis action then becomes

CS3012 Formal Languages and Compilers Symbol Table

CS3012 Formal Languages and Compilers Symbol Table
{L}+ {entry = lookup(yytext,stack); if (entry == -1) insert(yytext,ID_T, stack); }
insert now places an entry at the end of the table, and associates the pair of values at top of the stack as nesting level and scope attributes.
lookup now searches the symbol table for a matching string. When it finds a match, it checks the nesting level, and then moves down the stack until it finds the entry with the same nesting level. If the index of the match is less than the corresponding scope value, it ignores it and continues with the search. If no appropriate match is found, return -1.
decrement simply deletes the top element of the stack.
increment adds a new element to the top of the stack, incrementing the nesting level, and assigning the last index as the scope value.
A parse tree and associated symbol table for 13.3 are shown below.
Prog
Dec
VDec
int id
;
Prog
Dec
FDec
SFDec Par ) CStat{ }
i nt id ( VDec
int i d
VDec
int id
; . . .
Dec
FDec
SFDec Par ) CStat{ }
int id ( VDec
int id
; . . .
Prog
. . .
print )id( ;
i
f1
k j f2
j
i
1
2
3
4
Index Str Nest Scope Atts0 i 0 0 ...1 f1 0 02 k 1 13 j 1 14 f2 0 05 j 1 4
The changes in the stack are as follows (top on the right):
Event Last Stack (Nest,Scope)0 (0,0)
1 1 (0,0), (1,1)2 3 (0,0)3 4 (0,0), (1,4)4 5 (0,0)

CS3012 Formal Languages and Compilers Symbol Table
Instead of attempting to complete all compilation in a single pass, it is often easier to make a number of passes through the program. Using the techniques of section 11, an abstract syntax tree can be constructed during the parsing phase. This tree can then be processed to build the symbol table and to support the later phases of the compilation. Although this may be slower, it can result in more natural grammars, and simpler translation and analysis routines.
Example 13.5
A possible abstract syntax tree for the program of 13.3 is shown below. From this, it should be easy to see the nesting levels and scope of the different declarations.
Prog
VDec
int idi
func
i df1
int VDec
int id
VDec
int i dk j
idi
func
idf2
int VDec
int idj

CS3012 Formal Languages and Compilers Type Checking
14. Type Checking
The final part of the analysis phases of compilation we will consider is type checking, where the compiler checks operators, functions and procedures are not applied to objects of incompatible datatypes.
Definition 14.1
A type checker verifies that the type of a construct matches that expected by its context.
Example 14.2 type signature
The PASCAL arithmetic operator "mod" requires two integer operands, and returns an integer. We can describe this by a signature:
_mod_ : integer integer integer
The underscores on either side of the mod operator indicate that it is an infix operator (that is, it is placed between its two operands). After the colon is the signature, which here indicates that the operator takes two integers, and returns an integer.
Type information will be required when intermediate code is generated. Operators like "+" can be used in a number of different ways, and the particular way depends on the context. Four different signatures can be given for "+":
_+_ : integer integer integer
_+_ : integer real real
_+_ : real integer real
_+_ : real real real
In the second and third case, some form of type translation will be required, in order to allow the integers and reals to be added together. Once the types have been determined, the intermediate code generator can put in the required conversion operations.
The "+" operator is an example of an overloaded operator - that is, an operator which represents different operations in different contexts.
Type Expressions
In Pascal and C, types are either basic or constructed. Basic types have no internal structure as far as the programmer is concerned - for example, boolean, character and integer in Pascal. Constructed types are built from basic types and other constructed types, such as arrays, records and sets in Pascal.
Each language construct has a type associated with it implicitly; this will be denoted by a type expression.

CS3012 Formal Languages and Compilers Type Checking
Definition 14.3
A type expression is either a basic type, or is formed by applying an operator called a type constructor to other type expressions.
1. A basic type is a type expression (e.g. boolean, char, integer). A special basic type called type_error will indicate an error found during type checking. A basic type, void, indicates the absence of a value, allowing constructs with no type to be checked.
2. A type name is a type expression.
3. A type constructor applied to type expressions is a type expression. Constructors include:
(a) arrays - if T is a type expression, then array(I,T) is a type expression denoting the type of an array with elements of type T and index set I. For example, the Pascal declaration
var A : array[1..10] of integer;
associates the type expression array(1..10,integer) with A.
(b) products - if T1 and T2 are type expressions, then so is T1 T2
(c) records - a record is a product with names for its fields. The record type constructor will apply to a tuple formed from field names and types. E.g.:
type row = recordaddress : integer;lexeme : array[1..15] of char;end;
declares the type name row representing the type expression:
record((address integer) (lexeme array(1..15,char)))
(d) functions - mathematically a function maps elements of one set to another set. We will treat functions in programming languages as mapping from a type D to a type R (from domain to range). The type will be denoted D R. E.g.:
function f(a, b : char) : integer;
has the type expression
char char integer
It is sometimes convenient to represent type expressions as graphs. We can use abstract syntax trees, with nodes for type constructors, and leaves for basic types and names.

CS3012 Formal Languages and Compilers Type Checking
Example 14.4 type trees
Possible trees for the type expressions of 14.3 are:
record
address integer lexeme array
1..10 char
array
1..10 integer
T1 T2
product:
char char
integerf
function:
Note the use of sublings to represent the different elements of products, but the use of child nodes to represent the function name and return type.
Type Systems
A type system is a collection of rules for assigning type expressions to the different parts of a program. A type checker implements a type system.
Since type checking has the potential for discovering errors in programs, it is important for a type checker to do something reasonable when an error is discovered. The compiler must report the nature and location of the error, but again the checker should recover from the error so that the rest of the input can be processed. A type checker able to handle errors may result in a more complicated grammar than that required solely for processing correct programs. Again, for that reason, some type checkers operate on the abstract syntax tree rather than during parsing.
Example 14.5 Specifying the type checker
We now specify a type checker for a simple language which requires declaration of identifiers before their use. The grammar below generates programs, represented by the non-terminal P, consisting of a sequence of declarations D followed by a single expression E.
P -> D ; ED -> D ; D D ->id : TT -> char | integer | array[num] of TE -> num | id | E mod E | E [E] | id := E
The language has two basic types: char and integer. The two special basic types type_error and void are used to signal errors and the absence of a type respectively. Arrays are assumed to start at index 1, so the declaration

CS3012 Formal Languages and Compilers Type Checking
array [256] of char
leads to the type expression array(1..256,char).
In the translation scheme given below (for a one-pass compiler), actions add type information to the symbol table entry for the identifiers.
P -> D ; ED -> D ; DD -> id : T addtype(id.entry, T.type)T -> char T.type := charT -> integer T.type := integerT1 -> array[num] of T2 T1.type := array(1..num.value, T2.type)
These actions allow the type of all declared identifiers to be added to the symbol table. The expressions can now be checked.
E -> num E.type := integerE -> id E.type := lookup(id.entry)E1 -> E2 mod E3 E1.type := if E2.type = integer and E3 = integer
then integer else type_error
E1 -> E2 [E3] E1.type := if E3.type = integer and E2.type = array(s,t) then t else type_error
E1 -> id := E2 E1.type := if lookup(id.entry) = E2.type then void else type_error
Numbers are of type integer."lookup(x)" searches the symbol table and return the stored type of entry x.The mod operator requires that both its operands are of type integer. If so, then the resulting expression is also of type integer; if not, then there is an error.For the array lookups, the index to the array must be of type integer, and the type of the array name must , obviously, be an array. If both of these conditions are met, then the type of the expression is the same as the type of the elements of the array.For the assignment expressions, the type of the identifier must match the type of the expression. If so, then the special type void is returned; otherwise, the value type-error is returned.

CS3012 Formal Languages and Compilers Runtime Environment
15. Runtime Environment
After the analysis phases are complete, the compiler must generate executable code. In particular, the compiler must generate code to maintain the structure of the target machine's registers and memory during execution. In this section, we consider the types of environment that are required.
In most compiled languages executable code is stored in a fixed area of RAM which cannot be changed during execution. The code for each different function or procedure is stored separately, at a known address (or at a known offset from a base address). Static data (e.g. constants or strings known at compile time) and global variables can also be stored in this fixed area. The remainder of the data, plus bookeeping information for control flow, will be stored in areas that will be allocated dynamically during execution.
Example 15.1 Simple runtime storage structure
code for function 1
code for function 2
. . .
code for function n
entry address
entry address
entry address
global/static area
stack
heap
free space
The stack is used for data that can be allocated in a last-in, first-out manner, while the heap area is used for other data (e.g. C pointers).
Definition 15.2
A procedure activation record is a section of memory allocated each time a procedure is called. It contains space for arguments, local data and local temporary variables, and pointer to code area and the activation record which called it.

CS3012 Formal Languages and Compilers Runtime Environment
Definition 15.3
In a fully static environment, no procedures can be called recursively, there are no pointers, and no dynamic memory allocation - for example, FORTRAN77. In such an environment, we only ever need to maintain one procedure activation record for each procedure, as it is not possible for more than one copy of a single procedure to be in use simultaneously. Thus, at compile time, we can construct a procedure activation record for each procedure, Each time a procedure is called, we compute its arguments and store them in the appropriate record, and store the address of the calling procedure. We then jump to the start of the code for the current procedure, execute it, using the space in the current record for maintaining data, and on exit, jump back to the return address.
Example 15.4 A simple static environment
1 int i = 10;
2 int f1(int j) {3 int k;4 k = 3 * j;5 if (k < i) print(i);6 else print(j);7 }
8 main() {9 int k = 1;10 while (k < 5) {11 f1(k);12 k = k+1;13 }14 }
global areai (int):activation record: maink (int):start code ptr: 8current code ptr:activation record: f1j (int):start code ptr: 2current code ptr:return address:k (int):
global areai (int): 10activation record: maink (int): 1start code ptr: 8current code ptr:11activation record: f1j (int):1start code ptr: 2current code ptr: 2return address:11k (int):
global areai (int): 10activation record: maink (int): 2start code ptr: 8current code ptr:14activation record: f1j (int):start code ptr: 2current code ptr:return address:k (int):
initial environment on entry to f1 on reaching line 14

CS3012 Formal Languages and Compilers Runtime Environment
Definition 15.5
In a stack-based environment, procedures may be called recursively. It is not sufficient to maintain a single activation record for each procedure. A stack is required, onto which new records are placed each time a procedure is called, and from which old records are deleted when procedures exit. Each procedure may have several records on the stack at any one time. Each activation record should maintain a pointer to the previous activation record, to allow it to be recovered on exit. The environment requires a pointer to the current activation record, and a pointer to the last allocated position on the stack.
Example 15.6 A simple stack-based environment
1 int x, y;
2 int gcd(int u, int v) {3 if (v == 0) return u;4 else return gcd(v, u % v);5 }
6 main() {7 scanf("%d%d", &x, &y);8 printf("%d\n", gcd(x,y));9 }
global areax (int):y (int):activation record: mainstart code address: 6current code address:
activation record: gcdu (int): 15v (int): 10start code address: 2current code address:2return pointer: •return address: 8k (int):
initial environment on 1st entry to gcd on 3rd entry to gcdglobal areax (int): 15y (int): 10activation record: mainstart code address: 6current code address:8
free space
sp
fp
free space
spfp activation record: gcd
u (int): 15v (int): 10start code address: 2current code address: 4return pointer: •return address: 8k (int):
global areax (int): 15y (int): 10activation record: mainstart code address: 6current code address:8
free space
sp
fp
activation record: gcdu (int): 10v (int): 5start code address: 2current code address:4return pointer: •return address: 4k (int):activation record: gcdu (int): 5v (int): 0start code address: 2current code address:2return pointer: •return address: 4k (int):
global areax (int): 15y (int): 10activation record: mainstart code address: 6current code address:9
about to exit main
fp
free space
sp

CS3012 Formal Languages and Compilers Runtime Environment
The details of how much space to allocate for an activation record and the offsets to be computed to reach the appropriate data items must be provided by the compiler. This is covered in the next chapter. Note that the stack-based environment presented here is particularly simple - there is no discussion of variable length data, temporary variables, internal blocks and nested declarations, local procedures (as in Pascal), nor procedures as arguments. Detailed descriptions of methods for dealing with such situations are given by Aho et al. (1986).
Definition 15.7
In a dynamic environment, activation records are not maintained on a stack, but must exist and be accessible for as long as all references to them exist, and must be capable of being dynamically deallocated when they become inaccessible (a process called garbage collection).
Example 15.8 dangling references
int *dangle() { int x; return &x;}
In a stack-based environment, the variable x is allocated space only during the lifetime of the function dangle(). Once the function has returned, the space is reclaimed, and will be reused by subsequent procedure calls. However, the address of x has been returned, and will be assumed to point to an integer, although the memory location could now contain anything. C is a stack-based language, and the above procedure is defined to be a logical error. Other languages do not have this restriction, and so require dynamic environments.
Dynamic allocation is handled in the heap area. A heap provides two operations: allocate and free. Allocate takes a size parameter, and returns the address of a block of memory of the correct size. Free takes an address, and marks it as being free. The main problem in heap management is that the memory can quickly become fragmented, unless contiguous free memory blocks are combined into a whole. A second problem is in ensuring that free is only ever applied to the start of an allocated block of the appropriate size, or corruption can result.

CS3012 Formal Languages and Compilers Runtime Environment
Example 15.9 simple heap management
Maintain a circular linked list of allocated memory blocks. Each block to be allocated is headed by some bookkeeping information, with the address of the next allocated block, the size of the used space, and the size of the following free space. The first element of the list is the top of the heap, which also has a pointer to a block with some free space.
To allocate a new block, move round the list until we find an element with enough free space. Create a new element, insert it into the list after the selected element's used space, set the new element's free
size to the selected element's free size minus the size of the new element, and set the selected element's free size to null.
To free a block, move to the start of the list, and step through until the appropriate address is found - if it is not found, the address is invalid. Add the current block size and its free sizee to its predecessor's free size, and delete from the list.
The figure below shows the heap during a sequence of allocations and deallocations.
Note that the heap management system in Example 15.9 is for dealing with explicit manual allocation and deallocation commands, and as such is required in stack-based languages like C.Fully dynamic languages require additional routines for garbage collection.
16. Intermediate Code Generation
After a program has been parsed and statically checked, the compiler converts it to an intermediate language, and then optimises the code before producing the final executable version. The main advantage of developing this intermediate code is machine independence - the analysis techniques can be developed

CS3012 Formal Languages and Compilers Runtime Environment
without concern for the target language, a single optimisation procedure can be used, and porting the compiler to new machines only requires changing the final component.
In this section, we build on the previous material, and consider syntax-directed methods of generating the intermediate code, in the language known as three-address code.
Three Address Code
Statements in this language take the general form:
x := y op z
where x, y and z are names, constants or compiler-generated temporaries, and op stands for any operator. An expression like a+b*c has to be translated into the sequence
t1 := b * ct2 := a + t1
where t1 and t2 are compiler-generated temporary names. Unravelling complicated arithmetical expressions allows them to be optimised effectively and translated easily to the target language, as three-address code is similar to assembly language.
Example 16.1 three-address code
Three-address code is a linearised form of postfix expressions and syntax trees. For example, consider the statement
a := b * c + b / c
In postfix, this is
abc*bc/+ :=
As a syntax tree, it becomes: :=
a +
* /
cb cb

CS3012 Formal Languages Exercises
In three-address code, it is
t1 := b / ct2 := b * ct3 := t1 + t2
a := t3
The three-address statements used in this chapter are shown below:
• assignment statement - x := y op z
• unary assignment - x := op y (e.g. unary minus, negation, type conversion)
• copy - x := y
• unconditional jump - goto L (L is the label of a statement)
• conditional jump - if x relop y goto L (relop is a relational operator: <, ≤, =, ...)
• procedure call - param x (defines x as a parameter)
- call p n (call procedure p, passing the last n declared parameters)
- return y (optional)
• indexed assignments - x := y[i] (x is set to the value at i memory locations after y) x[i] := y (i memory locations after x is set to y)
We assume that statements in three-address code can be labelled (labels are referred to by the goto statement).
The choice of allowable memory operators is the critical issue in the design of an intermediate language. The operator set must be sufficiently rich to implement the operations in the source language, and expressive enough that the code generator does not need to generate long sequences of instructions to implement each operator.

CS3012 Formal Languages Exercises
Example 16.2 A Syntax-directed Translation
The syntax-directed definition given below translates assignment statements into three address code.
The synthesised attribute S.code in the definition that follows represents the three-address code fragment for assignment S. The non-terminal E has two attributes:
E.place - the name that will hold the value of EE.code - the three address code code fragment for E
The notation gen(x ":=" y "+" z) represents the three address code statement x := y+z.
Expressions appearing instead of the variables (x,y,z) are evaluated before being passed to gen, and the quoted strings are taken literally.
The notation <code fragment> || expression means concatenate the expression onto the end of the code fragment.
newtemp() creates a new temporary variable.
Production Semantic RulesS -> id := E S.code := E.code || gen(id.place ":=" E.place)E1 E2 + E3 E1.place := newtemp();
E1.code := E2.code || E3.code || gen(E1.place ":=" E2.place "+" E3.place)E1 -> E2 * E3 E1.place := newtemp();
E1.code := E2.code || E3.code || gen(E1.place ":=" E2.place "*" E3.place)E1 -> -E2 E1.place := newtemp();
E1.code := E2.code || gen(E1.place ":=" "uminus" E2.place)E1 -> (E2) E1.place := E2.place;
E1.code := E2.codeE -> id E.place := id.place;
E.code := ""

CS3012 Formal Languages Exercises
Example 16.3
The parse tree for a := b*c + b*-c is:
The attributes are constructed as follows:
Symbol place codeE1 bE2 cE3 t1 E1.code || E2.code || t1 := b * cE4 bE5 cE6 t2 E5.code || t2 := uminus cE7 t3 E4.code || E6.code || t3 := b * t2
E8 t4 E3.code || E7.code || t4 := t1 + t3
S E8.code || a:= t4
Expanding the code attribute for S then gives us the three address code:
t1 := b * ct2 := uminus ct3 := b * t2
t4 := t1 + t3
a := t4
a
S
:= E8
E3 + E7
c
E1 * E2 E4 * E6
b c b - E5

CS3012 Formal Languages Exercises
Example 16.4 flow of control
We can extend the language defined by 16.2 by including flow of control statements:
Production Semantic RulesS1 -> while E do S2 S1.begin := newlabel();
S1.after := newlabel();S1.code := gen(S1.begin ":") || E.code || gen("if" E.place "=" "0" "goto" S1.after) || S2.code || gen("goto" S1.begin) || gen(S1.after ":")
We have introduced new attributes, "begin" and "after", which will hold labels, and that the function newlabel() will create a new label and return it. A schematic drawing of the code created by this semantic rule is shown below:
We assume that if the expression E is non-zero, it is true, and thus if the expression, evaluated by E.code, is false, control shifts to S1.after; if the expression is true, S2.code is executed, then control shifts back to S1.begin, and the expression is evaluated again.
Assignment statements
The previous sections assumed that when variable names were used, they represented pointers to the symbol table. This section demonstrates how names corresponding to the terminal id are looked up in the symbol table - the function lookup(id.name) returns a pointer to the entry of the identifier if it is in the symbol table, or nil if not.
E.code
if E.place = 0 goto S1.after S2.code
...
codelabelsS1.begin :
S1.after : goto S1.begin

CS3012 Formal Languages Exercises
Example 16.5
We now redo the semantic rules of 16.2 to show the use of the lookup function. Instead of concatenating the code together in the attributes of the symbols, we now output the intermediate code to a file, using the emit() function.
Production Semantic RulesS -> id := E p := lookup(id.name);
if p ≠ nil then emit(p ":=" E.place)else error
E1 E2 + E3 E1.place := newtemp();emit(E1.place ":=" E2.place "+" E3.place)
E1 -> E2 * E3 E1 := newtemp();emit(E1.place ":=" E2.place "*" E3.place)
E1 -> -E2 E1.place := newtemp();emit(E1.place ":=" "uminus" E2.place)
E1 -> (E2) E1.place := E2.place;E -> id p := lookup(id.name);
if p ≠ nil then E.place := pelse error
Parsing the fragment
res := a * (alpha + -b)
assuming that res and alpha have already been declared and placed in the symbol table:lexptr token attributes index
: : :-> res ID_T 5-> a ID_T 6-> alpha ID_T 7-> b ID_T 8
gives the following sequence:
processed string attributes output res := a * (alpha + -b)res := E1 * (alpha + -b) E1.place = <6>res := E1 * (E2 + -b) E2.place = <7>res := E1 * (E2 + -E3) E3.place = <8>res := E1 * (E2 + E4) E4.place = <9> <9> := uminus <8>res := E1 * (E5) E5.place = <10> <10> := <7> + <9>res := E1 * E6 E6.place = <11>res := E7 E7.place = <12> <12> := <6> * <11>S <5> := <12>
For the remainder of the chapter, we will dispense with the <i> notation, and simply refer to identifiers by their name.

CS3012 Formal Languages Exercises
Arrays
We can access the elements of an array quickly if we store them in a block of consecutive locations. Let A be an array, the width of each array element be w, the lower bound of the index be low, and the address of the storage for A be base. The ith element of A then begins at location:
base + (i - low) w.
To speed up the access of array elements, we can partially evaluate this address at compile time by rewriting it as:
i w + (base - low w)
and evaluating the subexpression (base - low w). This value, c, say, is then stored in the table with A, and the relative address of an element A[i] can then be found by adding i w to c.
We can also do something similar for multi-dimensional arrays. Two-dimensional arrays can be stored either row by row or column by column. For arrays stored row by row, the relative address of A[i,j] can be calculated by the formula:
base + ((i - low1) n2 + j - low2) w
where low1 and low2 are the lower bounds on i and j, and n2 is the number of values that j can take. Assuming that i and j are the only two values not known at compile time, we can rewrite this as:
((i n2) + j) w + (base - ((low1 n2) + low2) w) (**)
As before, the last term can be pre-computed at compile time.
The chief problem in generating code for array references is to relate the computation of the positions of elements in an array to a grammar of array references. A grammar may be given as follows:
L -> id[Elist] | idElist -> Elist, E | E
It is useful to re-write this grammar to allow the dimensional limits of the array to be available as the index expressions are grouped into an Elist:
L -> Elist] | idEList -> Elist, E | id [E
These productions allow a pointer to the symbol table entry for the array name to be passed as a synthesised attribute of Elist.The following attributes are used below:
Elist.ndim: the number of dimensions of Elist;limit(array,j): function returning the number of elements along the jth dimension of the array;Elist.place: temporary variable holding a value computed from Elist;L.place: position in the symbol table;L.ofset: an offset into the array, or is null to indicate that the l-value is a simple name rather than an array reference.c(Elist.array): a function returning the pre-computed expression of (**) abovewidth(array): a function returning w in (**) above

CS3012 Formal Languages Exercises
Example 16.6 translation scheme for addressing array elements
Production Semantic Rules1 S -> L := E if L.offset = null then emit(L.place ":=" E.place)
else emit(L.place "[" L.offset "]" ":=" E.place)2 E1 E2 + E3 E1.place := newtemp();
emit(E1.place ":=" E2.place "+" E3.place)3 E1 -> (E2) E1.place := E2.place;4 E -> L if L.offset = null then E.place := L.place
else E.place := newtemp; emit(E.place ":=" L.place "[" L.offset "]")
5 L -> Elist] L.place := newtemp();L.offset = newtemp();emit(L.place ":=" c(Elist.array))emit(L.offset ":=" Elist.place "*" width(Elist.array))
6 L -> id L.place := id.place;L.offset := null
7 Elist1 -> Elist2, E t := newtemp();m := Elist2.ndim + 1;emit(t ":=" Elist2.place "*" limit(Elist2.array,m))emit(t ":=" t "+" E.place);Elist1.array := Elist2.array;Elist1.place := t;Elist1.ndim := m
8 Elist -> id [E Elist.array := id.place;Elist.place := E.place;Elist.ndim := 1

CS3012 Formal Languages Exercises
Example 16.7 generating code using the scheme of 16.6
Let A be a 10 20 array with low1 = low2 = 1. Therefore n1 = 10 and n2 = 20. Take w to be 4. The assignment x := A[y,z] is parsed and translated as follows:
sentential forms attributes generated codex := A[y, z]L1 := A[y, z] L1.place = x
L1.offset = nullL1 := A[L2, z] L2.place = y
L2.offset = nullL1 := A[E1, z] E1.place = yL1 := Elist1, z] Elist1.array = A
Elist1.place = yElist1.ndim = 1
L1 := Elist1, L3] L3.place = zL3.offset = null
L1 := Elist1, E2] E2.place = zL1 := Elist2] <t = t1>
<m = 2>Elist2.array = AElist2.place = t1
Elist2.ndim = 2
t1 := y * 20t1 := t1 + z
L1 := L4 L4.place = t2
L4.offset = t3
t2 := c /* baseA - 84 */t3 := t1 * 4
L1 := E3 E3.place = t4 t4 := t2[t3]S x := t4
Type Conversions
In practice, there are many different types of variables and constants, and the programmer may wish to combine their use in a single expression where appropriate; it is the task of the compiler to generate appropriate type conversion instructions. In the above, suppose there are reals and integers, and that integers can be converted to reals. The semantic rules for the arithmetic operations (and most of the other productions) must be modified to generate three-address statements which carry out the type conversion where necessary. We also include with the operator some indication of whether we intend fixed point or floating point operations.

CS3012 Formal Languages Exercises
Example 16.8 arithmetic type conversions
(for E1 -> E2 + E3 ). We need one additional attribute, E.type, which is either integer or real.
E1.place := newtemp();if E2.type = integer and E3.type = integer thenbegin emit(E1.place ":=" E2.place "int+" E3.place); E1.type := integerendelse if E2.type = real and E3.type = real thenbegin emit(E1.place ":=" E2.place "real+" E3.place); E1.type := realendelse if E2.type = integer and E3.type = real thenbegin u := newtemp(); emit(u ":=" "intotoreal" E2.place); emit(E1.place ":=" u "real+" E3.place); E1.type := realendelse if E2.type = real and E3.type = integer thenbegin u := newtemp(); emit(u ":=" "inttoreal" E3.place); emit(E1.place ":=" E2.place "real+" u); E1.type := realendelse E1.type = type_error;
Similar semantic functions are required for E -> E*E, replacing "int+" with "int*" etc.
Example 16.9
Parsing and translating the string x := y + i * j, where x and y are reals, and i and j are integers
symbols attributes codex := y + i * jx := E1 + i * j E1.place = y
E1.type = realx := E1 + E2 * j E2.place = i
E2.type = integerx := E1 + E2 * E3 E3.place = j
E3.type = integerx := E1 + E4 E4.place = t1
E4.type = integert1 := i int* j
x := E5 E5.place = t2
<u = t3>E5.type = real
t3 := inttoreal t1
t2 := y real+ t3
S x := t2