data distribution and management tim adye rutherford appleton laboratory babar computing review 9 th...
TRANSCRIPT

Data DistributionData Distributionand Managementand Management
Tim AdyeRutherford Appleton Laboratory
BaBar Computing Review9th June 2003

Tim Adye Data Distribution and Management
2
Overview
• Kanga Distribution system• New Computing Model requirements• Data Management• XRootd• Using the Grid
People:-Tim Adye (Kanga, Grid), Dominique Boutigny (Grid),Alasdair Earl (Grid, Objy), Alessandra Forti (Bookkeeping),Andy Hanushevsky (XRootd, Grid), Adil Hasan (Grid, Objy), Wilko Kroeger (Grid), Liliana Martin (Grid, Objy),Jean-Yves Nief (Grid, Objy), Fabrizio Salvatore (Kanga)
Tim Adye Data Distribution and Management
3
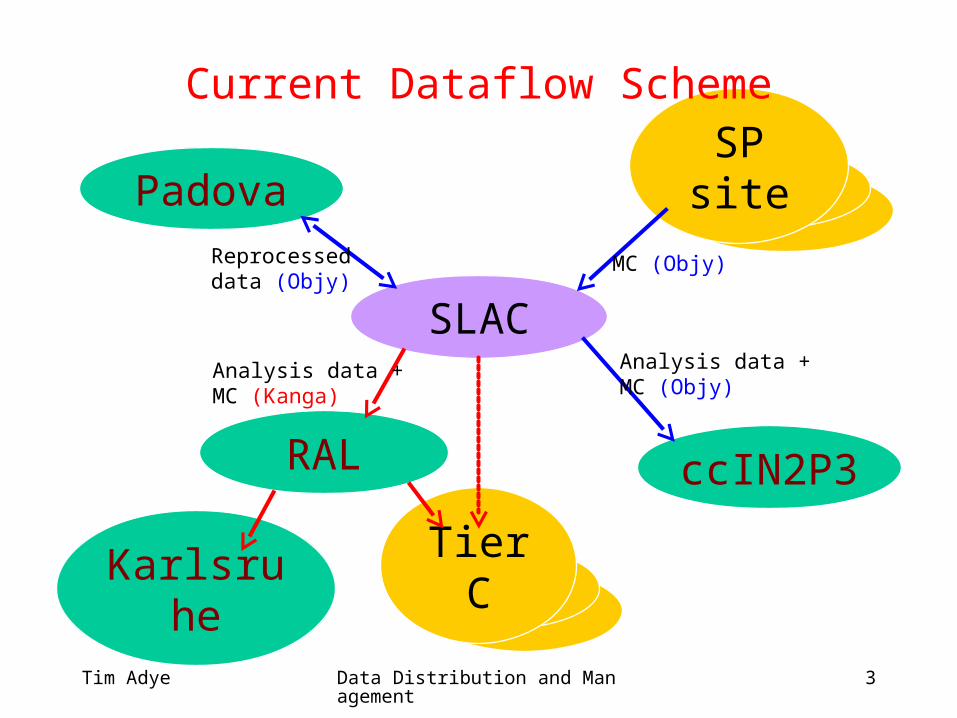
SP site
Current Dataflow Scheme
SLAC
RAL
Padova
ccIN2P3
Tier CKarlsruhe
Reprocesseddata (Objy)
MC (Objy)
Analysis data +MC (Objy)
Analysis data +MC (Kanga)
Tim Adye Data Distribution and Management
4
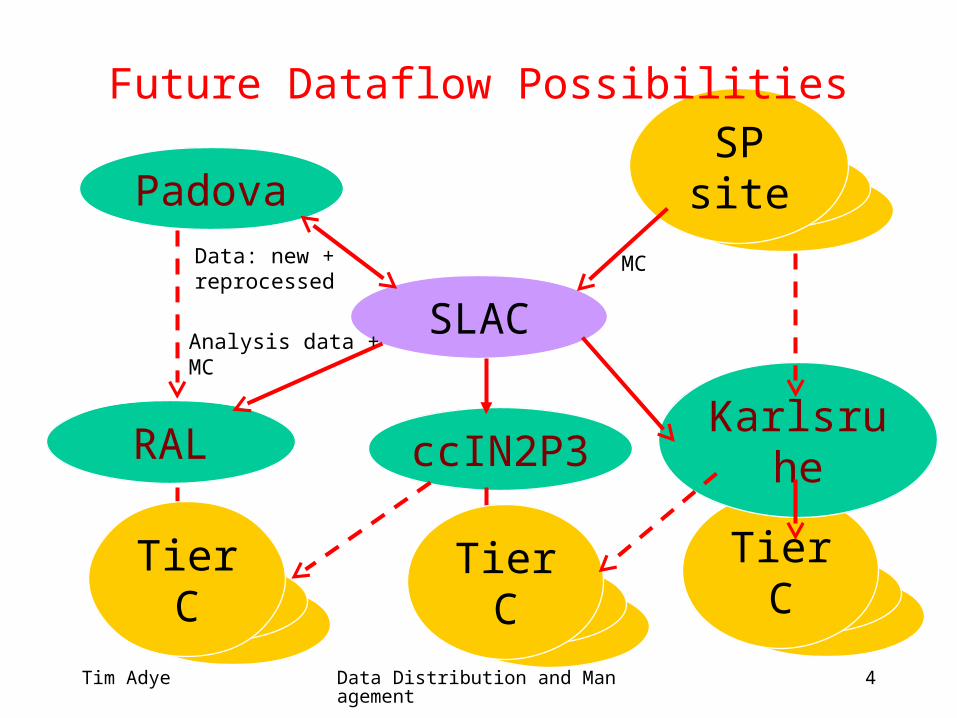
SP site
Future Dataflow Possibilities
SLAC
RAL
Padova
ccIN2P3
Tier C
Karlsruhe
Data: new +reprocessed
MC
Analysis data +MC
Tier C Tier C
Tim Adye Data Distribution and Management
5
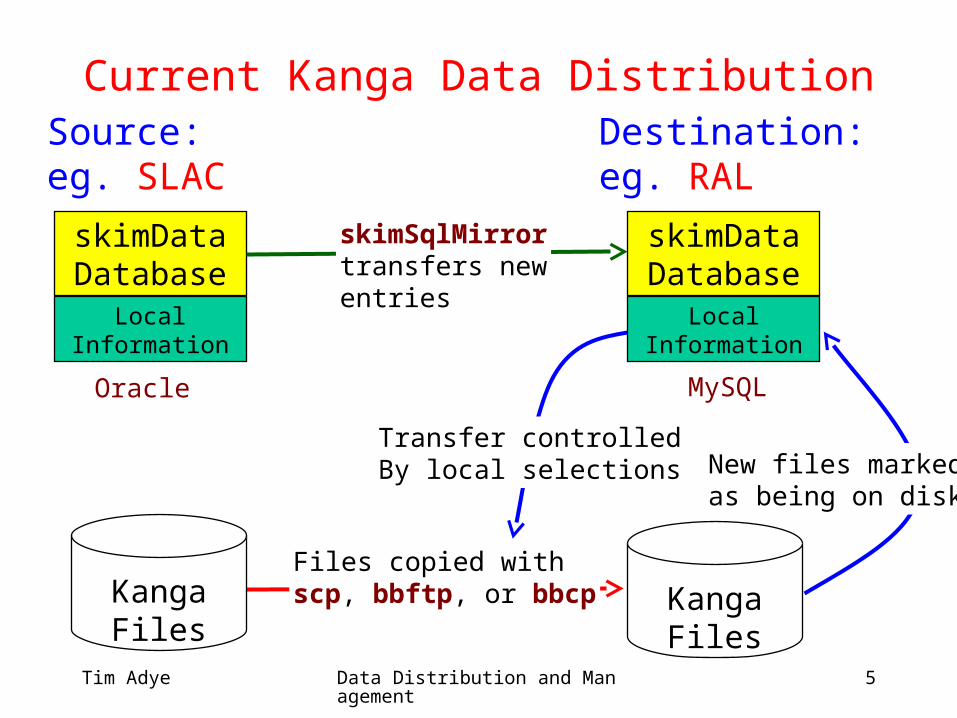
Current Kanga Data DistributionSource:eg. SLAC
skimDataDatabase
LocalInformation
skimDataDatabase
LocalInformation
Transfer controlledBy local selections
skimSqlMirrortransfers newentries
Files copied withscp, bbftp, or bbcp
Oracle MySQL
Kanga Files
Kanga Files
Destination:eg. RAL
New files markedas being on disk

Tim Adye Data Distribution and Management
6
Key Features
• Each site has its own copy of the meta-data (skimData database)• Once metadata/data is imported, all analysis is
independent of SLAC• Each site knows what is available locally
• Three-step update process (can run in a cron job)
1. New entries from SLAC added to DB (skimSqlMirror)
2. Local selections applied to new entries and flagged in the database (skimSqlSelect)• Uses the same selection command as used for user analysis• Selection can include an import priority
3. Selected files imported and flagged “on disk” (skimImport)• Database records what is still to do, so nothing is forgotten if
import is restarted

Tim Adye Data Distribution and Management
7
Data around the world
• Currently RAL holds the full Kanga dataset• 29 TB on disk
• 1.5 Mfiles, 1010 events including stream/reprocessing duplicates
• A further 4 TB of old data archived to RAL tape
• 10-20 Tier C sites import data from SLAC or RAL• Most copy a few streams• Karlsruhe copies full dataset (AllEvents), but not
streams
• Since August, Kanga data removed from SLAC1. First exported to RAL2. File checksums recorded and compared at RAL3. Archived to SLAC tape (HPSS) – 29 TB on tape now

Tim Adye Data Distribution and Management
8
Handling Pointer Skims
• 105 pointer skims for all series-10 real data now available• Each pointer skim file contains pointers to selected
events in AllEvents files• Big saving in disk space, but need to evaluate
performance implications
• Tier C sites do not have AllEvents files• “Deep copy” program creates a self-contained skim
file from specified pointer files• Needs to be integrated into import procedure to
allow automatic conversion• Plan is to run deep copy like another “ftp” protocol,
with output written directly to Tier C disk via ROOT daemon

Tim Adye Data Distribution and Management
9
New Analysis Model
Few changes are required for the new analysis model
1. April test output already exported to RAL2. Allow for multiple files per collection
• Simple extension to old bookkeeping system should allow easy transition to new system• Available for July test skim production• will not handle user data
• Full collection file mapping will come with new bookkeeping tables
3. Migrate to new bookkeeping tables and APIs• should simplify existing tools

Tim Adye Data Distribution and Management
10
Data Management
• All Kanga files stored in a single directory tree, accessed via NFS• Mapping to different file-systems/servers maintained
with symbolic links• Automatically created by import tools
• Cumbersome and error-prone to maintain• Tools for automatic reorganisation of disks at SLAC only
• Kanga files can be archived and restored on tape• Modular interface to local tape systems
• Implemented for SLAC, RAL, (and Rome)
• Small files packed into ~1GB archives for more efficient tape storage
• Archive and restore controlled with skimData selections• No automatic “stage on demand” or “purge unused data”

Tim Adye Data Distribution and Management
11
XRootd
XRootd, like Rootd (the ROOT daemon), provides remoteaccess to ROOT data – but greatly enhanced…
• High Performance and scalable• multi-threaded, multi-process, multi-server architecture• Dynamic load-balancing
• Files located using multi-cast lookup• No central point of failure• Allows files to be moved or staged dynamically• Allows servers to be dynamically added and removed

Tim Adye Data Distribution and Management
12
XRootd Dynamic Load Balancing
xrootd
dlbd
xrootd
dlbd
xrootd
dlbd
xrootd
dlbd
Client
subscribe
(any number)
(any number)
who has the file?who has the file?I doI do
Mass Storage System(Tape, HPSS, etc)

Tim Adye Data Distribution and Management
13
XRootd (cont)
• Flexible security• Allowing use of almost any protocol
• Includes interface to mass-storage system• Automatic “stage on demand” or “purge unused data”
• Reuses file-system, mass-store, and load-balancing systems from SLAC Objectivity (oofs, ooss, oolb)
• Compatibility with Rootd allows access from existing clients (and vice versa)
• Moving from NFS to XRootd should solve many of our data management problems• Still need tools for automatic redistribution of data
between servers

Tim Adye Data Distribution and Management
14
Using the Grid
• Extend existing tools to use Grid authentication• Use GridFTP or GSI-extended bbftp/bbcp for file
transfer• Add GSI authentication to deep copy
• BdbServer++ uses remote job submission to run deep copy and data transfer• Prototype currently being tested with Objectivity
exports
• SRB is a distributed file catalogue and data replication system• Have demonstrated bulk Objectivity data transfers
SLAC ccIN2P3• Both BdbServer++ and SRB could handle
Kanga distribution just as easily (if not more easily)

Tim Adye Data Distribution and Management
15
Conclusion
• Kanga distribution works now• Adapting to new computing model should be easy
• Data management is still cumbersome• Many of the problems should be addressed by
XRootd
• We are looking to take advantage of the Grid


Backup SlidesBackup Slides
Adil Hasan

Tim Adye Data Distribution and Management
18
SRB in BaBar (Tier A to Tier A)• SLAC, ccin2p3 and Paris VI et VII looking at using SDSC
Storage Resource Broker for data distribution (orig Objy).• SRB comes with a metadata catalog plus set of Apps to
move data and update location in metadata catalog. • Can remotely talk to the metadata catalog and move data
through SRB server, able to use GSI (ie X509 certs) or password for auth.
• Have managed to successfully carry out 2 prototypes at Super Computing 2001, 2002:• 1st prototype replicate objy databases between 2 servers at
SLAC• Had 1 metadata catalog for the replicated data.
• 2nd prototype copied objy databases between SLAC and ccin2p3
• Used 2 SRB metadata catalogs one at ccin2p3, one at SLAC.• See:
http://www.slac.stanford.edu/BFROOT/www/Computing/Offline/DataDist/DataGrids/index.html

Tim Adye Data Distribution and Management
19
SRB in BaBar (Tier A to Tier A)• Metadata cataog design for prototypes separate experiment-
specific from experiment-common metadata (eg file sizes, mtimes, etc are expt-common, BaBar collections are expt-specific).• Design also very flexible, should be easy to accommodate the new
Decoupling allows greater flexibility to system (SRB and BaBar can develop metadata structure how they want independently).
• Comp model – provided bookkeeping uses same principle in design.• Have been plan on demonstrating the co-existence of objy and root
files in SRB catalog. • Are putting this runs production objy metadata into SRB for
data dist to ccin2p3 NOW (running this week or next). Should give us useful information on running in production NOW.
• Are looking at technologies to federate local SRB metadata catalogs.

Tim Adye Data Distribution and Management
20
SRB in BaBar (Tier A to Tier A)
• Bi-weekly meetings with SRB developers are helping to get further requirements and experience fed-back to SRB (eg bulk loading, parallel file transfer app, etc).• Bug-fix release cycle ~weekly.• New feature releases ~3-4 weekly.• Meetings also have participation from SSRL folks.

Tim Adye Data Distribution and Management
21
BdbServer++ (Tier A to Tier C)
• Based on BdbServer developed by D. Boutigny et al. used to extract objy collections ready for shipping to Tier A or C.
• Extended to allow extraction of events of interest from Objy (effort from Edinburgh, SLAC, ccinp3)• Using BdbCopyJob to make deep-copy of collection of
events of interest.• BdbServer tools to extract the collection• Tools to ship collections from Tier A to Tier C
• Useful for “hot” collections of interest (ie deep copies that are useful for multiple Tier C’s).• “cache” the hot collections at Tier A to allow quicker
distrib to Tier C.

Tim Adye Data Distribution and Management
22
BdbServer++ Tier A to Tier C
• Grid-ified BdbServer++:• Take advantage of the distrib batch work for the
BdbCopyJob and extraction.• Take advantage of grid-based data dist to move files from
Tier A to C.• Design highly modular should make it easy to implement
changes based on prod running experience.
• Tested BdbCopyJob through EDG and Globus.• Tested extraction of collection through EDG.• Tested shipping collections through SRB.• Have not tested all steps together!• Production style running may force changes to how
collections are extracted and shipped (issues on disk space etc).

Tim Adye Data Distribution and Management
23
BdbServer++ Tier A to Tier C
• BdbServer++ work also producing useful by-products:• Client-based globus installation tool (complete with
CA info).
• Modular structure of BdbServer++ should make it easy to plug in the new tools for the new CM (eg BdbCopyJob -> Root-deep-copy-app, objy collection app -> root coll app).
• All Grid data dist tools being developed must keep in mind legacy apps (implies phased approach). However new development should not exclude Grid by design.