ddn | burst buffer 1 hpc advisory council perth july … · ddn.com any statements or...
TRANSCRIPT

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
1!
1 DDN | Burst Buffer HPC Advisory Council Perth July 2017 Justin Glen & Daniel Richards

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
2! Agenda
▶ What is Burst Buffer? ▶ What is it for? ▶ Recommendations ▶ Regional Solutions ▶ Performance Benchmarks

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
3!DDN | About Us Solving HPC, Enterprise Big Data & Web Scale Challenges
World-Renowned & Award Winning
History
Founded in ’98
World’s Largest Private Storage Company
Double Digit Growth, Profitable, Self Funded
Headquarters Chatsworth, CA

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
4! Sample Customers in Australia

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
5!
During acceptance testing
Why Burst Buffer?

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
6!
After the acceptance testing
Burst Buffer is a cache that caters for real-world IO patterns

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
7!Why Cache Matters in HPC A Day In the Life of A Multi-Disciplinary Cluster
• 90% of I/Os in a standard HPC environment are <32KB
• Cache is critical in aligning all-too-frequent unaligned writes and capturing small writes to preserve performance
• As a minimum include storage controllers with battery-backed mirrored write cache
DDN Proprietary & Confidential INTERNAL ONLY
11% 89%
Total Reads Total Writes
4KB 23%
8KB 23%
16KB 42%
32KB 5%
128KB 0%
256KB 0%
512KB 2%
1024KB 5%
Write Distribution for Multi-Disciplinary HPC Cluster
Sampling from DDN University
Lustre Customer

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
8!Where to put Cache (Flash) in HPC workflow?
▶ Add flash (NVMe) either 1. On the compute nodes for lower cost but more difficult to
use efficiently (may require changes in code) and share between compute nodes or
2. In the file system for easiest to use and share but greater cost and poor performance or
3. In a burst buffer between file system and compute nodes for optimal mix of price & performance. Benefit is data sharing, resilience & excellent performance.
- Adding flash to the file system does not
necessarily improve the performance. - Burst Buffer is about the software not the
hardware.

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
9!Burst Buffer | 3 Key Areas of Workflow Optimization
S3D Turbulent Flow Model
1. MITIGATES POOR PFS PERFORMANCE caused by PFS
locking, small I/O, and mal-aligned, fragmented I/O patterns
Burst Buffer “makes bad apps run well” and also prevents a poor-
behaving app from impacting the entire supercomputer
This is especially valuable to diverse
workload environments and ISV applications
IOR benchmarks indicate a
3x – 20x speedup on I/Os <32KB
2) PROVIDES HIGHER PERFORMANCE I/O (bandwidth and latency) to the application At ISC, we demonstrated three orders of magnitude speed-up due to this high performance tier
3) IME DRIVES SIGNIFICANTLY MORE EFFICIENT I/O TO THE PFS by re-aligning and coalescing data within the non-volatile storage At ISC, we demonstrated two orders of magnitude speed-up due to this efficiency
4 GB/s
25 MB/s
50 GB/s

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
10! What is it good for ?
▶ Initially designed for check pointing • Shared file write
▶ Developing into both read and write ▶ Extract the most benefit from Flash based
storage, design around POSIX/PFS limitations • Random IO • Small IO • Extreme number of threads • Slow components

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
11! Sizing a burst buffer
▶ Include a burst buffer in your new HPC system • Bandwidth of Burst Buffer is typically 3x to 5x back end
parallel file system bandwidth • Aggregate NVMe capacity of Burst Buffer around 0.5 to 3
times the aggregate memory capacity of the cluster • Burst Buffer investment is 25% to 50% of total working
storage

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
12!A*Star – Peak scientific system for Singapore

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
13! JCAHPC Oakforest-PACS
25PF 550K KNL cores
Burst Buffer 25xIME14K 1500GB/s,940TB Raw
Scratch 10xES14KX
400GB/s 26PB useable
OPA Interconnect
ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
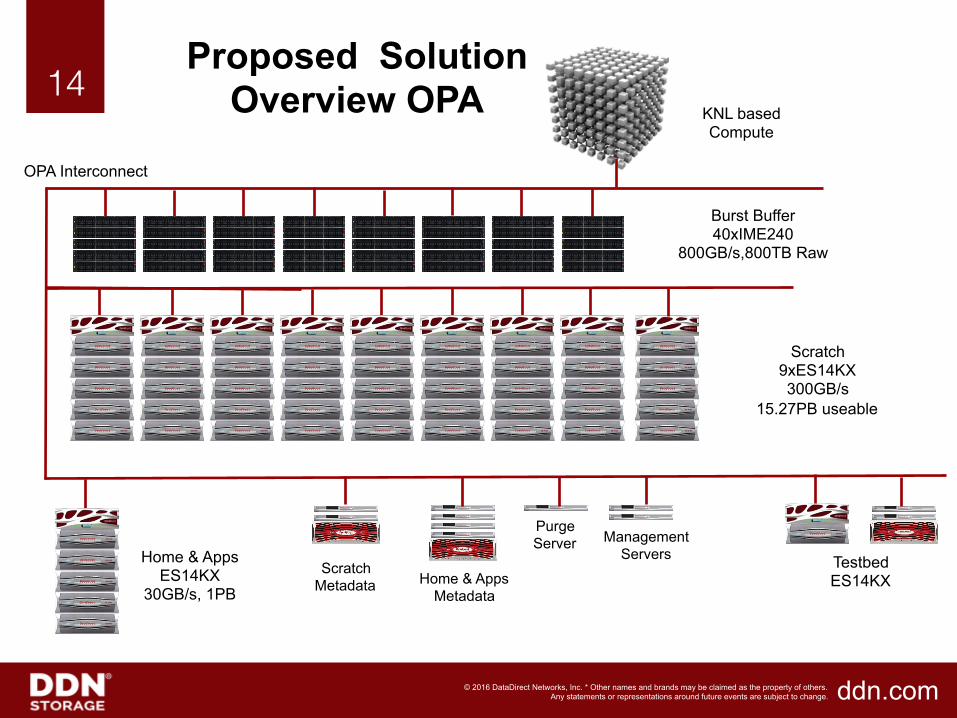
14!Proposed Solution
Overview OPA KNL based Compute
Burst Buffer 40xIME240
800GB/s,800TB Raw
Scratch 9xES14KX 300GB/s
15.27PB useable
OPA Interconnect
Home & Apps ES14KX
30GB/s, 1PB Home & Apps
Metadata
Scratch Metadata
Management Servers
Purge Server
Testbed ES14KX

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
15! Performance ▶ Like PFS’s:
• Excellent for some workloads • Good for some • Not so good for others
▶ Excellent for • Random IO, large number of threads • Shared file • Small IO
▶ Good for • Sequential
▶ Not so good for (at this point) • Metadata intensive
Also consider repeatability of execution, and performance under fault conditions

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
16! Brain Simulation Workflow
(Source: I/O Challenges in Brain Tissue Simulation (IME Neuromapp), Judit Planas. ISC17 DDN User group)

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
17! WRF on Lustre 48 job, total 240 compute node – throughput – focus, 5 minute window
~100GB/s

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
18! WRF on IME 48 job, total 240 compute node – throughput – focus, 5 minute window
IME capacity consumption
WRF output WRF checkpoint
~390GB/s

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
19! WRF on IME at scale Application runtime speedup over 1.5x

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
20!
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34
I/O timing variance, in seconds 48 concurrent job, 960 sample, 20 sample/job
IME Lustre
very small variance in IO times for jobs when run concurrently (fastest times don't show)
Lustre IO times vary widely from 2s to 34s

ddn.com © 2016 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
21!
21 Thank You [email protected], [email protected]