
Кластерний аналіз даних методом k-середніх
Бахрушин Володимир Євгенович,
професор, д.ф.-м.н[email protected]

Постановка завдання
Завданням класифікації даних є розбиття наявної множини точок на задану кількість кластерів так, щоб сума квадратів відстаней точок до центрів кластерів була мінімальною.
В точці мінімуму всі центри кластерів збігаються з центрами відповідних областей діаграми Вороного.
Основні алгоритми:
Хартігана-Вонга Ллойда
Форджи Маккуина

Початкове наближення
Перш за все необхідно задати початкові наближення центрів кластерів.
Для цього найчастіше використовують такі способи:
безпосередньо задають центри кластерів;задають кількість кластерів k та беруть як центри, координати k перших точок;задають кількість кластерів k та беруть як центри, координати k випадково обраних точок (доцільно здійснювати розрахунки для декількох випадкових запусків алгоритму).

Ітераційна процедура
1. Зарахування кожної точки до кластера, центр якого є найближчим до неї. Як міру близькості найчастіше беруть квадрат евклідової відстані, але можуть бути обрані й інші міри відстані.
2. Перерахунок координат центрів кластерів. Якщо мірою близькості є евклідова відстань (або її квадрат), центри кластерів розраховують як середні арифметичні відповідних координат точок, що належать до цих кластерів.
Ітерації зупиняють, коли здійснено задану максимальну кількість ітерацій або якщо перестає змінюватися склад кластерів.
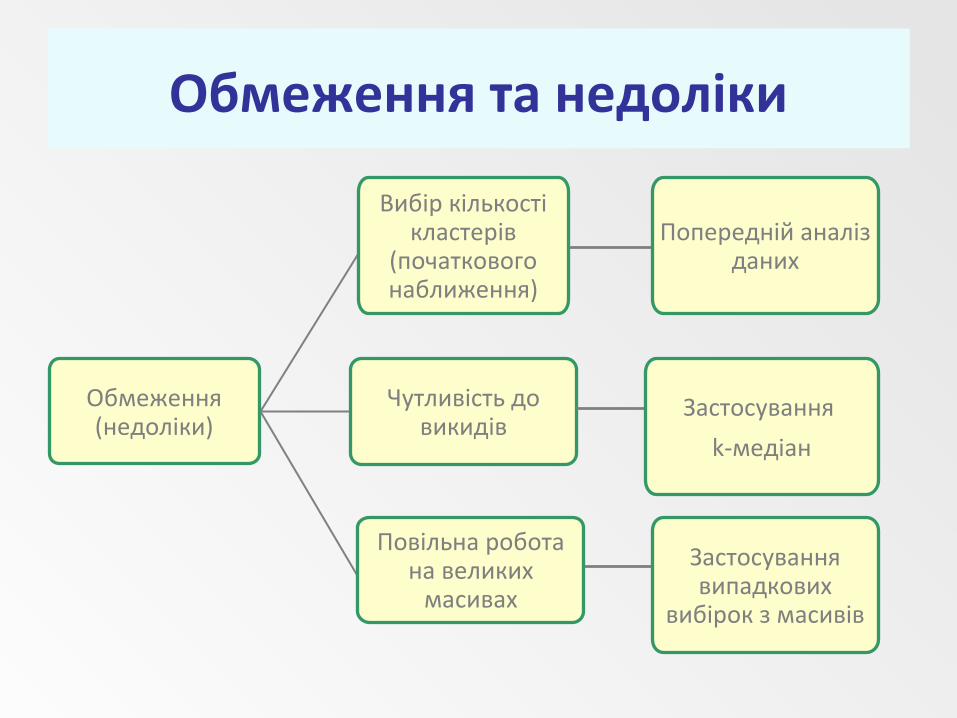
Обмеження (недоліки)
Вибір кількості кластерів
(початкового наближення)
Попередній аналіз даних
Чутливість до викидів
Застосування
k-медіан
Обмеження та недоліки
Застосування випадкових
вибірок з масивів
Повільна робота на великих
масивах

Формування масиву даних
a1 = matrix(c(rnorm(20, mean = 5, sd = 1), rnorm(20, mean = 5, sd = 1)), nrow=20, ncol = 2)
a2 = matrix(c(rnorm(20, mean = 5, sd = 1), rnorm(20, mean = 13, sd = 1)), nrow=20, ncol = 2)
a3 = matrix(c(rnorm(20, mean = 12, sd = 1), rnorm(20, mean = 6, sd = 1)), nrow=20, ncol = 2)
a4 = matrix(c(rnorm(20, mean = 12, sd = 1), rnorm(20, mean = 12, sd = 1)), nrow=20, ncol = 2)
a <- rbind(a1,a2,a3,a4)
Функція rbind() формує матрицю a, в якій перші 20 рядків є відповідними елементами матриці a1, наступні 20 – матриці a2 й т. д.

Центри груп
Розраховуємо матрицю значень центрів сформованих груп і виводимо результати розрахунків на екран:

Функція kmeans()
Для формування кластерів методом k-середніх можна використовувати функцію:
kmeans(x, centers, iter.max = 10, nstart = 1, algorithm = c("Hartigan-Wong", "Lloyd", "Forgy", "MacQueen") )
x – матриця числових даних;centers – початкове наближення центрів кластерів або кількість
кластерів (тоді як початкове наближення буде взято відповідну кількість випадково обраних рядків матриці x);
iter.max – максимальна кількість ітерацій;nstart – кількість випадкових множин, які треба вибрати, якщо
centers – це кількість кластерів;algorithm – вибір алгоритму кластеризації.

Результати кластеризації

Результати кластеризації

Результати кластеризації

Порівняння центрів
№ групи (кластера)
xa ya xcl ycl
a1 4,613619 5,169488 4,613619 5,169488
a2 4,570456 13,396202 4,570456 13,396202
a3 11,855793 5,936099 11,855793 5,936099
a4 12,197688 11,930728 12,197688 11,930728
b1 5,531175 5,405187 5,545309 5,527677
b2 5,340795 12,983168 5,472965 13,239925
b3 11,770917 6,725708 11,842934 6,916365
b4 11,701643 12,233062 11,792042 12,391985

Залишки
За допомогою команди sd(resid.a) можна розрахувати стандартні відхилення залишків. Вони є близькими до заданих значень стандартних відхилень вихідних масивів точок, що підтверджує адекватність результатів кластеризації.

Результати поділу на 3 кластери

Результати поділу на 5 кластерів
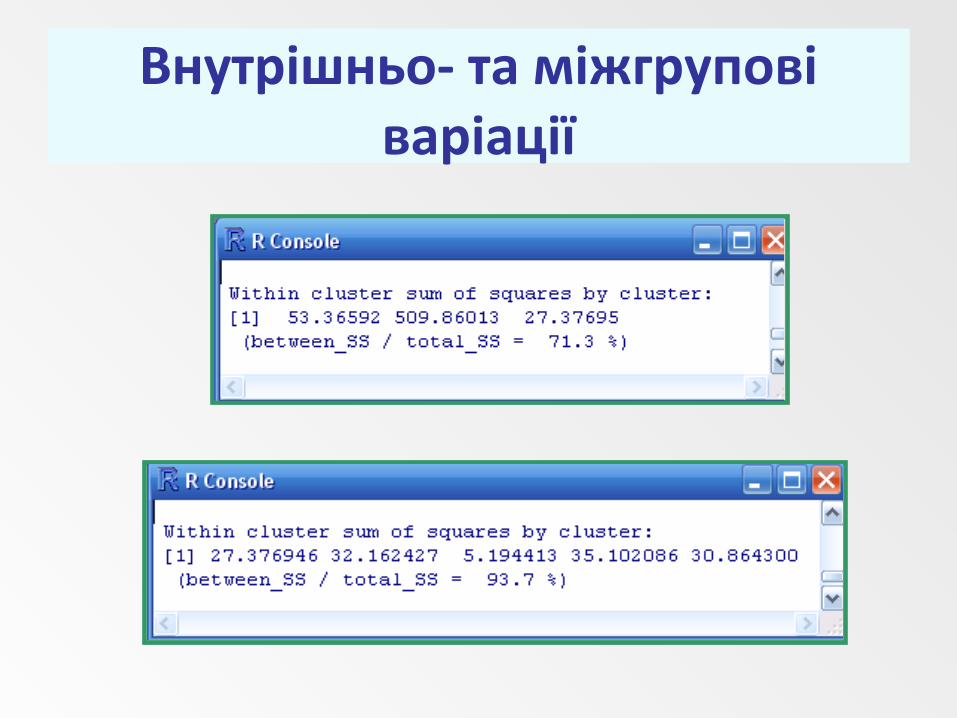
Внутрішньо- та міжгрупові варіації

Література
1.Бахрушин В.Є. Методи аналізу даних: Навчальний посібник / В.Є. Бахрушин – Запоріжжя: КПУ, 2011. – 268 с. https://www.researchgate.net/publication/235825660_The_Methods_of_Data_Analysis_%28in_Ukrainian%29
2.Лепский А.Е. Математические методы распознавания образов: Курс лекций / А.Е. Лепский, А.Г. Броневич – Таганрог: Изд-во ТТИ ЮФУ, 2009. – 155 с. http://window.edu.ru/resource/800/73800/files/lect_Lepskiy_Bronevich_pass.pdf
3.http://stat.ethz.ch/R-manual/R-devel/library/stats/html/kmeans.html







