dr. kristin bakken, no 2014 oddrun grønvik, no 2014 dr. daniel ridings, dok sept. 7th 2004
TRANSCRIPT

Dr. Kristin Bakken, NO 2014Oddrun Grønvik, NO 2014Dr. Daniel Ridings, DOK
Sept. 7th 2004

An old dictionary with new tools Norsk Ordbok (Norwegian Dictionary)
An old national dictionary with ambitious scope Initiated in 1930 A dictionary archive of some 3,2 mill. slips A combined literary and dialect dictionary Complex entry structure
Literary and dialect quotations with references Formal variants with geographical references Information on pronunciation, etymology, inflection and
historical standardization

New project organization in 2002 Fresh fundings directly from the government on
top of The University of Oslo share in the project Political acceptance of the national value of the dictionary
Conditions To complete the dictionary in 12 volumes by 2014 To develop and exploit computer-based tools in the
process Strengthened management

Our starting point 4 volumes already published – demands of continuity
vs. need for reform The University of Oslo wanted a general format for all
their digitalized academic archives Unit for digital documentation (DOK) was in charge of all
digitalization Our slip archive and other sources had been digitalized
and turned into a database by DOK during the 1990s An index (the Meta-dictionary) had been made to
access the database.

ChallengesTo make the dictionary writing more time-efficient
- the analysis and synthesis of data- the writing of dictionary entries
To ease the process of training many new editors in a short timeA simpler and faster production phaseTo improve the quality of the dictionary

Therefore: To build an integrated digital platform on which to
edit Norsk Ordbok To make a dictionary writing system on top of the
Meta-dictionary database, so that the sources are directly accessible through the DWS
To link a corpus to the DWS and to the Meta-dictionary
A database and work-station solution

Oddrun Grønvik: Resources and editor
NO 2014 gives specifications and coope-rates closely in application development with DOK (Unit for Digital Documentation, HF, UiO). Partners at DOK are:
Meta Dictionary: Dr. Christian-Emil Ore Dictionary database and editor: Lars
Jørgen Tvedt Corpus: Dr. Daniel Ridings

Organisation
Editor and database for Norsk Ordbok
Meta Dictionary(Language Archives)
NO 2014 in ”show print” or proof sheet
NO 2014 Corpus
Slip archiveRaw manuscript (1940)Other dictionaries(standard, special,dialect) larger texts
new materials
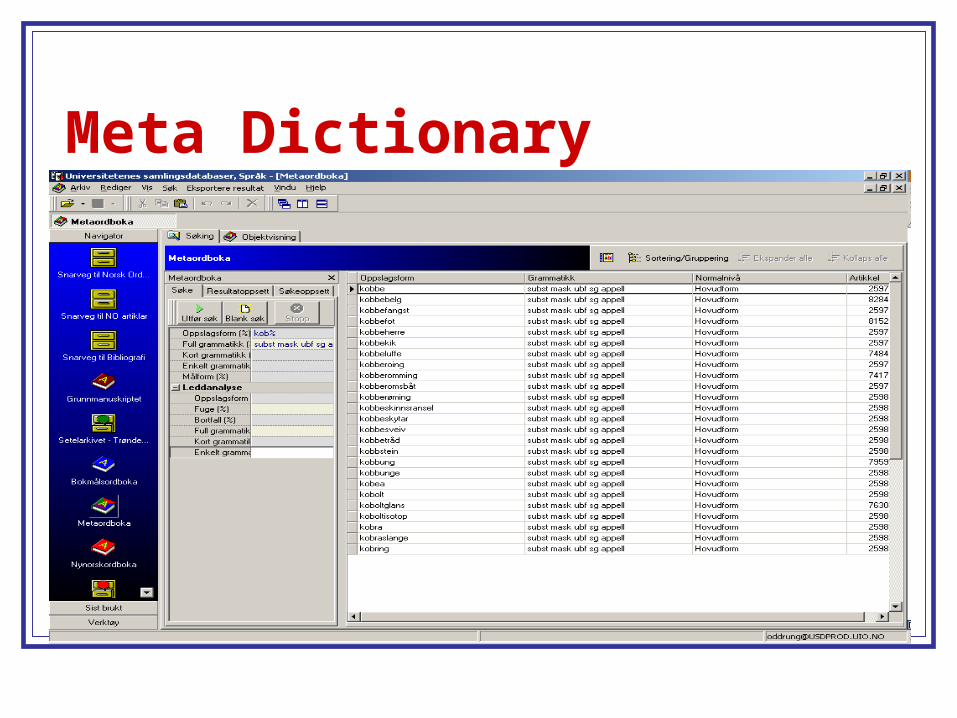
Meta Dictionary

MO normalisation window

Article in Meta Dictionary with facsimile

Special features of Norsk Ordbok – editor requirements
small group very large and complex entries (function words, central vocabulary)
extensive and complex indication of sources extensive and complex linking system in database
Result:
maximum format for Editor and Style manual way beyond needs for most of the entries

The NO 2014 editor Basic requirements Establish ”best practice” from vol 1-4 in new style manual Speed and capacity for large number simultaneous
operations Must show entry structure (”tree”), entry forms, print version Clear organisation of tree and entry forms one to one correspondence between tree and entry forms
(speed, equivalence) and to style manual finely graded tree (icons for all types of elements i.e. various
source types)

Menues and databases accessible from editorHeadword (from the Meta Dictionary)part of speech, status, morphologySpecial symbols and characters (not IPA)linguistic sources from before 1900Bibliography (source list)Geographical location and hierarchyLanguages (etymology form)Other entries (cross references)Usage markers

Entry form headword and grammar
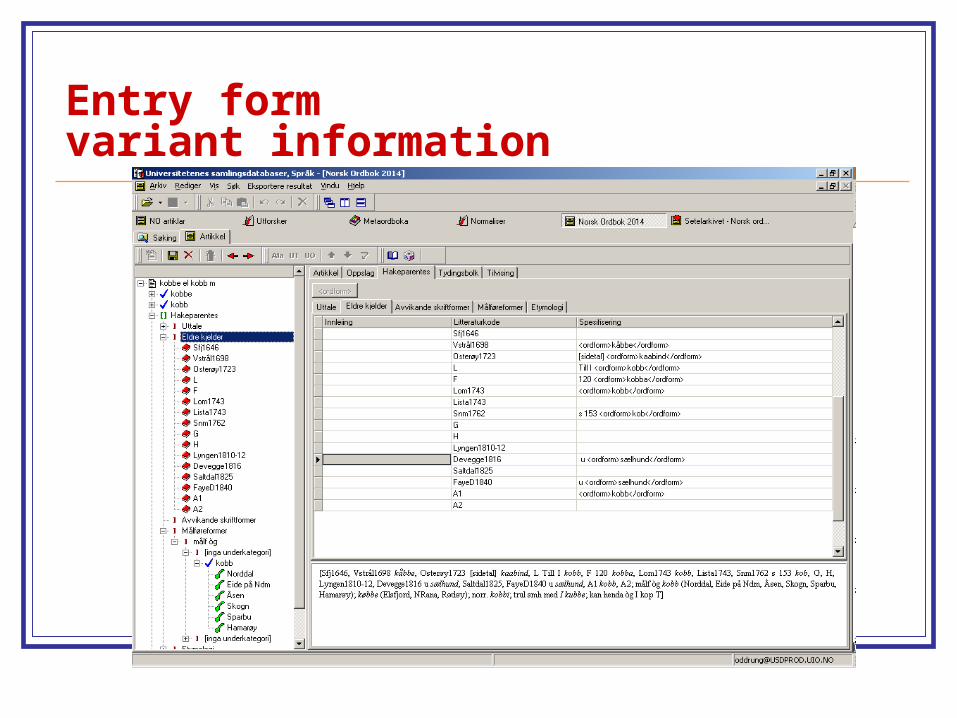
Entry form variant information

Entry form for ”unit of meaning”

NO 2014 editor search window

show entry

Entries in proof sheet style

Daniel Ridings: Corpus Designed to meet the needs of the
dictionary project Supplement existing paper and electronic slips Concentrate on modern language usage
Works as an independent application or as a module within the Meta-dictionary

Technical details SGML / TEI
Limited subset of importance for dictionary work Every element, from the top document element
to the lowest word element has its own ID 25634 documents, 19143247 words (Sept. 1)
Database access (Oracle) WWW PC application







Challenges met: Time efficiency Faster analysis: indexed computerized sources, the corpus The writing of dictionary entries: preset menus, structured
guide through the entry (… but maximum forms for simple entries)
Training advantages: preset menus, structure given Production phase: The database gives all information needed
to produce proof sheets Quality: The DWS secures higher consistency, the corpus
has enriched our empirical basis, no typing errors in everything that is preset, i.e. punctuation, abbreviations and typography

Standard questions Specific needs?
small group very large and complex entries (function words, central vocabulary)
extensive and complex indication of sources extensive and complex linking system in
database How does the current DWS meet the
needs? Too early to tell but it is looking good.

Standard questions 2 Corpus
Developed specifically for the project WWW access and integration with the Meta-
Dictionary and our DWS
What kind of software do you use? PC-based software developed locally

Standard questions 3 Management tools
Not yet developed, but specifications have been given
Is off-line work possible Laptops at home is possible but anyone wishing
to do so also has internet at home, so they are not off-line. All software will work from home.
Limitation is network speed, which in Norway is not really an issue.

Standard questions 4 Granularity of work
It is possible to divide up the categories (definitions, pronunciation, etc) among various lexicographers. Oracle is a multiuser database.
NLP context The dictionary has not been used in NLP projects.
Morphology and syntax are not usually expressed with the degree of formality that NLP requires. We are involved with a project for machine translation and can compare the needs.

http://no2014.uio.no