energy based models and boltzmann machines - v2.0
TRANSCRIPT

Energy-Based Models and Boltzmann MachinesLearning Deep Architectures for AI - Ch 5

목차
● Energy-Based Models● Boltzmann Machines● Restricted Boltzmann Machines● Contrastive Divergence● Examples

Definition
● 각 상태(x)에 대해 에너지를 정의하고, 모든 원하는 상태들의 에너지가 최소가 되도록 에너지 함수의 파라미터들을 학습하는 모델
● 에너지 기반의 확률 모델에서는 에너지 함수를 이용해 확률 분포를 다음과 같이 정의○ 자연계(물리학)에서의 볼츠만 분포 법칙을 신경망에 적용한 것○ 이 관점에서 본다면 뉴런은 볼츠만 분포 하에서 운동하는 분자라고 볼 수 있고 뉴런의 state는 분자의 에너지 상태라고 해석할 수 있다
Energy-Based Models

Energy-Based Models
Introducing Hidden Variables
● 모델의 표현력(expressive power)을 증가시키기 위해 관측되지 않는 (non-observed) 변수들을 추가하면 확률 분포를 아래와 같이 쓸 수 있음

Energy-Based Models
Free Energy
● 확률 분포를 아래와 같은 형태로 만들기 위해 자유 에너지(Free Energy)라는 개념을 도입한다.○ 즉, hidden 변수들이 포함된 확률 모델을 간단히 다루기 위한 수학적 테크닉으로 이해하면 된다.
○ 대부분의 설명에서는 이처럼 수학적 테크닉으로써의 자유 에너지를 설명하는데 그 이름은 물리학에서 말하는 깁스의 자유 에너지에서 이름을 가져왔다고 한다.
● 자유 에너지를 계산하면 다음과 같은 형태가 된다.

Energy-Based Models
Log-likelihood gradient
● EBM은 데이터의 log-likelihood를 이용해서 gradient descent 방법으로 학습 가능하다.
● Log-likelihood를 계산하면 다음과 같다. (계산 생략)○ 첫번째 항은 input vector(x)가 주어졌을 때 쉽게 구할 수 있지만 두번째 항은 모든 가능한 input에 대해 계산해야 하므로 정확하게 계산하는 것은 시간이 매우 오래 걸린다.
Energy-Based Models
Average log-likelihood gradient
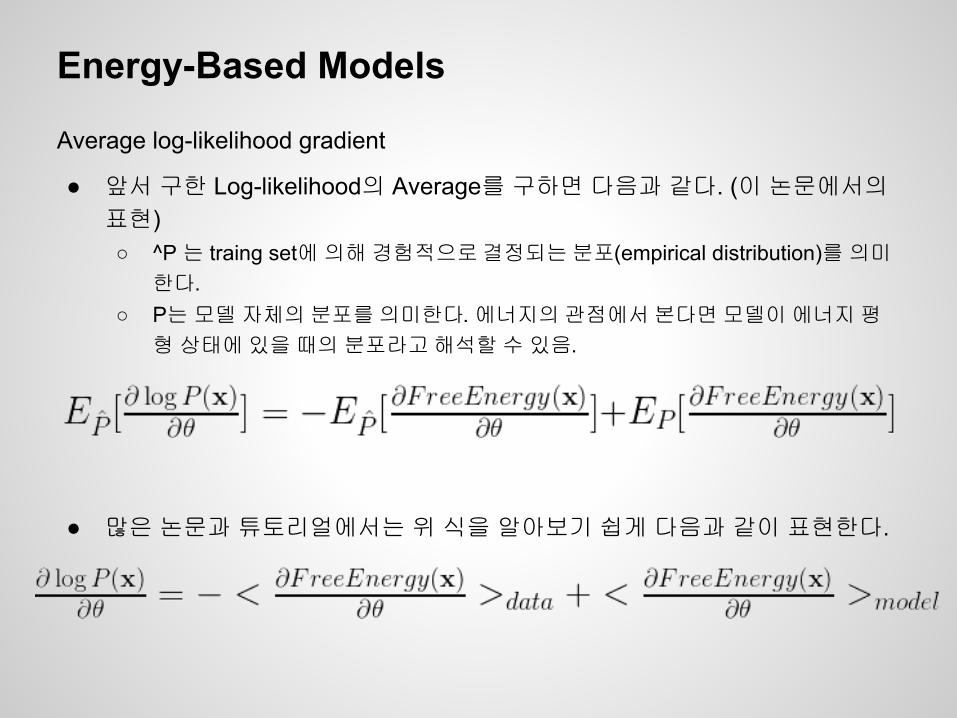
● 앞서 구한 Log-likelihood의 Average를 구하면 다음과 같다. (이 논문에서의 표현)○ ^P 는 traing set에 의해 경험적으로 결정되는 분포(empirical distribution)를 의미한다.
○ P는 모델 자체의 분포를 의미한다. 에너지의 관점에서 본다면 모델이 에너지 평형 상태에 있을 때의 분포라고 해석할 수 있음.
● 많은 논문과 튜토리얼에서는 위 식을 알아보기 쉽게 다음과 같이 표현한다.

The idea of stochastic estimator of the log-likelihood gradient
● EBM의 학습을 위해서는 위 식의 두 번째 항을 빠르게 계산해야 한다.● 만약 모델의 분포 P로부터 샘플링을 해서 자유 에너지를 빠르게 (tractably) 계산할 수 있다면 Monte-Carlo 방법을 사용해서 gradient 값을 추정할 수 있다.
Energy-Based Models

Approach overview
● 모델에 맞는 에너지 함수 정의● 자유 에너지 정의● 에너지 함수로부터 확률 분포 전개● Log-likelihood gradient 전개● MCMC method를 이용해 모델의 기대값을 계산하고 결과적으로 gradient 추정
Energy-Based Models

Definition
● Boltzmann Machine 은 hidden unit을 추가한 EBM의 일종이다. 또 MRF(Markov Random Field, Markov Network)의 일종이기도 하다.
● Unit들간의 연결에 제약이 없이 모두 연결될 수 있는 모델이다.
Boltzmann Machines

Energy Function
● 에너지 함수는 아래와 같다.
● 이 에너지 함수는 어떻게 정의된 것일까?○ BM의 에너지 함수는 Hopfield Network와 Ising Model로부터 정의된다(고 한다..).
BM & RBM 뿐만 아니라 RBM의 변형, 다른 EBM은 대부분 자연(물리학, 열역학 등)을 모델링하는 것으로부터 얻어진다.
Boltzmann Machines

Problems
● 모델이 대칭적이고 유닛이 Binary Unit이라는 가정 하에 EBM에서 했던 논의를 그대로 이어나갈 수 있다.
● 즉, 에너지로부터 확률을 구하고 Log-likelihood gradient를 계산한 다음 MCMC Sampling을 통해 stochastic 하게 gradient를 추정할 수 있다.○ 뒤에 RBM에서 자세히 다룰 것이다.
● 하지만 Stochastic하게 gradient를 추정한다고 해도 너무 많은 (제약이 없는) 연결때문에 일반적으로 계산이 비싸고 오래 걸린다.○ 에너지 평형 상태의 표본을 수집하는 시간이 모델의 사이즈, 연결 강도의 크기에 대해 지수적으로 증가한다.
Boltzmann Machines
Restricted Boltzmann Machines
Definition
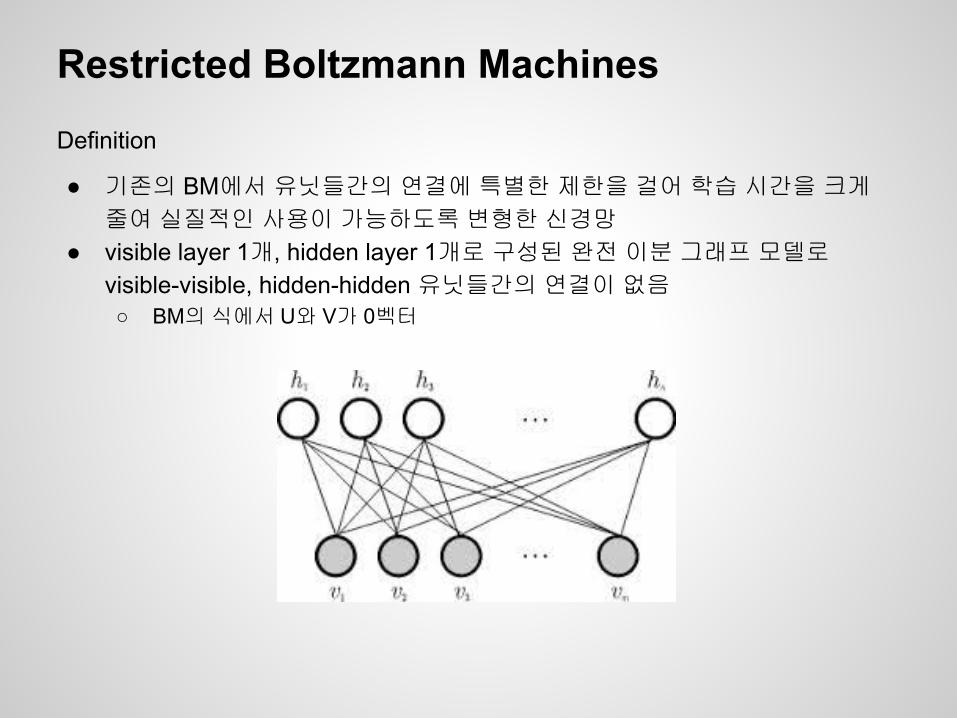
● 기존의 BM에서 유닛들간의 연결에 특별한 제한을 걸어 학습 시간을 크게 줄여 실질적인 사용이 가능하도록 변형한 신경망
● visible layer 1개, hidden layer 1개로 구성된 완전 이분 그래프 모델로 visible-visible, hidden-hidden 유닛들간의 연결이 없음○ BM의 식에서 U와 V가 0벡터

Restricted Boltzmann Machines
Energy, Free Energy
● RBM에서는 에너지가 다음과 같이 정의된다.
● RBM도 EBM의 일종이기 때문에 FreeEnergy와 Distribution은 그대로 따라간다.○ 여전히 Partition function Z는 intractable하다.

Restricted Boltzmann Machines
Conditional Distribution
● RBM의 구조에 의해 input이 주어지면 hidden unit들 간에는 conditionally independent하며 그 역도 동일하게 성립○ 이 속성이 계산 시간을 크게 줄여주는 이유가 됨

Restricted Boltzmann Machines
RBMs with Binary units
● Binary unit이라고 가정하면 P(h|x) 식을 전개하고 conditionally independent 하다는 속성을 이용해 P(h_i = 1|x) 을 얻을 수 있음. 그 역도 마찬가지. (계산 생략)○ 이 두 식은 뒤에서 Sampling을 할 때의 update rule이 된다.○ 각 unit이 0과 1 사이의 실수값인 경우로 확장한 것이 Gaussian-Bernoulli RBM
(GBRBM) 이다.

Restricted Boltzmann Machines
Negative Log-likelihood gradient
● 학습을 위해 Negative Log-likelihood gradient를 계산하면 다음과 같다.
● 첫번째 항을 positive phase, 두번째 항을 negative phase라고 한다.앞서 논의와 마찬가지로 negative phase는 계산하기 어렵다. ○ RBM에서는 Sampling을 통해 값을 추정한다.

Restricted Boltzmann Machines
Update Equations with Binary Units
● RBM의 에너지 함수로부터 각 파라미터에 대한 편미분을 계산하면 다음과 같다.○ 에너지 함수가 선형이기 때문에 미분값이 매우 간단해진다.
● RBM의 최종적인 Update Equation을 다음과 같이 얻을 수 있다.

Gibbs Sampling in RBMs
● 두 확률 변수의 조건부 확률 분포가 주어졌으므로 Gibbs Sampling을 통해서 모델 자체의 분포에 의한 표본을 수집할 수 있다.○ 임의의 데이터에서 출발해서 표집을 하면 초기에는 처음 값에 의존하지만 충분한 시간이 지난 후에는 초기 상태에 관계없이 모델 자체에 기반한 표본을 수집할 수 있다.
● 에너지 관점에서 설명하면 Gibbs Sampling을 충분히 많이 하면 RBM이 에너지 평형 상태에 도달하게 된다.
Restricted Boltzmann Machines

Contrastive Divergence
Definition
● negative phase를 모든 가능한 입력 데이터에 대한 기대값으로 계산하지 않고 모델의 에너지 평형 상태에서의 샘플값 하나로만 근사한다.○ 모델이 에너지 평형 상태에 있다면 그 때의 샘플값은 평균에 가까울 가능성이 높기 때문에 Reasonable 하다.
● Gibbs Sampling을 이용해 샘플을 얻는다.
● Update rule을 다음과 같이 다시 쓸 수 있다.

Contrastive Divergence
CD-k with Alternative Gibbs Sampling [Hinton 02]
● Gibbs Sampling의 시작을 임의의 값이 아니라 training data로 한다.● Gibbs Sampling을 무한번 하지 않고 k번만 한다.● 실질적으로는 1번만 해도 충분히 좋은 샘플을 얻을 수 있다.
○ Training을 할수록 모델이 가지는 분포는 training set의 분포를 따라간다. 즉, training data가 이미 모델의 분포를 어느 정도 표현하고 있다는 것이다. 따라서 training data로부터 샘플링을 시작하면 이미 어느 정도 수렴된 지점부터 샘플링을 시작하는 것이라고 볼 수 있어서 1번만에 좋은 샘플을 얻을 수 있다.
● 1번 샘플링해서 얻어진 visible data를 reconstrunction이라고 하고 트레이닝이 제대로 되고 있다면 reconstruction error가 감소한다. 즉, 이상적인 RBM은 input data를 집어넣으면 동일한 reconstruction visible data를 얻을 수 있다.

Contrastive Divergence
persistent CD [Tieleman 08]
● Gibbs Sampling을 할 때 기존 CD-k 에서는 매번 각각의 training data에 대해 샘플링하지만 persistent CD에서는 이전 Gibbs Sampling에서 계산된 data (reconstruction data)를 다음 번 Sampling의 시작으로 사용한다. 즉, 첫번째 training data가 persistent chain의 시작이 되고 전번의 Gibbs Sampling 결과를 다음 번 training의 시작으로 사용하여 Chain을 이어나간다.○ 이렇게 Chain을 이어 나가면 무한번 Sampling하는 것과 비슷해지는 효과를 갖게 된다. 물론 매 Gibbs Sampling마다 파라미터가 Update 되어서 모델이 변하긴 하지만 매우 작은 값이기 때문에 근사적으로 성립한다.

Examples [Hinton’s lecture]
숫자 2를 학습하는 예제
● 16 x 16 크기의 이미지 (256 개의 visible 뉴런)● 50개의 binary hidden 뉴런
○ 이 경우 Hidden unit = Feature detector = Feature Extractor● CD-1으로 학습● 각 뉴런의 Weight는 랜덤값으로 초기화

Examples [Hinton’s lecture]
50개의 Hidden Unit의 Weight를 이미지로 그린 것

Examples [Hinton’s lecture]

Examples [Hinton’s lecture]

Examples [Hinton’s lecture]

Examples [Hinton’s lecture]

Examples [Hinton’s lecture]

Examples [Hinton’s lecture]

Examples [Hinton’s lecture]

Examples [Hinton’s lecture]
각 뉴런이 숫자 2의 서로 다른 Feature를 잡아내는 것을 볼 수 있음
Examples [Hinton’s lecture]
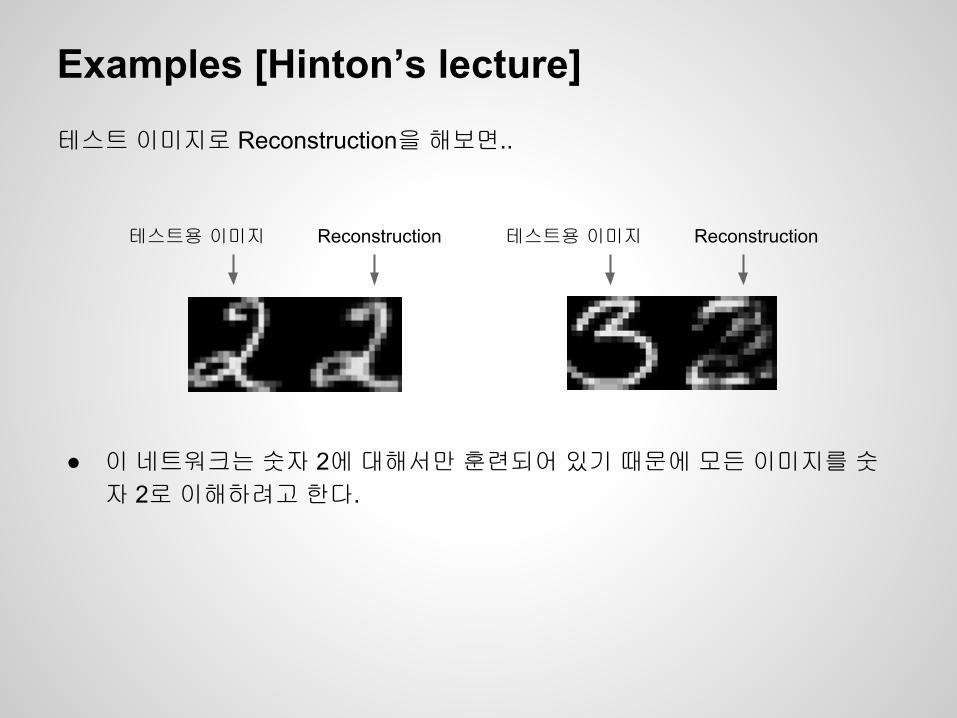
테스트 이미지로 Reconstruction을 해보면..
● 이 네트워크는 숫자 2에 대해서만 훈련되어 있기 때문에 모든 이미지를 숫자 2로 이해하려고 한다.
테스트용 이미지 Reconstruction 테스트용 이미지 Reconstruction

Examples [Larochelle 09]
MNIST

Examples [Larochelle 09]
MNIST
● 각 Hidden unit이 Edge(펜스트로크)를 뽑아내는 것을 볼 수 있음.

Unsupervised Learning
● Feature Extractor● 다른 Supervised Learning의 pre-training
○ Deep Belief Network [Hinton Neural Computation 06]○ Deep Auto-Encoder [Hinton Science 06]
● Collaborative Filtering (Netflix Prize 2007 winner) [Salakhutdinov 07]○ Conditional RBM (with Gaussian Unit)○ Conditional Factored RBM
● Generator (Human motion modeling) [Taylor 06]○ Conditional RBM
Extensions

Supervised Learning
● Classifier [Larochelle 08]○ Classification RBM○ Discriminitive RBM○ Hybrid Discriminitive RBM
Extensions

References● [Bengio 09] Learning Deep Architectures for AI● [Deeplearning.net] Deep learning tutorial - RBM● [Hinton 02] Training Products of Experts by Minimizing Contrastive Divergence● [Tieleman 08] Training Restricted Boltzmann Machines using Approximations to the
Likelihood Gradient● [Larochelle 09] Exploring Strategies for Training Deep Neural Networks● [Hinton Neural Computation 06] A Fast Learning Algorithm for Deep Belief Network● [Hinton Science 06] Reducing the Dimensionality of Data with Neural Networks● [Salakhutdinov 07] Restricted Boltzmann machines for collaborative filtering● [Taylor 06] Modeling Human Motion Using Binary Latent Variables● [Larochelle 08] Classification using Discriminative Restricted Boltzmann Machines

감사합니다.