enhancing fine-grained parallelism chapter 5 of allen and kennedy optimizing compilers for modern...
TRANSCRIPT

Enhancing Fine-Grained Parallelism
Chapter 5 of Allen and Kennedy
Optimizing Compilers for Modern Architectures

Optimizing Compilers for Modern Architectures
Fine-Grained Parallelism
Techniques to enhance fine-grained parallelism:
• Loop Interchange
• Scalar Expansion
• Scalar Renaming
• Array Renaming
• Node Splitting

Optimizing Compilers for Modern Architectures
Recall Vectorization procedure….
procedure codegen(R, k, D);// R is the region for which we must generate code.// k is the minimum nesting level of possible parallel loops. // D is the dependence graph among statements in R..
find the set {S1, S2, ... , Sm} of maximal strongly-connectedregions in the dependence graph D restricted to R
construct Rp from R by reducing each Si to a single node andcompute Dp, the dependence graph naturally induced on Rp by D
let {p1, p2, ... , pm} be the m nodes of Rp numbered in an orderconsistent with Dp (use topological sort to do the numbering);
for i = 1 to m do begin
if pi is cyclic then begin
generate a level-k DO statement;
let Di be the dependence graph consisting of all dependence edges in D that are at level k+1 or greater and are internal to p i;
codegen (pi, k+1, Di);
generate the level-k ENDDO statement;endelse
generate a vector statement for p i in r(pi)-k+1 dimensions, where r (pi) is the number of loops containing pi;
endend
We can fail here

Optimizing Compilers for Modern Architectures
Can we do better?
• Codegen: tries to find parallelism using transformations of loop distribution and statement reordering
• If we deal with loops containing cyclic dependences early on in the loop nest, we can potentially vectorize more loops
• Goal in Chapter 5: To explore other transformations to exploit parallelism

Optimizing Compilers for Modern Architectures
Motivational ExampleDO J = 1, M DO I = 1, N T = 0.0 DO K = 1,L T = T + A(I,K) * B(K,J) ENDDO C(I,J) = T ENDDOENDDO
codegen will not uncover any vector operations. However, by scalar expansion, we can get:
DO J = 1, M
DO I = 1, N
T$(I) = 0.0
DO K = 1,L
T$(I) = T$(I) + A(I,K) * B(K,J)
ENDDO
C(I,J) = T$(I)
ENDDO
ENDDO

Optimizing Compilers for Modern Architectures
Motivational Example
DO J = 1, M
DO I = 1, N
T$(I) = 0.0
DO K = 1,L
T$(I) = T$(I) + A(I,K) * B(K,J)
ENDDO
C(I,J) = T$(I)
ENDDO
ENDDO

Optimizing Compilers for Modern Architectures
Motivational Example II
• Loop Distribution gives us:DO J = 1, M
DO I = 1, N
T$(I) = 0.0
ENDDO
DO I = 1, N
DO K = 1,L
T$(I) = T$(I) + A(I,K) * B(K,J)
ENDDO
ENDDO
DO I = 1, N
C(I,J) = T$(I)
ENDDO
ENDDO

Optimizing Compilers for Modern Architectures
Motivational Example III
Finally, interchanging I and K loops, we get:DO J = 1, M
T$(1:N) = 0.0
DO K = 1,L
T$(1:N) = T$(1:N) + A(1:N,K) * B(K,J)
ENDDO
C(1:N,J) = T$(1:N)
ENDDO
• A couple of new transformations used:—Loop interchange—Scalar Expansion

Optimizing Compilers for Modern Architectures
Loop Interchange DO I = 1, N
DO J = 1, M
S A(I,J+1) = A(I,J) + B • DV: (=, <)
ENDDO
ENDDO
• Applying loop interchange: DO J = 1, M
DO I = 1, N
S A(I,J+1) = A(I,J) + B • DV: (<, =)
ENDDO
ENDDO
• leads to: DO J = 1, M
S A(1:N,J+1) = A(1:N,J) + B
ENDDO

Optimizing Compilers for Modern Architectures
Loop Interchange
• Loop interchange is a reordering transformation
• Why?—Think of statements being parameterized with the
corresponding iteration vector—Loop interchange merely changes the execution order of
these statements.— It does not create new instances, or delete existing
instances
DO J = 1, M
DO I = 1, N
S <some statement>
ENDDO
ENDDO
• If interchanged, S(2, 1) will execute before S(1, 2)

Optimizing Compilers for Modern Architectures
Loop Interchange: Safety
• Safety: not all loop interchanges are safe
DO J = 1, M
DO I = 1, N
A(I,J+1) = A(I+1,J) + B
ENDDO
ENDDO
• Direction vector (<, >)
• If we interchange loops, we violate the dependence

Optimizing Compilers for Modern Architectures
Loop Interchange: Safety
• A dependence is interchange-preventing with respect to a given pair of loops if interchanging those loops would reorder the endpoints of the dependence.

Optimizing Compilers for Modern Architectures
Loop Interchange: Safety
• A dependence is interchange-sensitive if it is carried by the same loop after interchange. That is, an interchange-sensitive dependence moves with its original carrier loop to the new level.
• Example: Interchange-Sensitive?
• Example: Interchange-Insensitive?

Optimizing Compilers for Modern Architectures
Loop Interchange: Safety
• Theorem 5.1 Let D(i,j) be a direction vector for a dependence in a perfect nest of n loops. Then the direction vector for the same dependence after a permutation of the loops in the nest is determined by applying the same permutation to the elements of D(i,j).
• The direction matrix for a nest of loops is a matrix in which each row is a direction vector for some dependence between statements contained in the nest and every such direction vector is represented by a row.

Optimizing Compilers for Modern Architectures
Loop Interchange: Safety
DO I = 1, N DO J = 1, M
DO K = 1, L
A(I+1,J+1,K) = A(I,J,K) + A(I,J+1,K+1)
ENDDO
ENDDO
ENDDO
• The direction matrix for the loop nest is:
< < =
< = >
• Theorem 5.2 A permutation of the loops in a perfect nest is legal if and only if the direction matrix, after the same permutation is applied to its columns, has no ">" direction as the leftmost non-"=" direction in any row.
• Follows from Theorem 5.1 and Theorem 2.3

Optimizing Compilers for Modern Architectures
Loop Interchange: Profitability
• Profitability depends on architecture
DO I = 1, N DO J = 1, M
DO K = 1, L
S A(I+1,J+1,K) = A(I,J,K) + B
ENDDO
ENDDO
ENDDO
• For SIMD machines with large number of FU’s:
DO I = 1, NS A(I+1,2:M+1,1:L) = A(I,1:M,1:L) + B
ENDDO
• Not suitable for vector register machines

Optimizing Compilers for Modern Architectures
Loop Interchange: Profitability
• For Vector machines, we want to vectorize loops with stride-one memory access
• Since Fortran stores in column-major order:—useful to vectorize the I-loop
• Thus, transform to:
DO J = 1, M DO K = 1, L
S A(2:N+1,J+1,K) = A(1:N,J,K) + B
ENDDO
ENDDO

Optimizing Compilers for Modern Architectures
Loop Interchange: Profitability
• MIMD machines with vector execution units: want to cut down synchronization costs
• Hence, shift K-loop to outermost level:
PARALLEL DO K = 1, L DO J = 1, M
A(2:N+1,J+1,K) = A(1:N,J,K) + B
ENDDO
END PARALLEL DO

Optimizing Compilers for Modern Architectures
Scalar Expansion DO I = 1, NS1 T = A(I)
S2 A(I) = B(I)
S3 B(I) = T ENDDO
• Scalar Expansion: DO I = 1, N
S1 T$(I) = A(I)
S2 A(I) = B(I)
S3 B(I) = T$(I) ENDDO T = T$(N)
• leads to:S1 T$(1:N) = A(1:N)
S2 A(1:N) = B(1:N)
S3 B(1:N) = T$(1:N)
T = T$(N)
Optimizing Compilers for Modern Architectures
Scalar Expansion
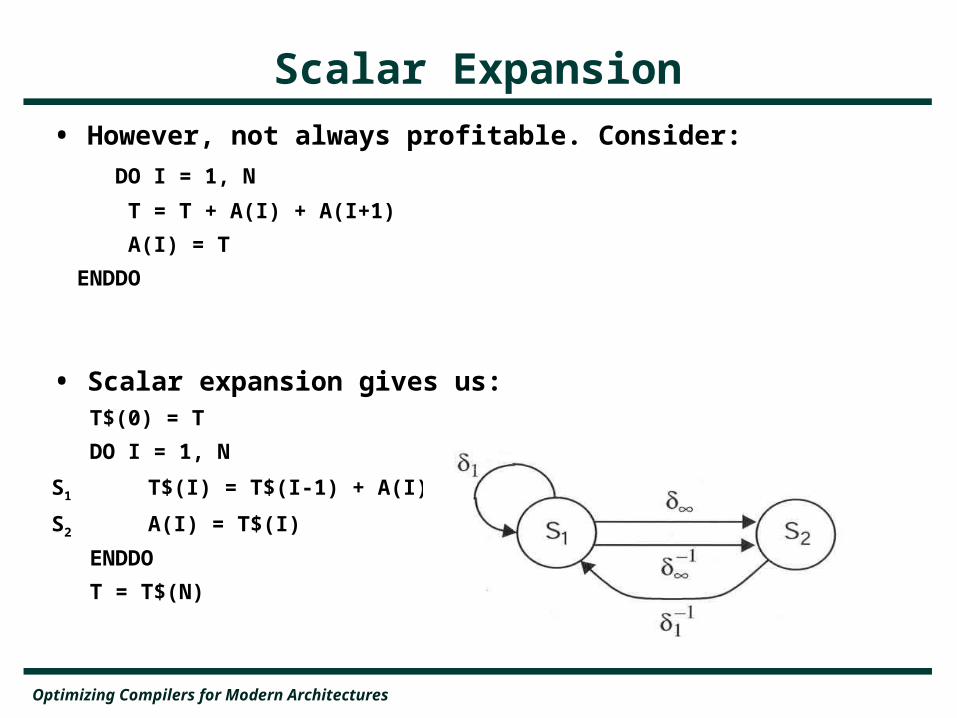
• However, not always profitable. Consider:
DO I = 1, N T = T + A(I) + A(I+1)
A(I) = T
ENDDO
• Scalar expansion gives us: T$(0) = T
DO I = 1, N
S1 T$(I) = T$(I-1) + A(I) + A(I+1)
S2 A(I) = T$(I)
ENDDO
T = T$(N)

Optimizing Compilers for Modern Architectures
Scalar Expansion: Safety
• Scalar expansion is always safe
• When is it profitable? —Naïve approach: Expand all scalars, vectorize, shrink all
unnecessary expansions.—However, we want to predict when expansion is profitable
• Dependences due to reuse of memory location vs. reuse of values—Dependences due to reuse of values must be preserved—Dependences due to reuse of memory location can be
deleted by expansion

Optimizing Compilers for Modern Architectures
Scalar Expansion: Drawbacks
• Expansion increases memory requirements
• Solutions:—Expand in a single loop—Strip mine loop before expansion—Forward substitution:
DO I = 1, N T = A(I) + A(I+1)
A(I) = T + B(I)
ENDDO
DO I = 1, N
A(I) = A(I) + A(I+1) + B(I)
ENDDO

Optimizing Compilers for Modern Architectures
Scalar Renaming DO I = 1, 100S1 T = A(I) + B(I)
S2 C(I) = T + T
S3 T = D(I) - B(I)
S4 A(I+1) = T * T
ENDDO
• Renaming scalar T:DO I = 1, 100
S1 T1 = A(I) + B(I)
S2 C(I) = T1 + T1
S3 T2 = D(I) - B(I)
S4 A(I+1) = T2 * T2
ENDDO

Optimizing Compilers for Modern Architectures
Scalar Renaming
• will lead to:S3 T2$(1:100) = D(1:100) - B(1:100)
S4 A(2:101) = T2$(1:100) * T2$(1:100)
S1 T1$(1:100) = A(1:100) + B(1:100)
S2 C(1:100) = T1$(1:100) + T1$(1:100)
T = T2$(100)

Optimizing Compilers for Modern Architectures
Node Splitting
• Sometimes Renaming fails
DO I = 1, N
S1: A(I) = X(I+1) + X(I)
S2: X(I+1) = B(I) + 32
ENDDO
• Recurrence kept intact by renaming algorithm

Optimizing Compilers for Modern Architectures
Node Splitting
DO I = 1, N
S1: A(I) = X(I+1) + X(I)
S2: X(I+1) = B(I) + 32
ENDDO
• Break critical antidependence
• Make copy of node from which antidependence emanates
DO I = 1, N
S1’:X$(I) = X(I+1)
S1: A(I) = X$(I) + X(I)
S2: X(I+1) = B(I) + 32
ENDDO
• Recurrence broken
• Vectorized toX$(1:N) = X(2:N+1)
X(2:N+1) = B(1:N) + 32
A(1:N) = X$(1:N) + X(1:N)

Optimizing Compilers for Modern Architectures
Node Splitting
• Determining minimal set of critical antidependences is in NP-C
• Perfect job of Node Splitting difficult
• Heuristic:—Select antidependences—Delete it to see if acyclic—If acyclic, apply Node Splitting