enhancing gpu for scientific computing some thoughts
TRANSCRIPT

Enhancing GPU for Scientific Computing
Some thoughts

Outline
Motivation Related work BLAS Library Execution Model Benchmarks Recommendations

Motivation
GPU Computing• Vector and Fragment Processor
streaming (super)-computers
• enormous performance!
• ATI 9700, NV30
They have become programmable Emerging application areas
• Numerical Sim.[Schroder’03], Sorting, Genomics, etc.
• Goal: Scientific Computing

Motivation
Most software built from small-efficient parts
Scientific apps built on top of s/w library routines
Harnessing GPU resources • Arithmetic Intensive
• Data parallel
BLAS Library

Related work
Using non-programmable GPUs [Erik’01] prog. vertex engine for lighting/morphing [Oskin’02] vector processing using VP [Ian’03] stream processing using FP Problems :
• Monolithic Big Programs
• One of VP or FP
• CPU – Passive Mode
• No Cascading Loop-backs (Parallelism, Setup Times)

BLAS Library
BLAS (Basic Linear Algebra Subprograms)• Building blocks for vector and matrix operations
• development of highly efficient linear algebra software • LINPACK and LAPACK
Operations• Scalar – Vector
• Vector – Vector
• Vector – Matrix
• Matrix – Matrix

Mapping
Operation processor
CPU/FP - All ops
VP - no memory access
Restricted data-flows• CPU FP
• VP CPU
CPU
VP
FP
Non-matrix ops
All operations
All operations
CPU VP FP CPU

Execution graphExecution graph
Vector Scalar Add Operation
1. In this example, a Vector of length n is segmented into m other vectors of length 4 in the CPU function vsAdd.
2. The vertex program vsAdd.cg is loaded onto the vertex processor and the scalar value is passed as a parameter.
3. Subsequently, CPU function vsAdd will stream the set of m vectors onto the CPU as openGL primitive points. Our vertex program, vsAdd.cg will add the scalar value to all fields in the m vertices.
4. Consequently, these vertices will proceed to the fragment processor and written onto the framebuffer memory.
5. The CPU function vsADD continues to read the color values off each pixel representation of the vertices. These color values contain result of a Vector Scalar add.
6. Lastly the CPU function concatenates the sequence of color values into a vector of length n as result.
vAddCPU
[vAdd.cg]Vertex Processor
vAddCPU
(Vectors, Vectors)
(Vectors)
[Vertex]m (GL_POINTS)
[Texture Color values]m
[None]Fragment Processor
[Vertex]m
G
P
U
Texture Mem PBuffer
vAdd.cg
TextureDatam

vAddCPU
[None]Vertex Processor
vAddCPU
GL_QUAD [Vector4]m
(Vectors)
[Vertex4]m GL_QUAD
[Texture Color values]m
[vAdd.cg]Fragment Processor
[Vertex4]m
Execution graphExecution graph
Vector Vector Add Operation1. In this example, 2 vectors of length s are
transformed into texture data in the CPU function vAdd.
2. The vertex program vAdd.cg, and texture data are loaded onto the fragment processor GPU memory respectively.
3. Subsequently, CPU function vAdd will draw a quadrilateral primitive having s pixels.
4. The vertex processor does nothing and passes on the vertices to the rasterizer to process into pixel representation.
5. The rasterizer creates the s pixels for fragment processing.
6. For each pixel, our fragment processor will lookup the values from both textures and determine the color value of each pixel. These pixels are written onto the Pbuffer memory.
7. The CPU function vADD continues to read the color values off each pixel representation of the vertices. These color values contain result of a Vector Vector add.
8. The output in Pbuffer is then converted into a texture entry.
9. Lastly the CPU function reads the texture entry and concatenates the sequence of color values into a vector of length s as result.
G
P
UTextureData1m
TextureData2mTexture Mem PBuffer
vAdd.cg
TextureData3m
vAddCPU
[None]Vertex Processor
vAddCPU
(Vectors)
[Vertex4]m
[Texture Color values]m
[vAdd.cg]Fragment Processor
[Vertex4]m
G
P
U
TextureData4m
Texture Mem PBuffer
TextureData3m
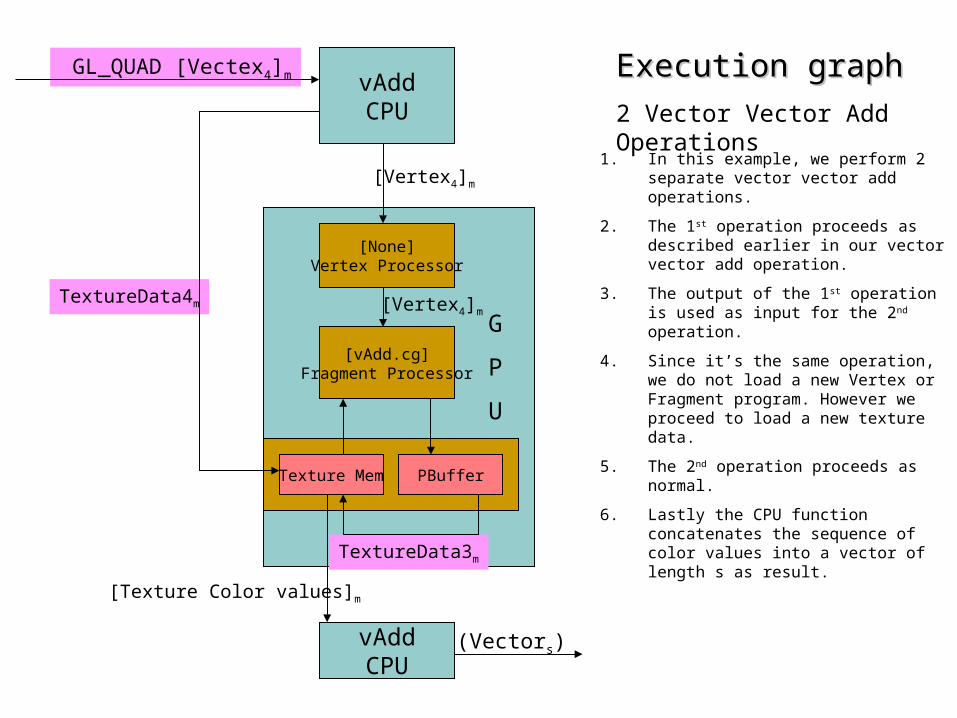
Execution graphExecution graph
2 Vector Vector Add Operations
1. In this example, we perform 2 separate vector vector add operations.
2. The 1st operation proceeds as described earlier in our vector vector add operation.
3. The output of the 1st operation is used as input for the 2nd operation.
4. Since it’s the same operation, we do not load a new Vertex or Fragment program. However we proceed to load a new texture data.
5. The 2nd operation proceeds as normal.
6. Lastly the CPU function concatenates the sequence of color values into a vector of length s as result.
GL_QUAD [Vectex4]m

Performance Issues
Representation inefficiency• Memory
• Data stored both in CPU and GPU
• Communication costs• Loading data onto GPU
• Reading data from GPU
Execution inefficiencies• Computation setup overhead
• Remodeling CPU data for GPU
• Problem execution time• Rendering
• Texture lookups

0%
20%
40%
60%
80%
100%
1 2 4 8 16 32
Operation breakdown
Fixed-Point processing
Readback
Compute
Setup
Load

Fixed-Point (Vector-Vector Add)
0
2000
4000
6000
8000
10000
12000
14000
16000
1 2 4 8 16 32
Number of Operations
Tim
e in
Mill
isec
onds
Resident Non-Resident

0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
1 2 4 8 16 32
Operation Breakdown FP32 processing
Readback
Compute
Setup
Load
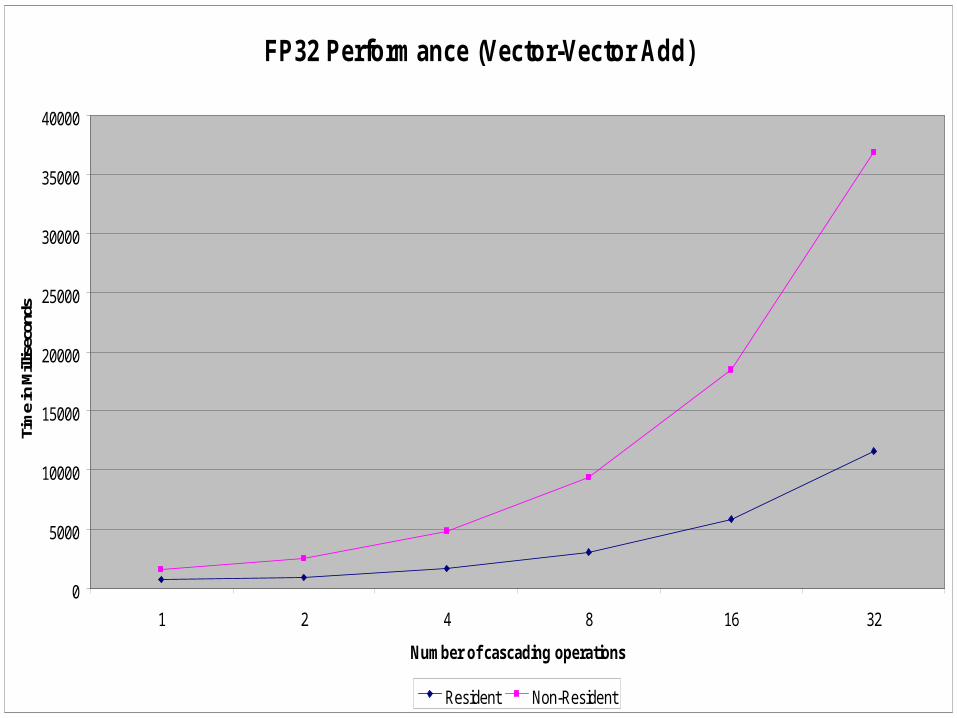
FP32 Performance (Vector-Vector Add)
0
5000
10000
15000
20000
25000
30000
35000
40000
1 2 4 8 16 32
Number of cascading operations
Tim
e in
Mill
isec
onds
Resident Non-Resident

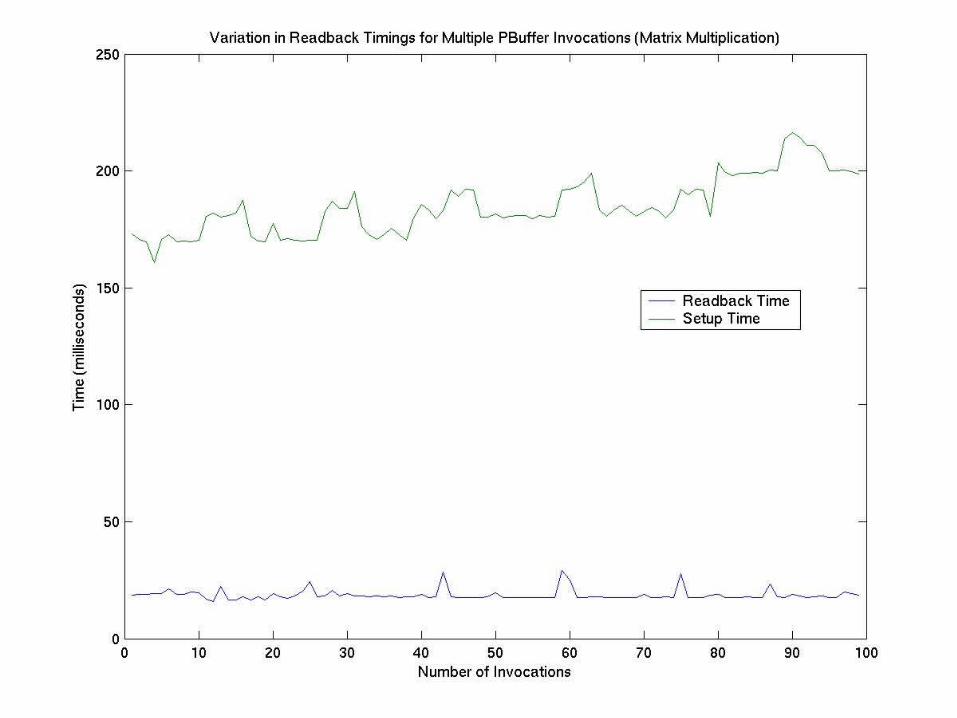


Observations
Fixed-point operations are much faster than FP16/FP32 operations
FP16/FP32 operations have similar performance
VP is slower than FP• Operation mappings involving both VP and
FP result in inefficient pipeline

Observations
Simple operations perform better on CPU Best to design whole algorithm as single
VP/FP program• Memory cost for storing intermediate results
• Execution cost ?
• More textures result in decreased performance

Bug Reports Filed!
Incorrect dump of floating point values after render to texture [NVIDIA confirmed]
cgSetcolor parameter does not update alpha values [Awaiting reply]

Recommendations (3D Graphics Hackers)
Load important data into Video memory
Maximum use of Fixed-point Pipeline
Code optimization important (Instr., Memory)
Upgrade your video card drivers (must!)• Hacking graphics hardware is a *real* pain!

Recommendations (Cg) Pointer meaningful for numerical computing
Texture fetch instructions (add. Offsets)
Accumulation registers (sum)
Preserving State across multiple calls
Introduce stack mechanisms
Introduce bit wise operators

Recommendations (Hardware)
Allow GPU to read/write from CPU memory VP and FP as 1st class processors on GPU
• Similar cores and instruction sets
• Allow full parallelism Allow CPU to read/write all registers in GPU
processors Introduce a stack Introduce bit wise operators

Deliverables!
A draft subset of the BLAS library
Architecture Insights (issues/constraints)
NV30 Improvements (Bug reports)
Technical Write-up

The End