examinations: amee guide no. 85 how to set standards on
TRANSCRIPT

Full Terms & Conditions of access and use can be found athttp://www.tandfonline.com/action/journalInformation?journalCode=imte20
Download by: [Sistema Integrado de Bibliotecas USP] Date: 27 March 2016, At: 18:55
Medical Teacher
ISSN: 0142-159X (Print) 1466-187X (Online) Journal homepage: http://www.tandfonline.com/loi/imte20
How to set standards on performance-basedexaminations: AMEE Guide No. 85
Danette W. McKinley & John J. Norcini
To cite this article: Danette W. McKinley & John J. Norcini (2014) How to set standards onperformance-based examinations: AMEE Guide No. 85, Medical Teacher, 36:2, 97-110, DOI:10.3109/0142159X.2013.853119
To link to this article: http://dx.doi.org/10.3109/0142159X.2013.853119
Published online: 20 Nov 2013.
Submit your article to this journal
Article views: 1670
View related articles
View Crossmark data
Citing articles: 2 View citing articles

2014
2014; 36: 97–110
AMEE GUIDE
How to set standards on performance-basedexaminations: AMEE Guide No. 85
DANETTE W. MCKINLEY & JOHN J. NORCINI
FAIMER, Research and Data Resources, USA
Abstract
This AMEE Guide offers an overview of methods used in determining passing scores for performance-based assessments. A
consideration of various assessment purposes will provide context for discussion of standard setting methods, followed by a
description of different types of standards that are typically set in health professions education. A step-by-step guide to the
standard setting process will be presented. The Guide includes detailed explanations and examples of standard setting methods,
and each section presents examples of research done using the method with performance-based assessments in health professions
education. It is intended for use by those who are responsible for determining passing scores on tests and need a resource
explaining methods for setting passing scores. The Guide contains a discussion of reasons for assessment, defines standards, and
presents standard setting methods that have been researched with performance-based tests. The first section of the Guide
addresses types of standards that are set. The next section provides guidance on preparing for a standard setting study. The
following sections include conducting the meeting, selecting a method, implementing the passing score, and maintaining the
standard. The Guide will support efforts to determine passing scores that are based on research, matched to the assessment
purpose, and reproducible.
Introduction
Standard setting is the process of defining or judging the level
of knowledge and skill required to meet a typical level of
performance and then identifying a score on the examination
score scale that corresponds to that performance standard.
Standard setting procedures are employed to provide a
conceptual definition of competence for an occupation or
educational domain and to operationalise the concept. When
considering the conceptual definition of competence, it is
helpful to think about the criteria developed in competency-
based medical education. The descriptive information pro-
vided in the development of milestones or benchmarks
(Holmboe et al. 2010) can be helpful in defining the
performance standard. The standard setting process is
designed to translate a conceptual definition of competence
to an operational version, called the passing score (Kane 1994;
Norcini 1994). Verification that the passing score is appropriate
is another critical element in collecting evidence to support the
validity of test score interpretation (American Educational
Research Association et al. 1999; Kane 2006). Various
approaches to determining passing scores for examinations
have been developed and researched. In this Guide, an
overview to the methods that have been typically used with
performance-based assessments will be provided. A consider-
ation of various assessment purposes will provide context for
discussion of standard setting methods, followed by a
description of different types of standards that are typically
set in health professions education. A step-by-step guide to the
standard setting process will be presented.
Assessment purposes
In education, it is often necessary to evaluate whether trainees
are attaining the knowledge, skills, and attitudes needed to
perform in the field of endeavour. In order to determine
whether ‘‘sufficient knowledge, skills and attitudes’’ are
Practice points
. Although there is extensive research on standard setting
with both multiple-choice and performance-based tests,
there is no ‘‘right’’ passing score, and no ‘‘best’’ method
. Different methods yield different results
. Pre-fixed passing scores set without consideration of test
content or examinee performance can vary greatly due
to test difficulty and content, affecting the appropriate-
ness of the decisions made
. Selecting a method depends on the purpose of the
examination and the resources available for the standard
setting effort
. The passing score should be determined by a group
(e.g. faculty members) familiar with the assessment
purpose and the domain assessed
. The standard setting method selected should: be closely
aligned with assessment goals; be easy to explain and
implement; require judgments that are based on per-
formance data; entail thoughtful effort; and be based on
research
Correspondence: Danette W. McKinley, PhD, Foundation for the Advancement of International Medical Education and Research, 3624 Market
Street, 4th Floor, Philadelphia, PA 19104, USA. Tel: 1 215 823 2231; fax: 1 215 386 3309; email: [email protected]
ISSN 0142–159X print/ISSN 1466–187X online/14/020097–14 � 2014 Informa UK Ltd. 97DOI: 10.3109/0142159X.2013.853119
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

present, different methods are typically employed as part of a
programme of assessment (Dijkstra et al. 2010). In health
professions education, there are many approaches to assessing
the knowledge, skills, attitudes and abilities of applicants,
students, graduates, and practitioners. For some time, health
professions educators used any available assessment method
to evaluate the competencies of a doctor, even if they were not
appropriate (Norcini & McKinley 2007). For example, although
it is important for a doctor to be able to communicate
effectively with the healthcare team, assessment of this aspect
is not appropriately tested through the use of written exam-
inations. Several methods of assessment have been developed
and implemented, with a movement towards assessment
based on performance that is tied to what is expected in
practice. In the education of health professionals, standardised
patients (SPs), lay people trained to portray complaints of
‘‘real’’ patients, are frequently used (e.g. Patil et al. 2003). This
type of assessment provides examinees the opportunity to
show what they can do (e.g. correctly perform a physical
examination, communicate with a patient), rather than what
they know (Miller 1990).
In developing methods that assess what examinees do,
other methods, or even combinations of modalities, have also
been used (Nestel et al. 2006). In many healthcare professions,
the use of various workplace-based assessments, including
chart reviews and 360 degree evaluations, have been instituted
(Norcini & Burch 2007). These assessments are usually
employed as quality improvement measures, and involve
peer review, evaluation of practice outcomes, and patient or
client satisfaction measures (Norcini 2003).
The varieties of instruments that are available have been
developed, at least in part, to meet different assessment goals.
Assessment goals may include determining who is eligible to
enter medical school (e.g. admissions testing); whether course
requirements are satisfied (e.g. classroom testing); if a student
is ready to advance to the next level of training (e.g. end-of-
year testing); whether the examinee is ready to enter a
profession (e.g. licensure and certification testing); or whether
the examinee has shown evidence of expertise (e.g. mainten-
ance of certification). The assumption is usually made that
scores obtained from assessments provide an indication of a
student’s ability to ‘‘use the appropriate knowledge, skills, and
judgment to provide effective professional services over the
domain of encounters defining the area of practice’’ (Kane
1992, p. 167). Scores are often used to make decisions (or
interpretations) regarding whether students (or graduates)
have sufficiently acquired the knowledge and skills to enter, or
continue practice in, a profession. In this manner, test scores
are used to classify people into two or more groups (e.g.
passing or failing an examination). Test scores can be used to
make decisions about who needs additional educational help,
whether the test-taker will go on to the next level of training, or
whether the test-taker has achieved mastery in the domain of
interest.
Kane (1992) defined competence as the extent to which the
individual can handle the various situations that arise in that
area of practice (p. 165). In education, licensure, and
certification, assessments are used to determine the profi-
ciency of candidates. For example, when performance
measures such as the objective structured clinical examination
(OSCE) are developed, principles associated with domain-
based assessment, including definition of characteristics
denoting adequate performance, can be employed (Pell
et al. 2010). Whether the test consists of multiple-choice
items or task performance, it is important to consider whether
the goal is to compare an individual with others taking the
same assessment, or to determine the level of proficiency. In
the next section of the Guide, we discuss types of standards
related to these different purposes.
Types of standards
Standards can be categorised as relative (sometimes called
norm-referenced) or absolute (sometimes called criterion-
referenced) (Livingston & Zieky 1982). Standards that are
established based on a comparison of those who take the
assessment to each other are relative standards. For example,
when the passing score is set based on the number or
percentage of examinees that will pass, the standard is relative.
This type of standard setting is typically used in selection for
employment or admission to educational programmes where
the positions available are limited. With high stakes examin-
ations (e.g. graduation, certification, licensure), relative stand-
ards are not typically used, because the ability of the groups of
test takers could vary over time and the content of the
assessment may also vary over time. When pre-determined
passing scores are used with educational (classroom) tests, the
ability of the students in the class and the difficulty of the test
given are not considered (Cohen-Schotanus & van der Vleuten
2010). Examinee ability and test difficulty are factors that could
adversely affect evidence of the appropriateness of the passing
score. To avoid the disadvantages associated with the relative
standard setting method, absolute standard setting approaches
are more commonly used in credentialing examinations (i.e.
licensure or certification).
Standards set by determining the amount of test material
that must be answered (or performed) correctly in order to
pass are absolute standards. For example, if the examinee must
answer 75% of the items on a multiple-choice test correctly in
order to pass, the standard is absolute. When absolute
standards are used, it is possible that decisions made will
result in all examinees passing or failing the examination.
Standard setting and performance-based assessments
Several standard setting methods have been used with
performance-based assessments. Because relative standards
are set based on the desired result (e.g. admitting the top 75
candidates to a school) and are, therefore, determined more
easily, this Guide will focus on absolute standard setting
methods (See Table 1 for comparisons). These methods
involve review of examination materials or examinee per-
formance, and the resulting passing scores can be derived
from the judgments of a group of subject matter experts.
Absolute standard setting approaches have been referred to as
either test-centred or examinee-centred (Livingston & Zieky
1982). When using test-centred methods, the judges focus on
D. W. McKinley & J. J. Norcini
98
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

exam content. The Angoff (1971), Ebel (1972), and Nedelsky
(1954) methods are examples of test-centred standard setting
methods. In contrast, when using examinee-centred methods,
judges focus on the performance of examinees. These
methods include contrasting groups, borderline group, and
borderline regression methods (Livingston & Zieky 1982;
Wood et al. 2006). The judges’ task in examinee-centred
methods is to determine whether the performance they review
depicts someone possessing the knowledge and skills needed
to meet the standard (e.g. are minimally competent).
Aspects of test-centred and examinee-centred approaches,
related to examinations containing multiple choice questions
(MCQs), were presented in a previous AMEE guide
(Bandaranayake 2008), and the application of some of these
approaches to the OSCE are presented here. Specifically, we
will provide guidance for the use of the Angoff, borderline
group, borderline regression, contrasting group, and com-
promise methods of standard setting using simulated OSCE
data. The remainder of the Guide is divided into four sections:
preparing for the standard setting study, conducting the
standard setting study, generating the passing score, and
implementing and maintaining standards.
Preparing for the standard settingstudy
Determining the passing score is typically accomplished by a
group familiar with the assessment purpose and the domain
assessed. Before this group meets, there are a number of steps
that should be completed. First, panellists need to be recruited.
To increase objectivity and to derive plausible passing scores,
panellists should be knowledgeable about the examination
content area and the purpose of the test (Jaeger 1991;
Raymond & Reid 2001). In addition, they should be familiar
with the qualifications of the students being tested. Finally,
experience with the assessment method is essential. Panellists
who make judgments about clinical proficiency should be
experts in the profession and should have familiarity with
expectations of trainees at various stages of education,
because they will readily understand the consequences
associated with passing the test. Because OSCEs are often
used to test clinical and communication skills, faculty members
who have participated in the OSCE as examiners or those who
have assisted in the development of materials used in the
administration (e.g. checklists) would be ideal for recruiting as
panellists in the standard setting meeting. To set standards for
communication skills of physicians, for example, other mem-
bers of the health care team could be considered (e.g. nursing
staff, standardised patient trainers) as judges. Because they are
familiar with the expected performance of physicians in
clinical settings, they would also be appropriate participants
in the standard setting process. A suitable mix of panellists
based on gender, discipline (e.g. paediatrics, general medi-
cine), and professional activity (e.g. faculty vs. practicing
physician) should be considered. This is particularly important
when the passing score identifies those candidates who will
enter a profession (e.g. licensure). The more panellists there
are, the more likely it is that the resulting passing score will be
Table 1. Features of standard setting methods.
Standard setting method Purpose Description Comments
Relative or norm-referenced Ranking examinees � Standard reflects group performance.
� Passing score is set based on test results (i.e.
percent passing).
Useful when a predetermined number (or per-
centage) of examinees should pass the
examination, e.g. admissions testing,
employment testing.
Passing score may fluctuate due to examinee
ability or test difficulty.
Pass rate (number or percentage passing) is
stable.
Absolute or
criterion-referenced
Determining mastery � Standard reflects a conceptual definition of
mastery, proficiency, or competence.
� Passing score is set independent of test
results.
Useful when determining whether examinees
meet requirements defined by the standard.
All examinees could pass or fail using this type
of standard.
Test-centred � Standard is translated to a passing score
based on review of test materials (e.g.
multiple-choice questions, cases, tasks).
� Standard is defined, and judges focus on
exam content.
Examinee-centred � Standard is translated to a passing score
based on the review of examinees’ per-
formance on tasks.
� Judges determine whether the performance
they review depicts someone possessing the
knowledge and skills needed to meet the
standard.
Compromise � Judges consider both the passing score and
the passing (or failing) rate.
� Judges give an opinion about what consti-
tutes an ‘‘acceptable’’ cut score and pas-
sing rate.
Can be a useful alternative when resources are
limited.
The approach assumes that a passing score
has been determined and test results are
available.
Useful when a balance between absolute and
relative methods is needed.
Standard setting on performance-based exams
99
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

stable (Jaeger 1991; Ben-David 2000). However, consideration
of management of a large group is also important. The number
of panellists needed should be balanced by a number of
factors: the consequences associated with examination deci-
sions, the number of performances to review a reasonable time
frame for completion of the standard setting meeting, and the
resources available for the meeting. Successful standard setting
meetings can be conducted with as few as four panellists or as
many as 20. Having a large group will provide the meeting
facilitator with the opportunity to assign panellists to smaller
groups so that more material can be covered. The deciding
factor will be resources (e.g. space, number of facilitators)
available for the meeting.
The next step in organising the meeting is preparing
materials to be used in training the panellists. Panellist training
is very important; developing a clear understanding of the
performance standard (e.g. student in need of remediation,
graduate ready for supervised practice, practitioner ready for
unsupervised practice) is essential (Ben-David 2000;
Bandaranayake 2008). To promote understanding of the
performance standard, criteria that are typically part of a
competency-based curriculum can be very useful. This type of
information can assist in the delineation of the knowledge,
skills, and abilities that comprise the performance standard in a
particular context, and at a particular stage in a health
professional’s career (Frank et al. 2010).
To support training, examination materials may be used as
part of the orientation. For example, as part of the orientation
to standard setting for an OSCE, panellists could complete
some of the stations as examinees. This allows them to
experience the examination from the perspective of the
examinee. Next, a discussion of the characteristics defining
with the performance standard would be conducted. Finally,
the panellists would be afforded the opportunity to practice
the method selected.
In the next section of the Guide, we present methods that
can be used to set passing scores for performance assessments,
using the OSCE as an example. These methods are commonly
used to derive passing scores for OSCE and standardised
patient examinations (Norcini et al. 1993; Boulet et al. 2003;
Downing et al. 2006). In each section, research regarding the
method as used with OSCEs or standardised patient examin-
ations is cited. In order to provide detailed guidelines for
deriving passing scores for an OSCE, we generated data for an
end-of-year examination for 50 students, using five OSCE
stations. Data for a multiple-choice examination consisting of
50 items was also generated. This simulated data set will be
used to illustrate a number of methods that can be used to
develop passing scores for an OSCE examination.
Conducting the standard settingmeeting: modified Angoff
Checklist items
Several studies have been conducted where the modified
Angoff was used to set standards for each item in a checklist
(e.g. Downing et al. 2003, 2006). For this process, it is
necessary to prepare case materials for all panellists, including
checklists and a form for providing ratings. The meeting
facilitator will need a way to display the ratings (flip chart,
projector) and should prepare forms for data entry and, if
possible, set up spreadsheets for each case checklist. This will
permit simple analyses of the data, calculating averages for
items, judges, and cases. In these studies, panellists review the
items on the checklist, and the task is to estimate the
percentage of examinees meeting the performance standard
(e.g. minimally competent) who will correctly perform the
action described in the OSCE checklist.
Table 2 shows a sample checklist for a case of a fall in an
elderly patient. Following a discussion of the performance
standard, and presentation of case materials, it is recom-
mended that the panellists review the first five checklist items
as a group. In the example, there is a large difference between
the ratings of raters 10 and 13 on item 3. Discussion of
discrepancies of 15% or more would be facilitated, with the
goal of reaching consensus on the definition and the rating
task. If there are items with discrepancies of 15% or more, they
should be reviewed after the meeting to determine if there is a
Table 2. Modified Angoff: checklist items.
Item Text Rater 10 Rater 11 Rater 12 Rater 13 Rater 14 Average
1 Describe the fall in more detail OR Tell me what happened. 65 80 65 80 75 73
2 Hit head when you fell? 75 70 60 65 70 68
3 Loss of consciousness? 65 72 75 85 68 73
4 Felt faint OR lightheaded OR dizzy recently or just before the fall? 70 80 85 80 55 74
5 Since fall, any new symptoms other than hip pain, OR double vision
OR speech problems OR weakness of an arm/hand?
75 65 60 70 45 63
6 Palpitations before fall? 80 55 40 62 60 59
7 What makes pain worse? 65 60 65 57 65 62
8 Other falls? 75 75 55 85 67 71
9 Past medical history? 65 68 75 50 70 66
10 Medications? 70 65 45 55 55 58
11 Checks symmetry of strength in lower extremities
(must include hip flexion on right)
67 68 70 65 65 67
12 Palpates over area(s) of pain and trochanteric area of hip. 65 70 68 75 60 68
13 Observes gait 60 80 65 70 72 69
14 Orientation to time OR assessment of recent memory. 65 75 78 60 70 70
15 Auscultates heart 60 50 50 65 65 58
Passing score for case 67
D. W. McKinley & J. J. Norcini
100
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

content-related problem with the checklist item. This item may
need to be removed from determination of the passing score,
and any discussion the panellists have can be useful in making
that decision. There may be some items where discrepancies
of 15% or more cannot be resolved through discussion, but
there should not be many of these items. After group rating
and discussion, panellists can proceed through the remaining
checklist items independently.
The table used for this example shows the average rating
across all panellists. To derive the passing score for the case,
the average rating across all items and panellists was calculated.
In this example, the passing score would be 67%. If examinees
correctly complete 67% or more of the items on the checklist,
they would achieve a passing score for that case. These are the
steps associated with using the modified Angoff method to
determine the passing score for a single case. This process
would be repeated with all checklists for stations included in
the OSCE administration. Once panellists have completed their
rating process, data entry can begin. Data entry can be
facilitated by using a spreadsheet for each case. Calculating
the mean across items and judges produces a cut score for each
case. Depending on the scoring and reporting of assessment
results, passing scores can be calculated for the OSCE by
averaging case passing scores, or OSCE content domains (e.g.
history taking, physical examination, communication).
Cases
Although the modified Angoff has been used by gathering
judgments at the checklist item level, it is more common to
have panellists make their judgments at the case or station
level. One rationale for this approach is that the items in a
checklist are inter-related; the likelihood of asking a question
or performing a manoeuvre is dependent on asking other
questions or other findings in a physical examination (Ben-
David 2000; Boulet et al. 2003). If the Angoff is conducted at
the case level, the panellists’ task is making an estimation of
the percentage of examinees who will meet the performance
standard based on the content of the case, rather than the
individual items within the checklist for the OSCE station (e.g.
Kaufman et al. 2000). Alternately, the panellists can be asked
to review the checklist items and estimate the percentage of
items for which the examinees meeting the performance
standard (e.g. minimally qualified) will get credit.
Case materials are reviewed by the panellists, and the
preparation for data entry is similar. However, a single
spreadsheet may be used, depending on the number of
cases to be analysed as part of the standard setting process.
Table 3 provides a sample spreadsheet format for the
simulation we mentioned earlier, with five OSCE stations for
an end-of-year test of 50 students. For this example, there are
five judges. Once again, the characteristics of the examinees
meeting the performance standard are discussed, test materials
are presented and reviewed, and panellists begin the rating
task. Practicing the method is essential. Using our example, a
sixth case would be used for practice and discussion amongst
panellists. The ratings from this case would not be used to
generate the passing score. The case scores (in percent correct
metric) for all students are presented in the last column of the
table. If time permits, panellists could provide their ratings and
then be given information on how all students performed on
the stations. They can then change their estimates. Calculating
the mean across judges and stations provides the passing score
for the OSCE.
Conducting the standard setting meeting: borderlinegroup
While both modified Angoff approaches (checklist items and
case level) are commonly used to determine passing scores in
OSCE and standardised patient examinations, panellists may
find the task of estimating the percentage of examinees
meeting the performance standard who will receive credit for
items or who will correctly manage the case challenging
(Boulet et al. 2003). A method that focuses on examinee
performance rather than examination materials that is fre-
quently used with OSCEs is the borderline group method.
The borderline group method requires the identification of the
characteristics (e.g. knowledge, skills, and abilities) of the
‘‘borderline’’ examinee. The ‘‘borderline’’ examinee is one
whose knowledge and skills are not quite adequate, but are
not inadequate (Livingston & Zieky 1982). Assessment mater-
ials (or actual examinee performances) are categorised by
panellists as clear fail, borderline, or clear pass. The passing
score is then set at the median (i.e. 50th percentile) score of the
borderline group (e.g. Rothman & Cohen 1996).
One modification to this method that has been used with
OSCEs is to use the judgments gathered during the OSCE
administration (e.g. see Reznick et al. 1996). In this modifica-
tion, a panel of judges is not used; instead, observers provide
information used to derive the passing score for each station. If
experts (e.g. physicians, faculty members) are used to score
the OSCE stations, they can be asked whether the performance
they have seen would be considered ‘‘borderline.’’ This
approach can save time by gathering examiners’ judgments
while the examination is being administered. Once examiners
Table 3. Modified Angoff: station-level passing score.
Station Rater 10 Rater 11 Rater 12 Rater 13 Rater 14 Rater Average Average Score (All students)
1 45 55 45 60 45 50 59.3
2 65 60 70 55 65 63 74.8
3 65 60 65 50 55 59 73.1
4 70 65 60 55 60 62 71.9
5 65 60 65 55 60 61 70.1
Passing score 59 69.8
Standard setting on performance-based exams
101
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

have identified examinees whose performance is considered
borderline, the passing score can be calculated by finding the
median score of all examinees who were classified as
‘‘borderline.’’
To illustrate this approach, we will use the same data set
used for the modified Angoff approach, which is presented in
Table 4. Fifty students were tested, and examiners provided a
rating indicating whether the observed performance was a
‘‘clear fail,’’ ‘‘borderline,’’ ‘‘clear pass,’’ or ‘‘superior’’ at each
station. Of the 50 students, nine were thought to have
demonstrated ‘‘borderline’’ performance at the OSCE station.
To derive the passing score for the station, the median (i.e.
50th percentile) score was calculated. For this example, the
passing score was identified using spreadsheet software:
MEDIAN (C23,C26,C29,C36,C37,C42,C43,G2,G6); where ‘‘C’’
and ‘‘G’’ indicate the columns where OSCE scores are located
and the numbers indicate the rows for the scores of the
borderline examinees. In this example, the median score is
64%, so examinees with scores of 64% or higher would pass
the station.
A modification of this approach is used by the Medical
Council of Canada (Smee & Blackmore 2001), where a six-
point rating scale is used: inferior, poor, borderline unsatis-
factory, borderline satisfactory, good, and excellent. The mean
station score for those examinees rated borderline unsatisfac-
tory and borderline satisfactory is calculated to derive the
passing score for the station. This Modified Borderline Group
Method works well when there are enough examinees who
were rated ‘‘borderline’’ for the station. However, the stability
of the passing score is dependent on the number of examinees
in the borderline unsatisfactory and borderline satisfactory
categories. If few examinees are rated ‘‘borderline’’, then
calculating the passing score based on the mean of their station
scores are not likely to be stable. That is, the reliability
associated with a cut score derived from two or three scores is
likely to be very low.
To overcome this potential disadvantage, a regression
approach was studied by Wood et al. (2006). Using the entire
range of OSCE scores can be particularly useful if only a small
number of examinees have participated. Because the number
of examinees classified as borderline could be very small, the
resulting passing score could be less precise than if all scores
were used (Wood et al. 2006). In this modification, the
checklist score is the dependent variable; the rating is the
independent variable. The goal of the regression analysis is to
predict the checklist score of the examinees classified as
‘‘borderline’’ for the station.
The borderline regression method is straightforward, and
can be done using a Microsoft Excel worksheet. Details on the
method are provided in Figures 1–5, which depict a series of
seven steps.
Step 1: Prepare a spreadsheet of OSCE scores and examiner
ratings.
Step 2: Click on the tab labelled ‘‘Data,’’ and when the pop-up
window appears, select ‘‘Data Analysis.’’ The analysis
tool you will select is ‘‘Regression.’’
Step 3: Identify the ‘‘Input Y Range’’ – what will be predicted.
In this case, it is the OSCE scores in Column C.
Step 4: Identify the ‘‘Input X Range’’ – what will be used to
predict scores. In this case, the ratings provided by
‘‘Examiner PF1’’ in Column D will be selected.
Step 5: Identify the location for analysis results. In the
example, we gave the spreadsheet the name
‘‘Sheet 3.’’ Click OK in the ‘‘Regression’’ window
(upper right side).
Table 4. Example of individual results for borderline group method.
Date Student number Case 6 score Examiner rating Date Student number Case 6 score Examiner rating
12-Apr-10 15 75 Clear Pass 14-Apr-11 12 64 Borderline
12-Apr-10 20 83 Superior 14-Apr-11 39 50 Clear Fail
12-Apr-10 43 75 Clear Pass 14-Apr-11 28 57 Clear Fail
12-Apr-10 42 100 Superior 14-Apr-11 50 43 Clear Fail
12-Apr-10 13 75 Clear Pass 14-Apr-11 10 64 Borderline
12-Apr-10 38 92 Superior 14-Apr-11 48 71 Clear Pass
12-Apr-10 5 92 Superior 14-Apr-11 30 71 Clear Pass
12-Apr-10 14 83 Superior 14-Apr-11 23 71 Clear Pass
12-Apr-10 29 83 Superior 13-Apr-11 19 89 Superior
10-Apr-11 37 60 Clear Fail 13-Apr-11 8 79 Clear Pass
10-Apr-11 36 40 Clear Fail 14-Apr-11 1 64 Borderline
10-Apr-11 16 50 Clear Fail 14-Apr-11 41 64 Borderline
10-Apr-11 47 60 Clear Fail 13-Apr-11 19 89 Superior
10-Apr-11 24 70 Clear Pass 13-Apr-11 17 58 Clear Fail
10-Apr-11 40 80 Superior 13-Apr-11 6 74 Clear Pass
10-Apr-11 33 70 Clear Pass 13-Apr-11 32 74 Clear Pass
10-Apr-11 35 90 Superior 13-Apr-11 27 95 Superior
10-Apr-11 26 70 Clear Pass 13-Apr-11 11 68 Borderline
10-Apr-11 7 80 Superior 13-Apr-11 3 68 Borderline
11-Apr-11 4 56 Clear Fail 13-Apr-11 34 89 Superior
11-Apr-11 18 75 Clear Pass 13-Apr-11 46 84 Superior
11-Apr-11 21 69 Borderline 11-Apr-11 9 94 Superior
11-Apr-11 2 50 Clear Fail 11-Apr-11 25 69 Borderline
11-Apr-11 31 81 Superior 11-Apr-11 22 75 Clear Pass
11-Apr-11 45 63 Borderline 12-Apr-11 44 92 Superior
11-Apr-11 49 50 Clear Fail
D. W. McKinley & J. J. Norcini
102
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

Figure 1. Spreadsheet of OSCE scores and examiner ratings.
Figure 2. Data analysis ‘‘regression.’’
Standard setting on performance-based exams
103
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

Figure 3. Define variables for analysis.
Figure 4. Location for analysis results.
D. W. McKinley & J. J. Norcini
104
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

Step 6: The output from the regression (‘‘Summary Output’’) is
in ‘‘Sheet 3.’’
Step 7: The formula for deriving the passing score is:
passing score¼ (median of ratings* ‘‘�Variable 1’’)þIntercept.
For this example, the passing score would be
75.4¼ (2� 11.561)þ 52.326
where 2 is the median of the ratings, 11.561 is the
‘‘�Variable 1’’, and 52.326 is the intercept.
The passing score could be adjusted by the standard error
of estimation (labelled ‘‘Standard Error’’ in the Summary
Output), if review leads to the conclusion that the examiner
at a station was particularly harsh (or lenient).
Conducting the standard setting meeting: contrast-ing groups
The Contrasting Groups method requires panellists to review
examinee work and classify the performance as acceptable or
unacceptable (Livingston & Zieky 1982). In education, infor-
mation external to the test is used to classify the examinees in
these categories (Hambleton et al. 2000). When other meas-
ures with similar content are available, two groups of
examinees are identified. Then, scores from the test on
which performance standards are being established are used
to generate distributions (one for each group), and the
distributions are compared to determine their degree of
overlap. This is done by tabulating the percentage of test-
takers in each category and at each score level who are
considered ‘‘competent’’. The passing score is the point at
which about 50% of the test-takers are considered competent.
For examination programmes in health professions education,
it is difficult to find an external measure that assesses the same
skills as those measured in the OSCE. The variation most
Figure 5. Output from regression analysis.
Table 5. Contrasting groups example.
Examiner decision
Score range Fail Pass Total Pass rate (%)
0–49a 3 1 4 92
50–54 3 0 3 86
55–59 5 2 7 72
60–64 2 4 6 60
65–69 0 5 5 50
70–74 0 13 13 44
75–79 0 3 3 38
85–89 0 4 4 32
90–94 0 4 4 24
95–100a 0 1 1 2
a‘‘Smoothed’’ averages cannot be created for the highest and lowest score
ranges.
Standard setting on performance-based exams
105
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6
commonly used in medical education is to have panellists
decide whether the performance they review on the measure
of interest (i.e. the OSCE or standardised patient examination)
meets the characteristics associated with the performance
standard. One example of a variation on this approach derived
the passing score by regressing the number of judges rating the
performance as ‘‘competent’’ to the test scores, and set the
passing score at the point at which 50% of the panellists rated
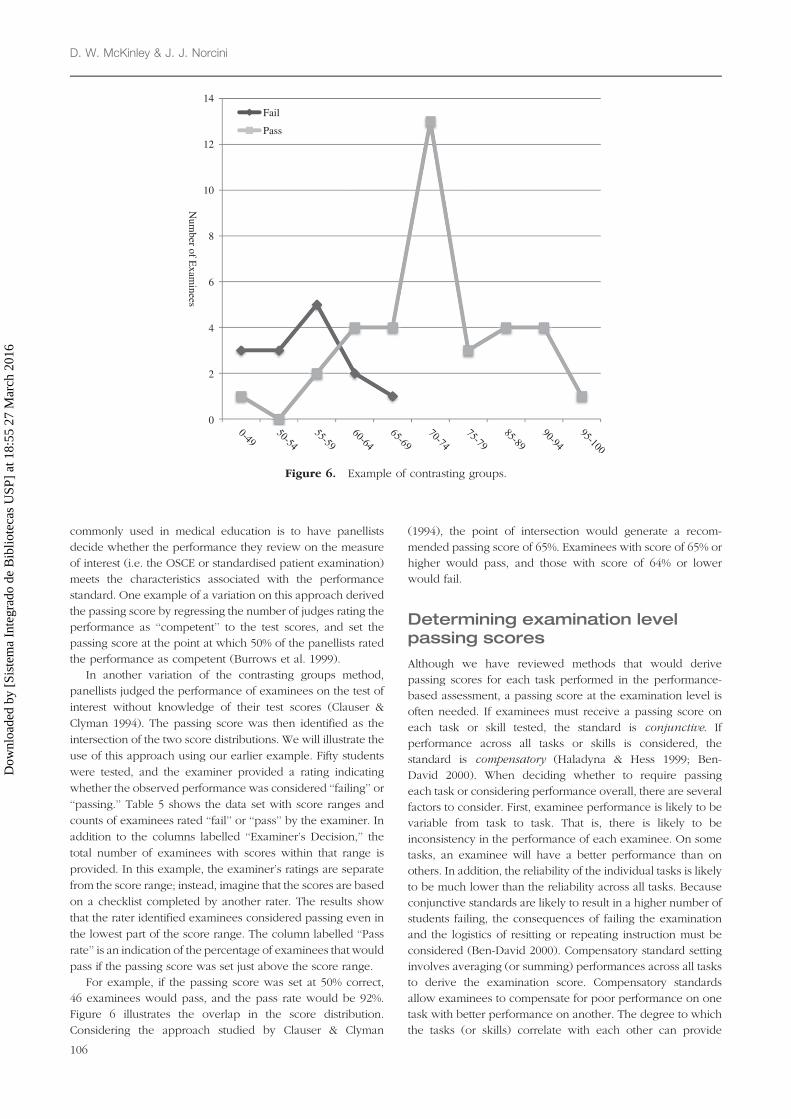
the performance as competent (Burrows et al. 1999).
In another variation of the contrasting groups method,
panellists judged the performance of examinees on the test of
interest without knowledge of their test scores (Clauser &
Clyman 1994). The passing score was then identified as the
intersection of the two score distributions. We will illustrate the
use of this approach using our earlier example. Fifty students
were tested, and the examiner provided a rating indicating
whether the observed performance was considered ‘‘failing’’ or
‘‘passing.’’ Table 5 shows the data set with score ranges and
counts of examinees rated ‘‘fail’’ or ‘‘pass’’ by the examiner. In
addition to the columns labelled ‘‘Examiner’s Decision,’’ the
total number of examinees with scores within that range is
provided. In this example, the examiner’s ratings are separate
from the score range; instead, imagine that the scores are based
on a checklist completed by another rater. The results show
that the rater identified examinees considered passing even in
the lowest part of the score range. The column labelled ‘‘Pass
rate’’ is an indication of the percentage of examinees that would
pass if the passing score was set just above the score range.
For example, if the passing score was set at 50% correct,
46 examinees would pass, and the pass rate would be 92%.
Figure 6 illustrates the overlap in the score distribution.
Considering the approach studied by Clauser & Clyman
(1994), the point of intersection would generate a recom-
mended passing score of 65%. Examinees with score of 65% or
higher would pass, and those with score of 64% or lower
would fail.
Determining examination levelpassing scores
Although we have reviewed methods that would derive
passing scores for each task performed in the performance-
based assessment, a passing score at the examination level is
often needed. If examinees must receive a passing score on
each task or skill tested, the standard is conjunctive. If
performance across all tasks or skills is considered, the
standard is compensatory (Haladyna & Hess 1999; Ben-
David 2000). When deciding whether to require passing
each task or considering performance overall, there are several
factors to consider. First, examinee performance is likely to be
variable from task to task. That is, there is likely to be
inconsistency in the performance of each examinee. On some
tasks, an examinee will have a better performance than on
others. In addition, the reliability of the individual tasks is likely
to be much lower than the reliability across all tasks. Because
conjunctive standards are likely to result in a higher number of
students failing, the consequences of failing the examination
and the logistics of resitting or repeating instruction must be
considered (Ben-David 2000). Compensatory standard setting
involves averaging (or summing) performances across all tasks
to derive the examination score. Compensatory standards
allow examinees to compensate for poor performance on one
task with better performance on another. The degree to which
the tasks (or skills) correlate with each other can provide
0
2
4
6
8
10
12
14
Num
ber of Exam
inees
Fail
Pass
Figure 6. Example of contrasting groups.
D. W. McKinley & J. J. Norcini
106
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

support to the compensatory vs. conjunctive decision (Ben-
David 2000). Another option is to consider how perform-
ance is reported to examinees. This decision is important
because those managing the standard setting process will
need to decide how the derived passing scores will be
used. In the conjunctive model, examinees must meet or
exceed the score for each task in order to pass the
examination. For the compensatory model, the average
passing score across tasks can be used to set the
examination-level passing score. With OSCE stations, it
may be that decisions can be made across tasks (compen-
satory) but each skill (e.g. communications, clinical deci-
sion-making) must be passed in order to pass the
examination. Consideration of the feedback provided to
the examinees will play an important role in determining
whether compensatory, conjunctive, or a combination will
be used to set the examination level passing score.
Compromise methods
Although results from the standard setting panellists are the
most important elements in determining the passing score,
additional information is often used to determine the final
passing score that will be applied to examinations (Geisinger
1991; Geisinger & McCormick 2010). One type of information
that is considered is the pass–fail rate for the passing score.
The compromise approaches proposed by Hofstee (1983),
Beuk (1984), and De Gruijter (1985) explicitly ask the
panellists to consider both the passing score and the passing
(or failing) rate. Each approach assumes that the judges have
an opinion about what constitutes an ‘‘acceptable’’ passing
score and passing rate.
Hofstee suggested that the chosen passing score was
only one out of a universe of possible passing scores. In
addition, it is feasible to plot all possible failure rates. To
ensure that panellists have considered these data, the
standard that is being set (e.g. minimal competence,
proficiency, etc.) is discussed, the details of the examin-
ation process are reviewed, and the panellists are asked to
answer four questions:
(1) What is the lowest acceptable percentage of students
who fail the examination? (Minimum fail rate; fmin)
(2) What is the highest acceptable percentage of students
who fail the examination? (Maximum fail rate; fmax)
(3) What is the lowest acceptable percent correct score that
would be considered passing? (Minimum passing score;
kmin)
(4) What is the highest acceptable percent correct score
that would be considered passing? (Maximum passing
score; kmax)
The four data points are calculated by averaging across all
judges. The percentage of examinees that would pass for every
possible value of the passing score on the test is graphed and
the four data points are plotted, based on the four judgments
of the standard setting panel. Figure 7 provides an example of
application of the Hofstee method. In this example, 140
students took a 50-item end-of-year test.
The curve in the chart shows the projected failure rate
based on percent correct scores on the test. Instructors were
asked the four questions that appeared above:
(1) What is the lowest acceptable percentage of students
who fail the examination? Average: 20%
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
22% 26% 30% 34% 38% 42% 46% 50% 54% 58% 62% 66% 70% 74% 78% 82% 86% 90% 94% 98%
60% min score30% max fail rate
75% max score20% min fail rate
Passingscore 63%
% E
xam
inee
s Pa
ssin
g
Test Scores (% Correct)
Figure 7. Example of the Hofstee method.
Standard setting on performance-based exams
107
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

(2) What is the highest acceptable percentage of students
who fail the examination? Average: 30%
(3) What is the lowest acceptable percent correct score that
would be considered passing? Average: 60%
(4) What is the highest acceptable percent correct score
that would be considered passing? Average: 75%
Using the information from the judges, two points are
plotted: the intersection of the lowest acceptable fail rate and
the highest acceptable percent correct score; and the intersec-
tion of the highest acceptable fail rate and the lowest
acceptable percent correct score (see Figure 7). These two
points create a line that intersects the curve that is defined by
percent correct score and projected failure rate. The passing
score is found by following the dotted line from the intersec-
tion to the x-axis (percent correct scores). The fail rate is found
by following the dotted line from the intersection to the y-axis
(percent fail).
In a modification of Hofstee method, Beuk (1984) sug-
gested that the panellists report to what extent each of their
judgments should be considered in deriving the final passing
score. That is, panellists are asked the degree to which their
decisions are examinee-oriented or test-oriented. The means
and standard deviations of both the passing scores and
acceptable pass rates are computed. The mean passing rate
and mean passing score are plotted. The point on the chart
where these two points intersect is identified. The compromise
consists of using the ratio of the standard deviation of pass rate
to the standard deviation of passing score. The point where the
distribution of scores intersects the line generated based on the
slope constitutes the passing score. De Gruijter (1985) further
suggested that an additional question be posed to panellists,
that of the level of uncertainty regarding these two judgments.
Beuk’s and De Gruijter’s methods have not been reported in
the literature for medical education, but the Hofstee method
has been used by a number of researchers.
Schindler et al. (2007) reported on the use of the Hofstee
approach to set passing scores for a surgery clerkship. Because
the goal was to set a passing score for the clerkship as a whole
instead of individual assessments (multiple-choice examin-
ations, OSCEs, clerkship grades, ratings of professionalism) the
standard setting panel determined that the use of the Hofstee
method was appropriate. The use of multiple, related assess-
ments led the group to conclude that compensatory standards
would be set, although a breech in professionalism could
result in failing. Panellists reviewed score distributions for all
students as well as those who had failed in previous years,
along with scoring rubrics and examination materials before
they responded to the four questions in the Hofstee method.
The authors found that there was a high level of agreement
amongst the judges, and that the pass rate derived was
reasonable when applied to previous clerkship data.
Selecting a standard settingmethod
With many methods available, it may seem difficult to decide
which the ‘‘best’’ method is. When selecting a standard setting
method, there are practical considerations to be made. The
method should permit judgments that are based on informa-
tion; processes that permit expert judgment in light of
performance data are preferable. The method chosen should
be closely aligned with the goal of assessment. The method
should require thoughtful effort of those participating in the
process, and it should be based on research. Finally, the
method should be easy to explain to participants, and easy to
implement.
It is important to keep in mind that the standard setting
study will generate a recommended passing score and that the
score should correspond to a level of performance that meets
the purpose for the test and the standard setting process. For
example, if the test is used for identification of students who
may need additional training or remediation, then passing
denotes the group of students ready for the next phase of
study, while failing identifies the group who may repeat the
course. In this case the level of performance may not be as
high as the level that corresponds to competence in inde-
pendent practice. If the test is used to represent those who are
ready to graduate, and enter a setting with supervised practice,
those who pass the test possess the characteristics associated
with readiness to enter supervised practice. The result of
passing these tests has different meanings and the final
determination of the passing score will take these differences
into account. While it is not possible to identify the best
method, the selection should be based on the purpose of the
test, as well as practical considerations delineated in this guide.
Implementing the standard
Since the standard setting study will generate a ‘‘recom-
mended’’ passing score, there are additional issues to be
considered before implementing the results of the standard
setting process. One important decision to make is whether the
passing score will be compensatory or conjunctive. For OSCEs
and standardised patient examinations, several stations are
typically included. If the assessment is averaged (or summed)
across cases, the passing score should be generated in a similar
fashion (i.e. averaged or summed across cases). In this
example, the standard would be considered compensatory;
those who meet or exceed the passing score will pass, and
poor performance at one station can be compensated by better
performance at another station. Alternately, a passing score
could be derived for each case/station, and an additional
requirement could be that a set number of cases have to be
passed in order to pass the assessment. In this case, the
standard would be conjunctive. Because cases often measure
both clinical and interpersonal skills, passing scores could be
generated for each of these skills, and the requirement to pass
would be to meet or exceed the passing score in each skill
area. This approach would also be considered conjunctive.
When deciding whether the pass–fail decision will be
compensatory or conjunctive, it is important to consider the
research done in this area. Performance on different tasks can
be quite variable (Traub 1994), and performance on a single
case is not likely to be a reliable indicator of an examinee’s
ability (Linn & Burton 1994). Conjunctive standards based on
individual stations will result in higher failure rates, and can
result in incorrect decisions due to measurement error
D. W. McKinley & J. J. Norcini
108
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

(Hambleton & Slater 1997; Ben-David 2000). While higher
failure rates will also result from conjunctive standards based
on skill area, it is reasonable to require that the passing score
be met for each area without compensation in each area. Ben-
David (2000) suggests that consideration of the construct
measured by the assessment is essential in making a decision
about compensatory and conjunctive standards. The purpose
of the assessment and the feedback given regarding the results
are important criteria to include in making a decision. For
example, it would be very useful to have examinees know that
they need to improve their physical examination manoeuvres,
but that their history taking and communication skills are
adequate. In this case, it would be reasonable to set separate
passing scores based on skills measured.
Another consideration is the format of reporting the results
of the examination to test-takers and other stakeholders. If the
OSCE is administered as an end-of-year assessment, students
who fail (and their instructors) may want to know about areas
of strength and weakness, so that they can concentrate their
efforts on skill improvement. Even students who pass may
want to know whether there were any areas in which they
could improve. Providing feedback is important, particularly
for failing examinees (Livingston & Zieky 1982; American
Educational Research Association et al. 1999).
Finally, consideration of the percentage of examinees
passing is essential. Understanding the consequences of the
decisions generated is vital to ensuring that decision makers
comprehend and endorse the process. It is not likely that it will
be feasible to generate the recommended passing score during
the standard setting meeting, so a meeting with stakeholders
(e.g. faculty members, head of departments) should be
conducted to inform them of the results of the study, and to
present the implications (i.e. number passed).
Maintaining the standard
Once the meetings have been conducted and the passing
score has been generated and endorsed, it is time to consider
how the passing score will be generated for the next testing
cycle. Because the performance of examinees and the
difficulty of the test can change from administration to
administration, the same passing score may not have the
same effect over time. If test materials are revised, it is
essential to conduct the standard setting meeting once again.
Even if the test materials are not changed, it is important to
monitor the performance of examinees and difficulty of the
test, as well as the consequences of implementing the
passing score (i.e. changes in passing rates). If the test
becomes easier (i.e. examinees obtain higher scores) and the
passing score remains the same, the passing rate is likely to
increase. Conversely, if the test becomes more difficult,
the passing rate is likely to decrease. Revisiting the definition
of the standard as well as the passing score in light of
changes associated with the test on a regular basis is advised.
Monitoring test performance is essential if the test is used
for determining examinee qualifications, whether it means
going on to the next level of training or entering
independent practice.
Conclusions
Although there is extensive research on standard setting with
both multiple-choice and performance-based tests, there is no
‘‘right’’ passing score, and no ‘‘best’’ method. Different
methods yield different results. Selecting a method depends
on the purpose of the examination and the resources
available for the standard setting effort. The methods
presented, the guidelines provided, and the examples given
are meant to provide information to inform decisions
regarding selection of a method, preparation for a standard
setting meeting, conducting the meeting and analysing the
data obtained, and implementing and maintaining the
standard.
Notes on contributors
DANETTE W. MCKINLEY, PhD, is the Director, Research and Data
Resources. Dr McKinley determines research priorities, defines scope,
and proposes methodology for studies focused on understanding and
promoting international medical education. She supports research activities
related to the certification of graduates of international medical programs.
Her interests include educational research methodology and assessment,
particularly for licensure or certification. With more than 20 years of
experience in licensure and certification testing, she now concentrates her
efforts on the development of research programs on international medical
education and the migration of health care workers.
JOHN J. NORCINI, PhD, President and Chief Executive Officer. Dr Norcini
became FAIMER’s first President and Chief Executive Officer in May 2002.
Before joining FAIMER, Dr Norcini spent 25 years with the American Board
of Internal Medicine serving in various capacities, including Director of
Psychometrics, Executive Vice President for Evaluation and Research, and
finally, Executive Vice President of the Institute for Clinical Evaluation.
Dr Norcini’s principal academic interest is the assessment of physician
performance. Current major research interests include methods for setting
standards, assessing practice performance, and testing professional com-
petence. His research also focuses on physician migration and workforce
issues, as well as the impact of international medical graduates on the U.S.
health care system.
Declaration of interest: The authors report no conflicts of
interests. The authors alone are responsible for the content
and writing of this article.
References
American Educational Research Association, American Psychological
Association, National Council on Measurement in Education, 1999.
Standards for educational and psychological testing. American
Educational Research Association, Washington DC.
Angoff WH. 1971. Scales, norms, and equivalent scores. In: Thorndike RL,
editor. Educational measurement. Washington, DC: American Council
on Education, pp 508–600.
Bandaranayake RC. 2008. Setting and maintaining standards in multiple
choice examinations: AMEE Guide No. 37. Med Teach 30:836–845.
Ben-David MF. 2000. AMEE Guide No. 18: Standard setting in student
assessment. Med Teach 22:120–130.
Beuk CH. 1984. A method for reaching a compromise between absolute
and relative standards in examinations. J Educ Measure 21:147–152.
Boulet JR, De Champlain AF, McKinley DW. 2003. Setting defensible
performance standards on OSCEs and standardized patient examin-
ations. Med Teach 25:245–249.
Burrows PJ, Bingham L, Brailovsky CA. 1999. A modified contrasting
groups method used for setting the passmark in a small scale
Standard setting on performance-based exams
109
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6

standardised patient examination. Adv Health Sci Educ Theory Pract
4:145–154.
Clauser BE, Clyman SG. 1994. A contrasting-groups approach to standard
setting for performance assessments of clinical skills. Acad Med
69:S42–S44.
Cohen-Schotanus J, van der Vleuten CPM. 2010. A standard setting method
with the best performing students as point of reference: Practical and
affordable. Med Teach 32:154–160.
De Gruijter DNM. 1985. Compromise models for establishing examination
standards. J Educ Measure 22:263–269.
Dijkstra J, Van der Vleuten CPM, Schuwirth LWT. 2010. A new framework
for designing programmes of assessment. Adv Health Sci Educ Theory
Pract 15:379–393.
Downing SM, Lieska NG, Raible MD. 2003. Establishing passing standards
for classroom achievement tests in medical education: A comparative
study of four methods. Acad Med 78:S85–S87.
Downing SM, Tekian A, Yudkowsky R. 2006. Procedures for establishing
defensible absolute passing scores on performance examinations in
health professions education. Teach Learn Med 18:50–57.
Ebel R. 1972. Essentials of educational measurement. 2nd ed. Englewood
Cliffs, NJ: Prentice-Hall.
Frank JR, Snell LS, Cate OT, Holmboe ES, Carraccio C, Swing SR,
Harris P, Glasgow NJ, Campbell C, Dath D, et al. 2010.
Competency-based medical education: Theory to practice. Med
Teach 32:638–645.
Geisinger KF. 1991. Using standard-setting data to establish cutoff scores.
Educ Measure: Issu Pract 10:17–22.
Geisinger KF, McCormick CM. 2010. Adopting cut scores: Post-standard-
setting panel considerations for decision makers. Educ Measure: Issu
Pract 29:38–44.
Haladyna T, Hess R. 1999. An evaluation of conjunctive and compensatory
standard-setting strategies for test decisions. Educ Assess 6:129–153.
Hambleton RK, Jaeger RM, Plake BS, Mills C. 2000. Setting performance
standards on complex educational assessments. Appl Psychol Measur
24:355–366.
Hambleton RK, Slater SC. 1997. Reliability of credentialing examinations
and the impact of scoring models and standard-setting policies. Appl
Measur Educ 10:19–28.
Hofstee WKB. 1983. The case for compromise in educational selection and
grading. In: Anderson SB, Helmick JS, editors. On educational testing.
San Francisco, CA: Jossey-Bass. pp 109–127.
Holmboe ES, Sherbino J, Long DM, Swing SR, Frank JR. 2010. The role of
assessment in competency-based medical education. Med Teach
32:676–682.
Jaeger RM. 1991. Selection of judges for standard-setting. Educ Measu:
Iss Pract 10:3–14.
Kane MT. 1992. The assessment of professional competence. Eval Health
Prof 15:163–182.
Kane MT. 1994. Validating interpretive arguments for licensure and
certification examinations. Eval Health Prof 17:133–159; discussion
236–241.
Kane MT. 2006. Validation. In: Brennan RL, editor. Educational measure-
ment. Westport, CT: American Council on Education and Praeger
Publishers. pp 17–64.
Kaufman DM, Mann KV, Muijtjens AMM, van der Vleuten CPM. 2000. A
comparison of standard-setting procedures for an OSCE in under-
graduate medical education. Acad Med 75:267–271.
Linn RL, Burton E. 1994. Performance-based assessment: Implications of
task specificity. Educ Measure: Issu Pract 13:5–8.
Livingston SA, Zieky MJ. 1982. Passing scores: A manual for setting
standards of perfromance on education and occupational tests. Educ
Testing Serv. Princeton, New Jersey.
Miller GE. 1990. The assessment of clinical skills/competence/performance.
Acad Med 65:S63–S67.
Nedelsky L. 1954. Absolute grading standards for objective tests. Educ
Psychol Measur 14:3–19.
Nestel D, Kneebone R, Black S. 2006. Simulated patients and the
development of procedural and operative skills. Med Teach 28:390–391.
Norcini J, Burch V. 2007. Workplace-based assessment as an educational
tool: AMEE Guide No. 31. Med Teach 29:855–871.
Norcini JJ. 1994. Principles for setting standards on certifying and licensing
examinations. In: Rothman AI, Cohen R, editors. The Sixth Ottawa
Conference on Medical Education. Toronto: University of Toronto
Bookstore, pp 346–347.
Norcini JJ. 2003. Work based assessment. Br Med J 326:753–755.
Norcini J, McKinley D. 2007. Assessment methods in medical education.
Teach Teacher Educ 23:239–250.
Norcini JJ, Stillman PL, Sutnick AI, Regan MB, Haley HL, Williams RG,
Friedman M. 1993. Scoring and standard setting with standardized
patients. Eval Health Prof 16:322–332.
Patil NG, Saing H, Wong J. 2003. Role of OSCE in evaluation of practical
skills. Med Teach 25:271–272.
Pell G, Fuller R, Homer M, Roberts T. 2010. How to measure the quality of
the OSCE: A review of metrics – AMEE guide no. 49. Med Teach
32:802–811.
Raymond MR, Reid J. 2001. Who made thee a judge? Selecting
and training participants for standard setting. In: Cizek GJ,
editor. Setting performance standards: Concepts, methods, and
perspectives. Mahwah, NJ: Lawrence Erlbaum Associates.
pp 119–158.
Reznick RK, Blackmore D, Dauphinee WD, Rothman AI, Smee S. 1996.
Large-scale high-stakes testing with an OSCE: Report from the Medical
Council of Canada. Acad Med 71:S19–S21.
Rothman AI, Cohen R. 1996. A comparison of empirically- and rationally-
defined standards for clinical skills checklists. Acad Med 71:S1–S3.
Schindler N, Corcoran J, DaRosa D. 2007. Description and impact of using a
standard-setting method for determining pass/fail scores in a surgery
clerkship. Am J Surg 193:252–257.
Smee SM, Blackmore DE. 2001. Setting standards for an objective structured
clinical examination: The borderline group method gains ground on
Angoff. Med Educ 35:1009–1010.
Traub RE. 1994. Facing the challenge of multidimensionality in perfor-
mance assessment. In: Rothman AI, Cohen R, editors. Proceedings of
the Sixth Annual Ottawa Conference on Medical Education. Toronto:
University of Toronto Bookstore. pp 9–11.
Wood TJ, Humphrey-Murto SM, Norman GR. 2006. Standard setting in a
small scale OSCE: A comparison of the modified borderline-group
method and the borderline regression method. Adv Health Sci Educ
11:115–122.
D. W. McKinley & J. J. Norcini
110
Dow
nloa
ded
by [
Sist
ema
Inte
grad
o de
Bib
liote
cas
USP
] at
18:
55 2
7 M
arch
201
6