exercise - cbs filecenter for biological sequence analysis exercise! prediction of mhc:peptide...
TRANSCRIPT

CENTER FOR BIOLOGICAL SEQUENCE ANALYSIS
Exercise Prediction of MHC:peptide binding using PSSM and ANN.

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
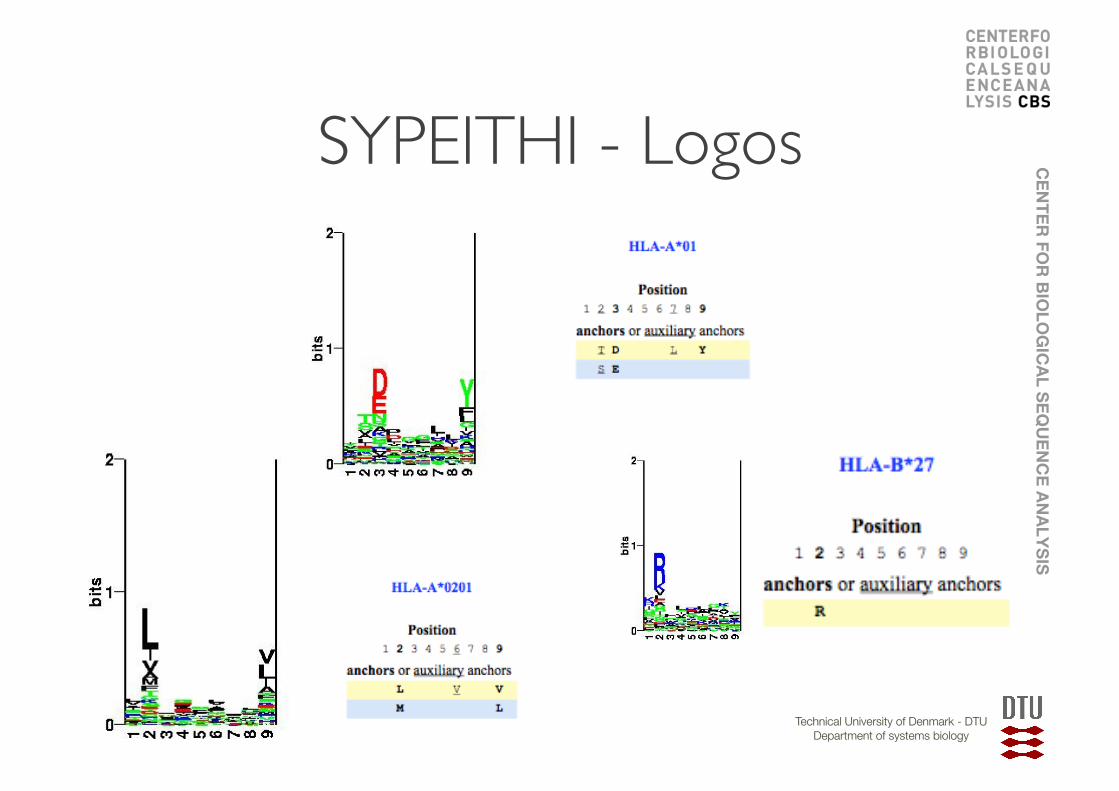
SYFPEITHI • Q1: What are the characteristics of the peptides that bind HLA-A*0201? Which positions are anchor position and what amino acids are found at the anchor positions?
CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
SYPEITHI - Logos

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
* Q4: What is the predictive performance of the matrix method (Pearson coefficient and Aroc value)? Pearson coefficient for N= 66 data: 0.63507 Aroc value: 0.83399
* Q5: How many of the 1200 peptides in the train set are included in the matrix construction? Number of positive training examples: 136 Go back to the EasyPred server window (use the Back bottom). Set clustering
method to No clustering and the weight on prior to zero and redo calculation. * Q6: What is the predictive performance of the matrix method now? Pearson coefficient for N= 66 data: 0.51898 Aroc value: 0.78954
EasyPred

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
EASYPRED
• * Q7: Does clustering and pseudo count (weight on prior) improve the prediction accuracy?
• Clustering down weights similar sequences in the training data thereby removing a non-biological bias.!
• Pseudo counts allow you to estimate amino acids frequencies for amino acids that are not observed in the data by use of blosum frequency substitution matrices. By setting the weight on prior (or weight on pseudo count) to zero the relative weight on these pseudo count is set to zero and the method becomes less capable of generalization.!

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
• A Network contains a very large set of parameters
• A network with 5 hidden neurons predicting binding for 9meric peptides has 9x20x5=900 weights
• Over fitting is a problem
• Stop training when test performance is optimal
Neural network training
years
Tem
pera
ture

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
Neural network training. Cross validation
Cross validation
Train on 4/5 of data Test on 1/5
=> Produce 5 different neural networks each
with a different prediction focus

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
Neural network training curve
Maximum test set performance Most capable of generalizing

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
EasyPred - ANN * Q8: What is the maximal test performance (maximal test set Pearson correlation), and in what epoch does it occur?"Maximal test set pearson correlation coefficent sum = 0.801300 in epoch 103 "
* Q9: What is evaluation performance (Pearson correlation and Aroc values)? "Pearson coefficient for N= 66 data: 0.58693 Aroc value: 0.85490 "
Go back to the EasyPred interface and change the parameters so that you use the bottom 80% of the train.set to train the neural network and the top 20% to stop the training. Redo the network training with the new parameters. "
* Q10: What is the maximal test performance, and in what epoch does it occur?"Maximal test set pearson correlation coefficent sum = 0.837800 in epoch 90 "
* Q11: What is evaluation performance?"Pearson coefficient for N= 66 data: 0.55571 Aroc value: 0.78170 "

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
EasyPred - ANN
* Q12: How does the performance differ from what you found in the previous training? The training stops faster and with a better test (stop) performance but the evaluation performances drop compared with the previous training. * Q13: Why do you think the performance differ so much? If the training set and the test (stop) set are to similar you get an artificially good test performance. However the training will be biased against this similarity thus when evaluating on a more dissimilar set the performance is not so good. !Or the evaluation set could share similarity to the top 80% of the training data thereby imposing a bias the evaluation performance !

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
Hidden Neurons
Go back to the EasyPred interface and change the parameters back so that you use the top 80% of the train.set of training. Next do neural network
training with a different set of hidden neurons (1 and 5 for instance). * Q14: How does the test performance differ when you vary the number of hidden neurons? It does not differ very much.! * Q15: How does the evaluation performance differ? It does not differ very mouch! * Q16: Can you decide on an optimal number of hidden neuron? No

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
Hidden Neurons (units)
Having more than one hidden neuron in the hidden layer will enable the network to solve higher order correlations like the “exclusive or” (XOR) function. That is in nature for example if two neighboring amino acids competes of a single binding pocket. One of the amino acids have to be large, but both of them cant. This problem can only be solved by methods that can handle higher order correlations like artificial neural networks.!
!Here we do not see any advantage of having more than 1 neuron so here we either do not have higher order correlations or the influence of those are so subtle that this training set is to small to learn from. We need much more data than what we have available to capture higher order correlations. We need to estimate amino acids pair frequencies to do this, and hence need to estimate in the order 400 such frequencies. This cannot be done from 136 binding peptides !
* Q17: Why do you think the number of hidden neurons has so little importance?
CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
v1 v2
Linear function
€
y = x1 ⋅ v1 + x2 ⋅ v2
Neural networks

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
w11 w12
v1
w21
w22
v2
Higher order function
Neural networks

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
Ensembles Write down the test performance for each of the five networks * Q18: How does the train/test performance differ between the different partitions? Test Pearson CC varies between 0.79 and 0.86!
* Q19: What is the evaluation performance and how does it compare to the performance you found previously? Pearson coefficient for N= 66 data: 0.61446 Aroc value: 0.83137 !Pearson better, AUC (Aroc) a little worse.

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
Hidden Units Q20: How many high binding epitopes (>0.5~200 nM or >0.426~500nM)do you find? 2 Is this number reasonable (how large a fraction of random 9meric peptides are expected to bind to a given HLA complex?) 2/400 = 0.5% or 1/200

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
• Q21: What is the predictive performance of the method?
• Pearson coefficient for N= 22 data: 0.35836
• Aroc value: 0.46875
• Threshold for counting example as positive: 0.362000

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
• Q22: What is the predictive performance of the method?
• Pearson coefficient for N= 22 data: 0.56559
• Aroc value: 0.83333
• Threshold for counting example as positive: 0.362000

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
• Q23: What is the predictive performance of the method?
• Pearson coefficient for N= 22 data: 0.57822
• Aroc value: 0.87500
• Threshold for counting example as positive: 0.362000

CE
NT
ER
FOR
BIO
LOG
ICA
L SE
QU
EN
CE
AN
ALY
SIS
• Q24: How does the logo compare to the binding motif described in the SYFPEITHI database? Server down"
• Q25: Which positions are most important for binding? P1, P3 and P9"
• What is the predictive performance of the method? and how does the performance compare to that of the TEPITOPE method? Pearson coefficient for N= 22 data: 0.74057, Aroc value: 0.88542. These values are much higher than what was obtained for the TEPITOPE method"