genome evolution. amos tanay 2009 genome evolution lecture 7: selection in protein coding genes
Post on 21-Dec-2015
220 views
TRANSCRIPT

Genome Evolution. Amos Tanay 2009
Genome evolution
Lecture 7:
Selection in protein coding genes

Genome Evolution. Amos Tanay 2009
Protein genes: codes and structure
1 2 3
codons
Introns/exons
Domains
Conformation
Degenerate code
Recombination easier?
Epistasis: fitness correlation between two remote loci
5’ utr3’ utr

Genome Evolution. Amos Tanay 2009
Identifying protein coding genes
From mRNAs
Spliced ESTs : short low quality fragments that are easier to get
Using computational methods. Limited accuracy
Using conservation or mapping from other genomes

Genome Evolution. Amos Tanay 2009
Questions on protein function and evolution
Identification:• Identify protein coding genes
– Not yet resolved for new species, but with new technology this question may be less important than before
Structure/Function:• Define functional domains
– Highly important for understanding protein function• Which parts of the proteins are “important” (e.g., catalytic?)
– Difficult since structural modeling is hard and context dependent
Evolution • Identify places and times where a new protein feature emerged
– Positive selection• Understand mutation/selection through codon degeneracy• Understanding processes of duplication and diversitification

Genome Evolution. Amos Tanay 2009
The classical analysis paradigm
BLAT/BLAST
Target sequence
Genbank
Matching sequences CLUSTALW
ACGTACAGAACGT--CAGAACGTTCAGAACGTACGGA
Alignment
PhylogeneticModeling
Analysis: rate, Ka/Ks…

Genome Evolution. Amos Tanay 2009
Basics: rates of substitution
We observe two sequences
The divergence D is the fraction of different amino acids
We want to find the rate of replacement (or substitution)
ttt DDD )2)(1(1 D
tDdtdD 22/ tt eD 21
tK 2 )ˆ1ln( DK
])ˆ1/[(ˆ)ˆ( LDDKVar
So if we computed the divergence D of two sequence, we can estimate the rate
Where L is the sequence length.
Note that for small D’s, K~D, but for larger values, K takes into account multiple substitutions
And:
)ˆ2/(ˆˆ tK

Genome Evolution. Amos Tanay 2009
Basics: rates of substitution - nucleotides
With nucleotides, we cannot ignore mutations that eliminate divergence
)1()31( )()()1( tAtAtA PPP
Probability to have the same value after two branches of length t:
So we can estimate the rate given the observed divergence d:
A
C T
G
A
C T
G
Jukes-Kantor (JK) KimurattAtAtAtA ePPPP 4)()()()1( 4
3
4
14
tNN eP 8
4
3
4
1
)3/ˆ41ln(4
3ˆ)1(4
3 8 dked t

Genome Evolution. Amos Tanay 2009
Using universal matrices: PAM/BLOSSOM62
Given a multiple alignment (of protein coding DNA) we can convert the DNA to proteins. We can then try to model the phylogenetic relations between the proteins using a fixed rate matrix Q, some phylogeney T and branch lengths ti
When modeling hundreds/thousands amino acid sequences, we cannot learn from the data the rate matrix (20x20 parameters!) AND the branch lengths AND the phylogeny.
Based on surveys of high quality aligned proteins, Margaret Dayhoff and colleuges generated the famous PAM (Point Accepted mutations): PAM1 is for 1% substitution probability.
Using conserved aligned blocks, Henikoff and Henikoff generated the BLOSUM family of matrices. Henikoff approach improved analysis of distantly related proteins, and is based on more sequence (lots of conserved blocks), but filtering away highly conserved positions (BLOSUM62 filter anything that is more than 62% conserved)
S. Henikoff

Genome Evolution. Amos Tanay 2009
Universal amino-acid substitution rates?
Jordan et al., Nature 2005
“We compared sets of orthologous proteins encoded by triplets of closely related genomes from 15 taxa representing all three domains of life (Bacteria, Archaea and Eukaryota), and used phylogenies to polarize amino acid substitutions. Cys, Met, His, Ser and Phe accrue in at least 14 taxa, whereas Pro, Ala, Glu and Gly are consistently lost. The same nine amino acids are currently accrued or lost in human proteins, as shown by analysis of non-synonymous single-nucleotide polymorphisms. All amino acids with declining frequencies are thought to be among the first incorporated into the genetic code; conversely, all amino acids with increasing frequencies, except Ser, were probably recruited late. Thus, expansion of initially under-represented amino acids, which began over 3,400 million years ago, apparently continues to this day. “

Genome Evolution. Amos Tanay 2009
Learning a rate matrix
3
2 1
5
4)exp()Pr( )( iiipa QtXX
,..),,|Pr(maxarg 21,..,, 121ttQs
nttQ
Learning is easy for a single, fixed length branch. Given (inferred) statistics nk for multiple branch lengths, we must optimize a non linear likelihood function
kijn
ijkjik QttQsL ))(exp(),|( ,,
Use generic optimization methods: (BFGS)
?))log(exp(
?),|(
u
Qt
t
tQsLL
k

Genome Evolution. Amos Tanay 2009
Molecular clocks and lineage acceleration
• How universal is the rate of the evolutionary process?• Mutations may depend on the number of cell division and thus in the
length of generation• Mutations depends on the genomic machinery to prevent them (• Mutations may also depend on the environment• The molecular clock (MC) hypothesis state that evolution is working
in a similar rate for all lineages
A B C
O
Relative rate test:
KOA – KOB = 0 ?
Test: KCA – KCB
Genome Evolution. Amos Tanay 2009
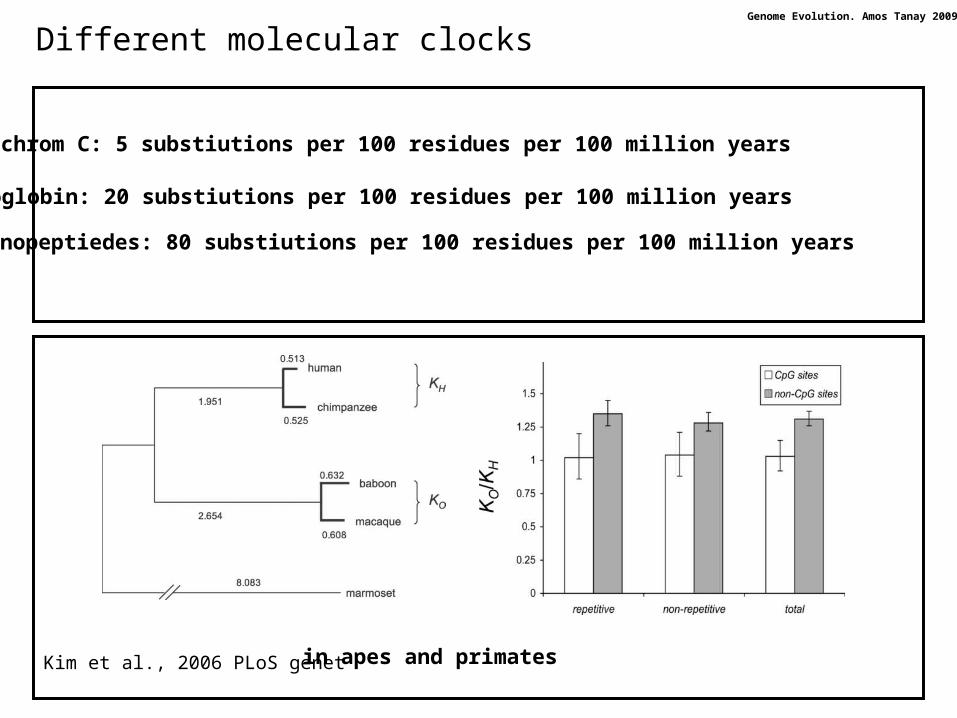
Different molecular clocks
Kim et al., 2006 PLoS genet in apes and primates
Cytochrom C: 5 substiutions per 100 residues per 100 million years
Hemoglobin: 20 substiutions per 100 residues per 100 million years
Fibrinopeptiedes: 80 substiutions per 100 residues per 100 million years
Genome Evolution. Amos Tanay 2009
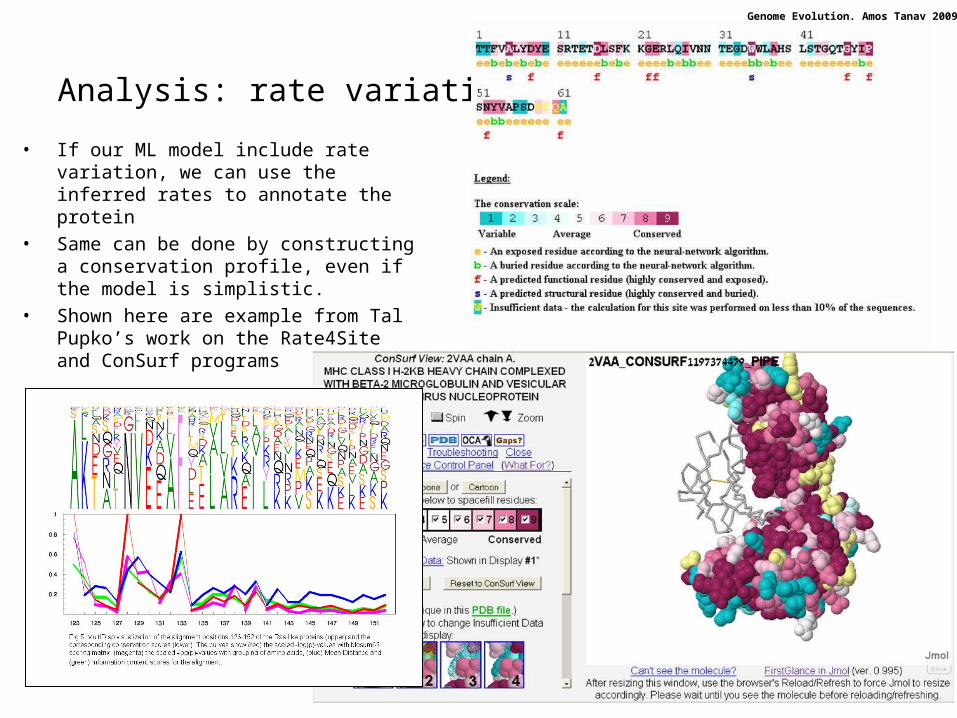
Analysis: rate variation
• If our ML model include rate variation, we can use the inferred rates to annotate the protein
• Same can be done by constructing a conservation profile, even if the model is simplistic.
• Shown here are example from Tal Pupko’s work on the Rate4Site and ConSurf programs

Genome Evolution. Amos Tanay 2009
Synonymous vs. non synonymous mutations
• Degenerate positions of codon are evolving more rapidly – free from selection on the coding sequence
• This provide us with a powerful “internal control” – we are comparing two different types of evolutionary events at the same loci, so all sources of variation in the mutational process are not affecting us.
Given aligned proteins, we can count:
MA – number of non-synonymous changes
Ms – number of synonymous changes
We then want to estimate:• Ka – rate of non-synonymous mutations (per syn site)• Ks – rate of synonymous mutations (per syn site)• Estimate V(Ka), V(Ks)
• Comparing Ka and Ks can provide evolutionary insights:– Ka/Ks<<1: negative selection may be purging protein modifying mutations
– Ks/Ka>>1: positive selection may help acquiring a new function
– (statistics using, e.g., T-test)
Non-SynSyn
ChangeMAMS
No Change
NA-MANS-MS
Chi-square test
Average number of sites

Genome Evolution. Amos Tanay 2009
From dN/dS to Ka and Ks
Consider the divergence of synonymous and non synonymous sites separately.
As discussed before, we can estimate the rates:
)3
)(41ln(
4
3
SS N
dSK )
3
)(41ln(
4
3
AA N
dNK
A more realistic approach should consider the genetic code and other effect
A codon model is defining a rate matrix over nucleotide triplets
We can use various parameterizations, for example:
][][ kQ jij
For transitions For non-synonymous
We learn the ML parameters. Small indicate selection

Genome Evolution. Amos Tanay 2009
Codon bias
• Different codons appears in significantly different frequencies, which is not expected assuming neutrality
• Bias is measured in several ways, most popular is the codon adaptation index:
• Possible sources of bias:
– Selection for translational efficiency given different tRNA abudnances• Highly expressed genes tend to have stronger codon adaptation indices
– Sequence context mutational effects• E.g. CpGs are highly mutable
– Selection for low insertion/deletion potential
• Weak selection for codon bias should be stronger for genomes with larger effective population size. In some cases this is true
L
i
iLi X
XCAI
1
max,1
Codon frequency divided by the frequency of the synonymous codon with maximal frequency

Genome Evolution. Amos Tanay 2009
Positive selection in humans vs chimp
Nielsen et al., 2005 PloS Biol
Testis genes: P<0.0001
Immunity genes, Gematogenesis, Olfaction P<1e-5Inhibition of apoptosis P<0.005Sensory perception P<0.02
Kn vs Ks Looking at trends for families of genes
Significantly enriched functions/tissues Example

Genome Evolution. Amos Tanay 2009
Mcdonald-Kreitman test
rM
sM
sr MMM
Possible neutral replacement mutations
Possible neutral synonymous mutations
Deleterious mutations
s
r
sb
rb
MM
MTMT )3/()3/(
Expected ratio of replacement to synonymous fixed mutations
s
r
sw
rw
MM
MTMT )3/()3/(
Expected ratio of replacement to synonymous polymorphic mutations
Outgroup
Tw
Tb
RFn
SFn
RPn
SPn
Replacement
Synonymous
Fixed Poly
M. Kreitman

Genome Evolution. Amos Tanay 2009
Mcdonald-Krietman test - example• Works by comparing Ka/Ks divergence between species and Ka/Ks diversity among
species populations• Negative selection should make the divergence Ka/Ks smaller than the diversity
Ka/Ks• Positive selection should drive the opposite effect
Busstamente et al, Nature 2005
humanchimp

Genome Evolution. Amos Tanay 2009
Reminder: the coalescent
Present 10
2)( 5
NTE
6
2)( 4
NTE
3
2)( 3
NTE
NTE 2)( 2
Past
1 2 3 54
Theorem: The amount of time during which there are k lineages, tk has approximately an exponential distribution with mean 2N * (2/(k(k-1)))
In the infinite sites model, mutations occur at distinct sites.
Back in time
)4(,2
2 NkNk
Coalescent:N
kk
2
1
2
)1(
mutation:

Genome Evolution. Amos Tanay 2009
Infinite sites model
n
j
n
jtot
n
jjtot
jjjjTE
jtT
22
2
)1(
12
)1(
2)(
Theorem: Let u be the mutation rate for a locus under consideration, and set =4Nu. Under the infinite sites model, the expected number of segregating sites is:
Proof: Let tj be the amount of time in the coalescent during which there are j lineages. We showed earlier that tj has approximately an exponential distribution with mean 2/(j(j-1)). The total amount of time in the tree for a sample size n is:
1
1
1)(
n
i iSE
Mutations occur at rate 2Nu:
)(2)( totn TNuESE
ii N 4

Genome Evolution. Amos Tanay 2009
Infinite sites model
Theorem: =4Nu. Under the infinite sites model, the number of segregating sites Sn has
Proof: Let sj be the number of segregating sites created when there were j lineages. While there are j lineages, we may get mutations at rate 2Nuj, and coalescence at rate j(j-1)/2. Mutations occur before coalescence with probability:
1
12
21
1
11)(
n
i
n
in ii
SV
14
4
2/)1(2
2
jNu
Nu
jjNuj
Nuj
,..2,1,01
1
1)Pr(
kj
j
jks
k
j
2
2
2
22
2
2
2
)1(1)1(
)1(
)1(
)1(
1
1)(
jjj
j
j
j
jp
psVar j
k successes:
It’s a shifted geometric distribution:

Genome Evolution. Amos Tanay 2009
The HKA test (Hudson, Kreitman, Aguade)
humanchimp
humanchimp
humanchimp
Slow
Fast
PurifyingSelection
Bi
Ai SS ,
iD
Number of segregating sites in locus i and population A and B (Polymorphism)
L loci are sequenced in populations A and B Each locus is supposed to be behaving as an infinite site locus
Number of difference between two random gametes from A and B (Divergence)
Our null hypothesis is of neutral evolution for T’ generations with population sizes 2N and 2Nf, but starting from a single ancestral population of size 2N(1+f)/2
We do not know:
1
1
1)(
An
ii
Ai i
SE
Nfi ,,
We want to allow different loci to have different mutation rates
1
1
1)(
Bn
ii
Bi i
fSE
1
12
2 1)()(
An
ii
Ai
Ai i
SESV
1
12
2 1)()()(
Bn
ii
Bi
Bi i
fSESV
What is the expected divergence?
ii N 4

Genome Evolution. Amos Tanay 2009
The HKA test (Hudson, Kreitman, Aguade)
B
Bi
Ai SS ,
iD
Number of segregating sites in locus i and population A and B (Polymorphism)
Number of difference between two random gametes from A and B (Divergence)
1
1
1)(
An
ii
Ai i
SE
1
1
1)(
Bn
ii
Bi i
fSE
1
12
2 1)()(
An
ii
Ai
Ai i
SESV
1
12
2 1)()()(
Bn
ii
Bi
Bi i
fSESV
A
NTT 2/' )2/)1(( fTED ii
DivergenceIs a Poisson variable
Coalescent in ancestral population
2)2/)1((2/)1()( ffTDVar iiii
Variance of Poisson variable
Variance of S with n=2

Genome Evolution. Amos Tanay 2009
The HKA test (Hudson, Kreitman, Aguade)
Bi
Ai SS ,
iD
Number of segregating sites in locus i and population A and B (Polymorphism)
Number of difference between two random gametes from A and B (Divergence)
1
1
1)(
An
ii
Ai i
SE
1
1
1)(
Bn
ii
Bi i
fSE
1
12
2 1)()(
An
ii
Ai
Ai i
SESV
1
12
2 1)()()(
Bn
ii
Bi
Bi i
fSESV
)2/)1(( fTED ii 2)2/)1(()( fEDDVar iii
There are L+2 parameters that we should estimate. This can be done by solving the equations:
L
iiA
L
i
Ai nCS
11
ˆ)(
L
iiB
L
i
Bi fnCS
11
ˆ)(
Find
L
ii
1
Find f
L
ii
L
ii fTD
11
ˆ)2/)ˆ1(ˆ( Find T
)()()2/)ˆ1(ˆˆBAii
Bi
Ai nCnCfTDSS Find i

Genome Evolution. Amos Tanay 2009
The HKA test (Hudson, Kreitman, Aguade)
Bi
Ai SS ,
iD
Number of segregating sites in locus i and population A and B (Polymorphism)
Number of difference between two random gametes from A and B (Divergence)
1
1
1)(
An
ii
Ai i
SE
1
1
1)(
Bn
ii
Bi i
fSE
1
12
2 1)()(
An
ii
Ai
Ai i
SESV
1
12
2 1)()()(
Bn
ii
Bi
Bi i
fSESV
)2/)1(( fTED ii 2)2/)1(()( fEDDVar iii
The goodness of fit can be expressed as:
L
iiii
L
i
Bi
Bi
Bi
L
i
Ai
Ai
Ai
DraVDED
SraVSES
SraVSESX
1
2
1
2
1
22
)(ˆ/))(ˆ(
)(ˆ/))(ˆ(
)(ˆ/))(ˆ(
Significance is best tested using simulations (although we can assume normality and independence and use chi square with 3L-(L+2) degrees of freedom)

Genome Evolution. Amos Tanay 2009
Example: Drosophila chromosome 4
humanchimp
humanchimp
humanchimp
Slow
Fast
PurifyingSelection
Collecting data from a target locus: Size, Polymorphism, divergence
Collecting data from a control neutral locus: Size, Polymorphism, divergence
ciD5’ Adh
Nucs11063326
Polymorphic030
Divergence5478
This data is unlikely given our model, why?
Population dynamics? (small turns bigger?)
Selective sweeps?
Mutational effects (gene conversion?)
Genome Evolution. Amos Tanay 2009
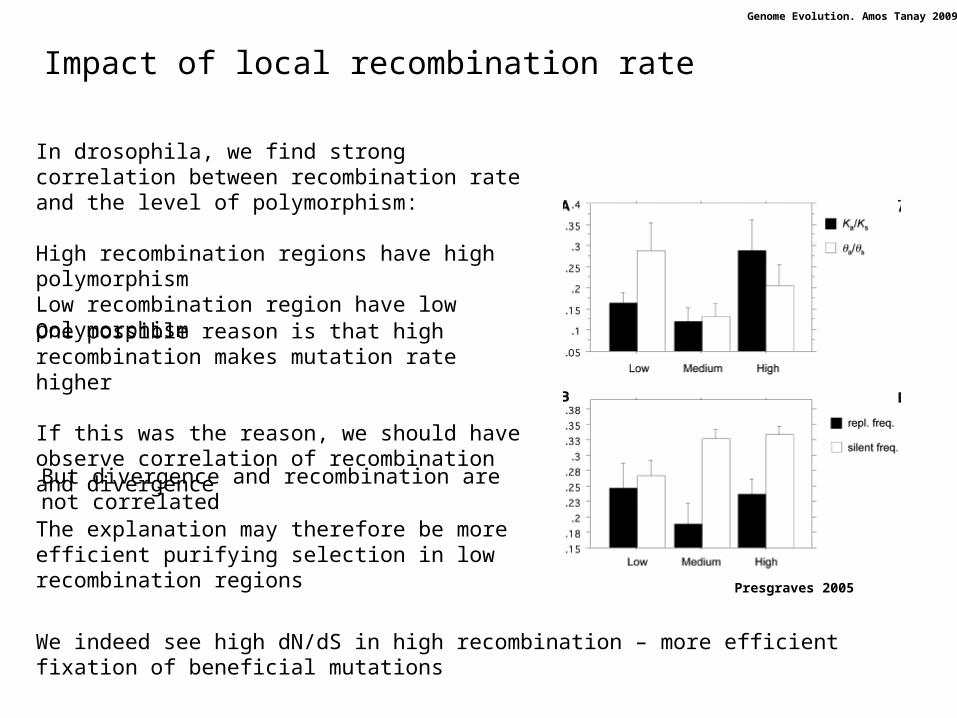
Impact of local recombination rate
Presgraves 2005
In drosophila, we find strong correlation between recombination rate and the level of polymorphism:
High recombination regions have high polymorphismLow recombination region have low polymorphism
One possible reason is that high recombination makes mutation rate higher
If this was the reason, we should have observe correlation of recombination and divergence
But divergence and recombination are not correlated
The explanation may therefore be more efficient purifying selection in low recombination regions
We indeed see high dN/dS in high recombination – more efficient fixation of beneficial mutations
Genome Evolution. Amos Tanay 2009
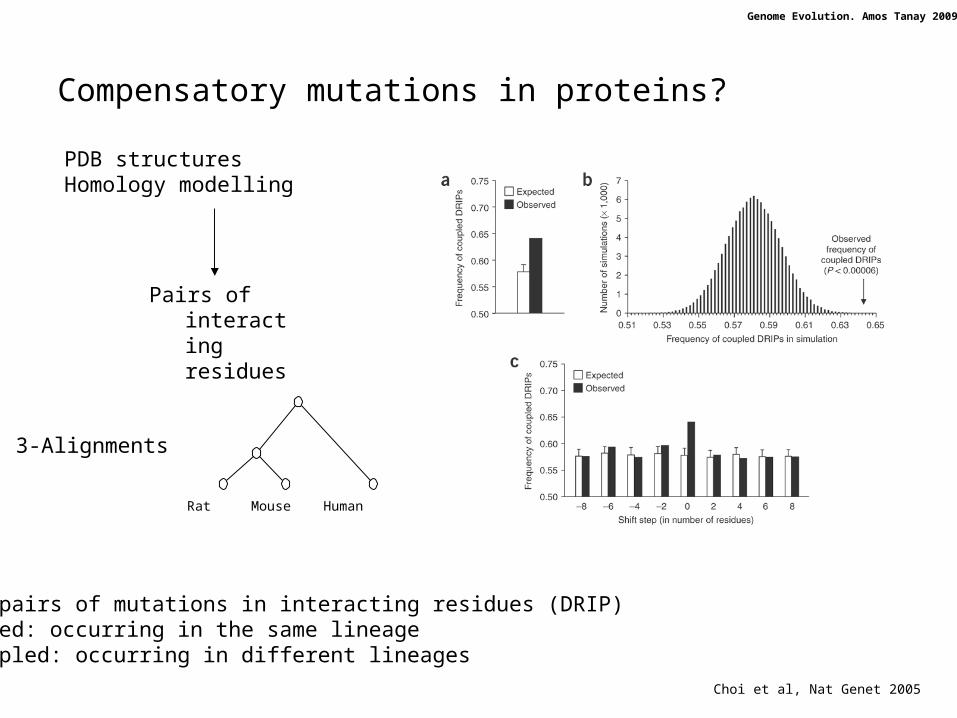
Compensatory mutations in proteins?
PDB structuresHomology modelling
3-Alignments
Pairs of interacting residues
Rat Mouse Human
Choi et al, Nat Genet 2005
Find pairs of mutations in interacting residues (DRIP)Coupled: occurring in the same lineageUncoupled: occurring in different lineages

Genome Evolution. Amos Tanay 2009
Codon volatility
• Volatility is the number/fraction of adjacent non-synonymous codons
• Genes under positive selection may have increased volatility
• Think about the distance from the stationary codon distribution
• No need to align!!
Plotkin et al, Nature 2004
Genome Evolution. Amos Tanay 2009
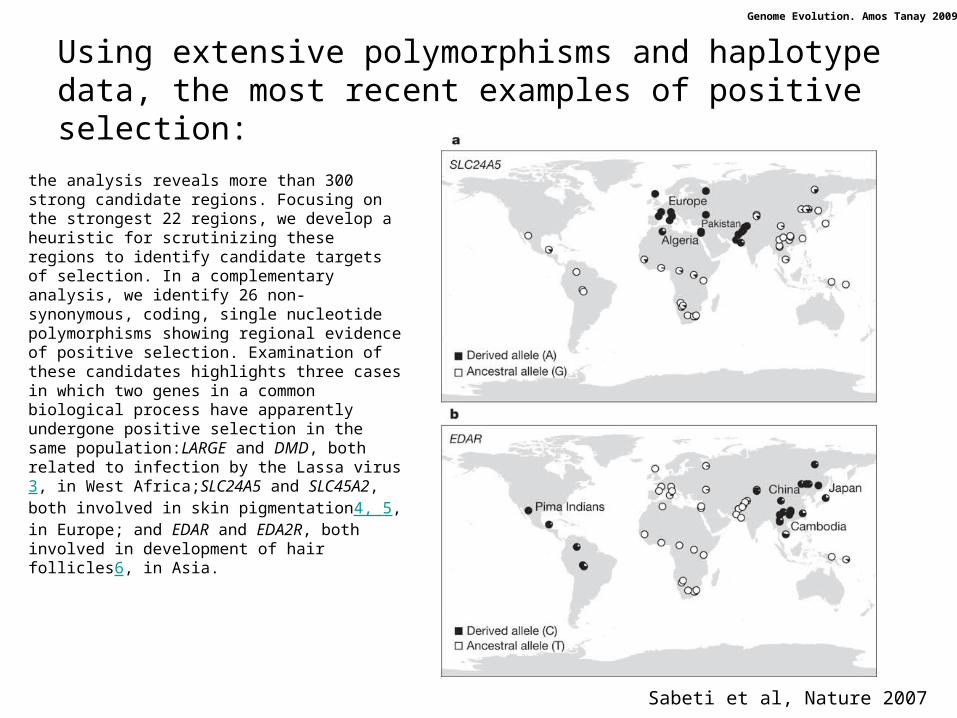
Using extensive polymorphisms and haplotype data, the most recent examples of positive selection:
Sabeti et al, Nature 2007
the analysis reveals more than 300 strong candidate regions. Focusing on the strongest 22 regions, we develop a heuristic for scrutinizing these regions to identify candidate targets of selection. In a complementary analysis, we identify 26 non-synonymous, coding, single nucleotide polymorphisms showing regional evidence of positive selection. Examination of these candidates highlights three cases in which two genes in a common biological process have apparently undergone positive selection in the same population:LARGE and DMD, both related to infection by the Lassa virus3, in West Africa;SLC24A5 and SLC45A2, both involved in skin pigmentation4, 5, in Europe; and EDAR and EDA2R, both involved in development of hair follicles6, in Asia.

Genome Evolution. Amos Tanay 2009
Time resolution of different positive selection methods
Sabeti et al, Science 2005