gulf of mexico hydrocarbon database: integrating heterogeneous data for improved model development
TRANSCRIPT

Gulf of Mexico Hydrocarbon Database: Integrating
Heterogeneous Data for Improved Model Development
Anne E. Thessen, Sean McGinnis, Elizabeth North, and Ian
Mitchellhttp://www.slideshare.net/athessen

Thank You to Data Providers• NOAA/NOS Office of Response and
Restoration• Commonwealth Scientific and Industrial
Research Organization• Environmental Protection Commission of
Hillsborough County• National Estuarine Research Reserves• Sarah Allan• Kim Anderson• Jamie Pierson• Nan Walker• Ed Overton• Richard Aronson• Ryan Moody• Charlotte Brunner• William Patterson• Kyeong Park• Kendra Daly• Liz Kujawinski• Jana Goldman• Jay Lunden• Samuel Georgian• Leslie Wade• British Petroleum
• Joe Montoya• Terry Hazen• Mandy Joye• Richard Camilli• Chris Reddy• John Kessler• David Valentine• Tom Soniat• Matt Tarr• Tom Bianchi• Tom Miller• Elise Gornish• Terry Wade• Steven Lohrenz• Dick Snyder• Paul Montagna• Patrick Bieber• Wei Wu• Mitchell Roffer• Dongjoo Joung• Mark Williams• Don Blake• Jordan Pino
• John Valentine• Jeffrey Baguely• Gary Ervin• Erik Cordes• Michaeol Perdue• Bill Stickle• Andrew Zimmerman• Andrew Whitehead• Alice Ortmann• Alan Shiller• Laodong Guo• A. Ravishankara• Ken Aikin• Tom Ryerson• Prabhakar Clement• Christine Ennis• Eric Williams• Ed Sherwood• Julie Bosch• Wade Jeffrey• Chet Pilley• Just Cebrian• Ambrose Bordelon

LTRANS
• Lagrangian Transport Model
• Open Source
• http://northweb.hpl.umces.edu/LTRANS.htm
• Used to predict transport of particles, subsurface hydrocarbons, and surface oil slicks (in development)
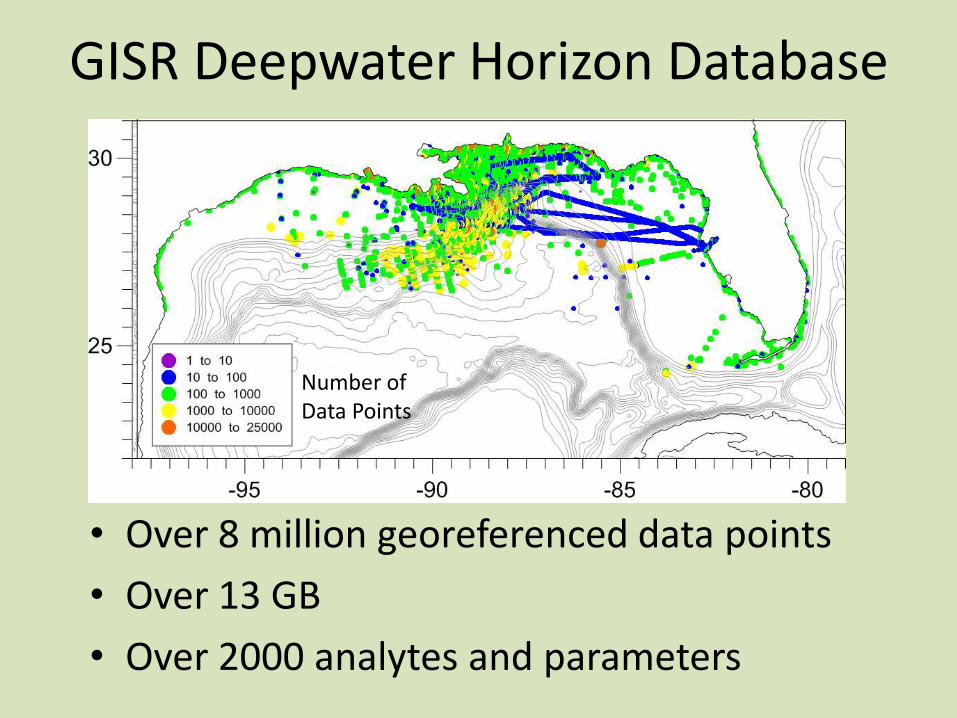
GISR Deepwater Horizon Database
• Over 8 million georeferenced data points
• Over 13 GB
• Over 2000 analytes and parameters
Number of Data Points

Database Contents
• Oceanographic Data
– Salinity
– Temperature
– Oxygen
– More
• Chemistry Data
– Hydrocarbons
– Heavy metals
– Nutrients
– More
n > 10,000
• Air
• Water
• Tissue
• Sediment/Soil
Challenges
• Obtaining the data
• Heterogeneity
• Metadata
• Comparison

The Great Data Hunt
• Discovery
– Project directory
– Funding agency records
– Literature
– Internet search
n = 146
Total Data Sets Discovered
Relevant

The Great Data Hunt
• Access
– Online
– Ask directly
– Literature
We received responses to 58% of our inquires and obtained 40% of the identified data sets
data and response
no data and response
no data no response
data no response
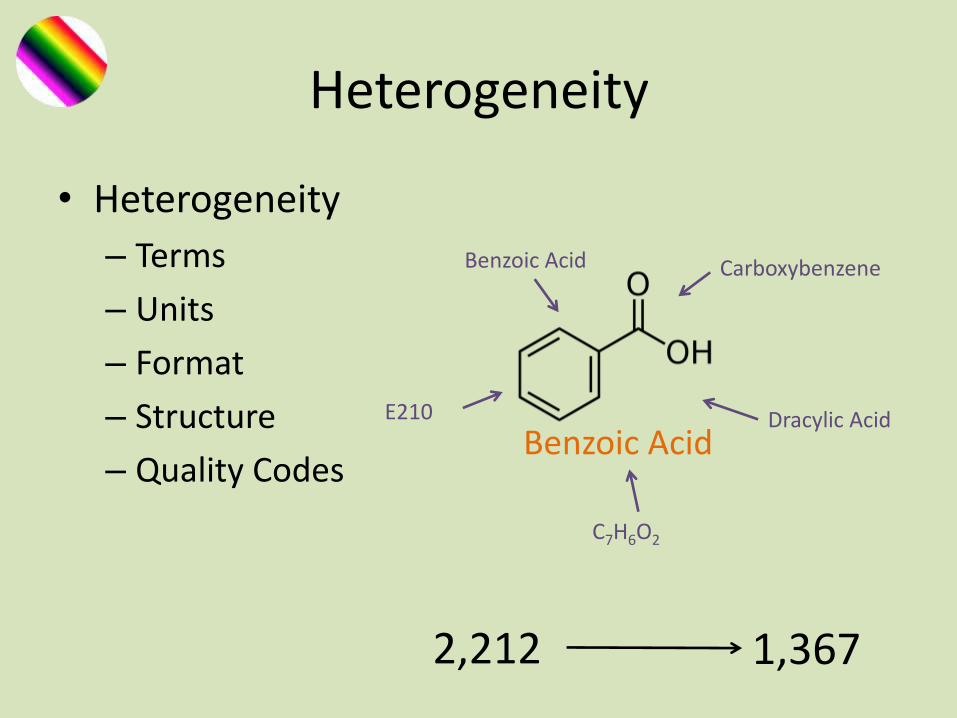
Heterogeneity
• Heterogeneity
– Terms
– Units
– Format
– Structure
– Quality Codes
Carboxybenzene
Benzoic AcidE210
C7H6O2
Dracylic Acid
Benzoic Acid
2,212 1,367

Heterogeneity
• Heterogeneity
– Terms
– Units
– Format
– Structure
– Quality Codes
n-Decane
ppb
ppbv ng/gμg/g mg/kgppt
parts per trillion
μg/kg
122 37
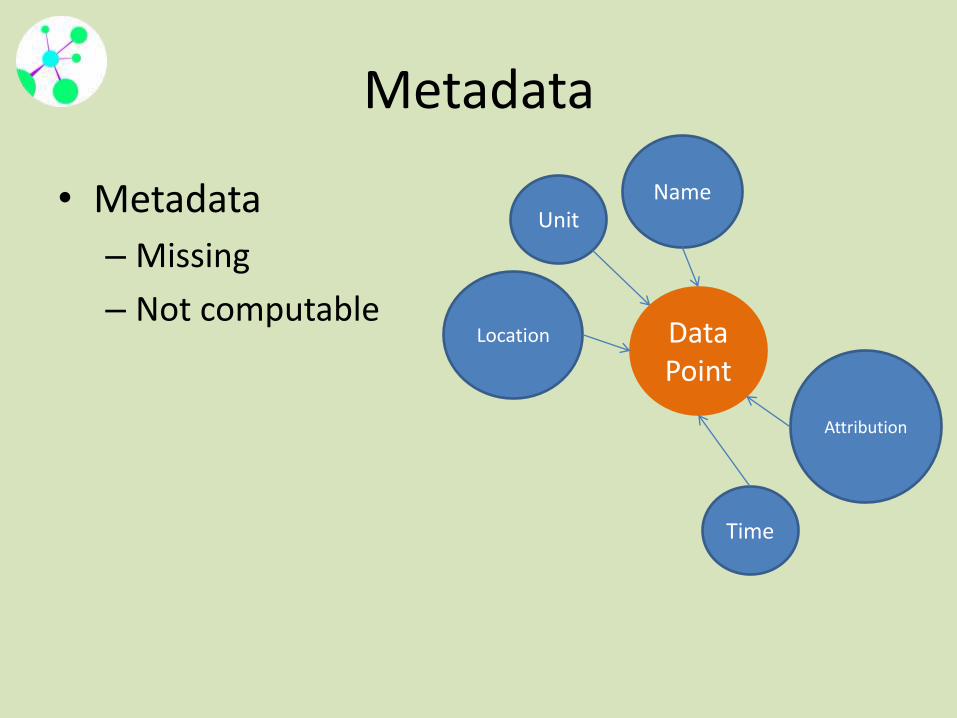
Metadata
• Metadata
– Missing
– Not computableData Point
UnitName
Location
Time
Attribution

Metadata
• Metadata
– Missing
– Not computableData Point
UnitName
Location
Time
Attribution
Uncertainty
Method
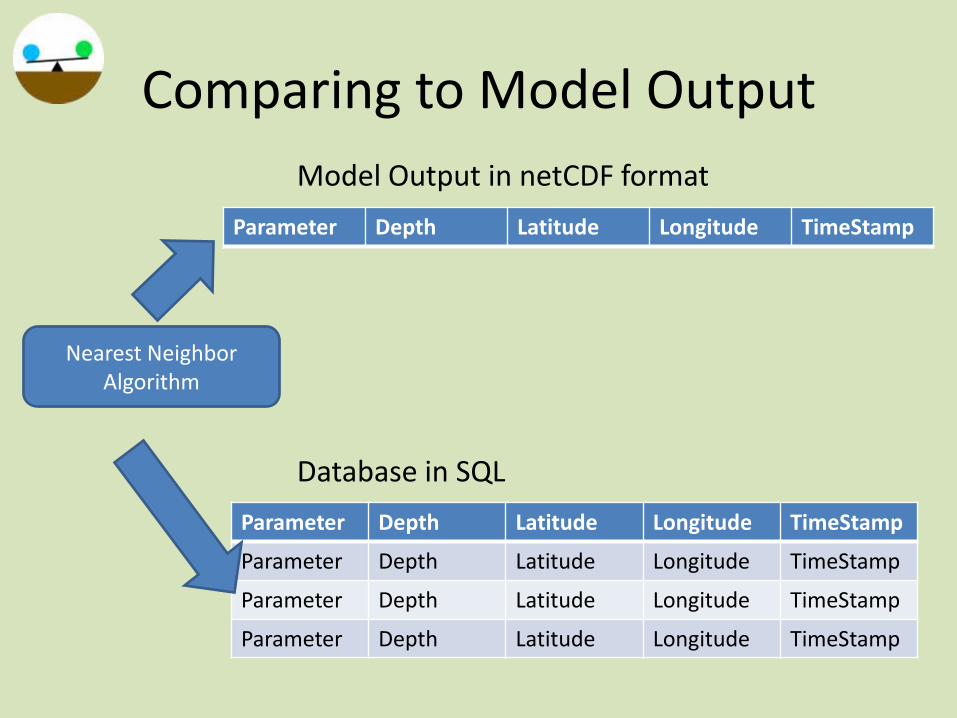
Comparing to Model Output
Parameter Depth Latitude Longitude TimeStamp
Model Output in netCDF format
Parameter Depth Latitude Longitude TimeStamp
Parameter Depth Latitude Longitude TimeStamp
Parameter Depth Latitude Longitude TimeStamp
Parameter Depth Latitude Longitude TimeStamp
Database in SQL
Nearest Neighbor Algorithm

Comparing to Model Output
• Set limits on what is considered nearest-neighbor
• Not all data points have to be matched
• Data points can have many neighbors
• Matching is done before query

Attribution and Citation
• Literature citation
• Repository identifier
• Generate new

Future Work
• More data
• User feedback
• Web Access
• Users’ Guide
• Manuscripts
• Improved query

Questions?

The Great Data Hunt
• Discovery
• Access
– Online
– Ask directly
– Literature
We received responses to 58% of our inquires and obtained 40% of the identified data sets
40% of those responses were received within 24 hours and 27% were received within the first week
0
5
10
15
20
25
First Day 2 to 7 8 to 30 31 to 60 61 to 90 91 to 120 121 to 150 151 to 180
Nu
mb
er o
f R
esp
on
ses
Time to First Response (Days)
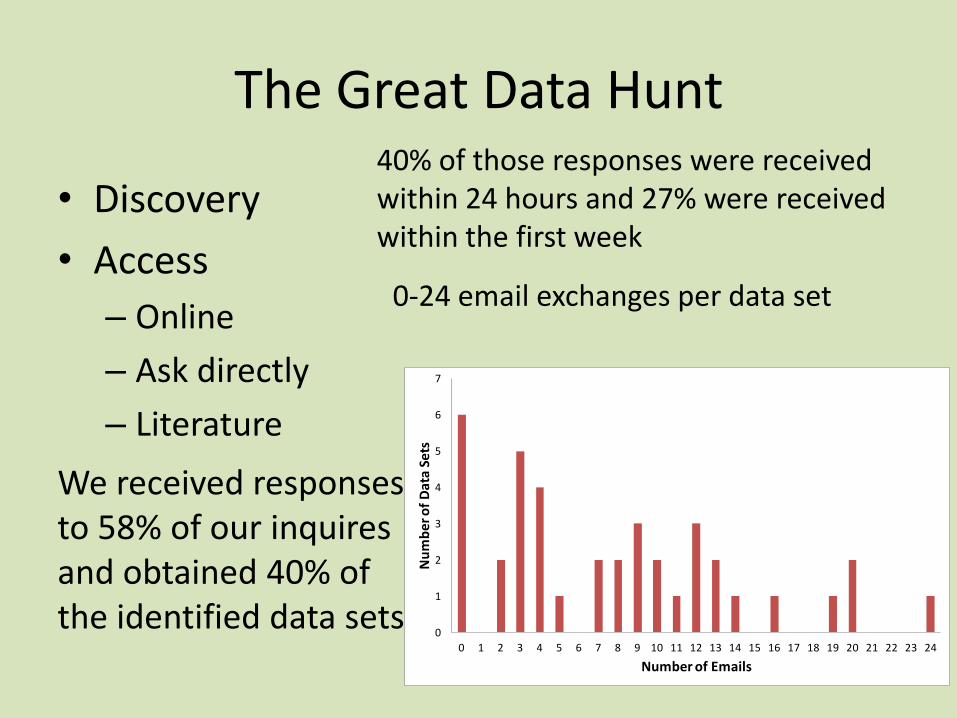
The Great Data Hunt
• Discovery
• Access
– Online
– Ask directly
– Literature
We received responses to 58% of our inquires and obtained 40% of the identified data sets
40% of those responses were received within 24 hours and 27% were received within the first week
0-24 email exchanges per data set
0
1
2
3
4
5
6
7
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Nu
mb
er o
f D
ata
Sets
Number of Emails

Why didn’t people share?
• Paper not published yet – 30%
• Passed the buck – 17%
• Too busy – 9%
• Medical problems – 9%
• Poor quality – 9%