implementation of speech tagging for teaching …
TRANSCRIPT

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
IMPLEMENTATION OF SPEECH TAGGING FOR TEACHING NIGERIA ENDANGERED LANGUAGE:
CASE OF YORUBA LANGUAGE
Tijani, R. A and Akiode, J. I Computer Science Department, Federal College of Education, Osiele Abeokuta
[email protected], [email protected] Abstract
Part of Speech tagging (POS) is usually a foundation stage for many Natural Language Processing (NLP) applications. Yoruba language is possibly going into extinction in few decades to come if proper measure is not taken. Therefore, this research paper proposes a stochastic learning approach, Hidden Markov Model (HMM), an existing model to be modified and implemented on Yoruba language (corpus) to ease its teaching and learning to younger generations. Yoruba literatures on grammar and morphology were reviewed to understand the syntax of the language and also to identify possible tagsets. 14 distinct tagsets were identified from Penn Treebank tagset and 500 randomly selected sentences from Lagos Nigerian Women Union (NWU) speech corpus were tagged for training when 100 sentences were set aside for testing purpose. Since there is no readymade standard annotated corpus, the manual tagging process to prepare corpus for this work was adopted. Raw Yoruba text was tagged as training data for HMM to learn the sentence structure of the language which it uses for tagging subsequently. Experiment was conducted on the model with 100 sentences to evaluate its accuracy using Tag-wise precision method; a precision of 0.71 and recall of 0.76 was achieved. The application was made platform independent.
Key words: Tagging, POS, Tagset, Corpus, NLP
Introduction
The importance of language in aiding human existence cannot be glossed over; it allows individual to
communicate meaningfully and also distinguished human from other animals. The only way Avogadro was
able to tell us that equal volume of all gases under identical temperature and pressure contains the same
number of molecules makes language unconventional to people which can be both an individual property
i.e. as knowledge and a social property i.e. when it performs its functions (Haruna, 2017).
NLP is an application and research area that enables machine to learn, read and understand human
languages (Abiola, Adetunmbi, & Oguntimilehin, 2013). Speech tagging, an aspect of NLP known as part
of speech tagging (POS tagging) is important in aspects such as Speech Synthesis, Information Retrieval,
Speech Recognition and machine translation (Francis, 2014).
African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
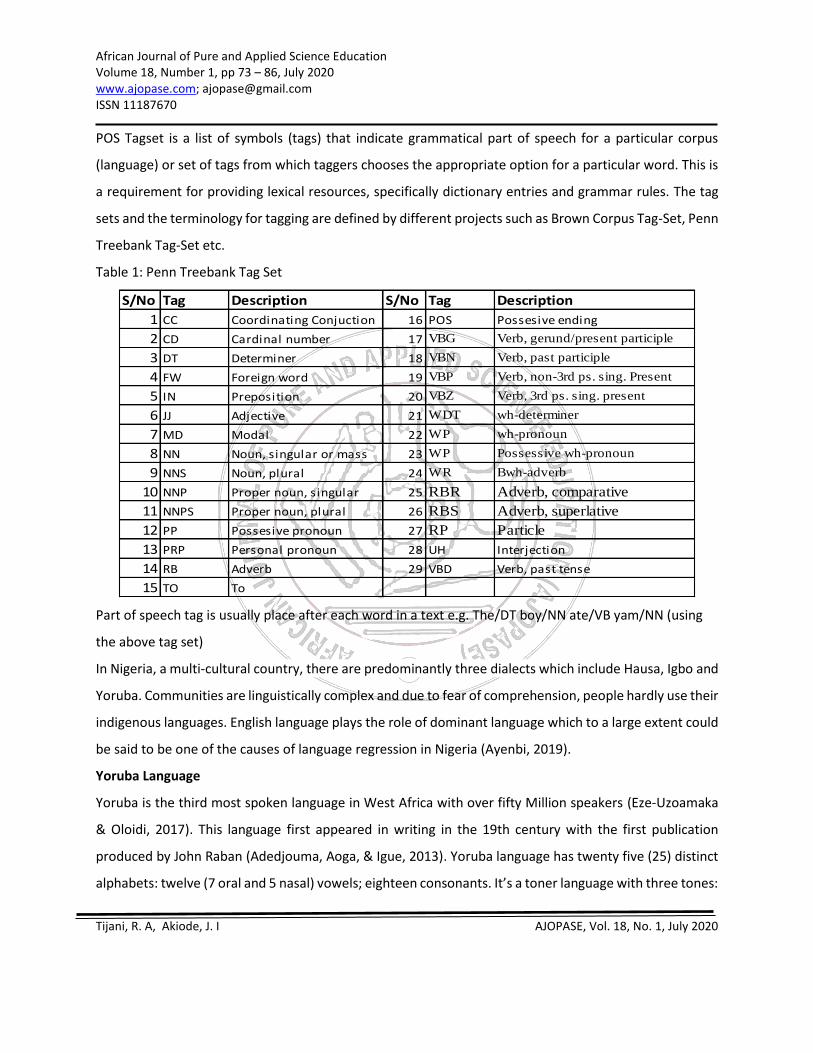
POS Tagset is a list of symbols (tags) that indicate grammatical part of speech for a particular corpus
(language) or set of tags from which taggers chooses the appropriate option for a particular word. This is
a requirement for providing lexical resources, specifically dictionary entries and grammar rules. The tag
sets and the terminology for tagging are defined by different projects such as Brown Corpus Tag-Set, Penn
Treebank Tag-Set etc.
Table 1: Penn Treebank Tag Set
S/No Tag Description S/No Tag Description
1 CC Coordinating Conjuction 16 POS Possesive ending
2 CD Cardinal number 17 VBG Verb, gerund/present participle
3 DT Determiner 18 VBN Verb, past participle
4 FW Foreign word 19 VBP Verb, non-3rd ps. sing. Present
5 IN Preposition 20 VBZ Verb, 3rd ps. sing. present
6 JJ Adjective 21 WDT wh-determiner
7 MD Modal 22 WP wh-pronoun
8 NN Noun, singular or mass 23 WP Possessive wh-pronoun
9 NNS Noun, plural 24 WR Bwh-adverb
10 NNP Proper noun, singular 25 RBR Adverb, comparative
11 NNPS Proper noun, plural 26 RBS Adverb, superlative
12 PP Possesive pronoun 27 RP Particle
13 PRP Personal pronoun 28 UH Interjection
14 RB Adverb 29 VBD Verb, past tense
15 TO To
Part of speech tag is usually place after each word in a text e.g. The/DT boy/NN ate/VB yam/NN (using
the above tag set)
In Nigeria, a multi-cultural country, there are predominantly three dialects which include Hausa, Igbo and
Yoruba. Communities are linguistically complex and due to fear of comprehension, people hardly use their
indigenous languages. English language plays the role of dominant language which to a large extent could
be said to be one of the causes of language regression in Nigeria (Ayenbi, 2019).
Yoruba Language
Yoruba is the third most spoken language in West Africa with over fifty Million speakers (Eze-Uzoamaka
& Oloidi, 2017). This language first appeared in writing in the 19th century with the first publication
produced by John Raban (Adedjouma, Aoga, & Igue, 2013). Yoruba language has twenty five (25) distinct
alphabets: twelve (7 oral and 5 nasal) vowels; eighteen consonants. It’s a toner language with three tones:

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
high, low and middle. The various Yorùbá dialects in Nigeria can be classified into three major dialect areas
viz:
i. North-West Yorùbá NW which include Ibadan, Oyo, Ogun and Lagos (Éko areas),
ii. Central Yoruba(CY) which include Igbomina, Yagba, Ife, Ekiti, Akure and Ijebu areas and
iii. South- East Yoruba (SEY) which include Okitipupa, Ondo, Owo, Sagamu and some parts of Ijebu
(Abiola, Adetunmbi & Oguntimilehin, 2015).
Morphology of Yoruba Language
Morphology in relation to linguistics simply means the study of the forms and structures of word in a
particular language. Morphological analysis is a fundamental piece of NLP; it is pivotal to language
comprehension and computerization as it represents word development in dialects.
Yoruba language is semi– agglutinative language which implies a language where words are comprised of
linearly successive morphemes with components representing a meaningful morpheme. As a rule, the
word order is Subject-Object-Action-word (Verb), though other word order applies since the language is
verse (Enikuomehin, 2015).
The language order can be
1. Sentence = Verb + Subject (Noun/Pronoun) + Object(Preposition/Noun)
Fig. 1.2: Tree diagram for Verb-Subject-Object (VSO)
Sentence
Verb Subject Object
Noun Pronoun Preposition
Noun
Yoruba Language
(25 Alphabets)
18 Consonants 12 Vowels
7 Oral 5 Nasal
Fig. 1.1: Yoruba Language Alphabets

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
2. Sentence = Subject + Verb(Noun/Pronoun) + Object(Adjective/Adverb)
Fig. 1.3: Tree diagram for Subject-Verb-Object (SVO)
Endangered Language
An endangered language is one on the path to extinction or a language that is at risk of falling out of use
as speakers die out i.e. speakers fail to pass it on from one generation to the next (Wamalwa & Maris,
2013). Research has it that the 7 billion inhabitants of the world speak only 3 per cent of the world’s 6,000
plus languages and more than half of the world’s population speaks English, Russian, Mandarin, Hindu or
Spanish. UNESCO decries the state that even languages with thousands of speakers are no longer being
acquired by children. It is estimated that about 90 per cent of the languages may be replaced by dominant
languages by the end of the 21st century. The threat posed by these five most spoken languages to the
third world countries where majority of their languages are minority is real and huge (Lee, 2016).
The identification of Yoruba language as endangered started a long time ago. Fabunmi (2005) and Fakoya
(2008), identified Yorùbá language as endangered and listed recommendations to help the language. Also,
in 2013, the same warning of extinction was made when research was done on its usage by secondary
school students in South Western part of the Country. He highlighted some recommendations which
include awareness, encouragement and making Yoruba an official language in its region (Balogun, 2013).
Oparinde (2018) could not agree less but also established Yoruba language as endangered and drew
attention to the eminent danger of extinction. He went further to list extinct languages such as Latin, Old
Dutch, Middle Dutch even Old English and Middle English among others. This paper upheld the position
that Yoruba language is endangered and proffers solution using POS tagging for easy
presentation/teaching of Yoruba language.
Model/Algorithms for POS Tagging
Existing Part of Speech tagging algorithms include Brill tagger, hidden Markov Model, the Baum-Weltch
algorithm e. t. c.
Sentence
Subject Verb Object
Noun Pronoun Adjective Adverb

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
i. Brill Tagger
Brill tagger is a machine learning method basically used for classification problems, where the goal is to
assign classifications to a set of samples. It does not use hand-crafted rules, language specific knowledge
or external lexicon but rather used rules learnt from detecting error (Larsson, 1995).
ii. Hidden Markov Model
The Hidden Markov Model (HMM) is a statistical tool for generating probabilistic sequence models
commonly used for POS-tagging which is an upgrade of Andrei Markov’s mathematical theory of Markov
process of the early 20’s. The tag sequence probability is determines by the product of transition
probability and emission probability (Garrette & Baldridge, 2012).
a. Viterbi Algorithm
This is a dynamic programming algorithm and the most common decoding algorithm for Hidden Markov
Models (HMMs). Viterbi algorithm is a search algorithm that avoids the polynomial expansion of a breadth
first search by trimming the search tree at each level. In a sentence or word sequence, HMM taggers
choose the tag sequence that maximizes as in formula:
𝑃 (𝑤𝑜𝑟𝑑| 𝑡𝑎𝑔) 𝑋 𝑃(𝑡𝑎𝑔| 𝑝𝑟𝑒𝑣𝑖𝑜𝑢𝑠 𝑁𝑡𝑎𝑔𝑠) (Antony, 2011).
b. Baum-Weltch / Expectation-Maximization (EM) algorithm
Baum-Weltch algorithm is one of the standard training algorithms for HMM. It is used where manually
annotated corpus is not available for training the Model. It works by iteratively computing an initial
estimate of the probabilities and use it to compute a better estimate thereby learn from each iteration.
Choice of POS Tagging Algorithm/Model
In 2003, HMM with Viterbi algorithm recorded overall highest accuracy and succeeded best in annotation
of both known and unknown words (Beata, 2003). In 2011, POS tagging on Malay using Trigram Hidden
Markov Model (THMM) recorded 67.9% accuracy (Mohamed, Omar, & Ab Aziz, 2011). Also in 2017, POS
Tagging of Bahasa Indonesia text achieved accuracy of 62.69 using Hidden Markov (Amrullah, Hartanto,
& Mustika, 2017). Hence, HMM is modified to accommodate Yoruba language since it has been used on
many other rich languages such as Malay, Swedish, Indonesia and so on.
Methodology
Word classes and sentence structure development of Yoruba language are evaluated from literature;
Penn Treebank tagset was adopted and discussions were made with Yoruba language experts to set

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
tagset. Also HMM was modified to accommodate Yoruba language. Finally, module from Natural
Language Toolkit (NLT) which is a suite of program modules, data sets and tutorials supporting research,
teaching in computational linguistics and natural language processing was adopted for the
implementation phase.
Tagset Preparation
We considered Penn Treebank tagset as a reference point for our tagset design diverging where
necessary. The Penn Treebank tagging guidelines for English proposed a set of 36 tags, which is believed
to be one of the standard tagset for English. However, the number and types of tags needed for POS
tagging differ from language to language. In the context of Yoruba language, we did not know of many
works on tagset design when we started the work. Thus, a Tagset of 14 distinctive tags was coined out of
the Penn Treebank tagset for the purpose of this study.
Table 2: Tagset used for Yoruba Language Tagging
Tag Description Tag Descriptio
n
Tag Description Tag Descriptio
NN Noun, singular or
Mass
RB Adverb CC Coordinating
Conjunction
MD Modal Verb
NNP Noun, plural DT Determina
nt
PRP Pronoun IN Preposition
NNPS Proper Noun
singular
TO To FW Foreign word
JJ Adjective VB Verb CD Cardinal number
Corpus Preparation
LAGOS-NWU (Lagos Nigeria Women Union) Yoruba Speech Corpus was our choice of digital resources due
to its arrangement and accuracy in words spelling. This is an open source material which may be used free
of licensing charges. The texts form this corpus required no cleaning; it has an arrangement of one
sentence per line which made it suitable for the study. LAGOS-NWU Yoruba Speech has 21,728 words
containing around 8000 distinct words. This may not be as large as some English corpus which may contain

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
millions of words but it is the best we could get as at the time of this research. 500 randomly selected
sentences where manually tagged as there was no readily available tagged corpus of Yoruba language
available. The manual tagging is done by the researcher with the aid of English-to-Yoruba Yoruba-to-
English Dictionary. Due to the cumbersome nature of manual tagging and time constraint, approximately
five hundred (500) randomly selected sentences were tagged from the main corpus. These tagged
sentences were used for training of the model (HMM).
Tagging Process
A training corpus consisting of manually annotated sentences (i.e. 500 sentences approximately 2,000
words) from the main corpus was prepared; this is used in the training of HMM model. Adopting the
supervised learning approach, the manually tagged corpus served as input which allows the model to learn
the rules of the language. The corpus reader reads the contents of the corpus and passes it to the
Tokenizer which breaks down the sentence to word level (tokens) using space character. The tagset
analyzer extracts the tags from the words and stores them in the database. The decoding algorithm
(Viterbi algorithm) computes the Part of Speech (POS) tag probabilities which are important for finding
the sequence of words in the input sentence. These tagged texts were used for training the POS tagger;
the trained tagger takes untagged text as an input and tags the words based on the knowledge that it has
acquired during the training to produce tagged text as output. Randomly 100 sentences distinctive of the
training data were selected for testing the model. This process can be represented using the diagram
below:
Fig. 2: Training process of HMM
Database
Training Corpus
Tokenizer
Tagset Tagset Analyzer
POS Tag
Probabilities
Tagger Model (HMM)

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
HMM Training Algorithm
# Input data format is “natural_JJ language_NN …”
make a map emit, transition, context
for each line in file
previous = “<s>” # Make the sentence start
context[previous]++
split line into wordtags with “ “
for each wordtag in wordtags
split wordtag into word, tag with “_”
transition[previous+“ “+tag]++ # Count the transition
context[tag]++ # Count the context
emit[tag+“ “+word]++ # Count the emission
previous = tag
transition[previous+” </s>”]++
# Print the transition probabilities
for each key, value in transition
split key into previous, word with “ “
print “T”, key, value/context[previous]
# Do the same thing for emission probabilities with “E”
Decoding with Viterbi Algorithm
Viterbi algorithm reduces the complexity of the HMM core issues ranging from finding the best part of
speech tag sequence for a given sequence of words in the input sentence to the polynomial time. For any
input sentence of length n, there are |K|n possible tag sequences. The exponential growth with respect to
the length 𝑛 means that for any reasonable length sentence, this search will not be tractable. The
probability of a label sequence given a set of observations is defined in terms of the transition probability
and the emission probability which is mathematically represented as:
𝑝(𝑥1 … 𝑥𝑛, 𝑦1 … 𝑦𝑛+1) = ∏ 𝑞(𝑦𝑖|𝑦1−2, 𝑦𝑖−1)
𝑛+1
1=1
∏ 𝑒(𝑥𝑖|𝑦𝑖)
𝑛
𝑖=1
… 𝑒𝑞 1.1

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
𝑟(𝑦1 … 𝑦𝑘) = ∏ 𝑞(𝑦𝑖|𝑦𝑖−2, 𝑦𝑖−1) ∏ 𝑒(𝑥𝑖|𝑦𝑖)
𝑘
𝑖=1
𝑘
𝑖=1
… 𝑒𝑞 1.1.1
Such that ‘r’ is considering the first k terms where 𝑘 ∈ {1. . 𝑛} and for any label sequence y1…yk. Also, is set
𝑆(𝑘, 𝑢, 𝑣) which is simply the set of all labeled sequences of length k that ends with the bigram(𝑢, 𝑣). We
have set of sequences 𝑦1 … 𝑦𝑘 such that 𝑦𝑘−1 = 𝑢, 𝑦𝑘 = 𝑣, 𝜋(𝑘, 𝑢, 𝑣) which is simply the sequence with
the maximum probability and can finally be defined as
𝜋(𝑘, 𝑢, 𝑣) = max⟨𝑦1…𝑦𝑘⟩ ∈ 𝑆(𝑘,𝑢,𝑣)
𝑟(𝑦1 … 𝑦𝑘) … 𝑒𝑞 1.2
𝜋(𝑘, 𝑢, 𝑣) = (𝜋(𝑘 − 1, 𝑤, 𝑢) × 𝑞(𝑣|𝑤, 𝑢) × 𝑒(𝑥𝑘|𝑣)) … 𝑒𝑞 1.3
Finally, we have
max
(𝑦1…𝑦𝑛+1)
𝑝(𝑥1 … 𝑥𝑛, 𝑦1 … 𝑦𝑛+1) = max𝑢∈𝑘,∈𝑣∈𝑘
(𝜋(𝑛. 𝑢, 𝑣) × 𝑞(𝑆𝑇𝑂𝑃|𝑢, 𝑣)) 𝑒𝑞 1.4
The pseudo code for Viterbi Algorithm
Input: a sentence 𝑥1 … 𝑥𝑛, parameters 𝑞(𝑠|𝑢, 𝑣) and 𝑒(𝑥|𝑠)
Initialization: Set 𝜋(0,∗,∗) = 1, and 𝜋(0, 𝑢, 𝑣) = 0 for all (𝑢, 𝑣) such that 𝑢 ≠∗ or 𝑣 ≠∗
Algorithm:
For 𝑘 = 1 … 𝑛,
- For 𝑢 ∈ 𝑘, 𝑣 ∈ 𝑘.
𝜋(𝑘, 𝑢, 𝑣) = max𝑤∈𝑘
(𝜋(𝑘 − 1, 𝑤, 𝑢) × 𝑞(𝑣|𝑤, 𝑢) × 𝑒(𝑥𝑘|𝑣))
𝑏𝑝(𝑘, 𝑢, 𝑣) = 𝑎𝑟𝑔 max𝑤∈𝑘
(𝜋(𝑘 − 1, 𝑤, 𝑢) × 𝑞(𝑣|𝑤, 𝑢) × 𝑒(𝑥𝑘|𝑣))
Set (𝑦𝑛−1, 𝑦𝑛) = max𝑢,𝑣
(𝜋(𝑛, 𝑢, 𝑣) × 𝑞(𝑆𝑇𝑂𝑃|𝑢, 𝑣))
For𝑘 = (𝑛 − 2) … 1,
𝑦𝑘 = 𝑏𝑝(𝑘 + 2, 𝑦𝑘+1, 𝑦𝑘+2)
Return the tag sequence 𝑦1 … 𝑦𝑛
The above algorithm has execution time of O(n|K|3), hence it is linear in the length of the sequence, and
cubic in the number of tags.
Implementation and Result
Software Specification

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
Natural Language Toolkit (NLTK) and Python programming Language Python with its Libraries are used.
PyCharm by jetbrain is adopted as the IDE and other Python libraries utilized for the purpose of this study
may include
● Scikit-learn, a Python module for machine learning which is built on SciPy. It runs on Python
version 3.5 or higher; NumPy version 1.11.0 or higher; SciPy version 0.17.0 or higher.
● Python NumPy which is often referred to as python alternative to MATLAB and often used with
SciPy module.
Flow Chat of Tagging Process
Tokenizer
Start
Input Yoruba Corpus (One sentence per
line)
Split sentence into words using space delimiter (“ ”)
Trained Model
Manually
Annotated
Corpus
Calculate Probable POS Tag
using Viterbi Algorithm
Assign POS Tag to each token
Display Tagged Corpus
Stop
Tokens
Fig. 3: Tagging Process

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
Result
Evaluation of the Model
Tag-wise precision recall is used to evaluate the model.
Precision = or
Recall = or
f-measure = or
Accuracy =
Where, TP= True positive, FP= False positive, TN= True negative and FN=False negative.
Tables 4.2 and 4.3 showed the precision and recall as obtained from the test as well as the F-measure
which is calculated from the relationship between recall and precision when β is 0.5.
Recall Precision
No of correct POS tag in gold data
No of correct tagged POS in tagged data
No of total POS tag in tagged data
No of correct tagged POS in tagged data
β (precision) + (Recall)
(β + 1.0) (Precision)(Recall)
TP
TP + FN
β x 1 + (1 - β) x 1 1
TP + TN
TP + TN+FP+FN
TP
TP + FP
HMM output- Notepad
Fig. 4.1: Output

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
S/No Tags Precision Recall F-measure
1 CC 0.73 0.76 0.74
2 CD 0.61 0.70 0.65
3 DT 0.68 0.71 0.69
4 FW 0.71 0.75 0.73
5 IN 0.63 0.69 0.66
6 JJ 0.59 0.61 0.60
7 MD 0.71 0.73 0.72
8 NN 0.61 0.69 0.65
9 NNS 0.71 0.71 0.71
10 NNPS 0.80 0.82 0.81
11 PRP 0.67 0.70 0.68
12 RB 0.78 0.80 0.79
13 TO 0.63 0.65 0.64
14 VB 0.71 0.72 0.71
Average 0.68 0.72 0.70
Discussion
The result of the experiment is satisfactory and it demonstrated the effectiveness of HMM as a POS
tagging algorithm using very small amount of training data set. However, this research might not record
a very high accuracy and precision like English language taggers but it is a ground breaking result for a
Language like Yoruba that has a few NLP tools such as tagset, corpus and so on. Also, the choice of
stochastic learning approach, HMM is a good choice known to improve in accuracy as size of training data
increases.
S/No Tags Precision Recall F-measure
1 CC 0.83 0.82 0.82
2 CD 0.64 0.72 0.68
3 DT 0.71 0.79 0.75
4 FW 0.69 0.73 0.71
5 IN 0.70 0.72 0.71
6 JJ 0.63 0.69 0.66
7 MD 0.70 0.74 0.72
8 NN 0.65 0.70 0.67
9 NNS 0.72 0.76 0.74
10 NNPS 0.83 0.87 0.85
11 PRP 0.65 0.73 0.69
12 RB 0.63 0.70 0.66
13 TO 0.75 0.80 0.77
14 VB 0.76 0.83 0.79
Average 0.71 0.76 0.73
Table 4.3: 100 Sentences
Fig.4.2.1: Accuracy graph for 50 sentences
Table 4.2: 50 Sentences
Fig.4.3.1: Accuracy graph for 100 sentences

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
Conclusion
This paper is focused on creating a platform that can break down Yoruba corpus into appropriate part of
speech for basic understanding of words, function and its uses. This platform will simplify the teaching of
the language to younger generation and also build their interest to want to learn more about the
language. Such modern digital resources will be attractive to younger learners, providing a fun and
painless route to serious learning.
References
Adedjouma, S. R, Aoga, J. O, & Igue, M. (2013). Part-of-Speech tagging of Yoruba Standard , Language of
Niger-Congo family, 1(1), 2–5.
Abiola, O. B., Adetunmbi, A. O., & Oguntimilehin, A. (2013). A Computational Model of English To Yoruba
Noun-Phrases Translation System, 2013(1), 34–43.
Abiola, O. B., Adetunmbi, A. O., & Oguntimilehin, A. (2015). Using Hybrid Approach for English- To-
Yoruba Text to Text Machine Translation System ( PROPOSED ), 4(8), 308–313.
Amrullah, A. Z, Hartanto, R & Mustika, I. W. (2017). A comparison of different part-of-speech tagging
technique for text in Bahasa Indonesia. Proceedings - 2017 7th International Annual Engineering
Seminar, InAES 2017. https://doi.org/10.1109/INAES.2017.8068538
Ayenbi, O. F. (2019). Language regression in Nigeria, (April), 51–64. https://doi.org/10.4000/esp.136
Balogun, T. A. (2013). African Nebula , Issue 6 , 2013 An Endangered Nigerian Indigenous Language : The
Case of Yorùbá Language Temitope Abiodun Balogun Balogun , An Endangered Nigerian Language,
(6). Retrieved from
https://pdfs.semanticscholar.org/8136/84d9e7b182ea85a0cdb53cef342e44122e1e.pdf?_ga=2.213
446038.326713198.1579613088-1127722245.1554325916
Beata, M. (2003). Comparing Data riven Algorithm for POS Tagging of Swedish. Centre for Speech
Technology,Department of Speech, Music and Hearing, Royal Insitute of Technology, Sweden, SE-
100, 44–52.
Enikuomehin Oluwatoyin A. (2015). A Computerized Identification System for Verb Sorting and
Arrangement in a Natural Language : Case Study of the Nigerian, 3(1), 43–52.
Eze-Uzoamaka, P., & Oloidi, J. (2017). International Journal of Arts and Humanities ( IJAH ). International
Journal of Arts and Humanities (IJAH) Bahir Dar- Ethiopia., 6(21), 2006–2017.

African Journal of Pure and Applied Science Education Volume 18, Number 1, pp 73 – 86, July 2020 www.ajopase.com; [email protected] ISSN 11187670
Tijani, R. A, Akiode, J. I AJOPASE, Vol. 18, No. 1, July 2020
https://doi.org/10.1111/MEC.14437
Fabunmi, F. A. (2005). Is Yorùbá an Endangered Language ? ∗, 14(August 2004), 391–408.
Fakoya, A. A. (2008). Endangerment scenario : The case of Yorùbá. California Linguistic, XXXIII(1), 1–23.
Francis, M. (2014). a Comprehensive Survey on Parts of Speech Tagging Approaches in Dravidian
Languages, (August), 7–10.
Garrette, D., & Baldridge, J. (2012). Type-Supervised Hidden Markov Models for Part-of-Speech Tagging
with Incomplete Tag Dictionaries. Emnlp, (July), 821–831.
Haruna, H. H. (2017). Linguistic Diversity and Language Endangerment: Towards the Revitalisation of
Bole Language In Nigeria. International Jornal for Innovative Research in Multidisciplinary Field,
3(10), 108–112. Retrieved from
https://www.researchgate.net/publication/324528843_Linguistic_Diversity_and_Language_Endan
gernment_Towards_the_Revitalisation_of_Bole_Langauge_in_Nigeria
Larsson, M. (1995). Part-of-Speech Tagging Using the Brill Method. Technology.
Lee, N. H. (2016). Assessing levels of endangerment in the Catalogue of Endangered Languages ( ELCat )
using the Language Endangerment Index. Language in Society, 2(45), 271–292.
https://doi.org/10.1017/S0047404515000962
Mohamed, H., Omar, N., & Ab Aziz, M. J. (2011). Statistical malay part-of-speech (POS) tagger using
Hidden Markov approach. 2011 International Conference on Semantic Technology and Information
Retrieval, STAIR 2011, (June), 231–236. https://doi.org/10.1109/STAIR.2011.5995794
Oparinde, K. M. (2018). Language Endangerment : The English Language Creating a Concern for the
Possible Extinction of Yorùbá Language Language Endangerment : The English Language Creating a
Concern for the Possible Extinction of Yorùbá Language *. Journal of Communication, 8(2), 112–
119. https://doi.org/10.1080/0976691X.2017.1396006
Antony, P. J (2011). Parts Of Speech Tagging for Indian Languages: A Literature Survey. International
Journal of Computer Applications, 34(8), 975–8887.
Wamalwa, E. W., & Maris, S. (2013). Language Endangerment and Language Maintenance : Can
Endangered Indigenous Languages of Kenya Be Electronically Preserved ? Language Endangerment
and Language Maintenance : Can Endangered Indigenous Languages of Kenya Be Electronically
Preserved ? Nternational Journal of Humanities and Social Science, 3(7), 258–266.