importancia del tratamiento de datos perdidos. aplicación en estudios longitudinales...
TRANSCRIPT

IMPORTANCIA DEL TRATAMIENTO DE DATOS PERDIDOS. APLICACIÓN EN ESTUDIOS
LONGITUDINALES PEQUEÑOS
PedroJ.MallolRosellóMásterBioinformáticayBioestadísticaDepartamentoEstadísticaUniversidaddeBarcelonaDirectora:NuriaPérezÁlvarezTutor:AlexandreSánchezPlaEntrega:31Mayo2017
EstaobraestásujetaaunalicenciadeReconocimiento-NoComercial-SinObraDerivada3.0EspañadeCreativeCommons

i
Títulodeltrabajo: Importanciadeltratamientodedatosperdidos.aplicaciónenestudioslongitudinalespequeños
Nombredelautor: PedroJ.MallolRosellóNombredelconsultor/a: NuriaPérezÁlvarezNombredelPRA: AlexandreSánchezPlaFechadeentrega(mm/aaaa): Mayo2017Titulación: MásterBioinformáticayBioestadísticaÁreadelTrabajoFinal: StrategiesfordealingwithMissingdatainlongitudinaldataIdiomadeltrabajo: Español
Palabrasclave EQ5D, calidad vida, MICE, datos perdidos, datoslongitudinales,MCAR,MAR,MNAR
Resumen del Trabajo (máximo 250 palabras): Con la finalidad, contexto de aplicación,metodología,resultadosiconclusionesdeltrabajo.Contexto: Pese a que se suele hacer un gran esfuerzo a la hora de la planificación yrealizacióndelasinvestigacionesclínicas,lapérdidadedatosesunfenómenoquesiemprevaaestar presente y está demostrado que una pérdida de datos puede conllevar unos resultadoserróneos.Aunqueenlasgrandesinvestigacionesestepuntosueleestarcontroladoparaasíevitarunapérdidainnecesariadetiempoydinero,enlasqueserealizanmásapequeñaescalanosesuele contemplar. Creemos pues conveniente realizar una pequeña demostración de laimportanciaquetienenlosdatosperdidosennuestrasinvestigacionesylasposiblesconsecuenciasquepuedendarsealnotenerlosencuenta.Métodos:Partiremosdeunabasededatossencillaybastante limitadatantoentamañocomoenvariabilidaddedatos.ParaellonosbasaremosenloscuestionariosdecalidaddevidaEQ5D,en loscualeshemossimuladounaperdida segúndiferentesmecanismos (MCAR,MAR,MNAR)yendiferentesporcentajes(10%,20%,30%).Resultados:Cuantomayorporcentajedepérdida,mayordesviaciónrespectoa larealidadpresentarán nuestros resultados. Para pérdidas de datosMCAR yMAR será mejor realizar latécnicadeImputaciónMúltiple,encambioparaMNAResmejoroptarporPairwiseConclusiones:EsmuyimportanteconocernuestraBasedeDatos.Saberquéporcentajedepérdida tenemosyqué tipodepérdidaestáafectandoanuestrosdatos,así comoconocer losdiferentesmétodosqueexistenpara tratar losdatosperdidosypoderaplicarelmás idóneoanuestrocasoparticular.

ii
Abstract(inEnglish,250wordsorless):
Background:Althoughagreateffortisusuallymadewhenplanningandconductingclinicalresearch,missingdatawillalwaysbepresentanditisdemonstratedthatthismaybiastheresultsobtained.Thissituation isusuallyundercontrol in largeandwellstructuredclinicalresearch inorder to avoid loss of time and money, but in a small scale, this situation is not usuallycontemplated.Forthisreason,ademonstrationoftheimportanceofdealingwithmissingdataismandatory.Methods:Asmallandlimiteddatasetiscreatedinordertosimulateasmallclinicalresearch.Weperformmissingdataaccordingtodifferenttypesoflossmechanisms(MCAR,MAR,MNAR)andindifferentpercentagesofmissing(10%,20%,30%).Results:Thegreaterpercentageofloss,thegreaterdeviationfromrealitywillpresentourresults.ForMCARandMARmechanisms,Multipleimputationmustbethemethod,whereasforMNARitisbettertochoosePairwise.Conclusions:Itisveryimportanttounderstandourdataset.Toknowwhatpercentageoflosswehaveandwhichmechanismofmissingdatawehave,aswellastoknowthedifferentmethodsthat exist to dealwith themissing data and to be able to apply themost appropriate to ourparticularresearch.

iii
ÍndiceResumen ............................................................................................................. 11. Introducción ..................................................................................................... 3
1.1.- Clasificación de los mecanismos de pérdidas de datos ........................... 61.2.- Clasificación de los patrones de pérdidas de datos ................................. 81.3.- Métodos de determinación de mecanismo de pérdida ............................ 81.4.- Principales métodos de imputación ......................................................... 9
2. Objetivos del Trabajo .................................................................................... 182.1 Enfoque y método seguido ....................................................................... 192.2 Planificación del Trabajo .......................................................................... 202.3 Creación de la Base de datos .................................................................. 222.4 Simulación de pérdidas ............................................................................ 232.5 Evaluación calidad vida ............................................................................ 24
2.5.1.- Comparación descriptiva ............................................................... 242.5.2.- Comparación variable “Índice” ....................................................... 25
2.6 Tratamiento de los datos perdidos ........................................................... 262.6.1.- Técnicas Tradicionales .................................................................. 27
2.6.1.1- Listwise/Pairwise en la fase descriptiva .................................. 272.6.1.2- Listwise en la variable “Índice” ............................................... 27
2.6.2.- Imputación de datos (Imputación múltiple) .................................... 282.6.2.1- Imputación en la fase descriptiva ............................................ 302.6.2.2- Imputación en la comparación de la variable “Índice” ............. 30
3. Evaluación de Resultados ............................................................................. 343.1- Fase Descriptiva ..................................................................................... 34
3.1.1- Independiente del mecanismo de pérdida ...................................... 343.1.2- Independiente del porcentaje de pérdida ....................................... 36
3.2- Variable Índice ........................................................................................ 383.2.1- Listwise ........................................................................................... 383.2.2- Imputación Múltiple ......................................................................... 40
4. Interpretación de Resultados ........................................................................ 424.1- Fase Descriptiva ..................................................................................... 424.2- Variable Índice ........................................................................................ 43
5. Conclusiones ................................................................................................. 466. Observaciones finales ................................................................................... 487. Glosario ......................................................................................................... 508. Bibliografia ..................................................................................................... 539. Anexos .......................................................................................................... 5610. Material Complementario ............................................................................ 68

1
Resumen Pese a que se suele hacer un gran esfuerzo a la hora de la planificación yrealización de las investigaciones clínicas, la pérdida de datos es un fenómeno quesiempre va a estar presente y está demostrado que una pérdida de datos puedeconllevarunosresultadoserróneos. En las grandes investigaciones que tienen una gran financiación detrás, estepuntosueleestarcontroladoparaasíevitarunapérdidainnecesariadetiempoydinero,peroaúnasí,nossorprendeencontrarnosalgunosestudiosrelevantesdondenosehatenidoencuentalosdatosfaltantes.Sihablamosdelosestudiosanivellocaldealgunoscentrosdeinvestigación,esteproblemaseagravaaúnmás. Losdatosfaltantessonunodelospuntosquesedeberíandetenerencuentaencualquierinvestigación.Creemospuesconvenienterealizarunapequeñademostraciónde la importancia que tienen los datos perdidos en nuestras investigaciones y lasposiblesconsecuenciasquepuedendarsesinosetratanadecuadamente. Paraello,nospondremosenuna situaciónmuy simpleperomuycomúnqueafectaalosestudioscondatoslongitudinales.Partiremosdeunabasededatossencillaybastantelimitadatantoentamañocomoenvariabilidad.ParaellonosbasaremosenloscuestionariosdecalidaddevidaEQ5D,enloscualeshemossimuladounapérdidasegúndiferentesmecanismos(MCAR,MAR,MNAR)yendiferentesporcentajes(10%,20%,30%).Veremos que cuantomayor porcentaje de pérdida tenemos, mayor desviaciónrespectoalarealidadpresentaránnuestrosresultados.ParapérdidasdedatosMCARyMARserámejorrealizar latécnicade ImputaciónMúltiple,encambioparaMNAResmejoroptarporPairwise.ConcluiremosqueesmuyimportanteconocernuestraBasedeDatos.Saberquéporcentajedepérdidatenemosyquétipodepérdidaestáafectandoanuestrosdatos,asícomoconocerlosdiferentesmétodosqueexistenparatratarlosdatosperdidosypoderaplicarelmásidóneoanuestrocasoparticular.

2

3
1. Introducción Lapérdidadedatoseninvestigaciónessiempreunarealidadyunproblemaaconsiderar.Esinevitableentodoestudiodeinvestigaciónexistandatosdelosquenopodamosdisponerpordebidosdiversosmotivos. Enelcampodelosensayosclínicostambiénvemoséstaproblemáticaconmásasiduidaddeloquenosgustaría. EnunarevisióndelopublicadosobreeltemaentreJulioyDiciembrede2001(Wood,White et al. 2004) [1] en revistasmédicas de alto impacto, se detectan 63ensayosconpresenciadedatosfaltantesdeuntotalde71,paraun89%.Enunarevisióndel2014deensayosaleatorizadosporgrupos(Díaz-Ordaz,Kenwardetal.2014)[2],sedetectan95deuntotalde132,paraun72%;sinembargoaquísedestacan41ensayos(31%) en los cuales “no pudo verificarse la presencia de datos faltantes a partir delreportepublicado”.Buuren(2012)criticalapobrezadelosreportesdedatosfaltantesenlaspublicaciones.Ejemplifica,medianteunacoleccióndepequeñasbasesdedatos(Hand,Dalyetal.1994) [3], labajacalidaddeestos reportes:de las510basesde lacolección,sólo13conteníanuncódigoparalosdatosfaltantes. Encualquiertipodeanálisisestadísticosedeseahacerinferenciasválidassobreunapoblacióndeinterés.Lapresenciadeinformaciónfaltanteenunamatrizdedatosllevaconsigociertosinconvenientes,dentrodeloscuales,segúnHorton&Lipsitz(2001)[5],seencuentran:pérdidadeeficiencia,complicacionesenelanálisisdedatosfaltantes,yademásestimadoressesgadosqueponenenriesgolavalidezdelproceso. Además, enmuchos ensayos clínicos a pequeña escala que suelen hacer losinvestigadoresensuspropioscentros,nosesueletenerencuentaestetipodesituación.Bienpordesconocimientodelamismaoporquesencillamentenoledanlaimportanciasuficienteasuinvestigación.Soloenelcasodeunaposiblepublicaciónexistenalgunosinvestigadoresquemandanarevisarsutrabajoporunprofesional. Enalgunosdiseñosdeexperimentosesmáscomúnlapresenciadeinformaciónfaltantequeenotros,comoeselcasodelosrelacionadosconmedidasrepetidas;estosdiseños en el campo de la experimentación son frecuentes, especialmente en lascienciasmédicas,biológicasyagronómicas;noobstante,presentanciertasdificultadescon sumanejo, debido no solo a la ocurrencia de observaciones faltantes, sino a lacaracterísticadedependenciaentrelasobservacionesrepetidashechassobrelamismaunidad experimental, pues este tipo de diseños son raramente balanceados ycompletos. Estas dificultades llevan consigo complicaciones en el modelamiento,pérdidadeprecisiónenestimaciones,yademáslainferenciaseveafectadayaquesepuedenpresentarfuncionesnoestimables.

4
Losdatoslongitudinalesenlosquecadasujetoounidadexperimentalsemideuobservaenocasionesmúltiplesesprobablequeposeanmuchosdatosperdidosdebidoa muy diversos motivos, como a la fatiga del informante, desconocimiento de lainformaciónsolicitada,alrechazodelaspersonasainformaracercadetemassensibles,a la negativa de participar en una investigación, incluso a problemas asociados a lacalidaddelmarcodelmuestreo.Además,tambiénhemosdeconsiderarlaposibilidaddelaexistenciadeobservaciones“aberrantes”opocoprobables. Paraevitaresapérdidadedatos,podríamosactuarentresmomentosdiferentesdelestudio:
1. Duranteeldiseñodelexperimento.Teniendoencuentaelporcentajededatosquepodemos“perder”yaumentandoeltamañomuestralparapoderllegaralmínimorequerido.
2. Durantelaetapaderecoleccióndedatosmedianteunadecuadomonitoreode
lacalidaddelosdatos.
3. Una vez recolectados los datos. Este momento corresponde al proceso deanálisisdeconsistenciadelosdatosyvaloresperdidos,quedebeformarpartede todo estudio, antes de la estimación de los estadísticos que permita darrespuestaalosobjetivosdefinidos.
Referente al último apartado, existen varias formas de resolver estaproblemática.Solucionesquepasanpor“obviar”esosdatos,oestimarlosenfuncióndevariosmétodos(imputación). Duranteladécadadelossetenta,laimputacióndedatossignificabaidentificarysustituirlosregistrossininformación.Enesecontexto,losprocedimientoshot-deck,ensusdistintasvariantes,seaplicabanparasuplirinformaciónencensosyencuestas,ylosmétodosdeajusteporpromediosycold-deckeranfrecuentementeutilizados. En Rubin (1976), se propuso un marco conceptual para el análisis de datosfaltantessustentadoenmétodosdeinferenciaestadística.Posteriormente,laaparicióndelalgoritmoExpectationMaximization(EM)permitiógenerarestimadoresrobustosapartirde laaplicacióndelmétododemáximaverosimilitud (MV) (Dempster, Laird, yRubin, 1977) [6], en donde las observaciones faltantes se asumen como variablesaleatoriasylosdatosimputadossegeneransinnecesidaddeajustarmodelos. Más tarde, Rubin (1987), introdujo el concepto de imputaciónmúltiple (IM),sustentadoenlapremisadequecadadatofaltantedebeserreemplazadoapartirdem>1 simulaciones. La aplicación de esta técnica se facilitó con los avancescomputacionales y el desarrollo de los métodos bayesianos de simulación queaparecieronhaciafinalesdelosochenta(Schafer,1997)[7].Apartirdeesemomento,sepropicióelusointensivodeestosalgoritmos,debidoaquedistintasrutinasdedeIMyMVseincluyeronenpaquetescomercialesydeaccesogratuito.

5
Duranteeldeceniodelosnoventaseregistraronavancesnotables.Elmétododereponderación,históricamenteutilizadoporlosestadísticosdeencuestas,semodificócon el propósito de utilizarlo en la imputación de datos en modelos de regresión(Ibrahim,1990)[8].Tambiénsedesarrollarontécnicasenelcampodelabioestadística,conelpropósitoderesolversituacionesenlasquelosdatosfaltantesdependíandelascaracterísticasdelapoblación. Elobjetivoeradisponerdealgoritmosapropiadosparaanalizardatosclínicos,yaqueenestetipodeinvestigacionesescomúnqueelnúmerodepacientessereduzca,ylosestudiosconcluyanconmenospersonasdelasqueiniciaron(Little,1995)[9]. EnLittle (1992) [10]yLittleyRubin(1987) [11], losmétodosde imputaciónseclasificancomosemuestraacontinuación:-Análisisdedatoscompletos(Listwise)-Análisisdedatosdisponibles(Pairwise)-Imputaciónpormediasnocondicionadas-Imputaciónpormediascondicionadasmediantemétodosderegresión-Máximaverosimilitud(MV)-Imputaciónmúltiple(IM) La literatura consideraqueeldesarrollodelmétodo IMha zanjadoeldebaterespectoalamejorformadeimputardatosomitidos.Sinembargo,losestadísticosdeencuestashandemostradoquelassolucionespropuestasnotienenencuentaeldiseñodelamuestra,nilasprobabilidadesdeseleccióndelasunidadesdeanálisis,cuandolosdatos provienen de muestras complejas, situación que introduce sesgos en lasestimaciones.

6
1.1.- Clasificación de los mecanismos de pérdidas de datos Esimportantedeterminarelpatrónymecanismodepérdidadedatosparapoderescogerunmétododeimputaciónapropiado.Rubin(1976)[12]clasificólosmecanismosdepérdidadedatosentrestiposdiferentes:• Completamente al azar (MCAR:missing completely at random). Representa una
situación para la cual la ausencia es independiente de las variables en suinvestigación.Esunaausenciadedatosdebidaexclusivamentealazar. Dicho de otra manera, la probabilidad de que un sujeto presente un valorausenteenunavariablenodependenideotrasvariablesdelcuestionarionidelosvalores de la propia variable con valores perdidos. Las observaciones con datosperdidossonunamuestraaleatoriadelconjuntodeobservaciones. Porejemplo,untuboquecontieneunamuestradesangredeun individuoesrotoporaccidenteoenelcontextodeloscalidadesdevida,cuandolapérdidadelainformaciónnotienenadaqueverconelpropiocuestionariodecalidaddevida.Es decir, se pierde un calidad de vida o se olvida la paciente de rellenar ciertoapartado.
• Perdidosalazar(MAR:missingatrandom).Serefierecuandolaausenciadedatos
está ligada a las variables independientes del estudio, pero no a la variabledependiente.
Cuandolossujetoscondatosincompletossondiferentessignificativamentedelosquepresentandatoscompletosenalgunavariable,yelpatróndeausenciadedatospuedeserpredecibleapartirdevariablescondatosobservadosenlabasededatosdelestudioquenomuestranausenciadedatos. Porejemplo,sisehaceuntestdeaptitudaunosalumnosyalosquesuperanunanotadecorteestablecidaseleshaceotromásdifícilmientrasquealosdemásno.Portantoéstostienendatosperdidosparalasegundavariableysedebealasobservacionesdelaprimera.
• UnprocesoquenoesniMCARniMARsedenominanoaleatorio(MNAR:missing
nonatrandom).Estoscasossedancuandolapérdidadedatossedebealavariabledependiente,yposiblementeaalgunavariableindependiente.
Porejemplo,uncasoMNARescuandoenuncuestionariolepreguntasaalguienporsurentaanualyéstenocontestaporqueesmuyalta.

7
Otraformamastécnicadeentenderestaclasificaciónseríaidentificandoalosregistrossininformaciónconunavariablebinaria(Z).Seasumeelvalor“1”sieldatoexistey“0”encasocontrario.Rubinnosdicequelaausenciadedatosdebeanalizarsecomounfenómenoestocástico,porloqueZdebeconsiderarseunavariablealeatoriacondistribucióndeprobabilidadconjunta,lacualdacuentadelporcentajedeomisiónexistenteydesurelaciónconlasobservacionescompletas. SeaYcom=(Yobs,Ymis)lavariabledeinterés,dondeYobscorrespondealvectordedatosobservadoseYmisalvectordedatosfaltantes.SeconsideraqueunprocesodedatosomitidossegeneraMARsiladistribucióndelosvaloresobservadosnodependedelpatróndecomportamientodelosregistrossininformación,esdecir,dependedelosvaloresobservados.
Ymis:P(Z|Ycom)=P(Z|Yobs) En el caso de MCAR, ocurre cuando la omisión no depende de los datosobservados,esdecir,dependedelosdatosnoobservados.
P(R|Ycom)=P(Z)
MCAR yMAR se suelen clasificar como ignorables, mientras queMNAR seconsiderancomonoignorables.

8
1.2.- Clasificación de los patrones de pérdidas de datos Además de esta clasificación según su mecanismo de pérdida, se puedenobservarvariospatronesdepérdidadedatos.Ambasclasificacionessonmuyútilesalahoradesaberquémecanismodeimputaciónpoderaplicar. Lospatronessepuedenclasificaren:
• Monótona(terminal):Losdatossepierdencuandounpacientenorealizamáscalidadesdevidaenunciertomomentodelestudio
• Intermitente:Lapérdidadedatossucedenentrelasdiferentesevaluacionesdel
paciente.
• Mixto:Estepatrónsucedecuandoaunprocesodepérdidaintermitentelesigueunodepérdidamonótona.
1.3.- Métodos de determinación de mecanismo de pérdida En la actualidad existen muchos métodos para determinar el mecanismo depérdidadedatos.Métodosbasadosentestdehipótesis.ShonaFielding(2009)[13]nosofreceun trabajocon ladescripciónde losmétodosmascomúnmenteusadosyunacomparaciónentreellos. Little(1986)[14]desarrollóuntestbasadoenmedias.ListingySchlittgen(1998)[15-16]desarrollarontambiénuntestbasadoenmediasyademásunprocedimientono-paramétrico que combina varios test de Wilcoxon. Schmitz y Franz (2002) [17]desarrollaronunversiónno-paramétricadelprimertestdelosanterioresautores.Diggle(1998)[18]utilizóunaaproximaciónparadeterminarsilaspérdidassonunamuestraaleatoriadelapoblacióntotal.Ridout(1991)[19]adoptóunenfoqueparecidoaDiggle,pero utilizando una regresión logística. Fairclough (2002) [20] describió unprocedimientomuyparecidoalmétododeRidout.

9
1.4.- Principales métodos de imputación Procedimientostradicionales• Análisisdedatoscompletos(ListwiseocasedeletionLD):Estaanálisisconsisteen
trabajarsoloconlainformacióncompletaparatodaslasvariables.Eslaprácticamásutilizada,aunquesereconocequenoeslamásapropiadaporquegenerasesgosenloscoeficientesdeasociaciónydecorrelación(KaltonyKaspryk,1982)[21].
• Análisis con losdatosdisponibles (Pairwisedeletion): Estaposibilidadabogapor
trabajar con toda la información disponible (Available-case(AC)). En este casoobtendremos distintos tamaños muestrales lo que limita la comparación deresultados.EstemétodotambiénasumeunpatrónMCARenlosdatosomitidos.
• Reponderación:Deestaformaseintentareducirelsesgocuandonosesatisfacees
supuestoMCARenlosdatosomitidos.Esposibleaplicardiferentesmétodosparareponderarlasobservaciones.Losponderadores(wi)seinterpretancomoelnúmerodeunidadesde lapoblaciónquerepresentaacadaelementoen lamuestra,yescomúnquelosalgoritmosdereponderaciónseapliquenparacompensarlafaltaderespuestaensubgruposdeinterés.
Cuandoenunasubclasesedetectaausenciadeinformación,losponderadoresde las unidades que sí respondieron se utilizan para ajustar los factores deexpansión, de tal forma que la submuestra observada genere estimacionescompatiblesconlosvalorespoblacionesdelasubclasedeinterés.Paraesteprocesosepuedenutilizartantodatospropiosdelamismamuestraparaponderarcomodatosexógenosprovenientedeotrasbasesdedatos.

10
ImputaciónSimple
• Imputaciónpormediaincondicional:Laimputaciónpormediaincondicionalesunaestrategiaqueconsisteencalcularlamediamuestralparacadaunadelasvariablesquetienedatosfaltantes,yluegoutilizarestevalorparasustituirtodoslosvaloresfaltantesquetienelavariablecorrespondiente.
Ejemplosdondesepuedeverclaramentelaineficienciadeestemétodosonestudiosdondequeremosverelsalariodeunafamilia.Sifaltaun30%delosdatos,estaremosobteniendoun30%deregistrosconunvalorfijo(lamedia)yvarianza 0, lo cual subestimará la dispersión de lamuestra total, además deincidirenelcoeficientedecorrelaciónconotrasvariables.Elvalormediodelavariable se mantiene, pero otros estadísticos que definen la forma de ladistribución (varianza, covarianza, quantiles, sesgo, kurtosis…) se pueden verafectados (Schafer yGraham2002) [22]. A pesar de todos los inconvenientesseñalados, es común el uso de esta metodología ya que se piensa que elpromediodelosdatosesunvalorrepresentativodelosvaloresquefaltan.
• Imputación por media condicional: Una variante del modelo anterior que
consiste en formar categorías a partir de covariables correlacionadas con lavariabledeinterés,eimputarlosdatosfaltantesconobservacionesprovenientesdelasubmuestraquecompartecaracterísticascomunes(AcockyDemo,1994)[23].
Al igualque la imputacióndemedias incondicionales, seasumeque lafalta de datos presenta un patrón MCAR y en este caso, existirán tantospromedioscomocategoríasseformen,locualayudaadisminuirlossesgos,peroenningúncasoloselimina.
• Imputaciónconvariablesficticias:Estemétodoconsisteencrearunavariable
indicadorparaidentificarlasobservacionescondatosomitidos(CohenyCohen1983yCohenetal2003)[24-25].Seestimaunmodeloderegresión𝑦 = 𝛼 + 𝛽𝑍,dondesuponemosquelavariablepredictora(y)eslacondiciónderespuesta(“1”sitenemosrespuestay“0”sinolatenemos),entonces,alaspersonascondatosfaltantesselesasignalamediadeestavariablepredictora.
Debido a las confusiones a las que puede inducir estemétodo, no serecomiendaestatécnicadeimputación.

11
• Imputación mediante una distribución no condicionada (Hot-deck): Estemétodo tiene como objetivo llenar los registros vacíos (receptores) coninformación de campos con información completa (donantes), y los datosfaltantes se reemplazan a partir de una selección aleatoria de valoresobservados,locualnointroducesesgosenlavarianzadelestimador(Madow,NilssenyOlkin,1983)[26].
EstemétodohasidoutilizadodesdehacemuchotiempopororganismostanimportantescomolaoficinadelcensodelosEEUU.Elalgoritmoconsisteenubicarregistroscompletoseincompletos,identificarcaracterísticascomunesdedonantesyreceptores,ydecidir losvaloresqueseutilizaránpara imputar losdatos omitidos. Para la aplicación del procedimiento es fundamental generaragrupaciones que garanticen que la imputación se llevará a cabo entreobservaciones con características comunes, y la selección de los donantes serealizaenformaaleatoriaevitandoqueseintroduzcansesgosenelestimadordelavarianza.
Existenvariantesdelprocedimientohot-deck.El“algoritmosecuencial”,partedeunprocesodeordenacióndelosdatosencadasubgrupoyseleccionadonantesenlamedidaquerecorreelarchivodedatos.Suaplicaciónsuponequela falta de respuesta se distribuye en forma aleatoria en cada una de lascategorías,peroencasodequelafaltaderespuestaseconcentreenunestratoconpocasobservaciones,esposiblequesegenerenestimadoressesgadosenlamedidaqueelprocedimientoseleccionevariasveceselmismodonante.
Porsuparte,el“métodoaleatorio”identificaregistrossindatosyeligeenformaestocásticaaldonante.Tambiénexistelaposibilidaddequeeldonanteseael“vecinomáscercano”alregistrosindatos,ylaselecciónseefectúaapartirdeladefinicióndecriteriosdedistancia.
Elhot-deckylasvariantesquesehancomentadoseconsideranmejoresopciones que los procedimientos listwise deletion, pairwise deletion, y essuperioralosmétodosdemediascondicionadasynocondicionadas,yaquenointroducesesgosenelestimadorysuerrorestándar.Sisedeseapreservar ladistribucióndeprobabilidaddelasvariablesimputadas,conformealaopinióndealgunosautoresseconsideraqueelprocedimientohot-deckesmáseficienteque el algoritmo la imputaciónmúltiple y la regresión paramétrica (Durrant,2005)[27].

12
• Imputaciónporregresión:Comosunombreindica,laimputaciónporregresiónreemplaza valores faltantes con respuestas predichas de un modelo deregresión.Enunanálisismultivariante,loscasoscompletossonutilizadosparaestimarunmodeloderegresióndondelavariableincompletaeslarespuestaylasvariablesexplicativassonalgunasdelasvariablescompletas.Elmodeloderegresión estimado permite estimar respuestas predichas para los casosincompletos.
• Imputaciónporregresiónestocástica:Laimputaciónporregresiónestocástica
tambiénutilizaecuacionesderegresiónparapredecirlasvariablesincompletasapartirdelasvariablescompletas,perorequiereunpasoadicionalqueconsisteenaumentarcadapredicciónconuntérminoresidualdistribuidomediante ladistribucióndelerror,generalmenteunadistribuciónnormal.Añadirresiduosalos valores imputados reestablece la pérdida de variabilidad de los datos yefectivamente elimina el sesgo asociado con los esquemas de imputación deregresiónestándar.Conestemétodode imputaciónobtenemosestimacionesinsesgadasdelosparámetrosbajodatosMAR.
• Imputaciónpormáximaverosimilitud:Losmétodosdemáximaverosimilitudse
pueden aplicar en cualquier problema de estimación. En el análisis de datosomitidos, y asumiendo que los datos faltantes siguen un patrón MAR, sedemuestraqueladistribuciónmarginaldelosregistrosobservadosestáasociadaaunafuncióndeverosimilitudparaunparámetrodesconocido,bajoelsupuestodequeelmodeloesadecuadoparaelconjuntodedatoscompleto.
DeacuerdoaLittleyRubin(1987),aestafunciónseleconocecomolafunción de verosimilitud, la cual ignora el mecanismo que generó los datosfaltantes (verosimilitudde losdatosobservados conformeaShafer yGraham(2002) [22]. El procedimiento para estimar los parámetros de un modeloutilizandounamuestracondatosfaltantesseresumeacontinuación:
i. Estimar losparámetrosdelmodelo con losdatos completos con lafuncióndemáximaverosimilitud.
ii. Utilizarlosparámetrosestimadosparapredecirlosvaloresomitidos.iii. Sustituirlosdatosporlaspredicciones,yobtenernuevosvaloresde
losparámetromaximizandolaverosimilituddelamuestracompleta.
Unprocedimientoeficienteparamaximarlaverosimilitudcuandoexistendatos faltantes es el algoritmo Expectarion-Maximization (Dempster, Laird yRubin(1977)[28]

13
ImputaciónMúltiple Elmétododeimputaciónmúltipleconsisteenrealizarvariasimputacionesdelasobservaciones faltantes para luego analizar los conjuntos de datos completados ycombinar los resultados obtenidos para obtener una estimación final. El análisis deimputaciónmúltipleestádivididoentresfases:Fasedeimputación,fasedeanálisisyfasedepuestaencomún.
o Lafasedeimputacióncreamúltiplescopiasdelosconjuntosdedatos(m),y cadaunadeellas contienediferentesestimacionesde los valoresperdidos.Conceptualmente, este paso es una versión iterativa de la imputación porregresión estocástica, aunque sus fundamentos matemáticos se basan enmuchasocasionesenlosprincipiosdeestimaciónbayesiana.
o Elobjetivodelafasedeanálisis,comosunombreindica,esanalizarlos
conjuntos de datos rellenados. Este paso aplica los mismos procedimientosestadísticosqueunindividuohubierautilizadosituvieratodoslosdatos.Laúnicadiferenciaesquerealizamoscadaanálisismveces,unaparacadaconjuntodedatosimputados.
o Lafasedeanálisisnosllevaamconjuntosdeestimacionesdeparámetros
yerroresestándar,con loqueelpropósitode la fasedepuestaencomúnescombinar todo en un conjunto simple de resultados. Rubin (1987) perfilófórmulasrelativamentesencillasparaponerencomúnlasestimacionesdelosparámetros y los errores estándar. Por ejemplo, la estimación del parámetropuestoencomúnessimplementelamediaaritméticadelasmestimacionesdelafasedeanálisis.Combinarloserroresestándaresligeramentemáscomplejoperosiguelamismalógica.Elprocesodeanalizarconjuntosdedatosmúltiplesyponerencomúnlosresultadosparecelaborioso,perolospaquetesdesoftwarede imputaciónmúltiple automatizan completamente el procedimiento. Lasmestimacionessoncombinadasenunaestimaciónenconjuntoyunamatrizdevarianzas-covarianzas utilizando las reglas de Rubin, que están basadas en lateoría asintótica en un marco bayesiano. La matriz de varianzas-covarianzascombinada incorpora la variabilidad dentro de la imputación (incertidumbresobre los resultados de unos conjuntos de datos imputados) y la variabilidadentre las imputaciones (relejando la incertidumbre debido a la informaciónperdida).

14
1.5 Calidad de vida eq-5d1 EQ-5Desunamedidaestandarizadadelasituacióndelasaluddesarrolladoporel “EUROQOLGroup”con la finalidaddeaportarunamedidadeevaluaciónsimpleygenérica. Nos aporta de unamanera fácil y sencilla una herramienta que nos permiteevaluar la calidad de vida de los pacientes. Además de ser una herramientaestandarizadaquenosotorgalaposibilidaddereproducirlo,dándoleasíungranvalorencualquierensayo/estudioclínico. ElcuestionarioEQ-5Destádesarrolladoparaqueelencuestadolopuedarellenarporsimismo,loqueleconfiereunagranversatilidadalahoradeadministrarlo.Puederealizarsepormediostanvariadoscomoelcorreopostal,emaileinclusoenlasaladeesperade las consultas.Ademásesuncuestionariobrevequeno llevamásdeunospocosminutoscompletarlo. Existendiferentestiposdecuestionariosenfuncióndeloquesequieraanalizar:EQ-5D-3L,EQ-5D-5LyEQ-5D-Y.Soncuestionariosbastantesimilaresylascaracterísticasdescritas anteriormente es común a todos ellos. Para nuestro trabajo, nos vamos acentrarenelprimero(EQ-5D-3L) 1http://www.euroqol.org/

15
EQ-5D-3L(ANEXO1)consisteendospáginas.Unapáginadescriptivayotraconunaescalavisualanalógica(VAS).• Laescalavisualanalógicaconstadeunareglaverticalquevadesdeel0(abajo)hasta
el100(arriba).Dondeel0serefierealpeorestadodesaludposibleyel100serefierealmejorestadodesalud.
La forma de determinar el estado de salud en este caso esmás sencillo. Basta conapuntarelvalorquevade0-100quemarqueelencuestado.Paravaloresperdidosseusael999.• Elsistemadescriptivoconstade:5dimensiones(5D):
o 1.-Movilidado 2.-CuidadoPersonalo 3.-Actividadesdetodoslosdíaso 4.-Dolor/Malestaro 5.-Ansiedad/Depresión.
Cadadimensióntiene3niveles(3L):
o 1.-Sinproblemaso 2.-Algunosproblemaso 3.-Verdaderosproblemas.
Para determinar el estado de salud se combinan todas las posibilidades queofrece el sistema descriptivo (5 dimensiones y 3 niveles), teniendo un total de 243estadosdesaludposibles.

16
Nosreferimosacadaestadodesaludcomouncódigode5dígitosqueseobtienedelasrespuestasdadasporelencuestado.Asípues,unaencuestaquenotieneningúnproblema en las cinco dimensiones se le asigna un valor de “11111”,mientras queestadodesalud“11223”nosindicaquenotieneningúnproblemaenlamovilidadyenelcuidadopersonal,algunosproblemasenlasactividadesdiariasyeneldolor/malestaryverdaderosproblemasconlasansiedad/depresión.Losvaloresperdidossecodificancomo9. Estosestadosdesaludsepuedenresumirenunúnicovalorparapodertrabajardeunaformamascómoda.Estevalordenominado“índice”seobtieneaplicandounafórmulaquebásicamenteañadeciertosvalores(tambiéndenominados“pesos”)alosdiferentesnivelesdelasdiferentesdimensiones. Estos “pesos” se han obtenido exclusivamente para cada país. Es importanteremarcarquecadapaístieneunosvaloresespecíficosquenohandeserlosmismosparaotrospaíses.Asípuespodemosencontrarnoselcasodequeparaunpaísenconcretoseledamasimportanciaalahoradetenerproblemasenlamovilidadqueenotro.Portantotendráunvalor“índice”másnegativoenesepaísunperfil“31111”queenotro(suponiendoqueelrestodedimensionessevalorenigual). Obtenemosdeestamaneraunvalor índicequevadesde 1(mejorestadodesaludposible)a0(peorestadodesaludposible).

17

18
2. Objetivos del Trabajo Comohemosvistohastaahora,esmuycomúntenerdatosfaltantesennuestrasinvestigaciones y está demostrado que esta pérdida de información afecta a losresultados.Unpuntopreocupanteesvercomoenlamayoríadelasinvestigacionesnotienenencuentaestehecho,obteniendoasíresultadosquepodríansercuestionables. El tratamiento de los datos faltantes debería ser tan importante como elplanteamiento inicial de la investigación y el posterior control de lamisma. Intentarevitarlapérdidadedatosdeberíadeserprioritarioparaevitarsesgosimportantesalahoradeobtenerresultados. Como hemos dicho anteriormente, las investigaciones importantes (comopueden ser los Ensayos Clínicos) suelen tener este punto en consideración, pero lasinvestigacionesmáspequeñasnosuelentenerencuentaesteproblema.Investigacioneshumildesquepueden tener su importancia, puestoquepuedendar pie a ideasquepueden acabar desarrollando una gran investigación. Un ejemplo de ésto son losestudiosqueserealizananivellocalenloscentrosdeinvestigación. Existemucha literatura acerca de cómo tratar los datos perdidos en grandesinvestigacionesycongrandesbasesdedatos,peronohemosencontradomuchoscasosdonde se hayan analizado estudios pequeños. Éstos, presentan unas limitacionesintrínsecasqueloshacenunpocomásespeciales.Porello,queremosrealizarnuestrotrabajosobreunestudiopequeño. Asípues,queremosconcienciaralosinvestigadoressobrelaimportanciadelosdatosqueperdemosdurantenuestroestudio.Además,queremosproponerdiferentesalternativasarealizarenelcasodequetengamosunapequeñaylimitadabasededatosinicialconlaquepretendamosiniciarnuestrainvestigación.

19
2.1 Enfoque y método seguido La forma más sencilla y evidente de ver la importancia de tratar los datosperdidos en cualquier investigación es partir de una base de datos completa e irgenerandopérdidas.Posteriormentesevuelvenaanalizarlosdatosysecomparanlosresultadosobtenidosparaversuvariación. Ennuestrocasovamosagenerarunabasededatosficticiayvamosagenerarpérdidasdedatosen funciónde losdiferentesmecanismosdepérdida (MCAR,MARMNAR)yenfuncióndediferentesporcentajedepérdidas(10%,20%,30%). De esta forma, a parte de ver el efecto de la pérdida de datos en nuestrosresultados,podemosestablecerapartirdequéporcentajedichapérdidaempiezaasersignificativaysiexistealgúntipoderelaciónconlosdiferentestiposdepérdidas. Partiremos de una base de datos pequeña y básica como ejemplo de unainvestigaciónsencillaquesepuedellevaracaboencualquiercentrodeinvestigación.

20
2.2 Planificación del Trabajo Debido al campo tan amplio al que puede aplicar este trabajo, nos vamos acentrarenunadelasáreasquemasseveafectadaporesteprocesodepérdidadedatos.Estamoshablandodelosestudiosconcalidaddevida. Unbuenensayoclínicopresentaundiseñoinicialvalidadoyunposteriorcontrolexhaustivoconsusconstantesmonitorizacionesyrevisionespertinentes,peroaúnasí,pareceserqueexistenciertosaspectosdeellosquenosetomantanencuentacomootrosobjetivosapriorimasimportantescomolasupervivencia,tiempoalarecaída,etc. Unejemplodeestosprocedimientossonloscalidadesdevida.Muchasvecesnose ledatanta importanciaarellenarunaencuestasobreelestadodesalud,comoalechodetenerquerecibiruntratamiento.Yestafaltadeimportanciavienetantodelinvestigadorcomodelpropiopaciente.Esraroqueunpacientesedejedetomarunadosisdesutratamiento,porqueentiendequeesloqueestámejorandosuenfermedad,encambio,noestanraroqueunpacientenorelleneuncalidaddevidaporquenoloveprioritarioalahoradesucuración. Enlaprácticahabitualsevenmuchoscasosdondeelmismopacienteesquienseniegaarellenarelcalidaddevida,seleolvidacumplimentarlo, lorellenaalazaroinclusoeselpropio familiardelpacientequiencontestaa laspreguntas.Además,elhechodetenerquehacerelmismocuestionariovariasvecesalolargodeltratamientolohacemástedioso.Todoésto,máslapocaimportanciaquelesuelendarlospacientes,hacequeseaunodelosprocedimientosquemásdatosfaltantesacumula. Porellovamosautilizarunabasededatosbasándonosenloscalidadesdevida.Por ser uno de los ítems mas castigados por este problema. En concreto noscentraremosenlacalidaddevidaEQ5Dquesesueleusarenlamayoríadelosensayosclínicosdeoncología. PartiremosdeunapoblacióndondeTODOSlosdatosestaránrecogidosyapartirde ella, obtendremos diferentes subgrupos donde existen pérdidas de datos. Sedefiniránpreviamentequétiposdepérdidasdedatosvamosarealizarytambién,enquéproporción.

21
Posteriormenteutilizaremosalternativasqueexistenparaabordarelproblema.Utilizaremosunadelastécnicasmáscomunesysencillasqueexisteyqueconsisteeneliminar los casos condatos faltantes (Listwise), trabajar con losdatosque tenemos(Pairwise) y una técnica de imputación que se considera de las más correctas parautilizarenestaproblemática,laImputaciónMúltiple. El trabajo se va a realizar mediante el programa estadístico R excepto lasimulacióndelosresultadosdelasencuestasylaobtencióndelavariable“Índice”,queseharealizadomedianteExcel.ÉstosedebeaqueparacalcularlavariableencuestiónserealizamedianteunafórmulaqueproporcionaEUROQOLgroupenformatoExcel2. LaplanificacióndeltrabajoserátalycomosedetallaenelANEXO2 2Seadjuntarájuntoconeltrabajodichaherramienta(“EQ-5D-5LCrosswalkIndexValueCalculatorMAC.xls”).

22
2.3 Creación de la Base de datos3 Comoesdeesperar,nopodemoshacerusodelosdatosgeneradosenunensayoclínicodebidoatodaslasclausulasdeprivacidadqueposeen.Realizarunapeticióndeuso,conllevaríaunacargadetrabajoextra,queparalafinalidaddenuestroTFMnoesnecesaria.Portodoello,noheutilizadolasvariablesdelensayoclínico,sinoquemehecentrado enunas variables específicas quenos interesan, partiendodeunabasededatosenblanco. Lascaracterísticasprincipalesdenuestrabasededatosson:
o Tamañode25pacientesqueseanalizanen2momentosdelainvestigación(50cuestionariosentotal).
o Variablesordinales,con3nivelescadauna.
o Sondatoslongitudinalesqueseobtienendelmismopacienteendiferentes
momentos.Loqueimplicaalahoraderealizaruntestdesignificancia,quequesondatospareados.
Generamos estocásticamente mediante la función RANDOM() de Excel lasrespuestasde los cuestionarios EQ5D.Dichas respuestashan sido introducidas en laherramienta de Excel específica proporcionada por EUROQOL para obtener así lasvariables“Perfil”e“Índice”.Guardamoslasimulaciónenunarchivoquesedenomina“Respuestas.xlxs”. Unavezcreadalabasededatosinicial,laexportamosaR.Laimportacióncreaunas variables que no están bien clasificadas, por ello se crea una función quemeayudaráare-clasificarlas(‘reclass’).Deestaforma,obtenemosunaestructuracorrectaparatrabajar. Para agilizar el proceso realizado hasta ahora, he unificado todos los pasosanterioresenunaúnicafunción.Llamamosalafunción‘DBprepare(BD)’yelargumentodeberádeserelnombredelaBasededatosentrecomillas(paraconvertirloen‘string’).LahojadelExceldondeseencuentranlosdatos,pordefectoserálaprimera. Paraelposteriorapartadodecreacióndepérdidas,vamosanecesitarunavariablenuevaparapoderutilizarlaalahoradesimularunapérdidaMAR.Porellocreamoslavariable“estudios”,quenosindicasielpacientetieneestudiossuperioresono.Unvalor0indicaquenotieney1nosestádiciendoqueelpacientetieneestudiossuperiores. 3TodoelcódigodeRutilizadoenestetrabajoseadjuntaráendosarchivodenominados“TFM.Rmd”y“TFM.html“.

23
2.4 Simulación de pérdidas NuestraideaescompararlosdiferentestiposdepérdidadedatossegúnpropusoRubinen1987asícomodiferentesgrados.Paraellovamosaestablecerpreviamenteelporcentajedepérdidadedatosquevamosatener:50cuestionariosx5variables=250ítems
• 10%depérdidasupone25ítemsmenos• 20%depérdidasupone50ítemsmenos• 30%depérdidasupone75ítemsmenos
Mediante R, generamos un código que genere la simulación de pérdidas,obteniendoasílasdiferentesbasesdedatosconlaspérdidascorrespondientes ParalageneracióndeunapérdidadedatosMCARhemossimuladoalazarlaspérdidasdetodoslos250ítemsquetenemosennuestroestudio.Obtenemosasí:
• MCAR_EQ5D10:BasededatosconpérdidasMCARal10%• MCAR_EQ5D20:BasededatosconpérdidasMCARal20%• MCAR_EQ5D30:BasededatosconpérdidasMCARal30%
Para la generación de una pérdida de datosMAR, hemos supuesto que lospacientesquenopresentanestudiossuperioresnorellenanelcuestionariodecalidadde vida correctamente y se dejan ítems sin rellenar. En cambio, los pacientes quepresentanestudiossuperioreshanrellenadoloscalidadesdevidacompletamenteysinpérdidas.Obtenemosasílassiguientesbasesdedatos:
• MAR_EQ5D10:BasededatosconpérdidasMARal10%• MAR_EQ5D20:BasededatosconpérdidasMARal20%• MAR_EQ5D30:BasededatosconpérdidasMARal30%
Porúltimo,paralageneracióndeunapérdidadedatosMNAR,simulamosquelospacientesquemenoríndicetienen(peorseencuentran),norellenancorrectamenteloscalidadesdevida.Obtenemoslassiguientesbasesdedatos:
• MNAR_EQ5D10:BasededatosconpérdidasMNARal10%• MNAR_EQ5D20:BasededatosconpérdidasMNARal20%• MNAR_EQ5D30:BasededatosconpérdidasMNARal30%
EnelANEXO3podemosencontrarunesquemade losdiferentespatronesdepérdidadedatosparapoderverlodeunaformamasvisual

24
2.5 Evaluación calidad vida Paraevaluarlacalidaddevidadelospacientesduranteeltratamiento,vamosaanalizarlodedosformas.Unaprimeramaneradescriptiva,dondevamosavervariacióndeporcentajesentrelospacientesquenotienenproblemasfrentealosquesípresentanalgún tipo de molestia. También lo veremos de manera más global dondecompararemos laevoluciónde lavariable“índice”comovariablequeaglutinaenunúnicovalortodaslascaracterísticasqueseconsideranimportantesalahoradeestimarlacalidaddevidadeunpaciente.2.5.1.-Comparacióndescriptiva Pararealizarunacomparacióndescriptiva,vamosareclasificarpreviamentelosnivelesdel calidadde vidaendos grupos.Unprimernivel quedenominaremos “Sinproblemas” y otro denominado “Con problemas”. El nuevo nivel “Sin problemas”englobalasrespuestasquetuvieroncomovalor“1”,yelnivel“Conproblemas”englobalasrespuestasquefueron“2”o“3”. De esta sencilla forma podemos ver si los pacientes pasan de un estado conciertosproblemasinicialesaunestadoenelqueseacabanresolviendo.Analizaremosestafasedescriptivaparalascincovariablesquerecogenuestrocalidaddevida. Para ello creamos una función en R denominada ‘Descriptiva (BD)’ que noscalculará el porcentaje de pacientes que no presentan problemas en los diferentesaspectos que estudia el calidad de vida (Movilidad, Cuidado Personal, Actividadesdiarias,Dolor,Ansiedad)

25
2.5.2.-Comparaciónvariable“Índice” Graciasalavariable“Índice”,podemosrealizarunacomparaciónglobaldeloscalidades de vida. Como ya se ha comentado anteriormente, existe un algoritmodependientedecadapaís,quenosidentificaelcalidaddevidaenunnúmeroquevaríaentre0.5y1.Amáscalidaddevidadelpaciente,estevalorseacercarámasal1. Asípues,vamosacompararelvaloríndicepromediodelasituaciónbasalfrenteal valor índice promedio de la situación final. Posteriormente evaluaremos si lasdiferencias son clínicamente significativas al 95% de confianzamediante un test designificancia. Hayquetenerencuentaquealutilizarunavariablecuyorangovade0.5a1,dichavariablevaaestartruncadaporarribayporabajo,porloquenopodremosteneruna distribución normal diga lo que diga nuestro test de normalidad. Ahora bien, situviéramosmuchasobservacionesentoncessiseríaprobablequesepuedaaproximarporunanormal,comopasaconlasproporciones,encuyocaso,elerrordeaproximaciónseríaasumible. Debidoaestadisyuntiva,paravalorarsihahabidodiferenciassignificativasentrelos diferentes timepoints, utilizaremos un test paramétrico (t-Student) y otro noparamétrico(Wilcoxon)yveremossicoincidenlosresultados. CreamosunafunciónenRdenominada‘Medias(BD)’quenosproporcionarálamediaylasdesviacionesestándardemaneraglobal,enloscuestionariosbasalesyenlosfinales,yotrafuncióndenominada‘ComparaMedias(BD)’,quenosaplicarálosdostestdesignificanciaestadísticaal5%(t-StudentyWilcoxon)sobrelamediabasalyfinaldelavariableÍndice. Un asunto importante a tener en cuenta en este punto es que debido a lascaracterísticas de nuestra investigación, necesitamos realizar un test estadístico condatospareados.Necesitamosquenuestropaciente tenga cuestionariode calidaddevidabasalyfinalparapoderhacerlascomparaciones.Porelloseránecesarioeliminardeestacomparativaalospacientesquenopresentenlosdoscalidadesdevida.

26
2.6 Tratamiento de los datos perdidos Debidoalascaracterísticasdenuestrabasededatos,vamosatrabajarconlosmétodosdeListwise,PairwiseeImputaciónMúltiple. Laformamásfácileintuitivadeactuaralahorademanejarlosdatosperdidosconsiste en obviarlos. Es decir, realizamos nuestras estadísticas simplemente nocontandocon losdatosque faltan. Enestapremisa sebasan técnicas comoListwise(análisisdedatoscompletos)oPairwise(análisisdedatosdisponibles). Mediantetécnicasdedatosdisponiblestenemosunapérdidademuestramenorque en el análisis de datos completos, pero obtenemos subgrupos con distintostamaños, loquedespuésnospuede limitara lahorade ciertosanálisis.Porello,ennuestrocaso,comoprocedimientotradicionalde imputacióntambiénutilizaremoselmétododeanálisisdedatoscompletos. Finalmente,yparacomparar los resultadosconunmétodomásactualymáscompleto, utilizaremos la ImputaciónMúltiple para imputar los datos faltantes y asípoderseguirtrabajandocontodalamuestra.

27
2.6.1.-TécnicasTradicionales 2.6.1.1-Listwise/Pairwiseenlafasedescriptiva Para realizar estemétodovamosa analizar lasbasesdedatos con la función‘Descriptiva’creadaparatalfin.Partimosdelabasededatosquenopresentaningunaperdidayseguimosconlasbasesdedatosconlaspérdidas.Deestemodo,estaremossimulandolatécnicaPairwise,puesestaremosanalizandosololosdatosdisponibles. Para realizar la técnica de Listwise crearemos una función denominada‘listwiseDB(DB)’quenosaplicarálafunción‘Descriptiva(DB)’soloenloscasoscompletosde nuestra base de datos. Aplicamos dicha función para obtener los resultadospertinentes. 2.6.1.2-Listwiseenlavariable“Índice” Mediante la función ‘Medias (BD)’ obtenemos las medias y desviacionesestándar de la variable Índice de las diferentes bases de datos, y gracias al test‘ComparaMedias(BD)’obtendremoslasignificanciaclínica. Antesde aplicar la función ‘ComparaMedias (BD)’prepararemos las basesdedatosparatrabajarsoloconlospacientesquepresentanlosdoscuestionariosdecalidaddevida.Crearemosasílassiguientesmasesdedatosnuevas:
• MCAR_EQ5D10comp:BasededatoscompensadaconpérdidasMCARal10%• MCAR_EQ5D20comp:BasededatoscompensadaconpérdidasMCARal20%• MCAR_EQ5D30comp:BasededatoscompensadaconpérdidasMCARal30%• MAR_EQ5D10comp:BasededatoscompensadaconpérdidasMARal10%• MAR_EQ5D20comp:BasededatoscompensadaconpérdidasMARal20%• MAR_EQ5D30comp:BasededatoscompensadaconpérdidasMARal30%• MNAR_EQ5D10comp:BasededatoscompensadaconpérdidasMNARal10%• MNAR_EQ5D20comp:BasededatoscompensadaconpérdidasMNARal20%• MNAR_EQ5D30comp:BasededatoscompensadaconpérdidasMNARal30%

28
2.6.2.-Imputacióndedatos(Imputaciónmúltiple) LatécnicadeImputaciónMúltiplelarealizaremosmediantelalibreríaMICE[29] de R. Este paquete realiza imputación múltiple utilizando Fully ConditionallySpecification(FCS)implementadoporelalgoritmoMICE(MultipleImputtionbyChainedEquations). El algoritmoMICE requiere una especificación de un método de imputaciónunivariante separadamente para cada variante incompleta. Para nuestro trabajo,realizaremoslaimputaciónmedianteelmétodo“polr”,queimputavaloresdedosomásnivelesordenadosporelmodelodeprobabilidadesproporcionales(Proportionaloddsmodel(ordered,>=2levels)). Noscentramossoloenlasvariablesquecontieneelcalidaddevida(Movilidad,Cuidado Personal, ActividadesDiarias,Dolor y Ansiedad) y usamos todas ellas comopredictoras.Unavez realizadas las imputacionesdeberemosexportarlasaExcelparapoderutilizarlaherramientaproporcionadaporEUROQOL(“EQ-5D-5LCrosswalkIndexValueCalculatorMAC.xls”).Unavezcreadaslasvariables“perfil”e“Índice”lasvolvemosaimportaraR4. 4Podremosverunresumendelaimputaciónenelarchivoadjunto“ResumenImputación.xlsx”

29
Obtenemosasílassiguientesbasesdedatos:
• MCAR_EQ5D10_i:BasededatosimputadaconpérdidasMCARal10%• MCAR_EQ5D20_i:BasededatosimputadaconpérdidasMCARal20%• MCAR_EQ5D30_i:BasededatosimputadaconpérdidasMCARal30%• MAR_EQ5D10_i:BasededatosimputadaconpérdidasMARal10%• MAR_EQ5D20_i:BasededatosimputadaconpérdidasMARal20%• MAR_EQ5D30_i:BasededatosimputadaconpérdidasMARal30%• MNAR_EQ5D10_i:BasededatosimputadaconpérdidasMNARal10%• MNAR_EQ5D20_i:BasededatosimputadaconpérdidasMNARal20%• MNAR_EQ5D30_i:BasededatosimputadaconpérdidasMNARal30%
• MCAR_EQ5D10_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMCARal10%• MCAR_EQ5D20_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMCARal20%• MCAR_EQ5D30_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMCARal30%• MAR_EQ5D10_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMARal10%• MAR_EQ5D20_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMARal20%• MAR_EQ5D30_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMARal30%• MNAR_EQ5D10_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMNARal10%• MNAR_EQ5D20_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMNARal20%• MNAR_EQ5D30_new:Basededatosimputadatrascalcularlasvariablesperfile
índiceconlaherramientadelEUROQOL,conpérdidasMNARal30%

30
2.6.2.1-Imputaciónenlafasedescriptiva Este apartado consistirá en aplicar la función creada previamente“Descriptiva(BD)”alasnuevasbasesdedatosimputadas. 2.6.2.2-Imputaciónenlacomparacióndelavariable“Índice” Esteapartadoconsistiráenaplicarlafuncióncreadapreviamente“Medias(BD)”yComparaMedias(BD)”alasnuevasbasesdedatosimputadas. EnlaTabla1,2y3podemosverunresumendelosresultadosobtenidos

31
Tabla1.-Resumenresultadosdelavariableíndice

32
Tabla3.-ResumenresultadosdelapartedescriptivaFinal
Tabla2.-ResumenresultadosdelapartedescriptivaBasal

33

34
3. Evaluación de Resultados5 3.1- Fase Descriptiva Recordamosquelapartedescriptivaconsisteenverelporcentajedepacientesquenotienenningúntipodeproblema.Paraanalizarlosresultados,hemoscalculadolasunidadesdevariacióndemaneraabsolutaentreeldatorealylosdatosobtenidosmediantelosdiferentestécnicasdedosmanerasdiferentes:
• Primerohemosestudiadolavariaciónindependientedelmecanismodepérdida,esdecir,solofijándonosenelporcentajedepérdida.
• Segundo,hemosanalizadolavariaciónenfuncióndelmecanismodepérdida. 3.1.1-Independientedelmecanismodepérdida En este caso nos vamos a centrar en el porcentaje de pérdida y el métodoutilizadopara imputarnuestrosdatos. La lógicaeneste tipode comparaciónesquecuando mayor porcentaje de pérdida, mayor variación encontraremos, y eso esjustamenteloquehemosencontrado. En la Tabla 4 podemos ver que de forma general, la variación global,independientedelmétodousado,enunabasededatosconun10%depérdidaesde4unidades,frentea6unidadesenelcasodeun20%yhasta7unidadesenelcasodehaberperdidoun30%. Centrándonos ahora en el mecanismo de pérdida y sin tener el cuenta elporcentaje,podemosobservarqueelmétodoquemásvariacióntieneeseldeListwisecon 8.1 unidades, frente a 3.8 unidades del método Pairwise y 6.1 del método deImputaciónMúltiple. Enlagráfica1,podemosverdemaneramásclaracomosecomportalavariaciónen conjunto. Podemos ver que elmejormétodo para este tipo de imputación es elPairwise,queofreceunasvariacionesmuchomenoresqueelrestodetécnicas.Asuvez,podemosverqueamayorporcentajedeperdidas,mayorvariaciónderesultados.Comodato curioso resaltar que la ImputaciónMúltiple y en Listwise, a partir del 20% deperdidaempiezaaofrecerunosresultadosmasdispares.5Seadjuntaarchivo“Interpretación.Rmd”paraverelcódigoutilizadoenelcálculo

35
Tabla4.-Variaciónsintenerencuentaeltipodepérdida
2,7
6,0
3,5
2,9
8,7
8,3
3,8
8,1
6,1
PA IRWIS E LI S TWIS E IM
VARIACIÓN INDEPENDIENTEDELTIPOPERDIDA
10% 20% 30%
Gráfica1.-Variaciónsintenerencuentaeltipodepérdida

36
3.1.2-Independientedelporcentajedepérdida Enesteapartadovamosatenerencuentaelmecanismodepérdidaqueestamosteniendoencadacasoalahoradetrabajarnuestrosdatos.EnlaTabla5podemosverelresumendelosresultadosobtenidos PodemosobservarcomoelmecanismodepérdidaquemásvariaciónpresentaesMNAR,6.8unidades,frentealas4.4unidadesdeMCARylas5.2unidadesdeMAR. Sitenemosencuentaelmétodousado,podemosverquelaImputaciónMúltipleobtieneunosresultadosmejoresqueelrestodemétodosensituacionesMCARyMAR.Comocontraste,elcasoconcretodeMNAR,la ImputaciónMúltiplesedisparayeselmétodoquemásvariaciónpresenta,presentadoelmétododePairwiselavariaciónmáspequeñadetodalaserie(2.6unidades).

37
Tabla5.-Variaciónindependientedelporcentajedepérdida
3,9
5,1
2,6
5,7 5,9
7,4
3,7
4,8
10,4
MCA R MAR MNAR
VARIACIÓN BASALSEGÚNTIPOPÉRDIDADATOS
Pairwise Listwise IM
Gráfica2.-Variaciónindependientedelporcentajedeperdida

38
3.2- Variable Índice HemoscalculadolaMediaGlobal,MediaBasalyMediaFinaldelavariablejuntoconsusdesviacionesestándarcorrespondiente.Además,lohemoshechodedosformasdiferentes:
• Contodoslosdatosdisponibles(Listwise)• RealizandounaImputaciónMúltiple
EnnuestrabasededatosinicialnohaydiferenciassignificativasentreelestadodecalidaddevidaBasalyelFinal,yesteeselresultadoquenosgustaríaencontrarconlosdiferentesmétodosutilizados.3.2.1-Listwise Como podemos ver en la Tabla 6, obtenemos unos resultados de medias ydesviacionesmuyparecidosentresi.Agrandesrasgospodemosvercomoamedidaquevanaumentando laspérdidas, losresultadospresentanmásvariación.Cabedestacarque en el mecanismo de pérdidaMAR, parece ser que tenemos unasmedias másestablesypareceserqueMCARpresentaunasdesviacionesmenores. Elproblemamásobvioquetenemosesqueal realizarelmétododeListwise,estamosobteniendotamañosmuestralesdiferentes.Enunacomparacióncomolaquenosocupaahora,esteproblemanosimpidepoderrealizareltestestadístico. Recordar que estamos trabajando con muestras pareadas, por lo quenecesitaremostenerlosdoscalidadesdevidaparapoderanalizarlosdatos.Porello,elsiguiente paso ha sido eliminar los pacientes que no tienen los dos cuestionarioscompletos.ObtenemosasílosresultadosquesemuestranenlaTabla7. Los resultados referentes a la variación de lasmedias y las desviaciones sonprácticamenteigualesqueantes.Peroloimportanteaquíesverquelosresultadosentodosloscasossonigualesqueelresultadoreal,esdecir,siguesinhaberdiferenciassignificativasentreelcalidaddevidainicialyfinal. MenciónespecialalmecanismoMCARconun30%depérdidadedatos,quegeneraunamuestrainsuficienteparaaplicarningúntest.

39
Tabla6.-EstudiodelavariableÍndicecontodoslosdatoscompletos(Listwise)
Tabla7.-Eliminacióndelospacientessinlosdoscalidadesdevida
40
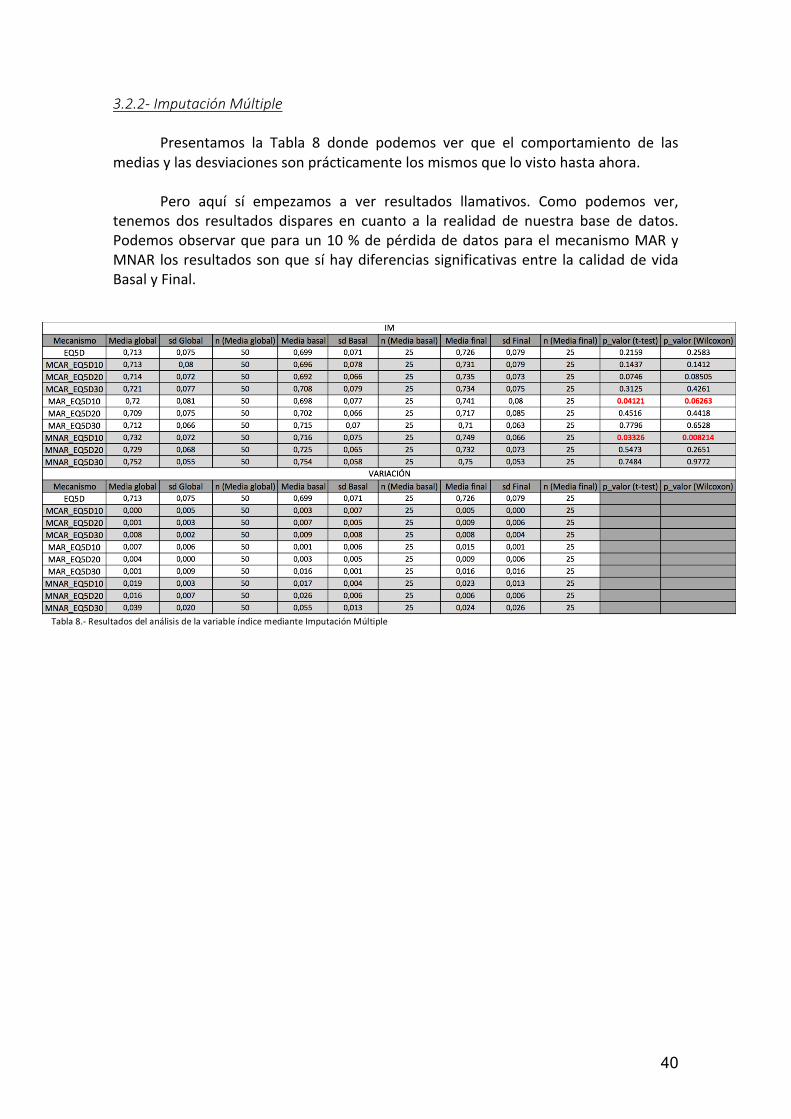
3.2.2-ImputaciónMúltiple Presentamos la Tabla 8 donde podemos ver que el comportamiento de lasmediasylasdesviacionessonprácticamentelosmismosquelovistohastaahora. Pero aquí sí empezamos a ver resultados llamativos. Como podemos ver,tenemos dos resultados dispares en cuanto a la realidad de nuestra base de datos.Podemosobservarqueparaun10%depérdidadedatosparaelmecanismoMARyMNAR losresultadossonquesíhaydiferenciassignificativasentre lacalidaddevidaBasalyFinal.
Tabla8.-ResultadosdelanálisisdelavariableíndicemedianteImputaciónMúltiple

41

42
4. Interpretación de Resultados 4.1- Fase Descriptiva Comohemospodidoobservar,elporcentajedepérdidaescríticoalahoradetrabajarconbasesdedatosquecontienendatosfaltantes.Esteesunhechoobvio,amayor falta de información, más difícil será obtener valores más reales. Un tareaimportanteenestepunto,seríapoderestimarapartirdequéporcentajedepérdidanosdebemos preocupar. En una fase puramente descriptiva, deberíamos definir quévariaciónestamosdispuestosatener,yenfuncióndeello,podemosfijarqueporcentajedepérdidapodemosasumir. Sinoscentramosenlosdiferentesmecanismosquehemosusadoparatrabajarnuestras pérdidas, podemos concluir que otro punto importante es conocer quémecanismo está causando nuestra pérdida de datos. Como se puede observar, elmétodoquemenosvariaciónpresentaeseldelaImputaciónMúltiple,siempreycuandonosetratadeunpatrónMCAR,encuyocasolamejoropciónseriaPairwise. EnningúncasoseríabuenaopciónListwise,puessereducemuchoeltamañodelamuestrayenuncasocomoelnuestroqueyapartimosdeunabasededatospequeña,esunapenalizaciónquenopodemosasumir. Sisenosplanteaunasituacióndondetenemoslostresmecanismosdepérdidaennuestrabasededatos,nosinclinaríamosporelmétododePairwise,puestoquedemanerageneral,sintenerencuentaelmecanismo,presentaunasvariacionesmenores.En este caso, la Imputación Múltiple pierde potencia. Parece ser que el hecho decontenerpérdidasMNAResunlastrebastantegrande.HayquetenerencuentaqueparaquefuncionecorrectamentelaImputaciónMúltiplesehandecumplirunaseriederequisitos,comoquelosdatosfaltantesseanMAR(MCARtambiénfuncionabienconunos ajustes) y además no siempre es fácil encontrar unmodelo adecuado para lavariabledeinterés. Otroaspectoimportantequesubyacedetodolodichoesquedebemosintentar,dentrodelamedidadeloposible,evitarlosmecanismosdepérdidaMNAR.Alteranalmejormétodoquehemosencontradoennuestroestudioyademás,eselmecanismoquemásvaloresdisparesofrece.Situviéramosestetipodemecanismoactuandosobrelapérdidadenuestrosdatos,sepodríaoptarporrealizarlatécnicadePairwise,queesdondehemosvistomenosvariación.

43
4.2- Variable Índice Para este tipode estudio, ya no son tan importante las variaciones entre losresultados, puesto que vamos a ver diferencias significativas entre dos poblaciones.Variacionespuedenexistir, ahorahayque ver si son lo suficientemente importantescomoparaafectaranuestrosresultados.Asípues,analizarlosresultadosmediantelavariableÍndiceesunmétodomásrobustoqueelanterior. Comohemospodidover,elprincipalproblemaquetenemosalrealizarelanálisissinimputarlosdatosesqueobtenemosunostamañosmuestralesdiferentes,cosaquenosvaaperjudicarporquedebilitalasignificanciadelaspruebas.Además,ennuestrocaso en concreto donde nuestros datos son pareados, debemos reducirmás aún lamuestraeliminandoalospacientesquenodispongandelosdoscalidadesdevida.Siyade partida venimos de una base de datos con una n pequeña, esto puede sercatastrófico,comosepuedeverenelcasoMCAR_EQ5D30,dondesolotenemosuncasoencadagrupoynosepuederealizareltest.Estepuntosepuedesolucionarfácilmenteteniendounamuestralosuficientementegrandecomoparapodersoportarunaperdidadedatos. Porlodichoanteriormente,elimputarnuestrosdatoscuandonuestrabasededatosnoeslosuficientementegrandecomoparasoportartalpérdida,deberíadeserlamejoropciónavalorar.Deestaforma,volveríamosatenerlamismanquealiniciodelestudio.Ahorabien,tambiénhayqueserconscientesdequenoesunatécnicaexentaderestricciones.Restriccionesquesinosecumplenpuedendarlugararesultadosnodeseadoscomohasidonuestrocaso. Podemosvercomotenemosdossituacionesdondesíseestánviendodiferenciassignificativas entre la calidad de vida Basal y la Final. Nos referimos a la situaciónMAR_EQ5D10yMNAR_EQ5D10. El hecho de que aparezcan cuando tenemos un porcentaje de pérdida máspequeño(10%)nospodríaestar indicandosimplementequealtenermenospérdida,tenemosmasdatosparacomparar,yesohacequepodamosvermásdiferenciasentrelosgrupos(éstovaenconsonanciaconlovistoenlosresultadosdelasbasesdedatosquehanquedadoaleliminar lospacientesquenodisponíandesusdoscalidadesdevida).

44
Pero es obvio que algo no funciona como debería, pues nos estámostrandodiferenciascuandoenrealidadnolashay.Paraintentarexplicarlosepuedenplanteardospropuestaquedeberíanserestudiadas:
• Cuando realizamos el test de Wilcoxon podemos observar como enalgunas comparaciones nos hace un aviso6 donde nos está indicando quetenemosmuestrasrepetidas.Éstohacequeperdamosvariabilidadennuestramuestrayporlotantonopodremoscalcularunosp_valoresexactos.
Habríaquetenerencuentaquealrealizaruntestconmuestraspareadasse está realizando un test de simetría y se está asumiendo que nuestrasdistribucionesnosonsesgadas,yenestetipodebasededatos,noestanraroencontrarelmismoresultadovariasveces.Éstoacompañadodeunamuestrainicialpequeñapuedehacerunproblemaalahoradetenerresultadosrepetidos.
• DebemosdeconocerbienlatécnicadelaImputaciónMúltiple.Partimosdeunabasededatospequeña,dondeestamosimputandovariablesordinalesycon pocos niveles. Hemos de saber que existen situaciones en las que lossupuestosdelmétodono se cumplenyqueno siemprees fácil encontrarunmodeloadecuadoparalavariabledeinterés.
NOTA:TrasloscomentariosdenuestradirectoradelTFM,realizamoslaimputacióndelavariable“Índice”medianteelmétodode“pmm”,elcualestáindicadoespecialmenteparaimputarvariablescuantitativasquenoestánnormalmentedistribuidas. Recordemosquelavariableencuestiónescuantitativa,noordinal,yademás,teníamosdudaencuantoasudistribución.ElresultadolopodemosverenlaTabla9
Comopodemosverahora,todaslasimputacionesexceptolasrealizadasconunabasededatosqueposeeunmecanismodepérdidaMNARal10%,sonnoclínicamentesignificativas,loquecoincideconelresultadoreal. ElhechodequenofuncionebienelmétododelaImputaciónMúltiplecuandoelmecanismodepérdidaesMNARyaloconocíamosypuedequesealaexplicaciónmasplausibleparaesteresultado.6Warninginwilcox.test.default(x=c(0.68,0.6,0.69,0.83,0.6,0.76,0.69,:cannotcomputeexactp-valuewithties
Tabla9.-ResultadosdelanálisisdelavariableíndicemedianteImputaciónMúltiple(método“pmm”)

45

46
5. Conclusiones Lasconclusionesqueobtenemosdenuestrotrabajosonlassiguientes:
• Debemos de conocer la estructura de nuestra base de datos y laslimitacionesdenuestroestudio.
• Amayorporcentajedepérdida,mayorvariaciónobtenemos.Esimportanteestimarquéporcentajedepérdidadedatosestamosdispuestosaasumirennuestrainvestigación.
• Hemosdeconocerelmecanismodepérdidadedatosqueestáafectandoanuestrainvestigación.
• Finalmente, hemos de conocer los diferentes métodos que existen paratratarlosdatosperdidos.
Además,podemosconcluirqueparauncasocomoelnuestro,dondepartimosdeunestudiolongitudinalpequeño,conmuestraspareadasyvariablesordinalesconpocosniveles:
• Elmétodode ImputaciónMúltipleeselmásefectivoparamecanismosdepérdidaMCARyMAR.
• LaImputaciónMúltiplenosdalaventajadenoperdertamañomuestral.• ParamecanismoMNAR,latécnicadePairwiseseríalamasapropiada.• Enelcasodepresentarlostresmecanismosdepérdidaennuestroestudio,
deberíamosutilizarPairwise.• EnningúncasoesaconsejableutilizarelmétodoListwise,puesproduceuna
pérdidadeltamañodelamuestra.• HemosdeevitarlaspérdidasMNAR

47

48
6. Observaciones finales Inicialmenteesteestudiopretendía sermásambicioso.Enprincipio sequeríatrabajarconunabasededatosrealytrabajarlapérdidadedatosconmástécnicasdelaspropuestas.Debidoalafaltadetiemposedecidiópartirdeunabasededatosenbanco e ir creándola desde cero. Ésto nos ha limitado de manera considerable elposteriortratamientodelosvaloresperdidos. Peroestecontratiemponosbeneficióenelsentidodehaberpodidoorientardeunaformamasconcretanuestrainvestigaciónhaciaunanecesidadexistenteyquenosehatratadotanafondoenlaliteratura. Lasconclusionesgeneralessonlasmismasqueseplanteanentodoslosestudiosencontradossobrevaloresperdidosylasconclusionesparticularesdenuestrabasededatostampocodifierentanto. Estetrabajonodejadeserunaaproximaciónaunasituacióntancomplejacomolaqueimplicanlosdatosfaltantes,ycomotal,aúnquedamuchotrabajoporhacer.Anivel de este estudio el siguiente paso sería encontrar el motivo real por el queobtenemos unos resultados diferentes mediante la técnica de Imputación Múltiplecuando analizamos la variable índice. Hemos propuesto varias alternativas, peroconvendríaconfirmarlas. Pensandoenunfuturo,sepodríaampliaresteestudiodediferentesformas:
• Aplicandomástécnicas,einclusoalgunamásespecifica• Verlosresultadosconunmayorporcentajedepérdidaytambiénconuntamaño
muestralmásgrande.• Encontrarnuevascovariablesquepudieranayudarnos
Porúltimo,encontrarunmecanismodeimputaciónespecíficoocrearfuncionesenRespecíficaspararealizaruntratamientobásicodelasbasesdedatos,facilitandoasílaintegracióndelosinvestigadoresmasnovelesenestecamposeríaunabuenametafinal.

49

50
7. Glosario
• TFM:TrabajoFindeMaster• FullyConditionallySpecification(FCS)• MICE(MultipleImputtionbyChainedEquations)• reclass(BD):FuncióncreadaenRparare-clasificarlasvariablesimportadasde
Excel.• DBprepare(BD):FuncióncreadaenRparaprepararautomáticamentelabase
dedatosimportadadeExcel• MCAR_EQ5D10:BasededatosconpérdidasMCARal10%• MCAR_EQ5D20:BasededatosconpérdidasMCARal20%• MCAR_EQ5D30:BasededatosconpérdidasMCARal30%• MAR_EQ5D10:BasededatosconpérdidasMARal10%• MAR_EQ5D20:BasededatosconpérdidasMARal20%• MAR_EQ5D30:BasededatosconpérdidasMARal30%• MNAR_EQ5D10:BasededatosconpérdidasMNARal10%• MNAR_EQ5D20:BasededatosconpérdidasMNARal20%• MNAR_EQ5D30:BasededatosconpérdidasMNARal30%• Descriptiva(BD):FuncióncreadaenRparaobtener losresultadosde laparte
descriptivadelestudio.• Medias(BD):FuncióndeRcreadaparaobtenerlamediayladesviaciónestándar
enloscuestionariosdemaneraglobal,basalyfinal.• ComparaMedias(BD):FuncióndeRcreadapararealizareltestdet-Studenty
Wilcoxon.• listwiseDB (DB): FuncióncreadaenRparaaplicar la función ‘Descriptiva(DB)’
soloenloscasoscompletosdenuestrabasededatos.• MCAR_EQ5D10comp:BasededatoscompensadasconpérdidasMCARal10%• MCAR_EQ5D20comp:BasededatoscompensadasconpérdidasMCARal20%• MCAR_EQ5D30comp:BasededatoscompensadasconpérdidasMCARal30%• MAR_EQ5D10comp:BasededatoscompensadasconpérdidasMARal10%• MAR_EQ5D20comp:BasededatoscompensadasconpérdidasMARal20%• MAR_EQ5D30comp:BasededatoscompensadasconpérdidasMARal30%• MNAR_EQ5D10comp:BasededatoscompensadasconpérdidasMNARal10%• MNAR_EQ5D20comp:BasededatoscompensadasconpérdidasMNARal20%• MNAR_EQ5D30comp:BasededatoscompensadasconpérdidasMNARal30%• MICE():LibreríadeRquenospermiterealizarlaImputaciónMúltiple• MCAR_EQ5D10_i:BasededatosimputadaconpérdidasMCARal10%• MCAR_EQ5D20_i:BasededatosimputadaconpérdidasMCARal20%• MCAR_EQ5D30_i:BasededatosimputadaconpérdidasMCARal30%• MAR_EQ5D10_i:BasededatosimputadaconpérdidasMARal10%• MAR_EQ5D20_i:BasededatosimputadaconpérdidasMARal20%• MAR_EQ5D30_i:BasededatosimputadaconpérdidasMARal30%• MNAR_EQ5D10_i:BasededatosimputadaconpérdidasMNARal10%• MNAR_EQ5D20_i:BasededatosimputadaconpérdidasMNARal20%• MNAR_EQ5D30_i:BasededatosimputadaconpérdidasMNARal30%

51
• MCAR_EQ5D10_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMCARal10%
• MCAR_EQ5D20_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMCARal20%
• MCAR_EQ5D30_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMCARal30%
• MAR_EQ5D10_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMARal10%
• MAR_EQ5D20_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMARal20%
• MAR_EQ5D30_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMARal30%
• MNAR_EQ5D10_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMNARal10%
• MNAR_EQ5D20_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMNARal20%
• MNAR_EQ5D30_new:BasededatosimputadatrascalcularlasvariablesperfileíndiceconlaherramientadelEUROQOL,conpérdidasMNARal30%

52

53
8. Bibliografia [1] WOOD, A. M., I. R. WHITE and S. G. THOMPSON (2004): Are missing outcome dataadequatelyhandled?Areviewofpublishedrandomizedcontrolledtrialsinmajormedicaljournals.Clinicaltrials,1,368-376.[2] DÍAZ-ORDAZ,K.,M.G.KENWARD,A.COHEN,C.L.COLEMANandS.ELDRIDGE(2014):Aremissingdataadequatelyhandledinclusterrandomisedtrials?Asystematicreviewandguidelines.ClinicalTrials,II(5),590-600.[3] BUUREN, S. (2012): Flexible imputation of missing data. Chapman & Hall/CRC Press,London-NewYork.[4] HAND,D.J.,F.DALY,A.D.LUNN,K.J.MCCONWAYandE.OSTROWSKI(1994):Ahandbookofsmalldatasets.Chapman&Hall,London.[5] Horton,N.&Lipsitz,S.(2001),‘MultipleImputationinPractice:ComparisonofSoftwarePackagesforRegressionModelsWithMissingVariables’,AmericanStatisticalAssociation55(3),244–254.[6] Dempster, A. P., Laird, N. M. & Rubin, D. B. (1977), ‘Maximum Likelihood from Incomplete Data Via the EM Algorithm’, Journal of the Royal Statistical 39 , 1–38. [7] Schafer,J.L (1997), Analysis of incomplete multivariate data, London, Chapman y Hall. [8] Ibrahim, J. G., (1990), Incomplete data in generalized linear models, Journal of the American Statistical Association . [9] Little, R. J. A. (1995), Modeling the dropout mechanism in repeated-measures studies, Journal of the American Statistical Association . [10] Little, R. J. A. (1992), Regression with missing X’s, A review, Journal of the American Statistical Association 87. [11] Little, R. J., y D. Rubin (1987). Statistical analysis with missing data, New York, Wiley. [12] Rubin, D. B. (1976), Inference and missing data, Biometrika 63. [13] Shona Fielding, Peter M Fayers and Craig R Ramsay, Investigating the missing data mechanism in quality of life outcomes: a comparison of approaches, Health and Quality of Life Outcomes 2009, 7:57 doi:10.1186/1477-7525-7-57 [14] Little, R. J. A. (1986), A test of Missing Completely at Random for multivariate data with missing values, Sociological Methods and Research 18. [15] Listing J, Schlittgen R: Tests if dropouts are missed at random. Biometrical Journal 1998, 40:929-935. [16] Listing J, Schlittgen R: nonparametric test for random dropouts. Biometrical Journal 2003, 45:113-127. [17] Schmitz N, Franz M: A bootstrap method to test if study dropouts are missing randomly. Quality & Quantity 2002, 36:1-16.

54
[18] Diggle PJ: Testing for random dropouts in repeated measurements data. Biometrics 1989, 45:1255-1258. [19] Ridout MS: Testing for random dropouts in repeated measurement data. Biometrics 1991, 47:1617-1619. [20] Fairclough DL: and Analysis of Quality of Life Studies in Clinical Trials Chapman and Hall; 2002. [21] Kalton, G. y D. Kasprzyk (1982), Imputing for Missing Surveys Responses, Proceedings of the Section on Survey Research Methods, American Statistical Association. [22] Schafer, J. L. y J. W. Graham (2002), Missing Data, Our View of the State of the Art, Psychological Methods .vol. 7, No. 2. [23] Acock, C. A., y D. Demo (1994), Family diversity and well-being, Thousand Oaks, C. A. Sage. [24] Cohen, J., y P. Cohen (1983), Applied multiple regression/correlation analysis for the behavioral sciences (Sec. ed.), Hillsdale, N. J., Erlbaum. [25] Cohen, J., P. Cohen, S. West, y L. Aiken, (2003), Applied multiple regression/correlation analysis for the behavioral sciences (Third ed.), Mahwah, N. J. Erlbaum. [26] Madow, W. G., J. Nisselson y I. Olkin (Eds.) (1983), Incomplete data in sample surveys, vol. 1, Report and case studies, New York, Academic Press. [27] Durrant, B. G. (2005), Imputation Methods for Handling Item-Non-response in the Social Science: A Methodological Review, ESRC National Centre for Research Methods and Southampton Statistical Science Research Institute, University of Southampton, NCRM Methods Review Papers , NCMR/002. [28] Dempster, A. P., N. M. Lair, y D. B. Rubin (1977), Maximum likelihood estimation from incomplete data via the EM algorithm (with discussion). Journal of the Royal Statistical Society, Series B , 39. [29] Stef van Buuren and Karin Groothuis-Oudshoorn, MICE: Multivariate Imputation by Chained Equations in R. Journal of Statistical Software

55

56
9. Anexos ANEXO1.-ModelocalidaddevidaEQ-5D-3L

57

58
ANEXO2.-Planificacióndeltrabajo
Real Vacaciones
ACTIVIDAD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
BusquedaBibliográficaCreaciónBasededatosComparacióndelasdiferentesalternativasMemoriaypresentacióndeltrabajofinalPreparacióndelaDefensaDefensaPública
ACTIVIDAD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
BusquedaBibliográficaCreaciónBasededatosComparacióndelasdiferentesalternativasMemoriaypresentacióndeltrabajofinalPreparacióndelaDefensaDefensaPública
ACTIVIDAD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
BusquedaBibliográficaCreaciónBasededatosComparacióndelasdiferentesalternativasMemoriaypresentacióndeltrabajofinalPreparacióndelaDefensaDefensaPública
ACTIVIDAD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
BusquedaBibliográficaCreaciónBasededatosComparacióndelasdiferentesalternativasMemoriaypresentacióndeltrabajofinalPreparacióndelaDefensaDefensaPública
ANEXO 1.- Planificador del proyecto
Marzo2017
Junio2017
PEC 3
PEC 2
PEC 2
PEC 3
Abril2017
Mayo2017

59
ANEXO3.-Observacióndelospatronesdepérdidadedatos

60

61

62
ANEXO4.-CódigoRusado
63

64

65

66
67

68
10. Material Complementario • EQ-5D-5LCrosswalkIndexValueCalculatorMAC:HerramientaenExcelquese
hautilizadoparacalcularlavariableíndiceyperfildenuestrabasededatos.• ResumenImputación:Resumendelosdatosimputados
• ResumenResultados:ResumendelosresultadosdelTFM
• Código R: Carpeta donde se adjunta el código utilizado para el TFM y la
interpretación,juntoconlonecesarioparareproducirlodenuevo.• Interpretación: Archivo html con el código utilizado ejecutado del archivo
Interpretación.Rmd.• TFM:ArchivohtmlconelcódigoutilizadoejecutadodelarchivoTFM.Rmd.