indice - infn.it alla detection di onde gravitazionali ed in particolare del progetto virgo ed...
TRANSCRIPT

Indice
Introduzione 3
Capitolo 1: Le onde gravitazionali 5
1.1 Introduzione alle onde gravitazionali.................................61.2 Fonti di emissione.............................................81.3 Sistemi binari coalescenti........................................91.4 Detection: rilevatori e Matched Filtering.............................111.5 Analisi del segnale proveniente da sistemi binari........................131.6 Analisi della scelta implementativa.................................19
Capitolo 2: I processori grafici: le GPU 21
2.1 Storia dei processori grafici......................................222.2 Classificazione delle architetture...................................242.3 Architettura di una GPU........................................262.4 GPGPU: General Purpose GPU computing............................292.5 CUDA....................................................302.6 OPENCL..................................................372.7 Differenze CUDA – OpenCL.....................................44
Capitolo 3: Descrizione dell'algoritmo 46
3.1 Inizializzazione del workspace....................................493.2 Calcolo del tempo di coalescenza..................................553.3 Generazione del template.......................................57
3.3.1 Codice Host.............................................573.3.2 Codice kernel............................................59
1

Capitolo 4: Testing dell'algoritmo 63
4.1 Accuracy test...............................................644.1.1 CPU vs GPU............................................644.1.2 CUDA vs OpenCL........................................66
4.2 Benchmark test..............................................684.2.1 CUDA vs OpenCL........................................704.2.2 CPU vs GPU............................................74
Capitolo 5: Conclusioni 76
Appendice A 79
Implementazione CUDA........................................79
Appendice B 86
Implementazione OpenCL.......................................86
Ringraziamenti 97
Bibliografia 98
2

3
Introduzione
La rilevazione di onde gravitazionali è tra le più grandi sfide che la ricerca scientifica
moderna si prefigge di vincere nei prossimi anni. Le onde gravitazionali, ipotizzate da Albert
Einstein nella Teoria della Relatività Generale, non sono ancora state oggetto di osservazione
diretta. Negli ultimi 10 anni sono entrati in funzione innovativi detector gravitazionali quali
ad esempio Virgo (INFN/CNRS) e LIGO (US) finalizzati a tale “prima” rilevazione.
Il presente lavoro di tesi è stato svolto presso l'INFN (Istituto Nazionale di Fisica Nucleare) di
Perugia e rientra nel progetto INFN MaCGO (Many-core Computing for future Gravitational
Observatories) che si occupa dello sviluppo di una libreria numerica su GPU e sistemi
manycore per l’analisi numerica dei dati propria dei detector Gravitazionali. Il lavoro, frutto
di questa collaborazione, sarà sfruttato nell'ambito dei diversi progetti internazionali rivolti
alla detection di onde gravitazionali ed in particolare del progetto VIRGO ed AdvancedVirgo.
L’attività svolta rientra inoltre nelle attività di design study per la parte di computing del
progetto Europeo Einsten Telescope.
La tecnica utilizzata nella elaborazione digitale e rilevazione di segnali gravitazionali, oggetto
di questa testi, si basa sul filtro digitale Matched-Filtering (MF) e metodo Neyman-Pearson.
Tale strategia risulta però computazionalmente onerosa, sia perché è necessario generare
migliaia o decine di migliaia di filtri ( detti “template”) per ogni ciclo di elaborazione e sia
perché l’elaborazione utilizza pesantemente FFT. Il presente lavoro è rivolto verso la prima
problematica sviluppando su GPU una libreria di generazione di filtri che altro non sono che
segnali gravitazionali di riferimento.
La GPU, acronimo per Graphics Processing Unit, è il processore grafico di una scheda video
per computer e console in grado di processare oltre 10 milioni di poligoni al secondo. Fino a

INTRODUZIONE
poco tempo fa le GPU erano esclusivamente utilizzate per le operazioni di rendering grafico,
ma negli ultimi anni si è cercato sfruttare le loro enormi potenzialità di calcolo anche in altri
settori. È così nato il General Purpose GPU computing (GPGPU), un settore della ricerca
informatica per l'utilizzo dei processori grafici per scopi diversi dalla tradizionale
elaborazione di applicazioni 3D. Difatti tutte le applicazioni che sono per loro natura di tipo
altamente parallelo possono beneficiare di una tale architettura. Attualmente l’orientamento
dell’HPC è fortemente orientato verso queste nuove tecnologie che permettono di ottenere un
fattore di guadagno in termini di prestazioni anche di due ordini di grandezza e di ridurre la
potenza per GFlops richiesta. Le GPU sono infatti, in un certo senso, sistemi many-core in
cui centinaia di cores sono presenti sulla stessa scheda e sono in grado di eseguire lo stesso
flusso di istruzioni su una molteplicità di dati in parallelo.
L'elaborato è così composto: nel capitolo 2 sono introdotti i concetti fondamentali riguardanti
le onde gravitazionali, facendo particolare riferimento ai sistemi binari coalescenti che sono
l'oggetto del generatore di segnali sviluppato; nel capitolo 3, invece, si focalizza l'attenzione
sull'architettura di una GPU e analizziamo due approcci differenti alla programmazione:
CUDA e OpenCL; nel capitolo 4 invece si riporta un'analisi dettagliata dell'algoritmo
sviluppato definendo la struttura del codice e descrivendo le singole macro-operazioni che
vengono elaborate; nel capitolo 5 sono riportati i risultati ottenuti dai test di accuratezza
numerica e prestazionale dell'algoritmo su GPU e confrontati con gli analoghi risultati ottenuti
su CPU, utilizzata come riferimento. Nell’ultimo capitolo si riportano le conclusioni di questo
lavoro. Nell'appendice, infine, sono presenti i codici CUDA e OpenCL sviluppati.
4

5
Capitolo 1
Le onde gravitazionali
L'obiettivo finale di questo elaborato è quello di presentare un nuovo algoritmo per la
generazione di segnali d'onda gravitazionale basato su un'architettura parallela in forte
espansione: le GPU.
Prima di passare all'analisi implementativa del codice, di cui si parlerà nel Capitolo 4, è
necessario fare una premessa sull'argomento, introducendo il concetto di onde gravitazionali,
o anche Gravitational Waveform (GW). Sebbene la loro presenza sia stata ipotizzata circa 90
anni fa, la loro individuazione risulta ancora oggi un grosso tabù che la scienza si è prefissata
di risolvere nell'arco di una decina di anni.
Lo scopo dei seguenti paragrafi è, pertanto quello di fare un identikit delle GW. Oltre a fare
una premessa sulle origini storiche, verranno messe a confronto le caratteristiche delle GW
con segnali d'onda ben più noti: quelli generati da onde elettromagnetiche (EMW). Verranno
definite le fonti di emissione e fra tutte analizzeremo una particolare sorgente di GW, quale la
coalescenza di due oggetti binari compatti in orbita tra di loro (coalescing inspiral compact
binaries). Di questi sistemi analizzeremo le caratteristiche della forma d'onda e forniremo
l'insieme di equazioni che ci permettono di descrivere un tale sistema. Infine illustreremo il
'perché' la rilevazione di GW ha suscitato tanto interesse nei ricercatori e il 'perché' si è deciso
di sfruttare le potenzialità computazionali delle GPU per la generazione di tali forme d'onda.

1.1 INTRODUZIONE ALLE ONDE GRAVITAZIONALI
1.1 Introduzione alle onde gravitazionali
Fu Albert Einstein nel 1916 a ipotizzare l'esistenza di tali onde come conseguenza della sua
rivoluzionaria teoria della relatività generale [1]. Secondo la sua teoria, mutazioni nella
concentrazione di masse (o energie) in una dimensione spazio-tempo, causa distorsioni che si
propagano nell'universo alla velocità della luce. Tali distorsioni sono l'effetto di quelle
radiazioni emesse da oggetti astrofisici che vengono definite onde gravitazionali.
Tuttavia all'epoca della nascita della teoria relativistica di Einstein, e quindi della “scoperta”
delle GW, non si disponevano di conoscenze tecnologiche adeguate e capaci di individuare
tali segnali. Sebbene il progresso scientifico e informatico e la ricerca svolta in questi settori
negli ultimi decenni abbia fatto grossi passi in avanti, a distanza di quasi un secolo non si è
ancora giunti a una prova tangibile della loro esistenza. Una prima individuazione indiretta
risale però al 1974 quando due scienziati, il professor Taylor e il suo allievo Hulse,
individuarono un sistema di due astri in orbita tra loro: si trattava di una pulsar, la
PSRB1913+16, ed un buco nero [2]. I due astronomi osservarono per molti anni il loro
comportamento e notarono che il periodo orbitale diminuiva col tempo. I due scienziati
sospettarono del fatto che tali cambiamenti nel periodo orbitale erano dovuti alla perdita di
energia emessa sotto forma di onde gravitazionali e provarono a ottenere riscontri con i
modelli matematici derivanti dalle approssimazioni post-newtoniane (PNA)1, riformulate da
Einstein. I risultati ottenuti da Taylor e Hulse valsero ai due il premio nobel per la fisica nel
1993.
Al giorno d'oggi sono stati individuati altri sistemi di astri simili a quello di Taylor e Hulse,
come ad esempio quello scoperto nel 2003 da un team di ricercatori e composto da due stelle
di neutroni piccolissime: PSR J0737-3039 [3].
Le GW non sono ancora state individuate direttamente, ma presumibilmente dovrebbero
esistere. Ma perché tali segnali rivestono un grande interesse? E perché andiamo alla ricerca
di questi segnali? L'individuazione di GW dimostrerebbe definitivamente la teoria della
relatività generale di Einstein e costituirebbero quindi la prova tangibile dell'esistenza di un
1 Formalismo che approssima le equazioni di Einstein sviluppando i coefficienti della metrica e la velocità dei corpi
6

1.1 INTRODUZIONE ALLE ONDE GRAVITAZIONALI
forte campo gravitazionale. Inoltre si conquisterebbe una nuova visione dell'intero universo e
sulla sua storia, e si aprirebbero le porte ad una nuova gamma di radiazioni oltre a quelle già
sfruttate e identificate dallo spettro elettro-magnetico.
Le onde gravitazionali sono simili alle onde elettro-magnetiche, con la differenza che le
EMW sono forme d'onda prodotte da magneti caricati elettricamente che generano un moto di
cariche che si propagano nello spazio alla velocità della luce, le onde gravitazionali sono
invece generate dal moto di masse (pianeti o astri in generale) e emettono radiazioni che si
propagano in una dimensione spazio-temporale alla velocità della luce. L'effetto di un'onda
gravitazionale è quello di incidere sulla curvatura spazio-tempo dell'universo. Tuttavia
l'ampiezza di queste onde è infinitesimale. Data la loro natura quadrupolare (a differenza delle
EMW caratterizzate da una polarizzazione di dipolo), le GW interagiscono con la materia
tramite due polarizzazioni di quadrupolo, definite plus(h+) e cross(hx) e causano distorsioni
spazio-temporali su di essa. Per spiegare meglio questo concetto facciamo un esempio.
Si dispongano ad anello un insieme di particelle su di un piano xy (illustrazione 1.1), e si
ipotizzi l'arrivo di un'onda gravitazionale, in direzione perpendicolare al piano lungo z. Nel
caso in cui l'onda abbia solo polarizzazione h+, si osserva una deformazione dell'anello lungo
gli assi principali, mentre per onda a polarizzazione hx, si osservano deformazioni lungo le
diagonali principali. Questo fenomeno è dovuto al fatto che le due polarizzazioni sono ruotate
l'una rispetta all'altra di 45 gradi.
7
Illustrazione 1.1: Effetto di un'onda gravitazionale

1.1 INTRODUZIONE ALLE ONDE GRAVITAZIONALI
La perturbazione è proporzionale all'ampiezza dell'onda gravitazionale e alla massa della
sorgente di gravitazione. Tuttavia l'ampiezza delle GW è infinitesimale e anche le fonti di
emissione più considerevoli hanno un'ampiezza generalmente dell'ordine di 10-21 e tale da
causare distorsioni molto piccole (10-18 metri, circa 1/1000 il diametro del protone),
impercettibili all'occhio umano ma che l'uomo potrebbe captare grazie alla costruzione di una
strumentazione in grado di realizzare una così precisa misurazione[2].
Le GW hanno inoltre una frequenza generalmente di molto inferiore delle EMW(in media al
disotto dell'ordine del Khz contro le decine di Mhz delle EMW) e pur trasportando una grossa
quantità di energia, la loro interazione con la materia è molto debole. Da questo si capisce la
grossa difficoltà della loro individuazione. Tuttavia negli ultimi anni ci sono stati dei
progressi, grazie alla realizzazione di detector sempre più sensibili (anche se siamo ancora
alla produzione di esemplari di prima generazione, e verso nuove macchine di seconda e terza
generazione) e allo sviluppo di modelli matematici, le Post-Newtonian Approximations
(PNA) [4], sempre più accurati applicabili a tale strumentazione. Le approssimazioni PN,
derivanti da modelli teorici, sono infatti in continua espansione. Difatti si parla di diversi
livelli di approssimazione; ad ogni livello corrisponde un fattore dell'equazione, con il livello
più basso, PN0, che rappresenta il fattore dominante.
Secondo le stime di alcuni scienziati, si pensa che nei prossimi dieci anni si riesca ad ottenere
una prova concreta della esistenza di GW, grazie all'avanzamento tecnologico nella
realizzazione dei detector e nello stesso tempo di modelli matematici e software da applicare a
questi.
1.2 Fonti di emissione
Ma quali sono le sorgenti che generano queste onde gravitazionali [5]?Si riconoscono varie
fonti che possono emettere questo tipo di radiazioni. Alcune di queste si prestano a una
possibile individuazione in quanto sono abbastanza predicibili, altre invece sono molto più
difficili da analizzare a causa di una forte imprevedibilità del sistema. Tra queste ultime
troviamo innanzitutto fonti di natura stocastica, derivanti dall'origine del cosmo
8

1.2 FONTI DI EMISSIONE
(cosmological background signals). Esempio di questa categoria è il famigerato Big Beng che
risulterebbe una delle prime sorgenti di onde gravitazionali (e probabilmente non la
primissima in assoluto). Altro fenomeno in cui si manifesta una buona emissione di GW
deriva dal collasso di una supernova, che porta alla formazione di una stella di neutroni: in
questo caso si parla di burst signal. Un tale evento avviene mediamente una volta ogni trenta
anni e ha una durata molto breve, risulta pertanto difficilmente predicibile e individuabile.
Una delle fonti che si potrebbe prestare a una buona probabilità di individuazione deriva da
isolated spinning neutron stars(stelle di neutroni rotanti e isolate), anche denominate pulsar.
Tali segnali sono periodici (periodic signal) e hanno il vantaggio di rimanere osservabili per
tempi molto lunghi. Questa caratteristica aumenta la speranza di rilevabilità delle onde
gravitazionali emesse.
Ma la nostra attenzione si focalizzerà su un'altra fonte, tra tutte probabilmente la più
interessante per applicabilità ai detector di prima generazione e particolarmente adatte a
VIRGO e del cui genere si è già avuto una prova indiretta grazie al lavoro dei sopracitati
Taylor e Hulse: coalescing inspiral non-spinning compact binaries, ovvero la coalescenza di
sistemi binari compatti.
1.3 Sistemi binari coalescenti
Il lavoro di tesi qui presentato, ha pertanto lo scopo di simulare il segnale gravitazionale
generato da coalescing inspiral non-spinning compact binaries, ovvero sistemi binari
compatti.
Tali sistemi sono composti da due masse, estremamente dense, come stelle di neutroni, buchi
neri e nane bianche(neutron stars2, black hole3, white dwarf4), in orbita tra loro, che ruotando
perdono energia, emessa sotto forma di radiazioni gravitazionali. A causa della variazione nel
2 Una stella compatta in cui il peso della stella è supportato dalla pressione di neutroni liberi. Hanno una massa simile a quella del Sole
3 Un corpo celeste dotato di una velocità di fuga dalla propria superficie maggiore della velocità della luce,tale da non permettere l' allontanamento di alcunché dalla propria superficie. Tale oggetto sarebbe quindi invisibile e rilevabile solo tramite glie effetti del suo enorme campo gravitazionale.
4 Una stella di bassa luminosità, dotata di un'altissima densità e gravità superficiale.
9

1.3 SISTEMI BINARI COALESCENTI
tempo della frequenza orbitale che tende a crescere, il raggio orbitale, inteso come la distanza
tra le due masse, di conseguenza tende a diminuire. I due corpi quindi si avvicinano sempre
più fino ad arrivare alla coalescenza. A questo punto essi finiscono per fondersi e danno vita a
un nuovo corpo, solitamente un Black Hole.
Da questo moto di sistemi binari compatti si distinguono tre fasi:
– inspiral: i due corpi ruotano a una distanza considerevolmente elevata; il segnale
d'onda ha un andamento predicibile e ben descritto dalle approssimazioni post-
newtoniane. Ha la forma d'onda di un inviluppo in frequenza ed ampiezza (chirp
signal);
– merger: quando la frequenza orbitale aumenta considerevolmente, le due masse
arrivano a una distanza relativamente piccola fino ad arrivare alla fusione e alla
formazione di un nuovo corpo. In questa fase il segnale è irregolare e fortemente
dipendente dai dettagli della collisione ed è stato recentemente studiato con i metodi
della relatività numerica;
– ringdown: il nuovo corpo generato dalla fusione, generalmente un buco nero
massiccio estremamente denso, raggiunge uno stato di equilibrio; la forma d'onda
assume le caratteristiche di una sinusoide decrescente.
Il presente lavoro è volto alla riproduzione della forma d'onda del segnale nella sola fase di
inspiral.
La predicibilità di un sistema binario compatto dipende dalle caratteristiche distintive del
10
Illustrazione 1.2: Moto di un sistema binario coalescente

1.3 SISTEMI BINARI COALESCENTI
sistema e in particolare dalla sua massa totale. Infatti la probabilità di individuazione è
direttamente proporzionale alla massa totale del sistema. La massa di un BH, che può arrivare
fino a 30 volte la massa solare, è di molto superiore a quella di una NS, 1-3 volte la massa del
sole. È per questo che un sistema BH-BH risulterebbe più predicibile e individuabile. Tuttavia
tali sistemi non sono ancora stati bene identificati, mentre si sono raggiunte buone conoscenze
riguardanti i sistemi composti da due NS.
1.4 Detection: rilevatori e Matched Filtering
Per riprodurre e successivamente individuare un segnale di questo tipo abbiamo bisogna di un
algoritmo esegua la cosiddetta tecnica di Matched Filtering, ma anche di strumentazione
(detector o interferometri) altamente sofisticata e precisa, su cui applicare il codice
implementato. Il software è naturalmente fortemente dipendente dall'hardware, oltre che a una
buona conoscenza della forma d'onda del segnale. Si ha pertanto bisogno di un detector
alquanto complesso e di grandi dimensioni. La costruzione di tali strumenti non è semplice e
richiede una massima accuratezza in ogni dettaglio. I primi progetti di costruzione, iniziati
negli anni sessanta, si basavano su rilevatori a barre risonanti. Questo tipo di rilevatori è
capace di osservare fenomeni con una frequenza maggiore a 1 Khz. Attualmente si è orientati
verso la realizzazione di rilevatori interferometrici, che sfrutta una tecnica basata
sull'interferenza dei raggi laser. A questa generazione di rilevatori appartengono i progetti
VIRGO [6] (in cui rientra il progetto che stiamo presentando), LIGO [7], GEO e TAMA che
possono intercettare fenomeni con bande di frequenze più basse, che vanno da qualche Hz
fino a 10 Khz. Tali interferometri sono ancora esemplari di prima generazione, ma si sta
investendo in questo settore per creare dei prototipi di seconda e poi terza generazione. A
questi va aggiunto il progetto LISA [8] per la costruzione di un interferometro spaziale, in
grado di esplorare le bande di frequenza da 10-4 Hz a 10-1 Hz.
Per la realizzazione di interferometri il disegno base è quello dell’interferometro di Michelson
(illustrazione 1.3): una sorgente laser che invia un fascio luminoso collimato verso uno
specchio semitrasparente (beam splitter) in posizione centrale; due specchi piani posti al
11

1.4 DETECTION: RILEVATORI E MATCHED FILTERING
termine di due
percorsi ortogonali a partire dallo specchio centrale; un misuratore d’intensità luminosa
(fotodiodo) disposto in modo da completare una croce insieme agli altri quattro elementi
ottici. Tali interferometri ricoprono un'area molto vasta, per esempio VIRGO è composto da
due bracci ortogonali della lunghezza di 3Km l'uno.
Lo scopo del presente lavoro è però quello di creare uno strumento software da applicare al
tipo di detector appena introdotto, al fine di rilevare la presenza di segnali d'onda
gravitazionale. Per l'identificazione di GW si utilizza una tecnica di Matched Filtering (MF).
Dato un campione del segnale h(t) che vogliamo cercare in una sequenza di dati caratterizzati
da un rumore n(t), si può dimostrare che la funzione che massimizza il rapporto segnale-
rumore è data da:
c t =∫ N f ∗H f S f
∗e−∞ dt
Dove H(f) e N(f) i corrispettivi del segnale e del rumore nel dominio delle frequenze e S(f) è
il power spectrum del rumore. I valori restituiti c(t) sono legati al rapporto SNR(Signal to
12
Illustrazione 1.3: Schema di un interferometro di Michelson

1.4 DETECTION: RILEVATORI E MATCHED FILTERING
Noise Ratio) fra il segnale e il rumore. Maggiore è l'altezza del segnale in uscita e maggiore
sarà la probabilità che nella posizione specifica sia presente il segnale cercato.
Quindi, più in generale, per la detection di GW si crea un algoritmo che opera nel seguente
modo:
1. genera un numero elevato di templates (segnali di riferimento) tale da produrre una
griglia che copre lo spazio di parametri su cui effettuare l'indagine;
2. eseguire la procedura di MF per ogni segnale di riferimento;
3. prelevare il picco massimo fra tutti i massimi registrati.
Durante la fase di MF, entrano in gioco delle teorie probabilistiche sull'evento e risulta
indispensabile valutare ed eliminare la presenza di rumori che potrebbero interferire nella
ricerca. Le principali fonti di rumore sono il rumore sismico, il rumore termico e lo shot
noise(derivante dal fascio luminoso). Questi rumori si possono attenuare in fase di
progettazione del rilevatore. Dal momento che l'intensità del segnale gravitazionale è molto
bassa, questa fase di eliminazione dei rumori è essenziale per aumentare la SNR e quindi per
l'individuazione di GW. Nel caso di VIRGO, dai test effettuati si sono potuti apprezzare ottimi
risultati che parlano di una quantità di rumore inferiore alla soglia stimata in fase di
progettazione.
Per ottenere un riscontro più attendibile dell'algoritmo di MF, la politica che si sta attuando è
quella di testare lo stesso segnale su diversi detector, posizionati in diverse parti del pianeta,
sfruttando le potenzialità di un sistema GRID, per stabilire se c'è coerenza con i risultati
ottenuti e definire con più precisione la probabilità che l'evento si sia verificato.
1.5 Analisi del segnale proveniente da sistemi binari
Lo scopo di questo lavoro, è quello di ottimizzare la fase di generazione dei segnali di onda
gravitazionale. Ottenere ciò, prescinde da una buona conoscenza della natura del segnale che
si vuole trattare [4]. Pertanto passiamo ora a una più precisa definizione di come si
caratterizzano le forme d'onda che andremo ad analizzare.
L'output del detector può essere sintetizzato come sovrapposizione del segnale d'onda
13

1.5 ANALISI DEL SEGNALE PROVENIENTE DA SISTEMI BINARI
gravitazionale h(t) e del rumore n(t):
Dal momento che il segnale gravitazionale è generalmente molto debole, risulta
fondamentale, ai fini della rivelabilità dell'onda gravitazionale, ridurre al minimo tali rumori
in fase di progettazione e realizzazione del detector.
Ma ovviamente, oltre alla riduzione del rumore, risulta fondamentale una corretta
riproduzione del segnale che deriva da una conoscenza approfondita della forma d'onda.
Il segnale gravitazionale è espresso come composizione delle due polarizzazioni di
quadrupolo h+ e hx:
dove h+ e hx rappresentano l'ampiezza delle due polarizzazioni e F+ e FX sono le cosiddette
beam-pattern function specifiche per il detector, che dipendono dalla posizione della sorgente
rispetto al detector. Nel caso del laser-interferometro VIRGO, esse sono definite come:
Le equazioni delle due polarizzazioni, h+ e hx, sono derivate dalle approssimazioni newtoniani
al primo ordine (PN0) nel seguente modo:
dove G è le costante gravitazionale e c la velocità della luce, i è l'angolo di incidenza, m è la
massa totale del sistema (m = m1 + m2 ), mentre ω e φ sono rispettivamente la frequenza e la
fase orbitale. Dalle formule delle due polarizzazioni, si possono isolare quindi alcuni termini,
14
[1.1]
[1.2]
[1.3]
[1.4]

1.5 ANALISI DEL SEGNALE PROVENIENTE DA SISTEMI BINARI
ottenendo un'espressione semplificata:
dove A è una costante che dipende dalla distanza del sistema dall'interferometro, mentre i due
fattori variabili che caratterizzano le polarizzazioni sono:
– la fase : ϕ(t), che dipende da m e da i;
– l'ampiezza : h(t), che dipende da m e da R.
Sia la fase che l'ampiezza sono esprimibili indipendentemente come approssimazioni PN.
Dal momento che il segnale h(t) può essere calcolato a diversi gradi di approssimazione, esso
è più generalmente espresso dalla seguente formula:
con le approssimazioni PN così definite, per la plus polarization:
15
[1.6]
[1.5]

1.5 ANALISI DEL SEGNALE PROVENIENTE DA SISTEMI BINARI
e per la cross polarization:
16
[1.8]
[1.7]

1.5 ANALISI DEL SEGNALE PROVENIENTE DA SISTEMI BINARI
dove:
• ν = (m1 * m2)/(m1 +m2) è la massa ridotta,
• m = m1 +m2 è la massa totale del sistema,
• δm = m1 - m2 è la differenza tra le masse,
• ϕ è la fase.
Il valore di ϕ è calcolato in funzione di ω e φ e viene espresso come:
dove ω e φ sono la fase e la frequenza istantanea e ω0 è la frequenza dell'onda all'istante t0 e
sarà presa uguale alla frequenza di taglio inferiore del detector.
Le approssimazioni di fase e frequenza sono descritte dalle seguenti equazioni:
17
[1.9]
[1.10]
[1.11]

1.5 ANALISI DEL SEGNALE PROVENIENTE DA SISTEMI BINARI
dove τ è la variabile temporale adimensionale legata alla variabile temporale t dalla seguente
equazione:
dove tc è il tempo di coalescenza, ovvero la durata della fase di inspiral del segnale (ref. 1.3).
Risulta quindi evidente dalle precedenti equazioni, che più ci avviciniamo alla coalescenza e
più l'ampiezza del segnale aumenta, diventando massima pochi istanti prima della fusione.
La forma d'onda risultante ha visualmente una forma di inviluppo in frequenza e in ampiezza,
che denota come più ci avviciniamo all'istante di coalescenza più l'intensità del segnale
aumenta (vedi illustrazione 1.4).
Dalle premesse fatte, risulta necessario per il calcolo delle due polarizzazioni calcolare la fase
e la frequenza orbitale del sistema, che prescinde dall'aver stimato la durata del segnale e
quindi il tempo di coalescenza.
Il calcolo del tempo di coalescenza può essere risolto usando diversi metodi. Nel nostro caso
si è utilizzato il metodo di “Newton-Raphson”5 che si traduce sostanzialmente nel trovare lo
zero della equazione della frequenza angolare, calcolata in un intervallo di tempo
sufficientemente grande, e quindi bisogna risolvere:
w(τ )=w0=2*π*f0 → w(τ ) - 2*π*f0 = 0
[1.13]
Quindi definita una w0 di partenza (uguale alla frequenza di taglio del detector) otteniamo
tramite la [1.11] il valore di τ0. Sostituendo alla [1.12] il vaore di τ0, appena trovato, ricaviamo
il tempo di coalescenza tc, che definisce la durata del segnale. A questo punto, una volta
calcolato il tempo di coalescenza, siamo in grado di generare i templates che stavamo
cercando, calcolando prima i valori di fase φ e frequenza ω istantanei, tramite la [1.10] e la
5 Anche detto metodo delle tangenti, è uno dei metodi usati per il calcolo approssimato della radice di un'equazione del tipo : f(x)=0. Esso si applica in un intervallo [a,b] in cui la funzione è continua e derivabile e le sue derivate prima e seconda esistono e sono diverse da zero.
18
[1.12]

1.5 ANALISI DEL SEGNALE PROVENIENTE DA SISTEMI BINARI
[1.11], e da questi la fase ϕ [1.9], per poi risolvere le equazioni delle due polarizzazioni h+ e
hx tramite le approssimazioni PN [1.7] e [1.8] e salvare i risultati in uscita (che costituiranno i
nostri templates) in appositi vettori.
1.6 Analisi della scelta implementativa
La corretta generazione di templates accurati permette di ricreare fedelmente il segnale.
Bisogna tener presente che la ricerca di questi tipi di segnali necessita di una potenza e
velocità di calcolo notevoli. La stessa generazione di template necessita di un'elevata capacità
computazionale. Difatti, la tecnica di MF richiede la generazione di un elevato numero di
segnali di riferimento, che per i detector di prossima generazione, potranno essere dell'ordine
di 10000-1000000. Devono perciò essere utilizzati strumenti hardware e software dedicati. In
questo lavoro di tesi, mi sono appunto dedicato alla fase di generazione dei templates,
ottimizzando questa parte.
Dal momento che le normali tecniche di programmazione basate su sistemi CPU multi-core
19
Illustrazione 1.4: Forma d'onda del segnale nella fase di inspiral

1.6 ANALISI DELLA SCELTA IMPLEMENTATIVA
presentano comunque dei limiti, quando si vuole eseguire parallelamente la stessa
elaborazione su una grossa mole di dati, si è cercato di puntare su un nuovo tipo di
architettura che può apportare enormi benefici sulle prestazioni: quella basata su GPU. Infatti
le GPUs, costituiscono un'architettura many-core che permette l'elaborazione di un elevato
numero di dati in parallelo, offrendo quindi una potenza di calcolo di molto superiore (in
media dai 10 ai 100x) rispetto all'architettura multi-core basata su CPU più performante
presente sul mercato.
20

21
Capitolo 2
I processori grafici: le GPU
Nelle ultime decine di anni, gli astronomi sono riusciti a trarre giovamenti dal crescente
aumento delle prestazioni delle CPU, che seguendo la legge di Moore6 raddoppiavano la loro
velocità ogni due anni. Tuttavia una tale tecnologia è praticamente satura perché si è ormai
arrivati quasi al limite prestazionale, dovuto al fatto che non è possibile aumentare
smisuratamente la frequenza del clock di una CPU perché porterebbe sia ad un enorme
consumo energetico che ad un'elevata generazione di calore ed inoltre esistono dei limiti
dovuti alle tecniche di miniaturizzazione. Pertanto è da qualche anno in atto una radicale
mutazione nell'architettura di un computer, che porterà ulteriori miglioramenti nelle
prestazioni grazie allo sviluppo del General Purpose GPU computing. Una GPU, acronimo
per Graphics Processing Unit, è un coprocessore della CPU basato su un'architettura parallela,
ovvero in grado di svolgere un elevato numero di operazioni in virgola mobile su diversi dati
in parallelo. Le GPU sono state in principio ideate e progettate per il rendering grafico e
difatti costituiscono le schede grafiche per computer e console. Fino a poco tempo fa il loro
compito era strettamente legato allo svolgimento di operazioni di decoding di file audio e
video, ma negli ultimi anni si è cercato di sfruttare le loro potenzialità anche in altri settori,
trovando applicazioni in molti campi come ad esempio l'esplorazione petrolifera,
l'elaborazione scientifica, ricerca medica e perfino la determinazione del prezzo delle opzioni
6 Le prestazioni dei processori, e il numero di transistor ad esso relativo, raddoppiano ogni 18 mesi.

2 I PROCESSORI GRAFICI: LE GPU
sulle azioni di borsa.
Sostanzialmente l'idea di GPU nasce in necessità del fatto che alcuni calcoli, come quelli
necessari per la resa grafica, graverebbero troppo su una normale CPU. Pertanto si è orientati
verso processori specifici a svolgere questo tipi di operazioni. Le GPU moderne, sebbene
operino a frequenze più basse delle normali CPU (e quindi consumano meno watt di potenza e
dissipano meno calore), sono molto più veloci di esse nell'eseguire i compiti in cui sono
specializzate ed offrono inoltre una valida soluzione low-cost.
Da vari test si è potuto evincere che un porting di codice da CPU a GPU può portare
giovamenti sulle prestazioni di un fattore 10x o addirittura di 100x e si pensa che entro il 2016
si possa arrivare fino a 1000x. Tuttavia non bisogna generalizzare questo dato, in quanto il
porting di codice da CPU a GPU può risultare non banale e soprattutto non tutti i problemi si
prestano a una buona “parallelizzazione”. Questo lavoro di tesi ha utilizzato come riferimento
di codice CPU per il generatore, quello realizzato dal Dr. Giancarlo Cella (INFN Pisa).
In questo capitolo analizzeremo gli aspetti fondamentali che riguardano le GPU, partendo
dalle premesse storiche sulla loro nascita e l'origine del loro sviluppo, per poi andare a
definire nello specifico il tipo di architettura su cui si basano, le caratteristiche hardware, e
proponendo due diversi approcci alla programmazione su GPU: CUDA e OpenCL.
2.1 Storia dei processori grafici
I primi chip grafici, di tipo monolitico, risalgono agli anni '80 e disponevano di un set limitato
di funzioni per l'elaborazione bidimensionale dell'immagine. A inizi degli anni '90 si inizia a
pensare all'idea di un processore dedito alle operazioni di rendering grafico. Si iniziano così a
produrre delle vere e proprie CPU disegnate e programmate per fornire le funzioni di disegno
utilizzate da applicazioni di tipo Computer Aided Design (CAD). Tuttavia questa tecnologia è
stata sorpassata dall'avvento dei primi chip grafici integrati per l'accellerazione 2D, che erano
meno flessibili di una CPU, ma di maggiore semplicità di fabbricazione e a costi minori. Una
grande svolta evolutiva è data soprattutto dall'industria dei videogame che ha spinto i
produttori ad integrare chip grafici in grado di fornire un set di funzioni per l'accelerazione
22

2.1 STORIA DEI PROCESSORI GRAFICI
3D. Nascono così le libreria OpenGL e DirectX, di MicrosoftWindows la cui crescita segue il
passo dell'evoluzione dell'hardware. Si arriva così alla fine degli anni 90 all'idea odierna di
GPU, grazie all'introduzione di shader programmabili per le funzioni grafiche. Se dal punto di
vista della computer graphics, gli shader servono a definire l'aspetto finale dell'oggetto sulla
superficie di disegno, dal punto di vista software essi costituiscono un insieme di istruzioni
che operano su pixel o vertici di un oggetto. Con il passare del tempo si sono aggiunte diverse
funzionalità agli shader che hanno acquistato la capacità di compiere cicli e un grosso numero
di operazione in virgola mobile, tanto da diventare flessibili tanto quanto una CPU. Scaturisce
proprio dagli shader prommabili quello che noi oggi definiamo General Purpose on GPU
computing, che si sviluppa concretamente a partire dalla creazione di shader unificati. Da qui
deriva la possibilità di esportare l'applicabilità delle GPU. È stato così possibile sfruttare le
potenzialità di una GPU non più solo per l'accelerazione 3D per console, computer e
workstation, ma anche in altri settori.
L'introduzione degli shader programmabili e il primo esempio di GPU viene dato da NVIDIA,
nel 1999. Successivamente ATI, oggi ormai inglobata da AMD, ha aggiunto innovazioni
tecnologiche e la forte concorrenza nel settore tra queste due aziende ha permesso una rapida
crescita evolutiva del General Purpose GPU computing (GPGPU).Basta pensare che le GPU
hanno fatto registrare un raddoppio di prestazioni ogni 6 mesi e se confrontiamo questo dato
con quello relativo alle CPU che per decenni hanno seguito la legge di Moore, notiamo come
l'evoluzione statistica di una GPU è di tre volte superiore rispetto alla rivale CPU (
illustrazione 2.1). Quest'ultima è oltretutto quasi arrivata al limite tecnologico, con frequenza
massima proponibile sul mercato attorno ai 3GHz, soglia dettata da un alto consumo di
energia e soprattutto da una elevata dispersione di calore. Le GPU invece lavorano a
frequenze più basse e riescono ad ottenere un massimo picco di performance dell'ordine dei
Tflop/s contro i 12 Gflops di una normale CPU moderna (Pentium IV).
Al giorno d'oggi ci sono più aziende che producono GPU (Intel, AMD, NVIDIA...) ma
ognuna applica politiche dal punto di vista dell'architettura dell'hardware differenti. Si sono
inoltre creati diversi ambienti di sviluppo software per GPU, di cui noi andremo ad analizzare
i due più significativi:
• CUDA, sviluppato da NVIDIA per la programmazione delle prorpie sche grafiche
prodotte, che è stato il primo framework e tuttora il più diffuso e utilizzato;
• OpenCL, riconosciuto come standard ufficiale e proposto dalla Kronos Group
23

2.1 STORIA DEI PROCESSORI GRAFICI
(associazione delle maggiori aziende nel settore della computer graphics, tra cui
Apple, NVIDIA, AMD/ATI...) che ha una sintassi leggermente più complessa di
CUDA, perchè richiede una serie di istruzioni di inizializzazione, che sono oscurate
dalla programmazione in ambiente CUDA; esso però si propone come unica
interfaccia di programmazione verso tutti gli ambienti multi e many core.
2.2 Classificazione delle architetture
Secondo la classificazione di Micheal J. Flynn si distinguono quattro diversi modelli di
sviluppo di un'architettura di un processore, che si differenziano per il flusso di istruzioni che
l'elaboratore può processare ad ogni istante e il flusso dei dati su cui può operare
24
Illustrazione 2.1: Evoluzione di CPU e GPU a confronto

2.2 CLASSIFICAZIONE DELLE ARCHITETTURE
simultaneamente. Dalla combinazione di queste due caratteristiche si definiscono le categorie
di Flynn, che sono:
– SISD: (Single Instruction Single Data) è la classica architettura della macchina di Von
Neumann, su cui si basano i convenzionali calcolatori. Un singolo flusso di istruzioni
viene eseguito sequenzialmente, su un singolo dato alla volta, senza implementare
nessun grado di parallelismo;
– SIMD: (Single Instruction Multiple Data) a questa categoria appartengono le
architetture composte da più unità di elaborazione, che eseguono lo stesso flusso di
istruzioni su dati diversi. Questo schema consiste di un processore principale che invia
lo stesso flusso di istruzioni da eseguire contemporaneamente da un insieme di unità di
elaborazione, che hanno il compito di eseguire le operazioni in parallelo;
– MISD: in questa tipo di architettura diverse unità di elaborazione operano
contemporaneamente sullo stesso dato. Una tale struttura non è ancora stata
implementata per essere commercializzata ma è stata sviluppata solo per scopi di
ricerca scientifica in alcuni super-computer;
– MIMD: rappresenta un evoluzione del SISD. In questo tipo di architettura più processi
sono attivi contemporaneamente su più processori, che utilizzano aree di memoria
proprie o condivise. Questo modello si implementa interconnettendo un numero
elevato di elaboratori di tipo convenzionale. Rientrano in questa categoria i sistemi di
calcolo a multiprocessori e sistemi di calcolo distribuiti.
Le categorie SIMD e MIMD si definiscono architetture parallele. In realtà, le GPU di
NVIDIA hanno sviluppato un'architettura parallela che non rientra propriamente nella
classificazione appena citata, e che viene denominata SIMT (Single Instruction Multiple
Thread). In effetti la stessa istruzione, o meglio flusso di istruzioni, viene eseguita non su una
molteplice di dati, bensì da una molteplicità di thread. Un'architettura SIMT richiede una
maggiore logica di controllo, rispetto alla convenzionale SIMD, che porta come conseguenza
un aumento della superficie del chip e un maggior consumo energetico. Ma a differenza della
SIMD, quest'architettura è in grado di massimizzare l'uso delle proprie unità di calcolo,
soprattutto quando l'applicazione è composta da un elevato numero di threads. Infatti le GPU
sfruttano appieno le proprie potenzialità quando il numero dei thread è dell'ordine delle
migliaia, permettendo in questo modo di avere un costo di creazione e di gestione degli stessi
praticamente nullo.
25

2.3 ARCHITETTURA DI UNA GPU
2.3 Architettura di una GPU
Le GPU di NVIDIA costituiscono un'architettura parallela multithread e manycore. Le
componenti principali sono Scalable Processor Array (SPA), che si occupa di eseguire tutte le
operazioni programmabili sulla GPU, e una Dynamic Random Access Memory (DRAM). Le
GPU necessitano anche di un Host Interface che si occupa delle operazioni tra l'Host e il
Device, ovvero tra la CPU e la periferica che si vuole interconnettere (la GPU nel nostro
caso). I suoi compiti sono quelli di trasferire i dati da e verso la CPU, interpretare i comandi
dell'host e verificare la consistenza di questi. Successivamente il lavoro passa al Compute
work distribution (CWD) che distribuisce il flusso di istruzioni sullo SPA. Il flusso di
istruzioni eseguito sul device prende il nome di kernel. Il Pixel e Vertex work distribution
svolgono un ruolo simile ma vengono utilizzati esclusivamente per operazioni di rendering
grafico, così come il Raster operation processor che opera direttamente con la DRAM e
svolge le operazioni di colorazione dei pixel. All'interno dello SPA sono presenti due Stream
Multiprocessor (SM).
In tutto, in una Tesla C1060 [9], sono presenti 30 SM, ognuno dei quali aventi 8 Stream
Processor (SP), per un totale di 240 cores. Ogni SM, ha inoltre al suo interno due Special
Function Unit (SFU), per eseguire operazioni complesse come funzioni logaritmiche,
26
Illustrazione 2.2: Architettura di una Tesla C1060

2.3 ARCHITETTURA DI UNA GPU
esponenziali, trigonometriche, una MTI (Multi Thread Injstruction fetch and Issue unit) che
serve a distribuire il carico dei thread all'interno di uno stesso SM, una cache per le istruzioni
e una per la memoria. Ogni SM ha inoltre una porzione di memoria condivisa di 16 Kb, tra
tutti gli SP al suo interno. Ogni SP, invece, ha una propria unità scalare MAD (Multiply-Add),
composta da una ALU (Arithmetic Logic Unit) ed una FPU (Floating Point Unit), in grado di
garantire un elevata potenza per i calcoli Floating Point (FP) a singola precisione (32 bit) e
permettono anche l'esecuzione di istruzioni FP a doppia precisione (64 bit). Tuttavia si ha una
sola unità di elaborazione in doppia precisione condivisa fra gli 8 SP dello stesso SM. Per
quanto riguarda la memoria, abbiamo diversi spazi di indirizzamento: global memory, local
memory, shared memory, registri e memoria cache (texture e constant). Nella global memory
vengono mossi tutti i dati prima di eseguire l'elaborazione. La local memory è invece uno
spazio riservato ad ogni singolo thread di 16 Kb, la constant cache è contenuta all'interno
della memoria globale ed ha a disposizione 64 Kb, mentre, come abbiamo già anticipato, la
shared memory ha 16 Kb a disposizione, divisi in 16 blocchi da 1 Kb ciascuno, ed è condivisa
dagli SP all'interno dello stesso SM.
27
Illustrazione 2.3: Insieme di multiprocessori SIMT con memoria condivisa

2.3 ARCHITETTURA DI UNA GPU
Da tale struttura si evince una mancanza di un sistema di caching generale, che può
comportare un'elevata latenza per le operazioni sui dati in memoria globale, che necessita di
400-600 cicli di clock. Tuttavia questa latenza può essere ben mascherata nel caso si abbia un
numero di thread per SM sufficientemente alto. Questo si ottiene attraverso uno scheduling
intelligente, in cui il thread che ha richiesto un accesso in memoria viene messo in attesa e
vengono così liberate risorse che possono essere sfruttate da un altro thread, rimasto inattivo
fino a quel momento, che può eseguire il proprio flusso di istruzioni. Al contrario di quanto
avviene per la memoria globale, i tempi di accesso alla memoria condivisa sono di poco
superiori a quelli per i registri. Tuttavia si dispone di soli 16Kbyte di memoria condivisi tra
tutti gli SP all'interno dello stesso SM. Questo può comportare a una conflittualità di accesso
ai dati, che porta alla serializzazione degli accessi e a un aumento della latenza a scapito delle
prestazioni.
La caratteristica distintiva di uno SM deriva dal meccanismo di esecuzione delle istruzioni,
associabile a un'architettura di tipo SIMD ma sostanzialmente differente. Difatti ogni singolo
SP infatti è in grado di gestire un flusso di esecuzione differente, comportandosi non come un
processore vettoriale ma come diverse unità di esecuzione scalari; perciò si parla di SIMT
(Single Instruction Multiple Threads).
Ogni SM gestisce fino a 24 Warps, ognuno composto da 32 thread. La MT Issue inoltra le
istruzioni ai warps. Può accadere che all'interno dello stesso warp, in presenza nel codice di
istruzioni di salto condizionato (ad esempio if-else, switch-case...) i threads divergano, ovvero
seguono percorsi differenti. Si ha un ottimizzazione delle prestazioni quando tutti i threads
dello stesso warp seguono lo stesso flusso di istruzioni. Infatti in caso contrario i flussi
vengono eseguiti serialmente con un conseguente degrado delle prestazioni. Pertanto bisogna
tener conto di questo possibile inconveniente quando si vuole scrivere software che sfruttino
appieno le potenzialità' di una GPU.
In generale se si vuole ottenere il picco massimo delle prestazioni bisogna tener conto dei
seguenti fattori:
• conditional branching (salto condizionato): se i threads all'interno dello stesso warp in
presenza di un istruzione di salto divergono, essi vengono eseguiti serialmente.
Pertanto un processore SIMT risulta efficiente al massimo quando tutti i thread dello
stesso warp seguono lo stesso flusso di istruzioni. Tuttavia si può mascherare la
28

2.3 ARCHITETTURA DI UNA GPU
penalità derivante dalla divergenza dei warps nel caso in cui si ha un numero elevato
di thread, solitamente almeno 5000;
• shared memory (memoria condivisa): ogni SM dispone di on-chip shared memory di
16 KB con un tempo di latenza di diversi ordini di grandezza inferiore rispetto alla
memoria globale. Pertanto risulta in alcuni casi essenziale disegnare un algoritmo che
sfrutti la memoria veloce per aumentare le performance;
• coalesced global memory operations: ogni qualvolta risulti necessario che più threads
richiedano accesso alla memoria globale è conveniente, laddove sia possibile, usare
tecniche per accedere ai dati in lettura o scrittura in blocco: coalesced access. È
possibile effettua coalesced accesses se i threads all'interno dello stesso blocco fanno
richiesta di accedere a una zona di memoria allineata. In particolare, un accesso in
lettura o scrittura può avvenire in maniera coalesced se almeno la metà dei threads in
un warp (half-warp), effettua un accesso in memoria in modo tale che il thread i-esimo
acceda alla locazione i-esima di uno spazio allineato ad un indirizzo multiplo delle
dimensioni di un half-warp (16). Un algoritmo che riesce a sfruttare questa tecnica
riesce ad ottenere una maggiore banda passante per la memoria, con prestazioni di 10
volte superiori rispetto ad operazioni con la memoria non coalesced.
2.4 GPGPU: General Purpose GPU computing
Fino a qualche anno fa la programmabilità delle GPU era utilizzata solo per applicazioni
audio e video, ma da qualche anno si è cercato di sfruttare le potenzialità di una tale
architettura anche per una più ampia gamma di applicazioni, dando vita al General Purpose
GPU computing (GPGPU) [10,11].
La nascita del GPGPU deriva dall'introduzione di shader programmabili, che erano in grado
di elaborare calcoli matriciali associando i dati da elaborare a delle texture. Gli shader infatti
sono nient'altro che semplici applicazioni eseguite su una grossa quantità di dati. Inizialmente
gli shader supportavano delle Apllication Programming Interface (API) ideate per il disegno
3D. Il loro compito era quello di eseguire operazioni su un insieme di vertici, pixel e texture.
29

2.4 GPGPU: GENERAL PURPOSE GPU COMPUTING
Il fattore che ha influenzato la nascita del GPGPU è stata la creazione di uno Shader Unified
Model, ovvero un modello di shading che utilizza lo stesso set di istruzioni per la definizione
di pixel, geometry e vertex shader. Nel 2006 nasce così una nuova generazione di GPU,
sviluppata da NVIDIA, che sfrutta queste nuove potenzialità degli shader. Questa nuova
architettura per le GPU prende il nome di CUDA, Compute Unified Driver Architecture, che
sfrutta tutti i vantaggi di un processore grafico anche per operazioni che non riguardano la
Computer Graphics. Oltre a CUDA sono nate in seguito anche altre piattaforme, come Stream
di AMD o Larrabee di Intel, che costituiscono anche ambienti per la programmazione di GPU
che si servono di API ideate appositamente per la programmazione General Purpose. Vista la
forte espansione e l'interesse dimostrato nei confronti di questa nuova generazione di GPU, la
Khronous Group, un consorzio che riunisce tutte le maggiore aziende del settore, ha deciso di
definire uno standard che alla lunga dovrebbe avere la meglio sui vari paradigmi di
programmazione fin qui creati, ovvero OpenCL, Open Compute Language. Al momento però
l'ambiente CUDA di NVIDIA è quello che vanta una maggiore documentazione e quindi offre
un migliore supporto per il programmatore. Questo spiega perchè circa il 90% dei programmi
implementati per GPU viene ancora scritto in CUDA, che riesce ad offrire anche migliori
strumenti per il debug.
2.5 CUDA
CUDA [12] è nello stesso tempo sia un'architettura parallela sviluppata da NVIDIA, ma
rappresenta anche un modello di programmazione API (Application Programming Interface)
che sfrutta le potenzialità dei sistemi manycore. Per maggiore chiarezza di qui in avanti
quando ci riferiremo al linguaggio di programmazione lo chiameremo C for CUDA o anche
C-CUDA, distinguendolo dall'architettura che nomineremo più semplicemente CUDA. Il
termine C-CUDA sta ad indicare che esso è essenzialmente un'estensione del C/C++ con
l'aggiunta di un ISA (Instruction Set Archietecture) in gradi di interfacciarsi verso un sistema
many-core. Questa stretta parentela del C-CUDA con il linguaggio C/C++ permette un facile
apprendimento ai programmatori già familiari con questo ambiente. CUDA offre inoltre due
30

2.5 CUDA
modelli di programmazione:
– uno ad alto livello, ovvero sullo stesso livello del C e che abbiamo identificato con C
for CUDA e che maschera al programmatore tutta una serie di funzioni, come quelle
per l'inizializzazione della periferica, e rende il codice più semplice da scrivere e più
compatto;
– uno ad un abstraction key più basso che necessita di un maggior numero di righe per la
scrittura di codice (allo stesso livello di OpenCL), che rappresenta l'interfacciamento
diretto al Driver API CUDA.
Di seguito descriveremo le specifiche del paradigma del C for CUDA, mentre
successivamente analizzeremo un linguaggio a livello più basso come l'OpenCL.
Gli elementi principali sui quali la piattaforma CUDA si basa sono:
• modello di esecuzione basato sui thread
• meccanismi di condivisione della memoria
• meccanismi di sincronizzazione
Il concetto che sta alla base dell'architettura CUDA è quello di partizionare il problema in
tanti piccoli sotto-problemi da risolvere indipendentemente. Questo è possibile tramite la
cooperazione di più flussi di esecuzione concorrenti, ognuno gestito da un thread, all'interno
31
Illustrazione 2.4: API di CUDA

2.5 CUDA
dello stesso programma. Ad ogni multiprocessore viene assegnato un blocco di threads, con
un limite massimo (solitamente di 512 threads per blocco, o fino a 1024 nelle più moderne
GPU) dovuto alle limitazioni dell'hardware. Ogni blocco condivide uno spazio di memoria
per tutti i suoi threads. I blocchi vengono suddivisi in una griglia adattabile a una, due o tre
dimensione a seconda della tipologia del problema da risolvere. La griglia ha lo scopo di fare
eseguire a tutti i threads del blocco lo stesso codice, o meglio lo stesso kernel. Questo
permette sia la risoluzione di ogni sotto-problema a ogni blocco, sia la cooperazione di più
blocchi per la risoluzione dello stesso problema. Da ciò ne deriva una scalabilità del sistema
sia rispetto al numero di SM, che rispetto al numero di threads che questi possono gestire.
Dal punto di vista software un programma C-CUDA è costituito da una parte Host, ovvero
eseguita dalla CPU, scritta in C-CUDA e che effettua chiamate di funzioni scritte in C sul
device (GPU) definiti kernel. Il codice host viene eseguito serialmente sulla CPU, mentre il
32
Illustrazione 2.5: Modello di esecuzione dei kernel e gestione dei threads

2.5 CUDA
codice del device viene elaborato parallelamente dalla GPU. La parte host si occupa di tutte le
inizializzazioni del device e quindi dei trasferimenti di memoria da e verso la periferica. Il
device è suddiviso in Stream Multiprocessor, indipendenti tra di loro aventi un certo numero
di Stream Processor (ad esempio in una Tesla C1060 sono presenti 30 SM, ed all'interno di
ogni SM ci sono 8 Stream Processor, per un totale di 240 cores).
Oltre a questa granularità architetturiale, anche a livello software è possibile suddividere in tre
livelli gerarchici tra loro: grid, block e thread. Ogni kernel viene suddiviso in blocchi,
indipendenti tra loro. Ogni blocco viene assegnato dallo scheduler ad uno SM. A sua volta
ogni SM assegnerà ai suoi SP i diversi thread generati dal programma. Sia i blocchi che i
threads vengono organizzati in una matrice, in cui indici adiacenti occupano zone di memoria
adiacenti. Tale matrice può essere, in rapporto al problema da risolvere, bidimensionale per i
blocchi e tridimensionale per i threads. Ogni thread in questo modo viene identificato da un
indice, tramite una politica di Thread Identifier. In questo modo è possibile identificare un
singolo thread dalla concatenazione di identificatore di blocco e di thread locale. L'idea è
quella che l'utente definisce la dimensionalità della griglia dei thread, tenendo conto delle
relative limitazione hardware, ma è l'hardware a decidere la distribuzione dei blocchi agli SM.
L'identificazione dei thread nel codice del kernel, avviene tramite alcune variabili built-in che
il compilatore C-CUDA mette a disposizione. Abbiamo quindi:
• threadIdx: rappresenta l'indice del thread all'interno dello stesso blocco, indirizzabile
fino a tre dimensioni in rapporto al problema da risolvere. Abbiamo quindi tre
possibili componenti: threadIdx.x , threadIdx.y, threadIdx.z;
• blockIdx: identifica il numero del blocco, può essere composto da una o due
componenti: blockIdx.x, blockIdx.y;
• blockDim: contiene il numero di thread per blocco;
• gridDim: numero di blocchi per il kernel in esecuzione.
La chiamata a un kernel necessita anch'essa di una speciale sintassi, dove devono essere
specificati il numero di threads per blocco e il numero di blocchi della griglia:
Kernel_name<<<BlocksPerGrid, ThreadsPerBlock>>>(Parameters)
dove BlocksPerGrid definisce il numero di blocchi ognuno con un numero di threads pari a
ThreadsPerBlock.
33

2.5 CUDA
Nella dichiarazione di funzioni C-CUDA si devono adottare dei particolari qualificatori:
• __global__ : definisce una funzione, o meglio un kernel, invocabile dall'host (CPU) ed
eseguibile dal device(GPU);
• __device__ : definisce un kernel, eseguibile ed invocabile esclusivamente dal device;
• __host__ : opzionale, definisce una funzione host, invocabile dall'host.
Le funzioni eseguite sul device, kernel, hanno delle limitazioni:
• non possono essere ricorsive;
• non possono presentare nella dichiarazione dei parametri statici;
• non possono avere un numero variabili di argomenti.
Fatte queste premesse, possiamo già scrivere con semplicità un kernel che effettua la somma
di due vettori e salva il risultato in un terzo vettore ed effettuare la chiamata ad esso nel main:
__global__ void addVector(float* A, float* B, float* C){
int threadID=blockDim.x*blockIdx.x+threadIdx.x;C[threadID]=A[threadID]+B[threadID];
}int main(){
...addVector<<<N,M>>>(A,B,C,)...
}
Nella variabile threadID è salvato l'ID globale di ogni singolo thread, mentre i parametri
compresi tra “<<< “e “>>>” stanno ad indicare che il kernel verrà eseguito su N blocchi
ognuno di M thread.
Come si nota, con poche righe di codice riusciamo a scrivere un kernel compatto, facilmente
leggibile e intuibile, che esegue molto più velocemente di un normale codice scritto per CPU.
Da questo semplice esempio risulta evidente che non c'è un maggior grado di difficoltà a
programmare oggetti di questo tipo, l'unica differenza sta nell'approccio che deve avere il
programmatore, che deve trovare il modo per parallelizzare l'algoritmo.
L'esecuzione parallela dei thread e l'utilizzo di spazi di memoria condivisa può portare a delle
conflittualità. Per questo i thread per cooperare senza contrasti devono riuscire a
sincronizzarsi. Per fare ciò C-CUDA mette a disposizione del programmatore delle funzioni
per la sincronizzazione. Ad esempio __syncthreads() se richiamata all'interno di un kernel,
34

2.5 CUDA
informa il singolo thread che deve interrompere la propria esecuzione ed attendere che anche
tutti gli altri threads all'interno dello stesso blocco l'abbiano anch'essi invocata a loro volta.
Un'altra funzione invece può essere richiamata nella parte host del codice è
cudaThreadSynchronize(). Questa viene di solito utilizzata prima di un trasferimento dei dati
dalla memoria del device a quella dell'host, per assicurarsi che tutti i thread abbiano terminato
il proprio lavoro.
Per le operazioni con la memoria del device, CUDA mette a disposizione funzioni per
l'allocamento e il deallocamento della memoria e funzioni per il trasferimento dati da e verso
la GPU. Abbiamo quindi:
• cudaMalloc(void** ptr, size_t count): che alloca una area di memoria nel device di
dimensione pari a count byte;
• cudaFree(void* devPtr): che libera la memoria puntata da devPtr;
• cudaMemCpy(void *des, const void *src, size_t count, enum cudaMemCpy kind):
dove:
- src è il puntatore all'area di memoria che contiene i dati da copiare;
- des è il puntatore all'area di memoria dove i dati devono essere trasferiti;
- count corrisponde al numero di byte che si vogliono trasferire;
- kind specifica il tipo di trasferimento da eseguire e può assumere i valori:
▪ cudaMemCpyHostToDevice: per indicare un trasferimento dati da CPU a GPU
▪ cudaMemCpyDeviceToHost: per indicare un trasferimento dati da GPU a CPU
A questo punto è possibile scrivere il codice completo in C-CUDA, compreso delle
allocazioni di memoria nel device, che esegue lo somma di due vettori e salva il risultato in un
terzo vettore:
#include <stdlib.h>#include <stdio.h>
#define N 10
__global__ void vetAdd(float* A, float* B, float* C){ int i = blockIdx.x * blockDim.x + threadIdx.x; if(i<N) { C[i] = A[i] + B[i]; }}
int main()
35

2.5 CUDA
{ size_t size = N * sizeof(float);
float hostA[N]; float hostB[N]; float hostC[N];
int i; for (i=0;i<N;i++) { hostA[i]= i+i; hostB[i]= i; //Allocazione della device memory float* devA; cudaMalloc((void**)&devA, size); float* devB; cudaMalloc((void**)&devB, size); float* devC; cudaMalloc((void**)&devC, size);
//trasferimento dati dall'host al device cudaMemcpy(devA, hostA, size, cudaMemcpyHostToDevice); cudaMemcpy(devB, hostB, size, cudaMemcpyHostToDevice);
//Esecuzione del kernel vetAdd<<<N,1>>>(devA, devB, devC); //Sincronizzazione cudaThreadSynchronize(); //Recupero dei dati: trasferimento dal device all'host cudaMemcpy(&hostC, devC, size, cudaMemcpyDeviceToHost);
for (i=0;i<N;i++) { printf("%f\n",hostC[i]); } //Stampa il risultato sullo schermo
//Liberazione della memoria cudaFree(devA); cudaFree(devB); cudaFree(devC);}
Bisogna tener presente che l'implementazione di strumenti di debug per codici scritti per GPU
è abbastanza complessa. C-CUDA mette comunque a disposizione del programmatore uno
strumento, cuda-gdb, per eseguire il debug dell'applicazione. Finora si è giunti alla versione
2.1 beta di gdb.
36

2.6 OPENCL
2.6 OPENCL
L'OpenCL [13,14] (Open Computing Language) nasce nel giugno 2008 da un'idea di Apple,
che pensa di creare un linguaggio standard e royalty-free per il calcolo parallelo di tipo
general purpose. La prima specifica di OpenCL (1.0) viene rilasciata nel dicembre 2008 da
Khronous Group, un consorzio che riunisce tutte le principali aziende del settore della
Computer Graphics (da NVIDIA a AMD/ATI, passando per Apple, Intel, Sony, Nokia e tutte
le maggiori aziende operanti nella Computer Graphics e non solo). Dopo 18 mesi di lavoro,
nel giugno 2010, viene anche rilasciata la versione 1.1 di OpenCL con l'aggiunta di nuove
funzionalità.
L'OpenCL nasce con lo scopo di essere un linguaggio a basso livello, portatile, rivolto a
sistemi multi-core e many-core, cross-platform per computers, servers e embedded devices e
operante su diversi sistemi operativi. Per questo OpenCL viene definito come un framework,
che permette di connettere alla CPU più devices e operare su di esse come se ci si trovasse
davanti ad un unico ed eterogeneo sistema. Inoltre stabilisce dei requisiti di precisione
numerica per fornire una consistenza matematica attraverso i diversi hardware e venditori (un
fattore di non poca rilevanza nella moderna comunità scientifica).
Quindi, a differenza di CUDA, OpenCL si propone come un'interfaccia di programmazione
non solo per GPU, ma per qualsiasi sistema multi o many-core. Inoltre, rispetto a CUDA, usa
una nomenclatura differente, ma concettualmente identica: ad esempio per definire le
dimensionalità della griglia l'equivalente del termine grid è costituito da NDRange, così come
il block è definito work-group e il thread come work-item. Ma la differenza sostanziale dal
punto di vista della programazione, è che OpenCL offre al programmatore un solo livello di
astrazione più basso rispetto al C-CUDA e che si interfaccia direttamente al driver API. Per
questo un codice scritto in OpenCL è molto più corposo rispetto ad uno CUDA, in quanto
sono richieste una serie di operazioni necessarie alla preparazione del device, che invece in C-
CUDA sono implicite e quindi nascoste al programmatore. OpenCL è comunque un
linguaggio abbastanza semplice da usare, per un programmatore già familiare con l'ambiente
C ed ancora più accessibile a chi ha già un minimo di esperienza con C-CUDA.
Nella costruzione di un applicativo in OpenCL si deve procedere per passi. Per prima cosa
37

2.6 OPENCL
bisogna interrogare il sistema per ottenere informazioni sulla piattaforma, per poi individuare
la lista delle devices disponibili per quella piattaforma e poterne selezionare una o più di una.
A partire dal o dai device selezionati si crea un context da associarli. La creazione del context
è il primo passo per l'inizializzazione e l'uso di OpenCL. Per memorizzare i dati, OpenCL
mette a disposizione degli oggetti di tipo buffer (per blocchi di memoria 1-dimensionali) o
image (per blocchi di memoria a 2 o 3 dimensioni). Una volta allocata la memoria sul device
e specificato il device, bisogna caricare e costruire il kernel. Per rendere possibile una
chiamata a un kernel, il programmatore deve costruire un kernel object. In questa fase viene
eseguita la compilazione del kernel a run-time, permettendo un'elevata portabilità del codice
ed un'ottimizzazione dello stesso in rapporto alla specifica GPU. Una volta creato il kernel
object, inizializzati e settati i suoi parametri, bisogna creare una command queue. La
command queue rappresenta un'interfaccia virtuale verso la periferica, tramite la quale si
eseguono tutte le elaborazioni sul device. Infatti nella command queue verranno inseriti i
kernel da eseguire sul device e le operazioni per il trasferimento dati tra la memoria host e
device; in seguito alla creazione del program object, lo si inserisce nella coda dei comandi e
successivamente si passa alla sua esecuzione. Per lanciare l'esecuzione del kernel è tuttavia
fondamentale stabilire dapprima le dimensionalità della griglia, o meglio dell'ND-range.
Terminata l'esecuzione del kernel, è necessario recuperare i dati elaborati, eseguendo un
trasferimento di memoria dal device all'host. In quest'ultima operazione è generalmente
necessario attuare delle tecniche di sincronizzazione, in modo da aspettare la conclusione di
tutti i threads che eseguono il kernel. Infine è possibile liberare le risorse impiegate.
Per effettuare questa serie di computazioni, OpenCL mette a disposizione una funzione per
ognuna di esse. Ecco di seguito elencate tutte le chiamate che è necessario invocare per
inizializzare la periferica, caricare un kernel ed eseguirlo su di essa:
– clGetPlaform: seleziona una piattaforma;
– clGetDeviceIDs: seleziona una lista di device;
– clCreateContext: associa un context ad uno o più deviceID;
– clCreateCommandQueue: crea una coda di comandi per un dato context;
– clCreateBuffer: alloca, e opzionalmente trasferisce, dati nella memoria del device;
– clEnqueWriteBuffer: trasferisce dati sul buffer object;
– clCreateProgram: crea un oggetto cl_program associato a un codice sorgente e ad un
38

2.6 OPENCL
context;
– clBuildProgram: effettua la compilazione a runtime del program;
– clCreateKernel: crea un oggetto cl_kernel associato a un determinato kernel presente
nel codice compilato;
– clSetKernelArg: setta i parametri del kernel;
– clEnqueueNDRangeKernel: inserisce il kernel in coda, se la coda è vuota il kernel
viene eseguito ;
– clEnqueueReadBuffer: per leggere e trasferire i dati appena elaborati dal kernel dal
device all'host.
Di seguito andiamo ad illustrare l'esempio di un codice OpenCL che effettua la somma di due
vettori ed è l'equivalente del codice scritto in C-CUDA precedentemente descritto.
Il seguente kernel OpenCL esegue la somma di due vettori e salva il risultato in un terzo
vettore.
1. __kernel void addVector (__global const float* a,2. __global const float* b,3. __global float* c)4. {5. //simple vector element index6. int thread_index = get_global_id (0);7.8. c[thread_index] = a[thread_index] + b[thread_index];9. }
Come si nota, per definire un kernel in OpenCL, si deve adottare una specifica sintassi
dichiarativa diversa da C-CUDA: __kernel void nome_kernel. I parametri di ingresso del
kernel devono essere dichiarati come puntatori e con due o più qualificatori che ne indicano,
oltre che al tipo di dato, la sua locazione in memoria. Il primo qualificatore indica in quale
regione della device memory risiede il dato. I tipi di dato indirizzabili nella device memory
sono:
• __global: memoria globale, read/write, accessibile dall'host, ma ad elevata latenza;
• __local (shared memory in CUDA): zona di memoria R/W condivisa dai work-item
all'interno dello stesso work group; è di dimensioni limitata ma molto veloce;
• __constant: porzione della memoria globale, ma di sola lettura;
39

2.6 OPENCL
• __private: memoria privata, generalmente risiedente nei registri, ovvero associata ed
accessibile da un singolo work-item e non dall'host.
Un'altra importante specifica è quella da adottare per l'indirizzamento dei thread.
Nell'esempio riportato è usato l'indirizzamento globale tramite la chiamata alla funzione
get_global_id(0). OpenCL mette a disposizione altre funzioni per l'indicizzazione dei work-
item o per la dimensionalità della griglia:
• uint get_work_dim(): ritorna il numero di dimensioni in uso;
• size_t get_global_size(uint D): numero di global work-items;
• size_t get_global_id(uint D): global work-item ID;
• size_t get_local_size(unit D): numero di local work-items;
• size_t get_local_id(unit D): local work-item ID;
• size_t get_num_groups(unit D): numero di work-groups;
• size_t get_group_id(unit D): work-group ID.
Se si presuppone che il codice del kernel sia contenuto nel file addVector.cl presente nella
directory corrente e che il nome del kernel da eseguire sia addVector, il codice host di seguito
esegue il kernel appena introdotto su una device di tipo GPU.
1. #include <stdio.h>2. #include <stdlib.h>3. #include <CL/cl.h>4. #include <string.h>5. 6. #define N 10 7.8. cl_platform_id my_platform; //OpenCL platform9. cl_context my_context; // OpenCL context10. cl_command_queue my_command_queue; // OpenCL command queue11. cl_device_id* devices; // OpenCL device list12. cl_program my_program; // OpenCL program13. cl_kernel my_kernel; // OpenCL kernel14.15. cl_int ciErr1; //Gestione dell'errore16.17. char* c_source_CL = NULL;18.
40

2.6 OPENCL
19. const char* ProgramSource = "addVector.cl"; //File in cui è contenuto il kernel
20. size_t kernel_length;21.22.//Utility per salvare il file sorgente in una stringa di caratteri23.char* utils_load_prog_source(const char* cFilename, const char* cPreamble,
size_t* szFinalLength)24.{25. ...26.}27.28.int main(int argc, char *argv[]){29.30.//Variabili Host31. float A[N];32. float B[N];33. float C[N];34.35.//Variabili device36. cl_mem devA;37. cl_mem devB;38. cl_mem devC;39.40. int i;41. for (i=0;i<N;i++)42. {43. A[i]=i;44. B[i]=i+i;45. }46. // Selezionare la platform47. cl_uint numPlatforms = 0;48. ciErr1 = clGetPlatformIDs(0, 0, &numPlatforms);49. if (ciErr1 != CL_SUCCESS) { printf("Error in clGetPlatformID !!!\n\n");
}50. cl_platform_id* platforms = NULL;51. platforms = (cl_platform_id*)malloc(sizeof(cl_platform_id)*numPlatforms);52. ciErr1 = clGetPlatformIDs(numPlatforms, platforms, &numPlatforms);53. if (ciErr1 != CL_SUCCESS) { printf("Error in clGetPlatformIDs !!!Err
code: %d\n\n",ciErr1); }54. //Selezionare il device55. cl_uint num_of_devices = 0;56. ciErr1 = clGetDeviceIDs(platforms[0], CL_DEVICE_TYPE_GPU, 0, 0,
&num_of_devices);
41

2.6 OPENCL
57. cl_device_id* devs = NULL;//new cl_device_id[10];]58. devs = (cl_device_id*)malloc(sizeof(cl_device_id)*num_of_devices);59. clGetDeviceIDs (platforms[0], CL_DEVICE_TYPE_GPU, num_of_devices, devs,
NULL);60. cl_device_id devid;61. devid = devs[0];62. //Creazione del context63. cl_context_properties cp[3];64. cp[0] = CL_CONTEXT_PLATFORM;65. cp[1] = (cl_context_properties)platforms[0];66. cp[2] = 0;67. my_context = clCreateContext(cp, 1, &devid,NULL,NULL,&ciErr1);68. if (ciErr1 != CL_SUCCESS) { printf("Error in
clCreateContext !!!\n\n" ); }69. //creazione della command queue 70. my_command_queue = clCreateCommandQueue(my_context, devid,
CL_QUEUE_PROFILING_ENABLE, &ciErr1 );71. if (ciErr1 != CL_SUCCESS) { printf("Error in
clCreateCommandQueue !!!\n\n" ); }72.73. //allocazione e trasferimento dati verso il device74. size_t size = sizeof(float)*N;75. devA = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
size, (void*)&A, &ciErr1);76. if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error
code: %d\n", ciErr1); }77. devB = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
size, (void*)&B, &ciErr1);78. if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error
code: %d\n", ciErr1); }79. devC = clCreateBuffer(my_context, CL_MEM_READ_WRITE, size, NULL, &ciErr1);80. if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error
code: %d\n", ciErr1); }81.82. //Creazione del program object83. c_source_CL = utils_load_prog_source(ProgramSource, "", &kernel_length);84. const char* CLsrc = c_source_CL;85. my_program = clCreateProgramWithSource(my_context, 1, &CLsrc,
&kernel_length, &ciErr1);86. if (ciErr1 != CL_SUCCESS) { printf("Error in
clCreateProgramWithSource !!!Err code %d\n\n", ciErr1 ); }87. clBuildProgram(my_program, 1, &devid, NULL, NULL, NULL);88. if (ciErr1 != CL_SUCCESS) { printf("Error in clBuildProgram !!!Err code
42

2.6 OPENCL
%d\n\n", ciErr1 ); }89. 90.// creazione del kernel object91. my_kernel = clCreateKernel(my_program, "addVector", &ciErr1);92. if (ciErr1 != CL_SUCCESS) { printf("Error in clCreateKernel !!!Err code
%d\n\n", ciErr1 ); }93. 94.// settaggio dei parametri del kernel95. size_t sizeofclmem = sizeof(cl_mem);96. ciErr1 = clSetKernelArg(my_kernel, 0, sizeofclmem, (void*)&devA);97. if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(ws), error code =
%d\n", ciErr1);98. ciErr1 = clSetKernelArg(my_kernel, 1, sizeofclmem, (void*)&devB);99. if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(N), error code =
%d\n", ciErr1);100. ciErr1 = clSetKernelArg(my_kernel, 2, sizeofclmem, (void*)&devC);101. if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(dt), error
code = %d\n", ciErr1);102.103. //definizione della dimensione della griglia104. const size_t cnBlockSize = 1;105. const size_t cnBlocks = N ;106. const size_t cnDimension = cnBlocks * cnBlockSize;107. 108. //Esecuzione del kernel109. cl_event event;110. clEnqueueNDRangeKernel(my_command_queue, my_kernel, 1, 0,
&cnDimension, &cnBlockSize, 0, 0, &event);111. //Sincronizzazione112. clWaitForEvents ( 1, &event);113. if (ciErr1!=CL_SUCCESS) printf("Error in clWaitForEvent\n");114.115. // Rcupero dei dati: trasferimento di memoria dal device all'host116. clEnqueueReadBuffer(my_command_queue, devC, CL_TRUE, 0, size, C, 0,
NULL, NULL);117.118. //Stampa dei risultati a video119. for (i=0;i<N;i++)120. {121. fprintf(stdout,"%f\n",C[i]);122. }123. }
43

2.6 OPENCL
È evidente che il codice OpenCL, rispetto all'equivalente C-CUDA, ha un maggior numero di
righe. Questo è dovuto al fatto che in OpenCL sono necessarie una serie di operazioni che
riguardano l'inizializzazione del device, che in C-CUDA sono implicite e mascherate al
programmatore. Tali operazioni consistono nella:
• creazione del context: righe da 46 a 68;
• creazione della command queue: righe da 69 a 71;
• creazione del program object e compilazione a run-time del kernel: righe da 82 a 92;
• inserimento del kernel nella command queue: riga 110;
Oltre a queste macro-operazioni è naturalmente necessario:
• allocare memoria sul device e copiarci i dati usati nell'elaborazione del kernel: righe
da 73 a 80.
• Settare ad uno ad uno i parametri del kernel: righe da 94 a 101;
• recuperare i dati ottenuti dall'esecuzione del kernel, trasferendo dalla memoria della
GPU a quella della CPU: riga 116.
Anche in OpenCL si devono attuare tecniche di sincronizzazione, per attendere che tutti i
work-item abbiano terminato l'esecuzione prima di eseguire il trasferimento dei dati dal
device all'host. Questo si ottiene tramite la gestione di un event object, associato
all'esecuzione del kernel (righe da 109 a 113).
2.7 Differenze CUDA – OpenCL
In questa sezione sintetizziamo le differenze di nomenclatura e di paradigma di
programmazione tra i due linguaggi introdotti precedentemente: a sinistra abbiamo la
specifica C-CUDA e a destra l'equivalente OpenCL.
Per quanto riguarda il modello di architettura:
• grid ↔ NDRange
• thread ↔ work-item
• block ↔ work-group
44

2.7 DIFFERENZE CUDA – OPENCL
Per i qualificatori:
• __global__ funtion ↔ __kernel function
• __device__ function ↔ function (nessun qualificatore richiesto)
• __device__ variable ↔ __global variable
• __shared__ variable ↔ __local variable
Per l'indicizzazione dei threads:
• threadIdx ↔ get_local_id()
• blockIdx ↔ get_group_id()
• blockDim ↔ get_local_size()
• gridDim ↔ get_num_groups()
• blockIdx.x*blockDim.x + threadIdx.x ↔ get_global_id(0)
• gridDim.x*blockDim.x ↔ get_global_size(0)
Per la sincronizzazione:
• cudaThreadSynchronize() ↔ clWaitForEvens(1,&event)
• __syncthreads() ↔ barrier()
Per il modello di memoria:
• shared memory ↔ local memory (memoria dedicata per ogni singolo blocco di thread)
• local memory ↔ private memory (memoria dedicata per ogni singolo thread)
45

46
Capitolo 3
Descrizione dell'algoritmo
Come anticipato, il presente lavoro di tesi è stato svolto nell'ambito della realizzazione di un
generatore di segnali simulati di forme d'onda gravitazionali, utilizzando GPU. Un generatore
di segnale è uno strumento utilizzato per simulare un segnale a partire da un modello teorico
che ne descrive l'andamento nel tempo. In particolare il generatore qui realizzato si basa sul
modello teorico definito dalle approssimazioni post-newtoniane per sistemi binari compatti
coalescenti. Il codice è stato sviluppato in due ambienti di programmazione GPGPU: CUDA e
OpenCL.
I segnali che siamo andati a simulare hanno una banda di frequenza utile compresa tra 1Hz e
2 – 4 Khz, dipendente da vari parametri. La sensibilità del detector VIRGO è invece compresa
tra i 30 e i 10000 Hz. Quindi per il teorema di Nyquist, secondo cui la frequenza di
campionamento deve essere almeno il doppio della banda del segnale, è sufficiente
campionare a una frequenza superiore ai 4 – 8 Khz.
L'obiettivo è quello di disegnare un algoritmo che sia il più efficiente possibile ed in grado di
generare questi modelli d'onda. Pertanto si è scelto di usare la GPU per eseguire questo
elevato numero di operazioni su più dati in parallelo. Essendo il nostro programma scritto per
GPU, sarà composto da una parte di codice che verrà eseguita serialmente dall'host(CPU) e
una parte invece parallelamente dal device(GPU).
Di seguito è descritta la sequenza di macro-operazioni richieste, di cui è composto l'algoritmo:

3 DESCRIZIONE DELL'ALGORITMO
1. inizializzazione del sistema: init_workspace():
Ogni sistema binario compatto è identificabile da un set di parametri. Per
comodità e per efficienza, nel nostro codice è stata creata una struttura
apposita, chiamata nel codice workspace, che identifica un singolo sistema
binario compatto a partire da :
▪ le due masse coinvolte: m1 e m2;
▪ la distanza dal detector: R;
▪ l'angolo d'incidenza rispetto al detector: i.
Tale struttura sarà sfruttata in seguito per il calcolo del tempo di coalescenza e
delle approssimazioni PN di fase, ampiezza e delle due polarizzazioni.
L'inizializzazione della struttura non è sicuramente gravosa dal punto di vista
computazionale e viene eseguita dalla CPU;
2. Calcolo del tempo di coalescenza: find_tc()
Il tempo di coalescenza costituisce la durata temporale del segnale. Definita
una frequenza iniziale f0 di un dato sistema binario compatto (identificato dalla
struttura precedentemente inizializzata) si esegue il calcolo del tempo di
coalescenza. La lunghezza del segnale influenza la dimensione del template e
di conseguenza il tempo di esecuzione dell'algoritmo. Anche questa
elaborazione è eseguita dall'host;
3. generazione del segnale: signal_generation():
A partire da un set di parametri, quali un workspace, il tempo di coalescenza, la
frequenza di campionamento, fase e frequenza iniziali, viene generato il
segnale d'onda gravitazionale. Questa è la parte computazionalmente più
dispendiosa ma parallelizzabile ed è pertanto svolta dalla GPU tramite
l'invocazione di un singolo kernel.
4. recupero dei dati :trasferimento dati da GPU a CPU:
Una volta terminata l'esecuzione del kernel, bisogna recuperare i dati risiedenti
sulla memoria della GPU, che costituiscono il template che stavamo cercando.
È per questo necessario un trasferimento di memoria dalla GPU alla CPU.
47

3 DESCRIZIONE DELL'ALGORITMO
Nella prima parte del codice eseguita dall'host sono presenti le fasi di inizializzazione dei
parametri e del device, il calcolo del tempo di coalescenza, le operazioni di trasferimento con
la memoria e la chiamata al kernel. Una volta invocato un kernel, lo si carica e lo si esegue sul
device. Quando la GPU ha finito l'elaborazione, il flusso di esecuzione del programma torna
alla CPU, che potrà salvare i dati ottenuti sulla propria memoria per renderli usufruibili
dall'host. In alcuni casi operativi si può fare eseguire ad entrambi i processori(GPU e CPU)
contemporaneamente il proprio flusso di istruzioni.
Andiamo ora ad illustrare un po più nello specifico il codice sviluppato, andando ad
esaminare il ruolo svolto dalle funzioni coinvolte nell'elaborazione.
48
Illustrazione 3.1: Schema di esecuzione dell'algoritmo

3.1 INIZIALIZZAZIONE DEL WORKSPACE
3.1 Inizializzazione del workspace
Come abbiamo già osservato, il segnale di GW è definito univocamente a partire da un set di
parametri. In particolare a partire da due masse m1 e m2, aventi l'asse inclinato di un certo
angolo i rispetto al detector e a distanza R (espressa in anni-luce) da esso, vengono emesse
onde gravitazionali che provocano distorsioni spazio-temporali la cui intensità è espressa dalle
equazioni delle due polarizzazioni, plus e cross.
Tutti i parametri (presenti nelle equazioni [1.7] [1.8] [1.9] [1.10] [1.11]) necessari alla
simulazione, sono stati organizzati all'interno di una struttura dati, chiamata nel nostro codice
workspace, che descrive univocamente le caratteristiche di un dato sistema. Questa è poi la
stessa struttura dati che verrà inviata alla GPU, per eseguire l'elaborazione del kernel. Tale
struttura viene inizializzata, tramite una funzione scritta in C/C++, a partire dai valori delle
due masse e della distanza dal detector. La struttura è composta da 73 campi di tipo float.
Ecco come è definito il nostro workspace, facendo riferimento all'indicizzazione:
➢ 0 – > costante gravitazionale in rapporto alla massa totale: Tm = G*TotalMass/c3;
➢ 1 – > massa totale: mass_total = (m1+m2) * SolarMass;
➢ 2 – > massa ridotta: mass_reduced = ((m1*m2) / (m1+m2)) * SolarMass;
➢ 3 – > differenza tra le masse: dMoverM = (m1-m2) * SolarMass;
➢ 4 – > rapporto tra la massa ridotta e la massa totale : nu = m1*m2/((m1+m2)*(m1+m2))
( 0 <= nu <= ¼ );
➢ da 5 a 12 – > coefficienti di frequenza istantanea:
▪ aw = 1;
▪ bw = (743./2688. + 11./32.*nu);
▪ cw = -3.*M_PI/10.;
▪ dw = 1855099./14450688. + 56975./258048.*nu + 371./2048.*nu2;
▪ ew = -M_PI*(7729./21504. - 13./256.*nu);
▪ fw = -720817631400877./288412611379200. + 107./280.*GAMMAE +
53./200.*M_PI*M_PI + (123292747421./20808990720.0 -
77./48.*lambda - 451./2048.*M_PI*M_PI + 11./16.*theta)*nu -
49

3.1 INIZIALIZZAZIONE DEL WORKSPACE
30913./1835008.*nu2 + 235925./1769472.*nu3;
▪ gw = -107./2240. * (-8.0);
▪ hw = -188516689./433520640.*M_PI - 97765./258048.*M_PI*nu +
141769./1290240.*M_PI*nu2;
➢ da 13 a 20 – >coefficienti di fase istantanea:
▪ ap; = -1.0/nu;
▪ bp = -(3715./8064. + 55./96.*nu)/nu;
▪ cp = 3.*M_PI/(4.*nu);
▪ dp = -(9275495./14450688. + 284875./258048.*nu + 1855./2048.*nu2)/nu;
▪ ep = (38645./172032. - 65./2048.*nu)*M_PI/nu;
▪ fp = -(831032450749357./57682522275840. - 53./40.*M_PI*M_PI -
+ 107./56.*GAMMAE + (-123292747421./4161798144. +
+ 2255./2048.*M_PI*M_PI + 385./48.*lambda -55./16.*theta)*nu +
+ 154565./1835008.*nu2 - 1179625./1769472.*nu3)/nu;
▪ gp = -(107./448.)/nu;
▪ hp = -M_PI/nu*(188516689./173408256. + 488825./516096.*nu +
-141769./516096.*nu2);
➢ 21 – > h0 = 2*G*ReducedMass/(c2*R*MegaParsecConstant);
➢ da 22 a 46 – > coefficienti per la plus polarization:
▪ plus_c00 = -1./96.*si2*(17. + ci2);
▪ plus_c02 = -(1.0+ci2);;
▪ plus_c11 = -si/8.0*dMoverM*(5.0+ci2);
▪ plus_c13 = 9.0*si/8.0*dMoverM*(1.0+ci2);
▪ plus_c22 = 1.0/6.0*((19.0+9.0*ci2-2.0*ci4)- nu*(19.0-11.0*ci2-6.0*ci4));
▪ plus_c24 = -4.0/3.0*si2*(1.0+ci2)*(1.0-3.0*nu);
▪ plus_c31 = si/192.0*dMoverM*((57.0+60*ci2-ci4)-2.0*nu*(49.0-12.0*ci2+
-ci4));
▪ plus_c32 = -2.0*M_PI*(1.0+ci2);
▪ plus_c33 = si/192.0*dMoverM*(-27.0/2.0)*((73.0+40.0*ci2-9.0*ci4)+
-2.0*nu*(25.0-8.0*ci2-9.0*ci4));
50

3.1 INIZIALIZZAZIONE DEL WORKSPACE
▪ plus_c35 = si/192.0*dMoverM*(625.0/2.0)*(1.0-2.0*nu)*si2*(1.0+ci2);
▪ plus_c41 = si/40.0*dMoverM*(-5.0*M_PI)*(5.0+ci2);
▪ plus_c42 = 1.0/120.0*((22.0+396.0*ci2+145.0*ci4-5.0*ci6) +
+5.0/3.0*nu*(706.0-216*ci2-251.0*ci4+15.0*ci6)+
- 5.0*nu2*(98.0-108*ci2+7.0*ci4+5.0*ci6));
▪ plus_c43 = si/40.0*dMoverM*135.0*M_PI*(1.0+ci2);
▪ plus_c44 = 2.0/15.0*si2*((59.0+35.0*ci2-8.0*ci4)+
-5.0/3.0*nu*(131.0+59.0*ci2-24.0*ci4)+
+ 5.0*nu2*(21.0-3.0*ci2-8.0*ci4));
▪ plus_c46 = -81.0/40.0*(1.0-5.0*nu + 5.0*nu2)*si4*(1.0+ci2);
▪ plus_s41 = si/40.0*dMoverM*(11.0+7.0*ci2+10.0*(5.0+ci2)*M_LN2);
▪ plus_s43 = si/40.0*dMoverM*(-27.0)*(7.0-10.0*log(1.5))*(1.0+ci2);
▪ plus_c51 = si*dMoverM*(1771./5120. - 1667./5120.*ci2 + 217./9216.*ci4 +
- 1./9216.*ci6 + nu*(681./256. + 13./768.*ci2 - 35./768.*ci4 +
+ 1./2304.*ci6) + nu2*(-3451./9216. + 673./3072.*ci2 +
+ 5./9216.*ci4 - 1./3072.*ci6));
▪ plus_c52 = M_PI/3.0*(19. + 9.*ci2 - 2.*ci4 + nu*(-16. + 14.*ci2 + 6.*ci4));
▪ plus_c53 = si*dMoverM*(1./512*(5.*3537. - 22977.*ci2 - 15309.*ci4 +
+ 729.*ci6) + nu/1280.*(-23829. + 5529.*ci2 + 7749.*ci4 +
- 729.*ci6) + nu2/5120.*(29127. - 27267.*ci2 -1647.*ci4 +
+ 2187.*ci6));
▪ plus_c54 = -16./3.*M_PI*(1 + ci2)*si2*(1 - 3.*nu);
▪ plus_c55 = si*dMoverM*(1./9216.*(-108125. + 40625.*ci2 + 83125.*ci4 +
-15625.*ci6) + nu/2304.*(9.*8125. - 40625.*ci2 - 48125.*ci4 +
+ 15625.*ci6) + nu2/9216*(-119375. + 3.*40625.*ci2 +
+ 44375.*ci4 - 15625.*ci6));
▪ plus_c57 = dMoverM*117649./46080.*si4*si*(1.0 + ci2)*(1. - 4.*nu +
+ 3.*nu2);
▪ plus_s52 = 1./5.*(-9. + 14.*ci2 + 7.*ci4 + nu*(96. - 8.*ci2 - 28.*ci4));
▪ plus_s54 = si2*(1.0 + ci2)*(56./5. - 32./3.*M_LN2 - nu*(1193./30. +
- 32.*M_LN2));
51

3.1 INIZIALIZZAZIONE DEL WORKSPACE
➢ da 47 a 71 – > coefficienti per la cross polarization:
▪ cross_s02 = -2.0*ci;
▪ cross_s11 = -3.0/4.0*si*ci*dMoverM;
▪ cross_s13 = 9.0/4.0*si*ci*dMoverM;
▪ cross_s22 = ci/3.0*((17.0-4.0*ci2)-nu*(13.0-12.0*ci2));
▪ cross_s24 = -8.0/3.0*(1.0-3.0*nu)*ci*si2;
▪ cross_s31 = si*ci/96.0*dMoverM*((63.0-5.0*ci2)-2.0*nu*(23.0-5.0*ci2));
▪ cross_s32 = -4.0*M_PI*ci;
▪ cross_s33 = si*ci/96.0*dMoverM*(-27.0/2.0)*((67.0-15.0*ci2)-2.0*nu*(19.0-
15.0*ci2));
▪ cross_s35 = si*ci/96.0*dMoverM*(625.0/2.0)*(1.0-2.0*nu)*si2;
▪ cross_s41 = -si*ci*dMoverM*3./4.*M_PI;
▪ cross_s42 = ci/60.0*((68.0+226.0*ci2-15.0*ci4)+5.0/3.0*nu*(572.0 +
- 490.0*ci2+45.0*ci4) -5.0*nu2*(56.0-70.0*ci2+15.0*ci4));
▪ cross_s43 = si*ci*dMoverM*27./4.*M_PI;
▪ cross_s44 = 4.0/15.0*ci*si2*((55.0-12.0*ci2)- 5.0/3.0*nu*(119.0-36.0*ci2)+
+ 5.0*nu2*(17.0-12.0*ci2));
▪ cross_s46 = -81.0/20.0*(1.0-5.0*nu + 5.0*nu2)*ci*si4;
▪ cross_c41 = -3./20.*si*ci*dMoverM*(3. + 10.*M_LN2);
▪ cross_c43 = 27./20.*si*ci*dMoverM*(7. - 10.*log(1.5));
▪ cross_c50 = 6./5.*si2*ci*nu;
▪ cross_c52 = ci/5.*(10. - 22.*ci2 + nu*(-154. + 94.*ci2));
▪ cross_c54 = ci*si2*(-112./5. + 64./3.*M_LN2 + nu*(1193./15.-64.*M_LN2));
▪ cross_s51 = si*ci*dMoverM*(-913./7680. + 1891./11520.*ci2 - 7./4608.*ci4 +
+ nu*(1165./384. - 235./576.*ci2 + 7./1152.*ci4) +
+ nu2*(-1301./4608. + 301./2304.*ci2 - 7./1536.*ci4));
▪ cross_s52 = M_PI/3.*ci*(34. -8.*ci2 - nu*(20. - 24.*ci2));
▪ cross_s53 = si*ci*dMoverM*(12501./2560. - 12069./1280.*ci2 +
+ 1701./2560.*ci4 + nu*(-19581./640. + 7821./320.*ci2 +
- 1701./640.*ci4) + nu2*(18903./2560. - 11403./1280.*ci2 +
52

3.1 INIZIALIZZAZIONE DEL WORKSPACE
+ 5103./2560.*ci4));
▪ cross_s54 = si2*ci*(-32./3.*M_PI*(1. - 3.*nu));
▪ cross_s55 = si*ci*dMoverM*(-101875./4608. + 6875./256.*ci2 +
- 21875./4608.*ci4 + nu/1152.*(66875. - 2.*44375.*ci2 +
+ 21875.*ci4) + nu2*(-100625./4608. + 83125./2304.*ci2 +
- 21875./1536.*ci4));
▪ cross_s57 = si*si4*ci*dMoverM*117649./23040.*(1. - 4.*nu + 3.*nu2);
➢ 72 – > normalizzazione della frequenza: norm(w) = 1/8 * Tm.
Dove ci e si sono abbreviazioni per cos(i) e sin(i) (a loro volta ci2 corrisponde a cos(i)2, ci4 a
cos(i)4, e così via...) con 'i' che equivale all'angolo d'inclinazione (di default π/3), mentre
'M_PI' rappresenta la costante π. Inoltre:
• dMoverM = mass_difference/mass_total;
• GAMMAE = 0.577215664901532860607,
• lambda = -1987/3080
• theta = -11831/9240,
• SOLARMASS = 1.98892e30,
• LIGHTSPEED = 2.99792458e8,
• GRAVITATIONAL_G = 6.67259e-11,
• MPC = 3.0856775807e22.
Le prime cinque locazioni identificano variabili che derivano dalla massa dei due oggetti. Dai
valori delle masse derivano i valori di tutti i coefficienti. I coefficienti rappresentano i fattori
costanti che devono essere combinati aritmeticamente con altri fattori variabili nella
risoluzione delle rispettive equazioni. Ad esempio i coefficienti tra gli 'indici 5 e 20 sono
utilizzati per risolvere le approssimazioni di fase (5-12) e frequenza orbitali (13-20), mentre i
restanti coefficienti (da 22 a 71) si riferiscono ai diversi livelli di approssimazione PN per il
calcolo delle polarizzazioni.
Inoltre, come si nota nell'illustrazione 3.2, i coefficienti per le due polarizzazioni sono
dichiarati seguendo una logica ben precisa; ad esempio il coefficiente cross_s02 indica che si
tratta del coefficiente per la cross polarization al livello zero di approssimazione (PN0) che
dovrà essere moltiplicato per la funzione trigonometrica seno(indicata dalla lettera 's') di 2 w,
53

3.1 INIZIALIZZAZIONE DEL WORKSPACE
dove per w si intende la frequenza istantanea. Ogni coefficiente è associato a uno dei fattori
che compongono le equazioni delle approssimazioni [1.7] e [1.8] descritte nel capitolo 1.
Questa struttura ci permette di implementare il calcolo delle polarizzazione a diversi livelli di
approssimazione. Ad esempio per il calcolo della PN0, verranno utilizzati solo gli indici 22 e
23 per la H+ e l'indice 47 per la Hx, mentre per il livello più alto (PN2 che corrisponde al
quinto livello di approssimazione) sono necessari tutti i coefficienti. L'indice 21 (h0)
rappresenta l'ampiezza del segnale che è uno dei due fattori, insieme alla fase, che influenza il
calcolo delle polarizzazioni H+ e Hx, e quindi la forma d'onda del segnale.
L'inizializzazione del workspace avviene a partire dalle due masse m1 e m2 e dalla distanza R
dalla sorgente (di default uguale a 1*MPC), ed è eseguita da una funzione C++ che salva in
ws la struttura inizializzata. La chiamata a tale funzione è quindi definta come:
init_workspace(workspace* ws, float m1, float m2, float R);
Nell'inizializzazione del workspace, viene inoltre anche definito l'angolo d'incidenza i fissato
a π/3.
Una tale struttura è essenziale al fine di ottimizzare il passaggio dei parametri e l'accesso
all'area dati nei calcoli permettendo, inoltre, una migliore leggibilità e debugging del codice.
54
Illustrazione 3.2: Corrispondenza tra variabile e coeficente dell'approssimazione PN

3.1 INIZIALIZZAZIONE DEL WORKSPACE
Dopo avere definito la struttura, per completare l'inizializzazione è necessario calcolare il
tempo di coalescenza.
3.2 Calcolo del tempo di coalescenza
Il calcolo del tempo di coalescenza deriva dall'evoluzione nel tempo della fase orbitale. È
possibile descrivere tale variazione una volta definita una frequenza orbitale iniziale f0: questa
in generale è scelta uguale alla frequenza di taglio inferiore del detector. Per valori minori
della frequenza f0 si hanno tempi di coalescenza più lunghi, al contrario per valori maggiori
di f0 si hanno tempi di coalescenza più brevi: ovvero si può definire che il tempo di
coalescenza è inversamente correlato alla frequenza di taglio f0 (vedi illustrazione 3.3).
55
Illustrazione 3.3: Tempo di coalescenza in funzione della frequenza iniziale

3.2 CALCOLO DEL TEMPO DI COALESCENZA
Il valore di f0 non può essere scelto arbitrariamente, in quanto influisce su una corretta analisi
del segnale. Infatti nel caso si applichi una frequenza troppo alta, si potrebbero scartare
regioni di frequenza in cui c'è presenza del segnale, che porterebbe a una diminuzione del
rapporto segnale-rumore (SNR). Frequenze di taglio troppo piccole, al contrario,
aumenterebbero esponenzialmente il tempo di coalescenza e quindi il periodo di osservabilità
del segnale e di conseguenza necessiterebbero di template di dimensioni troppo grandi per
riprodurre interamente il segnale. Pertanto è opportuno scegliere una frequenza di taglio
ottimale. Questa è una scelta estremamente importante e critica nei detector di nuova
generazione. L'illustrazione 3.3 mostra appunto la corrispondenza tra tempo di coalescenza e
frequenza di taglio.
Per calcolare il tempo di coalescenza si deve eseguire un integrazione numerica, seguendo il
metodo di Raphson-Newton, che calcola lo zero di una funzione continua e derivabile. Nel
nostro caso si devo trovare la τ0 tale che, definita la frequenza iniziale f0 :
w(τ0 )=w0=2*π*f0 → w(τ0 ) - 2*π*f0 = 0
Ricordiamo a proposito che la w(t) è definita dalla [1.11] del capitolo 1 e che la variabile
temporale τ è definita dalla [1.12], da cui è possibile ricavare il tempo di coalescenza una
volta ricavata la radice τ0.
La funzione che calcola il tempo di coalescenza ha in ingresso un puntatore alla struttura
workspace, precedentemente inizializzata, e un floating point fmin, che rappresenta la
frequenza di taglio inferiore (o frequenza iniziale del sistema) e ritorna un floating point
equivalente al tempo di coalescenza. Ecco un esempio di chiamata a tale funzione:
float ct = cuInspiral_PN5_find_coalescence_time(&ws, fmin);
PN5 sta ad indicare che la frequenza orbitale w(t) è calcolata al quinto livello di
approssimazione.
Stimato il tempo di coalescenza si può passare alla fase computazionalmente più dispendiosa,
ovvero la generazione del template.
56

3.3 GENERAZIONE DEL TEMPLATE
3.3 Generazione del template
Il calcolo vero e proprio del segnale è svolto dalla GPU, essendo questa la parte
computazionalmente più importante. Prima di eseguire il kernel sul device, si inizializza la
periferica e si trasferiscono i dati necessari all'esecuzione del kernel dalla memoria principale
alla memoria della GPU. Una volta eseguite queste operazioni di inizializzazione nella parte
host del codice, si richiama il kernel che costituisce la parte operativa del codice (calcolo di
fase e frequenza istantanea, plus e cross polarization) e che trasferisce il flusso di esecuzione
del programma sul device. Andiamo quindi a descrivere il codice sviluppato, distinguendolo
in codice host e codice device.
3.3.1 Codice Host
Come abbiamo introdotto precedentemente, nella parte host vengono svolte tutte quelle
operazioni che riguardano la dichiarazione, l'allocazione e l'inizializzazione dei parametri
oltre che alla preparazione del device e l'invocazione del kernel. Avendo già calcolato il tempo
di coalescenza e quindi inizializzato il workspace, bisogna ora creare ed allocare tutte le
restanti variabili che entrano in gioco nell'analisi e nella generazione di un segnale d'onda
gravitazionale, e quindi:
– omega0 : frequenza iniziale, di default = 15 Hz;
– phase0 : fase iniziale = 0;
– dt: intervallo temporale che intercorre tra una campione e l'altro, uguale all'inverso
della frequenza di campionamento, dt =1/fc;
– N: numero totale di thread;
– hpt e hqt: i vettori dove viene salvato l'output ottenuto;
– scalef: speciale fattore di scala, = 10-21: questo fattore dipende dal fatto che
solitamente le elaborazioni sui calcolatori convenzionali (quali le CPU) svolgono le
57

3.3 GENERAZIONE DEL TEMPLATE
operazioni in virgola mobile in doppia precisione (64 bit), mentre l'elaborazione da noi
eseguita sulla GPU, per ottimizzare il tempo di esecuzione, esegue calcoli in singola
precisione (32 bit); quindi per mantenere l'accuratezza numerica si adottano alcuni
accorgimenti informatici, come ad esempio nel nostro caso introducendo un
appropriato fattore di scala.
Una caratteristica importante della programmazione GPGPU è il modello della memoria: in
particolare il processore grafico, durante l'esecuzione del kernel, vede esclusivamente la
memoria della scheda grafica. Pertanto per ognuna delle variabili precedentemente elencate e
coinvolte nell'esecuzione del kernel, si devono eseguire le seguenti operazioni:
1. creare due riferimenti per ciascuna variabile, uno risiedente sulla memoria dell'host e
l'altro invece sul device.
2. scrivere prima sulla memoria host;
3. copiare dalla memoria host alla memoria device;
Volendo riassumere ecco tutte le operazioni che devono essere svolte dalla CPU, per
preparare l'invocazione del kernel ed eseguirlo sul device:
1. inizializzazione del device;
2. dichiarazione e inizializzazione delle variabili host;
3. dichiarazione delle variabili del device;
4. allocazione della memoria del device;
5. trasferimento dati dall'host al device;
6. invocazione del kernel;
7. trasferimento dati dal device all'host (una volta terminato il kernel);
8. rilascio della memoria.
A seconda del linguaggio di programmazione adottato si utilizza una sintassi specifica per
effettuare questo processo. In CUDA per utilizzare zone di memoria della periferica è
necessario creare un puntatore del tipo desiderato ed allocare la quantità di memoria
sufficiente a contenere il dato tramite un'opportuna funzione, simile alla malloc() nel cpp:
cudaMalloc(). Per scrivere e leggere sulla locazione di memoria, o più generalmente per
trasferire dati con essa, si invoca cudaMemCpy(). OpenCL mette invece a disposizione un
tipo di dato specifico per far riferimento alla memoria del device: cl_mem, che risulta essere a
tutti gli effetti un oggetto di tipo buffer che consente trasferimenti dati da e verso la GPU. La
funzione che permette di gestire questi oggetti è clCreateBuffer, che consente di eseguire sia
58

3.3 GENERAZIONE DEL TEMPLATE
l'allocazione e che il trasferimento di memoria in una singola chiamata. Nel caso in cui si
vuole scrivere su un buffer precedentemente allocato si invoca invece clEnqueueWriteBuffer.
Per leggere dal buffer e scrivere sulla memoria della CPU, OpenCL mette a disposizione del
programmatore clEnqueueReadBuffer().
Una volta terminate le operazioni di inizializzazione, si può invocare il kernel e lanciare la sua
esecuzione sul device. Tuttavia quando si lancia un kernel, bisogna stabilire le dimensionalità
della griglia, e quindi l'indicizzazione dei thread, e la distribuzione dei thread. Ancora una
volta i due linguaggi usano una sintassi differente. Questa è per esempio l'invocazione di un
kernel in CUDA:
cuInspiral_signal_proc<<<blocksPerGrid,threadsPerBlock>>>(list_of_kernel_pa
rameters);
e questo è l'equivalente in OpenCL:
clEnqueueNDRangeKernel(my_command_queue, my_kernel, 1, 0, totalThreads,
threadsPerBlock, 0, 0, &event);
Conclusa l'esecuzione del kernel, il controllo passa di nuovo alla CPU che deve effettuare un
nuovo trasferimento di memoria, questa volta dal device all'host, per salvare i campioni
ottenuti (corrispondenti ai valori delle polarizzazioni H+ e Hx) e contenuti nei vettori hpt e hqt.
Questi costituiranno i templates che consentiranno la simulazione e quindi l'analisi di tali
segnali. Infine è possibile liberare le risorse di memoria precedentemente allocata.
Ora passiamo alla descrizione del kernel che viene eseguito dalla GPU.
3.3.2 Codice kernel
La funzione che genera il template è dichiarata come:
__global__ void Inspiral_signal_proc(float* workspace, int* N,float* dt,
59

3.3 GENERAZIONE DEL TEMPLATE
float* ct, float* omega0, float* phase0, float* d_scalef, float* hpt,
float* hqt);
Andando ad analizzare nello specifico i parametri di ingresso del kernel, abbiamo:
• workspace: la struttura dati che identifica il sistema, precedentemente inizializzata;
• N: numero totale di threads, scelto dall'utente;
• dt: l'inverso della frequenza di campionamento fc, definita da riga di comando;
• ct: tempo di coalescenza, calcolato precedentemente;
• omega0 e phase0: definiti in compilazione e pari a 15 e 0, rispettivamente;
• d_scalef: uno speciale parametro per scalare in maniera corretta i valori delle tue
polarizzazioni di un fattore di e21;
• hpt e hqt: i vettori dove vengono salvati i campioni ottenuti e che costituiscono il
template.
Oltre a questi parametri, quando si lancia il kernel deve essere stabilita la dimensionalità della
griglia. Il parametro N deve essere opportunamente scelto, in rapporto al tempo di
coalescenza e alla frequenza di campionamento. Quindi, se il nostro segnale per esempio ha
un tempo di coalescenza stimato a 50sec ed usiamo una frequenza di campionamento di 4000
Hz, saranno necessari almeno 50*4,000=200,000 campioni per riprodurre il segnale
interamente e, per come è disegnato il nostro algoritmo, significa che il numero totale di
threads N deve essere maggiore o uguale a 200,000. Traducendo questa dipendenza in una
formula, otteniamo:
[3.1]
Dove fc è la frequenza di campionamento e tc il tempo di coalescenza. In realtà si fissa N
uguale alla prima potenza di 2 tale che : 2N≥ fc∗tc [3.2].
Il kernel effettua tutte le operazioni descritte nel capitolo 1 per la generazione dei templates;
in particolare ogni singolo punto del segnale è associato ad un thread CUDA/OpenCL, che
deve eseguire:
60
N≥ fc∗tc

3.3 GENERAZIONE DEL TEMPLATE
1. il calcolo della frequenza istantanea ω(t);
2. il calcolo della fase istantanea φ(t);
3. il calcolo della fase attuale ϕ, calcolata in funzione di φ(t) e ω(t);
4. il calcolo delle polarizzazioni plus e cross, H+(t) e Hx(t);
Per identificare ogni singolo thread gli viene assegnato un indice threadIndex. Ad ogni thread
corrisponderà un'istante temporale t, secondo la seguente relazione:
t = CoalescenceTime – ( dt * ThreadIndex)
L'algoritmo procede e deriva il valore di frequenza ω associato e fase φ associato a
quell'istante temporale 't'.
Nel codice, sono stati inoltre inseriti dei controlli per garantire:
1. t > 0 → ovvero che l'istante temporale rientra nella durata del segnale;
2. ω > 0 → ovvero che la frequenza orbitale sia positiva;
Successivamente, si procede con il calcolo della fase orbitale psi, definito come:
psi = phase0+p-2.0*Tm*w*log(w/(omega0))
dove p e w sono la fase φ(t) e la frequenza istantanea ω(t) appena calcolate nei passaggi
precedenti, Tm è una costante derivante dalla massa e definita nel workspace, omega0 e
phase0 sono due dei parametri di ingresso del kernel, già introdotti precedentemente.
A questo punto vengono calcolate le due polarizzazioni, cross e plus, tramite le
approssimazioni post-Newtoniane tramite le [1.7] e [1.8] introdotte nel capitolo 1. La
complessità del calcolo e la quantità di risorse da impiegare aumenta all'aumentare del grado
di approssimazione utilizzato. Terminata l'elaborazione dei dati non rimane altro che salvare
in due array, hpt e hqt, il dato ottenuto corrispondente al valore della polarizzazione in un
determinato istante temporale.
Quando tutti gli N thread hanno completato la loro esecuzione, gli array hpt e hqt contengono
il segnale simulato dell'onda gravitazionale che verrebbe emessa da due masse m1 e m2 a
distanza R e angolo d'incidenza i rispetto all'interferometro, calcolato con il metodo delle
61

3.3 GENERAZIONE DEL TEMPLATE
approssimazioni PN proposto da Luc Blanchet[4].
L'ultimo passo da compiere è il salvataggio dei dei dati ottenuti sulla memoria dell'host,
effettuando un trasferimento di memoria dalla GPU verso la CPU.
62
Illustrazione 3.4: Schema del kernel di generazione del segnale
Kernel signal_proc()
t = CT - (*dt)*thid;
If (t>0)
Calculate_w()
Calculate_p()Calculate_psi()Calculate_H+()Calculate_Hx()
hpt[thid]=H+hqt[thid]=Hx
hpt[thid]=0.0hqt[thid]=0.0
hpt[thid]=0.0hqt[thid]=0.0
NO
NO
SI
SI
If (t>0)

63
Capitolo 4
Testing dell'algoritmo
In questo capitolo sono riportati i risultati dei test effettuati al fine di verificare la soluzione
GPU sia sotto il profilo delle performance che di accuratezza numerica. A tale scopo sono
state organizzate due prove:
1. l'accuratezza numerica = ACCURACY TEST: test per definire l'accuratezza numerica
dell'algoritmo; tale test è stato valutato mettendo a confronto:
✗ CPU e GPU: le due diverse architetture;
✗ CUDA vs OpenCL: i due diversi ambienti di programmazione GPGPU trattati;
2. tempo di esecuzione = BENCHMARK TEST: test per stimare il tempo di elaborazione
dell'algoritmo; anche in questo caso per valutarne l'efficienza sono state eseguite due
tipologie di test:
✗ CPU vs GPU: confronto di prestazioni tra i due diversi approcci architetturiali;
✗ CUDA vs OpenCL: confornto di prestazioni tra i due ambienti di
programmazione GPGPU trattati.
Andiamo ora ad introdurre i test effettuati ed analizzare i risultati ottenuti.

4.1 ACCURACY TEST
4.1 Accuracy test
Nel caso delle GPU, effettuare un test di accuratezza numerica è estremamente importante
essendo questo un aspetto potenzialmente critico. Difatti le elaborazioni su GPU, pur
supportando le operazioni in doppia precisione, forniscono prestazioni nettamente superiori se
svolte in singola precisione, per motivi architetturiali che descriveremo in seguito.
Il fattore di accuratezza, inoltre, è tanto più importante nel nostro caso dal momento che si
vuole simulare un segnale di onda gravitazionale sulla base di modelli matematici teorici dalla
cui accuratezza dipende la rilevazione di onde gravitazionali. Infatti il segnale è
numericamente al limite del range numerico della singola precisione con reali rischi di
overflow.
In particolare in questa tipologia di test vengono messi a confronto due set di dati (templates)
derivanti dallo stesso set di parametri (masse, distanza e angolo d'incidenza) ma generati con
codici differenti: CUDA, OpenCL e CPU
Nel dettaglio, durante il test di accuratezza i dati sono stati confrontati nel seguente modo:
• CUDA vs OpenCL : in cui vengono messi a confronto i templates generati su GPU dai
due diversi linguaggi; questo test permette di valutare l'accuratezza numerica tra le due
implementazioni su GPU;
• GPU vs CPU: in cui viene valutata la differenza di accuratezza numerica tra un codice
scritto su GPU e uno su CPU; questo test permette di verificare l'accuratezza numerica
tra CPU e GPU, prendendo la CPU come riferimento, poiché su essa i calcoli sono
svolti in doppia precisione.
Andiamo ad analizzare entrambi, partendo dal confronto fra GPU e CPU
4.1.1 CPU vs GPU
Al fine di verificare l'accuratezza della GPU nei calcoli del nostro algoritmo, abbiamo
effettuato un confronto fra i risultati ottenuti tra il codice GPU e quello CPU compilato in
64

4.1 ACCURACY TEST
doppia precisione. Così facendo abbiamo utilizzato la CPU come riferimento e verificato i
risultati ottenuti dalla GPU. Difatti l'implementazione su GPU qui presentata effettua calcoli
di tipo float in singola precisione (32 bit). Seppure il tipo float a doppia precisione (64 bit) sia
stato introdotto già nelle Tesla di compute capability7 1.3, le prestazioni diminuiscono
notevolmente quando si vogliono utilizzare dati di tipo double, ovvero floating point (FP) a
doppia precisione. Questo è dovuto al fatto che le architetture Tesla, su cui è eseguito il
codice, dispongono di una sola unità di elaborazione di dati a doppia precisione per
MultiProcessore, contro le 8 unità di elaborazioni (una per ogni SP) di tipo floating point a
singola precisione. Da ciò ne deriva che le elaborazioni di dati a 64 bit (double) sono peggiori
nella media di 8x di quelli a 32 bit (float). In particolare, dalle specifiche della Tesla C1060
[8] su cui viene eseguito l'algoritmo di generazione dei templates, il picco massimo di FP a
singola precisione è di 933 Gflops contro i 78 Gflpos della doppia precisione.
Premesso ciò andiamo a definire le modalità in cui è stato eseguito il testing dell'accuratezza
tra CPU e GPU.
Per valutare l'accuratezza abbiamo utilizzato l'energia E del segnale definita come la
sommatoria, per ogni istante temporale, della somma dei quadrati delle due polarizzazioni Hi+
e Hix diviso per il numero totale di campioni N; in termini matematici:
E=i
N H i+ 2 H i
x 2
N
La tabella 4.1 di seguito mostra i risultati ottenuti dall'esecuzione dei due codici (CPU e GPU)
variando il set di parametri. In particolare sono stati presi in considerazione due set di masse:
• m1 = 1.4, m2 = 1.4;
• m1 = 1, m2 = 5
e due frequenze iniziali:
• 10 Hz;
• 20Hz;
Dai test effettuati si osserva uno scarto in termini di energia generalmente inferiore al 6%.
Questo valore è tollerabile in fase di analisi essendo comunque inferiore all'errore indotto dal
processo rumoroso.
7 Definisce il set di istruzioni supportato dalla periferica
65

4.1 ACCURACY TEST
Parametri Durata del segnale (s) EGPU ECPU Scarto Scarto %
Fc=20 Hz, m1 = 1.4, m2 = 1.4 160.679794 8.57e-37 9.04e-37 0.47e-37 5.2%
Fc=10 Hz, m1 = 1.4, m2 = 1.4 1015.946899 2.16e-36 2.31e-36 0.15e-36 6.5%
Fc=20 Hz, m1 = 1, m2 = 5 80.905273 1.65e-36 1.71e-36 0.06e-36 3,50%
Fc=10 Hz, m1 = 5, m2 = 5 513.744934 4.24e-36 4.46e-36 0.24e-36 5,38%
Tabella 4.1
4.1.2 CUDA vs OpenCL
Partendo dal fatto che entrambi i codici sono stati eseguiti sullo stesso sistema di calcolo (e
quindi dalla stessa GPU), ci aspettiamo di avere una differenza di accuratezza numerica molto
bassa se non nulla tra i due ambienti di programmazione. Difatto, come si può già notare da
un confronto visivo (vedi illustrazione 4.1), si riscontra un'effettiva corrispondenza tra i
segnali d'onda generati dai due algoritmi.
66
Illustrazione 4.1: Template generati da CUDA e OpenCL a confronto

4.1 ACCURACY TEST
In tale grafo le due curve disegnate si riferiscono a una sola delle due polarizzazioni. Si nota
che le due sinusoidi si sovrappongono e quindi coincidono. Questo, ovviamente, non è un
confronto quantitativo.
Per definire con precisione numerica la misura in cui la corrispondenza tra i due segnali si
manifesta, è stato effettuato un test che genera e confronta due templates, uno ottenuto con il
codice CUDA e uno con quello OpenCL. I due segnali descrivono lo stesso sistema fisico
avendo entrambi la stessa parametrizzazione (masse, distanza, angolo d'inclinazione, fase e
frequenza iniziale). Il confronto è svolto calcolando lo scarto quadratico medio tra di essi.
Tale scarto quadratico medio è definito dalla seguente formula:
sqm= i
N hCUDAi−hOpenCLi2
N
dove :
hCUDAi=H i+ 2H i
x2 hOpenCL i=H i+2H i
x2
Tale test è stato implementato tramite un programma scritto in c++, che esegue le seguenti
funzioni:
1. legge i file in cui sono stati salvati i due templates, CUDA e OpenCL;
2. estrae le colonne che corrispondono al valore delle polarizzazioni;
3. calcola la somma dei quadrati delle due polarizzazioni, per entrambi i template CUDA
e OpenCL;
4. effettua la differenza tra i valori CUDA e OpenCL, ed eleva al quadrato il risultato
ottenuto;
5. per ogni riga del file esegue i punti 2, 3 e 4 e in una variabile accumulatore viene di
volta in volta sommato lo scarto quadratico ottenuto;
6. terminato il file, il contenuto dell'accumulatore viene diviso per il numero N di righe
del file: il risultato ottenuto rappresenta lo scarto quadratico medio.
La tabella 4.2 illustra i risultati ottenuti dall'esecuzione del test, variando il set di parametri in
ingresso. In particolare sono stati presi due set di masse:
• m1 = 1.4, m2 = 1.4;
• m1 = 1, m2 = 5
67

4.1 ACCURACY TEST
e due frequenze iniziali:
• 10 Hz;
• 20Hz.
Dall'esecuzione dell'algoritmo si è giunti alla conclusione che ci aspettavamo, ovvero che lo
scarto quadratico medio tra le due diverse implementazioni CUDA e OpenCL sullo stesso
harware è effettivamente inferiore al minimo numero rappresentabile in singola precisione
(10-45) e quindi operativamente nullo.
Parametri Tempo di coalescenza Scarto quadratico medioFc=20 Hz, m1 = 1.4, m2 = 1.4 160.679794 0Fc=12 Hz, m1 = 1.4, m2 = 1.4 1015.946899 0Fc=20 Hz, m1 = 1, m2 = 5 80.905273 0Fc=12 Hz, m1 = 5, m2 = 5 513.744934 0
Tabella 4.2
4.2 Benchmark test
Il benchmark effettuato ha lo sopo di valutare l'efficienza computazionale del codice
sviluppato. L'algoritmo proposto, come già visto (ref. Capitolo 3) si divide in diverse fasi di
elaborazione:
1. inizializzazione del sistema;
2. calcolo del tempo di coalescenza;
3. generazione dei templates;
4. salvataggio dei dati.
La parte di codice eseguita dalla GPU è quella relativa alla generazione del template (punto3)
e sarà quindi l'oggetto di questo test di benchmark. Bisogna ricordare che il tempo di
generazione dei templates (da qui in avanti faremo riferimento ad esso come tempo di
generazione) è fortemente dipendente dalla lunghezza temporale del segnale stesso e quindi
68

4.2 BENCHMARK TEST
dal tempo di coalescenza, che a sua volta dipende dai parametri che definiscono il sistema, le
due masse e la frequenza iniziale applicata. Per come è implementato l'algoritmo, il tempo di
generazione è atteso aumentare linearmente al crescere del tempo di coalescenza.
Di particolare interesse sarà, quindi, mettere in rapporto il tempo di generazione
dell'algoritmo (asse y) in funzione del tempo di coalescenza del segnale (asse x). Per ottenere
una variazione del tempo di coalescenza di un dato sistema binario, fissate le masse dei due
corpi, è necessario far variare la frequenza iniziale del sistema o meglio la frequenza di taglio
applicata al detector (ref. Capitolo 3).
Le prove di benchmark sono state pertanto eseguite mantenendo costanti le massa dei due
corpi e la frequenza di campionamento (e nel caso dell'elaborazione su GPU anche il numero
totale di thread) e variando la frequenza di taglio inferiore. Inoltre, al fine di avere un po' di
statistica sui risultati, fissati i parametri, la generazione del segnale è ripetuta per un numero
di cicli pari a 1000 calcolando, infine, la media del tempo di generazione.
Prima di valutare i risultati ottenuti, bisogna fare alcune premesse. In particolare occorre
ricordare che prima di lanciare un kernel devono essere definite le dimensionalità della
griglia. Nel nostro caso, il numero di thread per blocco è fissato a 256 (valore ottimale
consigliato) per tutte le esecuzioni del kernel. Il numero totale di blocchi, invece, è correlato
al numero totale di thread 'N' che è uno dei parametri di ingresso del kernel ed è scelto
opportunamente dall'utente quando viene lanciato l'eseguibile da riga di comando. Difatti
ricordiamo che il numero totale di thread deve essere scelto in relazione al tempo di
coalescenza e alla frequenza di campionamento utilizzata (vedi [3.1] e [3.2]). Dal momento
che il tempo di coalescenza ha una dipendenza inversa rispetto alla frequenza di taglio
applicata (ref. 3.2), col diminuire della frequenza di taglio (e quindi con l'aumentare del
tempo di coalescenza) è necessario aumentare la dimensione dei buffer e quindi il numero
totale di thread.
Nel test di benchmark effettuato sono state valutate le prestazioni del kernel in relazione al
numero totale di threads 'N' applicato. In particolare sono stati scelti valori di N uguali a 2n,
con n compreso tra 19 e 23, essendo queste le dimensioni tipiche utilizzate in produzione. Il
numero massimo di thread applicabile è dipendente dalle caratteristiche dell'hardware e nel
nostro caso ha un limite uguale a 223 = 8.388.608 thread.
La tabella 4.3 seguente illustra appunto la corrispondenza tra il numero di thread, il tempo di
coalescenza massimo e la frequenza iniziale minima del segnale, proveniente da due masse
69
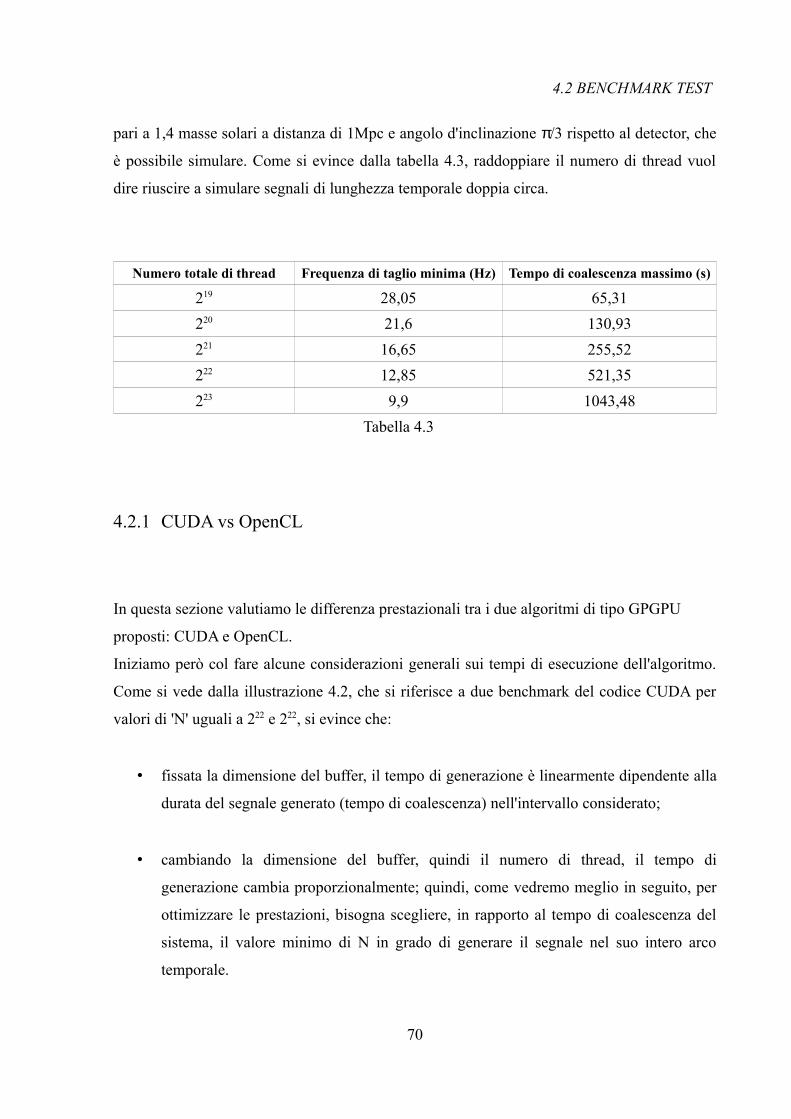
4.2 BENCHMARK TEST
pari a 1,4 masse solari a distanza di 1Mpc e angolo d'inclinazione π/3 rispetto al detector, che
è possibile simulare. Come si evince dalla tabella 4.3, raddoppiare il numero di thread vuol
dire riuscire a simulare segnali di lunghezza temporale doppia circa.
Numero totale di thread Frequenza di taglio minima (Hz) Tempo di coalescenza massimo (s)
219 28,05 65,31220 21,6 130,93221 16,65 255,52222 12,85 521,35223 9,9 1043,48
Tabella 4.3
4.2.1 CUDA vs OpenCL
In questa sezione valutiamo le differenza prestazionali tra i due algoritmi di tipo GPGPU
proposti: CUDA e OpenCL.
Iniziamo però col fare alcune considerazioni generali sui tempi di esecuzione dell'algoritmo.
Come si vede dalla illustrazione 4.2, che si riferisce a due benchmark del codice CUDA per
valori di 'N' uguali a 222 e 222, si evince che:
• fissata la dimensione del buffer, il tempo di generazione è linearmente dipendente alla
durata del segnale generato (tempo di coalescenza) nell'intervallo considerato;
• cambiando la dimensione del buffer, quindi il numero di thread, il tempo di
generazione cambia proporzionalmente; quindi, come vedremo meglio in seguito, per
ottimizzare le prestazioni, bisogna scegliere, in rapporto al tempo di coalescenza del
sistema, il valore minimo di N in grado di generare il segnale nel suo intero arco
temporale.
70

4.2 BENCHMARK TEST
Ora passiamo più propriamente al confronto delle prestazioni tra le due implementazioni su
GPU proposte.
Dalla illustrazione 4.3 si denota che anche il codice OpenCL presenta un aumento lineare tale
che un aumento del tempo di coalescenza implica un aumento del tempo di generazione. Si
osserva, però, che i tempi generazione di OpenCL risultano sistematicamente maggiori
rispetto a CUDA.
Oltre al tempo di generazione, un altro fattore che descrive l'efficienza computazionale
dell'algoritmo è il numero di punti del segnale elaborati ogni millisecondo. Tale fattore è
calcolato dividendo il numero totale di punti del segnale da simulare (uguale alla frequenza di
campionamento moltiplicata per la durata del segnale) per il tempo di generazione.
L' illustrazione 4.4 mostra appunto la corrispondenza tra punti del segnale elaborati ogni
millisecondo (asse y) in funzione della durata del segnale stesso (asse x).
71
Illustrazione 4.2: Tempo di generazione in funzione della durata del segnale in CUDA
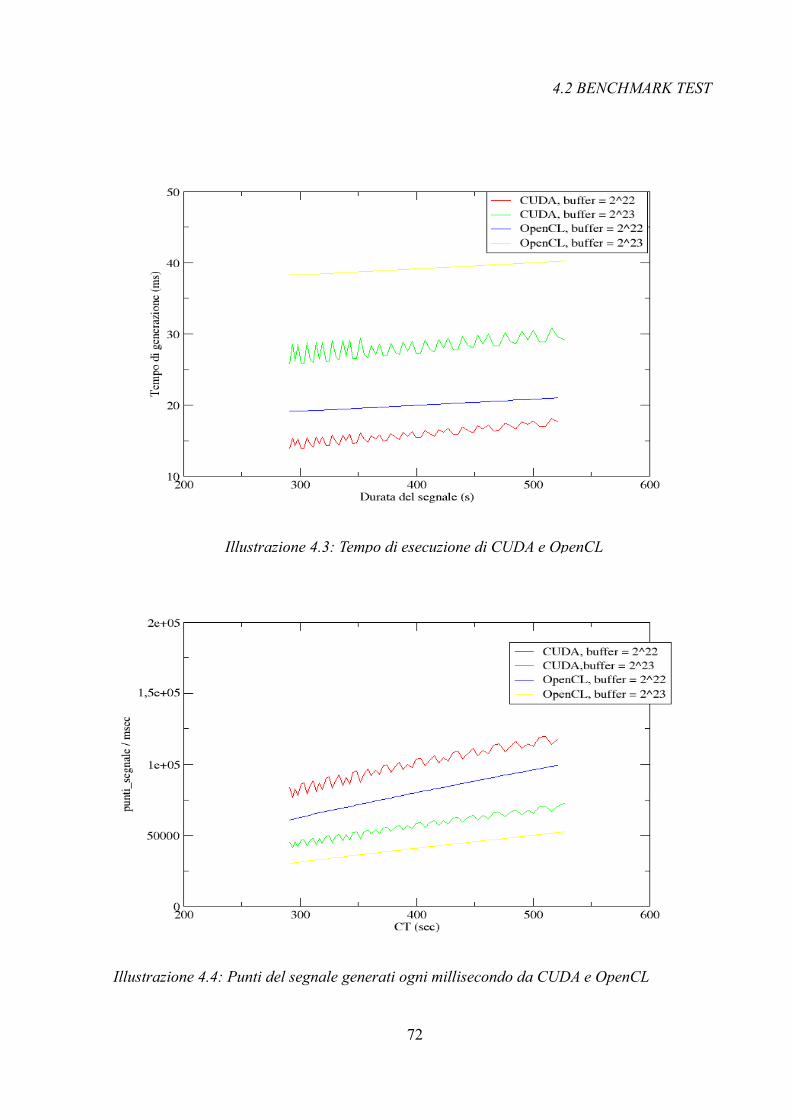
4.2 BENCHMARK TEST
72
Illustrazione 4.3: Tempo di esecuzione di CUDA e OpenCL
Illustrazione 4.4: Punti del segnale generati ogni millisecondo da CUDA e OpenCL

4.2 BENCHMARK TEST
Come è evidente, emerge ancora una superiorità prestazionale del codice CUDA rispetto ad
OpenCL. Si osserva inoltre un altro fenomeno in entrambe le implementazioni: col crescere
del tempo di coalescenza aumenta anche il numero di punti del segnale generati ad ogni
istante temporale. Ciò significa che seppure l'aumento della lunghezza del segnale, e quindi
del tempo di coalescenza, implichi un aumento assoluto del tempo di generazione, questa però
mostra anche un aumento delle prestazioni normalizzate per punti del segnale elaborati. Tale
aumento di performance è probabilmente dovuto ad effetti di coding.
Questa caratteristica è particolarmente evidente anche dalla illustrazione 4.5, in cui viene
messo in relazione il rapporto tra tempo di generazione e tempo di coalescenza (asse y) in
funzione del tempo di coalescenza stesso (asse x). Infatti la funzione è decrescente, ovvero il
rapporto tra tempo di generazione e tempo di coalescenza diminuisce all'aumentare della
lunghezza del segnale. Si osserva quindi un aumento prestazionale.
73
Illustrazione 4.5: Rapporto tra tempo di esecuzione e durata del segnale in CUDA e OpenCL
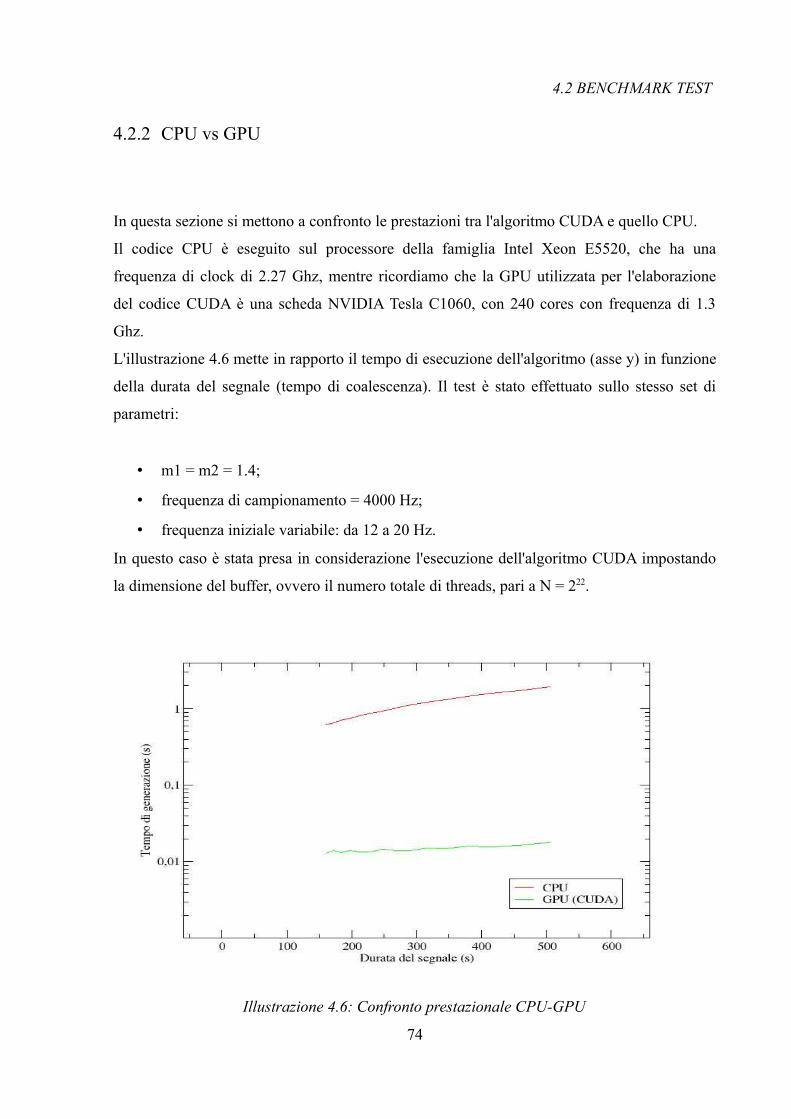
4.2 BENCHMARK TEST
4.2.2 CPU vs GPU
In questa sezione si mettono a confronto le prestazioni tra l'algoritmo CUDA e quello CPU.
Il codice CPU è eseguito sul processore della famiglia Intel Xeon E5520, che ha una
frequenza di clock di 2.27 Ghz, mentre ricordiamo che la GPU utilizzata per l'elaborazione
del codice CUDA è una scheda NVIDIA Tesla C1060, con 240 cores con frequenza di 1.3
Ghz.
L'illustrazione 4.6 mette in rapporto il tempo di esecuzione dell'algoritmo (asse y) in funzione
della durata del segnale (tempo di coalescenza). Il test è stato effettuato sullo stesso set di
parametri:
• m1 = m2 = 1.4;
• frequenza di campionamento = 4000 Hz;
• frequenza iniziale variabile: da 12 a 20 Hz.
In questo caso è stata presa in considerazione l'esecuzione dell'algoritmo CUDA impostando
la dimensione del buffer, ovvero il numero totale di threads, pari a N = 222.
74
Illustrazione 4.6: Confronto prestazionale CPU-GPU

4.2 BENCHMARK TEST
L'asse y è rappresentato in scala logaritmica in base 10. Quindi, come si nota dal grafico
dell'illustrazione 4.6, il guadagno prestazionale dell'algoritmo su GPU è di circa due ordini di
grandezza (un fattore di circa 100x) migliore di quello su CPU. Inoltre, un altro fattore che si
evidenzia dal grafico è che il guadagno prestazionale aumenta al crescere della durata del
segnale.
Queste caratteristiche sono numericamente espresse dalla tabella 4.4, in cui sono riportati i
tempi di esecuzione degli algoritmi valutati, in rapporto alla frequenza di taglio e quindi alla
durata del segnale. Nell'ultima colonna è riportato il fattore di guadagno prestazionale
dell'algoritmo su GPU rispetto a quello su CPU. Come si ben nota, l'algoritmo proposto ha un
fattore massimo di guadagno che è anche leggermente superiore a due ordini di grandezza
(106,95 x). Il guadagno prestazionale aumenta proporzionalmente insieme al tempo di
coalescenza.
Frequenza di taglio (Hz)
Tempo di coalescenza (secondi)
Tempo Generazione CPU (secondi)
Tempo Generazione GPU (secondi)
Guadagno prestazionale
13 505,498 1,91986 0,01795 106,9513,5 457,207 1,73440 0,01626 106,6614 415,043 1,57699 0,01565 100,7614,5 378,048 1,43836 0,01598 90,0115 345,443 1,31877 0,01492 88,3915,5 316,584 1,21118 0,01504 80,5316 290,941 1,11684 0,01390 80,3516,5 268,071 1,03043 0,01400 73,617 247,603 0,93572 0,01451 64,4917,5 229,225 0,87122 0,01347 64,6818 212,672 0,81376 0,01337 60,8618,5 197,720 0,75242 0,01415 53,1719 184,176 0,70169 0,01334 52,619,5 171,877 0,65514 0,01394 46,9920 160,680 0,61462 0,01302 47,2
Tabella 4.4
75

76
Capitolo 5
Conclusioni
Il lavoro svolto in questa testi analizza l’utilizzo delle GPU nell’ambito dell’analisi dati e
detection di segnali gravitazionali. In particolare queste nuove architetture many-core
permettono di ridurre notevolmente i tempi di elaborazione e di guadagnare quindi in capacità
di indagine scientifica. I risultati riportati in questa testi oltre a confermare le previsioni in
termini di incremento prestazionale, data la loro originalità saranno utilizzati concretamente
come base per l’analisi in produzione e sviluppo di progetti futuri.
In questo lavoro di tesi ho acquisito conoscenza in merito al modello di programmazione ed
esecuzione CUDA ed OpenCL, che sono i due framework più importanti per lo sviluppo di
applicazioni su GPU. Inoltre ho acquisito confidenza con il problema inerente l'elaborazione
digitale dei segnali ed in particolar modo con le problematiche di generazione di segnali
gravitazionali simulati su GPGPU. Il tipo di segnale simulato è stato quello proveniente da
binaria coalescenti calcolato con approssimazioni Post Newtoniane all’ordine 3.5 in fase e 2
in ampiezza.
Per lo scopo del mio lavoro, ho sviluppato una libreria di generazione di segnali che è
attualmente inclusa ed utilizzata all’interno del programma cuInspiral, primo prototipo
avanzato multi-GPU per la detection di segnali gravitazionali sui dati di detector
gravitazionali quali Virgo e LIGO. L’algoritmo da me realizzato prende in ingresso un set di
parametri fisici quali masse e distanza delle sorgenti, inizializza i parametri delle serie

5 CONCLUSIONI
utilizzando tecniche di approssimazioni, quali Newton-Raphson, e calcola gli elementi che
compongono le serie Post-Newtoniana in successione. La criticità di queste operazioni sta
nella complessità delle stesse, nella reale possibilità di overflow dovuto all’intervallo
numerico di lavoro e dalla necessità di introdurre alcuni elementi di ottimizzazione al fine di
cercare di utilizzare le potenzialità delle GPU nel calcolo in singola precisione su funzioni
aritmetiche. A tale scopo abbiamo introdotto trucchi di ricalibrazione numerica, di definizione
di variabili temporanee per la memorizzazione dei valori potenza su funzioni trascendentali e
trigonometriche.
Inoltre al fine di analizzare le prestazione dell’algoritmo ed accuratezza numerica ho
realizzato dei benchmark in cui si confrontano sia i risultati su GPU fra le due soluzioni
CUDA ed OpenCL che fra GPU e CPU.
Nell’attuale versione del codice CUDA si sono ottenuto risultati più performanti rispetto ad
OpenCL. Inoltre è da ricordare che OpenCL ha un livello di complessità di programmazione
superiore a CUDA. Sicuramente sul lato OpenCL ci sono ancora notevoli margini di
miglioramento.
Nel confrontare invece la soluzione CUDA con l’analogo algoritmo su CPU si sono ottenuti
risultati estremamente importanti che confermano la bontà della soluzione GPU. Infatti il
guadagno ottenuto nei test è nell’intervallo di 80-100 volte rispetto al codice su CPU. Questo
permette di dimostrare come queste nuove architetture many-core non solo offrono fattori di
guadagno notevoli ma si candidano come la probabile risposta nelle problematiche di HPC
future, sempre più bisognose di potenza di calcolo.
Nell’ambito del problema oggetto di questa testi, cioè l’analisi di onde gravitazionali, le GPU,
ed in prospettiva le architetture many-core, sono la probabile soluzione per i detector futuri
quali ad esempio l’Einstein Telescope, progetto europeo attualmente nella fase di design
finanziato dal 7° programma quadro (FP7/2007-2013) grant agreement n.211743. Questo
progetto infatti cambierà il modo di vedere l'universo introducendo le onde gravitazionali al
pari delle onde elettromagnetiche come strumento di osservazione. Infatti come oggi si guarda
il cosmo in funzione della luce visibile, X, onde radio ed altro, in futuro potremo studiarlo
anche in funzione delle onde gravitazionali con un approccio di osservazione completamente
nuovo. Questo tipo di approccio richiederà quindi un ingente sforzo anche computazionale,
dove le GPU, e questo lavoro di testi lo hanno dimostrato, potranno essere un’ottima
soluzione potenziale.
77

5 CONCLUSIONI
Ringrazio sentitamente i miei relatori per avermi permesso di compiere questa esperienza e
ringrazio inoltre l'esperimento INFN MaCGO (Manycore Computing for future gravitational
observatory) ed il progetto europeo Einstein Telescope design finanziato dal 7° programma
quadro (FP7/2007-2013) grant agreement n 211743 avendo fornito il supporto tecnico e
teorico per lo sviluppo di questa tesi
78

79
Appendice A
Implementazione CUDA
#include <cuInspiral.h>#include <cuInspiral_PN.h>#include <sys/time.h>
#define THREADXBLOCK 256
int main(int argc, char* argv[]){
//Definizione del set di parametri float m1 = atof(argv[3]); //prima massa float m2 = atof(argv[4]); //seconda massa float r = 1.; //distanza long N = pow(2,atoi(argv[1])); //numero totale di thread float dt = 1./atof(argv[2]); float fsampling = atof(argv[2]); //frequenza di campionamento float fmin = atof(argv[5]); //frequenza di taglio float omega0 = 15.; //frequenza iniziale float phase0 = .0; //fase iniziale scalef = CUINSPIRAL_SCALE_F; //Fattore di scala
float * hpt = (float *) malloc(sizeof(float) * N); float * hqt = (float *) malloc(sizeof(float) * N); //Dichiarazione dei parametri per il device float *d_omega0, *d_phase0; float *hpt_dev, *hqt_dev;

IMPLEMENTAZIONE CUDA
float* d_start; float* d_ct; int* d_N; float* d_dt; float *ws_dev; float scalef, * d_scalef;
int sizeofns = sizeof(float)*N; int sizeofws = sizeof(float)*73; int sizeoffloat = sizeof(float); double Tstart, Tstop;
//Definizione della dimensione della griglia int threadsPerBlock= THREADXBLOCK; int threadsPerGrid = (N + THREADXBLOCK-1 - 1) / THREADXBLOCK; int nthread = threadsPerBlock * threadsPerGrid;
workspace ws;
//Allocazione della memoria del device cudaMalloc((void**)&d_omega0,sizeoffloat); cudaMalloc((void**)&d_phase0,sizeoffloat); cudaMalloc((void**)&hpt_dev,sizeofns); cudaMalloc((void**)&hqt_dev,sizeofns); cudaMalloc((void**)&d_start,sizeoffloat); cudaMalloc((void**)&d_ct,sizeoffloat); cudaMalloc((void**)&d_dt,sizeof(float)); cudaMalloc((void**)&d_N, sizeof(int)); cudaMalloc((void**)&ws_dev,sizeofws); cudaMalloc((void**)&d_scalef,sizeof(float));
//Inizializzazione del workspace cuInspiral_PN6_init_workspace(&ws, m1, m2, r); //Calcolo del tempo di coalescenza float ct = cuInspiral_PN6_find_coalescence_time(&ws, fmin);
//Trasferimento dati sulla memoria del device cudaMemcpy(d_phase0,&phase0,sizeoffloat,cudaMemcpyHostToDevice); cudaMemcpy(d_omega0,&omega0,sizeoffloat,cudaMemcpyHostToDevice); cudaMemcpy(d_start,&start,sizeoffloat,cudaMemcpyHostToDevice);
80

IMPLEMENTAZIONE CUDA
cudaMemcpy(d_ct,&ct,sizeoffloat,cudaMemcpyHostToDevice); cudaMemcpy(d_dt,&dt,sizeoffloat,cudaMemcpyHostToDevice); cudaMemcpy(d_N,&N,sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(ws_dev,&ws,sizeofws,cudaMemcpyHostToDevice); cudaMemcpy(d_scalef, &scalef,sizeof(float),cudaMemcpyHostToDevice);
if (ct>N/fsampling) { printf("Increase vector size.\n"); }else { //Esecuzione del kernel cuInspiral_kernel_PN6_0_signal_proc<<<threadsPerGrid,threadsPerBlock>>>
ws_dev,d_N, d_dt, d_ct,d_omega0, d_phase0, d_scalef, hpt_dev, hqt_dev); } //Sincronizzazione tra host e device cudaThreadSynchronize();
//Trasferimento dati dal device all'host cudaMemcpy(hpt,hpt_dev,sizeofns,cudaMemcpyDeviceToHost); cudaMemcpy(hqt,hqt_dev,sizeofns,cudaMemcpyDeviceToHost);
//Liberazione della memoria cudaFree(ws_dev); cudaFree(hpt_dev);
free( hpt ); free( hqt );}
//Codice del kernel che genera il segnal al primo livello di approssimazione__global__ void cuInspiral_kernel_PN6_0_signal_proc(float* workspace, int *N, float *dt, float*ct, float* omega0, float* phase0, float *d_scalef, float *hpt, float *hqt){ //Indicizzazione dei thread int thid = blockDim.x*blockIdx.x+threadIdx.x;
//Definizione della struttura
float Tm =workspace[0]; //Tm = Gm/c^3
81

IMPLEMENTAZIONE CUDA
float mass_total =workspace[1]; //Massa totale del sistema in Kg float mass_reduced =workspace[2]; //Massa ridotta float dM =workspace[3]; //Differenza di massa tra i due corpi float nu =workspace[4]; //Rapporto tra massa totale e massa ridotta
float aw=workspace[5]; //Coefficienti per la frequenza istantanea float bw=workspace[6]; float cw=workspace[7]; float dw=workspace[8]; float ew=workspace[9]; float fw=workspace[10]; float gw=workspace[11]; float hw=workspace[12];
//Coeddicienti per la fase istantanea float ap=workspace[13]; float bp=workspace[14]; float cp=workspace[15]; float dp=workspace[16]; float ep=workspace[17]; float fp=workspace[18]; float gp=workspace[19]; float hp=workspace[20];
float h0=workspace[21];
float plus_c00=workspace[22]; //Coefficienti per la plus polarization float plus_c02=workspace[23]; //float plus_c11=workspace[24]; //float plus_c13=workspace[25]; //float plus_c22=workspace[26]; //float plus_c24=workspace[27]; //float plus_c31=workspace[28]; //float plus_c32=workspace[29]; //float plus_c33=workspace[30]; //float plus_c35=workspace[31]; //float plus_c41=workspace[32]; //float plus_c42=workspace[33]; //float plus_c43=workspace[34]; //float plus_c44=workspace[35]; //float plus_c46=workspace[36]; //float plus_s41=workspace[37]; //float plus_s43=workspace[38];
82

IMPLEMENTAZIONE CUDA
//float plus_c51=workspace[39]; //float plus_c52=workspace[40]; //float plus_c53=workspace[41]; //float plus_c54=workspace[42]; //float plus_c55=workspace[43]; //float plus_c57=workspace[44]; //float plus_s52=workspace[45]; //float plus_s54=workspace[46];
float cross_s02=workspace[47]; //Coefficienti per la cross polarization //float cross_s11=workspace[48]; //float cross_s13=workspace[49]; //float cross_s22=workspace[50]; //float cross_s24=workspace[51]; //float cross_s31=workspace[52]; //float cross_s32=workspace[53]; //float cross_s33=workspace[54]; //float cross_s35=workspace[55]; //float cross_s41=workspace[56]; //float cross_s42=workspace[57]; //float cross_s43=workspace[58]; //float cross_s44=workspace[59]; //float cross_s46=workspace[60]; //float cross_c41=workspace[61]; //float cross_c43=workspace[62]; //float cross_c50=workspace[63]; //float cross_c52=workspace[64]; //float cross_c54=workspace[65]; //float cross_s51=workspace[66]; //float cross_s52=workspace[67]; //float cross_s53=workspace[68]; //float cross_s54=workspace[69]; //float cross_s55=workspace[70]; //float cross_s57=workspace[71];
float normw =workspace[72]; //Normalizzazione di 'w'
float t, tau; float w, p, ph; float y, y2, y3, iy, iy2, iy3, x, Plus0, Cross0; float duration= *ct;
83

IMPLEMENTAZIONE CUDA
if (thid<=(*N)) { t = duration - (*dt)*thid; if (t>0) { tau = nu*t/(5.0*Tm); y = powf(tau,-0.125); iy = 1.0/y; y2 = y*y; y3 = y*y*y; iy2 = iy*iy; iy3 = iy*iy*iy; //Calculate omega w = normw*y*y*y*(1 + bw*y2 + cw*y3 + dw*y2*y2 + ew*y2*y3 + (fw + gw*logf(2.*y))*y3*y3 + hw*y3*y3*y); if (w>0) { //Calcolo della fase p = ap*iy3*iy2 + bp*iy3 + cp*iy2 + dp*iy + 8.0*ep*logf(iy)+ fp*y + (-8.)*gp*logf(2.*y) + hp*y2;
//Calcolo della fase in funzione di 'p' e 'w' ph = *phase0+p-2.0*Tm*w*logf(w/(*omega0)); ph - ceil(ph/(2.0*M_PI))*2.0*M_PI;
x = cbrt(Tm*w); // NOTE : x=(Tm*w)^2/3 float cos2 = cosf (2.*ph); float sin2 = sinf (2.*ph); plus_c00 = 0;
//Calcolo della plus e cross polarization
84

IMPLEMENTAZIONE CUDA
Plus0 = plus_c00 + plus_c02*cos2; Cross0= cross_s02*sin2; //Salavataggio dei dati finali hpt[thid] = (h0*x*x*Plus0) * (*d_scalef); //Inphase hqt[thid] = (h0*x*x*Cross0) * (*d_scalef); //Inquadrature } else
{ hpt[thid] = 0.0; hqt[thid] = 0.0; } } else { hpt[thid] = 0.0; hqt[thid] = 0.0; } }}
85

86
Appendice B
Implementazione OpenCL
#include <stdio.h>#include <stdlib.h>#include <math.h>#include <CL/cl.h>#include <string.h>#include <fcntl.h>#include <sys/time.h>
#define CUINSPIRAL_SCALE_F 1.0e21#define THREADXBLOCK 256
static double MPC = 3.0856775807e22; static double GRAVITATIONAL_G = 6.67259e-11; static double LIGHTSPEED = 2.99792458e8; static double SOLARMASS = 1.98892e30; static double GAMMAE = 0.577215664901532860607; static double lambda = -1987./3080.; static double theta = -11831./9240.; static double TMIN = 1e-2; static double TMAX = 1e8;
//Dichiarazione degli OpenCL objects cl_platform_id my_platform; // OpenCL platform cl_context my_context; // OpenCL context cl_command_queue my_command_queue; // OpenCL command queue cl_device_id* devices; // OpenCL device list cl_program my_program; // OpenCL program cl_kernel my_kernel; // OpenCL kernel
//Dichiarazione dei parametri del device

IMPLEMENTAZIONE OPENCL
cl_mem d_omega0; cl_mem d_phase0; cl_mem hpt_dev; cl_mem hqt_dev; cl_mem d_ct; cl_mem d_N; cl_mem d_dt; cl_mem ws_dev; cl_mem d_scalef;
cl_int ciErr1;
char* c_source_CL = NULL;
const char* ProgramSource = "inspiral_pn.cl"; //File del kernel size_t kernel_length;
int main(int argc, char *argv[]){
//Definizione dei parametri float m1 = atof(argv[3]); float m2 = atof(argv[4]); float r = 1.;//*MPC; int exp = atoi(argv[1]); long N = pow(2,atoi(argv[1])); float dt = 1./atof(argv[2]); float fcut = atof(argv[5]); int ID = atoi(argv[6]);
float omega0 = 15.; float phase0 = .0; float * hpt = (float *) malloc(sizeof(float) * N); float * hqt = (float *) malloc(sizeof(float) * N); float scalef = CUINSPIRAL_SCALE_F;
size_t sizeofns = sizeof(float)*N; size_t sizeofws = sizeof(float)*73; size_t sizeoffloat = sizeof(float);
float* _omega0 = (float*) malloc(sizeoffloat);
87

IMPLEMENTAZIONE OPENCL
float* _phase0 = (float*) malloc(sizeoffloat); float* _ct = (float*) malloc(sizeoffloat); long* _N = (long*) malloc(sizeof(long)); float* _dt = (float*) malloc(sizeoffloat); float* _scalef = (float*) malloc(sizeoffloat);
*_omega0 = omega0; *_phase0 = phase0; *_N = N; *_dt = dt; *_scalef = scalef;
//Inizializzazione del workspace workspace ws; cuInspiral_PN6_init_workspace(&ws, m1, m2, r);
// Calculolo del tempo di coalescenza float ct = cuInspiral_PN6_find_coalescence_time(&ws, fcut); *_ct = ct;
//Preparazione del device //Creazione della platform cl_uint numPlatforms = 0; ciErr1 = clGetPlatformIDs(0, 0, &numPlatforms); if (ciErr1 != CL_SUCCESS) { printf("Error in clGetPlatformID !!!\n\n"); } printf("Number of platforms = %d\n", numPlatforms);
cl_platform_id* platforms = NULL; platforms = (cl_platform_id*)malloc(sizeof(cl_platform_id)*numPlatforms); ciErr1 = clGetPlatformIDs(numPlatforms, platforms, &numPlatforms); if (ciErr1 != CL_SUCCESS) { printf("Error in clGetPlatformIDs !!!Err code: %d\n\n",ciErr1); } //Selezione del device cl_uint num_of_devices = 0; ciErr1 = clGetDeviceIDs(platforms[0], CL_DEVICE_TYPE_GPU, 0, 0,
&num_of_devices); char device_name[1024]; int x;
cl_device_id* devs = NULL;
88

IMPLEMENTAZIONE OPENCL
devs = (cl_device_id*)malloc(sizeof(cl_device_id)*num_of_devices); clGetDeviceIDs (platforms[0], CL_DEVICE_TYPE_GPU, num_of_devices, devs, NULL); if (ciErr1 != CL_SUCCESS) { printf("Error in clGetDeviceIDs !!!Err code :
%d\n\n", ciErr1); } printf("Number of devices = %d\n", num_of_devices); for ( x=0; x < num_of_devices; x++) { clGetDeviceInfo(devs[x], CL_DEVICE_NAME,sizeof(device_name), &device_name, NULL); printf("DEVICE %d = %s \n \n \n", x, device_name); } //Creazione del context cl_context_properties cp[3]; cp[0] = CL_CONTEXT_PLATFORM; cp[1] = (cl_context_properties)platforms[0]; cp[2] = 0;
cl_device_id devid; devid = devs[ID];
my_context = clCreateContext(cp, 1, &devid,NULL,NULL,&ciErr1); if (ciErr1 != CL_SUCCESS) { printf("Error in clCreateContext !!!\n\n" ); }
//Creazione della command queue my_command_queue = clCreateCommandQueue(my_context, devid,
CL_QUEUE_PROFILING_ENABLE, &ciErr1 ); if (ciErr1 != CL_SUCCESS) { printf("Error in clCreateCommandQueue !!!\n\n" ); }
//Allocazione e trasferimento dei dati sul device
d_omega0 = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeoffloat, (void*)_omega0, &ciErr1);
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
d_phase0 = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeoffloat, (void*)_phase0, &ciErr1);
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
d_ct = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeoffloat, (void*)_ct, &ciErr1);
89

IMPLEMENTAZIONE OPENCL
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
d_dt = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeoffloat, (void*)_dt, &ciErr1);
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
d_scalef = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeoffloat, (void*)_scalef, &ciErr1);
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
d_N = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(long), (void*)_N, &ciErr1);
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
ws_dev = clCreateBuffer(my_context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeofws, (void*)&ws, &ciErr1);
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
hpt_dev = clCreateBuffer(my_context, CL_MEM_READ_WRITE, sizeofns, NULL, &ciErr1);
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
hqt_dev = clCreateBuffer(my_context, CL_MEM_READ_WRITE, sizeofns, NULL, &ciErr1);
if (ciErr1 != CL_SUCCESS) { printf ("Error in clCreateBuffer!!!Error code: %d\n", ciErr1); }
//Creazione e costruzione del program objectc_source_CL = utils_load_prog_source(ProgramSource, "", &kernel_length);
const char* CLsrc = c_source_CL;my_program = clCreateProgramWithSource(my_context, 1, &CLsrc, &kernel_length,
&ciErr1); if (ciErr1 != CL_SUCCESS) { printf("Error in clCreateProgramWithSource !!!Err
code %d\n\n", ciErr1 ); }
clBuildProgram(my_program, 1, &devid, NULL, NULL, NULL);
90

IMPLEMENTAZIONE OPENCL
if (ciErr1 != CL_SUCCESS) { printf("Error in clBuildProgram !!!Err code %d\n\n", ciErr1 ); }
//Creazione del kernel my_kernel = clCreateKernel(my_program, "kernel_PN6_0_signal_proc", &ciErr1); if (ciErr1 != CL_SUCCESS) { printf("Error in clCreateKernel !!!Err code
%d\n\n", ciErr1 ); }
//Settaggio dei parametri del kernel
size_t sizeofclmem = sizeof(cl_mem);
ciErr1 = clSetKernelArg(my_kernel, 0, sizeofclmem, (void*)&ws_dev); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(ws), error code = %d\n",
ciErr1); ciErr1 = clSetKernelArg(my_kernel, 1, sizeofclmem, (void*)&d_N); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(N), error code = %d\n",
ciErr1); ciErr1 = clSetKernelArg(my_kernel, 2, sizeofclmem, (void*)&d_dt); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(dt), error code = %d\n",
ciErr1); ciErr1 = clSetKernelArg(my_kernel, 3, sizeofclmem, (void*)&d_ct); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(ct), error code = %d\n",
ciErr1); ciErr1 = clSetKernelArg(my_kernel, 4, sizeofclmem, (void*)&d_omega0); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(omega0), error code =
%d\n", ciErr1); ciErr1 = clSetKernelArg(my_kernel, 5, sizeofclmem, (void*)&d_phase0); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(phase0), error code =
%d\n", ciErr1); ciErr1 = clSetKernelArg(my_kernel, 6, sizeofclmem, (void*)&d_scalef); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(scalef), error code =
%d\n", ciErr1); ciErr1 = clSetKernelArg(my_kernel, 7, sizeofclmem, (void*)&hpt_dev); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(hpt), error code = %d\n",
ciErr1); ciErr1 = clSetKernelArg(my_kernel, 8, sizeofclmem, (void*)&hqt_dev); if (ciErr1!=CL_SUCCESS) printf("Error in setKernelArg(hqt), error code = %d\n",
ciErr1);
//Definizione della dimensionalità della griglia const size_t cnBlockSize = THREADXBLOCK;
91

IMPLEMENTAZIONE OPENCL
const size_t cnBlocks = (N + THREADXBLOCK-1 - 1) / THREADXBLOCK; const size_t cnDimension = cnBlocks * cnBlockSize;
cl_event event;
if(1/dt*ct >= N/2) printf("WARNING : Increase vector size!!! N = 2^%d\n", exp); //Esecuzione del kernel clEnqueueNDRangeKernel(my_command_queue, my_kernel, 1, 0, &cnDimension,
&cnBlockSize, 0, 0, &event); if (ciErr1 != CL_SUCCESS) printf("Error in Barrier()!!!Err code: %d\n",ciErr1); //Sincronizzazione tra CPU e GPU clWaitForEvents ( 1, &event);
// Trasferimento dei dati dal device all'host clEnqueueReadBuffer(my_command_queue, hpt_dev, CL_TRUE, 0, sizeofns, hpt, 0,
NULL, NULL); clEnqueueReadBuffer(my_command_queue, hqt_dev, CL_TRUE, 0, sizeofns, hqt, 0,
NULL, NULL);
float l = (1/dt)*ct; for (i=0;i<=l;i++) {
//Stampa i dati sullo schermo fprintf(stdout,"%12f:%12.10g:%12.10g\n",(float)i*dt,hpt[i]/
(double)scalef,hqt[i]/(double)scalef); } //Liberazione delle risorse
free( hpt ); free( hqt );
}
//Codice del kernel OpenCL che esegue il primo livello di approssimazione: PN0
__kernel void kernel_PN6_0_signal_proc( __global float* workspace, __global long *N, __global const float* dt,
92

IMPLEMENTAZIONE OPENCL
__global const float* ct, __global const float* omega0, __global const float* phase0, __global const float* d_scalef, __global float* hpt, __global float* hqt){ unsigned int gid = get_global_id(0);
//Definizione della struttura
float Tm =workspace[0]; // The time constant \f$T_m = Gm/c^3\f$. float mass_total =workspace[1]; // The total mass of the system, in Kg float mass_reduced =workspace[2]; // The reduced mass of the system, in Kg float dM =workspace[3]; // The mass difference between the two bodies
of the system, in Kg float nu =workspace[4]; // Ratio between reduced and total mass
//float aw=workspace[5]; // Coeff. for istantaneous frequency float bw=workspace[6]; float cw=workspace[7]; float dw=workspace[8]; float ew=workspace[9]; float fw=workspace[10]; float gw=workspace[11]; float hw=workspace[12];
float ap=workspace[13]; // Coeff. for istantaneous phase float bp=workspace[14]; float cp=workspace[15]; float dp=workspace[16]; float ep=workspace[17]; float fp=workspace[18]; float gp=workspace[19]; float hp=workspace[20];
float h0=workspace[21];
float plus_c00=workspace[22]; // Coeff. for the plus polarization float plus_c02=workspace[23]; //float plus_c11=workspace[24]; //float plus_c13=workspace[25];
93

IMPLEMENTAZIONE OPENCL
//float plus_c22=workspace[26]; //float plus_c24=workspace[27]; //float plus_c31=workspace[28]; //float plus_c32=workspace[29]; //float plus_c33=workspace[30]; //float plus_c35=workspace[31]; //float plus_c41=workspace[32]; //float plus_c42=workspace[33]; //float plus_c43=workspace[34]; //float plus_c44=workspace[35]; //float plus_c46=workspace[36]; //float plus_s41=workspace[37]; //float plus_s43=workspace[38]; //float plus_c51=workspace[39]; //float plus_c52=workspace[40]; //float plus_c53=workspace[41]; //float plus_c54=workspace[42]; //float plus_c55=workspace[43]; //float plus_c57=workspace[44]; //float plus_s52=workspace[45]; //float plus_s54=workspace[46];
float cross_s02=workspace[47]; // Coeff. for the cross polarization //float cross_s11=workspace[48]; //float cross_s13=workspace[49]; //float cross_s22=workspace[50]; //float cross_s24=workspace[51]; //float cross_s31=workspace[52]; //float cross_s32=workspace[53]; //float cross_s33=workspace[54]; //float cross_s35=workspace[55]; //float cross_s41=workspace[56]; //float cross_s42=workspace[57]; //float cross_s43=workspace[58]; //float cross_s44=workspace[59]; //float cross_s46=workspace[60]; //float cross_c41=workspace[61]; //float cross_c43=workspace[62]; //float cross_c50=workspace[63]; //float cross_c52=workspace[64]; //float cross_c54=workspace[65]; //float cross_s51=workspace[66];
94

IMPLEMENTAZIONE OPENCL
//float cross_s52=workspace[67]; //float cross_s53=workspace[68]; //float cross_s54=workspace[69]; //float cross_s55=workspace[70]; //float cross_s57=workspace[71];
float normw =workspace[72]; // Normalization of 'w'
float t, tau; float w, p, ph; float y, y2, y3, iy, iy2, iy3, x, Plus0, Cross0; float duration= *ct;
if (gid<=(*N)) {e
t = duration - (*dt)*gid; if (t>0) { //Calculate omega tau = nu*t/(5.0*Tm); y = pow(tau,-0.125); iy = 1.0/y; y2 = y*y; y3 = y*y*y; iy2 = iy*iy; iy3 = iy*iy*iy; w = normw*y*y*y*(1 + bw*y2 + cw*y3 + dw*y2*y2 + ew*y2*y3 + (fw + gw*log(2.*y))*y3*y3 + hw*y3*y3*y); if (w>0) { //Calculate phase p = ap*iy3*iy2 + bp*iy3 + cp*iy2 + dp*iy +
95

IMPLEMENTAZIONE OPENCL
8.0*ep*log(iy)+ fp*y + (-8.)*gp*log(2.*y) + hp*y2; ph = *phase0+p-2.0*Tm*w*log(w/(*omega0));
ph - ceil(ph/(2.0*M_PI))*2.0*M_PI;
//ALIASES x = cbrt(Tm*w); // NOTE : x=(Tm*w)^2/3 float cos2 = cos(2.*ph); float sin2 = sin(2.*ph); plus_c00 = 0; //Calculate plus and cross polarization Plus0 = plus_c00 + plus_c02*cos2; Cross0= cross_s02*sin2;
//SAVING FINAL RESULTS hpt[gid] = (h0*x*x*Plus0) * (*d_scalef); //Inphase hqt[gid] = (h0*x*x*Cross0) * (*d_scalef); //Inquadrature
}else { hpt[gid] = 0.0; hqt[gid] = 0.0; } } else { hpt[gid] = 0.0; hqt[gid] = 0.0; } }}
96

97
Ringraziamenti
Qualche breve e doveroso ringraziamento al termine di questo lavoro. In particolar modo
desidero ringraziare i miei genitori, a cui dedico questo lavoro, per avermi dato la possibilità
di intraprendere la carriera universitaria ed avermi sostenuto moralmente ed economicamente;
vorrei che questo mio traguardo raggiunto, per quanto possibile, fosse un premio anche per
loro.
Un grazie speciale va a Giovanna per essermi stata sempre vicina anche nei momenti di gran
difficoltà e per avermi sempre dato una parola d’incoraggiamento e ai miei fratelli Vincenzo,
Roberto ed Erminia che sono parte di me.
Voglio anche ringraziare tutti le persone, amici e familiari che sono stati presenti nella mia
vita e che con il loro affetto mi hanno aiutato ad arrivare fin qui.
Un particolare ringraziamento ai miei relatori, Dr. Leonello Servoli e Dr. Leone Bosi, che
sono stati estremamente disponibili nell’aiutarmi durante tutto il lavoro svolto per questa tesi
di laurea. Infine ringrazio l'esperimento INFN MaCGO (Manycore Computing for future
gravitational observatory) ed il progetto europeo Einstein Telescope design finanziato dal 7°
programma quadro (FP7/2007-2013) grant agreement n. 211743 avendo fornito il supporto
tecnico e teorico per lo sviluppo di questa tesi.

98
Bibliografia
[1] Albert Einstein, Come io vedo il mondo – La teoria della relatività, Newton Compton 2010
[2] http://www.einsteinathome.org
[3] http://it.wikipedia.org/wiki/PSR_J0737-3039
[4] Luc Blanchet, Post Newtonian Computatio for binary inspiral waveform, arxiv:gr-qc/0104084, Aprile 2001
[5] Curt Cuttler, Kip S. Thorne, An overview of Gravitaional-Wave Sources, arXiv:gr-qc/0204090v 1, Aprile 2002
[6] http://www.virgo.infn.it
[7] http://www.ligo.caltche.edu
[8] http://lisa.jpl.nasa.gov
[9] http://www.nvidia.it/object/tesla_c1060_it.html
[10] http://www.gpgpu.it
[11] http://gpgpu.org/developer
[12] NVIDIA, NVIDIA CUDA Programming Guide, 2009
[13] NVIDIA, OpenCL programming guide for the CUDA architecture, version 2.3, 2010
[14] Aafttab Munshi, Khronos OpenCL Working Group, The OpenCL specification, version 1.0, 2009

99
Indice delle illustrazioni
Illustrazione 1.1: Effetto di un'onda gravitazionale.............................7
Illustrazione 1.2: Moto di un sistema binario coalescente........................10
Illustrazione 1.3: Schema di un interferometro di Michelson......................12
Illustrazione 1.4: Forma d'onda del segnale nella fase di inspiral...................19
Illustrazione 2.1: Evoluzione di CPU e GPU a confronto........................24
Illustrazione 2.2: Architettura di una Tesla C1060.............................26
Illustrazione 2.3: Insieme di multiprocessori SIMT con memoria condivisa............27
Illustrazione 2.4: API di CUDA.........................................31
Illustrazione 2.5: Modello di esecuzione dei kernel e gestione dei threads.............32
Illustrazione 3.1: Schema di esecuzione dell'algoritmo..........................48
Illustrazione 3.2: Corrispondenza tra variabile e coeficente dell'approssimazione PN......54
Illustrazione 3.3: Tempo di coalescenza in funzione della frequenza iniziale............55
Illustrazione 3.4: Schema del kernel di generazione del segnale....................62
Illustrazione 4.1: Template generati da CUDA e OpenCL a confronto................66
Illustrazione 4.2: Tempo di generazione in funzione della durata del segnale in CUDA.....71
Illustrazione 4.3: Tempo di esecuzione di CUDA e OpenCL......................72
Illustrazione 4.4: Punti del segnale generati ogni millisecondo da CUDA e OpenCL......72
Illustrazione 4.5: Rapporto tra tempo di esecuzione e durata del segnale in CUDA e OpenCL 73
Illustrazione 4.6: Confronto prestazionale CPU-GPU...........................74