information retrieval lecture 4 test collections and the...
TRANSCRIPT

Information Retrieval Lecture 4
Test collections and the Cranfield Paradigm
Queries and query language
April 2015
Karin Friberg Heppin

Today
• About queries in general • The Cranfield paradigm • Test collections • The construction of MedEval
Swedish medical test collection
• The syntax of the Indri/Lemur query language

Information Need – the reason why the search is done
An information need is the underlying cause of the query that a person submits to a search engine Categorized using variety of dimensions – type of information needed domain > subject question that needs to be answered level of expertise: professional – layperson – type of task that led to the requirement for information: are you writing a paper, are you preparing for a meeting or for an exam…

Formal Information need / Topic
<TOP> <TOPNO>1</TOPNO> <TITLE> HDL och LDL </TITLE> <DESC> Hur påverkar en fettsnål, energifattig kost
koncentrationerna av HDL och LDL i blodet? </DESC> <NARR> Relevanta dokument ska innehålla information om
lipoproteinerna HDL och LDL och deras funktion, samt beskriva hur en kostförändring med fettsnål, energifattig kost påverkar koncentrationen av dessa i blodet.
</NARR> </TOP>

Queries
A query is the formulation of a user information need put to the system Keyword based queries are popular, since they are intuitive, easy to express, and allow for fast ranking However, a query can also be a more complex combination of operations using different kinds of operators

Information Needs vs. Queries

The double meaning of ’query’
• The term ’query’ is used both for the input the user gives to the system and for the modified version of this which the system uses for the matching with the index terms
• In Web search, the user writes a key word based query in the field for search keys
• Which the system translates into a more complex form for the matching process

Queries in the past
Query languages in the past were designed for professional searchers – intermediaries
The user put a natural language query to the intermediary, who translated it to a query the system could interpret

Key word based queries
The result of key word queries for most retrieval models is the set of documents containing at least one of the words of the query
The resulting documents are ranked according to the degree of similarity with respect to the query
How the ranking is done depends on the retrieval model. More on that later in the course

Complex queries
Queries can also be complex with different kinds of operators This is the case with - the query put to the matching process - and for seach engines used by information retrieval specialists

Query in the Indri/Lemur query language
#combine( #syn( fettsnål energifattig ) #syn( kost diet föda dricka kosthållning kostförändring) #syn( koncentration halt) #syn( ldl kolesterol lågdensitetslipoprotein kolesterolester #uw5(lätt lipoprotein)) #syn( hdl kolesterol högdensitetslipoprotein kolesterolester lipoprotein ) #syn( blod ) )

Query modification
The process of query modification is commonly referred to as Query expansion, when information related to the query is used to expand it, by the system or by the user Relevance feedback, when information about relevant documents is
put to the system, by the system itself or by the user We refer to both of them as feedback methods Two basic approaches of feedback methods: explicit feedback, in which the information for query reformulation is
provided directly by the users implicit feedback, in which the information for query reformulation is implicitly derived by the system

Query expansion
Baseline #combine(upptäckt samband gen cancer)
Inflections #combine(#syn(upptäckt upptäckten upptäckter)
#syn(samband sambandet) #syn(gen genen gener) #syn(cancer cancern))
Inflection + synonyms #combine(#syn(upptäckt upptäckten upptäckter)
#syn(samband sambandet orsak orsaka) #syn(gen gener arvsmassa arvsmassan) #syn(cancer cancern tumör tumörer))

Facets
#combine( #syn( fettsnål energifattig ) #syn( kost diet föda dricka kosthållning kostförändring) #syn( koncentration halt)… Corresponds to the Boolean statement: ( fettsnål OR energifattig ) AND ( kost OR diet OR föda OR dricka OR kosthållning OR kostförändring) AND ( koncentration OR halt)…
The main subjects within a query are called facets. A facet may contain serveral search terms which are near synonyms or words within a related semantic field.

Visualizing facets with Boolean syntax
fettsnål OR
energifattig
kost OR
diet OR
föda
OR
dricka
OR
kosthållning
OR kostförändring
koncentration OR
halt AND AND …
The facets may be visualized with blocks connected with the AND operator containing terms connected with the OR operator
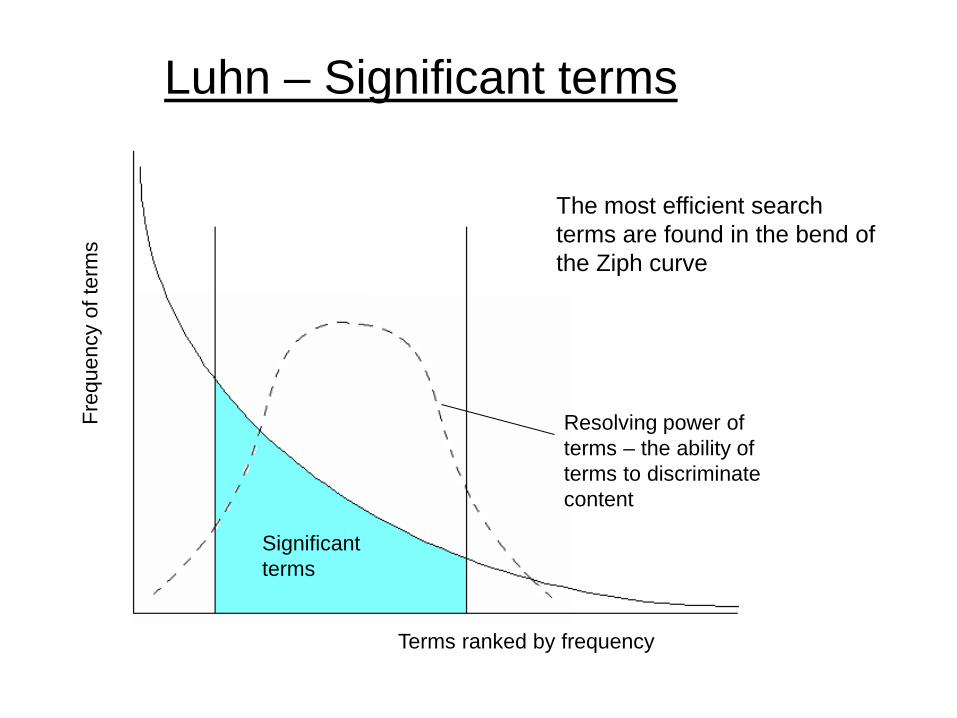
Terms ranked by frequency
Freq
uenc
y of
term
s
Significant terms
Resolving power of terms – the ability of terms to discriminate content
Luhn – Significant terms
The most efficient search terms are found in the bend of the Ziph curve

Frequent case forms
Instead of conflation (stemming/lemmatizing), use the frequent case forms as search terms.
Finnish nouns have 17 cases which makes thousands of inflectional
forms for each noun. However, only a handful of these are frequently used. And seldom used forms rarely occur without more common forms in the same document.
Kimmo Kettunen (2008). Automatic Generation of Frequent Case Forms of Query Keywords in Text Retrieval. In Advances in Natural
Language Processing, GoTAL. Kimmo Kettunen (2008). Frequent Case Form Generation of Query Keywords in Text Retrieval. In Proceedings of IADIS International
Conference Applied Computing.

Feedback
The user indicates, consciously or unconsciously, which documents are relevant to their query or to indicate which terms extracted from those documents are relevant The user or the system then constructs a new query from this information by
- Boosting weights of terms from relevant documents - Adding terms from relevant documents to the query
Idea: you may not know what you’re looking for, but you’ll know when you see it
How do we know which searches are good?
Search results are usually given as lists of documents which may contain document ID, document title, link and snippet from the content. To know which documents are hits, you need to look at them.
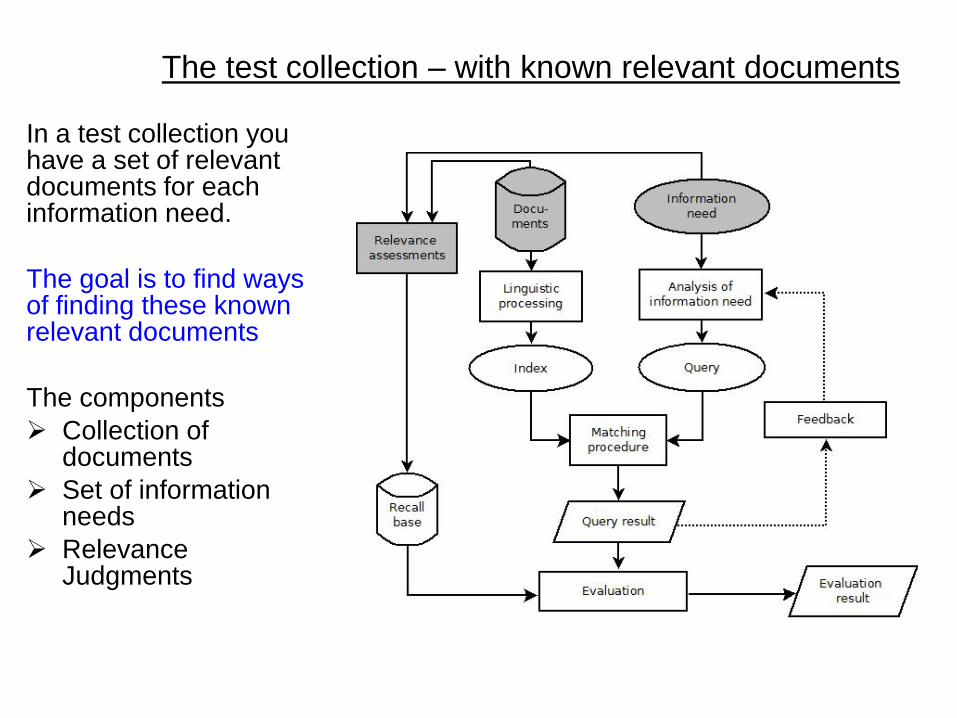
In a test collection you have a set of relevant documents for each information need. The goal is to find ways of finding these known relevant documents
The components Collection of
documents Set of information
needs Relevance
Judgments
The test collection – with known relevant documents

Test collection – a stable environment
To test and compare search strategies you need a laboratory environment that doesn’t change – a test collection
- determine how well IR systems
perform - compare the performance of the IR
system with that of other systems - compare search alghoritms with
each other - compare search strategies with each
other

The Cranfield Paradigm
Evaluation of IR systems is the result of early experimentation initiated by Cyril Cleverdon
Cleverdon started a series of projects, called the Cranfield
projects, in 1957 that lasted for about 10 years in which he and his colleagues set the stage for information retrieval research.
In the Cranfield project, retrieval experiments were
conducted on test databases in a controlled, laboratory-like setting.
The Cranfield projects provided a foundation for the
evaluation of IR systems

The first laboratory environment Experiments at the Cranfield College of Aeronautics The objective was to study what kinds of indexing languages
were most effective. At this time documents were indexed manually with a few
keywords from controlled vocabularies/thesauri 1 100 documents of research in metallurgy Small enough to have every document assessed for
relevance to every topic - A database with, for the time, a large set of documents - A set of information needs expressed in plain text - A relevance judgement for every document in relation to
every information need

Recall/precision
The Cranfield experiments culminated in the modern
metrics of precision and recall
Recall ratio: the fraction of relevant documents retrieved Precision ration: the fraction of documents retrieved that are relevant

Model a real user application, with realistic information needs
Collect enough documents and create enough topics to allow significant testing on results
Make relevance judgments before the experiments. This prevents human bias and enables re-usability
Define metrics that reflect real user situations
Run strategy A and B Evaluate A and B using appropriate metrics Compare A with B statistically State whether A works better than B, A and B are equivalent, or B works better than A
The Cranfield Paradigm today

Test collection
To test and compare strategies a test collection is needed
A test collection is a laboratory
testbed representing the real world
A test collection consists of:
• A static set of documents • A set of information needs/topics • A set of known relevant
documents for each of the information needs

Test collection based IR evaluation
System function • separate relevant from non-relevant documents
• rank relevant above non-relevant documents
• rank highly relevant above less relevant documents
Pupose of evaluation decide how well a system performs the function above
determine the best system/queries/algorithms

Why no users? Users are unpredictable and homogenous They have different levels of knowledge and different learning and working strategies
Having users makes it difficult to design an experiment that actually measures what you expect it to measure, unless you want to measure user satisfaction, verify user simulation studies, etc
Having users makes experiments take months instead of minutes, hours, or days, especially if you need to do many runs with small variations
It is often difficult to get enough users for reliable significance testing
Users expect to be paid!

Why not just use a web search engine?
• Static set of documents and set of known relevant documents
• Control over index, compound splitting, lemmatization
• Ranking calculated on text
• Known search algorithm
• Structured syntax for search queries
• Hits are for instances of search terms
• Constantly changing content and random servers with different documents indexed
• No control over index
• Ranking calculated, links, click-through data, user context…
• Unknown search algorithm • Limited structure for search
syntax • Hits are for pages
Test collection Web search engine

Collection of documents
A static set of documents Usually text Can also be Images Videos Music etc…

MedEval (Medical Evaluation)
• MedEval is created, by the Department of Swedish, from the medical corpus MedLex (University of Gothenburg)
• 42 000 documents, 15 million tokens The size of MedLex in October 2007
• Articles from scientific journals and newspapers, medical information, internet
• The documents are tokenized, tagged, lemmatized and indexed
• 2 indexes: with and without segmented compounds

Document in the trec text format <DOC> <DOCNO> GPXX-0002 </DOCNO> <TITLE> Svårt utvärdera effektiviteten i psykvården </TITLE> <DATE> 2006-09-04 </DATE> <TEXT>http://www.gp.se/STOCKHOLMDet går inte att avgöra om den psykiatriska
öppenvården är effektiv . Landstingen bryter mot lagen och rapporterar för få besök i den öppna psykiatrin till det nationella patientregistret .
Det visar Socialstyrelsens granskning som Svenska Dagbladet tagit del av . Omkring 30 procent av alla läkarbesök i öppenvården rapporteras aldrig in till
registret .Den granskade statistiken från 2004 visar att det saknas uppgift om patienternas diagnoser för 60 procent av de rapporterade läkarbesöken .För förra året visar de preliminära siffrorna att det rör sig om 55 procent av besöken .
De stora bristerna i det nationella registret leder till att en utvärdering av
verksamheten försvåras enligt den nationelle psykiatrisamordnaren Anders Milton .</TEXT>
</DOC>

Information needs – what you need to know
The subjects that you want to find documents about
Expressed in natural language - Title - Description - Narrative

TREC Topic Example

MedEval Information needs
• 50 – 60 information needs/topics
• Representative of real needs In MedEval: physicians and patients
• In MedEval created by a medically trained persons
• ~10-100 relevant documents per need

MedEval Information need / Topic
<TOP> <TOPNO>1</TOPNO> <TITLE> HDL och LDL </TITLE> <DESC> Hur påverkar en fettsnål, energifattig kost
koncentrationerna av HDL och LDL i blodet? </DESC> <NARR> Relevanta dokument i ska innehålla information om
lipoproteinerna HDL och LDL och deras funktion, samt beskriva hur en kostförändring med fettsnål, energifattig kost påverkar koncentrationen av dessa i blodet.
</NARR> </TOP>

The ideal test collection
The ideal test collection would have every document assessed for every topic
Which was the case with
the first testcollections

Assessment
• The documents are assessed for relevance to each topic by assessors with knowledge of the domain
• Either a binary scale: relevant – not relevant, or a graded scale
• Assessments vary between judges and for one judge over time
• To keep consistency within each topic: not more than one assessor per topic or crowd sourcing
• Effectiveness is not compared in absolute numbers. What is studied is the relative value of different strategies

Assessments in MedEval
The documents were assessed by medically trained
persons (students) The documents were assessed for
topic relevance: 0,1,2,3 intended readers: Doctors, Patients

Scale of relevance
0 – Not relevant
1 – Marginally relevant
2 – Fairly relevant
3 – Highly relevant
Contains no information about the topic
No other relevant information than what is contained in the the description of the topic
More information about the topic than the description, but not exhaustive
All themes of the topic are discussed

MedEval documents assessed for intended readers
Documents intended for the general public. No medical training neccessary to understand the text.
Documents intended for physicians.
Medical training neccessary to understand the text.
P – Patient group
M – Medically trained group

Laymen – Professionals Physician: - Rätt dosering av metoprolol vid hypertoni? - Correct dosage of metoprolol for a patient with
hypertension?" The physician uses name of substance and the terms
hypertension and dosage.
Patient: - Hur mycket av min blodtrycksmedicin skall jag ta? - How much of my blood pressure medicine should I
take? The patient asks about dosage in another way and uses layman
terms.


Pooling – Don’t assess the ones which probably are not relevant
If each document takes an average of 8 minutes to judge, judging 48 000 for 50 topics would require 8 000 full-time working weeks or 4 persons working 40 years.
In the ideal collection all documents
are assessed for relevance for each information need.

Pooling
Pooling is done on a large scale for the TREC Conference tasks
– Pooling technique is used in TREC – top k results (for TREC, k varied between 50 and 200)
from the rankings obtained by different search engines (or retrieval algorithms) are merged into a pool
– duplicates are removed – documents are presented in some random order to the
relevance judges
Produces a large number of relevance judgments for each query, although still incomplete

1
Strategy 1 Strategy 2 Strategy 3 Strategy 4 Strategy 1 Strategy 2 Strategy 3 Strategy 4 Strategy 1 Strategy 2 Strategy 3 Strategy 4
Pooling
Topic 1
Topic 2
Topic n n n
2
1


Thank God for electronic search engines…

The web based assessment tool

Relevance assessments in MedEval
91 BMSX-0347 0 P 91 FRSK-0039 0 D 91 FYSS-1230 0 D 91 GPXX-0312 2 P 91 HUDF-0008 0 P 91 LKBK-0073 0 D 91 LTXX-0177 1 D 91 LTXX-0205 0 D 91 ABXX-0275 0 P 91 MDLL-3401 0 P 91 NOVO-3344 0 D 91 NTDK-0411 3 P 91 NTDK-0975 0 P 91 PFZR-00027 0 D 92 PRTK-4331 0 D 92 SVDK-0003 0 D 92 SVRD-0589 0 P 92 VRDG-0078 1 P 92 VRDG-0275 0 P
For each topic (column 1) there are there are assessed documents (column 2) with assessed relevance (column 3) and intended audience (column 4)

None Doctors Patients 91 ABXX-0275 0 91 BMSX-0347 0 91 FRSK-0039 0 91 FYSS-1230 0 91 GPXX-0312 2 91 HUDF-0008 0 91 LKBK-0073 0 91 LTXX-0177 1 91 LTXX-0205 0 91 MDLL-3401 0 91 NOVO-3344 0 91 NTDK-0411 3 91 NTDK-0975 0 91 PFZR-00027 0 92 PRTK-4331 0 92 SVDK-0003 0 92 SVRD-0589 0 92 VRDG-0078 1 92 VRDG-0275 0
91 ABXX-0275 0 91 BMSX-0347 0 91 FRSK-0039 0 91 FYSS-1230 0 91 GPXX-0312 1 91 HUDF-0008 0 91 LKBK-0073 0 91 LTXX-0177 1 91 LTXX-0205 0 91 MDLL-3401 0 91 NOVO-3344 0 91 NTDK-0411 2 91 NTDK-0975 0 91 PFZR-00027 0 92 PRTK-4331 0 92 SVDK-0003 0 92 SVRD-0589 0 92 VRDG-0078 0 92 VRDG-0275 0
91 ABXX-0275 0 91 BMSX-0347 0 91 FRSK-0039 0 91 FYSS-1230 0 91 GPXX-0312 2 91 HUDF-0008 0 91 LKBK-0073 0 91 LTXX-0177 0 91 LTXX-0205 0 91 MDLL-3401 0 91 NOVO-3344 0 91 NTDK-0411 3 91 NTDK-0975 0 91 PFZR-00027 0 92 PRTK-4331 0 92 SVDK-0003 0 92 SVRD-0589 0 92 VRDG-0078 1 92 VRDG-0275 0
User scenarios – adjusted relavance grades In MedEval the relevance grade are adjusted in the Doctor and Patient scenarios

The test collection is finished!
Time to pose queries to the test collection!

Query for Topic 1
#combine( #syn( fettsnål energifattig ) #syn( kost diet föda kosthållning kostförändring) #syn( koncentration halt) #syn( ldl kolesterol lågdensitetslipoprotein #uw5(lätt lipoprotein)) #syn( hdl kolesterol högdensitetslipoprotein lipoprotein ) )

The result for baseline query 1
1 Q0 ntdk-0077 1 -6.68144 indri 1 Q0 nmdc-0652 2 -6.76833 indri 1 Q0 ltxx-1297 3 -6.813 indri 1 Q0 ntdk-0074 4 -6.88695 indri 1 Q0 ltxx-2525 5 -6.94228 indri 1 Q0 svrd-1865 6 -6.9971 indri 1 Q0 mdll-0226 7 -7.01527 indri 1 Q0 pfzr-0047 8 -7.02031 indri 1 Q0 nmdc-0937 9 -7.07394 indri 1 Q0 vrdg-0434 10 -7.12576 indri 1 Q0 svdx-0089 11 -7.13687 indri 1 Q0 svdx-0087 12 -7.15393 indri 1 Q0 svrd-0614 13 -7.19322 indri 1 Q0 svrd-1443 14 -7.19562 indri 1 Q0 nmdc-0843 15 -7.20493 indri 1 Q0 flkb-0015 16 -7.23677 indri 1 Q0 nmdc-0621 17 -7.29184 indri 1 Q0 fyss-0025 18 -7.30071 indri 1 Q0 bmsx-2066 19 -7.30643 indri 1 Q0 bmsx-0044 20 -7.31138 indri 1 Q0 ltxx-1087 21 -7.34271 indri 1 Q0 ltxx-3768 22 -7.4061 indri 1 Q0 svrd-1867 23 -7.43562 indri 1 Q0 dnxx-0683 24 -7.51783 indri 1 Q0 dagm-0549 25 -7.54264 indri 1 Q0 ltxx-1255 26 -7.57046 indri 1 Q0 bmsx-0021 27 -7.57146 indri 1 Q0 frsk-0461 28 -7.5796 indri 1 Q0 svrd-1862 29 -7.58203 indri 1 Q0 bmsx-2305 30 -7.58903 indri 1 Q0 nmdc-0086 31 -7.59473 indri 1 Q0 ntdk-1325 32 -7.62016 indri 1 Q0 nmdc-0392 33 -7.63131 indri 1 Q0 lkbk-0015 34 -7.63304 indri
1 Q0 gpxx-0023 35 -7.64715 indri 1 Q0 svrd-1866 36 -7.66673 indri 1 Q0 fyss-0002 37 -7.67032 indri 1 Q0 ltxx-0478 38 -7.67949 indri 1 Q0 elli-0015 39 -7.69401 indri 1 Q0 ltxx-0943 40 -7.69744 indri 1 Q0 svrd-1096 41 -7.70263 indri 1 Q0 mdll-0185 42 -7.70869 indri 1 Q0 frsk-0262 43 -7.71503 indri 1 Q0 frsk-0477 44 -7.71505 indri 1 Q0 frsk-0497 45 -7.72518 indri 1 Q0 dagm-0552 46 -7.72721 indri 1 Q0 elli-0017 47 -7.73269 indri 1 Q0 elli-0012 48 -7.73473 indri 1 Q0 bmsx-2006 49 -7.73993 indri 1 Q0 nmdc-0144 50 -7.74181 indri 1 Q0 schr-0074 51 -7.74259 indri 1 Q0 dnxx-0184 52 -7.77071 indri 1 Q0 nmdc-0306 53 -7.77286 indri 1 Q0 elli-0013 54 -7.7747 indri 1 Q0 ltxx-2526 55 -7.78337 indri 1 Q0 ntdk-2403 56 -7.78677 indri 1 Q0 dagm-0645 57 -7.78689 indri 1 Q0 nmdc-0803 58 -7.7875 indri 1 Q0 ltxx-1043 59 -7.78828 indri 1 Q0 schr-0049 60 -7.78855 indri 1 Q0 ltxx-0944 61 -7.79202 indri 1 Q0 schr-0043 62 -7.79536 indri 1 Q0 dagm-1070 63 -7.79913 indri 1 Q0 ltxx-2514 64 -7.80579 indri 1 Q0 bmsx-1981 65 -7.81331 indri 1 Q0 ntdk-0677 66 -7.82148 indri 1 Q0 mrck-0062 67 -7.82615 indri
1 Q0 mdll-0205 68 -7.84119 indri 1 Q0 bmsx-0035 69 -7.84249 indri 1 Q0 mrck-0087 70 -7.84605 indri 1 Q0 ntdk-2710 71 -7.84657 indri 1 Q0 mrck-0050 72 -7.8479 indri 1 Q0 dagm-0742 73 -7.85168 indri 1 Q0 whpl-0930 74 -7.85455 indri 1 Q0 schr-0040 75 -7.86163 indri 1 Q0 schr-0061 76 -7.86744 indri 1 Q0 bmsx-2140 77 -7.8778 indri 1 Q0 mrck-0086 78 -7.88484 indri 1 Q0 ntdk-2471 79 -7.88642 indri 1 Q0 bmsx-2863 80 -7.89441 indri 1 Q0 pfzr-0054 81 -7.90202 indri 1 Q0 mrck-0074 82 -7.90292 indri 1 Q0 mdll-0361 83 -7.90519 indri 1 Q0 schr-0042 84 -7.90544 indri 1 Q0 abxx-0103 85 -7.91486 indri 1 Q0 svrd-0113 86 -7.91705 indri 1 Q0 dnxx-0105 87 -7.91795 indri 1 Q0 mrck-0063 88 -7.92239 indri 1 Q0 schr-0044 89 -7.92376 indri 1 Q0 bmsx-0045 90 -7.93384 indri 1 Q0 svrd-0032 91 -7.94811 indri 1 Q0 ltxx-3941 92 -7.95155 indri 1 Q0 bmsx-0020 93 -7.95468 indri 1 Q0 ltxx-0918 94 -7.95792 indri 1 Q0 nmdc-0713 95 -7.96319 indri 1 Q0 nmdc-0729 96 -7.9632 indri 1 Q0 dnxx-0101 97 -7.97049 indri 1 Q0 frsk-0575 98 -7.97514 indri 1 Q0 mdll-0057 99 -7.9756 indri 1 Q0 dnxx-0360 100 -7.97735 indri

Effectivity
precision =
recall =
|retrieved relevant documents|
| retrieved relevant documents |
| retrieved documents|
|(known) relevant documents|

trec_eval – evalutation program
trec_eval is a program evaluates results using a number of standard evaluation procedures
Input: the recall base and the result file Output is a file containing the results in a variety
of different measures

trec_eval results Topic: 1 Query: fett Index: LemSeg

Visualization for precision and recall
QPA - Query Performance Analyzer
Developed at the University of Tampere
Using the Indri/Lemur software
A probabilistic system, based on the combination of the inference network model and the language model, which give high effectiveness and possibility to create structured queries
A probabilistic system that calculates the belief that a document is relevant to an information need

Choose index, information need and user scenario

The search page

The result page
Segmented index

Hur påverkar en fettsnål, energifattig kost koncentrationerna av HDL och LDL?
Visualizations in QPA Histograms and
Precision-recall curves
Non-segmented index
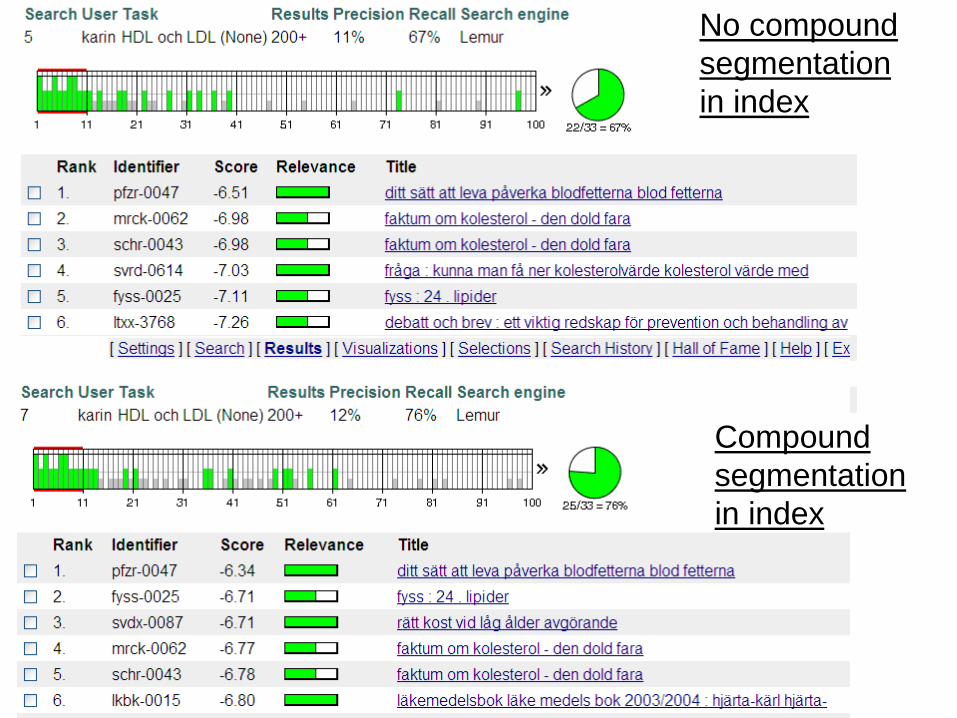
No compound segmentation in index
Compound segmentation in index

anemi (anemia) blodbrist (lack of blood)
None
Doctors
Patients
Topic 51 Varför kan en patient med cancer drabbas av anemi? non-segmented index

Vilka risker för utvecklandet av blodpropp finns vid användande av kombinationspreparat som innehåller östrogen och gestagen?
non-segmented index
Different levels in the hierarchy
General-Specific

The Indri query language
• The Indri query language, was designed to be robust. It can handle both simple keyword queries and extremely complex queries.
• It allows complex phrase matching, synonyms, weighted expressions, Boolean filtering, numeric (and dated) fields, and the extensive use of document structure (fields), among others.

• terms • field restriction / evaluation • numeric • combining beliefs • field / passage retrieval • filters
http://www.lemurproject.org/lemur/IndriQueryLangua
ge.html
Indri Query Language

Simple key word queries: #combine()
For a basic query, just type in the terms you wish to search on. Each term will be weighted equally and combined in an "or" fashion The more terms found, and the more occurrences of each term the better score The #combine() operator returns a ranked list that is equivalent to the query likelihood ranking (the likelyhood of the query generating each document). Search terms: white house #combine( white house)

Indri terms
Terms are the basic building blocks of Indri queries. Terms come in the form of single term, ordered and unordered phrases, synonyms, etc.
Type Example Matches Stemmed term dog All occurrences of dog (and
its stems) Surface term “dogs” Exact occurrences of dogs
(without stemming) Term group (synonym group) <”dogs” canine> All occurrences of dogs
(without stemming) or canine (and its stems)
Extent match #any:person Any occurrence of an extent of type person
Synonym list #syn(car automobile) Occurrence of car or automobile

The ordered window operator #n
#1(white house) The search would return only documents where the terms
"white" and "house" appear in that order and within one term of each other.
You can also specify larger window sizes.
#5(white house) The search results would return any documents where the
term "white" occurs before "house" and they are within five terms of each other.

Proximity terms
#odN( ... ) -- ordered window -- terms must appear ordered, with at most N-1 terms between each
#N( ... ) -- same as #odN
#od( ... ) -- unlimited ordered window -- all terms must appear ordered anywhere within current context
#uwN( ... ) unordered window -- all terms must appear within window of length N in any order
#uw( ... ) -- unlimited unordered window -- all terms must appear within current context in any order

Examples
#1(white house) -- matches "white house" as an exact phrase #2(white house) -- matches "white * house" (where * is any word or null) #uw2(white house) -- matches "white house" and "house white"

Synonym operators
#syn( ... ) { ... } < ... > #wsyn( ... )
The first three expressions are equivalent. They each treat all of the expressions listed as synonyms, as if they are occurrences of the same expression. The #wsyn operator treats the terms as synonyms, but allows weights to be assigned to each term.

Synonym operators - examples
#syn( #1(united states) #1(united states of america) ) {dog canine} <#1(light bulb) lightbulb> #wsyn( 1.0 donald 0.8 don 0.5 donnie 0.2 donny )

Wildcard operations
To specify a suffix-based wildcard, use the #wildcard operator or place an asterisk (*) at the end of term.
A wildcard term must have at least one character at the beginning and the wildcard operator (*) must occur at the end.
Examples: #wildcard( lem ) - would match "lemur", "lemming", etc. lem* - would also match "lemur", "lemming", etc. le*ur - will actually generate two tokens - "le*" and "ur". You should ensure that you use only suffix-based wildcards.

Restrictions with extent types
Documents may be tagged with extent types, something which enables searches only within certain parts of the documents
dog.title -- matches the term dog appearing in a title extent -- evaluates the term based on the title language model for the
document #1(trevor strohman).person -- matches the phrase "trevor strohman" when it appears in a person
extent

"Any" operator
To use this, the documents must be tagged with extent types #any -- used to match extent types Examples: #any:PERSON -- matches any occurence of a PERSON extent. Note
that the syntax #any(PERSON) is also accepted.
#1(napoleon died in #any:DATE) -- matches exact phrases of the form:
"napoleon died in <date>...</date>"

Belief operators
Belief operators allow you to combine beliefs (scores) about terms, phrases, etc.
There are both unweighted and weighted belief operators. With the weighted operators, you can assign varying weights to certain
expressions. This allows you to control how much of an impact each expression within your query has on the final score.

Belief operators #combine #weight #not #band (boolean and) #wand (weighted and) Examples: #combine( <dog canine> training ) #combine( #1(white house) <#1(president bush) #1(george bush)> ) #weight( 1.0 #1(white house) 2.0 #1(easter egg hunt) )

Filter operators
The filter operators may be used to require certain terms. #band() says which terms are required #combine() how the scoring is done
#filreq( #band( #syn( sheep lamb) #syn( dolly cloning) ) #combine( #syn( sheep lamb) #syn( dolly cloning) ) )

Numeric / Date field operators
• Numeric and date field operators provide a number of facilities for matching different criteria. These operators are useful when used in combination with the filter operators. General numeric operators:
• #less( F N ) -- matches numeric field extents of type F if value < N • #greater( F N ) -- matches numeric field extents of type F if value >
N • #between( F N_low N_high ) -- matches numeric field extents of
type F if N_low <= value <= N_high • #equals( F N ) -- matches numeric field extents of type F if value ==
N

Date operators
#dateafter( D ) -- matches numeric "date" extents if date is after D #datebefore( D ) -- matches numeric "date" extents if date is before D #datebetween( D_low D_high ) -- matches numeric "date" extents if D_low < date < D_high #dateequals( D ) -- matches numeric "date" extents if date == D

name example behavior
term dog occurrences of dog
(Indri will stem and stop)
“term” “dog” occurrences of dog
(Indri will not stem or stop)
ordered window #odn(blue car) blue n words or less before
car
unordered window
#udn(blue car) blue within n words of car
synonym list #syn(car
automobile) occurrences of car or
automobile
weighted synonym
#wsyn(1.0 car 0.5 automobile)
like synonym, but only counts occurrences of automobile
as 0.5 of an occurrence
any operator #any:person all occurrences of the person field
Term Operations

name example behavior
combine #combine(dog
train) 0.5 log( b(dog) ) + 0.5 log( b(train) )
weight, wand #weight(1.0 dog
0.5 train) 0.67 log( b(dog) ) + 0.33 log( b(train) )
wsum #wsum(1.0 dog
0.5 dog.(title)) log( 0.67 b(dog) +
0.33 b(dog.(title)) )
not #not(dog) log( 1 - b(dog) )
max #max(dog train) returns maximum of b(dog) and b(train)
or #or(dog cat) log(1 - (1 - b(dog)) * (1 - b(cat)))
Belief Operations

name example behavior
restriction dog.title
counts only occurrences of dog in title field
dog.title,header counts occurrences of dog
in title or header
evaluation
dog.(title) builds belief b(dog) using title language model
dog.(title,header)
b(dog) estimated using language model from
concatenation of all title and header fields
#od1(trevor strohman).person(title)
builds a model from all title text for
b(#od1(trevor strohman).person)
- only counts “trevor strohman” occurrences in
person fields
Field Restriction/Evaluation

name example behavior
less #less(year 2000) occurrences of year field <
2000
greater #greater(year
2000) year field > 2000
between #between(year 1990
2000) 1990 < year field < 2000
equals #equals(year 2000) year field = 2000
Numeric Operators

name example behavior
field retrieval #combine[title](
query )
return only title fields ranked according to
#combine(query) - beliefs are estimated on each title’s language
model -may use any belief node
passage retrieval
#combine[passage200:100]( query )
dynamically created passages of length 200
created every 100 words are ranked by
#combine(query)
Field/Passage Retrieval

name example behavior
filter require #filreq(elvis #combine(blue
shoes))
rank documents that contain elvis by
#combine(blue shoes)
filter reject #filrej(shopping #combine(blue
shoes))
rank documents that do not contain shopping by
#combine(blue shoes)
Filter Operations

The lab today
• Prepare a test collection for use
• Use the test collection to compare queries of different types
• Use different types of search keys: general, specific, compounds etc…
• Use different types of query operators: proximity, synomym etc…

Comparing queries
Baseline #sum(upptäckt samband gen cancer) Inflections #sum(#syn(upptäckt upptäckten upptäckter) #syn(samband sambandet) #syn(gen genen gener) #syn(cancer cancern)) Inflection + synonyms #sum(#syn(upptäckt upptäckten upptäckter) #syn(samband sambandet orsak orsaka) #syn(gen gener arvsmassa arvsmassan) #syn(cancer cancern tumör tumörer))

Example index parameter file
<parameters> <memory>200m</memory> <index>LATimes/laIndex</index> #The name index for the #index you are creating <corpus> <path>/LATimes/GH95</path> #Path to corpus <class>trectext</class> </corpus> <corpus> <path>/LATimes/LAT</path> #Path to corpus <class>trectext</class> </corpus> <field><name>LD</name></field> #Here you can include <field><name>TE</name></field> #fields other than <text> #that you want to index </parameters> #check in the data files for #field names e.g. <title>, #<headline> etc.

Template query parameter file
<parameters> <memory>256M</memory> <index>LATimes/laIndex</index> #The name of your index <count>25</count> #The number of documents retrived <trecFormat>true</trecFormat> <query> <number>201</number> #The topic number <text> #combine( fire home) #Your query </text> </query> </parameters>

Example query parameter file
<parameters> <memory>256M</memory> <index>lemIndex</index> <count>1000</count> <trecFormat>true</trecFormat> <query> <number>001</number> <text> #combine(fett ) </text> </query> <query> <number>090</number> <text> #combine( #syn( diabetes #1(diabetes mellitus) mellitus sockersjuka sockersjuk socker glukosintolerans glukos intolerans hyperglycemia glycemia hyperglycemi glycemi hyperglykemi glykemi #od3(typ 1 diabetes) #od3(typ i diabetes) insulinberoende insulinbrist) #syn( #1(diabetesinducerad acidos) diabetes inducerad acidos diabetesketoacidos ketoacidos ketos ketonkroppar glukagonkoncentration glukagon syraförgiftning) #syn(diabetespatient diabetiker diabetisk insulinbehandling insulin behandling) ) </text> </query> </parameters>