inspire 2015 - alteryx: apache spark: scale your analytics without coding
TRANSCRIPT

#inspire15
Apache Spark:Scale your Analytics without Coding
Wednesday, May 20, 2015
Dr. Dan Putler, Chief Scientist, AlteryxChris Freeman, Content Engineer, Alteryx

#inspire15
The Agenda
• What is Spark?• The basics• Its components• How it relates to Hadoop
• How Spark is being integrated into Alteryx• For data blending• For predictive analytics
• A demonstration that uses Spark for predictive analytics workflows in Alteryx
• How Spark fits into the overall In-DB roadmap for Alteryx predictive analytics

#inspire15
Spark Basics
• Spark is a general-purpose, in-memory, cluster computing system that can scale to allow for distributed computation on large volumes of data
• Cluster computing• Distributed data• Distributed, parallel computations• Spark handles the distributed part for you, behind the scenes
• In-memory• Spark allows you to persist data in-memory when performing costly
computations• No disk I/O means much faster processing time

#inspire15
Spark’s Components
• Core Spark and Resilient Distributed Datasets (RDDs)• Spark SQL• Allows structured data to be loaded into a Spark cluster and be
manipulated via SQL queries or SQL-like functions (sort, join, filter, groupBy, etc.)
• Spark DataFrames act as tables within the system• MLlib machine learning library• Provides functionality for performing several different predictive
algorithms (linear regression, logistic regressions, K-means clustering, etc.) using distributed data
• Spark streaming (a mini-batch oriented streaming analytics system)• GraphX (a distributed graph processing framework)

#inspire15
How Alteryx has Contributed to the Spark Project
• SparkR: The R API for Spark• We developed much of the code that enabled R to work with Spark
DataFrame API, and provided a R data frame abstraction layer over Spark DataFrames
• We have developed the bindings between R and a number of MLlib predictive algorithms
• MLlib• We are developing an MLlib traditional linear regression algorithm• We provided a means of taking MLlib algorithm predictions and
joining them to other Spark DataFrame tables• We developed model summary methods for a number of MLlib
models

#inspire15
How Spark Relates to the Hadoop Ecosystem
• Spark can be closely tied to Hadoop• The Hadoop File System (HDFS) can be used for distributed storage of
the files that back RDDs and DataFrames• Hadoop YARN can be used as Spark’s cluster manager• Apache Hive Metastore can be used for metadata management
• However, Spark does not require the use of Hadoop components• Distributed storage can be provided by Cassandra, Tachyon, Open
Stack Swift, and Amazon S3• Cluster management can be provided by Spark itself or Mesos• Spark can manage its own metadata

#inspire15
Spark Integration in the Next Release of Alteryx
• The Spark components being integrated into the next release of Alteryx are• Spark core• Spark SQL• MLlib
• The core architecture uses• A distributed data store than can work with the WebHDFS API• Currently only HDFS
• The Hive Metastore is used for metadata management• There is no requirement with respect to the cluster manager that is
used

#inspire15
Why In-DB Data Blending?
• Alteryx In-DB tools allow the user to blend and analyze data that resides in a remote database without having to pull the data into their local environment
• In-DB workflows create an XML-based SQL query description that evolves as the user adds and configures In-DB tools. The query “evolves” through a workflow, but is only executed at specific nodes of the workflow (lazy-evaluation)
• The Benefits:• No need to pull large datasets across the network for use in Alteryx• Lazy evaluation of In-DB queries means that Alteryx materializes the fewest
number of tables possible. No need to use the iterative “Create Table” -> “Select” -> “Create Table” pattern often seen in SQL environments
• Allows the user to take advantage of the considerable processing power of a database server or cluster without needing to write any code

#inspire15
Data Blending in Hadoop with Spark
• Alteryx works with Spark by creating and manipulating tables stored in a Hadoop cluster and managed via the Hive Metastore
• New tables are created by issuing a “Create Table” statement via SparkSQL or Impala and then backing the table with an Avro file sent from Alteryx via WebHDFS
• Once the table exists in the Hive Metastore, users can manipulate and prepare the data via Alteryx’s In-DB tools
• In-DB predictive tools work by reading the data out of the Hive Metastore and using SparkR to perform model estimation and scoring. The results can be streamed back into Alteryx for further analysis and reporting
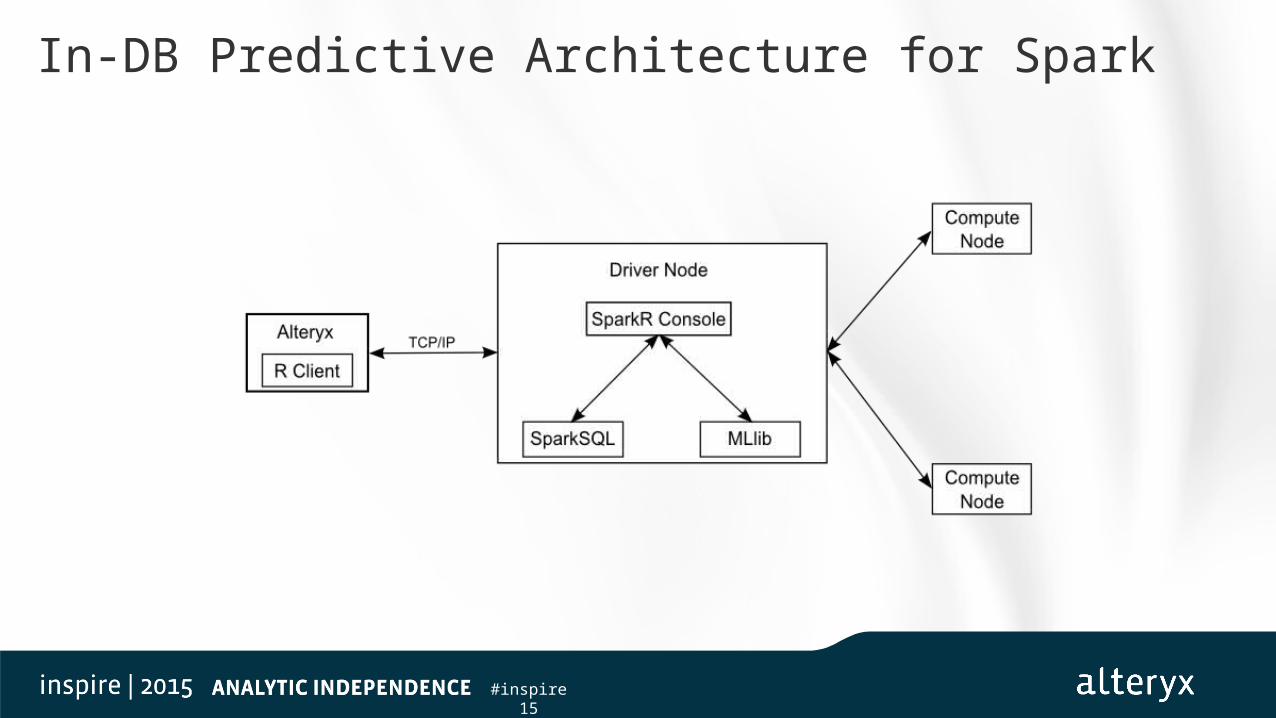
#inspire15
In-DB Predictive Architecture for Spark

#inspire15
In-DB for Spark Components
• Cluster driver node• HDFS (currently) and WebHDFS• Hive with Hive Metastore• Thrift server• Spark with MLlib and SparkR support installed• R installed and the Rserve package installed• Rserve is run in daemon mode
• Cluster compute nodes• R installed
• Desktop client• RSclient package installed (which is being added to the Predictive Plugin)

#inspire15
Demonstration
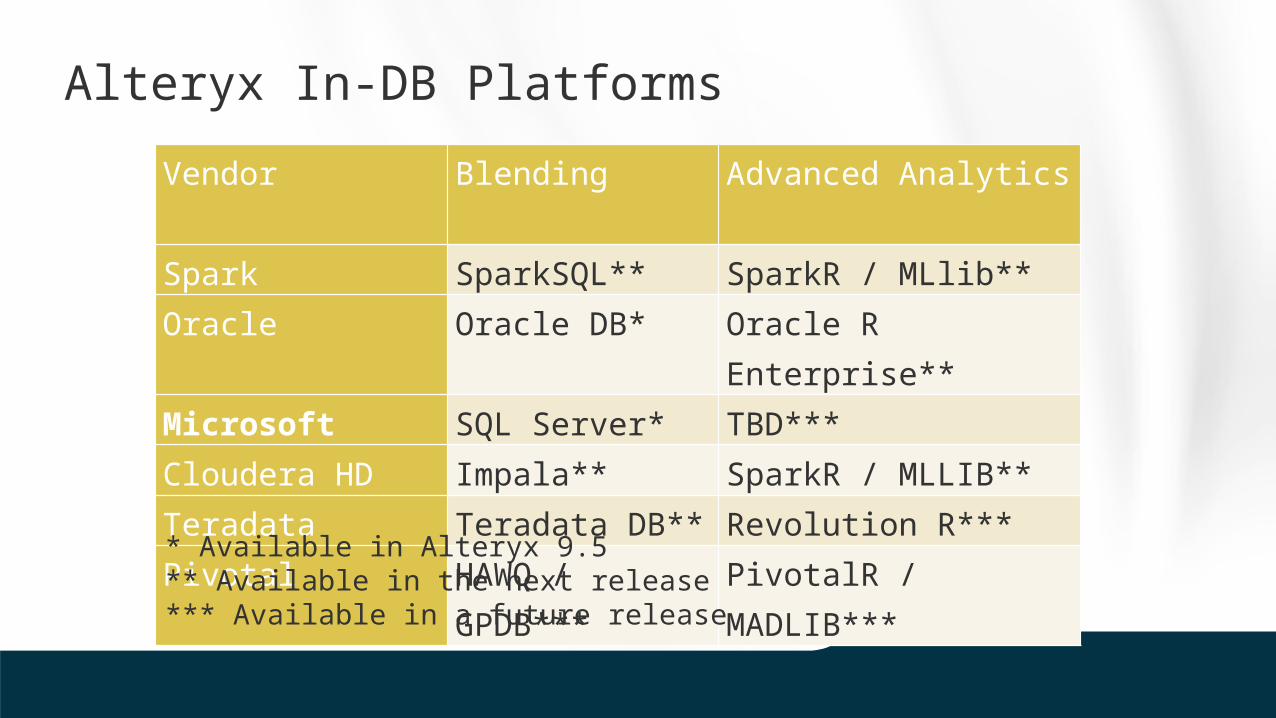
Alteryx In-DB Platforms
Vendor Blending
Advanced Analytics
Spark SparkSQL** SparkR / MLlib**
Oracle Oracle DB* Oracle R Enterprise**
Microsoft SQL Server* TBD***
Cloudera HD Impala** SparkR / MLLIB**
Teradata Teradata DB** Revolution R***
Pivotal HAWQ / GPDB***
PivotalR / MADLIB***
* Available in Alteryx 9.5** Available in the next release*** Available in a future release

THANK YOU!
#inspire15