ivory : ivory : pairwise document similarity in large collection with mapreduce tamer elsayed, jimmy...
Post on 21-Dec-2015
216 views
TRANSCRIPT

IvoryIvory:: Pairwise Document Similarity
in Large Collection with MapReduce
Tamer Elsayed, Jimmy Lin, and Doug OardLaboratory for Computational Linguistics and Information Processing
(CLIP Lab)
UM Institute for Advanced Computer Studies (UMIACS)

Problem
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
0.200.300.540.210.000.340.340.130.74
0.200.300.540.210.000.340.340.130.74
0.200.300.540.210.000.340.340.130.74
0.200.300.540.210.000.340.340.130.74
0.200.300.540.210.000.340.340.130.74
Applications: “more-like-that” queries Clustering
e.g., co-reference resolution

Solutions Trivial
For each pair of vectors Compute the inner product
Loads each vector O(N) times
Better Each term contributes only if appears in
Vt
dtdtji jiwwddsim ,,),(
ji dd
ji
jiddt
dtdtji wwddsim ,,),(
ji ddt
jiji ddtcontribtermddsim ),,(_),(

Algorithm
Loads each posting once Matrix must fit in memory
Works for small collections Otherwise: disk access optimization

Hadoopify : 2-Step Solution
1) Indexing one MapRedcue step term posting file
2) Pairwise Similarity another MapRedcue step term contribution for all possible pairs
Generate ½ df*(df-1) intermediate contribution / term

Indexing
(A,(d1,2))
(B,(d1,1))
(C,(d1,1))
(B,(d2,1))
(D,(d2,2))
(A,(d3,1))
(B,(d3,2))
(E,(d3,1))
(A,[(d1,2),
(d3,1)])
(B,[(d1,1),
(d2,1),
(d3,2)])
(C,[(d1,1)])
(D,[(d2,2)])
(E,[(d3,1)])
mapmap
mapmap
mapmap
shuffleshuffle
reducereduce
reducereduce
reducereduce
reducereduce
reducereduce
(A,[(d1,2),
(d3,1)])
(B,[(d1,1),
(d2,1),
(d3,2)])
(C,[(d1,1)])
(D,[(d2,2)])
(E,[(d3,1)])
A A B C
B D D
A B B E
d1
d2
d3

Pairwise Similarity
mapmap
mapmap
mapmap
mapmap
mapmap
(A,[(d1,2),
(d3,1)])
(B,[(d1,1),
(d2,1),
(d3,2)])
(C,[(d1,1)])
(D,[(d2,2)])
(E,[(d3,1)])
((d1,d3),2)
((d1,d2),1)
((d1,d3),2)
((d2,d3),2)
shuffleshuffle
((d1,d2),[1])
((d1,d3),[2,
2])
((d2,d3),[2])
reducereduce
reducereduce
reducereduce
((d1,d2),1)
((d1,d3),4)
((d2,d3),2)

Implementation Issues
df-cut Drop common terms
Intermediate tuples dominated by very high df terms efficiency Vs. effectiveness
Space saving tricks Common doc + stripes Blocking Compression

Experimental Setup
Hadoop 0.16.0 Cluster of 19 nodes (w/double processors) Aquaint-2 collection
906K documents Okapi BM25 Subsets of collection

Efficiency (running time)
R2 = 0.997
0
20
40
60
80
100
120
140
0 10 20 30 40 50 60 70 80 90 100
Corpus Size (%)
Co
mp
uta
tio
n T
ime
(m
inu
tes
)
99% df-cut

Efficiency (disk usage)
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
9,000
0 10 20 30 40 50 60 70 80 90 100
Corpus Size (%)
Inte
rmed
iate
Pai
rs (
bil
lio
ns)
df-cut at 99%df-cut at 99.9%df-cut at 99.99%df-cut at 99.999%no df-cut
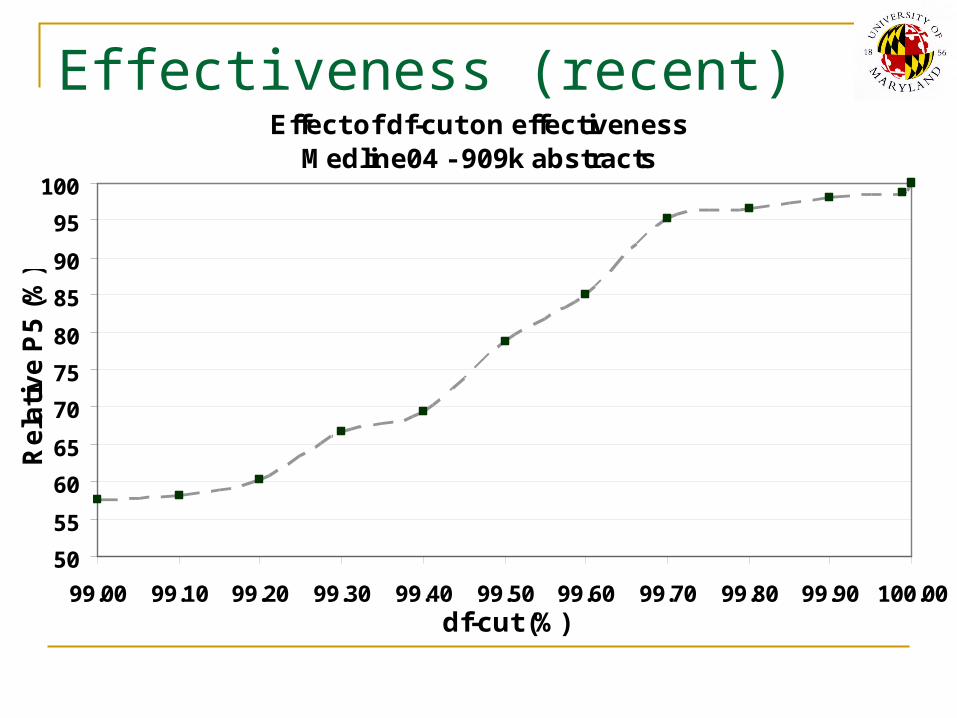
Effectiveness (recent)Effect of df-cut on effectiveness
Medline04 - 909k abstracts
50
55
60
65
70
75
80
85
90
95
100
99.00 99.10 99.20 99.30 99.40 99.50 99.60 99.70 99.80 99.90 100.00df-cut (%)
Re
lati
ve
P5
(%
)

Conclusion
Simple and efficient MapReduce solution 2H (using 38 nodes, 99% df-cut) for ~million-doc
collection Play tricks for I/O bound jobs
Effective linear-time-scaling approximation 99.9% df-cut achieves 98% relative accuracy df-cut controls efficiency vs. effectiveness tradeoff

Future work
Bigger collections! More investigation of df-Cut and other techniques Analytical model Compression techniques (e.g., bitwise) More effectiveness experiments
Joint resolution of personal names in email Co-reference resolution of names and organization
MapReduce IR research platform Batch query processing

Thank You!

MapReduce Framework
Shuffling: group values by keysShuffling: group values by keys
mapmap mapmap mapmap mapmap
reducereduce reducereduce reducereduce
input input input input
output output output