knowledge engineering data mining &. we must find a tool to automatically people have no time...
TRANSCRIPT

Knowledge Engineering
Data mining
&

we must find a tool to automatically
People have no time to look at this data!
We are deluged by data!
This magic tool is "Dataminig."
scientific data ,medical data,demographic data,financial data ,
and marketing data
analyze the data,classify it ,summarize it ,discover and characterize trends in it ,and flag anomalies.

Increase in use of electronic data gathering devices e.g. point-of-sale, remote sensing devices etc .
Data storage became easier and cheaper with increasing computing power
The data explosion

? What is Data Mining
<Definition>
non trivial extraction of implicit, previously unknown, and potentially useful information from data
the variety of techniques to identify nuggets of information or decision-making knowledge in bodies of data, and extracting these in such a way that they can be put to use in the areas such as decision support, prediction, forecasting and estimation. The data is often voluminous, but as it stands of low value as no direct use can be made of it; it is the hidden information in the data that is useful
extraction of hidden predictive information from large databases
OR
OR

Data Mining and DBMSData Mining and DBMS
DBMSDBMS
Queries based on the data held e.gQueries based on the data held e.g..
* *last months sales for each productlast months sales for each product * sales grouped by customer age etc. * sales grouped by customer age etc.
* *list of customers who lapsed their policylist of customers who lapsed their policy
Data Mining
Infer knowledge from the data held to answer queries e.g.
*what characteristics do customers share who lapsed their policies and how do they differ from those who renewed their policies?
*why is the Cleveland division so profitable?

Characteristics of a Data Mining Characteristics of a Data Mining
SystemSystem •Large quantities of data
•volume of data so great it has to be analyzed by automated techniques e.g. satellite information, credit card transactions etc.
•Noisy, incomplete data
•imprecise data is characteristic of all data collection
•databases - usually contaminated by errors, cannot assume that the data they contain is entirely correct e.g. some attributes rely on subjective or measurement judgments
•Complex data structure - conventional statistical analysis not possible
•Heterogeneous data stored in legacy systems

Data Mining GoalsData Mining Goals
• ClassificationClassification
• AssociationAssociation
• Sequence / Temporal analysisSequence / Temporal analysis
• Cluster & outlier analysisCluster & outlier analysis

Data Mining and Machine Data Mining and Machine
LearningLearning Data Mining or Knowledge
Discovery in Databases (KDD) is about finding understandable knowledge
Machine Learning is concerned with improving performance of an agent
e.g. , training a neural network to balance a pole is part of ML, but not of KDD
DM is concerned with very large, real-world databases
ML typically looks at smaller data sets
DM deals with real-world data , which tends to have problems such as: missing values , dynamic data , noise , and pre-existing data
ML has laboratory type examples for the training set
Efficiency of the algorithm and scalability is more important in DM or KDD .

Issues in Data MiningIssues in Data Mining
Noisy data Noisy data Missing values Missing values Static data Static data Sparse data Sparse data Dynamic data Dynamic data Relevance Relevance Interestingness Interestingness Heterogeneity Heterogeneity Algorithm efficiency Algorithm efficiency Size and complexity of dataSize and complexity of data

Data Mining ProcessData Mining ProcessData pre-processing
heterogeneity resolution data cleansing data warehousing
Data Mining Tools applied extraction of patterns from the pre-processed data
Interpretation and evaluation user bias i.e. can direct DM tools to areas of interest
oattributes of interest in databases ogoal of discovery odomain knowledge oprior knowledge or belief about the domain

TechniquesTechniques
• Object-oriented database Object-oriented database methods methods
• Statistics Statistics
• Clustering Clustering
• Visualization Visualization
• Neural networks Neural networks
• Rule InductionRule Induction

Object-oriented
approaches/Databases
Making use of DBMSs to discover knowledge, SQL is limiting .
Advantages •Easier maintenance. Objects may be understood as stand-alone entities•Objects are appropriate reusable components•For some systems, there may be an obvious mapping from real world entities to system objects
TechniquesTechniques

TechniquesTechniquesStatistics Statistics Can be used in several data mining stagesCan be used in several data mining stages
– data cleansingdata cleansing i.e. the removal of erroneous or i.e. the removal of erroneous or irrelevant data known as outliers irrelevant data known as outliers
– EDAEDA, exploratory data analysis e.g. frequency , exploratory data analysis e.g. frequency counts, histograms etc. counts, histograms etc.
– data selectiondata selection - sampling facilities and so reduce - sampling facilities and so reduce the scale of computation the scale of computation
– attribute re-definitionattribute re-definition e.g. Body Mass Index, BMI, e.g. Body Mass Index, BMI, which is Weight/Height2 which is Weight/Height2
– data analysisdata analysis - measures of association and - measures of association and relationships between attributes, interestingness relationships between attributes, interestingness of rules, classification etcof rules, classification etc. .

TechniquesTechniquesVisualizationVisualization
Visualization enhances EDA and makes patterns more visible
1-d, 2-d, 3-d visualizations
Example : NETMAP , a commercial data mining tool , uses this
technique

TechniquesTechniquesCluster & outlier analysisCluster & outlier analysis
Clustering according to similarity .Clustering according to similarity .
Partitioning the database so that each partition or group is similar according Partitioning the database so that each partition or group is similar according to some criteria or metric .to some criteria or metric .
Appears in many disciplinesAppears in many disciplines e.g. e.g. in chemistry the clustering of moleculesin chemistry the clustering of molecules
Data mining applications make use of it Data mining applications make use of it e.g. to segment a client/customer e.g. to segment a client/customer base .base .
Provides sub-groups of a population for further analysis or actionProvides sub-groups of a population for further analysis or action - very - very important when dealing with very large databases important when dealing with very large databases
Can be used for profile generation for target marketingCan be used for profile generation for target marketing

Artificial Neural Networks (ANN) •An trained ANN can be thought of as an "expert" in the category of information it has been given to analyze .
•It provides projections given new situations of interest and answers "what if" questions .
Problems include: o the resulting network is viewed as a black box ono explanation of the results is given i.e. difficult for the user to interpret the results odifficult to incorporate user intervention oslow to train due to their iterative nature
TechniquesTechniques

Artificial Neural Networks (ANN) Data mining example using neural networks .
TechniquesTechniques

TechniquesTechniquesDecision trees Decision trees Built using a training set of data and can then Built using a training set of data and can then
be used to classify new objects be used to classify new objects
Description : internal node is a test on an attribute. branch represents an outcome of the test, e.g., Color=red. leaf node represents a class label or class label distribution. At each node, one attribute is chosen to split training examples into distinct classes as much as possible new case is classified by following a matching path to a leaf node.

TechniquesTechniquesDecision treesDecision treesBuilding a decision tree
Top-down tree constructionAt start, all training examples are at the root.Partition the examples recursively by choosing one attribute each time.
Bottom-up tree pruningRemove sub-trees or branches, in a bottom-up manner, to improve the estimated accuracy on new cases

TechniquesTechniquesDecision treesDecision trees
Example :
overcast
high normal falsetrue
sunny rain
No NoYes Yes
Yes
Outlook
HumidityWindy
Decision Tree
for “Play?”

TechniquesTechniquesRulesRules
The extraction of useful if-then rules from data based on statistical significance.
Example format
If X
Then Y

TechniquesTechniques
FramesFramesFrames are templates for holding clusters of related knowledge Frames are templates for holding clusters of related knowledge
about a very particular subject .about a very particular subject .
It is a natural way to represent knowledge .It is a natural way to represent knowledge .
It has a taxonomy approachIt has a taxonomy approach . .
ProblemProblem : : they are more complex than rule representation .they are more complex than rule representation .

TechniquesTechniques
FramesFramesExample:Example:
Vacation
Albury
March
$1000
Frame Name
Where
When
Cost
Vacation
Albury
March
$1000
Frame Name
Where
When
Cost

Data Warehousing Data Warehousing
Warehousing makes it possible toWarehousing makes it possible to • extract archived operational data .extract archived operational data .• overcome inconsistencies between different overcome inconsistencies between different
legacy data formats .legacy data formats .• integrate data throughout an enterprise, integrate data throughout an enterprise,
regardless of location, format, or regardless of location, format, or communication requirements .communication requirements .
• incorporate additional or expert information .incorporate additional or expert information .
Definition :Any centralized data repository which can be queried for business benefit .

1. subject-oriented - data organized by subject instead of application e.g. o an insurance company would organize their data by customer, premium,
and claim, instead of by different products (auto, life, etc.) o contains only the information necessary for decision support processing
2. integrated - encoding of data is often inconsistent e.g. o gender might be coded as "m" and "f" or 0 and 1 but when data are
moved from the operational environment into the data warehouse they assume a consistent coding convention
3. time-variant - the data warehouse contains a place for storing data that are five to 10 years old, or older e.g. o this data is used for comparisons, trends, and forecasting o these data are not updated
4. non-volatile - data are not updated or changed in any way once they enter the data warehouse o data are only loaded and accessed
Characteristics of a Data Characteristics of a Data WarehouseWarehouse

Data Warehousing Data Warehousing Processes Processes 1.1. insulate datainsulate data - - i.e. the current operational informationi.e. the current operational information
o preserves the security and integrity of mission-preserves the security and integrity of mission-critical OLTP applications critical OLTP applications
o gives access to the broadest possible base of data gives access to the broadest possible base of data 2.2. retrieve dataretrieve data - - from a variety of heterogeneous from a variety of heterogeneous
operational databases operational databases o data is transformed and delivered to the data data is transformed and delivered to the data
warehouse/store based on a selected model (or warehouse/store based on a selected model (or mapping definition) mapping definition)
o metadata - information describing the model and metadata - information describing the model and definition of the source data elements definition of the source data elements
3.3. data cleansingdata cleansing - - removal of certain aspects of removal of certain aspects of operational dataoperational data, such as low-level transaction , such as low-level transaction information, which slow down the query times. information, which slow down the query times.
4.4. transfertransfer - - processed data transferred to the data processed data transferred to the data warehousewarehouse, a large database on a high performance , a large database on a high performance boxbox
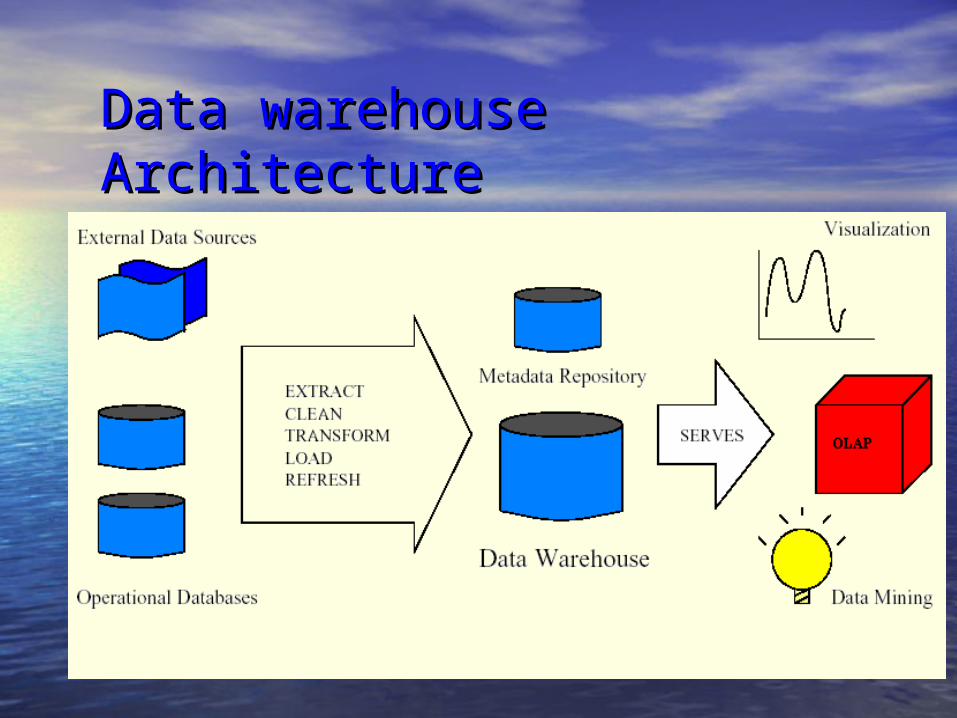
Data warehouse Architecture Data warehouse Architecture

1. Load Performance require incremental loading of new data on a periodic basis & must not artificially constrain the volume of data
2. Load Processing data conversions, filtering, reformatting, integrity checks, physical storage, indexing, and metadata update
3. Data Quality Management ensure local consistency, global consistency, and referential integrity despite "dirty" sources and massive database size
4. Query Performance must not be slowed or inhibited by the performance of the data warehouse RDBMS
5. Terabyte Scalability Data warehouse sizes are growing at astonishing rates so RDBMS must have no architectural limitations. It must support modular and parallel management.
Criteria for Data Criteria for Data WarehousesWarehouses

6. Mass User Scalability Access to warehouse data must not be limited to the elite few has to support hundreds, even thousands, of concurrent users while maintaining acceptable query performance.
7. Networked Data Warehouse Data warehouses rarely exist in isolation, users must be able to look at and work with multiple warehouses from a single client workstation
8. Warehouse Administration large scale and time-cyclic nature of the data warehouse demands administrative ease and flexibility
9. The RDBMS must Integrate Dimensional Analysis dimensional support must be inherent in the warehouse RDBMS to provide highest performance for relational OLAP tools
10. Advanced Query Functionality End users require advanced analytic calculations, sequential & comparative analysis, consistent access to detailed and summarized data
Criteria for Data WarehousesCriteria for Data Warehouses

The rush of companies to jump on the band wagon as these companies have slapped "data warehouse" labels on traditional transaction-processing products and co- opted the lexicon of the industry in order to be considered players in this fast-growing category .
Chris Erickson, Red Brick
Problems with Data Problems with Data WarehousingWarehousing
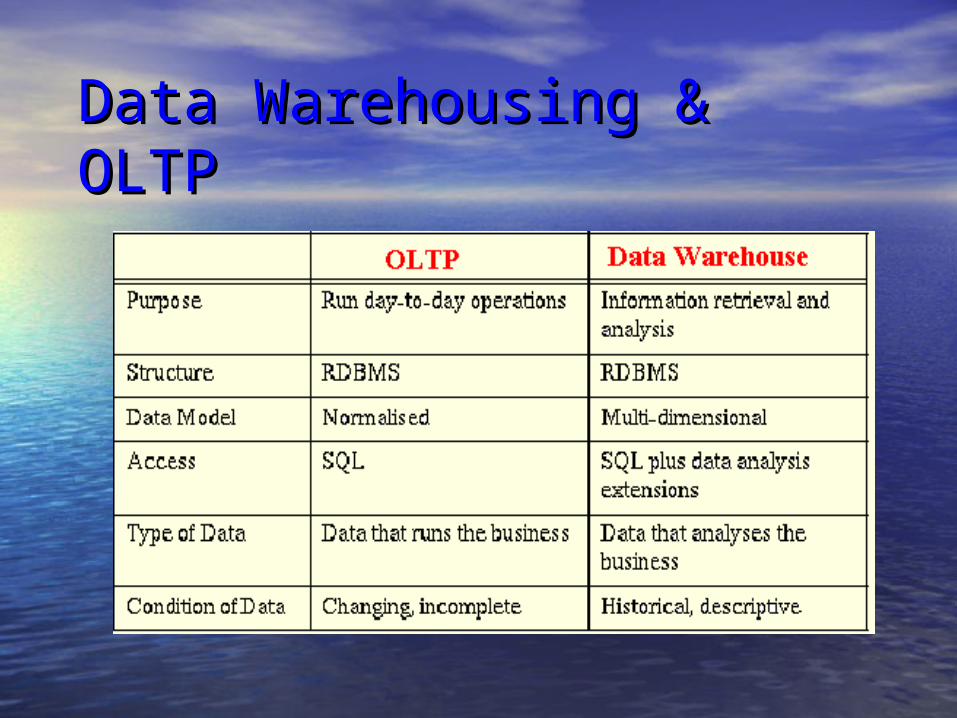
Data Warehousing & OLTP Data Warehousing & OLTP

OLTP SystemsOLTP SystemsDesigned to maximize transaction capacity But they: ocannot be repositories of facts and historical data for business
analysis ocannot quickly answer ad hoc queries orapid retrieval is almost impossible odata is inconsistent and changing, duplicate entries exist,
entries can be missing oOLTP offers large amounts of raw data which is not easily understood oTypical OLTP query is a simple aggregation e.g.
what is the current account balance for this customer? oData Warehouse SystemsoData warehouses are interested in query processing
as opposed to transaction processing

OLAP :OLAP :On-Line Analytical Processing On-Line Analytical Processing Problem is how to process larger and larger databases Problem is how to process larger and larger databases
OLAP involves many data items (many thousands or OLAP involves many data items (many thousands or even millions) which are involved in complex even millions) which are involved in complex relationships .relationships .
Fast response is crucial in OLAP .Fast response is crucial in OLAP .
Difference between OLAP and OLTP :Difference between OLAP and OLTP :– OLTPOLTP servers handle mission-critical production data servers handle mission-critical production data
accessed through simple queries accessed through simple queries
– OLAPOLAP servers handle management-critical data accessed servers handle management-critical data accessed through an iterative analytical investigationthrough an iterative analytical investigation

The endThe end
Thanks!
We hope you enjoy it .