laboratorio pls equazioni lineari e matrici: la … · matlab. apprese e consolidate le nuove...
TRANSCRIPT

Piano Nazionale Lauree Scientifiche - a.a. 2010/11
Laboratorio PLS
EQUAZIONI LINEARI E MATRICI:LA MATEMATICA IN RETE
conI.T.C. “ZANON” (Udine)
L.S. “LE FILANDIERE” (San Vito al Tagliamento)
Dimitri Breda1, Alessandra Maniglio2, Paola Pignoni3, Stefania Pividori3
1Dipartimento di Matematica e InformaticaUniversita degli Studi di [email protected]
http://users.dimi.uniud.it/˜dimitri.breda/
2Liceo Scientifico “Le Filandiere”San Vito al Tagliamento
2Istituto Tecnico Commerciale “Zanon”Udine
[email protected] [email protected]
1

Indice1 Introduzione 3
2 Vettori, matrici e sistemi lineari 52.1 Piano cartesiano e vettori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 Trasformazioni lineari e matrici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3 Sistemi lineari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.4 Un po’ di trigonometria non nuoce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.5 Ma quanto costa? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3 Google 293.1 Matrici di connettivita e navigatori casuali . . . . . . . . . . . . . . . . . . . . . . . . . 303.2 La fortuna di Google: il metodo delle potenze e tanti zeri . . . . . . . . . . . . . . . . . 363.3 Pagine penzolanti e ricerche personalizzate . . . . . . . . . . . . . . . . . . . . . . . . 403.4 Pagerank finalmente?! . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
A Appendice: cifre significative, accuratezza e precisione 56
B Codici Pagerank realizzati 57
2

1 IntroduzioneQueste pagine vogliono rappresentare una breve guida alle attivita svolte all’interno del Piano Nazio-nale Lauree Scientifiche (PLS) per il Laboratorio “Equazioni lineari e matrici: la matematica in rete”.Esse sono rivolte a selezioni di alunni di classi quarte provenienti dall’Istituto Tecnico Commerciale “Za-non” di Udine e dal Liceo Scientifico “Le Filandiere” di San Vito al Tagliamento, nonche progettatecongiuntamente tra i docenti universitari e gli insegnanti di cui nel frontespizio.
Si premette che, seguendo le direttive del PLS, gli argomenti sviluppati non vengono presentati in mo-do meramente nozionistico, piuttosto con l’intento di stimolare la curiosita e l’interesse dei partecipantiverso tematiche a forte contenuto matematico - anche avanzato rispetto agli standard dei programmi mi-nisteriali previsti per l’istruzione secondaria - ma che, tutto sommato, si possono spesso incontrare nellavita quotidiana, soprattutto in una realta permeata dall’intensivo utilizzo della teconologia e dell’infor-matica come quella attuale. E bene avvisare il lettore piu preparato che le esigenze di semplificazioneemerse nella scrittura di queste note hanno spesso invaso lo spazio normalmente destinato al rigore e allacompletezza caratteristici di una trattazione matematica.
A tale scopo, e vista la disponibilita dei laboratori della Facolta di Scienze MFN dell’Universita di Udi-ne, dove si svolge parte dell’attivita, ci si avvale del software MATLAB© come veicolo di apprendimento.Rimandiamo una volta per tutte a [1, 2] gli eventuali lettori dall’interesse “insaziabile”, sottolineando cheparte del materiale presentato e preso da tali riferimenti, frutto del creatore stesso di Matlab, Cleve Moler.
I protagonisti di queste note sono in primo luogo i vettori, le matrici ed i sistemi lineari. Tralasciando-ne le piu profonde connotazioni algebriche e geometriche per le ragioni premesse, vettori e matrici sonointrodotti in Sezione 2 nel caso bidimensionale, ovvero il piu semplice possibile. Aldila delle esigenzedi semplificazione, questo caso si presta ottimamante all’interpretazione geometrica della matrice cometrasformazione lineare nel piano cartesiano. Dopo aver introdotto - e “digerito” - operazioni quali ilprodotto scalare di vettori e il prodotto righe-colonne di matrici, rivisiteremo sotto un’altra prospettiva isistemi di equazioni lineari che gia ben conosciamo. La parte finale di tale sezione sara dedicata all’analisidei costi computazionali che comportano le operazioni base dell’algebra matriciale. L’intera Sezione epoi accompagnata da esempi ed esercizi con lo scopo di avvicinare gradualmente gli alunni all’utlizzo diMatlab.
Apprese e consolidate le nuove nozioni di cui sopra, le sfrutteremo in Sezione 3 per addentrarci nelmondo della rete e del World Wide Web (WWW) in particolare. L’obiettivo che ci poniamo consiste nelcomprendere gli aspetti fondamentali che ci permettono di ordinare le informazioni che ci interessanoin un mondo tanto vasto come il WWW, di capirne la modellizzazione matematica che e ivi nascosta,per arrivare infine a realizzare delle implementazioni Matlab dell’algoritmo PAGERANK© utilizzato daGOOGLE©.
Riguardo alla struttura delle attivita, e bene osservare che il laboratorio inizia con la conferenza “Dalmattone a Google: equazioni ovunque” tenuta dal docente universitario presso gli Istituti aderenti, alloscopo di introdurre gli alunni alle tematiche trattate. Esso continua poi con una fase di “azzeramento” deirequisiti (coprente a grandi linee i contenuti della Sezione 2), condotta dagli insegnanti coinvolti presso irelativi Istituti. Si giunge quindi allo “stage” degli alunni presso i laboratori della Facolta, dove vengonoimpartite le nozioni base di Matlab e si procede all’implementazione dei codici. Seguono poi opportunefasi di approfondimento e verifica.
Con un po’ di pazienza, e guidati dal motore principe della ricerca e delle innovazioni scientifiche e,in genere, culturali - la curiosita - alla fine di quest’esperienza guarderemo alle matrici e ai sistemi conun riguardo maggiore di quello che potremmo abitualmente concedere ad una semplice tabella di numeri
3

o a delle noiose equazioni da risolvere. Certo non pretenderemo di coglierne a pieno tutte le notevolipotenzialita che celano al loro interno, ma per questo...c’e sempre l’opportunita di iscriversi ai Corsi diLaurea della Facolta di Scienze!
4

2 Vettori, matrici e sistemi lineari
2.1 Piano cartesiano e vettoriTutti noi conosciamo bene il piano cartesiano (da Rene Descartes [1596-1650], filosofo e matematicofrancese) e sappiamo che ogni suo punto puo essere univocamente associato ad una coppia di numeri, lesue coordinate. Indichiamo tali numeri in un modo forse un po’ diverso da quello abituale, ovvero con unvettore colonna:
x =
[x1
x2
].
Ad esempio, il punto associato al vettore x di Figura 1 ha coordinate
x =
[24
].
Sono definite in modo naturale operazioni quali la somma algebrica di vettori
x + y =
[x1
x2
]+
[y1
y2
]=
[x1 + y1
x2 + y2
]e la moltiplicazione per uno scalare
sx = s
[x1
x2
]=
[sx1
sx2
]Il loro significato geometrico e fornito, nel primo caso, dalla cosiddetta regola del parallelogramma e,nel secondo, dall’allungamento se |s| > 1 o accorciamento se |s| < 1, eventualmente accompagnati dalcambio di verso se s < 0. La loro “combinazione” prende il nome, appunto, di combinazione lineare divettori:
ax + by = a
[x1
x2
]+ b
[y1
y2
]=
[ax1
ax2
]+
[by1
by2
]=
[ax1 + by1
ax2 + by2
].
Esempio 1 In Figura 1 e rappresentato il vettore
x =
[24
]relativo al punto di coordinate x1 = 2 ed x2 = 4. Inoltre abbiamo il vettore
y =
[−12
],
la loro somma
x + y =
[2− 14 + 2
]=
[16
]ed, infine, il prodotto di x con lo scalare s = −0.5:
s · x = −0.5 · x =
[−0.5 · 2−0.5 · 4
]=
[−1−2
].
Da notare che, come anticipato, uno scalare negativo ha l’effetto di cambiare il verso del vettore chemoltiplica.
5

Esercizio 1 Secondo la regola del parallelogramma, il vettore somma di due vettori corrisponde geo-metricamente alla diagonale principale del parallelogramma che ha per lati i due vettori addendi, vediEsempio 1. A cosa corrisponde invece il vettore differenza? (Sugg.: non servono regole nuove, bastausare sapientemente la somma e la moltiplicazione per uno scalare)
Matlab 1 In Matlab potremmo eseguire il contenuto dell’Esempio 1 con le seguenti istruzioni (premeteinvio alla fine di ogni istruzione):
>> x=[2;4]x =
24
>> y=[-1;2]y =
-12
>> x+yans =
16
>> s=-0.5s =
-0.5000>> s*xans =
-1-2
Cogliamo l’occasione per dire che il simbolo “+” indica la somma algebrica, mentre “*” la moltipli-cazione in genere. Osserviamo poi che i vettori colonna si inseriscono separando gli elementi con “;”all’interno di parentesi quadre.
Meno naturale puo risultare l’operazione di prodotto scalare di due vettori, definito come
x · y =
[x1
x2
]·[y1
y2
]= x1y1 + x2y2,
ovvero la somma dei prodotti delle componenti corrispondenti.
Esempio 2 Per
x =
[23
]e
y =
[31
]risulta
x · y = 2 · 3 + 3 · 1 = 9,
6

−2 0 2−1 1 3
−1
0
1
2
3
4
5
6
7
−2
−3−0.5! x
y
x
m
Figura 1: somma algebrica e moltiplicazione per uno scalare.
mentre con
z =
[−32
]risulta
x · z = 2 · (−3) + 3 · 2 = 0.
I vettori sono rappresentati in Figura 2.
Matlab 2 In Matlab:
>> x=[2;3]x =
23
>> y=[3;1]y =
31
>> x’*yans =
9>> z=[-3;2]z =
-3
7

2>> x’*zans =
0
Per eseguire il prodotto scalare usiamo “’*”. Ma per ora non occupiamoci del significato del simbolo“’”, lo apprenderemo strada facendo.
−4 −3 −2 −1 0 1 2 3 4−1
0
1
2
3
4
z
x
y
Figura 2: prodotto scalare e vettori perpendicolari.
Dal precedente esempio potremmo indurre che due vettori sono perpendicolari (od ortogonali) se illoro prodotto scalare risulta nullo. Questo fatto costituisce in realta un fondamentale Teorema dell’algebralineare e della geometria piana:
x ⊥ y⇔ x · y = 0⇔ x1y1 + x2y2 = 0. (1)
Di seguito proponiamo un esempio interessante di uso del prodotto scalare. Ad ogni modo, il signifi-cato geometrico di tale operazione verra approfondito piu avanti.
Esempio 3 Per apprezzare alcune implicazioni “reali” del prodotto scalare, prendiamo in prestito dal-la Fisica il concetto di lavoro. Il lavoro L (scalare) che una forza F (vettore) compie a seguito dellospostamento s (vettore) del suo punto di applicazione e il prodotto scalare
L = F · s.
8
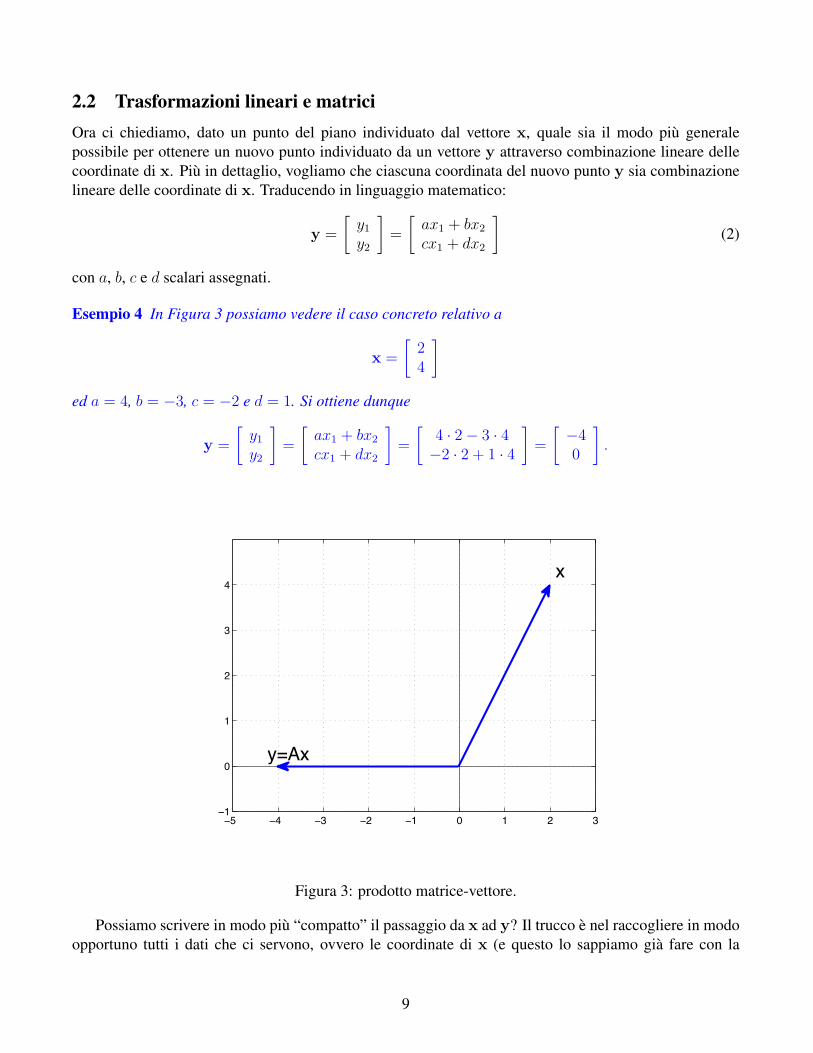
2.2 Trasformazioni lineari e matriciOra ci chiediamo, dato un punto del piano individuato dal vettore x, quale sia il modo piu generalepossibile per ottenere un nuovo punto individuato da un vettore y attraverso combinazione lineare dellecoordinate di x. Piu in dettaglio, vogliamo che ciascuna coordinata del nuovo punto y sia combinazionelineare delle coordinate di x. Traducendo in linguaggio matematico:
y =
[y1
y2
]=
[ax1 + bx2
cx1 + dx2
](2)
con a, b, c e d scalari assegnati.
Esempio 4 In Figura 3 possiamo vedere il caso concreto relativo a
x =
[24
]ed a = 4, b = −3, c = −2 e d = 1. Si ottiene dunque
y =
[y1
y2
]=
[ax1 + bx2
cx1 + dx2
]=
[4 · 2− 3 · 4−2 · 2 + 1 · 4
]=
[−40
].
−5 −4 −3 −2 −1 0 1 2 3−1
0
1
2
3
4
y=Ax
x
Figura 3: prodotto matrice-vettore.
Possiamo scrivere in modo piu “compatto” il passaggio da x ad y? Il trucco e nel raccogliere in modoopportuno tutti i dati che ci servono, ovvero le coordinate di x (e questo lo sappiamo gia fare con la
9

notazione di vettore colonna) e i quattro scalari a, b, c e d. Un modo semplice e quello di utilizzare unasorta di tabella con due righe e due colonne: [
a bc d
],
che ricalca fedelmente la posizione degli scalari nella (2).Ma come faccio a sapere che posizione occupa lo scalare c nella mia tabella se ne conosco solamente
il “nome”? Per superare questa lieve difficolta cambiamo notazione e diamo un nome (ragionevole) allatabella:
A =
[a11 a12
a21 a22
].
Allora aij indichera l’elemento della tabellaA che occupa l’i-esima riga e la j-esima colonna. Ad esempioa21 indichera l’elemento di A in seconda riga e prima colonna. Da questo momento in poi possiamo usarea pieno diritto il termine matrice per indicare l’oggetto matematico A.
Tornando alla nostra trasformazione x→ y, scriveremo dunque in modo compatto:
y =
[y1
y2
]=
[a11x1 + a12x2
a21x1 + a22x2
]=
[a11 a12
a21 a22
] [x1
x2
]= Ax,
definendo cosı il prodotto matrice-vettore.Riassumendo: tutte le trasformazioni che, preso un vettore ne producono un altro attraverso combi-
nazioni lineari delle coordinate del primo sono esprimibili in modo compatto con l’applicazione di unamatrice al vettore stesso. Si parla allora di trasformazioni lineari nel piano e le matrici vengono anchedette applicazioni lineari.
Ora, come facciamo a memorizzare le regole usate per esprimere il prodotto matrice-vettore appenaintrodotto? Denotiamo con a1,: il vettore riga costituito dagli elementi della prima riga di A (la ragionedi tale notazione sara chiara in Matlab 3):
a1,: =[a11 a12
].
Finora abbiamo utilizzato pero vettori colonna. Allora introduciamo quella che si chiama trasposizione(da cui il simbolo T come apice):
a1,:T =
[a11
a12
].
In seguito approfondiremo la vera natura di tale operazione. Adesso che abbiamo la prima riga di A comecolonna, possiamo usare l’abituale prodotto scalare con il vettore x per accorgerci che, se y = Ax, allora
y1 = a11x1 + a12x2 = a1,:T · x.
Analagomente:y2 = a21x1 + a22x2 = a2,:
T · xper
a2,: =[a21 a22
]ovvero
a2,:T =
[a21
a22
].
Deduciamo che ogni coordinata risultante da un prodotto matrice-vettore Ax e data dal prodotto scalaredella relativa “riga” con il vettore x stesso.
10

Esempio 5 L’esempio 4 puo essere rivisto nel seguente modo compatto:
y = Ax =
[4 −3−2 1
] [24
]=
[4 · 2− 3 · 4−2 · 2 + 1 · 4
]=
[−40
].
Esercizio 2 Non dovrebbe sorprendere che per qualunque vettore risulta sempre
(vT )T = v.
Matlab 3 Per usare Matlab dobbiamo prima imparare ad inserire una matrice, la qualcosa e abbastanzasemplice ed intuitiva. Infatti, la matrice
A =
[a11 a12
a21 a22
]viene creata con il comando:
A=[a11,a12;a21,a22]
ovvero:
• inserendo gli elementi tra parentesi quadre
• separando le righe con “;”
• separando gli elementi all’interno di una stessa riga con “,” (o spazi “ ”).
Allora il nostro prodotto matrice-vettore si esegue nel seguente modo:
>> A=[4,-3;-2,1]A =
4 -3-2 1
>> x=[2;4]x =
24
>> y=A*xy =
-40
L’esito si e gia visto in Figura 3. Osserviamo anche l’uso del simbolo “:” per indicare righe e colonnedi A:
11

>> A(1,:)ans =
4 -3>> A(2,:)ans =
-2 1>> A(:,1)ans =
4-2
>> A(:,2)ans =
-31
Verifichiamo quindi che le componenti di y sono i prodotti scalari delle corrispondenti righe di A per ilvettore x. Innanzitutto dobbiamo “trasporre” le righe diA per farle diventare vettori colonna. Per questousiamo l’apice “’”:
>> b1=A(1,:)’b1 =
4-3
>> b2=A(2,:)’b2 =
-21
ed effettuiamo il prodotto scalare come abbiamo imparato:
>> b1’*xans =
-4>> b2’*xans =
0
Ora, avrete notato che abbiamo usato l’apice di traposizione due volte, il che non cambia le cose(Esercizio 2):
>> b1b1 =
4-3
>> b1’’ans =
4-3
12

Ma su questo apparente corto circuito torneremo in seguito.
Esercizio 3 Date due matrici A e B, la loro somma e definita estendendo in maniera naturale la sommacomponente per componente vista per i vettori, quindi:
A+B =
[a11 a12
a21 a22
]+
[b11 b12
b21 b22
]=
[a11 + b11 a12 + b12
a21 + b21 a22 + b22
].
Dimostrate ora che per il prodotto matrice-vettore vale la proprieta distributiva sia rispetto alla matrice,ovvero:
(A+B)x = Ax +Bx,
sia rispetto al vettore, ovvero:A(x + y) = Ax + Ay.
Bene, adesso che abbiamo imparato il prodotto matrice-vettore, non sara assolutamente difficile im-parare il prodotto righe-colonne di due matrici. Consideriamo infatti le matrici
A =
[a11 a12
a21 a22
]e
B =
[b11 b12
b21 b22
].
Che cosa significa il prodotto
C = AB =
[a11 a12
a21 a22
] [b11 b12
b21 b22
]?
Se non l’avete gia intuito, basta considerare la matrice B come una “collezione” di colonne, che indiche-remo come (ricordando la notazione “:”)
B = [b:,1,b:,2]
dove indichiamo con
b:,1 =
[b11
b21
]e
b:,2 =
[b12
b22
]i vettori corrispondenti, rispettivamente, alla prima e alla seconda colonna della matrice B, usando unanotazione analoga a quanto gia visto per le righe. Allora il prodotto C = AB puo essere visto come lamatrice
C = [c:,1, c:,2]
dove ciascuna colonna e il prodotto della matrice A per la relativa colonna di B:
c:,1 = Ab:,1 =
[a11b11 + a12b21
a21b11 + a22b21
]13

e
c:,2 = Ab:,2 =
[a11b12 + a12b22
a21b12 + a22b22
].
Quindi il prodotto viene distribuito ad ogni colonna:
AB = A[b:,1,b:,2] = [Ab:,1, Ab:,2] = [c:,1, c:,2] = C (3)
ovvero [a11 a12
a21 a22
] [b11 b12
b21 b22
]=
[a11b11 + a12b21 a11b12 + a12b22
a21b11 + a22b21 a21b12 + a22b22
].
Esempio 6 Per
A =
[4 −3−2 1
]e
B =
[1 05 2
]si ottiene
AB =
[4 −3−2 1
] [1 05 2
]=
[4 · 1− 3 · 5 4 · 0− 3 · 2−2 · 1 + 1 · 5 −2 · 0 + 1 · 2
]=
[−11 −63 2
].
Matlab 4 In Matlab (ricordando che A esiste gia!):
>> B=[1,0;5,2]B =
1 05 2
>> A*Bans =
-11 -63 2
Esercizio 4 Provate a costruire una matrice I che, moltiplicando qualunque vettore x, lo lascia invariato,ovvero:
Ix = x.
Esercizio 5 Date tre matrici qualunqueA,B eC di 2 righe e 2 colonne, dimostrate ora che per il prodottorighe-colonne valgono sia la proprieta distributiva
A(B + C) = AB + AC
sia la proprieta associativaA(BC) = (AB)C.
14

Senza ulteriori spiegazioni, non dovrebbe essere difficile accertarsi della validita delle seguente gene-ralizzazione derivante dalla (3):
A[b:,1,b:,2, . . . ,b:,n] = [c:,1, c:,2, . . . , c:,n].
Come si suol dire, “fatto 30 facciamo 31”. Visto che abbiamo appena usato una matrice che ha piucolonne (ovvero n) che righe (ovvero 2), allora diciamo che se una matrice M ha r righe e c colonne ed isuoi elementi sono numeri reali, cioe
M =
m11 m12 · · · m1c
m21 m22 · · · m2c...
......
mr1 mr2 · · · mrc
,con mij ∈ R per ogni i = 1, 2, . . . , r e per ogni j = 1, 2, . . . , c, indicheremo questo fatto con
M ∈ Rr×c.
Commento 1 (importante!) Il prodotto matriciale appena introdotto ha l’unico vincolo di richiedereche il numero di colonne della prima matrice corrisponda al numero di righe della seconda matri-ce. Ne convenite? Se la risposta e affermativa, allora cosa rispondereste alla domanda sulla proprietacommutativa:
AB = BA?
Provate con un esempio, poi proveremo con Matlab...
Bene, se non avete accusato il colpo allora non avrete problemi a considerare un vettore colonna di nelementi
v =
v1
v2...vn
come una particolare matrice: v ∈ Rn×1(= Rn). Esistono poi, come visto, anche i vettori riga:
w = [w1, w2, . . . , wm].
In tal caso w ∈ R1×m (indicabile anch’esso come Rm). Ad ogni modo, la convenzione considera i vettorisempre come colonna, se non diversamente specificato. Bene, visto che i vettori sono particolari matrici,nulla ci vieta di applicare loro il prodotto “vettore-vettore” inteso come caso particolare del prodottomatriciale righe-colonne appena appreso. Siccome la regola dice che il numero di colonne del primofattore deve coincidere col numero di righe del secondo, se entrambi i fattori sono vettori con lo stessonumero di elementi (diciamo n) ci rimangono solo due possibilita. Una consiste nel moltiplicare il vettoreriga per il vettore colonna, ottenendo cosı un numero scalare:
R1×n · Rn×1 = R1×1 (= R).
Ma questo e proprio il prodotto scalare di vettori, ecco spiegato finalmente l’uso della trasposizione sesono entrambi colonna: il primo deve diventare riga! Per la seconda avete un po’ piu di tempo perpensarci: la incontreremo in Sezione 3.3.
15

Matlab 5 Proviamo ad eseguire diversi prodotti matriciali in Matlab, verificandone le proprieta riguar-danti la dimensione dei fattori. Iniziamo con A ∈ R3×2 e B ∈ R3×4, il cui prodotto AB non e possibiledato che il numero di colonne di A (2, primo fattore) differisce dal numero di righe di B (3, secondofattore):
>> A=[1,2;3,4;5,6]A =
1 23 45 6
>> B=[12,11,10,9;8,7,6,5;4,3,2,1]B =
12 11 10 98 7 6 54 3 2 1
>> A*B??? Error using ==> mtimesInner matrix dimensions must agree.
Modifichiamo allora con B ∈ R2×4, ottenendo AB ∈ R3×4:
>> B=[8,7,6,5;4,3,2,1]B =
8 7 6 54 3 2 1
>> A*Bans =
16 13 10 740 33 26 1964 53 42 31
Verifichiamo che il prodotto di matrici non e, in generale, commutativo, cioe AB 6= BA. Questo succedesempre se le dimensioni non sono compatibili con la regola del prodotto, ad esempio con le matrici A eB inserite, AB e lecito ma BA non lo e:
>> B*A??? Error using ==> mtimesInner matrix dimensions must agree.
Ad ogni modo, in generale, il prodotto non e commutativo nemmeno quando i fattori sono “quadrati”:
>> A=[1,2;3,4]A =
1 23 4
>> B=[4,3;2,1]B =
4 3
16

2 1>> A*Bans =
8 520 13
>> B*Aans =
13 205 8
Vediamo ora cosa succede con i prodotti di vettori:
>> v=[1;2;3]v =
123
>> w=[3;2;1]w =
321
>> v*w??? Error using ==> mtimesInner matrix dimensions must agree.>> v’*wans =
10>> v*w’ans =
3 2 16 4 29 6 3
2.3 Sistemi lineariIn questa sezione osserveremo i sistemi di equazioni lineari (in breve sistemi lineari) da un’altra prospet-tiva.
Cominciamo dalle cose veramente essenziali. Come rappresentante delle piu semplici equazionilineari possiamo considerare a pieno titolo la seguente:
3x = 21,
la cui soluzione (ricordando i principi di equivalenza) e banalmente
x =21
3= 7.
17

Questo vale ovviamente per tutte le equazioni del tipo
ax = b (4)
con soluzionex =
b
a
avendo preventivamente assunto a 6= 0. Se invece fosse a = 0, allora non avremmo soluzione per b 6= 0(dato che non esiste alcun numero che moltiplicato per 0 fornisca un numero diverso da 0) mentre neavremmo infinite per b = 0 (dato che qualunque numero moltiplicato per 0 fornisce 0).
Complichiamoci ora un po’ la vita, ma non troppo, e consideriamo il classico problema della spesa cheviene proposto in mille versioni a partire dalle scuole elementari (osservando tra l’altro come l’appren-dimento di certe proprieta matematiche notevoli non richieda per forza di cose la trattazione di problemicomplessi e lontani dalla realta quotidiana piu spicciola).
Problema 1 Anna compra dal fruttivendolo 2 kg di mele e 1 kg di pere, spendendo 7 euro. Marco compradallo stesso fruttivendolo 4 kg di mele e 3 kg di pere, spendendo 17 euro. Quanto costano, rispettivamente,1 kg di mele e 1 kg di pere?
La risoluzione di questo semplice quesito consiste nel tradurlo nelle equazioni di primo grado (ovverolineari) {
2x1 + x2 = 74x1 + 3x2 = 17
avendo assunto la convenzione che x1 ed x2 rappresentino, rispettivamente, il numero incognito di kg dimele e pere. E facile verificare che la soluzione e x1 = 2 e x2 = 3. Oppure si puo procedere medianteil metodo di eliminazione di Gauss (Carl Friedrich [1777-1855], matematico tedesco) e la sostituzioneall’indietro, come visto alla conferenza iniziale.
Guardiamo con attenzione i due membri sinistri: ci ricordano qualcosa? Ciascuno di essi rappresentauna combinazione lineare delle incognite x1 ed x2, attraverso rispettivamente gli scalari 2 ed 1 per laprima equazione e 4 e 3 per la seconda. Avendo imparato come esprimere le combinazioni lineari con lematrici, allora potremmo scrivere il nostro sistema lineare in forma vettoriale:[
2 14 3
] [x1
x2
]=
[717
],
infatti [2 14 3
] [x1
x2
]=
[2x1 + 1x2
4x1 + 3x2
]=
[717
].
Se ora indichiamo con
A =
[2 14 3
]la cosiddetta matrice dei coefficienti, con
x =
[x1
x2
]il vettore delle incognite e, infine, con
b =
[717
]18

il vettore dei termini noti, allora il nostro sistema diventa
Ax = b
che ricalca fedelemente la scrittura dell’equazione (4).Ora, ricordando il caso (scalare) della singola equazione (4), saremmo tentati di risolvere per x an-
dando a dividere entrambi i membri per la matrice A. Ma questa, ahime, non e certamente una stradamatematicamente percorribile. La versione matematicamente corretta passa effettivamente per
ax = b⇔ ax
a=b
a⇔ x =
b
a,
ma, non essendo permessa la divisione per A, corrisponde piuttosto a:
ax = b⇔ a−1(ax) = a−1b⇔ (a−1a)x = a−1b⇔ x = a−1b
che, nel caso della (4), e basata sull’identita
a−1 =1
a,
sempre sotto l’ipotesi a 6= 0. Quindi la soluzione del nostro sistema lineare e rappresentata da
Ax = b⇔ A−1(Ax) = A−1b⇔ (A−1A)x = A−1b⇔ x = A−1b
dove A−1 e la cosiddetta matrice inversa di A. Ovviamente abbiamo “scommesso” che (A−1A)x = x.Ma vale questa proprieta? E chi e A−1? Per rispondere, dobbiamo capire bene chi e a−1. Tutti sappiamoche tale numero soddisfa a
a−1a = 1 = aa−1
(sempre per a 6= 0, chiaramente). Allora, per analogia, definiamo A−1 come quella matrice che soddisfaa
AA−1 = I = A−1A (5)
con I la matrice identita, vedi Esercizio 4. Infatti I e il corrispondente di 1 nel caso scalare. Che proprietaha il numero 1 nella moltiplicazione? Esso lascia invariato qualunque numero moltiplichi:
1 · a = a = a · 1.
Ma questo vale anche per I se per moltiplicazione intendiamo il prodotto righe-colonne, infatti:
IA = A = AI.
Tale proprieta puo essere verificata nel caso bidimensionale, dove
I =
[1 00 1
],
ma vale ovviamente per qualunque dimensione con
I =
1 0 · · · 0
0 1...
... . . . 00 · · · 0 1
.
19

Esempio 7 Possiamo verificare formalmente la proprieta della matrice identita:[1 00 1
] [a11 a12
a21 a22
]=
[1 · a11 + 0 · a21 1 · a12 + 0 · a22
0 · a11 + 1 · a21 0 · a12 + 1 · a22
]=
[a11 a12
a21 a22
].
Analogamente:[a11 a12
a21 a22
] [1 00 1
]=
[a11 · 1 + a12 · 0 a11 · 0 + a12 · 1a21 · 1 + a22 · 0 a21 · 0 + a22 · 1
]=
[a11 a12
a21 a22
].
Matlab 6 La matrice inversa si ottiene con il comando Matlab
inv(A)
che per il nostro esempio fornisce
>>A=[2,1;4,3];>> iA=inv(A)iA =
1.5000 -0.5000-2.0000 1.0000
cioe
A−1 =
[3/2 −1/2−2 1
](se volete, provate a verificare che quest’ultima soddisfa la definizione appena data).
Commento 2 (il determinante) Si puo sempre definireA−1? Fidandoci ancora dell’analogia con il casoscalare, sappiamo che si puo parlare del numero a−1 se e sole se a 6= 0. Ma cosa vorrebe dire nel casodelle matrici? Bisogna ricorrere alla nozione di determinante. Si definisce determinante di una matrice
A =
[a11 a12
a21 a22
]la quantita
det (A) = a11a22 − a12a21.
Allora si puo parlare di A−1 se e sole se det (A) 6= 0: questo, in realta, e un vero e proprio Teoremadell’algebra lineare. Una matrice A tale per cui det (A) = 0 si dice anche singolare.
Matlab 7 In Matlab il determinante si ottiene facilmente con il comando
det(A)
Ad esempio:
20

>> A=[2,1;4,3];>> det(A)ans =
2
infattidet (A) = 2 · 3− 1 · 4 = 6− 4 = 2.
Succede ad esempio che
>> A=[2,1;4,2];>> det(A)ans =
0>> iA=inv(A)Warning: Matrix is singular to working precision.iA =
Inf InfInf Inf
Matlab 8 In Matlab il comando per la risoluzione dei sistemi lineari ricorda proprio la divisione. Infatti,dopo aver inserito i nostri dati (basta il vettore dei termini noti ora):
>>b=[7;17];
si ottiene agevolmente la soluzione con il comando “\” (“backslash”):
>>x=A\bx=
23
Con A−1 a disposizione, risolvere un sistema di 2 equazioni o di 20 equazioni non fa molta differenza.Inoltre, e interessante osservare come tale notazione vettoriale permetta di gestire contemporaneamentepiu sistemi lineari che abbiano la stessa matrice dei coefficienti A ma diversi vettori dei termini noti,diciamo b1,b2, . . . ,bn:
Ax1 = b1
Ax2 = b2
...
Axn = bn.
Infatti, se consideriamo la matriceB = [b1,b2, . . . ,bn]
ottenuta collezionando le colonne corrispondenti ai diversi termini noti e la matrice incognita
X = [x1,x2, . . . ,xn]
21

ottenuta collezionando le colonne corrispondenti ai diversi vettori incogniti, allora possiamo riassumereil tutto nel “sistemone”
AX = B.
Matematicamente l’operazione corrisponde a
X = A−1B.
Dal punto di vista computazionale pero (cioe dal punto di vista di come risolviamo i problemi con l’utiliz-zo del calcolatore), l’operazione di inversione di una matrice, seppur rappresenti un concetto matematicoraffinato ed ineccepibile, non e una buona pratica! Quindi, invece di invertire una matrice e preferibilerisolvere il sistema lineare corrispondente (cioe con matrice dei coefficienti A e termini noti dati dallamatrice identita I , perche?), meglio se con metodi efficienti come quello di eliminazione di Gauss.
Infine, proviamo a cambiare leggermente il nostro problema iniziale ipotizzando che Marco acquisti 2kg di pere, anziche 1, spendendo cosı 14 euro. Quindi:{
2x1 + x2 = 74x1 + 2x2 = 14
la cui matrice
A =
[2 14 2
]e singolare, infatti:
det(A) = 2 · 2− 1 · 4 = 4− 4 = 0.
Geometricamente, cio significa che le righe (e, analogamente, le colonne) di A rappresentano vettoriparalleli e questo si traduce nel fatto algebrico che il membro sinistro di ciascuna delle due equazioniconsiderate e in realta lo stesso (fatto deducibile dividendo per 2 la seconda), ovvero l’informazione fornitada una qualunque delle due equazioni e gia contenuta nell’altra e percio risulta superflua ai fini dellarisoluzione del problema. Inoltre (ancor peggio), se i termini noti non sono nella medesima proporzione,allora non esiste alcuna soluzione, il che e in perfetta analogia con il caso scalare (o se preferite pensateai sistemi lineari di dimensione 2 come intersezioni di rette nel piano). In generale quindi, se det (A) = 0non ha senso scrivere x = A−1b, sarebbe come dividere per 0!
Matlab 9 Sistemi lineari con termini noti multipli sono risolvibili in Matlab con lo stesso comando “\”:
X=A\B
e quindi il risultato puo essere ottenuto con l’istruzione
X=inv(A)*B,
che e equivalente dal punto di vista teorico, ma non da quello computazionale. Infatti dietro “\” inMatlab c’e in realta il metodo di eliminazione di Gauss.
Passando invece al problema modificato della spesa:
>>A=[2,1;4,2];>>x=A\bx
Inf-Inf
22

Cos’e accaduto? Proviamo a rispondere utilizzando la matrice inversa, sempre in Matlab:
>>iA=inv(A)Warning: Matrix is singular to working precision.ans=
Inf InfInf Inf
infatti
>>det(A)ans=
0
2.4 Un po’ di trigonometria non nuoceDimentichiamoci ora delle matrici e torniamo ai vettori e al prodotto scalare. Prima pero apriamo unabreve parentesi parlando di trigonometria.
Consideriamo il triangolo rettangoloAOB rappresentato in Figura 4. Esso ha l’ipotenusa di lunghezza1. Per facilitare le cose quest’ultima e vista come il raggio di un cerchio (detto cerchio trigonometrico).Chiamiamo θ l’angolo al centro, cioe quello formato dal raggio (l’ipotenusa) e l’orizzontale. Alloradefiniamo il coseno dell’angolo θ come
cos (θ) =OA
OB= OA
e il seno dell’angolo θ come
sin (θ) =AB
OB= AB.
Dunque cos (θ) e il rapporto tra la lunghezza del cateto adiacente l’angolo θ e l’ipotenusa, mentre sin (θ)e il rapporto tra la lunghezza del cateto opposto all’angolo θ e l’ipotenusa. Non dovrebbe sorprendere che
cos (0◦) = 1, sin (0◦) = 0,
mentrecos (90◦) = 0, sin (90◦) = 1.
Esercizio 6 Sapreste dire che valori si ottengono per θ = 45◦? Pensate alla diagonale del quadrato e alTeorema di Pitagora ([∼575-495 a.C.], filosofo e matematico greco)!
Torniamo finalmente al prodotto scalare di due vettori introdotto in Sezione 1 come:
x · y = x1y1 + x2y2 (6)
per i vettori del piano
x =
[x1
x2
]23

Figura 4: seni e coseni.
ed
y =
[y1
y2
].
Una definizione alternativa, piu legata alla geometria, e
x · y = |x||y| cos (θ) (7)
dove θ e l’angolo compreso tra i due vettori, mentre |x| ed |y| rappresentano la loro lunghezza, ovvero
|x| =√x2
1 + x22
e|y| =
√y2
1 + y22
come ci insegna il Teorema di Pitagora, Figura 5.Ma siamo sicuri che (6) e (7) coincidono? La risposta e affermativa e la dimostrazione (riportata di
seguito per gli amanti...) si basa sul cosiddetto Teorema del Coseno o Teorema di Carnot (da Lazare Carnot[1753-1823], anche se in realta il risultato si deve a Francois Viete [1540-1603], entrambi matematicifrancesi - errate attribuzioni non sono poi cosı rare in matematica!).
Teorema 1 Per ogni coppia di vettori piani x ed y che formano tra loro un angolo θ vale
x · y = x1y1 + x2y2 = |x||y| cos (θ).
Dimostrazione. Consideriamo il triangolo ABC di lati AB = x e AC = y, Figura 6. Sia θ l’angolo traessi compreso. Allora, per il Teorema del Coseno (il quadrato costruito su un lato e pari alla somma dei
24
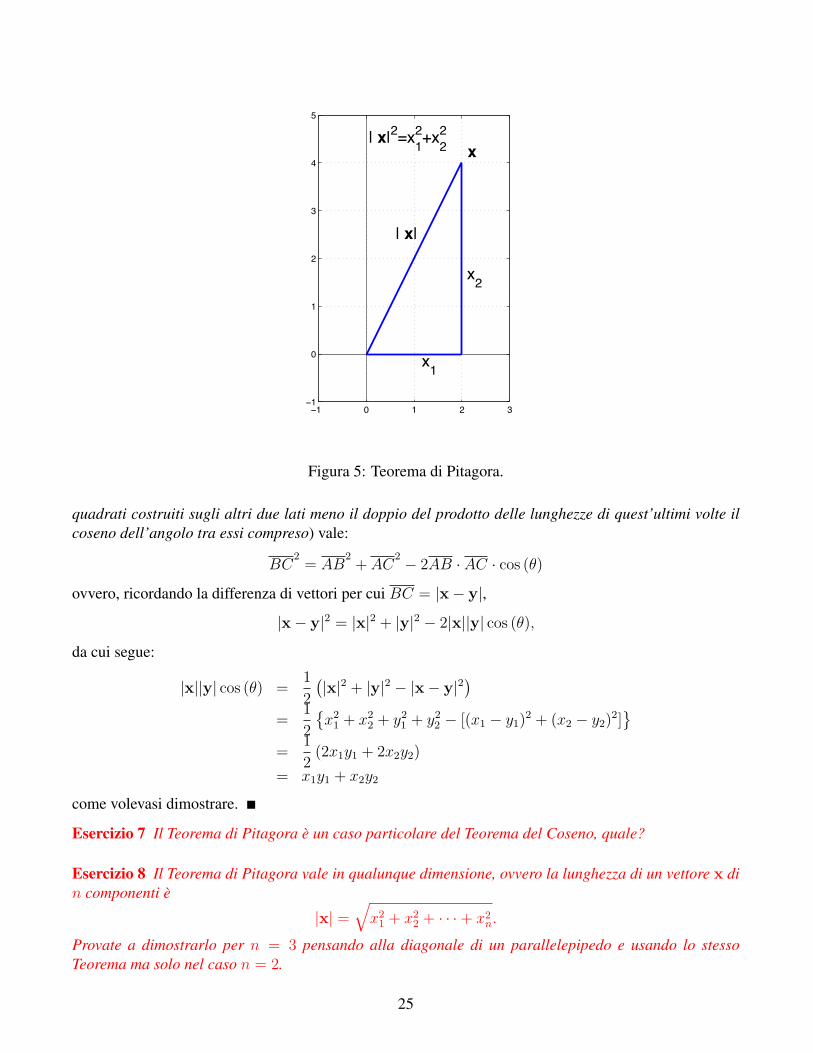
0 2−1 1 3−1
0
1
2
3
4
5
| x|
x1
x2
| x|2=x12+x2
2
x
Figura 5: Teorema di Pitagora.
quadrati costruiti sugli altri due lati meno il doppio del prodotto delle lunghezze di quest’ultimi volte ilcoseno dell’angolo tra essi compreso) vale:
BC2
= AB2+ AC
2 − 2AB · AC · cos (θ)
ovvero, ricordando la differenza di vettori per cui BC = |x− y|,
|x− y|2 = |x|2 + |y|2 − 2|x||y| cos (θ),
da cui segue:
|x||y| cos (θ) =1
2
(|x|2 + |y|2 − |x− y|2
)=
1
2
{x2
1 + x22 + y2
1 + y22 − [(x1 − y1)
2 + (x2 − y2)2]}
=1
2(2x1y1 + 2x2y2)
= x1y1 + x2y2
come volevasi dimostrare.
Esercizio 7 Il Teorema di Pitagora e un caso particolare del Teorema del Coseno, quale?
Esercizio 8 Il Teorema di Pitagora vale in qualunque dimensione, ovvero la lunghezza di un vettore x din componenti e
|x| =√x2
1 + x22 + · · ·+ x2
n.
Provate a dimostrarlo per n = 3 pensando alla diagonale di un parallelepipedo e usando lo stessoTeorema ma solo nel caso n = 2.
25
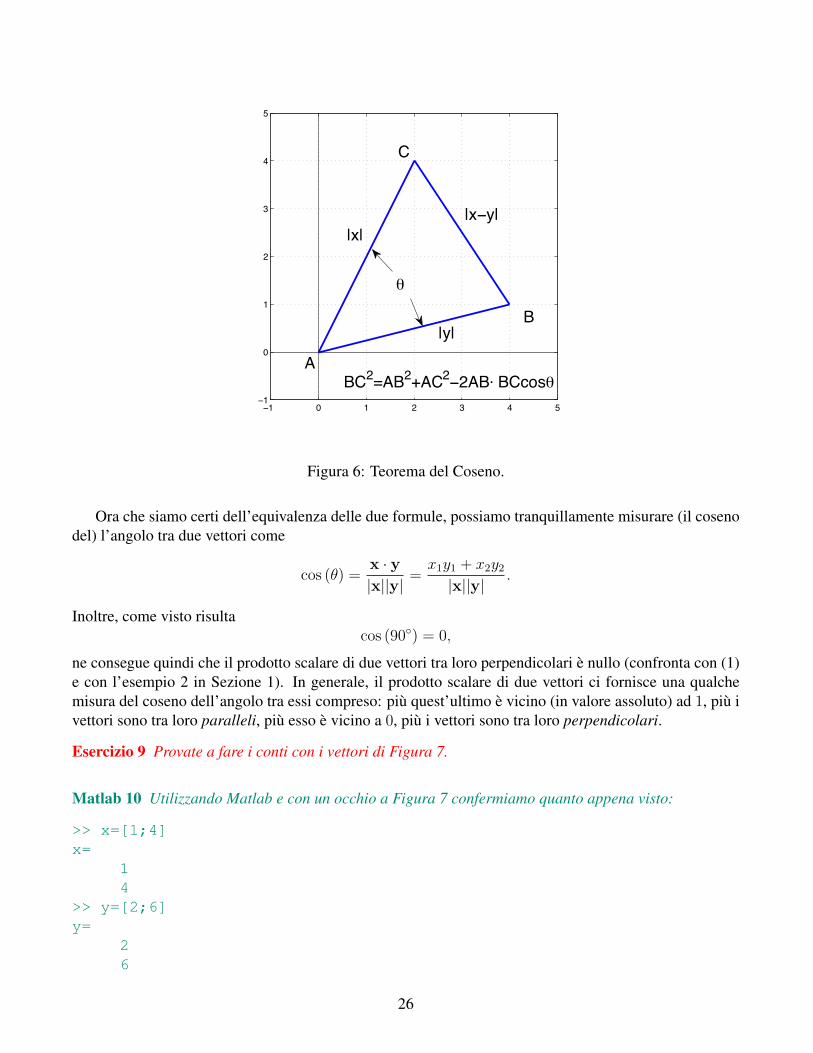
0 2−1 1 3 4 5−1
0
1
2
3
4
5
!
B
ABC2=AB2+AC2−2AB" BCcos!
C
|x−y|
|y|
|x|
Figura 6: Teorema del Coseno.
Ora che siamo certi dell’equivalenza delle due formule, possiamo tranquillamente misurare (il cosenodel) l’angolo tra due vettori come
cos (θ) =x · y|x||y|
=x1y1 + x2y2
|x||y|.
Inoltre, come visto risultacos (90◦) = 0,
ne consegue quindi che il prodotto scalare di due vettori tra loro perpendicolari e nullo (confronta con (1)e con l’esempio 2 in Sezione 1). In generale, il prodotto scalare di due vettori ci fornisce una qualchemisura del coseno dell’angolo tra essi compreso: piu quest’ultimo e vicino (in valore assoluto) ad 1, piu ivettori sono tra loro paralleli, piu esso e vicino a 0, piu i vettori sono tra loro perpendicolari.
Esercizio 9 Provate a fare i conti con i vettori di Figura 7.
Matlab 10 Utilizzando Matlab e con un occhio a Figura 7 confermiamo quanto appena visto:
>> x=[1;4]x=
14
>> y=[2;6]y=
26
26
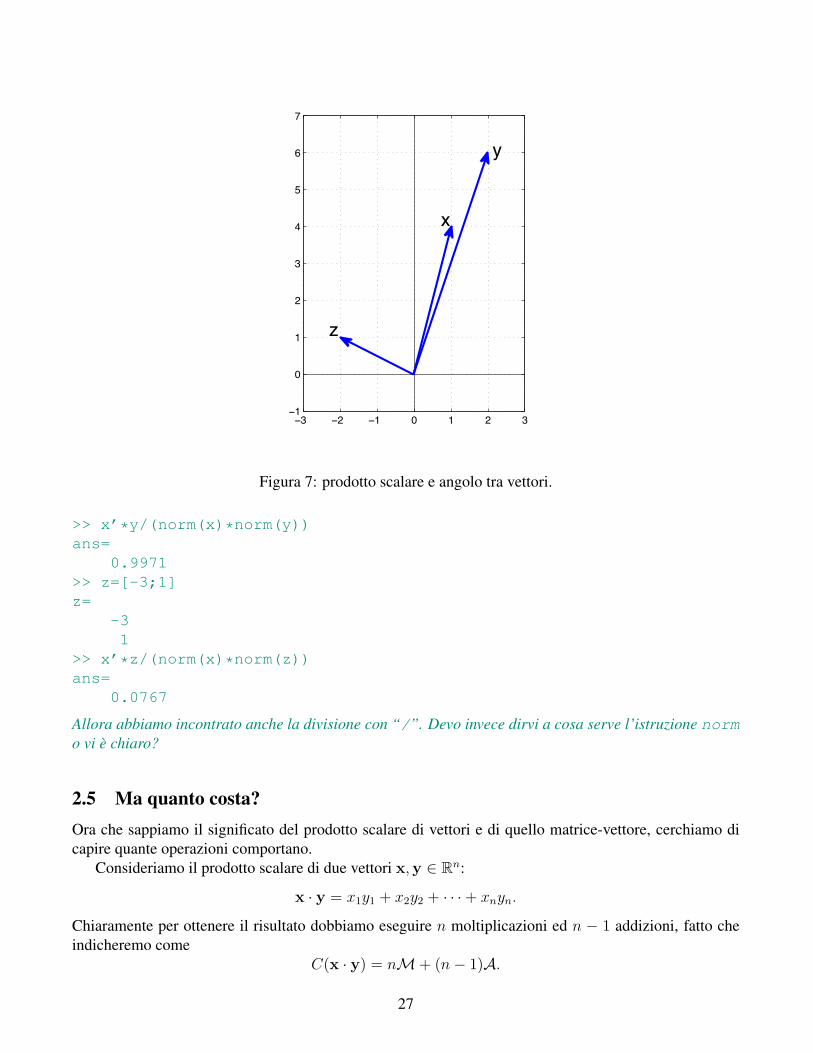
−2 0 2−1 1 3−3−1
0
1
2
3
4
5
6
7
y
x
z
Figura 7: prodotto scalare e angolo tra vettori.
>> x’*y/(norm(x)*norm(y))ans=
0.9971>> z=[-3;1]z=
-31
>> x’*z/(norm(x)*norm(z))ans=
0.0767
Allora abbiamo incontrato anche la divisione con “/”. Devo invece dirvi a cosa serve l’istruzione normo vi e chiaro?
2.5 Ma quanto costa?Ora che sappiamo il significato del prodotto scalare di vettori e di quello matrice-vettore, cerchiamo dicapire quante operazioni comportano.
Consideriamo il prodotto scalare di due vettori x,y ∈ Rn:
x · y = x1y1 + x2y2 + · · ·+ xnyn.
Chiaramente per ottenere il risultato dobbiamo eseguire n moltiplicazioni ed n − 1 addizioni, fatto cheindicheremo come
C(x · y) = nM+ (n− 1)A.
27

Consideriamo ora il prodotto matrice-vettore di una matrice A ∈ Rm×n e di un vettore x ∈ Rn.Abbiamo imparato che ogni componente del risultato
y = Ax
e in realta il prodotto scalare tra il vettore riga corrispondente di A e il vettore x:
yi = ai,:T · x, i = 1, . . . ,m.
Poiche ognuno di questi costa quanto visto sopra e ne dobbiamo calcolare m, segue
C(Ax) = m[nM+ (n− 1)A] = mnM+ (mn−m)A.
Riscrivendo comeC(Ax) = mn(M+A)−mA,
si nota che il termine che “pesa” maggiormente e il primo, mn, possiamo quindi trascurare il secondo,m, soprattutto quando m ed n sono ragguardevoli. Diremo percio che il costo dell’intera operazione eall’incirca mn flop e scriveremo O(mn) flop (si dice “dell’ordine di mn flop”).
Commento 3 Il termine flop e l’abbreviazione di “floating point operation”: 1 flop e l’operazione baseche puo fare il calcolatore, diciamo che corrisponde ad una moltiplicazione ed un’addizione.
Supponiamo ora (anche se capiremo il perche di tutto cio solo piu avanti...) che la matrice A contengamolti elementi nulli, diciamo piu precisamente che la riga i-esima diA contiene solo nnzi elementi diversida 0 (nnz sta infatti generalmente per “Number of Non-Zero elements”), per i = 1, . . . ,m. Se cosı e,allora non e difficile intuire che il costo per il calcolo della componente i-esima yi risulta
C(yi) = nnziM+ (nnzi − 1)A = O(nnzi),
basta infatti non contare le moltiplicazioni per (e le addizioni con) 0! Allora il costo del prodotto finaley = Ax si ottiene sommando i costi di ciascuna componente, quindi:
C(Ax) =m∑
i=1
O(nnzi) = O
(m∑
i=1
nnzi
)= O(nnz)
dove
nnz =m∑
i=1
nnzi
e il numero totale di elementi non nulli contenuti nella matrice A.Quello che servira ricordare di tutto questo e che, in generale, un prodotto matrice-vettore di dimen-
sione n (quindi A ∈ Rn×n ed x ∈ Rn) costa O(n2), ma se la matrice A ha solo nnz elementi diversi da0, allora il costo scende a O(nnz). Ovviamente vale sempre nnz ≤ n2, ma a noi interessera in particolarmodo il caso nnz� n2 (leggi “molto minore”), ovvero in cui la matrice A contiene per la maggior parteelementi nulli: si parla di matrici sparse, e rivestono un ruolo particolare nelle computazioni data la loropeculiarita.
28

3 GoogleInternet e il WWW rappresentano fonti di problemi matematici tanto interessanti quanto difficili, almenoa livello computazionale. Tra questi potremmo annoverare:
• la gestione dei flussi di informazioni;
• la ricerca delle informazioni;
• l’ordinamento delle informazioni.
Abbiamo accennato alle prime due tipologie durante la conferenza. In riferimento alla seconda, in parti-colare, e bene sottolineare che il problema nel contesto del World Wide Web (di seguito WWW) differisceabbastanza da quello relativo, ad esempio, ad una biblioteca. I motivi sono diversi:
• la dimensione del WWW (numero di pagine web) e di gran lunga maggiore di quella di normalicataloghi di documenti: miliardi contro milioni (o migliaia);
• il WWW si evolve molto piu rapidamente di quanto lo possa fare, ad esempio, il patrimonio di unabiblioteca;
• la struttura a collegamenti ipertestuali (i link) e una caratteristica peculiare del WWW che non sitrova da altre parti.
Viste tali caratteristiche, l’ordinamento delle informazioni presenti nel WWW viene a rivestire un ruoloparticolarmente cruciale. Non sorprende dunque che quest’ultimo rappresenti un argomento di ricercaattuale e tra i piu gettonati. Tra l’altro e una tematica molto recente, si pensi che i primi lavori scientificiapparsi in letteratura risalgono appena alla fine degli anni 90. D’altronde la prima volta che si sonoconnessi due computer tra loro risale al 1969, il protocollo TCP/IP (Transmission Control Protocol /Internet Protocol) e stato introdotto negli anni 70, l’ipertesto HTTP (Hyper Text Transfer Protocol) neglianni 80 e il WWW ha fatto il suo ingresso ufficiale nella storia il 6 agosto 1991 (esattamente 46 anni dopoHiroshima).
La tecnologia messa in piedi da Google non e certamente l’unica a soddisfare l’esigenza di miliardi diutenti di trovare le informazioni desiderate in rete. Abbiamo deciso di occuparci limitatamente di questa (ein maniera semplificata) dato il suo notevole successo attuale. Altri metodi (vecchi e nuovi) condividonocomunque con Google alcuni aspetti fondamentali:
• sfruttano la caratteristica struttura a link del WWW (teoria dei grafi);
• descrivono il problema con matrici e vettori (algebra lineare);
• lo interpretano in senso probabilistico (teoria della probabilita);
• lo risolvono con metodi efficienti (analisi numerica).
Nel loro famoso lavoro (una copia e disponibile in rete, [3]), Larry Page and Sergey Brin (fondatoridi Google) spiegano i concetti fondamentali con cui hanno gettato le regole per ordinare il contenuto delWWW. Al tempo erano due studenti, entrambi venticinquenni, della Stanford University. Presentiamobrevemente di seguito gli aspetti principali della loro teoria, riprendendo il percorso seguito durante laconferenza.
29

Innanzitutto l’obiettivo da raggiungere e quello di classificare (to rank in inglese) le pagine (pagesin inglese) del WWW secondo la loro importanza relativa (e non assoluta: ci interessa sapere se unapagina e piu importante di un’altra, ma non quanto e importante in assoluto). Da qui il nome dell’algorit-mo noto come PageRank (http://www.google.it/intl/it/why_use.html). Ma che cos’el’importanza (di seguito anche pagerank) di una pagina web? Potremmo ipotizzare che tale caratteristica
• dipenda dal contenuto della pagina;
• sia legata al numero di link che puntano alla pagina (entranti o inlink);
• sia legata al numero di link che partono dalla pagina (uscenti o outlink);
• etc..
Come si vede, vi sono diverse possibilita. I criteri proposti da Page e Brin sono i seguenti:
(G1) il pagerank di una pagina e indipendente dal suo contenuto;
(G2) il pagerank di una pagina e trasferito in parti uguali alle pagine collegate in uscita da questa(mediante gli outlink);
(G3) il pagerank di una pagina e la somma delle frazioni di pagerank delle pagine collegate a questa inentrata (mediante gli inlink).
I collegamenti di cui sopra si riferiscono, ovviamente, ai link ipertestuali tra le varie pagine. Il seguenteesempio sara di aiuto.
Esempio 8 Consideriamo una piccolossima porzione del WWW, schematizzata come in Figura 8. Comesi vede, la pagina 1 ha un pagerank 100 e, avendo 2 outlink, ne trasferira 50 alla pagina 3 e 50 allapagina 4 (criterio (G2)). La pagina 3 ha due inlink, riceve cosı un pagerank di 50 (meta) dalla pagina 1 eun pagerank di 10 (un terzo) dalla pagina 2, totalizzando quindi un pagerank di 60 (criterio (G3)). Infine,osserviamo come tali calcoli siano stati fatti senza conoscere il contenuto delle pagine (criterio (G1)).
Partendo da queste tre semplici regole svilupperemo il modello matematico su cui si basa il motoredi ricerca Google. Inizieremo con un modello piuttosto primitivo e per questo richiedente alcune ipotesisemplificative rispetto alla situazione reale (Sezione 3.1). Impareremo poi a risolvere in maniera efficienteil problema matematico associato (Sezione 3.2). Infine rimuoveremo le ipotesi inziali per avvicinarci ilpiu possibile alla realta (Sezione 3.3). Nel frattempo, lungo il percorso, forniremo un’interpretazionealternativa a quella algebrica.
3.1 Matrici di connettivita e navigatori casualiCome prima cosa, numeriamo le pagine web da 1 ad n e indichiamo con xi il pagerank della pagina i, i =1, 2, . . . , n. Naturalmente n e molto grande, si stima essere attualmente intorno ai 18 miliardi (http://www.worldwidewebsize.com/). Per il momento, visto che dobbiamo introdurre i concetti generali,ci avvaleremo di esempi con nmolto basso, dell’ordine dell’unita (un WWW piccolissimo!). Supponiamoinoltre che ogni pagina abbia almeno un link entrante ed uno uscente, ipotesi che, come vedremo inseguito, ha un ruolo fondamentale.
30

Figura 8: pagine web e pagerank.
Costruiamo la cosiddetta matrice di connettivita C ∈ Rn×n come segue: l’elemento cij di C, quelloche occupa la riga i-esima e la colonna j-esima, vale
cij =
{1 se c’e un link dalla pagina j alla pagina i0 altrimenti.
Esempio 9 Conisderiamo il WWW di n = 4 pagine rappresentato con i suoi link tramite il grafo (sem-plicemente un insieme di nodi e archi orientati) di Figura 9. In base alla regola precedente, la matrice diconnettivita associata risulta:
C =
0 1 0 00 0 1 11 1 0 00 1 1 0
.Per costruirla possiamo seguire due strade:
• per righe: ciascuna riga e relativa ad una pagina e dobbiamo guardare gli inlink di quest’ultima(entranti in);
• per colonne: ciascuna colonna e relativa ad una pagina e dobbiamo guardare gli outlink di que-st’ultima (uscenti da).
Cosı, ad esempio, se osserviamo la pagina 3, questa riceve i link in ingresso dalle pagine 1 e 2, per cuila riga 3 della matrice C sara c3,: = [1, 1, 0, 0]. Invece, se osserviamo i link in uscita da questa, andandoessi alle pagine 2 e 4 daranno luogo alla colonna 3 di C, ovvero c:,3 = [0, 1, 0, 1]T .
31

Figura 9: il grafo di un WWW con n = 4 pagine.
Adesso che abbiamo costruito la matrice di connettivita C, effettuiamo quella che si chiama normaliz-zazione. Prendiamo dunque ciascuna colonna c:,j di C e la dividiamo per il numero di outlink outj dellapagina relativa (possiamo farlo perche abbiamo supposto che ve ne sia almeno uno, quindi outj 6= 0).Formiamo cosı la nuova matrice H di colonne:
h:,j =c:,j
outj
, j = 1, 2, . . . , n.
Questa operazione realizza il corrispondente matematico del criterio (G2). Da notare che risulta essere
0 ≤ hij ≤ 1, i, j = 1, 2, . . . , n,
en∑
i=1
hij = 1, j = 1, 2, . . . , n.
Inoltre (visto che ci siamo...), il numero di outlink della pagina j non e altro che la somma degli elementidi c:,j , quindi:
n∑i=1
cij = outj, j = 1, 2, . . . , n,
mentre il numero di inlink della pagina i non e altro che la somma degli elementi di ci,:, quindi:
n∑j=1
cij = ini, i = 1, 2, . . . , n.
32

Esempio 10 Tornando all’esempio di Figura 9, osserviamo che
out1 =4∑
i=1
ci1 = 1
out2 =4∑
i=1
ci2 = 3
out3 =4∑
i=1
ci3 = 2
out4 =4∑
i=1
ci4 = 1.
Quindi la matrice H risulta
H =
0 1
30 0
0 0 12
11 1
30 0
0 13
12
0
.Come stabilito dal criterio (G2) la pagina 3, ad esempio, trasferira due meta del suo pagerank, in parti-colare alle pagine 2 e 4. Analogamente, la pagina 2 trasferira tre terzi del suo pagerank, rispettivementealle pagine 1, 3 e 4. Infine le pagine 1 e 4 trasferiranno tutto il loro pagerank, rispettivamente alle pagine3 e 2.
Per completezza contiamo anche gli inlink:
in1 =4∑
j=1
c1j = 1
in2 =4∑
j=1
c2j = 2
in3 =4∑
j=1
c3j = 2
in4 =4∑
j=1
c4j = 2.
Come osservato, avendo assunto che ogni pagina ha almeno un outlink, la somma degli elementi diciascuna colonna di H vale sempre 1. Si parla in questo caso di matrice stocastica (a colonne). Perspiegare questa terminologia ricorriamo ad un modello interpretativo di tipo probabilistico. Immaginiamodunque di osservare un navigatore che sta visitando il WWW di Figura 9 e che sia obbligato a cambiarepagina ad ogni istante utilizzando a caso gli outlink a disposizione. Supponiamo ad esempio che adun certo istante di tempo tale navigatore stia visitando la pagina 3 (che ha 2 outlink). Allora all’istantesuccessivo dovra per forza di cose trovarsi a visitare la pagina 2 o la pagina 4. Siccome si muove a caso,la probabilita di scegliere una o l’altra pagina e suddivisa in modo uguale, quindi 1/2 e 1/2 (o 50% e 50%se preferite). Per lo stesso principio, se scegliesse la pagina 4 (che ha 1 outlink), all’istante successivo sitroverebbe obbligatoriamente sulla pagina 2, giungendovi con probabilita 1 (o 100%). Se invece avessescelto la pagina 2 (che ha 3 outlink), allora all’istante successivo si ritroverebbe a visitare rispettivamentele pagine 1, 3 o 4 con uguale probabilita, ovvero 1/3, 1/3 e 1/3 (o tutte 33.333 . . .%).
La metafora probabilistica di cui sopra va sotto il nome di navigatore virtuale. Sotto questo punto divista, la matrice H e una matrice di transizione di probabilita: il suo generico elemento hij rappresentala probabilita che ad un certo istante il navigatore virtuale passi dalla pagina j alla pagina i, seguendo
33

ovviamente l’outlink j → i. Per usare una terminologia piu tecnica (e di richiamo), il navigatore virtualee un modello di random walk lungo il grafo associato al WWW esaminato e rappresenta una catena diMarkov.
Veniamo adesso al criterio (G3). Esso esprime una legge di tipo ricorsivo: il pagerank di una paginae definito sulla base del pagerank di altre pagine (quelle che hanno outlink verso di essa in particolare).Seguendo tale ricetta, possiamo ricostruire il pagerank di ciascuna pagina. Ogni pagina, come detto,riceve solo una frazione del pagerank di ogni altra pagina che abbia un outlink diretto alla prima. Talefrazione corrisponde al relativo elemento della matrice H , ed esprime appunto la probabilita di percorrereeffettivamente quel link (e quindi di trasferire tramite esso parte del pagerank della pagina di partenza).Ad esempio, per la prima:
x1 = h11x1 + h12x2 + h13x3 + · · ·+ h1nxn,
per la seconda:x2 = h21x1 + h22x2 + h23x3 + · · ·+ h2nxn,
per la terza:x3 = h31x1 + h32x2 + h33x3 + · · ·+ h3nxn
e via dicendo fino all’ultima:
xn = hn1x1 + hn2x2 + hn3x3 + · · ·+ hnnxn.
Raccogliamo tutte queste informazioni come segue:
x1 = h11x1 + h12x2 + h13x3 + · · ·+ h1nxn
x2 = h21x1 + h22x2 + h23x3 + · · ·+ h2nxn
x3 = h31x1 + h32x2 + h33x3 + · · ·+ h3nxn...
xn = hn1x1 + hn2x2 + hn3x3 + · · ·+ hnnxn,
e, vista l’esperienza acquisita con l’algebra lineare, riscriviamo il tutto come
x = Hx
dove
x =
x1
x2
x3...xn
e il cosiddetto vettore pagerank. Attenzione: x e proprio l’incognita del nostro problema!
Esempio 11 Sempre con riferimento al WWW di Figura 9, otteniamo le equazioni
x1 = 0 · x1 +1
3· x2 + 0 · x3 + 0 · x4
x2 = 0 · x1 + 0 · x2 +1
2· x3 + 1 · x4
x3 = 1 · x1 +1
3· x2 + 0 · x3 + 0 · x4
x4 = 0 · x1 +1
3· x2 +
1
2· x3 + 0 · x4,
34

ovvero, togliendo gli zeri superflui,
x1 =1
3x2
x2 =1
2x3 + x4
x3 = x1 +1
3x2
x4 =1
3x2 +
1
2x3.
Nella notazione vettoriale scriviamo invecex1
x2
x3
x4
=
0 1
30 0
0 0 12
11 1
30 0
0 13
12
0
x1
x2
x3
x4
.E a che cosa corrisponde tale problema? L’espressione x = Hx non rappresenta un vero e proprio
sistema lineare: il vettore incognito compare anche al posto di quello noto. D’altro canto, non e nemmenoun prodotto matrice-vettore. Se pero ci ricordiamo della matrice identica I di dimensione n, allora essendo
x = Ix,
sostituendo al primo membro otteniamoIx = Hx,
ovvero (ricordate Esercizio 3)(I −H)x = 0.
Quest’ultimo e un vero e proprio sistema lineare, con matrice dei coefficienti I − A, vettore incognito xe vettore noto 0 (un caso veramente particolare).
Esempio 12 Sempre con riferimento al WWW di Figura 9, le equazioni
x1 =1
3x2
x2 =1
2x3 + x4
x3 = x1 +1
3x2
x4 =1
3x2 +
1
2x3
vengono riscritte nella forma (I−H)x = 0 semplicemente portando tutti i termini a sinistra dell’uguale:
x1 −1
3x2 = 0
x2 −1
2x3 − x4 = 0
−x1 −1
3x2 + x3 = 0
−1
3x2 −
1
2x3 + x4 = 0.
35

Nella notazione vettoriale scriviamo invece1 −1
30 0
0 1 −12−1
−1 −13
1 00 −1
3−1
21
x1
x2
x3
x4
=
0000
.Bene, visto che siamo riusciti a tradurre il tutto in un sistema lineare, sappiamo anche come risol-
verlo. Purtroppo pero abbiamo visto al seminario che il metodo di eliminazione gaussiana (seguito dallasostituzione) comporta un costo di O(2/3n3) flop. Essendo n dell’ordine dei miliardi, ci ritroveremmo adover fare miliardi di miliardi di miliard di flop, troppi anche per i calcolatori piu potenti (milioni di annicon il “Tianhe-1A”! http://www.nccs.gov/jaguar/, http://www.top500.org/). Comesuperiamo questo ostacolo? La risposta nella prossima sezione.
3.2 La fortuna di Google: il metodo delle potenze e tanti zeriVisto il costo non affrontabile del metodo di Gauss, abbandoniamo questa strada in favore di un’ideache si applica spesso in matematica: l’iterazione. In questo contesto, potremmo riassumere la strategiadicendo che rinunciamo alla soluzione esatta x ma, partendo da un’opportuna approssimazione inizialex(0), costruiamo una successione di soluzioni x(1),x(2),x(3), . . . via via sempre piu vicine a quella esatta(questa almeno e la nostra speranza). Quando siamo sufficientemente “vicini”, ci fermiamo. Il vantaggioconsiste nel costruire queste soluzioni approssimate in modo piu semplice e ad un costo computazionalemolto piu basso.
Tornando al problemax = Hx,
potremmo procedere iniziando da un certo x(0) e calcolare x(1) come
x(1) = Hx(0),
poi x(2) comex(2) = Hx(1),
x(3) comex(3) = Hx(2)
e via dicendo. Ad ogni passo calcoliamo dunque la soluzione “nuova” facendo il prodotto della matriceH con la soluzione “vecchia”. In generale, dopo k di questi passi ci ritroviamo con
x(k) = Hx(k−1), k = 1, 2, . . . .
Ma quando ci si ferma? Potrebbe (il condizionale e d’obbligo per ora) essere ragionevole fermarsiquando due soluzioni successive, quindi x(k) ed x(k−1), differiscono di poco, cioe quando la lunghezzadel vettore differenza (o errore)
e(k) = x(k) − x(k−1)
e prossima allo zero, o perlomeno molto piccola. Abbiamo gia visto nell’Esercizio 8 come calcolare lalunghezza di un vettore, ovvero il Teorema di Pitagora generalizzato. Nel nostro caso la lunghezza di e(k),che indicheremo con ‖e(k)‖, risulta (in Matlab basta usare norm)
‖e(k)‖ =
√(x
(k)1 − x
(k−1)1
)2
+(x
(k)2 − x
(k−1)2
)2
+ · · ·+(x
(k)n − x(k−1)
n
)2
.
36

Ci fermeremo quindi dopo k passi, con k tale per cui
‖e(k)‖ < TOL
dove TOL sara una tolleranza da noi fissata.L’algoritmo appena presentato e noto come metodo delle potenze (perche secondo voi?).
Matlab 11 Applichiamo il metodo delle potenze sempre con riferimento al WWW di Figura 9. Questavolta ci affidiamo a Matlab. Inseriamo H:
>> H=[0,1/3,0,0;0,0,1/2,1;1,1/3,0,0;0,1/3,1/2,0]H =
0 0.3333 0 00 0 0.5000 1.0000
1.0000 0.3333 0 00 0.3333 0.5000 0
Inseriamo quindi un vettore soluzione iniziale x(0). Supponiamo ad esempio che, inizialmente, ognipagina abbia lo stesso pagerank, quindi 1/n = 1/4 (capiremo poi perche).
>> x=[1/4;1/4;1/4;1/4]x =
0.25000.25000.25000.2500
Nella nostra implementazione Matlab chiameremo il vettore soluzione sempre x. Terremo conto delnumero di iterazioni mediante un indice k. Siccome siamo all’inizio, diciamo che siamo al passo k = 0:
>> k=0;
Finalmente possiamo procedere con il metodo, che scriviamo tutto in una riga (!). Quest’ultima laripeteremo finche non saremo soddisfatti dell’errore (abbiamo gia incontrato l’istruzione norm).
>> k=k+1,e=norm(H*x-x),x=H*xk =
1e =
0.2282x =
0.08330.37500.33330.2083
>> k=k+1,e=norm(H*x-x),x=H*xk =
2e =
37

0.1559x =
0.12500.37500.20830.2917
>> k=k+1,e=norm(H*x-x),x=H*xk =
3e =
0.0780x =
0.12500.39580.25000.2292
Gia dopo 3 passi abbiamo ridotto l’errore. La Tabella 1 riporta i dati sui calcoli successivi. La soluzioneesatta e
x =
0.1250.3750.2500.250
.Osserviamo come si ottengono errori molto piccoli gia con poche decine di passi. Inoltre, osservando ilvettore pagerank soluzione x, concludiamo che, supponendo 1 l’importanza di tutto il WWW, allora 1/8e nella pagina 1, 3/8 nella 2 e 1/4 in ciascuna delle pagine 3 e 4.
Commento 4 La Tabella 1 non deve trarre in inganno: per motivi di spazio i valori di pagerank (ultimequattro colonne) sono riportati con 4 cifre significative (vedi Appendice A) , per cui essi possono sembrareesatti per k ≥ 16. In realta quelli che si vedono sono valori arrotondati a 4 cifre. Matlab li calcolaeffettivamente con 15 cifre significative, fatto che corrisponde alla massima precisione del sistema dirappresentazione dei numeri di macchina. Ecco perche e inutile proseguire le iterazioni dopo che l’errorescende sotto 10−15: tutto quello che segue la 15a cifra non avrebbe comunque senso!
E dopo k passi, quanto sara costata la nostra soluzione finale x(k) (che e comunque un’approssi-mazione)? Per saperlo basta capire quanto costa eseguire ogni singolo passo dell’algoritmo. Osservia-mo che ogni passo comporta sempre la stessa operazione, cioe il prodotto della matrice di connettivitanormalizzata H volte il vettore soluzione del passo precedente:
x(k) = Hx(k−1), k = 1, 2, . . . .
Quindi un singolo passo costa in genere O(n2) flop, come spiegato in Sezione 2.5. In totale O(kn2) flopse facciamo k passi. Se pensiamo che in generale bastano poche decine di passi (tipicamente k � n), egia un bel risparmio. Ma non e sufficiente: siamo ancora a miliardi di miliardi di operazioni.
Abbiamo visto che ogni passo del metodo delle potenze consiste in un prodotto matrice-vettore, inparticolare Hx. Abbiamo imparato che le n componenti del vettore risultante si calcolano ciascuna come
38

k e(k) x(k)1 x
(k)2 x
(k)3 x
(k)4
1 2.2822× 10−1 0.0833 0.3750 0.3333 0.20836 1.9018× 10−2 0.1285 0.3715 0.2465 0.253511 1.7455× 10−3 0.1247 0.3754 0.2502 0.249716 1.6475× 10−4 0.1250 0.3750 0.2500 0.250021 1.5752× 10−5 0.1250 0.3750 0.2500 0.250026 1.5148× 10−6 0.1250 0.3750 0.2500 0.250031 1.4602× 10−7 0.1250 0.3750 0.2500 0.250036 1.4090× 10−8 0.1250 0.3750 0.2500 0.250041 1.3601× 10−9 0.1250 0.3750 0.2500 0.250046 1.3131× 10−10 0.1250 0.3750 0.2500 0.250051 1.2677× 10−11 0.1250 0.3750 0.2500 0.250056 1.2239× 10−12 0.1250 0.3750 0.2500 0.250061 1.1816× 10−13 0.1250 0.3750 0.2500 0.250066 1.1429× 10−14 0.1250 0.3750 0.2500 0.250071 1.1012× 10−15 0.1250 0.3750 0.2500 0.250076 9.3095× 10−17 0.1250 0.3750 0.2500 0.2500
Tabella 1: dati sul metodo delle potenze per il WWW di Figura 9.
prodotto scalare della relativa riga della matrice per il vettore colonna. Ad esempio per la componentei-esima:
x(k)i = hi1x
(k−1)1 + hi2x
(k−1)2 + · · ·+ hinx
(k−1)n = hi,: · x(k−1).
Ma siamo sicuri che tutti gli elementi di H sono diversi da 0? E proprio qui il nocciolo della questione:hij 6= 0 se e solo se esiste il link j → i. Ma, in generale, i link esistenti tra le pagine web sono molto menodi tutti quelli possibili. Questo si traduce nel fatto che molti elementi di H sono 0 e che quindi H ha pochielementi diversi da 0, numero che abbiamo chiamato nnz in Sezione 2.5. Qui vale esattamente lo stessodiscorso fatto alla fine di quest’ultima: il costo ad ogni passo del prodotto matrice-vettore e O(nnz) e nonpiu O(n2). Questa ragione e alla base della ragguardevole riduzione del costo computazionale, dato cheper il WWW, il numero di link esistenti nnz e di gran lunga inferiore al quadrato del numero delle pagineweb. In un’altra salsa, ogni pagina ha ben pochi link rispetto al totale delle pagine.
Esempio 13 Per il WWW di Figura 9, la matrice H risulta avere n2 = 16 elementi, di cui solo nnz = 7diversi da 0 (meno della meta). 7 e ovviamente il numero totale di link esistenti, come si puo verificareosservando il grafo associato.
Esempio 14 Come esempio reale, riportiamo in Figura 10 una rappresentazione della matrice H per ilWWW sottostante la pagina http://www.harvard.edu, punto di accesso della Harvard University.In tale rappresentazione, ogni punto colorato e un elemento diverso da 0 della matrice, ovvero un link.Come si evince a colpo d’occhio, i link esistenti sono davvero pochi. Infatti si contano n = 500 pagine,con un totale di nnz = 2636 link (notare che n2 = 250000, circa 1000 volte tanto!).
Ma quanto vale nnz per il WWW reale? Per abbozzare una stima (ma come ordine di grandezzanon andremo molto distanti), ci basiamo sul fatto che, mediamente, una pagina ha pochi link entranti.
39
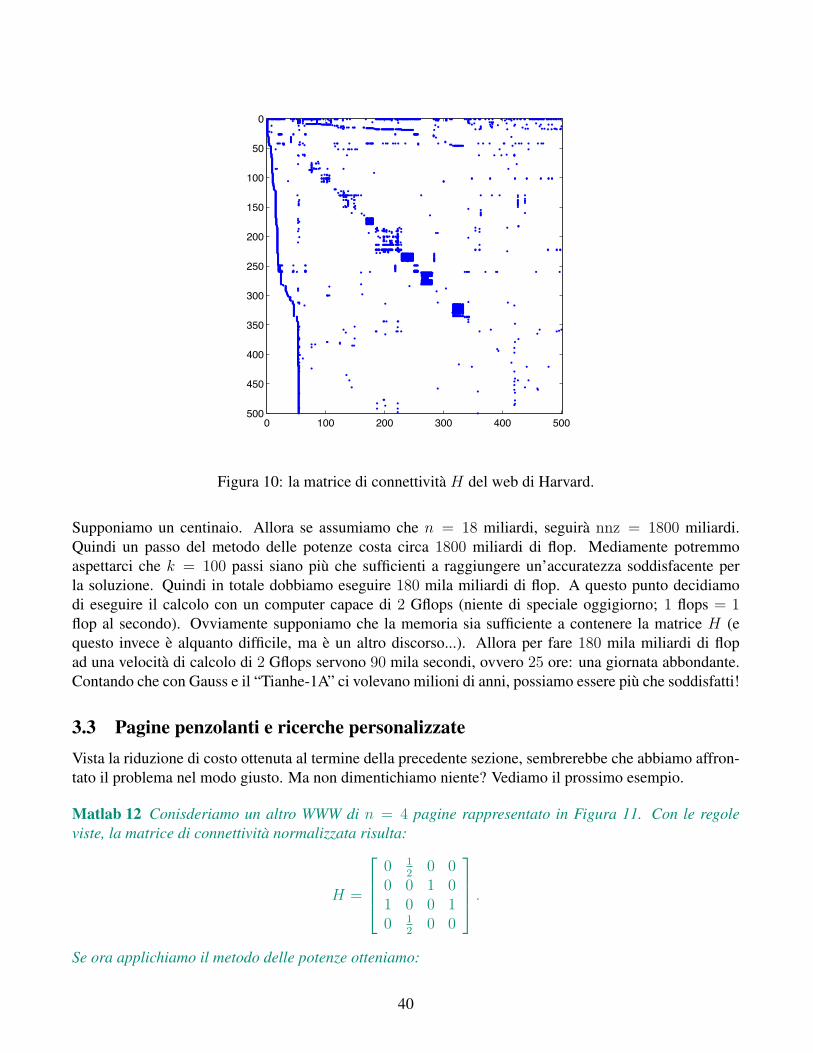
0 100 200 300 400 500
0
50
100
150
200
250
300
350
400
450
500
Figura 10: la matrice di connettivita H del web di Harvard.
Supponiamo un centinaio. Allora se assumiamo che n = 18 miliardi, seguira nnz = 1800 miliardi.Quindi un passo del metodo delle potenze costa circa 1800 miliardi di flop. Mediamente potremmoaspettarci che k = 100 passi siano piu che sufficienti a raggiungere un’accuratezza soddisfacente perla soluzione. Quindi in totale dobbiamo eseguire 180 mila miliardi di flop. A questo punto decidiamodi eseguire il calcolo con un computer capace di 2 Gflops (niente di speciale oggigiorno; 1 flops = 1flop al secondo). Ovviamente supponiamo che la memoria sia sufficiente a contenere la matrice H (equesto invece e alquanto difficile, ma e un altro discorso...). Allora per fare 180 mila miliardi di flopad una velocita di calcolo di 2 Gflops servono 90 mila secondi, ovvero 25 ore: una giornata abbondante.Contando che con Gauss e il “Tianhe-1A” ci volevano milioni di anni, possiamo essere piu che soddisfatti!
3.3 Pagine penzolanti e ricerche personalizzateVista la riduzione di costo ottenuta al termine della precedente sezione, sembrerebbe che abbiamo affron-tato il problema nel modo giusto. Ma non dimentichiamo niente? Vediamo il prossimo esempio.
Matlab 12 Conisderiamo un altro WWW di n = 4 pagine rappresentato in Figura 11. Con le regoleviste, la matrice di connettivita normalizzata risulta:
H =
0 1
20 0
0 0 1 01 0 0 10 1
20 0
.Se ora applichiamo il metodo delle potenze otteniamo:
40

>> H=[0 1/2 0 0;0 0 1 0;1 0 0 1;0 1/2 0 0]H =
0 0.5000 0 00 0 1.0000 0
1.0000 0 0 1.00000 0.5000 0 0
>> x=[1/4;1/4;1/4;1/4]x =
0.25000.25000.25000.2500
>> k=0;>> k=k+1,e=norm(H*x-x),x=H*xk =
1e =
0.3062x =
0.12500.25000.50000.1250
>> k=k+1,e=norm(H*x-x),x=H*xk =
2e =
0.3536x =
0.12500.50000.25000.1250
>> k=k+1,e=norm(H*x-x),x=H*xk =
3e =
0.3062x =
0.25000.25000.25000.2500
>> k=k+1,e=norm(H*x-x),x=H*xk =
41

4e =
0.3062x =
0.12500.25000.50000.1250
>> k=k+1,e=norm(H*x-x),x=H*xk =
5e =
0.3536x =
0.12500.50000.25000.1250
>> k=k+1,e=norm(H*x-x),x=H*xk =
6e =
0.3062x =
0.25000.25000.25000.2500
>> k=k+1,e=norm(H*x-x),x=H*xk =
7e =
0.3062x =
0.12500.25000.50000.1250
>> k=k+1,e=norm(H*x-x),x=H*xk =
8e =
0.3536x =
0.1250
42

0.50000.25000.1250
>> k=k+1,e=norm(H*x-x),x=H*xk =
9e =
0.3062x =
0.25000.25000.25000.2500
>> k=k+1,e=norm(H*x-x),x=H*xk =
10e =
0.3062x =
0.12500.25000.50000.1250
>> k=k+1,e=norm(H*x-x),x=H*xk =
11e =
0.3536x =
0.12500.50000.25000.1250
Si osserva dunque che dopo ogni 3 passi ci si ritrova al punto di partenza. Lo si vede meglio in Tabella 2.
Il WWW dell’esempio precedente e rappresentato da una matrice H per la quale il metodo dellepotenze entra in un ciclo (di periodo 3). Eppure soddisfa a tutte le ipotesi che abbiamo assunto. None dunque vero che tali ipotesi sono sufficienti a garantire quella che si chiama convergenza del metodo,ovvero il fatto che aumentando il numero di iterazioni ci si avvicina sempre piu alla soluzione esatta, unconcetto di limite:
limk→∞
x(k) = x.
C’e poi un ulteriore problema: l’ipotesi che abbiamo fatto in partenza, cioe che ogni pagina abbiaalmeno un link in ingresso e uno in uscita (ini 6= 0 e outj 6= 0) non e affatto veritiera. Esistono infattinel WWW reale molte pagine che non hanno link entranti (ini = 0) e molte pagine che non hanno linkuscenti (outj = 0). Anzi, sono la maggior parte. Questo si traduce in una matrice di connettivita C con
43
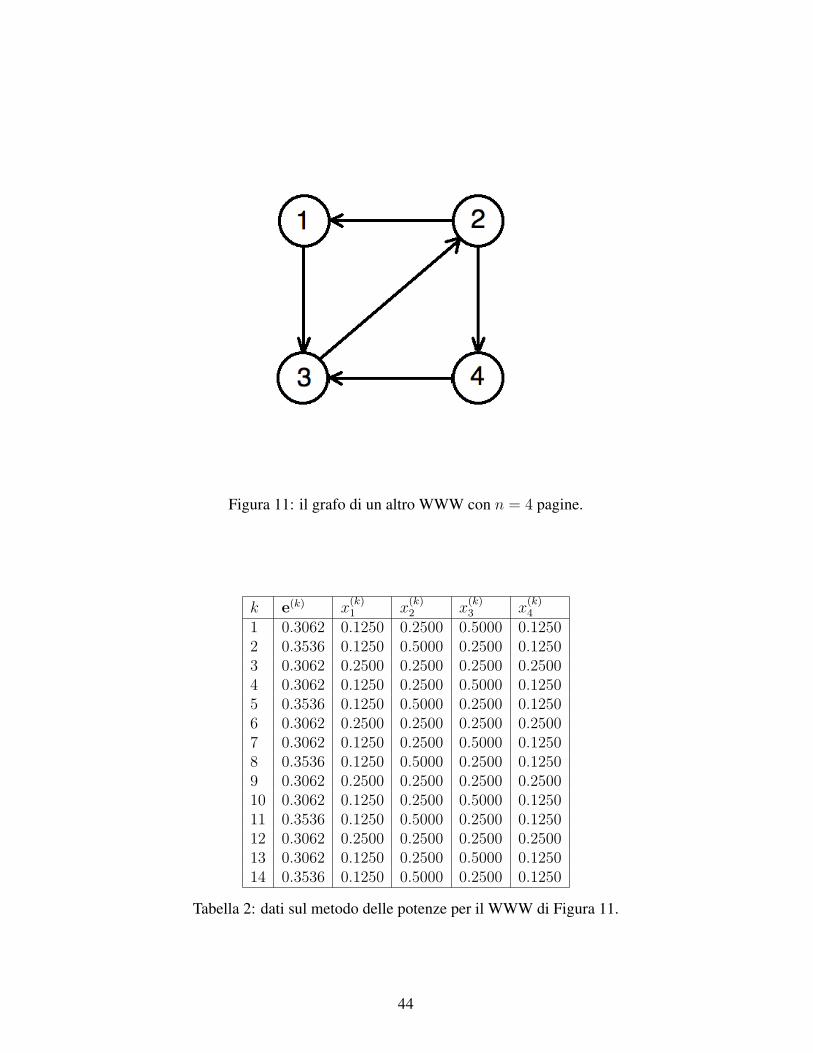
Figura 11: il grafo di un altro WWW con n = 4 pagine.
k e(k) x(k)1 x
(k)2 x
(k)3 x
(k)4
1 0.3062 0.1250 0.2500 0.5000 0.12502 0.3536 0.1250 0.5000 0.2500 0.12503 0.3062 0.2500 0.2500 0.2500 0.25004 0.3062 0.1250 0.2500 0.5000 0.12505 0.3536 0.1250 0.5000 0.2500 0.12506 0.3062 0.2500 0.2500 0.2500 0.25007 0.3062 0.1250 0.2500 0.5000 0.12508 0.3536 0.1250 0.5000 0.2500 0.12509 0.3062 0.2500 0.2500 0.2500 0.250010 0.3062 0.1250 0.2500 0.5000 0.125011 0.3536 0.1250 0.5000 0.2500 0.125012 0.3062 0.2500 0.2500 0.2500 0.250013 0.3062 0.1250 0.2500 0.5000 0.125014 0.3536 0.1250 0.5000 0.2500 0.1250
Tabella 2: dati sul metodo delle potenze per il WWW di Figura 11.
44

intere righe o intere colonne vuote (cioe di soli zeri). In particolare, le pagine che non hanno link uscentisi chiamano anche penzolanti (in analogia con la rappresentazione del relativo grafo). Se pensiamo almodello del navigatore virtuale, questo non funziona piu: navigando solo tramite link, se si visita unapagina penzolante vi si rimane incastrati per sempre.
Per risolvere entrambi i problemi appena menzionati, gli ideatori di Google hanno scelto una “scor-ciatoia” che consiste nell’assicurarsi
• da una parte di non bloccare il navigatore virtuale durante la sua random walk;
• dall’altra di soddisfare ad ipotesi matematiche che garantiscono la convergenza del metodo dellepotenze (per qualunque scelta del vettore pagerank iniziale x(0)).
Tale duplice obiettivo viene raggiunto andando a modificare la matrice originale eliminando tutti gli zeripresenti (NB: questo non e necessario, ma e sufficiente), quindi creando una matrice sempre stocastica (acolonne) ma con elementi tutti strettamente positivi. L’operazione viene fatta in due passi partendo dallamatrice H .
Il primo passo (daH adH ′) serve ad eliminare le pagine penzolanti. Se la matrice originaleH presentadelle colonne vuote, allora queste vengono riempite ovunque con 1/n. Quindi, partendo dalla matrice Ccostruita come al solito, si ottiene direttamente H ′ come
h′ij =
cij
outj
se outj 6= 0
1
nse outj = 0.
Cosı siamo sicuri di non bloccare il navigatore virtuale: se ad un dato istante questi si trova su una paginacon link uscenti, allora ne sceglie uno a caso (quindi probabilita 1/outj) , altrimenti immette un nuovoindirizzo nella barra degli strumenti, sempre a caso (quindi probabilita 1/n dato che ci sono n possibilita).
Esempio 15 Per il WWW di Figura 12 (lo stesso di Figura 9, ma con il collegamento 1→ 3 rimosso), lamatrice H originale sarebbe
H =
0 1
30 0
0 0 12
10 1
30 0
0 13
12
0
.La pagina 1 e penzolante, infatti la corrispondente colonna di H e vuota. Seguendo la regola appenaspiegata, si modifica H in H ′ aggiungendo 1/4 su tutta la prima colonna:
H ′ =
14
13
0 014
0 12
114
13
0 014
13
12
0
.Il secondo passo (da H ′ ad H ′′) serve ad assicurarci la convergenza del metodo delle potenze. Per
realizzarlo togliamo gli zeri rimanenti di H ′ nel seguente modo. Scegliamo un numero α ∈ [0, 1], cheesprime una probabilita. Imponiamo quindi al navigatore virtuale
• con probabilita α di comportarsi come prima, cioe secondo H ′;
45

Figura 12: il grafo di un WWW con n = 4 pagine, di cui una penzolante.
• con probabilita 1− α di immettere invece un indirizzo a caso (probabilita 1/n), indipendentementedalla presenza o meno di link uscenti.
Certamente questo modello e piu aderente alla navigazione sul WWW reale: infatti, le possibilita dinavigazione offerte all’utente si riducono proprio a muoversi attraverso i link o a digitare nuovi indirizziindipendentemente dalla presenza o meno di link uscenti. Matematicamente, la nuova matrice H ′′ siottiene da H ′ come
h′′ij = αh′ij + (1− α)1
n.
Osserviamo che in questo secondo passo stiamo semplicemente aggiungendo la quantita costante (1 −α)/n in ogni posizione della matrice αH ′. Quindi:
H ′′ = αH ′ + (1− α)
1n
1n· · · 1
n1n
1n· · · 1
n...
... . . . ...1n
1n· · · 1
n
= αH ′ +1− αn
1 1 · · · 11 1 · · · 1...
... . . . ...1 1 · · · 1
.Ma come possiamo esprimere diversamente una matrice con tutti 1? Lo possiamo fare costruendo il
46

vettore colonna
u =
11...1
e facendo il prodotto righe-colonne di questo (colonna: u ∈ Rn×1), con il suo trasposto (riga: uT ∈ R1×n),ottenendo appunto la matrice Rn×n di tutti 1:
uuT =
11...1
[ 1 1 · · · 1]
=
1 1 · · · 11 1 · · · 1...
... . . . ...1 1 · · · 1
.Osservate che per quest’ultimo passaggio non abbiamo fatto altro che applicare il prodotto righe-colonnead un vettore colonna per uno riga, cioe il contrario del prodotto scalare, che corrisponde al prodottorighe-colonne di un vettore riga per uno colonna. Abbiamo cosı chiuso la questione lasciata in sospesoalla fine della Sezione 2.2.
Applichiamo quanto appena visto al passaggio da H ′ ad H ′′, ottenendo cosı
H ′′ = αH ′ + (1− α)uuT
n.
Riassumendo, questa formula ci dice che il navigatore virtuale esce da una certa pagina secondo H ′ conprobabilita α o immettendo un nuovo indirizzo a caso con probabilita 1− α.
Ma quanto vale α? Google dichiara di utilizzare α = 0.85. Aldila che questo sia vero o meno, certo eche se α = 0, allora il navigatore si muove sempre immettendo indirizzi nuovi a caso:
H ′′ =uuT
n,
mentre se α = 1 il navigatore si muove sempre secondo H ′:
H ′′ = H ′,
cioe secondo i link esistenti, o immettendo un indirizzo nuovo a caso solo se la pagina in cui si trova epenzolante. Potremmo dunque affermare che una scelta di α prossimo a uno e senz’altro piu fedele allarealta. Ma la questione non finisce qui come vedremo.
Esempio 16 Riprendiamo la matrice
H ′ =
14
13
0 014
0 12
114
13
0 014
13
12
0
.associata al WWW di Figura 12 e supponiamo α = 0.85. Otteniamo allora
H ′′ = 0.85
14
13
0 014
0 12
114
13
0 014
13
12
0
+ 0.15
14
14
14
14
14
14
14
14
14
14
14
14
14
14
14
14
'
0.25 0.32 0.04 0.040.25 0.04 0.46 0.880.25 0.32 0.04 0.040.25 0.32 0.46 0.04
.47

Osserviamo come la matrice finale H ′′ rimane stocastica (a colonne). Il suo significato finale non cambiarimanendo sempre una matrice di transizione di probabilita: ad esempio, l’elemento h23 = 0.46 in riga 2e colonna 3 indica che il passaggio dalla pagina 3 alla pagina 2 avviene con il 46% di probabilita.
Matlab 13 Con Matlab:
>> H=[0,1/3,1/2,0;0,0,0,1;0,1/3,1/2,0;0,1/3,0,0]H =
0 0.3333 0.5000 00 0 0 1.00000 0.3333 0.5000 00 0.3333 0 0
>> u=ones(n,1)u =
1111
>> H1=H;H1(:,1)=u/nH1 =
0.2500 0.3333 0.5000 00.2500 0 0 1.00000.2500 0.3333 0.5000 00.2500 0.3333 0 0
>> alfa=0.85;>> H2=alfa*H1+(1-alfa)*(u*u’)/nH2 =
0.2500 0.3208 0.4625 0.03750.2500 0.0375 0.0375 0.88750.2500 0.3208 0.4625 0.03750.2500 0.3208 0.0375 0.0375
Abbiamo usato anche la nuova istruzione ones, il cui significato dovrebbe risultare chiaro. Cosa piuimportante, osserviamo come Matlab esegue qualunque prodotto con “*”, arrangiandosi a capire se stamoltiplicando scalari, vettori o matrici (e se questo si puo fare!).
Ora, provate voi ad eseguire il metodo delle potenze sulla matrice H ′′.
Nell’esempio precedente vi e stato chiesto di applicare il metodo delle potenze alla matriceH ′′. Osser-viamo pero che questa non ha nemmeno uno zero. Quindi il costo che paghiamo e O(kn2) flop. Abbiamodunque perso tutto quanto avevamo guadagnato prima?
La risposta e fortunatamente negativa. Basta solo ragionare e non agire di fretta. Supponiamo alloradi aver gia costruito H ′ e riconsideriamo la matrice
H ′′ = αH ′ + (1− α)uuT
n.
48

Il metodo delle potenze diventa, assegnato x(0),
x(k) = H ′′x(k−1), k = 1, 2, . . . .
Ma abbiamo visto che, essendo H ′′ priva di zeri, paghiamo il costo pieno. Se invece sostituiamo l’espres-sione diH ′′ nel generico passo del metodo e applichiamo le proprieta distributiva ed associativa (Esercizio5 per le matrici, ma vale anche per i vettori ovviamente!) otteniamo
x(k) =
(αH ′ + (1− α)
uuT
n
)x(k−1)
= αH ′x(k−1) + (1− α)(uuT )x(k−1)
n
= αH ′x(k−1) + (1− α)u(uTx(k−1))
n, k = 1, 2, . . . .
Ma quanto vale uTx(k−1)? Vediamo:
uTx(k−1) =[
1 1 · · · 1]x
(k−1)1
x(k−1)2
...x
(k−1)n
= x(k−1)1 + x
(k−1)2 + · · ·+ x(k−1)
n ,
quindi questo prodotto (scalare) mi restituisce semplicemente la somma del pagerank di tutto il WWW alpasso k − 1: il pagerank totale. Per capire quanto vale, ci vuole ancora un po’ di attenzione. Se x risolveil problema originale
x = H ′′x
allora anche ax risolve lo stesso problema per qualunque numero scalare a, infatti
H ′′(ax) = aH ′′x = ax.
Questo vuol dire che se x e soluzione, allora lo sono anche tutti i vettori paralleli ad x. Dal punto divista del nostro problema non ha importanza: se il vettore x ha le componenti in una certa proporzione,allora tale proporzione non cambia se prendo un vettore parallelo ad x. Quindi l’importanza relativa dellepagine e sempre la stessa, ed e giusto quello che a noi interessa! Allora, se dobbiamo scegliere uno tratutti questi vettori paralleli, prendiamo per semplicita quello le cui componenti si sommano a 1, ovveroquello per cui il pagerank totale e 1. Segue quindi
1 = x(k−1)1 + x
(k−1)2 + · · ·+ x(k−1)
n = uTx(k−1).
Sostituendo nel generico passo del metodo delle potenze si ottiene infine
x(k) = αH ′x(k−1) + (1− α)u(uTx(k−1))
n= αH ′x(k−1) + (1− α)
u
n, k = 1, 2, . . . .
La precedente formula ci dice che ciascun passo e composto da un prodotto matrice-vettore (il primoaddendo) a cui sommiamo un altro vettore (il secondo addendo). La differenza e che cosı facendo ilprodotto matrice-vettore coinvolge la matrice H ′, la quale ha (di nuovo) tanti zeri, ripristinando dunque ilnotevole risparmio computazionale che avevamo raggiunto in precedenza! Ricordiamo che il costo finalee percio O(k · nnz), dove nnz e il numero totale di link esistenti (non proprio...perche?) e k il numero dipassi eseguiti con il metodo delle potenze.
49

Commento 5 La scelta di avere un pagerank totale unitario si presta a completare la metafora del navi-gatore virtuale: ciascuna componente xi, i = 1, 2, . . . , n, del vettore soluzione x rappresenta la probabi-lita di trovarsi sulla pagina i dopo un tempo di navigazione infinito. La soluzione rappresenta quello chesi dice stato stazionario della catena di Markov associata e ogni sua componente, sotto questo punto divista, e sicuramente un fedele indicatore dell’importanza della pagina considerata.
3.4 Pagerank finalmente?!Ora siamo pronti a raccogliere tutto quanto appreso finora in un codice Matlab. Ma questo lo dovete farevoi!
Prima pero dobbiamo imparare a scrivere un “programma” Matlab, quello che si chiama un m-filefunction: questo non e altro che un file di testo. Matlab ha il suo editor, altrimenti potete usare tranquil-lamente un notepad qualunque a patto che salviate il file con estensione “.m”. All’interno del corpo siscrivono le istruzioni che prevedete di eseguire, seguendo le regole di sintassi viste sinora senza alcunadifferenza. L’unica caratteristica che e necessario aggiungere riguarda la relazione Input-Output (I/O),e tutto questo viene inserito nella prima riga di testo, detta “intestazione”, che comincia obbligatoria-mente con la parola function. Supponiamo quindi di dover scrivere un m-file che implementa unalgoritmo di risoluzione di un problema che prende in Input i dati I1, I2, . . . , Ir e fornisce in Output i datiO1, O2, . . . , Os. Allora bastera scrivere come intestazione:
function [O1,O2,...,Os]=nome(I1,I2,...Is)
dove nome e il nome che daremo al file, quindi nome.m.
Matlab 14 Si consideri il problema di trovare le radici x1 ed x2 dell’equazione di secondo grado
ax2 + bx+ c = 0
assegnati i coefficienti a, b e c. Il codice Matlab radici.m riportato nel riquadro e un esempio di m-filefunction che risolve il problema. Si osservino le linee di commento 2, . . . , 5 precedute dal simbolo “%”.Risultano molto utili in quanto il testo del commento compare se al prompt di comando si usa l’istruzionehelp seguita dal nome del file:
>> help radici[x1,x2]=radici(a,b,c)calcola le radici x1 ed x2dell’equazione di secondo gradoaxˆ2+bx+c=0
Per eseguire bastera invece richiamare cio che segue la parola chiave function nel testo di radici.m, specificando ovviamente gli input, ad esempio:
>> [x1,x2]=radici(1,3,2)x1 =
-1x2 =
-2
50

1 f u n c t i o n [ x1 , x2 ]= r a d i c i ( a , b , c )2 % [ x1 , x2 ]= r a d i c i ( a , b , c )3 % c a l c o l a l e r a d i c i x1 ed x24 % d e l l ' e q u a z i o n e d i secondo grado5 % ax ˆ2+ bx+c =0 .6
7 D e l t a =b ˆ2 - 4* a * c ;8 x1 =( - b+ s q r t ( D e l t a ) ) / ( 2 * a ) ;9 x2 =( - b - s q r t ( D e l t a ) ) / ( 2 * a ) ;
Ora avete tutti gli ingredienti per costruire il vostro pagerank.m partendo da una qualunque matricedi connettivita non normalizzata: ad essere onesti non li avete proprio tutti, ma ci aspettiamo che facciatedelle domande! Nel frattempo vediamo qualche simulazione con quello gia scritto.
Esercizio 10 Costruite la matrice di connettivita non normalizzata associata al web rappresentato infigura 13 e testate il vostro prank.m calcolando il pagerank con il valore di default α = 0.85. Laclassifica di importanza deve risultare P1, P6, P2, P4, P3, P5.
P1 P4
P3
P2
P6P5
Figura 13: il web di dimensione 6 per l’esercizio 10.
Matlab 15 Testiamo pagerank.m sulla matrice del WWW di Harvard. Questa la possiamo caricare (eispezionare) come
>> load harvard>> whos
Name Size Bytes Class AttributesC 500x500 15184 logical sparse
51

Quindi la possiamo “dare in pasto” a pagerank.m come segue:
>> load harvard>> whos
Name Size Bytes Class AttributesC 500x500 15184 logical sparse
>> [x,ind,e,k]=pagerank(C,0.85,1e-5,100);
ottenendo l’intero vettore pagerank x ordinato dalla pagina piu importante alla meno importante (che nonriportiamo, essendo molto lungo), il vettore ind che contiene gli indici delle pagine ordinate secondo xed infine l’errore e ed il numero di passi fatti k. Possiamo ad esempio vedere chi sono le prime 10 pagineimportanti, l’errore e i passi con
>> ind(1:10),e,kans =
754531891511022255
e =8.7680e-006
k =28
Proviamo ora a ripetere l’eseprimento per diversi valori di α (sempre tra 0 e 1):
>> [x,ind,e,k]=pagerank(C,0.9,1e-5,100);>> ind(1:10),e,kans =
7545318915101
22276
e =8.9850e-006
52

k =38
>> [x,ind,e,k]=pagerank(C,0.8,1e-5,100);>> ind(1:10),e,kans =
754531815911022255
e =8.7392e-006
k =22
>> [x,ind,e,k]=pagerank(C,0.5,1e-5,100);>> ind(1:10),e,kans =
7545315189110222
3e =
3.4844e-006k =
10>> [x,ind,e,k]=pagerank(C,0.1,1e-5,100);>> ind(1:10),e,kans =
5453157189
53

α 0.9 0.85 0.8 0.5 0.1k 38 28 22 10 5
ind 7 7 7 7 5454 54 54 54 5353 53 53 53 1518 18 18 15 79 9 15 18 18
15 15 9 9 910 1 1 1 101 10 10 10 222
222 222 222 222 176 55 55 55 19
Tabella 3: dati sul metodo delle potenze per il WWW di Harvard al variare di α.
10222
119
e =7.0210e-007
k =5
Che cosa notate (Tabella 3)?
Dall’esempio precedente si osserva che piu α e prossimo ad 1, piu passi si devono compiere perraggiungere la stessa tolleranza. Contrariamente, piu α e prossimo a 0, meno passi si devono compiereper raggiungere la stessa tolleranza. Questo fatto indica che il metodo delle potenze e tanto piu velocequanto piu α e vicino a 0. Tutto cio puo essere dimostrato rigorosamente studiando la convergenza delmetodo, ma dovremmo introdurre i concetti di autovalore e di autovettore di una matrice...ma per questie meglio iscriversi all’universita!
D’altro canto possiamo notare che cambiando α cambia pure la classifica delle pagine. Quindi laquestione e alquanto delicata: da una parte vorremmo essere veloci (α prossimo a 0), dall’altra vorremmorestare fedeli al WWW reale (α prossimo a 1).
Affrontiamo infine un’ultima faccenda curiosa. Ricordiamo cha abbiamo modificato la matrice da H ′
ad H ′′ imponendo alla soluzione x di soddisfare a
x = αH ′x + (1− α)u(uTx)
n,
ovverox = αH ′x + (1− α)
u
n(8)
54

dato che
uTx =[
1 1 · · · 1]x1
x2...xn
= x1 + x2 + · · ·+ xn = 1.
Come abbiamo spiegato, questo equivale a scegliere tra tutti i vettori soluzione paralleli quello che fornisceun pagerank totale pari ad 1, il che e in accordo con la metafora del navigatore virtuale: deve infattimuoversi con probabilita 1 ad ogni istante. Come conseguenza si puo osservare che stiamo aggiungendoal comportamento secondo i link H ′ un comportamento con probabilita 1−α che coincide con immettereun nuovo indirizzo scelto a caso, ovvero con probabilita
ui
n=
1
n
per ogni pagina xi, i = 1, . . . , n. Questo corrisponde ad una scelta “democratica” o imparziale. Ed equella che porta ai risultati principali che si vedono in una normale ricerca con Google. Ma non e l’unica:cosa succede, infatti, se questo nuovo indirizzo non viene scelto cosı casualmente, ma “forzando” la sceltaverso una pagina piuttosto che un’altra? Matematicamente dovremmo sostituire le precedenti probabilitacon nuove probabilita, diciamo
pi
n
per la pagina xi, i = 1, . . . , n, con il vincolo che
n∑i=1
pi
n= 1
ovveron∑
i=1
pi = n
(come del resto accadeva per il vettore u). Cio equivale a modificare la (8) in
x = αH ′x + (1− α)p
n,
dove il vettorep =
[p1 p2 · · · pn
]Tdetto vettore di personalizzazione, permette appunto di forzare in qualche modo il calcolo del pagerankin modo da dare piu importanza a certe pagine piuttosto che ad altre, e questo a priori scegliendo oppor-tunamente i vari pesi p1, p2, etc.. Questo e quello che succede per i cosiddetti “link sponsorizzati” checompaiono evidenziati in cima (o a destra) della normale lista di risultati. Provate infatti a cercare la paro-la “automobile” su http://www.google.it/. E se proprio non siete stufi, provate pure a modificareil codice pagerank.m per adattarlo a questa nuova versione!
Esercizio 11 Modificate il vostro prank.m adottando la versione con vettore di personalizzazione p e,con riferimento al web rappresentato in figura 13, provate a scegliere p in modo tale da far risalire lapagina meno importante in classifica.
55

A Appendice: cifre significative, accuratezza e precisioneNel Commento 4 in Sezione 3.2 abbiamo spesso nominato il concetto di cifre significative. Brevemente,la cifra piu significativa e sempre la prima da sinistra diversa da zero, quella meno significativa e l’ultimaa destra (anche se zero): le cifre significative sono tutte quelle comprese tra queste (incluse).
Esempio 17 Il numero 0.034 ha solo 2 cifre significative (si puo scrivere infatti come 3.4× 10−2. Inveceil numero 0.0340 ne ha 3: anche l’ultimo zero e significativo.
Nella visualizzazione dei risultati Matlab abbiamo usato fino a 15 cifre dopo il punto decimale. Quindiun totale di 16 cifre significative (ad es. per mk). Servono tutte?
La risposta a questa apparentemente banale domanda richiede confidenza con i seguenti concetti:
• accuratezza: numero di cifre significative esatte;
• precisione: numero di cifre significative rappresentate.
In base a quanto appena definito, risulta inutile usare un’elevata precisione (tante cifre) in presenza diuna limitata accuratezza (poche esatte). In genere poi il vincolo e posto dalla precisione del dato menopreciso. Il seguente esempio servira a chiarire eventuali dubbi.
Esempio 18 Siano a = 1 e b = 3 e supponiamo di voler calcolare
c =
√a
b=
√1
3.
Il risultato corretto ec = 0.577350269189626 . . .
di cui rappresentiamo 15 cifre significative esatte. Quindi diremo che c e preciso alla 15a cifra (percherappresento 15 cifre significative) e altrettanto accurato (perche sono tutte e 15 corrette). Ad es.
c = 0.577350269183210 . . .
sarebbe parimenti preciso ma accurato solo alla 11a cifra (le ultime 4, in grassetto, sono errate).Supponiamo ora di calcolare prima
d =1
3' 0.33
rappresentando il risultato con una precisione di sole 2 cifre (a altrettanta accuratezza essendo entrambeesatte). Se ora calcoliamo c come
√d otteniamo√d = 0.574456264653803 . . .
con una precisione di 15 cifre. Peccato che l’accuratezza sia limitata a sole 2 cifre, ovvero la stessa deldato d. Quindi le cifre significative di
√d dalla 3a in poi (in grassetto) non sono affatto “significative”!
L’esempio precedente ci serve da monito per evitare un utilizzo sconsiderato delle numerose cifre chepossono uscire da una calcolatrice scientifica. Ricordate: l’accuratezza di un risultato e comunque limitatadal numero di cifre significative del dato meno preciso!
56

Matlab 16 Proviamo a vedere diversi formati di visualizzazione calcolando√
0.005:
>> format short>> sqrt(.005)ans =
0.0707>> format long>> sqrt(.005)ans =
0.070710678118655>> format long e>> sqrt(.005)ans =
7.071067811865475e-02
Come si vede dall’ultimo risultato Matlab fornisce sempre 15 cifre decimali significative, le quali sempli-cemente non sono tutte visibili negli altri formati pur essendo memorizzate nel calcolatore.
B Codici Pagerank realizzati
1 f u n c t i o n [ x , ind , e , k ]= prank (C , a l f a , TOL, kmax )2 % [ x , ind , e , k ]= prank (C , a l f a , TOL, kmax )3 % c a l c o l a i l p a g e r a n k x a s s o c i a t o a l l a m a t r i c e4 % d i c o n n e t i v i t a ' C a meno d i una t o l l e r n a z a TOL5 % con numero d i i t e r a z i o n i massimo kmax p e r i l6 % metodo d e l l e p o t e n z e . i n d e ' i l v e t t o r e d e g l i7 % i n d i c i d e l l e p a g i n e web r e l a t i v e a C o r d i n a t o8 % secondo i l p a g e r a n k x . e e ' l ' e r r o r e f i n a l e9 % e f f e t t i v o e k i l numero d i i t e r a z i o n i e s e g u i t e .
10
11 %0 v e r i f i c a d i s p a r s i t a '12 i f ¬ i s s p a r s e (C)13 d i s p ( 'ATTENZIONE : l a m a t r i c e d i c o n n e t t i v i t a ' ' non e ' ' s p a r s a ! ' )14 r e t u r n15 end16 %1 : i n i z i a l i z z a z i o n e17 n= s i z e (C , 1 ) ;%numero p a g i n e web18 u= ones ( n , 1 ) ;%v e t t o r e u n i t a r i o19 c=sum (C , 1 ) ; %numero o u t l i n k20 %2 : c o s t r u z i o n e m a t r i c e d i c o n n e t t i v i t a ' n o r m a l i z z a t a H121 H1= s p a r s e ( n , n ) ;22 f o r j =1 : n23 i f c ( j ) 6=024 H1 ( : , j )=C ( : , j ) / c ( j ) ;25 e l s e H1 ( : , j )= u / n ;26 end27 end28 %2 b i s : c o s t r u z i o n e ' g oog l e ma t r ix ' H2 ( non s e r v e p e r i l c a l c o l o ! ! )
57

29 H2= a l f a *H1+(1 - a l f a ) * ( u*u ' ) / n ;30 %3 : metodo p o t e n z e p e r c a l c o l o p a g e r a n k x31 k =0;32 xnew=u / n ;33 e =2*TOL;34 w h i l e ( e≥TOL)&( k≤kmax )35 k=k +1;36 xo ld =xnew ;37 xnew= a l f a *H1* xo ld +(1 - a l f a )* u / n ;38 e=norm ( xnew - xo ld ) ;39 end40 %4 : o u t p u t o r d i n a t o secondo p a g e r a n k x41 [ x , i n d ]= s o r t ( xnew , ' de scend ' ) ;42
43 %NB: i comandi t i p o ' s p a r s e ' s e r v o n o a non t e n e r c o n t o d e g l i z e r i44 %n e i c a l c o l i . Ad esempio H1= s p a r s e ( n , n ) c r e a una m a t r i c e nxn d i t u t t i z e r i45 %ma l a memorizza come s p a r s a : quando v i e n e m o d i f i c a t a n e l l e s u c c e s s i v e46 %i s t r u z i o n i , comunque g l i z e r i che r imangono ( t a n t i ! ) non s a r a n n o47 %c o n s i d e r a t i n e i c a l c o l i .
1 f u n c t i o n [ x , ind , e , k ]= p r a n k p e r s (C , p , a l f a , TOL, kmax )2 % [ x , ind , e , k ]= prank (C , p , a l f a , TOL, kmax )3 % c a l c o l a i l p a g e r a n k x a s s o c i a t o a l l a m a t r i c e4 % d i c o n n e t i v i t a ' C con v e t t o r e d i p e r s o n a l i z z a -5 % z i o n e p a meno d i una t o l l e r n a z a TOL6 % con numero d i i t e r a z i o n i massimo kmax p e r i l7 % metodo d e l l e p o t e n z e . i n d e ' i l v e t t o r e d e g l i8 % i n d i c i d e l l e p a g i n e web r e l a t i v e a C o r d i n a t o9 % secondo i l p a g e r a n k x . e e ' l ' e r r o r e f i n a l e
10 % e f f e t t i v o e k i l numero d i i t e r a z i o n i e s e g u i t e .11
12 %0 v e r i f i c a d i s p a r s i t a '13 i f ¬ i s s p a r s e (C)14 d i s p ( 'ATTENZIONE : l a m a t r i c e d i c o n n e t t i v i t a ' ' non e ' ' s p a r s a ! ' )15 r e t u r n16 end17 %1 : i n i z i a l i z z a z i o n e18 n= s i z e (C , 1 ) ;%numero p a g i n e web19 u= ones ( n , 1 ) ;%v e t t o r e u n i t a r i o20 c=sum (C , 1 ) ; %numero o u t l i n k21 %2 : c o s t r u z i o n e m a t r i c e d i c o n n e t t i v i t a ' n o r m a l i z z a t a H122 H1= s p a r s e ( n , n ) ;23 f o r j =1 : n24 i f c ( j ) 6=025 H1 ( : , j )=C ( : , j ) / c ( j ) ;26 e l s e H1 ( : , j )= u / n ;27 end28 end29 %2 b i s : c o s t r u z i o n e ' g oog l e ma t r ix ' H2 ( non s e r v e p e r i l c a l c o l o ! ! )30 H2= a l f a *H1+(1 - a l f a ) * ( p*u ' ) / n ;31 %3 : metodo p o t e n z e p e r c a l c o l o p a g e r a n k x32 k =0;33 xnew=u / n ;
58

34 e =2*TOL;35 w h i l e ( e≥TOL)&( k≤kmax )36 k=k +1;37 xo ld =xnew ;38 xnew= a l f a *H1* xo ld +(1 - a l f a )* p / n ;39 e=norm ( xnew - xo ld ) ;40 end41 %4 : o u t p u t o r d i n a t o secondo p a g e r a n k x42 [ x , i n d ]= s o r t ( xnew , ' de scend ' ) ;43
44 %NB: i comandi t i p o ' s p a r s e ' s e r v o n o a non t e n e r c o n t o d e g l i z e r i45 %n e i c a l c o l i . Ad esempio H1= s p a r s e ( n , n ) c r e a una m a t r i c e nxn d i t u t t i z e r i46 %ma l a memorizza come s p a r s a : quando v i e n e m o d i f i c a t a n e l l e s u c c e s s i v e47 %i s t r u z i o n i , comunque g l i z e r i che r imangono ( t a n t i ! ) non s a r a n n o48 %c o n s i d e r a t i n e i c a l c o l i .
Riferimenti bibliografici[1] C. Moler. Numerical computing with MATLAB. 2004. Freely available at http://www.
mathworks.com/moler/index_ncm.html.
[2] C. Moler. Experiments with MATLAB. 2008. Freely available at http://www.mathworks.com/moler/index_exm.html.
[3] L. Page, S. Brin, R. Motwani, and T. Winograd. The pagerank citation ranking: Bringing order to theweb. Technical Report 1999-66, Stanford InfoLab, November 1999. Previous number = SIDL-WP-1999-0120.
59