learning to detect hedges and their scope in natural language text
TRANSCRIPT

Proceedings of the Fourteenth Conference on Computational Natural Language Learning: Shared Task, pages 1–12,Uppsala, Sweden, 15-16 July 2010. c©2010 Association for Computational Linguistics
The CoNLL 2010 Shared Task: Learning to Detect Hedges and theirScope in Natural Language Text
Richard Farkas1,2, Veronika Vincze1, Gyorgy Mora1, Janos Csirik1,2, Gyorgy Szarvas3
1 University of Szeged, Department of Informatics2 Hungarian Academy of Sciences, Research Group on Artificial Intelligence3 Technische Universitat Darmstadt, Ubiquitous Knowledge Processing Lab{rfarkas,vinczev,gymora,csirik}@inf.u-szeged.hu,
AbstractThe CoNLL 2010 Shared Task was dedi-cated to the detection of uncertainty cuesand their linguistic scope in natural lan-guage texts. The motivation behind thistask was that distinguishing factual anduncertain information in texts is of essen-tial importance in information extraction.This paper provides a general overviewof the shared task, including the annota-tion protocols of the training and evalua-tion datasets, the exact task definitions, theevaluation metrics employed and the over-all results. The paper concludes with ananalysis of the prominent approaches andan overview of the systems submitted tothe shared task.
1 Introduction
Every year since 1999, the Conference on Com-putational Natural Language Learning (CoNLL)provides a competitive shared task for the Com-putational Linguistics community. After a five-year period of multi-language semantic role label-ing and syntactic dependency parsing tasks, a newtask was introduced in 2010, namely the detectionof uncertainty and its linguistic scope in naturallanguage sentences.
In natural language processing (NLP) – and inparticular, in information extraction (IE) – manyapplications seek to extract factual informationfrom text. In order to distinguish facts from unre-liable or uncertain information, linguistic devicessuch as hedges (indicating that authors do notor cannot back up their opinions/statements withfacts) have to be identified. Applications shouldhandle detected speculative parts in a differentmanner. A typical example is protein-protein in-teraction extraction from biological texts, wherethe aim is to mine text evidence for biological enti-ties that are in a particular relation with each other.
Here, while an uncertain relation might be of someinterest for an end-user as well, such informationmust not be confused with factual textual evidence(reliable information).
Uncertainty detection has two levels. Auto-matic hedge detectors might attempt to identifysentences which contain uncertain informationand handle whole sentences in a different man-ner or they might attempt to recognize in-sentencespans which are speculative. In-sentence uncer-tainty detection is a more complicated task com-pared to the sentence-level one, but it has bene-fits for NLP applications as there may be spanscontaining useful factual information in a sentencethat otherwise contains uncertain parts. For ex-ample, in the following sentence the subordinatedclause starting with although contains factual in-formation while uncertain information is includedin the main clause and the embedded question.
Although IL-1 has been reported to con-tribute to Th17 differentiation in mouseand man, it remains to be determined{whether therapeutic targeting of IL-1will substantially affect IL-17 in RA}.
Both tasks were addressed in the CoNLL 2010Shared Task, in order to provide uniform manu-ally annotated benchmark datasets for both and tocompare their difficulties and state-of-the-art so-lutions for them. The uncertainty detection prob-lem consists of two stages. First, keywords/cuesindicating uncertainty should be recognized theneither a sentence-level decision is made or the lin-guistic scope of the cue words has to be identified.The latter task falls within the scope of semanticanalysis of sentences exploiting syntactic patterns,as hedge spans can usually be determined on thebasis of syntactic patterns dependent on the key-word.
1

2 Related Work
The term hedging was originally introduced byLakoff (1972). However, hedge detection has re-ceived considerable interest just recently in theNLP community. Light et al. (2004) used a hand-crafted list of hedge cues to identify specula-tive sentences in MEDLINE abstracts and severalbiomedical NLP applications incorporate rules foridentifying the certainty of extracted information(Friedman et al., 1994; Chapman et al., 2007; Ara-maki et al., 2009; Conway et al., 2009).
The most recent approaches to uncertainty de-tection exploit machine learning models that uti-lize manually labeled corpora. Medlock andBriscoe (2007) used single words as input featuresin order to classify sentences from biological ar-ticles (FlyBase) as speculative or non-speculativebased on semi-automatically collected training ex-amples. Szarvas (2008) extended the methodologyof Medlock and Briscoe (2007) to use n-gram fea-tures and a semi-supervised selection of the key-word features. Kilicoglu and Bergler (2008) pro-posed a linguistically motivated approach basedon syntactic information to semi-automatically re-fine a list of hedge cues. Ganter and Strube (2009)proposed an approach for the automatic detec-tion of sentences containing uncertainty based onWikipedia weasel tags and syntactic patterns.
The BioScope corpus (Vincze et al., 2008) ismanually annotated with negation and specula-tion cues and their linguistic scope. It consistsof clinical free-texts, biological texts from full pa-pers and scientific abstracts. Using BioScope fortraining and evaluation, Morante and Daelemans(2009) developed a scope detector following a su-pervised sequence labeling approach while Ozgurand Radev (2009) developed a rule-based systemthat exploits syntactic patterns.
Several related works have also been publishedwithin the framework of The BioNLP’09 SharedTask on Event Extraction (Kim et al., 2009), wherea separate subtask was dedicated to predictingwhether the recognized biological events are un-der negation or speculation, based on the GENIAevent corpus annotations (Kilicoglu and Bergler,2009; Van Landeghem et al., 2009).
3 Uncertainty Annotation Guidelines
The shared task addressed the detection of uncer-tainty in two domains. As uncertainty detectionis extremely important for biomedical information
extraction and most existing approaches have tar-geted such applications, participants were askedto develop systems for hedge detection in bio-logical scientific articles. Uncertainty detectionis also important, e.g. in encyclopedias, wherethe goal is to collect reliable world knowledgeabout real-world concepts and topics. For exam-ple, Wikipedia explicitly declares that statementsreflecting author opinions or those not backed upby facts (e.g. references) should be avoided (see3.2 for details). Thus, the community-edited en-cyclopedia, Wikipedia became one of the subjectsof the shared task as well.
3.1 Hedges in Biological Scientific ArticlesIn the biomedical domain, sentences were manu-ally annotated for both hedge cues and their lin-guistic scope. Hedging is typically expressed byusing specific linguistic devices (which we refer toas cues in this article) that modify the meaning orreflect the author’s attitude towards the content ofthe text. Typical hedge cues fall into the followingcategories:
• auxiliaries: may, might, can, would, should,could, etc.
• verbs of hedging or verbs with speculativecontent: suggest, question, presume, suspect,indicate, suppose, seem, appear, favor, etc.
• adjectives or adverbs: probable, likely, possi-ble, unsure, etc.
• conjunctions: or, and/or, either . . . or, etc.
However, there are some cases where a hedge isexpressed via a phrase rather than a single word.Complex keywords are phrases that express un-certainty together, but not on their own (either thesemantic interpretation or the hedging strength ofits subcomponents are significantly different fromthose of the whole phrase). An instance of a com-plex keyword can be seen in the following sen-tence:
Mild bladder wall thickening {raisesthe question of cystitis}.
The expression raises the question of may be sub-stituted by suggests and neither the verb raises northe noun question convey speculative meaning ontheir own. However, the whole phrase is specula-tive therefore it is marked as a hedge cue.
2

During the annotation process, a min-max strat-egy for the marking of keywords (min) and theirscope (max) was followed. On the one hand, whenmarking the keywords, the minimal unit that ex-presses hedging and determines the actual strengthof hedging was marked as a keyword. On the otherhand, when marking the scopes of speculative key-words, the scope was extended to the largest syn-tactic unit possible. That is, all constituents thatfell within the uncertain interpretation were in-cluded in the scope. Our motivation here was thatin this way, if we simply disregard the marked textspan, the rest of the sentence can usually be usedfor extracting factual information (if there is any).For instance, in the example above, we can be surethat the symptom mild bladder wall thickening isexhibited by the patient but a diagnosis of cystitiswould be questionable.
The scope of a speculative element can be de-termined on the basis of syntax. The scopes ofthe BioScope corpus are regarded as consecutivetext spans and their annotation was based on con-stituency grammar. The scope of verbs, auxil-iaries, adjectives and adverbs usually starts rightwith the keyword. In the case of verbal elements,i.e. verbs and auxiliaries, it ends at the end of theclause or sentence, thus all complements and ad-juncts are included. The scope of attributive ad-jectives generally extends to the following nounphrase, whereas the scope of predicative adjec-tives includes the whole sentence. Sentential ad-verbs have a scope over the entire sentence, whilethe scope of other adverbs usually ends at the endof the clause or sentence. Conjunctions generallyhave a scope over the syntactic unit whose mem-bers they coordinate. Some linguistic phenomena(e.g. passive voice or raising) can change scopeboundaries in the sentence, thus they were givenspecial attention during the annotation phase.
3.2 Wikipedia Weasels
The chief editors of Wikipedia have drawn the at-tention of the public to uncertainty issues they callweasel1. A word is considered to be a weaselword if it creates an impression that something im-portant has been said, but what is really commu-nicated is vague, misleading, evasive or ambigu-ous. Weasel words do not give a neutral accountof facts, rather, they offer an opinion without any
1http://en.wikipedia.org/wiki/Weasel_word
backup or source. The following sentence doesnot specify the source of information, it is just thevague term some people that refers to the holder ofthis opinion:
Some people claim that this results in abetter taste than that of other diet colas(most of which are sweetened with as-partame alone).
Statements with weasel words usually evoke ques-tions such as Who says that?, Whose opinion isthis? and How many people think so?.
Typical instances of weasels can be grouped inthe following way (we offer some examples aswell):
• Adjectives and adverbs
– elements referring to uncertainty: prob-able, likely, possible, unsure, often, pos-sibly, allegedly, apparently, perhaps,etc.
– elements denoting generalization:widely, traditionally, generally, broadly-accepted, widespread, etc.
– qualifiers and superlatives: global, su-perior, excellent, immensely, legendary,best, (one of the) largest, most promi-nent, etc.
– elements expressing obviousness:clearly, obviously, arguably, etc.
• Auxiliaries
– may, might, would, should, etc.
• Verbs
– verbs with speculative content and theirpassive forms: suggest, question, pre-sume, suspect, indicate, suppose, seem,appear, favor, etc.
– passive forms with dummy subjects: Itis claimed that . . . It has been men-tioned . . . It is known . . .
– there is / there are constructions: Thereis evidence/concern/indication that. . .
• Numerically vague expressions / quantifiers
– certain, numerous, many, most, some,much, everyone, few, various, one groupof, etc. Experts say . . . Some peoplethink . . . More than 60% percent . . .
3

• Nouns
– speculation, proposal, consideration,etc. Rumour has it that . . . Commonsense insists that . . .
However, the use of the above words or grammat-ical devices does not necessarily entail their beinga weasel cue since their use may be justifiable intheir contexts.
As the main application goal of weasel detec-tion is to highlight articles which should be im-proved (by reformulating or adding factual is-sues), we decided to annotate only weasel cuesin Wikipedia articles, but we did not mark theirscopes.
During the manual annotation process, the fol-lowing cue marking principles were employed.Complex verb phrases were annotated as weaselcues since in some cases, both the passive con-struction and the verb itself are responsible for theweasel. In passive forms with dummy subjects andthere is / there are constructions, the weasel cueincluded the grammatical subject (i.e. it and there)as well. As for numerically vague expressions, thenoun phrase containing a quantifier was markedas a weasel cue. If there was no quantifier (in thecase of a bare plural), the noun was annotated asa weasel cue. Comparatives and superlatives wereannotated together with their article. Anaphoricpronouns referring to a weasel word were also an-notated as weasel cues.
4 Task Definitions
Two uncertainty detection tasks (sentence clas-sification and in-sentence hedge scope detec-tion) in two domains (biological publications andWikipedia articles) with three types of submis-sions (closed, cross and open) were given to theparticipants of the CoNLL 2010 Shared Task.
4.1 Detection of Uncertain SentencesThe aim of Task1 was to develop automatic proce-dures for identifying sentences in texts which con-tain unreliable or uncertain information. In par-ticular, this task is a binary classification problem,i.e. factual and uncertain sentences have to be dis-tinguished.
As training and evaluation data
• Task1B: biological abstracts and full articles(evaluation data contained only full articles)from the BioScope corpus and
• Task1W: paragraphs from Wikipedia possi-bly containing weasel information
were provided. The annotation of weasel/hedgecues was carried out on the phrase level, and sen-tences containing at least one cue were consideredas uncertain, while sentences with no cues wereconsidered as factual. The participating systemshad to submit a binary classification (certain vs.uncertain) of the test sentences while marking cuesin the submissions was voluntary (but participantswere encouraged to do this).
4.2 In-sentence Hedge Scope Resolution
For Task2, in-sentence scope resolvers had to bedeveloped. The training and evaluation data con-sisted of biological scientific texts, in which in-stances of speculative spans – that is, keywordsand their linguistic scope – were annotated manu-ally. Submissions to Task2 were expected to auto-matically annotate the cue phrases and the left andright boundaries of their scopes (exactly one scopemust be assigned to a cue phrase).
4.3 Evaluation Metrics
The evaluation for Task1 was carried out at thesentence level, i.e. the cue annotations in the sen-tence were not taken into account. The Fβ=1 mea-sure (the harmonic mean of precision and recall)of the uncertain class was employed as the chiefevaluation metric.
The Task2 systems were expected to mark cue-and corresponding scope begin/end tags linked to-gether by using some unique IDs. A scope-levelFβ=1 measure was used as the chief evaluationmetric where true positives were scopes which ex-actly matched the gold standard cue phrases andgold standard scope boundaries assigned to the cueword. That is, correct scope boundaries with in-correct cue annotation and correct cue words withbad scope boundaries were both treated as errors.
This scope-level metric is very strict. For in-stance, the requirement of the precise match of thecue phrase is questionable as – from an applicationpoint of view – the goal is to find uncertain textspans and the evidence for this is not so impor-tant. However, the annotation of cues in datasetsis essential for training scope detectors since lo-cating the cues usually precedes the identificationof their scope. Hence we decided to incorporatecue matches into the evaluation metric.
4

Another questionable issue is the strict bound-ary matching requirement. For example, includ-ing or excluding punctuations, citations or somebracketed expressions, like (see Figure 1) froma scope is not crucial for an otherwise accuratescope detector. On the other hand, the list ofsuch ignorable phenomena is arguable, especiallyacross domains. Thus, we considered the strictboundary matching to be a straightforward and un-ambiguous evaluation criterion. Minor issues likethose mentioned above could be handled by sim-ple post-processing rules. In conclusion we thinkthat the uncertainty detection community may findmore flexible evaluation criteria in the future butthe strict scope-level metric is definitely a goodstarting point for evaluation.
4.4 Closed and Open Challenges
Participants were invited to submit results in dif-ferent configurations, where systems were allowedto exploit different kinds of annotated resources.The three possible submission categories were:
• Closed, where only the labeled and unla-beled data provided for the shared task wereallowed, separately for each domain (i.e.biomedical train data for biomedical test setand Wikipedia train data for Wikipedia testset). No further manually crafted resourcesof uncertainty information (i.e. lists, anno-tated data, etc.) could be used in any domain.On the other hand, tools exploiting the man-ual annotation of linguistic phenomena notrelated to uncertainty (such as POS taggersand parsers trained on labeled corpora) wereallowed.
• Cross-domain was the same as the closed onebut all data provided for the shared task wereallowed for both domains (i.e. Wikipediatrain data for the biomedical test set, thebiomedical train data for Wikipedia test setor a union of Wikipedia and biomedical traindata for both test sets).
• Open, where any data and/or any additionalmanually created information and resource(which may be related to uncertainty) wereallowed for both domains.
The motivation behind the cross-domain and theopen challenges was that in this way, we could
assess whether adding extra (i.e. not domain-specific) information to the systems can contributeto the overall performance.
5 Datasets
Training and evaluation corpora were annotatedmanually for hedge/weasel cues and their scopeby two independent linguist annotators. Any dif-ferences between the two annotations were laterresolved by the chief annotator, who was also re-sponsible for creating the annotation guidelinesand training the two annotators. The datasetsare freely available2 for further benchmark experi-ments at http://www.inf.u-szeged.hu/rgai/conll2010st.
Since uncertainty cues play an important rolein detecting sentences containing uncertainty, theyare tagged in the Task1 datasets as well to enhancetraining and evaluation of systems.
5.1 Biological Publications
The biological training dataset consisted of the bi-ological part of the BioScope corpus (Vincze et al.,2008), hence it included abstracts from the GE-NIA corpus, 5 full articles from the functional ge-nomics literature (related to the fruit fly) and 4 ar-ticles from the open access BMC Bioinformaticswebsite. The automatic segmentation of the doc-uments was corrected manually and the sentences(14541 in number) were annotated manually forhedge cues and their scopes.
The evaluation dataset was based on 15 biomed-ical articles downloaded from the publicly avail-able PubMedCentral database, including 5 ran-dom articles taken from the BMC Bioinformat-ics journal in October 2009, 5 random articles towhich the drosophila MeSH term was assignedand 5 random articles having the MeSH termshuman, blood cells and transcription factor (thesame terms which were used to create the Geniacorpus). These latter ten articles were also pub-lished in 2009. The aim of this article selectionprocedure was to have a theme that was close tothe training corpus. The evaluation set contained5003 sentences, out of which 790 were uncertain.These texts were manually annotated for hedgecues and their scope. To annotate the training andthe evaluation datasets, the same annotation prin-ciples were applied.
2under the Creative Commons Attribute Share Alike li-cense
5

For both Task1 and Task2, the same dataset wasprovided, the difference being that for Task1, onlyhedge cues and sentence-level uncertainty weregiven, however, for Task2, hedge cues and theirscope were marked in the text.
5.2 Wikipedia Datasets2186 paragraphs collected from Wikipediaarchives were also offered as Task1 trainingdata (11111 sentences containing 2484 uncertainones). The evaluation dataset contained 2346Wikipedia paragraphs with 9634 sentences, out ofwhich 2234 were uncertain.
For the selection of the Wikipedia paragraphsused to construct the training and evaluationdatasets, we exploited the weasel tags added bythe editors of the encyclopedia (marking unsup-ported opinions or expressions of a non-neutralpoint of view). Each paragraph containing weaseltags (5874 different ones) was extracted from thehistory dump of English Wikipedia. First, 438 ran-domly selected paragraphs were manually anno-tated from this pool then the most frequent cuephrases were collected. Later on, two other setsof Wikipedia paragraphs were gathered on the ba-sis of whether they contained such cue phrases ornot. The aim of this sampling procedure was toprovide large enough training and evaluation sam-ples containing weasel words and also occurrencesof typical weasel words in non-weasel contexts.
Each sentence was annotated manually forweasel cues. Sentences were treated as uncer-tain if they contained at least one weasel cue, i.e.the scope of weasel words was the entire sentence(which is supposed to be rewritten by Wikipediaeditors).
5.3 Unlabeled DataUnannotated but pre-processed full biological arti-cles (150 articles from the publicly available Pub-MedCentral database) and 1 million paragraphsfrom Wikipedia were offered to the participants aswell. These datasets did not contain any manualannotation for uncertainty, but their usage permit-ted data sampling from a large pool of in-domaintexts without time-wasting pre-processing tasks(cleaning and sentence splitting).
5.4 Data FormatBoth training and evaluation data were releasedin a custom XML format. For each task, a sep-arate XML file was made available containing the
whole document set for the given task. Evaluationdatasets were available in the same format as train-ing data without any sentence-level certainty, cueor scope annotations.
The XML format enabled us to provide moredetailed information about the documents such assegment boundaries and types (e.g. section titles,figure captions) and it is the straightforward for-mat to represent nested scopes. Nested scopeshave overlapping text spans which may containcues for multiple scopes (there were 1058 occur-rences in the training and evaluation datasets to-gether). The XML format utilizes id-referencesto determine the scope of a given cue. Nestedconstructions are rather complicated to representin the standard IOB format, moreover, we did notwant to enforce a uniform tokenization.
To support the processing of the data files,reader and writer software modules were devel-oped and offered to the participants for the uCom-pare (Kano et al., 2009) framework. uCompareprovides a universal interface (UIMA) and severaltext mining and natural language processing tools(tokenizers, POS taggers, syntactic parsers, etc.)for general and biological domains. In this wayparticipants could configure and execute a flexiblechain of analyzing tools even with a graphical UI.
6 Submissions and Results
Participants uploaded their results through theshared task website, and the official evaluation wasperformed centrally. After the evaluation period,the results were published for the participants onthe Web. A total of 23 teams participated in theshared task. 22, 16 and 13 teams submitted outputfor Task1B, Task1W and Task2, respectively.
6.1 Results
Tables 1, 2 and 3 contain the results of the submit-ted systems for Task1 and Task2. The last nameof the first author of the system description pa-per (published in these proceedings) is used hereas a system name3. The last column contains thetype of submission. The system of Kilicoglu andBergler (2010) is the only open submission. Theyadapted their system introduced in Kilicoglu andBergler (2008) to the datasets of the shared task.
Regarding cross submissions, Zhao et al. (2010)and Ji et al. (2010) managed to achieve a no-ticeable improvement by exploiting cross-domain
3Ozgur did not publish a description of her system.
6

Name P / R / F typeGeorgescul 72.0 / 51.7 / 60.2 CJi 62.7 / 55.3 / 58.7 XChen 68.0 / 49.7 / 57.4 CMorante 80.6 / 44.5 / 57.3 CZhang 76.6 / 44.4 / 56.2 CZheng 76.3 / 43.6 / 55.5 CTackstrom 78.3 / 42.8 / 55.4 CSanchez 68.3 / 46.2 / 55.1 CTang 82.3 / 41.4 / 55.0 CKilicoglu 67.9 / 46.0 / 54.9 OTjong Kim Sang 74.0 / 43.0 / 54.4 CClausen 75.1 / 42.0 / 53.9 COzgur 59.4 / 47.9 / 53.1 CZhou 85.3 / 36.5 / 51.1 CLi 88.4 / 31.9 / 46.9 CPrabhakaran 88.0 / 28.4 / 43.0 CJi 94.2 / 6.6 / 12.3 C
Table 1: Task1 Wikipedia results (type ∈{Closed(C), Cross(X), Open(O)}).
data. Zhao et al. (2010) extended the biologicalcue word dictionary of their system – using it asa feature for classification – by the frequent cuesof the Wikipedia dataset, while Ji et al. (2010)used the union of the two datasets for training(they have reported an improvement from 47.0 to58.7 on the Wikipedia evaluation set after a post-challenge bugfix).
Name P / R / F typeMorante 59.6 / 55.2 / 57.3 CRei 56.7 / 54.6 / 55.6 CVelldal 56.7 / 54.0 / 55.3 CKilicoglu 62.5 / 49.5 / 55.2 OLi 57.4 / 47.9 / 52.2 CZhou 45.6 / 43.9 / 44.7 OZhou 45.3 / 43.6 / 44.4 CZhang 46.0 / 42.9 / 44.4 CFernandes 46.0 / 38.0 / 41.6 CVlachos 41.2 / 35.9 / 38.4 CZhao 34.8 / 41.0 / 37.7 CTang 34.5 / 31.8 / 33.1 CJi 21.9 / 17.2 / 19.3 CTackstrom 2.3 / 2.0 / 2.1 C
Table 2: Task2 results (type ∈ {Closed(C),Open(O)}).
Each Task2 and Task1W system achieved a
Name P / R / F typeTang 85.0 / 87.7 / 86.4 CZhou 86.5 / 85.1 / 85.8 CLi 90.4 / 81.0 / 85.4 CVelldal 85.5 / 84.9 / 85.2 CVlachos 85.5 / 84.9 / 85.2 CTackstrom 87.1 / 83.4 / 85.2 CShimizu 88.1 / 82.3 / 85.1 CZhao 83.4 / 84.8 / 84.1 XOzgur 77.8 / 91.3 / 84.0 CRei 83.8 / 84.2 / 84.0 CZhang 82.6 / 84.7 / 83.6 CKilicoglu 92.1 / 74.9 / 82.6 OMorante 80.5 / 83.3 / 81.9 XMorante 81.1 / 82.3 / 81.7 CZheng 73.3 / 90.8 / 81.1 CTjong Kim Sang 74.3 / 87.1 / 80.2 CClausen 79.3 / 80.6 / 80.0 CSzidarovszky 70.3 / 91.0 / 79.3 CGeorgescul 69.1 / 91.0 / 78.5 CZhao 71.0 / 86.6 / 78.0 CJi 79.4 / 76.3 / 77.9 CChen 74.9 / 79.1 / 76.9 CFernandes 70.1 / 71.1 / 70.6 CPrabhakaran 67.5 / 19.5 / 30.3 X
Table 3: Task1 biological results (type ∈{Closed(C), Cross(X), Open(O)}).
higher precision than recall. There may be tworeasons for this. The systems may have appliedonly reliable patterns, or patterns occurring in theevaluation set may be imperfectly covered by thetraining datasets. The most intense participationwas on Task1B. Here, participants applied vari-ous precision/recall trade-off strategies. For in-stance, Tang et al. (2010) achieved a balanced pre-cision/recall configuration, while Li et al. (2010)achieved third place thanks to their superior preci-sion.
Tables 4 and 5 show the cue-level performances,i.e. the F-measure of cue phrase matching wheretrue positives were strict matches. Note that it wasoptional to submit cue annotations for Task1 (ifparticipants submitted systems for both Task2 andTask1B with cue tagging, only the better score ofthe two was considered).
It is interesting to see that Morante et al. (2010)who obtained the best results on Task2 achieveda medium-ranked F-measure on the cue-level (e.g.their result on the cue-level is lower by 4% com-
7

pared to Zhou et al. (2010), while on the scope-level the difference is 13% in the reverse direc-tion), which indicates that the real strength of thesystem of Morante et al. (2010) is the accurate de-tection of scope boundaries.
Name P / R / FTang 63.0 / 25.7 / 36.5Li 76.1 / 21.6 / 33.7Ozgur 28.9 / 14.7 / 19.5Morante 24.6 / 7.3 / 11.3
Table 4: Wikipedia cue-level results.
Name P / R / F typeTang 81.7 / 81.0 / 81.3 CZhou 83.1 / 78.8 / 80.9 CLi 87.4 / 73.4 / 79.8 CRei 81.4 / 77.4 / 79.3 CVelldal 81.2 / 76.3 / 78.7 CZhang 82.1 / 75.3 / 78.5 CJi 78.7 / 76.2 / 77.4 CMorante 78.8 / 74.7 / 76.7 CKilicoglu 86.5 / 67.7 / 76.0 OVlachos 82.0 / 70.6 / 75.9 CZhao 76.7 / 73.9 / 75.3 XFernandes 79.2 / 64.7 / 71.2 CZhao 63.7 / 74.1 / 68.5 CTackstrom 66.9 / 58.6 / 62.5 COzgur 49.1 / 57.8 / 53.1 C
Table 5: Biological cue-level results (type ∈{Closed(C), Cross(X), Open(O)}).
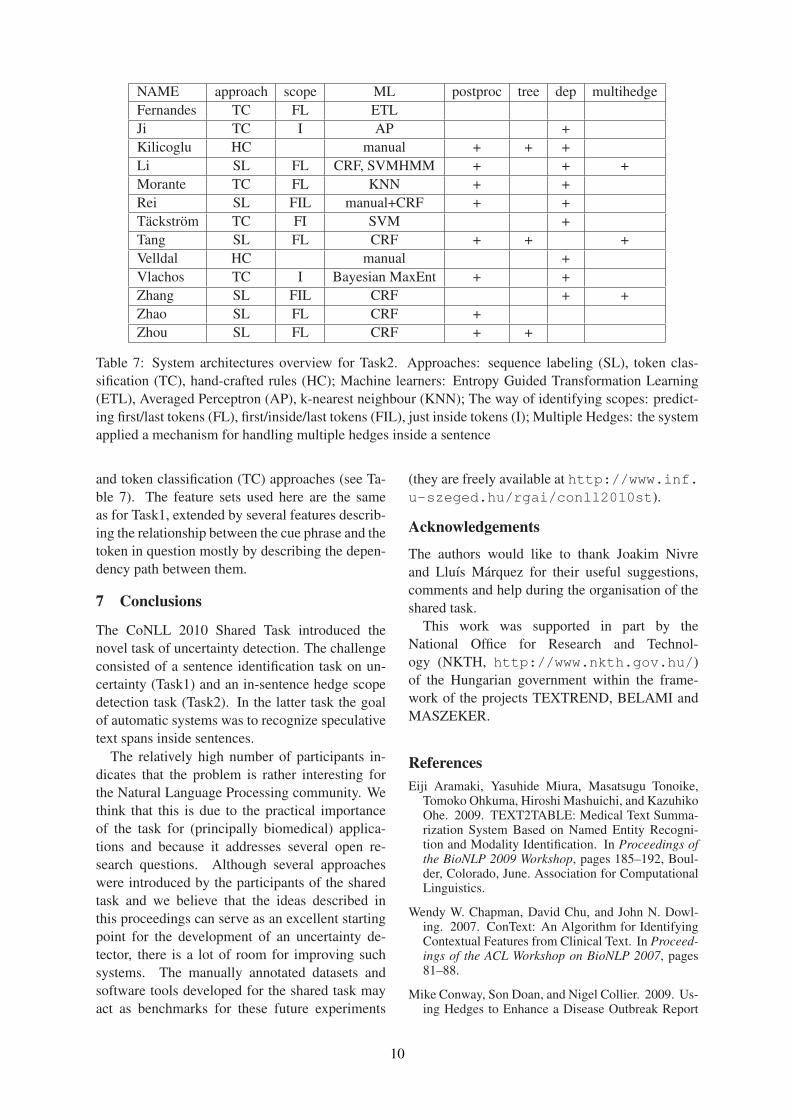
6.2 ApproachesThe approaches to Task1 fall into two major cat-egories. There were six systems which handledthe task as a classical sentence classification prob-lem and employed essentially a bag-of-words fea-ture representation (they are marked as BoW inTable 6). The remaining teams focused on thecue phrases and sought to classify every token ifit was a part of a cue phrase, then a sentence waspredicted as uncertain if it contained at least onerecognized cue phrase. Five systems followed apure token classification approach (TC) for cue de-tection while others used sequential labeling tech-niques (usually Conditional Random Fields) toidentify cue phrases in sentences (SL).
The feature set employed in Task1 systems typ-ically consisted of the wordform, its lemma or
stem, POS and chunk codes and about the half ofthe participants constructed features from the de-pendency and/or constituent parse tree of the sen-tences as well (see Table 6 for details).
It is interesting to see that the top ranked sys-tems of Task1B followed a sequence labeling ap-proach, while the best systems on Task1W applieda bag-of-words sentence classification. This maybe due to the fact that biological sentences haverelatively simple patterns. Thus the context of thecue words (token classification-based approachesused features derived from a window of the tokenin question, thus, they exploited the relationshipamong the tokens and their contexts) can be uti-lized while Wikipedia weasels have a diverse na-ture. Another observation is that the top systemsin both Task1B and Task1W are the ones whichdid not derive features from syntactic parsing.
Each Task2 system was built upon a Task1 sys-tem, i.e. they attempted to recognize the scopesfor the predicted cue phrases (however, Zhang etal. (2010) have argued that the objective functionsof Task1 and Task2 cue detection problems aredifferent because of sentences containing multiplehedge spans).
Most systems regarded multiple cues in a sen-tence to be independent from each other andformed different classification instances fromthem. There were three systems which incor-porated information about other hedge cues (e.g.their distance) of the sentence into the featurespace and Zhang et al. (2010) constructed a cas-cade system which utilized directly the predictedscopes (it processes cue phrases from left to right)during predicting other scopes in the same sen-tence.
The identification of the scope for a certain cuewas typically carried out by classifying each to-ken in the sentence. Task2 systems differ in thenumber of class labels used as target and in themachine learning approaches applied. Most sys-tems – following Morante and Daelemans (2009)– used three class labels (F)IRST, (L)AST andNONE. Two participants used four classes byadding (I)NSIDE, while three systems followeda binary classification approach (SCOPE versusNONSCOPE). The systems typically included apost-processing procedure to force scopes to becontinuous and to include the cue phrase in ques-tion. The machine learning methods applied canbe again categorized into sequence labeling (SL)
8

NA
ME
appr
oach
mac
hine
feat
ure
feat
ures
empl
oyed
lear
ner
sele
ctio
ndi
ctor
tho
lem
ma/
stem
POS
chun
kde
pdo
cpar
tot
her
Cla
usen
BoW
Max
Ent
++
hedg
ecu
edi
stan
ceC
hen
BoW
Max
Ent
stat
istic
al+
++
+se
nten
cele
ngth
Fern
ande
sSL
ET
L+
++
Geo
rges
cul
BoW
SVM
+par
amtu
ning
+Ji
TC
Mod
Avg
Perc
eptr
on+
Kili
cogl
uT
Cm
anua
l+
++
exte
rnal
dict
Li
SLC
RF+
post
proc
gree
dyfw
d+
++
Mor
ante
(wik
i)T
CSV
M+p
ostp
roc
stat
istic
al+
++
++
Mor
ante
(bio
)SL
KN
Nst
atis
tical
++
++
++
Prab
haka
ran
SLC
RF
gree
dyfw
d+
++
+L
evin
Cla
ssR
eiSL
CR
F+
++
+Sa
nche
zB
oWSV
MTr
eeK
erne
l+
++
++
Shim
izu
SLB
ayes
Poin
tMac
hine
sG
A+
++
+N
Es,
unla
bele
dda
taSz
idar
ovsz
kySL
CR
Fex
haus
tive
++
+T
acks
trom
BoW
SVM
gree
dyfw
d+
++
++
sent
ence
leng
thTa
ngSL
CR
F,SV
MH
MM
stat
istic
al+
++
++
Tjo
ngK
imSa
ngT
CN
aive
Bay
esV
elld
alT
CM
axE
ntm
anua
l+
++
+V
lach
osT
CB
ayes
ian
Log
Reg
man
ual
++
++
Zha
ngSL
CR
F+fe
atur
eco
mbi
natio
ngr
eedy
fwd
++
++
+N
Es
Zha
oSL
CR
Fst
atis
tical
++
++
Zhe
ngSL
CR
F,M
axE
ntm
anua
l+
++
+C
onst
ituen
tPar
sing
Zho
uSL
CR
Fst
atis
tical
++
++
Wor
dNet
Tabl
e6:
Syst
emar
chite
ctur
esov
ervi
ewfo
rTas
k1.A
ppro
ache
s:se
quen
cela
belin
g(S
L),
toke
ncl
assi
ficat
ion
(TC
),ba
g-of
-wor
dsm
odel
(BoW
);M
achi
nele
arne
rs:
Ent
ropy
Gui
ded
Tran
sfor
mat
ion
Lea
rnin
g(E
TL
),A
vera
ged
Perc
eptr
on(A
P),k
-nea
rest
neig
hbou
r(K
NN
);Fe
atur
ese
lect
ion:
gath
erin
gph
rase
sfr
omth
etr
aini
ngco
rpus
usin
gst
atis
tical
thre
shol
ds(s
tatis
tical
);Fe
atur
es:
orth
ogra
phic
alin
form
atio
nab
outt
heto
ken
(ort
ho),
lem
ma
orst
emof
the
toke
n(s
tem
),Pa
rt-o
f-Sp
eech
code
s(P
OS)
,syn
tact
icch
unk
info
rmat
ion
(chu
nk),
depe
nden
cypa
rsin
g(d
ep),
posi
tion
insi
deth
edo
cum
ento
rsec
tion
info
rmat
ion
(doc
pos)
9
NAME approach scope ML postproc tree dep multihedgeFernandes TC FL ETLJi TC I AP +Kilicoglu HC manual + + +Li SL FL CRF, SVMHMM + + +Morante TC FL KNN + +Rei SL FIL manual+CRF + +Tackstrom TC FI SVM +Tang SL FL CRF + + +Velldal HC manual +Vlachos TC I Bayesian MaxEnt + +Zhang SL FIL CRF + +Zhao SL FL CRF +Zhou SL FL CRF + +
Table 7: System architectures overview for Task2. Approaches: sequence labeling (SL), token clas-sification (TC), hand-crafted rules (HC); Machine learners: Entropy Guided Transformation Learning(ETL), Averaged Perceptron (AP), k-nearest neighbour (KNN); The way of identifying scopes: predict-ing first/last tokens (FL), first/inside/last tokens (FIL), just inside tokens (I); Multiple Hedges: the systemapplied a mechanism for handling multiple hedges inside a sentence
and token classification (TC) approaches (see Ta-ble 7). The feature sets used here are the sameas for Task1, extended by several features describ-ing the relationship between the cue phrase and thetoken in question mostly by describing the depen-dency path between them.
7 Conclusions
The CoNLL 2010 Shared Task introduced thenovel task of uncertainty detection. The challengeconsisted of a sentence identification task on un-certainty (Task1) and an in-sentence hedge scopedetection task (Task2). In the latter task the goalof automatic systems was to recognize speculativetext spans inside sentences.
The relatively high number of participants in-dicates that the problem is rather interesting forthe Natural Language Processing community. Wethink that this is due to the practical importanceof the task for (principally biomedical) applica-tions and because it addresses several open re-search questions. Although several approacheswere introduced by the participants of the sharedtask and we believe that the ideas described inthis proceedings can serve as an excellent startingpoint for the development of an uncertainty de-tector, there is a lot of room for improving suchsystems. The manually annotated datasets andsoftware tools developed for the shared task mayact as benchmarks for these future experiments
(they are freely available at http://www.inf.u-szeged.hu/rgai/conll2010st).
Acknowledgements
The authors would like to thank Joakim Nivreand Lluıs Marquez for their useful suggestions,comments and help during the organisation of theshared task.
This work was supported in part by theNational Office for Research and Technol-ogy (NKTH, http://www.nkth.gov.hu/)of the Hungarian government within the frame-work of the projects TEXTREND, BELAMI andMASZEKER.
ReferencesEiji Aramaki, Yasuhide Miura, Masatsugu Tonoike,
Tomoko Ohkuma, Hiroshi Mashuichi, and KazuhikoOhe. 2009. TEXT2TABLE: Medical Text Summa-rization System Based on Named Entity Recogni-tion and Modality Identification. In Proceedings ofthe BioNLP 2009 Workshop, pages 185–192, Boul-der, Colorado, June. Association for ComputationalLinguistics.
Wendy W. Chapman, David Chu, and John N. Dowl-ing. 2007. ConText: An Algorithm for IdentifyingContextual Features from Clinical Text. In Proceed-ings of the ACL Workshop on BioNLP 2007, pages81–88.
Mike Conway, Son Doan, and Nigel Collier. 2009. Us-ing Hedges to Enhance a Disease Outbreak Report
10

Text Mining System. In Proceedings of the BioNLP2009 Workshop, pages 142–143, Boulder, Colorado,June. Association for Computational Linguistics.
Carol Friedman, Philip O. Alderson, John H. M.Austin, James J. Cimino, and Stephen B. Johnson.1994. A General Natural-language Text Processorfor Clinical Radiology. Journal of the AmericanMedical Informatics Association, 1(2):161–174.
Viola Ganter and Michael Strube. 2009. FindingHedges by Chasing Weasels: Hedge Detection Us-ing Wikipedia Tags and Shallow Linguistic Features.In Proceedings of the ACL-IJCNLP 2009 Confer-ence Short Papers, pages 173–176, Suntec, Singa-pore, August. Association for Computational Lin-guistics.
Feng Ji, Xipeng Qiu, and Xuanjing Huang. 2010. De-tecting Hedge Cues and their Scopes with AveragePerceptron. In Proceedings of the Fourteenth Con-ference on Computational Natural Language Learn-ing (CoNLL 2010): Shared Task, pages 139–146,Uppsala, Sweden, July. Association for Computa-tional Linguistics.
Yoshinobu Kano, William A. Baumgartner, LukeMcCrohon, Sophia Ananiadou, Kevin B. Cohen,Lawrence Hunter, and Jun’ichi Tsujii. 2009. U-Compare: Share and Compare Text Mining Toolswith UIMA. Bioinformatics, 25(15):1997–1998,August.
Halil Kilicoglu and Sabine Bergler. 2008. Recogniz-ing Speculative Language in Biomedical ResearchArticles: A Linguistically Motivated Perspective.In Proceedings of the Workshop on Current Trendsin Biomedical Natural Language Processing, pages46–53, Columbus, Ohio, June. Association for Com-putational Linguistics.
Halil Kilicoglu and Sabine Bergler. 2009. Syn-tactic Dependency Based Heuristics for BiologicalEvent Extraction. In Proceedings of the BioNLP2009 Workshop Companion Volume for Shared Task,pages 119–127, Boulder, Colorado, June. Associa-tion for Computational Linguistics.
Halil Kilicoglu and Sabine Bergler. 2010. A High-Precision Approach to Detecting Hedges and TheirScopes. In Proceedings of the Fourteenth Confer-ence on Computational Natural Language Learning(CoNLL 2010): Shared Task, pages 103–110, Up-psala, Sweden, July. Association for ComputationalLinguistics.
Jin-Dong Kim, Tomoko Ohta, Sampo Pyysalo, Yoshi-nobu Kano, and Jun’ichi Tsujii. 2009. Overviewof BioNLP’09 Shared Task on Event Extraction. InProceedings of the BioNLP 2009 Workshop Com-panion Volume for Shared Task, pages 1–9, Boulder,Colorado, June. Association for Computational Lin-guistics.
George Lakoff. 1972. Linguistics and natural logic.In The Semantics of Natural Language, pages 545–665, Dordrecht. Reidel.
Xinxin Li, Jianping Shen, Xiang Gao, and XuanWang. 2010. Exploiting Rich Features for Detect-ing Hedges and Their Scope. In Proceedings of theFourteenth Conference on Computational NaturalLanguage Learning (CoNLL 2010): Shared Task,pages 36–41, Uppsala, Sweden, July. Associationfor Computational Linguistics.
Marc Light, Xin Ying Qiu, and Padmini Srinivasan.2004. The Language of Bioscience: Facts, Spec-ulations, and Statements in Between. In Proceed-ings of the HLT-NAACL 2004 Workshop: Biolink2004, Linking Biological Literature, Ontologies andDatabases, pages 17–24.
Ben Medlock and Ted Briscoe. 2007. Weakly Super-vised Learning for Hedge Classification in ScientificLiterature. In Proceedings of the ACL, pages 992–999, Prague, Czech Republic, June.
Roser Morante and Walter Daelemans. 2009. Learningthe Scope of Hedge Cues in Biomedical Texts. InProceedings of the BioNLP 2009 Workshop, pages28–36, Boulder, Colorado, June. Association forComputational Linguistics.
Roser Morante, Vincent Van Asch, and Walter Daele-mans. 2010. Memory-based Resolution of In-sentence Scopes of Hedge Cues. In Proceedings ofthe Fourteenth Conference on Computational Nat-ural Language Learning (CoNLL 2010): SharedTask, pages 48–55, Uppsala, Sweden, July. Associa-tion for Computational Linguistics.
Arzucan Ozgur and Dragomir R. Radev. 2009. De-tecting Speculations and their Scopes in ScientificText. In Proceedings of the 2009 Conference onEmpirical Methods in Natural Language Process-ing, pages 1398–1407, Singapore, August. Associ-ation for Computational Linguistics.
Gyorgy Szarvas. 2008. Hedge Classification inBiomedical Texts with a Weakly Supervised Selec-tion of Keywords. In Proceedings of ACL-08: HLT,pages 281–289, Columbus, Ohio, June. Associationfor Computational Linguistics.
Buzhou Tang, Xiaolong Wang, Xuan Wang, Bo Yuan,and Shixi Fan. 2010. A Cascade Method for De-tecting Hedges and their Scope in Natural LanguageText. In Proceedings of the Fourteenth Confer-ence on Computational Natural Language Learning(CoNLL 2010): Shared Task, pages 25–29, Uppsala,Sweden, July. Association for Computational Lin-guistics.
Sofie Van Landeghem, Yvan Saeys, Bernard De Baets,and Yves Van de Peer. 2009. Analyzing Text inSearch of Bio-molecular Events: A High-precisionMachine Learning Framework. In Proceedings ofthe BioNLP 2009 Workshop Companion Volume for
11

Shared Task, pages 128–136, Boulder, Colorado,June. Association for Computational Linguistics.
Veronika Vincze, Gyorgy Szarvas, Richard Farkas,Gyorgy Mora, and Janos Csirik. 2008. The Bio-Scope Corpus: Biomedical Texts Annotated for Un-certainty, Negation and their Scopes. BMC Bioin-formatics, 9(Suppl 11):S9.
Shaodian Zhang, Hai Zhao, Guodong Zhou, and Bao-liang Lu. 2010. Hedge Detection and Scope Find-ing by Sequence Labeling with Procedural FeatureSelection. In Proceedings of the Fourteenth Confer-ence on Computational Natural Language Learning(CoNLL 2010): Shared Task, pages 70–77, Uppsala,Sweden, July. Association for Computational Lin-guistics.
Qi Zhao, Chengjie Sun, Bingquan Liu, and YongCheng. 2010. Learning to Detect Hedges andtheir Scope Using CRF. In Proceedings of theFourteenth Conference on Computational NaturalLanguage Learning (CoNLL 2010): Shared Task,pages 64–69, Uppsala, Sweden, July. Associationfor Computational Linguistics.
Huiwei Zhou, Xiaoyan Li, Degen Huang, Zezhong Li,and Yuansheng Yang. 2010. Exploiting Multi-Features to Detect Hedges and Their Scope inBiomedical Texts. In Proceedings of the FourteenthConference on Computational Natural LanguageLearning (CoNLL 2010): Shared Task, pages 56–63, Uppsala, Sweden, July. Association for Compu-tational Linguistics.
12