lecture: regular expressions and regular languages
TRANSCRIPT

Regular Expressions & Regular Languages
slideshare: http://www.slideshare.net/marinasantini1/regular-expressions-and-regular-languages
Mathematics for Language Technology http://stp.lingfil.uu.se/~matsd/uv/uv15/mfst/
Last Updated 6 March 2015
Marina Santini [email protected]
Department of Linguistics and Philology Uppsala University, Uppsala, Sweden
Spring 2015 1

Acknowledgements Several slides borrowed from Jurafsky and Mar6n (2009).
Prac6cal ac6vi6es by Mats Dahllöf and Jurafsky and Mar6n (2009).
2

Reading Required Reading: E&G (2013): Ch. 9 (pp. 252-256) Compendium (3): 7.2, 7.3, 8.2.3 Mats Dahllöf: Reguljära uttryck
• http://stp.lingfil.uu.se/~matsd/uv/uv14/mfst/dok/oh6.pdf
Further Reading: Chapters 2 in Jurafsky D. & Mar6n J. (2009) Speech and Language Processing:
An introduc5on to natural language processing, computa5onal linguis5cs, and speech recogni5on. Online draG version: hIp://stp.lingfil.uu.se/~san6nim/ml/2014/JurafskyMar6nSpeechAndLanguageProcessing2ed_draG%202007.pdf
3

Outline
Regular Expressions Regular Languages
Practical Activities
(Pumping Lemma)
4

5
Regular Expressions
Definitions Equivalence to Finite Automata

6
Regular Expressions and Text Searching
Everybody does it Emacs, vi, perl, grep, etc..
Regular expressions are a compact textual representation of a set of strings representing a language.

7
Example
Find all the instances of the word “the” in a text. /the/ /[tT]he/ /\b[tT]he\b/

8
Errors
The process we just went through was based on two fixing kinds of errors Matching strings that we should not have
matched (there, then, other) • False positives (Type I)
Not matching things that we should have matched (The) • False negatives (Type II)

9
Errors Reducing the error rate for an application
often involves two antagonistic efforts: Increasing accuracy, or precision, (minimizing
false positives) Increasing coverage, or recall, (minimizing
false negatives).

10
REs: What are they?
Regular expressions describe languages by an algebra.

Link: https://www.youtube.com/watch?v=eOfMcdeyrMU
11

DFA
12

Converting the regular expression (a|b)* to a DFA
13
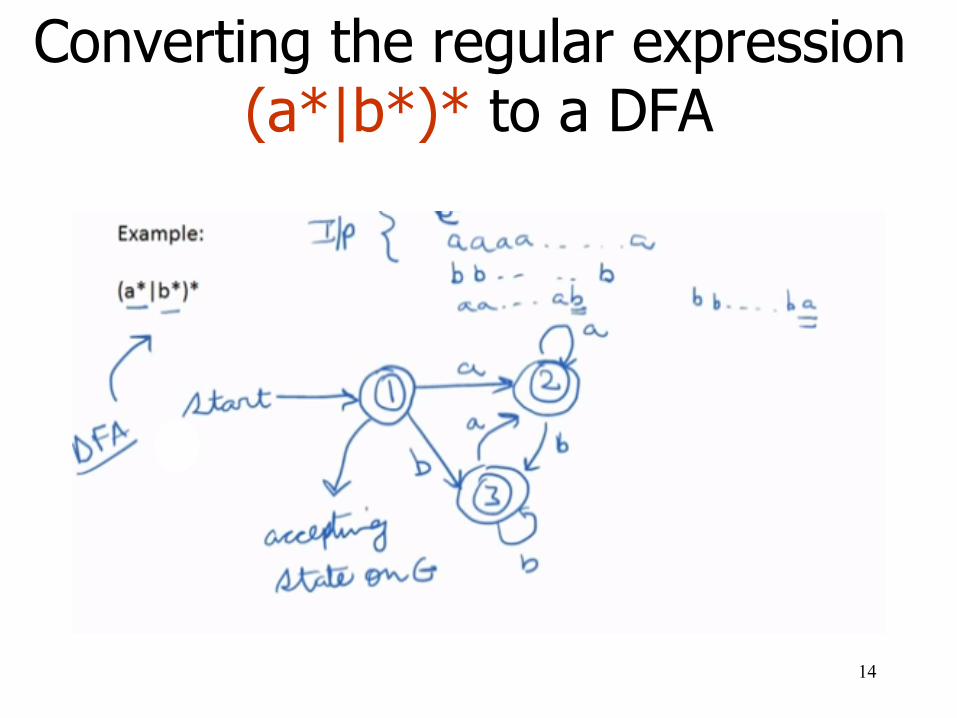
Converting the regular expression (a*|b*)* to a DFA
14

Converting the regular expression ab(a|b)* to a DFA
15

Remember Jeff Ullman video?
16

17
Operations on Languages
REs use three operations: union concatenation Kleene star (*) [cleany star]

Union ∪ (aka: disjunction, OR, |, +)
The union of languages is the usual thing, since languages are sets.
Example: {01,111,10}∪{00, 01} = {01,111,10,00}.
18
01 happens to be in both sets, so it will be once in the union

19
Concatenation: represented by juxtaposition (no punctuation) or middle dot ( · )
The concatenation of languages L and M is denoted LM.
It contains every string wx such that w is in L and x is in M.
Example: {01,111,10}{00, 01} = {0100, 0101, 11100, 11101, 1000, 1001}.
In the example, we take 01 from the first language, and we concatenate it with 00 in the second language. That gives us 0100. We then take 01 from the first language again, and we concatenate it with 01 in the second language, and that gives us 0101. Then we take 111 from the first language and we concatenated it with 00 in the second language and this gives us 11100 …. and so on.

20
Kleene Star: represented by an asterisk aka star (*)
If L is a language, then L*, the Kleene star or just “star,” is the set of strings formed by concatenating zero or more strings from L, in any order.
L* = {ε} ∪ L ∪ LL ∪ LLL ∪ … Example: {0,10}* = {ε, 0, 10, 00, 010,
100, 1010,…}
If you take no strings from L, that would give you the empty string.

IMPORTANT!
FROM NOW ON, LET’S STICK TO THE FOLLOWING CONVENTIONS (OTHERWISE WE WILL BE CONFUSED):
Union ∪ (aka: disjunction, OR) represented by: | or + Concatenation: represented by juxtaposition (= no
punctuation) or middle dot ( · ) Kleene Star: represented by *
21

22
Precedence of Operators
Parentheses may be used wherever needed to influence the grouping of operators.
Order of precedence is * (highest), then concatenation, then + (lowest).
Remember: + = union/disjunction

23
Examples: REs 1. L(01) = {01}. 2. L(01+0) = {01, 0}. 3. L(0(1+0)) = {01, 00}. Note order of precedence of
operators. 4. L(0*) = {ε, 0, 00, 000,… }. 5. L((0+10)*(ε+1)) = all strings
of 0s and 1s without two consecutive 1s.
1) The regular expression 01 represents the concatenation of the language consisting of one string, 0 and the language consisting of one string, 1. The result is the language containing the one string 01. 2) The language of 01+0 is the union of the language containing only string 01 and the language containing only string 0. 3) The language of 0 concatenated with 1+0 is the two strings 01 and 00. Notice that we need parentheses to force the + to group first. Without them, since concatenation takes precedence over +, we get the interpretation in the second example. 4) The language of 0* is the star of the language containing only the string 0. This is all strings of 0’s, including the empty string. 5) This example denotes the language with all strings of 0s and 1s without two consecutive 0s. To see why this works, in every such string, each 1 is either followed immediately by a 0, or it comes at the end of the string. (0+10)* denotes all strings in which every 1 is followed by a 0. These strings are surely in the language we want. But we also want these strings followed by a final 1. Thus, we concatenate the language of (0+10)* with epsilon+1. This concatenation gives us all the strings where 1s are followed by 0s, plus all those strings with an additional 1 at the end.

24
Equivalence of REs and Finite Automata
For every RE, there is a finite automaton that accepts the same language.
And we need to show that for every finite automaton, there is a RE defining its language.

25
Summary
Automata and regular expressions define exactly the same set of languages: the regular languages.

REGULAR LANGUAGES
26

27
The Chomsky Hierachy
Regular (DFA)
Context- free
(PDA)
Context- sensitive
(LBA)
Recursively- enumerable
(TM)
• Hierarchy of classes of formal languages
One language is of greater generative power or complexity than another if it can define a language that other cannot define. Context-free grammars are more powerful that regular grammars

28
Regular Languages
A language L is regular if it is the language accepted by some DFA. Note: the DFA must accept only the strings
in L, no others.
Some languages are not regular.

Only languages that meet the following criteria are regular languages:
29

Regular language derive their name from the fact that the strings they recognize are (in a formal computer science sense) “regular.”
This implies that there are certain kinds of strings that it will be very hard, if not impossible, to recognize with regular expressions, especially nested syntactic structures in natural language.
30

Formal languages vs regular languages
A formal language is a set of strings, each string composed of symbols from a finite set called an alphabet. Ex: {a,b!}
Formal languages are not the same as regular languages….
31

32
But Many Languages are Regular
They appear in many contexts and have many useful properties.

How to tell if a language is not regular The most common way to prove that a
language is regular is to build a regular expression for the language.
33

Pumping Lemma
34

Prac6cal Ac6vity 1 The language L contains all strings over the alphabet {a,b} that begin with a and end with b, ie:
Write a regular expression that defines the language L.
35

Practical Activity 1: Possible Solution
36

Your Solutions
37
In between the concatenation of a and b there must be 0 or more unions (disjuctions) of a and b. Reference: slides 17-22

Practical Activity 2
Draw a deterministic finite-state automaton that accepts the following regular expression:
38
( (ab) | c)*
Alternative notation style:
ie: 0 or more occurences of the disjunction ab | c
Test the automaton with these legal strings in the language : 0 abc a ab cccabc cbacccabababccc ….

Practical Activity 2: Possible Correct Solution
39
Having the initial state as a final state gives us the empty string as an element in the language.

Your solutions (1): when we interpret ”+” as disjunction, these solutions are wrong because
”c” happens only after ”a” and ”b”…
40
Test these automata with the string on slide 35

Your solutions (2): same as previous slide. In addition, here no
final states are shown…
41
Test these automata with the string on slide 35

Practical Activity 3
Construct a grep regular expression that matches patterns containing at least one “ab” followed by any number of bs.
Construct a grep regular expression that matches any number between 1000 and 9999.
42

Practical Activity 3: Possible Solutions
grep ‘\(ab\)+b*’
[1-9][0-9]{3}
43

Exercises: E&G (2013)
Övning 9.40 Optional: as many as you can
AGer having completed the exercises, check out the solu6ons at the end of the book.
44

The End
45