leveraging social network knowledge in data...
TRANSCRIPT

Leveraging Social Network Knowledge in Data Mining
Maurizio Marchese Department of Information Engineering and Computer Science,
University of Trento, Italy
Work presented done in collaboration with Fabio Casati, Alejandro Mussi, Mikalai Krapivin and many more people in the LiquidPub project
(EU FET-Open grant number 213360)

Outline
• Introduction: Social Informatics • Three Applications
– Discovering Communities – Scientific impact evaluation – Navigation in scientific publishing
• Conclusions

Introduction
• Social informatics is the study of ICT tools in cultural, institutional contexts and their applications in social domains (Kling, Rosenbaum, & Sawyer,2005).
• It is naturally a trans-disciplinary field and is part
of a larger body of socio-technical research that examines the ways in which the technological artifact and human social context interact

Social Informatics and Complex Systems
• In this lecture, we will focus on a specific aspect in SI, namely: – set of complex systems approaches – how to use methods and tools from IT to mine
social networks information/knowledge – explicit vs. implicit knowledge
• In particular we will present some current experimentations in two scenario – scientific publishing – scientific impact evaluation

Alejandro Mussi, "Discovering and analyzing scientic communities using conference network", thesis work at Departamento de Electronica e Informatica -Universidad Catolica Nuestra Senora de la Asuncion in collaboration with the University of Trento, Italy
Discovery and Analyzing Scientific Communities

Scientific Community Discovery
• In research, researchers write contributions together, they publish their advances in some event or journal.
• contributions refer other contributions, some contributions are organized in collections, and so on.
• The emerging community structure and rich contextual information could be used (among others) to improve two main aspect in the research scope: search and assessment. – search for a contribution, or group them; people working in similar
content, events that are related to a contribution, – measure the impact on a specific community (normalize the actual
metrics), narrow down the search space into a community structure, and so on.
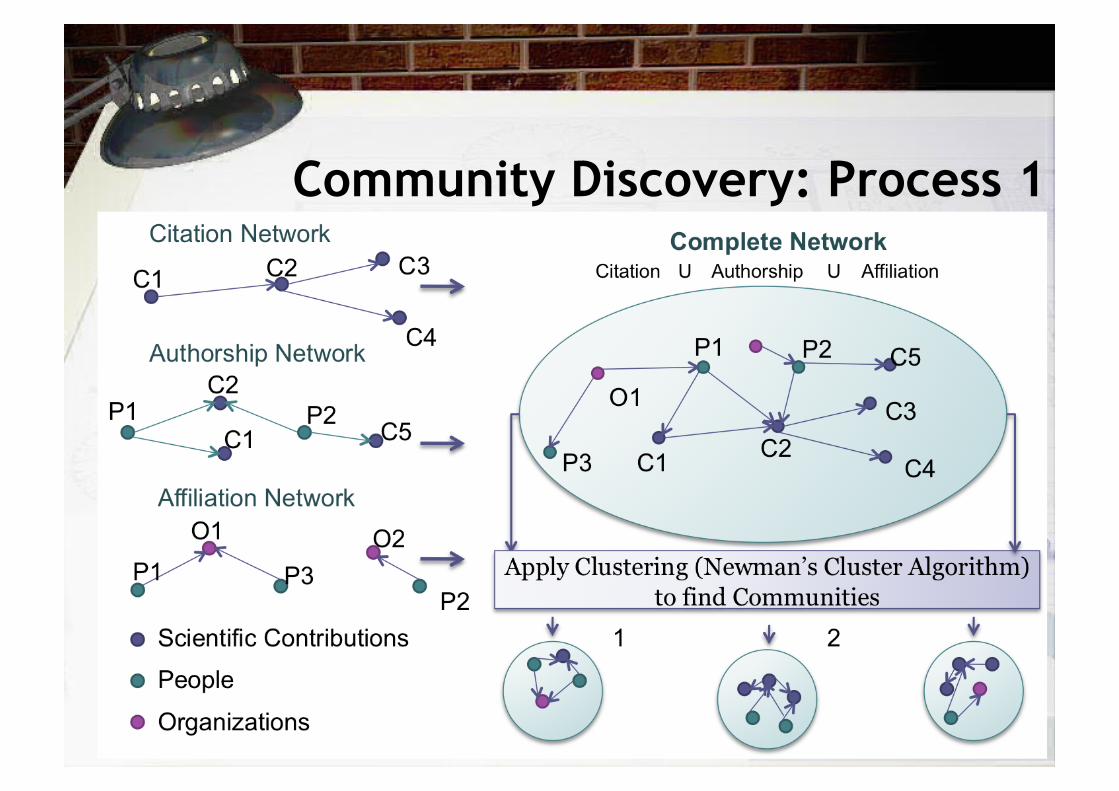
Community Discovery: Process 1

Community Discovery: Process 2
Conf A Conf B Conf A Conf B
1 (one author in common)
2
1
3
4
5
6
2
1
3
4
5
6
Community A Community B Conference Network
% of Common Authors Overlapping Between Communities
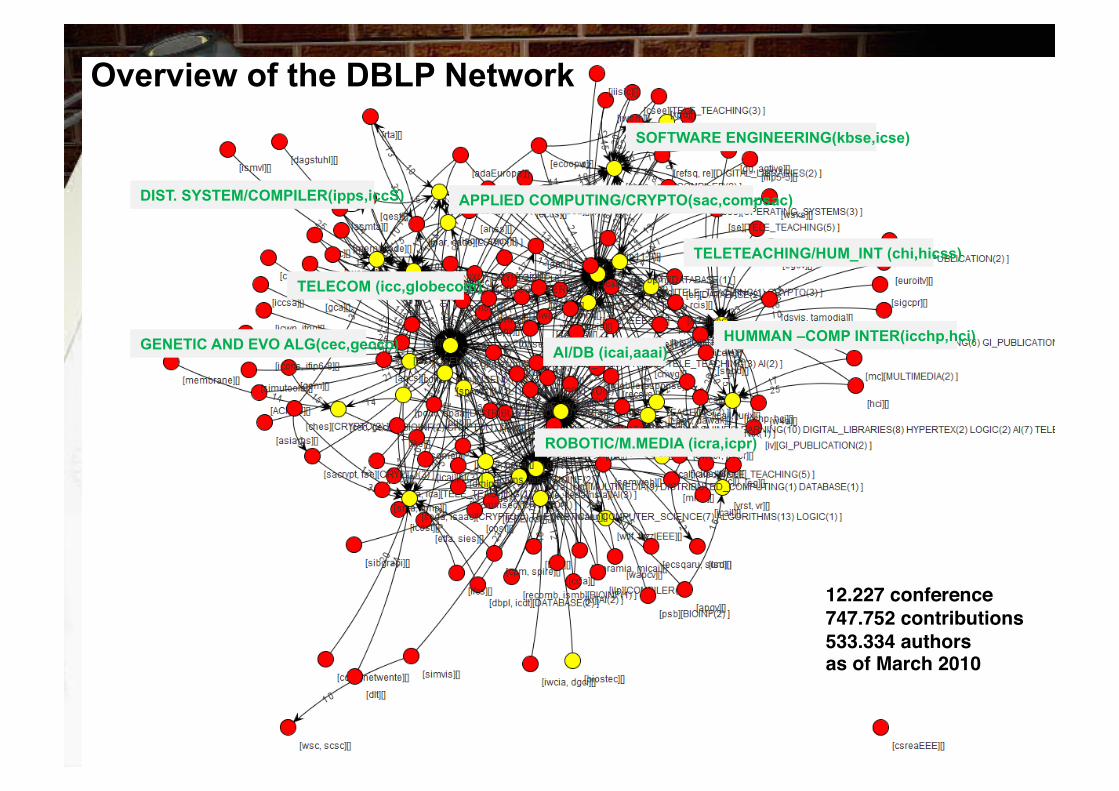
TELETEACHING/HUM_INT (chi,hicss)
AI/DB (icai,aaai)
ROBOTIC/M.MEDIA (icra,icpr)
TELECOM (icc,globecom)
APPLIED COMPUTING/CRYPTO(sac,compsac)
SOFTWARE ENGINEERING(kbse,icse)
DIST. SYSTEM/COMPILER(ipps,iccS)
GENETIC AND EVO ALG(cec,gecco) HUMMAN –COMP INTER(icchp,hci)
Overview of the DBLP Network
12.227 conference!747.752 contributions!533.334 authors !as of March 2010

Community Based Metrics
• Community Impact (Cimp) A community has a scientific impact n if n of their authors have h-
index equal to at least n, and the other authors have at most n h-index each.
• Community Health/Diversity (Cht) The health/diversity of a community is defined as the number of
communities that share authors in common with the specific community.
• Author Membership Degree (Amd) The community membership degree of an author is defined as the
number of scientific publication the author has published in the community divided by the total number of publication of the author
…

Community Engine Tool
Clustering Engine
Network Manager
Network Metadata
Communities Database
Reseval
REST/HTTP/SOAP
CET Services
REST/HTTP/SOAP
UI
Community Network Analysis
Community Engine Tool Architecture External Services

CET - Community Network

CET – Community Members Community Impact Community Name DBLP Tags
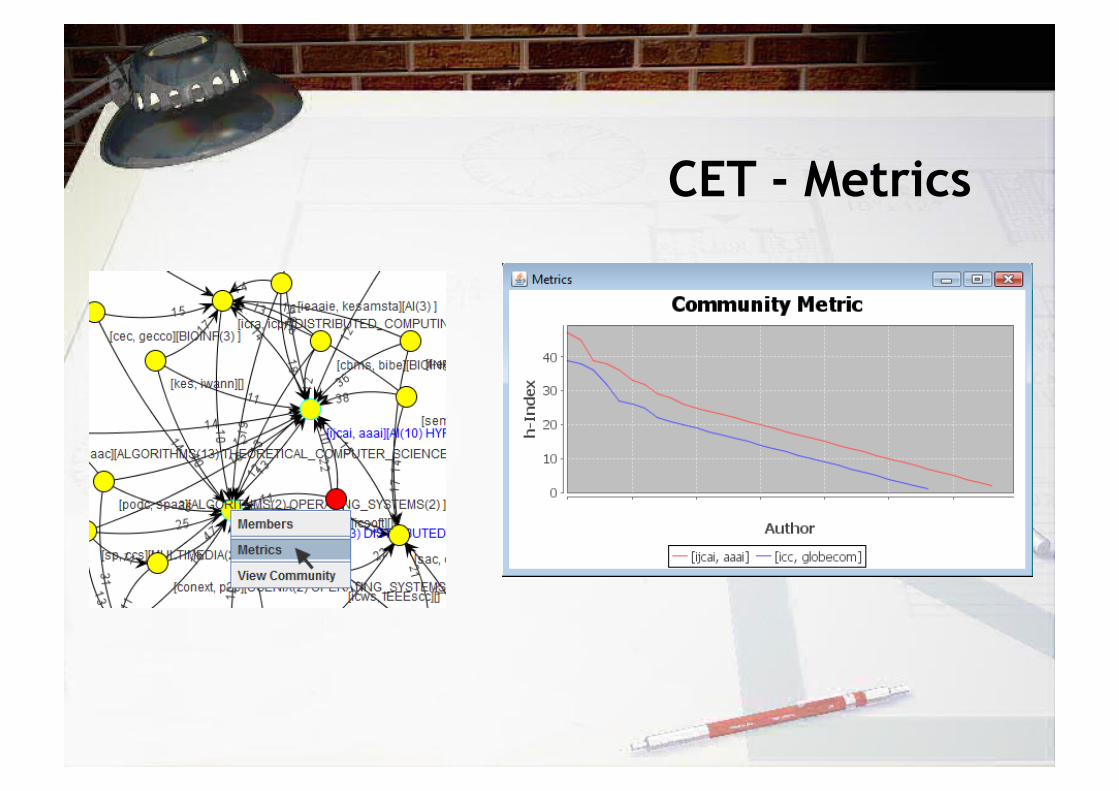
CET - Metrics

Community Impact
18.8
24.6
38.6
25
14.25 13
25.2 21.2 20.4
h-index
1332.8
2846
6676.6
3587
749.5 579.8
3008
2055.2 1989.4
Citations
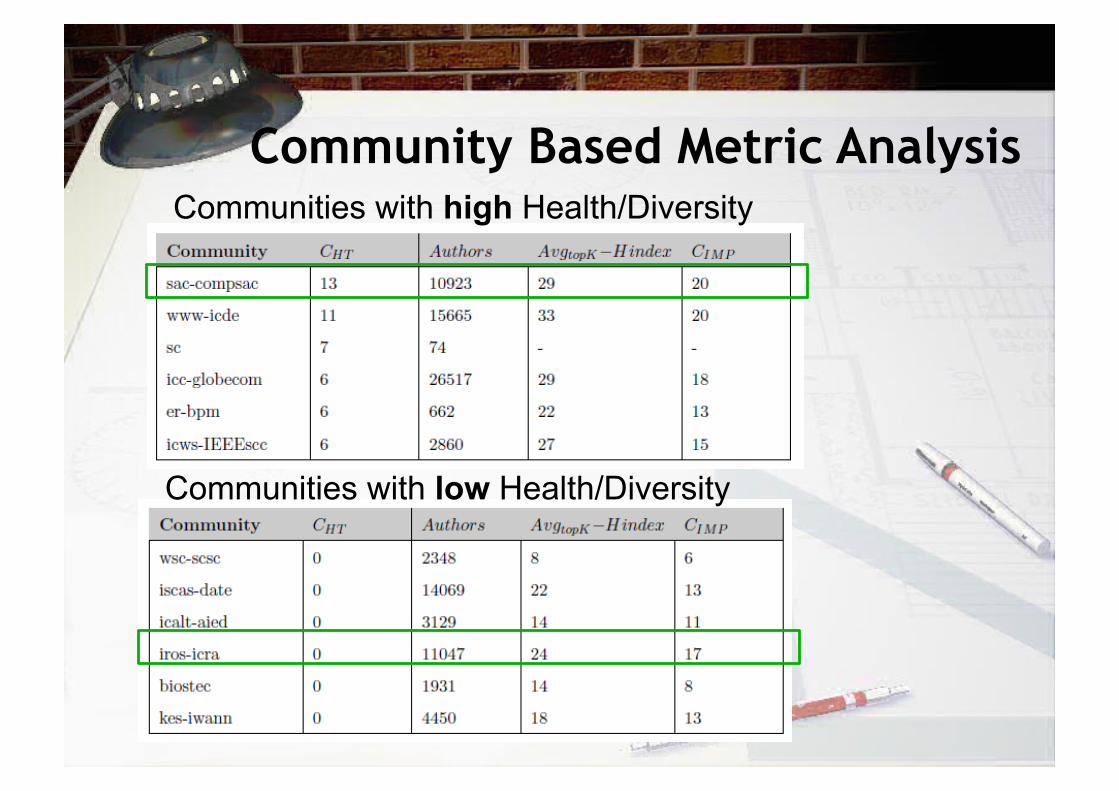
Community Based Metric Analysis Communities with high Health/Diversity
Communities with low Health/Diversity

Lesson Learned & Future Work
• We developed a model and a tool that implements community discovery mining from existing social network information (conferences, papers, affiliations..)
• We propose community-based metrics that aim at improving how scientific content and researchers are searched and assessed
• Future Work includes: – Provide different algorithms for discovering communities using different
networks. – The approach is part of a larger research effort aimed at studying how
scientific communities are born, evolve, remain healthy or become unhealthy (e.g., self-referential), and eventually vanish.

M. Krapivin, M. Marchese, F. Casati, "Exploring and Understanding Citation-Based Scientific Metrics”, Advances in Complex Systems, vol. 13, No.1, p1-23, 2010.
Exploring and Understanding Scientific Metrics in Citation Networks

Metrics, Indicators. The context.
Web crawlers • Search “relevant” papers in a specific domain/topic • Navigation cited papers in a specific domain/topic
Scientific domain • Measuring progress of researcher, group, institution • For Hiring, Career promotion • Seeking for conferences, committee members, workshops Chairs,…
Standard Metrics • P-index, number of papers. • CC – index, citation index excluding self citation. • Modification to improve the metric
– CPP – average number of citation per paper. – "Crown" indicator, which is the average number of citations per article normalized by
the CPP, but average in the domain.

Citation Network metrics
• Hypertext-Induced Topic Selection (HITS) (1998) • Page Rank (PR) (1998) • Hilltop algorithm (1999) • Trust Rank (2004)
Describing person but citation based • H-index – Hirsch index (2005) • G-index • M-indexes

PageRank
• PageRank (Brin S., Page L,1998)
• Adaptation to citations
• Focusing (changing the Markov matrix)
(CN, no loops)
(PR)
Mikalai Krapivin and Maurizio Marchese Focused Page Rank in Scientific Papers Ranking ICADL 2008
Potential Weight
PR of the citing papers
Dispersed Weight
outgoing links of citing papers
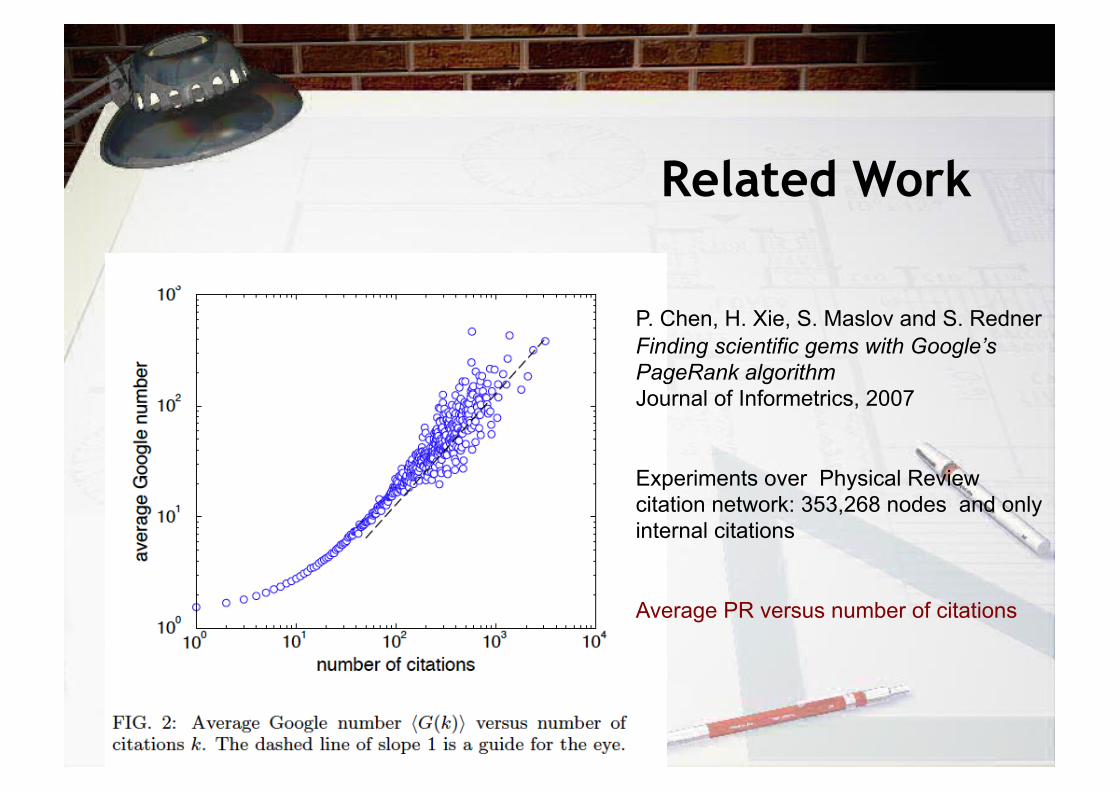
Related Work
P. Chen, H. Xie, S. Maslov and S. Redner Finding scientific gems with Google’s PageRank algorithm Journal of Informetrics, 2007
Experiments over Physical Review citation network: 353,268 nodes and only internal citations
Average PR versus number of citations

Experiments
• Data set: – ACM portal based: metadata crawled by Citeseer – 260K papers, 240K authors and ca. one million
internal citations – Completeness ?
• internal citations represent between 1/5 to 1/3 of all citations
• “ACM world” vs. Google Scholar ? – Less errors, manually or semi-supervised
processed, trusted origin

Plotting the difference: mirrored banding

Plotting the difference
All 266K of papers are presented in one plot
May be applied to arbitrary quantity of papers (i.e. citation graph nodes)
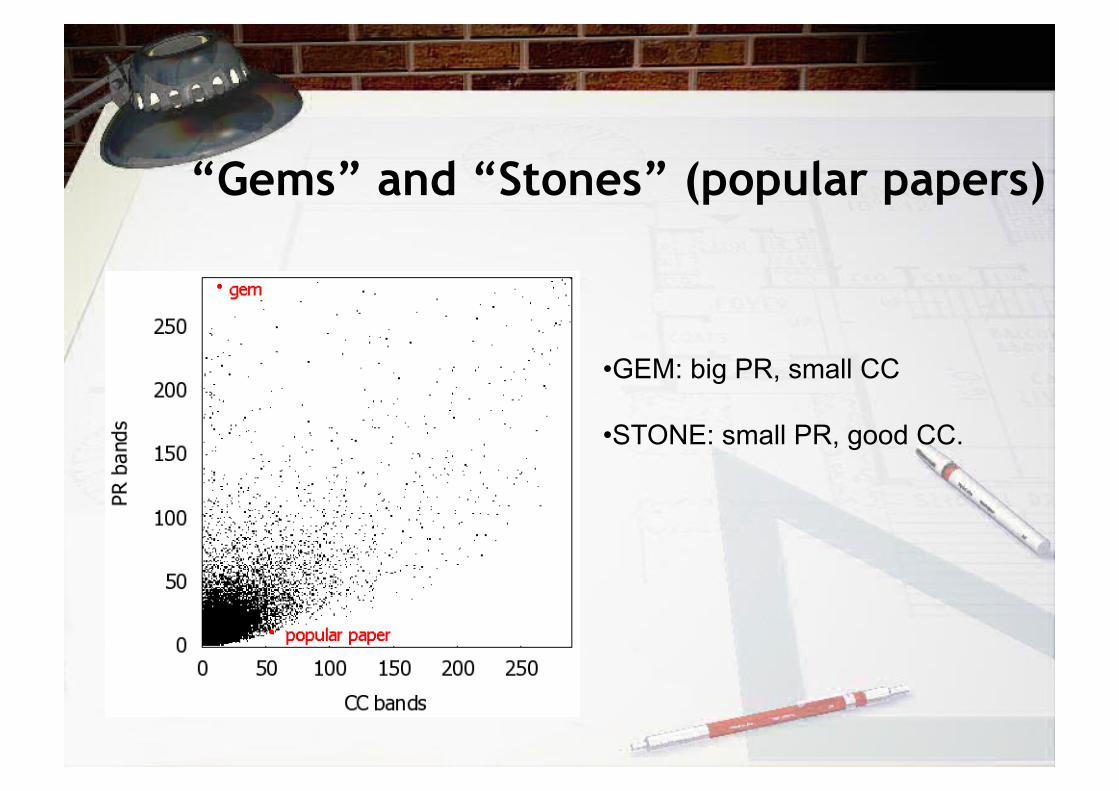
“Gems” and “Stones” (popular papers)
• GEM: big PR, small CC
• STONE: small PR, good CC.
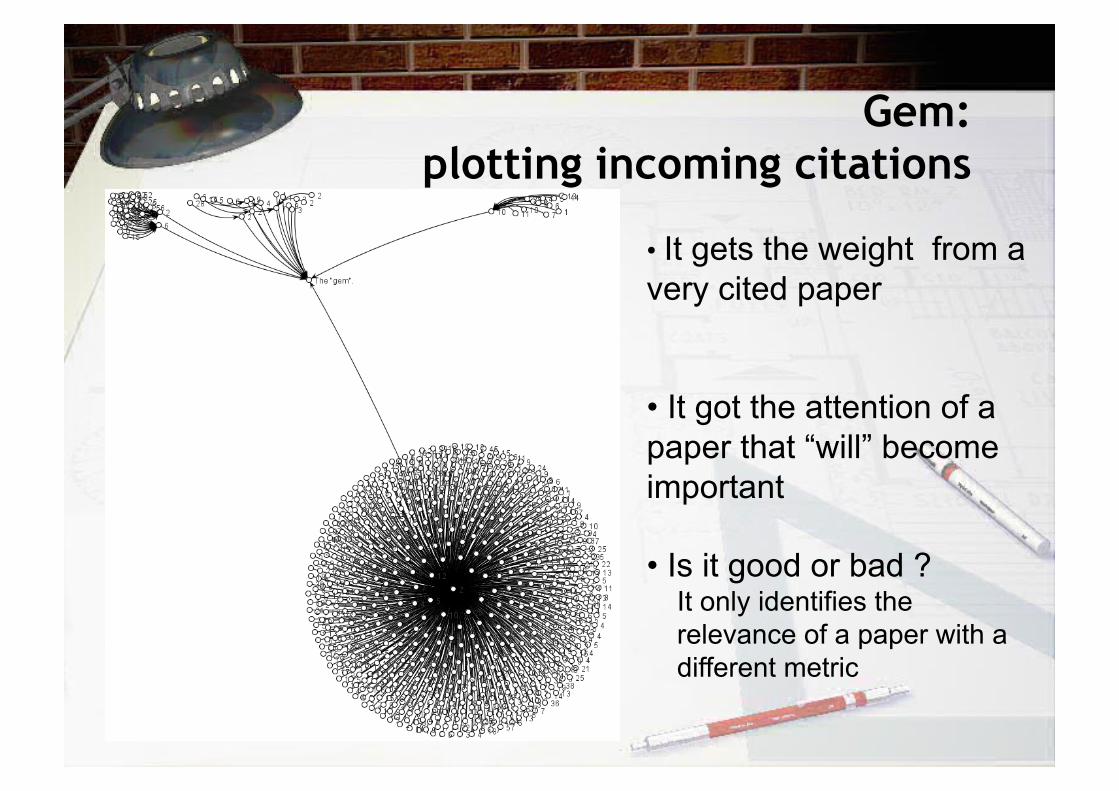
Gem: plotting incoming citations
• It gets the weight from a very cited paper
• It got the attention of a paper that “will” become important
• Is it good or bad ? It only identifies the relevance of a paper with a different metric

Stone (popular paper): plotting outgoing links
Paper with a significant number of citations
Effect of outgoing links: the more a paper cites, the less weight it brings to each cited papers

PR-Hirsch vs Hirsch
The same band-based plotting to see the difference between H-index and PRH-index

Impact of different metrics
• Pragmatic Approach:
– to understand divergence of the two indexes is how often, on average, the top t results would contain different papers, with significant values for t = 1, 10, 20
– – Divergence: DivM1,M2 (t,n,S)
• t top results (search window) • n subset of documents • S the complete set of documents
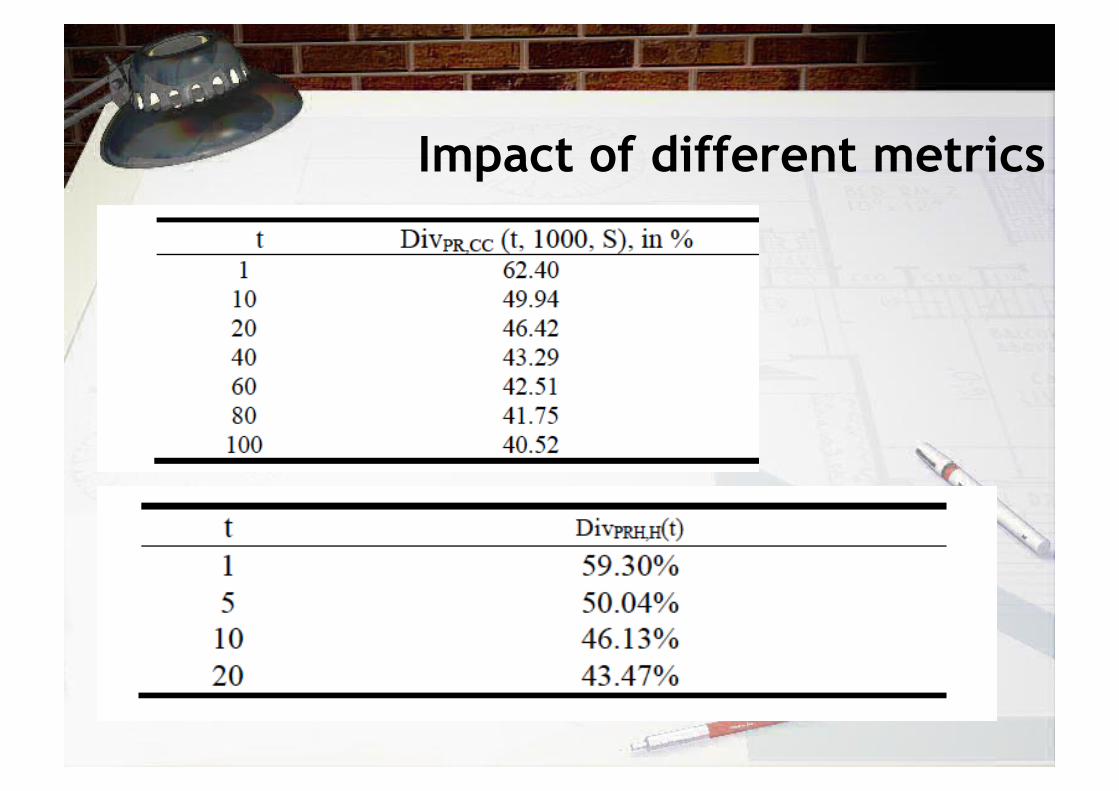
Impact of different metrics

Lesson Learned
• PR and CC are quite different metrics for ranking papers. A typical search would return half of the results different.
• There are a significant number of “gems” while there are relatively few “stones”. (To be explored in the future work).
• The main factor contributing to the difference is weight dispersion: gems are caused by high weight concentration, while stones are caused by dispersion.
• The PR based metrics may be applied for authors as well.For authors the difference between PRH and H is again very significant, and index selection is likely to have a strong impact on how people are ranked based on indexes

Mikalai Krapivin, Aliaksandr Autayeu, Maurizio Marchese, Enrico Blanzieri, and Nicola Segata, “Improving Machine Learning Approaches with Natural Language Processing” in International Conference on Asia-Pacific Digital Libraries 2010, ICADL 2010
Keyphrases Extraction from Scientific Documents from Scientific Communites

Keyphrases Extraction: Motivations
• Keyphrase is a phrase that shortly describes the content of a document
• Stakeholders – Librarians
• Content classification / categorization • Adding more meta information/support for facets • Improved navigation • ...
– End users/researchers • Tagged search • State-of-the-art search • Search for collaborators • Search for appropriate venue for publication • ..

Data Mining From Scientific Papers: Challenges and Problems
• Explicit information – title, references, authors (name, mail, …),
venues, keywords, …
• Implicit information – keyphrases, keywords (tags) – concepts
present in the header after the token “Keyphrases/
Ketwords:”

Data Mining: Explicit Keyphrases Extraction
• State-of-the-art techniques – Hidden Markov Model (Seymore et al, 1999) – Conditional Random Field (Peng et al, 2004) – Support Vector Machine (SVN) (Hui et al, 2003)
• Datasets: – a few exists and are publicly available – e.g. Rexa 5000 scholar documents headers
• Results: up to 97% F-measure

Data Mining: Implicit Keyphrases Extraction
• State-of-the-art techniques – KEA (naïve Bayes), Witten et al, 1999 – Support Vector Machine (SVN), Wang et al, 2005 – Decision trees, Tourney et al., 2002 – Genetic algorithms + heuristics, Tourney, 2002
• Datasets: – News, emails, meeting notes, scientific papers,.. – No standard set yet !
• Results – vary from 10% to 30% in F-measure – It is difficult to compare results from different datasets
• Small dimensionality: 10-200 documents, manual quality control , different types of content

Our Approach: methodology
• Build high quality documents’ dataset – Domain specific, i.e. community
• Analyze linguistic characteristics of the dataset • Propose heuristics for potential keyphrases
candidates • Define the feature set • Analyze and compare different machine learning
methods

Keyphrases Extraction: Text Processing
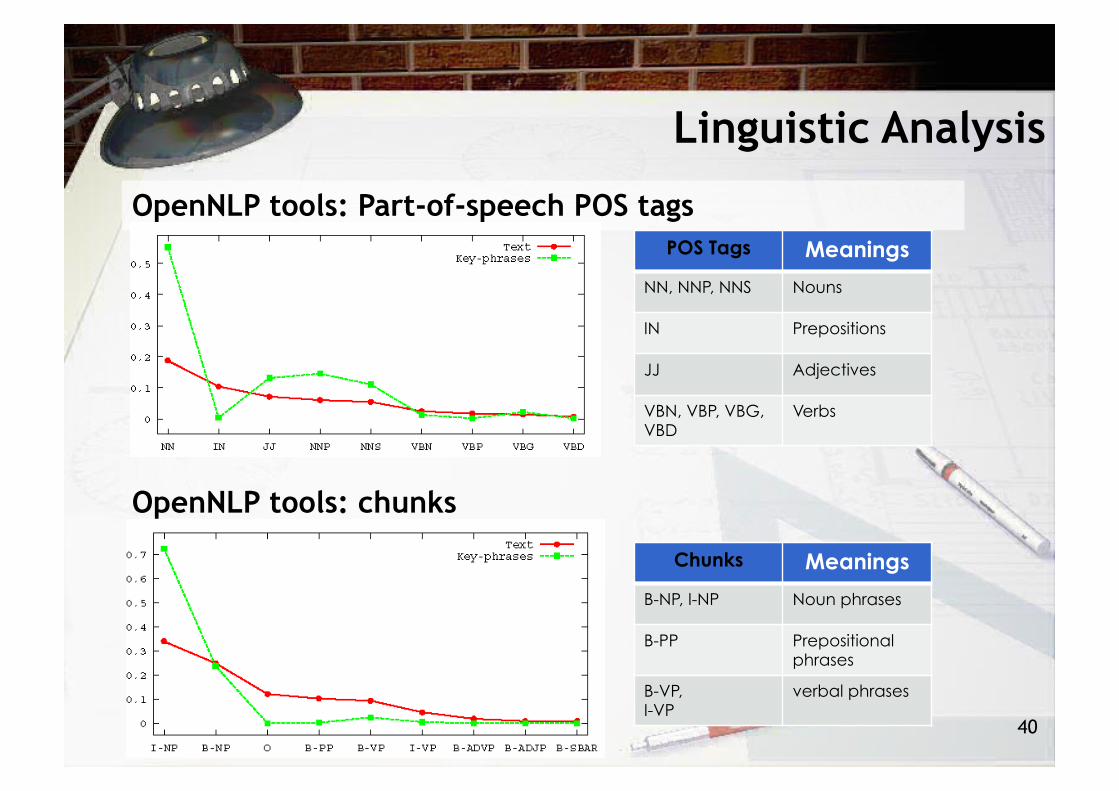
Linguistic Analysis
40
OpenNLP tools: Part-of-speech POS tags
OpenNLP tools: chunks
POS Tags Meanings
NN, NNP, NNS Nouns
IN Prepositions
JJ Adjectives
VBN, VBP, VBG, VBD
Verbs
Chunks Meanings
B-NP, I-NP Noun phrases
B-PP Prepositional phrases
B-VP, I-VP
verbal phrases

Keyphrases Extraction: Heuristic
• Filter by chunk type, only NP chunk
• Filter by PoS tags, NN, NNP, JJ, NNS, VBG and VBN
Sentence Candidates
Therefore, the seat reservation problem is an on-line problem, and a competitive analysis is appropriate.
seat seat reservation seat reservation problem reservation reservation problem problem on-line problem analysis competitive analysis

Keyphrases Extraction: Feature Set
# Feature # Feature 1 Term Frequency 6-8 i-th token POS tag
2 Inverse Document Frequency 9-11 i-th token head POS tag
3 Position in text 12,15,18 i-th token dependency label
4 Quantity of tokens 13,16,19 distance for i-th incoming arc
5 Part of text 14,17,20 distance for i-th outgoing arc
42

Keyphrases Extraction: Machine Learning Methods
• SVM (FAST SVM library ) – Universal, slow, – not really scalable for large datasets
• FaLKM-SVM – SVM with Local Search – Faster, more scalable
• Random Forest – Fastest – Probabilistic – Based on decision trees
• KEA Naïve Bayes + Heuristics – Fast, 3 features only: not powered by linguistic features 43
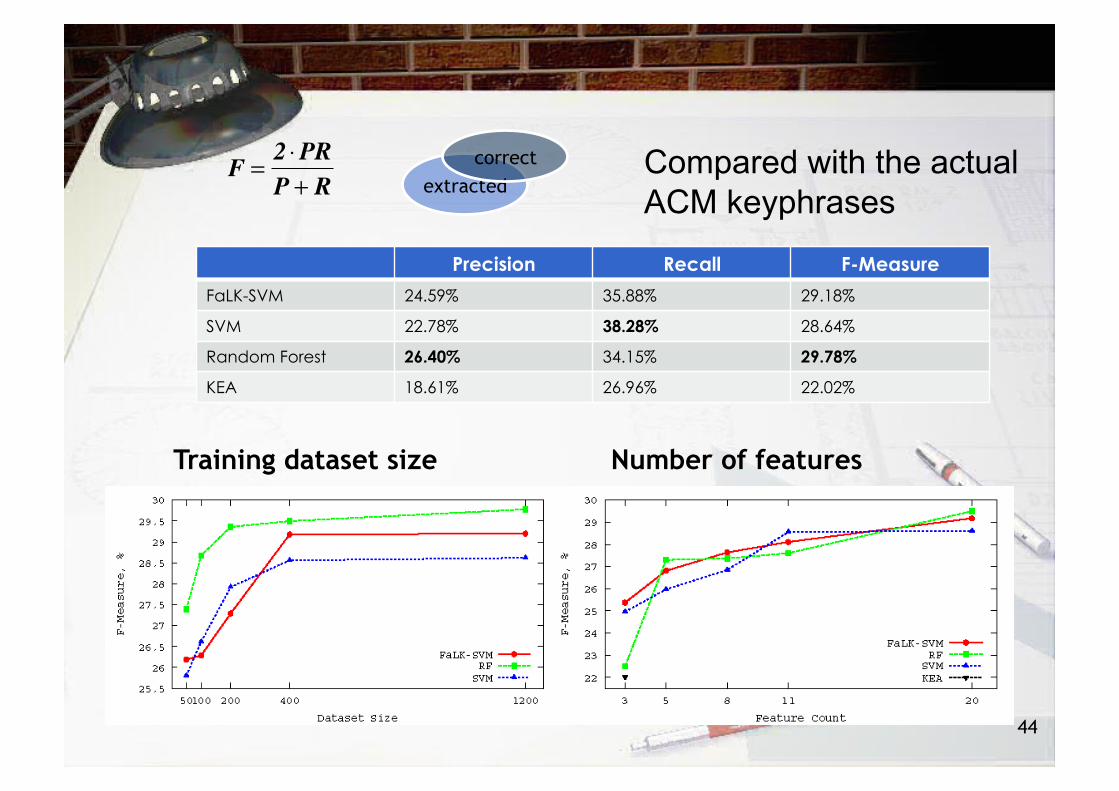
44
Precision Recall F-Measure
FaLK-SVM 24.59% 35.88% 29.18%
SVM 22.78% 38.28% 28.64%
Random Forest 26.40% 34.15% 29.78%
KEA 18.61% 26.96% 22.02%
�
F =2 ⋅PRP + R extracted
correct
Number of features Training dataset size
Compared with the actual ACM keyphrases

Qualitative Analysis of Results


Current Work
• Include tags navigation in community Digital Libraries or Liquid Journals
• Use extracted key phrases as seeds in clustering algorithms – Seeds Affinity Propagation algorithm (Renchu
et al, 2010)
• Propose automatically tags to users of DL

Conclusions
• Social Network contains important information both explicitly (tags, topics, interactions, etc..) and implicitly (their inner structure)
• This information can be successfully mined with state-of-the-art IT methods and tools and used in various applications: – Improving digital library navigation – Innovative ways to access scientific impact – New ways of disseminating knowledge
(LiquidJournal, Fabio Casati Lecture..) – Recommendations systems – …

Acknowledgements
• Work presented done in collaboration with Fabio Casati, Alejandro Mussi, Mikalai Krapivin and many more people in the LiquidPub group
• Part of the work has been supported by the EU ICT project LiquidPub, under FET-Open grant number 213360.

Thank you for attention.
• Any questions?