linux internals for database administrators at linux piter 2016
TRANSCRIPT


Why this talk
• Linux is a most common OS for databases• DBAs often run into IO problems• Most of the information on topic is written by kerneldevelopers (for kernel developers) or is checklist-style
• Checklists are useful, but up to certain workload

The main IO problem for databases
• How to maximize page throughput between memory anddisks
• Things involved:I DisksI MemoryI CPUI IO SchedulersI FilesystemsI Database itself
• IO problems for databases are not always only about disks

A typical database
DRAM
Disks
Shared memory
Database
Linux
Page cache
User space
Kernel space
WAL bu�er
WAL Data�le

Key things about such workload
• Shared memory segment can be very large• Keeping in-memory pages synchronized with disk generateshuge IO
• WAL should be written fast and safe• One and every layer of OS IO stack involved

Memory allocation and mapping
CPU L1
MMU TLB
Memory
L2 L3
pagetable
Virtual addressing
Translation
Physical addressing

DBAs takeaways:
• Database with huge shared memory segment benefits fromhuge pages
• But not from transparent huge pagesI Databases operate large continuous shared memory segmentsI THP defragmentation can lead to severe performance
degradation in such cases

Freeing memory
Page cache
Swap
Free list Free list Free list
alloc()free()
page-out
vm.min_free_kbytes
reclaim
vm.swapiness
OOM-killer
vm.panic_on_oom

Page-out
• Page-out happens if:I someone calls fsyncI 30 sec timeout exceeded (vm.dirty_expire_centisecs)I Too many dirty pages (vm.dirty_background_ratio and
vm.dirty_ratio)
• It is reasonable to tune vm.dirty_* on rotating disks withRAID controller, but helps a little on server class SSDs

DBAs takeaways:
• vm.overcommit_memoryI 0 - heuristic overcommit, reduces swap usageI 1 - always overcommitI 2 - do not overcommit (vm.overcommit_ratio = 50 by
default)
• vm.min_free_kbytes - reasonably high (can be easy 1000000on a server with enough memory)
• vm.swappiness = 1I 0 - swap disabledI 60 - defaultI 100 - swap preffered instead of other reaping mechanisms
• Your database would not like OOM-killer

OOM-killer: plague and cholera
• vm.panic_on_oom effectively disables OOM-killer, but that isprobably not the result you desire
• Or for a certain process: echo -17 > /proc/12465/oom_adjbut again

Filesystems: write barriers
Journal
Kernel bu�er
Journalated fylesystem
Data
Journal entryData

DBAs takeaways:
• ext4 or xfs• Disable write barrier (only if SSD/controller cache is protectedby capacitor/battery)
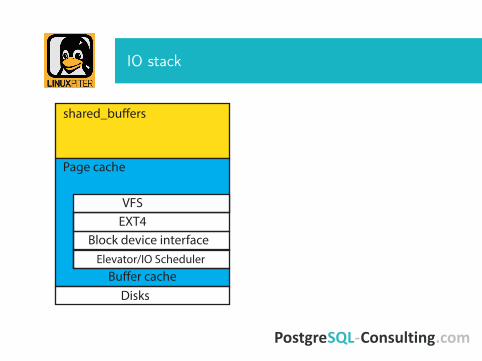
IO stack
shared_bu�ers
Page cache
VFSEXT4
Block device interface
DisksBu�er cache
Elevator/IO Scheduler

Elevators
• noop or none - then disks throughput is so high, that it cannot benefit from keen scheduling
I PCIe SSDsI SAN disk arrays
• deadline - rotating disks• CFQ - universal, default one

Thanks
to my collegues Alexey Lesovsky and Max Boguk for a lot ofresearch on this topic
