machine learning in a twitter etl using elk
TRANSCRIPT

Machine Learning in a Twitter ETL using ELK
(ELASTICSEARCH, LOGSTASH, KIBANA)
MELVYN [email protected]
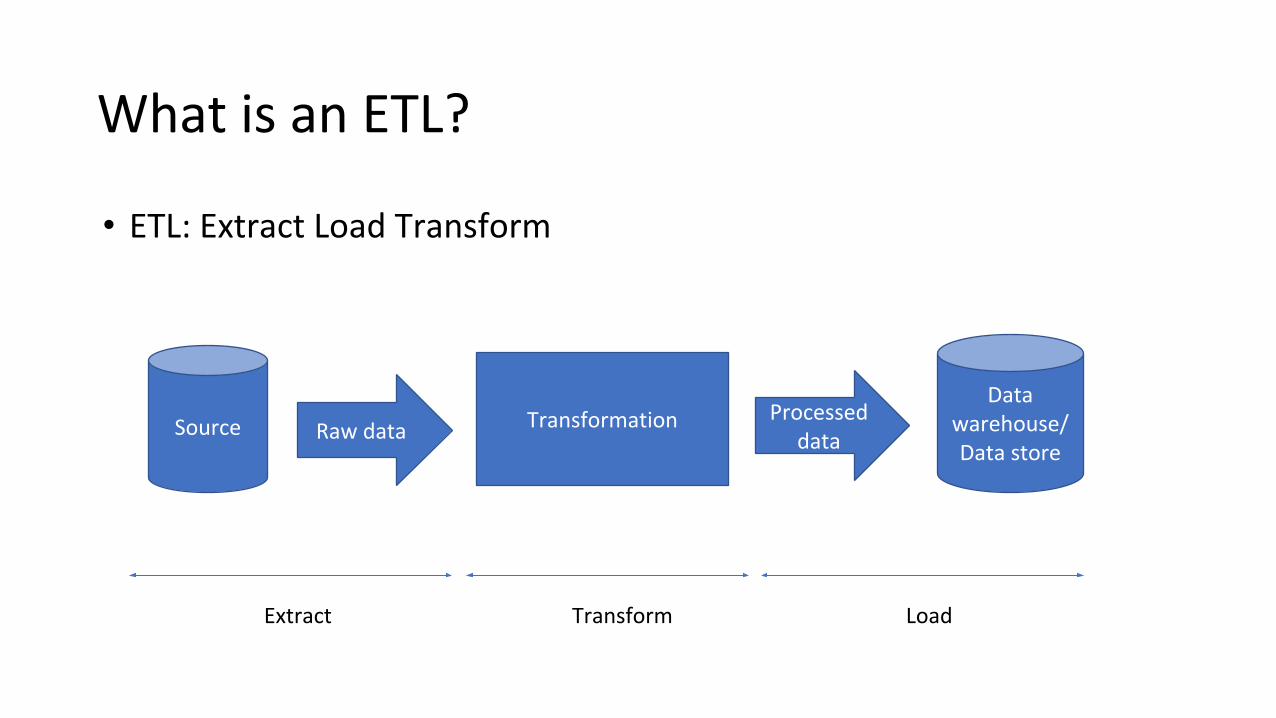
What is an ETL?
• ETL: Extract Load Transform
Source TransformationData
warehouse/Data store
Raw dataProcessed
data
Extract Transform Load

Our use case: An ETL for Twitter
https://github.com/melvynator/ELK_twitter
Goals:
• Simplify a recurrent task for several members of the lab•Normalize the data collection (Have a “universal” format)•Have tweets analyzed the way we want (Emoji, punctuation)• Include some machine learning model in our ETL

Our tools: ELK
•E : ElasticsearchElasticsearch is a distributed, RESTful search and analytics engine
• L : LogstashLogstash is an open source, server-side data processing pipeline that simultaneously ingests data from multiple sources transforms it, and then sends it to your favorite “stash”.
•K: Kibana Kibana lets you visualize your Elasticsearch data and navigate the Elastic Stack
Source: Elastic website
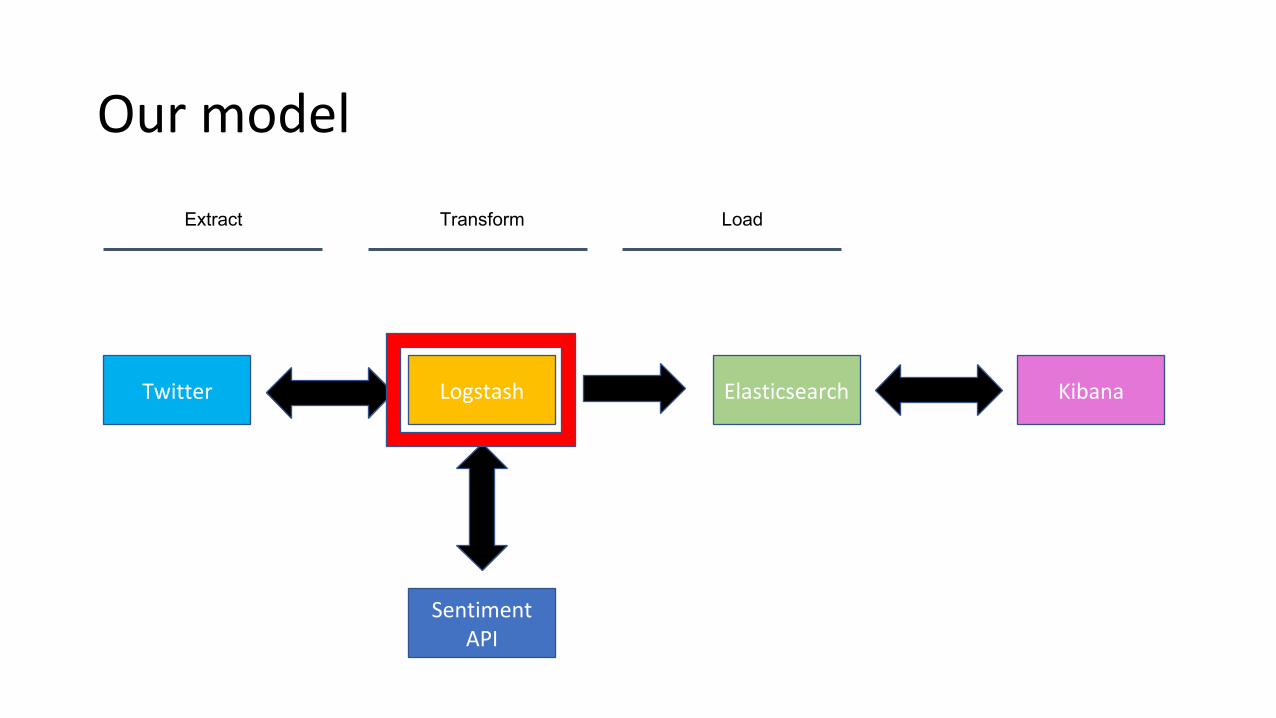
Our model
Twitter Logstash Elasticsearch Kibana
Sentiment API
Extract Transform Load

Logstash
Logstash allows you to ingest data from multiple sources, transform the data and then store your processed data.
Notions you need to know:
•Event
• Input
• Filter
•Output

Petrol Pipeline
Storage
Truck
Refinery
Pipeline
Petrol Chemical
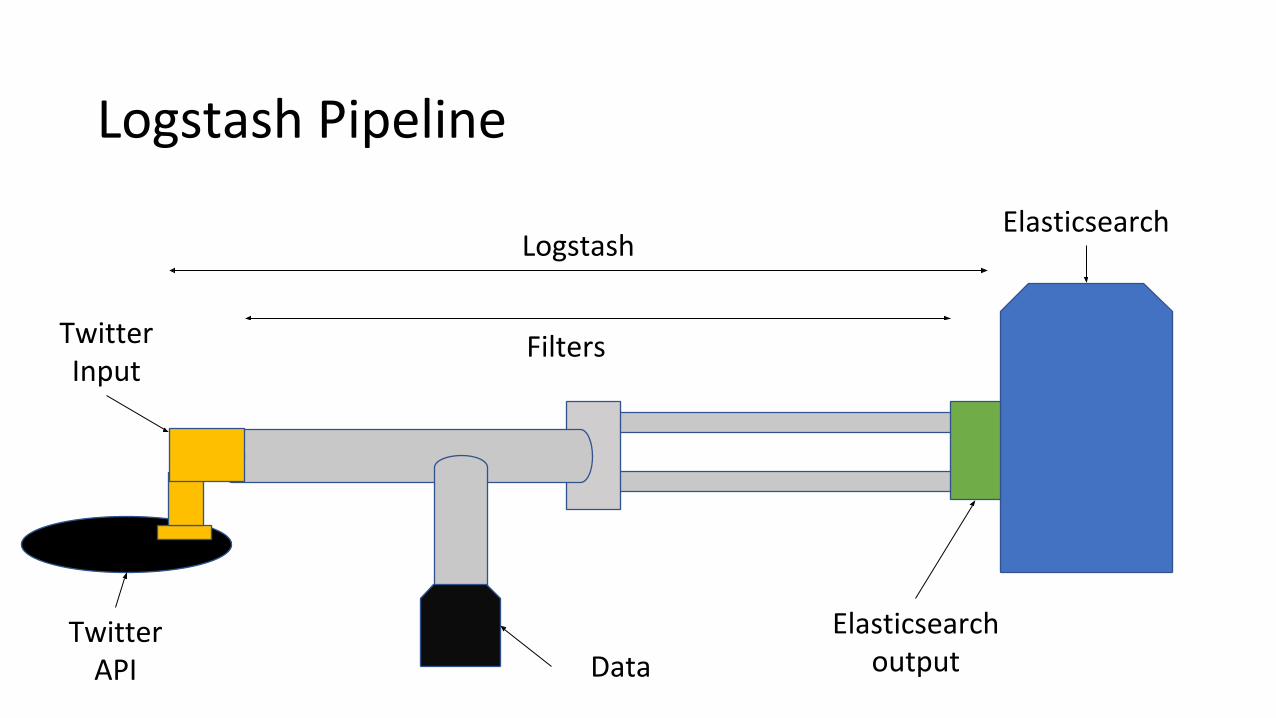
Logstash Pipeline
Elasticsearch
Filters
Twitter API
Twitter Input
Elasticsearch outputData
Logstash

Logstash: Event
An event can be described as one raw data traveling across the pipeline:
•A Log•A Line•A JSON•…

Logstash: Input
The input plugins consume data from a source.
• File•Elasticsearch•Twitter API•Github API•…

Logstash: Filter
A filter plugin performs intermediary processing on an event. Filters are often applied conditionally depending on the characteristics of the event.
•Clone
•Mutate
•Ruby
•…

Logstash: Output
An output plugin sends event data to a particular destination.
•Elasticsearch
•MongoDB
• File
•…
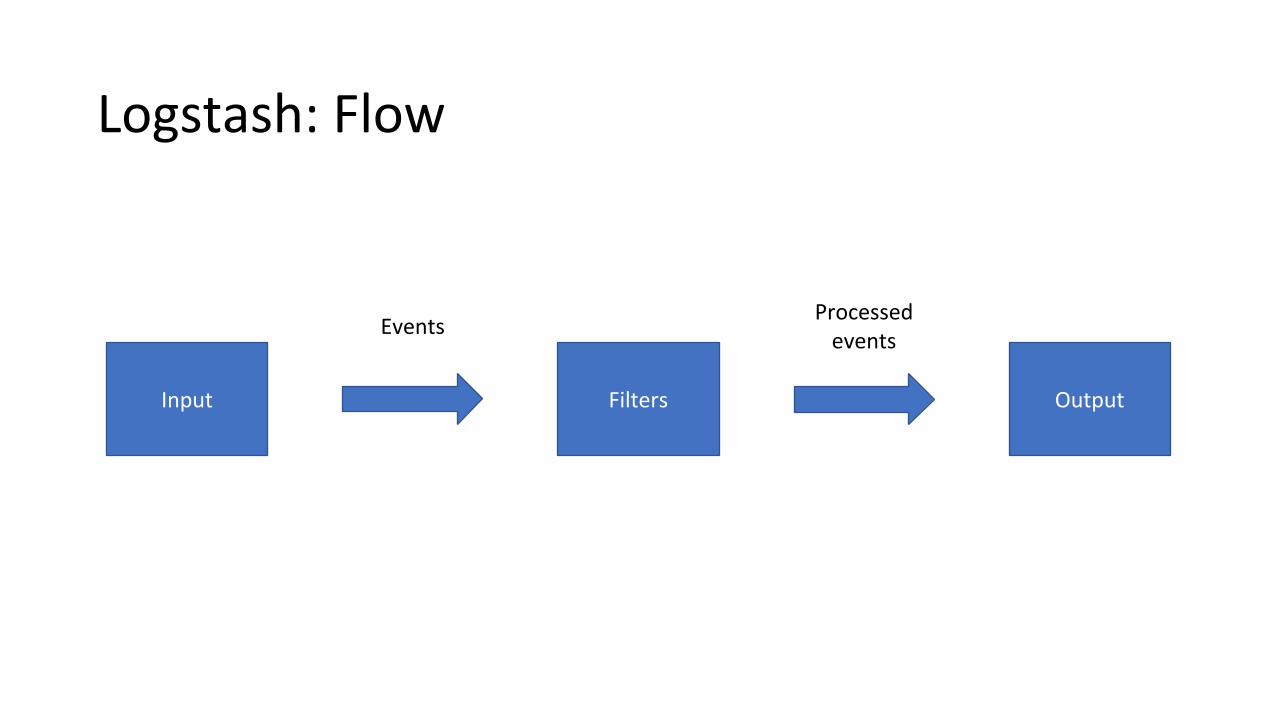
Logstash: Flow
Input Filters Output
EventsProcessed
events

Example: tutorial_input.txt
{
"last_name":"John",
"first_name":"Doe",
"age": 25,
"degree":"Master",
"school":"Stanford",
"comment": "A guy from somewhere"
}
{
"name":"John Doe",
"age": 25,
"comment": "A guy from somewhere",
"created_at" : 2017-09-04T08:39:54.847Z
}
{
"school": "Stanford",
"degree": "Master",
"created_at" : 2017-09-04T08:39:54.877Z
}
What we have: What we want:

Example: Building the configuration file
input {
file {
path => "/usr/local/Cellar/logstash/5.5.2/tutorial_input.txt"
start_position => beginning
sincedb_path => "/dev/null"
codec => "json"
} # the input will be a file containing JSON (takes only absolute path)
}
filter {} # Empty for the moment (We will only fill this)
output { stdout {codec => rubydebug}} # Print the result to the console

Example: Output{
"path" => "/usr/local/Cellar/logstash/5.5.2/tutorial_input.txt",
"@timestamp" => 2017-09-04T07:03:26.388Z,
"degree" => "Master",
"@version" => "1",
"host" => "Melvyns-MacBook-Pro.local",
"last_name" => "Doe",
"school" => "Stanford",
"comment" => "A guy from somewhere",
"first_name" => "John",
"age" => 25
}

Example: Building “name” key
ruby { # Allows you to insert ruby code
code =>
‘ event.set("name", event.get("[first_name]") + " " +
event.get("[last_name]")) ’
} #event.get() allows retrieving a value given a key, event.set() to create
one
mutate {
remove_field => ["first_name", "last_name", "host", "path"]
} # mutate allows basic transformation on events; here we are removing 4 keys
The order used to modify the document matters! Here “Ruby” will be applied first then “Mutate”.
1. Merging “first_name” and “last_name” into ”name”2. Removing “first_name” and “last_name”

Example: Output{
"@timestamp" => 2017-09-04T08:33:26.599Z,
"school" => "Stanford",
"degree" => "Master",
"@version" => "1",
"name" => "John Doe",
"comment" => "A guy from somewhere",
"age" => 25
}

Example: Building two events out of oneclone {
clones => ["education"]
} # we are duplicating our event and add in the replica a key "type" with "education" as a value.
if ([type] == "education") {
mutate {
remove_field => ["name", "age", "comment", "type"]
}
}
else {
mutate {
remove_field => ["school", "degree"]
}
}

Example: Output{
"@timestamp" => 2017-09-04T08:39:54.847Z,
"name" => "John Doe",
"comment" => "A guy from somewhere",
"@version" => "1",
"age" => 25
}
{
"@timestamp" => 2017-09-04T08:39:54.897Z,
"school" => "Stanford",
"@version" => "1",
"degree" => "Master"
}

Example: Changing the name of a field
mutate {
remove_field => ["@version"] # @version, @timestamp are created
for every events
rename => { "@timestamp" => "created_at" } # change the name of a
field
}
The order inside mutate may vary. You cannot know if “remove_field” will be applied before or after “rename”

Example: Output{
"created_at" => 2017-09-04T08:39:54.847Z,
"name" => "John Doe",
"comment" => "A guy from somewhere",
"age" => 25
}
{
"created_at" => 2017-09-04T08:39:54.897Z,
"school" => "Stanford",
"degree" => "Master"
}

Logstash: Twitter input
input {
twitter {
consumer_key => "<YOUR-KEY>"
consumer_secret => "<YOUR-KEY>"
oauth_token => "<YOUR-KEY>"
oauth_token_secret => "<YOUR-KEY>"
keywords => [ "random", "word"]
full_tweet => true
type => "tweet"
}
}
Only one input:

Logstash: Our filters
There are many filters, but the overall goals of the filters are to:
•Remove depreciated fields•Divide the tweet into two or three events (users and tweet)•Remove the nesting of the JSON•Remove the fields not used

Our model
Twitter Logstash Elasticsearch Kibana
Sentiment API

Building the API
•Python• Flask•Building your model based on labeled data•Design an endpoint that will receive the data you want to predict

Logstash REST filter
•https://github.com/lucashenning/logstash-filter-rest
•Allows RESTful resources inside Logstash•Will call your Machine learning API•Will add information to your events

Logstash REST filter: Example
rest {
request => {
url => http://localhost:5000/predict
method = "post"
params => {
"submit" => "%{tweet_content}"
}
headers => {
"Content-Type" => "application/json"
}
}
target => 'rest_result'
}
Time to do it yourself
•https://github.com/melvynator/Logstash_tutorial
•https://docs.google.com/forms/d/e/1FAIpQLSdDdFxmT5ZCXInaSohJBBo6fKKmCg3KLegeOOrxl1l4_sc-7g/viewform

Thank you!
Questions?