managing the data bonanza: generating, analyzing and sharing data for megasequencing projects...
Post on 19-Dec-2015
215 views
TRANSCRIPT

Managing the Data Bonanza:Generating, Analyzing and Sharing Data for Megasequencing Projects
Narayan Desai
Mathematics and Computer Science DivisionArgonne National LaboratoryandUniversity of ChicagoXLDB 5 – October 19, 2011

Talk Overview
Metagenomics Primer Data Production Analysis Data Sharing Megasequencing Projects

Metagenomics …Definition:: “random shotgun DNA sequencing applied directly to environmental samples” whole shotgun metagenomicsResult is a combination of short reads of DNA from all organisms in sampled community
Mixed together
Who are they?What are they doing?

Metagenomics and Discovery
Today:Mapping our knowledge to help understand microbial ecology
using existing knowledge
Future:Discover new biology from computationally mining the unknowns
Patterns co-occurrence Exclusion ..
ExampleSystematic discovery of patterns e.g. CRSPR by Jill Banfield
Via:Mapping to curated databases
Known
unknown

Western Channel Observatory
Feb
Mar
MarApr
May
Jun
Jun
Jul
Aug
Sep
Oct
Dec
Jan
Jan
AugAug
AugAug
AprApr
2D Stress: 0.12

Biology rapidly changing. From this …
http://www.ferrum.edu/majors/biology.jpg
http://www.oneocean.org/ambassadors/track_a_turtle/biology
http://www.the-aps.org/education/
These are: “biology.png”, “biology.gif” and “biology.jpg”.6

… to this. (in ~2003)
7

… benchtop scale now in 2011
8
From factory to bench-top in 5 years And>70% of Illumina machines go to “small” customers(1)
1) From Illumina at 2010 GIA meeting
.5 GBp / run
60 GBp / run
600 GBp / run
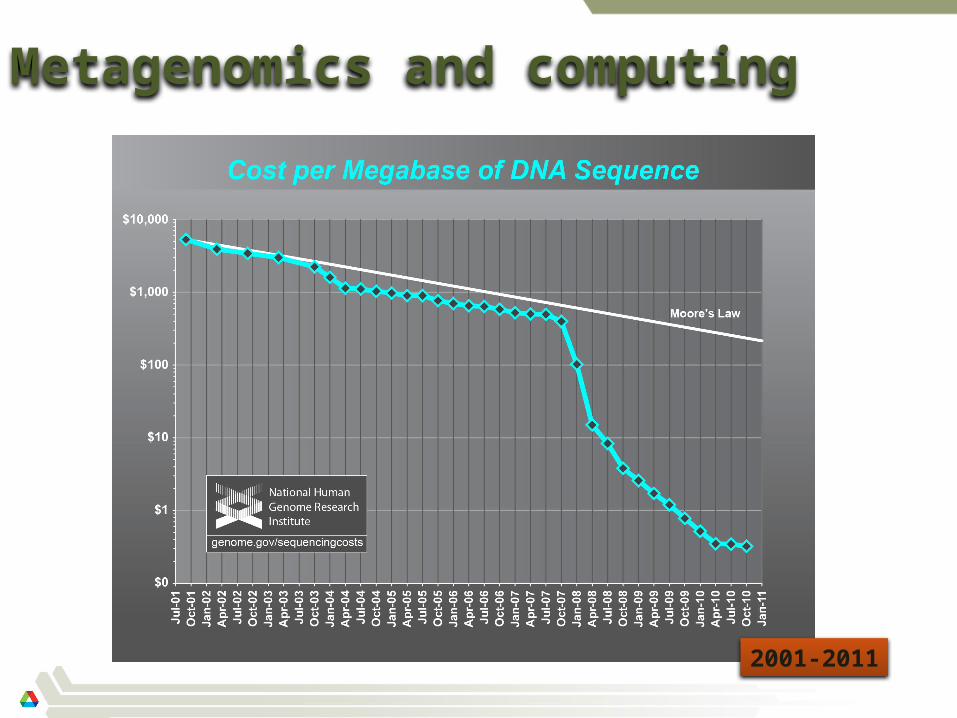
Metagenomics and computing
2001-2011

Data generation cost
Sequencing cost for single lane of Illumina 1x100bp is $1170.62 for approx 10 GBp (gigabasepairs)
For many large studies sequencing cost are dominated by sample preparation (and sequencing library construction)
100,000 16S amplicon reads(Source: Rob Knight, Colorado)• sample extraction: $8 • PCR and pooling:
$5• Sequencing:
$4Sum: $17
Metagenomics 10GBp (or 20GBp)(Source: Marc Domanus, ANL)• Sample prep: $100• Lib prep: $64 (non mate-pair)
$389 (mate-pair)
• Sequencing: $1171 @ 10GBp$2174 @ 20GBp
Sum: $1335 Sum: $2663
Example cost:

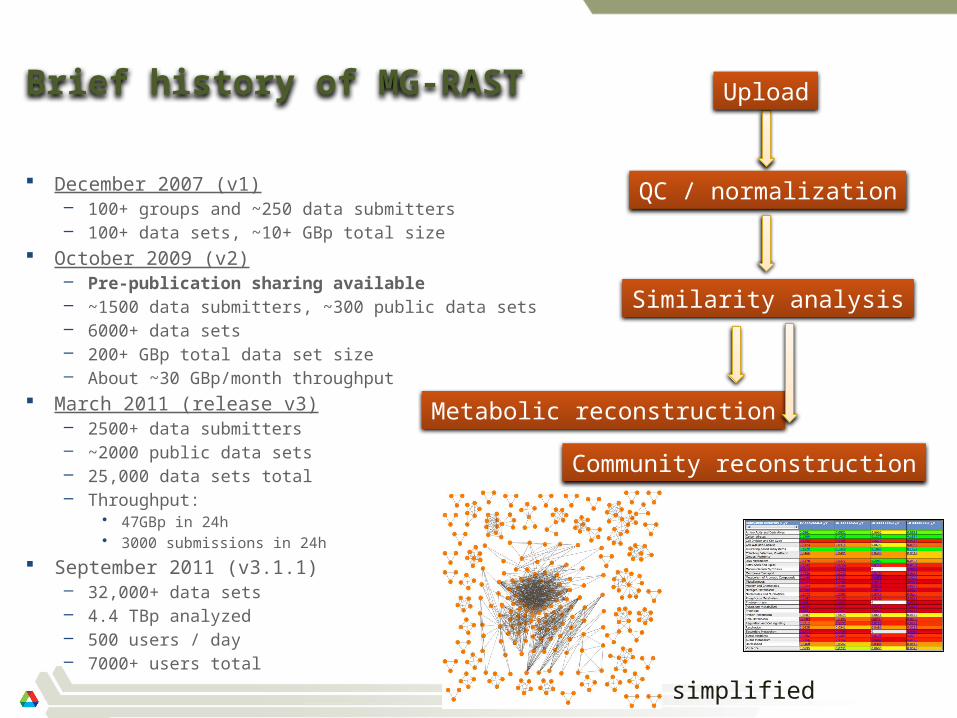
Brief history of MG-RAST
December 2007 (v1)– 100+ groups and ~250 data submitters– 100+ data sets, ~10+ GBp total size
October 2009 (v2)– Pre-publication sharing available– ~1500 data submitters, ~300 public data sets– 6000+ data sets– 200+ GBp total data set size– About ~30 GBp/month throughput
March 2011 (release v3)– 2500+ data submitters– ~2000 public data sets– 25,000 data sets total– Throughput:
• 47GBp in 24h• 3000 submissions in 24h
September 2011 (v3.1.1)– 32,000+ data sets– 4.4 TBp analyzed– 500 users / day– 7000+ users total
Upload
QC / normalization
Similarity analysis
Metabolic reconstruction
Community reconstruction
simplified
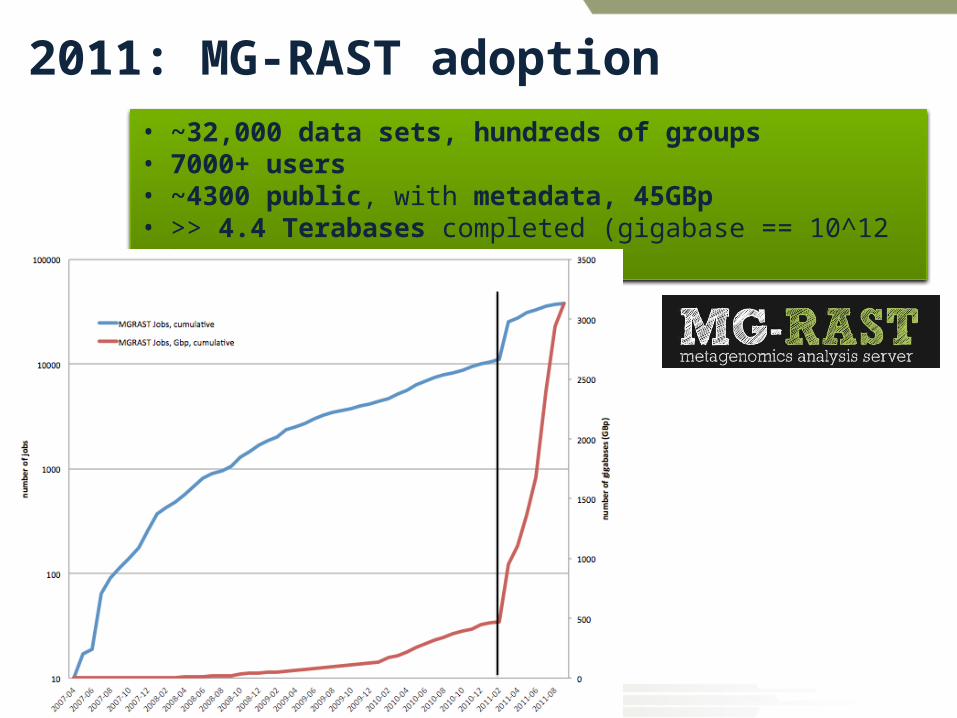
2011: MG-RAST adoption• ~32,000 data sets, hundreds of groups• 7000+ users• ~4300 public, with metadata, 45GBp• >> 4.4 Terabases completed (gigabase == 10^12 basepairs)

Analysis Open Challenges
Data volume reduction is the key goal– Superlinear algorithms– Data growth faster than Moore’s law
Read assembly might help– Reduces number of strings– But will produce some chimeric contigs
Need fast screening techniques– Which data sets are actually interesting
Before long, analysis of all data sets may be unsustainable– Computational costs dwarfing all others
Cost breakdown means metagenomic results are more valuable than raw data– Sea change in bioinformatics data ecosystem
Virtual surveys are the long term goal

Data Archives and Sharing
Value is in analyzed metagenomic data sets, not raw data– Though raw data is still useful in many cases
Sharing of analysis results requires improvements in metadata– All sample collection details (biome, ph, etc)– Provenance– Formats emerging through the Genomic Standards Consortium
Centralized archives exist (NCBI, EMBL, etc)– But can’t possibly scale to handle data volume from decentralized, democratized
sequencing– Not clear this architecture is even correct for the new workload
More likely, a moderate number of community brokers will fill the gap– Driven by domain or funding– Consensus metadata, analysis, and provenance– Federation with other archives– Bilateral peering/data sharing arrangements

Results sharing
Raw data sharing is established– GenBank, SRA, EMBL, …
Suitable for low volume data science Reproducibility no longer exists for current data Large volume data science requires result sharingRequire community agreement and standardsGSC’s M5 initiative provides transport encoding
Metagenome transport format (MTF)
Fixes the re-computing issue

OSDF: Data access API for community bioinformatics resources
Open Science Data Framework APIs for data discovery, storage and retrieval
– Metadata-based queries (environmental data, assays, etc)– Analysis graph queries (provenance traversal)
Reference implementation of the archive layer ( Shock)– Tools ecosystem built on top of OSDF APIs– Initial release available
Support from major metagenomics service providers– MG-RAST and IMG/M– QIIME (16S amplicon analysis software)– CLOVR (Bio VM environment)
Major projects (EMP & HMP) will support OSDF API for data access


EMP Products:– Earth Microbiome Gene Atlas (EM-GA) – a repository and
database for all sequencing and metadata information. – Earth Microbiome Assembled Genomes (EM-AG) –
~500,000 microbial genomes and extra chromosomal elements derived from metagenomic data.
– Earth Microbiome Metabolic Reconstruction (EMMR) –describe changes in metabolite profiles between all samples, providing another metric against which to refine biome descriptions.
– Earth Microbiome VIsualization Portal (EM-VIP) – A web portal like Google Earth – exploring microbial space.
Earth Microbiome Projectwww.earthmicrobiome.org

Challenges– 2.4 Quadrillion Base Pairs (2.4 Peta bp) = 8000 HiSEQ2000
runs.– Global Environmental Sample Database (GESD):
identification and selection of 200,000 environmental samples, soil, air, marine and freshwater, host-associated, etc.
– The standardization of sampling, sample prep and sample processing, cataloging and sample metadata – Genomic Standards Consortium.
Earth Microbiome Projectwww.earthmicrobiome.org

The Earth Microbiome Project
Jack A. Gilbert, Folker Meyer, Rick Stevens, Janet Jansson, Rob Knight, Jonathan A Eisen, Jed Furhman, Jeff Gordon, Norman Pace, James Tiedje, Ruth Ley, Noah Fierer, Dawn Field, Nikos Kyrpides, Frank-Oliver Glockner, Hans-Peter Klenk, K. Eric Wommack, Elizabeth M. Glass, Kathryn Docherty, Rachel Gallery,, George Kowalchuk, Mark Bailey, Dion Antonopoulos, Pavan Balaji, C. Titus Brown, C. Titus Brown, Narayan Desai, Dirk Evers, Wu Feng, Daniel Huson, James Knight, Eugene Kolker, Kostas Konstantindis, Joel Kostka, Rachel Mackelprang, Alice McHardy, Christopher Quince, Jeroen Raes, Alexander Sczyrba, Ashley Shade

Questions?