master en marketing e investigaciÓn de …¡lisis datos 15-16.pdf · preparaciÓn y anÁlisis de...
TRANSCRIPT

MASTER EN MARKETING E
INVESTIGACIÓN DE MERCADOS
Complemento formativo:
INVESTIGACIÓN DE MERCADOS
Dr. Antonio Carlos Cuenca Ballester
Dra. María José Miquel Romero
Octubre 2015

Definición del problema
Enfoque del problema a investigar
Diseño de la investigación
Trabajo de campo
PREPARACIÓN Y ANÁLISIS DE LOS DATOS
Preparación del informe y presentación
Preparación de la información
Relación con el proceso de investigación de marketing
PREPARACIÓN Y ANÁLISIS DE LOS DATOS
Paquetes estadísticos y preparación de datos
• SPSS www.spss.com
• SAS www.sas.com
• MINITAB www.minitab.com
• ODEC www.odec.es
• BARWIN www.tesigandia.com
• Dyane4 www.miguelsantesmases.com
• R R-studio

Preparación de la información
El Programa SPSS de análisis de datos
SPSS for windows es un paquete estadístico que permite realizar una gran variedad de análisis estadísticos con relativa facilidad, en un entorno Windows.
Toda la gestión y análisis de datos puede realizarse con el programa SPSS.
Con SPSS podemos “manipular” datos, hacer gráficos y aplicar técnicas estadísticas (desde univariante a multivariante, descriptivo y causal).
Es absolutamente compatible con los programas del paquete Office de Windows
Proceso SPSS for Windows
Creación de variables (vista variables)
Grabación de datos (vista datos)
Análisis (menú análisis)
Resultados archivos .spo
Gráficos archivos .cht
Historial de análisis archivos .sps

Creación de variables
Nombre: dar un código reconocible y distintivo. Hasta 8 caracteres, el
primero siempre LETRA. Puede ser adecuado relacionarlo con la pregunta.
Tipo: NUMÉRICO-numeric, CADENA-string,...
Anchura: número de carácteres posibles. Por defecto, 8.
Decimales: número de decimales posibles. Por defecto, 2.
Etiqueta: Identificación del contenido de la variable.
Valores: posibles respuestas a las preguntas. Adecuado sin son preguntas
cerradas o variables nominales. Por ejemplo: 1: Sí; 2: No
Perdidos: el usuario define valores que SPSS tratará como perdidos
Columnas: ancho de la columna para visualizción. Por defecto, 8 puntos.
Alineación: alineación en que aparecerán los datos en la vista de datos.
Medida: Tipo de escala o de varible: Nominal, Ordinal, Escalar.

Fichero de datos
• EDITOR DE DATOS – compuesta de celdas/casillas, en las cuales se indican los valores de los datos.
Columnas: variables Filas: cuestionarios

Depuración de datos
Verificación de la congruencia y el tratamiento de los valores perdidos.
En la comprobación de la congruencia se identifican los datos impropios,
ilógicos o extremos. Los datos impropios son inadmisibles y hay que
corregirlos. Por ejemplo, si se pide a los entrevistados que expresen su grado de
acuerdo/desacuerdo con una serie de afirmaciones en una escala de 1 a 5. ¿Y si
encontramos grabado un 9? Se puede identificar el error mediante el paquete SPSS y ver
el cuestionario en papel codificado por si hubiera algún error al grabarlo.
Los valores perdidos son valores de una variable que se desconocen, bien
porque los entrevistados dieron respuestas ambiguas, no están bien anotadas,
o o no dieron respuesta.
El tratamiento de los valores perdidos presenta problemas cuando su
proporción es de más de 10% de los cuestionarios recibidos.
Para el tratamiento de los valores perdidos, se tienen tres opciones:
• Reemplazar con un valor neutro, (p.ejem. valor promedio de la variable).• Eliminación de casos, con valores perdidos. Si muchos entrevistados tienen algún valor
perdido, este método reduce el tamaño de la muestra.• Eliminación por pares, donde en vez de descartar todos los casos con valores
perdidos, el investigador toma sólo los casos o entrevistados con respuestas completas para los cálculos. En consecuencia, los diferentes cálculos del análisis se basarán en distintos tamaños de la muestra.

Plan de Análisis
Detenerse a planificar los análisis que se harán para: describir cada una de las preguntas; dar cumplimiento a los objetivos de la investigación; contrastar las hipótesis planteadas.
¿Qué tipo de análisis de datos será llevado a cabo? ¿Cómo se interpretarán los resultados?
¿qué enfoque tiene el estudio?
¿qué escalas básicas se han utilizado?
Conocer las características de los datos.
Propiedades de las técnicas estadísticas (univariables, bivariables y multivariables).
Estrategia de análisis de datos.
Debe incluir: • Tratamientos univariados (frecuencias, medias…)
• Tratamientos bivariados (tablas cruzadas, análisis varianza, test no paramétricos...)
• Tratamientos multivariados (factorial, cluster, discriminante…)
1 variable
Más de 2 variables
2 variables
simples

Plan de Análisis: Ejemplo
Finalidad Cuestiones a investigar e
hipótesis
Preguntas del cuestionario
Análisis
Conocer los hábitos de los jóvenes universitarios frente al tabaco
- ¿Cuáles son los hábitos de consumo de tabaco?
- Edad media de los fumadores
- ¿Existen diferencias de consumo de tabaco por género?
P1 (Nominal)
P1 (Nominal) y P13 (Escalar)
P1 (Nominal) y P14 (Nominal)
Frecuencias
Medias
Tabla cruzada Test de hipótesis Χ2
…… …… ……. ……

Análisis descriptivo de la
información
Análisis descriptivo: transformacion de los datos en bruto de tal forma
que se conviertan en sencillos de comprender e interpretar; recolocación,
ordenamiento y transformación de datos para generar información
descriptiva.
En general, el primer paso del análisis es la descripción de respuestas u
observaciones. Las formas más comunes de resumir los datos son los
promedios y las distribuciones de frecuencias y porcentajes.
Tratamientos con una variable: univariados o
descriptivos
• Distribución de frecuencias
• Tendencia central
• Medidas de dispersión
• Medidas de forma de la distribución

Análisis descriptivo de la
informaciónEscalas no continuas Frecuencias
Escalas continuas Medias
Distribución de frecuencias
• La tabulación simple de respuestas u observaciones en una disposición
pregunta por pregunta o ítem por ítem proporciona la forma de información
más sencilla – y en muchos casos la más útil. Le dice al investigador con
qué frecuencia aparece cada respuesta. Este punto de arranque del análisis
requiere que el investigador recuente respuestas u observaciones para cada
categoría o código asignado a una variable.
¿FUMA USTED?
174 39,9 40,0 40,0
32 7,3 7,4 47,4
229 52,5 52,6 100,0
435 99,8 100,0
1 ,2
436 100,0
SI
DEJADO
NO
Total
Válidos
SistemaPerdidos
Total
Frecuencia Porcentaje
Porcentaje
v álido
Porcentaje
acumuladoEstadísticos
¿FUMA USTED?
435
1
Válidos
Perdidos
N
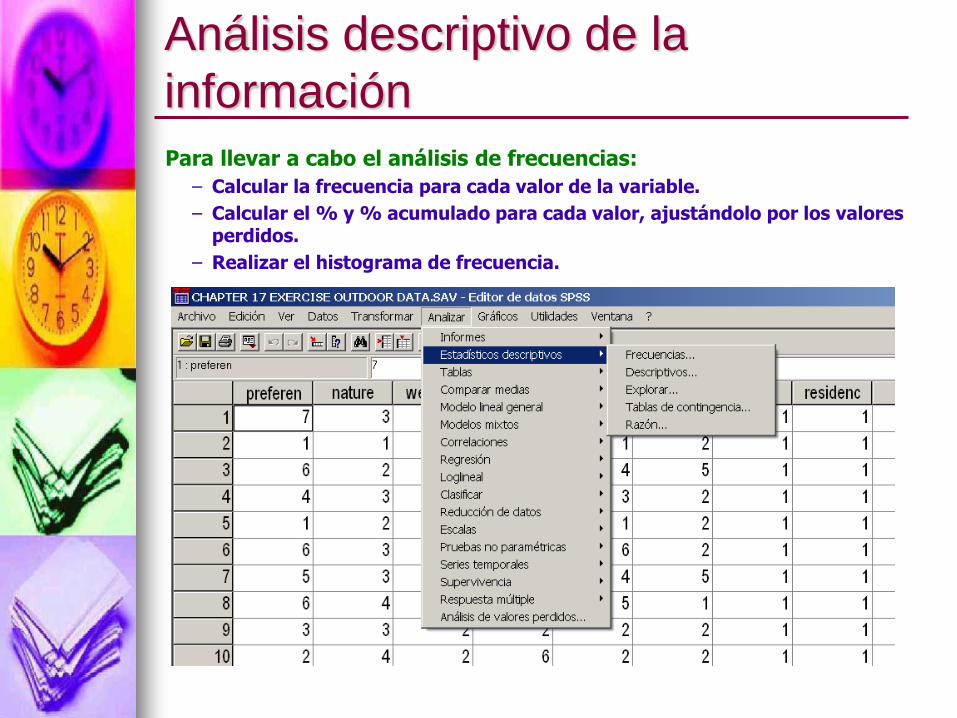
Análisis descriptivo de la
información
Para llevar a cabo el análisis de frecuencias:
– Calcular la frecuencia para cada valor de la variable.
– Calcular el % y % acumulado para cada valor, ajustándolo por los valores perdidos.
– Realizar el histograma de frecuencia.

Análisis descriptivo de la
información
Tabulación y tabla de frecuencia
La tabulación implica la disposición ordenada de los datos en una tabla o en otro formato de resumen.
El recuento de las distintas respuestas a una pregunta y su disposición en una distribución de frecuencias es la TABULACIÓN SIMPLE, o tabulaciónmarginal.
Nota: Cuando el proceso de tabulación se realiza a mano, se denomina“recuento”.
Estadísticos
¿POR QUE FUMA?
174
262
Válidos
Perdidos
N
¿POR QUE FUMA?
124 28,4 71,3 71,3
18 4,1 10,3 81,6
15 3,4 8,6 90,2
2 ,5 1,1 91,4
15 3,4 8,6 100,0
174 39,9 100,0
262 60,1
436 100,0
Me gusta
Me calma
Me distrae
Quita apetito
Otros
Total
Válidos
SistemaPerdidos
Total
Frecuencia Porcentaje
Porcentaje
v álido
Porcentaje
acumulado

Análisis descriptivo de la
información
Preference for Community
High Preference65432Low Preference
Co
unt
50
48
46
44
42
40
38
36
En el histograma se representa mediante barras las frecuencias, en él es posible examinar si la distribución observada coincide con alguna distribución esperada o presupuesta, como la distribución normal.

Análisis descriptivo de la
información
Medidas de tendencia central y medidas de dispersión
Mediante la utilización de estadísticos descriptivos, el investigador puede resumir la información. Existen dos tipos de estadísticos descriptivos:
Medidas de ubicación o tendencia central.Medidas de dispersión o variabilidad.
Media o valor promedioMediana o valor centralModa o valor que ocurre con más frecuencia
Medidas de ubicación:estadísticos que describen la localización en el conjunto de datos.
Medidas de dispersión:estadísticos que indican la dispersión de la distribución.
RangoVarianza Desviación típica
Media, mínimo, máximo y desviación típica
174 1 17 5,57 2,752
174
Cuanto tiempo hace que fuma
N v álido (según lis ta)
N Mínimo Máximo Media Desv. típ.

Análisis descriptivo de la
informaciónMedia:• Es el valor promedio. Se estima la media cuando los datos fueron recopilados
con una escala de intervalo o de ratio. • Se obtiene de sumar todos los elementos y dividir entre el número de estos. La
fómula de la media es ∑X/n.
Mediana:• Medida de la tendencia central que corresponde al valor sobre el cual se
encuentran la mitad de los valores y bajo el cual se localiza la otra mitad.
– Conjunto de datos: 27 39 65 47 95 32 76 85 94 40 (n=10)
– Orden ascendente: 27 32 39 40 47 65 76 85 94 95
– Valor(es) central(es): 27 32 39 40 47 65 76 85 94 95
– En este caso, la mediana se estima como el punto medio entre los dos valorescentrales (se suman y se dividen entre dos): (47+65)/2), at 56
Moda:• La moda es el valor que ocurre con más frecuencia. Representa el punto más
alto de la distribución. La moda es una buena medida de la ubicación si la variable es inherentemente categórica o si está organizada en categorías.

Análisis descriptivo de la
información
Rango
• Mide la dispersión de los datos. Simplemente es la diferencia entre el mayor
y el menor valor de la muestra. Como tal, sufre el efecto de los valores
extremos.
Varianza y desviación típica
• La diferencia entre la media y el valor observado se llama desviación de la
media. La varianza es la desviación promedio al cuadrado de la media. La
varianza nunca es negativa. Cuando los datos se agrupan alrededor de la
media, la varianza es pequeña. Cuando están dispersos, la varianza es
grande. La S es la raíz cuadrada de la varianza.
1
2
n
XXiS

La tabulación cruzada
• Aunque las respuestas relacionadas con una sola variable son
interesantes, por lo regular suscitan nuevas preguntas sobre la
vinculación de esa variable con otras. Por ejemplo:
¿Cuántos visitantes leales a un parque temático son hombres?
¿El conocimiento del parque se relaciona con la edad?
• La tabulación cruzada es una técnica estadística que describe dos
variables simultáneamente y produce cuadros en que se muestra la
distribución conjunta de dos variables que tienen un número limitado
de categorías o valores distintos.
• Las tabulaciones cruzadas también se llaman tablas de contingencia.
• La tabulación cruzada se emplea mucho en la investigación de
mercados

La tabulación cruzada
Tabla de contingencia ¿FUMA USTED? * sexo
67 107 174
38,5% 61,5% 100,0%
42,7% 38,6% 40,1%
8 23 31
25,8% 74,2% 100,0%
5,1% 8,3% 7,1%
82 147 229
35,8% 64,2% 100,0%
52,2% 53,1% 52,8%
157 277 434
36,2% 63,8% 100,0%
100,0% 100,0% 100,0%
Recuento
% de ¿FUMA USTED?
% de sexo
Recuento
% de ¿FUMA USTED?
% de sexo
Recuento
% de ¿FUMA USTED?
% de sexo
Recuento
% de ¿FUMA USTED?
% de sexo
SI
DEJADO
NO
¿FUMA
USTED?
Total
Hombre Mujer
sexo
Total
Ejemplo

Contraste de hipótesis
Hipótesis nula y alternativa
Una hipótesis nula es un enunciado del estado en que se
encuentran las cosas y en el que no se espera ninguna
diferencia ni efecto. Si se acepta la hipótesis nula, no se
hacen cambios.
Una hipótesis alternativa es un enunciado en el que se
espera alguna diferencia o efecto.
¿Qué es una hipótesis?
Una hipótesis es una proposición o conjetura no probada que
explica tentativamente ciertos hechos o fenómenos; proposición
que puede ser sometida empíricamente a prueba.

Contraste de hipótesis
Pro
ceso
de
con
trast
e d
e h
ipóte
sis
Formular las hipótesis H0 y H1
Elegir una prueba apropiada
Extraer conclusiones para la investigación de mercado
Elegir el nivel de significación,
Recoger datos y calcular el test estadístico
Determinar la probabilidad associada
con el test estadístico (TSCAL)
Rechazar o aceptar H0
1
2
3
4
5
7
8
Determinar el valor crítico del test
estadístico (TSCR)
6Comparar la probabilidad
con el grado especificado del nivel de significación,
Determinar si TSCR cae en la región de rechazo
o aceptación

Contraste de hipótesis
¿Qué significa “pequeño” en Ciencias Sociales?
Se suele considerar una probabilidad inferior a 1% o 5%.
A estos valores se les llama niveles de significación α.
Los programas informáticos nos facilitan el contraste de hipótesis. Nos ofrecen el nivel de significación crítico α’, que suele aparacer como p-value.
Se rechaza la Hº cuando α’ < α
p-value: probabilidad que tenemos de equivocarnos al rechazar la Hº
¿En qué consiste el análisis estadístico?
Partiendo de una hipótesis de partida (Hipótesis Nula), el análisis estadístico consistirá en encontrar un criterio que me lleve a rechazar esta hipótesis sólo cuando la probabilidad de que me equivoque sea muy pequeña.

Contraste de hipótesis
NORMALIDAD : La distribución de las frecuencias de cada variable métrica debe seguir una normal
MÉTODOS:• Gráficos: gráfico q-q de residuos• Estadísticos: prueba KSL (Hº = la variable se distribuye normalmente)
Si NO SE CUMPLE LA CONDICIÓN DE NORMALIDAD
Transformación potencial o logarítmica
Condiciones de aplicabilidad
HOMOSCEDASTICIDAD: Igualdad de varianzas de las variables independientes respecto a las dependientes
MÉTODO:• Test de Levene (Hº = igualdad de varianzas)
NO SE CUMPLE LA CONDICIÓN DE HOMOCEDASTICIDAD
Transformación monótona creciente de la variables

Contraste de hipótesis: Test Chi-
CuadradoTest Chi-Cuadrado
¿Para qué sirve?
¿Cuál es la Hº?
¿Cómo son las variables?
Sirve para comprobar si en una tabla de contingencia una de las
variables influye sobre la otra
Las variables son independientes (no hay influencia)
O bien las dos variables son no métricas. Opción habitual
O bien una variable es métrica (con pocas alternativas de respuesta)
y la otra no métrica. Ojo, este caso no es aceptado por todos los investigadores
si p<0,05 se rechaza Ho = hay dependencia entre las variables, es
decir, están relacionadas.
CUIDADO: si trabajamos con una variable de razón (métrica) para utilizarla en
la tabla de contingencia y poderla cruzar con otras debemos antes recodificarla
(dejarla con pocas alternativas de respuesta).

Pruebas de chi-cuadrado
1,866a 2 ,393
1,940 2 ,379
,262 1 ,609
434
Chi-cuadrado de Pearson
Razón de verosimilitud
Asociac ión lineal por
lineal
N de casos válidos
Valor gl
Sig. asintót ica
(bilateral)
0 casillas (,0%) tienen una f recuencia esperada inf erior a 5.
La f recuencia mínima esperada es 11,21.
a.
Ejemplo: sexo (no métrica) y¿Fumas? (no métrica).Me planteo si el sexoinfluye en fumar o no.
Tabla de contingencia ¿FUMA USTED? * sexo
67 107 174
38,5% 61,5% 100,0%
42,7% 38,6% 40,1%
8 23 31
25,8% 74,2% 100,0%
5,1% 8,3% 7,1%
82 147 229
35,8% 64,2% 100,0%
52,2% 53,1% 52,8%
157 277 434
36,2% 63,8% 100,0%
100,0% 100,0% 100,0%
Recuento
% de ¿FUMA USTED?
% de sexo
Recuento
% de ¿FUMA USTED?
% de sexo
Recuento
% de ¿FUMA USTED?
% de sexo
Recuento
% de ¿FUMA USTED?
% de sexo
SI
DEJADO
NO
¿FUMA
USTED?
Total
Hombre Mujer
sexo
Total
P>0,05.
Hay independencia.
No influencia.
Ser hombre o mujer no influye en fumar.
Contraste de hipótesis: Test Chi-
Cuadrado

Contraste de hipótesis: Test Chi-
Cuadrado
Tabla de contingencia Frecuencia viajar * Nivel de estudios
5 17 15 13 50
10,0% 34,0% 30,0% 26,0% 100,0%
14,3% 12,4% 6,0% 6,3% 7,9%
14 57 84 53 208
6,7% 27,4% 40,4% 25,5% 100,0%
40,0% 41,6% 33,3% 25,6% 33,0%
11 50 100 80 241
4,6% 20,7% 41,5% 33,2% 100,0%
31,4% 36,5% 39,7% 38,6% 38,2%
4 7 30 40 81
4,9% 8,6% 37,0% 49,4% 100,0%
11,4% 5,1% 11,9% 19,3% 12,8%
1 6 23 21 51
2,0% 11,8% 45,1% 41,2% 100,0%
2,9% 4,4% 9,1% 10,1% 8,1%
35 137 252 207 631
5,5% 21,7% 39,9% 32,8% 100,0%
100,0% 100,0% 100,0% 100,0% 100,0%
Recuento
% de Frecuencia v iajar
% de Nivel de estudios
Recuento
% de Frecuencia v iajar
% de Nivel de estudios
Recuento
% de Frecuencia v iajar
% de Nivel de estudios
Recuento
% de Frecuencia v iajar
% de Nivel de estudios
Recuento
% de Frecuencia v iajar
% de Nivel de estudios
Recuento
% de Frecuencia v iajar
% de Nivel de estudios
Menos de una vez al año
Una vez al año
2 o 3 v eces al año
4 o 5 v eces al año
Con mayor f recuencia
Frecuencia
v iajar
Total
Sin estudios
Básicos/
Primarios FP-BUP-COU Univ ersitarios
Niv el de estudios
Total
Pruebas de chi-cuadrado
33,248a 12 ,001
34,353 12 ,001
24,000 1 ,000
631
Chi-cuadrado de Pearson
Razón de v erosimilitudes
Asociación lineal por
lineal
N de casos válidos
Valor gl
Sig. asintótica
(bilateral)
3 casillas (15,0%) tienen una f recuencia esperada inferior a 5.
La f recuencia mínima esperada es 2,77.
a.
Ejemplo: nivel de estudios (no métrica) y frecuencia con la que se viaja (no métrica). Me planteo si el nivel de estudios influye en la frecuencia con la que se viaja.

Contraste de hipótesis: Correlación
OBJETIVO DE LA CORRELACIÓN: CONOCER SI UNA DE LAS VARIABLES INFLUYE O NO SOBRE LA OTRA. CONOCER LA DEPENDENCIA O INDEPENDENCIA
DE LAS VARIABLES.
El coeficiente de correlación está acotado entre –1 (existe una fuerte influencia pero ésta es inversa) y 1 (existe una fuerte influencia y esta es directa). Si es 0 no existe influencia.
Ho a contrastar=Hipótesis nula: el coeficiente es cero (no hay influencia).si p<0,05 se rechaza Ho= hay influencia entre las variables
(coeficiente distinto de 0).
si p>0,05 se acepta Ho= no hay influencia entre las variables.
Las dos son métricas
¿Para qué sirve?
¿Cuál es la Hº?
¿Cómo son las variables?
Sirve para comprobar una de las variables influye sobre la otra
El coeficiente es 0 (no hay influencia)

Contraste de hipótesis: Correlación
Coeficiente de correlación
Ejemplo: edad (métrica) y subida de impuestos (métrica). Me planteo porejemplo si la edad influye en estar de acuerdo o no con que se suban losimpuestos.
La secuencia a seguir es: analizar/correlaciones/bivariadas/selección de las dosvariables (por defecto dejar Pearson)
El coeficiente es casi cero
p >0,05
No hay influencia entre las variables
Correlaciones
1 -,048
, ,322
434 434
-,048 1
,322 ,
434 434
Correlación de Pearson
Sig. (bilateral)
N
Correlación de Pearson
Sig. (bilateral)
N
Edad
Deben aumentarse
los impuestos
Edad
Deben
aumentarse
los impuestos

Contraste de hipótesis: Correlación
Estadísticos descriptivos
38,94 17,894 191
3,73 1,106 95
4,17 1,001 94
Edad
Importancia en un
museo: f ácil de entender
Importancia en un
museo: serv ic io amable
Media
Desviac ión
típica N
Coeficiente de correlación
Correlaciones
1 ,287** ,025
,005 ,808
191 95 94
,287** 1 ,366**
,005 ,000
95 95 94
,025 ,366** 1
,808 ,000
94 94 94
Correlac ión de Pearson
Sig. (bilateral)
N
Correlac ión de Pearson
Sig. (bilateral)
N
Correlac ión de Pearson
Sig. (bilateral)
N
Edad
Importanc ia en un
museo: f ácil de entender
Importanc ia en un
museo: serv ic io amable
Edad
Importanc ia
en un
museo: f ácil
de entender
Importanc ia
en un museo:
serv ic io
amable
La correlación es signif icat iv a al niv el 0,01 (bilateral).**.

Contraste de hipótesis: Test T para
la media de una muestra
Estadísticos para una muestra
177 7,20 1,265 ,095
¿Cómo quedó de
sat isf echo tras su
participación en
las activ idades?
N Media
Desviac ión
típ.
Error t íp. de
la media
Test T para la media de una muestra
¿Para qué sirve?
¿Cuál es la Hº?
¿Cómo es la variable?
Sirve para comprara el valor muestral de una media con un valor poblacional teórico
El valor muestral coincide con el teórico
Prueba para una muestra
23,144 176 ,000 2,201 2,01 2,39
¿Cómo quedó de
sat isf echo tras su
participación en
las activ idades?
t gl Sig. (bilateral)
Dif erencia
de medias Inferior Superior
95% Intervalo de
conf ianza para la
dif erencia
Valor de prueba = 5
Métrica

Contraste de hipótesis: Test T para
la media de una muestra
Secuencia a seguir: analizar/comparar medias/prueba t para una muestra.
Estadísticos para una muestra
434 2,80 1,447 ,069Deben aumentarse
los impuestos
N Media
Desviación
típ.
Error típ. de
la media
Prueba para una muestra
-2,820 433 ,005 -,20 -,33 -,06Deben aumentarse
los impuestos
t gl Sig. (bilateral)
Dif erencia
de medias Inferior Superior
95% Intervalo de
conf ianza para la
dif erencia
Valor de prueba = 3
P<0,05.
No coincidencia

Contraste de hipótesis: Test T para
muestras independientes
Estadísticos de grupo
39 2,46 1,166 ,187
48 3,44 1,147 ,166
39 2,08 1,326 ,212
48 2,06 1,137 ,164
Género
Hombre
Mujer
Hombre
Mujer
Voy con f ines educat ivos
Voy por su bajo precio
N Media
Desviación
típ.
Error típ. de
la media
Métrica
Test T para muestras independientes
¿Para qué sirve?
¿Cuál es la Hº?
¿Cómo es la variable?
Comprobar si la media de una variable es la misma o distinta en dos grupos determinados. Las muestras son distintas, independientes.
Las medias son iguales
Prueba de muestras independientes
,083 ,775 -3,918 85 ,000 -,976 ,249 -1,471 -,481
-3,911 80,825 ,000 -,976 ,250 -1,473 -,479
,263 ,609 ,055 85 ,957 ,014 ,264 -,511 ,540
,054 75,285 ,957 ,014 ,268 -,520 ,549
Se han asumido
v arianzas iguales
No se han asumido
v arianzas iguales
Se han asumido
v arianzas iguales
No se han asumido
v arianzas iguales
Voy con f ines educativ os
Voy por su bajo prec io
F Sig.
Prueba de Lev ene
para la igualdad de
v arianzas
t gl Sig. (bilateral)
Dif erencia
de medias
Error t íp. de
la diferenc ia Inferior Superior
95% Intervalo de
conf ianza para la
dif erencia
Prueba T para la igualdad de medias

Contraste de hipótesis: Test T para
muestras independientes
Prueba de muestras independientes
,783 ,377 -,508 432 ,612 -,04 ,086 -,212 ,125
-,501 310,858 ,617 -,04 ,087 -,214 ,127
Se han asumido
v arianzas iguales
No se han asumido
v arianzas iguales
Fumar perjudica salud
F Sig.
Prueba de Lev ene
para la igualdad de
v arianzas
t gl Sig. (bilateral)
Dif erencia
de medias
Error t íp. de
la diferencia Inferior Superior
95% Intervalo de
conf ianza para la
dif erencia
Prueba T para la igualdad de medias
Estadísticos de grupo
157 4,65 ,883 ,071
277 4,69 ,840 ,050
sexo
Hombre
Mujer
Fumar perjudica salud
N Media
Desviac ión
típ.
Error t íp. de
la media
Test T para muestras independientes
Ho a contrastar: las medias son iguales.
• Secuencia a seguir: analizar/comparar medias/prueba t para muestras independientes.
• Contrasto si la opinión media de que fumar perjudica la salud es la misma entre hombres y mujeres
P>0,05, por tanto las medias son iguales.

Contraste de hipótesis: Test T para
muestras relacionadas
Estadísticos de muestras relacionadas
3,29 83 2,116 ,232
1,63 83 2,202 ,242
Valoración talleres
didácticos 2
Valoración talleres
didácticos 1
Par 1
Media N
Desviac ión
típ.
Error t íp. de
la media
Test T para muestras relacionadas
¿Para qué sirve?
¿Cuál es la Hº?
¿Cómo es la variable?
Las variables son independientes (no hay influencia)
Métrica
Comprobar si la media de una variable es la misma o distinta en dos grupos determinados. La muestra es la misma.
Prueba de muestras relacionadas
1,663 2,706 ,297 1,072 2,254 5,597 82 ,000
Valoración talleres
didácticos 2 - Valoración
talleres didáct icos 1
Par 1
Media
Desv iac ión
típ.
Error t íp. de
la media Inferior Superior
95% Intervalo de
conf ianza para la
dif erencia
Dif erencias relacionadas
t gl Sig. (bilateral)
Por ejemplo puedo contrastar si la opinión media de que fumar perjudica la salud es la misma después de emitirse un documental sobre los perjuicios del tabaco.

Análisis de la varianza
Análisis de la Varianza. Test ANOVA
¿Para qué sirve?
¿Cómo son las variables?
¿Cuál es la Hº?
Condiciones de aplicabilidad
• Analizar el comportamiento de la media de la variable dependiente en los grupos que forma la variable independiente (factor)
• Determina si una variable determinada toma valores medios iguales o distintos en los grupos que forma otra variable
VARIABLE DEPENDIENTE: la que queremos saber si toma valores medios iguales o distintos. MétricaFACTOR: la variable que supuestamente ejerce una influencia sobre la variable dependiente. Es la que establece los grupos. No métrica, forma mas de 2 grupos
Las medias son iguales: media grupo 1 = media grupo 2 = media grupo 3 …
• Homoscedasticidad (homogeneidad de varianzas)• Normalidad
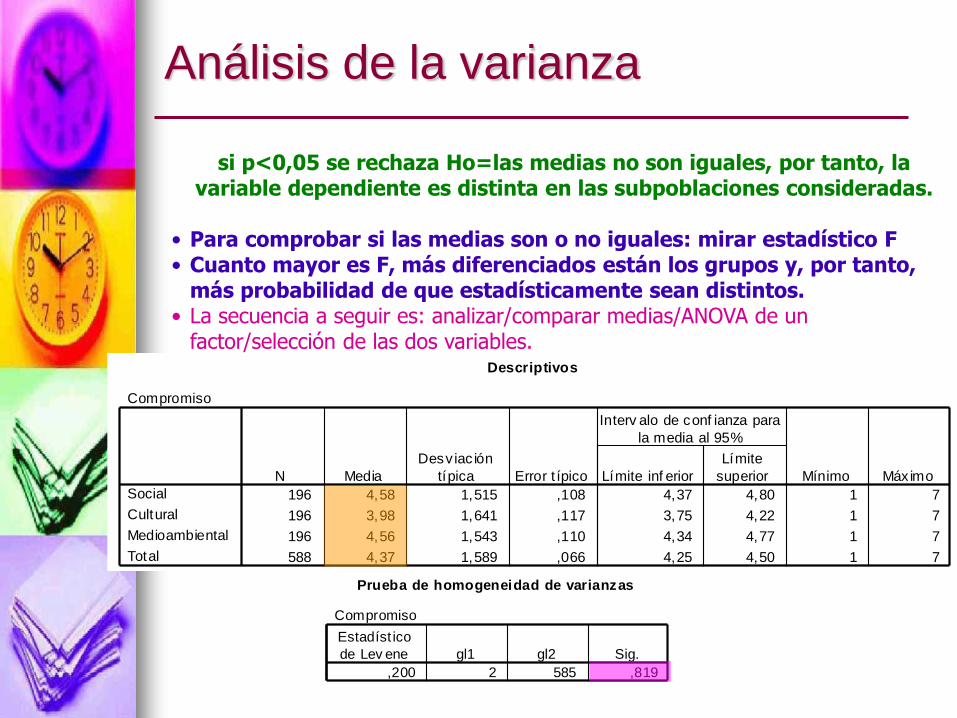
Análisis de la varianza
si p<0,05 se rechaza Ho=las medias no son iguales, por tanto, la variable dependiente es distinta en las subpoblaciones consideradas.
• Para comprobar si las medias son o no iguales: mirar estadístico F• Cuanto mayor es F, más diferenciados están los grupos y, por tanto,
más probabilidad de que estadísticamente sean distintos.• La secuencia a seguir es: analizar/comparar medias/ANOVA de un
factor/selección de las dos variables.Descriptivos
Compromiso
196 4,58 1,515 ,108 4,37 4,80 1 7
196 3,98 1,641 ,117 3,75 4,22 1 7
196 4,56 1,543 ,110 4,34 4,77 1 7
588 4,37 1,589 ,066 4,25 4,50 1 7
Social
Cultural
Medioambiental
Total
N Media
Desv iac ión
típica Error t ípico Límite inf erior
Límite
superior
Interv alo de conf ianza para
la media al 95%
Mínimo Máximo
Prueba de homogeneidad de varianzas
Compromiso
,200 2 585 ,819
Estadíst ico
de Lev ene gl1 gl2 Sig.

Análisis de la varianza
Comparaciones múltiples
Variable dependiente: Compromiso
HSD de Tukey
,60* ,158 ,001 ,22 ,97
,03 ,158 ,986 -,35 ,40
-,60* ,158 ,001 -,97 -,22
-,57* ,158 ,001 -,94 -,20
-,03 ,158 ,986 -,40 ,35
,57* ,158 ,001 ,20 ,94
(J) Categoría
Cultural
Medioambiental
Social
Medioambiental
Social
Cultural
(I ) Categoría
Social
Cultural
Medioambiental
Dif erencia de
medias (I-J) Error t ípico Sig. Límite inf erior
Límite
superior
Interv alo de conf ianza al
95%
La dif erencia entre las medias es signif icativ a al nivel .05.*.
Compromiso
HSD de Tukeya
196 3,98
196 4,56
196 4,58
1,000 ,986
Categoría
Cultural
Medioambiental
Social
Sig.
N 1 2
Subconjunto para alf a
= .05
Se muestran las medias para los grupos en los
subconjuntos homogéneos.
Usa el tamaño muestral de la media armónica
= 196,000.
a.
ANOVA
Compromiso
44,656 2 22,328 9,090 ,000
1437,031 585 2,456
1481,687 587
Inter-grupos
Intra-grupos
Total
Suma de
cuadrados gl
Media
cuadrát ica F Sig.

Análisis de la varianza
Ejemplo: Me planteo si el que fuma, no fuma o lo ha dejado tiene opinionesdistintas sobre si deben subirse los impuestos sobre el tabaco.
• variable dependiente subida de impuestos (métrica).• variable independiente ¿Fumas? (no métrica): un grupo (subpoblación) son
los que fuman, otro los que no fuman y otro los que lo han dejado.

Análisis de la varianza

MASTER EN MARKETING E
INVESTIGACIÓN DE MERCADOS
Complemento formativo:
INVESTIGACIÓN DE MERCADOS
Dr. Antonio Carlos Cuenca Ballester
Dra. María José Miquel Romero
Octubre 2015