measuring translation quality in today’s automated lifecycle
TRANSCRIPT

Measuring Translation Quality in Today’s Automated Lifecycle
!
Arle Lommel & Aljoscha Burchardt (DFKI) with help from Lucia Specia (University of Sheffield) and Hans Uszkoreit (DFKI)
Funded by the 7th Framework Programme of the European Commission through the contract 296347.
Funded by the 7th Framework Programme of the European Commission through the contract 296347.

PROBLEMS IN ASSESSING QUALITY

95% of professionally translated content at one major LSP is never evaluated for
quality.

“Translators are thegarbage collectors of the documentation world” –Alison
Toon, HP

“I know it when I see it”

Machine Translation quality scores (BLEU, NIST, etc.) are
totally different from human evaluation.

MT methods requirereference translations:
Cannot be used for production purposes

Change the reference translation(s) and
the score changes

The problem with BLEU
No substantial improvement for human use

The problem with BLEU
Substantial human improvement but no BLEU improvement

Human quality assessment takes too much time.

Sampling is random but errors are not.

Wait a minute… What do you mean by
quality?

Quality: A New Definition
A quality translation demonstrates required accuracy and fluency
for the audience and purpose andcomplies with all other negotiated specifications,
taking into account end-user needs.
Source: Alan Melby

Sounds simple, right?

It’s actually quite radical and it drags translation
kicking and screaming into the modern world of
quality management

Multidimensional Quality Metrics

Why not use ashared metric?

OK. !
Which one?

LISA QA Model SAE J2450 SDL TMS
Acrocheck ApSIC XBench
CheckMate QA Distiller XLIFF:Doc
EN15038…

All of them disagree* about what is important to
quality
*The only thing they agree on is terminology

(Probably because there isno single set of criteria that applies to all kinds of
translation)

There is no one-size-fits-all metric

MQM provides a catalog of issue types suitable for
various tasks
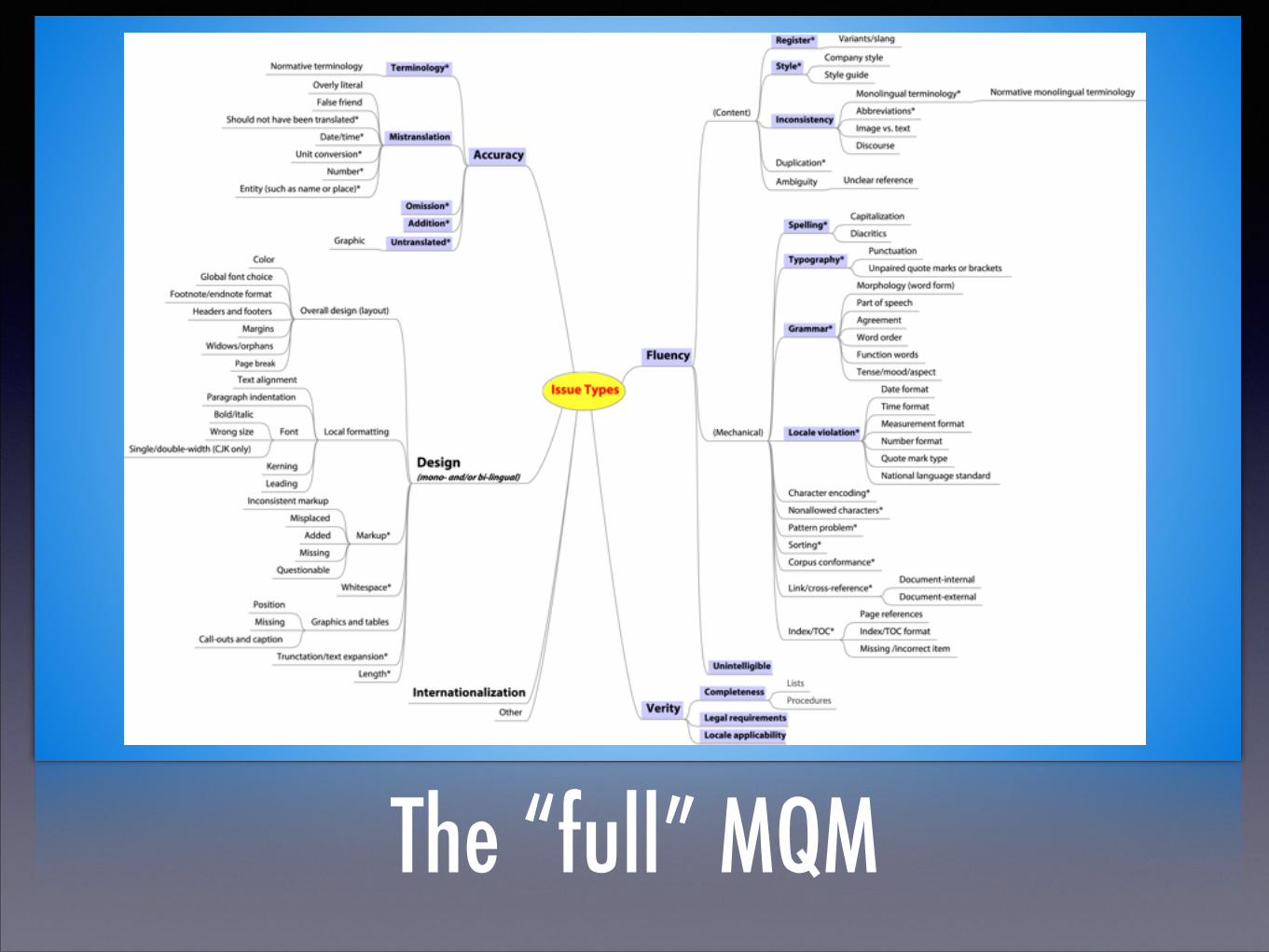
The “full” MQM

The “full” MQM

Wait! Weren’t we trying to improve things?
(That looks like a bowl of noodles!)

The MQM Core

Accuracy and Fluency What’s Verity?

Verity provides a way to deal with the text in relation to
the real world.

You don’t use all of MQM (or its core):you use the
parts you need.

MQM for MT Diagnostics

SAE J2450

MQM lets you declare your quality metric in a shared
vocabulary.

Dimensions help you decide what to check
(and also help you communicate with your LSP)

No more assuming what the parties want or how to check it

12 Dimensions(from ISO/TS-11669)
1. Language/locale 2. Subject field/domain 3. Terminology (source/
target) 4. Text type 5. Audience 6. Purpose
7. Register 8. Target text style 9. Content
correspondence 10. Output modality 11. File format 12. Production technology

Open-source tools* to demonstrate MQM
*translate5 source code is published.Other tools’ code will be published in 2014

An Online Tool for Building Dimensions and Metrics
http
://w
ww
.qt2
1.eu
/MQ
M



translate5
DEMO: http://www.translate5.net

Currently discussing with TAUS how to harmonize MQM
and the DQF Error Typology

Quality Estimation (QuEst)

How can you evaluate MT quality when you don’t
have reference translations?

QuEst (Quality Estimation) An open-source tool for
estimating translation quality

Quality Estimation (QE) Metrics• Automatic metrics that provide an estimate on the quality
of (machine) translated segments, without reference translations
• Quality defined according to the problem at hand: • Adequacy • Fluency • Post-editing effort, etc.

Task-Based Quality• Does it need human revision to achieve HT
quality?
• Can a reader get the gist?
• How much effort is required to post-edit the text? (If we know this we have a business case for MT)

QuEst Framework• Open source tool for QE: http://www.quest.dcs.shef.ac.uk/
• E.g. predict 1-5 scores for post-editing effort:
• 1 highest, 5 lowest
• English-Spanish news data, but can be used for other language pairs
• System built from 1,000 examples of translated segments annotated by humans

Uses a set of bilingual training data* to establish linguistic
baselines* Uses source+MT for training, but can also use extra resources (e.g., language models trained on TM)

Provides an estimate for how well the translation fits with
your existing translations

QuEst can rank multiple translations to find the best
one

QuEst Rating Example
Reliability: QuEst rating differs on average 0.61 from human-assigned scores

No more random samples. QuEst can identify sentences that
are likely to require human attention

QuEst can tell you where it makes sense to post-edit and
where it makes sense to start from scratch.

QuEst Improves Post-Editing Time
Language PE time without QE PE time with QE % increase in PE productivity
FR→EN 0.75 words/second 1.09 words/second 45%
EN→ES 0.32 words/second 0.57 words/second 78%

QuEst + MQM Targeted quality evaluation combining the strengths of
humans and machines

MQM will be turned over to industry for long-term
maintenance and eventual standardization


Detailed presentation covering MQM pilot study
(in German) today at 5:15

Join us tomorrow morning for a detailed demonstration
of how to use MQM (9:45–10:30)

Questions?