mining data streams challenges, techniques, and future work ruoming jin joint work with prof. gagan...
TRANSCRIPT

Mining Data Streams Challenges, Techniques, and Future Work
Ruoming Jin Joint work with Prof. Gagan Agrawal

August 10-17, 2003 Major Power outrage simultaneously hits a dozen of
big cities in the east of America and Canada Suddenly, millions of people have to live without electricity
Internet Worm Millions of computers were attacked In a single day, I received almost 100 emails generated by
the worm Capable to collect and monitor the data from power
grid and email server
Unable to extract knowledge fast enough from the dynamic and huge amount of data!

Data Explosion
The Challenge: Our ability to access, collect, generate, and store the data
has been exceeding our ability to understand them Real Applications
WALMART: 20M transactions per day AT&T: 300 M calls per day Earth Observing System from NASA: 50 GB per hour Amazon. COM: 4-5M sessions per day Power Grid/Sensor Network Internet/Intranet

Data Streams
What is Data Streams? Continuous streams Hugh, Fast and Changing
Why Data Streams? The arrival of streams and the volume of data are beyond our
capability to store them Real-time processing Evolution of Data (Static/Dynamic)
You can only have one look at the data!

Data Mining
Extracting useful information or knowledge from large amounts of data Interesting patterns Regularity or Anomaly
Typical Data Mining Tasks Association Rule Mining Classification Clustering
Disk-resident or in-core datasets
Traditional data mining needs multi-pass of the data!

Stream Data Mining
How to run traditional mining tasks over data streams Single pass/multi-pass
How to discover new information over data streams Changing
How to perform data mining over dynamic data streams Concept drifting

Roadmap
Thesis Statement Current Work
Decision Tree Construction Frequent Itemsets Mining
Future Work Mining Maximal/Closed/Approximate Frequent Itemsets Mining New Knowledge from Data Streams Mining Dynamic Data Streams
Applications Conclusion

Motivation
The need for efficient computation and low memory mining algorithms Real-time constraint Memory requirements
The need to mine new information from data streams
The need for having results with high accuracy and confidence Approximate results with high accuracy

Thesis Statement
“Designing computation and memory efficient algorithms to provide approximate results with high accuracy and confidence helps mine useful information from data streams”

Roadmap
Thesis Statement Current Work
Decision Tree Construction Frequent Itemsets Mining
Future Work Mining Maximal/Closed/Approximate Frequent Itemsets Mining New Knowledge from Data Streams Mining Dynamic Data Streams
Applications Conclusion

Decision Tree Construction
30
Salary Age Employment Group
30K Self C
40K 35 Industry C
70K 50 Academia C
50K 45 Self B
70K 30 Academia B
60K 35 Industry A
60K 35 Self A
70K 30 Self A
40K 45 Industry C
Salary
Age
Employment
Group C
Group C
Group B Group A
<= 50K > 50K
<= 40 > 40
Academia, Industry Self
Three predictor attributes: Numerical (salary, age), Categorical (employment) Class label attribute: group

The problem Basic algorithm (a greedy algorithm)
Tree will be built in a top-down recursive way At start, all the training records are at the root; the records are partitioned
recursively based on split criteria Split criteria are selected based on a heuristic or statistical measure (e.g.,
information gain or gini function) Analysis
To find the split criteria, all the records falling into the node need to be scanned
Scanning the entire datasets multiple times The difficulty to handle numerical attributes
Streaming Data You can only have one look at the data Real-time constraint and memory requirement

Outline of Our Solution
Motivation Three New Techniques Experimental results Conclusion

Very Fast Decision Tree (VFDT)─Domingo and Hulten (SIGKDD’00)
Sampling based approach Given a desired confidence level (α), applying Hoeffding
Inequality to test if enough samples has collected to find the best split criteria
Accuracy Probabilistic bound on the different number of nodes between
the tree built on samples and the one built on complete data Limitation
Focus on processing categorical attributes Ideal environment

Our Contributions Efficient processing of numerical attributes
High memory and computational overheads Numerical Interval Pruning (NIP)
Determining exact split points in one pass Confidence interval ExactSplit algorithm
Using smaller samples size for the same probabilistic bound Normal Test
•Efficient Decision Tree Construction on Streaming Data (R. Jin and G. Agrawal, SIGKDD’03)•Accurate One Pass Mining of Streaming Data (R. Jin, A. Goswami and G. Agrawal, submitted to SDM’04)

Numerical Interval Pruning (NIP) –Efficiently Handling Numerical Attributes
Existing methods Preprocessing Online sorting Full Class Histogram
Basic Ideas of NIP Hierarchical Information
– Concise class Histogram and Detailed Information Divide the range of numerical attributes into intervals Summarize class histogram for intervals Only visit intervals likely to have best split point Drop the detailed information for pruned intervals
(Approximate)

Finding Best Split PointComplete Class Histograms
02040
Age
Co
un
ts
class-2
class-1
The data comes from a IBM Quest synthetic dataset for function 0
Gain Function
00.020.040.060.080.1
Age
gain
gain function
Best Split Point

Summarizing and Pruning IntervalsSummarized class histogram for intervals
from sample set
0
10
20
30
20,2
4
25,2
9
30,3
4
35,3
9
40,4
4
45,4
9
50,5
4
55,5
9
60,6
4
65,6
9
70,7
4
75,7
9
Age
Co
un
ts
Class-2
Class-1
gain function on sample set
0
0.05
0.1
0.15
Age
gain
gains forintervalboundaries
upper bound ofgain
gain function
Upper bound of gains for intervals

Visiting Detailed InformationSummarized Class Histograms for Intervals
050
100150
Class-2
Class-1
Detailed class histogram for Interval[35,39]
0
5
10
15
20
25
35 36 37 38 39
Class-2
Class-1
Gain function from partial materialized class histogram
00.020.040.060.080.1
Age
Gain Complete
gain function
Partial gainfunction
Best Split Point

Re-pruning and Verification
Gain function and upper bound from partial materialized class histogram
0
0.05
0.1
20
27
34
41
48
55
62
69
76
Age
Gain
Complete gainfunction
Partial gainfunction
Upper boundfor Intervals
Gain of Best Split PointFalse Pruning
Additional intervals needs to be visited if false pruning happens

Least Upper Bound of Gain for an Interval
Class Histograms for Intervals
0
50
100
150
Class-2
Class-1
Possible Best Configuration-1 Possible Best Configuration-2
[ 50 ,54 ] [ 50 ,54 ]
Class Histogram for Interval [50,54]
0
10
20
30
50 51 52 53 54
Class-2
Class-1

Finding Exact Split Points in a Single Pass
Confidence Interval (CI) Build CI near the approximate split points If the exact split points after processing all data falls into the
CI, we will be able to determine it, and correct the descendant nodes also
ExactSplit algorithm Recursively find exact split points and correct the descendant
nodes from the root Dynamic shrinking
Reduce the length of CI as more data instances are processed

Sample Size Problem Let n be the sample size of S, N be the normal distribution.
Then, for the entropy function g, we have
where,
Normal Test
Normal Test is better than Hoeffding Bound because later one does not utilize the normal distribution property.
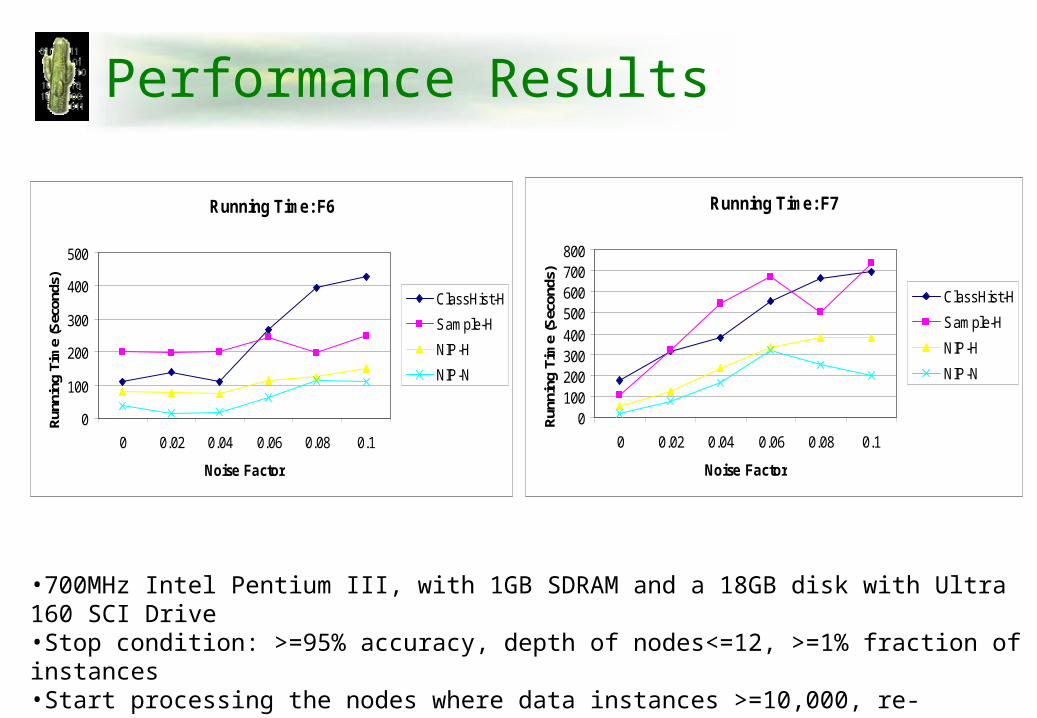
Performance Results
Running Time: F7
0100200300400500600700800
0 0.02 0.04 0.06 0.08 0.1
Noise Factor
Run
ning
Tim
e (S
econ
ds)
ClassHist-H
Sample-H
NIP-H
NIP-N
•700MHz Intel Pentium III, with 1GB SDRAM and a 18GB disk with Ultra 160 SCI Drive•Stop condition: >=95% accuracy, depth of nodes<=12, >=1% fraction of instances•Start processing the nodes where data instances >=10,000, re-evaluate each node every 5,000 data instances
Running Time: F6
0
100
200
300
400
500
0 0.02 0.04 0.06 0.08 0.1
Noise Factor
Run
ning
Tim
e (S
econ
ds)
ClassHist-H
Sample-H
NIP-H
NIP-N

Instances Utilization
•ClassHist-H: Hoeffding bound and full class histograms•Sample-H: Hoeffding bound and samples to evaluate candidate split conditions•NIP-H: Hoeffding bound and Numerical Interval Pruning•NIP-N: Normal test and Numerical Interval Pruning
Instances Actively Processed (IAP): F7
0.00
1.00
2.00
3.00
4.00
5.00
6.00
7.00
0.00 0.02 0.04 0.06 0.08 0.10
Noise Factor
Num
ber
of In
stan
ces
(Mill
ions
)
ClassHist-H
Sample-H
NIP-H
NIP-N
Total Instances Read (TIR): F7
0.0010.0020.0030.0040.0050.0060.0070.0080.00
0.00 0.02 0.04 0.06 0.08 0.10
Noise Factor
Num
ber
of In
stan
ces
(Mill
ions
)
ClassHist-H
Sample-H
NIP-H
NIP-N

Adult Dataset
Predicting whether income exceeds $50K/yr based on census data 48842 instances, 14 attributes (6 continuous and 8 nominal)
Algorithm Concept Size Inaccuracy Running Time TIR IAP
ClassHist-H 92 13.8% 308.655 27.0 3.0
Sample-H 104 13.8% 366.095 27.2 2.9
NIP-H 92 13.8% 262.369 27.0 3.1
NIP-N 100 13.7% 157.217 19.5 1.7
Running Time in seconds, TIR and IAP in millions

Summary
Three new techniques enable an average of 39% reduction in execution times a 37% reduction in the number of data instances required an average of 79% accuracy to determine the exact split
condition for the non-leaf nodes on the top 5 levels. The techniques can be applied to other applications,
such as K-mean clustering (ongoing work)

Roadmap
Thesis Statement Current Work
Decision Tree Construction Frequent Itemsets Mining
Future Work Mining Maximal/Closed/Approximate Frequent Itemsets Mining New Knowledge from Data Streams Mining Dynamic Data Streams
Applications Conclusion

Frequent Itemsets MiningTID Transactions
100 A,B,E
200 B,D
300 A, B, E
400 A,C
500 B, C
600 A, C
700 A, B
800 A, B,C,E
900 A, B, C
1000 A, C, E
Desired frequency 50% {A},{B},{C},{A,B}, {A,C}
Down-closure property If an itemset is frequent, all of its
subset must also be frequent Multi-pass algorithms or in-core
datasets Apriori, Eclat, FP-tree

The Problem
Streaming data You can only have one look of the data Impossible to find all the frequent itemsets in one pass
Proposed solutions (with θ,ε) A one-pass algorithm to find a superset of the frequent (θ)
itemsets, and each itemset in the superset has to appear more than a desired frequency(θ(1-ε))
A two-pass algorithm will find the exact frequent itemsets (eliminate the false positive)

Outline of Our Solution
A simplified problem and its solution StreamMining Implementing Issues Experimental Results Conclusion

A Simplified Problem
Finding frequent items Given a sequence (x1,…xN) where xi ∈[1,n], and a real
number θ between zero and one. Looking for xi whose frequency > θ N>>n>>1/θ
The number of frequent items ≤ 1/θ
P*(Nθ) ≤ N

KRP algorithm ─ R. Karp, et. al (TODS’ 03)
Θ=0.35
⌈1/θ⌉ = 3
N=30 n=12
N/ (⌈1/θ⌉) ≤ Nθ

Frequent Itemsets
2-itemset is the key!
n=10K, Θ=0.1%, average length=10, n*n=100M, |frequent 2-itemsets| ≤ 50K
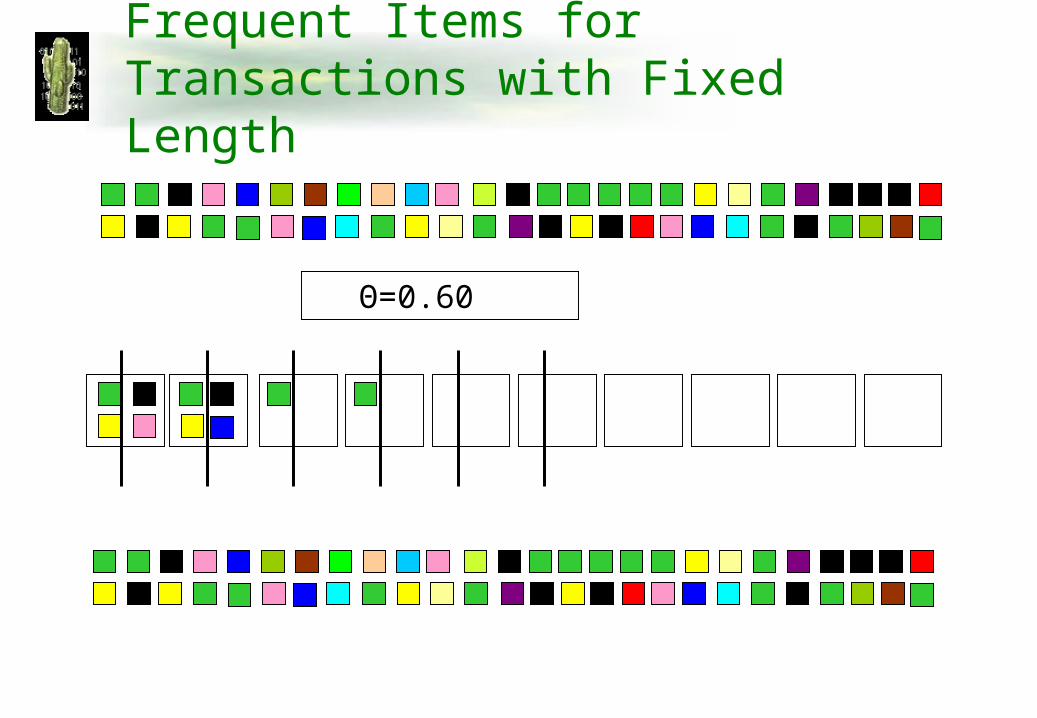
Frequent Items for Transactions with Fixed Length
Θ=0.60

Frequent Items for Transactions with Varied Length
Θ=0.60

Enhance the Accuracy
Θ=0.35
⌈1/θ⌉ = 3
ε=0.5 Θ(1- ε )=0.175
⌈1/(θ ε) ⌉ = 6
N=30 n=12

StreamMining Sketch
Put a transaction into the buffer Update 1-itemset counts Update/insert 2-itemsets If the 2-itemsets is beyond a threshold
Crossover Applying the transactions in the buffer to update 3-itemsets, 4-
itemsets … Clear buffer
Perform additional Crossover

Implementing Issues
Data Structure TreeHash, a prefix tree encoded into a hash table Frequently insert/delete/increment the potential frequent
itemsets Optimizations
Online dataset trimming Reducing subset checking Online checking

Experimental Results
T10.I4.N10K Dataset, 12M transactions

Experimental Results (Cont’)
T10.I4.N10K Dataset, 0.1% support level

Results for very large number of distinctive items
T25.I4.N100K Dataset, 12M transactions

Real Dataset
BMS-WebView-1 Dataset

Related Work
One-pass algorithm Manku and Motwani Two-pass algorithm
Partition Sampling based CARMA Oracle FP-tree and FP-stream
Multi-pass algorithm

Discussion The new algorithm StreamMining
High accuracy ( even when ε=1, the accuracy is 94% or higher) Memory efficient Handle very large number of distinctive itemsets and low
threshold using reasonable amounts of memory Observations
Reducing passes can not directly contribute to the performance Computational Intensive instead of I/O Intensive In-core algorithm is the key

Roadmap
Thesis Statement Current Work
Decision Tree Construction Frequent Itemsets Mining
Future Work Mining Maximal/Closed/Approximate Frequent Itemsets Mining New Knowledge from Data Streams Mining Dynamic Data Streams
Applications Conclusion

Mining Frequent Itemsets
The problem Computational Intensive
Different Solutions Maximal Frequent Itemsets Closed Frequent Itemsets Approximate Frequent Itemsets
StreamMax Contour sets

Stream*
Common characteristics of one-pass and two-pass algorithms for streaming data and very large datasets Maintaining a superset of frequent itemsets Different methods to update the supersets Applying slightly different in-core algorithms
A framework to efficiently incorporate different in-core algorithms for mining streams Apriori, Eclat and FP-tree TreeHash and StreamMining/MM

Frequent Itemsets Mining over Dynamic Data Streams
Sliding Window Model Recent data
New queries raised from sliding window Frequent itemsets for the current window The intersection and union of frequent itemsets over windows Itemsets with large frequency changes
Two key issues How to forget/delete information obsolete Computing the new queries systematically

Learning over Dynamic Streaming Data
Concept Drifting CVFDT Ensemble classifiers Clustering
Mining changes Demon Burst detection Cluster Changes

Can a single classifier perform as good as or even better than ensemble classifiers?
Advantage of a single classifier Simple Intuitive
Sampling approach Incorporating time and change as factors to sample data
streams Dynamic Sample Sets

How the knowledge of changes will help us to mine under concept drifting?
What’s the appropriate model to describe the changes Kernel methods
How to incorporate the knowledge of changes into classifiers?

Roadmap
Thesis Statement Current Work
Decision Tree Construction Frequent Itemsets Mining
Future Work Mining Maximal/Closed/Approximate Frequent Itemsets Mining New Knowledge from Data Streams Mining Dynamic Data Streams
Applications Conclusion

Network-based Network Intrusion Detection

Very large and Evolving Databases
Some very large datasets are not streaming data Possibly recorded on storage No real time constraints But arrives in order and updated in a block fashion
Typical Examples War-Mart AT&T EOS
Stream mining which provides approximate results is helpful and even necessary to monitor and facilitate mining exact knowledge from such databases

Roadmap
Thesis Statement Current Work
Decision Tree Construction Frequent Itemsets Mining
Future Work Mining Maximal/Closed/Approximate Frequent Itemsets Mining New Knowledge from Data Streams Mining Dynamic Data Streams
Applications Conclusion

Rule of Thumbs
Application Driven Network Security E-Commercial Sensor Network
The key techniques Sampling Counting Approximation Data structure

Conclusion
The model of data streams and our motivation to mine streams
Decision tree construction and frequent Itemsets mining over data streams
Future work Applications