modeling music with words a multi-class naïve bayes approach douglas turnbull luke barrington gert...
Post on 21-Dec-2015
213 views
TRANSCRIPT

Modeling Music with Wordsa multi-class naïve Bayes approach
Douglas Turnbull
Luke Barrington
Gert Lanckriet
Computer Audition Laboratory
UC San Diego
ISMIR 2006
October 11, 2006
Image from vintageguitars.org.uk

2
People use words to describe music
How would one describe “I’m a Believer” by The Monkees?
We might use words related to:• Genre: ‘Pop’, ‘Rock’, ‘60’s’• Instrumentation: ‘tambourine, ‘male vocals’, ‘electric piano’ • Adjectives: ‘catchy’, ‘happy’, ‘energetic’• Usage: ‘getting ready to go out’ • Related Sounds: ‘The Beatles’, ‘The Turtles’, ‘Lovin’ Spoonful’
We learn to associate certain words with the music we hear.
Image: www.twang-tone.de/45kicks.html

3
Modeling music and words
Our goal is to design a statistical system that learns a relationship between music and words.
Given such a system, we can:1. Annotation: Given a audio-content of a song, we can
‘annotate’ the song with semantically meaningful words.song words
• Retrieval: Given a text-based query, we can ‘retrieve’ relevant songs based on the audio content of the songs.
words songs
Image from: http://www.lacoctelera.com/

4
Modeling images and words
Content-based image annotation and retrieval has been a hot topic in recent years [CV05, FLM04, BJ03, BDF+02, …].
• This application has benefited from and inspired recent developments in machine learning.
*Images from [CV05], www.oldies.com
Retrieval
Query String: ‘jet’
Annotation
How can MIR benefit from and inspire new developments in machine learning?

5
Related work:
Images from www.sixtiescity.com
Modeling music and words is at the heart of MIR research.• jointly modeling semantic labels and audio content
• genre, emotion, style, usage classification• music similarity analysis
Whitman et al. have produced a large body of work that is closely related to our work [Whi05, WE04, WR05].
Others have looked at joint model of words and sound effects. • Most focus on non-parametric models (kNN) [SAR-Sla02, AudioClas-CK04]

6
Representing music and words
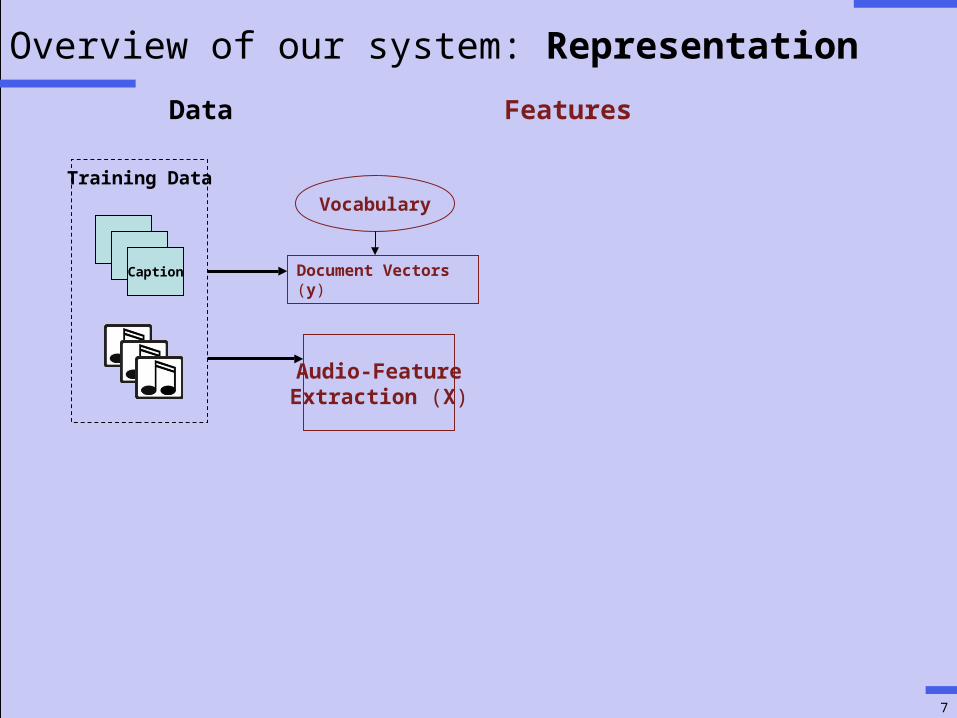
Consider a vocabulary and a heterogeneous data set of song-caption pairs:• Vocabulary - predefined set of words• Song - set of audio feature vectors (X = {x1 ,…, xT})• Caption - binary document vector (y)
Example: “I’m a believer” by The Monkees is a happy pop song that features tambourine.
• Given the vocabulary {pop, jazz, tambourine, saxophone, happy, sad}• X = set of MFCC vectors extracted from audio track• y = [1, 0, 1, 0, 1, 0]
Image from www.bluesforpeace.com
7
Overview of our system: Representation
TTCaption
Audio-FeatureExtraction (X)
Training Data
Document Vectors (y)
Data Features
Vocabulary

8
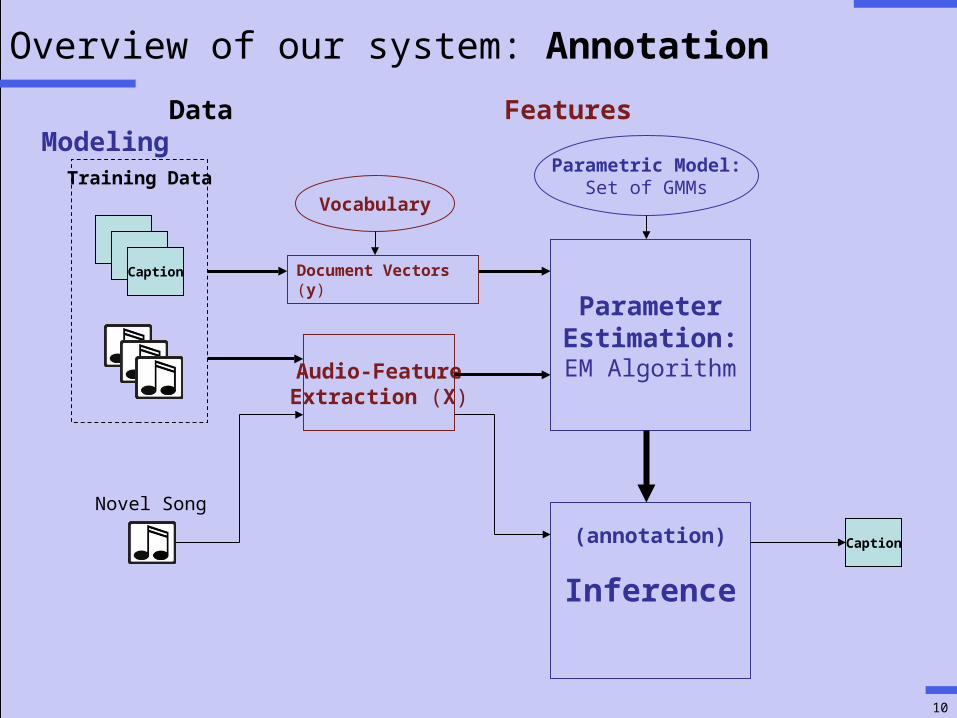
Probabilistic model for music and words
Consider a vocabulary and a set of song-caption pairs• Vocabulary - predefined set of words • Song - set of audio feature vectors (X = {x1 ,…, xT})• Caption - binary document vector (y)
For the i-th word in our vocabulary, we estimate a ‘word’ distribution, P(x|i).
• Probability distribution over audio feature vector space• Modeled with a Gaussian Mixture Model (GMM)• GMM estimated using Expectation Maximization (EM)
Key idea: training data for each ‘word’ distribution is the set of all feature vectors from all songs that are labeled with that word.
• Multiple Instance Learning: includes some irrelevant feature vectors • Weakly Labeled Data: excludes some relevant feature vectors
Our probabilistic model is a set of ‘word’ distributions (GMMs)Image from www.freewebs.com

9
Overview of our system: Modeling
TTCaption
Audio-FeatureExtraction (X)
ParameterEstimation:EM Algorithm
Parametric Model:Set of GMMsTraining Data
Document Vectors (y)
Data Features Modeling
Vocabulary
10
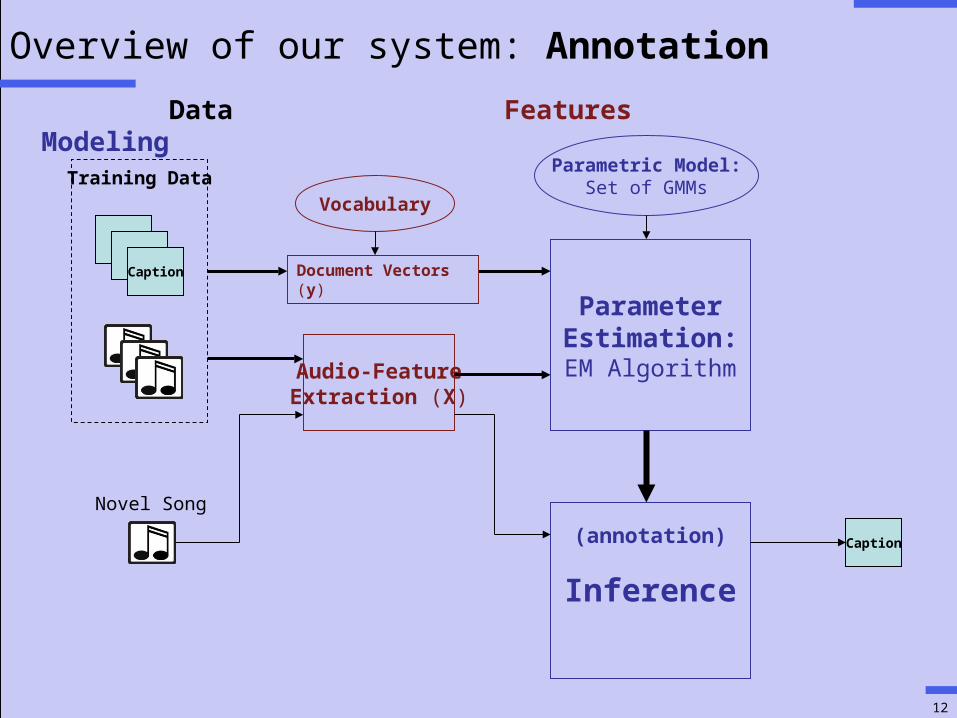
Overview of our system: Annotation
TTCaption
Audio-FeatureExtraction (X)
ParameterEstimation:EM Algorithm
Parametric Model:Set of GMMs
(annotation)
Inference
Caption
Training Data
Novel Song
Document Vectors (y)
Data Features Modeling
Vocabulary

11
Given ‘word’ distributions P(x|i) and a query song (x1,…,xT), we annotate with word i*:
Naïve Bayes Assumption: we assume xi and xj are conditionally independent, given i:
Assuming a uniform prior and taking a log transform, we have
Using this equation, we annotate the query song with the top N words.
Inference: Annotation
www.cascadeblues.org
12
Overview of our system: Annotation
TTCaption
Audio-FeatureExtraction (X)
ParameterEstimation:EM Algorithm
Parametric Model:Set of GMMs
(annotation)
Inference
Caption
Training Data
Novel Song
Document Vectors (y)
Data Features Modeling
Vocabulary

13
Overview of our system: Retrieval
TTCaption
Audio-FeatureExtraction (X)
ParameterEstimation:EM Algorithm
Parametric Model:Set of GMMs
(annotation)
Inference
(retrieval)Text Query
Caption
Training Data
Novel Song
Document Vectors (y)
Data Features Modeling
Vocabulary

14
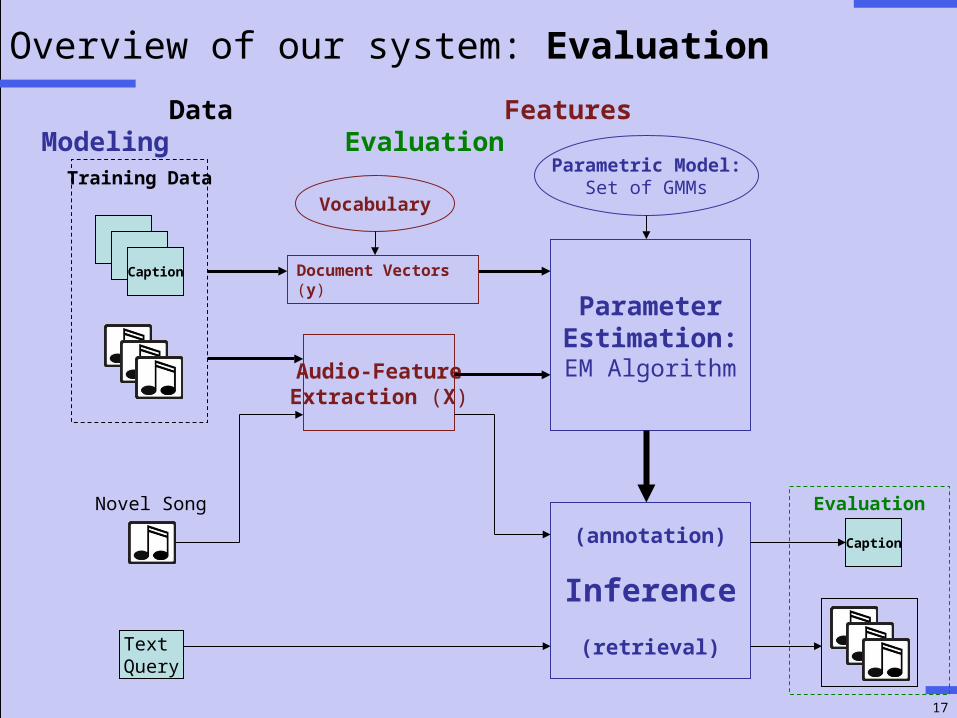
Inference: Retrieval
We would like to rank test songs by the posterior probability P(x1, …,xT|q) given a query word q.
Problem: this results in almost the same ranking for all query words.
There are two reasons:• Length Bias
• Longer songs will have proportionately lower likelihood resulting from the sum of additional log terms.
• This results from the naïve Bayes assumption of conditional independence between audio feature vectors [RQD00].
Image from www.rockakademie-owl.de

15
Inference: Retrieval
We would like to rank test songs by the posterior probability P(x1, …,xT|q) given a query word q.
Problem: this results in almost the same ranking for all query words.
There are two reasons:• Length Bias • Song Bias
• Many conditional word distributions P(x|q) are similar to the generic song distribution P(x)
• High probability (e.g. generic) songs under P(x) often have high probability under P(x|q)
Solution: Rank by likelihood P(q|x1, …,xT) instead.
• Normalize P(x1, …,xT|q) by P(x1, …,xT)Image from www.rockakademie-owl.de

16
Overview of our system
TTCaption
Audio-FeatureExtraction (X)
ParameterEstimation:EM Algorithm
Parametric Model:Set of GMMs
(annotation)
Inference
(retrieval)Text Query
Caption
Training Data
Novel Song
Document Vectors (y)
Data Features Modeling
Vocabulary
17
Overview of our system: Evaluation
TTCaption
Audio-FeatureExtraction (X)
ParameterEstimation:EM Algorithm
Parametric Model:Set of GMMs
(annotation)
Inference
(retrieval)Text Query
Caption
Training Data
Novel Song Evaluation
Document Vectors (y)
Data Features Modeling Evaluation
Vocabulary

18
Experimental Setup
Data: 2131 song-review pairs– Audio: popular western music from the last 60 years
• DMFCC feature vectors [MB03]• Each feature vector summarize 3/4 seconds of audio content• Each song is represent by between 320-1920 feature vectors
– Text: song reviews from AMG Allmusic database• We create a vocabulary of 317 ‘musically relevant‘ unigrams and bigrams• A review is a natural language document written by a musical expert• Each review is converted into a binary document vector
– 80% Training Set: used for parameters estimation– 20% Testing Set: used for model evaluation
Image from www.chrisbarber.net

19
Experimental Setup
Tasks:1. Annotation: annotate each test song with 10 words2. Retrieval: rank order all test songs given a query word
Metrics: We adopt evaluation metrics developed for image annotation and retrieval [CV05].
1. Annotation:• mean per-word precision and recall
2. Retrieval:
1. mean average precision
2. mean area under the ROC curve
Image from www.chrisbarber.net

20
Quantitative Results
Our Model .072 .119 .109 0.61
Baseline .032 .060 .072 0.50
AnnotationRecall Precision
RetrievalmaPrec AROC
Our model performs significantly better than random for all metrics.
• one-sided paired t-test with = 0.1• recall & precision are bounded by a value less 1• AROC is perhaps the most intuitive metric
Image from sesentas.ururock.com

21
Discussion
1. Music is inherently subjective• Different people will use different words to describe the same song.
2. We are learning and evaluating using a very noisy text corpus
• Reviewer do not make explicit decisions about the relationships between individual words when reviewing a song.
• “This song does not rock.”• Mining the web may not suffice.• Solution: manually label data (e.g., MoodLogic, Pandora)
Image from www.16-bits.com.ar

22
Discussion
3. Our system performs much better when we annotate & retrieve sound effects
• BBC sound effect library• More objective task• Cleaner text corpus• Area under the ROC = 0.80 (compare with 0.61 for music)
4. Best results for content-based image annotation and retrieval are comparable to our sound effect results.
Image from www.16-bits.com.ar

“Talking about music is like dancing about architecture”
- origins unknown
Please send your questions and comments to
Douglas Turnbull - [email protected]
Image from vintageguitars.org.uk

24
References
25
References