modelo de bases de datos usando logica...
TRANSCRIPT

MODELO DE BASES DE DATOS USANDO LÓGICA DIFUSA QUE PERMITA
MEJORAR EL PROCESO DE ATENCIÓN A LOS AFILIADOS EN UNA EPS EN
EL TERRITORIO COLOMBIANO, ENFOCADOS EN EL GRUPO ETAREO
Ing. Raúl Hernán Ramírez Ocampo
Ing. Giovanni Castaño Ocampo
UNIVERSIDAD DE SAN BUENAVENTURA
FACULTAD DE INGENIERÍA
ESPECIALIZACIÓN EN GESTION DE INFORMACION Y BASE DE DATOS
MEDELLÍN
2010

MODELO DE BASES DE DATOS USANDO LOGICA DIFUSA QUE PERMITA
MEJORAR EL PROCESO DE ATENCION A LOS AFILIADOS EN UNA EPS EN
EL TERRITORIO COLOMBIANO, ENFOCADOS EN EL GRUPO ETAREO
Autores
Ing. Giovanni Castaño Ocampo
Ing. Raúl Hernán Ramírez Ocampo
Monografía para optar por el titulo de especialización en Gestión de
Información y Base de datos
Asesor
Ing. Libardo Antonio Londoño
UNIVERSIDAD DE SAN BUENAVENTURA
FACULTAD DE INGENIERÍA
ESPECIALIZACIÓN EN GESTION DE INFORMACION Y BASE DE DATOS
MEDELLÍN
2010

Nota de Aceptación.
________________________________________________
________________________________________________
________________________________________________
________________________________________________
________________________________________________
Presidente del Jurado
________________________________________________
Firma del jurado
_______________________________________________
Firma del Jurado
Medellín

2
DEDICATORIA
A nuestras familias por su apoyo y
paciencia.
A todas las personas quienes nos
ayudaron a corregir y complementar el
contenido de este trabajo, quienes han
sido un gran apoyo.

CONTENIDO
Pág. LISTA DE FIGURAS INTRODUCCION OBJETIVOS 1 INFORMACION GENERAL DEL PROYECTO……………………………. 3
1.1 TITULO………….……..………………………………………………….. 3
1.2 INTEGRANTES……………………………………………….………….. 3
1.3 TIPO DE INVESTIGACION….………………………………………….. 4
1.4 NIVEL DE INVESTIGACION ….…………………………….………….. 4
1.5 TIPO PROYECTO…....………………………………………………….. 4
1.6 LINEA DE INVESTIGACION USB………………………….………….. 4
2 MARCO CONCEPTUAL……………………………………………………… 5
2.1 SITUACION ACTUAL……..……………………… ……...…………….. 5
2.2 NECESIDADES BASICAS DE LOS GRUPOS ETAREOS………….. 6
3 APLICACIÓN DE LA LOGICA DIFUSA EN LA BASE DE DATOS……….. 8
3.1 DEFINICION………………………………………………………………. 8
3.2 ALCANCE…………………………………………………………………. 8
3.2.1 A nivel estratégico………………………..………………………... 8
3.2.2 A nivel metodológico……………………..……………………….. 9
3.2.3 A nivel de contenido……………………………………………….. 9
3.3 FUENTES DE INFORMACION…………………………………………. 9
4 CONCEPTOS DIFUSOS…………………………………………….……….. 10
4.1 TECNICAS PARA DETERMINAR MODELOS DIFUSOS……………. 10
4.2 IMPLEMENTACIONES REALIZADAS EN LOGICA DIFUSA……….. 11
4.3 DEFINICION DE LOGICA DIFUSA…………………………...………... 12
4.3.1 Definición de Conjuntos Difusos………………………………….. 12
4.3.1.1 Soporte……………………….……………………………. 14
4.3.1.2 Núcleo………………………..…………………………….. 15
4.3.1.3 Altura…………………………………………..…………… 15
4.3.1.4 Cardinalidad……………..……………………..…………. 15
4.3.2 Operaciones sobre los Conjuntos Difusos………………………. 15
4.3.3 Atributos Difusos…………………………………………………… 16
4.3.3.1 Tipo 1……………………………………………………...… 16

4.3.3.2 Tipo 2……………………………………………………….. 16
4.3.3.3 Tipo 3……………………………………………………….. 16
4.4 LISTAS DE SIMBOLOS Y ABREVIATURAS………...………………... 17
4.5 DISTRIBUCIONES DE POSIBILIDAD…………………………………. 18
4.5.1 Cuantificadores………………………..…………….......…………
19
4.5.1.1 Clásicos…………………………………………………...… 19
4.5.1.2 Lógica……………………………………………………….. 19
5 METODOLOGIA…………………….…………………………………………. 20
5.1 ANALISIS SITUACION ACTUAL……...………………………………... 20
5.2 ANALISIS CON BASE DE DATOS DIFUSA………...………………… 21
5.2.1 Definición de SQLf…………………………………………………. 21
5.2.2 Características de SQL…………………….……...………………. 21
5.2.2.1 Bloque Básico………………..…….…………...………… 21
5.2.2.2 Clausula Select……………….……....………..…………. 22
5.2.2.3 Clausula From………………………..…………………… 22
5.2.2.4 Clausula Where…………….…………….………………. 22
5.2.2.5 Anidamiento…………………..………….……………….. 22
5.2.2.6 Comparadores…………………………..………………… 22
5.2.3 Operaciones de Conjuntos………….…………………………… 22
5.2.4 Comparadores Difusos……………..…………………………….. 24
6 PROPUESTA PARA LA EPS………………………………………………… 26
6.1 DESCRIPCION………..…………………………………………………. 26
6.2 REGLAS EXPERTAS DIFUSAS…...…………………………………… 29
6.2.1 Función de Implicación………………….……………………….. 29
6.2.2 Reglas difusas IF THEN………………….………………………. 30
6.2.3 Función de Membresía a la altura……….….…………………… 30
6.2.4 Función de Membresía del peso…………..…………………….. 31
6.2.5 Método del Centroide………………………..……………………. 33
7 DETALLE DEL CASO DE USO…...…………………………………………. 35
7.1 REGISTRAR PACIENTE……….……………………………………….. 35
7.1.1 Descripción de Caso de Uso…………………………………….. 35
7.1.2 Actores……………………………………………………………… 35
7.1.3 Precondiciones…………………………….……………………… 35
7.1.4 Secuencia básica de eventos…………….……………………… 35
7.1.5 Secuencias alternativas………………………………………….. 36
7.1.6 Pos condiciones…………………………………………………… 36
7.1.7 Diagrama de Actividades…………………………………………. 36
7.2 ACTUALIZAR PACIENTE…………………………....…………………... 36
7.2.1 Descripción de Caso de Uso……………….………………….. 36
7.2.2 Actores……………………………………….…………………… 37
7.2.3 Precondiciones……………………………….……………………. 37
7.2.4 Secuencia básica de eventos……………….…………………. 37

7.2.5 Secuencias alternativas………………………………………….. 37
7.2.6 Pos condiciones…………………………………………………… 37
7.2.7 Diagrama de Actividades…………………………………………. 38
7.3 EVALUACION DE CUESTIONARIO……....………………….…………. 38
7.3.1 Descripción de Caso de Uso…….…………………….………….. 38
7.3.2 Actores…………………………………………………….…………. 38
7.3.3 Precondiciones……………………………………………………… 38
7.3.4 Secuencia básica de eventos……………………………………... 39
7.3.5 Secuencias alternativas……………………………………………. 39
7.3.6 Pos condiciones…………………………………………………….. 39
7.3.7 Diagrama de Actividades…………………………………………... 40
7.4 EVALUACION PARA LOS PADRES……..………….………..…………. 40
7.4.1 Descripción de Caso de Uso………………………………………. 40
7.4.2 Actores……………………………………………………………….. 40
7.4.3 Precondiciones……………………………………………………… 41
7.4.4 Secuencia básica de eventos……………………………………... 41
7.4.5 Secuencias alternativas…………………………………………… 41
7.4.6 Pos condiciones……………………………………………………. 41
7.4.7 Diagrama de Actividades………………………………………….. 42
7.5 AUTOEXAMEN…………………….………………………………………. 42
7.5.1 Descripción de Caso de Uso……………………………………… 42
7.5.2 Actores………………………………………………………………. 42
7.5.3 Precondiciones………………….………………………………….. 43
7.5.4 Secuencia básica de eventos……………………………………... 43
7.5.5 Secuencias alternativas…………………………………………… 43
7.5.6 Pos condiciones…………………………………………………….. 43
7.5.7 Diagrama de Actividades…………………………………………... 44
7.6 BUSCAR PACIENTES…………………..………………………………… 44
7.6.1 Descripción de Caso de Uso………………………………………. 44
7.6.2 Actores……………………………………………………………….. 44
7.6.3 Precondiciones……………………………………………………… 45
7.6.4 Secuencia básica de eventos……………………………………... 45
7.6.5 Secuencias alternativas……………………………………………. 45
7.6.6 Pos condiciones…………………………………………………….. 45
7.6.7 Diagrama de Actividades…………………………………………... 46
7.7 GENERACION DE REPORTES………………………..………………… 46
7.7.1 Descripción de Caso de Uso………………………………………. 46
7.7.2 Actores………………………………………………………………... 46
7.7.3 Precondiciones……………………………………………………… 47
7.7.4 Secuencia básica de eventos……………………………………… 47
7.7.5 Secuencias alternativas……………………………………………. 47
7.7.6 Pos condiciones………….…………………………………………. 47
7.7.7 Diagrama de Actividades…………………………………………… 48
8 MODELO DE BASE DE DATOS……………………..………………………. 49

8.1 DIAGRAMA ENTIDAD RELACION…………….……………………….. 49
8.2 DESCRIPCION DEL MODELO DE DATOS…….……………………… 50
8.3 IMAGEN DE LA BASE DE DATOS CREADA EN ORACLE 9I…….…. 58
8.4 DISEÑO DE LA BASE DE DATOS EN POWER DESIGNER…………. 60
8.5 DISEÑO ENTIDAD RELACION ELABORADA EN POWER BUILDER 61
8.6 SCRIPTS PARA CREAR LA BASE DE DATOS………..……………….. 61
REFERENCIAS BIBLIOGRAFICAS

LISTA DE FIGURAS
Pág. Figura 1. Formula representativa de los conjuntos difusos….…………… 14
Figura 2. Función trapezoide………………………………………………… 14
Figura 3. Altura de un conjunto difuso……………………………………… 15
Figura 4. Formula de la cardinalidad………………………….…………….. 15
Figura 5. Representación de toma de información en la EPS…………… 20
Figura 6. Representación trapezoidal de joven……………………………. 24
Figura 7. Representación difusa de personas altas………………………. 26
Figura 8. Representación clásica de personas altas……………………… 27
Figura 9. Función de membresía…………………………………………….. 27
Figura 10. Representación de altura de una persona…………………….. 28
Figura 11. Representación del peso de una persona……………………… 28
Figura 12. Representación de estado saludable…………………………… 29
Figura 13. Representación del peso y la altura……………………………. 30
Figura 14. Membresía de la altura…………………………………………… 30
Figura 15. Membresía del peso……………………………………………… 31
Figura 16. Estados críticos del peso………………………………………… 31
Figura 17. Estados críticos de la altura……………………………………... 31
Figura 17a. Estados críticos de la altura con la operación AND………… 32
Figura 18. Representación estados críticos del peso y la altura……….. 32
Figura 19. Grado de decisión saludable……………………………………. 33
Figura 20. Grado de decisión………………………………………………… 34
Figura 21. Diagrama de clases registrar paciente………………………... 36
Figura 22. Diagrama de clases actualizar paciente………………………. 38
Figura 23. Diagrama de clases Evaluar cuestionario……………………. 40
Figura 24. Diagrama de clases Evaluación para padres………………… 42
Figura 25. Diagrama de clases auto-examen…………………………….. 44
Figura 26. Diagrama de clases Buscar paciente…………………………. 46
Figura 27. Diagrama de clases Buscar paciente…………………………. 48
Figura 28. Diagrama Entidad-Relación……………………………………… 49

INTRODUCCIÓN
El manejo de la información y la manipulación de la misma en un mundo en el cual estamos esperando cada día mejorar en estos aspectos, son los temas que queremos abordar, para esto se plantea el tema de la lógica difusa con la cual lograremos que la información sea precisa, oportuna y que pueda aportar algo en el bien del ser humano. Lo más importante no es la cantidad de información a la que se pueda acceder, sino a la calidad a la calidad de los mecanismos que se disponen para acceder a esta información que nos interesa en un momento dado. Es por este motivo que queremos enfocarnos hacia el grupo de la edad de oro, la cual en el campo de la salud ayudaría para la toma de mejores decisiones y una más óptima clasificación de este desarrollando programas preventivos y de mejoramiento para la calidad de vida. Por lo anterior, este trabajo de grado pretende dar una propuesta para mejorar la calidad de vida al grupo de la tercera edad, basándonos en información que podemos extraer de las bases de datos de una EPS colombiana y realizando algoritmos que clasifiquen de acuerdo a parámetros que se establezcan logrando detectar formas de prevenir enfermedades a futuro. Es por esto que se toman varios autores que han trabajado con la lógica difusa y el modelado de esta en base de datos.

OBJETIVOS
OBJETIVO GENERAL Proponer un modelo de base de datos utilizando lógica difusa que permita mejorar el proceso de atención a los afiliados enfocados en el grupo etáreo. OBJETIVOS ESPECIFICOS
1. Estudiar las tecnologías de gestión de datos de bases de datos difusas. 2. Analizar los modelos y notaciones existentes para modelos conceptuales de bases de datos. 3. Crear y Definir los conjuntos difusos [categorización del grupo etáreo] y establecer las etiquetas adecuadas para los conjuntos. 4. Identificar las variables que nos permitan establecer las reglas de decisión para los conjuntos difusos. 5. Crear un modelo de bases de datos difuso para acceder a los datos etáreos de las EPS colombianas que mejore la atención de este notablemente.

3
1 INFORMACIÓN GENERAL DEL PROYECTO
1.1 TÍTULO
Modelo de bases de datos usando lógica difusa que permita mejorar el proceso de
atención a los afiliados en una EPS Colombiana enfocados en el grupo etáreo
1.2 INTEGRANTES
Nombre: Raúl Hernán Ramírez Ocampo
Código: 15438622
Cédula: 15438622
Programa Académico: Especialización en gestión de información y administración de bases de datos.
Teléfono: 318 835 51 13
E-mail: [email protected]
Nombre: Giovanni Castaño Ocampo
Código: 71312166
Cédula: 71312166
Programa Académico: Especialización en gestión de información y administración de bases de datos.
Teléfono: 3147801497
E-mail: [email protected]

4
1.3 TIPO DE INVESTIGACIÓN
Exploratoria Predicativa
Descriptiva Proyectiva X
Comparativa Interactiva
Analítica Confirmativa
Explicativa Evaluativa
1.4 NIVEL DE INVESTIGACIÓN
Exploratoria X
Descriptiva
Explicativa
1.5 TIPO DE PROYECTO
Investigación en Ciencia básica
Investigación aplicada X
Desarrollo tecnológico
1.6 LÍNEA DE INVESTIGACIÓN USB
Línea y grupo de investigación USB
Gimsc
Trabajo empresarial Se realizará en una EPS colombiana

5
2 MARCO CONCEPTUAL
2.1 SITUACION ACTUAL El sistema de salud en nuestro país, a través de la historia se ha dividido en unos grandes hechos que han permitido el surgimiento de varios cambios trascendentales los cuales son: El primer periodo que surge con la instauración de la constitución de 1886 hasta mediados de 1950, este se llamó el modelo higienista donde se limitaba a atender aspectos de carácter sanitario mientras que la atención preventiva y curativa en salud tenía que ser financiada por los propios usuarios o por algunas instituciones religiosas de caridad. El segundo periodo que va desde 1970 hasta 1989, tuvo la creación del Sistema Nacional de Salud bajo el esquema de subsidios a la oferta, en el cual los recursos del gobierno central para la salud eran transferidos a la red de instituciones públicas hospitalarias. También se crea un esquema tripartito [estado - empleadores - empleados] de financiación para la prestación de los servicios de salud a la población trabajadora; sin embargo, tal Sistema seguía sin proporcionar una atención integral en salud a la población de escasos recursos. El tercer periodo arranca desde 1990, con la expedición de la Ley 100 en acuerdo con el artículo 36 de la Constitución Política del 86 que elevó el servicio de salud al rango de servicio público, hasta la actualidad. En este período hubo dos fuerzas importantes que determinaron los cambios institucionales que experimentó el sistema de salud pública en Colombia. La primera es la Constitución Política de 1991, según la cual Colombia se declara como un Estado Social de Derecho que consagra la vida como un derecho fundamental e inviolable [Art.11, Constitución Política de Colombia, 1991]. De allí se deriva la obligatoriedad jurídica para la provisión de servicios de salud por parte del Estado [y/o agentes particulares delegados por éste] en aras de garantizar el mencionado derecho fundamental. La Constitución de 1991 eleva a la Seguridad Social como “un servicio público de carácter obligatorio” [Art.48], dentro de la cual “la atención de la salud y el saneamiento ambiental son servicios públicos a cargo del Estado” [Art.49]. La segunda fuerza es el conjunto de reformas estructurales a partir de 1990, las

6
reformas estructurales tendientes a la privatización de algunas empresas del Estado, en combinación con la creación de incentivos de mercado para la competencia en la prestación de servicios sociales como la salud, inspiraron la concepción del esquema de competencia regulada que se instauró en Colombia a partir de la Ley 100 de 1993. El articulado final de la ley concilia las posiciones extremas favorables a la total privatización del sistema de salud y las favorables a un servicio nacional de salud estatal. El producto fue un sistema mixto donde el Estado asumió un papel rector y modulador, pero se liberó de las responsabilidades de aseguramiento y prestación de servicios que pasaron a ser asumidas, dentro de un esquema competitivo, por entidades públicas y privadas con y sin ánimo de lucro. La reforma de la seguridad social generó unas entidades intermediarias encargadas del aseguramiento y de la conformación de sus redes de prestadores de servicios. Estas aseguradoras, denominadas Entidades Promotoras de Salud [EPS] para el régimen contributivo y Administradoras del Régimen Subsidiado [ARS] para el régimen subsidiado, ofrecen un seguro que consiste en un Paquete Obligatorio de Salud, determinado por el CNSSS Consejo Nacional de Seguridad Social en Salud, captan de los afiliados sus contribuciones al sistema, reciben del Fondo de Solidaridad y Garantía [FOSYGA] una Unidad de Pago por Capitación por cada afiliado y cada persona de su grupo familiar [cónyuge e hijos menores de 25 años] y contratan con una red de Instituciones Prestadoras de Salud [IPS] la entrega de servicios de salud a sus afiliados. Los recursos captados son del sistema, no de las EPS. Estas solo pueden apropiarse las unidades de capitación que les correspondan según el número de afiliados que documenten ante el FOSYGA. Para ello deben manejar los aportes de sus afiliados en cuentas especiales de las cuales solo pueden hacer retiros previa autorización del FOSYGA, una vez han documentado satisfactoriamente los pagos recibidos con los nombres e identificación de sus asegurados. 2.2 NECESIDADES BASICAS DE LOS GRUPOS ETAREOS Las problemáticas que se identifican en el grupo de afiliados etáreos y basados en los factores críticos de éxito de las EPS, se encuentran:
La atención del grupo etáreo se enfatiza en una edad promedio desconociendo las necesidades particulares de cada afiliado. Las EPS no ofrecen planes diferenciados que puedan prevenir futuros tratamientos más costosos; a todos los usuarios del grupo etáreo se atienden y tratan por igual, por ello desde el tratamiento en edades tempranas se genera

7
el tratamiento en etapas finales. Con el actual modelo de base de datos se dificultan los tiempos de respuesta, ya que en la búsqueda de información de los registros del grupo etáreo estos no se están discriminado lo cual afecta la atención oportuna de dichos afiliados. Como no se cuenta con planes diferenciadores, no existen opciones que respondan a las características y necesidades especificas de los afiliados las cuales están condicionada por los rangos de edad; no es lo mismo atender a un afiliado que tenga 50 años de edad y unas condiciones de salud específicas que un paciente de 70 años con otras características.

8
3 APLICACION DE LA LOGICA DIFUSA EN LAS BASES DE DATOS
3.1 DEFINICIÓN
Las EPS en busca de mejorar la calidad de vida de los colombianos deben promover la búsqueda de mecanismos más eficientes de acceso a los datos, lo que lleva a un desarrollo vertiginoso de la tecnología de Bases de Datos. Asimismo, se hacen esfuerzos por “humanizar” el acceso a la información: se busca el crear mecanismos de modelación de datos y especificación de requerimientos que sean más cercanos a la expresión del lenguaje natural y a la manera de pensar del ser humano. A pesar de los esfuerzos realizados, la representación de la información y el tratamiento de la misma, se encuentran todavía lejos de los mecanismos utilizados habitualmente por el ser humano. Para subsanar esta carencia, se han hecho grandes esfuerzos de utilización de técnicas de Inteligencia Artificial en las Bases de Datos, con lo que han surgido las llamadas Bases de Datos Inteligentes o con técnicas difusas. Es por eso que con esta investigación se busca crear un modelo de base de datos que permita realizar búsquedas y generar informes utilizando lógica difusa que logre mejorar la atención integral prestada al grupo de afiliados etáreos; con la implementación del modelo obtenemos mejoramiento en la productividad, la competitividad y en el aspecto económico de una EPS colombiana. 3.2 ALCANCE 3.2.1 A Nivel Estratégico: Esta propuesta desde el nivel estratégico tiene como objetivo que las EPS puedan tener una información más específica de sus afiliados enfocados en el grupo etáreo para mejorar su calidad de vida y ser más competitivas entre ellas mismas.

9
3.2.2 A Nivel Metodológico: En la recolección de la información, se desea realizar un levantamiento de información del estado actual de los usuarios de las EPS que pertenecen al grupo etáreo. La información se obtendrá por medio de entrevistas, cuadros, visitas a las EPS. 3.2.3 A Nivel de Contenido: El documento da una propuesta de los beneficios de tener una base de datos de afiliados del grupo etáreo pertenecientes a una EPS con lógica difusa. 3.3 FUENTES DE INFORMACION: Para realizar este documento se utilizaron: -información de afiliados del grupo etáreo de una EPS. -Conceptos de autores que trabajan en el tema de lógica difusa. -Opiniones médicas.

10
4 CONCEPTOS DIFUSOS
4.1 TÉCNICAS PARA DETERMIINAR MODELOS DIFUSOS: Los conjuntos difusos fueron introducidos por L.A. Zadeh [1] en 1965 para procesar, manipular información datos afectados de incertidumbre e imprecisión no probabilística, este señor estableció los fundamentos de la teoría de los conjuntos difusos la cual es un cuerpo de conceptos y técnicas que establecen una forma de precisión matemática esto aplicado para el pensamiento humano el cual son poco precisas. Autores como Kaacprzyk y Staniewski [2] desarrollaron un algoritmo para trabajarlo con un inventario el cual tenía como objetivo el poder determinar la estrategia óptima invariable en el tiempo para determinar la reposición de los niveles de inventario existentes que maximice la función de pertenencia de la decisión. Se realiza un diseño para un sistema experto a través de reglas lingüísticas. Autores como Rinks [1981, 1982a y 1982b], TURKSEN y Ward [3] utiliza 40 reglas condicionales “if-then” para desarrollar algoritmos heurísticos fuzzy para la planificación agregada. Estos autores definen un conjunto de términos lingüísticos muy importantes en la planificación agregada para construir protocolos de gestión (reglas de decisión). El algoritmo adopta funciones de pertenencia. La programación lineal tiene también su papel, es el caso de Miller et al. [4] desarrollan una formulación de programación lineal para analizar el programa de producción de una empresa envasadora de tomate fresco en Ruskin [Florida]. En el envasado de tomate, la existencia de elementos inciertos atribuidos a la percepción humana es bastante común, tales como la cosecha, el ratio de envasado de tomate, la demanda y los costes de la escasez o pérdida de ventas. Petrovic et al. [1998 y 1999][5] Describe el modelado y la simulación fuzzy de una cadena de suministro en un entorno de incertidumbre. El objetivo es determinar las cantidades a producir y los niveles de stock durante un horizonte temporal finito, para un nivel de servicio aceptable y a un coste razonable. Du y Wolfe [6] Proponen un sistema MRP activo en tiempo real sin la limitación de

11
la planificación período a período. El sistema activo MRP utiliza una arquitectura híbrida que tiene una base de datos orientada a objetos, controladores de lógica difusa y redes neuronales. El módulo de control creado por estos dos autores combinan la lógica difusa con un algoritmo de control Proporcional-Integral-Derivativo [PID].Samanta y Al-Araimi [7] Da un modelo basado en la lógica difusa para el control del inventario. El modelo considera una revisión periódica del inventario con una cantidad variable de pedido. Pendharkar [8] Desarrolla un modelo de programación lineal fuzzy para evaluar las diferentes alternativas de producción en el contexto de la industria del carbón. Pendharkar argumenta que existen dos medidas fuzzy en la industria del carbón, una desde el punto de vista de la empresa explotadora del carbón, y otra desde el punto de vista de las plantas productoras de energía y consumidoras del carbón. Desde el punto de vista de la empresa comercializadora, la medida fuzzy es el “nivel aceptable de beneficio”. Reynoso et al. [9] presentan un primer enfoque sobre un MRP II (Planificación del los requerimientos de material) basado en la lógica difusa para el tratamiento de la incertidumbre y la imprecisión de la demanda. Este enfoque, denominado F-MRP [Fuzzy-MRP], diferencia entre demanda incierta e imprecisa y considera ambas. El modelo se formaliza a través del lenguaje de modelado UML. Mula [10] Proporciona un nuevo modelo de programación lineal, denominado MRPDet, para la Planificación de la Producción a medio plazo en un entorno de fabricación MRP con restricciones de capacidad, multi-producto, multi-nivel y multi-período. Posteriormente, este modelo se transforma en 15 modelos fuzzy basados en diferentes enfoques de programación matemática fuzzy, donde los coeficientes de coste en la función objetivo, la demanda del mercado, la capacidad requerida y la capacidad disponible pueden considerarse, dependiendo de cada modelo, datos imprecisos y/o ambiguos. Finalmente, los modelos se testan usando datos reales de un fabricante del asientos para automóviles.
4.2 IMPLEMENTACIONES REALIZADAS EN LOGICA DIFUSA PARA BASES DE DATOS
En el área de la salud también hay autores que han trabajado en este tema como es el caso del estudio de los genes a través de la lógica difusa para predecir enfermedades y así mejorar la calidad de vida de los seres humanos, es el caso del profesor de una universidad de España el profesor Pedro Larrañaga [11]

12
aseguró que a través del estudio de los genes, pueden llegar a predecirse enfermedades como el cáncer. Este profesor, señaló que los seres humanos compartimos un 99,9 por ciento de genes; la tarea es estudiar ese 0,1 por ciento restante para establecer grupos de individuos y con esa información se sabrá si las personas son propensas a padecer una u otra enfermedad. Dice también que cuando se disponga de esa información el médico podrá hacer un análisis de los síntomas externos y otro de los internos tan sólo con analizar el código genético. Pese a todo el señor Larrañaga dice que estos avances tienen un aspecto negativo. Las instituciones podrían llegar a tener un control muy grande sobre los individuos y el manejo de esa información podría caer en malas manos, sentencia. Larrañaga ha estudiado enfermedades como el lupus eritematoso muy conocido. 4.3 DEFINICION DE LOGICA DIFUSA: La lógica borrosa es una rama de la inteligencia artificial que se funda en el concepto "Todo es cuestión de grado”, Roman [12] lo cual permite manejar información vaga o de difícil especificación si quisiéramos hacer cambiar con esta información el funcionamiento o el estado de un sistema especifico. Es entonces posible con la lógica borrosa gobernar un sistema por medio de reglas de 'sentido común' las cuales se refieren a cantidades indefinidas. 4.3.1 Definición de Conjuntos Difusos En la investigación realizada se encontraron varios conceptos que nos ilustran una definición de los conjuntos difusos en los cuales tenemos: Los conjuntos clásicos están definidos por varios autores en los cuales llegan a un concepto muy similar a este: Un predicado que da lugar a una clara división del Universo con los valores de “Verdadero” y “Falso”, sin embargo, el pensamiento humano utiliza frecuentemente predicados que no se pueden reducir a este tipo de división: Son los denominados predicados vagos, los cuales son esos estados infinitos que pueden existir entre estos dos estados. La teoría de conjuntos difusos también llamados borrosos, Zadeh en 1965 [13] define que parte de la teoría clásica de conjuntos, agrega una función de pertenencia al conjunto, está definida como un número real entre 0 y 1. Así, se introduce el concepto de conjunto o subconjunto difuso asociado a un determinado valor lingüístico, definido por una palabra, adjetivo o etiqueta lingüística A. Para cada conjunto o subconjunto difuso se define una función de pertenencia o

13
inclusión μA [u], que indica el grado en que la variable u está incluida en el concepto representado por la etiqueta [[10]].Un conjunto difuso A sobre un universo de discurso U [Dominio ordenado] es un conjunto de pares dado por: A = {μA [u] /u : u ∈ U, μA [u] ∈ [0,1]} Donde, μ es la función de pertenencia y μA [u] es el grado de pertenencia del elemento u al conjunto difuso A. Este grado oscila entre los extremos 0 y 1, definido como: μA [u] = 0, indica que u no pertenece en absoluto al conjunto difuso A. μA [u] = 1, indica que u pertenece totalmente al conjunto difuso A. Esta función define que, para cada dominio D, escalar o numérico, se establece una relación de similitud que sirve para medir la similitud o parecido entre cada dos elementos del dominio Tineo, [14], formula que puede utilizar en la lógica de la base de datos a implementar para analizar el estado de salud de personas del grupo etáreo de la EPS. Normalmente, los valores de similitud están normalizados en un intervalo [0,1], correspondiendo el 0 al significado “totalmente diferente” y el 1 al significado “totalmente parecido” o iguales. Por tanto, una relación de similitud puede ser vista como una función sr, tal que: sr : D×D → [0,1] sr[di, dj] l→ [0,1] con di, dj ∈U Tanto los dominios con referencial ordenado y no ordenado pueden representar de forma adecuada conceptos de “imprecisión” con la teoría de conjuntos difusos. Es necesario hacer notar que muchos de estos conceptos naturales dependen, en mayor o menor medida, de la persona que los expresa. Estos conjuntos regulares no son adecuados para expresar clases cuyos bordes no están definidos, por ejemplo: personas, jóvenes, distancias, estos conjuntos difusos permiten la representación de estas clases que se asocia al concepto que se desea expresar en este trabajo investigativo. En estos hay discontinuidad entre los miembros del conjunto y elementos del universo que son cercanos al conjunto, pero no pertenecen al mismo, es decir que en sus límites no están incluidos, pero tampoco completamente excluidos. Para representar el grado de referencia a la función de pertenencia, donde el rango está entre los intervalos [0,1], cada elemento tiene un grado de pertenencia donde esta función de membrecía se representa con el símbolo µf, siendo F el identificador del conjunto difuso.

14
La fórmula para representar conjuntos difusos extraída de la investigación de interrogaciones flexibles en base de datos relacionales, la utilizaremos en este proyecto para crear los scripts que definirán los grados de adultos mayores: Por extensión (para universo discreto) el conjunto difuso F sobre el universo U se representa así:
Figura 1. Formula representativa de los conjuntos difusos Zadeh
Con la siguiente función mf:U→[0,1]. Tiene forma de trapezoide la cual representa valores del universo (a, b, c, d).
Figura 2. Función trapezoide Zadeh
Las siguientes definiciones fueron tomadas basándonos en el concepto de Zadeh, que están incluidas en el proyecto investigativo de interrogaciones flexibles y que se utilizarán para crear los scripts de análisis de decisión en la base de datos. 4.3.1.1 Soporte: Es el que está formado por todos aquellos componentes de un universo que no están completamente excluidos del conjunto difuso. Tineo leonid [15] Se representa así: Supp (F) = { xÎU / mf (x)>0}

15
4.3.1.2 Núcleo: Es el conjunto que se forma de todos los elementos del universo que están completamente incluidos en el conjunto difuso. Se representa así: Core (F) = { xÎU / mf (x)=1} 4.3.1.3 Altura: La altura de un conjunto difuso es el valor de membrecía más grande presente en el conjunto. Se representa así:
Figura 3. Altura de un conjunto difuso Zadeh
4.3.1.4 Cardinalidad: Tiene varias definiciones basadas en enteros, en números reales y otras en números difusos. La representación más clara la dio Zadeh [11], la cual está dada por la expresión:
Figura 4. Formula de la cardinalidad Zadeh
4.3.2 Operaciones sobre los conjuntos difusos Los conjuntos difusos, como los conjuntos tradicionales manejan las operaciones básicas Zadeh en 1965 [16] La Igualdad: Esta función está representada en la siguiente fórmula: F=G ÛxÎU left (m rSub { size 8{F} } \( x \) =m rSub { size 8{g} } \( x \) right )} {} La Inclusión: En la lógica difusa se da se asigne un valor menor o igual que le valor del otro conjunto: FÍG ÛxÎU left (m rSub { size 8{F} } \( x \) <= m rSub { size 8{g} } \( x \) right )} {} . El Complemento: Esta dada de la siguiente función: mF( x)=1−mF( x) La Intersección: En la lógica difusa se determina mediante la siguiente formula T: mFG ( x)=T(mF( x) ,mG( x).

16
La Unión: De dos conjuntos difusos se define mediante una forma triangular. S: mFEG ( x)=S(mF(x), G(x)). La Diferencia: Dos conjuntos difusos se determina con un operador que permite vincular un conjunto difuso con otros conjuntos: F es Fα={xÎUn /mF ( x)³α} . o también Fα ={xÎUn /mF (x)> α} Con estas operaciones son las que se tendrán en cuenta para crear los scripts que permitirán analizar los datos y procesarlos para dar un resultado acorde a los patrones que se ingresen y puedan dar un punto de vista diferente para cada paciente. 4.3.3 Atributos Difusos
Para modelar atributos difusos se consideran datos con un dominio referencial ordenado y no ordenado. En esta base de datos se tienen un historial con todos los pacientes del grupo de la ESP. En un referencial ordenado tenemos las representaciones de: Distribución de posibilidad trapezoidal de Zadeh,. Etiquetas lingüísticas, Valores aproximados, Intervalos de posibilidad. En un referencial no ordenado: Escalares simples y Distribución de posibilidad sobre escalares. También son considerados los valores Unknown, Undefined y Null. Por otro lado, los atributos clásicos que su dominio sea impreciso pueden ser tratados pero con un formato especial para representar atributos difusos. La clasificación adoptada se basa en criterios de representación y de tratamiento de los datos “imprecisos”: se clasifica según el tipo del dominio que les subyace y por si permiten representar la información imprecisa o sólo permiten el tratamiento impreciso de datos sin imprecisión. Los atributos difusos pueden ser de 3 tipos Urruti, Angelica [17] 4.3.3.1 TIPO 1: Estos son atributos con “datos precisos”, este tipo de atributos reciben una representación igual que los datos precisos, pero admiten que se puedan transformar utilizando condiciones difusas.
4.3.3.2 TIPO 2: Son atributos que pueden recoger “datos imprecisos sobre referencial ordenado”. Estos admiten tanto datos crisp como difusos, en forma de distribuciones de posibilidad sobre un dominio ordenado. 4.3.3.3 TIPO 3: Son atributos sobre “datos de domino discreto no ordenado con analogía”. En estos atributos se definen algunas etiquetas [“rubio”, “pelirrojo”,

17
“castaño”...], que son escalares con una relación de similitud [o proximidad] definida sobre ellas, de forma que esta relación indique en qué medida se parecen entre sí cada par de etiquetas. Hay que anotar que, el conjunto difuso de posibles valores que puede tomar una determinada característica se denomina dominio difuso. Cada una de las propiedades o características que tiene una clase se denomina atributo. 4.4 LISTA DE SIMBOLOS Y ABREVIATURAS
Estas son una lista de símbolo estándar que se utilizan en la lógica difusa y los cuales se mencionarán en este trabajo.
[x,y] Intervalo Real cerrado [x,y]. →f Implicación difusa α-cut Operador que permite vincular los conjuntos difusos con conjuntos precisos. am(P1,..,Pn) Media aritmética de P1,..,Pn core(F) Núcleo de un conjunto difuso F ∑count(F) Cardinalidad de un conjunto difuso F fc Denota un conjunto difuso gm(P1,..,Pn) Media geométrica de P1,..,Pn height(F) Altura de un conjunto difuso F hm(P1,..,Pn) Media armónica de P1,..,Pn mF Función de membresía del conjunto difuso F mS(X) Grado de satisfacción de la sentencia S por el conjunto X max(P1,..,Pn) Máximo entre P1,..,Pn min(P1,..,Pn) Mínimo entre P1,..,Pn N(A) Medida de necesidad de un subconjunto A owa(P1,..,Pn) Media ponderada ordenada de P1,..,Pn P(U) Conjunto de todas las distribuciones de posibilidad sobre el universo U. Π Distribución de posibilidad Q Cuantificador Lingüístico supp(F) Soporte de un conjunto difuso F sup ( ) El más grande de los valores f(x) <término> El término encerrado en los símbolos “<” “>” denota un término difuso. U Un universo cualquiera wm(P1,..,Pn) Media ponderada de P1,..,Pn

18
4.5 DISTRIBUCIONES DE POSIBILIDAD
L.A. Zadeh las utilizó para representar los datos imprecisos o inciertos y que están recopiladas en el texto de interrogaciones flexibles en base de datos relacionales. Tineo leonid [18]. Una distribución de posibilidad es una función de un universo U al intervalo real [0,1], tal como la funciones de membresía de los conjuntos difusos. Una distribución de posibilidad indica para un objeto los posibles valores que toma en el universo U, estos posibles valores forman un conjunto difuso F: p( x=a)=Mf( a). Sobre las distribuciones de posibilidad se definen dos medidas llamadas posibilidad y necesidad, las cuales se entienden como el grado de certeza de una afirmación. La medida de posibilidad P es una función de las partes del universo U en [0,1] tal que; P(Æ)=0 ; P(U)=1. Las distribuciones de posibilidad representan varios posibles valores que puede tener un objeto en un universo U, es deseable que las operaciones sobre U puedan aplicarse a estos objetos. Para ello Zadeh definió el principio de extensión, el cual establece: si el operador binario es definido sobre cualquier par de elementos a1 y a2 de los dominios U1 y U2, respectivamente; la operación binaria sobre cualquier par de distribuciones de posibilidad. Realicemos un cálculo de una distribución de posibilidad de la información que tenemos con el universo de pacientes de la EPS a revisar. Sea un universo constituido por las edades de los pacientes desde 0 años hasta los 100 años. U=[0,100] p1 = {0.90/0.70,0.80/0.50,0.40/0.30} y p2 = {0.80/0.70,0.8/0.5,1/0.40} La conjunción se calcula mediante el método de extensión, la cual sería así para las edades de los pacientes de la EPS: {0.90/0.70,0.80/0.5,0.40/0.30} ^ {0.80/0.70,0.80/0.50,1/0.40} = { 0.90^0.80/0.70^0.70, 0.90^0.80/0.70^0.50, 0.90^1/0.70^0.40, 0.80^0.80/0.50^0.70, 0.80^0.80/0.50^0.50, 0.80^1/0.50^0.40, 0.40^0.80/0.30^0.70, 0.40^0.80/0.30^0.50, 0.40^1/0.30^0.40} = { 0.80/0.70, 0.80/0.50, 0.90/0.40,0.80/0.50, 0.80/0.50, 0.80/0.40,0.40/0.30, 0.40/0.30, 0.40/0.30} = { 0.80/0.70, 0.80^0.80^0.80/0.50, 0.90^0.80/0.40 0.40^0.40^0.40/0.30} =

19
{ 0.80/0.70, 0.80/0.50, 0.90/0.40, 0.40/0.30}
4.5.1 Cuantificadores 4.5.1.1 Clásicos: Son los que se consideran como los extremos cuya interpretación no es tan absolutamente rígido, estos son considerados cuantificadores lingüísticos o difusos. Se representan de dos maneras: lógica y numérica
4.5.1.2 Lógica: esta consiste en definir un conjunto de expresiones lógicas basado en los valores del dominio sobre el cual se hace la cuantificación, no es la más recomendada para las bases de datos. Numérica: Consiste en dar un valor a una variable numérica que produce un valor en el intervalo [0,1] esto es que en el caso que los cuantificadores son absolutos, el número de elementos que satisface la condición cuantificada y para los relativos la proporción de elementos que satisfacen la condición respecto al tamaño del universo U.

20
5 METODOLOGIA
5.1 ANÁLISIS SITUACIÓN ACTUAL
En la recolección de los datos de los pacientes de la tercera edad se tienen manejos genéricos con estos pacientes, tal es el caso de la creación de grupo de hipertensos, que en la actualidad, el análisis que hacen es que si el paciente pasa de 50 años ingresa automáticamente a este grupo o al grupo de control mensual. De los cuales sacan resultados como talla, peso, presión arterial, los cuales al ingresarlos al algoritmo de la base de datos difusa, dará como resultado un análisis especial a cada paciente dependiendo de los valores ingresados en las premisas anteriores. NOMBRE EDAD PESO PRESION
ARTERIAL
Jorge Antonio Sánchez
55
82 k
120-180
Carlos Arango Builes
60 75 125-150
María Mercedes
70 80 150-160
Figura 5. Representación de toma de información en la EPS (propia)
La propuesta lo que quiere es que no sean tan genéricos con pacientes de este grupo y se puedan clasificar por características similares que en esto nos ayudaría la lógica difusa, para aplicar medicina preventiva para que al avanzar en la edad, los pacientes no tengan enfermedades graves que se pudieron tratar desde antes. En este sistema clásico, si deseamos saber que pacientes están con problemas de salud en el cual este afectándole la salud tendremos que realizar un requerimiento para indicar un máximo de valor en la columna de presión arterial y un máximo en la columna peso, esto podría llevarnos a un resultado vacio o una respuesta no confiable. Select * from usuarios where peso<=70 and edad<=50 sqlr
Esto podría dar una solución más precisa permitiendo especificar más los

21
requerimientos haciendo uso de la lógica difusa. Las bases de datos son compartidas por muchas aplicaciones y usuarios para los cuales los términos imprecisos podrían cambiar de semántica. Es por esto que este trabajo tiene como finalidad mostrar el beneficio en el campo de la salud la teoría de las bases de datos difusas, se mostrará los conceptos de la teoría de conjuntos difusos y el tema de la teoría de las posibilidades.
5.2 ANÁLISIS CON BASE DE DATOS DIFUSA SQLF, es una extensión del actual SQL, la cual esta extensión va a tener la virtud de ser más completa de las actuales en cuanto a que tendrá más diversidad de interrogantes difusas que permite y extiende todas las construcciones de SQL. 5.2.1 De SQLf:
Permite analizar una información la cual tiene estados imprecisos o subjetivos, de una manera similar a como lo hace el cerebro humano
5.2.2 Características de SQL
Algunas de las características principales de SQL, se mostraran como un marco de referencia para poder presentar las extensiones difusas hechas a este lenguaje. SQL es un lenguaje estructurado para la interrogación de Bases de Datos relacionales, basado principalmente en el Álgebra Relacional y en el Cálculo Relacional y que incluye operaciones como la unión de conjuntos, operadores aritméticos y funciones de agregación, entre otros.
5.2.2.1 Bloque Básico: Esta estructura está basada en las tres operaciones básicas del álgebra relacional: Proyección, Producto Cartesiano y Selección. Así, un bloque Básico en SQL consiste de una cláusula SELECT, una cláusula FROM y una cláusula WHERE.

22
5.2.2.2 Select: Corresponde a la proyección, especifica los atributos de las relaciones que serán seleccionados y operaciones sobre estos atributos. 5.2.2.3 From: Determina las relaciones sobre las cuales se hace la consulta; esta cláusula corresponde al Producto Cartesiano: la consulta se hace sobre el producto cartesiano de las relaciones indicadas. 5.2.2.4 Where: Corresponde a la selección, especifica los predicados que deben satisfacer las relaciones para ser seleccionadas. Estos pueden complicarse haciendo uso de otros operadores que se presentan en lo sucesivo. 5.2.2.5 Anidamiento: En SQL es posible usar dentro de la cláusula WHERE de un bloque una nueva sentencia de selección, lo que permite hacer anidamientos de bloques de interrogaciones de profundidad arbitraria; esta es una de las características más resaltantes de este lenguaje de interrogación a Bases de Datos. 5.2.2.6 Comparadores: Consiste en tener un valor y compararlo con el que estamos analizando 5.2.3 Operaciones de Conjuntos
Son las posibles combinaciones que podemos hacer, en varios bloques de selección pueden ser asociados usando el operador de conjuntos UNIÓN. El SQL estándar no permite traducir una diferencia o una intersección como la ayuda de un operador específico, aunque tales operadores sí existen en algunos sistemas (como los operadores: inter, differ). Para hacer estas operaciones en SQL, se tiene que usar alguna expresión equivalente que utilice operadores existentes en el lenguaje. Esencialmente se usan NOT IN, NOT EXISTS o ! = ALL para la diferencia, y IN, = ANY o un join para la intersección. Particionamiento Tineo, [19], SQL también ofrece la posibilidad de hacer un particionamiento de la relación mediante el uso de la cláusula GROUP BY. El atributo (o conjunto de atributos) mencionado en la cláusula GROUP BY indica cómo agrupar. SQL también tiene las siguientes funciones: AVERAGE, MINIMUN, MAXIMUN, SUM, CARDINALITY. En ciertos casos, un requerimiento que involucra un particionamiento puede ser utilizado para traducir un auto-join. La operación relacional División, para la cual

23
no hay operador específico en SQL, puede también ser expresada por este tipo de consultas. DDL para componentes difusos (SQLf-DDL) En general, las interrogaciones difusas involucran términos (predicados atómicos, modificadores, conectores, comparadores y cuantificadores) y alguno de ellos tiene un significado que es específico para un grupo de usuarios (o un individuo). Por ello se hace necesario proveer de un lenguaje para la definición de estos componentes difusos, tal es el Sublenguaje de definición de datos de SQLf, el cual se inspira en el DDL de SQL. Predicados difusos: Existen, en primera instancia, predicados básicos (o atómicos). Cada uno de ellos es representado por una función de membresía sobre un subconjunto de un dominio subyacente. Se consideran predicados P que aplican a elementos individuales X: P: → R[0,1] . Estos se definen mediante la sentencia: CREATE FUZZY PREDICATE <nombre> ON <dominio> AS <cjto difuso> Donde: <dominio > es un rango de caracteres, enteros o reales un tipo escalar definido por el usuario <cjto difuso> es una especificación de conjunto difuso, que puede ser: Una distribución de posibilidades representada por un trapezoide con la sintaxis: (<valor1>,<valor2>,<valor3>,<valor4>) Pudiendo usarse el valor especial “infinit” cuya semántica es infinito. Una distribución de posibilidades representada por extensión, con la sintaxis: {<grado1>/<valor1>,...,<gradon>/<valorn>} una expresión aritmética que usa la variable predefinida “x” que denota el argumento del predicado. Para nuestro caso: Definición de joven CREATE FUZZY PREDICATE joven ON 0...120 AS (0, 0, 25,50) Representación en trapezoide

24
Figura 6. Representación trapezoidal de joven
5.2.4 Comparadores Difusos
Además, de los comparadores usuales, un requerimiento difuso podría usar comparadores difusos cuya semántica puede variar dependiendo de los datos, o del usuario. Estos comparadores se crean mediante la sentencia CREATE COMPARATOR <símbolo> ON <dominio> AS <expresión> Donde <símbolo> es el identificador del comparador, el cual puede ser un nombre alfabético o un símbolo <dominio> es como en el caso de los predicados atómicos. <expresión> es la expresión que permite calcular el valor de la comparación a partir de los dos elementos comparados, los cuales son denotados con la variable x (para el término izquierdo) y la variable y (para el término derecho). Esta expresión puede utilizar conjuntos difusos. Extensiones para el DML flexible (SQLf-DML) SQL ha sido extendido haciendo uso de la Teoría de Posibilidades y de Conjuntos Difusos; tratando de mantener la máxima similitud en sintaxis y en semántica de SQL original; el resultado de esta extensión es SQLf. Bloque Básico La estructura fundamental de consulta en SQLf, al igual que en SQL, es el bloque multirelacional. La diferencia fundamental con SQL radica en que la condición de

25
la cláusula WHERE es una condición difusa, como se describe en la próxima sección. También el uso de la calibración es un añadido en SQLf. Otra diferencia es que el resultado de la consulta no es un multiconjunto sino un conjunto, es decir, una consulta en SQLf se comporta como si se especificara la palabra clave DISTINCT. La sintaxis del bloque básico es SELECT [n|t|n,t] <atributos> FROM <relaciones> WHERE <condición difusa> La semántica de esta construcción puede expresarse en términos del álgebra relacional difusa como el producto cartesiano de las relaciones indicadas en la cláusula FROM, al cual se le aplica la selección difusa mediante la condición expresada en la cláusula WHERE, tomando como resultado final la proyección difusa de las tuplas seleccionadas sobre los atributos indicados en la cláusula SELECT. Condiciones en Bloques simples En esta sección se muestra el uso de los distintos elementos difusos de SQLf en bloques de interrogación simples . Predicados difusos Los predicados difusos, definidos por el usuario, son utilizados como etiquetas lingüísticas que se comparan con igualdad a una expresión como si se tratara de un valor (debe haber compatibilidad de tipos para usarlos). La sintaxis es: <expresión> = <etiqueta> Donde <etiqueta> es el nombre del predicado difuso definido por el usuario.

26
6 PROPUESTA PARA LA EPS
6.1 DESCRIPCIÓN El sistema de la lógica difusa es una herramienta con la cual ayudara a optimizar el proceso de análisis y patologías que pueda tener un paciente con ciertas características similares y que puede mejorar el proceso de atención según nuestro enfoque de implementación.
Vamos a evaluar la salud de la persona dependiendo de su edad. Debemos tener en cuenta variables de entrada o números limitados a un rango para evaluar su estado de salud serán su peso y su altura ingresaremos El conjunto clásico de personas altas:
A= { X | X > 1.8} ; B= { X | X <1.8} Visión de la lógica difusa
Figura 7. Representación difusa de personas altas
Visión en la lógica clásica

27
Figura 8. Representación clásica de personas altas
Aplicando la función de membresía definida anteriormente tenemos la siguiente grafica:
Figura 9. Función de membresía
Función de membresía altura:

28
Figura 10. Representación de altura de una persona
Convenciones: MB= Muy bajo B= Bajo M= Medio A= Alto MA = Muy alto Función de membrecía del peso
Figura 11. Representación del peso de una persona
Convenciones: MD = Muy delgado D = Delgado M = Medio P = Pesado
29
MP = Muy pesado 6.2 REGLAS EXPERTAS DIFUSAS
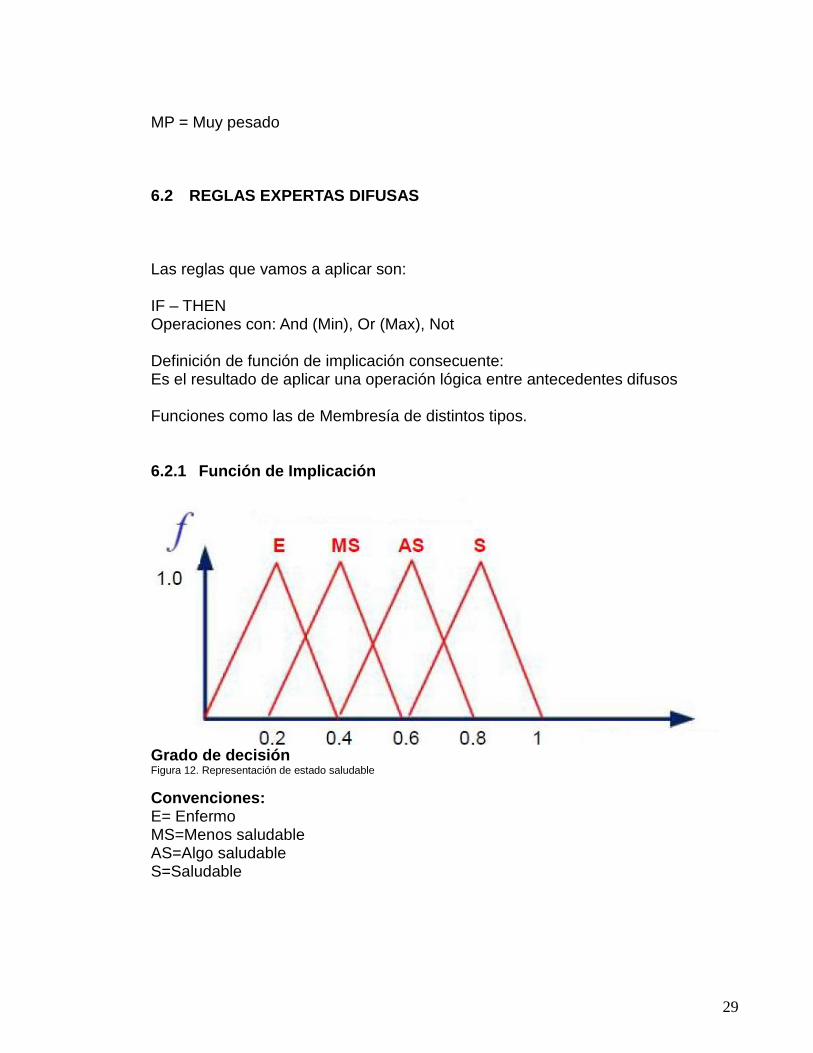
Las reglas que vamos a aplicar son: IF – THEN Operaciones con: And (Min), Or (Max), Not Definición de función de implicación consecuente: Es el resultado de aplicar una operación lógica entre antecedentes difusos Funciones como las de Membresía de distintos tipos. 6.2.1 Función de Implicación
Grado de decisión Figura 12. Representación de estado saludable
Convenciones: E= Enfermo MS=Menos saludable AS=Algo saludable S=Saludable

30
6.2.2 Reglas Difusas para analizar el peso y la altura IF THEN
PESO
ALT
UR
A
Muy delgado
Delgado Medio Pesado Muy pesado
Muy bajo
S AS MS E E
Bajo AS S AS MS E
Medio MS S S MS E
Alto E AS S AS E
Muy alto E MS S AS MS Figura 13. Representación del peso y la altura
Vamos a hacer una prueba con un adulto mayor con las siguientes características:
Peso: 53 Kg y mide 1.77 cm
Aplicamos la función de membresía a la altura y al peso 6.2.3 Función de Membresía a la altura
Figura 14. Membresía de la altura

31
6.2.4 Función de Membresía del Peso
Figura 15. Membresía del peso
Según la grafica estaría el peso y la altura así:
PESO
ALT
UR
A
Muy delgado
Delgado Medio Pesado Muy pesado
Muy bajo
S AS MS E E
Bajo AS S AS MS E
Medio MS S S MS E
Alto E AS S AS E
Muy alto E MS S AS MS Figura 16. Estados críticos del peso
PESO
ALT
UR
A
0.8 0.2 Medio Pesado Muy pesado
Muy bajo
S AS MS E E
Bajo AS S AS MS E
0.7 MS S S MS E
0.3 E AS S AS E
Muy alto E MS S AS MS Figura 17. Estados críticos de la altura
Aplicando la función AND(min) OR (max) NOT

32
AND µc (X)= min (µa(X), µb(X)) = µa (X) ∩ µb(X) OR µc (X)= max (µa(X), µb(X)) = µa (X) U µb(X) NOT µ~a (X)= 1 - µa(X) Con la operación AND.
PESO
ALT
UR
A
0.8 0.2 Medio Pesado Muy pesado
Muy bajo
S AS MS E E
Bajo AS S AS MS E
0.7 0.7 0.2 S MS E
0.3 0.3 0.2 S AS E
Muy alto E MS S AS MS Figura 17a. Estados críticos de la altura con la operación AND
f={0.3,0.7,0.2,0.2 } f={E,MS,AS,S} Convenciones: E= Enfermo MS=Menos saludable AS=Algo saludable S=Saludable Gráficamente seria así:
Figura 18. Representación grafica de los estados críticos del peso y la altura

33
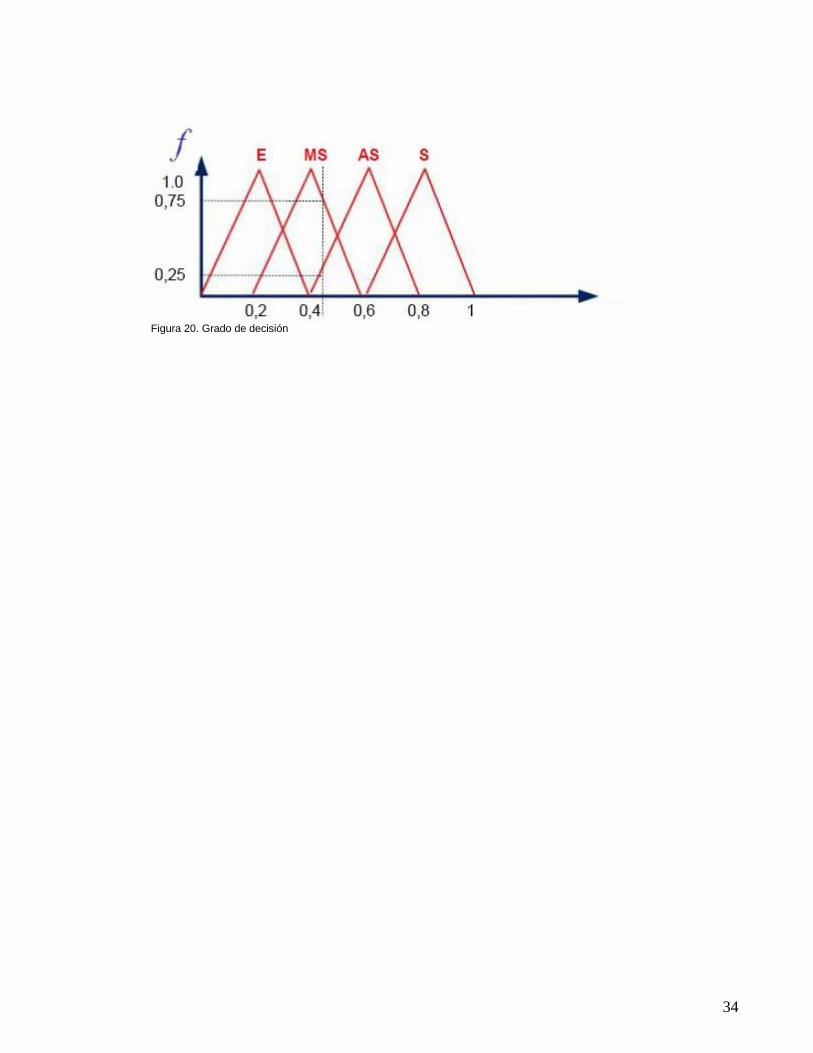
Aplicando el método de agregación Se le aplica dsos el cual consiste en dos métodos los cuales son el de Suma y el de máximo. Para este cálculo de esta operación aplicamos el método del centroide el cual retorna el centro del área bajo la curva. 6.2.5 Método del Centroide
EL grado de decisión sería: 0.429
Figura 19. Grado de decisión saludable
75 % La persona es menos saludable 25 % La persona es algo saludable
34
Figura 20. Grado de decisión

35
7 DETALLE DE CASO DE USO
7.1 REGISTRAR PACIENTE
7.1.1 Descripción de caso de uso
Describe el proceso mediante el cual un funcionario de la EPS registra un paciente en el sistema, de la base de datos .El objetivo es almacenar la información personal del paciente para usarla en las diferentes validaciones que se realizaran en la lógica difusa
7.1.2 Actores
Paciente Funcionario de la EPS
7.1.3 Precondiciones
EL paciente debe estar afiliado a la EPS. Funcionario con privilegios de inserción a la base de datos
7.1.4 Secuencia básica de eventos
-Funcionario ingresa al sistema de registro de paciente -El funcionario ingresa la identificación del paciente -El sistema almacena la información en la base de datos -Muestra pantalla de confirmación de registro del paciente -Proceso termina

36
7.1.5 Secuencias Alternativas
-El funcionario ingresa la identificación del paciente -El sistema detecta que la información del paciente existe en la base de datos. -Muestra pantalla de paciente existe en el sistema -Proceso termina
7.1.6 Pos condiciones
El paciente es registrado en la base de datos ó el paciente existía como registrado previamente.
7.1.7 Diagrama de actividades
Figura 21. Diagrama de clases registrar paciente
7.2 ACTUALIZAR PACIENTE 7.2.1 Descripción de caso de uso Este caso de uso describe el proceso mediante el cual un funcionario de la EPS actualiza los datos personales de un paciente existente en el sistema. El objetivo es mantener la información actualizada de los pacientes la cual es utilizada en los diferentes reportes que genera el sistema y con la base de datos montada con

37
lógica difusa ayudar al proceso de análisis y toma de decisiones. 7.2.2 Actores
Funcionario de la EPS Interface gráfica del sistema de registro de pacientes
7.2.3 Precondiciones
El paciente debe existir en la base de datos del sistema. 7.2.4 Secuencia Básica de Eventos
1. Sistema muestra menú de opciones. 2. El funcionario de la EPS selecciona la opción de actualización de pacientes. 3. El funcionario de la EPS ingresa la identificación del paciente. 4. El funcionario de la EPS sobre escribe la información personal del paciente. 5. El sistema actualiza la información en la base de datos. 6. Muestra pantalla de confirmación de actualización del paciente. 7. Proceso termina.
7.2.5 Secuencias alternativas
- El funcionario de la EPS ingresa la identificación del paciente. - El sistema detecta que el usuario no existe en la base de datos. - Muestra pantalla de error en el sistema. - Proceso termina.
7.2.6 Pos condiciones
El paciente es actualizado en la base de datos del sistema

38
7.2.7 Diagrama de actividades
Figura 22. Diagrama de clases actualizar paciente
7.3 EVALUACION DE CUESTIONARIO
7.3.1 Descripción de caso de uso Este caso de uso describe el proceso mediante el cual los funcionarios de la EPS, preparan la información necesaria para la evaluación del paciente. El objetivo es relacionar la información del paciente, edad, peso enfermedades frecuentes, antecedentes familiares para poder así, disponer de la información propia del cuestionario a realizarse por medio del sistema. 7.3.2 Actores
Funcionarios de la EPS Interface gráfica del sistema de registro de pacientes
7.3.3 Precondiciones
El paciente debe existir en la base de datos del sistema de la EPS

39
7.3.4 Secuencia básica de eventos
1. Interfaz grafica muestra menú de opciones. 2. El funcionario de la EPS selecciona la opción de evaluar prueba. 3. El funcionario de la EPS ingresa la identificación del paciente. 4. El sistema muestra la información del paciente en modo no editable. 5. El funcionario de la EPS selecciona la categoría de la prueba. 6. El funcionario de la EPS selecciona la opción cargar cuestionario 7. El sistema carga las preguntas del cuestionario. 8. El funcionario de la EPS completa las diferentes preguntas del cuestionario. 9. El funcionario de la EPS selecciona la opción analizar cuestionario. 10. El sistema registrar la información en la base de datos. 11. El sistema realiza el proceso de análisis. 12. El sistema genera un reporte con el análisis del cuestionario. 13. Proceso termina.
7.3.5 Secuencias alternativas
3a-1. El funcionario de la EPS ingresa la identificación del paciente. 3a-2. El sistema detecta que el usuario no existe en la base de datos. 3a-3. Muestra pantalla de error en el sistema. 3a-4. Proceso termina.
7.3.6 Pos condiciones
Prueba del paciente analizada.

40
7.3.7 Diagrama de actividades
Figura 23. Diagrama de clases Evaluar cuestionario
7.4 EVALUACION POR LOS PADRES 7.4.1 Descripción de caso de uso Este caso de uso describe el proceso mediante el cual un funcionario de la EPS prepara la información necesaria de la evaluación para los padres del paciente. El objetivo es relacionar la información recopilada de los padres del paciente por medio de un cuestionario el cual será almacenado en la base de datos, esto con el fin de revisar el historial médico y las posibles enfermedades hereditarias que pueda tener el paciente 7.4.2 Actores
Funcionario de la EPS Interface gráfica

41
7.4.3 Precondiciones
El funcionario de la EPS elige cuestionario para padres. 7.4.4 Secuencia básica de eventos
1. Ingresa al sistema. 2. El funcionario de la EPS selecciona la opción de ingresar datos de paciente. 3. El funcionario de la EPS ingresa la identificación del paciente. 4. El sistema muestra la información del paciente. 5. El funcionario de la EPS selecciona padres como categoría del
cuestionario. 6. El funcionario de la EPS ingresa los datos del paciente. 7. El funcionario de la EPS ingresa los datos adicionales de la prueba. 8. El funcionario de la EPS selecciona la opción cargar cuestionario 9. El sistema carga las preguntas del cuestionario para padres. 10. El funcionario de la EPS completa las diferentes preguntas del cuestionario. 11. El funcionario de la EPS selecciona la opción cargar datos. 12. El sistema registrar la información en la base de datos. 13. El sistema realiza el proceso de análisis de datos. 14. El sistema genera un reporte con la información del cuestionario. 15. Proceso termina.
7.4.5 Secuencias alternativas
3a-1. El funcionario de la EPS ingresa la identificación del paciente. 3a-2. El sistema detecta que el usuario no existe en la base de datos. 3a-3. Muestra pantalla de error en el sistema. 3a-4. Proceso termina.
7.4.6 Pos condiciones
Prueba para padres del paciente analizado.

42
7.4.7 Diagrama de actividades
Figura 24. Diagrama de clases Evaluación para padres
7.5 AUTO EXAMEN
7.5.1 Descripción de caso de uso Este caso de uso describe el proceso mediante el cual un funcionario de la EPS prepara la información necesaria de la auto-evaluación del paciente. El objetivo es relacionar la información recopilada del mismo paciente por medio de un cuestionario, el cual será analizado por el sistema para verificar enfermedades que se le hayan presentado y que en el momento tenga. 7.5.2 Actores
Funcionario de la EPS Interface gráfica

43
7.5.3 Precondiciones
El funcionario de la EPS elige cuestionario auto-evaluación. 7.5.4 Secuencia básica de eventos
1. Funcionario de la EPS ingresa al sistema. 2. El funcionario de la EPS selecciona la opción de evaluar prueba. 3. El funcionario de la EPS ingresa la identificación del paciente. 4. El sistema muestra la información del paciente. 5. El funcionario de la EPS selecciona auto-evaluación. 6. El funcionario de la EPS ingresa los datos del paciente. 7. El funcionario de la EPS selecciona la opción cargar cuestionario 8. El sistema carga las preguntas del cuestionario auto-examen. 9. El funcionario de la EPS completa las diferentes preguntas del cuestionario. 10. El funcionario de la EPS selecciona la opción analizar cuestionario. 11. El sistema registra la información en la base de datos. 12. El sistema realiza el proceso de calificación. 13. El sistema genera un reporte con la calificación del cuestionario. 14. Proceso termina.
7.5.5 Secuencias alternativas
3a-1. El funcionario de la EPS ingresa la identificación del paciente. 3a-2. El sistema detecta que el usuario no existe en la base de datos. 3a-3. Muestra pantalla de error en el sistema. 3a-4. Proceso termina.
7.5.6 Pos condiciones
Prueba auto informe del paciente calificado.

44
7.5.7 Diagrama de actividades
Figura 25. Diagrama de clases auto-examen
7.6 BUSCAR PACIENTE 7.6.1 Descripción de caso de uso Este caso de uso describe el proceso mediante el cual un funcionario de la EPS busca un paciente al que se le va a relacionar la información de un cuestionario. El objetivo es recuperar de la base de datos la información médica del paciente en el momento en que el funcionario de la EPS ingresa el documento de identificación.
7.6.2 Actores
Funcionario de la EPS Interface gráfica

45
7.6.3 Precondiciones
Ninguna. 7.6.4 Secuencia básica de eventos
1. El sistema muestra un campo para ingresar la identificación del paciente. 2. El funcionario de la EPS ingresa la identificación del paciente. 3. EL sistema busca en la base de datos la información personal asociada a la
identificación ingresada por el funcionario de la EPS. 4. El sistema presenta la información médica del paciente buscado 5. Proceso termina.
7.6.5 Secuencias alternativas
El funcionario de la EPS ingresa la identificación del paciente. El sistema detecta que el usuario no existe en la base de datos. Muestra pantalla de error en el sistema. Proceso termina.
7.6.6 Pos condiciones Información del paciente cargada en la base de datos, ó Pantalla de error cuando el paciente no se encuentra en la base de datos.

46
7.6.7 Diagrama de actividades
Figura 26. Diagrama de clases Buscar paciente
7.7 GENERACION DE REPORTES 7.7.1 Descripción de caso de uso Este caso de uso describe el proceso mediante el cual un funcionario de la EPS visualiza un informe de los cuestionarios realizados que cumplan el criterio de búsqueda. El objetivo permitir al funcionario de la EPS visualizar el resultado de un cuestionario en específico por medio del sistema. 7.7.2 Actores
Funcionario de la EPS Interface gráfica

47
7.7.3 Precondiciones
El cuestionario debe haber sido ingresado al sistema.
7.7.4 Secuencia básica de eventos
1. Interfaz grafica muestra menú de opciones. 2. El funcionario de la EPS selecciona la opción de generar reporte. 3. El funcionario de la EPS ingresa un rango de fechas. 4. El funcionario de la EPS selecciona la opción recuperar información. 5. El sistema consulta en la base de datos la consulta en ese rango de fechas. 6. El sistema muestra un listado con los resultados de la búsqueda. 7. El funcionario de la EPS selecciona la opción visualizar reporte en el
registro que desea. 8. El sistema muestra el reporte con los resultados de la prueba elegida. 9. Proceso termina.
7.7.5 Secuencias alternativas
El funcionario de la EPS ingresa la identificación de paciente. Retornar al paso 4. El funcionario de la EPS ingresa la categoría o tipo de prueba. Retornar al paso 4. El sistema consulta en la base de datos la información existente No hay registros que cumplan con el criterio de búsqueda. Muestra pantalla de error en el sistema Proceso termina.
7.7.6 Pos condiciones
Visualización de resultado de la información del paciente.

48
7.7.7 Diagrama de actividades
Figura 27. Diagrama de clases Buscar paciente

49
8 MODELO DE BASE DE DATOS
8.1 DIAGRAMA ENTIDAD RELACIÓN
Figura 28. Diagrama Entidad-Relación

50
8.2 DESCRIPCION DEL MODELO DE DATOS TABLA: T_PERSONAS
DESCRIPCIÓN: Almacena los datos personales de los funcionarios de la EPS y pacientes.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
Nmdocumento Numeric(11,0) No Cédula, documento de identidad
DsNombre1 Varchar(15) No Primer Nombre.
DsNombre2 Varchar(15) Si Segundo Nombre.
Dsapellido1 Varchar(15) No Primer apellido.
Dsapellido2 Varchar(15) Si Segundo apellido.
Fenacim Date No Fecha de nacimiento.
Cdsexo Varchar(1) No Sexo.
Dsdireccion Varchar(60) Si Dirección de residencia.
Dstelefono Varchar(15) Si Teléfono.
Dsobservacion Varchar(100) Si Observaciones generales.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK Nmdocumento
FK (S) fk_persona_usuari
o
Nmdocumento T_Usuarios
TABLA: T_RESULTADO_EVALUACION
DESCRIPCIÓN: Almacena los resultados por evaluación.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
Nmtest Integer No Identifica el test.
Nmevaluacion Integer No Identifica la calificación.
Sncritico Varchar(1) No Indica si la calificación es crítica.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest, nmevaluación
FK (S) fk_califeval_eval nmest T_calificaciones
fk_califeval_calif Nmcalificacion T_calificaciones

51
TABLA: T_CALIFICACIONES_PRUEBA
DESCRIPCIÓN: Almacena los resultados por prueba.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
Nmtest Integer No Identifica el test.
Nmestrato_soc Integer No Identifica el estrato
socioeconómico.
Cdsexo Varchar(1) No Sexo.
Nmpuntaje Integer Si Puntaje para la prueba.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest,
nmestrato_soc,
cdsexo
FK (S) fk_califpru_esceva
l
nmtest
T_escalas_evaluacio
n
fk_califpru_prueba nmtest, mcategoria,
nmestrato_soc, cdsexo
T_pruebas
TABLA: T_CALIFICACIONES
DESCRIPCIÓN: Almacena las diversas preguntas que se utilizan para responder los
cuestionarios de todas las pruebas.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
Nmpregunta Integer No Identifica la pregunta.
Dscalificacion Integer No Descripción de la calificación.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK Nmpregunta
TABLA: T_CATEGORIAS
DESCRIPCIÓN: Almacena las diversas categorías que se utilizan para clasificar las
pruebas.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
nmcategoria Integer NO Identifica la categoría.
dscategoria Varchar(20) NO Descripción de la categoría.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK Nmcategoria

52
TABLA: T_DATOS_PRUEBA
DESCRIPCIÓN: Almacena los datos básicos de las pruebas.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
nmtest Integer No Identifica el test.
nmestrato_soc Integer No Identifica el estrato
socioeconómico.
cdsexo Varchar(1) No Sexo.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest,
nmestrato_soc,
cdsexo
FK Fk_califpru_prueba nmtest, mcategoria,
nmestrato_soc,
cdsexo
T__pruebas
TABLA: T_DETALLES_CRITICOS_PRUEBA
DESCRIPCIÓN: Almacena las preguntas criticas de todas las pruebas efectuadas a los
pacientes.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
nmtest Integer No Identifica el test.
nmestrato_soc Integer No Identifica el estrato
socioeconómico.
cdsexo Varchar(1) No Sexo.
nmdocumento Numeric(11,0) No Documento del evaluado.
nmpregunta Integer No Identifica la pregunta.
Nmevaluacion Integer No Identifica la evaluación.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest,
nmestrato_soc,
cdsexo,
nmdocumento,
nmpregunta
FK (S) fk_detcriprue_pret nmtest, nmpregunta T_preguntas_evalua
cion
fk_detcriprue_pru nmtest,nmestrato_soc,
cdsexo, nmdocumento
T_pruebas_paciente

53
TABLA: T_DETALLES_PRUEBA
DESCRIPCIÓN: Almacena la evaluación final de todas las pruebas.
COLUMNAS TIPO DE DATO NULO DESCRIPCIÓN
nmtest Integer No Identifica el test.
nmestrato_soc Integer No Identifica el estrato
socioeconómico.
cdsexo Varchar(1) No Sexo
nmdocumento Numeric(11,0) No Documento del evaluado.
nmcalif_acum Integer Si Calificación acumulada.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest, mestrato_soc,
cdsexo, nmdocumento
FK (S) fk_detprue_escala nmtest
T_escalas_evaluació
n
fk_detprue_punt Nmpunt_t_inf T_puntuaciones
fk_detprue_pru nmtest,nmestrato_soc,
cdsexo, nmdocumento
T_pruebas_paciente
TABLA: T_ESCALAS_EVALUACION
DESCRIPCIÓN: Almacena las diferentes escalas por evaluación.
COLUMNAS TIPO DE DATO NULO DESCRIPCIÓN
nmtest Integer No Identifica el test.
nmfactor_error Numeric(5,2) Si Factor de Error.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest,
FK (S) fk_escalaeval_eval Nmtest T_evaluaciones
TABLA: T_ESTRATOS_SE
DESCRIPCIÓN: Almacena los diversos estratos socioeconómicos.
COLUMNAS TIPO DE DATO NULO DESCRIPCIÓN
nmestrato_soc Integer No Identifica el estrato socioeconómico.
dsestrato_soc Varchar(15) No Descripción del estrato
socioeconómico.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK Nmestrato_soc

54
TABLA: T_EVALUACIONES
DESCRIPCIÓN: Almacena la información específica de todas las evaluaciones.
COLUMNAS TIPO DE DATO NULO DESCRIPCIÓN
nmtest Integer No Identifica el test.
snborrar Varchar(1) No Indica si se puede borrar la
evaluación.
dsencabezado Long Varchar Si Descripción para el encabezado de
los cuestionarios.
dsinstructivo Long Varchar Si Descripción del instructivo para los
cuestionarios.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK Nmtest
FK (S) fk_eval_test Nmtest T_tests
TABLA: T_PREGUNTAS_EVALUACION
DESCRIPCIÓN: Almacena las diferentes preguntas por evaluación.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
nmtest Integer No Identifica el test.
nmpregunta Integer No Identifica la pregunta.
nmconsecutivo Integer No Consecutivo de la pregunta.
Nmevaluacion Integer Identifica la evaluación.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest, nmpregunta
FK (S) fk_pregeval_eval nmtest T_evaluaciones
fk_pregeval_preg nmpregunta T_preguntas
fk_pregeval_escev
al
nmtest, T_escalas_evaluacio
n
TABLA: T_PREGUNTAS
DESCRIPCIÓN: Almacena las diferentes preguntas utilizadas en todas las pruebas.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
nmpregunta Integer No Identifica la pregunta.
dspregunta Varchar(256) No Descripción de la pregunta.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmpregunta

55
TABLA: T_PRUEBAS
DESCRIPCIÓN: Almacena la información específica de todas la pruebas.
COLUMNAS TIPO DE DATO NULO DESCRIPCIÓN
nmtest Integer No Identifica el tipo de test.
nmestrato_soc Integer No Identifica el estrato
socioeconómico.
cdsexo Varchar(1) No Sexo.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest,nmestrato_soc,
cdsexo
FK (S) fk_prueba_evaluac
ion
nmtest T_evaluaciones
fk_prueba_estratos
oc
nmestrato_soc T_estratos_se
TABLA: T_PRUEBAS_PACIENTE
DESCRIPCIÓN: Almacena los datos adicionales que se tienen en cuenta al momento de
evaluar las pruebas.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
Nmtest Integer No Identifica el test.
nmestrato_soc Integer No Identifica el estrato
socioeconómico.
cdsexo Varchar(1) No Sexo.
nmdocumento Numeric(11,0) No Documento del evaluado.
dsinstitucion Varchar(50) No Nombre de la EPS
fecalificado Date No Fecha de calificación de la prueba.
sncalificado Varchar(1) No Indica si la prueba está evaluada.
dsNombre1 Varchar(15) Si Primer nombre del padre del
evaluado.
dsNombre2 Varchar(15) Si Segundo nombre del padre del
evaluado.
dsapellido1 Varchar(15) Si Primer apellido del padre del
evaluado.
dsapellido2 Varchar(15) Si Segundo apellido del padre del
evaluado.
cdsexo_otro Varchar(1) Si Sexo del padre del evaluado.
dsobservacion Varchar(25) Si Observaciones generales.
dsrespuesta Long Varchar Si Respuestas de la prueba.
nmcriticos Integer Si Número de preguntas criticas.

56
nmespeciales Integer Si Número de preguntas especiales.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest,
nmestrato_soc,
cdsexo, nmdocumento
FK (S) fk_pruepac_pru nmtest,nmestrato_soc,
cdsexo
T_pruebas
fk_pruepac_pac Nmdocumento T_personas
TABLA: T_ PUNTUACIONES
DESCRIPCIÓN: Almacena las puntuaciones y estándar utilizadas para evaluar las
diferentes análisis de una prueba.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
nmpunt_t_inf Integer No Puntuación t inferior.
nmpunt_t_sup Integer No Puntuación t superior.
nmpunt_std_inf Integer No Puntuación estándar inferior.
nmpunt_std_sup Integer No Puntuación estándar Superior.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmpunt_std_inf
TABLA: T_TESTS
DESCRIPCIÓN: Almacena la información específica de todos los test.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
nmtest Integer NO Identifica el test.
dstest Varchar(50) NO Descripción del test.
nmedad_inf Integer NO Edad inferior.
nmedad_sup Integer NO Edad superior.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest
TABLA: T_DETALLE_RESPUESTAS_PRUEBAS_PACIENTE
DESCRIPCIÓN: Almacena los datos de las respuestas por pruebas.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
Nmtest Integer No Identifica el test.
nmestrato_soc Integer No Identifica el estrato
socioeconómico.

57
cdsexo Varchar(1) No Sexo.
nmdocumento Numeric(11,0) No Documento del evaluado.
nmpregunta Integer No Número de pregunta
cdrespuesta Varchar(10) No Código de equivalencia de la
respuesta
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK nmtest, mestrato_soc,
cdsexo, nmdocumento
FK (S) fk_pruepac_pru
nmtest,nmestrato_soc,
cdsexo
T_pruebas
fk_pruepac_pac Nmdocumento T_personas
TABLA: T_ PERFILES_USUARIO
DESCRIPCIÓN: Almacena las diferentes tipos de perfiles para los usuarios que acceden al
sistema que pueden ser médicos o enfermeros.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
Código Varchar(10) No Identifica el perfil del usuario
Descripción Varchar(100) No Descripción del perfil.
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK Código
TABLA: T_USUARIOS
DESCRIPCIÓN: Almacena los datos de acceso de los usuarios que usan al sistema.
COLUMNAS TIPO DE DATO NULO DESCRIPCION
Dslogin Varchar(30) No Nombre de usuario para acceso
Nmdocumento Integer No Documento del usuario del sistema
Password Varchar(30) No Password de acceso
Cdperfil Varchar(10) No Perfil del usuario
CONSTRAINT NOMBRE CAMPO(S) TABLA REF.
PK dslogin
FK (S) fk_usuario_perfil Cdperfil T_perfiles_usuario

58
8.3 Imagen de la base de datos creada en Oracle 9i Para simular la base de datos difusa se creó en el motor de oracle9i con las tablas relacionadas.
Creación de las tablas de la base de datos:

59

60
8.4 Diseño de la base de datos en power designer

61
8.5 Diseño entidad relación elaborada en Power Builder
8.6 SCRIPTS PARA CREAR LA BASE DE DATOS
alter table T_CALIFICACIONES_PRUEBA drop constraint FK_T_CALIFI_FK_CALIFP_T_PRUEBA; alter table T_DATOS_PRUEBA drop constraint FK_T_DATOS__FK_CALIFP_T_PRUEBA; alter table T_DETALLES_CRITICOS_PRUEBA drop constraint FK_T_DETALL_FK_PRUEBA_T_PRUEBA; alter table T_DETALLES_PRUEBA drop constraint FK_T_DETALL_REFERENCE_T_DETALL; alter table T_DETALLE_RESPUESTAS_PRUEBAS_P drop constraint FK_T_DETALL_FK_PRUEPA_T_PRUEBA; alter table T_ESCALAS_EVALUACION

62
drop constraint FK_T_ESCALA_FK_CALIFP_T_PRUEBA; alter table T_ESTRATOS_SE drop constraint FK_T_ESTRAT_REFERENCE_T_DATOS_; alter table T_EVALUACIONES drop constraint FK_T_EVALUA_FK_EVAL_T_T_TESTS; alter table T_EVALUACIONES drop constraint FK_T_EVALUA_FK_PREGEV_T_ESCALA; alter table T_PERSONAS drop constraint FK_T_PERSON_FK_PERSON_T_USUARI; alter table T_PERSONAS drop constraint FK_T_PERSON_FK_PRUEPA_T_PRUEBA; alter table T_PERSONAS drop constraint FK_T_PERSON_REFERENCE_T_DETALL; alter table T_PREGUNTAS drop constraint FK_T_PREGUN_FK_PREGEV_T_PREGUN; alter table T_PREGUNTAS drop constraint FK_T_PREGUN_REFERENCE_T__PUNTU; alter table T_PREGUNTAS_EVALUACION drop constraint FK_T_PREGUN_FK_PREGEV_T_EVALUA; alter table T_PRUEBAS drop constraint FK_T_PRUEBA_REFERENCE_T_PRUEBA; alter table T_PRUEBAS drop constraint FK_T_PRUEBA_REFERENCE_T_CATEGO; alter table T_RESULTADO_EVALUACION drop constraint FK_T_RESULT_FK_CALIFE_T_CALIFI; alter table T__PERFILES_USUARIO drop constraint FK_T__PERFI_FK_USUARI_T_USUARI; drop table T_CALIFICACIONES cascade constraints; drop table T_CALIFICACIONES_PRUEBA cascade constraints;

63
drop table T_CATEGORIAS cascade constraints; drop table T_DATOS_PRUEBA cascade constraints; drop table T_DETALLES_CRITICOS_PRUEBA cascade constraints; drop table T_DETALLES_PRUEBA cascade constraints; drop table T_DETALLE_RESPUESTAS_PRUEBAS_P cascade constraints; drop table T_ESCALAS_EVALUACION cascade constraints; drop table T_ESTRATOS_SE cascade constraints; drop table T_EVALUACIONES cascade constraints; drop table T_PERSONAS cascade constraints; drop table T_PREGUNTAS cascade constraints; drop table T_PREGUNTAS_EVALUACION cascade constraints; drop table T_PRUEBAS cascade constraints; drop table T_PRUEBAS_PACIENTE cascade constraints; drop table T_RESULTADO_EVALUACION cascade constraints; drop table T_TESTS cascade constraints; drop table T_USUARIOS cascade constraints; drop table T__PERFILES_USUARIO cascade constraints; drop table T__PUNTUACIONES cascade constraints; /*==============================================================*/ /* Table: T_CALIFICACIONES */ /*==============================================================*/ create table T_CALIFICACIONES ( NMPREGUNTA INTEGER not null, DSCALIFICACION INTEGER not null, constraint PK_T_CALIFICACIONES primary key (NMPREGUNTA)

64
); /*==============================================================*/ /* Table: T_CALIFICACIONES_PRUEBA */ /*==============================================================*/ create table T_CALIFICACIONES_PRUEBA ( NMTEST INTEGER not null, NMESTRATO_SOC INTEGER not null, CDSEXO VARCHAR2(1) not null, NMPUNTAJE INTEGER, constraint PK_T_CALIFICACIONES_PRUEBA primary key (NMTEST, NMESTRATO_SOC, CDSEXO) ); /*==============================================================*/ /* Table: T_CATEGORIAS */ /*==============================================================*/ create table T_CATEGORIAS ( NMCATEGORIA INTEGER not null, DSCATEGORIA VARCHAR2(20) not null, constraint PK_T_CATEGORIAS primary key (NMCATEGORIA) ); /*==============================================================*/ /* Table: T_DATOS_PRUEBA */ /*==============================================================*/ create table T_DATOS_PRUEBA ( NMTEST INTEGER not null, NMESTRATO_SOC INTEGER not null, CDSEXO VARCHAR2(1) not null, constraint PK_T_DATOS_PRUEBA primary key (NMTEST, NMESTRATO_SOC, CDSEXO) ); /*==============================================================*/ /* Table: T_DETALLES_CRITICOS_PRUEBA */ /*==============================================================*/

65
create table T_DETALLES_CRITICOS_PRUEBA ( NMTEST INTEGER not null, NMESTRATO_SOC INTEGER not null, CDSEXO VARCHAR2(1) not null, NMDOCUMENTO NUMBER(11,1) not null, NMPREGUNTA INTEGER not null, NMEVALUACION_ INTEGER not null, constraint PK_T_DETALLES_CRITICOS_PRUEBA primary key (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO) ); /*==============================================================*/ /* Table: T_DETALLES_PRUEBA */ /*==============================================================*/ create table T_DETALLES_PRUEBA ( NMTEST INTEGER not null, NMESTRATO_SOC INTEGER not null, CDSEXO VARCHAR2(1) not null, NMDOCUMENTO NUMBER(11,1) not null, NMCALIF_ACUM INTEGER, constraint PK_T_DETALLES_PRUEBA primary key (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO) ); /*==============================================================*/ /* Table: T_DETALLE_RESPUESTAS_PRUEBAS_P */ /*==============================================================*/ create table T_DETALLE_RESPUESTAS_PRUEBAS_P ( NMTEST INTEGER not null, NMESTRATO_SOC INTEGER not null, CDSEXO VARCHAR2(1) not null, NMDOCUMENTO NUMBER(11,1) not null, NMPREGUNTA INTEGER not null, CDRESPUESTA VARCHAR2(10) not null, constraint PK_T_DETALLE_RESPUESTAS_PRUEBA primary key (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO) ); /*==============================================================*/ /* Table: T_ESCALAS_EVALUACION */

66
/*==============================================================*/ create table T_ESCALAS_EVALUACION ( NMTEST INTEGER not null, NMESTRATO_SOC INTEGER, CDSEXO VARCHAR2(1), NMFACTOR_ERROR NUMBER(5,2), constraint PK_T_ESCALAS_EVALUACION primary key (NMTEST) ); /*==============================================================*/ /* Table: T_ESTRATOS_SE */ /*==============================================================*/ create table T_ESTRATOS_SE ( NMESTRATO_SOC INTEGER not null, CDSEXO VARCHAR2(1), NMTEST INTEGER, DSESTRATO_SOC VARCHAR2(15) not null, constraint PK_T_ESTRATOS_SE primary key (NMESTRATO_SOC) ); /*==============================================================*/ /* Table: T_EVALUACIONES */ /*==============================================================*/ create table T_EVALUACIONES ( NMTEST INTEGER not null, T_T_NMTEST INTEGER, SNBORRAR VARCHAR2(1) not null, DSENCABEZADO LONG VARCHAR, DSINSTRUCTIVO LONG VARCHAR, constraint PK_T_EVALUACIONES primary key (NMTEST) ); /*==============================================================*/ /* Table: T_PERSONAS */ /*==============================================================*/ create table T_PERSONAS ( NMDOCUMENTO VARCHAR2(11) not null, NMTEST INTEGER,

67
NMESTRATO_SOC INTEGER, DSNOMBRE1 VARCHAR2(15) not null, DSNOMBRE2 VARCHAR2(15) not null, DSAPELLIDO1 VARCHAR2(15), DSAPELLIDO2 VARCHAR2(15) not null, FENACIM DATE not null, CDSEXO VARCHAR2(1) not null, T_D_NMDOCUMENTO NUMBER(11,1), T_P_NMTEST INTEGER, T_P_NMESTRATO_SOC INTEGER, T_P_CDSEXO VARCHAR2(1), T_P_NMDOCUMENTO NUMBER(11,0), DSDIRECCION VARCHAR2(60), DSTELEFONO VARCHAR2(15), DSOBSERVACION VARCHAR2(100), constraint PK_T_PERSONAS primary key (NMDOCUMENTO) ); /*==============================================================*/ /* Table: T_PREGUNTAS */ /*==============================================================*/ create table T_PREGUNTAS ( NMPREGUNTA INTEGER not null, NMTEST INTEGER, NMPUNT_STD_INF INTEGER, DSPREGUNTA VARCHAR2(256) not null, constraint PK_T_PREGUNTAS primary key (NMPREGUNTA) ); /*==============================================================*/ /* Table: T_PREGUNTAS_EVALUACION */ /*==============================================================*/ create table T_PREGUNTAS_EVALUACION ( NMTEST INTEGER not null, NMPREGUNTA INTEGER not null, NMCONSECUTIVO INTEGER not null, NMEVALUACION_ INTEGER not null, constraint PK_T_PREGUNTAS_EVALUACION primary key (NMTEST, NMPREGUNTA) );

68
/*==============================================================*/ /* Table: T_PRUEBAS */ /*==============================================================*/ create table T_PRUEBAS ( NMTEST INTEGER not null, NMESTRATO_SOC INTEGER not null, CDSEXO VARCHAR2(1) not null, NMDOCUMENTO NUMBER(11,0), NMCATEGORIA INTEGER, constraint PK_T_PRUEBAS primary key (NMTEST, NMESTRATO_SOC, CDSEXO) ); /*==============================================================*/ /* Table: T_PRUEBAS_PACIENTE */ /*==============================================================*/ create table T_PRUEBAS_PACIENTE ( NMTEST INTEGER not null, NMESTRATO_SOC INTEGER not null, CDSEXO VARCHAR2(1) not null, NMDOCUMENTO NUMBER(11,0) not null, DSINSTITUCION VARCHAR2(50) not null, FECALIFICADO DATE not null, SNCALIFICADO VARCHAR2(1) not null, DSNOMBRE1 VARCHAR2(15), DSNOMBRE2 VARCHAR2(15), DSAPELLIDO1 VARCHAR2(15), DSAPELLIDO2 VARCHAR2(15), CDSEXO_OTRO VARCHAR2(1), DSOBSERVACION VARCHAR2(25), DSRESPUESTA LONG VARCHAR, NMCRITICOS INTEGER, NMESPECIALES INTEGER, constraint PK_T_PRUEBAS_PACIENTE primary key (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO) ); /*==============================================================*/ /* Table: T_RESULTADO_EVALUACION */ /*=============================================================

69
=*/ create table T_RESULTADO_EVALUACION ( NMTEST INTEGER not null, NMEVALUACION INTEGER not null, NMPREGUNTA INTEGER, SNCRITICO VARCHAR2(1) not null, constraint PK_T_RESULTADO_EVALUACION primary key (NMTEST, NMEVALUACION) ); /*==============================================================*/ /* Table: T_TESTS */ /*==============================================================*/ create table T_TESTS ( NMTEST INTEGER not null, DSTEST VARCHAR2(50) not null, NMEDAD_INF INTEGER not null, NMEDAD_SUP INTEGER not null, constraint PK_T_TESTS primary key (NMTEST) ); /*==============================================================*/ /* Table: T_USUARIOS */ /*==============================================================*/ create table T_USUARIOS ( DSLOGIN VARCHAR2(30) not null, NMDOCUMENTO VARCHAR2(11) not null, PASSWORD VARCHAR2(30) not null, CDPERFIL VARCHAR2(10) not null, constraint PK_T_USUARIOS primary key (NMDOCUMENTO) ); /*==============================================================*/ /* Table: T__PERFILES_USUARIO */ /*==============================================================*/ create table T__PERFILES_USUARIO ( CODIGO VARCHAR2(10) not null, NMDOCUMENTO VARCHAR2(11), DESCRIPCION VARCHAR2(100) not null,

70
constraint PK_T__PERFILES_USUARIO primary key (CODIGO) ); /*==============================================================*/ /* Table: T__PUNTUACIONES */ /*==============================================================*/ create table T__PUNTUACIONES ( NMPUNT_T_INF INTEGER not null, NMPUNT_T_SUP INTEGER not null, NMPUNT_STD_INF INTEGER not null, NMPUNT_STD_SUP INTEGER not null, constraint PK_T__PUNTUACIONES primary key (NMPUNT_STD_INF) ); alter table T_CALIFICACIONES_PRUEBA add constraint FK_T_CALIFI_FK_CALIFP_T_PRUEBA foreign key (NMTEST, NMESTRATO_SOC, CDSEXO) references T_PRUEBAS (NMTEST, NMESTRATO_SOC, CDSEXO); alter table T_DATOS_PRUEBA add constraint FK_T_DATOS__FK_CALIFP_T_PRUEBA foreign key (NMTEST, NMESTRATO_SOC, CDSEXO) references T_PRUEBAS (NMTEST, NMESTRATO_SOC, CDSEXO); alter table T_DETALLES_CRITICOS_PRUEBA add constraint FK_T_DETALL_FK_PRUEBA_T_PRUEBA foreign key (NMTEST, NMESTRATO_SOC, CDSEXO) references T_PRUEBAS (NMTEST, NMESTRATO_SOC, CDSEXO); alter table T_DETALLES_PRUEBA add constraint FK_T_DETALL_REFERENCE_T_DETALL foreign key (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO) references T_DETALLES_CRITICOS_PRUEBA (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO); alter table T_DETALLE_RESPUESTAS_PRUEBAS_P add constraint FK_T_DETALL_FK_PRUEPA_T_PRUEBA foreign key (NMTEST, NMESTRATO_SOC, CDSEXO) references T_PRUEBAS (NMTEST, NMESTRATO_SOC, CDSEXO); alter table T_ESCALAS_EVALUACION add constraint FK_T_ESCALA_FK_CALIFP_T_PRUEBA foreign key (NMTEST, NMESTRATO_SOC, CDSEXO)

71
references T_PRUEBAS (NMTEST, NMESTRATO_SOC, CDSEXO); alter table T_ESTRATOS_SE add constraint FK_T_ESTRAT_REFERENCE_T_DATOS_ foreign key (NMTEST, NMESTRATO_SOC, CDSEXO) references T_DATOS_PRUEBA (NMTEST, NMESTRATO_SOC, CDSEXO); alter table T_EVALUACIONES add constraint FK_T_EVALUA_FK_EVAL_T_T_TESTS foreign key (T_T_NMTEST) references T_TESTS (NMTEST); alter table T_EVALUACIONES add constraint FK_T_EVALUA_FK_PREGEV_T_ESCALA foreign key (NMTEST) references T_ESCALAS_EVALUACION (NMTEST); alter table T_PERSONAS add constraint FK_T_PERSON_FK_PERSON_T_USUARI foreign key (NMDOCUMENTO) references T_USUARIOS (NMDOCUMENTO); alter table T_PERSONAS add constraint FK_T_PERSON_FK_PRUEPA_T_PRUEBA foreign key (T_P_NMTEST, T_P_NMESTRATO_SOC, T_P_CDSEXO, T_P_NMDOCUMENTO) references T_PRUEBAS_PACIENTE (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO); alter table T_PERSONAS add constraint FK_T_PERSON_REFERENCE_T_DETALL foreign key (NMTEST, NMESTRATO_SOC, CDSEXO, T_D_NMDOCUMENTO) references T_DETALLE_RESPUESTAS_PRUEBAS_P (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO); alter table T_PREGUNTAS add constraint FK_T_PREGUN_FK_PREGEV_T_PREGUN foreign key (NMTEST, NMPREGUNTA) references T_PREGUNTAS_EVALUACION (NMTEST, NMPREGUNTA); alter table T_PREGUNTAS add constraint FK_T_PREGUN_REFERENCE_T__PUNTU foreign key (NMPUNT_STD_INF) references T__PUNTUACIONES (NMPUNT_STD_INF); alter table T_PREGUNTAS_EVALUACION

72
add constraint FK_T_PREGUN_FK_PREGEV_T_EVALUA foreign key (NMTEST) references T_EVALUACIONES (NMTEST); alter table T_PRUEBAS add constraint FK_T_PRUEBA_REFERENCE_T_PRUEBA foreign key (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO) references T_PRUEBAS_PACIENTE (NMTEST, NMESTRATO_SOC, CDSEXO, NMDOCUMENTO); alter table T_PRUEBAS add constraint FK_T_PRUEBA_REFERENCE_T_CATEGO foreign key (NMCATEGORIA) references T_CATEGORIAS (NMCATEGORIA); alter table T_RESULTADO_EVALUACION add constraint FK_T_RESULT_FK_CALIFE_T_CALIFI foreign key (NMPREGUNTA) references T_CALIFICACIONES (NMPREGUNTA); alter table T__PERFILES_USUARIO add constraint FK_T__PERFI_FK_USUARI_T_USUARI foreign key (NMDOCUMENTO) references T_USUARIOS (NMDOCUMENTO);

73
REFERENCIAS BIBLIOGRAFICAS [1] L.A.Zadeh information and control , Department of Electrical Engineering and Electronics Laboratory,University of California, Berkeley pp 25-29
[2] Kaacprzyk y Staniewski [1982], Archiwum Automatyki i Telemechaniki 25:44, 433-443, 1980 [3] Rinks, D.B. [1981] A heuristic approach to aggregate production scheduling using linguistic variables. Applied Systems and Cibernetics, vol. VI, Lasker, GE, Pergamon Press: New York, 2877-2883. [4] Miller, W.A., Leung, L.C., Azhar, T.M. y Sargent, S. [1997] Fuzzy production planning model for fresh tomato packing. International Journal of Production Economics, 53, 227-238. [5] Petrovic, D., Roy, R. y Petrovic, R. [1998] Modelling and Simulation of a Supply Chain in an Uncertain Environment. European Journal of Operational Research, 109, 2, 299-309. [6] Du, T.C. y Wolfe, P. [2000] Building an active material requirements planning. International Journal of Production Research, 38, 2, 241-252. [7] Samanta, B. y Al-Araimi, S.A. [2001] An inventory control model using fuzzy logic. International Journal of Production Economics, 73, 217-226. [8] Pendharkar, P.C. [1997] A fuzzy linear programming model for production planning in coal mines. Computers Operations Research, 24, 12, 1141-1149. [9] Reynoso, G., Grabot, B., Geneste, L. y Vérot, S. [2002] “Integration of uncertain and imprecise orders in MRPII”, 9th International Multi-Conference on Advanced Computer Systems. Conference on Production System Design, Supply Chain Management & Logistics, Miedzyzdroje, Pologne, October, 23-25. [10] Mula, J. [2004] Modelos para la planificación de la producción bajo incertidumbre. Aplicación en una empresa del sector del automóvil. Tesis Doctoral. Universidad Politécnica de Valencia.

74
[11] Pedro Larrañaga en articulo La lógica difusa ayudará a predecir enfermedades mediante el estudio de los genes. http://www.lne.es/secciones/noticia.jsp?pRef=1697_38_539227__Cuencas-logica-difusa-ayudara-predecir-enfermedades-mediante-estudio-genes [12] Ingeniare. Revista chilena de ingeniería, vol. 15 No 3, 2007, pp. 216-217 [13] ZADEH,l.A Fuzzy sets, Information and Control 8[1965]338-353 en articulo conjuntos difusos y lógicas difusas. 8, pp. 338-353. [14] Tineo leonid, Interrogaciones flexibles en bases de datos relacionales. http://www.ldc.usb.ve/~leonid/Trabajos%20de%20Ascenso/Interrogaciones%20Flexibles%20en%20Bases%20de%20Datos%20Relacionales.pdf [15] Tineo leonid, Interrogaciones flexibles en bases de datos relacionales. http://www.ldc.usb.ve/~leonid/Trabajos%20de%20Ascenso/Interrogaciones%20Flexibles%20en%20Bases%20de%20Datos%20Relacionales.pdf [16] ZADEH,l.A Fuzzy sets, Information and Control en articulo conjuntos difusos y lógicas difusas. 8, pp. 300-320. [17] Urrutia Sepulveda, Bases de datos difusas modeladas con UML, http://www.inf.udec.cl/~mvaras/papers/2002/varas-urrutia-final.pdf [18] Tineo leonid, Interrogaciones flexibles en bases de datos relacionales. http://www.ldc.usb.ve/~leonid/Trabajos%20de%20Ascenso/Interrogaciones%20Flexibles%20en%20Bases%20de%20Datos%20Relacionales.pdf
[19] Tineo leonid, Interrogaciones flexibles en bases de datos relacionales. http://www.ldc.usb.ve/~leonid/Trabajos%20de%20Ascenso/Interrogaciones%20Flexibles%20en%20Bases%20de%20Datos%20Relacionales.pdf