multi-spectral satellite image processing on a platform...
TRANSCRIPT

Multi-Spectral Satellite Image Processingon a Platform FPGA Engine
Martin Fleury, Robert P. Self, and Andy C. Downton
e-mail: {fleum;acd}@essex.ac.uk
University of Essex
Department ofDepartment of
Electronic SystemsElectronic SystemsEngineeringEngineering

Outline of Presentation
• Multispectral imagery.
• Properties of the Karhunen-Loeve Transform (KLT)
(or Principal Components).
• Mapping the KLT to parallel pipeline.
• FPGA development environment.
• Scaling performance up.
• Single-pass KLT engine?
Fleury MAPLD 2005/133 1

LANDSAT bands 1-6 of Washington D.C. (L to R, T to B) 512×512
Fleury MAPLD 2005/133 2

LANDSAT image of Washington D.C. ‘closeup’, showing edge
features likely to be blurred by edge-detector pre-filtering.
Fleury MAPLD 2005/133 3

KLT change of basis
Signal
x(image 1 intensity)
y(image 2intensity)
multi-spectral data vector
2D Cartesianbasis
y_klt
x_klt
y
x
After axis rotation the dataset are aligned with just
one axis of the new basis.
Note: all datavectors are zero-
meaned resulting inalignment with acommon basis.
x
Additive noise forms an n-sphere around the origin
and its distribution istherefore unaffected by
the rotation.
y
2D Cartesianbasis
Fleury MAPLD 2005/133 4

Features of KLT
• KLT kernel is data-dependent. i.e. the initial step is to calculate
the transform vectors.
• Transform vectors are the (orthogonal) eigenvectors of the image
set covariance matrix.
• Zero-meaning of the image data is required so that the new basis
is shifted to the origin.
Fleury MAPLD 2005/133 5

Practical Applications
• Rotation and shift invariant representation — useful for target
identification, after region selection.
• Eigenvalue magnitude indicates compressible images (zeroize
others).
• Avoids blurring of high frequencies from wavelet encoders —
helps detect buildings.
• Low-order eigenimages allow analysis of noise-dominated images.
• Prior logarithmic transform is step towards removing multiplicative
noise.
Fleury MAPLD 2005/133 6

Formation of multi-spectral pattern vectors
imaged
1Dij
ij
0ij
k
x
x
x
xM
1
D images
N
M
• Assume the images are registered (aligned).
• The corresponding pixel is selected from each frequency band in
the set to form a pattern vector.
• D dimension is of low-order.
Fleury MAPLD 2005/133 7

Computational steps
1. Form the sample mean vector:
mx =1
MN
MN−1∑k=0
xk
2. Calculate the (sample) covariance matrix:
Cx =1
MN
MN−1∑k=0
xkxTk −mxm
Tx ,
Fleury MAPLD 2005/133 8

Computational steps (continued)
1. Form the covariance matrix eigenvector set:
Cxuk = λkuk, k = 0, 1, . . . , D − 1,
2. Zero-mean data vectors: x′k = xk −mx
3. Transform using eigenvector matrix. yk = V Tx′k
Fleury MAPLD 2005/133 9

Computational analysis
• Both steps 1 & 2 are suitable for an FPGA, as the sub-algorithms
are fine-grained and independent of each other.
• Step 3 is usually performed iteratively (e.g. Jacobi) & hence is
not well suited to this logic.
• Steps 4 & 5 require floating-point calculations - fixed-point in
hardware.
• Obviously, the data-width is significant in a hardware
implementation — affects accuracy, cell-usage, placement of
components.
Fleury MAPLD 2005/133 10

Mapping the KLT algorithm to a pipeline (1)
mean-vector
(1a)
covariancematrix
(1b)
Tk
mn
kkx xxC ∑
−
=
=1
0
eigenvectorcalculation
normalize
normalizedata
eigenmapping
Data in
Output
xx mmn
m1' =
Txxxmnx mmCC ''1' −=
''xkk mxx −= '
kT
k xVy =
∑−
=
=1
0
mn
kkx xm
Sample mean &covariance matrix
formation
Eigencalculation
Eigen space transform
Stage 1 Stage 2 Stage 3
Fleury MAPLD 2005/133 11

Mapping the KLT algorithm to a pipeline (2)
• In a balanced pipeline, three images occupy the pipeline.
• Processing proceeds in lock-step, and is synchronous between the
stages.
• The middle eigenvector calculation stage is placed on a RISC or
on custom hardware.
Fleury MAPLD 2005/133 12
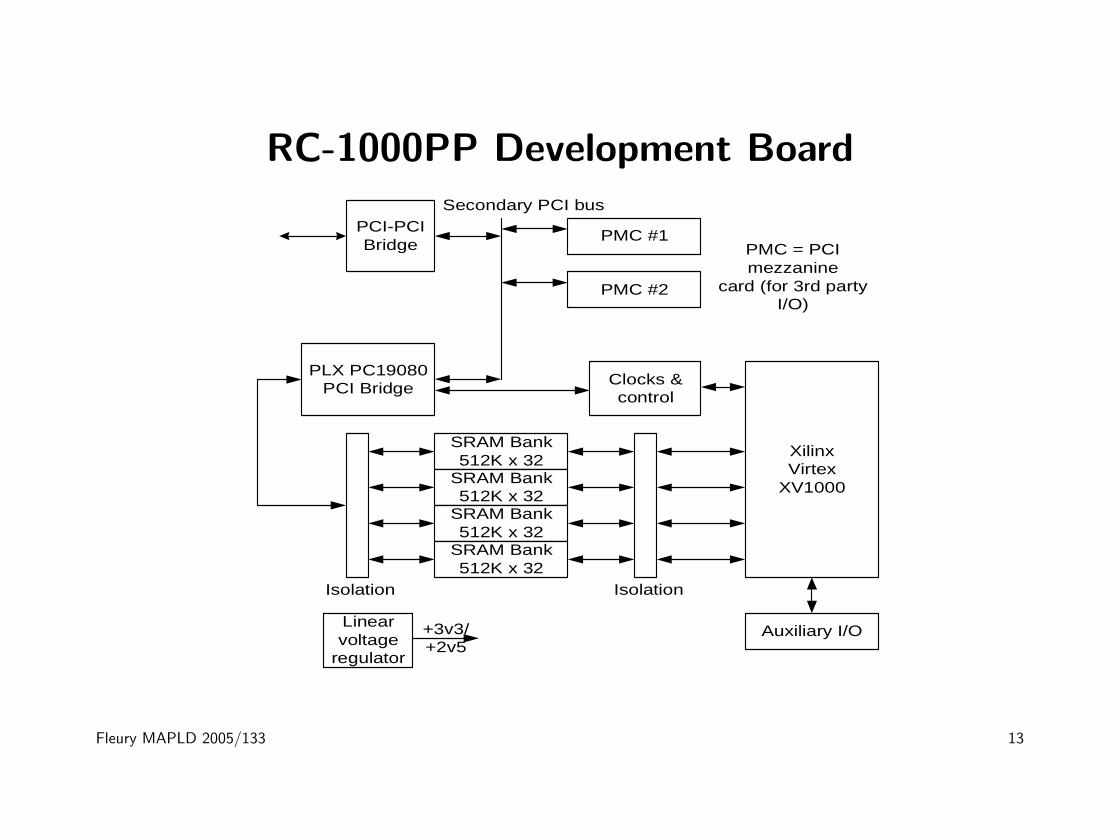
RC-1000PP Development Board
PCI-PCIBridge
PLX PC19080PCI Bridge
Clocks &control
SRAM Bank512K x 32
SRAM Bank512K x 32
SRAM Bank512K x 32
SRAM Bank512K x 32
Secondary PCI bus
PMC #1
PMC #2
Isolation Isolation
Linearvoltage
regulator
+3v3/+2v5
XilinxVirtex
XV1000
Auxiliary I/O
PMC = PCImezzanine
card (for 3rd partyI/O)
Fleury MAPLD 2005/133 13

RC-1000PP Development Board (continued)
• ‘Fast’ switch isolation arbitrates access contention.
• I/O bottleneck exists across the secondary PCI-bus (33 MHz
32-bit wide) and the RAM banks (accessible word- or byte-wise).
Therefore, such boards can only emulate custom hardware.
• Virtex-2 Pro would allow a host, e.g. PowerPC405 core (fixed-
point), to be placed on the FPGA but PCI bottleneck still exists
on development boards.
• Xilinx ML300 board — includes Rocket transceivers, PowerPC
embedded core but possible learning & possible simulation model
cost. Digilent XUP V2P now available.
Fleury MAPLD 2005/133 14

Some Suitable FPGAs (1)
Company Celoxica Xilinx DigilentBoard RC-1000 ML300 XUP V2PFamily Virtex-I Virtex-II Virtex-II ProDevice XCV1000 XC2V10000 XC2VP4 XC2VP7 XC2VP30CLBs 6,144 15,360 752 1,232 3,424Slices 12,288 61,440 3,008 4,928 13,696IOBs 512 1,108 348 396 644Mults. 0 192 28 44 136PPCs 0 0 1 1 2Max. 200 450 420 420 420clockBlocks (32) 192 28 44 136(4 Kb) 18 Kb
Fleury MAPLD 2005/133 15

Some Suitable FPGAs (2)
• Trade-off between number of slices and various embedded cores.
• Streaming requires selectRAM blocks (36-bit ports) - possible
limiting factor.
• Power usage is critical to location of device — Virtex-4 series may
give lower power.
Fleury MAPLD 2005/133 16

Architecture and Development Environment
• FPGA/RISC pair can form two-tier computer node.
• Rocket transceiver cores (3.125 Gbps - ‘aggregatable’) (4,8 on
XVC2P4, XVC2P8) provide optical interconnect.
• Handel-C hardware compiler abstracts from hardware details
(though including constructs for parallelism etc.).
• DK3 environment has ‘look-and-feel’ of MS Visual Studio.
Automatic re-timing can reduce max. clock width.
• Compare Impulse C and SystemC which use library calls rather
than constructs.
Fleury MAPLD 2005/133 17

Data modelling
• Fixed-point modelling. Alternatives: distributed or logarithmic
arithmetic. SystemC library helpful in finding data widths.
• Stage 1 covariance multiplication uses integer calculations, as
pilot study showed fixed-point width exceeded width of potential
h/w multipliers.
• Stage 1 normalization of mean vector postponed to RISC stage 3
to use floating-point - not possible if PPC core.
• Stage 3 cannot use integer calculations and data width is large
(34 bits) for 6×512×512 and 7-bit data. Soft CoreGen multiplier
used.
Fleury MAPLD 2005/133 18

Virtex-I Solution
Replic- ‘Equivalent’ Number Capacity Clock
ations gate count of slices (%) speed
(n) (MHz)
1 39,705 1,077 9 25.295
8 270,126 8,065 66 22.444
10 334,306 9,920 80 22.077
12 400,334 11,921 97 20.115
FPGA usage with scaled data widths of 26 bits for mean vector and
34 bits for covariance accumulation.
Fleury MAPLD 2005/133 19

KLT execution times for a 6× 512× 512 pixelimage ensemble
Description Timing (ms)
Pentium IV (1.7 GHz) 301.0
Virtex-I (20 MHz) 59.0
• Twelve replications imply 1,093 passes through 6 × 512 × 512data.
• Stage 2: 50µs on Pentium 4 at CPU clock 1.7 GHz, balances
stage one max. 54 µs — may require ASIC not RISC core to
deliver this.
Fleury MAPLD 2005/133 20

Virtex-II Pro Design
µPstage two
KLT pipeline 0
stage threebuffer
sum
KLT pipeline 1
stage onebuffer
stage onebuffer
sm
mv & evresults
cvVirtex-Pro FPGAoff-chipsystem logic
20MHzdomain
120MHzdomain
clock domainboundary
I/Ocontroller
output
DRAMmemory
Fleury MAPLD 2005/133 21

Virtex-II Pro Design (continued)
• Dual clock domains can provide streaming by accumulating in
on-chip selectRAM blocks.
• 120 MHz is typical DRAM speed, 20 MHz is KLT speed.
• Dual-ported selectRAM blocks form buffer.
• Number of streams per stage is limited by number of selectRAM
blocks (two per stream).
• Handel-C supports multiple clock domains through multiple ‘main’
functions.
Fleury MAPLD 2005/133 22

Stage 1 & 3unit 0
PPC
sum
Virtex-II Pro
DRAMbank 0
Stage 1 & 3unit 1
Stage 1 & 3unit n
Stage 1 & 3unit 0
Stage 1 & 3unit 1
Stage 1 & 3unit 2
Stage 1 & 3unit 3
Stage 1 & 3unit 58
Stage 1 & 3unit 59
Stage 1 & 3unit 0
Stage 1 & 3unit 1
Stage 1 & 3unit 2
Stage 1 & 3unit 3
Stage 1 & 3unit 58
Stage 1 & 3unit 59
Virtex-II FPGAs
DRAMbank 1
DRAMbank219
sm & cv
mv & ev
Output
Output
Output
PPC = PowerPC 450x3
(XC2V10000)
Single pass Virtex-II engine
Fleury MAPLD 2005/133 23

Single-pass Virtex-II Engine (continued)
• Largest Virtex-II ‘may’ support 60 streams (but note selectRAM
block problem)
• If so then 219 Virtex-II units for single pass.
• Min. thruput 1 image set/54 µs and latency 162 µs.
Fleury MAPLD 2005/133 24

Conclusion
• In principle, FPGA KLT engine is possible — SoC would have
many applications, especially in remote sensing (image-size 512×512), but target identification also possible.
• Due to determinism of algorithm (apart from Jacobi iteration) —
performance is incrementally scalable.
• Impediments:
– Number of selectRAM blocks limits designs.
– Eigenvector calculation may become bottleneck stage if using
on-chip RISC.
Fleury MAPLD 2005/133 25